Dynamic Model Averaging in Economics and Finance with fDMA: A Package for R


Abstract
1. Introduction
2. Economic Motivation
3. Theoretical Framework
3.1. Dynamic Model Averaging (DMA)
3.2. Dynamic Model Selection (DMS)
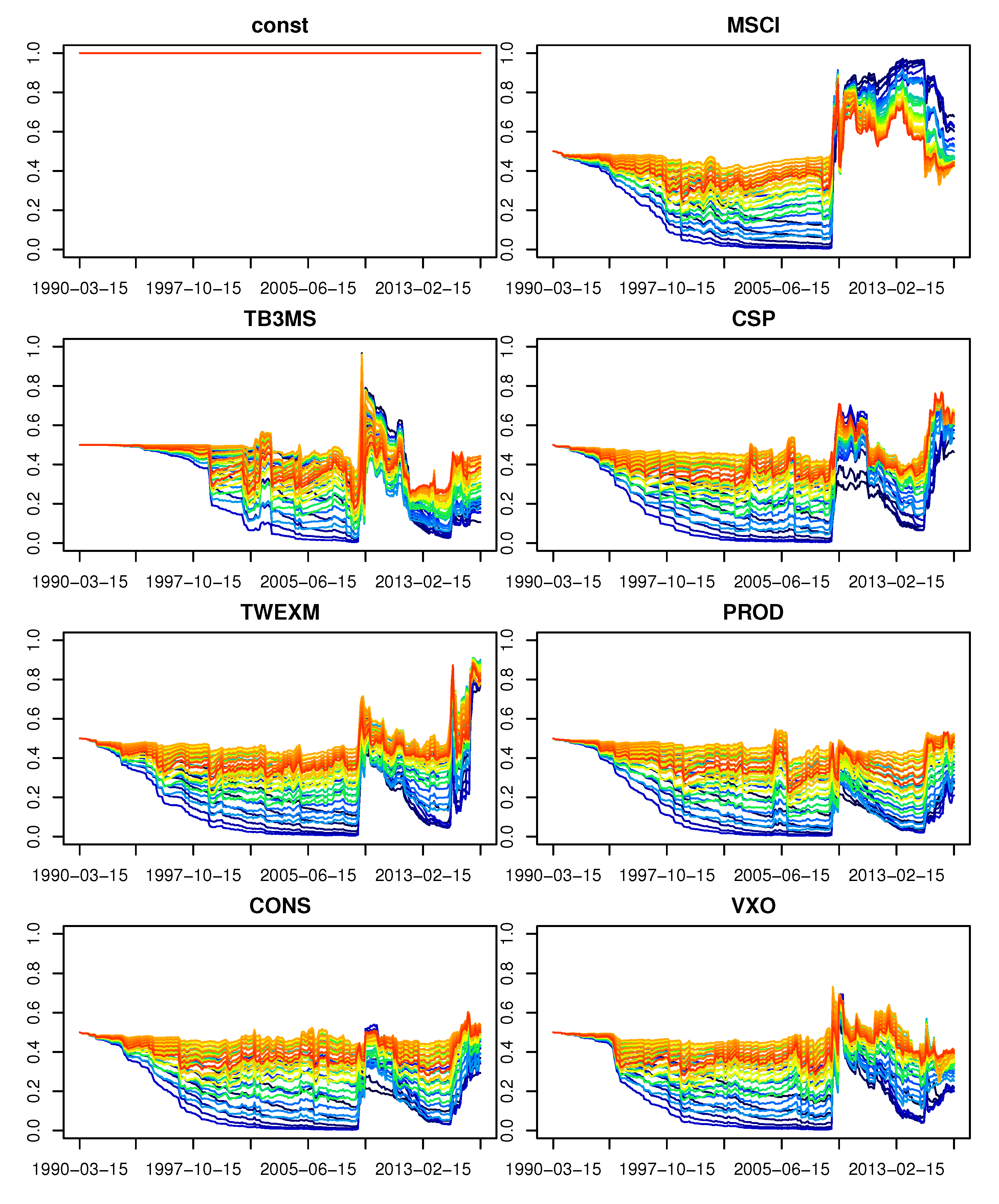
3.3. Relative Variable Importance
3.4. Median Probability Model
3.5. Internet Searches
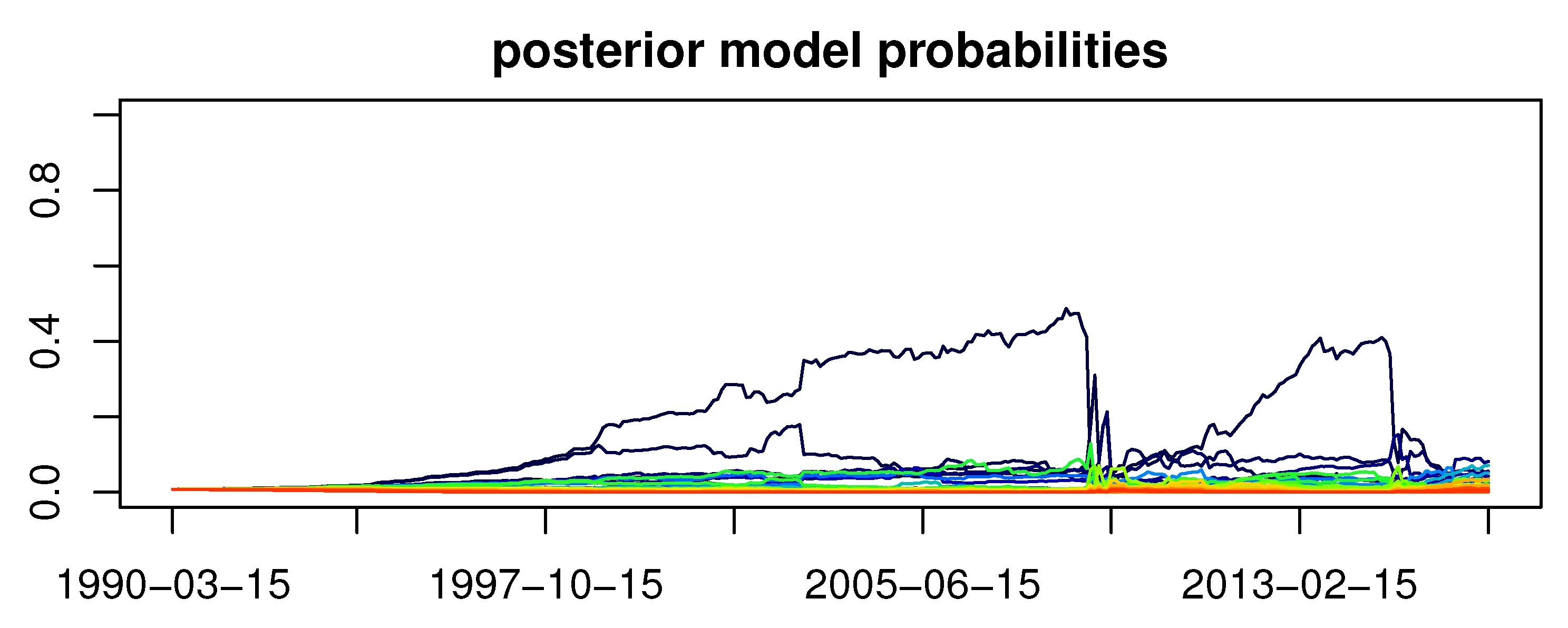
3.6. Dynamic Occam’s Window
- Assume that the standard DMA was performed for some subset of models , but for the observations up to time .
- The DMA forecast is produced. It is called DMA-E. Basing on the weights given by Equation (5) the cut-off is performed, i.e., DMA forecast for the period t is made only from models withOf course, the weights for the remaining models are normalized to sum up to 1. This forecast is called DMA-R.
- The above cut-off reduces the set of models . Such a reduced set is now expanded by new models constructed by adding or removing exactly one explanatory variable from all possible variables to each model in this reduced set of models. The constant term is not included in this adding/removing procedure. As a result, the set of models is created.
- If Step 1 is performed with the updated set of models. Otherwise, the procedure is stopped.
4. Fundamental Functions
- y should be a numeric or a column matrix representing the dependent variable. If it is xts, then plots will have time index on the x axis,
- x should be a matrix of explanatory variables. Observations should go by rows, and different columns should correspond to different variables,
- alpha should be a numeric representing the forgetting factor used in Equation (2),
- lambda should be a numeric representing the forgetting factor used in Equation (4), It is also possible to specify lambda as numeric vector. Then, its values are automatically ordered in descending order, and if numbers are not unique they are reduced to become unique. The idea is that if more than one value is given for lambda, then the model state space, i.e., mods.incl, is expanded by considering all these models with given values of lambda. The outcomes of fDMA are then ordered by columns in a way that first outcomes from models with first value of lambda are presented, then from models with second value of lambda, etc. This specification can be used if the user would like to perform the model combination scheme in which models specified by mods.incl are additionally treated as separate new models each with different value of given by lambda. Such an approach is given by Raftery et al. [1] at the end of their paper,
- initvar should be a numeric. It represents the initial variances in the state space equation, . It is taken the same for all models,
- W is optional. If W = “reg” then are specified in the initial step as in Equation (13). On the other hand, if a positive numeric is given, then Equation (13) is modified in the following way:By default W = “reg”,
- initial.period is optional. This numeric indicates since which moment MSE (Mean Squared Error) and MAE (Mean Absolute Error) should be computed. As fDMA already produces some forecast quality measures, the user might require to treat some first observations as “training period”. By default the whole sample is used to produce forecast quality measures, i.e., initial.period = 1,
- V.meth is optional. If V.meth = “rec”, then the recursive moment estimator as in Equation (7) is used. If V.meth = “ewma”, then the exponentially weighted moving average (EWMA) is used, i.e., Equation (7) is replaced bywhere (kappa) has to be also specified. EWMA is a common estimator in finance. For instance, Riskmetrics calls a decay factor and suggests for monthly data, and for daily data. Koop and Korobilis [157] used for quarterly data. EWMA was also used by them when ARCH effects in Equation (1) were suspected, as other methods would increase the computational burden too much. By default V.meth = “rec” is used,
- kappa is optional numeric. It has to be specified if V.meth = “ewma”. Then, it corresponds to in Equation (20),
- gprob is optional. This matrix represents Google probabilities, , as in (17). In other words, columns should correspond to different explanatory variables, i.e., the columns of x. These values should be not a direct Google Trends data, but these search volumes index divided by 100. It should also be noticed that gprob is not lagged one period back automatically inside the function. If nrow(gprob) < length(y), then the method by Koop and Onorante [170] is used for the last nrow(gprob) observations. For the preceding ones the original method by Raftery et al. [1] is used. In such case a warning is generated.
- omega is optional. This numeric has to be specified if gprob is used, and it represents the parameter from Equation (18),
- model is optional. If model = “dma” then Dynamic Model Averaging (DMA) is computed. If model = “dms” then Dynamic Model Selection (DMS) is computed. If model = “med” then Median Probability Model is computed. By default model = “dma” is used,
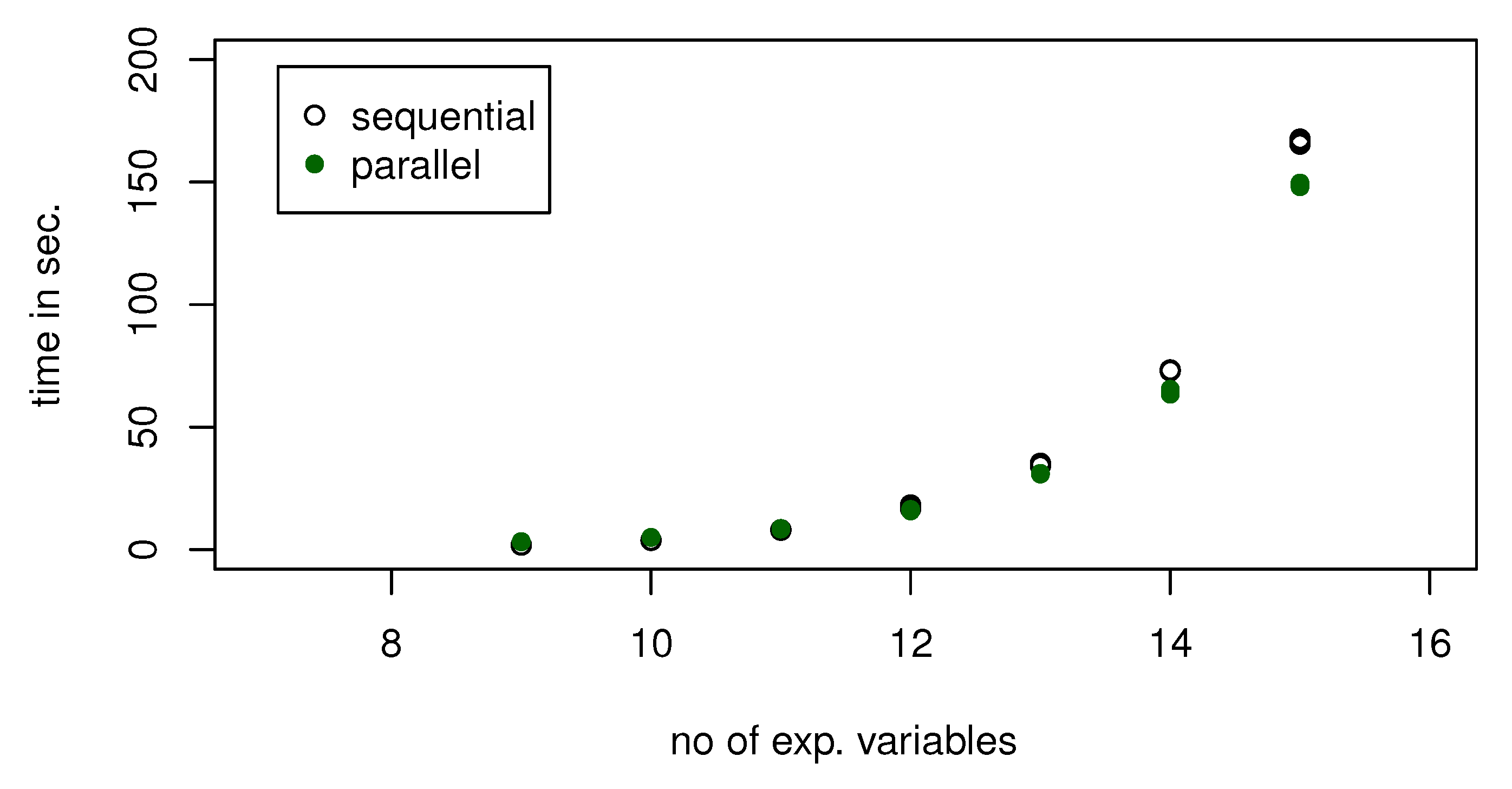
- parallel is optional. This logical indicates whether parallel computations should be used. If parallel = TRUE all cores less 1 are used. (But it can be changed, see fcores below.) However, it should be noticed that parallel computations are not always desired. It can happen that additional time for overheads will take too much time, and sequential computations would be faster. Therefore, if dynamic Occam’s window is applied, and parallel = TRUE, then parallel computations are turned on only for rounds in which or more models are estimated. This was chosen basing on some tests. The reason for such a methodology is that forcing all rounds to be computed in a parallel way can result in a situation that in rounds where too few models are generated overheads would increase the computation time. By default parallel = FALSE is used,
- m.prior is optional. This numeric represents a parameter for general model prior. In other words, Equation (11) can be replaced bywhere is the number of variables including constant term in k-th model and m is the total number of potential explanatory variables including constant considered in the forecast combination scheme [173,174]. By default m.prior = 0.5, which corresponds to the uniform distribution, i.e., non-informative priors. Then, Equation (21) reduces to Equation (11). The interpretation of is that the prior expected number of explanatory variables in the model is , so by changing the user can modify the initial weights giving more attention to models with more variables or to rather parsimonious models,
- mods.incl is optional. This matrix indicates which models should be used for the estimation. The first column indicates inclusion of a constant. In other words, different models are differentiated by rows, whether columns correspond to the explanatory variables. Inclusion of a variable is indicated by 1, omitting by 0. By default all possible models with a constant are used,
- DOW is optional. This numeric represents the threshold for dynamic Occam’s window, i.e., the parameter C in Equation (19). If DOW = 0, then no dynamic Occam’s window is applied. By default DOW = 0 is used. Dynamic Occam’s window can be applied only to Dynamic Model Averaging (DMA), i.e., if model = “dma”,
- DOW.nmods is optional. This numeric indicates the initial number of models for dynamic Occam’s window. Of course, it should be less than the number of all possible models and larger than or equal to 2. These models are randomly chosen. So if the user wants to start with all models specified by mods.incl, then he or she should just specify DOW.nmods equal to the number of all models given by mods.incl. If DOW.nmods = 0, then initially models with exactly one explanatory variable and a constant term are taken. By default DOW.nmods = 0 is used,
- DOW.type is optional. DOW.type = “r” corresponds to DMA-R in dynamic Occam’s window. DOW.type = “e” corresponds to DMA-E in dynamic Occam’s window. By default DOW.type = “r” is used,
- DOW.limit.nmods is optional. This numeric indicates the maximum number of models selected by dynamic Occam’s window. In other words, it can happen that the cut-off specified by C in dynamic Occam’s window will leave too many models for efficient computations. If the user wants to use the additional limitation, i.e., to be sure that no more than DOW.limit.nmods models are left after the cut-off, this parameter should be specified. By default no limit is set,
- progress.info is optional. This logical is applicable only if dynamic Occam’s window is used. Otherwise it is ignored. If progress.info = TRUE then the number of the current recursive DMA computation round and number of models selected for this round are printed on the screen as the computations go. This feature can be useful if the user is uncertain about the existence of some bottleneck in dynamic Occam’s window. For instance, the cut-off level can result in reasonably small number of model up to some period, but then suddenly too many models would be taken. Therefore, this feature helps the user to have a preview on what is going on with dynamic Occam’s window in real time. By default progress.info = FALSE,
- forced.models is optional. This matrix is applicable only if Dynamic Occam’s Window is used. Otherwise it is ignored. It indicates models that have to be always included in the expanded set of models. The use is similar as that of models.incl. By default forced.models = NULL,
- forbidden.models is optional. This matrix is applicable only if Dynamic Occam’s Window is used. Otherwise it is ignored. It indicates models that cannot be present in the expanded set of models. The use is similar as that of mods.incl. By default forbidden.models = NULL,
- forced.variables is optional. This vector is applicable only if Dynamic Occam’s Window is used. Otherwise it is ignored. It indicates variables that have to be always included in models constituting the set of expanded models. The use is similar as that of mods.incl. The first slot indicates the inclusion of constant. By default forced.variables = NULL,
- bm is optional. This logical indicates whether Auto ARIMA benchmark forecast should be computed. In particular, these benchmarks are naive forecast (i.e., all forecasts are set to be the value of the last observation), which is always computed. But Auto ARIMA (auto.arima from forecast) by Hyndman and Khandakar [20] is optional. By default bm = FALSE,
- small.c is optional. Specifying this numeric allows to modify the value of c in Equation (3),
- fcores is optional. Specifying this numeric allows to control the number of cores that should not be used. This is used only if parallel = TRUE, otherwise it is ignored. By default fcores = 1,
- mods.check is optional. This logical indicates if mods.incl should be checked, for missing values, duplication, etc. However, for the large number of considered models it can be time-costing. Therefore, by default mods.check = FALSE,
- red.size is optional. This logical indicates if outcomes should be reduced to save memory, by default red.size = FALSE,
- av is optional. If av = “dma”, then the original DMA averaging scheme is performed. If av = “mse” then predictive densities in Equation (5) are replaced by the inverses of Mean Squared Errors of the models [175,176]. If av = “hr1”, then they are replaced by Hit Ratios (assuming time-series are in levels). If av = “hr2”, then they are replaced by Hit Ratios (assuming time-series represent changes, i.e., differences). By default av = “dma”.
- $y.hat: forecasted values,
- $post.incl: relative variable importance for all explanatory variables (also called posterior inclusion probabilities), as given by Equation (15),
- $MSE: MSE (Mean Squared Error) of forecast,
- $MAE: MAE (Mean Absolute Error) of forecast,
- $models: models included in estimations, i.e., mods.incl; or models used in the last step of dynamic Occam’s window method, if this method was used,
- $post.mod: posterior probabilities of all used models, i.e., values given by Equation (2); or NA if dynamic Occam’s window method was used,
- $exp.var: the expected number of variables including the constant term, as given by Equation (16),
- $exp.coef.: the expected values of regression coefficients, i.e., the weighted average of regression coefficients from all models used in the forecast combination scheme, averaged with the weights given by Equation (2),
- $parameters: parameters of the estimated model,
- $yhat.all.mods: predictions from all single models used in the forecast combination method,
- $y: the dependent variable,
- $benchmarks: RMSE (Root Mean Squared Error) and MAE (Mean Absolute Error) of naive and Auto ARIMA forecast,
- $DOW.init.mods: models initially selected to dynamic Occam’s window (if this method has been selected),
- $DOW.n.mods.t: number of models used in dynamic Model Averaging at time t, if Dynamic Occam’s Window method has been selected,
- $p.dens.: predictive densities from the last period of all models used in estimations of the forecast combination scheme, i.e., as in Equation (2) for all from the last period,
- $exp.lambda: the expected values of lambda parameter. This is meaningful only if lambda was specified as numeric vector. Then, as the models are given different weights given by Equation (2) the average value of varies in time.
- actual and predicted values,
- residuals,
- the expected number of variables (including constant),
- relative variable importance for all explanatory variables both on one plot, or in separate png files, saved in the current working directory, and joining them into one big plot, also saved as png file in the current working directory,
- the expected coefficients (including constant) on one plot, or in separate png files, saved in the current working directory, and joining them into one big plot, also saved as png file in the current working directory,
- the expected value of lambda,
- posterior model probabilities, i.e., the ones given by Equation (2),
- the number of models used in Dynamic Model Averaging (DMA), if dynamic Occam’s window was selected,
- which variables (including constant) were included in DMS or Median Probability Model model each time.
- grid.alpha is a numeric vector of different values of the forgetting parameter to be used,
- grid.lambda is a numeric vector of different values of the forgetting parameter to be used, or a list of numeric vectors for multiple lambda in one model,
- parallel.grid is optional. This logical indicates whether parallel computations of models with different forgetting factors should be used. By default parallel.grid = FALSE is used.
- $models: list of list of models,
- $RMSE: matrix with RMSE (Root Mean Squared Error) for all estimated models,
- $MAE: matrix with MAE (Mean Absolute Error) for all estimated models.
- RMSE for all estimated models,
- MAE for all estimated models,
- relative variable importance for all estimated models in separate png files in the current working directory, and additionally join them in one big plot also saved as png file in the current working directory,
- the expected coefficients (including constant) for all estimated models in separate png files in the current working directory, and additionally join them in one big plot also saved as png file in the current working directory.
0.99 0.98 0.97
0.99 0.0861 0.0860 0.0860
0.95 0.0912 0.0904~0.0897
0.99 0.98 0.97
0.99 0.0661 0.0660 0.0660
0.95 0.0695 0.0688~0.0683
* alphas by columns, lambdas by rows
- $y.hat: fitted (forecasted) values,
- $thetas: estimated regression coefficients,
- $pred.dens.: predictive densities from each period,
- $y: the dependent variable time-series.
- actual and predicted values,
- residuals,
- regression coefficients on one plot, or in separate png files, saved in the current working directory, and moreover, to paste them into one big plot (also saved as png file in the current working directory).
const MSCI TB3MS CSP TWEXM PROD CONS VXO
0.0025 0.0636 0.0712 0.2289 −0.3353 −0.2311 0.1314~−0.0075
- $models: list of estimated tvp objects,
- $fq: matrix with RMSE and MAE of all estimated models.
- RMSE for all estimated models,
- MAE for all estimated models,
- coefficients (including constant) for all estimated models, both in separate png files in the current working directory, and collected into one big plot (also saved as png file in the current working directory).
5. Information-Theoretic Averaging
- y should be a numeric or a column matrix of a dependent variable,
- x should be a matrix of explanatory variables, in which different columns correspond to different explanatory variables, and rows enumerate the observations,
- mods.incl is optional. This matrix indicates which models, constructed out of explanatory variables given by x, should be used in the averaging scheme. If not specified all possible models are taken. This argument is similarly used as in the already described fDMA function,
- gprob is optional. This is a matrix of Google probabilities, columnwisely corresponding to explanatory variables given by x; similarly like the one in fDMA function,
- av is optional. This parameter indicates a method for model averaging.
- –
- av = “ord” corresponds to equal weights for each model, i.e., weights are computed from Equation (25),
- –
- av = “aic” corresponds to information theoretic model averaging based on Akaike Information Criterion (AIC), i.e., weights are computed from Equation (22),
- –
- –
- av = “bic”| corresponds to information theoretic model averaging based on Bayesian Information Criterion (BIC), i.e., weights are computed from Equation (24),
- –
- av = “mse” corresponds to setting weights proportionally to the inverse of the models’ MSE (Mean Squared Error), i.e., weights are computed from Equation (26).
By default av = “ord” is used, - window is optional. This numeric corresponds to the size of a rolling regression window (i.e., a number of observations taken for the model). If not specified of all observations are taken,
- initial.period is optional. This numeric represents the number of an observation since which forecast quality measures are computed. If not specified the whole sample is used, i.e., initial.period = 1, this argument also divides the sample into in-sample and out-of-sample for av. OLS method,
- d is optional. This logical is a parameter used for HR (Hit Ratio) calculations. It should be set d = FALSE for level dependent time-series used, and d = TRUE if the dependent variable represent changes (differences). If not specified d = FALSE is taken,
- f is optional. This logical vector indicates which of the alternative forecast – av. OLS, av. rec. OLS, av. roll. OLS and av. TVP – should be computed. If not specified f = c(rep(TRUE, 4), i.e., all alternative forecast are computed. The possible methods are:
- –
- av. OLS – averaging is done over Ordinary Least Squares linear regression models (for each t the in-sample estimates are used),
- –
- av. rec. OLS – averaging is done over Ordinary Least Squares recursive linear regression models (for t only data up to are used),
- –
- av. roll. OLS – averaging is done over Ordinary Least Squares rolling window linear regression models (for t only data between and are used),
- –
- av. TVP – averaging is done over time-varying parameters linear regressions (TVPs), i.e., models like the ones being averaged in Dynamic Model Averaging (DMA). In other words, the models computed by the function tvp, described already in this paper, are averaged. V = 1 and lambda = 0.99 are used inside the function as tvp arguments.
- fmod is optional. This represents a class dma object. Then previously estimated DMA, DMS or Median Probability Model can be quickly compared with alternative forecast in a sense of forecast quality measures,
- parallel is optional. This logical indicates whether parallel computations should be used. By default parallel = FALSE is used.
- $summary: matrix of forecast quality measures ordered by columns, forecast methods are ordered by rows,
- $y.hat: list of predicted values from all forecasting methods which were applied,
- $y: y, the dependent (forecasted) time-series,
- $coeff.: list of coefficients from all forecasting methods which were applied,
- $weights: list of weights of models used in averaging for all forecasting methods which were applied,
- $p.val.: list of p-values (averaged with respect to suitable weights) for t-test of statistical significance for coefficients from all forecasting methods which were applied (for av. TVP they are not computed),
- $rel.var.imp.: list of relative variable importance from all forecasting methods which were applied, i.e., the sum of weights of exactly those models used in averaging which contain a given variable as the explanatory variable,
- $exp.var.: list of expected number of variables (including constant) from all forecasting methods which were applied, i.e., the weighted average of explanatory variables in the models.
- mean values of coefficients,
- minimum, maximum and mean relative variable importance reached during the analysed time period for each explanatory variable,
- frequency when relative variable importance is over for each explanatory variable,
- how often p-values (averaged over used models) for t-test of statistical significance for each explanatory variable are below , and , respectively.
- expected coefficients in separate png files, saved in the current working directory, and moreover, to paste them into one big plot (also saved as png file in the current working directory),
- p-values (averaged over used models) for t-test of statistical significance for regression coefficients from applied models, in separate png files, saved in the current working directory, and moreover, to paste them into one big plot (also saved as png file in the current working directory),
- weights of all models used in the averaging scheme,
- relative variable importance in separate png files, saved in the current working directory, and moreover, to paste them into one big plot (also saved as png file in the current working directory),
- the expected number of variables (including constant) from all models used in the averaging scheme.
ME RMSE MAE MPE MAPE HR
av. OLS −0.0359 0.1201 0.0874 −308.5960 821.7701 0.6667
av. rec. OLS −0.0104 0.0838 0.0660 34.8456 470.4977 0.6154
av. roll. OLS −0.0003 0.0711 0.0537 26.9362 282.1520 0.6474
6. Alternative Forecasts
- naive forecast (naive), i.e., all forecasts are set to be the value of the last observation,
- Ordinary Least Squares linear regression (OLS),
- recursive OLS (rec. OLS), i.e., later described rec.reg,
- rolling OLS (roll. OLS), i.e., later described roll.reg,
- AR(1) estimated by Least Squares method,
- AR(2) estimated by Least Squares method,
- TVP linear regression, i.e., tvp with V = 1 and lambda = 0.99,
- TVP-AR(1), i.e., TVP as above with explanatory set expanded by the first lags of the dependent variable,
- TVP-AR(2), i.e., TVP as above with explanatory set expanded by the first and the second lags of the dependent variable,
- Auto ARIMA, i.e., auto.arima from the package forecast of Hyndman and Khandakar [20].
- y should be a numeric or a column matrix of the dependent variable,
- x should be a matrix of the explanatory variables, where different columns correspond to different explanatory variables,
- window is optional. This numeric represents the size of a rolling regression window (a number of observations). If not specified, then of all observations are taken. For the details, please see the description of the function roll.reg further,
- initial.period is optional. This numeric represents the number of observation since which forecast quality measures are computed. If not specified the whole sample is used, i.e., initial.period = 1 is taken, this argument also divides the sample into in-sample and out-of-sample for non-recursive methods (OLS, AR(1), AR(2), auto ARIMA),
- d is optional. This logical is a parameter used for HR (Hit Ratio) calculation. It should be d = FALSE taken for level time-series in the dependent variable, and d = TRUE if the dependent time-series represents changes. If not specified, then d = FALSE is taken,
- f is optional. This logical vector indicates which of the alternative forecasts:
- naive,
- OLS,
- rec. OLS,
- roll. OLS,
- TVP,
- AR(1),
- AR(2),
- Auto ARIMA,
- TVP-AR(1),
- TVP-AR(2),
should be computed. If not specified, then f = c(rep(TRUE, 10)) is taken, i.e., all the alternative forecasts are computed, - fmod is optional. This should be a class dma object—a model which will be compared with the alternative forecast,
- c is optional. This logical indicates whether a constant term should be included in the models. If not specified c = TRUE is used, i.e., constant term is included in the estimated models.
- $summary: a matrix of forecast quality measures ordered by columns (forecast methods are ordered by rows),
- $y.hat: a list of predicted values from all forecasting methods which were applied,
- $y: the dependent (forecasted) time-series,
- $coeff.: a list of coefficients from all forecasting methods which were applied (for naive forecast they are not computed),
- $p.val.: a list of p-values for t-test of statistical significance for coefficients from all forecasting methods which were applied (for naive and TVP models they are not computed, and for Auto ARIMA z-test is used).
- regression coefficients in separate png files, saved in the current working directory, and moreover, to paste them into one big plot (also saved as png file in the current working directory),
- p-values for t-test of statistical significance for regression coefficients from applied models, in separate png files, saved in the current working directory, and moreover, to paste them into one big plot (also saved as png file in the current working directory).
- y should be a numeric or a column matrix representing the dependent variable,
- x is optional. This matrix represents the explanatory variables. Different columns should correspond to different explanatory variables. However, if it is not specified, then only the constant term is included,
- windows should be a numeric vector representing the sizes of rolling regression windows (i.e., numbers of observations),
- av is optional. It indicates the method for model averaging. In particular,
- –
- av = “ord” corresponds to equal weights for each model,
- –
- av = “aic” corresponds to information theoretic model averaging based on Akaike Information Criterion (AIC),
- –
- av = “aicc” corresponds to information theoretic model averaging based on Akaike Information Criterion with a correction for finite sample sizes (AICc),
- –
- av = “bic” corresponds to information theoretic model averaging based on Bayesian Information Criterion (BIC),
- –
- av = “mse” corresponds to setting weights proportional to the inverse of the models Mean Squared Error (MSE),
- –
- If av is numeric, then weights are computed proportionally to the av-th power of the window size. In particular let there be K models considered with windows . Then, the weight of k-th model is given by
- initial.period is optional. This numeric represents the number of observation since which forecast quality measures are computed. If not specified the whole sample is used, i.e., initial.period = 1 is taken,
- d is optional. This logical is a parameter used for HR (Hit Ratio) calculation. It should be d = FALSE for level dependent time-series and d = TRUE if the dependent time-series represents changes. If not specified d = FALSE is taken,
- fmod is optional. This class dma object indicates the model to be compared with the alternative forecast,
- parallel is optional. This logical indicates whether parallel computations should be used. By default parallel = FALSE is taken,
- c is optional. This logical indicates whether a constant term should be included in the models. If not specified c = TRUE is used, i.e., constant term is included in the estimated models. Of course it is not possible to set simultaneously x = NULL and c = FALSE, as such settings would be automatically turned inside the function into c = TRUE.
- $summary: a matrix of forecast quality measures ordered by columns,
- $y.hat: a list of predicted values from the rolling regressions averaged over the selected window sizes,
- $y: the dependent (forecasted) time-series,
- $coeff.: a list of coefficients from the rolling regressions averaged over the selected window sizes,
- $weights: a list of weights of the models used in averaging,
- $p.val.: a list of p-values (averaged over the selected window sizes) for t-test of statistical significance for the coefficients from the rolling regressions,
- $exp.win.: a list of the expected window size, i.e., weighted average of the window sizes.
- the expected coefficients in separate png files, saved in the current working directory, and moreover, to paste them into one big plot (also saved as png file in the current working directory),
- p-values (averaged over selected window sizes) for t-test of statistical significance for coefficients from the rolling regressions, in separate png files, saved in the current working directory, and moreover, to paste them into one big plot (also saved as png file in the current working directory),
- weights of all the models used in averaging,
- the expected window size, i.e., weighted average of the widow sizes.
const MSCI TB3MS CSP TWEXM PROD CONS VXO
0.0068 −0.0154 0.3069 −0.0541 −0.5156 0.0855 0.0142~0.0342
const MSCI TB3MS CSP TWEXM PROD CONS VXO
0.01 0.00 0.00 0.03 0.02 0.00 0.00 0.00 0.00
0.05 0.01 0.07 0.25 0.10 0.01 0.00 0.07 0.00
0.10 0.07 0.16 0.33 0.17 0.08 0.11 0.14~0.11
ME RMSE MAE MPE MAPE HR
av. roll. OLS 0.0043 0.076 0.0614 105.2163 305.6757 0.5994
- y should be a numeric or a column matrix of the dependent variable,
- x should be a matrix of the explanatory variables, and different columns should correspond to different explanatory variables,
- windows should be a numeric vector. It indicates the sizes of the rolling regression windows (i.e., the numbers of observations),
- V is optional. This numeric represents the value of the parameter V in tvp function (taken for the rolling regression case). If not specified V = 1 is taken,
- lambda is optional. This numeric represents the forgetting factor used in tvp function. If not specified lambda = 0.99 is taken,
- alpha is optional. This numeric represents the forgetting factor in Equation (2). If not specified alpha = 0.99 is taken,
- initial.period is optional. This numeric represents the number of observation since which forecast quality measures are computed. If not specified the whole sample is used, i.e., initial.period = 1 is used,
- d is optional. This logical is a parameter used for HR (Hit Ratio) calculation. It should be d = FALSE for level dependent time-series and d = TRUE if the dependent time-series represent changes. If not specified d = FALSE is used,
- fmod is optional. This class dma object represents the model which can be compared with the alternative forecast,
- parallel is optional. This logical indicates whether parallel computations are used. By default parallel = FALSE is used,
- c is optional. This logical indicates whether the constant term should be included in the models. If not specified c = TRUE is used, i.e., the constant term is included in the estimated models,
- small.c is optional. Specifying this numeric allows to modify the value of c in Equation (3).
- $summary: a matrix of forecast quality measures ordered by columns,
- $y.hat: a list of predicted values from the time-varying parameters rolling regressions averaged over the selected window sizes,
- $y: the dependent (forecasted) time-series,
- $coeff.: a list of coefficients from the time-varying parameters rolling regressions averaged over the selected window sizes,
- $weights: a list of weights of models used in averaging,
- $exp.win.: a list of the expected window size, i.e., the weighted average of the widow sizes.
- the expected coefficients in separate png files, saved in the current working directory, and moreover, to paste them into one big plot (also saved as png file in the current working directory),
- the weights of all the models used in averaging,
- the expected window size.
MSCI TB3MS CSP TWEXM PROD CONS VXO
0.0994 0.0781 0.2859 −0.4134 −0.3340 0.1200~−0.0222
ME RMSE MAE MPE MAPE HR
av. roll. TVP 0.0044 0.0951 0.0743 222.0851 353.0323 0.5155
7. Forecast Comparison
- y should be a numeric, vector, or one row or one column matrix or xts object, representing the dependent (forecasted) time-series,
- y.hat should be a numeric, vector, or one row or one column matrix or xts object, representing the forecast predictions,
- d is optional. This logical should be set d = FALSE for the level dependent time-series and d = TRUE if the dependent time-series already represent changes (i.e., differences). By default d = FALSE is used.
- y should be a vector of the dependent (forecasted) time-series,
- f should be a matrix of the predicted values from various models. The forecasts should be ordered by rows. The first row should correspond to the method that is compared with the alternative ones (corresponding to the subsequent rows).
DM stat. DM p-val. different DM p-val. greater DM p-val. less
[1,] "−0.2573" " 0.7970" " 0.6015" " 0.3985"
[2,] "2.4589" " 0.0139" " 0.0070" " 0.9930"
[3,] " 3.9460" " 0.0001" " 0.0000" " 1.0000"
[4,] " 1.2575" " 0.2086" " 0.1043" " 0.8957"
8. Make Work Easier
- mean,
- standard deviation,
- variance,
- median,
- minimum value,
- maximum value,
- skewness, i.e., ,
- kurtosis, i.e., ,
- coefficient of variation.
WTI MSCI TB3MS
mean 46.64500 1082.97500 2.82200
sd 30.51700 379.83900 2.29900
variance 931.28300 144277.32900 5.28500
median 32.64000 1091.68000 2.99000
min 11.35000 423.14000 0.01000
max 133.90000 1779.30000 7.90000
skew 0.78767 0.02822 0.14938
kurtosis −0.67540 −1.04620 −1.31570
coeff. of variation 1.52800 2.85100 1.22700
- ts should be a vector representing the tested time-series,
- lag is optional. This numeric represents the suspected order of ARCH process, i.e., p from the above considerations. If not specified, then lag = 1 is taken.
- statistic: the test statistic,
- parameter: the argument lag used in the test,
- alternative: the alternative hypothesis of the test,
- p.value: p-value of the test,
- method: the name of the test,
- data.name: the name of the tested time-series.
ADF stat. ADF p-val. PP stat. PP p-val. KPSS stat. KPSS p-val.
MSCI −6.5991 0.01 −300.5006 0.01 0.0546 0.1000
TB3MS −6.7647 0.01 −245.1034 0.01 0.0822 0.1000
CSP −6.4724 0.01 −458.5101 0.01 0.0792 0.1000
TWEXM −7.6516 0.01 −200.0467 0.01 0.1304 0.1000
PROD −7.6770 0.01 −452.8701 0.01 0.5389 0.0329
CONS −9.3762 0.01 −467.6868 0.01 0.0389 0.1000
VXO −9.2563 0.01 −325.9003 0.01 0.0282 0.1000
- y should be a numeric or a column matrix representing the dependent variable,
- x is optional. This matrix represents the explanatory variables. Different columns should correspond to different variables. If not specified, then only the constant term is used in the regression,
- c is optional. This logical is the parameter indicating whether the constant term should be included in the regression equation. If not specified c = TRUE is used, i.e., the constant term is included.
- $y.hat: a vector of fitted (forecasted) values,
- $AIC: a vector of Akaike Information Criterion (AIC), from the current set of observations,
- $AICc: a vector of Akaike Information Criterion with a correction for finite sample sizes (AICc) from the current set of observations,
- $BIC: a vector of Bayesian Information Criterion (BIC), from the current set of observations,
- $MSE: a vector of Mean Squared Error (MSE), from the current set of observations,
- $coeff.: a matrix of regression coefficients,
- $p.val: a matrix of p-values for t-test for statistical significance of regression coefficients,
- $y: a vector of the dependent time-series.
- residuals,
- regression coefficients on one plot, or in separate png files, saved in the current working directory, and moreover, to paste them into one big plot (also saved as png file in the current working directory),
- p-values for t-test of statistical significance for regression coefficients on one plot, or in separate png files, saved in the current working directory, and moreover, to paste them into one big plot (also saved as png file in the current working directory).
-
grid.window should be a numeric vector indicating the different values of window argument for roll.reg.
-
parallel.grid is optional. This logical indicates whether parallel computations should be used. By default parallel.grid = FALSE is used.
- $models: a list of reg objects,
- $fq: a matrix with RMSE (Root Mean Squared Error) and MAE (Mean Absolute Error) for all estimated models.
- RMSE for all estimated models,
- MAE for all estimated models,
- coefficients (including the constant term) for all estimated models – the outcomes are saved in separate png files in the current working directory, and additionally, plots for different variables are collected into one big plot (also saved as png file in the current working directory),
- p-values for t-test of statistical significance for regression coefficients for all estimated models—the outcomes are saved in separate png files in the current working directory, and additionally, plots for different variables are collected into one big plot (also saved as png file in the current working directory).
9. An Example: Oil Market
- crudeoil$WTI represents WTI (West Texas Intermediate) spot price in USD per barrel,
- crudeoil$MSCI represents MSCI World Index (a broad global equity benchmark that represents large and mid-cap equity performance across selected developed markets),
- crudeoil$TB3MS represents U.S. 3-month treasury bill secondary market rate in %,
- crudeoil$CSP represents crude steel production in thousand tonnes (which can be a way to measure global economic activity),
- crudeoil$TWEXM represents trade-weighted U.S. dollar index (Mar, 1973 = 100),
- crudeoil$PROD represents U.S. product supplied for crude oil and petroleum products in thousands of barrels,
- crudeoil$CONS represents total consumption of petroleum products in OECD in quad BTU,
- crudeoil$VXO represents implied volatility of S&P 100 (i.e., stock market volatility).
- trends$stock_markets represents Google Trends for “stock markets”,
- trends$interest_rate represents Google Trends for “interest rate”,
- trends$economic_activity represents Google Trends for “economic activity”,
- trends$exchange_rate represents Google Trends for “exchange rate”,
- trends$oil_production represents Google Trends for “oil production”,
- trends$oil_consumption represents Google Trends for “oil consumption”,
- trends$market_stress represents Google Trends for “market stress”.
ADF stat. ADF p-val. PP stat. PP p-val. KPSS stat. KPSS p-val.
MSCI −6.5991 0.01 −300.5006 0.01 0.0546 0.1000
TB3MS −6.7647 0.01 −245.1034 0.01 0.0822 0.1000
CSP −6.4724 0.01 −458.5101 0.01 0.0792 0.1000
TWEXM −7.6516 0.01 −200.0467 0.01 0.1304 0.1000
PROD −7.6770 0.01 −452.8701 0.01 0.5389 0.0329
CONS −9.3762 0.01 −467.6868 0.01 0.0389 0.1000
VXO −9.2563 0.01 −325.9003 0.01 0.0282 0.1000
mean sd variance median min max
WTI 0.00265415 0.08648 0.007480 0.0114849 −0.33198 0.3922
MSCI 0.00358386 0.04368 0.001908 0.0092134 −0.21128 0.1035
TB3MS −0.00879474 0.28379 0.080537 0.0000000 −1.84583 1.7918
CSP 0.00228619 0.04407 0.001942 −0.0052036 −0.13723 0.1346
TWEXM 0.00004198 0.01673 0.000280 0.0008499 −0.04784 0.0647
PROD 0.00039764 0.05570 0.003102 0.0010922 −0.26236 0.2075
CONS 0.00035543 0.05425 0.002943 0.0063261 −0.13512 0.1319
VXO −0.00207592 0.19108 0.036511 −0.0113524 −0.47960 0.7587
skew kurtosis coeff. of variation
WTI −0.29526 2.0239 0.030689
MSCI −0.82550 1.9446 0.082055
TB3MS 0.30278 15.4820 −0.030990
CSP 0.70715 0.8223 0.051873
TWEXM 0.05247 0.4998 0.002509
PROD −0.33301 2.1423 0.007139
CONS −0.04308 −0.4467 0.006552
VXO 0.44436 1.0880 −0.010864
10. Comparison with Other Packages
Funding
Conflicts of Interest
References
- Raftery, A.; Kárný, M.; Ettler, P. Online Prediction under Model Uncertainty via Dynamic Model Averaging: Application to a Cold Rolling Mill. Technometrics 2010, 52, 52–66. [Google Scholar] [CrossRef] [PubMed]
- Barbieri, M.; Berger, J. Optimal Predictive Model Selection. Ann. Stat. 2004, 32, 870–897. [Google Scholar] [CrossRef]
- McCormick, T.; Raftery, A.; Madigan, D. dma: Dynamic Model Averaging. 2017. Available online: https://CRAN.R-project.org/package=dma (accessed on 25 June 2020).
- Catania, L.; Nonejad, N. eDMA: Dynamic Model Averaging with Grid Search. 2017. Available online: https://CRAN.R-project.org/package=eDMA (accessed on 25 June 2020).
- Drachal, K. fDMA: Dynamic Model Averaging and Dynamic Model Selection for Continuous Outcomes. 2017. Available online: https://CRAN.R-project.org/package=fDMA (accessed on 25 June 2020).
- Ryan, J.; Ulrich, J.; Bennett, R. xts: EXtensible Time Series. 2017. Available online: https://CRAN.R-project.org/package=xts (accessed on 25 June 2020).
- Calaway, R.; Weston, S. iterators: Provides Iterator Construct for R. 2015. Available online: https://CRAN.R-project.org/package=iterators (accessed on 25 June 2020).
- Calaway, R.; Weston, S. foreach: Provides Foreach Looping Construct for R. 2015. Available online: https://CRAN.R-project.org/package=foreach (accessed on 25 June 2020).
- Calaway, R.; Weston, S.; Tenenbaum, D. doParallel: Foreach Parallel Adaptor for the ’parallel’ Package. 2017. Available online: https://CRAN.R-project.org/package=doParallel (accessed on 25 June 2020).
- Eddelbuettel, D.; Francois, R. Rcpp: Seamless R and C++ Integration. J. Stat. Softw. 2011, 40, 1–18. [Google Scholar] [CrossRef]
- Eddelbuettel, D.; Sanderson, C. RcppArmadillo: Accelerating R with High-performance C++ Linear Algebra. Comput. Stat. Data Anal. 2014, 71, 1054–1063. [Google Scholar] [CrossRef]
- Sanderson, C.; Curtin, R. Armadillo: A Template-based C++ Library for Linear Algebra. J. Open Source Softw. 2016, 1, 26. [Google Scholar] [CrossRef]
- Belmonte, M.; Koop, G. Model Switching and Model Averaging in Time-varying Parameter Regression Models. Adv. Econom. 2014, 34, 45–69. [Google Scholar] [CrossRef]
- Hwang, Y. Forecasting with Specification-Switching VARs. J. Forecast. 2017, 36, 581–596. [Google Scholar] [CrossRef]
- Koop, G. Forecasting with Dimension Switching VARs. Int. J. Forecast. 2014, 30, 280–290. [Google Scholar] [CrossRef][Green Version]
- Koop, G.; Korobilis, D. Large Time-varying Parameter VARs. J. Econom. 2013, 177, 185–198. [Google Scholar] [CrossRef]
- Reichl, J.; Dedecius, K. Likelihood Tempering in Dynamic Model Averaging. In Bayesian Statistics in Action; Springer: Cham, Switzerland, 2017; Volume 194, pp. 67–77. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Barton, K. MuMIn: Multi-Model Inference. 2017. Available online: https://CRAN.R-project.org/package=MuMIn (accessed on 25 June 2020).
- Hyndman, R.; Khandakar, Y. Automatic Time Series Forecasting: The forecast Package for R. J. Stat. Softw. 2008, 26, 1–22. [Google Scholar]
- Revelle, W. psych: Procedures for Psychological, Psychometric, and Personality Research. 2017. Available online: https://CRAN.R-project.org/package=psych (accessed on 25 June 2020).
- Sanchez-Espigares, J.; Lopez-Moreno, A. MSwM: Fitting Markov Switching Models. 2014. Available online: https://CRAN.R-project.org/package=MSwM (accessed on 25 June 2020).
- Urbanek, S. png: Read and Write PNG Images. 2013. Available online: https://CRAN.R-project.org/package=png (accessed on 25 June 2020).
- Warnes, G.; Bolker, B.; Bonebakker, L.; Gentleman, R.; Huber, W.; Liaw, A.; Lumley, T.; Maechler, M.; Magnusson, A.; Moeller, S.; et al. gplots: Various R Programming Tools for Plotting Data. 2016. Available online: https://CRAN.R-project.org/package=gplots (accessed on 25 June 2020).
- Zeileis, A.; Grothendieck, G. zoo: S3 Infrastructure for Regular and Irregular Time Series. J. Stat. Softw. 2005, 14, 1–27. [Google Scholar] [CrossRef]
- Raftery, A.; Hoeting, J.; Volinsky, C.; Painter, I.; Yeung, K. BMA: Bayesian Model Averaging. 2017. Available online: https://CRAN.R-project.org/package=BMA (accessed on 25 June 2020).
- Zeugner, S.; Feldkircher, M. Bayesian Model Averaging Employing Fixed and Flexible Priors: The BMS Package for R. J. Stat. Softw. 2015, 68, 1–37. [Google Scholar] [CrossRef]
- Sevcikova, H.; Raftery, A. mlogitBMA: Bayesian Model Averaging for Multinomial Logit Models. 2013. Available online: https://CRAN.R-project.org/package=mlogitBMA (accessed on 25 June 2020).
- Fraley, C.; Raftery, A.; McLean Sloughter, J.; Gneiting, T. ensembleBMA: Probabilistic Forecasting using Ensembles and Bayesian Model Averaging. 2018. Available online: https://CRAN.R-project.org/package=ensembleBMA (accessed on 25 June 2020).
- Heck, D.; Gronau, Q.; Wagenmakers, E.J. metaBMA: Bayesian Model Averaging for Random and Fixed Effects Meta-Analysis. 2017. Available online: https://CRAN.R-project.org/package=metaBMA (accessed on 25 June 2020).
- Bivand, R.; Gómez-Rubio, V.; Rue, H. Spatial Data Analysis with R - INLA with Some Extensions. J. Stat. Softw. 2015, 63, 1–31. [Google Scholar] [CrossRef]
- Johndrow, J.; Lum, K.; Ball, P. dga: Capture-Recapture Estimation using Bayesian Model Averaging. 2015. Available online: https://CRAN.R-project.org/package=dga (accessed on 25 June 2020).
- Lenkoski, A. spatial.gev.bma: Hierarchical Spatial Generalized Extreme Value (GEV) Modeling with Bayesian Model Averaging (BMA). 2014. Available online: https://CRAN.R-project.org/package=spatial.gev.bma (accessed on 25 June 2020).
- Marbac, M.; Sedki, M. MHTrajectoryR: Bayesian Model Selection in Logistic Regression for the Detection of Adverse Drug Reactions. 2016. Available online: https://CRAN.R-project.org/package=MHTrajectoryR (accessed on 25 June 2020).
- Koop, G. Bayesian Methods for Empirical Macroeconomics with Big Data. Rev. Econ. Anal. 2017, 9, 33–56. [Google Scholar]
- Basturk, N.; Cakmakli, C.; Ceyhan, S.; van Dijk, H. On the Rise of Bayesian Econometrics after Cowles Foundation Monographs 10, 14. Oeconomia 2014, 4–3, 381–447. [Google Scholar] [CrossRef]
- Gary, K.; Poirier, D.; Tobias, J. Bayesian Econometric Methods; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Geweke, J.; Koop, G.; Dijk, H.V. (Eds.) The Oxford Handbook of Bayesian Econometrics; Oxford University Press: Oxford, UK, 2011. [Google Scholar] [CrossRef]
- Greenberg, E. Introduction to Bayesian Econometrics; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Rachev, S.; Hsu, J.; Bagasheva, B.; Fabozzi, F. Bayesian Methods in Finance; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Zellner, A. An Introduction to Bayesian Inference in Econometrics; John Wiley & Sons: Hoboken, NJ, USA, 1996. [Google Scholar]
- Behmiri, N.; Manso, J. Crude Oil Price Forecasting Techniques: A Comprehensive Review of Literature. CAIA Altern. Invest. Anal. Rev. 2013, 2, 30–48. [Google Scholar] [CrossRef]
- Frey, G.; Manera, M.; Markandya, A.; Scarpa, E. Econometric Models for Oil Price Forecasting: A Critical Survey. CESifo Forum 2009, 10, 29–44. [Google Scholar]
- Gabralla, L.; Abraham, A. Computational Modeling of Crude Oil Price Forecasting: A Review of Two Decades of Research. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. 2013, 5, 729–740. [Google Scholar]
- Hamdi, M.; Aloui, C. Forecasting Crude Oil Price Using Artificial Neural Networks: A Literature Survey. Econ. Bull. 2015, 35, 1339–1359. [Google Scholar]
- Sehgal, N.; Pandey, K. Artificial Intelligence Methods for Oil Price Forecasting: A Review and Evaluation. Energy Syst. 2015, 6, 479–506. [Google Scholar] [CrossRef]
- Fan, Y.; Liang, Q.; Wei, Y.M. A Generalized Pattern Matching Approach for Multi-step Prediction of Crude Oil Price. Energy Econ. 2008, 30, 889–904. [Google Scholar] [CrossRef]
- Ghaffari, A.; Zare, S. A Novel Algorithm for Prediction of Crude Oil Price Variation Based on Soft Computing. Energy Econ. 2009, 31, 531–536. [Google Scholar] [CrossRef]
- Ismagilov, I.; Khasanova, S. Short-term Fuzzy Forecasting of Brent Oil Prices. Asian Soc. Sci. 2015, 11, 60–67. [Google Scholar] [CrossRef]
- Jammazi, R.; Aloui, C. Crude oil Price Forecasting: Experimental Evidence from Wavelet Decomposition and Neural Network Modeling. Energy Econ. 2012, 34, 828–841. [Google Scholar] [CrossRef]
- Li, X.; Yu, L.; Tang, L.; Dai, W. Coupling Firefly Algorithm and Least Squares Support Vector Regression for Crude Oil Price Forecasting. In Proceedings of the 2013 Sixth International Conference on Business Intelligence and Financial Engineering, Hangzhou, China, 14–16 November 2013; pp. 80–83. [Google Scholar] [CrossRef]
- Mostafa, M.; El-Masry, A. Oil Price Forecasting Using Gene Expression Programming and Artificial Neural Networks. Econ. Model. 2016, 54, 40–53. [Google Scholar] [CrossRef]
- Mu, X.; Ye, H. Small Trends and Big Cycles in Crude Oil Prices. Energy J. 2015, 36, 49–72. [Google Scholar] [CrossRef]
- Ramyar, S.; Kianfar, F. Forecasting Crude Oil Prices: A Comparison between Artificial Neural Networks and Vector Autoregressive Models. Comput. Econ. 2017, 1–19. [Google Scholar] [CrossRef]
- E Silva, E.G.D.S.; Legey, L.; E Silva, E.A.D.S. Forecasting Oil Price Trends Using Wavelets and Hidden Markov Models. Energy Econ. 2010, 32, 1507–1519. [Google Scholar] [CrossRef]
- Xiao, J.; He, C.; Wang, S. Crude Oil Price Forecasting: A Transfer Learning Based Analog Complexing Model. In Proceedings of the 2012 Fifth International Conference on Business Intelligence and Financial Engineering, Lanzhou, China, 18–21 August 2012; pp. 29–33. [Google Scholar] [CrossRef]
- Yu, L.; Wang, S.; Lai, K. Forecasting Crude Oil Price with an EMD-based Neural Network Ensemble Learning Paradigm. Energy Econ. 2008, 30, 2623–2635. [Google Scholar] [CrossRef]
- Zhang, J.L.; Zhang, Y.J.; Zhang, L. A Novel Hybrid Method for Crude Oil Price Forecasting. Energy Econ. 2014, 49, 649–659. [Google Scholar] [CrossRef]
- Zhang, X.; Lai, K.; Wang, S.Y. A New Approach for Crude Oil Price Analysis based on Empirical Mode Decomposition. Energy Econ. 2008, 30, 905–918. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, J.; Yu, L. A Deep Learning Ensemble Approach for Crude Oil Price Forecasting. Energy Econ. 2017, 66, 9–16. [Google Scholar] [CrossRef]
- Zhao, Y.; Yu, L.; He, K. A Compressed Sensing-based Denoising Approach in Crude Oil Price Forecasting. In Proceedings of the 2013 Sixth International Conference on Business Intelligence and Financial Engineering, Hangzhou, China, 14–16 November 2013; pp. 147–150. [Google Scholar] [CrossRef]
- Kalman, R. A New Approach to Linear Filtering and Prediction Problems. Trans. ASME J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Tucci, M. Time-varying Parameters: A Critical Introduction. Struct. Chang. Econ. Dyn. 1995, 6, 237–260. [Google Scholar] [CrossRef]
- Bates, J.; Granger, C. The Combination of Forecasts. Oper. Res. Q. 1969, 20, 451–468. [Google Scholar] [CrossRef]
- Amini, S.; Parmeter, C. Comparison of Model Averaging Techniques: Assessing Growth Determinants. J. Appl. Econom. 2012, 27, 870–876. [Google Scholar] [CrossRef]
- Baumeister, C.; Kilian, L. Forecasting the Real Price of Oil in a Changing World: A Forecast Combination Approach. J. Bus. Econ. Stat. 2015, 33, 338–351. [Google Scholar] [CrossRef]
- Baumeister, C.; Kilian, L.; Lee, T. Are There Gains from Pooling Real-time Oil Price Forecasts? Energy Econ. 2014, 46, S33–S43. [Google Scholar] [CrossRef]
- Bernard, J.T.; Khalaf, L.; Kichian, M.; Yelou, C. Oil Price Forecasts for the Long Term: Expert Outlooks, Models, or Both? Macroecon. Dyn. 2017, 1–19. [Google Scholar] [CrossRef]
- Ravazzolo, F. Forecasting Financial Time Series Using Model Averaging; Erasmus University: Rotterdam, The Netherlands, 2007. [Google Scholar]
- Wang, Y.; Liu, L.; Wu, C. Forecasting the Real Prices of Crude Oil Using Forecast Combinations over Time-varying Parameter Models. Energy Econ. 2017, 66, 337–348. [Google Scholar] [CrossRef]
- Kaya, H. Forecasting the Price of Crude Oil with Multiple Predictors. Siyasal Bilgiler Fakültesi Derg. (İSMUS) 2016, 1, 133–151. [Google Scholar]
- Buncic, D.; Piras, G. Heterogeneous Agents, the Financial Crisis and Exchange Rate Predictability. J. Int. Money Financ. 2016, 60, 313–359. [Google Scholar] [CrossRef]
- Hansen, B.; Racine, J. Jackknife Model Averaging. J. Econom. 2012, 167, 38–46. [Google Scholar] [CrossRef]
- Skorepa, M.; Komarek, L. Real Exchange Rates: Are They Dominated by Fundamental Factors? Appl. Econ. Lett. 2017, 24, 1389–1392. [Google Scholar] [CrossRef]
- Wan, A.; Zhang, X.; Zou, G. Least Squares Model Averaging by Mallows Criterion. J. Econom. 2010, 156, 277–283. [Google Scholar] [CrossRef]
- Yang, H.; Hosking, J.; Amemiya, Y. Dynamic Latent Class Model Averaging for Online Prediction. J. Forecast. 2015, 34, 1–14. [Google Scholar] [CrossRef]
- Burnham, K.; Anderson, D. Model Selection and Multimodel Inference: A Practical Information—Theoretic Approach; Springer: Berlin, Germany, 2002. [Google Scholar]
- Burnham, K.; Anderson, D. Multimodel Inference: Understanding AIC and BIC in Model Selection. Sociol. Methods Res. 2004, 33, 261–304. [Google Scholar] [CrossRef]
- Raftery, A.; Gneiting, T.; Balabdaoui, F.; Polakowski, M. Using Bayesian Model Averaging to Calibrate Forecast Ensembles. Mon. Weather Rev. 2005, 133, 1155–1174. [Google Scholar] [CrossRef]
- Kapetanios, G.; Labhard, V.; Price, S. Forecasting using Bayesian and Information-theoretic Model Averaging. J. Bus. Econ. Stat. 2008, 26, 33–41. [Google Scholar] [CrossRef]
- Steel, M. Model Averaging and its Use in Economics. arXiv 2019, arXiv:1709.08221. [Google Scholar]
- Magnus, J.; De Luca, G. Weighted-average Least Squares (WALS): A Survey. J. Econ. Surv. 2016, 30, 117–148. [Google Scholar] [CrossRef]
- Moral-Benito, E. Model Averaging in Economics: An Overview. J. Econ. Surv. 2015, 29, 46–75. [Google Scholar] [CrossRef]
- Sala-I-Martin, X. I Just Ran Two Million Regressions. Am. Econ. Rev. 1997, 87, 178–183. [Google Scholar]
- Drachal, K. Forecasting Spot Oil Price in a Dynamic Model Averaging Framework - Have the Determinants Changed over Time? Energy Econ. 2016, 60, 35–46. [Google Scholar] [CrossRef]
- Naser, H. Estimating and Forecasting the Real Prices of Crude Oil: A Data Rich Model Using a Dynamic Model Averaging (DMA) Approach. Energy Econ. 2016, 56, 75–87. [Google Scholar] [CrossRef]
- Fishelson, G. Hotelling Rule, Economic Responses and Oil Prices. Energy Econ. 1983, 5, 153–156. [Google Scholar] [CrossRef][Green Version]
- Amano, A. A Small Forecasting Model of the World Oil Market. J. Policy Model. 1987, 9, 615–635. [Google Scholar] [CrossRef]
- Benes, J.; Chauvet, M.; Kamenik, O.; Kumhof, M.; Laxton, D.; Mursula, S.; Selody, J. The Future of Oil: Geology versus Technology. Int. J. Forecast. 2015, 31, 207–221. [Google Scholar] [CrossRef]
- Hubbard, R.; Weiner, R. Modeling Oil Price Fluctuations and International Stockpile Coordination. J. Policy Model. 1985, 7, 339–359. [Google Scholar] [CrossRef]
- Kaufmann, R.; Dees, S.; Gasteuil, A.; Mann, M. Oil Prices: The Role of Refinery Utilization, Futures Markets and Non-linearities. Energy Econ. 2008, 30, 2609–2622. [Google Scholar] [CrossRef]
- Masoumzadeh, A.; Möst, D.; Ookouomi Noutchie, S. Partial Equilibrium Modelling of World Crude Oil Demand, Supply and Price. Energy Syst. 2017, 8, 217–226. [Google Scholar] [CrossRef]
- Ye, M.; Zyren, J.; Blumberg, C.; Shore, J. A Short-run Crude Oil Price Forecast Model with Ratchet Effect. Atl. Econ. J. 2009, 37, 37–50. [Google Scholar] [CrossRef]
- Yun, V. Interrelations between the Dynamics of Oil Prices and Demand: Contemporary Characteristics. Stud. Russ. Econ. Dev. 2009, 20, 610–613. [Google Scholar] [CrossRef]
- Aloui, R.; Aissa, M. Relationship between Oil, Stock Prices and Exchange Rates: A Vine Copula based GARCH Method. N. Am. J. Econ. Financ. 2016, 37, 458–471. [Google Scholar] [CrossRef]
- Balcilar, M.; Hammoudeh, S.; Asaba, N.A. A Regime-dependent Assessment of the Information Transmission Dynamics between Oil Prices, Precious Metal Prices and Exchange Rates. Int. Rev. Econ. Financ. 2015, 40, 72–89. [Google Scholar] [CrossRef]
- Beckmann, J.; Czudaj, R. Is There a Homogeneous Causality Pattern between Oil Prices and Currencies of Oil Importers and Exporters? Energy Econ. 2013, 40, 665–678. [Google Scholar] [CrossRef]
- Benhmad, F. Modeling Nonlinear Granger Causality between the Oil Price and U.S. Dollar: A Wavelet Based Approach. Econ. Model. 2012, 29, 1505–1514. [Google Scholar] [CrossRef]
- Guesmi, K.; Jlassi, N.; Atil, A.; Haouet, I. On the Influence of Oil Prices on Financial Variables. Econ. Bull. 2016, 36, 2261–2274. [Google Scholar]
- Obadi, S.; Othmanova, S. Oil Prices and the Value of US Dollar: Theoretical Investigation and Empirical Evidence. Ekon. Cas. 2012, 60, 771–790. [Google Scholar]
- Reboredo, J. Modelling Oil Price and Exchange Rate Co-movements. J. Policy Model. 2012, 34, 419–440. [Google Scholar] [CrossRef]
- Zhu, H.M.; Li, R.; Li, S. Modelling Dynamic Dependence between Crude Oil Prices and Asia - Pacific Stock Market Returns. Int. Rev. Econ. Financ. 2014, 29, 208–223. [Google Scholar] [CrossRef]
- Arouri, M.; Jawadi, F.; Nguyen, D. Nonlinear Modeling of Oil and Stock Price Dynamics: Segmentation or Time-varying Integration? Econ. Bull. 2012, 32, 2481–2489. [Google Scholar]
- Arslan-Ayaydin, O.; Khagleeva, I. Energy Economics and Financial Markets; Chapter The Dynamics of Crude Oil Spot and Futures Markets; Springer: Berlin, Germany, 2013; pp. 159–173. [Google Scholar] [CrossRef]
- Bein, M.; Aga, M. On the Linkage between the International Crude Oil Price and Stock Markets: Evidence from the Nordic and Other European Oil Importing and Oil Exporting Countries. Rom. J. Econ. Forecast. 2016, 19, 115–134. [Google Scholar]
- Chen, P.F.; Lee, C.C.; Zeng, J.H. The Relationship between Spot and Futures Oil Prices: Do Structural Breaks Matter? Energy Econ. 2014, 43, 206–217. [Google Scholar] [CrossRef]
- Chen, S.S. Forecasting Crude Oil Price Movements with Oil-sensitive Stocks. Econ. Inq. 2014, 52, 830–844. [Google Scholar] [CrossRef]
- Coppola, A. Forecasting Oil Price Movements: Exploiting the Information in the Futures Market. J. Futur. Mark. 2008, 28, 34–55. [Google Scholar] [CrossRef]
- Gupta, R.; Wohar, M. Forecasting Oil and Stock Returns with a Qual VAR Using over 150 Years Off Data. Energy Econ. 2017, 62, 181–186. [Google Scholar] [CrossRef]
- Ho, L.C.; Huang, C.H. Nonlinear Relationships between Oil Price and Stock Index - Evidence from Brazil, Russia, India and China. Rom. J. Econ. Forecast. 2016, 19, 116–126. [Google Scholar]
- Jawadi, F.; Bellalah, M. Nonlinear Mean Reversion in Oil and Stock Markets. Rev. Account. Financ. 2011, 10, 316–326. [Google Scholar] [CrossRef]
- Salisu, A.; Oloko, T. Modeling Oil Price—US Stock Nexus: A VARMA-BEKK-AGARCH Approach. Energy Econ. 2015, 50, 1–12. [Google Scholar] [CrossRef]
- Caporale, G.; Ciferri, D.; Girardi, A. Time-varying Spot and Futures Oil Price Dynamics. Scott. J. Political Econ. 2014, 61, 78–97. [Google Scholar] [CrossRef]
- Ellen, S.; Zwinkels, R. Oil Price Dynamics: A Behavioral Finance Approach with Heterogeneous Agents. Energy Econ. 2010, 32, 1427–1434. [Google Scholar] [CrossRef]
- Lammerding, M.; Stephan, P.; Trede, M.; Wilfling, B. Speculative Bubbles in Recent Oil Price Dynamics: Evidence from a Bayesian Markov-switching State-space Approach. Energy Econ. 2013, 36, 491–502. [Google Scholar] [CrossRef]
- Lee, Y.H.; Hu, H.N.; Chiou, J.S. Jump Dynamics with Structural Breaks for Crude Oil Prices. Energy Econ. 2010, 32, 343–350. [Google Scholar] [CrossRef]
- Panopoulou, E.; Pantelidis, T. Speculative Behaviour and Oil Price Predictability. Econ. Model. 2015, 47, 128–136. [Google Scholar] [CrossRef]
- Reitz, S.; Slopek, U. Non-linear Oil Price Dynamics: A Tale of Heterogeneous Speculators? Ger. Econ. Rev. 2009, 10, 270–283. [Google Scholar] [CrossRef]
- Byun, S. Speculation in Commodity Futures Markets, Inventories and the Price of Crude Oil. Energy J. 2017, 38, 93–113. [Google Scholar] [CrossRef]
- Ghalayini, L. Modeling and Forecasting Spot Oil Price. Eurasian Bus. Rev. 2017, 7, 355–373. [Google Scholar] [CrossRef]
- Ryan, L.; Whiting, B. Multi-model Forecasts of the West Texas Intermediate Crude Oil Spot Price. J. Forecast. 2016, 36, 395–406. [Google Scholar] [CrossRef]
- Ye, M.; Zyren, J.; Shore, J. Forecasting Crude Oil Spot Price Using OECD Petroleum Inventory Levels. Int. Adv. Econ. Res. 2002, 8, 324–333. [Google Scholar] [CrossRef]
- Al-Harthy, M. Stochastic Oil Price Models: Comparison and Impact. Eng. Econ. 2007, 52, 269–284. [Google Scholar] [CrossRef]
- Morana, C. A Semiparametric Approach to Short-term Oil Price Forecasting. Energy Econ. 2001, 23, 325–338. [Google Scholar] [CrossRef]
- Bremmer, D.; Kesselring, R. The Relationship between U.S. Retail Gasoline and Crude Oil Prices During the Great Recession: “Rockets and Feathers” or “Balloons and Rocks” Behavior? Energy Econ. 2016, 55, 200–210. [Google Scholar] [CrossRef]
- Choi, H.; Leatham, D.; Sukcharoen, K. Oil Price Forecasting Using Crack Spread Futures and Oil Exchange Traded Funds. Contemp. Econ. 2015, 9, 29–44. [Google Scholar] [CrossRef][Green Version]
- Enders, W.; Jones, P. Grain Prices, Oil Prices, and Multiple Smooth Breaks in a VAR. Stud. Nonlinear Dyn. Econom. 2016, 20, 399–419. [Google Scholar] [CrossRef]
- Hassan, M.; Nassar, R. Empirical Investigation and Modeling of the Relationship between Gas Price and Crude Oil and Electricity Prices. J. Econ. Econ. Educ. Res. 2013, 14, 119–130. [Google Scholar]
- Lee, C.C.; Chiu, Y.B. Nuclear Energy Consumption, Oil Prices, and Economic Growth: Evidence from Highly Industrialized Countries. Energy Econ. 2011, 33, 236–248. [Google Scholar] [CrossRef]
- Masih, M.; Algahtani, I.; De Mello, L. Price Dynamics of Crude Oil and the Regional Ethylene Markets. Energy Econ. 2010, 32, 1435–1444. [Google Scholar] [CrossRef]
- Murat, A.; Tokat, E. Forecasting Oil Price Movements with Crack Spread Futures. Energy Econ. 2009, 31, 85–90. [Google Scholar] [CrossRef]
- Tiwari, A.; Sahadudheen, I. Understanding the Nexus between Oil and Gold. Resour. Policy 2015, 46, 85–91. [Google Scholar] [CrossRef]
- Alquist, R.; Kilian, L.; Vigfusson, R. Forecasting the Price of Oil. Handb. Econ. Forecast. 2013, 2, 427–507. [Google Scholar] [CrossRef]
- Apergis, N.; Payne, J. The Causal Dynamics between Renewable Energy, Real GDP, Emissions and Oil Prices: Evidence from OECD Countries. Appl. Econ. 2014, 46, 4519–4525. [Google Scholar] [CrossRef]
- Cross, J.; Nguyen, B. The Relationship between Global Oil Price Shocks and China’s Output: A Time-varying Analysis. Energy Econ. 2017, 62, 79–91. [Google Scholar] [CrossRef]
- Le, T.H.; Chang, Y. Oil Price Shocks and Trade Imbalances. Energy Econ. 2013, 36, 78–96. [Google Scholar] [CrossRef]
- Vo, M. Regime-switching Stochastic Volatility: Evidence from the Crude Oil Market. Energy Econ. 2009, 31, 779–788. [Google Scholar] [CrossRef]
- Wang, J.; Ngene, G. Symmetric and Asymmetric Nonlinear Causalities between Oil Prices and the U.S. Economic Sectors. Rev. Quant. Financ. Account. 2017, 1–20. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, L.; Diao, X.; Wu, C. Forecasting the Real Prices of Crude Oil under Economic and Statistical Constraints. Energy Econ. 2015, 51, 599–608. [Google Scholar] [CrossRef]
- Yang, W.; Han, A.; Hong, Y.; Wang, S. Analysis of Crisis Impact on Crude Oil Prices: A New Approach with Interval Time Series Modelling. Quant. Financ. 2016, 16, 1917–1928. [Google Scholar] [CrossRef]
- Tan, X.; Ma, Y. The Impact of Macroeconomic Uncertainty on International Commodity Prices: Empirical Analysis Based on TVAR Model. China Financ. Rev. Int. 2017, 7, 163–184. [Google Scholar] [CrossRef]
- Chen, H.; Liao, H.; Tang, B.J.; Wei, Y.M. Impacts of OPEC’s Political Risk on the International Crude Oil Prices: An Empirical Analysis Based on the SVAR Models. Energy Econ. 2016, 57, 42–49. [Google Scholar] [CrossRef]
- Bekiros, S.; Gupta, R.; Paccagnini, A. Oil Price Forecastability and Economic Uncertainty. Econ. Lett. 2015, 132, 125–128. [Google Scholar] [CrossRef]
- Chai, J.; Lu, Q.; Hu, Y.; Wang, S.; Lai, K.; Liu, H. Analysis and Bayes Statistical Probability Inference of Crude Oil Price Change Point. Technol. Forecast. Soc. Chang. 2017. [Google Scholar] [CrossRef]
- Kim, J.M.; Jung, H. Time Series Forecasting Using Functional Partial Least Square Regression with Stochastic Volatility, GARCH, and Exponential Smoothing. J. Forecast. 2017. [Google Scholar] [CrossRef]
- Lee, C.Y.; Huh, S.Y. Forecasting Long-term Crude Oil Prices Using a Bayesian Model with Informative Priors. Sustainability 2017, 9, 190. [Google Scholar] [CrossRef]
- Fattouh, B.; Scaramozzino, P. Uncertainty, Expectations, and Fundamentals: Whatever Happened to Longterm Oil Prices? Oxf. Rev. Econ. Policy 2011, 27, 186–206. [Google Scholar] [CrossRef]
- Han, L.; Lv, Q.; Yin, L. Can Investor Attention Predict Oil Prices? Energy Econ. 2017, 66, 547–558. [Google Scholar] [CrossRef]
- Aye, G.; Gupta, R.; Hammoudeh, S.; Kim, W. Forecasting the Price of Gold Using Dynamic Model Averaging. Int. Rev. Financ. Anal. 2015, 41, 257–266. [Google Scholar] [CrossRef]
- Baur, D.; Beckmann, J.; Czudaj, R. A Melting Pot - Gold Price Forecasts under Model and Parameter Uncertainty. Int. Rev. Financ. Anal. 2016, 48, 282–291. [Google Scholar] [CrossRef]
- Risse, M.; Ohl, L. Using Dynamic Model Averaging in State Space Representation with Dynamic Occam’s Window and Applications to the Stock and Gold Market. J. Empir. Financ. 2017, 44, 158–176. [Google Scholar] [CrossRef]
- Buncic, D.; Moretto, C. Forecasting Copper Prices with Dynamic Averaging and Selection Models. N. Am. J. Econ. Financ. 2015, 33, 1–38. [Google Scholar] [CrossRef]
- Koop, G.; Tole, L. Forecasting the European Carbon Market. J. R. Stat. Soc. Ser. A Stat. Soc. 2013, 176, 723–741. [Google Scholar] [CrossRef]
- Baxa, J.; Plašil, M.; Vašiček, B. Inflation and the Steeplechase between Economic Activity Variables: Evidence for G7 Countries. BE J. Macroecon. 2017, 17. [Google Scholar] [CrossRef]
- Di Filippo, G. Dynamic Model Averaging and CPI Inflation Forecasts: A Comparison between the Euro Area and the United States. J. Forecast. 2015, 34, 619–648. [Google Scholar] [CrossRef]
- Ferreira, D.; Palma, A. Forecasting Inflation with the Phillips Curve: A Dynamic Model Averaging Approach for Brazil. Rev. Bras. De Econ. 2015, 69, 451–465. [Google Scholar] [CrossRef]
- Koop, G.; Korobilis, D. Forecasting Inflation Using Dynamic Model Averaging. Int. Econ. Rev. 2012, 53, 867–886. [Google Scholar] [CrossRef]
- Del Negro, M.; Hasegawa, R.; Schorfheide, F. Dynamic Prediction Pools: An Investigation of Financial Frictions and Forecasting Performance. J. Econom. 2016, 192, 391–405. [Google Scholar] [CrossRef]
- Koop, G.; Korobilis, D. UK Macroeconomic Forecasting with Many Predictors: Which Models Forecast Best and When Do They Do So? Econ. Model. 2011, 28, 2307–2318. [Google Scholar] [CrossRef]
- Bork, L.; Moller, S. Forecasting House Prices in the 50 States Using Dynamic Model Averaging and Dynamic Model Selection. Int. J. Forecast. 2015, 31, 63–78. [Google Scholar] [CrossRef]
- Risse, M.; Kern, M. Forecasting House-price Growth in the Euro Area with Dynamic Model Averaging. North Am. J. Econ. Financ. 2016, 38, 70–85. [Google Scholar] [CrossRef]
- Wei, Y.; Cao, Y. Forecasting House Prices Using Dynamic Model Averaging Approach: Evidence from China. Econ. Model. 2017, 61, 147–155. [Google Scholar] [CrossRef]
- De Bruyn, R.; Gupta, R.; Van Eyden, R. Can We Beat the Random-walk Model for the South African Rand—U.S. Dollar and South African Rand - UK Pound Exchange Rates? Evidence from Dynamic Model Averaging. Emerg. Mark. Financ. Trade 2015, 51, 502–524. [Google Scholar] [CrossRef]
- Gupta, R.; Hammoudeh, S.; Kim, W.; Simo-Kengne, B. Forecasting China’s Foreign Exchange Reserves Using Dynamic Model Averaging: The Roles of Macroeconomic Fundamentals, Financial Stress and Economic Uncertainty. N. Am. J. Econ. Financ. 2014, 28, 170–189. [Google Scholar] [CrossRef]
- Koop, G.; Korobilis, D. A New Index of Financial Conditions. Eur. Econ. Rev. 2014, 71, 101–116. [Google Scholar] [CrossRef]
- Liu, J.; Wei, Y.; Ma, F.; Wahab, M. Forecasting the Realized Range-based Volatility Using Dynamic Model Averaging Approach. Econ. Model. 2017, 61, 12–26. [Google Scholar] [CrossRef]
- Naser, H.; Alaali, F. Can Oil Prices Help Predict US Stock Market Returns? Evidence Using a Dynamic Model Averaging (DMA) Approach. Empir. Econ. 2017, 1–21. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, F.; Wei, Y.; Wu, C. Forecasting Realized Volatility in a Changing World: A Dynamic Model Averaging Approach. J. Bank. Financ. 2016, 64, 136–149. [Google Scholar] [CrossRef]
- Ley, E.; Steel, M. Jointness in Bayesian Variable Selection with Applications to Growth Regression. J. Macroecon. 2007, 29, 476–493. [Google Scholar] [CrossRef]
- Koop, G.; Onorante, L. Macroeconomic Nowcasting Using Google Probabilities. Available online: http://www.ecb.europa.eu/events/pdf/conferences/140407/OnoranteKoop_MacroeconomicNowcastingUsingGoogleProbabilities.pdf (accessed on 25 June 2020).
- Google. Google Trends; Google: Mountain View, CA, USA, 2017. [Google Scholar]
- Onorante, L.; Raftery, A. Dynamic Model Averaging in Large Model Spaces Using Dynamic Occam’s Window. Eur. Econ. Rev. 2016, 81, 2–14. [Google Scholar] [CrossRef] [PubMed]
- Eicher, T.; Papageorgiou, C.; Raftery, A. Default Priors and Predictive Performance in Bayesian Model Averaging, with Application to Growth Determinants. J. Appl. Econom. 2011, 26, 30–55. [Google Scholar] [CrossRef]
- Mitchell, T.; Beauchamp, J. Bayesian Variable Selection in Linear Regression (with Discussion). J. Am. Stat. Assoc. 1988, 83, 1023–1036. [Google Scholar] [CrossRef]
- Koop, G.; Korobilis, D. Variational Bayes Inference in High-dimensional Time-varying Parameter Models. Available online: https://arxiv.org/pdf/1809.03031 (accessed on 25 June 2020).
- Yin, X.; Peng, J.; Tang, T. Improving the Forecasting Accuracy of Crude Oil Prices. Sustainability 2018, 10, 454. [Google Scholar] [CrossRef]
- Gelman, A.; Hwang, J.; Vehtari, A. Understanding Predictive Information Criteria for Bayesian Models. Stat. Comput. 2014, 24, 997–1016. [Google Scholar] [CrossRef]
- Timmermann, A. Handbook of Economic Forecasting; Chapter Forecast Combinations; Elsevier: Amsterdam, The Netherlands, 2006; pp. 135–196. [Google Scholar]
- Pesaran, M.; Pick, A. Forecast Combination across Estimation Windows. J. Bus. Econ. Stat. 2011, 29, 307–318. [Google Scholar] [CrossRef]
- Diebold, F.; Mariano, R. Comparing Predictive Accuracy. J. Bus. Econ. Stat. 1995, 13, 253–263. [Google Scholar]
- Diebold, F. Comparing Predictive Accuracy, Twenty Years Later: A Personal Perspective on the Use and Abuse of Diebold-Mariano Tests. J. Bus. Econ. Stat. 2015, 33. [Google Scholar] [CrossRef]
- Harvey, D.; Leybourne, S.; Newbold, P. Testing the Equality of Prediction Mean Squared Errors. Int. J. Forecast. 1997, 13, 281–291. [Google Scholar] [CrossRef]
- Newbold, P.; Harvey, D. A Companion to Economic Forecasting; Chapter Forecast Combinations; Blackwell Publishing Ltd.: Hoboken, NJ, USA, 2002; pp. 268–283. [Google Scholar]
- Joanes, D.; Gill, C. Comparing Measures of Sample Skewness and Kurtosis. J. R. Stat. Soc. D (Stat.) 1998, 47, 183–189. [Google Scholar] [CrossRef]
- Engle, R. Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Trapletti, A.; Hornik, K. tseries: Time Series Analysis and Computational Finance; R package Version 0.10-43. 2018. Available online: https://CRAN.R-project.org/package=tseries (accessed on 25 June 2020).
- World Steel Association. Crude Steel Production; World Steel Association: Brussels, Belgium, 2017. [Google Scholar]
- CBOE. VIX Options and Futures Historical Data; CBOE: Chicago, IL, USA, 2017. [Google Scholar]
- EIA. Petroleum and Other Liquids; EIA: Washington, DC, USA, 2017. [Google Scholar]
- FRED. Economic Data; FRED: St. Louis, MO, USA, 2017. [Google Scholar]
- MSCI. End of Day Index Data Search; MSCI: New York, NY, USA, 2017. [Google Scholar]
- Mersmann, O.; Beleites, C.; Hurling, R.; Friedman, A.; Ulrich, J. microbenchmark: Accurate Timing Functions. 2017. Available online: https://CRAN.R-project.org/package=microbenchmark (accessed on 25 June 2020).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Driver | Reason to Treat as a Potential Driver and Source |
|---|---|
| Interest rate | Higher rate results in higher price of a non-renewable resource (Hotelling’s rule). Higher rate results in lower price of a commodity because of the cost of holding inventory [87]. |
| Supply and demand | Increase in demand results in price increase. Increase in supply – in price decrease. This is sometimes known as the law of supply and demand [88,89,90,91,92,93,94]. |
| Exchange rates | The price of oil in the domestic currency changes as the exchange rate changes. This has different implications for oil-exporting and oil-importing countries [95,96,97,98,99,100,101,102]. |
| Stock markets | Empirically it was found that oil price and stock indices are usually following similar time paths. Also, that predictive accuracy of oil price forecasts increase when data from stock markets is used. Oil price can affect interest rates, production, GDP, which further affects the expected free cash flow. This further affects stock prices. Moreover, there is a rising financialization of oil market, i.e., since 2000s increasing links between oil and stocks markets [95,103,104,105,106,107,108,109110111112]. |
| Speculative forces | Links between spot and futures markets. Above mentioned financialization. Trading on OTC electronic exchanges [113,114,115,116,117,118]. |
| Inventories | They can be released to cover supply shortages, as so called buffer inventory. Also, they can be stored to be sold at higher prices in the future. This is called speculative inventory [119,120,121,122]. |
| Oil price volatility | It has a direct effect on the energy sector. Higher volatility might put pressure on consumers to switch to alternative energy sources, and therefore, demand decrease [123,124]. |
| Other commodities | Empirically, correlations between oil price and prices of other commodities, for example gold, are found. Gold price usually increase during market downturns [96,125,126,127,128,129,130,131,132]. |
| Economic activity | Economic growth stimulates oil demand [109,133,134,135,136,137,138,139,140]. |
| Policy uncertainty | Empirically, economic policy uncertainty increases predictive accuracy of oil price forecasts. Usually, positive uncertainty shocks affect commodity prices returns negatively [141,142,143]. |
| Package | Min | Mean | Median | Max |
|---|---|---|---|---|
| fDMA | 7.80 | 7.89 | 7.91 | 7.94 |
| eDMA | 0.88 | 0.88 | 0.88 | 0.89 |
| dma | 61.55 | 62.07 | 62.05 | 62.50 |
| Feature\Package | dma | eDMA | fDMA |
|---|---|---|---|
| Speed | √ | ||
| DMS | √ | √ | |
| Median Probability Model | √ | ||
| Google Trends | √ | ||
| Dynamic Occam’s window | √ | ||
| EWMA | √ | √ | |
| General prior | √ | ||
| Multiple | √ | √ | |
| Grid on forgetting factors | √ | ||
| Choosing models for averaging | √ | √ | |
| Information-theoretic averaging | √ | ||
| Alternative forecasts | √ | ||
| User friendly plotting of outcomes | √ | √ | |
| Additional tests, functions, etc. | √ | √ |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Drachal, K. Dynamic Model Averaging in Economics and Finance with fDMA: A Package for R. Signals 2020, 1, 47-99. https://doi.org/10.3390/signals1010004
Drachal K. Dynamic Model Averaging in Economics and Finance with fDMA: A Package for R. Signals. 2020; 1(1):47-99. https://doi.org/10.3390/signals1010004
Chicago/Turabian StyleDrachal, Krzysztof. 2020. "Dynamic Model Averaging in Economics and Finance with fDMA: A Package for R" Signals 1, no. 1: 47-99. https://doi.org/10.3390/signals1010004
APA StyleDrachal, K. (2020). Dynamic Model Averaging in Economics and Finance with fDMA: A Package for R. Signals, 1(1), 47-99. https://doi.org/10.3390/signals1010004