3.1. Problem Formalization of Open-Set Recognition
The general closed-set classifier
comprises two primary components: (1) the feature extractor
, where
x denotes the original input to the neural network and
represents the neural network itself; and (2) the classifier
, which utilizes the feature extraction result
for classification and assesses the network’s effectiveness. In traditional closed-set recognition tasks, training is typically conducted using the cross-entropy loss function. To review the computation of the cross-entropy loss function, we consider
N samples, each belonging to one of
C categories. For the
ith sample, the true label is
, and the output at the
layer of the model is
, where
represents the
score of the
ith sample in the
jth category. By applying a Softmax operation to the
layer’s output, we convert it into a probability distribution:
where
represents the probability that the
ith sample belongs to the
jth class.
According to Equation (
1), the probability for each output at the
layer is computed, and the negative log-likelihood leads to the formulation of the cross-entropy loss. This expression quantifies the difference between the predicted probability distribution and the true distribution of labels, serving as a critical metric for evaluating the performance of the classifier:
However, the aforementioned calculation method directly assumes that , focusing solely on the known samples during training and neglecting the consideration of unknown classes. Furthermore, when utilizing cross-entropy (CE) for training, the model emphasizes classification without addressing intra-class and inter-class distance issues. As a result, models trained with CE tend to perform poorly when encountering unknown samples.
To facilitate explanation and understanding, we model the open-set recognition problem as follows. The region distant from the known data, encompassing both known known classes (KKCs) and known unknown classes (KUCs), is defined as the open space O. The dataset of known classes is denoted as
with corresponding class labels
, where
and C represents the known classes. Conversely, the dataset of unknown classes is represented as
with unknown class labels
, where
. Consequently, the dataset within the open space
O is given by
. Classifying any sample in the open space
O into one of the known classes inherently introduces a risk termed open-space risk
. Given that unknown samples remain entirely uncharacterized during training, conducting a quantitative analysis of the open-space risk proves challenging. Below, we provide a qualitative description of
:
where
O is an open space,
is the overall measure space,
f is the measurable recognition function,
indicates that the sample is classified as one of the KKC types; otherwise,
. This means that as the number of samples labeled as KKC types in the open space increases, the open-space risk
becomes larger.
Additionally, in the process of classifying samples, there exists the empirical risk
. The formal expression for
is as follows:
where
L represents the discrepancy between the predicted values and the true labels.
The goal of the open-set recognition task is to minimize the following open-set risk
:
where
is the regularization parameter.
Thus, we complete the modeling of the open-set recognition problem.
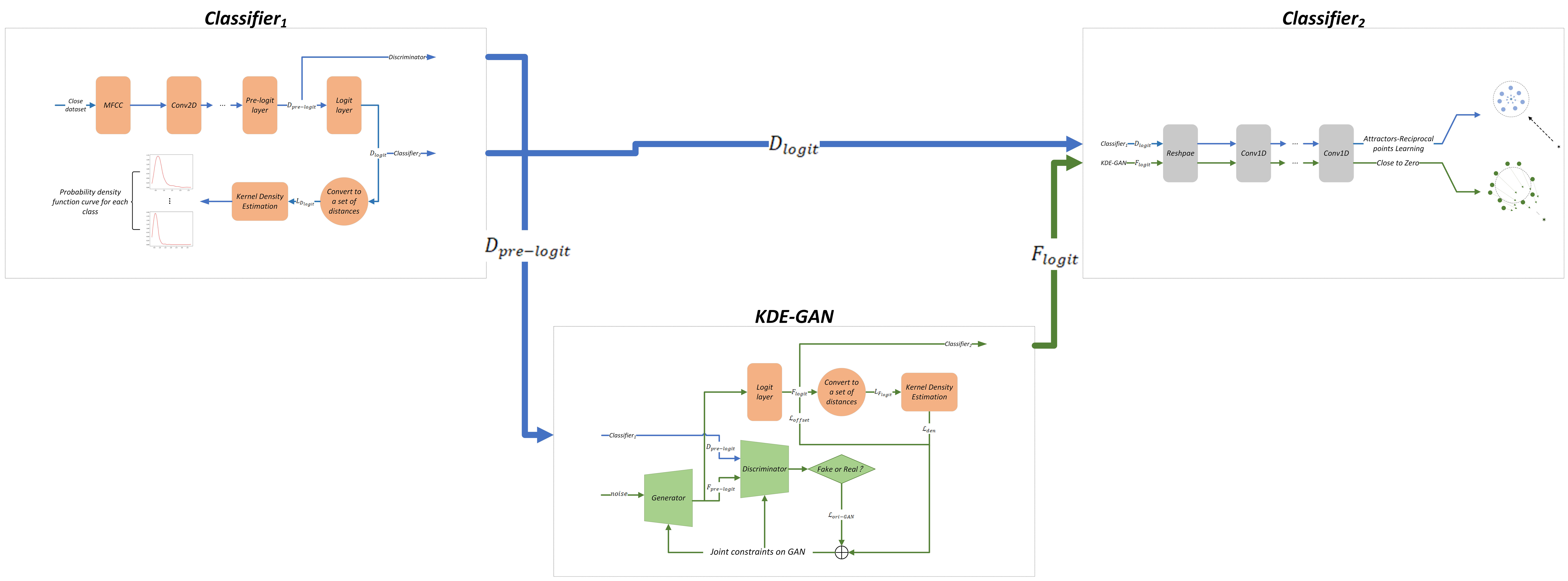
In this study, we first select a closed-set classification algorithm and a closed-set classification model, denoted as
, to conduct preliminary classification of environmental audio targets. From this, we obtain the output vectors from the
pre-logit layer (the second-to-last layer of the network) which serve as the training set for sample generation. Subsequently, we employ a KDE-constrained GAN to generate edge samples in the
layer (this is due to the fact that samples situated at the edges of the
pre-logit layer do not necessarily align with those at the edges of the
layer, thereby necessitating constraints at the
layer), resulting in a series of edge sample datasets,
. The training of the
KDE-GAN is accomplished through a combination of the original GAN optimization objectives in the
pre-logit layer, along with the Density Loss and Offset Loss in the
layer. Finally, we design a two-stage classification model, denoted as
, utilizing
and
as datasets. We implement attractors and reciprocal point learning algorithms as optimization objectives to complete the two-stage training process. During this process, the data in
are pushed away from low-density regions by the counterpoints while maintaining strong intra-class cohesion under the influence of attractors. Concurrently, the data in
are constrained to remain within low-density regions. The overall process is illustrated in
Figure 1, with detailed architectural components visualized in
Figure 2,
Figure 3 and
Figure 4.
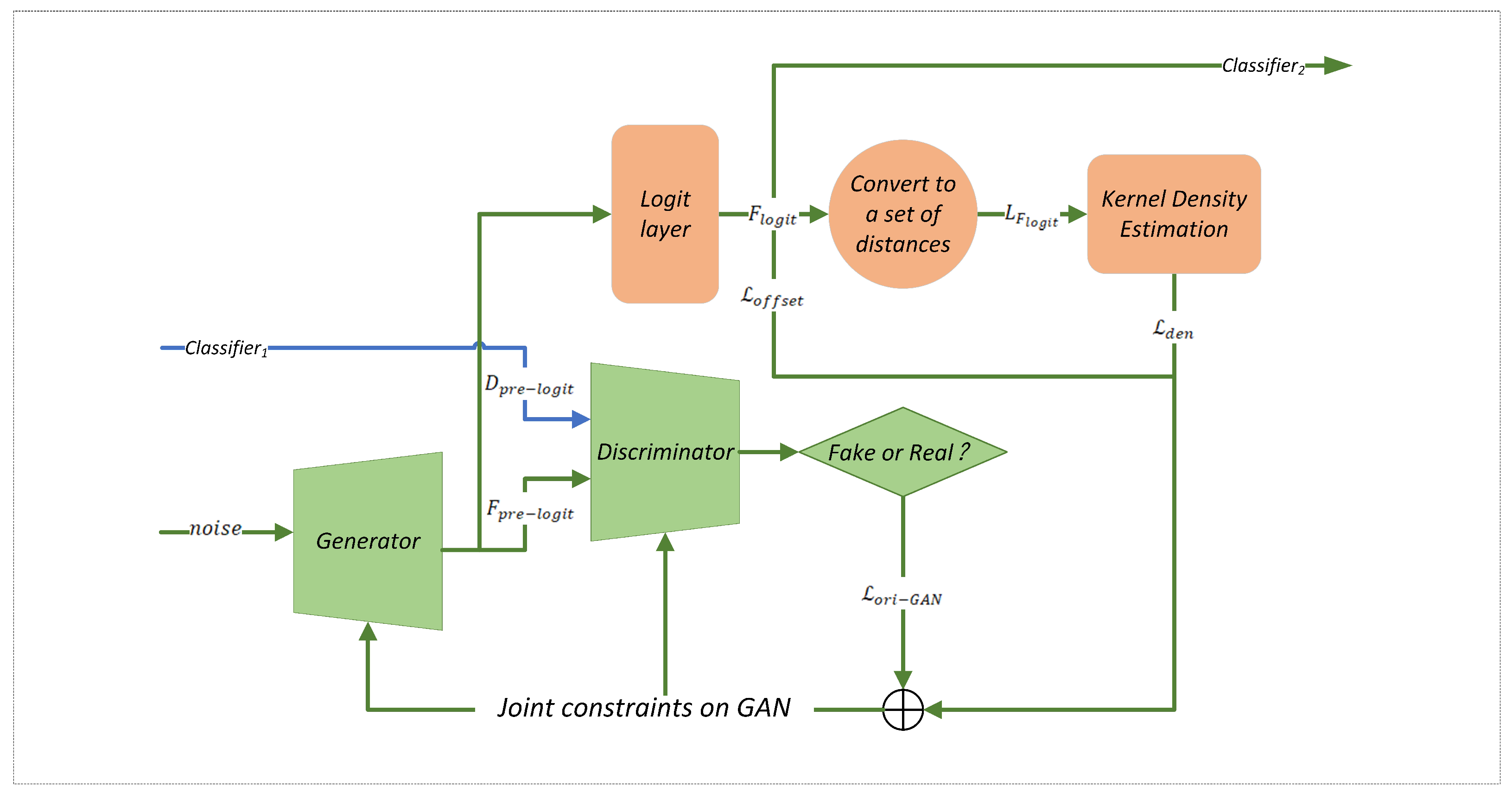
The overall algorithm flowchart delineates the primary process of our proposed algorithm, which consists of three main components: , , and KDE-GAN. Initially, raw samples are input into to generate pre-logit layer samples, which subsequently serve as the training set for KDE-GAN. Within the KDE-GAN framework, we employ the original GAN optimization objective while incorporating additional constraints to produce edge samples that simulate open-set scenarios. Specifically, the fake samples generated by the GAN in the pre-logit layer are mapped to the layer, where Density Loss is computed based on the Kernel Density Estimation (KDE) of the original samples. This methodology ensures that the generated samples are situated at the boundaries of each class. To prevent the generated samples from drifting in any direction, we introduce an Offset Loss. The mapped original samples in the layer, along with the generated outputs, are then fed into . For the original samples, we utilize an Attractor–Reciprocal Point learning algorithm, whereas for the generated outputs, we encourage the results to converge toward zero. This strategy effectively ensures that closed-set data points remain proximate to attractors and distant from reciprocal points, while open-set data points are preserved within low-density regions.
3.2. Generation of Edge Samples Based on KDE-GAN
Open-set samples are inherently unknown, making it challenging to apply even the most advanced closed-set classifiers to open-set recognition problems. As discussed in the introduction, UIK samples are particularly difficult to differentiate, as they may lie closer to the sample center. In this study, we focus on distinguishing between USK and UO samples. UO samples can be effectively rejected based on their distance from the sample center, while USK samples are treated as interference items. These USK samples typically surround the clusters of known samples, significantly complicating the model’s decision-making process. To address these challenges, this section introduces the use of a KDE-constrained GAN for the generation of edge samples, aimed at enhancing the dataset. This approach seeks to improve the model’s ability to recognize and differentiate between closed-set and open-set scenarios by augmenting the training data with strategically generated edge samples. To address the challenges of high-dimensional environmental audio data points and the relatively limited dataset size compared to image datasets, which often lead to training difficulties, we propose a sample generation strategy leveraging the pre-logit layer vectors to adapt to the unique characteristics of audio samples. Specifically, the pre-logit feature representations are utilized to guide the Generative Adversarial Network (GAN) in synthesizing augmented samples. Furthermore, to ensure the quality and diversity of generated samples, Kernel Density Estimation (KDE) is introduced as a constraint during GAN training, effectively regularizing the generation of boundary samples that lie near the decision regions of the classifier. This approach enhances the model’s robustness and generalizability by enriching the training distribution while maintaining alignment with the intrinsic statistical properties of the original audio data.
GANs consist primarily of a Generator and a Discriminator. The Generator takes a random noise distribution
and generates synthetic data that closely resemble the original sample distribution
in order to deceive the Discriminator. The Discriminator’s role is to assess whether the input sample originates from the real data or the generated data. This setup embodies a two-player game concept, where adversarial training between the Generator and the Discriminator drives the optimization process. The optimization objective function of the original GAN is defined as follows:
where
represents the probability that a sample comes from
and
represents the probability that a sample comes from
.
Given that environmental audio datasets are typically much smaller than image or text datasets, directly performing data augmentation on raw samples presents significant challenges. To address this, this study proposes an alternative strategy: performing data augmentation on the output of a specific neural network layer.
In Generative Adversarial Networks (GANs), the generator typically involves a dimension-increasing process to effectively capture the structural patterns of the data distribution, rather than relying directly on high-dimensional input at this stage. This approach helps avoid overfitting while improving generation efficiency. To ensure the generated samples maintain the same dimensionality as the training samples, the generator’s input dimension is usually kept low. Considering the limited number of categories involved in this study’s recognition task, the generator’s input dimension is further reduced, posing certain challenges for the GAN’s architectural design.
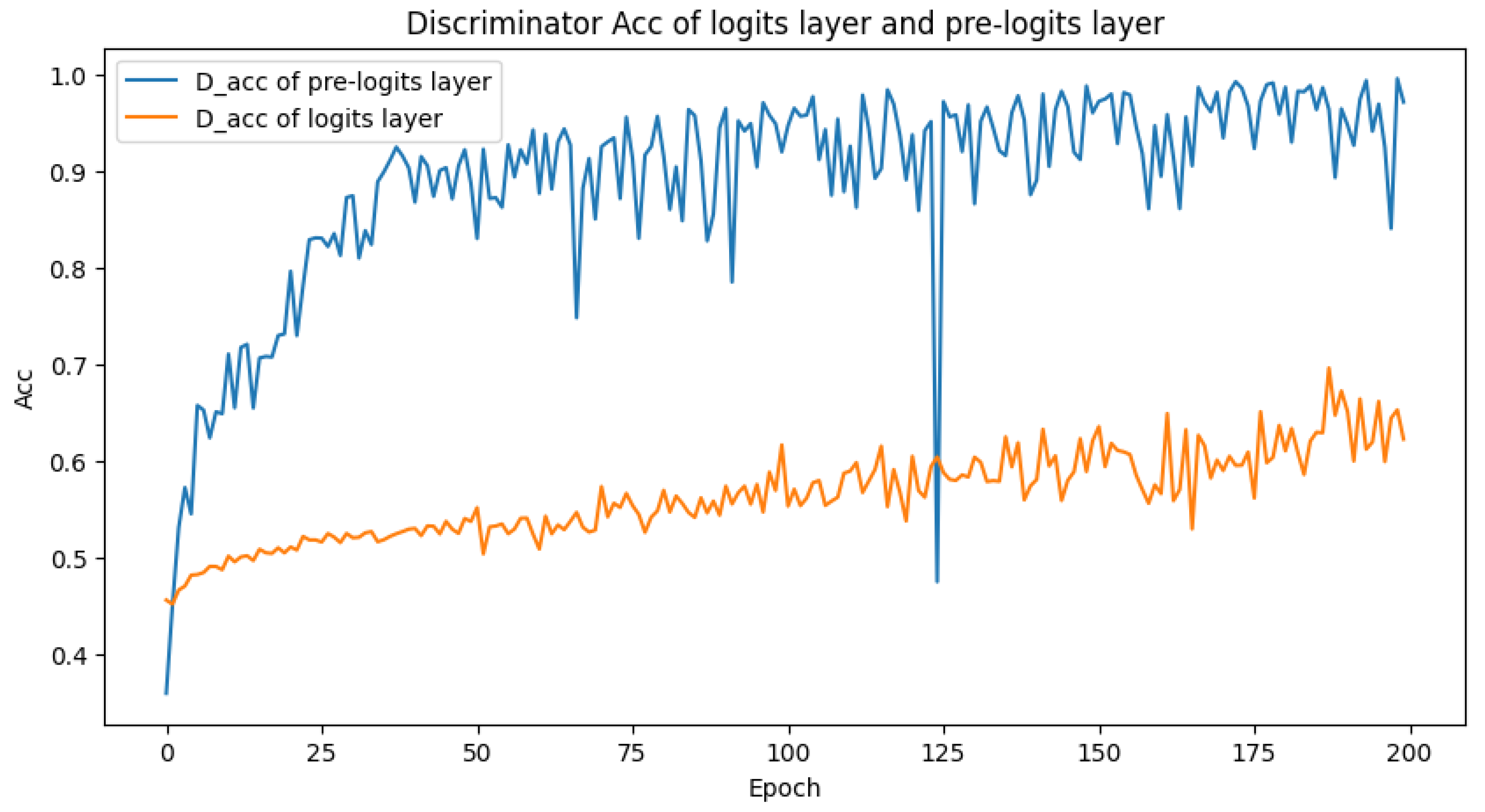
Therefore, this research proposes using the pre-logit layer output (i.e., the layer preceding the logit output) as the GAN’s input to optimize the generator design. In this section, since the generated samples are high-dimensional vectors that are difficult to evaluate directly, we leverage the discriminator’s accuracy as an indirect measure of the generator’s performance. This is possible because the generator and discriminator engage in a zero-sum game during training. Under the constraint that the generator’s input dimension must be smaller than its output dimension, samples are generated at both the pre-logit and logit layers, with the discriminator’s accuracy curves visualized as shown in
Figure 5.
So as illustrated in
Figure 5, which displays the accuracy curves of the discriminator during GAN training on samples from both the
layer and the
pre-logit layer, it is clear that the small dimensionality of the
layer in environmental recognition tasks where most datasets contain only a few classes poses a risk of overfitting when the latent space dimension of the GAN is only slightly larger. Conversely, if the latent space dimension is smaller than that of the
layer, the GAN network has an insufficient number of parameters, leading to failure in convergence.
In contrast, generating samples at the pre-logit layer enables the attainment of higher-quality results with the GAN. Consequently, the subsequent sections focus on training the GAN using a dataset composed of outputs from the pre-logit layer.
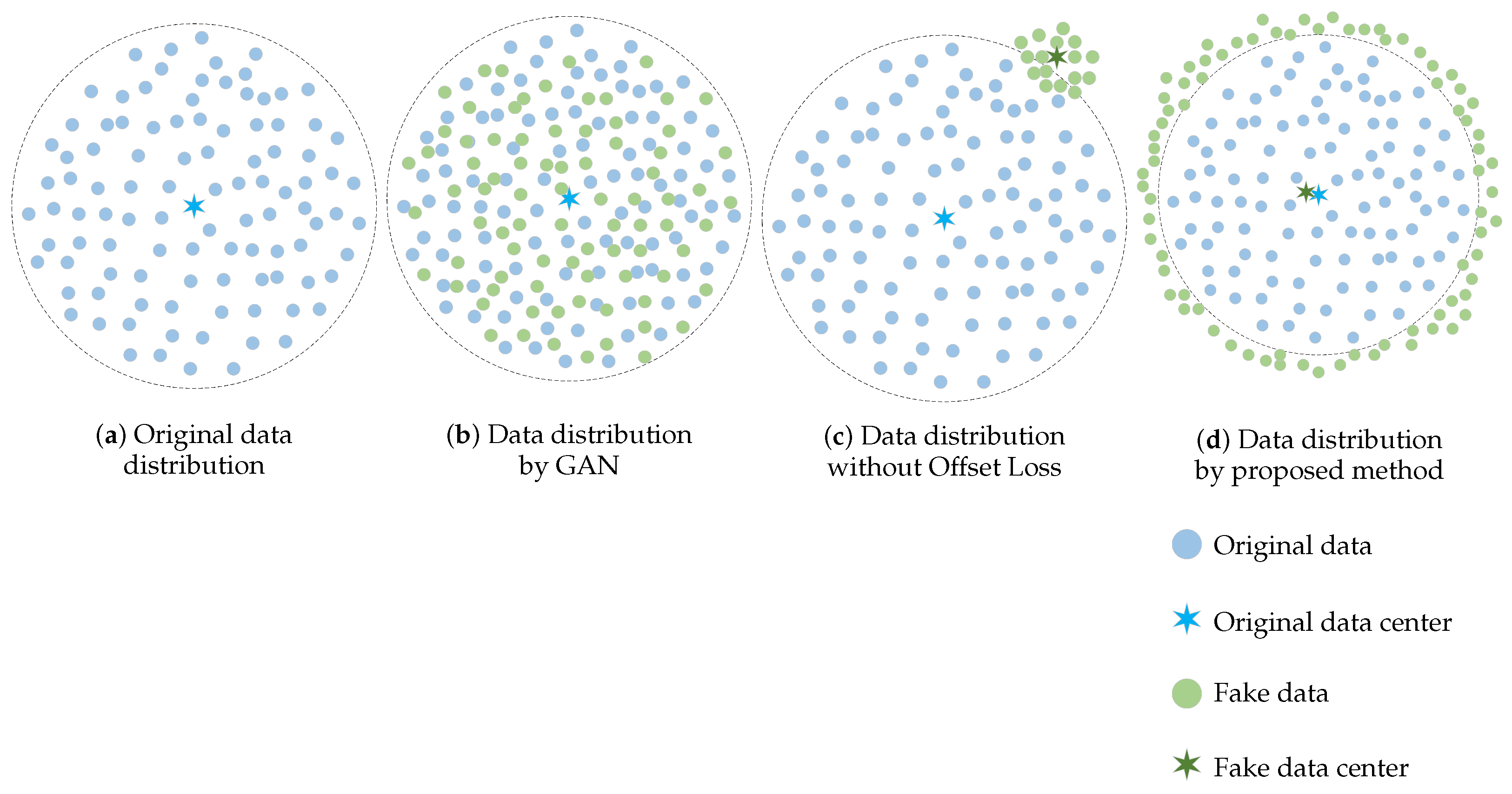
However, the aforementioned optimization objective function merely compels the fake data distribution to approximate the original sample distribution, as illustrated in
Figure 6a,b. Consequently, generating edge samples using this function alone proves challenging, necessitating additional optimization strategies.
Given that the
layer dataset
comprises high-dimensional vectors and considering that environmental audio datasets are typically smaller than image or text datasets, fitting their distribution poses a challenge. Furthermore, generating edge data for each class of samples is essential. If the original data are represented as several hyperspherical distributions, edge samples are located at the peripheries of these hyperspheres, complicating visualization. To facilitate modeling, we partition
into
C subsets
, compute the center points
for each class, and derive the corresponding distances to form a new one-dimensional dataset
, where
represents the distance set for the
ith class. For any
, the calculation formula is as follows:
where
is the distance function,
, and
is the corresponding center point.
We reduce high-dimensional data points to one-dimensional representations, facilitating modeling and enabling histogram visualization, as illustrated in
Figure 7a. The edge samples we aim to generate correspond to those located at the tail of this histogram. However, as previously noted, the optimization objective defined in Equation (
6) of the original GAN only ensures that the generated samples approximate the original data distribution, complicating the direct acquisition of boundary samples. Consequently, the generated samples from the original GAN are also represented as a distance histogram, as depicted in
Figure 7b.
We now introduce the Kernel Density Estimation (KDE) method to model
. We let
denote the cumulative distribution function of
and let
represent its probability density function. Then
However, discrete data points alone do not allow us to derive analytical expressions for
and
. Therefore, we introduce
, which serves as the empirical distribution function corresponding to
.
is an unbiased estimation of
. It approximates
by the ratio of the number of times
occurs in
n observations to
n. Substituting this into
, we can obtain its approximate estimation
:
Upon introducing the kernel function, Equation (
10) can be transformed into
In this context, represents the kernel function and h denotes the bandwidth of the kernel function.
After fitting the probability density function, we can calculate the probability of data points falling within
.
What we need to generate are data points surrounding each class sample, specifically points that are farther from the corresponding center. This means that
should be larger. To address this, we propose the Density Loss:
where
,
, and
represents the center of the corresponding class;
is the distance function.
Additionally, we aim for the generated samples to be as uniformly distributed as possible on the surface of the corresponding class hypersphere. Relying solely on
as a constraint may cause the network output to shift in a specific direction on the hypersphere, rather than achieving a uniform distribution across its surface, as illustrated in
Figure 6c. In such instances, the constraint of
may still be satisfied. Therefore, we must introduce an additional constraint to guide the network toward convergence in the desired direction.
In fact, we can conceptualize the desired generated fake samples as a spherical shell surrounding a hypersphere. This spherical shell should share the same center as the hypersphere of the corresponding class. By constraining the distance between the center of the shell and the center of the hypersphere, we can ensure that the generated fake samples are uniformly distributed on the surface of the hypersphere. To facilitate this, we propose the Offset Loss:
where
is the mean of the samples belonging to the
ith class within the current batch size.
By incorporating , any shift of the generated samples within a batch in a particular direction results in an increased loss. This, in conjunction with , compels the generated samples to be as uniformly distributed as possible on the surface of the spherical shell surrounding the hypersphere.
In summary, we propose an optimization objective function for Generative Adversarial Network (GAN) specifically tailored for generating edge samples:
Utilizing the improved optimization objective function to generate fake samples, we classify them by distance, calculate the distance from the center for each sample, and present the results as a histogram, as illustrated in
Figure 7c. A comparison between
Figure 7b,c confirms that the enhanced generator is more effective in producing samples situated at the edges compared to the original GAN.
In this context, we generate edge data for each sample category, as illustrated in
Figure 8. This approach enables us to leverage the data to simulate open-set samples, thereby facilitating data augmentation.
3.3. Attractor–Reciprocal Point Learning
Before introducing our method, it is essential to review the reciprocal point algorithm [
18,
26]. For a given class sample set
, which is partitioned into C distinct subsets
based on labels, we define C reciprocal points
. The training objective for the reciprocal points is to maximize the difference between each training subset
and its corresponding reciprocal point
. Therefore, the relationship between data points in other subsets
and the unknown sample set
with respect to the reciprocal point
must satisfy
where
denotes a function used to compute their difference.
In [
18,
26], the authors use euclidean distance
and the dot product
to describe this difference
.
We can predict a sample’s class based on this difference: the greater the distance from a reciprocal point, the higher the probability that the sample belongs to that class. Conversely, if the distance is below a certain threshold, the sample can be classified as unknown. These measures aim to minimize the empirical risk . Additionally, the author implements an Adversarial Margin Constraint to limit the open space within a bounded range, addressing the open-space risk . Despite the effectiveness of the aforementioned methods, several issues persist: (1) Reciprocal points are randomly selected and updated via backpropagation, making it susceptible to local optima; (2) The training process primarily emphasizes distancing data points from their corresponding reciprocal points without addressing intra-class relationships, which may result in a wider distribution of known class samples in the open space and an elevated open set risk; (3) The generation of edge samples is not accounted for.
In our algorithm, each class is assigned an attractor
and a reciprocal point
. The role of the reciprocal point is to maximize the distance from the samples, while the attractor ensures that the distribution of samples within a class is minimized. Furthermore, by incorporating edge samples from
, we restrict the open set data to a low-density region. For each sample
x in the known set
, we first extract its feature vector
through the neural network. We then compute the distances to each pair of attractor and reciprocal points, classifying the sample as belonging to the class whose attractor is closest and whose reciprocal point is farthest, expressed as follows:
where
represents a certain distance metric.
Therefore, the probability that
x belongs to class
i can be assessed based on the distances between the sample’s feature vector
and the attractor
as well as the reciprocal point
of class
i:
To satisfy the properties of non-negativity and normalization of probabilities, we can provide two different probability expressions:
where
is a small value introduced to ensure that the denominator is not zero.
Equation (
20)-1 primarily measures the probability by examining the difference in distances between the feature vector of the sample point,
, to the reciprocal point and the attractor. In contrast, Equation (
20)-2 assesses the probability by considering the distances from the feature vector
to the reciprocal point and the attractor separately. Both equations adhere to the aforementioned probability constraints and necessitate appropriate selection and differentiation processes.
Firstly, the attractor should be positioned as centrally as possible within a class of sample points, while the reciprocal point should be maximally distinct from these samples. Thus, the relative position and angle of both the reciprocal point and the attractor in the feature space are critical. To minimize open-space risk, it is essential to cluster each class of samples tightly while also limiting the overall distribution range of all samples, effectively reducing the spread of known samples in open space. When employing Equation (
20)-1 for probability calculations, the constraint only considers the difference
. This may lead to situations where
becomes excessively large, diminishing the relevance of
. Consequently, even if
is substantial, it might still satisfy the equation, inadvertently expanding the sample distribution range and increasing open-space risk. Our training objective should ensure that sample points lie within the vicinity of both the attractor and reciprocal point, remaining close to the attractor while distancing from the reciprocal point, as illustrated in
Figure 9.
Therefore, Equation (
20)-2 better meets our training expectations. We can then define the Attractor and Reciprocal Point Distance Cross-Entropy Loss as follows:
In this study, we employ Euclidean distance
to quantify the positional distance between the reciprocal points, attractors, and sample points. Additionally, we utilize the dot product
to assess the angular difference between the reciprocal points and sample points in the feature space, specifically
Similarly, we implement a boundary
R to restrict the overall distribution range of the sample points:
The loss functions
and
are designed to constrain the data within
. Additionally, we utilize the edge sample dataset
, obtained in
Section 3.2, to approximate open-set samples. Our objective is to maintain unknown samples in a low-density region while pushing known samples away. To achieve this, we constrain the
of the samples in
to approach zero, specifically
So the total training loss is
where
and
are hyperparameters that control the weights. Clearly, the computation process of
is differentiable.
In the original reciprocal point algorithm, the reciprocal points for each class were initialized randomly. We contend that this random initialization, in conjunction with network updates, is susceptible to local optima. Since the ultimate goal of training is to separate samples of different classes from their respective reciprocal points, the selection of reciprocal points should adhere to a systematic pattern. Given that the activation function used in the models for this experiment is ReLU, which discards negative values, we can strategically position the reciprocal points in opposite quadrants or along the same coordinate axis in opposite directions relative to the sample feature vectors. This approach maximizes both positional and angular differences. Thus, we propose using orthogonal basis vectors for initialization:
where
is the basis vector in that space and
is the reciprocal point coefficient.
In other words, we set the reciprocal points in the negative direction of the C coordinate axes. Since the attractors and the reciprocal points are relative in terms of angle and position, the optimal attractors
should satisfy
where
is the scaling factor between the attractors
and the reciprocal points
.
3.4. Network Architecture
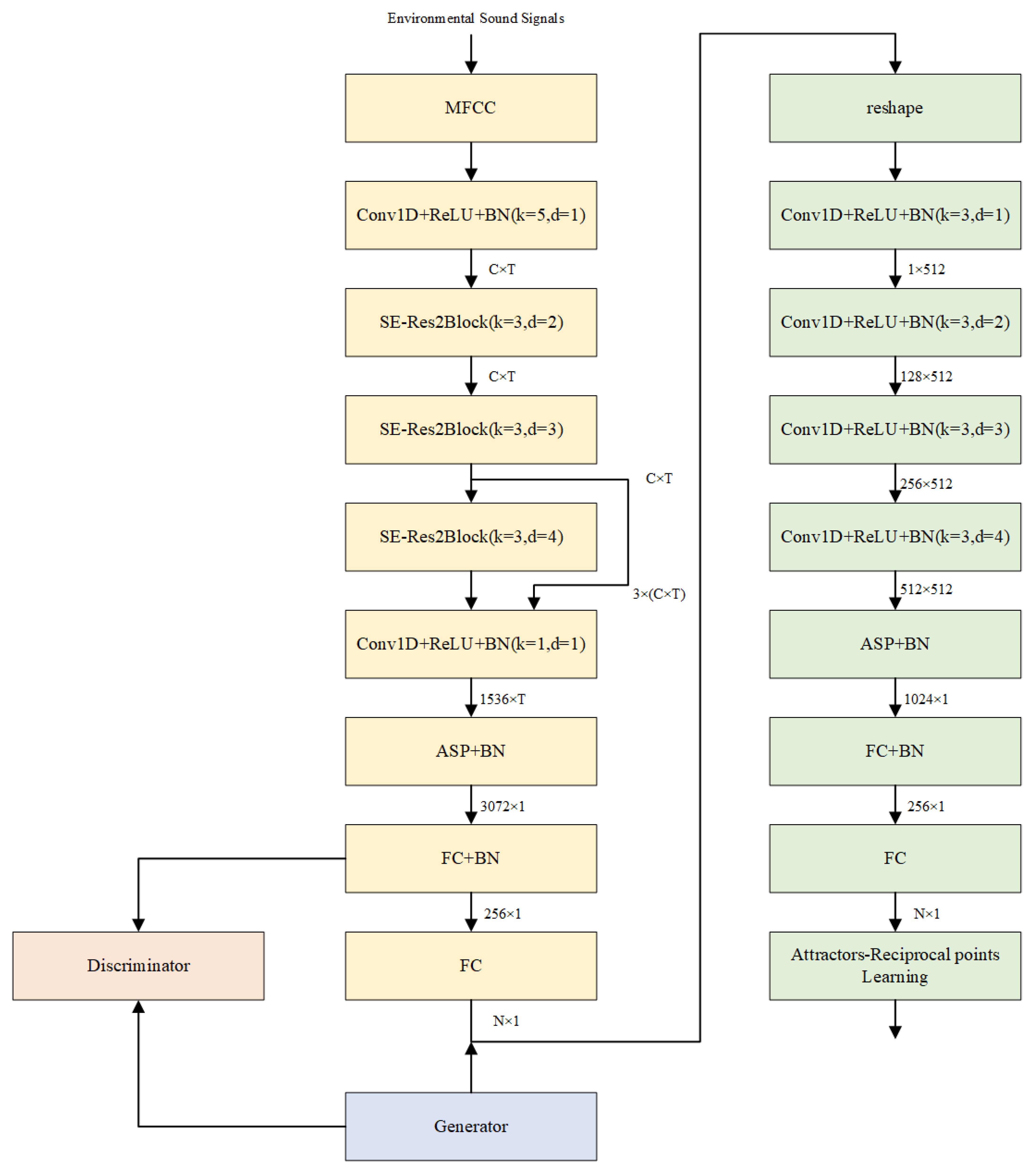
The previous sections provide a detailed introduction to the proposed open-set recognition algorithm. This section presents the corresponding network architecture, as shown in
Figure 10.
The environmental audio signal first undergoes Mel-Frequency Cepstral Coefficient (MFCC) feature extraction, which is then fed into
.
employs the ECAPA-TDNN model [
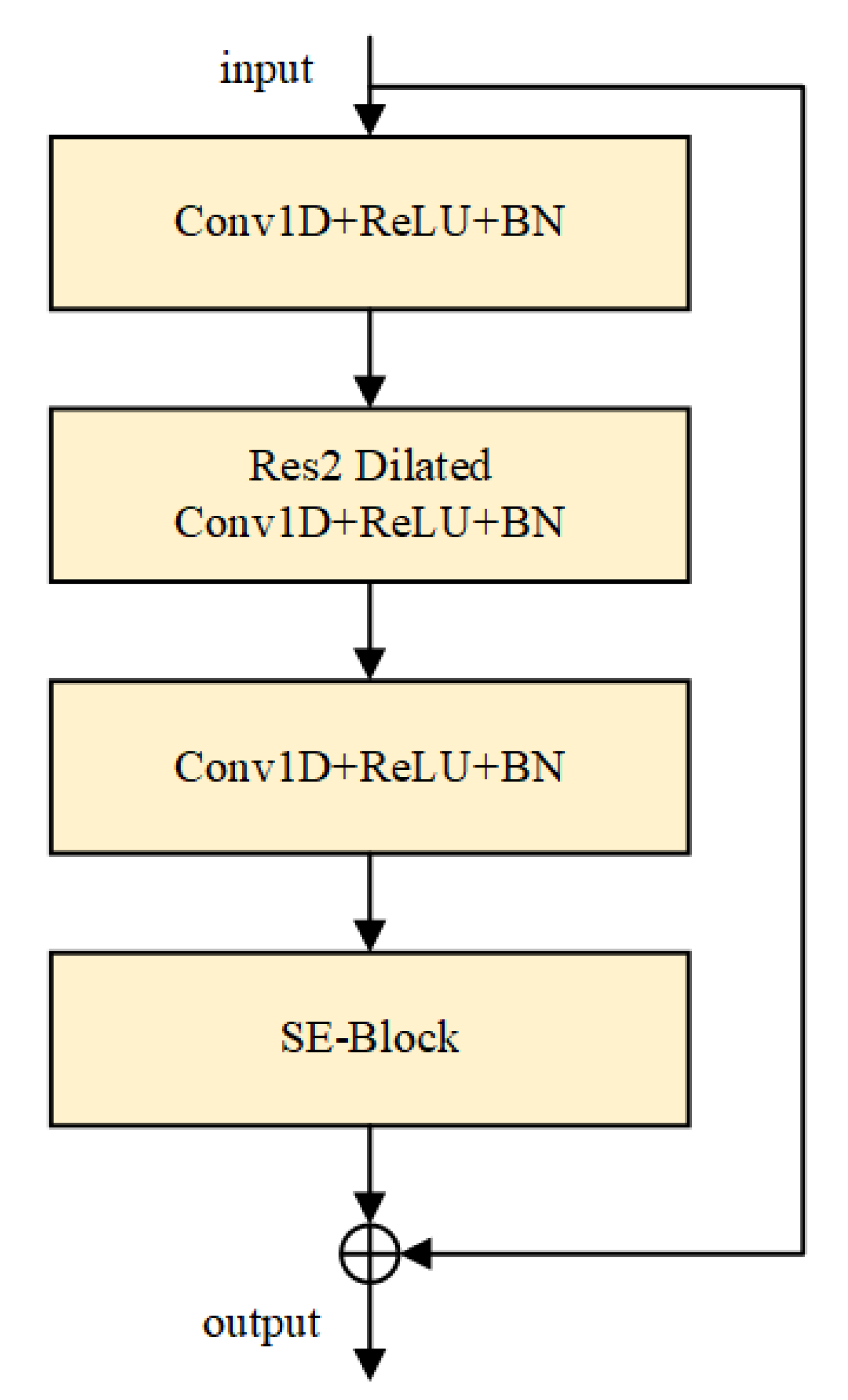
1], a speaker recognition architecture based on time-delay neural networks. The model comprises three main modules: the SE-Res2Block (Squeeze-and-Excitation Res2Block) module (illustrated in
Figure 11), the Multi-Layer Feature Aggregation and Summation (MFA) module, and the Attentive Statistic Pooling (ASP) module.
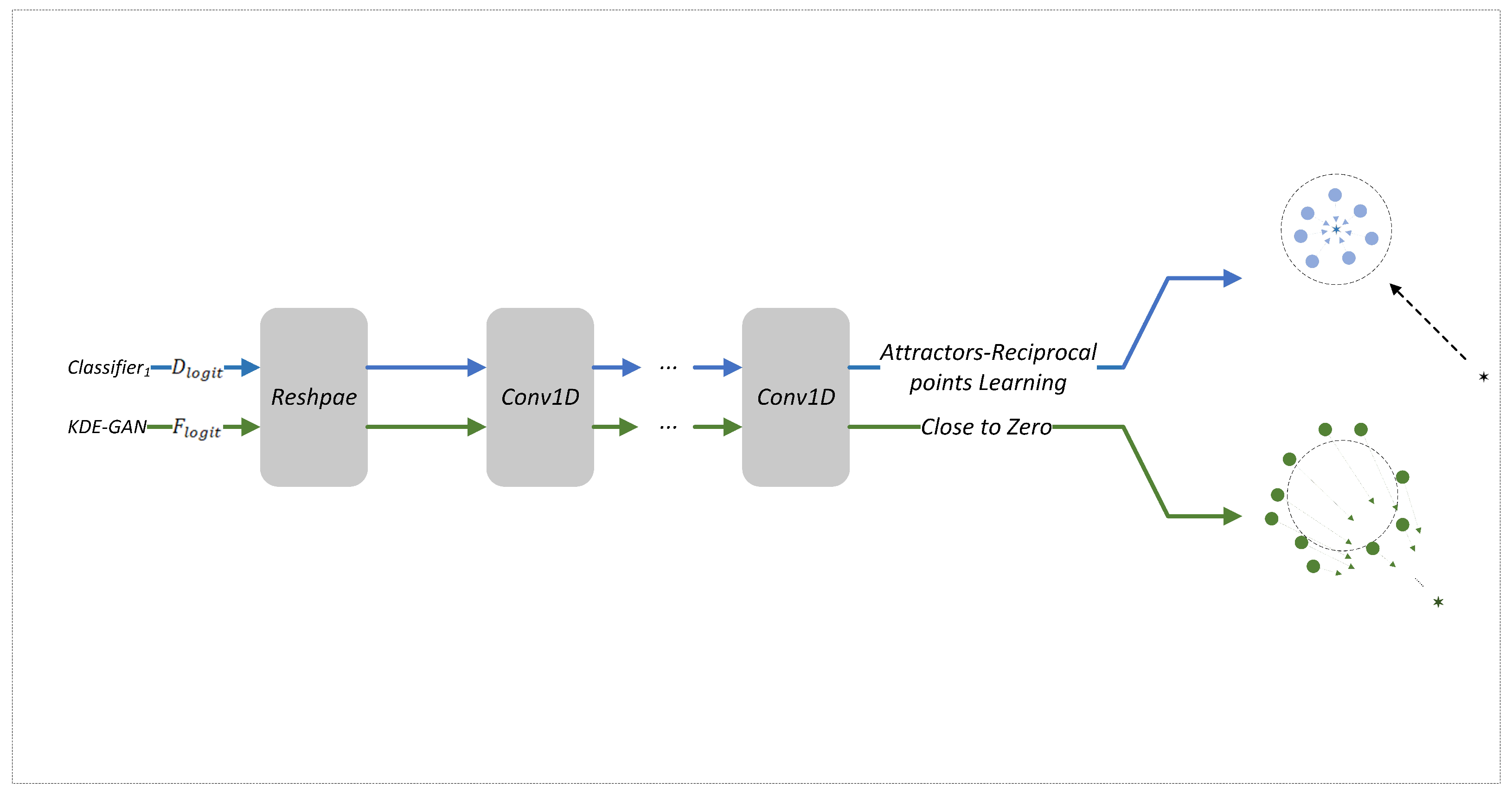
The MFCC features are initially transformed via a Conv1D+ReLU+Batch Normalization (BN) layer to adjust their dimensionality. Subsequently, three SE-Res2Block modules with dilation rates of k = 2, 3, 4, respectively, perform squeeze-and-excitation operations. The outputs of these SE-Res2Block modules with varying dilation rates are concatenated through a Conv1D+ReLU layer for multi-layer feature aggregation (MFA), generating refined features for attentive statistical pooling. These features are then aggregated and pooled via the ASP module. The pooled features pass through a fully connected (FC) layer with 256 nodes to produce the pre-logit output vector. A subsequent FC layer reduces the dimensionality to N, yielding the logit output vector, where N denotes the number of known classes. Additionally, the pre-logit output vector is fed into the for adversarial training, while the logit output vector, combined with the boundary samples generated by the , is input to .
For , the input vectors first undergo dimensionality transformation to ensure a feature dimension of 3. A Conv1D+ReLU+BN layer then maps the features to 512 dimensions while retaining a channel dimension of 1. This is followed by three sequential Conv1D+ReLU+BN layers that progressively expand the channel dimensions to 128, 256, and 512, with dilation rates incrementally increased to capture multi-scale temporal features. After feature extraction, the ASP module compresses the dimensionality to 1024. Two FC layers further reduce the dimensionality to N. The final output undergoes Attractor–Reciprocal Point Learning to update the network parameters.
In the
(
Figure 12), the input random noise (dimension 100) passes through four Conv1D+ReLU+BN and Dropout modules, with intermediate dimensions of 2048, 1024, 512, and 1024. A final 1D convolutional layer reduces the dimensionality to 256, producing synthetic data points.
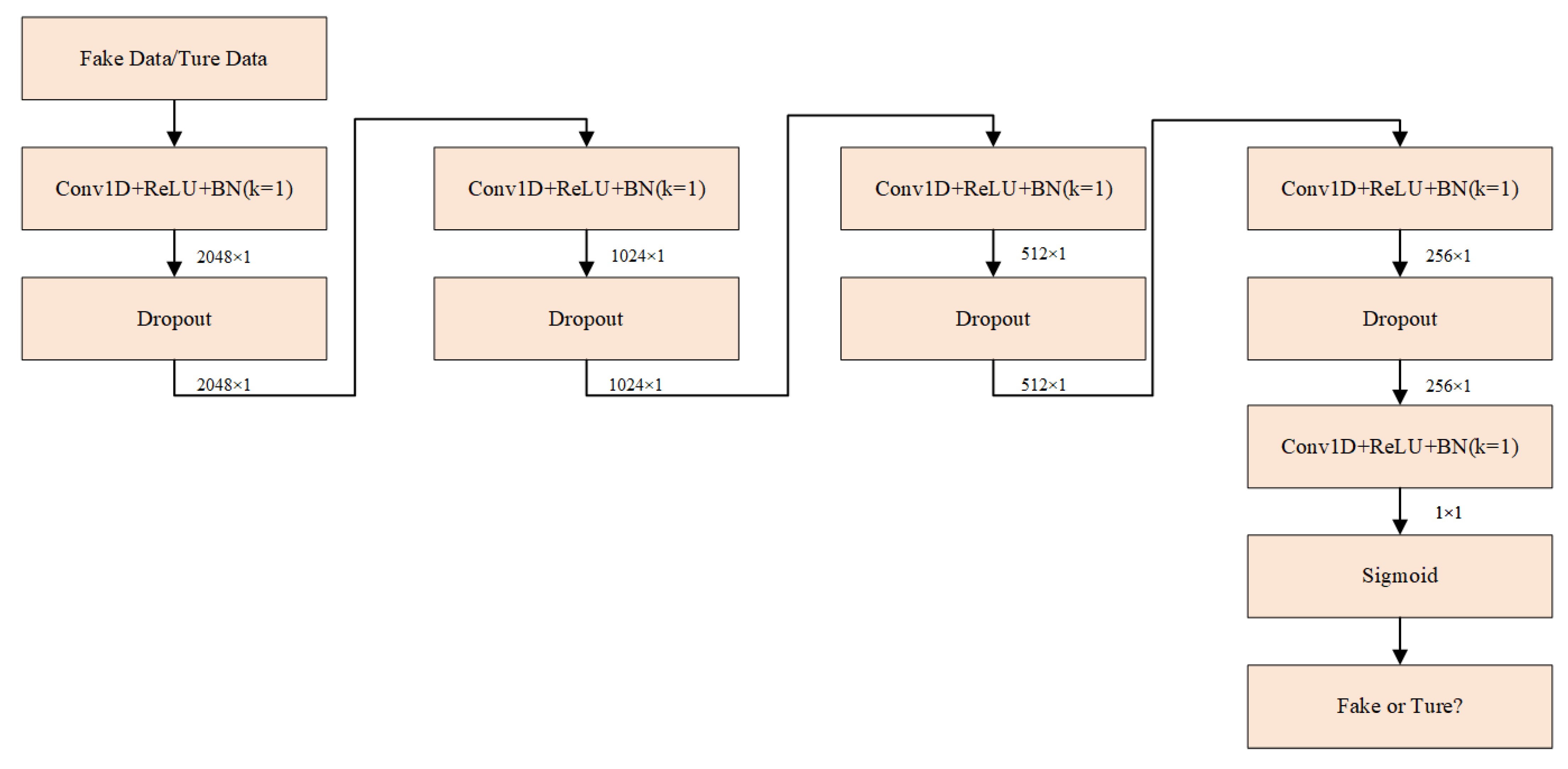
In the
(
Figure 13), the input consists of generated data points and the pre-logit output vector (both 256-dimensional). These pass through four Conv1D+ReLU+BN and Dropout modules with intermediate dimensions of 2048, 1024, and 512. A final 1D convolutional layer reduces the dimensionality to 1, followed by a Sigmoid activation function to map outputs to the range [0, 1].









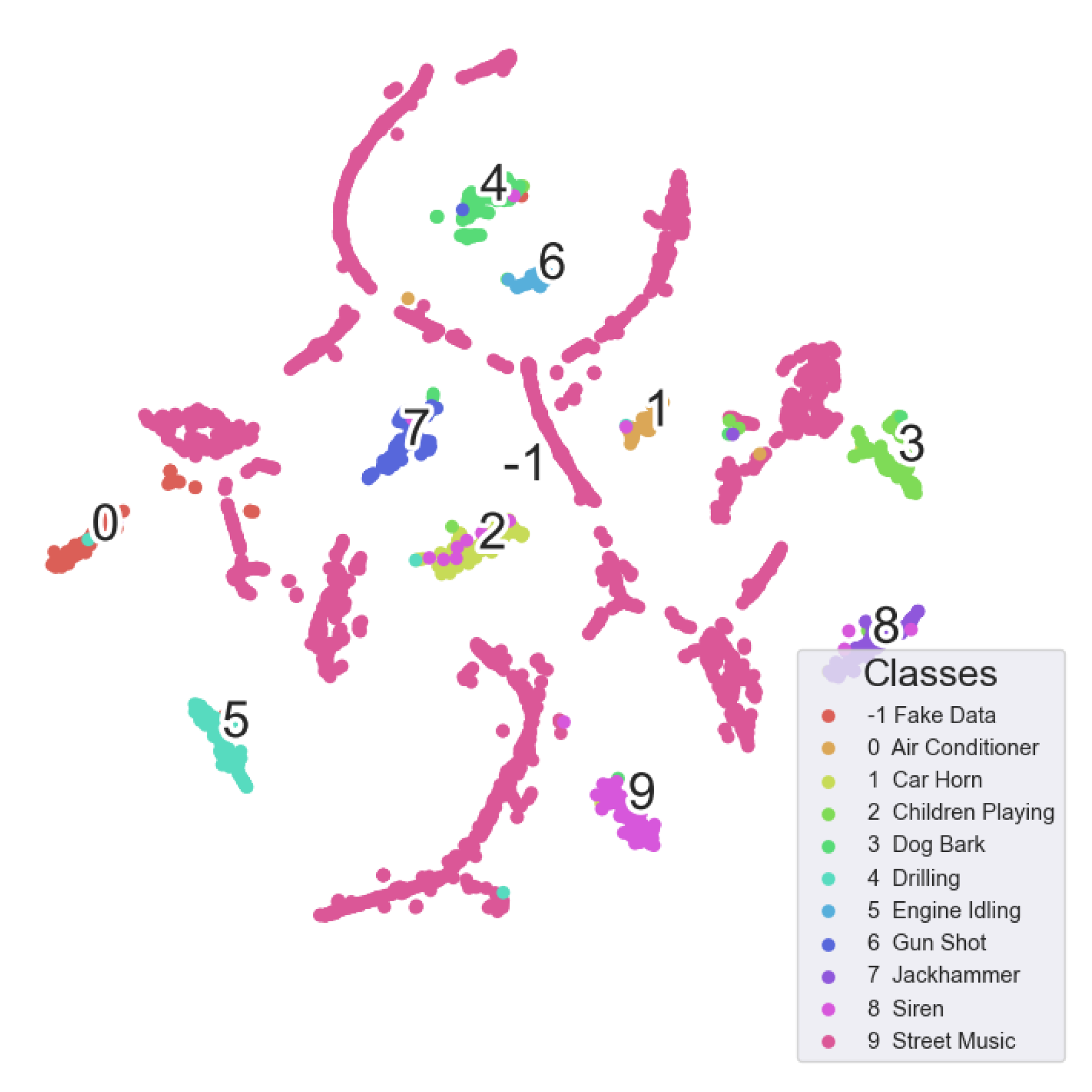
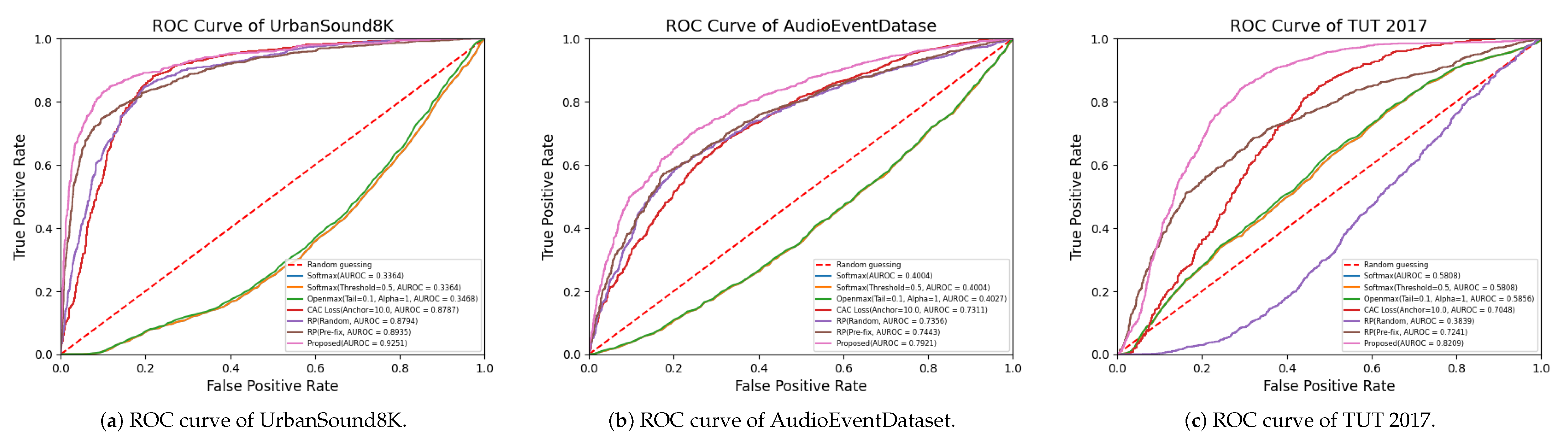
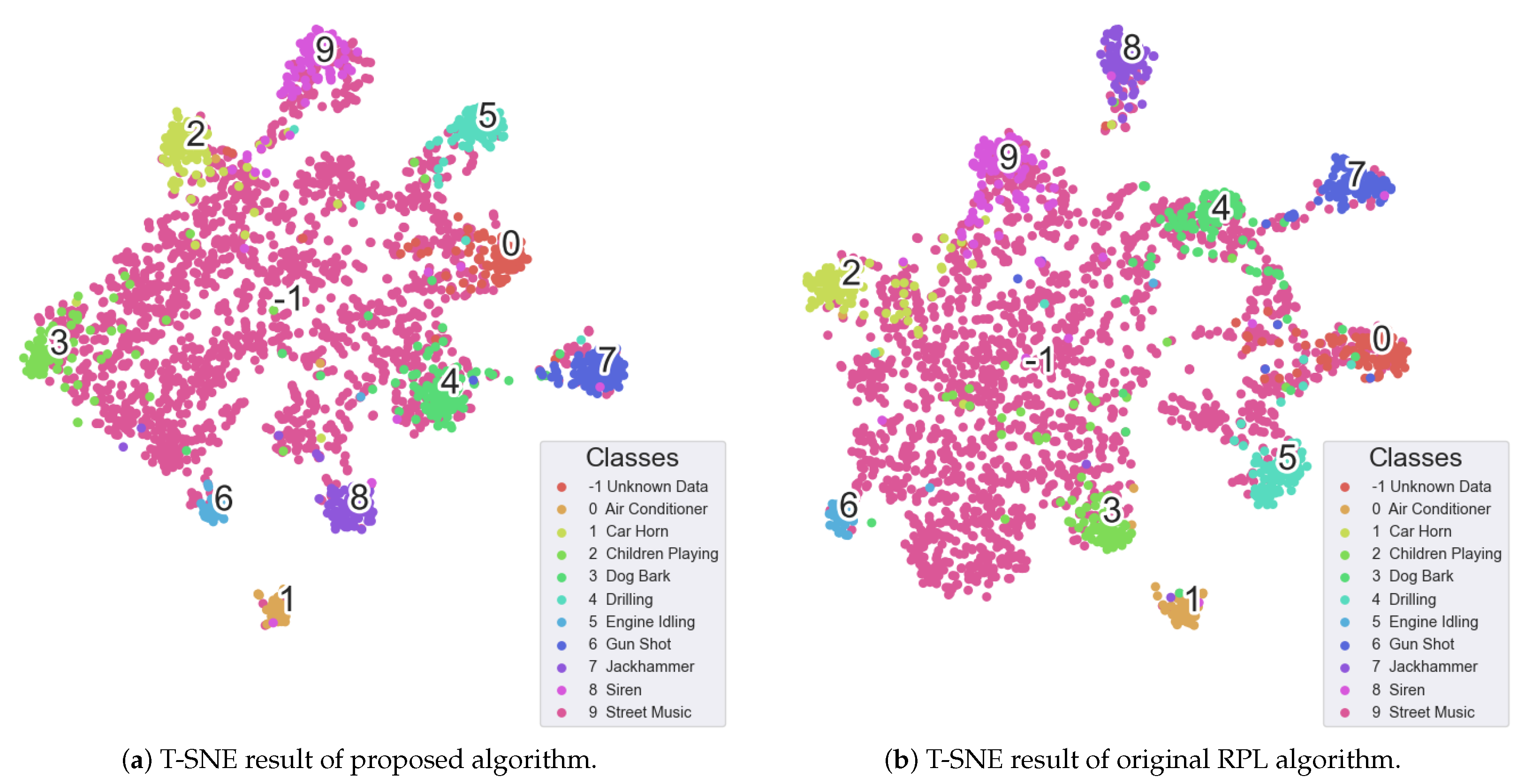

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}