1. Introduction
Speech reinforcement (SR) applications, whether in-room communication systems or remote audio teleconference systems, usually encompass an inherited level of acoustic feedback due to reverberation within the end-users’ locations. Such SR systems include public announcement (PA) systems, live shows, in-car communications, in-room and remote conference calls, and online video calls. SR systems consist of microphones, which aim to acquire each speaker’s direct (and least reverberant) speech, and loudspeakers that amplify the received speech signals and play them—back into the room or to the rooms of the end-users (assuming no earphones). Unfortunately, when the amplification gain rises, or the microphone is placed close to the loudspeaker, the level of acoustic feedback may become excessively high, i.e., electro-acoustic coupling, manifesting as grating howling noises. Namely, the acoustic echo from the loudspeaker might reach the speaker’s microphone due to reverberation, i.e., reflections of sound waves inside the room [
1].
A room’s reverberation time (T
60) is dependent on the structure of the room, i.e., room dimensions, the materials of the walls, and its interior, where all of these affect the time taken for the sound signal to decay [
2,
3,
4,
5]. The room’s reverberation characteristics, together with the loudspeaker and microphone positions in the room, determine the sound waves’ direct path and reflections. These loudspeaker-enclosure-microphone (LEM) paths characterize the channel of the echo signal and directly affect the acoustic feedback in the room, which at some level of amplification gain might trigger electro-acoustic coupling and instability within the SR system, evoking howling at resonance frequencies of the system’s closed-loop transfer function (TF) [
6,
7,
8]. The attainable gain of the loudspeakers is thus limited by a maximum stable gain (MSG) of the SR system [
9]. However, the amplification gain is only limited around the howling frequencies. When a clean speech signal arrives at the microphone of a closed-loop SR system, assuming no thermal noise, only speech harmonics close to the poles of the TF can evoke howling. Therefore, evoked frequency-howls can be instinctively suppressed by changing the system’s TF, i.e., by reducing the amplification gain or altering the LEM paths. After that, it is possible to return the SR system to its initially configured state.
Two approaches are commonly used to tackle the howling problem in SR systems. To prevent electro-acoustic coupling, an acoustic echo canceller (AEC) is often used, both in hearing aids and in hands-free communication. AECs aim to cancel the echo signal from the loudspeaker by adaptively identifying the room-impulse-response (RIR) of the LEM paths and subtracting the estimated echo signal [
1,
3,
10,
11,
12,
13,
14,
15,
16,
17]. Another common (complementary) approach for acoustic feedback control is the use of notch-filter-based howling suppression (NHS) techniques, a private case of howling control mechanisms that aim at stabilizing the SR system by handling the appearance of frequency-howls (rather than preventing it) [
12,
13]. This approach consists of a howling detection algorithm and a notch filter design method, as in [
7,
18,
19]. The state-of-the-art howling detection features are the PTPR (Peak-to-Threshold Power Ratio), PAPR (Peak-to-Average Power Ratio), PNPR (Peak-to-Neighboring Power Ratio), PHPR (Peak-to-Harmonic Power Ratio), IPMP (Interframe Peak Magnitude Persistence), and the IMSD (Interframe Magnitude Slope Deviation), as reviewed in [
6,
20]. The temporal IMSD feature evaluates the magnitude-increase of a frequency component as a function of time, by measuring the logarithmic magnitude’s frame-wise slope variation. Accordingly, Green et al. proposed the computationally efficient ‘summing’ method for assessing the MSD of frequency spectrum data [
19]. Alternatively, a deep-learning-based approach for howling detection is proposed in [
21], utilizing a convolutional recurrent neural network (CRNN)-based method for howling detection in real-time communication applications, which is robust to device-dependent howling features.
While AECs work very well in several cases, unobservable input speech signals acquired with the loudspeaker’s echo signal (double-talk), or changes in the room acoustics (RIR), may get the AEC out of tune and affect the sound quality and the stability of the SR system for the currently applied amplification gain [
7,
18]. Moreover, an AEC’s processing delay must be lower than the minimal propagation delay that may exist in the room (shortest LEM path) [
22]. While NHS techniques may serve as a backup mechanism for handling the appearance of frequency-howls, they depend on an accurate and early howling detection algorithm. Furthermore, they may compromise speech quality in the case of over-filtering. Consequently, feedback control via howling detection remains a significant challenge for real-time applications. While the deep-learning-based approach was reported to achieve a high detection rate and a low false-alarm rate, its spectral image of 32 frames (1.28 s) suggests that howling would be noticed before being detected. Although the MSD measure is reported to be accurate [
19], the temporal IMSD feature, on which it is based, is said to be extremely sensitive to the threshold choice [
20]. Based on this, using the MSD measure alone might not be sufficient.
In this paper, a temporal howling detection algorithm, based on the MSD measure, is proposed for SR systems. The proposed algorithm aims to early detect frequency-howls in the system, before the human ear notices. Thus, laying the foundation for howling control mechanisms, and maintaining high-quality speech communication. The howling detection algorithm includes two cascaded stages: Soft Howling Detection and Howling False-Alarm Detection. The Soft Howling Detection is based on the temporal magnitude-slope-deviation measure, identifying potential candidate frequency-howls. As opposed to using a plain MSD-based detector, the Soft Howling Detection stage is designed to be less strict, detecting as many potential candidate frequency-howls as possible. Therefore, the detection process is immediate, identifying suspected feedback howls across all frequency bins. As the majority of howling false alarms can be attributed to frequency components of speech harmonics, the proposed solution aims to authenticate each suspected frequency-howl with regard to the signal behavior before detection. Inspired by the temporal approach, the Howling False-Alarm Detection stage is added to refute candidate frequency-howl false alarms that are not caused by feedback, based on their prior magnitude behavior under the system’s steady state. Thus, examining the extended magnitude history only at the suspected frequency bins, and refuting false-positive howling candidates. The contributions of this paper are as follows: First, mathematical analysis of the howling’s temporal behavior within the SR system in terms of a closed-loop feedback TF. Second, expansion of the temporal analysis approach to assess identified frequency-howls with respect to the ongoing effect of the system dominant poles on frequency components of speech. Thus, further exploiting the MSD measure. Third, utilization of standard ISO 226:2003 [
23] for early detection of frequency-howls, i.e., before the human ear notices. Finally, a performance evaluation framework for howling detection techniques is provided, characterizing the response time and measuring the detection accuracy.
This paper is organized as follows:
Section 2 describes the signal model and problem formulation.
Section 3 provides a mathematical analysis of the howling effect and its origins. Accordingly,
Section 4 analyzes the magnitude slope of a howl, and introduces the temporal analysis approach and a plain howling detector based on the MSD measure.
Section 5 presents the proposed MSD-based howling detection algorithm.
Section 6 describes the proposed performance evaluation framework. Then,
Section 7 and
Section 8 demonstrate and discuss the howling detection improvement, in terms of detection accuracy and response time, that lies in further expanding the temporal analysis approach. Finally,
Section 9 presents the conclusions of the study.
4. Magnitude-Slope-Deviation-Based Howling Detection
Following
Section 3.3, there are two types of howls. First, an increasing howl corresponds to the More Unstable Pole scenario, i.e., when an unstable pole of the system’s TF is excited by a frequency component of the input signal. Second, an underdamped howl corresponds to the Close Stable Pole scenario, i.e., when a stable pole of the system’s TF, located close to and inside the unit circle, is excited by a frequency component of the input signal. This type of howling implies that a noticeable howling sound may arise even before the SR system reaches instability.
Green et al. [
19] suggest a temporal method to intelligently identify feedback howls within candidate frequency bins. Namely, measuring the Magnitude Slope Deviation (MSD) via the ‘summing’ MSD method. This method relies on the fact that the howling components’ power changes linearly over time when calculated on a dB scale, i.e., the gradient change (second-order derivative) is consistently close to zero.
Accordingly, this section first proves the linear magnitude change along time (when calculated on a dB scale), for both howling types. Next, as suggested by the temporal approach, the magnitude history buffer is introduced for an effective analysis of candidate frequency bins. Then, a plain MSD-based howling detector is presented and discussed. The cons of the plain detector will be addressed in the following section via the proposed MSD-based howling detection algorithm.
4.1. Magnitude Slope of a Frequency-Howl
Let the output signal be the response to a frequency component of the input signal, the magnitude slope shall be calculated on a dB scale, i.e., where
For an increasing howl at the pole’s frequency, following the development in Equation (
9),
Thus, the magnitude slope of the increasing signal is calculated by
Since , when n is large enough, the increase rate is .
For an underdamped howl, following Equation (
10),
Thus, the magnitude slope of the decaying output signal is calculated by
Hence, the gradient change should be consistently close to zero for both types of howls. This means that the standard deviation of the magnitude’s second-order derivative should be small.
Furthermore, considering the sampling frequency
, the magnitude change rate of the output signal (when calculated on a dB scale) is determined by
Accordingly, for a desired slope of the output signal, given a complex exponential input signal at the pole’s frequency, the configured pole magnitude
is determined by
4.2. Temporal Analysis Approach
To analyze the temporal behavior of the signal along the spectrum, i.e., the magnitude behavior of each frequency component over time, the power spectral density (PSD) is calculated on subsequent sample frames. In practice, signal samples are buffered in a sample frame of length
, referred to as the MSD-buffer. Once the MSD-buffer is filled with
samples, the dB-scale normalized PSD of the signal is calculated, and inserted into the magnitude history buffer. This process repeats itself every
samples. In detail, the PSD of the MSD-buffer is calculated by
Since the Fourier transform of a real-valued signal has Hermitian symmetry, the negative frequencies in the spectrum do not provide new information with respect to the positive frequencies. Therefore, using the normalized frequency units
, the positive frequencies (
) of the PSD are considered. Then, the PSD is normalized by its squared length, and the result is converted to a dB scale as follows:
where
is the FFT length, which is equal to
. The howling detection process begins when the magnitude history buffer is full, and repeats itself after each PSD calculation. Thus, tracking the magnitude change using a dB-scale magnitude history buffer.
Considering the complex exponential input signal from
Section 4.1, analyzing the signal in terms of sample frames provides an average-magnitude estimate for each frame. Then, a frequency-howl’s magnitude change rate within a frequency bin is the dB-Slope of Equation (
16) times
.
Accordingly, a temporal detection method depends on feature extraction based on the magnitude history buffer and its gradients. The calculation of the gradient and the gradient change is as follows:
where
is the dB-scale magnitude history buffer data, at frequency bin
k and analysis frame
n; and
is the time-difference between two subsequent frames.
4.3. Plain Magnitude-Slope-Deviation-Based Howling Detector
Based on the fact that the gradient change should be consistently close to zero for both types of frequency-howls, the plain MSD-based howling detector measures the MSD and determines howling detection accordingly. In detail, the MSD at a suspected frequency bin
k is the root-mean-square deviation (RMS-Deviation) of the historical magnitude gradient-change measurements
relative to zero, calculated by averaging the squared absolute values as follows:
where
m denotes the current frame, last inserted into the magnitude history buffer, and
N is the number of frames in the magnitude history buffer. Accordingly, a low MSD value of a candidate frequency bin implies a probable howl. Unfortunately, the MSD measure alone is not sufficient for immediate real-time howling detection.
4.3.1. Howling Detection Safety Mechanisms
Two safety mechanisms are used to refute false frequency-howls. First, detected frequency-howls below 15 Hz are refuted, since only acoustic waves within the frequency range of 20 Hz to 20 kHz are considered sound waves [
25,
26]. Furthermore, low MSD values may be obtained for frequency bins with no (or very low) energy over time. Namely, Close Stable Poles that are triggered by low noises in the microphone signal will decay slowly, but will not be noticed by the human ear. Human sensitivity to sound varies across the acoustic frequency range, as studied in the field of psychoacoustics [
27]. That is, the listener may perceive the same level of loudness from two pure tones, presented to the human ear, at different frequencies and sound pressure levels (SPL). Accordingly, standard ISO 226:2003 [
23] of the International Organization for Standardization defines the equal-loudness contours representing the average judgment of otologically normal people. These contours lie in the SPL/frequency plane, where each such curve represents the sound-pressure-level values in dB (dB SPL) of pure tones that are judged to be equally loud. The loudness level of a contour is measured in phon units, which are equal to the dB SPL of a similarly perceived 1 kHz pure tone. The equal-loudness contours provided by the standard, fully apply to frequencies from 20 Hz to 12.5 kHz and loudness levels between 20 and 80 phon, where the hearing threshold is below 20 phon. Regarding a received sound as a combination of pure continuous tones, within a speech sample frame, the hearing threshold can be determined for each frequency bin. Hence, the minimal howl energy threshold for each frequency bin was determined using the equal-loudness-level contour of 20 phon, as implemented in [
28] according to [
23], minus a safety gap of 5 dB. In detail, calculating the dB SPL values of pure tones at all frequency bins between 0 Hz–8 kHz (sampling frequency of 16 kHz), according to the equal-loudness-level contour at the loudness level of 20 phon. As it is unlikely that the human ear would perceive a howl or any other sound under this threshold-contour, it is considered silence. Therefore, candidate frequency-howls are refuted if their mean energy (among the magnitude history buffer) is below the corresponding value on the threshold-contour.
4.3.2. Inherited Trade-Offs of the Temporal Approach
Given a sampling frequency
, the following set of temporal parameters needs to be set: the frame-length (in samples), the frame-shift (in samples), and the number of frames in the magnitude history buffer used for howling detection; denoted by:
,
, and
. Although a longer
means averaging the linearly changing magnitude of a frequency-howl, it provides a higher frequency resolution and allows averaging the effect of noise on the signal’s magnitude. Furthermore, the typical speech analysis frame length is 20–40 ms, due to the quasi-stationarity of the speech signal [
29]. Appropriately, a longer
provides a more distinct magnitude-change tracking. Based on that, a large number of frames in the magnitude history buffer provides a more accurate estimation of the MSD along the frequency-howl. On the other hand, the total length of the magnitude history buffer determines the delay of the howling detection process. The minimum delay of such a temporal howling detection process, from the beginning of a howl, is calculated by
This means that a long magnitude history buffer, followed by a long howling detection delay, is likely to result in frequency-howls being noticed by the human ear before being counter-treated, as well in miss detection of short but noticeable underdamped frequency-howls.
Accordingly, the plain MSD-based howling detector was configured with a set of parameters fine-tuned to maintain a low false-alarm rate. For the sample rate of 16 kHz, where (the power of 2, closest to 60 ms—about twice the typical length of a speech-analysis frame), and corresponds to a shift of 10 ms between subsequent sample frames. Hence, resulting in a minimum howling detection delay of 154 ms. However, it appears that frequency-howls are still noticeable before they are detected, and it miss-detects short howls.
5. Proposed MSD-Based Howling Detection Algorithm
The proposed howling detector includes two cascaded stages: Soft Howling Detection and Howling False-Alarm Detection. As opposed to the performance constraint on the plain MSD-based detector, the Soft Howling Detection stage is designed to be less strict, aiming to detect as many potential candidate frequency-howls as possible. Thus, achieving a low miss-detect probability at the cost of a high false-alarm rate. Analysis of the howling false alarms reveals that they are primarily caused by speech harmonics. Namely, similarly to frequency-howls, the frequency components of speech harmonics (especially the low-number harmonics): rise (like an increasing howl), keep steady for a few moments, and then decay (like an underdamped howl). Accordingly, the second stage is added to refute candidate frequency-howl false alarms that are not caused by feedback, based on their prior magnitude behavior under the system’s steady state.
The proposed MSD-based howling detection algorithm, within the in-room SR system, is illustrated in
Figure 3. The MSD-buffer stores the samples of the microphone signal
. The magnitude history buffer stores the magnitude per frequency bin, for each iteration of the MSD-buffer, as detailed in
Section 4.2. As denoted in
Figure 3, all frame-blocks, of the magnitude history buffer and its gradients, are related to the history-buffer; and the gray-colored frames are related to the detection-buffer. Accordingly, the detection-buffer is used in the Soft Howling Detection stage, and the history-buffer is used in the subsequent Howling False-Alarm Detection stage. Thus, achieving a fast and reliable howling detection process.
5.1. History-Buffer Analysis
As illustrated in
Figure 3, the magnitude history buffer and its gradients are used in both stages of the howling detector to extract features, where each stage analyzes the part of the history-buffer relevant to its analysis. The first stage analyzes the recent
frames of the history-buffer, i.e., the detection-buffer, to detect suspected feedback howls across all frequency bins. The second stage analyzes the entire
frames of the history-buffer, at the suspected frequency bins, to refute the false-positive howling candidates.
Accordingly, for a fast howling detection as well as a legitimate behavioral analysis of the magnitude’s history, the magnitude history buffer parameters were fine-tuned. For the sample rate of 16 kHz, and the frame-length is shortened to (the power of 2, closest to 30 ms—a typical length of a speech-analysis frame). Thus, enabling an early howling detection while still minimizing irrelevant false alarms. Besides, remains similar to the plain MSD-based detector. Regarding the history-buffer, . Hence, resulting in a minimum howling detection delay of 82 ms, and an initial delay of 1.222 s until the history-buffer is filled with samples.
5.2. Soft Howling Detection
The detection of frequency-howls is based on the theory of the MSD measure, see
Section 4.1. Namely, the power of howling components changes linearly over time, when calculated on a dB scale, and the gradient change (second-order derivative) should be consistently close to zero. Accordingly, regarding the detection-buffer
at all frequency bins
, the Immediate Feature Extraction relates to extracting the mean gradient for each frequency bin
, which is supposed to be constant; the gradient’s standard-deviation
, which assesses the linearity assumption; the absolute value of the mean gradient-change, which should be close to 0; and the RMS-Deviation of the gradient-change, which is the MSD measure, see Equation (
21) in
Section 4.3. Accordingly, the Immediate Feature Extraction process is summarized as follows:
As the value of is used to determine the howling type of a candidate frequency-howl, frequency bins with positive mean gradients are examined with thresholds, fine-tuned for increasing howls; and frequency bins with negative mean gradients, greater than −1000 dB/s, are examined with thresholds fine-tuned for underdamped howls. When magnitude slopes are below −1000 dB/s, frequency-howls will disappear before one can notice them.
5.3. Howling False-Alarm Detection
The false-alarm detection of frequency-howls is based on the understanding of the over-time behavior of frequency components under different levels of acoustic feedback, see
Section 3. As the majority of howling false alarms can be attributed to frequency components of speech harmonics, the proposed solution aims to authenticate each suspected frequency-howl with regard to the signal behavior before detection.
Figure 4 illustrates the signal behavior of a speech signal’s frequency component under no feedback and when the system’s output is underdamped. Observing the energy decays over time, shows that while a natural speech signal decays with different slopes along time, the signal decay rate in the underdamped scenario is lower-bounded, as can also be seen by the less noisy magnitude gradient and gradient-change of the analyzed frequency bin, which is mainly due to the dominant pole of the TF.
The possible spectral component sources are: thermal noise of the microphone, background noise, or speech. At the same time, the considered feedback types, per frequency, are: Stable Pole, which results in no feedback; Close Stable Pole, which results in an underdamped howl and an underdamped behavior of the signal prior to detection; and More Unstable Pole, which results in an increasing howl. The magnitude signal analysis along time thus aims to diagnose the origins of the suspected frequency-howl. Accordingly, for analysis of underdamped and increasing howling false alarms, a simulated signal is injected, composed of Gaussian thermal noise, a chirp signal, and four speech samples from the TIMIT speech database [
30].
Regarding underdamped howls, such a howl can be detected at two stages. The first stage is at the beginning of the howl, i.e., at the end of magnitude rising—before its decay rate is “about-constant”, i.e., stationary. The second stage is during the time the decay rate is stationary. At this stage, the momentary estimation of the magnitude slope (the immediate mean gradient) should be similar to the average estimation (or median estimation—for dealing with outliers) over a larger time period. As for increasing howls, after an input energy rise, an increasing howl can be distinguished only when the increase rate is already stationary. Clearly, it is easier to examine suspected frequency-howls when the change rate is stationary. However, it is desired to detect howling as early as possible.
5.3.1. Historical Feature Extraction
Regarding the history-buffer
for each candidate frequency bin
k, the Historical Feature Extraction relates to extracting features that assess the entire history of the frequency-component signal, before detection. The features are extracted from the magnitude-gradient buffer
and from the centered magnitude-gradient buffer
, where
(calculated in
Section 5.2) can also be referred to as the momentary howl average gradient. The numerical extracted features are the percentages of
and of
.
To examine the momentary immediate-estimations before the soft howling detection, moving filters are calculated along the history-buffers, where the window length is
for magnitude-based estimations, and
for magnitude-gradient-based estimations. The moving magnitude average buffer is denoted as
, and the moving magnitude-gradient average buffer is denoted as
. Moreover, since the slope of an ongoing howl should be about-constant when an increasing- or underdamped-howl is stationary, then a moving RMS filter is applied to the centered magnitude-gradient buffer, resulting in
. The centered magnitude-gradient buffer is utilized, rather than the gradient change (which would result in the MSD measure), since the deviation around the momentary howl average gradient is desired. Thus, low-RMS sequences are detected from
, in order to formulate valid slope estimations by combining several subsequent momentary immediate-estimations. Valid slope estimations are calculated as the median of subsequent average gradient immediate-estimations from
, where the minimum length of a low-RMS subsequence is lower bounded by 5. Namely, 6 momentary immediate-estimations are required for a valid middle slope estimation, and 5 for a valid final slope estimation. Additionally, a second set of higher- (although still acceptable) RMS sequences is also detected, to be used in cases where no low-RMS sequences are detected and noisy underdamped speech is suspected. Accordingly, the process of extracting the moving filters and their features is summarized as follows:
where all history-buffers, after applying the moving filters, have a length of
.
Subsequently, the analysis of each suspected frequency-howl is done by classifying the state of the detected suspected howl, and then evaluating the extracted features. In the beginning, the suspected frequency-howl is tested as an underdamped howl if , or as an increasing howl otherwise. In both cases, the state of the detected howl is determined based on whether ends with a low-RMS sequence (howl is stationary) or not. Without loss of generality, for an underdamped howl, if the history-buffer ends with a low-RMS sequence, the valid final slope estimation is expected to be negative, i.e., an underdamped low-RMS sequence. If so, the quality of the momentary howl average gradient is determined by the difference from the valid final slope estimation, relative to a threshold, and used as a feature. Also, since the decay rate in the underdamped scenario is lower-bounded, another numerical extracted feature is the percentage of above the valid final slope estimation.
Next, it is desired to determine whether the suspected howl comes after a potential silence, i.e., silence and then an energy rise that is followed by a howl, which means that there is no history to rely on for refuting a possible false detected howl, see
Figure 4. In practice, to prove that there is an energy rise after silence, it is checked that the energy before the howl is considered silence, and that there is a distinct overall energy change in the magnitude buffer. First, a check for a prior silence is done by comparing the median energy before the howl with the minimal howl energy threshold, which corresponds to frequency bin
k, see
Section 4.3.1. If
ends with a low-RMS sequence, the median energy before the howl is calculated via
until the beginning of the final low-RMS sequence. Otherwise, a median is taken on the entire
, since the suspected howl is considered momentary in this case. Second, checking for a distinct overall energy change is done by calculating the mid-range of the magnitude buffer
before the howl; and then calculating the percentage of this magnitude buffer above the mid-range magnitude. Hence, low median energy before the howl and low percentage above the mid-range magnitude suggest that the suspected howl comes after a potential silence and can not be refuted.
Otherwise, a howl preceded by no silence is probably preceded by speech or a noisy speech. In that case, as the number of middle underdamped low-RMS sequences increases, the valid middle slope estimations may assist in determining the type of feedback that is evident in the history-buffer .
5.3.2. False-Alarm Detection Algorithm
Naturally, to classify the state of each suspected frequency-howl, according to the extracted features, the Howling False-Alarm Detection algorithm is implemented as a decision tree. The thresholds for each decision node were fine-tuned, based on the performance of the aforementioned simulated signal, under different levels of feedback within a simulated amplification system in a car cabin, see
Section 6. The thresholds were calibrated for a relatively clean channel, i.e., with a low noise level. As the channel is noisier, underdamped howls are less likely to decay “naturally”, as the model assumes, and performance might deteriorate.
Furthermore, another safety mechanism is added to cope with speech harmonics-induced howling false alarms, detected in the soft howling detection stage, based on the natural properties of speech harmonics. During speech production, voiced sounds are excited at the vocal cords, where the volume flow of air through the glottis has a frequency spectrum consisting of voice harmonics [
31]. The frequency distribution of the voice harmonics constitutes a series of band-limited peaks at integer multiples of the fundamental frequency (pitch) [
32]. Analyzing the vocal tract in terms of a TF, the normal modes (that correspond to the poles) of the vocal tract are manifested as spectral peaks in the output sound, i.e., the formants [
31]. Different formants produce spectral variations in the sound radiated from the mouth, thus filtering the voice harmonics to generate different vowels. In light of this, the impact of fundamental frequency changes along a vowel, on harmonic structure, tends to increase with harmonic number [
32]. On the contrary, as low-number harmonics may be quite insensitive to fundamental frequency variations, it results in frequency bins having energy that may rise or decay like a frequency-howl. Accordingly, the howling false-alarm detector shall disregard frequency components below 1 kHz.
5.4. Post-Detection Howling Detection
In general, once howling is detected, a howling cancellation solution should take place for suppressing the feedback in the system. Since the RIR is unknown and dynamic, one can only treat the symptom, rather than the cause, i.e., eliminate the frequency-howls. Instinctively, such a solution may be based on reducing the amplification gain factor
K, see
Section 2. However, it is likely that the amplification gain will be raised again after the howling effect has passed. Therefore, a gain-change coping mechanism is applied to appropriately manage the howling detection process after an amplification-gain reduction or increment.
Based on that, each time a frame is added to the magnitude history buffer, see
Section 4.2, the time difference from the last gain-change,
, is calculated. Initially, to provide the howling cancellation solution enough time to act, the howling detection process is frozen for a time-span
. In that case, as long as
, the howling detection process is paused. After that, the number of added frames
is calculated from
, based on Equation (
22), as
Then, the number of frames actually used for howling false-alarm detection shall be the closest value to
that is between a pre-determined threshold of
and the entire length of the history-buffer
, see
Section 5.1. Appropriately, some of the False-Alarm Detection algorithm’s thresholds are also modified.
6. Performance Evaluation
A howling detection algorithm aims to detect frequency-howls, in advance of being noticed by the human ear. Therefore, the performance of a howling detector shall be evaluated in terms of detection accuracy, as well as the time it takes for detection. Since both types of frequency-howls correspond to different levels of feedback within the SR system, a devised set of feedback scenarios shall be composed. One feasible way for analyzing the response of an SR system within a feedback scenario, is by simulating a simple amplification system within a specific room configuration, i.e., room dimensions and characteristics as well as microphone and loudspeaker locations, see
Appendix B. That is, simulating the LEM paths of the room configuration, e.g., via the Room Impulse Response (RIR) Generator [
33], and setting a system amplification gain. This way, for each room configuration, the MSG is empirically obtained and then used for setting different amplification gain values for triggering underdamped and increasing frequency-howls within the system. Alternatively, a simpler approach is to simulate feedback using a two-pole system TF, by setting a pair of pole magnitude and frequency. That way, the devised set of scenarios consists of simulated TFs that correspond to different signal-magnitude change rates, at various frequencies across the acoustic spectrum, see Equation (
17) in
Section 4.1. This generic approach can cover a wider scope of acoustic feedback scenarios than simulating an SR system within a specific sample room configuration. However, simulated room configurations may provide complex feedback scenarios, which are closer to reality.
6.1. Detection Response Time
In order to measure the response time of a howling detector within an SR system under a given feedback scenario, a devised input signal is inserted into the system, providing a clean response for acquiring the first detection time. The devised input signal comprises a preamble, an energy burst, and silence for analyzing the response. The preamble consists of silence or a speech sample, for a time span larger than the minimum delay of the history-buffer (until it is filled), see
Section 5.1. Afterward, the energy burst should be long enough to excite the poles of the SR system, yet short enough to affect the system’s response as little as possible. Accordingly, the length of the energy burst is set to a time span of at least one MSD-buffer, specifically,
samples. Hence, acquiring the first howling detection time, relative to the energy burst.
In order to thoroughly examine the response time of a howling detector at all feedback scenarios per frequency, the generic TF approach is utilized. Namely, considering a sampling frequency of 16 kHz, examining TFs with poles at frequencies between 2000 and 6750 Hz, with pole-magnitudes that correspond to change rates dB/s. Thus, examining the scenarios: Close Stable Pole, Unstable Pole, and More Unstable Pole.
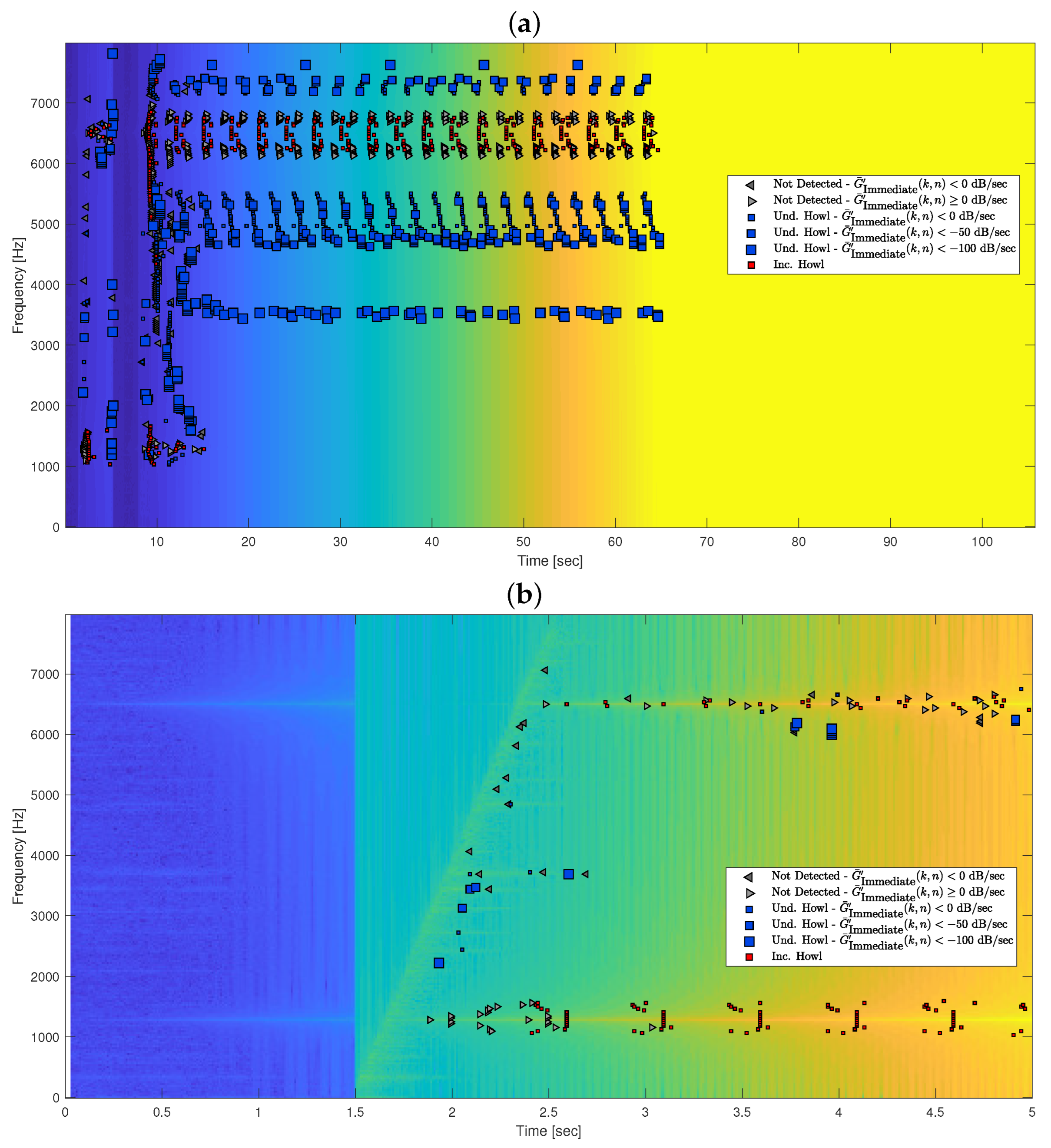
These feedback scenarios shall be tested under the following set of five howling scenarios, as summarized in
Figure 5 for a Close Stable Pole feedback scenario. The Impulse Response Howl scenario measures the response time to an energy burst that comes after silence. Since acquiring the first detection time around a specific known pole frequency, only detected frequency-howls within 50 Hz around the pole frequency are considered. For the same reason, the energy burst is a short sine wave at the evaluated pole frequency (rather than white noise). To prevent a situation where the system’s output diverges before the energy burst occurs (due to thermal noise), for pole magnitudes greater than or equal to 1 (Unstable Pole), a neutral TF (
) is applied during the preamble and the examined two-pole TF is applied from the beginning of the energy burst. Next, the Speech Howl scenario measures the response time to an energy burst that comes after speech. For a valid response time estimation, multiple speech samples shall be inserted, taking the median on the obtained response time measurements. As opposed to the Impulse Response Howl scenario, in this scenario, the examined two-pole TF is applied to the entire input signal. The following three tests relate to Gain-Control Howl scenarios, as mentioned in
Section 5.4. When howling is noticed by the human ear, the natural response is to reduce the amplification gain of the SR system. Afterward, when the howling disappears, naturally it is desired to increase the amplification gain back to the desired amplification level. All of the following tests measure the response time to an energy burst that comes after speech. First, the Full Stability Gain-Control Howl scenario evaluates howling detection after a positive gain-change, that comes after full stability. To simulate full stability, a neutral two-pole TF is applied to the preamble, with the same pole frequency and a pole magnitude that corresponds to a signal-magnitude change rate of −3000 dB/s. Second, the Recovery Gain-Control Howl scenario evaluates howling detection after a positive gain-change, that comes after a gain-reduction—as if howling was noticed and then eliminated due to gain-reduction. For this purpose, an extreme two-pole TF is applied to the preamble until 0.5 s before the energy burst, then the neutral two-pole TF is applied to the rest of the preamble, and the examined two-pole TF is applied from the beginning of the energy burst. The extreme two-pole TF is simply a TF with the same pole frequency as the examined TF, and a pole magnitude that corresponds to a signal-magnitude change rate greater than that of the examined TF by 100 dB/s. Third, the Increasing Gain-Control Howl scenario evaluates howling detection after a positive gain-change, that comes after a previous positive gain-change—as if howling was not noticed even after an initial gain-increment. For this purpose, the neutral two-pole TF is applied to the preamble until 0.5 s before the energy burst, then a moderate two-pole TF is applied to the rest of the preamble, and the examined two-pole TF is applied from the beginning of the energy burst. Similar to the extreme two-pole TF, the moderate two-pole TF is simply a TF with the same pole frequency as the examined TF, and a pole magnitude that corresponds to a signal-magnitude change rate less than that of the examined TF by 100 dB/s.
To obtain a valid response time in howling scenarios where a speech sample is inserted in the preamble, a long test speech signal is composed of the TIMIT speech database [
30], lasting for about 98 s. Thus, providing a variety of speech samples by splitting the long speech signal into 1.5 s speech samples with a shift of half the time-span of the history-buffer, see
Section 5.1. Accordingly, a collection of devised input signals is inserted for each two-pole TF and the median is taken on the resulting first detection time measurements.
6.2. Detection Accuracy
To evaluate the detection accuracy of a howling detector, a devised input signal is inserted into a simulated SR system under a given feedback scenario, providing the feedback effect on the input signal. Post factum, a retrospective howling detection is applied to the output signal and analyzed. First of all, evaluation of the retrospective howling detection results on the clean input signal provides a measure of the false-alarm rate over a clean signal.
6.2.1. Feedback Scenario Simulation
To evaluate the howling detection accuracy in situations as close to reality as possible, simple SR system TFs are simulated, i.e., by generating RIRs for a cherry-picked set of room configurations, and simply setting the system amplification gain to obtain the desired feedback scenarios, as mentioned in
Section 6. The cherry-picked set of room configurations includes a car cabin, characterized as a relatively small room (short LEM paths) with a very short reverberation time (due to the sound-absorbing materials), and a study room, which is larger and has a longer reverberation time (although still short), where the MSG is obtained empirically for each room configuration [
2,
3,
4,
5], see
Appendix B. Such simulated TFs provide complex feedback scenarios, consisting of Stable Poles and Close Stable Poles and, above the MSG, also Unstable Poles and More Unstable Poles. That is, while amplification gain values below the MSG may produce underdamped frequency-howls, amplification gain values above the MSG may provide a mixture of underdamped and increasing frequency-howls. Note that above the MSG, once the output signal exceeds the dynamic range of the computer due to a certain unstable pole, the magnitude values of other frequency bins are affected as well, and the howling effect of other poles cannot be analyzed. Therefore, considering that the poles of a simulated TF are unknown, only retrieved howling detections can be used for performance evaluation.
6.2.2. Accuracy Performance Evaluation
Knowing whether a detected frequency-howl is a true-positive or a false-positive, requires mapping the howling frequencies of the system, i.e., retrieving a ground truth from the output signal regarding the sensitive TF pole frequencies. For underdamped frequency-howls, the sensitive frequency bins can be triggered using a chirp signal, followed by silence to analyze the response. For increasing frequency-howls, even low-level thermal noise can trigger divergence within the system, i.e., excite the unstable poles of the closed-loop system TF. Therefore, the frequency-howl ground truth shall be obtained using a chirp signal. Similar to the energy burst in
Section 6.1, the chirp signal needs to cover each frequency bin for a short, yet adequate, time span. Exploiting the fact that no false-positive frequency-howls can appear after an energy burst within a frequency bin, a sensitive howling detector shall be utilized to obtain the ground truth. Specifically, a howling detector that successfully identifies true frequency-howls, even at the cost of identifying false frequency-howls that have a similar temporal behavior along the spectrum, e.g., speech harmonics. After obtaining the frequency-howl ground truth, retrospectively detected frequency-howls can be reviewed with regard to the ground truth, and false-positive detections can be disclosed. Since the howling detector’s performance evaluation can only be conducted using retrieved instances, it is evaluated in terms of precision and recall. Identifying the relevant frequency-howl candidates via a sensitive howling detector provides data for a posterior classification, where labeling true and false frequency-howl candidates is done with respect to whether a corresponding frequency bin is flagged by the ground truth. Hence, the recall of an examined howling detector is calculated as the number of true-positive instances that were retrieved, over the number of true frequency-howl candidates. On the other hand, the precision is calculated as the number of true-positive instances that were retrieved, over the number of the entire retrieved positive instances.
For all of the above reasons, the devised input signal is responsible for composing a valid frequency-howl ground truth under the analyzed feedback scenario, and for retrieving enough howling detection instances to create a legitimate corpus, so the number of false-positive detections is negligible within ground-truth frequency bins. Therefore, the devised input signal consists of a silence preamble to fill up the history-buffer (as in
Section 6.1), a chirp signal followed by silence, another silence preamble to initialize the history-buffer, and the entire long-duration speech signal used in
Section 6.1. Considering a sampling frequency of 16 kHz, the chirp signal varies linearly between 200 and 7800 Hz for a duration of 1 s, and is followed by 4 s of silence in order to identify the howling frequency bins of the SR system under the given feedback scenario. Then, the test speech signal lasts for about 98 s, providing the opportunity to detect a variety of howling instances. Respectively, the simulated TF is first applied during the preamble, the 1-second chirp signal and the following 2.5 s of silence. Then, a neutral TF (
) is applied during 1.5 s of silence, to suppress any evoked frequency-howl. After that, the simulated TF is applied for the rest of the input signal—the additional silence preamble and the long-duration speech signal.
6.2.3. Evaluating Multiple Detection Methods
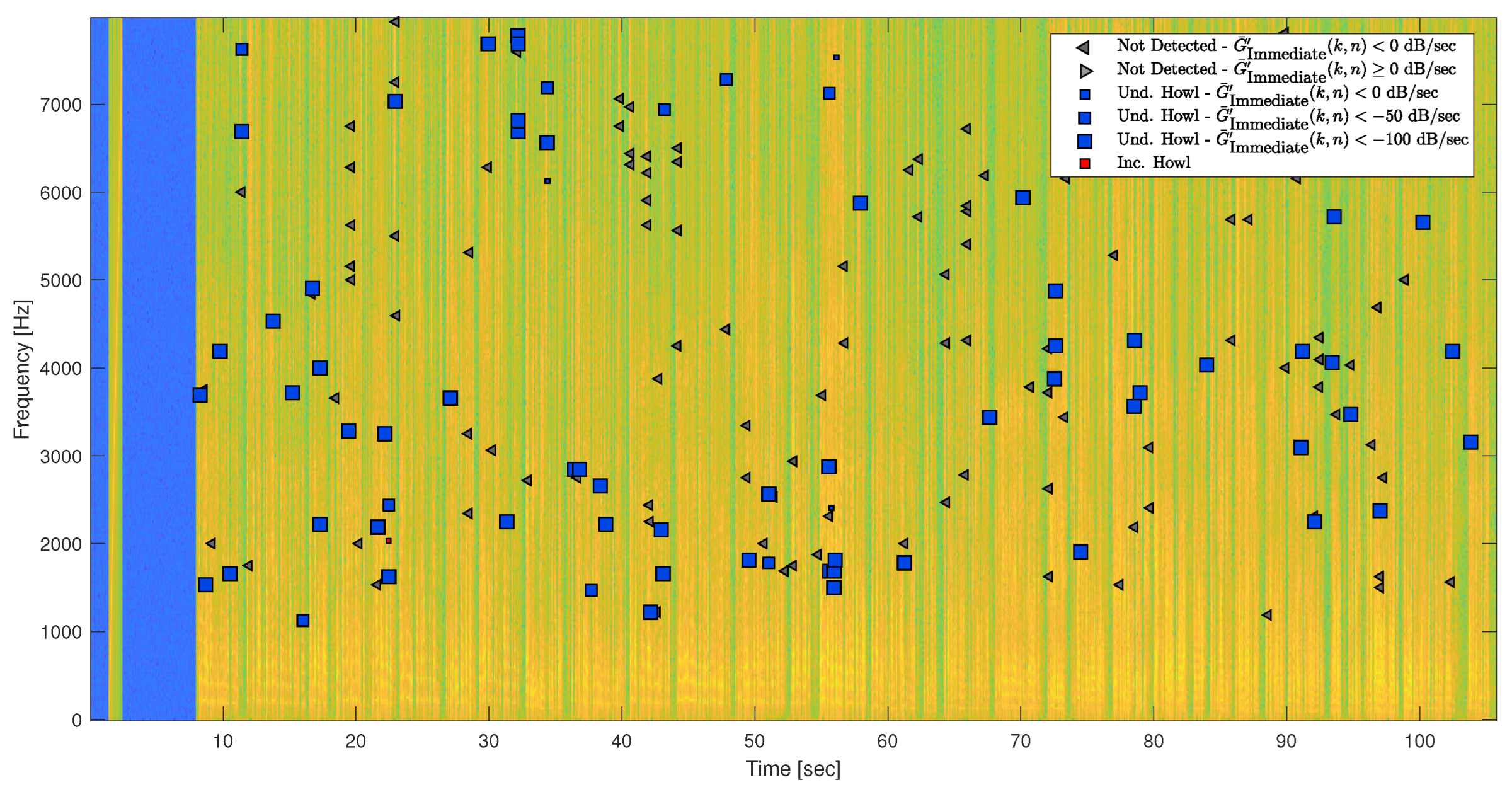
In practice, comparing multiple howling detection methods, where each may divide the frequency and time domains differently, may result in detecting a specific frequency-howl at different times and frequencies. Therefore, a united corpus of howling detection instances is created by appending the retrospective howling detections from all detection methods. Before analyzing a given temporal detection method with respect to the united howling detection corpus, one must first match the frequencies of the howling instances to the frequency bins determined by the given method. For a given decreased-resolution method, the howling frequencies are rounded (down) to fit the frequency grid, and duplicates are dropped. For a given increased-resolution method, the howling instances are duplicated based on their resolution ratio, to fit the middle frequency bins. Appropriately, one must also match the detection times of the instances to the determined time division. Specifically, reviewing the detection times for each howling frequency, finding the relevant frame indices, and solving duplicates by choosing the instance with the frame length closest to that of the given method. Thus, the spectrogram of the devised input signal is calculated based on the parameters of the given temporal method, getting the magnitude history of the entire signal. After that, for each howling frequency bin, evaluating the magnitude history buffers ending at each of the matched detection times, via the given detection method. Regarding the duplicated howling instances, in case of an increased-resolution method, the howling detection labels are united, where at least one of the duplicated instances is hopefully detected. Finally, since simulating complex feedback scenarios, each detector’s performance is evaluated separately for underdamped and increasing frequency-howls.
8. Discussion
The proposed performance evaluation framework compares the group of howling detection techniques in terms of both the response time and detection accuracy. The generic TF approach is applied in order to analyze the response time of a howling detector under each of the devised set of howling scenarios, illustrating the detection response time distributions over the set of howling change-rate configurations. In the simple howling scenarios, the Soft MSD-based with FA Detection detector provides a faster howling detection response time than the Plain MSD-based detector, especially in Close Stable Pole feedback scenarios. The advantage of a shortened history-buffer in these scenarios, as used in the Soft MSD-based with FA Detection & GC Coping detector, is not absolute for all feedback scenarios. Nevertheless, the improvement by the gain-change coping mechanism is significant in Gain-Control Howl scenarios for the Close Stable Pole feedback scenarios, although not much better than the Plain MSD-based detector in the More Unstable Pole feedback scenarios. Since aiming to detect howling before the SR system becomes unstable, the improvement in detection response time is more significant for Close Stable Pole feedback scenarios.
The Detection Accuracy is measured in terms of the false-alarm rate over a clean signal, and the detectors’ recall and precision in complex feedback scenarios, generated by simulating a simple SR system TF in a cherry-picked set of room configurations. Regarding the clean signal, almost 60% of the false-positive underdamped frequency-howls detected in the Soft Howling Detection stage are refuted by the Howling FA Detection stage. However, the two false-positive increasing frequency-howls were not refuted. Regarding the detection accuracy in complex feedback scenarios below the MSG, the FA Detection stage improves the precision of the Soft Howling Detection stage, while keeping a good recall for the detection of underdamped howls. In feedback scenarios above the MSG, the FA Detection stage resulted in better recall and precision measurements for increasing howls, although the precision for underdamped howls was low for all detectors within the simulated study room. As mentioned above, a few aspects need to be considered in this case. First, the diverging output signal has affected the magnitude values among the entire frequency bins, and has possibly added artifacts to the signal that were identified as howling. In addition, it seems that the howling detectors were not sensitive enough to obtain all of the frequency-howl ground truth in this scenario. Thus, the low precision can be attributed to identifying many underdamped howls along the output signal, and not identifying all of the howling frequencies in the system at the beginning. Still, the detection accuracy of increasing howls within the More Unstable Pole feedback scenario is good.
As the algorithm thresholds were calibrated within the simulated car cabin, the better results may indicate overfitting. However, the results are satisfying for the study room as well.
9. Conclusions
We have considered a howling detection algorithm within in-room speech reinforcement system applications, for utilization in howling control mechanisms. The loudspeaker-enclosure-microphone paths and the room’s reverberation characteristics directly affect the acoustic feedback in the room, and the resonance frequencies of the system’s closed-loop TF. Therefore, the amount of gain that can be applied to the acquired speech in the closed-loop system is constrained by electro-acoustic coupling in the system, manifested in howling noises appearing as a result of acoustic feedback. In fact, these howling noises can be divided into underdamped and increasing frequency-howls, based on what happens to the frequency component of the output signal after exciting a pole of the system’s closed-loop TF. A temporal howling detection algorithm based on the MSD measure is proposed for SR systems. The proposed algorithm aims to early detect frequency-howls in the closed-loop system, before the human ear notices. Thus, laying the foundation for howling control mechanisms, and maintaining high-quality speech communication. In reality, when the applied gain is increased gradually, a howling detection algorithm mainly aims to detect underdamped frequency-howls when the system is stable, rather than increasing howls when the system is unstable. The howling detection algorithm includes two cascaded stages: Soft Howling Detection and Howling False-Alarm Detection. The Soft Howling Detection stage is designed to identify potential candidate frequency-howls, and is calibrated for a low miss-detect probability. Accordingly, the proposed Howling False-Alarm Detection stage aims to authenticate each suspected frequency-howl with regard to the signal behavior prior to detection. As the majority of howling false alarms can be attributed to frequency components of speech harmonics, candidate frequency-howl false alarms can be refuted based on their prior magnitude behavior under the system’s steady state. Furthermore, a gain-change coping mechanism is applied to appropriately manage the howling detection process when the applied gain is reduced or increased as part of a howling control mechanism. In order to judge whether a candidate frequency-howl is about to be heard by the human ear, i.e., relevant for howling detection, a hearing threshold-contour is defined across the frequency bins based on standard ISO 226:2003 [
23].
A comprehensive performance evaluation process was designed to characterize and compare a group of howling detection algorithms, under a devised set of howling detection scenarios. Namely, examining the howling detection algorithms in terms of the detection response time and the detection accuracy. First, characterizing the howling detection response time as a function of howling change rate, under different howling detection scenarios, shows that the proposed algorithm provides a faster howling detection response time than the plain MSD-based detector; and that the improvement of the gain-change coping mechanism is significant in the gain-control scenarios for underdamped feedback scenarios. Second, evaluating the detection accuracy on a clean test signal and under complex stable- and unstable-feedback scenarios, within simulated room configurations of a car cabin and a study room, shows that the proposed temporal howling detection algorithm provides better accuracy than the plain MSD-based detector as well as the Soft Detection stage alone. Hence, the proposed temporal howling detection algorithm is fast and reliable and, all in all, outperforms the plain howling detector, which does not benefit from utilizing the past of the detected frequency-howls due to its prominent trade-offs.
Future work may concern optimizing the thresholds of the proposed howling detection algorithm for each type of room configuration, e.g., room dimensions and reverberation time. Moreover, incorporating more advanced algorithms for howling detection that make use of the proposed temporal approach and features.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









