Abstract
Culinary heritage is central to preserving cultural identity. The present study analyses the content of culinary notebooks from 1946 and 1947 using large language models (LLMs) and a dedicated AI plugin, Linguistic Insight (LI-AI). The general goal was to analyse content in Granny Josie’s Notebooks (the BaJa corpus) with AI tools. The specific objective was to create and test a dedicated analytical tool, an LI-AI ChatGPT plugin for the in-depth analysis of the BaJa corpus, focusing on ingredients, techniques, and recipes. LI-AI identified keywords and main themes in the large textual dataset. It then visualised them as word clouds. Compared to manual tools, LI-AI’s semantic analysis was more precise and comprehensive. This study contributes to the analysis of historical culinary practices in post-war Poland, revealing that cooking had not only a pragmatic role but also a symbolic one as it supported social and family bonds. This finding was not evident in the word clouds. Instead, it emerged from an in-depth semantic analysis. This study has confirmed the practical value of LLMs in historical text interpretation. It also established that the parallel use of AI and manual tools is advisable for a fuller analysis of textual data.
1. Introduction
Culinary heritage is considered a vital part of cultural identity at the regional and international level [1]. It reflects the community’s history, customs, and individual traits with such means of expression as traditional flavours, aromas, sounds, and cooking, serving, and eating methods [2]. This is why the value of archiving and investigating historical sources is appreciated in the face of vanishing local traditions, including such points of insights as documents with information on bygone culinary practices, recipes, food traditions, plant varieties, animal breeds, ingredients, and cooking techniques along with their cultural and socioeconomic contexts [3,4,5]. The efforts aim to preserve cultural heritage for posterity and reinterpret the past in the context of current needs, taking into account new possibilities, particularly those offered by advancing technology [5].
Archaic autographs offer valuable insights into the tangible and intangible cultural heritage of the past. They can contain information on traditional cooking techniques and ingredients available and used at a specific time and place. Archaic notes can help understand the everyday diet of a given era and the factors that shaped it [6]. They can also inform about local customs, occasions, or practices linked to eating food, which can be useful for reconstructing the community’s culture [7]. These source materials demonstrate that specific socioeconomic, natural, and cultural circumstances fuelled creativity and boosted resourcefulness in the kitchen and regarding everyday chores. Therefore, they can also bear witness to past values, such as thrift or care for family traditions, which is an essential component of tangible and intangible cultural heritage.
The role of new technologies in history and cultural research is growing. Large language models (LLMs) are one of the latest technological achievements. They can analyse texts automatically and extensively [8]. A large language model is an advanced artificial intelligence (AI) model trained on large textual datasets to process natural languages. Its primary functions are understanding, translating, and analysing texts and generating textual, numeric, and graphic reports. Large language models can recognise the context, answer questions, summarise information, and process languages similarly to humans thanks to sophisticated machine-learning techniques, such as highly parametrised neural networks [9]. The present work focuses on employing LLM-based AI to analyse handwritten notes from 1946 and 1947 taken down by Józefa Kmieć from Tarnów, southern Poland, called Granny Josie (Babcia Józia in Polish) by her family. Apart from documenting the practical aspects of education and curriculum of the Rural Domestic Science School for Girls in Szynwałd, Poland, the notebooks contain cooking recipes and also offer a peek into everyday cooking practices and techniques, along with housekeeping conventions in post-war Poland. The textual dataset is three handwritten notebooks analysed with computer tools after digitisation.
Analysis of a large corpus, particularly enormous textual databases, can pose numerous obstacles or even be out of the reach of the research team. The first difficulty is navigating the extensive database, identifying central information, and presenting statistics. Moreover, manually analysing recurring motifs and identifying keywords can be time-consuming or even impossible in the case of huge datasets. In addition, it is a substantial effort to find thematic similarities among sections or to classify textual data manually. Such tools as LLM-based AI can substantially streamline operations or facilitate them.
The general goal is to analyse the content in Granny Josie’s Notebooks with LLM-based AI tools. The specific goal is to build and test a dedicated analytical tool, an AI plugin, for analysing corpora and visualising results with charts, word clouds, etc. This study also aims to perform a thematic analysis of Granny Josie’s Notebooks, focusing on traditional ingredients, techniques, and recipes. The primary assumption of this study is that an analysis of archaic autographs with AI may elevate the understanding of old Polish cuisine and everyday food-related practices in Polish households of the 1950s. This study preserves old Polish culinary traditions from oblivion, but through the use of new technologies, it is also a step towards a better understanding of the future. The primary results of this study are visualisations of words, identification of keywords, and semantic analysis results for Granny Josie’s Notebooks in the context of Polish culinary heritage. To this end, the author poses the following research questions:
- What lexemes and themes related to food dominate Granny Josie’s Notebooks? This question concerns identifying primary theme areas, such as ingredients, cooking techniques, and types of dishes emerging from the content analysis of Granny Josie’s Notebooks;
- How can today’s textual analysis tools, such as LLM-based AI plugins, support research on historical corpora? This question evaluates the usefulness of AI tools for processing and interpreting large datasets, such as Granny Josie’s Notebooks.
The remainder of the article is structured as follows. Section 2 offers a glimpse into the figure of Granny Josie and the historical context of her notebooks. The background is followed by a literature review of publications on culinary heritage, concentrated on the application of LLMs in investigations of corpora of archaic texts. That section also provides an overview of new technologies that help restore historical recipes and identify changes in culinary traditions based on written sources. Section 3 introduces the methodology. It outlines data processing methods, specifications of the Linguistic Insight plugin, and the procedure of semantic analyses and visualisation of the results. Section 4 contains the results, together with analytical outcomes and word cloud visualisations. Section 5 discusses the results and observations. The final section covers conclusions, limitations, and further research.
2. Background
2.1. Granny Josie’s Culinary Heritage
Granny Josie, actually Józefa Kmieć nee Kapusta (1925–2008), was an outstanding woman who earned an eternal place in the history of her family and community. She took down extensive notes during her education at the nun-run Rural Domestic Science School for Girls in Szynwałd (Małopolskie Voivodeship, Poland). Thanks to the dedication of her daughter, Alicja Wiązowska from Tarnów (Małopolskie Voivodeship, Poland), the notebooks were preserved to this day. The Rural Domestic Science School for Girls in Szynwałd aimed to provide comprehensive education to girls and equip them with the skills and knowledge needed in housekeeping [10].
The Rural Domestic Science School for Girls in Szynwałd was established by Rev. Aleksander Siemieński and supported by Deputy to the Diet of Galicia and Lodomeria Wincenty Witos and President of Farmer Associations in Lviv Bronisław Dulęba. The construction process lasted from 1907 to 1 October 1909. The nuns acquired appropriate pedagogical qualifications on a year-long training course in Czechia [10]. Initially, the first year accommodated 21 students in 1909. Then, the number increased to 30–50 girls a year. The typical student was 16 to 22 years old. Most were peasants, although some workers and officials’ daughters also attended the school.
The curriculum concentrated on preparing the girls for diverse challenges of housekeeping. The school year was usually from October to July. Theoretical classes were followed by practical skill learning, such as cooking, laundry and ironing, garden work, husbandry, sewing, and fruit tree grafting [10]. In 1921, the curriculum was expanded to include history, environment, agriculture, hygiene, and singing. The school was ruined, and its equipment was stolen during the Second World War. After the war, the school resumed its mission but had to be shut down in 1949 despite the best efforts [10].
In 1947, after completing her education, Józefa Kmieć returned home to Łysa Góra, Małopolskie Voivodeship, where she could put her skills to the test. She married in 1948 and lived in Gdańsk Oliwa, Karpacz, and Brzesko before settling down in Tarnów, where she spent the rest of her life. Granny Josie’s Notebooks, containing her school notes, survived numerous removals. For her, these were not only a collection of food recipes and practical guidelines but also priceless souvenirs of her youth. Today, they offer us insight into the everyday food practices of post-war Poland, reflecting the availability of ingredients, traditional cooking techniques, and customs linked to eating and housekeeping.
2.2. Related Work
Conservation of culinary heritage is central to preserving cultural identity. Digitisation of historical written materials opens new possibilities for analysing and safeguarding the legacy. New technologies play a crucial role in the process. LLM-based AI can process and interpret vast textual datasets. This empowers researchers to trace the evolution of cooking practices, identify ingredients used predominantly in texts, and analyse changes in how people prepare, serve, and eat food [11]. Large language models revolutionise research on archaic texts through automated processing, in-depth analysis, and interpretation at an unprecedented scale. Sophisticated pattern and context recognition algorithms allow LLMs to unravel hidden meaning, reconstruct missing fragments, identify relationships between texts, analyse the evolution of language, and classify and categorise content based on thematic and stylistic characteristics. They streamline transliteration and translation, which precipitates research on heritage texts [12]. Furthermore, LLMs can perform topical modelling, data classification, and visualisation for easier exploration of culinary heritage in a new, systematic way.
Gagliardi and Artese [13] analysed historical food recipes using topic modelling and data visualisation. They employed an unsupervised analysis process, LLMs, and visualisation techniques. Their method was tested on cookbooks in English and yielded insight into the evolution of culinary practices. Magomere et al. [11] investigated differences in the performance of base models regarding generating content on regional dishes with their original World Wide Dishes database. Their research demonstrated that language models and generative text–image systems have difficulties properly representing dishes typical of various regions. The authors pointed out errors in cultural representation that could harm diversity and reinforce stereotypes. This study shows that the limitation of training data can contribute to regional exclusion and distort culinary heritage representation in AI systems.
Zhang et al. [12] analysed challenges in translating culture-specific items (CSIs) in restaurant menus, particularly in Chinese and English. They built the ChineseMenuCSi dataset, the most extensive corpus of Chinese–English menus with flagged CSIs. Then, they developed a method for flagging CSIs automatically, which surpasses methods based on GPT suggestions. They also proposed three levels of CSI figurativeness for a more precise analysis. Bagler and Goel [14] introduced computational gastronomy as a novel approach to analysing culinary techniques with computational methods. They demonstrated that culinary data modelling paves the way for systematic investigation of recipes regarding the taste, nutritive value, health impact, and carbon footprint. They believe AI can generate new recipes, combining aesthetics, taste, health, and environmental qualities.
The literature review has demonstrated that such new technologies as LLM-based AI offer new opportunities for analysing and protecting cultural heritage (Table 1). Large language models can automatically process historical culinary texts, identify ingredients and cooking techniques, and analyse the evolution of cooking practices, advancing systematic research on the culinary domain in the cultural and regional context.

Table 1.
Summary of selected studies on the application of LLMs in cultural heritage analysis.
Culinary heritage plays a vital role in tourism as a significant component of regional cultural identity. Culinary heritage adds value to tourist potential with unique food trails and as the leitmotif of festivals and fêtes that improve a region’s position in the tourist market. Regional cuisine attracts tourists who seek an authentic experience, allowing them to commune with local traditions, history, and lifestyle. Culinary tourism promotes local products, fuels the economy, and endorses the protection of traditional recipes and cooking techniques [16]. This is why LLMs are employed to analyse archaic texts and investigate current industry content, such as tourist reviews of gastronomic and lodging services. They can automatically classify sentiment, extract key information, and identify trends, supporting decision-making in the tourism industry. For instance, Guidotti et al. [15] investigated how LLMs were applied to analyse reviews of tourism services by classifying sentiment and extracting keywords. They used zero-shot classifiers to automatically classify the type of opinion and identify key phrases without pretraining the language models. Experiments on diverse datasets confirmed that the method effectively helped to better understand customer preferences. Loureiro et al. [17] demonstrated that LLMs could be used as travel advisers (assistants), but their propensity for hallucinations could dent user confidence in AI-generated suggestions.
Carvalho and Ivanov [18] established that the rapid advances in AI have significantly affected tourism. They analysed the applications, advantages, and risks of using ChatGPT in the tourism industry. Their results suggest that ChatGPT can precipitate front-office customer service and improve the effectiveness of back-office activities. Furthermore, this study revealed that the benefits come at a specific price of using LLMs, the most common being hallucinations.
Applications of AI in tourism are often researched globally in light of the potential it has regarding customer service automation, offering personalisation, and optimisation of back-office operations. Other conclusions were that AI can support both tourists and businesses, improving the overall operational performance and the quality of experience. From a slightly more focused perspective and considering the context of culinary heritage, AI tools can identify covert links between traditional cuisine and historical socioeconomic changes, such as migrations, trade, and colonial impact. Moreover, an in-depth analysis of old recipes with AI supports reconstructing past dishes to use them in tourism or adapting to today’s consumer tastes and preferences [19]. Therefore, AI in culinary heritage research helps expand the knowledge of past culinary practices and contributes to protecting and promoting vanishing gastronomic traditions.
Considering the AI boom and the increasing impact of AI tools on analysing heritage texts, it is critical to adopt a research methodology for using them effectively. The present study combines natural language processing (NLP) techniques, semantic analysis, and data visualisation. It focuses on building and testing a dedicated AI plugin for extracting information, classifying content, and identifying patterns in large textual datasets. The research methods and tools are discussed in detail below.
3. Materials and Methods
3.1. Research Object
The objective could be pursued, and the word clouds could be generated only after the analogue autographs of Granny Josie’s Notebooks had been digitised. The three notebooks were written in 1946 and 1947 and were contributed for research purposes by Alicja Wiązowska from Tarnów, Granny Josie’s daughter. First, the notebooks were scanned, saved as raster PDF files, and deposited in the digital repository of the Library of the University of Agriculture in Kraków [20]. The files were then converted into vector data (docx files). The conversion was performed with the SpeechTexter [21] voice-to-text software. The process consisted of reading the content out to be recorded by the software as editable text (transcription: voice-to-text conversion). The effort resulted in the BaJa corpus of 91 pages (Times New Roman, 11 point, line spacing 1.0) or 44,788 words in Polish (Corpus {input data}: https://doi.org/10.6084/m9.figshare.27889698 (accessed on 15 April 2025)). BaJa is an abbreviation of the Polish phrase Babcia Józia, meaning Granny Josie. The corpus was then subjected to AI-powered evaluation [22] with ChatGPT (GPT-4o, Open AI, San Francisco, CA, USA).
3.2. Research Tools and Design
For the sake of the research, a ‘word (form)’ is the smallest independent language form conveying lexical or grammatical meaning. It may change depending on the declension, case, number, genus, tense, etc. ‘Lexeme’ is an abstract language unit that covers all forms of a word. For example, COOK as a lexeme covers all word forms created through inflection, such as cooks, cooking, and cooked. Therefore, the visualisations contain word (form) clouds, while the description of analysis results usually concerns keywords (lexemes).
A dedicated analytical AI plugin was created for this study: Linguistic Insight (abbreviated as LI-AI) [23]. Artificial intelligence plugins are components (extensions) with specific functions. These are highly specialised GPT models designed for particular tasks to expand the functionality of the standard version of ChatGPT [9,24]. The Linguistic Insight plugin works in the LLM ecosystem of ChatGPT, as shown in Figure 1. Figure 1 outlines the hierarchy of notions related to LLMs.

Figure 1.
Hierarchical relationships from a general notion of artificial intelligence to highly specific tools or AI plugins.
Artificial Intelligence (AI) is a general term for systems simulating human intelligence capable of learning and making decisions. Large language models (LLMs) are extensive language models trained on large textual datasets for a better understanding of natural languages [25]. Generative Pre-Trained Transformer (GPT) is a sophisticated AI model capable of generating text from context using a transformer architecture [26]. ChatGPT (Open AI) is an LLM tool adapted to conversations, answering questions, and generating personalised content in a conversational user interface (CUI) [24]. Finally, Linguistic Insight is an LLM-powered AI plugin in the ChatGPT ecosystem offering linguistic analysis functions.
The research design around the Linguistic Insight plugin involves automated processing of text in Polish with the potential to translate the results into other languages. The process starts with importing the input textual database (the corpus) for algorithmic analysis. The scope of the analysis is defined through prompts. The plugin generates visualisations for easier interpretation of the results and conclusions based on the analysis of the corpus (input data).
Declared Technical and Performance Specifications of Linguistic Insight
Linguistic Insight (LI-AI) operates in ChatGPT Plus based on GPT-4 natural language processing (NLP) models. The tool runs in a cloud such as SaaS (Software as a Service), which adds scalability, availability, and rapid processing of large textual datasets. It can be operated on any online device. Linguistic Insight can identify context, classify sentiment, and automatically identify keywords. The analyses are presented as reports modifiable with prompts (Table 2).
Table 2.
Technical and performance specifications of Linguistic Insight.
Linguistic Insight was designed to support the linguistic analysis of large corpora. The tool offers semantic analysis for identifying themes found in the corpus and relationships between notions in the text to help better understand the context. Another function of LI-AI is the identification of keywords, their frequency, and co-occurrence for extracting the most important information from the corpus. Furthermore, the plugin can analyse sentiment, reporting the emotional tone of the content as positive, negative, or neutral, or according to a different predefined classification. Linguistic Insight can also perform more sophisticated linguistic analyses, such as (1) syntactic analysis of the grammatical structure of clauses to identify relationships between subjects, verbs, and other parts of a sentence and (2) pragmatic analysis focused on the context of language use, intentions of the sender, and potential interpretations. Linguistic Insight can analyse rhetoric to identify rhetorical devices, such as metaphors, analogies, or persuasive strategies. Cohesion analysis by LI-AI investigates the logical links between parts of the text, considering both lexical and semantic cohesion. It can, additionally, perform morphological analysis to identify such morphemes as stems, prefixes, or inflection suffixes to support inflection and derivation studies.
Linguistic Insight runs in the LLM ecosystem and uses a CUI. It means that the operator can instruct it through prompts to perform analyses other than those declared in the specification. However, the analytical capabilities declared and results generated by the LLM should be analysed critically. It is due to the propensity for hallucinations typical of LLMs [35]. Therefore, the research employed a cautious and conservative approach [9].
3.3. Visualisation of Results
The word clouds are generated based on an analysis of the text in the input file for LI-AI. First, the text was read from the source file and prepared by AI for further processing. Next, semantically insignificant (in the context of the Polish language) phrases (stop words) were filtered out, including personal and possessive pronouns (I, you, my), prepositions (in, on, from, to), conjunctions (and, or, although), particles (oh, not), numerals, auxiliary verbs (be, have), and adverbs of frequency (often, never, always).
Linguistic Insight creates visualisations with the WordCloud library, the purpose of which is to visualise the most common words in a text, with the size of each word reflecting its frequency in the corpus. When defining the cloud, the author increased word spacing to improve readability and redefined the colour theme. The visualisation is a low-resolution raster file by default.
The word cloud generation stages are shown in Figure 2. The visualisation is generated with the python-docx library from data loaded from a text file. Next, stop words are stripped, and the text is converted into all lowercase letters. Word frequency is determined with collections. Counter (a class in the collections module of Python 3.11). Finally, a word cloud is generated with the WordCloud library. The sizes of the words reflect their frequency in the corpus.

Figure 2.
Stages of the word cloud generation process with LI-AI.
Linguistic Insight can also visualise results with charts. TreeMap is a method for visualising data as nested rectangles. Each rectangle represents a data component. Their areas reflect the components’ values. Linguistic Insight generates the visualisation with the Matplotlib Python library (version 3.6.3, Matplotlib Chart). Matplotlib is one of the most popular libraries for generating charts and visualising data [34].
The AI plugin was tested by comparing its results with those from two manual tools. The success criteria were results cohesion and consistency, their alignment with the corpus topic, and data usefulness for in-depth semantic analysis.
3.4. Results Validation: Manual Visualisation of Data
The results generated by LI-AI were verified using two manual tools: (1) Word Cloud Generator [37] and (2) WordClouds [38]. Word Cloud Generator (WCG) is an online manual tool for generating word clouds from large corpora. The tool has a GUI. It generates raster and vector (SVG) graphics based on frequency analysis. No additional desktop software is needed, as WCG runs in a browser window.
Word Cloud Generator uses JavaScript and the D3.js library (Data-Driven Documents) to generate dynamic, responsive, and interactive data visualisations. Thanks to using D3.js, WCG’s word clouds’ appearance can be adjusted. Fonts, text orientation, number of words, and layout can be changed manually. The tool is compatible with many languages, so diacritics are visualised appropriately. Automated text analysis can detect the most frequent word forms and highlight them. The more frequent a word, the larger its size in the cloud.
WordClouds (WC) offer similar functional characteristics. It is an interactive generator for visualising text as graphics where the size of words reflects their frequency in the analysed corpus. The user can modify the graphic’s attributes in a GUI, including the shape, colour theme, font, and word layout. WordCloud can save the graphics it generated as raster or vector files.
Both tools are manual and controlled in a GUI control dashboard. Therefore, they work and operate differently from AI plugins. The employment of various tools contributed to the diversification of the research design and allowed the author to compare their usability for analysing large corpora.
4. Results
4.1. Selected Statistics on BaJa and Thematic Analysis Results
According to LI-AI, BaJa comprises 35,544 word forms, 7591 of which are lexemes (about 21.36%). This demonstrates the lexical diversity of the corpus. The total character count with whitespace characters is 221,188. With spaces removed, the number drops to 185,333. The average word in the corpus has 5.21 characters, which may indicate a relatively large number of complex or expert words. The average sentence has 35.54 words, which suggests relatively extensive structures.
Content analysis revealed three primary themes in BaJa. The first one is recipes and ingredients due to the frequency of such words as ‘cukier’ (sugar), ‘masło’ (butter), and ‘mąka’ (flour). The second dominant theme is cooking techniques. The frequent use of terms like ‘gotowanie’ (boiling), ‘pieczenie’ (roasting/baking), ‘smażenie’ (frying), or ‘mieszanie’ (stirring, mixing) indicates a significant portion of descriptions of practical aspects of food preparation. The third theme is baked products, pies, and cakes, which suggests a substantial part of the corpus concerns desserts and confectionery.
Sentiment analysis employed the TextBlob Python library, a component of LI-AI. The sentiment of every sentence was evaluated as positive, neutral, or negative. The results show that most sentences in the corpus are neutral. Positive or negative sentences are rare, which confirms that the text conveys nearly no emotions.
Figure 3a shows the density distribution of sentiment analysis results for BaJa. The horizontal axis (X) represents sentiment. Negative values reflect negative sentiment. Zero means neutral sentiment. Positive values are associated with positive sentiment. The vertical axis (Y) illustrates the frequency of sentences with specific sentiment values. Sentiment ranged from 0.0 to 0.8, which means no negative content in the corpus dominated by neutral sentences. The lower density in positive values suggests minuscule positive sentiment. The lack of negative values confirms the absence of negative content in the corpus. Figure 3b presents quantitative statistics of sentiment distribution. They also confirm the neutral sentiment of the text. Therefore, the text can be considered descriptive, informational, and instructional. It focuses on conveying practical guidelines and knowledge at a minimal emotional level.
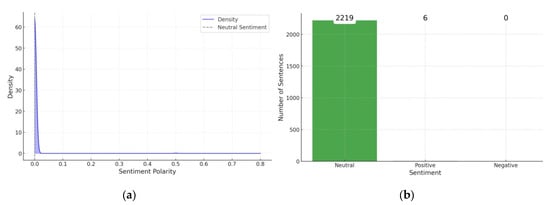
Figure 3.
Sentiment analysis results, kernel density estimate plot (a). Quantitative statistics of sentiment distribution (b). Source: Original work with LI-AI.
The TreeMap generated by LI-AI shows the hierarchy of the nine most common lexemes from the corpus (Figure 4). The lexemes were identified after word filtering stopped. Each rectangle represents one lexeme. Its size reflects the frequency in the corpus. Colours help identify categories.
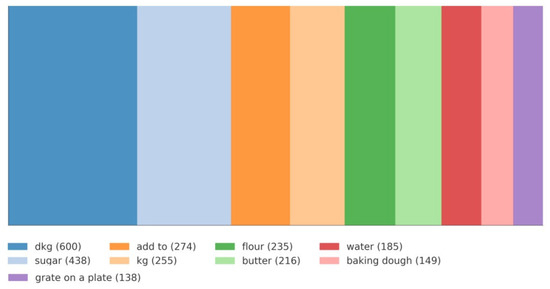
Figure 4.
The most frequent lexemes in BaJa. Source: Original work with LI-AI.
Figure 4 shows the dominant lexemes in BaJa. The largest rectangle is ‘dkg’ (600 occurrences), which indicates the dominant role of units of measure in the corpus. It further demonstrates that the notes have a pragmatic focus, where precise measurement of ingredients is critical. Other frequent terms are basic ingredients like ‘sugar’ (438 occurrences), ‘flour’ (235 occurrences), ‘butter’ (216 occurrences), and ‘water’ (185 occurrences). Another group of commonly used terms is cooking techniques and operations, i.e., ‘add to’ (274 occurrences), ‘baking dough’ (149 occurrences), and ‘grate on a plate’ (138 occurrences). This suggests that the corpus contains detailed instructions on preparing food and processing ingredients.
4.2. Word Cloud Analysis
Linguistic Insight generated a word cloud for BaJa. The following prompts were used: analyse the corpus; generate a list of word forms; filter out stop words; use the list to visualise a word cloud, where the word frequency determines the word size in the image.
A pilot word cloud was generated from the prompts, but it had to be improved. The revision removed digits, numbers, and words and characters irrelevant to the semantic analysis, such as ‘gdy’, ‘się’, ‘½’, and ‘a’. This improved the visualisation significantly (Figure 5).

Figure 5.
Word cloud of the most frequent terms in BaJa. Source: Original work with LI-AI.
The corpus is in Polish. It was impossible to machine-translate the word forms and visualise the cloud in English. According to LI-AI, some words in the corpus were not included in the translation dictionary. Therefore, the Polish words are used as input for the visualisation.
The word cloud identified the following most common words in BaJa: ‘cukier’ (sugar), ‘mąka’ (flour), ‘masło’ (butter), ‘woda’ (water), ‘ciasto’ (dough, batter, cake), and also ‘dodać’ (add), ‘utrzeć’ (grate, cream, grind), ‘wymieszać’ (mix, stir), and ‘piec’ (bake, roast). The word cloud confirms that the corpus contains culinary descriptions. The primary components of the image are ingredients. The large sizes of the words ‘cukier’ (sugar) and ‘masło’ (butter) confirm the high frequency of themes linked to baked products. Words in smaller font, like ‘żółtka’ (yolks), ‘sos’ (sauce, gravy, dressing), ‘syrop’ (syrup), ‘gotować’ (cook, boil), ‘posypać’ (sprinkle, dust), ‘ułożyć’ (arrange), are ingredients and techniques that add significant informational value regarding cooking techniques.
4.2.1. Thematic Word Cloud Focused on Ingredients
The thematic word cloud revealed the most common ingredients in the corpus. They are highly diversified. Words in the most prominent front are ‘ser’ (cheese), ‘cukier’ (sugar), ‘masło’ (butter), ‘jajka’ (eggs), ‘ryż’ (rice), ‘pomidor’ (tomato), ‘śliwki’ (plums), ‘pieprz’ (pepper), and ‘orzech’ (nut), and fruits such as ‘maliny’ (raspberries), ‘wiśnie’ (sour cherries), and ‘gruszki’ (pears) (Figure 6). The visualisation revealed that the words ‘mleko’ (milk), ‘mięso’ (meat), ‘kasza’ (groats), ‘płatki’ (flakes), and ‘olej’ (oil) are in a slightly smaller font, meaning they are not as common as the other ingredients. It also contains vegetables, including ‘ziemniaki’ (potatoes), ‘pietruszka’ (parsnip, parsley), ‘buraki’ (beetroot), ‘ogórki’ (cucumber), ‘kapusta’ (cabbage), ‘sałata’ (lettuce), and ‘marchew’ (carrot). This figure could be machine-translated with LI-AI into English.
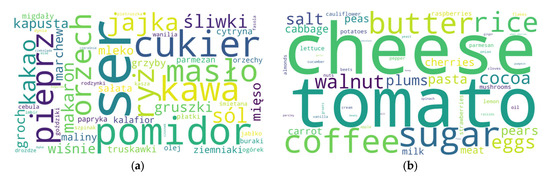
Figure 6.
Word cloud: the most common ingredients in Polish (a) and machine-translated into English with LI-AI (b). Source: Original work with LI-AI.
Words in a smaller font, such as ‘parmezan’ (Parmesan), ‘szpinak’ (spinach), ‘papryka’ (sweet peppers), ‘grzyby’ (mushrooms), ‘kalafior’ (cauliflower), ‘goździki’ (cloves), ‘wanilia’ (vanilla), ‘rodzynki’ (raisins), ‘migdały’ (almonds), and ‘czereśnie’ (sweet cherries), suggest themes related to more sophisticated dishes for special occasions and desserts. The word cloud shows the thematic diversity within the corpus, still focused on food, from desserts to main courses, and reflects the abundance of ingredients. Note the differences between the point clouds in Polish and in English. They are due to automated translation and the AI method for calculating word frequency. The figure in Polish (Figure 6a) shows results for the original corpus. At the same time, its counterpart in English is based on automated AI translation, which resulted in a changed location, size, and number of words in the cloud (Figure 6b). Therefore, the proper results are those in the figures in Polish. In contrast, their English counterparts’ role is auxiliary.
4.2.2. Thematic Word Cloud Focused on Food Preparation Techniques
The word cloud with cooking techniques unambiguously identifies terms for food preparation methods. The cloud is dominated by such frequent techniques as ‘pieczenie’ (baking, roasting), ‘tarcie’ (grating), ‘mieszanie’ (mixing, stirring), ‘gotowanie’ (boiling), ‘duszenie’ (braising), ‘siekanie’ (chopping), ‘obieranie’ (peeling, shelling), ‘ubijanie’ (whipping, whisking), ‘krojenie’ (cutting, slicing), and ‘szatkowanie’ (shredding), which reflects their importance for the text (Figure 7). The corpus additionally contains less frequent terms printed in a smaller font or not included at all, such as ‘marynowanie’ (marinating), ‘mrożenie’ (freezing), ‘karmelizowanie’ (caramelisation), and ‘fermentowanie’ (fermenting).
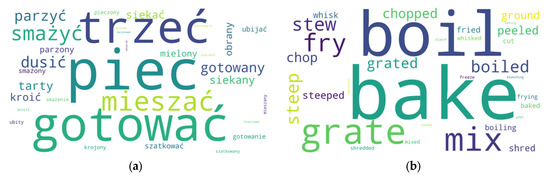
Figure 7.
Word cloud: the most common cooking techniques; keywords in Polish (a) and machine-translated into English with LI-AI (b). Source: Original work with LI-AI.
The word clouds revealed the most common ingredients: sugar, flour, butter, and water. The most frequent techniques are baking/roasting, boiling, mixing/stirring, and grating. The charts demonstrated that most sentences exhibit neural sentiment, typical of instructional and informational materials.
4.3. Manual Visualisation of Data
Neither the WCG [37] nor the WC [38] offers analytical functions. They can visualise words from a corpus but facilitate no in-depth text analysis. Their sole purpose is to visualise data.
The image from the WCG visualises the words in BaJa (Figure 8a). The most common words include ‘dkg’, ‘cukru’ (sugar), ‘mąki’ (flour), ‘masła’ (butter), ‘dodać’ (add), and ‘proporcja’ (proportion), which indicate ingredients and units of measure. Cooking-related verbs are also present, such as ‘ucierać’ (grate/cream), ‘piec’ (bake, roast), ‘smażyć’ (fry), ‘pokroić’ (cut, slice), ‘wymieszać’ (mix, stir), and ‘utrzeć’ (grate/cream), which confirms that the text contains instructions on food preparation. The cloud additionally contains numbers, units of measure, names of objects (‘kg’, ‘łyżki’ (spoons), ‘szklanka’ (glass)), and names of ingredients, such as ‘żółtka’ (yolks), ‘białka’ (whites), ‘śmietana’ (cream), ‘sok’ (juice), ‘cytryny’ (lemons), ‘wanilia’ (vanilla), and ‘czekolada’ (chocolate). At this stage, it is clear that the WCG does not filter the database, resulting in a denser and apparently fuller word cloud. Therefore, it is better at representing the lexical diversity of the corpus.

Figure 8.
Word clouds generated with WCG [37] (a) and WC [38] (b).
Visually, Figure 8a offers diversified colours and random word placement. A lack of specific thematic arrangement leads to a dynamic, irregular shape that can represent lexical diversity. The presence of numerous units of measure, names of ingredients, and cooking-related verbs clearly demonstrates the culinary context of the input data. On the other hand, the words seem to be mixed and presented chaotically. It hinders any manual interpretation of the results.
WordCloud generated an image shaped like a cup (Figure 8b). It contains words related to cooking and baking, which confirms that the input data contains cooking recipes. The largest and most prominent words, such as ‘mąka’ (flour), ‘cukier’ (sugar), ‘masło’ (butter), ‘mleko’ (milk), ‘dodać’ (add), and ‘dkg’, and smaller ones like ‘proporcja’ (proportion), ‘zagotować’ (bring to the boil), and ‘posypać’ (sprinkle, dust), indicate critical ingredients and typical cooking instructions. The cup shape additionally brings to mind a homely atmosphere and corresponds with the themes in the input data. Generally, visualisations with LI-AI, WCG, and WC offer similar conclusions, which makes them complementary.
5. Discussion
5.1. Content of BaJa and the Socioeconomic Context of Post-War Poland and Changes in Poles’ Culinary Habits
The socioeconomic and cultural changes in post-war Poland significantly shaped culinary habits among Poles, gradually leading to a more spartan diet, loss of some traditions, and subsequent rekindling of fascination with the national cuisine over time [39]. The period of 1946–1950 saw a reorganisation and restoration of everyday life in Poland, which also affected culinary education. Despite food supply issues, gastronomic schools and girls’ vocational and domestic science schools, in particular, taught diverse culinary techniques. Curricula included basic cooking methods and more advanced techniques, such as fermentation, preservation, and freezing, intended to prepare dishes that keep well [10]. The teachers passed down skills to adapt recipes to the available ingredients as a way of handling the post-war reality. Local and readily available ingredients, such as potatoes, cabbage, milk, butter, or groats, were promoted, along with reasonable management of the available resources. Some schools have introduced their students to dietetics and food hygiene so that future housewives would be familiar with the principles of healthy cooking in difficult times.
Despite diversified curricula focused on regional culinary traditions, war damage, migration, the beginning of communism, and a shortage economy led to the homogenisation of culinary culture. Traditional and varied regional dishes were slowly replaced with a unified menu promoted by the communists as suitable for the working class [40]. Due to this policy and propaganda, Poles ate mainly at home, in staff canteens, and in subsidised cafeterias, where they were fed simple dishes from readily available ingredients, such as cabbage, potatoes, and root vegetables. On the other hand, some forces countered the homogenisation of culinary culture. Post-war migration, particularly the relocation of people from the Eastern Borderlands to the Recovered Territories, contributed to the amalgamation of culinary traditions. The settlers brought native recipes and cooking techniques, slowly shaping a new, syncretic regional cuisine [41]. Moreover, despite the general trend towards uniformity, many regions of Poland adhered to their culinary traditions, such as the Lemko, Kashubian, Podhale, Hutsul, Borderland, and other cuisines [42]. During the Polish People’s Republic, the government promoted simplified food, focusing on calories and nutritional value, often at the expense of diversity and flavour. This has led to the loss or marginalisation of many pre-war culinary traditions [43]. It was not until after the sociopolitical transformation in 1989 that the public grew more interested in regional dishes and old recipes [5,42].
5.2. Culinary Traditions and Eating Customs Depicted in BaJa
According to the in-depth semantic analysis by LI-AI, the notes from 1946 and 1947 are dominated by traditional cooking techniques, such as braising, boiling, roasting, and frying. Other essential practices include dough kneading, creaming in a makitra, and preparing various types of roux. The recipes often mention grinding and mincing, such as of poppy seeds, meat, or potatoes, and long and careful kneading. Fermentation was critical for yeast-leavened cakes and beet sour for borscht. Another important process was to cool down completely and ‘rest’ dishes to improve their flavour and structure.
The corpus is dominated by local products: potatoes, flour, milk, butter, eggs, and cabbage. Less popular are mushrooms, beetroots, rice, and dried fruit (Table 3). Ammonia and baking powder are the go-to rising agents. Fats like lard, butter, and oil are used as bases for soups, sauces, and baked products. Natural spices like salt, sugar, pepper, dill, cinnamon, and vanilla play an essential role in the corpus. Hence, considering the in-depth descriptive analysis, the content of the word clouds seems limited and provides much less information.
Table 3.
The most common words in BaJa are cooking techniques, ingredients, and eating customs.
According to the notes from 1946 and 1947, the staple diet included simple, satiating seasonal meals from currently available ingredients. Breakfast often included bread with butter, boiled eggs, and chicory coffee. Dinner consisted of the first course, usually a soup (such as borscht or cabbage soup), main course of potatoes, meat, and/or vegetables, and a dessert, such as a yeasted cake. Suppers were lighter, with crêpes, groats, or salads.
Serving was described in detail. The students were encouraged to use clean tablecloths and arrange plates and cutlery at regular intervals. The central part of the table was reserved for platters and a bouquet. The idea behind the clean setting and aesthetically pleasing table was to emphasise respect for the meal and family. The corpus demonstrated the great importance of the family eating together, which was paramount on an everyday basis and on special occasions. Therefore, the culinary domain was much more than a pragmatic act. It had a symbolic meaning and reinforced social and family ties. This finding was not evident in the word clouds. Instead, it emerged from an in-depth semantic analysis.
BaJa contains recipes for special occasions, such as gingerbread, poppy-seed cake, poppy-seed pudding with biscuits, stuffed cabbage rolls, or borscht with mini dumplings. Granny Josie clearly distinguished between fasting and meat dishes, which helps better understand old Polish practices related to Lent and holidays.
5.3. Experimental Observations and Comparison of the Analytical Tools
The primary difference between manual and AI tools is the scope of analysis and automation of analytical operations. Linguistic Insight can analyse texts completely autonomously without manual data filtering and processing. Thanks to NLP algorithms, LI-AI automatically removes stop words and performs a thematic analysis followed by an in-depth semantic analysis (Table 4). These operations are not automated in manual tools, which increases the duration of analyses and the risk of human errors.
Table 4.
Comparison of selected attributes of LI-AI and manual tools for large corpus visualisation.
Another difference is the flexibility of analytical parametrisation. The operator can instruct Linguistic Insight with different prompts depending on the circumstances to conduct semantic and sentiment analysis, classify the emotional background of the text, or detect linguistic structures. This makes the research process open and responsive to unexpected results. The plugin can also perform analyses that were not predefined (Table 5).
Table 5.
Functional comparison of LI-AI and manual tools.
The functionality of the manual tools is limited to word cloud visualisation based on their frequency in the corpus, and there is no option for advanced semantic analysis. The scope of analysis is standardised and predefined. It has one advantage. While AI tools process large datasets, which may leave some information uncovered, manual tools operate on the entire corpus content. Therefore, even though the visualisation may seem chaotic, it perfectly complements AI’s somewhat ‘sterile’ visualisation.
5.4. Strengths and Weaknesses of Word Clouds in the Context of the Literature
Word clouds are employed in textual analysis and results visualisation. Cui et al. [44] demonstrated the usefulness of word clouds in identifying key themes in corpora and helping track semantic changes over time. In addition, they are intuitive and support large textual dataset exploration. Conversely, an excessive population of words blurs the visualisation. It also does not reveal the semantic context or relationships between words. As a result, this type of visualisation is usually considered a quantitative analysis and an addition to advanced semantic analyses [45].
The present study corroborates these observations. Linguistic Insight can perform advanced analyses and present the results as word clouds. The manual tools are functionally limited in visualising corpus content. While a word cloud can reveal specific patterns, in-depth semantic and sentiment analyses with LI-AI offer greater cognitive value.
The two approaches differ in how word clouds are generated. Linguistic Insight visualises data in a way that is more optimised for linguistic analysis; it takes contextualised meaning into account and can group synonyms and inflected word forms. On the other hand, it may miss or underrepresent certain essential words. Manual generators use relatively simple algorithms that count word occurrences in the corpus. This may lead to redundant or irrelevant results. Manual tools generate a word collage with the most frequent words being emphasised. The visualisation covers all textual components. The main criterion for emphasising some words over others is their frequency. Moreover, the AI plugin can generate word clouds using various colour themes and formatting. It can also translate the words. One can change the colours and layout of manually generated word clouds as well, but these tools are limited to standard editing options predefined and available in the dashboard (GUI). Therefore, the AI plugin is more precise, better automated, and offers broader linguistic (qualitative, in-depth) analytical capabilities. Manual tools, on the other hand, generate aesthetically pleasing visualisations of corpora, which are simplified in analytical terms (quantitative analysis). Both types are effective and suitable depending on the analytical goal. Manual tools may be sufficient for quickly outlining the text structure, while AI plugins may be more beneficial for in-depth linguistic research and analysing large corpora. Other studies corroborate these observations. Large language models and tools such as ChatGPT can support qualitative tasks but have certain limitations. One is the propensity for generating false information, called AI hallucinations [9]. In addition, AI models may put the urge to answer questions over facts. In addition, they exhibit no ethical accountability [46].
6. Conclusions
The analyses answered the question of what culinary themes are the most common in Granny Josie’s Notebooks. The texts focus on the practical aspects of everyday food preparation, which is evident from the frequent use of local ingredients and operations related to cooking and baking. The neutral sentiment and such cooking techniques as roasting, baking, mixing, and chopping emphasise the instructional profile of the notes. The corpus also contains extensive passages on serving food, which indicate attention to aesthetics and traditions related to eating.
Regarding the question about how new textual analysis tools, such as LLMs and AI plugins, can contribute to studies on historical corpora, it is worth noting their versatility. The new textual analysis tools provide meaningful support for corpus linguistics through automated analysis and interpretation of the results. Linguistic Insight and similar AI plugins can quickly identify words and themes central to large textual datasets. Artificial intelligence algorithms can perform thematic classification and semantic and sentiment analysis for easier understanding of the content and context of the investigated corpus. They automate extracting highly relevant information and visualise data as word clouds and charts. Compared to manual tools, AI can efficiently process large texts and adjust the scope of analysis mid-research.
The comparative analysis demonstrated that LI-AI offers much better performance than manual tools. It is capable of rapid processing and multi-dimensional analysis of large textual data sets, automated word filtering, translating the results into foreign languages, and generating visualisations. On the other hand, the manual tools give the user better control over the appearance of the word cloud, thanks to more options in the graphic user interface. Note that the methods yielded cohesive results, which adds to the analytical reliability. Limitations of AI tools include the risk of hallucinations and limited insight into their decision-making processes (why the AI made a specific decision). They are balanced with such advantages as scalability and analytical completeness. Manual tools have limited analytical capabilities or none at all. This makes them suitable mainly for data visualisation.
Research Limitations and Future Directions
This study comes with certain limitations, which have to be considered when interpreting the results. As the notes were taken by hand, the analysis could be affected by problems related to archaic syntax, non-standard spelling, and abbreviations. The input data are specific texts. They may not reflect the entire diversity of all culinary practices in post-war Poland. The question arises whether the notes reflect the author’s subjective selection or represent an objective landscape of culinary practices of the time. Note, however, that the analyses confirmed the instructional profile of the texts with no phrases suggesting opinions, views, judgment, or beliefs.
Note also a particular characteristic of LLMs. Despite being highly effective at corpus analysis, they may hallucinate or misinterpret non-existent correlations within data or exaggerate, distort, or even fabricate information. Moreover, LLMs are founded on probabilistic projections of linguistic structures, which may lead to inaccurate or erroneous conclusions. To control the risk of these problems, the author employed a cautious and conservative approach. The results generated by LI-AI were verified against those of two independent manual tools. This way, data cohesion could be evaluated, and the semantic analysis of the BaJa corpus was improved.
Future research can cover a more extensive range of texts, like more cooking notebooks from various periods and regions of Poland, to improve representation. Therefore, the primary limitation today seems to be the lack of digitised (vectorised) archaic texts rather than the availability of research tools. The most time-consuming practical operation is to decode and convert handwritten text into digital form. Future studies could also employ such comparative analysis techniques as juxtaposing the post-war corpus with earlier or more recent sources, which could reveal long-term changes in culinary practices. An in-depth semantic analysis could also be considered. It could help determine the degree to which ‘archaic home cuisine’ differed from today’s official nutritional recommendations and cookbooks.
Funding
Co-financed by the Minister of Science under the ‘Regional Initiative of Excellence’ programme. Agreement No. RID/SP/0039/2024/01. Subsidised amount: PLN 6,187,000.00. Project period: 2024–2027.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the author.
Conflicts of Interest
The author declares no conflicts of interest. The funders had no role in the design of this study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | artificial intelligence |
| CSIs | culture-specific items |
| CTA | call-to-action |
| CUI | conversational user interface |
| GPT | Generative Pre-Trained Transformer |
| GUI | graphical user interface |
| LI-AI | Linguistic Insight |
| LLM | large language model |
| NLP | natural language processing |
| Portable Document Format | |
| SaaS | Software as a Service |
| SVG | Scalable Vector Graphics |
| WCs | word clouds |
| WCG | word cloud generator |
References
- Basinyi, S.; Sagiya, M.E. World Heritage Communities, Anchors and Values for the Safeguarding of Intangible Cultural Heritage in Southern Africa. In Safeguarding Intangible Heritage; Akagawa, N., Smith, L., Eds.; Routledge: London, UK, 2018; pp. 174–186. [Google Scholar]
- Partarakis, N.; Kaplanidi, D.; Doulgeraki, P.; Karuzaki, E.; Petraki, A.; Metilli, D.; Bartalesi, V.; Adami, I.; Meghini, C.; Zabulis, X. Representation and Presentation of Culinary Tradition as Cultural Heritage. Heritage 2021, 4, 612–640. [Google Scholar] [CrossRef]
- Twiss, K. The Archaeology of Food and Social Diversity. J. Archaeol. Res. 2012, 20, 357–395. [Google Scholar] [CrossRef]
- Jönsson, H. A Food Nation Without Culinary Heritage? Gastronationalism in Sweden. J. Gastron. Tour. 2020, 4, 223–237. [Google Scholar] [CrossRef]
- Knapik, W.; Król, K. Inclusion of Vanishing Cultural Heritage in a Sustainable Rural Development Strategy–Prospects, Opportunities, Recommendations. Sustainability 2023, 15, 3656. [Google Scholar] [CrossRef]
- Šlehoferová, T.; Fatková, G. Manuscript Cookbooks on the Move: Social Functions, Heritage Management and Women’s Narratives in the Czech-Bavarian Borderland. Food Cult. Soc. 2023, 1–22. [Google Scholar] [CrossRef]
- Cashman, D. An Investigation of Irish Culinary History through Manuscript Cookbooks, with Particular Reference o the Gentry of County Kilkenny (1714-1830). Ph.D. Theses, Dublin Institute of Technology, Dublin, Ireland, 2016. [Google Scholar] [CrossRef]
- Ghatora, P.S.; Hosseini, S.E.; Pervez, S.; Iqbal, M.J.; Shaukat, N. Sentiment Analysis of Product Reviews Using Machine Learning and Pre-Trained LLM. BDCC 2024, 8, 199. [Google Scholar] [CrossRef]
- Król, K. Between Truth and Hallucinations: Evaluation of the Performance of Large Language Model-Based AI Plugins in Website Quality Analysis. Appl. Sci. 2025, 15, 2292. [Google Scholar] [CrossRef]
- Mącior, B.; Mądel, A.; Podraza, S.; Wójtowicz, E.; Zięba, P. Szynwałd—Tak Było. Historia Szynwałdu na Starych Fotografiach i Dokumentach; Stowarzyszenie Mój Szynwałd: Szynwałd, Poland, 2017. [Google Scholar]
- Magomere, J.; Ishida, S.; Afonja, T.; Salama, A.; Kochin, D.; Yuehgoh, F.; Hamzaoui, I.; Sefala, R.; Alaagib, A.; Dalal, S.; et al. You are what you eat? Feeding foundation models a regionally diverse food dataset of World Wide Dishes. arXiv 2024, arXiv:2406.09496. [Google Scholar] [CrossRef]
- Yang, H.; Zhao, Y.; Wu, Y.; Wang, S.; Zheng, T.; Zhang, H.; Ma, Z.; Che, W.; Qin, B. Large language models meet text-centric multimodal sentiment analysis: A survey. arXiv 2024, arXiv:2406.08068. [Google Scholar] [CrossRef]
- Gagliardi, I.; Artese, M.T. Exploring and Visualizing Multilingual Cultural Heritage Data Using Multi-Layer Semantic Graphs and Transformers. Electronics 2024, 13, 3741. [Google Scholar] [CrossRef]
- Goel, M.; Bagler, G. Computational Gastronomy: A Data Science Approach to Food. J. Biosci. 2022, 47, 12. [Google Scholar] [CrossRef]
- Guidotti, D.; Pandolfo, L.; Pulina, L. Discovering Sentiment Insights: Streamlining Tourism Review Analysis with Large Language Models. Inf. Technol. Tour. 2025, 27, 227–261. [Google Scholar] [CrossRef]
- Liberato, P.; Mendes, T.; Liberato, D. Culinary Tourism and Food Trends. In Advances in Tourism, Technology and Smart Systems; Rocha, Á., Abreu, A., De Carvalho, J.V., Liberato, D., González, E.A., Liberato, P., Eds.; Springer: Singapore, 2020; Volume 171, pp. 517–526. [Google Scholar]
- Loureiro, S.M.C.; Guerreiro, J.; Friedmann, E.; Lee, M.J.; Han, H. Tourists and Artificial Intelligence-LLM Interaction: The Power of Forgiveness. Curr. Issues Tour. 2025, 28, 1172–1190. [Google Scholar] [CrossRef]
- Carvalho, I.; Ivanov, S. ChatGPT for Tourism: Applications, Benefits and Risks. Tour. Rev. 2024, 79, 290–303. [Google Scholar] [CrossRef]
- Almansouri, M.; Verkerk, R.; Fogliano, V.; Luning, P.A. The Heritage Food Concept and Its Authenticity Risk Factors—Validation by Culinary Professionals. Int. J. Gastron. Food Sci. 2022, 28, 100523. [Google Scholar] [CrossRef]
- Digitized Granny Josie’s Notebooks. Main Library, University of Agriculture in Krakow [Zdigitalizowane (Zeskanowane) Zeszyty Babci Józi Umieszczone w Repozytorium Biblioteki Uniwersytetu Rolniczego w Krakowie]. Available online: http://ruralstrateg.pl/zeszyty-babci-jozi-w-bibliotece-cyfrowej-urk/ (accessed on 25 April 2025).
- SpeechTexter. Available online: https://www.speechtexter.com (accessed on 25 April 2025).
- Hsiao, J.-C.; Chang, J.S. Enhancing EFL Reading and Writing through AI-Powered Tools: Design, Implementation, and Evaluation of an Online Course. Interact. Learn. Environ. 2024, 32, 4934–4949. [Google Scholar] [CrossRef]
- Linguistic Insight. LLM-Based AI, ChatGPT Plugin. Available online: https://chatgpt.com/g/g-6783566ee4b08191a33700a5286f7942-linguistic-insight (accessed on 25 April 2025).
- Kulkarni, A.; Shivananda, A.; Kulkarni, A.; Gudivada, D. The ChatGPT Architecture: An In-Depth Exploration of OpenAI’s Conversational Language Model. In Applied Generative AI for Beginners; Apress: Berkeley, CA, USA, 2023; pp. 55–77. [Google Scholar]
- Lozić, E.; Štular, B. Fluent but Not Factual: A Comparative Analysis of ChatGPT and Other AI Chatbots’ Proficiency and Originality in Scientific Writing for Humanities. Future Internet 2023, 15, 336. [Google Scholar] [CrossRef]
- Rudolph, J.; Tan, S.; Tan, S. War of the chatbots: Bard, Bing Chat, ChatGPT, Ernie and beyond. The new AI gold rush and its impact on higher education. J. Appl. Learn. Teach. 2023, 6, 364–389. [Google Scholar] [CrossRef]
- Lister, K.; Coughlan, T.; Iniesto, F.; Freear, N.; Devine, P. Accessible Conversational User Interfaces: Considerations for Design. In Proceedings of the 17th International Web for All Conference, Taipei Taiwan, 20–21 April 2020; pp. 1–11. [Google Scholar]
- Cutler, K. ChatGPT and Search Engine Optimisation: The Future Is Here. Appl. Mark. Anal. 2023, 9, 8. [Google Scholar] [CrossRef]
- Zhang, W.; Deng, Y.; Liu, B.; Pan, S.J.; Bing, L. Sentiment analysis in the era of large language models: A reality check. arXiv 2023, arXiv:2305.15005. [Google Scholar]
- Yang, Z.; Zhou, Z.; Wang, S.; Cong, X.; Han, X.; Yan, Y.; Liu, Z.; Tan, Z.; Liu, P.; Yu, D.; et al. Matplotagent: Method and evaluation for llm-based agentic scientific data visualization. arXiv 2024, arXiv:2402.11453. [Google Scholar] [CrossRef]
- Falatouri, T.; Hrušecká, D.; Fischer, T. Harnessing the Power of LLMs for Service Quality Assessment From User-Generated Content. IEEE Access 2024, 12, 99755–99767. [Google Scholar] [CrossRef]
- Huang, A.H.; Wang, H.; Yang, Y. FinBERT: A Large Language Model for Extracting Information from Financial Text*. Contemp. Accting Res. 2023, 40, 806–841. [Google Scholar] [CrossRef]
- Delnevo, G.; Andruccioli, M.; Mirri, S. On the Interaction with Large Language Models for Web Accessibility: Implications and Challenges. In Proceedings of the 2024 IEEE 21st Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 6–9 January 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Vázquez, P.-P. Are LLMs Ready for Visualization? In Proceedings of the 2024 IEEE 17th Pacific Visualization Conference (PacificVis), Tokyo, Japan, 23–26 April 2024; pp. 343–352. [Google Scholar] [CrossRef]
- Emsley, R. ChatGPT: These Are Not Hallucinations—They’re Fabrications and Falsifications. Schizophr 2023, 9, 52. [Google Scholar] [CrossRef] [PubMed]
- Martino, A.; Iannelli, M.; Truong, C. Knowledge Injection to Counter Large Language Model (LLM) Hallucination. In The Semantic Web: ESWC 2023 Satellite Events; Pesquita, C., Skaf-Molli, H., Efthymiou, V., Kirrane, S., Ngonga, A., Collarana, D., Cerqueira, R., Alam, M., Trojahn, C., Hertling, S., Eds.; Springer Nature: Cham, Switzerland, 2023; Volume 13998, pp. 182–185. [Google Scholar] [CrossRef]
- WordClouds (WC). Zygomatic. Available online: https://www.wordclouds.com/ (accessed on 25 April 2025).
- Word Cloud Generator (WCG). Available online: https://www.jasondavies.com/wordcloud/ (accessed on 25 April 2025).
- Czarniecka-Skubina, E.; Kowalczuk, I. Eating out in Poland: History, Status, Perspectives and Trends. Zeszyty Naukowe Uniwersytetu Szczecińskiego. Serv. Manag. 2015, 16, 75–83. [Google Scholar] [CrossRef][Green Version]
- Stańczak-Wiślicz, K. Eating Healthy, Eating Modern. The “Urbanization” of Food Tastes in Communist Poland (1945–1989). Ethnol. Pol. 2020, 41. [Google Scholar] [CrossRef]
- Janowski, M. Food in Traumatic Times: Women, Foodways and ‘Polishness’ During a Wartime ‘Odyssey’. Food Foodways 2012, 20, 326–349. [Google Scholar] [CrossRef]
- Łukasiewicz, M.; Zięć, G.; Topolska, K.; Berski, W.; Florkiewicz, A. Ruthenian Culinary Traditions of Lemkivshchyna. In Cultural Heritage—Possibilities for Land-Centered Societal Development; Hernik, J., Walczycka, M., Sankowski, E., Harris, B.J., Eds.; Springer International Publishing: Cham, Switzerland, 2022; Volume 13, pp. 113–125. [Google Scholar]
- Henson, S.; Sekuła, W. Market Reform in the Polish Food Sector: Impact upon Food Consumption and Nutrition. Food Policy 1994, 19, 419–442. [Google Scholar] [CrossRef]
- Cui, W.; Wu, Y.; Liu, S.; Wei, F.; Zhou, M.X.; Qu, H. Context preserving dynamic word cloud visualization. In Proceedings of the 2010 IEEE Pacific Visualization Symposium (PacificVis), Taipei, Taiwan, 2–5 March 2010; pp. 121–128. [Google Scholar] [CrossRef]
- Padmanandam, K.; Bheri, S.P.V.D.S.; Vegesna, L.; Sruthi, K. A Speech Recognized Dynamic Word Cloud Visualization for Text Summarization. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20–22 January 2021; pp. 609–613. [Google Scholar]
- Roberts, J.; Baker, M.; Andrew, J. Artificial Intelligence and Qualitative Research: The Promise and Perils of Large Language Model (LLM) ‘Assistance’. Crit. Perspect. Account. 2024, 99, 102722. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).