1. Introduction
Murals refer to paintings created on natural or artificial wall surfaces and include forms such as temple murals, tomb murals, and cave murals [
1,
2]. Color paintings on ancient Chinese architecture, commonly used to decorate the surfaces of building columns, beams, walls, and other structural elements, primarily consist of pigment and a ground layer [
3]. As an important form of cultural heritage, these paintings contain extensive social, artistic, religious, and historical information, making them invaluable for cultural research and heritage preservation. However, due to prolonged exposure to weathering, temperature and humidity fluctuations, pollution, microbial erosion, and human-induced damage, the pigment layers of murals and color paintings experience various forms of deterioration, including paint loss, cracking, flaking, and soot deposition [
4]. Among these, paint loss is one of the most severe forms of deterioration, significantly compromising the artistic integrity of murals and color paintings, and potentially causing large-scale, irreversible damage [
5]. Therefore, accurate identification and segmentation of deteriorated areas have become key challenges in the conservation and restoration of murals and color paintings.
Traditional detection of paint loss primarily relies on visual inspection, which is highly dependent on expert experience, time-consuming, labor-intensive, and inherently subjective, making it difficult to ensure consistency in detection results. To improve detection efficiency, researchers have applied various image processing techniques, including region-growing [
6,
7], morphological segmentation [
8], and clustering-based segmentation [
9,
10], to the detection of paint loss. Cao et al. [
11] proposed a region-growing algorithm based on threshold segmentation, utilizing features such as color, saturation, chromaticity, and brightness of the deteriorated areas. However, determining the optimal threshold requires multiple experiments, and the method is prone to creating voids or over-segmentation. Deng et al. [
12] extracted initial disease masks using automatic threshold segmentation, followed by tensor voting and morphological hole filling to generate a complete mask. However, due to the similarity in color between deteriorated areas and the background, this method suffers from false negatives and false positives. Yu et al. [
13] used a combination of hyperspectral imaging and simple linear iterative clustering segmentation to find areas that were getting worse. However, background noise made disease edge extraction less accurate. Although these methods achieve relatively high detection accuracy in specific contexts, they typically rely on manually extracting disease features (such as color, shape, and texture), leading to limited generalization ability and vulnerability to environmental noise.
In recent years, deep learning technologies have achieved remarkable advancements in the domain of computer vision, particularly concerning semantic segmentation and object detection and segmentation tasks. These tasks require that models not only identify objects or diseased areas within images but also execute precise pixel-level segmentation of these areas. This capability provides more detailed information for subsequent analysis and processing. Semantic segmentation methods, such as U-Net [
14], have been widely applied in the detection of paint loss in murals. However, traditional semantic segmentation methods often face challenges in mural images due to complex backgrounds and blurred boundaries of deteriorated areas. Therefore, it is usually necessary to modify the original models to better meet the requirements of paint loss detection. To make the most of features at different sizes and improve the link between decoder and encoder features, Wu et al. built U-Net around ConvNet [
15], a Channel Cross Fusion (CCT) module with Transformer [
16], and a Bidirectional Feature Pyramid Network (BiFPN) [
17]. This allowed them to extract and combine features at different sizes, which led to accurate crack segmentation in murals. To fully extract disease features and effectively integrate low-level and high-level semantic information, Zhao et al. [
18] proposed an ancient mural paint layer delamination detection model based on a residual dual-channel attention U-Net, enhancing feature extraction by incorporating residual connections, channel attention, and spatial attention. To get around U-Net’s problems with finding edges and keeping details, multi-scale module construction [
19] and detail feature injection mechanisms [
20] were used to get the edges and texture details of murals that had been delaminated. However, these semantic segmentation methods have shown favorable results in specific study areas but still face issues such as small patch noise and holes in the damaged areas, which affect detection accuracy and stability.
Unlike semantic segmentation methods, object detection methods can precisely locate target areas and effectively alleviate the issues encountered in semantic segmentation. Wang et al. [
21] suggested an automatic damage detection model based on the ResNet [
22] framework. This model uses Faster R-CNN to find weathering and spalling damage in historical masonry structures so that damage can be found quickly. Mishra et al. [
23] optimized the YOLO V5 model structure to achieve rapid and automated detection of discoloration, exposed bricks, cracks, and delamination, addressing the inefficiency of traditional manual inspection. Wu et al. [
24] enhanced the YOLOv5 model by incorporating the Ghost Conv module [
25] and the Channel Attention Module Squeeze and Excitation (SE Module) [
26], and subsequently tested the improved model on the Yungang Grottoes mural crack and delamination dataset. The results showed that compared to the original model, training time and model size were reduced by 36.21% and 46.04%, respectively, while accuracy increased by 1.29%. These studies primarily focus on object detection for weathering, spalling, cracks, and other damage, but they do not achieve pixel-level segmentation of damaged areas, which limits their ability to support subsequent virtual repair of the damage.
In recent years, instance segmentation models have been developed based on object detection methods to perform pixel-level segmentation of target objects. Instance segmentation models can be further categorized into two-stage models, such as Mask R-CNN [
27], and one-stage models, such as You Only Look at CoefficienTs (YOLACT) [
28]. These methods combine object detection and segmentation techniques to achieve the precise localization and segmentation of target objects. Currently, fields such as medicine, agriculture, and forestry widely apply certain instance segmentation models. Zhang et al. [
29] mixed F-YOLOv8n-seg with the connected domain analysis algorithm (CDA), and obtained the F-YOLOv8n-seg-CDA model. This model effectively lowers the computational cost in the convolution process and achieves a 97.2% accuracy rate for weed segmentation. The ASF-YOLO model was made by Kang et al. [
30] using the YOLOv5l segmentation framework and a scale sequence feature fusion module to improve the network’s ability to extract features at multiple scales. In experiments on a cell dataset, the model achieved a segmentation accuracy of 0.887 and a target detection accuracy of 0.91. Khalili et al. [
31] used the YOLOv5 framework and the Segment Anything Model (SAM) to create a lung segmentation model for chest X-ray movies. The results showed that the proposed model has significant robustness, generalization capability, and high computational efficiency. Balasubramani et al. [
32] suggested a better YOLOv8n-seg model that did better than semantic models like SegNet, DeepLabv3, and EchoNet in tasks that needed to segment the left ventricle. This model was more accurate and complete, with no small patch noise or abnormal voids in the damaged areas. It was suggested by Khan et al. [
33] that fruit trees should use a YOLOv8-based crown segmentation method that includes improvements like dilated convolution (DilConv) [
34] and GELU activation function [
35]. In various complex environments, their method achieved more complete crown segmentation compared to other instance segmentation models.
Although segmentation methods based on YOLO series models have been successfully applied in fields such as agriculture and forestry, the significant variation in shape and size of paint loss areas, as well as their distinct characteristics compared to natural objects, impose higher demands on the adaptability of existing models.
In these damage extraction tasks, YOLO and other deep learning models continue to face several challenges. First, high-quality public datasets are extremely scarce, and segmentation tasks rely on precise annotations, which are costly and heavily dependent on manual input, making it difficult to construct large-scale training datasets and impacting the optimization of model performance. Second, the large variation in the shape and scale of the damage areas often results in incomplete segmentation and missed detection of small targets. Additionally, the damage areas frequently blend with complex backgrounds, which hinders the model’s ability to accurately determine boundaries and recognize regions, thereby decreasing segmentation accuracy. Finally, image segmentation tasks are computationally intensive, and although lightweight models can improve inference efficiency, they typically suffer from a trade-off in accuracy. As such, effectively balancing segmentation accuracy with computational resource consumption has become a critical challenge in improving the practical application of paint loss detection.
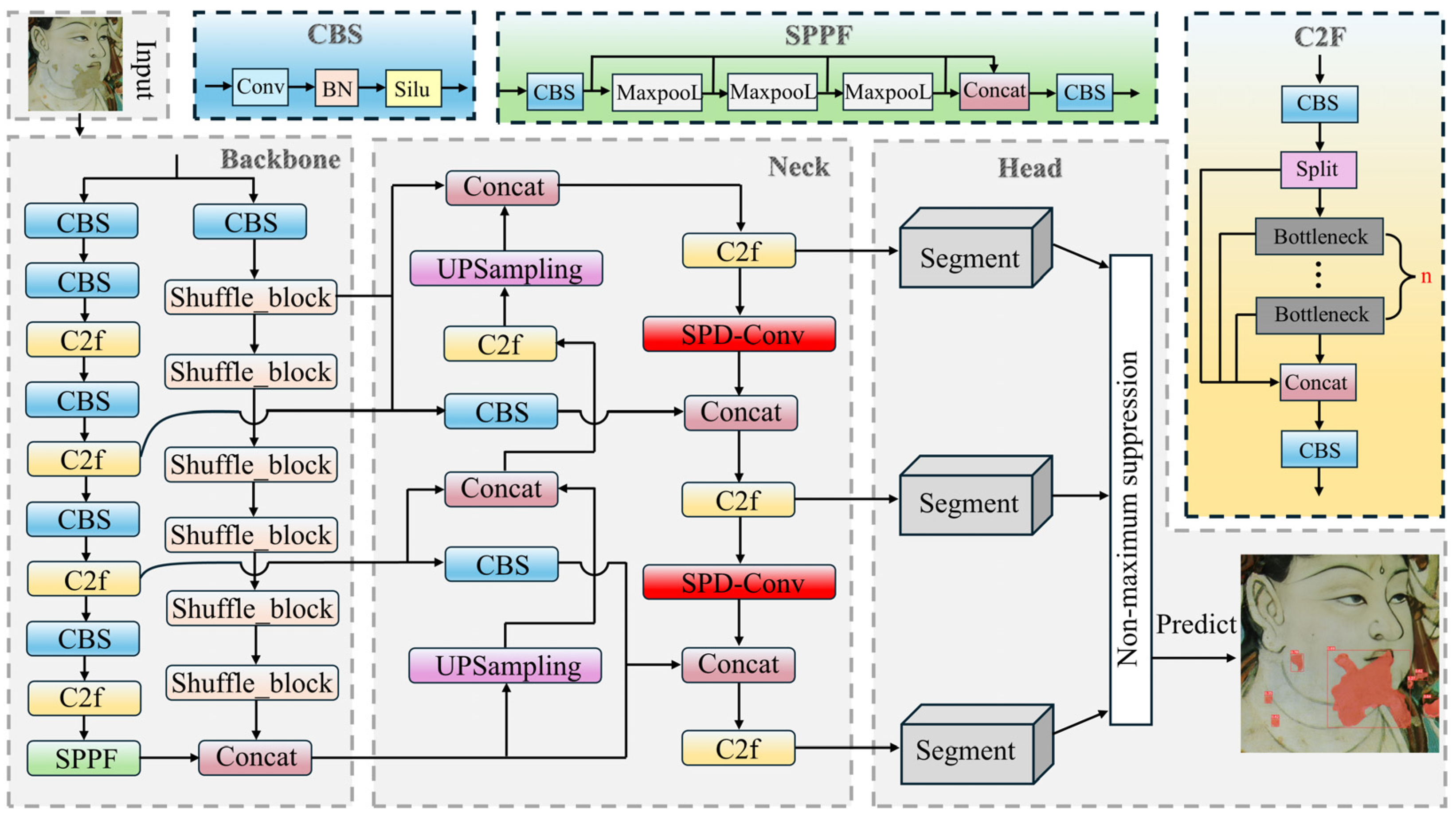
To tackle the problems of incomplete boundary segmentation, missed small target detection, and insufficient overall segmentation accuracy in mural paint loss segmentation tasks, this paper proposes PLDS-YOLO, a paint loss detection and segmentation algorithm for murals based on YOLOv8s-seg. The aim is to improve segmentation accuracy, optimize boundary extraction, and reduce missed detections. The main contributions of this paper are as follows:
- (1)
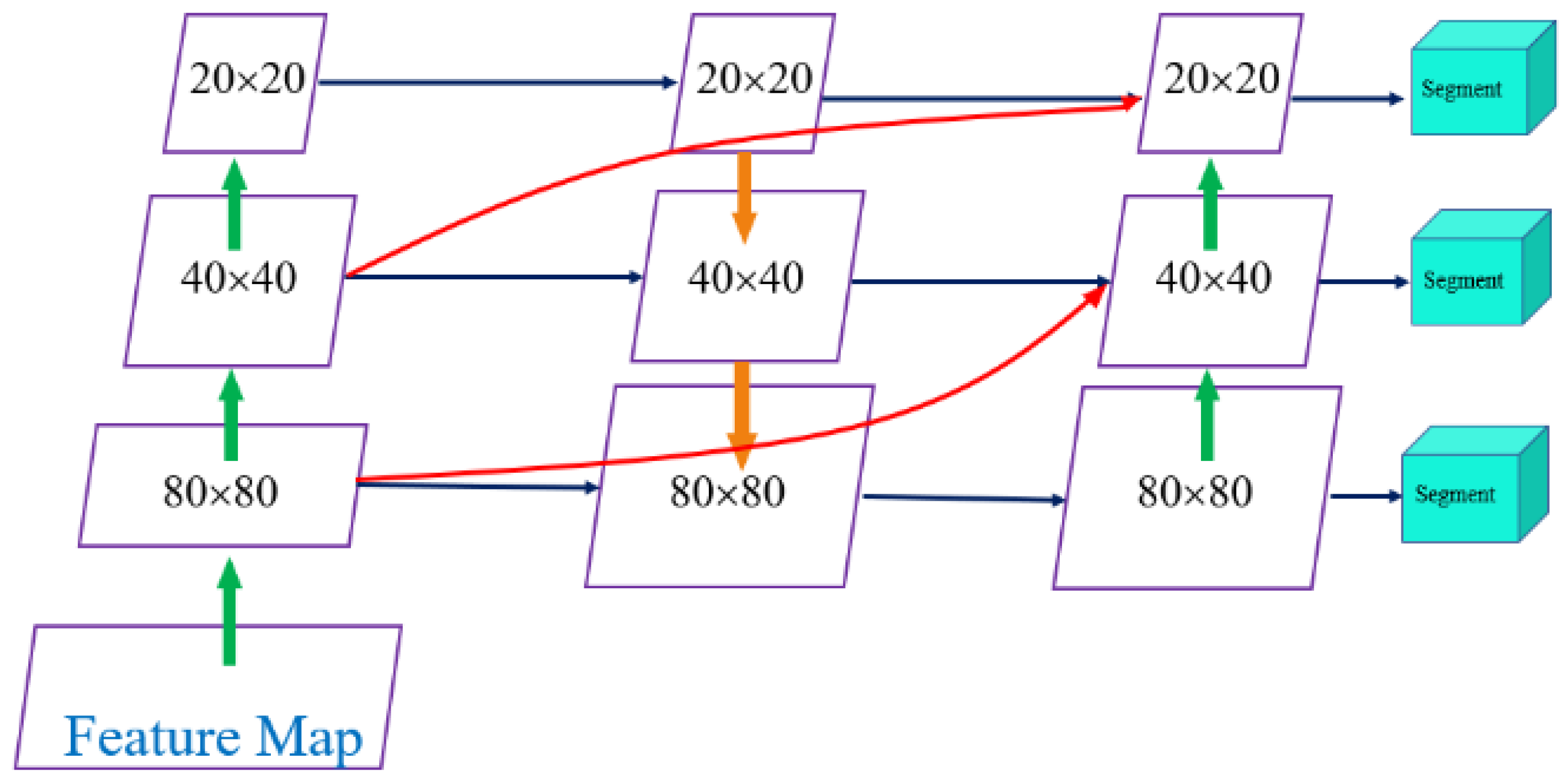
An improvement to the PA-FPN network is proposed, incorporating residual connections to enhance segmentation accuracy at paint loss boundaries by fusing shallow high-resolution features with deep semantic features.
- (2)
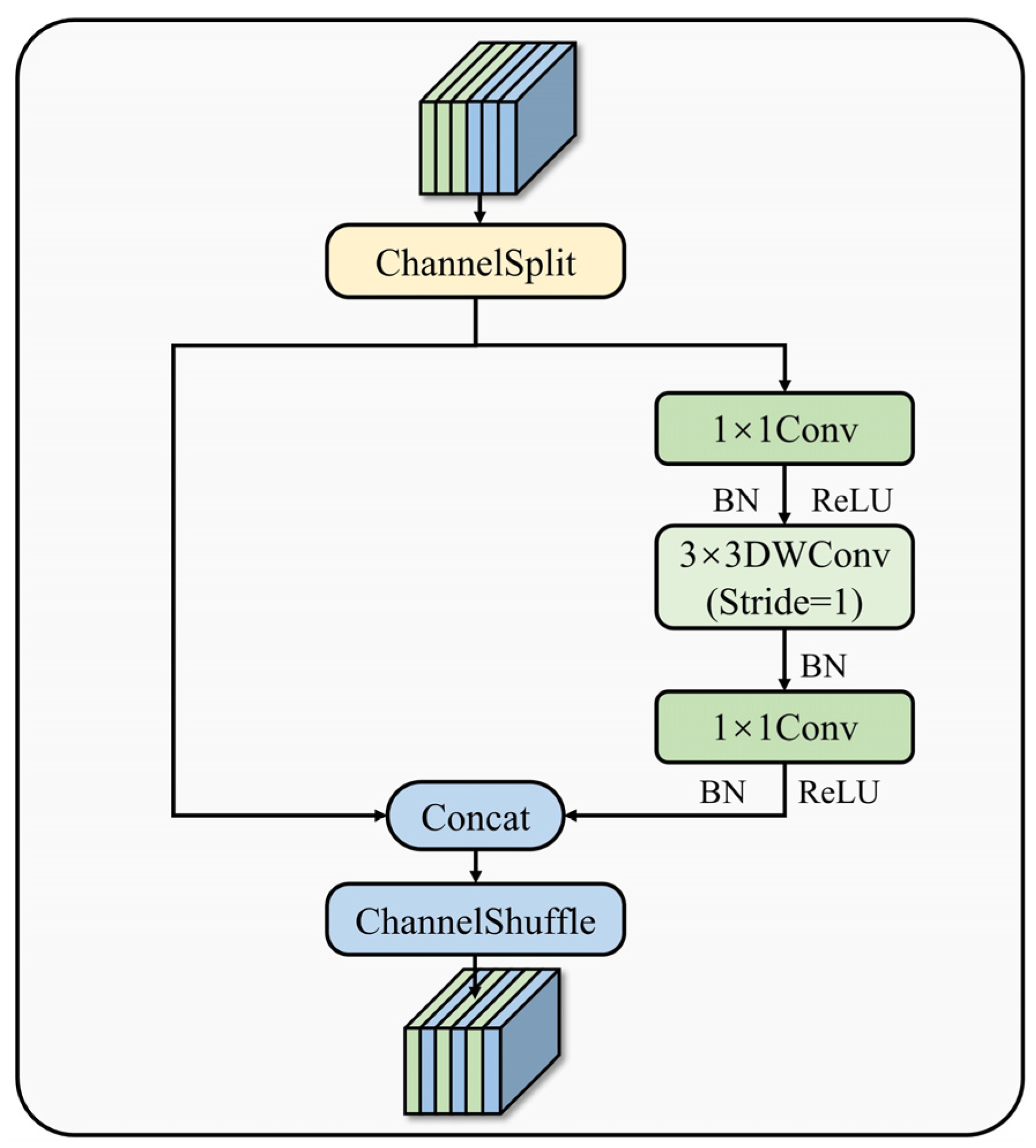
A dual-backbone network architecture is designed, combining CSPDarkNet and ShuffleNet V2, to optimize multi-scale feature extraction capability and enhance the model’s ability to detect paint loss in complex backgrounds.
- (3)
The SPD-Conv module is introduced to enhance feature representation, thereby improving the detection rate of small targets and reducing missed detections.
- (4)
Using a self-constructed paint loss dataset, the PLDS-YOLO was able to accurately segment 86.2% of the cases, which is 2.9% better than YOLOv8s-Seg. It also strikes a good balance between inference speed and computational complexity.
The paper is organized as follows:
Section 2 describes the overall architecture of the MPLD-YOLO model and the improvement strategies implemented;
Section 3 covers the construction of the experimental dataset, experimental parameter settings, evaluation metrics, comparative experimental results, and ablation experiment; discussion and conclusion are presented in
Section 4 and
Section 5, respectively.
3. Experiments and Results
3.1. Dataset
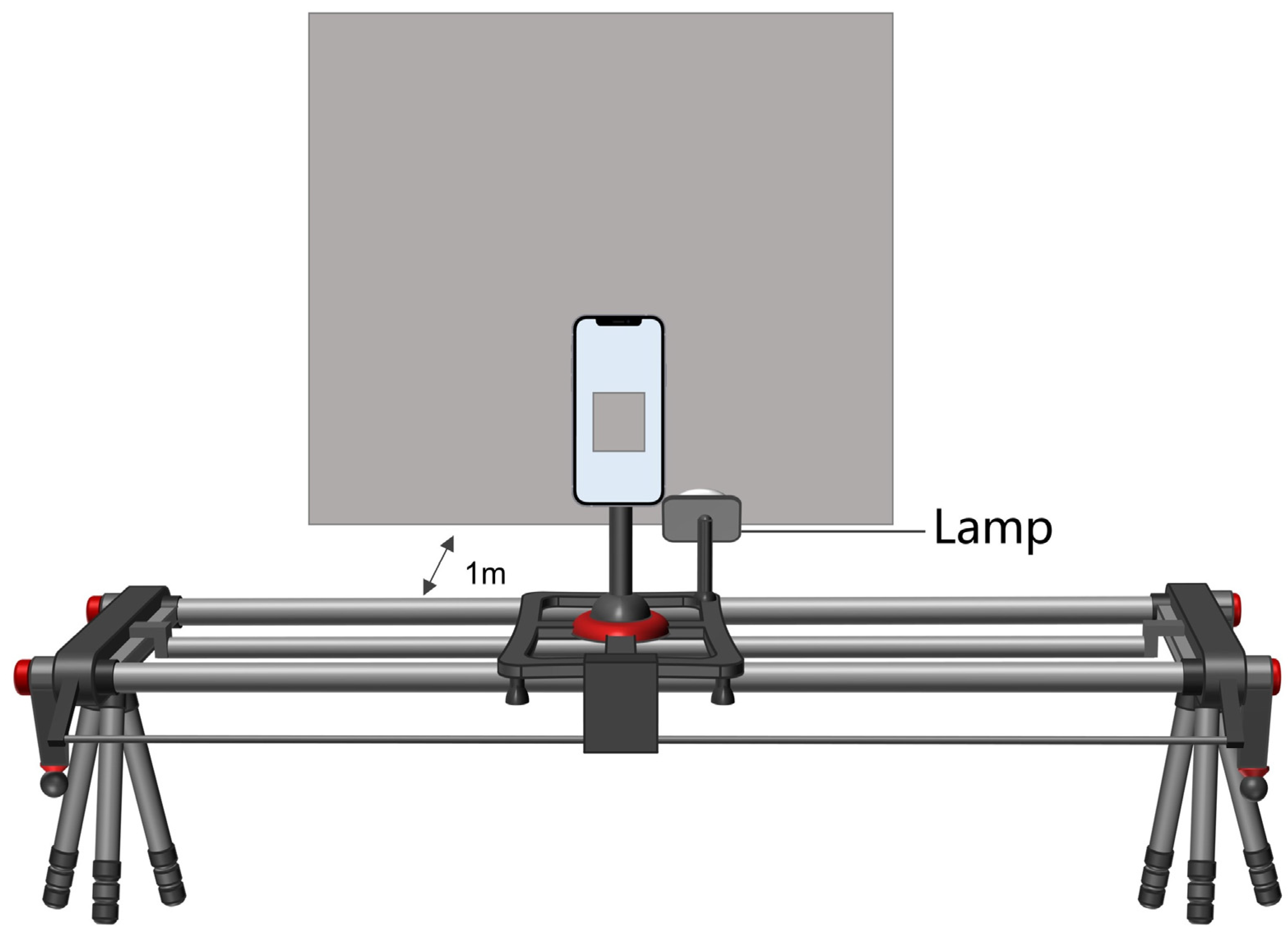
Due to the limited availability of ancient mural and color painting image resources and the absence of publicly available standard datasets, this study has collected Dunhuang mural data from the China Academy of Cultural Heritage to build a high-quality damage dataset. These data span key historical periods, including the Northern Wei, Sui, Tang, Song, and Yuan dynasties, covering over a millennium of history. The Dunhuang murals are located inside caves, preventing direct external lighting, which minimizes the impact of lighting changes on the images. The images were captured by a professional photography team, ensuring high-quality data. Additionally, ancient architectural color painting images were collected at the historical site of Peking Union Medical College Research Institute using an iPhone 15, along with the NewTech S18 rail system, tripod, and lighting system to ensure stable image capture. All images were captured at a fixed distance of 1 m using a tripod to ensure consistency, with artificial lighting used to prevent external lighting changes from affecting the images. To ensure the image quality of the dataset, we excluded Dunhuang mural images with damage regions whose boundaries were difficult to distinguish from the background, as well as ancient architectural color painting images blurred by external interference, ultimately resulting in 856 high-quality pigment layer detachment damage images.
Figure 5 shows a schematic of the photographic setup for capturing ancient architectural color paintings.
To ensure the broad applicability and credibility of the research findings, we selected ancient murals and ancient architectural color paintings, two representative art forms, as the experimental datasets. Murals are generally made up of three layers, relying mainly on environmental stability, while color paintings are supported by wood, with a more complex ground layer that emphasizes waterproofing and durability. The Dunhuang murals cover several historical periods and showcase significant stylistic differences, reflecting the artistic characteristics of different cultural backgrounds. In contrast, the color paintings from the historical site of Peking Union Medical College Research Institute, created during the Republican era, have a relatively homogeneous style and background.
Although both types of artworks are influenced by factors such as temperature, humidity changes, and material aging, murals are more susceptible to salt crystallization, leading to peeling and detachment of the pigment layer. On the other hand, color paintings, protected by tung oil, experience accelerated pigment detachment due to moisture infiltration and oil film cracking. Moreover, the shrinkage and deformation of the wood can also result in the detachment of the pigment layer in color paintings. By choosing these two datasets, we are able to comprehensively assess the model’s detection ability across different artistic forms and damage conditions, thereby ensuring the broad applicability and practical significance of the research findings.
In this study, 90 images were randomly selected from the 856 images, representing 10% of the total dataset, to form the test set, and were annotated using LabelMe version 3.16.2. Next, the images were uniformly cropped to a size of 640 × 640 pixels, followed by data augmentation techniques including image flipping, rotation, color adjustment, and random noise addition. A final set of 500 images (with an equal distribution between murals and color paintings) was selected as the test set.
Regarding the division of the training and validation sets, the remaining 766 images were processed in the same way as the test set, resulting in a total of 5070 images for model training. These images were split into training and validation sets at an 80:20 ratio. During the distribution process, this study ensured an equal representation of murals and color paintings, each constituting 50% of both the training and validation sets, thereby guaranteeing balanced data distribution.
The dataset division strategy employed in this study ensures a balanced distribution of data across the training, validation, and testing phases, thereby providing reliable data support for the subsequent pigment layer detachment damage detection and segmentation tasks.
3.2. Evaluation Metrics
In this study, a variety of key metrics were employed to assess the performance of the PLDS-YOLO model in detecting paint loss and performing image segmentation tasks. We defined our classification based on three possible states: True Positive (
TP), False Positive (
FP), and False Negative (
FN). Metrics like Precision (
P), Recall (
R), mAP@0.5, and mAP@0.5:0.95 were used to test the model’s performance in tasks like object detection and segmentation. These measure how accurate, complete, and well the model works overall [
24,
42].
where
represents the number of disease pixels accurately identified by the model within the test set,
indicates the number of background or non-disease pixels that have been incorrectly classified as disease pixels, and
represents the true disease pixels that were misclassified as background or non-disease pixels by the model.
where the precision-recall (P-R) curve is represented by
, while recall is on the
x-axis and precision is on the
y-axis. Average Precision (AP) is the area under the P-R curve, calculated as the area enclosed by the curve and the axes in the P-R plot.
mAP@0.5 represents the average precision computed with a fixed Intersection over Union (IoU) threshold of 0.5. It indicates the model’s performance in detecting and separating objects at a specific threshold. mAP@0.5:0.95, on the other hand, shows the average precision found when IoU thresholds are raised by 0.05 units every time from 0.5 to 0.95. This gives a more complete picture of how well the model detects things at different levels of overlap. A higher mAP@0.5 indicates that the model has higher detection and segmentation accuracy at the fixed threshold of 0.5. A higher mAP@0.5:0.95 value means that the model gives accurate and stable detection results across a range of thresholds. This shows that the algorithm is robust and can be used in different situations. In this study, there is only one category, the paint loss; thus, = 1.
In evaluating the model’s efficiency and speed, this study uses floating point operations (FLOPs) to measure the computational complexity and operation requirements of the model. A higher FLOPs value indicates that the device can complete more floating-point operations per unit of time, reflecting greater computational power. To evaluate the model’s inference speed, we use frames per second (FPS) as a metric. A higher FPS value indicates faster image processing and higher inference efficiency. Typically, a detection speed greater than 30 fps is required [
24]. By considering these metrics together, we can obtain a comprehensive understanding of the performance of the PLDS-YOLO model in detecting and segmenting paint loss in murals.
3.3. Experimental Setup
This study uses the Windows 10 operating system and an RTX 3090 GPU with 16 GB of memory for model training. The software environment includes CUDA 11.3, Python 3.11, and PyTorch 2.12. In this study, the proposed PLDS-YOLO model and all ablation and comparison models are trained and tested on a server GPU. In the ablation experiments and baseline models, the YOLOv8s-seg model is used as the base model for comparison and analysis. The algorithm’s stochastic gradient descent (SGD) momentum is set to 0.937, the initial learning rate is set to 0.01, weight decay is set to 0.0005, and a warm-up learning rate optimization strategy is used, with a warm-up period of 50 epochs. All experiments in this study are conducted for 500 training epochs.
3.4. Comparison of Loss and Segmentation Performance Between the Improved Model and the Baseline Model
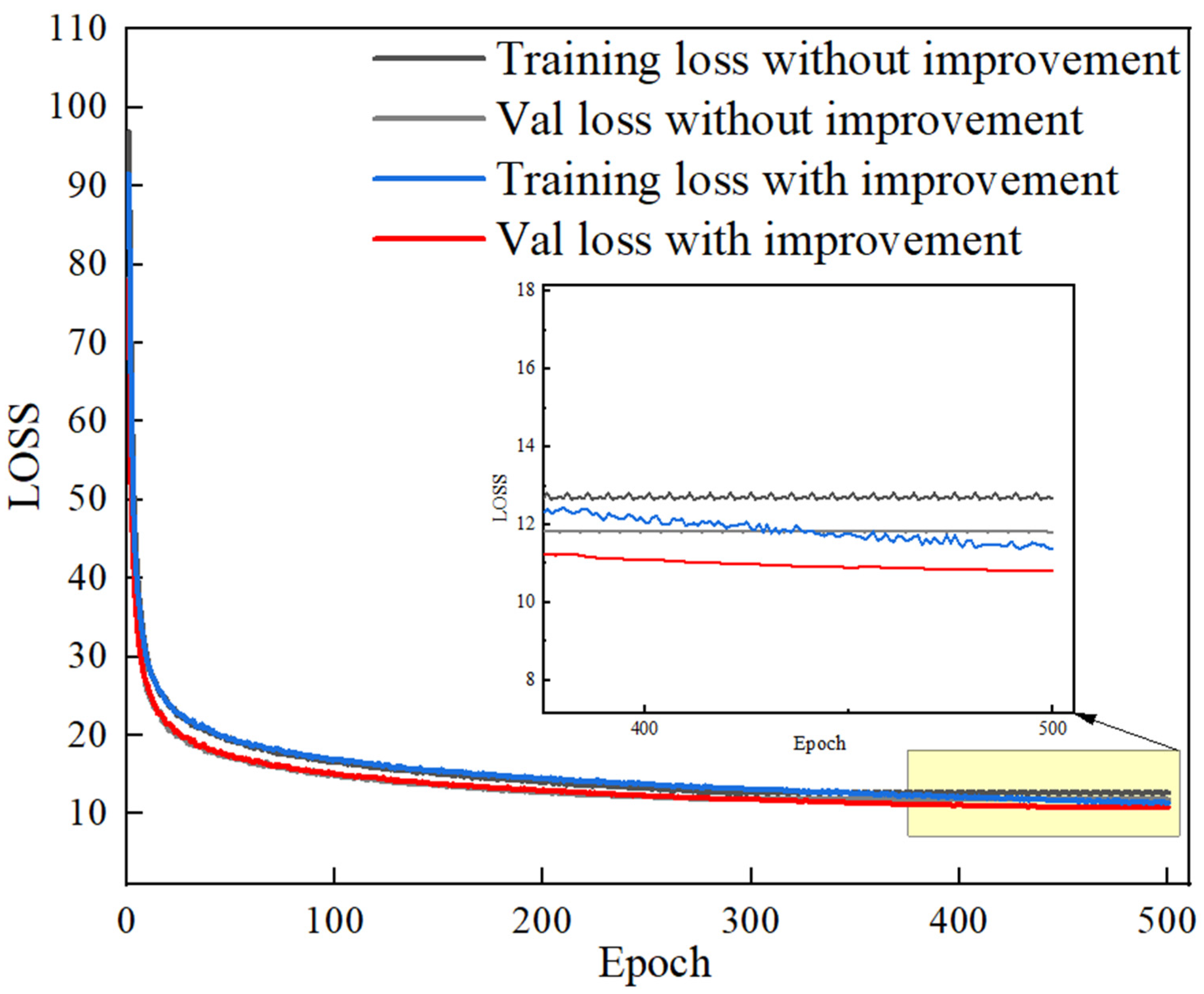
The variation curves of the loss values for both the training and validation sets after 500 iterations are presented in
Figure 6, comparing the baseline YOLOv8s-seg model with the enhanced PLDS-YOLO model. During the first 100 rounds of training, both the training and validation sets experience a rapid decrease in loss values. After reaching 300 iterations, the loss value decreases more gradually, and the curve converges, indicating that the model training process stabilizes. The PLDS-YOLO model has a lower loss compared to the baseline model.
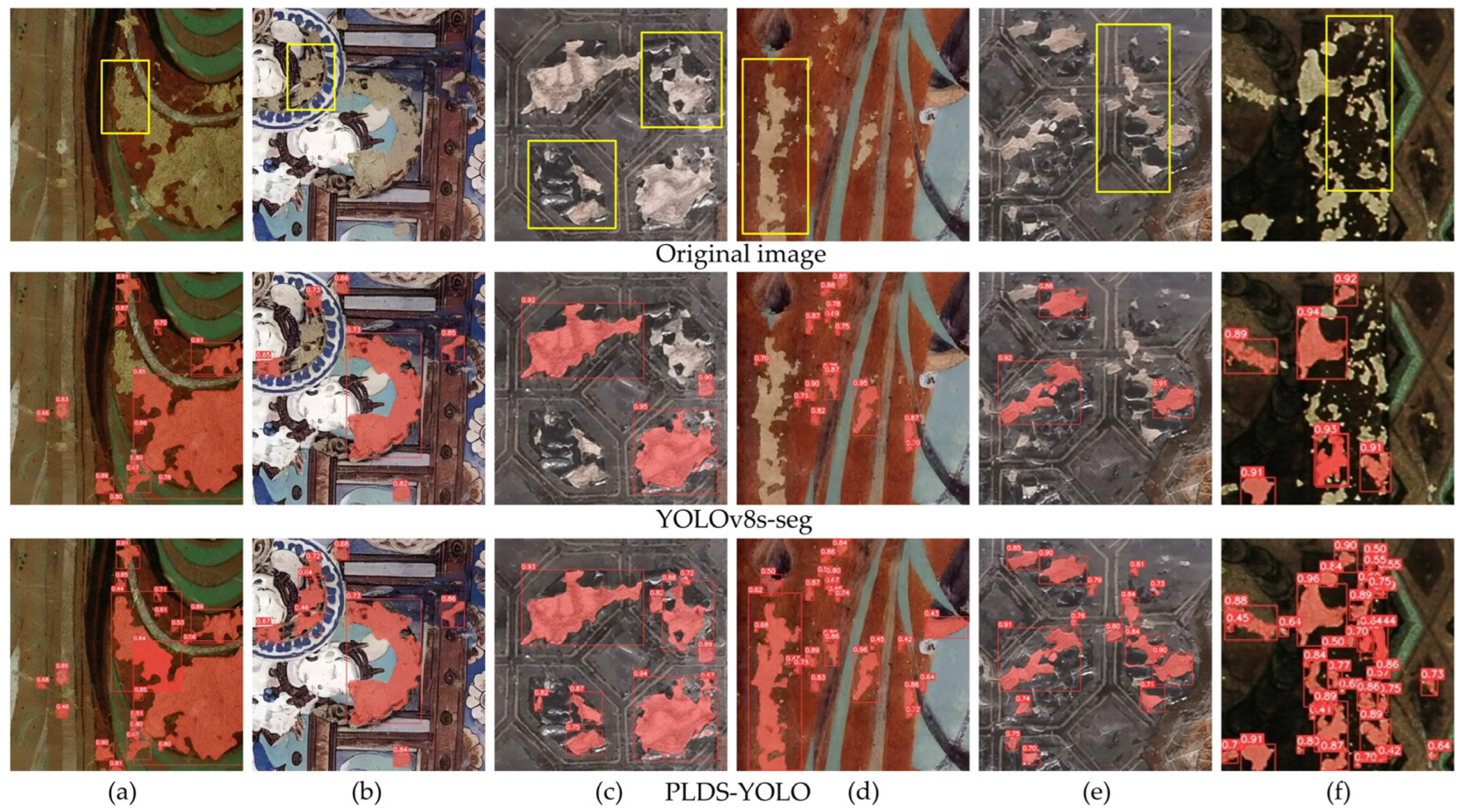
Figure 7 presents a comparative analysis of the baseline model and PLDS-YOLO in the segmentation of paint loss.
Figure 7a demonstrates that PLDS-YOLO enhances the completeness of paint loss region boundary segmentation, effectively reducing instances of incomplete segmentation.
Figure 7b indicates that, in complex textured backgrounds, the improved model accurately identifies hard-to-distinguish paint loss regions, whereas the baseline model exhibits relatively weaker performance.
Figure 7c,d illustrate large paint loss areas, characterized by complex boundary structures, where the baseline model fails to detect certain regions, while PLDS-YOLO achieves more comprehensive paint loss segmentation.
Figure 7e,f further reveal that PLDS-YOLO detects a greater number of small-sized paint loss areas. In contrast, the baseline model demonstrates varying degrees of missed detections, indicating that the improved model exhibits higher sensitivity in detecting small paint loss regions. Overall, PLDS-YOLO outperforms the baseline model in both paint loss detection capability and segmentation accuracy. Although some instances of missed detections remain, the proposed model enables more precise extraction of paint loss areas and improves the completeness and stability of the segmentation results.
3.5. Comparison with Different Models
This study performed a series of comparison tests using different object detection and segmentation algorithms, such as Mask R-CNN, SOLOv2, and the YOLO series models (YOLOv5s-seg, YOLOv7-seg, YOLOv8-seg, and YOLOv9-seg). The goal was to evaluate the performance and benefits of PLDS-YOLO in detecting and segmenting paint loss areas. Specifically, Mask R-CNN, as a classic region proposal-based two-stage method, demonstrates excellent performance in terms of accuracy. However, its complex network architecture and high computational cost may become a bottleneck in large-scale data processing, particularly in terms of inference speed and computational efficiency. In contrast, YOLO series models and SOLOv2 adopt an end-to-end single-stage detection and segmentation framework, significantly improving inference speed while effectively optimizing accuracy. Especially in YOLOv5s-seg, YOLOv7-seg, YOLOv8s-seg, and YOLOv9-seg models, their simplified structure and faster inference speed meet the requirements for real-time detection and segmentation.
To ensure the validity of the method comparison, all models were trained on an identical dataset utilizing consistent data preprocessing techniques and standardized evaluation metrics. To verify the stability of the experimental results, each method was independently trained ten times, with the average of these results computed as the final overall score.
Table 1 shows the quantitative metrics of each model in the paint loss detection and segmentation tasks. In terms of overall segmentation performance, the PLDS-YOLO model outperforms the compared models in segmentation accuracy. Compared to Mask R-CNN, mAP@0.5 improved by 33.9%, mAP@0.5:0.95 increased by 21.6%, and FPS is approximately 2.6 times faster than Mask R-CNN. The core task of this study is the extraction of pigment layer detachment damage, with mAP@0.5 serving as the primary evaluation metric and the basis for model ranking. PLDS-YOLO achieved an 86.2% result on this metric, surpassing the second-ranked YOLOv7-seg, which scored 84.0%. Compared to YOLOv7-seg, PLDS-YOLO improved segmentation accuracy by 2.2 percentage points while reducing model complexity. The PLDS-YOLO model outperforms the baseline YOLOv8s-seg model in terms of accuracy, recall, mAP@0.5, and mAP@0.5:0.95. This indicates that PLDS-YOLO is more effective in detecting and segmenting objects.
Combining the comparison results of GFLOPs and FPS, PLDS-YOLO has a GFLOPs value of 49.5, which is much lower than Mask R-CNN (258.2), SOLOv2 (217), as well as YOLOv7-seg (141.9) and YOLOv9-seg (145.7). This indicates that the model has lower computational complexity, reducing its dependence on hardware resources and making it suitable for deployment in hardware-limited environments, such as mobile devices. The FPS of PLDS-YOLO reaches 75.6, significantly higher than that of Mask R-CNN (28.5 FPS) and SOLOv2 (35.8 FPS), and it also surpasses the more computationally complex YOLOv7-seg and YOLOv9-seg. This indicates that the proposed model can meet the real-time requirements of tasks while providing fast responses. Overall, PLDS-YOLO strikes a balance between segmentation accuracy and computational complexity, improving both inference speed and segmentation performance without significantly increasing computational cost.
Figure 8 presents the segmentation results of paint loss detected by various models. As shown in
Figure 8a,b, the paint loss areas closely resemble the background. In these cases, PLDS-YOLO demonstrates a relatively high accuracy in segmenting the paint loss areas, while other models struggle to differentiate between the paint loss areas and the background, resulting in varying degrees of missed detections. As shown in
Figure 8c,d, the paint loss areas exhibit larger paint loss areas and complex edges. All five comparison methods fail to fully detect the complete boundaries of the larger paint loss areas. In contrast, PLDS-YOLO not only detects the complete boundaries of the larger paint loss areas but also identifies more smaller paint loss areas, although some instances of missed detections are observed. As shown in
Figure 8e, the sizes of the paint loss areas vary. Larger areas, with higher contrast against the background, are accurately detected by all models. However, smaller paint loss areas, due to their lower contrast and complex shapes, result in varying degrees of missed detection across all models. As shown in
Figure 8f, the paint loss areas are small paint loss areas with complex edges. In this case, different models exhibit varying degrees of missed detection, with some models performing poorly in segmenting complex paint loss boundaries. PLDS-YOLO, however, can detect more small paint loss areas and performs better in boundary segmentation accuracy. Overall, PLDS-YOLO demonstrates superior segmentation performance in tasks involving paint loss areas with complex shapes, low contrast, and varying scales. Compared to other models, PLDS-YOLO effectively reduces the occurrence of missed detections for small paint loss areas and is capable of achieving complete segmentation of larger paint loss areas.
3.6. Ablation Experiments
A series of ablation experiments were conducted in this study to evaluate the impact of the improved PA-FPN, dual-backbone model, and SPD-Conv modules on the performance of the PLDS-YOLO model. These experiments sequentially integrated each module into the baseline model to quantify their individual contributions. This approach provides a systematic evaluation of each component’s effectiveness in detecting and segmenting paint loss, demonstrating the potential for further model enhancements.
Table 2 and
Table 3 show the impact of different improved modules on the detection and segmentation tasks. The original YOLOv8s-seg model achieves an average detection accuracy (Box mAP@0.5) of 91.7% and an average segmentation accuracy (Mask mAP@0.5) of 83.3% in detecting and segmenting paint loss. By gradually incorporating the improved modules, the model’s performance has been significantly enhanced.
If you change the PA-FPN structure in the base model, the detection task got better by 0.8% for Box mAP@0.5 and 2.6% for Box mAP@0.5:0.95. On the other hand, the segmentation task got better by 0.9% for Mask mAP@0.5 and 1.2% for Mask mAP@0.5:0.95. This finding shows that the PA-FPN module effectively combines low-level detail information with high-level semantic information by adding residual skip connections. This improves the ability to detect small targets and the accuracy of segmentation.
When the dual-backbone module based on PA-FPN was added, the Box mAP@0.5:0.95 in the detection task went up even more, to 72.7% (a 2.8% improvement over the baseline), and the Mask mAP@0.5:0.95 in the segmentation task went up from 51.8% to 52.2%. By combining the best features of CSPDarkNet and ShuffleNet V2, this module showed a better ability to understand both big picture and finer details in segmentation tasks with complicated texture flaws.
Finally, after adding the SPD-Conv module, the model performance reached its highest level. In the detection task, box mAP@0.5 and Box mAP@0.5:0.95 increased to 93.3% and 74.7%, respectively; in the segmentation task, Mask mAP@0.5 and Mask mAP@0.5:0.95 increased to 86.2% and 53.1%, respectively. SPD-Conv expands the receptive field by converting spatial information into depth information, effectively capturing small targets and detail information that is easily lost in traditional downsampling under complex backgrounds.
Overall, models under different improvement strategies are all better than the original YOLOv8s-seg model. The final improved PLDS-YOLO model, compared to the baseline model, showed improvements of 1.6%, 4.8%, 2.9%, and 2.5% in Box mAP@0.5, Box mAP@0.5:0.95, Mask mAP@0.5, and Mask mAP@0.5:0.95, respectively. The results demonstrate that the proposed strategies, which incorporate multiple layers of information, effectively enhance the model’s ability to capture both global and local context. These improvements significantly boost the model’s performance in detecting and segmenting paint loss. Therefore, the suggested strategies prove to be valuable for intelligent detection in the protection of cultural heritage.
Figure 8 presents the P-R curves for paint loss detection and segmentation under different improvement strategies. As the model is optimized, the area under the P-R curve progressively increases (
Figure 9a,b), indicating that the proposed strategies effectively enhance the model’s ability to detect and segment objects. The PLDS-YOLO model has the largest enclosed area, indicating that the proposed model performs the best in target detection and segmentation tasks. As illustrated in
Figure 9b, in the low recall rate region (recall < 0.3), the accuracy decline trend of the improved model is comparatively slower than that of the baseline model. This finding suggests that the improved model exhibits enhanced stability in high-confidence predictions, leading to a reduction in false positives and missed detections. In the area with a high recall rate, the P-R curve of the improved model is usually higher than that of the baseline model. The PLDS-YOLO model has the largest P-R curve area, which means it is the most accurate and reliable at finding instances, especially when the backgrounds are complicated and the targets are small.
4. Discussion
Given the diversity of ancient mural and color painting styles across China, and the varying morphological characteristics of pigment layer detachment damage in different regions, this study chose Dunhuang murals and color paintings from the historical site of Peking Union Medical College Research Institute as the research subjects. While data augmentation methods have helped mitigate the limitation of the training dataset, the limited amount of collected mural data may introduce some redundancy in the augmented data, potentially affecting the model’s performance and generalization capability. Therefore, future studies will focus on further expanding mural and color painting datasets from diverse regions, increasing the dataset size and optimizing model training to improve the model’s adaptability and generalization capability.
In terms of model construction, the MPLD-YOLO model, which is an improvement based on YOLOv8, achieves a good balance between accuracy and efficiency, but there is still room for further improvement in accuracy. At present, the method proposed in this study has not been validated in the newer versions of the YOLO series. However, previous research has applied defect detection, such as building damage, using YOLOv10 [
43,
44] and YOLOv11 [
45] versions, and has achieved certain results. In terms of method improvements, several innovative modules, including multiple aggregate trail attention mechanisms [
46] and multiple-dimension attention [
47], have been implemented in damage detection tasks and have effectively enhanced model performance. Future research will explore transferring the improvements proposed in this study to newer versions of the YOLO series, incorporating the latest innovative modules to optimize the model structure. This approach will improve accuracy while achieving model lightweighting, thus enhancing efficiency and performance in real-world applications.
The primary objective of this study is to develop a reliable model capable of accurately extracting pigment layer detachment damage areas, thereby providing a solid technological foundation for damage detection in murals, color paintings, and other cultural heritage artifacts of various artistic styles. However, we emphasize that the developed model should serve as an auxiliary tool for damage detection, not as a replacement for expert evaluation. Compared to expert-driven damage detection methods, automated technologies offer significant advantages in processing large-scale image data, improving detection consistency, and reducing subjective bias, making them particularly effective for tasks such as preliminary damage screening and monitoring changes. Nevertheless, manual evaluation continues to play an irreplaceable role in analyzing the semantic information of damage, understanding the historical and cultural context, and making complex repair decisions. Thus, automated detection technologies and expert evaluation will complement each other in the workflow of cultural heritage preservation.
In future image restoration tasks, alongside the powerful capabilities of the model, the expertise of specialists will also be essential to ensure the fine detail and accuracy of the restoration process. Particularly in the restoration of large-scale pigment layer detachment, the integration of the model with expert experience will enable efficient and precise cultural heritage restoration.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}