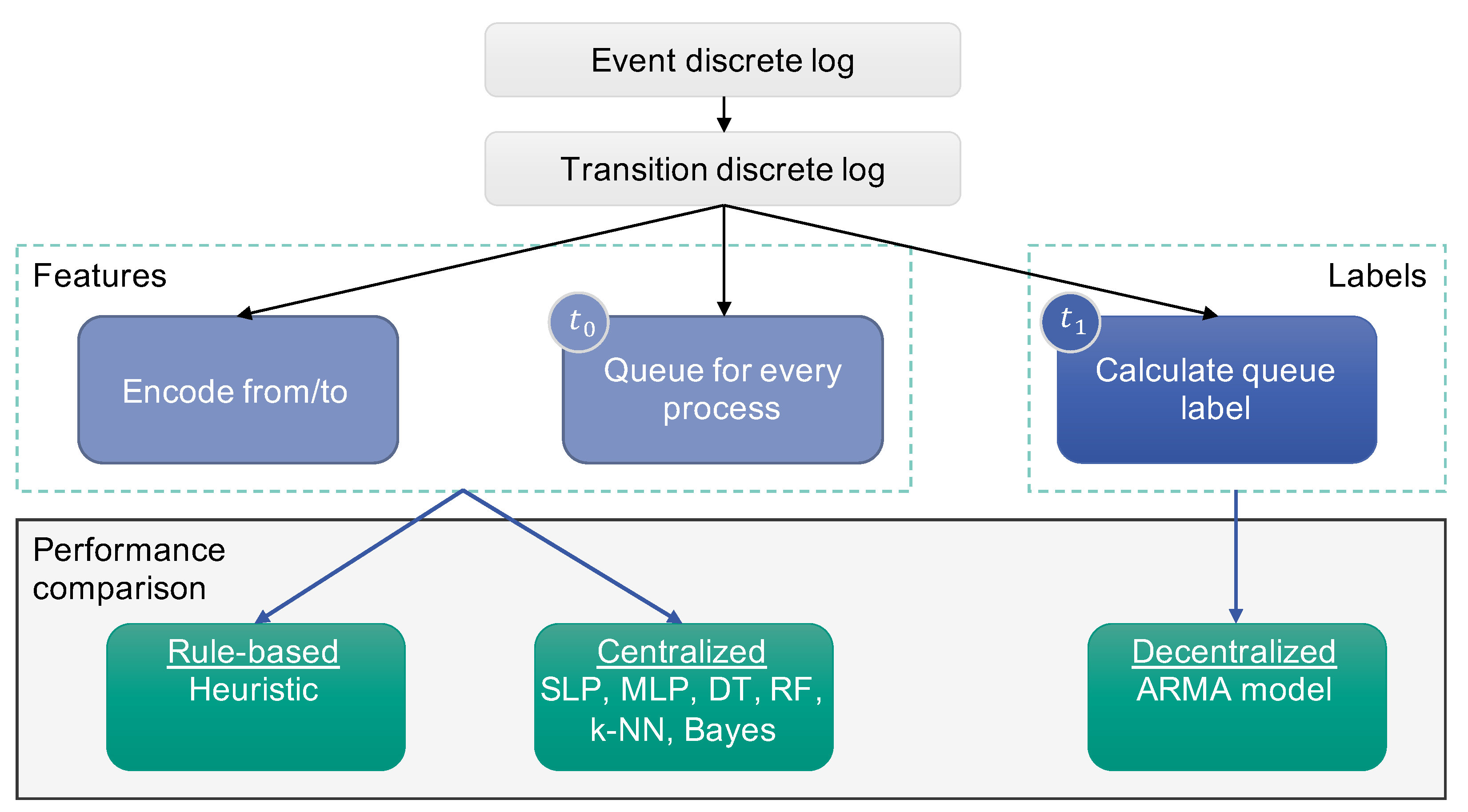
In the following section, the materials and methods are presented one by one, as these form the basis for the evaluation and the subsequent results. In
Figure 1, an overview of the general approach that is followed throughout this paper is illustrated. The different models that are considered are listed in the lower part of
Figure 1 and are described in detail in this section. First, in
Section 2.1, the queue and its possible length are defined.
Section 2.2 then describes the developed rule-based heuristic. The decentralized approach and the underlying model are presented in
Section 2.3. Last but not least, different possible models for the centralized perspective are listed and discussed.
2.1. Delimitation
The aim of this paper is to predict the queue in a manufacturing system as accurately as possible using various models. Queuing theory was born in 1909 when mathematician Agner Krarup Erlang first attempted to dimension telephone exchanges [
7]. In later years, more research was done in the direction of queuing theory and identified applications in many different areas. Because of the development of computer networks, the research has gained renewed importance in recent years [
9]. The range of applications extends from the health care sector to transportation, shop floor design in production, to computing and beyond. Queues are also indispensable in manufacturing today [
8].
In queuing theory, a node describes a place that offers a service performed by a limited number of servers to jobs. If there are more jobs at a node than there are servers, a queue of currently unserved jobs emerges. These jobs wait in the queue until it is their turn to be processed. There is a standard notation, Kendall’s notation, which has become established for queuing models [
15]:
A denotes the arrival process, i.e., the distribution between two arrivals.
S denotes the service time distribution and c the corresponding number of servers.
Simple and well-known models are for example M/M/1 (single server), M/M/s (multiple servers), and M/G/1. The latter was first solved by Pollaczek in 1930. M is the abbreviation for Markov and reflects a Poisson input with exponential service times. G resembles any other possible distribution (normal distribution, equal distribution, etc.) [
16].
In addition, there are different service disciplines that arrange the order in which jobs leave the queue. The most famous of these is the FIFO (First-In First-Out) principle, which is also known as the first-come-first-serve principle. If the FIFO principle is applied, the order with the longest waiting time is always served first [
17].
In many manufacturing operations, products are produced using flow production or batch production, where an order passes through a predefined sequence of machines. Under these conditions, production planners can easily use the given key figures and lead times and, thus, determine buffer times and suitable queues precisely in advance. However, these conditions do not exist in complex manufacturing job shops, where identical processes can be executed by several different machines and jobs remain within the production system for a comparably long time. Due to this fact, a product can follow different routes through the factory [
18]. The properties of complex manufacturing job shops are explained in more detail in
Section 3.1 with reference to the case study.
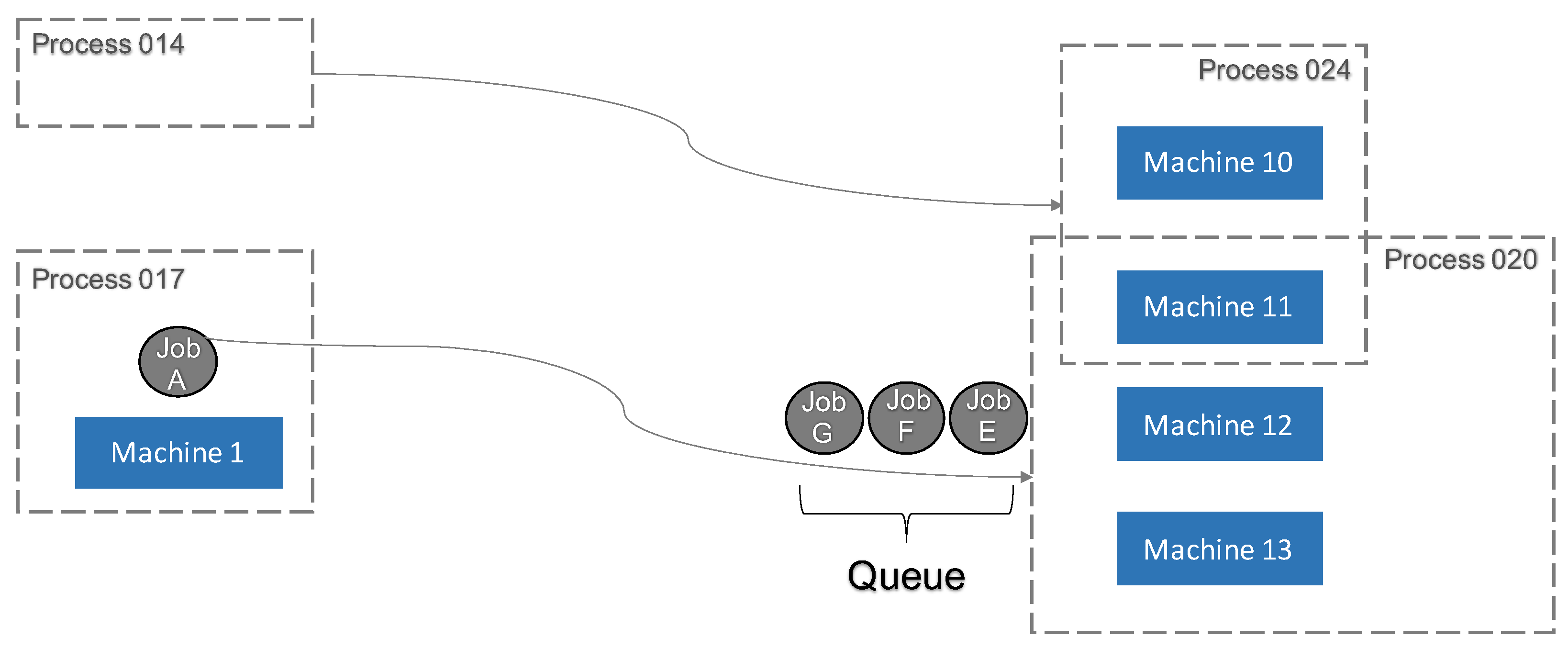
In the context of this paper, the queue definition was slightly augmented, to accommodate complex job shop manufacturing environments. Before introducing the definition, it is necessary to understand the concept of dispatching, as visualized in
Figure 2: Before a job is sent to Machine 1 for processing, the length of the queue in front of the next machine (for instance, Machine 11) needs to be known. If the waiting time resulting from this queue is expected to exceed a specified time limit, it may be more favorable to skip processing those jobs and continue with jobs along a different route instead, which can thereby retain their time constraint limit. Time constraints limit the time between processing on two or more possibly consecutive machines [
19]. As introduced by Little’s law, the queue length and transition time can be related, and hence, it is promising to regard queue lengths for subsequently controlling dispatching.
The main difference from other manufacturing definitions of a queue is that the newly determined queue does not map jobs in front of individual machines or connections between two specific machines. Instead, the waiting queue in front of several machines is summarized. In
Figure 2, Job A is first processed by Machine 1. After finishing, depending on the specifications and properties of the product, it is mandatory to carry out the next process step within production. Since in complex manufacturing, job shops machines have the ability to run several different processes, it is not clear in advance to which machine Job A will be sent next to be processed further.
The products are therefore not distinguished or identified by a sequence of machines, but by a specific sequence of processes. If a particular process, such as Process 020 in
Figure 2, has to be executed as the next step, it is very likely that more than one machine can execute this process. In the given example, these are Machines 11–13. It does not matter which of these machines processes the job; it is only important that the right process is conducted. Thus, the approach is to relate the cumulative queue to the processes rather than to machines. The characteristics of machines in complex manufacturing job shops are the ability to execute several different processes, which makes the calculation of machine-specific queues difficult. It is insufficient to consider only the jobs that are currently waiting for a given process at the next machining process. Because other machines can also execute different processes, it is possible and, therefore, very probable that there are jobs in the combined queue that have another process as the next processing step. Thus, in the example, Jobs G, F, and E are in the combined queue of Machines 11–13, which adds to the complexity of the calculation/prediction of this queue.
Regarding the problem from a different perspective, jobs that are in the combined queue of multiple processes are not processed exclusively by the same machines. For instance, consider a job waiting for Process 024 that could be performed on a machine that shares two or more processes, as is the case with Machine 11 in
Figure 2. This probability, that a job waiting for a different process is not exclusively processed by the regarded machines of the initial process, can be quantitatively analyzed and was included in further analyses.
Formally, for conventional manufacturing systems, a queue at time
t in front of process
p can be defined as the number of all jobs
j that have finished processing at a time
, are currently transitioning to the next process
, and will start to be processed at time
in the future:
In order to calculate the newly introduced queue, we first created a mapping between machines and processes. The set of machines
M for a process
p is defined by all machines
that can execute this process. The same is defined conversely for all processes
p that can be executed by machine
m:
The expanded set of subsequently relevant processes for a job
j is defined as:
This finally leads to our new definition of a queue, which sums up all queue values of the expanded set of succeeding processes multiplied by their weight. This weight is defined as the percentage of machines that overlap with the machines of the initial succeeding process:
Due to the problem characteristics, there are two mutually exclusive approaches that either focus on predicting individual queue lengths based on previous information about this particular queue (decentralized) or that are based on a prediction that takes into account the entire production system state from a centralized perspective. While several machine learning models are applicable to both decentralized and centralized approaches, only the most prospective combinations are reported in the following.
2.2. Heuristic Approach
The first model for calculating the queue is the heuristic approach. To simplify its introduction, it is necessary to define the variable points of time first:
is the time just before a job enters a machine. The time directly after this job has been finished in the machine is defined as
. As already mentioned, the goal at
is to calculate the queue at
for the next process in order to be able to decide in
whether the job should be dispatched or not. In the example of
Figure 2, Job A will be sent to Machine 1 in
. From the route description, it is known which process must be executed after Process 017. Thus, it becomes clear that the queue for Process 020 must be considered at time
.
The general formula for the calculation can be stated as:
At time
, all current data of the factory are assumed to be known. More precisely, it must be known where every job is located within the whole production system at that moment. With this knowledge, the queue for Process 020 can be determined easily at time
. Further, Queue
is simply the queue at time
plus all jobs that are added to the queue from all predecessors while Job A is processed. In addition, any jobs in the queue at
that finish processing and, thus, leave the queue while Job A is processed must be subtracted from the term. In the given example (
Figure 2), Job E may be sent to one of Machines 11, 12, or 13 while Job A is being processed on Machine 1. Consequently, this job leaves the queue under consideration and must be deducted. At the same time, other jobs enter the queue that are finished on another machine between
and
and have to be processed next.
This can be used for two purposes, firstly to determine the queue lengths from a log file for all discrete time steps and, secondly, for heuristic anticipation of future queue lengths. With the assumption that a process always takes the same time to execute, this information can be used in the prediction of the process end time. We used the historical median in this case because the expected time is easily distorted by rare overlong times, which can occur in the case of problems such as machine breakdowns.
In addition to the heuristic just described and the two approaches that follow, another perspective is considered as a kind of reference method to evaluate the quality of the newly introduced approaches. This method does not try to predict the queue length for
, but looks at the queue at time
. The length is calculated by simply counting and adding up the waiting jobs before the next process. Thus, the approach neglects the leaving jobs and arriving jobs from Equation (
7) and is hence based on the assumption that no large state changes occur between the times
and
. In general, this method can be declared as the current State-of-the-Art (SotA) in the determination of queue lengths.
2.3. Decentralized Approach
Besides the described heuristic in
Section 2.2, two more general approaches were considered for the task of queue length forecasting. These were based on using known models and methods from statistics and machine learning. First, a decentralized approach for predicting the queue length for a single edge between two machines, or a machine and a process group, was used, and second, a centralized perspective was probed, taking all the available processes into account for the forecast.
Looking only at two consecutive processes at a time allows the usage of time series analysis for the forecasting of the queue length in front of the subsequent process [
19]. For this decentralized approach, an Autoregressive Moving Average (ARMA) model was chosen to analyze and predict the sequence of queue lengths over time. Thereby, the prediction of the current value
via ARMA follows Equation (
8) using a sequence of predecessors
and white noise
[
20]. The ARMA model and its prediction consist of two parts. Through a linear combination of a constant change
c, a random noise
, and the estimated process parameters
, the Autoregressive (AR) part models the partial autocorrelation, i.e., the direct linear relationship between time steps [
20]. The influence of random effects
on the values over time combined with estimated process parameters
is modeled by the Moving Average (MA) part [
20]. Decisive for the performance of an ARMA model is the right choice of the values
p and
q [
20]. These determine how many past time steps and noise influence the values of the time series [
20]. For the task in this paper, this was determined by the selection of the past
p and
q queue lengths of the chosen edge. These can be deduced by looking at autocorrelation and partial autocorrelation plots.
The second model applied in the decentralized approach uses weighted averages. Exponential smoothing is used for this purpose, which was introduced by Holt and Winter in the late 1960s [
21,
22]. Many other successful forecasting methods have been derived from this initial research. The Simple Exponential Smoothing (SES) model is one of the easiest ways to forecast a time series [
23]. Its forecasts are weighted averages of past observations, which are increasingly discounted the older the observed values are [
24]. Accordingly, more recent observations have a greater influence on the prediction than older ones. A disadvantage of the simple exponential smoothing model in its standard model is that it cannot deal with trends or seasonality [
24]. The forecast of value ŷ can be any given data, for example the future demand that is an estimation of the actually observed demand y. We initialized the very first forecast as zero and the second forecast as the value of the first observation. When the time t is greater than 1, the formula of the simple exponential smoothing model is:
can be set arbitrarily and has a great influence on the prediction performance. When
approaches 1, the first part of the formula becomes larger, and the focus is on the most recent observations. On the opposite side, if
is lower, there is more weight on the last forecast
. Setting
creates a tradeoff between a forecast that can quickly adjust to short-term changes and a forecast that is not too sensitive to noise and outliers [
24].
2.4. Centralized Approach
For the centralized approach, different supervised machine learning models are applied for the forecasting task. Thereby, the centralized perspective takes all possible edges between the different manufacturing processes at a given time into account. Here, the most commonly used algorithms discussed in the literature for predicting numerical values were chosen and studied in detail.
Generally, in supervised machine learning, a model tries to predict a specific target value of a given data set [
25]. This set usually contains selected relevant information on which the model is trained [
25], so that labeled input-output pairs can be used. Through a model-specific learning process, the target value is predicted and compared with the label included in the data set [
25]. If the true value and prediction deviate, the model adapts automatically to achieve a better result in the next run [
25], based on a predetermined loss function, which relates to this deviation. The selection and generation of relevant input features for the training are some of the first and also most important steps for machine learning [
25]. As mentioned in the previous subsections, the overall goal of this paper was to determine methods to forecast the queue length for
forward from the point
. Therefore, an important input for the training of the different algorithms is the exact knowledge about the current state of the processes. In other words, the queue length at
in front of the next process step need to be provided as an input. The values can be generated as described in
Section 2.1. Following the calculation of these values, they are adjusted by multiplication with the fraction of relevant machines. This adjustment is necessary to get more accurate results since the queue length was previously calculated for a wider range of machines (see
Section 2.1). The current state is also described through another second input feature by counting the queue length in front of every possible process step. To facilitate quick learning, these values require normalization. By applying one-hot-encoding, the starting and target process are fixed. The three given features together with a previously determined queue length as the label represent the data set for training the models. Finally, testing on previously unseen data and a comparison of the results with the true values of the queue lengths allows the evaluation of the performance of the considered models.
2.4.1. Decision Tree
A Decision Tree (DT) is the recursive partitioning of a data space to determine a discrete or continuous value for a given instance [
26]. In so-called internal nodes, different logical rules are applied to split the given data into groups [
27]. At the lowest level of the tree, the leaf nodes, the target value for the instance is assigned [
27]. If the target value like for the task of this paper is continuous, so-called regression trees are used for the prediction [
26]. For the decision on which of the given features the split is based, the most informative one has to be determined [
27]. Regression trees usually use the feature with the greatest reduction in the sum of squared differences for the split (entropy) [
28]. Normally, the application of decision trees on regression tasks relies on the assumption of a linear relationship in the data [
28]. Such a relationship for queue length forecasting is quite possible, which motivates the use of this model.
The limitation to model only linear relationships and the tendency to overfit quite fast [
27], despite reducing the DT size through so-called pruning, could also be significant disadvantages in the use of decision trees for the task. For this reason, among others, further models must be considered and are discussed in the following.
2.4.2. Random Forest
A Random Forest (RF) relies on the idea of ensemble learning [
29]. The algorithm combines different decision trees for classification or regression tasks, using two kinds of randomization methods to generate and train these trees [
29]. First, a technique called “bootstrap aggregating (bagging)” is applied [
29]. Through this technique, training samples are generated by drawing with replacement from the original dataset [
30]. The second randomization relies on training the decision trees only on a random subset of the available features [
29]. The application of these two methods of randomization yields different results for the target value [
29]. The ultimate prediction of a random forest is then achieved by the aggregation of the different results from the trees to one final value [
31]. In the end, the forecast of the queue lengths by using the random forest algorithm is given by the arithmetic mean of the different generated results from the decision trees.
2.4.3. Bayesian Regression
In contrast to a classical point estimation of the unknown weights of a regression model, the Bayesian approach relies on the usage of probability distributions to characterize the uncertainty of weights [
32]. In other words, the aim of Bayesian regression is not to find a single “best” value for the model parameters, but a posterior distribution. This posterior distribution is conditional and calculated by multiplying the likelihood of the data with the prior probability of the parameters and divided by a normalization constant [
33]. The concept behind this is the Bayesian inference, using the Bayesian theorem [
32]. As mentioned previously, this approach allows including the uncertainty of the desired prediction, which is also the main advantage of the model [
32].
2.4.4. Single-Layer Perceptron
A single-layer perceptron (SLP) constitutes the simplest neural network and the key element of other more complex networks [
34]. The basic concept of a neural network is that input values are multiplied by learned weights, then combined within nodes and layers and aggregated to an output via an activation function [
34]. In these models, the learning process is typically based on the idea of the backpropagation algorithm [
35]. Thereby, the input weights are updated regularly based on a potential deviation between the predicted value and the label [
35]. To find the optimal weights with the least deviation within the solution space, a variety of optimization algorithms exist currently. One of the most popular and promising is adaptive moment estimation [
36], which is applied here. Another important factor for the successful application of neural networks is the right choice of the previously mentioned activation function [
37]. These define the output of a node for a given input [
37]. In recent years, many different functions have become increasingly popular, in contrast to the original sigmoid function, such as the rectified linear activation function (ReLU) [
37]. The biggest advantage of ReLU is that it solves the vanishing gradient problem [
38]. Like in some of the previously described models, the typical SLP is a linear model, but through the application of ReLU as the activation function in the output, the model is able to map non-linear behavior [
37]. Therefore, an SLP model was also considered and evaluated for the task of queue length forecasting.
2.4.5. Multi-Layer Perceptron
Adding one or more additional layers with an arbitrary number of neurons between the input and output of an SLP leads to more general non-linear models, the Multi-layer Perceptrons (MLPs) [
34]. The structure and interconnection of MLPs are usually organized in a feedforward way [
34]. These feedforward networks are neural networks in which the so-called nodes are fully connected and the information flows only in one direction [
39]. The additional layers are also known as hidden layers and are the key aspect for deep learning neural networks [
40]. Due to the danger of overfitting and the desire to keep the models as basic as possible (Occam’s razor), only simple neural networks with a single hidden layer were tested in the scope of this paper. Thus, deep learning was not considered further for the task of queue length forecasting. For the MLP model in this paper, the activation function and optimization algorithm remained similar to the SLP model.
2.4.6. k-Nearest Neighbor
Contrary to the other previously described machine learning models, the technique of k-Nearest Neighbor (k-NN) is a nonparametric, instance-based approach [
41]. The prediction of the value of a new instance is performed by looking at the k-nearest neighbors with the smallest distance to the currently considered data point(s) [
41]. The most commonly used norm for calculating this distance is the Euclidean distance, which was also the chosen approach in this paper. Numeric values can be predicted by calculating the arithmetic mean of the k-nearest neighbors and assign the result to the instance under investigation [
42]. Therefore, for the task of forecasting the queue length in front of a process for a future point in time, this can be achieved by taking the average over the values of the k-nearest neighbors of the process.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




