
Fighting Deepfakes Using Body Language Analysis



Abstract
1. Introduction
- To provide a general literature review of deep learning technologies, deepfake detection, and human pose estimation.
- To develop a human pose estimation program to detect upper body keypoints.
- To implement a deep learning network to learn the upper body languages of the target world leader.
- A comprehensive dataset of world leaders, which could serve as a pre-training arrangement for the smaller dataset (with less real/fake data samples).
- To examine the effectiveness of detecting deepfakes through upper-body language analysis.
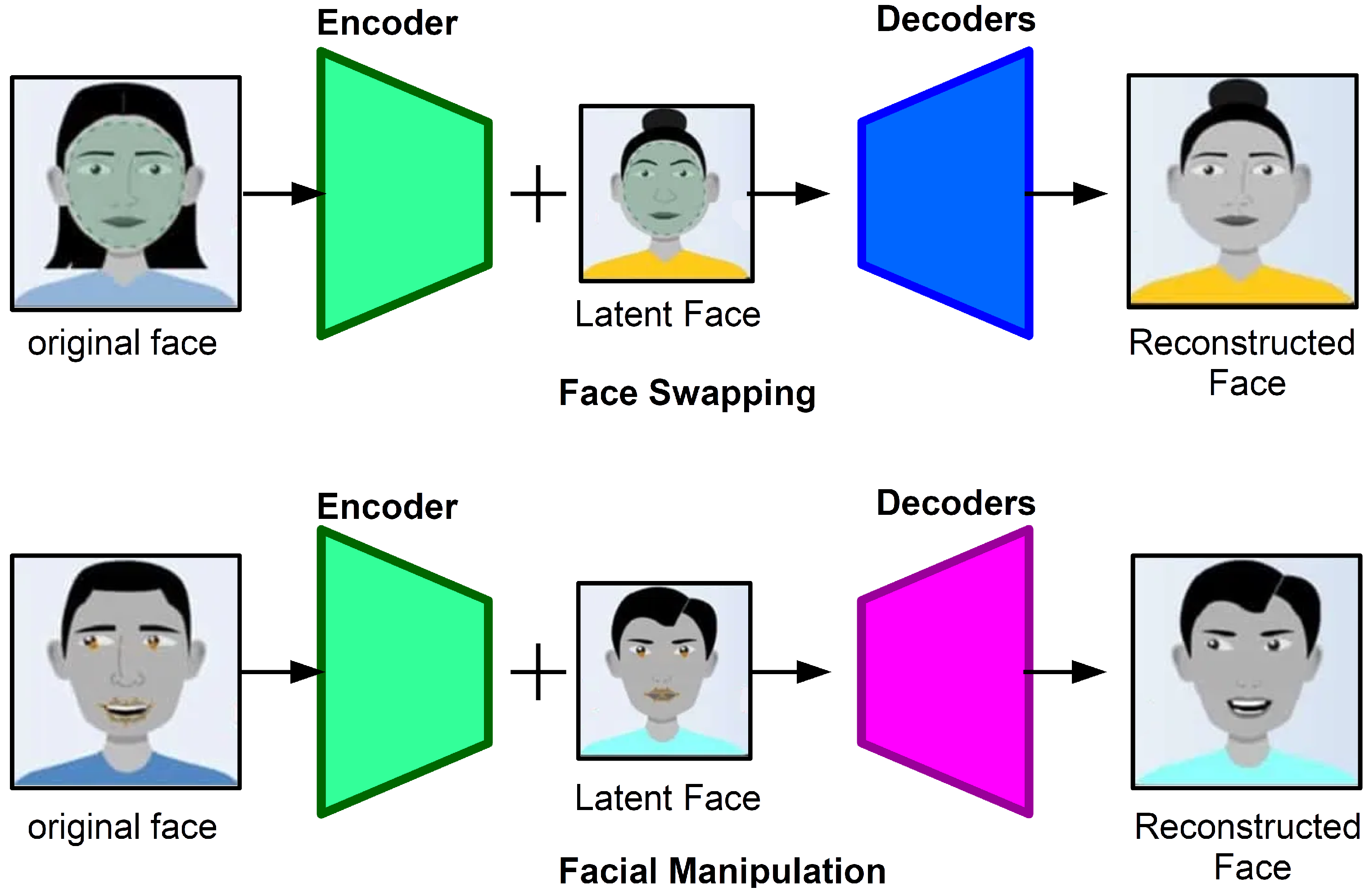
2. Literature Review
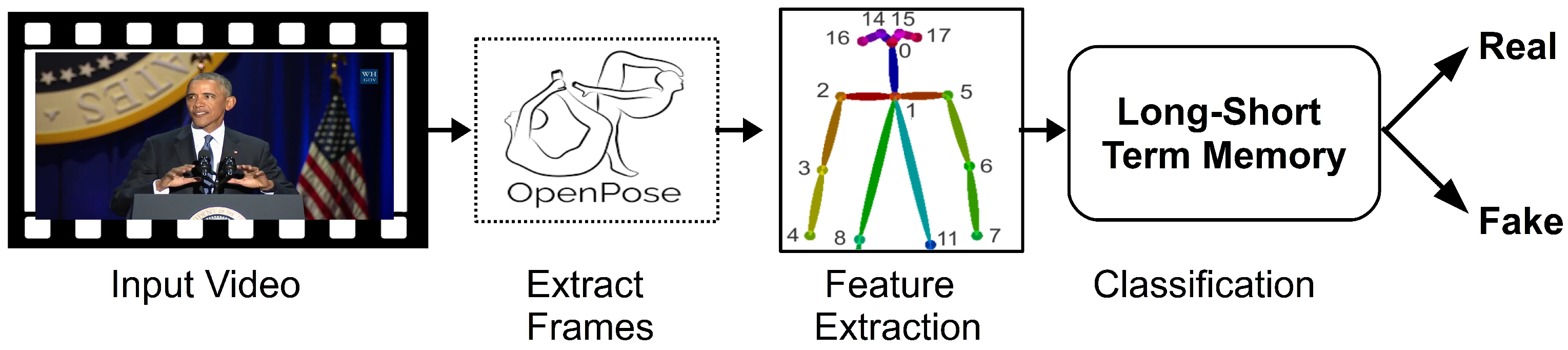
3. Method
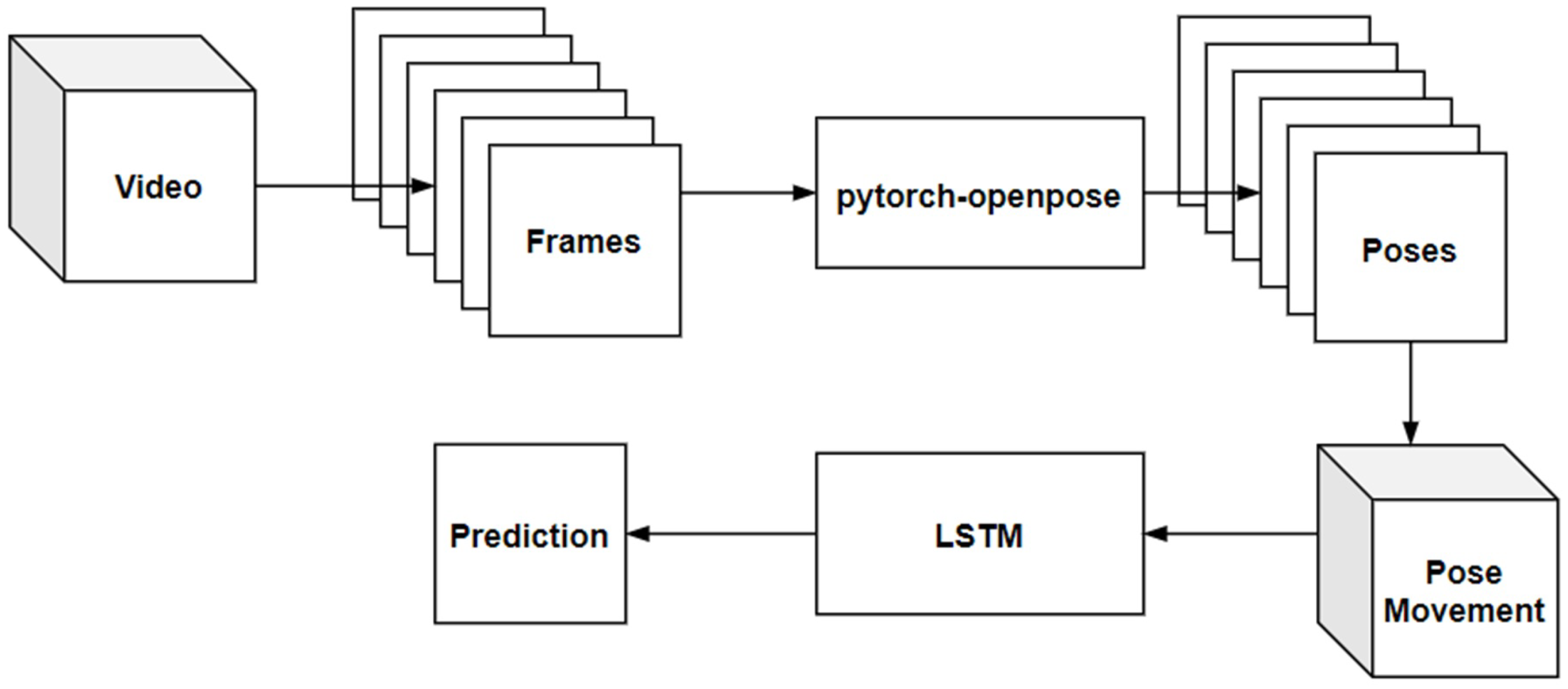
3.1. Dataset and Preprocessing
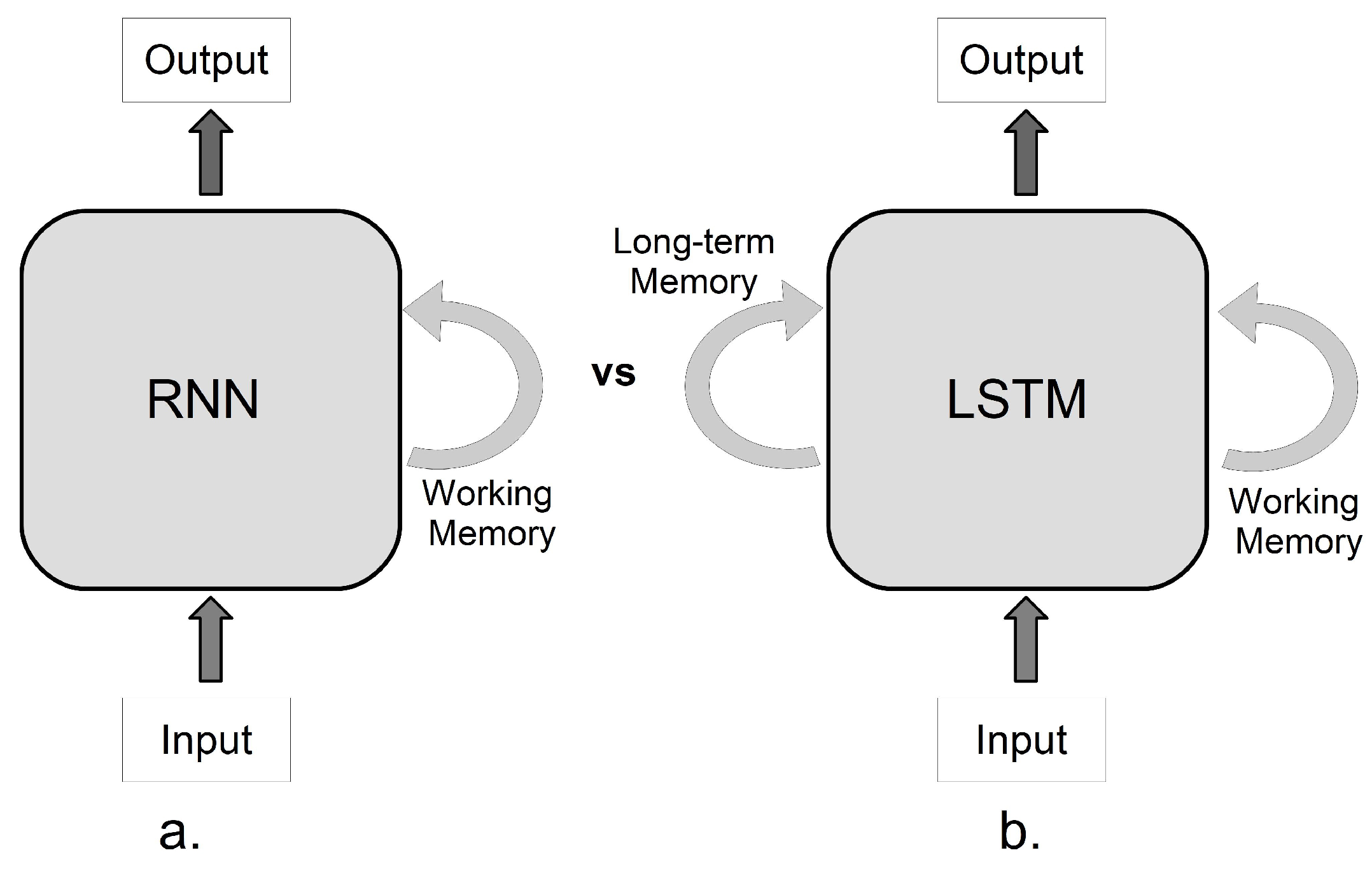
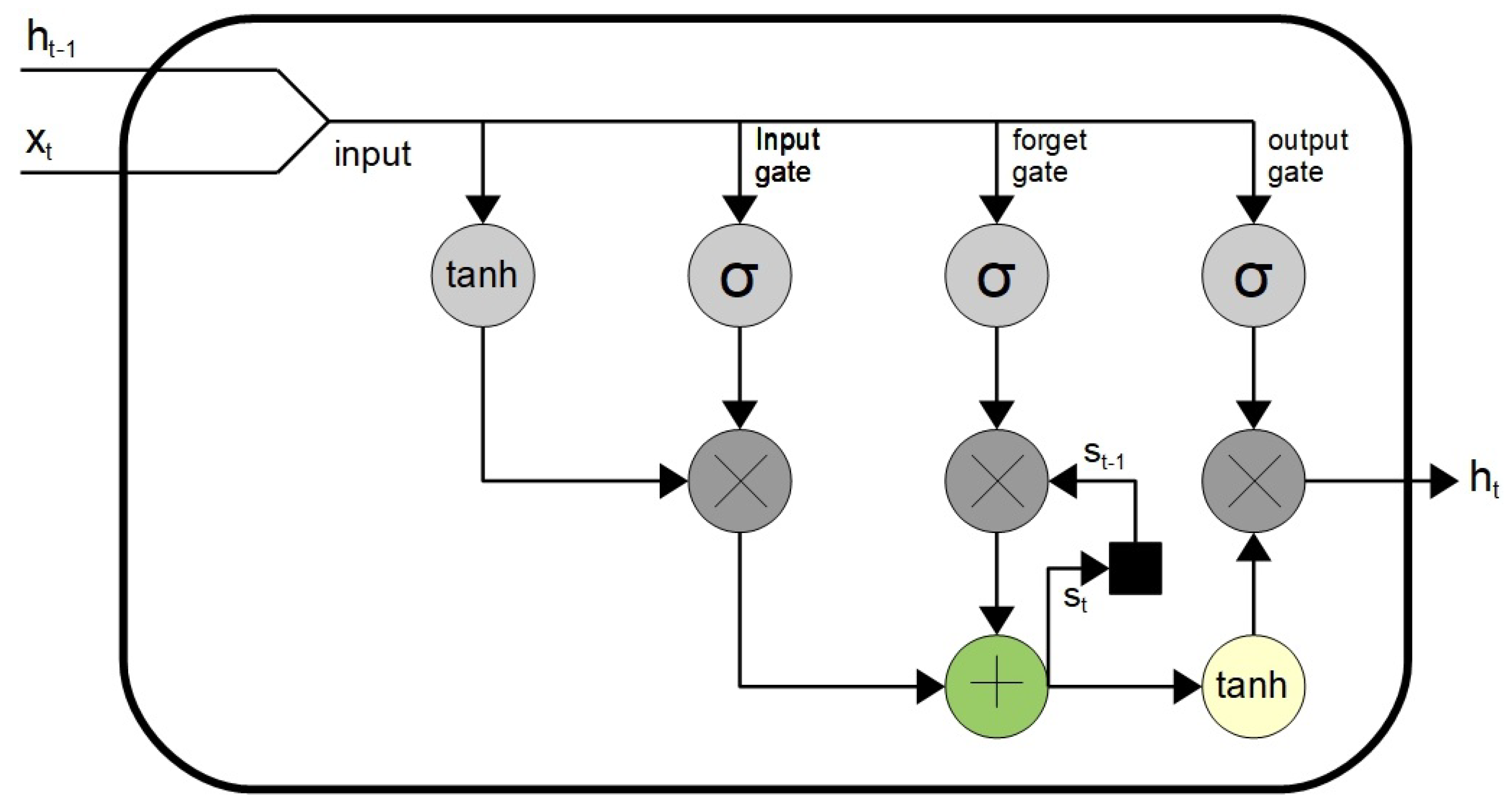
3.2. RNN Architecture
3.3. Experimental Setup
3.4. Evaluation Metrics
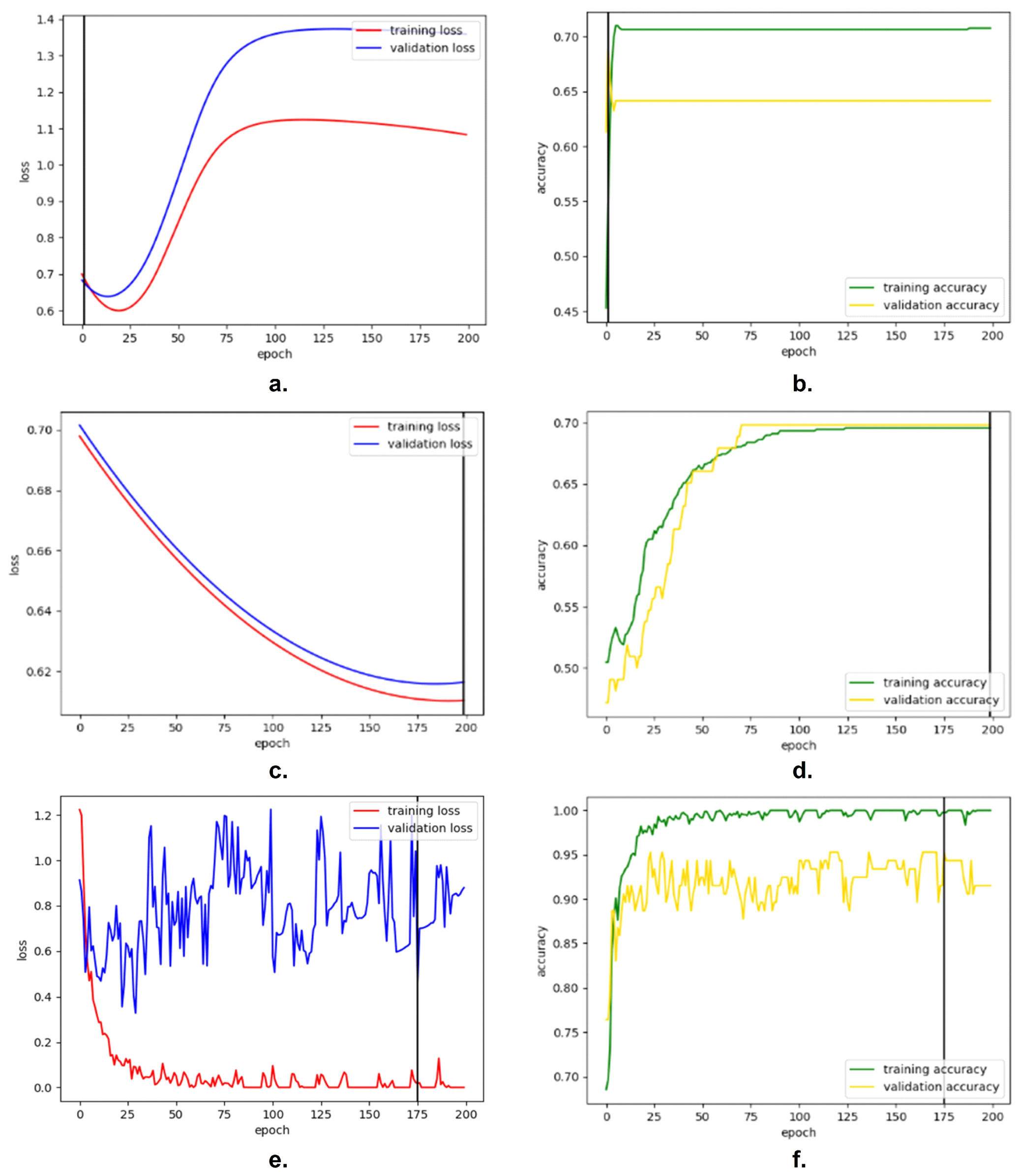
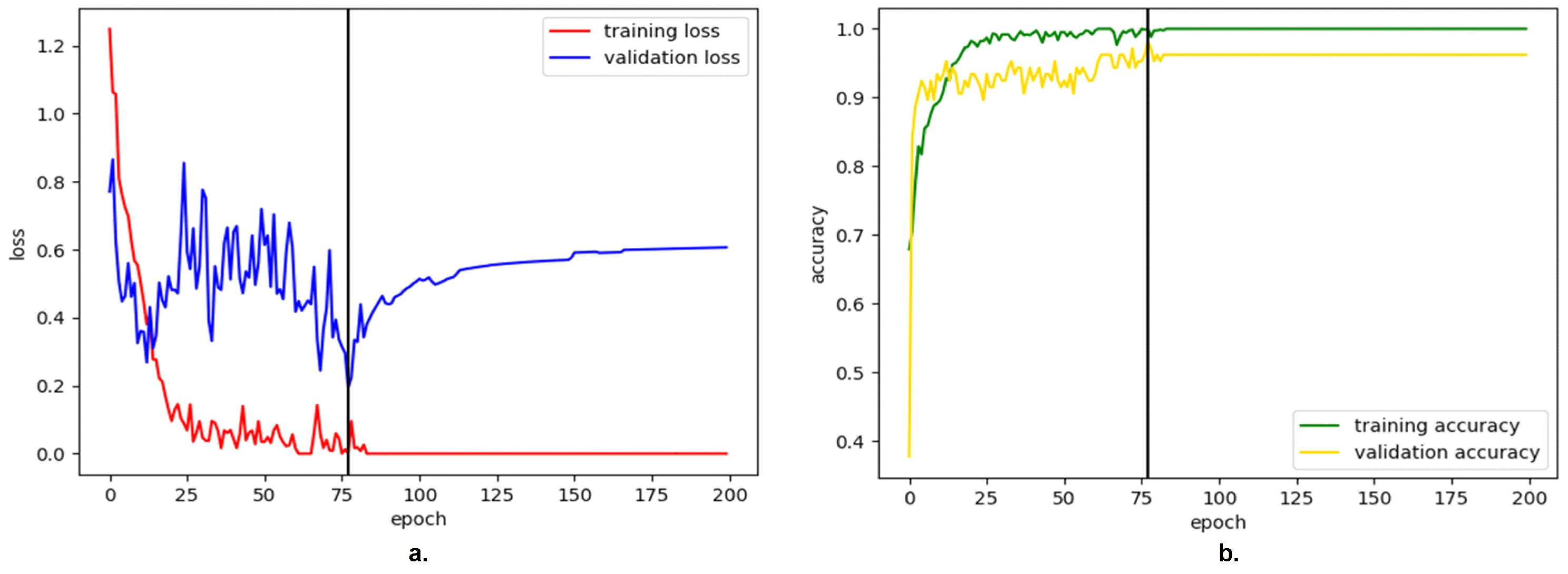
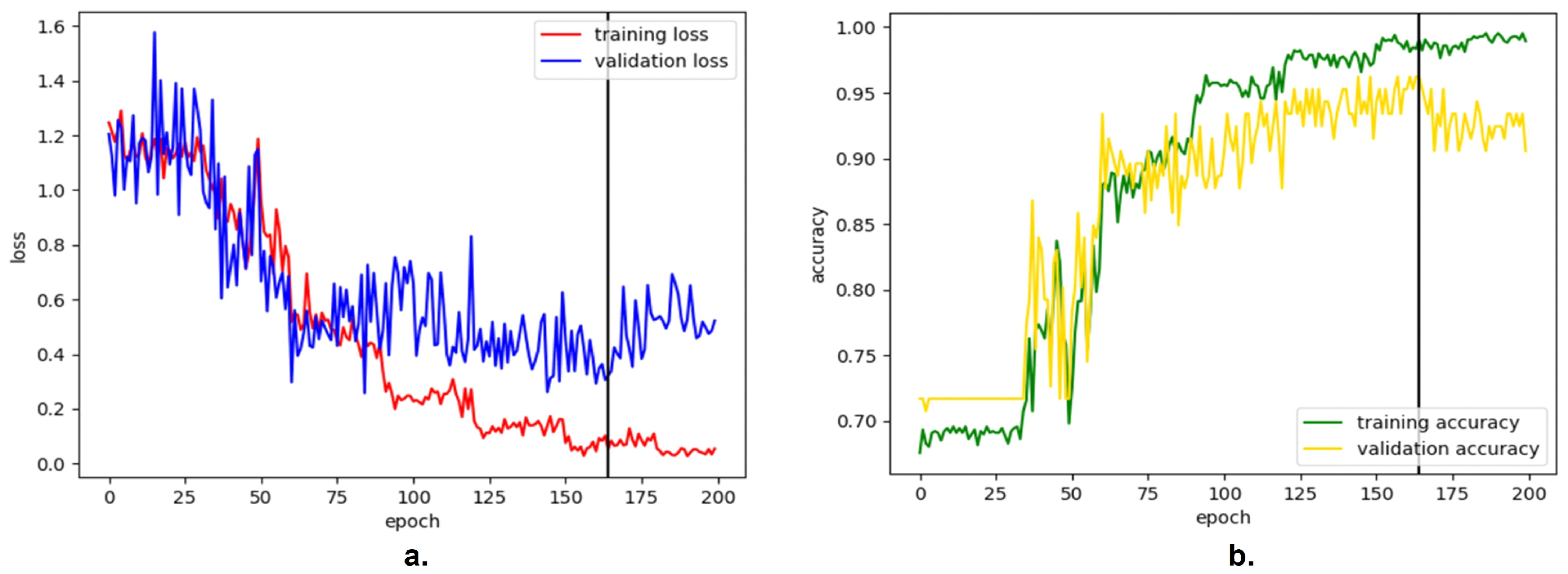
4. Results
5. Discussion
6. Conclusions and Future Work
- Collecting more real videos to produce positive instances. Instead of downloading deepfakes from the internet, developing synthetic instances of videos using advanced deepfake creation approaches.
- Training using a larger dataset might enhance the generalization performance, so the researcher can continue training the new models using transfer learning. The future researcher can create datasets for multiple world leaders and train models for different world leaders, in order to test whether the proposed method is still useful.
- Defining a new RNN network and train a model that allows input sequences with different lengths. Use the 3D head pose to replace head keypoints. The 3D pose might be more informative, because it contains spatial position instead of planimetric position.
- Using an upper-body pose and a hand pose to train the model. The PyTorch-OpenPose also provided a model for hand pose estimation. Adding a hand pose is similar to upper body languages, as different people might have distinct hand gestures.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Fiore, U.; De Santis, A.; Perla, F.; Zanetti, P.; Palmieri, F. Using generative adversarial networks for improving classification effectiveness in credit card fraud detection. Inf. Sci. 2019, 479, 448–455. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [PubMed]
- Yasrab, R.; Atkinson, J.A.; Wells, D.M.; French, A.P.; Pridmore, T.P.; Pound, M.P. RootNav 2.0: Deep learning for automatic navigation of complex plant root architectures. GigaScience 2019, 8, giz123. [Google Scholar] [CrossRef] [PubMed]
- Yasrab, R.; Zhang, J.; Smyth, P.; Pound, M.P. Predicting Plant Growth from Time-Series Data Using Deep Learning. Remote Sens. 2021, 13, 331. [Google Scholar] [CrossRef]
- Chesney, B.; Citron, D. Deep fakes: A looming challenge for privacy, democracy, and national security. Calif. Law Rev. 2019, 107, 1753. [Google Scholar] [CrossRef]
- Dyer, C. Trump Shares ’Deep Fake’ GIF of Joe Biden Sticking His Tongue Out in Series of Late-Night Twitter Posts after His Briefing was Cut Short-Even Retweeting HIMSELF Three Times. Available online: https://www.dailymail.co.uk/news/article-8260455/Trump-shares-deep-fake-GIF-Joe-Biden-sticking-tongue-series-late-night-posts.html (accessed on 1 March 2021).
- Qi, H.; Guo, Q.; Juefei-Xu, F.; Xie, X.; Ma, L.; Feng, W.; Liu, Y.; Zhao, J. DeepRhythm: Exposing deepfakes with attentional visual heartbeat rhythms. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 4318–4327. [Google Scholar]
- Hern, A. I Don’t Want to Upset People’: Tom Cruise Deepfake Creator Speaks Out. The Guardian, 5 March 2021. [Google Scholar]
- Dolhansky, B.; Howes, R.; Pflaum, B.; Baram, N.; Ferrer, C.C. The deepfake detection challenge (dfdc) preview dataset. arXiv 2019, arXiv:1910.08854. [Google Scholar]
- Li, Y.; Chang, M.C.; Lyu, S. In ictu oculi: Exposing ai created fake videos by detecting eye blinking. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. arXiv 2020, arXiv:2001.00179. [Google Scholar] [CrossRef]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin, Germany, 2014; pp. 740–755. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Jain, A.; Tompson, J.; Andriluka, M.; Taylor, G.W.; Bregler, C. Learning human pose estimation features with convolutional networks. arXiv 2013, arXiv:1312.7302. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4732. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative embedding: End-to-end learning for joint detection and grouping. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 2277–2287. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 700–708. [Google Scholar]
- Nguyen, T.T.; Nguyen, C.M.; Nguyen, D.T.; Nguyen, D.T.; Nahavandi, S. Deep learning for deepfakes creation and detection. arXiv 2019, arXiv:1909.11573. [Google Scholar]
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv 2018, arXiv:1811.00656. [Google Scholar]
- Mirsky, Y.; Lee, W. The creation and detection of deepfakes: A survey. ACM Comput. Surv. 2021, 54, 1–41. [Google Scholar] [CrossRef]
- Agarwal, S.; Farid, H.; Gu, Y.; He, M.; Nagano, K.; Li, H. Protecting World Leaders Against Deep Fakes. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 38–45. [Google Scholar]
- Vincent, J. Deepfake Detection Algorithms Will Never Be Enough. The Verge, 27 June 2019; Volume 27. [Google Scholar]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Zhang, X.; Karaman, S.; Chang, S.F. Detecting and simulating artifacts in gan fake images. In Proceedings of the 2019 IEEE International Workshop on Information Forensics and Security (WIFS), Delft, The Netherlands, 9–12 December 2019; pp. 1–6. [Google Scholar]
- Jain, A.; Majumdar, P.; Singh, R.; Vatsa, M. Detecting GANs and retouching based digital alterations via DAD-HCNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 672–673. [Google Scholar]
- Guarnera, L.; Giudice, O.; Battiato, S. Fighting Deepfake by Exposing the Convolutional Traces on Images. IEEE Access 2020, 8, 165085–165098. [Google Scholar] [CrossRef]
- Guarnera, L.; Giudice, O.; Battiato, S. Deepfake detection by analyzing convolutional traces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 666–667. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Dang, H.; Liu, F.; Stehouwer, J.; Liu, X.; Jain, A.K. On the detection of digital face manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5781–5790. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A Large-scale Challenging Dataset for DeepFake Forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 1 September 2020).
- Center, M. Miller Center Foundation Website. Available online: https://millercenter.org/ (accessed on 1 September 2020).
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef] [PubMed]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An empirical exploration of recurrent network architectures. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2342–2350. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wilson, A.C.; Roelofs, R.; Stern, M.; Srebro, N.; Recht, B. The marginal value of adaptive gradient methods in machine learning. arXiv 2017, arXiv:1705.08292. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Keskar, N.S.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tang, P.T.P. On large-batch training for deep learning: Generalization gap and sharp minima. arXiv 2016, arXiv:1609.04836. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Keypoint | Body Part | Keypoint | Body Part | Keypoint | Body Part |
|---|---|---|---|---|---|
| 0 | Nose | 1 | Neck | 2 | Right_Shoulder |
| 3 | Right_Elbow | 4 | Right_Wrist | 5 | Left_Shoulder |
| 6 | Left_Elbow | 7 | Left_Wrist | - | - |
| 14 | Right_Eye | 15 | Left_Eye | 16 | Right_Ear |
| 17 | Left_Ear |
| Person of Interest | Total Videos | Video Duration | Segments |
|---|---|---|---|
| (POI) | (Count) | (Hours) | (Count) |
| Real | |||
| George W. Bush (2001–2009) | 35 | 11.56 | 560 |
| Barack Obama (2009–2016) | 46 | 15.33 | 689 |
| Donald Trump (2017–2020) | 38 | 12.89 | 542 |
| Joe Biden (2021) | 4 | 1.9 | 32 |
| Fake | |||
| George W. Bush | 6 | 0.23 | 12 |
| Barack Obama | 23 | 0.36 | 54 |
| Donald Trump | 35 | 0.56 | 66 |
| Joe Biden | 4 | 0.10 | 8 |
| Input | Hidden | Hidden | Dropout | Output | Optimizer | Learning |
|---|---|---|---|---|---|---|
| Size | Size | Layers | Size | Rate Decay | ||
| 24 | 512 | 2 | 0.5 | 1 | ADAM | lr = 1e−2 |
| stepsize = 30 | ||||||
| gamma = 0.5 | ||||||
| Time | Weight | Gradient | Batch | Epoch | ||
| Step | decay | clipping | size | |||
| 150 | 1e−4 | 0.25 | 1 | 200 |
| Model A LSTM | Model B LSTM | Model C LSTM |
|---|---|---|
| 2 Hidden Layer | 2 Hidden Layer | 3 Hidden Layer |
| 512 Hidden Units | 256 Hidden Units | 128 Hidden Units |
| 94.39% | 91.24% | 86.62% |
| Model | Training | Validation | Testing |
|---|---|---|---|
| Accuracy | Accuracy | Accuracy | |
| VGG16 [47] | |||
| ResNet50 [28] | |||
| ResNet101 [28] | |||
| ResNet152 [28] | |||
| CNN (VGG16) + LSTM | |||
| Proposed LSTM |
| Model | Testing Accuracy |
|---|---|
| Li et al. [22] ResNet152 | |
| Proposed LSTM |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yasrab, R.; Jiang, W.; Riaz, A. Fighting Deepfakes Using Body Language Analysis. Forecasting 2021, 3, 303-321. https://doi.org/10.3390/forecast3020020
Yasrab R, Jiang W, Riaz A. Fighting Deepfakes Using Body Language Analysis. Forecasting. 2021; 3(2):303-321. https://doi.org/10.3390/forecast3020020
Chicago/Turabian StyleYasrab, Robail, Wanqi Jiang, and Adnan Riaz. 2021. "Fighting Deepfakes Using Body Language Analysis" Forecasting 3, no. 2: 303-321. https://doi.org/10.3390/forecast3020020
APA StyleYasrab, R., Jiang, W., & Riaz, A. (2021). Fighting Deepfakes Using Body Language Analysis. Forecasting, 3(2), 303-321. https://doi.org/10.3390/forecast3020020