
A Time-Varying Gerber Statistic: Application of a Novel Correlation Metric to Commodity Price Co-Movements †


Abstract
1. Introduction
2. Materials and Methods
2.1. Dynamic Models
2.1.1. Historical Simulation
2.1.2. Conditional Auto-Regressive Multithreshold Logit Models
2.1.3. Dynamic Conditional Correlation Models
2.1.4. Filtered Historical Simulation
2.1.5. The Time-Varying Gerber Correlation
3. Empirical Analysis
3.1. Data Description
3.2. In-Sample Analysis
3.3. Out-of-Sample Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ali, S.; Bouri, E.; Czudaj, R.L.; Shahzad, S.J.H. Revisiting the valuable roles of commodities for international stock markets. Resour. Policy 2020, 66, 101603. [Google Scholar] [CrossRef]
- Hamilton, J.D.; Wu, J.C. Effect Of Index-Fund Investing On Commodity Futures Prices. Int. Econ. Rev. 2015, 56, 187–205. [Google Scholar] [CrossRef]
- Henderson, B.J.; Pearson, N.D.; Wang, L. New Evidence on the Financialization of Commodity Markets. Rev. Financ. Stud. 2015, 28, 1285–1311. [Google Scholar] [CrossRef]
- Cheng, I.H.; Xiong, W. Financialization of Commodity Markets. Annu. Rev. Financ. Econ. 2014, 6, 419–441. [Google Scholar] [CrossRef]
- Tang, K.; Xiong, W. Index Investment and the Financialization of Commodities. Financ. Anal. J. 2012, 68, 54–74. [Google Scholar] [CrossRef]
- Algieri, B. Fast & furious: Do psychological and legal factors affect commodity price volatility? World Econ. 2021, 44, 980–1017. [Google Scholar] [CrossRef]
- Yuan, X.; Tang, J.; Wong, W.K.; Sriboonchitta, S. Modeling Co-Movement among Different Agricultural Commodity Markets: A Copula-GARCH Approach. Sustainability 2020, 12, 393. [Google Scholar] [CrossRef]
- Mensi, W.; Beljid, M.; Boubaker, A.; Managi, S. Correlations and volatility spillovers across commodity and stock markets: Linking energies, food, and gold. Econ. Model. 2013, 32, 15–22. [Google Scholar] [CrossRef]
- Baur, D.G. What Is Co-Movement? Technical Report 20759; EUR European Commission Joint Research Centre: Ispra, Italy, 2003. [Google Scholar]
- Tadasse, G.; Algieri, B.; Kalkuhl, M.; von Braun, J. Drivers and Triggers of International Food Price Spikes and Volatility. In Food Price Volatility and Its Implications for Food Security and Policy; Kalkuhl, M., von Braun, J., Torero, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 59–82. [Google Scholar] [CrossRef]
- Algieri, A.; Morrone, P.; Bova, S. Techno-Economic Analysis of Biofuel, Solar and Wind Multi-Source Small-Scale CHP Systems. Energies 2020, 13, 3002. [Google Scholar] [CrossRef]
- Brück, T.; d’Errico, M. Reprint of: Food security and violent conflict: Introduction to the special issue. World Dev. 2019, 119, 145–149. [Google Scholar] [CrossRef]
- Bellemare, M.F. Rising Food Prices, Food Price Volatility, and Social Unrest. Am. J. Agric. Econ. 2015, 97, 1–21. [Google Scholar] [CrossRef]
- Byrne, J.P.; Fazio, G.; Fiess, N. Primary commodity prices: Co-movements, common factors and fundamentals. J. Dev. Econ. 2013, 101, 16–26. [Google Scholar] [CrossRef]
- Umar, Z.; Zaremba, A.; Olson, D. Seven centuries of commodity co-movement: A wavelet analysis approach. Appl. Econ. Lett. 2020, 1–5. [Google Scholar] [CrossRef]
- Gerber, S.; Javid, B.; Markowitz, H.; Sargen, P.; Starer, D. The Gerber Statistic: A Robust Measure of Correlation; Technical Report; Hudson Bay Capital Management: New York, NY, USA, 2019. [Google Scholar]
- Zaremba, A.; Umar, Z.; Mikutowski, M. Commodity financialisation and price co-movement: Lessons from two centuries of evidence. Financ. Res. Lett. 2021, 38, 101492. [Google Scholar] [CrossRef]
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Taylor, J.W. Probabilistic forecasting of wind power ramp events using autoregressive logit models. Eur. J. Oper. Res. 2017, 259, 703–712. [Google Scholar] [CrossRef]
- Engle, R. Dynamic Conditional Correlation: A Simple Class of Multivariate Generalized Autoregressive Conditional Heteroskedasticity Models. J. Bus. Econ. Stat. 2002, 20, 339–350. [Google Scholar] [CrossRef]
- Dufour, J.M.; Valéry, P. Exact and asymptotic tests for possibly non-regular hypotheses on stochastic volatility models. J. Econ. 2009, 150, 193–206. [Google Scholar] [CrossRef][Green Version]
- Luger, R. Finite-sample bootstrap inference in GARCH models with heavy-tailed innovations. Comput. Stat. Data Anal. 2012, 56, 3198–3211. [Google Scholar] [CrossRef]
- Abdelkhalek, T.; Dufour, J.M. Statistical Inference for Computable General Equilibrium Models, with Application to A Model of the Moroccan Economy. Rev. Econ. Stat. 1998, 80, 520–534. [Google Scholar] [CrossRef]
- Engle, R.F. Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Vigne, S.A.; Lucey, B.M.; O’Connor, F.A.; Yarovaya, L. The financial economics of white precious metals—A survey. Int. Rev. Financ. Anal. 2017, 52, 292–308. [Google Scholar] [CrossRef]
- O’Connor, F.A.; Lucey, B.M.; Batten, J.A.; Baur, D.G. The financial economics of gold — A survey. Int. Rev. Financ. Anal. 2015, 41, 186–205. [Google Scholar] [CrossRef]
- Jaffe, J.F. Gold and Gold Stocks as Investments for Institutional Portfolios. Financ. Anal. J. 1989, 45, 53–59. [Google Scholar] [CrossRef]
- Erb, C.B.; Harvey, C.R. The Strategic and Tactical Value of Commodity Futures. Financ. Anal. J. 2006, 62, 69–97. [Google Scholar] [CrossRef]
- Caldara, D.; Cavallo, M.; Iacoviello, M. Oil price elasticities and oil price fluctuations. J. Monet. Econ. 2019, 103, 1–20. [Google Scholar] [CrossRef]
- Algieri, B.; Leccadito, A. Extreme price moves: An INGARCH approach to model coexceedances in commodity markets. Eur. Rev. Agric. Econ. 2020, jbaa030. [Google Scholar] [CrossRef]
- Taylor, J.W.; Yu, K. Using auto-regressive logit models to forecast the exceedance probability for financial risk management. J. R. Stat. Soc. Ser. (Stat. Soc.) 2016, 179, 1069–1092. [Google Scholar] [CrossRef]
- Gneiting, T.; Balabdaoui, F.; Raftery, A.E. Probabilistic forecasts, calibration and sharpness. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2007, 69, 243–268. [Google Scholar] [CrossRef]



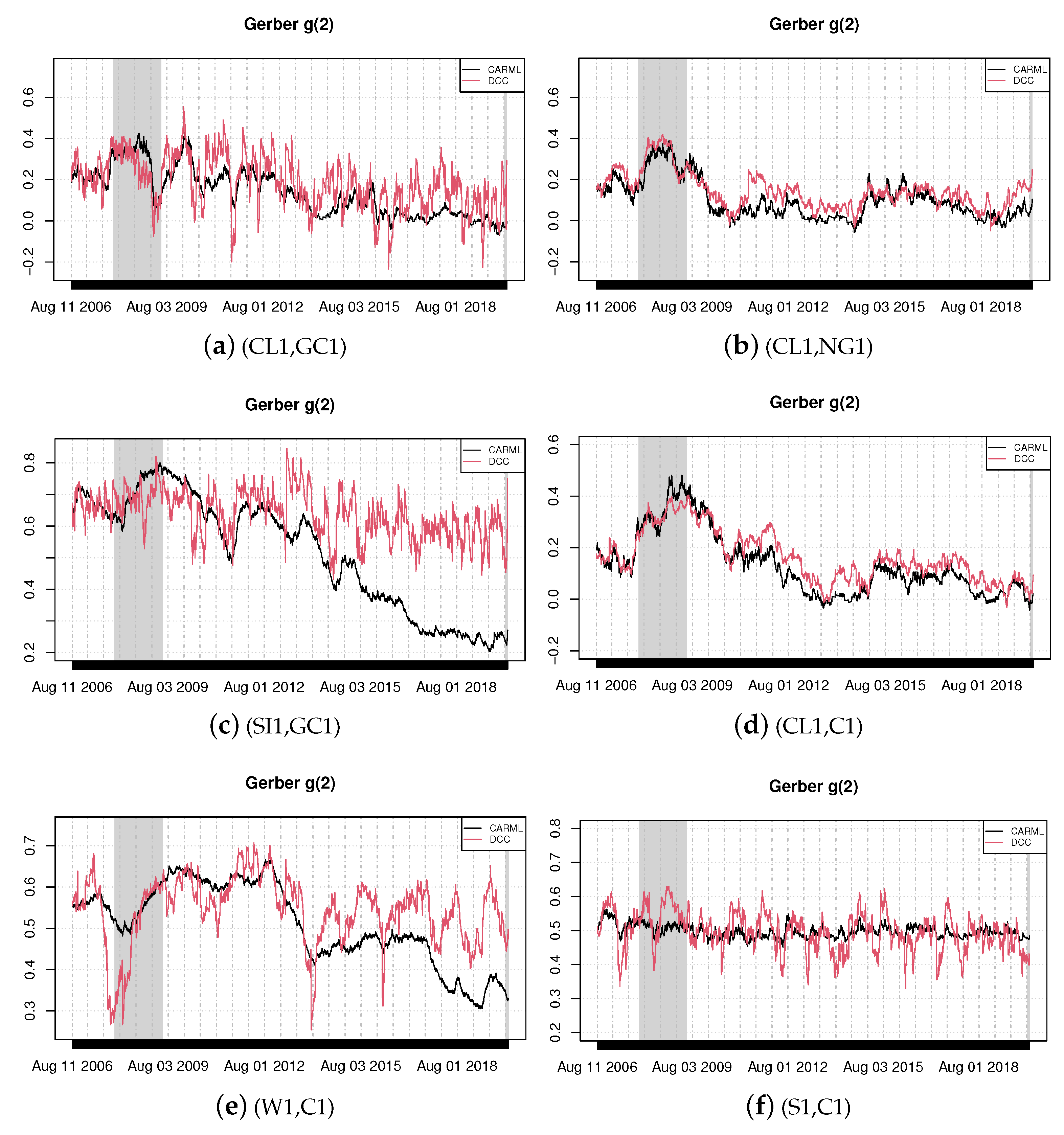{kind=link}
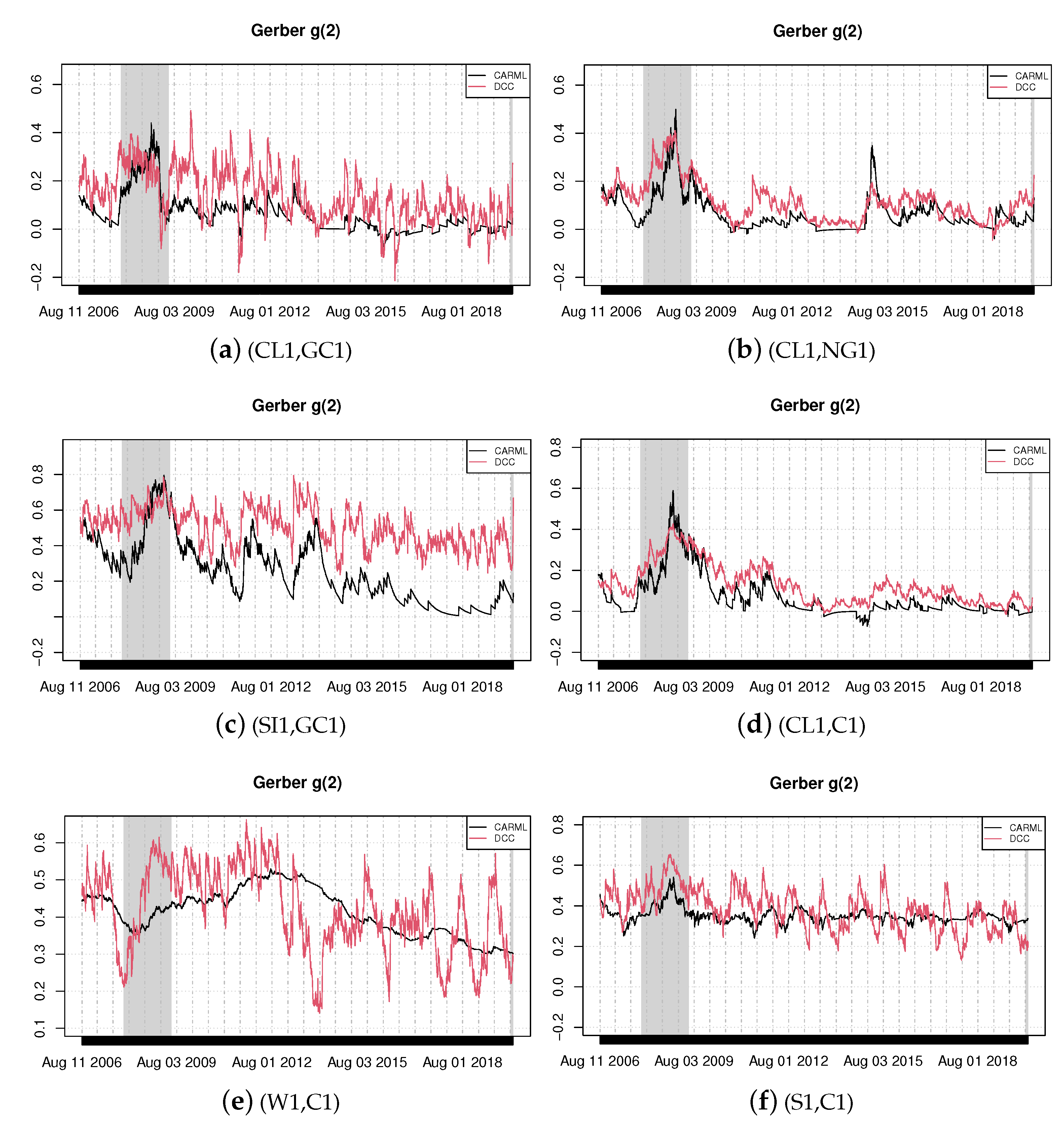{kind=link}
| Selected Commodities | |
|---|---|
| Ticker | Description |
| C1 Comdty | Generic 1st Corn No. 2 Yellow futures, US$ |
| S1 Comdty | Generic 1st Soybean No. 2 Yellow futures, US$ |
| W1 Comdty | Generic 1st Wheat futures, US$ |
| CL1 Comdty | WTI crude oil |
| NG1 Comdty | Natural Gas |
| GC1 Comdty | Gold |
| SI1 Comdty | Silver |
| Remaining Agricultural Commodities | |
| Ticker | Description |
| KC1 Comdty | Generic 1st Coffee futures contract |
| SB1 Comdty | Generic 1st Sugar No. 11 (raw) futures |
| RR1 Comdty | Generic 1st Rice futures |
| CC1 Comdty | Generic 1st Cocoa |
| Remaining Energy Commodities | |
| Ticker | Description |
| CO1 Comdty | Brent Oil |
| HO1 Comdty | Heating oil |
| Remaining Metals | |
| Ticker | Description |
| HG1 Comdty | Copper |
| Selected Commodities | |||||||
|---|---|---|---|---|---|---|---|
| C1 | S1 | W1 | CL1 | NG1 | GC1 | SI1 | |
| Min. | −0.081 | −0.073 | −0.098 | −0.119 | −0.186 | −0.098 | −0.195 |
| 1st Qu | −0.008 | −0.007 | −0.010 | −0.010 | −0.015 | −0.004 | −0.007 |
| Median | 0.000 | 0.000 | 0.000 | 0.000 | −0.001 | 0.001 | 0.001 |
| Mean | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 3rd Qu | 0.009 | 0.007 | 0.010 | 0.010 | 0.014 | 0.006 | 0.009 |
| Max. | 0.086 | 0.065 | 0.086 | 0.135 | 0.166 | 0.086 | 0.124 |
| Std. Dev. | 0.016 | 0.013 | 0.018 | 0.020 | 0.026 | 0.011 | 0.019 |
| Skewness | −0.043 | −0.252 | 0.034 | 0.030 | 0.141 | −0.475 | −0.916 |
| Kurtosis | 5.411 | 5.818 | 5.033 | 7.013 | 5.862 | 10.335 | 11.132 |
| JB stat. | 1214.252 | 1710.147 | 863.537 | 3360.445 | 1726.199 | 11,407.754 | 14,491.883 |
| JB pval. | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Q1 | 652.816 | 667.872 | 577.179 | 765.575 | 796.927 | 777.274 | 846.418 |
| Q5 | 961.155 | 1241.034 | 842.120 | 1436.187 | 1068.713 | 935.768 | 951.451 |
| Q1 pval. | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Q5 pval. | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LM1 | 5073.130 | 5761.032 | 4919.449 | 6467.057 | 4966.216 | 8230.659 | 7457.130 |
| LM5 | 1567.114 | 1661.710 | 1531.263 | 1845.515 | 1577.667 | 2625.688 | 2431.796 |
| LM1 pval. | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LM5 pval. | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Remaining Agricultural Commodities | Remaining Energy Commodities | Remaining Metals | |||||
| KC1 | SB1 | RR1 | CC1 | CO1 | HO1 | HG1 | |
| Min. | −0.111 | −0.124 | −0.062 | −0.096 | −0.103 | −0.098 | −0.116 |
| 1st Qu | −0.010 | −0.009 | −0.007 | −0.009 | −0.009 | −0.009 | −0.007 |
| Median | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Mean | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 3rd Qu | 0.010 | 0.009 | 0.007 | 0.009 | 0.009 | 0.009 | 0.008 |
| Max. | 0.110 | 0.087 | 0.054 | 0.082 | 0.133 | 0.103 | 0.117 |
| Std. Dev. | 0.017 | 0.018 | 0.012 | 0.016 | 0.019 | 0.017 | 0.016 |
| Skewness | 0.047 | -0.313 | −0.003 | −0.210 | 0.047 | 0.064 | −0.043 |
| Kurtosis | 5.104 | 6.087 | 4.298 | 5.472 | 7.267 | 6.115 | 7.703 |
| JB stat. | 925.756 | 2071.051 | 351.917 | 1312.606 | 3800.539 | 2028.498 | 4615.341 |
| JB pval. | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Q1 | 519.798 | 679.805 | 566.418 | 393.100 | 790.971 | 646.284 | 930.245 |
| Q5 | 578.844 | 779.116 | 691.245 | 462.829 | 1514.100 | 1230.272 | 1894.352 |
| Q1 pval. | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Q5 pval. | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LM1 | 5203.071 | 5511.624 | 3811.809 | 6051.277 | 6428.943 | 5983.694 | 6486.196 |
| LM5 | 1683.965 | 1809.333 | 1238.506 | 1962.049 | 1828.758 | 1717.633 | 1737.276 |
| LM1 pval. | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LM5 pval. | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| and | |||
|---|---|---|---|
| (GC1,CL1) | 3.245 | 1.229 | 1.152 |
| (CL1,NG1) | 3.534 | 1.805 | 0.870 |
| (GC1,SI1) | 0.461 | −0.512 | −0.270 |
| (CL1,C1) | 3.689 | 1.979 | 1.120 |
| (C1,W1) | 2.325 | 0.744 | −0.415 |
| (C1,S1) | 0.220 | 0.294 | −3.201 |
| and | |||
| (GC1,CL1) | 1.553 | 2.827 | 1.149 |
| (CL1,NG1) | 0.489 | 2.885 | −0.034 |
| (GC1,SI1) | 1.818 | 0.064 | −0.125 |
| (CL1,C1) | 3.418 | 4.242 | −0.373 |
| (C1,W1) | 2.833 | 1.425 | −0.079 |
| (C1,S1) | 0.526 | 0.873 | −2.625 |
| and | |||
|---|---|---|---|
| NUM | 89 | 90 | 84 |
| FREQ | 0.978 | 0.989 | 0.923 |
| and | |||
| NUM | 88 | 91 | 73 |
| FREQ | 0.967 | 1.000 | 0.802 |
| and | |||
| NUM | 89 | 91 | 51 |
| FREQ | 0.978 | 1.000 | 0.560 |
| and | |||
| NUM | 89 | 91 | 51 |
| FREQ | 0.978 | 1.000 | 0.560 |
| and | |||
|---|---|---|---|
| (GC1,CL1) | 3.280 | 2.568 | 2.125 |
| (CL1,NG1) | 3.489 | 2.885 | 0.897 |
| (GC1,SI1) | 1.270 | 0.064 | 0.970 |
| (CL1,C1) | 3.418 | 4.242 | 1.373 |
| (C1,W1) | 2.833 | 1.425 | 1.079 |
| (C1,S1) | 1.896 | 2.843 | 0.297 |
| and | |||
| (GC1,CL1) | 1.297 | 2.272 | 0.791 |
| (CL1,NG1) | 0.386 | 2.269 | −0.123 |
| (GC1,SI1) | 1.192 | 0.164 | −0.070 |
| (CL1,C1) | 2.942 | 3.722 | −0.373 |
| (C1,W1) | 2.138 | 2.675 | −0.079 |
| (C1,S1) | 0.397 | 0.973 | 0.059 |
| and | |||
|---|---|---|---|
| NUM | 90 | 90 | 87 |
| FREQ | 0.989 | 0.989 | 0.956 |
| and | |||
| NUM | 87 | 91 | 89 |
| FREQ | 0.956 | 1.000 | 0.978 |
| and | |||
| NUM | 86 | 91 | 63 |
| FREQ | 0.945 | 1.000 | 0.692 |
| and | |||
| NUM | 54 | 91 | 91 |
| FREQ | 0.593 | 1.000 | 1.000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Algieri, B.; Leccadito, A.; Toscano, P. A Time-Varying Gerber Statistic: Application of a Novel Correlation Metric to Commodity Price Co-Movements. Forecasting 2021, 3, 339-354. https://doi.org/10.3390/forecast3020022
Algieri B, Leccadito A, Toscano P. A Time-Varying Gerber Statistic: Application of a Novel Correlation Metric to Commodity Price Co-Movements. Forecasting. 2021; 3(2):339-354. https://doi.org/10.3390/forecast3020022
Chicago/Turabian StyleAlgieri, Bernardina, Arturo Leccadito, and Pietro Toscano. 2021. "A Time-Varying Gerber Statistic: Application of a Novel Correlation Metric to Commodity Price Co-Movements" Forecasting 3, no. 2: 339-354. https://doi.org/10.3390/forecast3020022
APA StyleAlgieri, B., Leccadito, A., & Toscano, P. (2021). A Time-Varying Gerber Statistic: Application of a Novel Correlation Metric to Commodity Price Co-Movements. Forecasting, 3(2), 339-354. https://doi.org/10.3390/forecast3020022