Load Forecasting in an Office Building with Different Data Structure and Learning Parameters




Abstract
1. Introduction
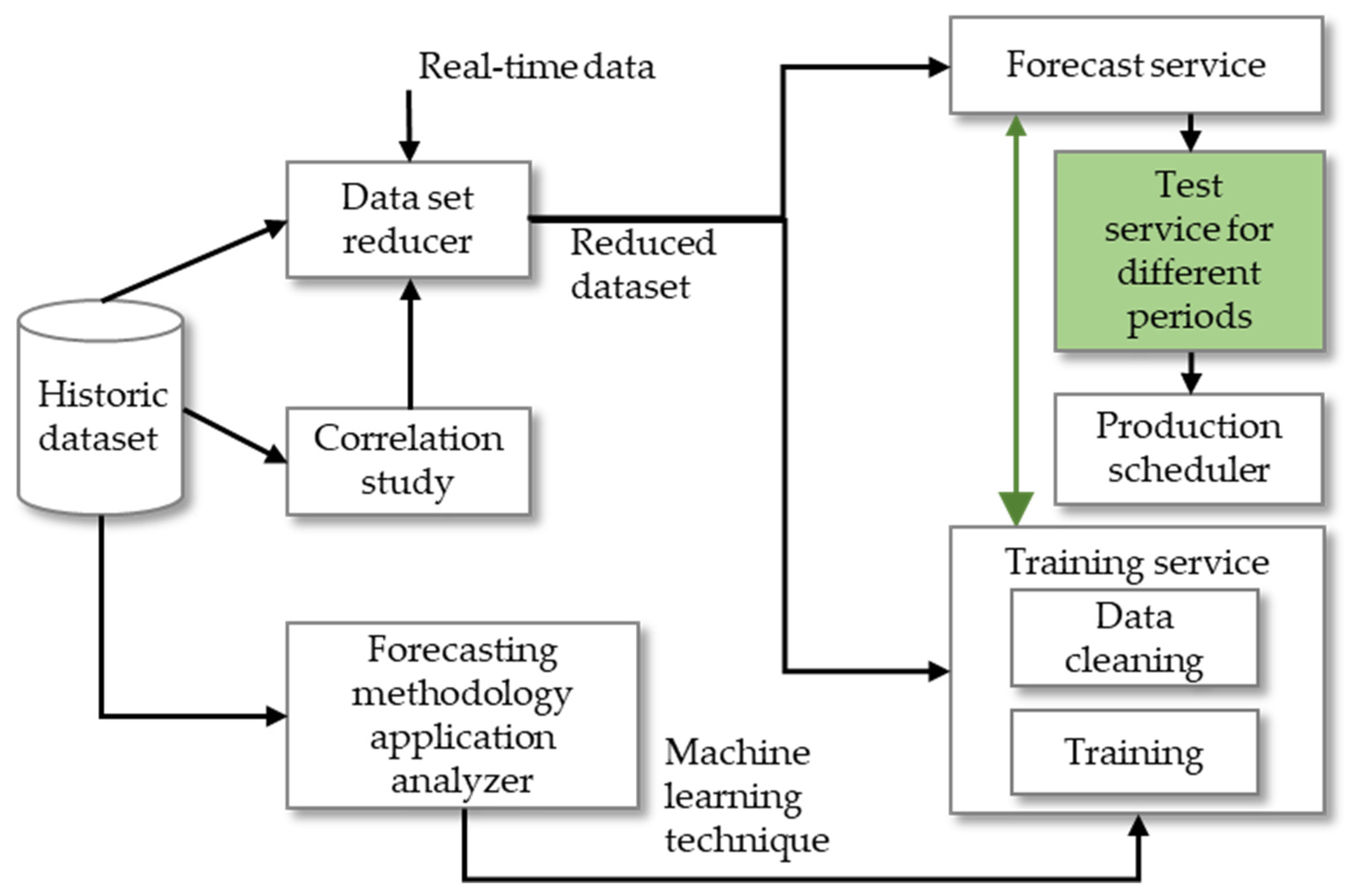
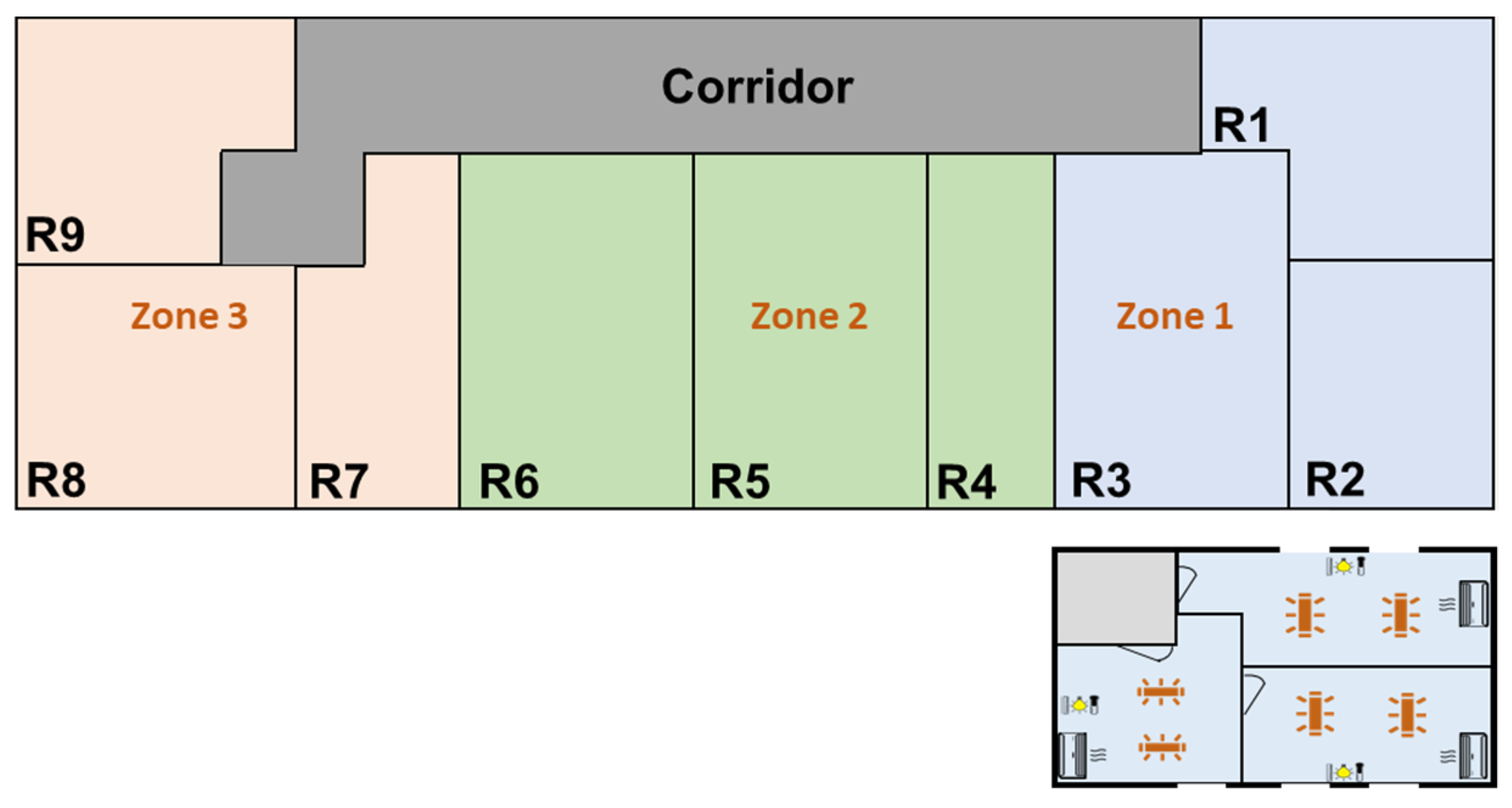
2. Materials and Methods
- A—average consumption in F;
- n—current moment;
- P—consumption;
- t—index of time;
- F—frame (time interval) used for calculation.
- S—standard deviation consumption in F;
- F—frame used for calculation.
- PF—forecast consumption;
- F—frame used for calculation;
- t—period.
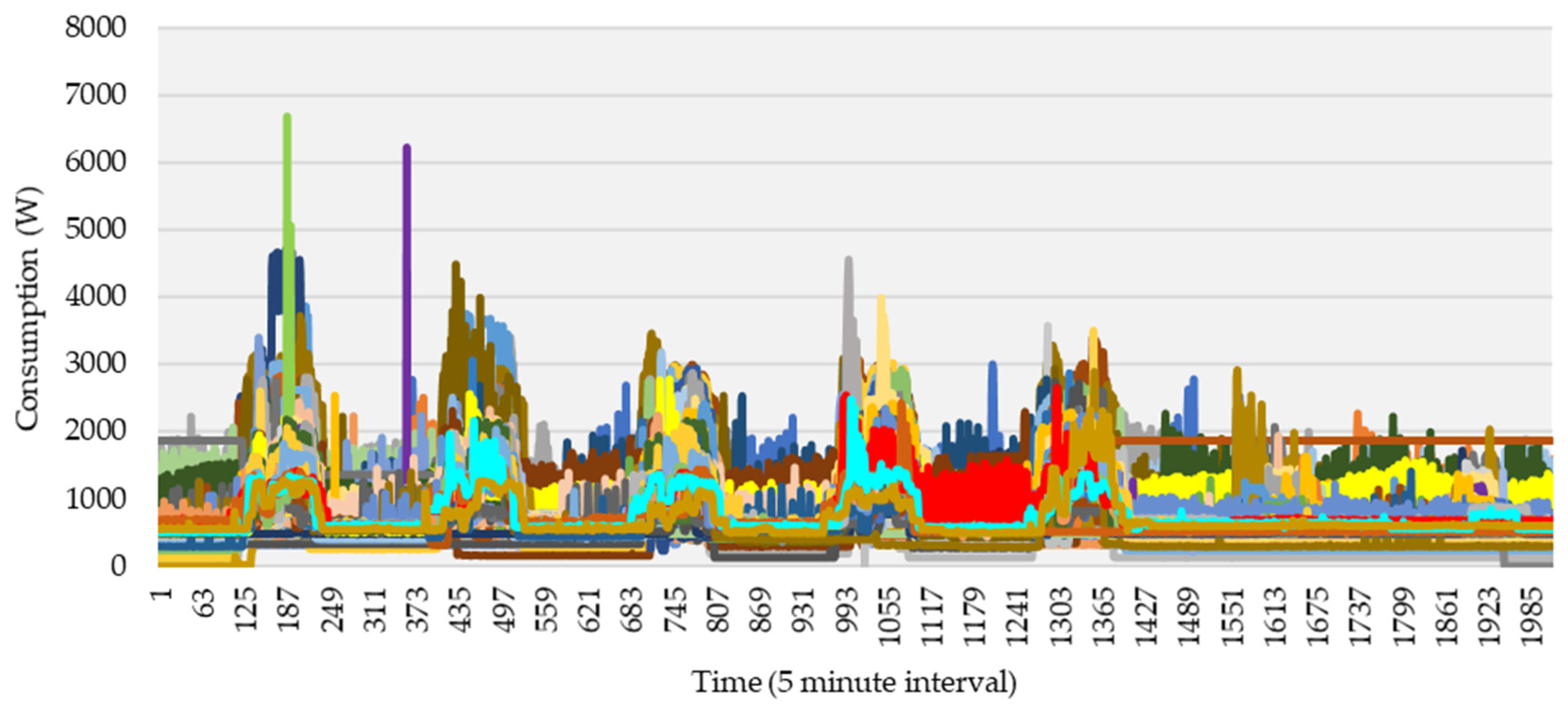
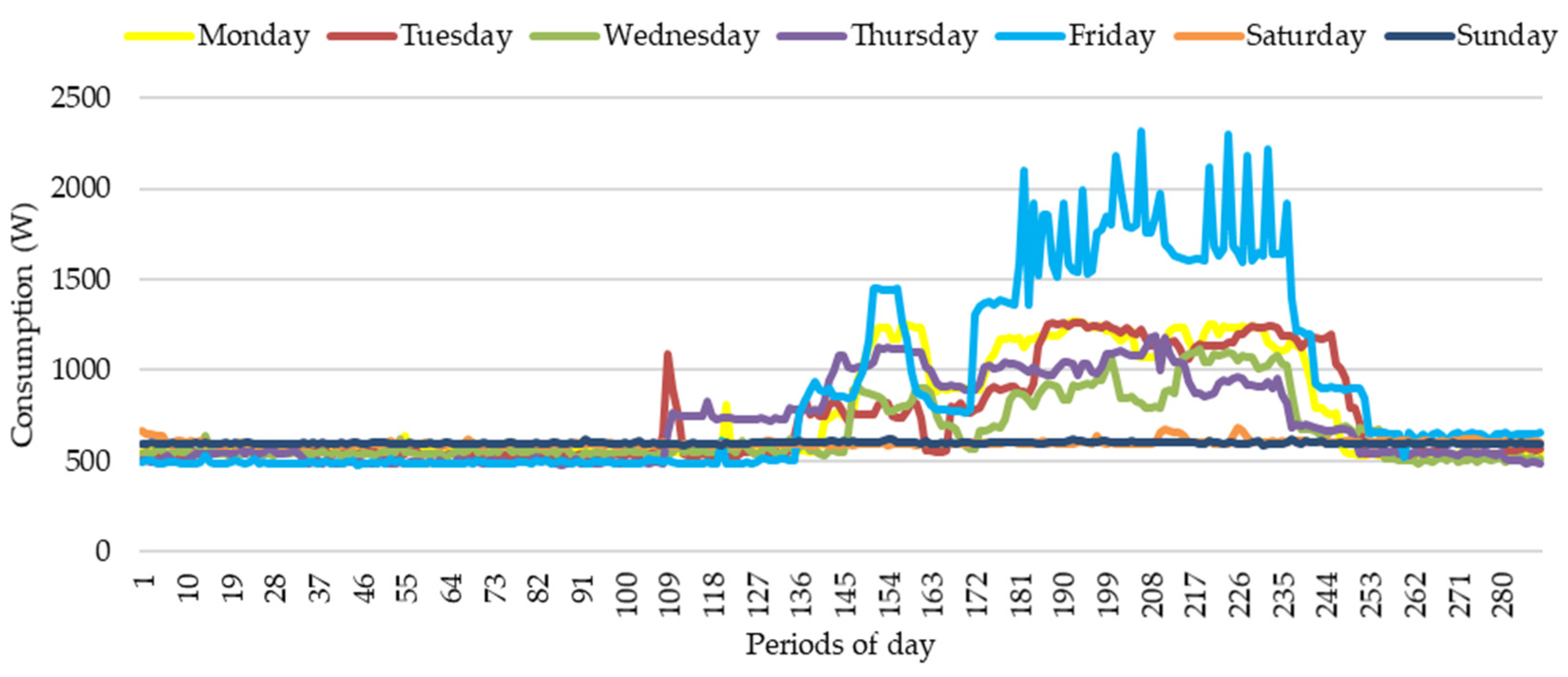
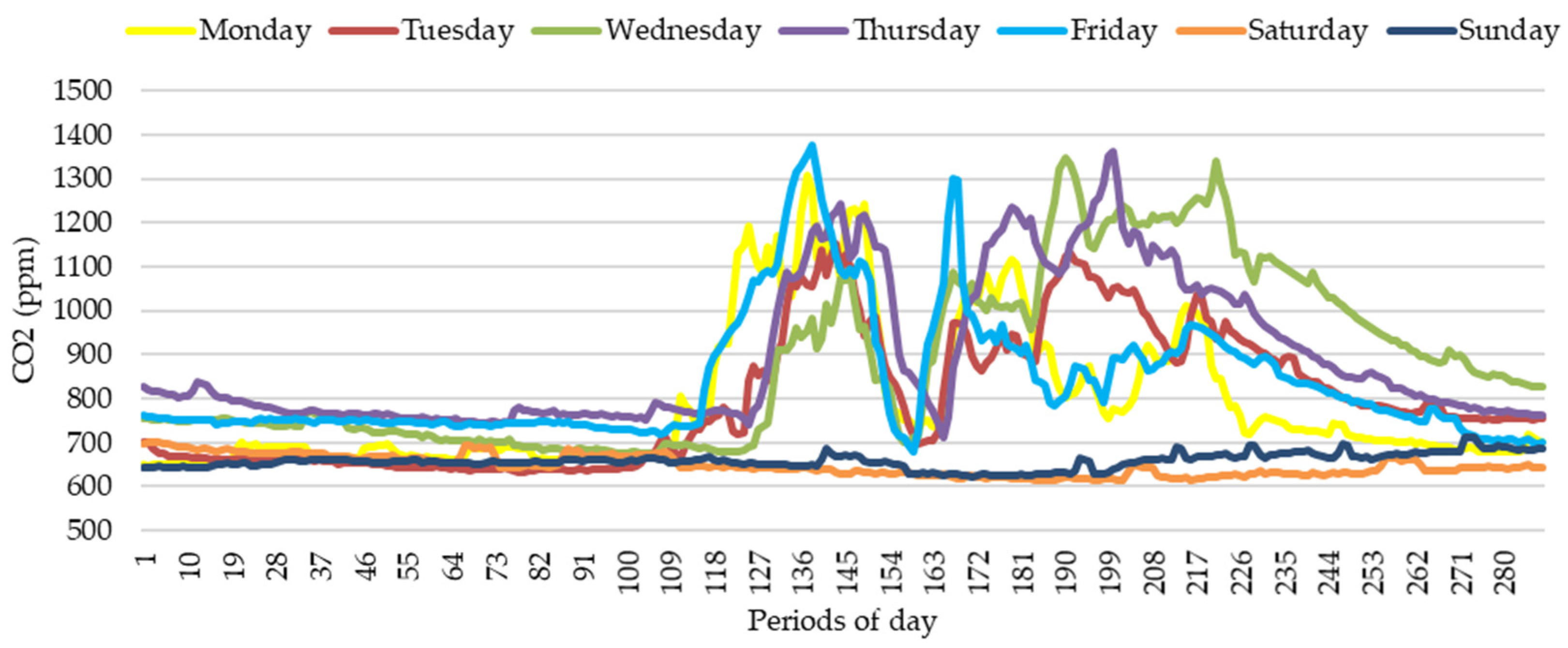
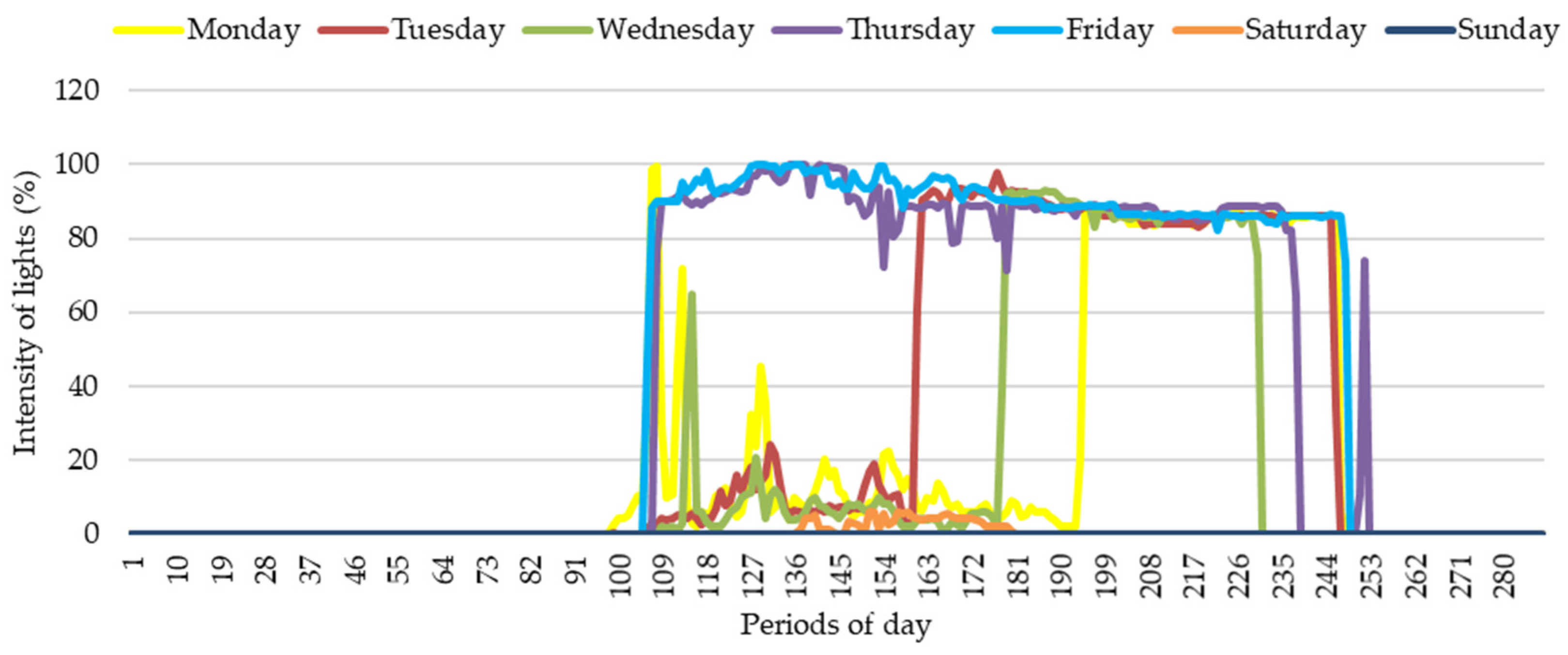
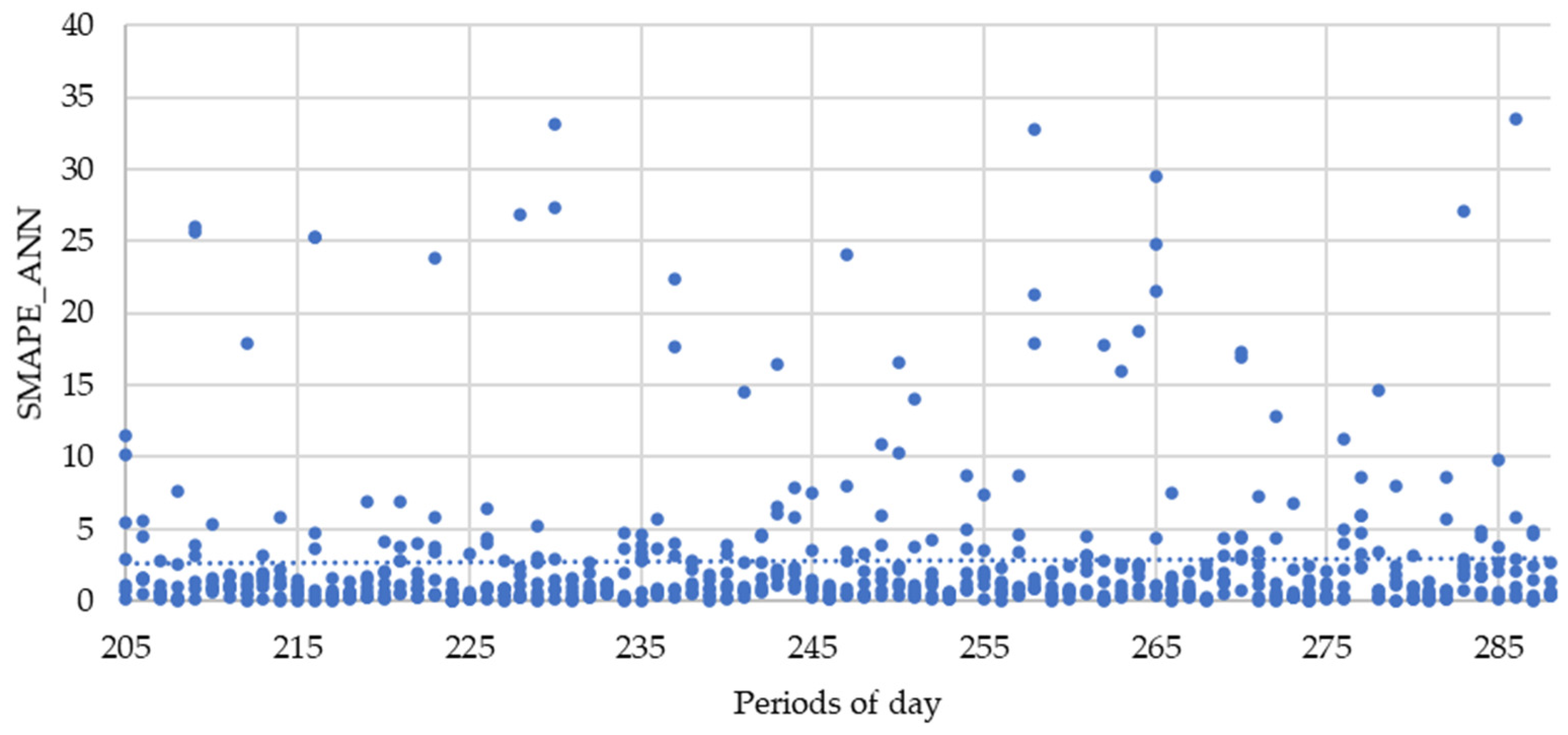
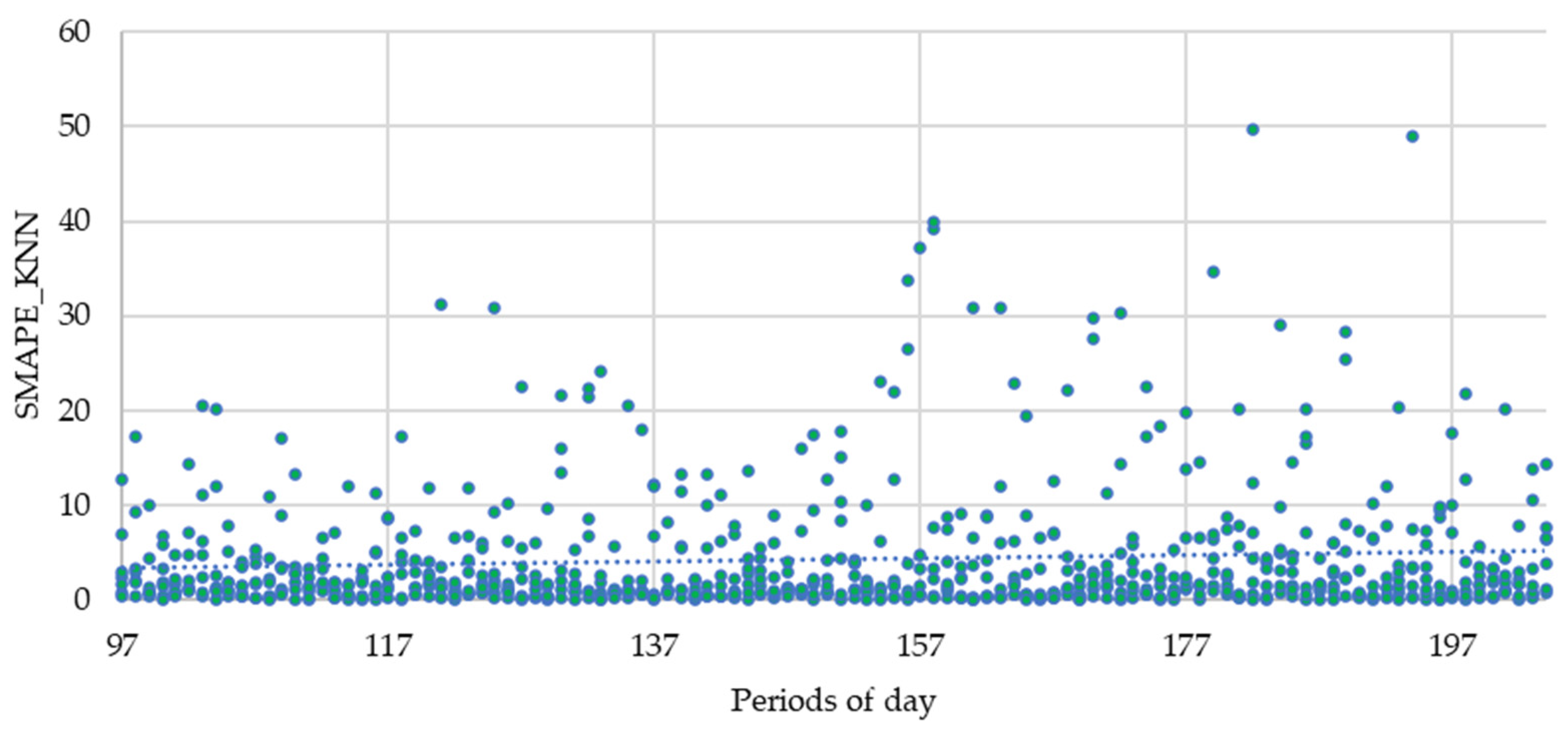
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A






References
- Ramos, D.; Teixeira, B.; Faria, P.; Gomes, L.; Abrishambaf, O.; Vale, Z. Use of Sensors and Analyzers Data for Load Forecasting: A Two Stage Approach. Sensors 2020, 20, 3524. [Google Scholar] [CrossRef]
- Bless, K.; Furong, L. Allocation of Emission Allowances to Effectively Reduce Emissions in Electricity Generation. In Proceedings of the 2009 IEEE Power & Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Rudnick, H. Environmental impact of power sector deregulation in Chile. In Proceedings of the 2002 IEEE Power Engineering Society Winter Meeting. Conference Proceedings (Cat. No.02CH37309), New York, NY, USA, 27–31 January 2002; Volume 1, p. 392. [Google Scholar] [CrossRef]
- Faria, P.; Vale, Z. A Demand Response Approach to Scheduling Constrained Load Shifting. Energies 2019, 12, 1752. [Google Scholar] [CrossRef]
- Pop, C.; Cioara, T.; Antal, M.; Anghel, I.; Salomie, I.; Bertoncini, M. Blockchain Based Decentralized Management of Demand Response Programs in Smart Energy Grids. Sensors 2018, 18, 162. [Google Scholar] [CrossRef] [PubMed]
- Faria, P.; Vale, Z. Demand response in electrical energy supply: An optimal real time pricing approach. Energy 2011, 36, 5374–5384. [Google Scholar] [CrossRef]
- Cao, Y.; Du, J.; Soleymanzadeh, E. Model predictive control of commercial buildings in demand response programs in the presence of thermal storage. J. Clean. Prod. 2019, 218, 315–327. [Google Scholar] [CrossRef]
- Law, Y.; Alpcan, T.; Lee, V.; Lo, A. Demand Response Architectures and Load Management Algorithms for Energy-Efficient Power Grids: A Survey. In Proceedings of the 2012 7th International Conference on Knowledge, Information and Creativity Support Systems, KICSS 2012, Melbourne, Australia, 8–10 November 2012; pp. 134–141. [Google Scholar] [CrossRef]
- Abrishambaf, O.; Faria, P.; Vale, Z. Application of an optimization-based curtailment service provider in real-time simulation. Energy Inform. 2018, 1, 1–17. [Google Scholar] [CrossRef]
- Marzband, M.; Ghazimirsaeid, S.S.; Uppal, H.; Fernando, T. A real-time evaluation of energy management systems for smart hybrid home Microgrids. Electr. Power Syst. Res. 2017, 143, 624–633. [Google Scholar] [CrossRef]
- Allen, J.; Snitkin, E.; Nathan, P.; Hauser, A. Forest and Trees: Exploring Bacterial Virulence with Genome-wide Association Studies and Machine Learning. Trends Microbiol. 2021. [Google Scholar] [CrossRef] [PubMed]
- Kilincer, I.; Ertam, F.; Sengur, A. Machine Learning Methods for Cyber Security Intrusion Detection: Datasets and Comparative Study. Comput. Netw. 2021, 188, 107840. [Google Scholar] [CrossRef]
- Trivedi, S. A study on credit scoring modeling with different feature selection and machine learning approaches. Technol. Soc. 2020, 63, 101413. [Google Scholar] [CrossRef]
- Merghadi, A.; Yunus, A.; Dou, J.; Whiteley, J.; ThaiPham, B.; Bui, D.; Avtar, R.; Abderrahmane, B. Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance. Earth Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Jozi, A.; Ramos, D.; Gomes, L.; Faria, P.; Pinto, T.; Vale, Z. Demonstration of an Energy Consumption Forecasting System for Energy Management in Buildings. In Progress in Artificial Intelligence, EPIA 2019, Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; p. 11804. [Google Scholar]
- Chen, G.H.; Shah, D. Explaining the success of nearest neighbor methods in prediction. Found. Trends Mach. Learn. 2018, 10, 337–588. [Google Scholar] [CrossRef]
- Matsumoto, T.; Kitamura, S.; Ueki, Y.; Matsui, T. Short-term load forecasting by artificial neural networks using individual and collective data of preceding years. In Proceedings of the Second International Forum on Applications of Neural Networks to Power Systems, Yokohama, Japan, 19–22 April 1993; pp. 245–250. [Google Scholar] [CrossRef]
- Barrash, S.; Shen, Y.; Giannakis, G.B. Scalable and Adaptive KNN for Regression Over Graphs. In Proceedings of the 2019 IEEE 8th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), Le Gosier, Guadeloupe, 15–18 December 2019; pp. 241–245. [Google Scholar]
- Liu, S.; Zhou, F. On stock prediction based on KNN-ANN algorithm. In Proceedings of the 2010 IEEE Fifth International Conference on Bio-Inspired Computing: Theories and Applications (BIC-TA), Changsha, China, 23–26 September 2010; pp. 310–312. [Google Scholar]
- Xie, J.; Liu, B.; Lyu, X.; Hong, T.; Basterfield, D. Combining load forecasts from independent experts. In Proceedings of the 2015 North American Power Symposium (NAPS), Charlotte, NC, USA, 4–6 October 2015; pp. 1–5. [Google Scholar]
- Imdad, U.; Ahmad, W.; Asif, M.; Ishtiaq, A. Classification of students results using KNN and ANN. In Proceedings of the 2017 13th International Conference on Emerging Technologies (ICET), Islamabad, Pakistan, 27–28 December 2017; pp. 1–6. [Google Scholar]
- González-Vidal, A.; Jiménez, F.; Gómez-Skarmeta, A.F. A methodology for energy multivariate time series forecasting in smart buildings based on feature selection. Energy Build 2019, 196, 71–82. [Google Scholar] [CrossRef]
- Ahmad, T.; Zhang, H.; Yan, B. A review on renewable energy and electricity requirement forecasting models for smart grid and buildings. Sustain. Cities Soc. 2020, 55, 102052. [Google Scholar] [CrossRef]
- Ahmad, T.; Huanxin, C.; Zhang, D.; Zhang, H. Smart energy forecasting strategy with four machine learning models for climate-sensitive and non-climate sensitive conditions. Energy 2020, 198, 117283. [Google Scholar] [CrossRef]
- Bourdeau, M.; Zhai, X. qiang, Nefzaoui, E.; Guo, X.; Chatellier, P. Modeling and forecasting building energy consumption: A review of data-driven techniques. Sustain. Cities Soc. 2019, 48, 101533. [Google Scholar] [CrossRef]
- Yaïci, W.; Krishnamurthy, K.; Entchev, E.; Longo, M. Internet of Things for Power and Energy Systems Applications in Buildings: An Overview. In Proceedings of the 2020 IEEE International Conference on Environment and Electrical Engineering and 2020 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Madrid, Spain, 9–12 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Marinakis, V.; Doukas, H. An Advanced IoT-based System for Intelligent Energy Management in Buildings. Sensors 2018, 18, 610. [Google Scholar] [CrossRef] [PubMed]
- Jayasuriya, D.; Rankin, M.; Jones, T.; Hoog, J.; Thomas, D.; Mareels, I. Modeling and validation of an unbalanced LV network using Smart Meter and SCADA inputs. In Proceedings of the IEEE 2013 Tencon—Spring, Sydney, NSW, Australia, 17–19 April 2013; pp. 386–390. [Google Scholar] [CrossRef]
- Gomes, L.; Sousa, F.; Vale, Z. An Intelligent Smart Plug with Shared Knowledge Capabilities. Sensors 2018, 18, 3961. [Google Scholar] [CrossRef] [PubMed]
- Shah, I.; Iftikhar, H.; Ali, S. Modeling and Forecasting Medium-Term Electricity Consumption Using Component Estimation Technique. Forecasting 2020, 2, 163–179. [Google Scholar] [CrossRef]
- Nespoli, A.; Ogliari, E.; Pretto, S.; Gavazzeni, M.; Vigani, S.; Paccanelli, F. Electrical Load Forecast by Means of LSTM: The Impact of Data Quality. Forecasting 2021, 3, 91–101. [Google Scholar] [CrossRef]
- Keras. Available online: https://www.tensorflow.org/guide/keras (accessed on 4 May 2020).
- K-Neighbors. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsRegressor.html (accessed on 4 May 2020).
- Leva, S. Editorial for Special Issue: “Feature Papers of Forecasting”. Forecasting 2021, 3, 135–137. [Google Scholar] [CrossRef]
- Faria, P.; Vale, Z.; Baptista, J. Constrained consumption shifting management in the distributed energy resources scheduling considering demand response. Energy Convers. Manag. 2015, 93, 309–320. [Google Scholar] [CrossRef]
- Vale, Z.; Morais, H.; Faria, P.; Ramos, C. Distribution system operation supported by contextual energy resource management based on intelligent SCADA. Renew. Energy 2013, 52, 143–153. [Google Scholar] [CrossRef]
- Armstrong, J.S. Long-Range Forecasting from Crystal Ball to Computer; Wiley: Hoboken, NJ, USA, 1985. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
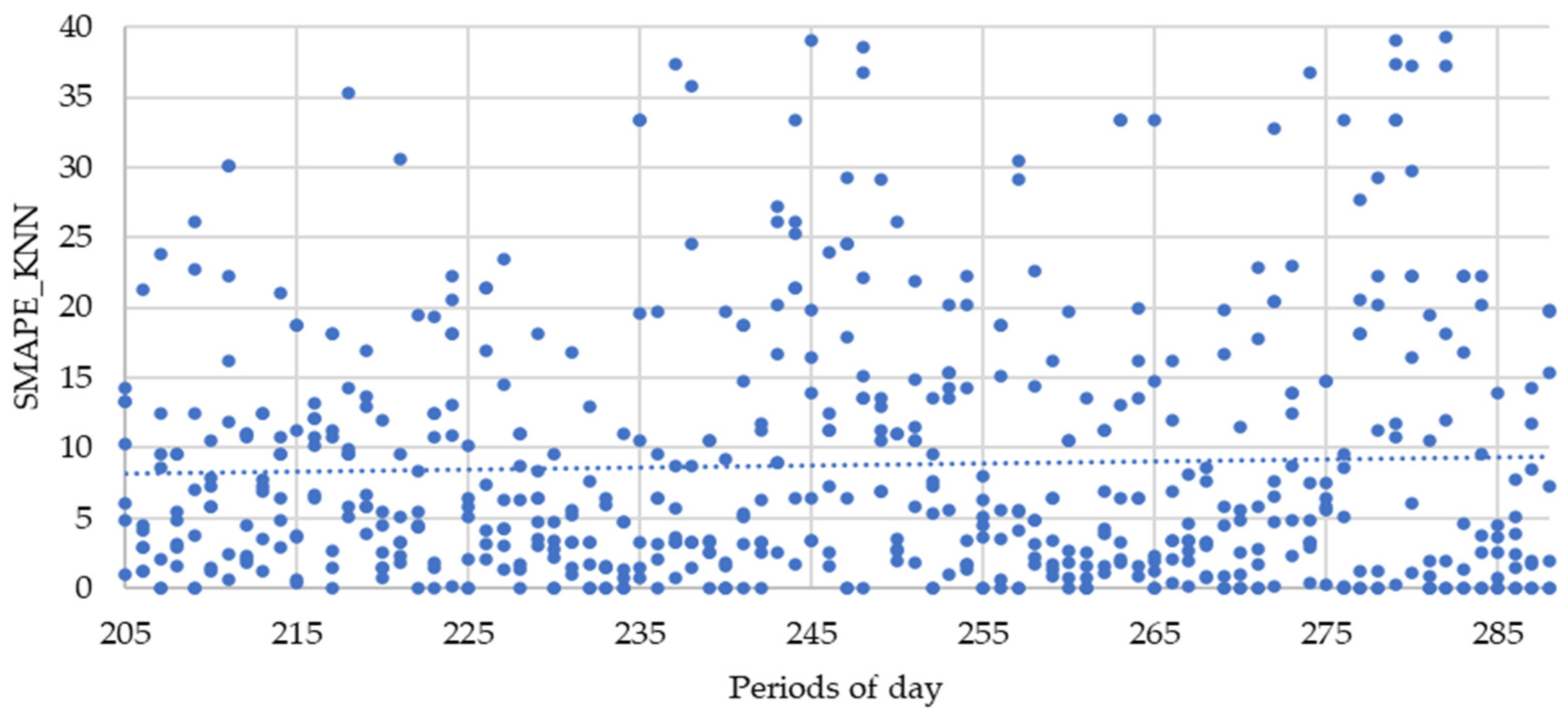{kind=link}
| Learn. Rate | # Neurons | Clipping Ratio | Epochs | Early Stopping | Validation Split | Days of the Week | SMAPE_ANN (Entries) | SMAPE_KNN (Entries) | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 50 | 100 | 10 | 50 | 100 | |||||||
| 0.001 | 32 | 5 | 500 | 20 | 0.2 | – | 2.77 * | 2.75 | 4.14 | 3.60 *** | 5.27 | 7.57 |
| 0.001 | 32 | 5 | 500 | 20 | 0.2 | x | 3.37 | 2.73 | 5.83 | 3.61 | 5.27 | 7.57 |
| 0.001 | 32 | 6 | 200 | 10 | 0.3 | – | 2.75 | 5.75 | 3.29 | 3.60 | 5.27 | 7.57 |
| 0.001 | 32 | 6 | 200 | 10 | 0.3 | x | 2.53 ** | 3.63 | 5.24 | 3.61 | 5.27 | 7.57 |
| 0.001 | 128 | 5 | 500 | 20 | 0.2 | – | 3.63 | 3.52 | 5.97 | 3.60 | 5.27 | 7.57 |
| 0.001 | 128 | 5 | 500 | 20 | 0.2 | x | 2.56 | 2.72 | 3.72 | 3.61 | 5.27 | 7.57 |
| 0.001 | 128 | 6 | 200 | 10 | 0.3 | – | 4.17 | 3.07 | 3.98 | 3.60 | 5.27 | 7.57 |
| 0.001 | 128 | 6 | 200 | 10 | 0.3 | x | 3.38 | 3.10 | 3.44 | 3.61 | 5.27 | 7.57 |
| 0.005 | 32 | 5 | 500 | 20 | 0.2 | – | 6.26 | 3.97 | 5.41 | 3.60 | 5.27 | 7.57 |
| 0.005 | 32 | 5 | 500 | 20 | 0.2 | x | 2.78 | 8.64 | 5.29 | 3.61 | 5.27 | 7.57 |
| 0.005 | 32 | 6 | 200 | 10 | 0.3 | – | 5.31 | 6.42 | 7.76 | 3.60 | 5.27 | 7.57 |
| 0.005 | 32 | 6 | 200 | 10 | 0.3 | x | 3.66 | 2.74 | 6.94 | 3.61 | 5.27 | 7.57 |
| 0.005 | 128 | 5 | 500 | 20 | 0.2 | – | 4.31 | 4.66 | 3.99 | 3.60 | 5.27 | 7.57 |
| 0.005 | 128 | 5 | 500 | 20 | 0.2 | x | 4.04 | 4.21 | 6.74 | 3.61 | 5.27 | 7.57 |
| 0.005 | 128 | 6 | 200 | 10 | 0.3 | – | 4.26 | 4.24 | 8.11 | 3.60 | 5.27 | 7.57 |
| 0.005 | 128 | 6 | 200 | 10 | 0.3 | x | 6.36 | 5.06 | 7.91 | 3.61 | 5.27 | 7.57 |
| 0.005 | 64 | 5 | 500 | 20 | 0.2 | – | 5.10 | 4.52 | 5.64 | 3.60 | 5.27 | 7.57 |
| 0.005 | 64 | 5 | 500 | 20 | 0.2 | X | 3.03 | 3.44 | 5.94 | 3.61 | 5.27 | 7.57 |
| 0.005 | 64 | 6 | 200 | 10 | 0.3 | – | 5.40 | 7.00 | 6.48 | 3.60 | 5.27 | 7.57 |
| 0.005 | 64 | 6 | 200 | 10 | 0.3 | x | 3.49 | 4.79 | 11.38 | 3.61 | 5.27 | 7.57 |
| Method | Full Period | Monday | Tuesday | Wednesday | Thursday | Friday | Saturday | Sunday |
|---|---|---|---|---|---|---|---|---|
| ANN | 2.69 | 2.61 | 3.04 | 3.45 | 2.62 | 5.16 | 1.13 | 0.81 |
| KNN | 3.95 | 3.41 | 4.94 | 4.67 | 5.52 | 6.85 | 1.38 | 0.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramos, D.; Khorram, M.; Faria, P.; Vale, Z. Load Forecasting in an Office Building with Different Data Structure and Learning Parameters. Forecasting 2021, 3, 242-255. https://doi.org/10.3390/forecast3010015
Ramos D, Khorram M, Faria P, Vale Z. Load Forecasting in an Office Building with Different Data Structure and Learning Parameters. Forecasting. 2021; 3(1):242-255. https://doi.org/10.3390/forecast3010015
Chicago/Turabian StyleRamos, Daniel, Mahsa Khorram, Pedro Faria, and Zita Vale. 2021. "Load Forecasting in an Office Building with Different Data Structure and Learning Parameters" Forecasting 3, no. 1: 242-255. https://doi.org/10.3390/forecast3010015
APA StyleRamos, D., Khorram, M., Faria, P., & Vale, Z. (2021). Load Forecasting in an Office Building with Different Data Structure and Learning Parameters. Forecasting, 3(1), 242-255. https://doi.org/10.3390/forecast3010015