Robust Non-Parametric Mortality and Fertility Modelling and Forecasting: Gaussian Process Regression Approaches



Abstract
1. Introduction
2. Theoretical Background of Gaussian Process Regression
Gaussian Process Regression
3. Methodology
3.1. Gaussian Process Regression (GPR) Model for Mortality and Fertility Modelling and Forecasting
3.1.1. Specified Gaussian Process Prior Mean Function
3.1.2. Specified Gaussian Process Prior Covariance Function
3.1.3. Likelihood Function of the Proposed GPR Model
3.1.4. Out-of-Sample Forecasts and Prediction Intervals of the Proposed GPR Model
4. Applications
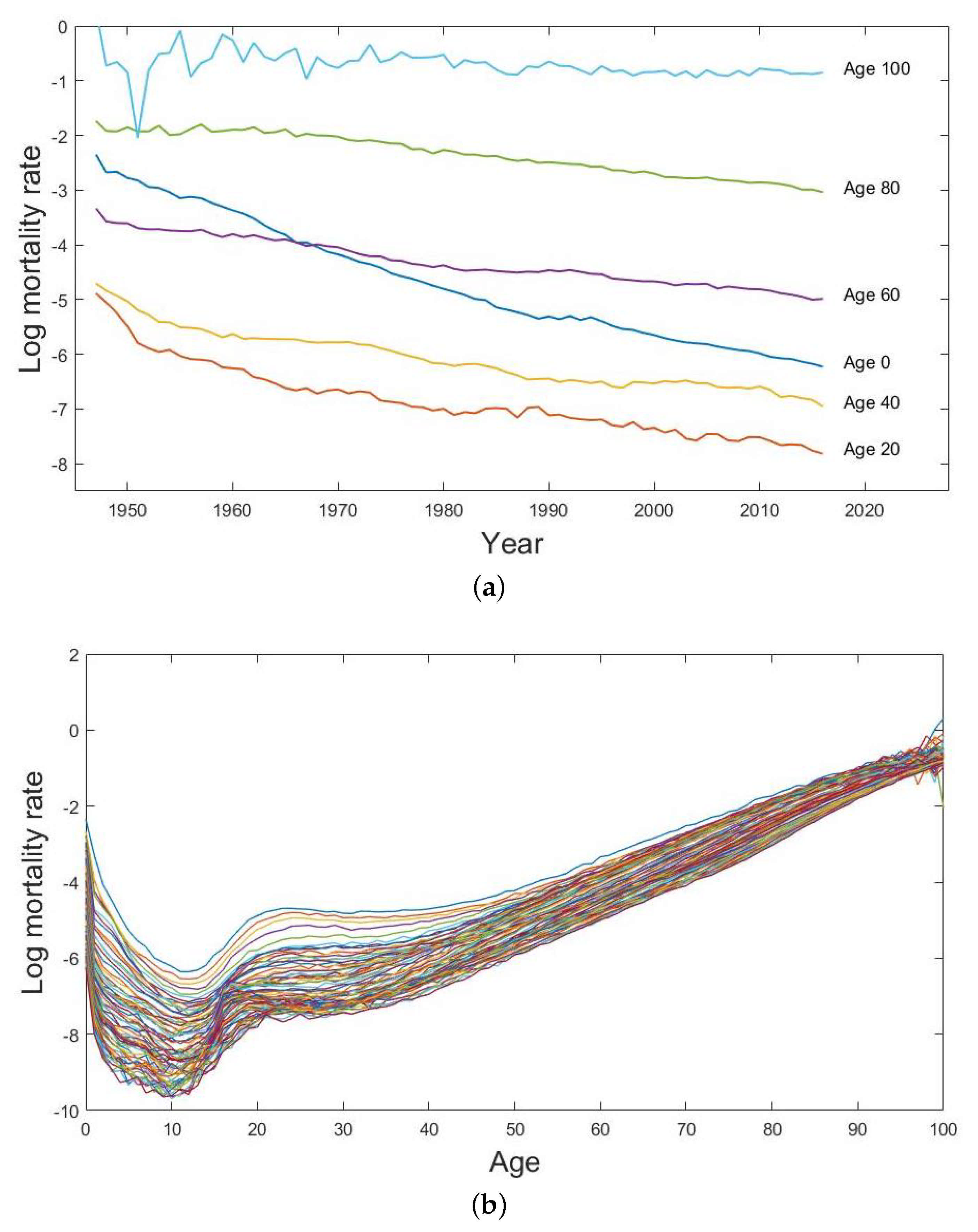
4.1. Male Mortality Data
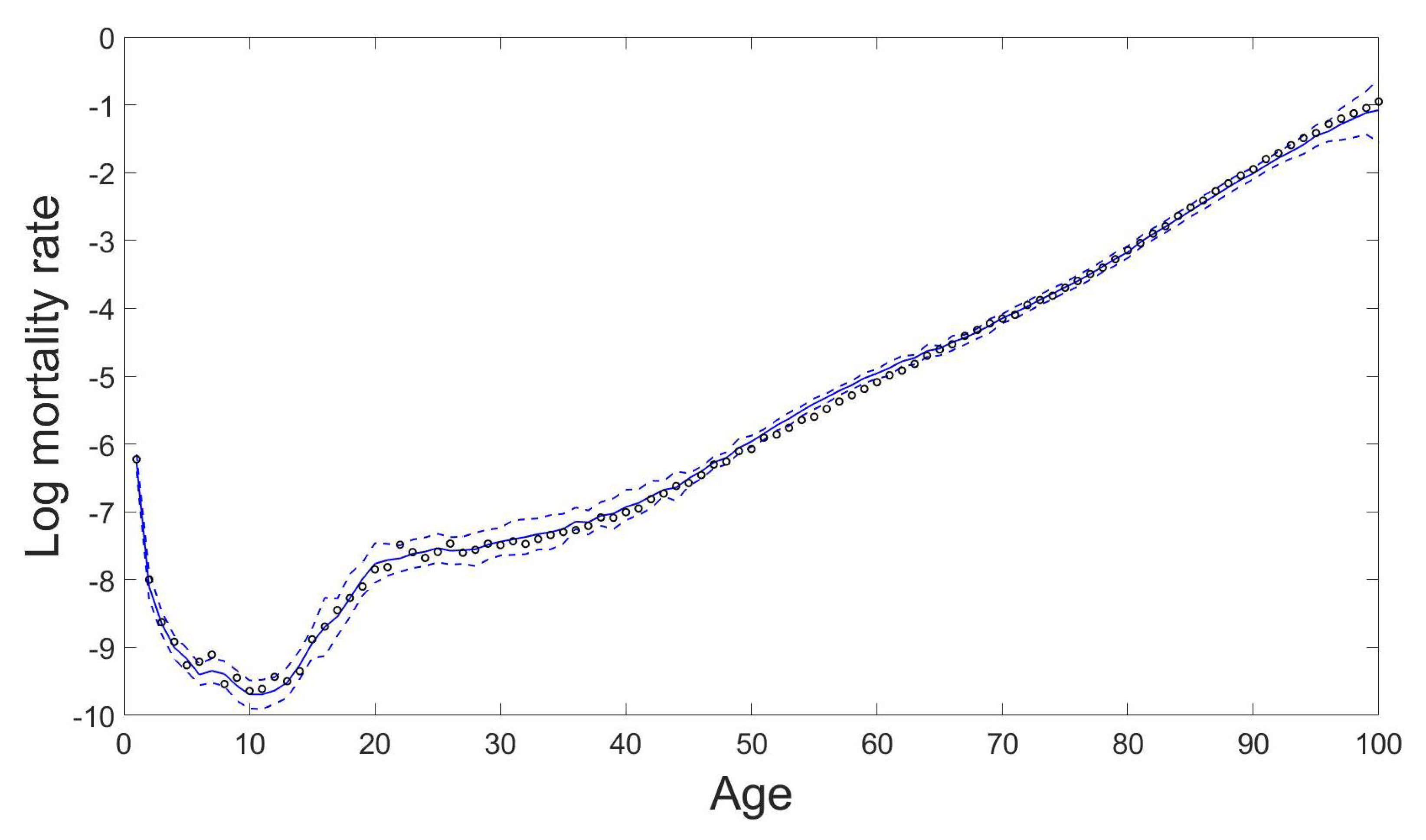
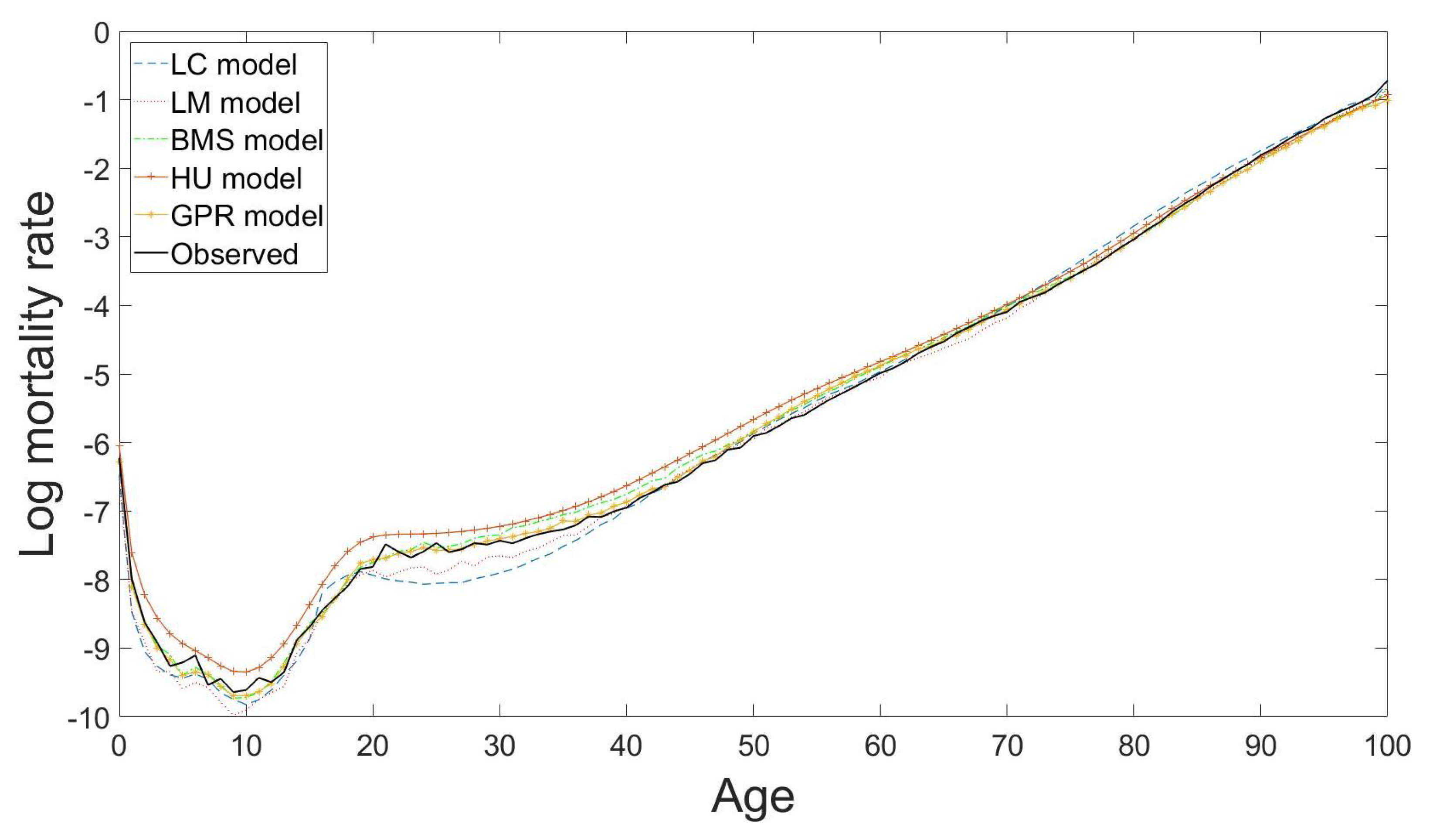
4.2. Mortality Modelling and Forecasting
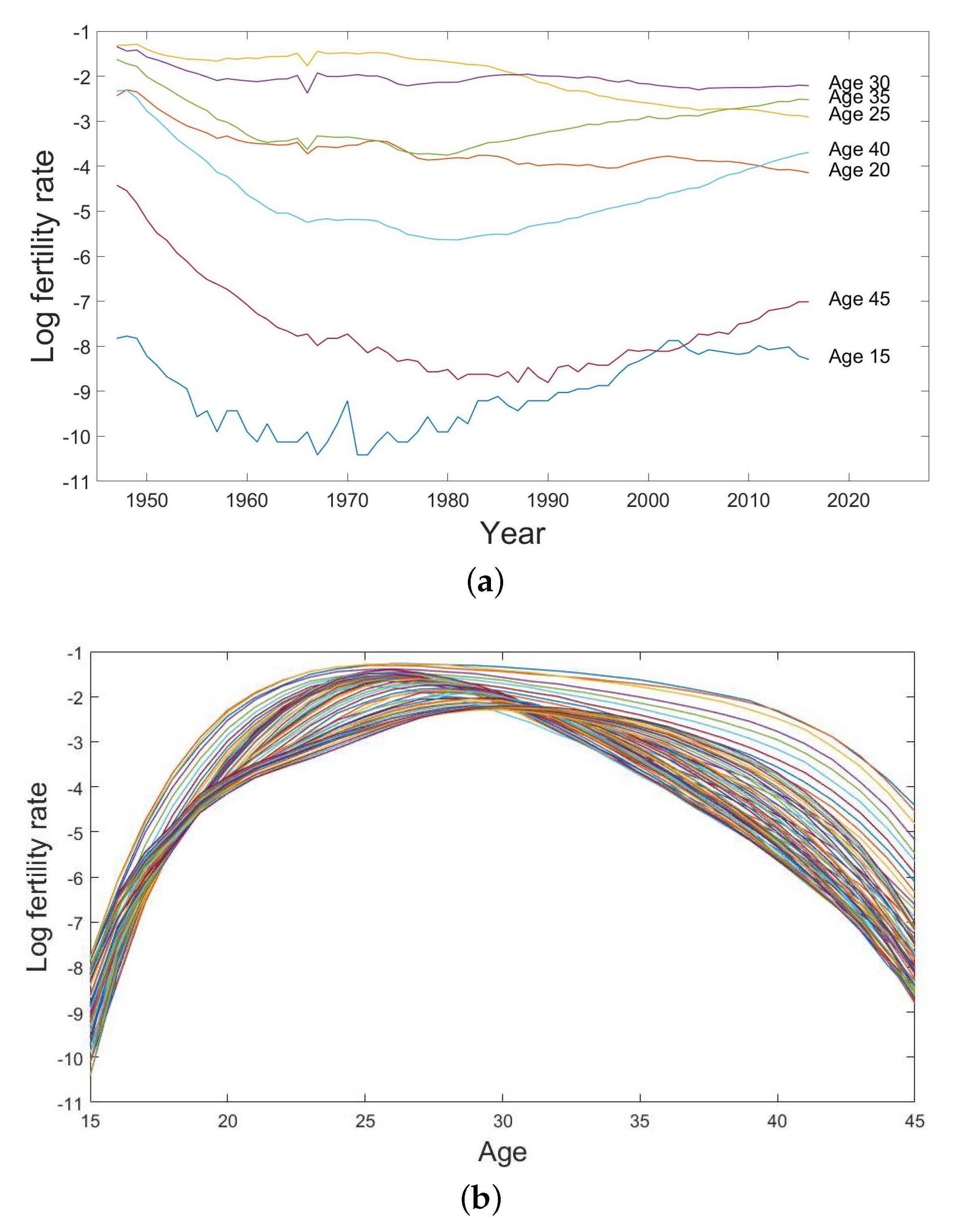
4.3. Fertility Data
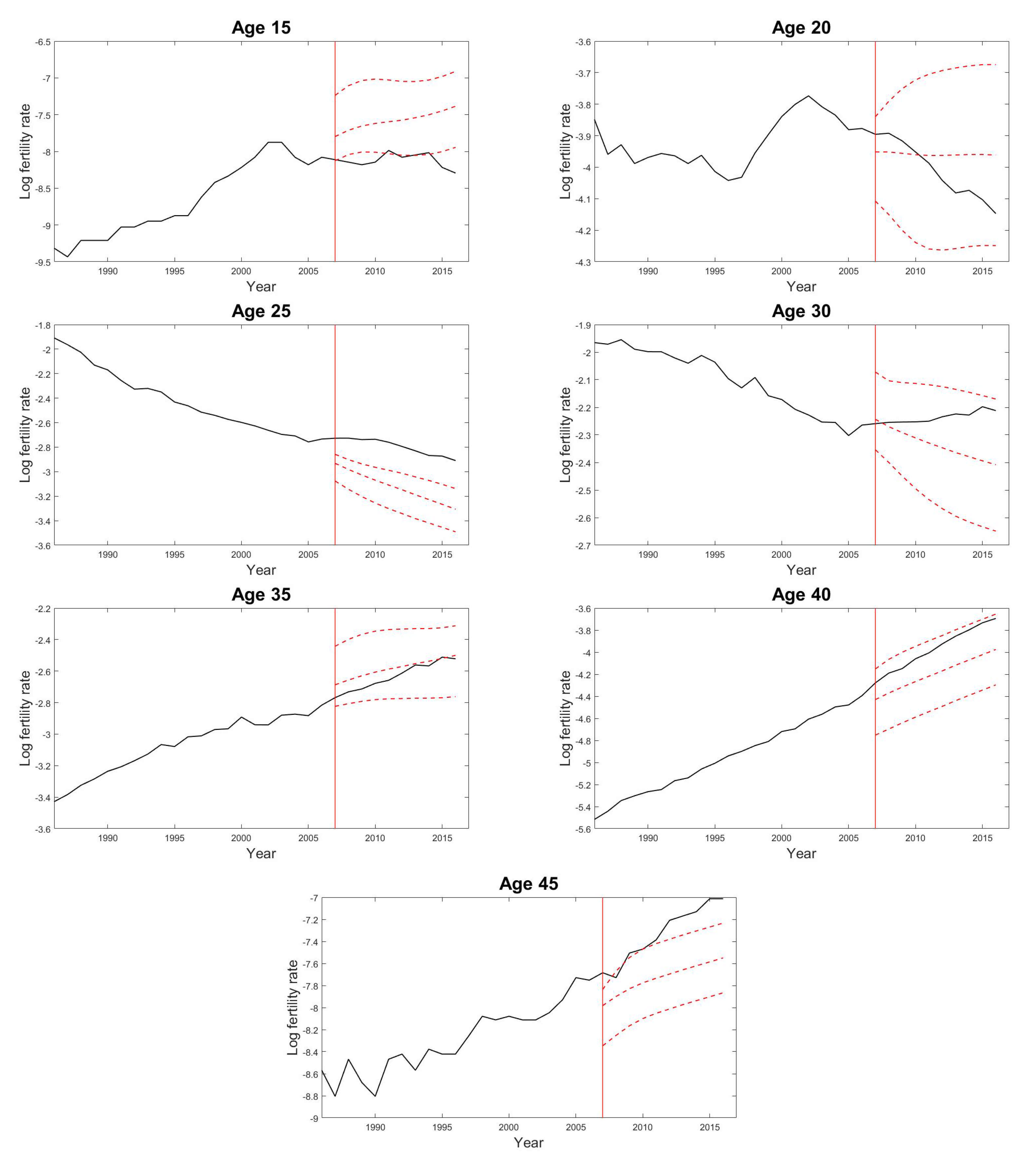
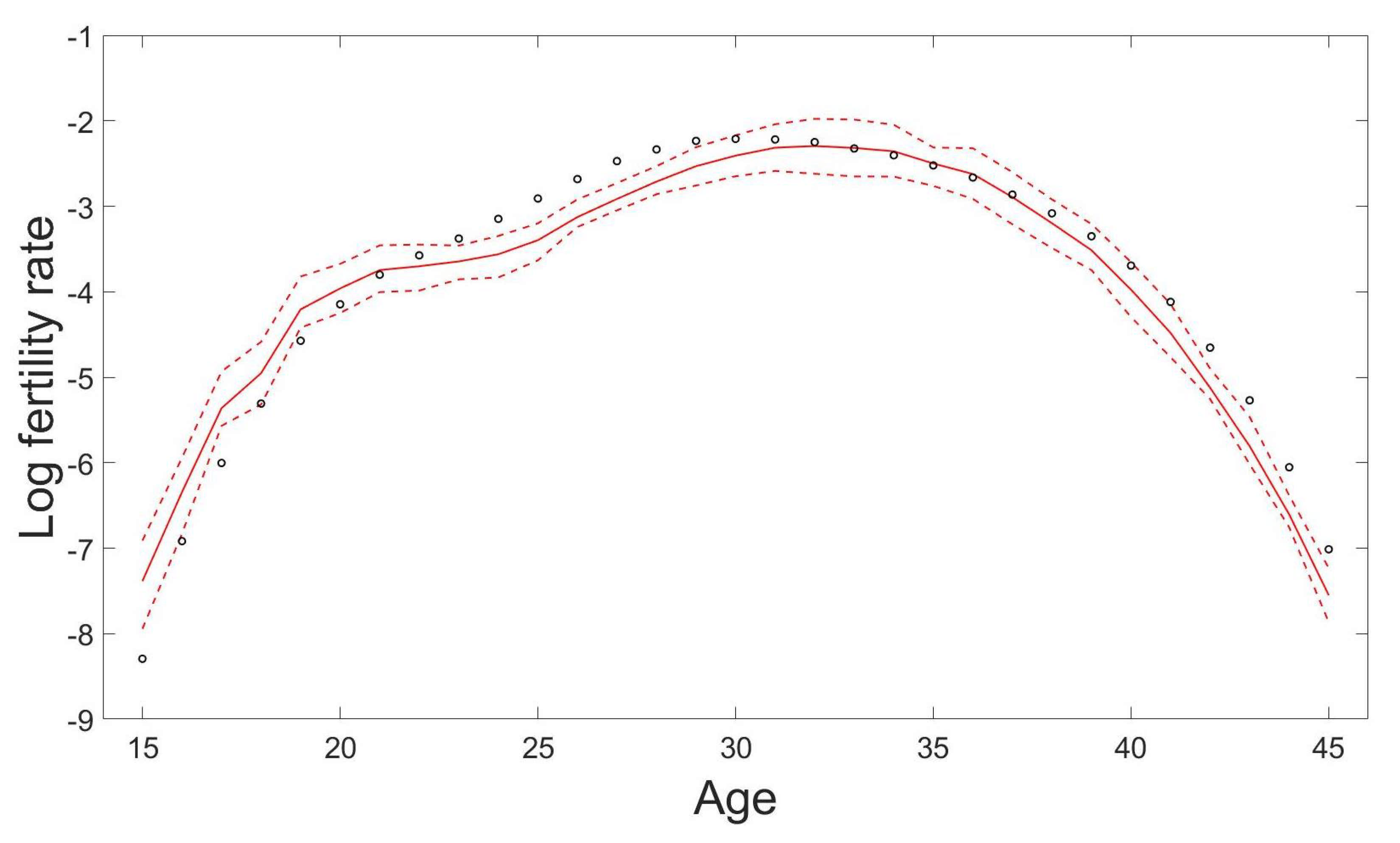
4.4. Fertility Modelling and Forecasting
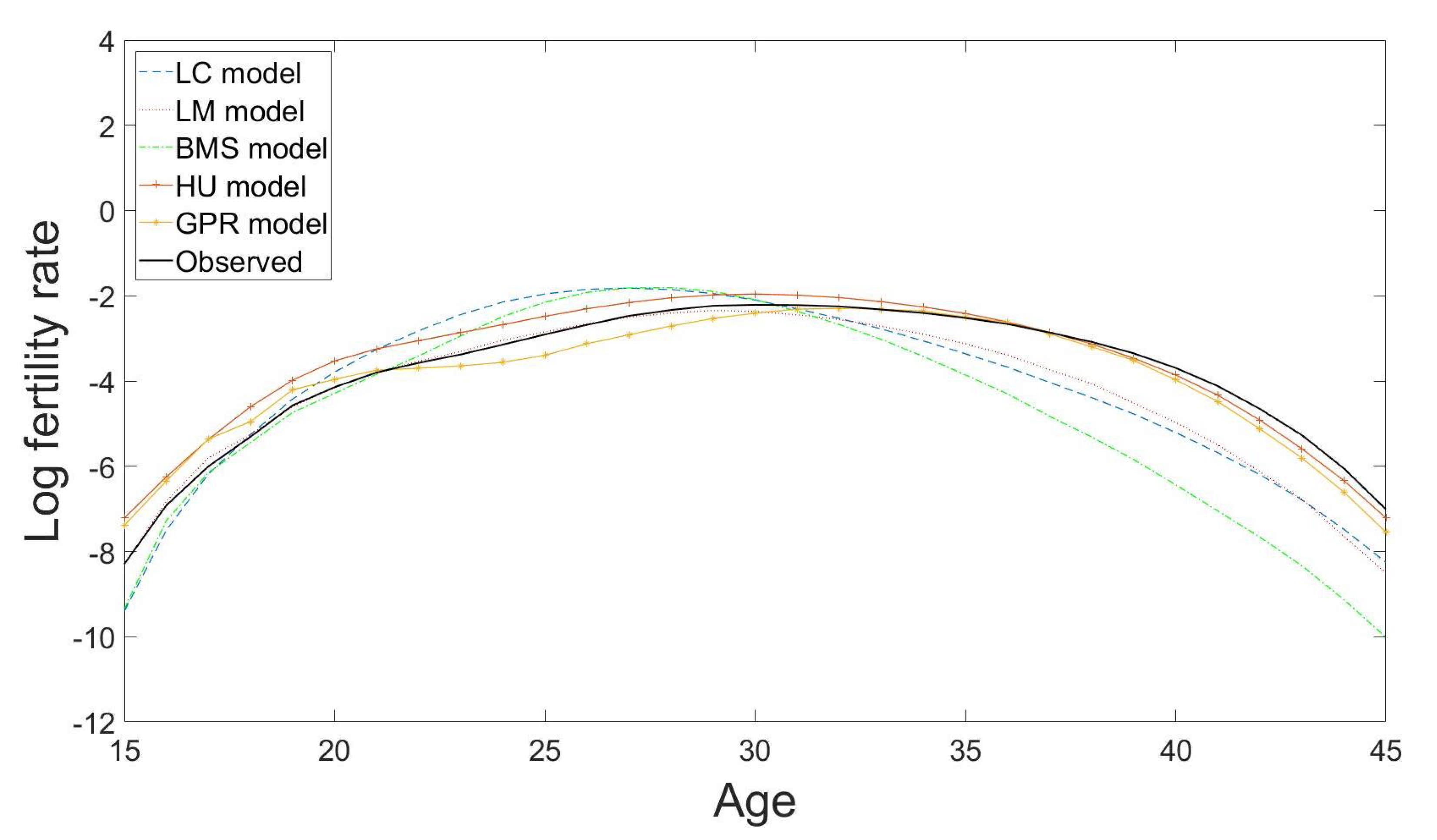
4.5. Comparisons and Forecast Accuracy Evaluations with Existing Models
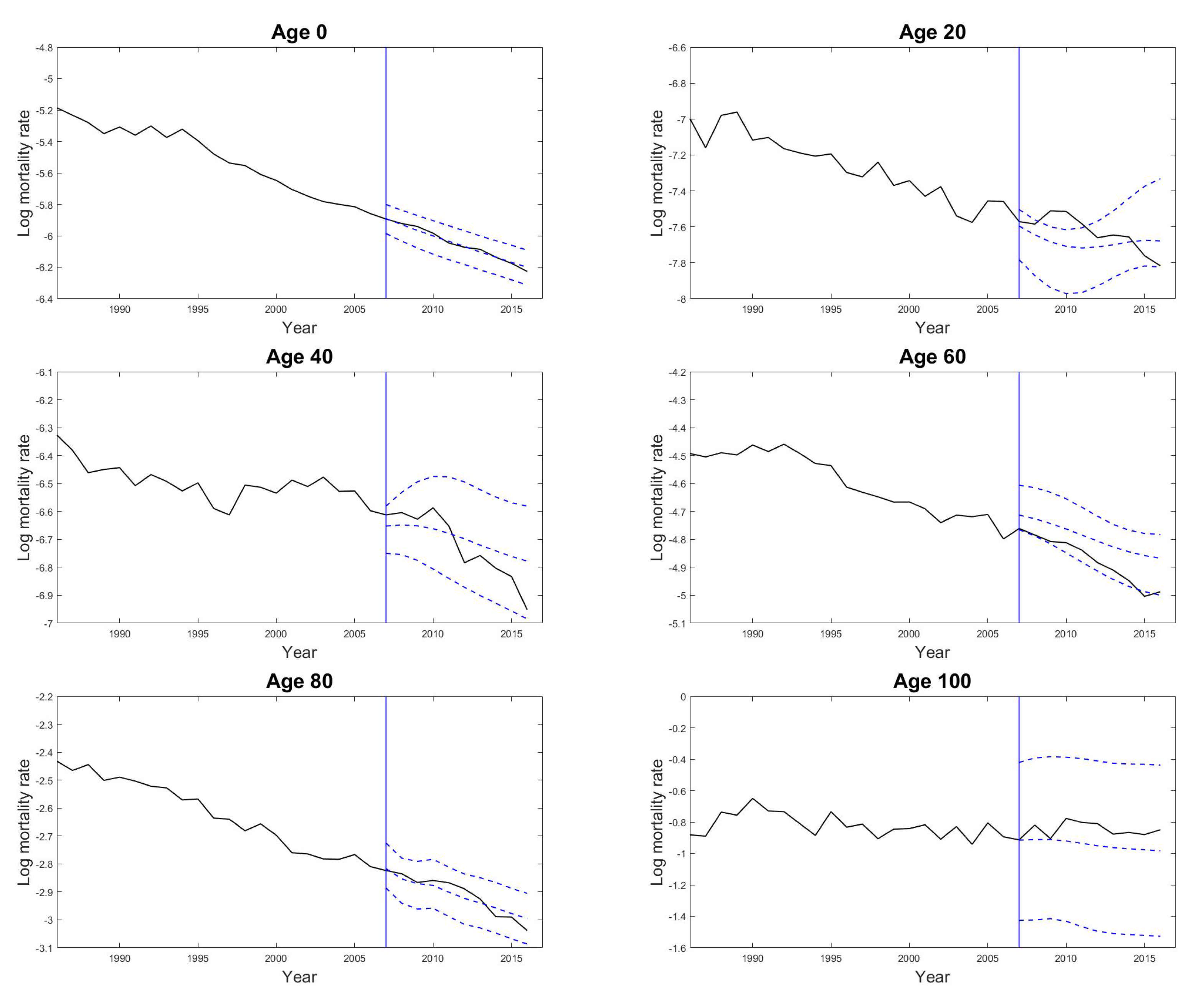
Forecast Accuracy Evaluations Using Rolling-Window Analysis
5. Discussion and Conclusion Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Preston, S.; Heuveline, P.; Guillot, M. Demography: Measuring and Modeling Population Processes; Blackwell Publishers: Malden, MA, USA, 2000. [Google Scholar]
- Gompertz, B. On the nature of the function expressive of the law of human mortality, and on a new mode of determining the value of life contingencies. Philos. Trans. R. Soc. Lond. 1825, 115, 513–583. [Google Scholar]
- Makeham, W.M. On the law of mortality and the construction of annuity tables. J. Inst. Actuar. 1860, 8, 301–310. [Google Scholar] [CrossRef]
- Lee, R.D.; Carter, L.R. Modeling and forecasting US mortality. J. Am. Stat. Assoc. 1992, 87, 659–671. [Google Scholar]
- Lee, R.D. Modeling and forecasting the time series of US fertility: Age distribution, range, and ultimate level. Int. J. Forecast. 1993, 9, 187–202. [Google Scholar] [CrossRef]
- Bell, W.R. Comparing and assessing time series methods for forecasting age-specific fertility and mortality rates. J. Off. Stat. 1997, 13, 279–303. [Google Scholar]
- Lee, R.; Miller, T. Evaluating the performance of the Lee-Carter method for forecasting mortality. Demography 2001, 38, 537–549. [Google Scholar] [CrossRef]
- Booth, H.; Maindonald, J.; Smith, L. Applying Lee-Carter under conditions of variable mortality decline. Popul. Stud. 2002, 56, 325–336. [Google Scholar] [CrossRef] [PubMed]
- Brouhns, N.; Denuit, M.; Vermunt, J.K. A Poisson log-bilinear regression approach to the construction of projected lifetables. Insur. Math. Econ. 2002, 31, 373–393. [Google Scholar] [CrossRef]
- Renshaw, A.; Haberman, S. Lee-Carter mortality forecasting: A parallel generalized linear modelling approach for England and Wales mortality projections. J. R. Stat. Soc. Ser. C Appl. Stat. 2003, 52, 119–137. [Google Scholar] [CrossRef]
- Cairns, A.J.; Blake, D.; Dowd, K. A two-factor model for stochastic mortality with parameter uncertainty: Theory and calibration. J. Risk Insur. 2006, 73, 687–718. [Google Scholar] [CrossRef]
- Hunt, A.; Blake, D. A general procedure for constructing mortality models. N. Am. Actuar. J. 2014, 18, 116–138. [Google Scholar] [CrossRef]
- Whittaker, E.T. On a new method of graduation. Proc. Edinb. Math. Soc. 1922, 41, 63–75. [Google Scholar] [CrossRef]
- Currie, I.D.; Durban, M.; Eilers, P.H. Smoothing and forecasting mortality rates. Stat. Model. 2004, 4, 279–298. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Ullah, M.S. Robust forecasting of mortality and fertility rates: A functional data approach. Comput. Stat. Data Anal. 2007, 51, 4942–4956. [Google Scholar] [CrossRef]
- Delwarde, A.; Denuit, M.; Eilers, P. Smoothing the Lee-Carter and Poisson log-bilinear models for mortality forecasting: A penalized log-likelihood approach. Stat. Model. 2007, 7, 29–48. [Google Scholar] [CrossRef]
- Debón, A.; Martínez-Ruiz, F.; Montes, F. A geostatistical approach for dynamic life tables: The effect of mortality on remaining lifetime and annuities. Insur. Math. Econ. 2010, 47, 327–336. [Google Scholar] [CrossRef]
- Li, H.; O’Hare, C.; Zhang, X. A semiparametric panel approach to mortality modeling. Insur. Math. Econ. 2015, 61, 264–270. [Google Scholar] [CrossRef]
- Ludkovski, M.; Risk, J.; Zail, H. Gaussian process models for mortality rates and improvement factors. ASTIN Bull. J. IAA 2018, 48, 1307–1347. [Google Scholar] [CrossRef]
- Dokumentov, A.; Hyndman, R.J.; Tickle, L. Bivariate smoothing of mortality surfaces with cohort and period ridges. Stat 2018, 7, e199. [Google Scholar] [CrossRef]
- Wu, R.; Wang, B. Gaussian process regression method for forecasting of mortality rates. Neurocomputing 2018, 316, 232–239. [Google Scholar] [CrossRef]
- Alexopoulos, A.; Dellaportas, P.; Forster, J.J. Bayesian forecasting of mortality rates by using latent Gaussian models. J. R. Stat. Soc. Ser. A Stat. Soc. 2019, 182, 689–711. [Google Scholar] [CrossRef]
- Krige, D.G. A statistical approach to some basic mine valuation problems on the Witwatersrand. J. S. Afr. Inst. Min. Metall. 1951, 52, 119–139. [Google Scholar]
- Matheron, G. Principles of Geostatistics. Econ. Geol. 1963, 58, 1246–1266. [Google Scholar] [CrossRef]
- Journel, A.G.; Huijbregts, C.J. Mining Geostatistics; Academic Press: Cambridge, MA, USA, 1978. [Google Scholar]
- Cressie, N. Geostatistics. Am. Stat. 1989, 43, 197–202. [Google Scholar]
- Engel, Y.; Mannor, S.; Meir, R. Reinforcement learning with Gaussian processes. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 201–208. [Google Scholar]
- Krause, A.; Singh, A.; Guestrin, C. Near-optimal sensor placements in Gaussian processes: Theory, efficient algorithms and empirical studies. J. Mach. Learn. Res. 2008, 9, 235–284. [Google Scholar]
- Neal, R.M. Bayesian Learning for Neural Networks; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 118. [Google Scholar]
- Alamaniotis, M.; Ikonomopoulos, A.; Tsoukalas, L.H. Evolutionary multiobjective optimization of kernel-based very-short-term load forecasting. IEEE Trans. Power Syst. 2012, 27, 1477–1484. [Google Scholar] [CrossRef]
- Wu, Q.; Law, R.; Xu, X. A sparse Gaussian process regression model for tourism demand forecasting in Hong Kong. Expert Syst. Appl. 2012, 39, 4769–4774. [Google Scholar] [CrossRef]
- MacKay, D.J. Introduction to Gaussian processes. NATO ASI Ser. F Comput. Syst. Sci. 1998, 168, 133–166. [Google Scholar]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Volume 2. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001; Volume 1. [Google Scholar]
- Wilson, A.; Adams, R. Gaussian process kernels for pattern discovery and extrapolation. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1067–1075. [Google Scholar]
- Human Mortality Database. University of California, Berkeley (USA), and Max Planck Institute for Demographic Research (Germany). Available online: https://www.mortality.org/ (accessed on 21 March 2020).
- Shi, J.; Wang, B.; Murray-Smith, R.; Titterington, D. Gaussian process functional regression modeling for batch data. Biometrics 2007, 63, 714–723. [Google Scholar] [CrossRef]
- Human Fertility Database. University of California, Berkeley (USA), Max Planck Institute for Demographic Research (Germany) and Vienna Institute of Demography (Austria). Available online: https://www.humanfertility.org (accessed on 2 April 2020).
- Booth, H.; Tickle, L. Mortality modelling and forecasting: A review of methods. Ann. Actuar. Sci. 2008, 3, 3–43. [Google Scholar] [CrossRef]
- Booth, H.; Hyndman, R.J.; Tickle, L. Prospective life tables. In Computational Actuarial Science with R; Taylor & Francis: Boca Raton, FL, USA, 2014; pp. 319–344. [Google Scholar]
- Zivot, E.; Wang, J. Modeling Financial Time Series with S-Plus®; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007; Volume 191. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | LC Model | LM Model | BMS Model | HU Model | GPR Model |
|---|---|---|---|---|---|
| Austria | 0.3122 | 0.3191 | 0.2596 | 0.2591 | 0.2581 |
| Belgium | 0.2560 | 0.2783 | 0.2429 | 0.2458 | 0.2359 |
| Canada | 0.1850 | 0.1574 | 0.1762 | 0.1519 | 0.1583 |
| France | 0.1879 | 0.1260 | 0.1365 | 0.1477 | 0.1457 |
| Japan | 0.1903 | 0.1365 | 0.1564 | 0.1533 | 0.1164 |
| Netherlands | 0.2679 | 0.2284 | 0.2046 | 0.2265 | 0.2233 |
| Sweden | 0.2873 | 0.3178 | 0.2695 | 0.2633 | 0.2566 |
| Switzerland | 0.3346 | 0.3597 | 0.3077 | 0.3109 | 0.2774 |
| UK | 0.1805 | 0.1301 | 0.1382 | 0.1584 | 0.1504 |
| USA | 0.1266 | 0.0875 | 0.1324 | 0.1183 | 0.1258 |
| Average | 0.2328 | 0.2141 | 0.2024 | 0.2035 | 0.1948 |
| Austria | 0.3504 | 0.3289 | 0.2793 | 0.2809 | 0.2783 |
| Belgium | 0.2902 | 0.2945 | 0.2820 | 0.3044 | 0.2634 |
| Canada | 0.2197 | 0.1837 | 0.2078 | 0.1862 | 0.2017 |
| France | 0.2443 | 0.1871 | 0.2074 | 0.2391 | 0.1985 |
| Japan | 0.2630 | 0.2187 | 0.2824 | 0.2382 | 0.1208 |
| Netherlands | 0.3294 | 0.2706 | 0.2629 | 0.2861 | 0.2678 |
| Sweden | 0.3153 | 0.3311 | 0.2869 | 0.2813 | 0.2740 |
| Switzerland | 0.3888 | 0.4087 | 0.3942 | 0.4030 | 0.3842 |
| UK | 0.2271 | 0.1730 | 0.1987 | 0.2133 | 0.1899 |
| USA | 0.1514 | 0.1231 | 0.1706 | 0.1474 | 0.1724 |
| Average | 0.2780 | 0.2519 | 0.2572 | 0.2580 | 0.2351 |
| Austria | 0.4022 | 0.3707 | 0.3119 | 0.3582 | 0.3130 |
| Belgium | 0.3251 | 0.3148 | 0.3050 | 0.3558 | 0.2906 |
| Canada | 0.2659 | 0.2413 | 0.2340 | 0.2220 | 0.2595 |
| France | 0.2992 | 0.2699 | 0.2937 | 0.3431 | 0.2924 |
| Japan | 0.3631 | 0.3366 | 0.3551 | 0.2688 | 0.2063 |
| Netherlands | 0.3787 | 0.3316 | 0.3145 | 0.3335 | 0.2992 |
| Sweden | 0.3677 | 0.3637 | 0.3194 | 0.3331 | 0.2986 |
| Switzerland | 0.4574 | 0.4724 | 0.5270 | 0.5347 | 0.5279 |
| UK | 0.2836 | 0.2292 | 0.2373 | 0.2604 | 0.2310 |
| USA | 0.1855 | 0.1825 | 0.2109 | 0.1798 | 0.2172 |
| Average | 0.3328 | 0.3113 | 0.3109 | 0.3189 | 0.2936 |
| Austria | 0.4600 | 0.4289 | 0.3833 | 0.4275 | 0.3813 |
| Belgium | 0.3666 | 0.3402 | 0.3330 | 0.3740 | 0.3200 |
| Canada | 0.3113 | 0.2747 | 0.2394 | 0.2594 | 0.2613 |
| France | 0.3491 | 0.3218 | 0.3236 | 0.4051 | 0.3105 |
| Japan | 0.5193 | 0.5120 | 0.4385 | 0.3333 | 0.2828 |
| Netherlands | 0.4218 | 0.3828 | 0.3968 | 0.3739 | 0.3321 |
| Sweden | 0.4214 | 0.3943 | 0.3794 | 0.4154 | 0.3270 |
| Switzerland | 0.4910 | 0.5259 | 0.5930 | 0.6774 | 0.6169 |
| UK | 0.3529 | 0.2894 | 0.2750 | 0.3774 | 0.2717 |
| USA | 0.2017 | 0.2089 | 0.1856 | 0.2159 | 0.2122 |
| Average | 0.3895 | 0.3679 | 0.3548 | 0.3859 | 0.3316 |
| Country | LC Model | LM Model | BMS Model | HU Model | GPR Model |
|---|---|---|---|---|---|
| Austria | 0.6112 | 0.2509 | 0.6203 | 0.2287 | 0.1801 |
| Canada | 0.6044 | 0.2481 | 0.1330 | 0.3236 | 0.2432 |
| France | 0.4927 | 0.1565 | 0.2334 | 0.0981 | 0.2462 |
| Germany | 0.6495 | 0.2420 | 0.5870 | 0.1608 | 0.1489 |
| Italy | 0.5414 | 0.2635 | 0.3719 | 0.4402 | 0.2805 |
| Japan | 0.6533 | 0.3876 | 0.6721 | 0.5302 | 0.2769 |
| Sweden | 0.5970 | 0.1905 | 0.1562 | 0.2768 | 0.1553 |
| Switzerland | 0.6734 | 0.2822 | 0.4553 | 0.2536 | 0.2059 |
| UK | 0.4280 | 0.2392 | 0.2554 | 0.2970 | 0.2920 |
| USA | 0.4499 | 0.1757 | 0.2170 | 0.3554 | 0.2431 |
| Average | 0.5701 | 0.2436 | 0.3702 | 0.2964 | 0.2272 |
| Austria | 0.7328 | 0.5081 | 0.7915 | 0.3370 | 0.3276 |
| Canada | 0.7476 | 0.5054 | 0.2581 | 0.3630 | 0.2881 |
| France | 0.6026 | 0.3428 | 0.4888 | 0.2043 | 0.3742 |
| Germany | 0.7531 | 0.4990 | 0.7365 | 0.2909 | 0.2008 |
| Italy | 0.7064 | 0.5449 | 0.8189 | 0.5346 | 0.4802 |
| Japan | 0.8998 | 0.7846 | 1.2119 | 0.6443 | 0.3424 |
| Sweden | 0.7524 | 0.4169 | 0.2699 | 0.3857 | 0.1789 |
| Switzerland | 0.7926 | 0.5536 | 0.4835 | 0.4489 | 0.3274 |
| UK | 0.5928 | 0.4780 | 0.3448 | 0.3594 | 0.3294 |
| USA | 0.5058 | 0.3172 | 0.3092 | 0.4458 | 0.4241 |
| Average | 0.7086 | 0.4950 | 0.5713 | 0.4014 | 0.3273 |
| Austria | 0.8863 | 0.7721 | 0.9997 | 0.4972 | 0.6215 |
| Canada | 0.9300 | 0.8080 | 0.5972 | 0.4347 | 0.4894 |
| France | 0.7871 | 0.5908 | 0.8119 | 0.4960 | 0.5973 |
| Germany | 0.9231 | 0.7684 | 0.9732 | 0.4319 | 0.2961 |
| Italy | 0.9339 | 0.8319 | 1.3051 | 0.7208 | 0.9365 |
| Japan | 1.2392 | 1.2202 | 1.5252 | 0.6989 | 0.5641 |
| Sweden | 0.8930 | 0.6031 | 0.5837 | 0.5307 | 0.3582 |
| Switzerland | 0.9837 | 0.8390 | 0.9742 | 0.6711 | 0.6488 |
| UK | 0.7850 | 0.7286 | 0.4473 | 0.5277 | 0.4505 |
| USA | 0.6125 | 0.5309 | 0.4280 | 0.5312 | 0.5539 |
| Average | 0.8986 | 0.7690 | 0.8495 | 0.5603 | 0.5439 |
| Austria | 1.0445 | 1.0165 | 1.2876 | 0.6219 | 1.0984 |
| Canada | 1.2030 | 1.1651 | 1.2181 | 0.5261 | 0.9405 |
| France | 0.9948 | 0.8514 | 1.1597 | 0.8039 | 0.9926 |
| Germany | 1.1324 | 1.0523 | 1.3186 | 0.6835 | 0.6710 |
| Italy | 1.1945 | 1.1354 | 1.6735 | 0.9316 | 1.6623 |
| Japan | 1.6871 | 1.7571 | 1.6005 | 0.7553 | 0.8688 |
| Sweden | 1.0161 | 0.7615 | 0.9025 | 0.6986 | 0.6580 |
| Switzerland | 1.2332 | 1.1462 | 1.4133 | 0.7295 | 1.2452 |
| UK | 1.0005 | 0.9784 | 0.7820 | 0.8654 | 0.6823 |
| USA | 0.7946 | 0.7948 | 0.7017 | 0.6077 | 0.6676 |
| Average | 1.1301 | 1.0659 | 1.2057 | 0.7224 | 0.9487 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lam, K.K.; Wang, B. Robust Non-Parametric Mortality and Fertility Modelling and Forecasting: Gaussian Process Regression Approaches. Forecasting 2021, 3, 207-227. https://doi.org/10.3390/forecast3010013
Lam KK, Wang B. Robust Non-Parametric Mortality and Fertility Modelling and Forecasting: Gaussian Process Regression Approaches. Forecasting. 2021; 3(1):207-227. https://doi.org/10.3390/forecast3010013
Chicago/Turabian StyleLam, Ka Kin, and Bo Wang. 2021. "Robust Non-Parametric Mortality and Fertility Modelling and Forecasting: Gaussian Process Regression Approaches" Forecasting 3, no. 1: 207-227. https://doi.org/10.3390/forecast3010013
APA StyleLam, K. K., & Wang, B. (2021). Robust Non-Parametric Mortality and Fertility Modelling and Forecasting: Gaussian Process Regression Approaches. Forecasting, 3(1), 207-227. https://doi.org/10.3390/forecast3010013