1. Introduction
Modern-day technologies not only permit firms to accurately track their point of sales data and lost sales (purchases not made by customers due to a lack of inventory) data but also gather more granular data. These data streams deluge firms with information which can be either aggregated for planning purposes or considered in its entirety or follow an in-between approach. In this paper we analyze a model in which a retailer is faced with exactly the same choices and provide guidelines for combining the data for the purpose of forecasting demand.
Consider a retailer who has access to its individual customers’ demand streams. Assume that each of these demand streams follow an ARMA model having possibly contemporaneously correlated shock sequences. The primary contribution of this research is to quantify to what extent such a retailer would benefit from forecasting each of the individual streams as opposed to the aggregate. In general, retailers forecast their aggregate demand stream since historically the retailer may only have accurate aggregate demand information, and the forecasting of the individual customer demand streams is often thought of as being cumbersome and time consuming. We demonstrate that a retailer observing multiple demand streams generated by ARMA models can drastically reduce its mean squared forecasting error (MSFE) by forecasting the individual demand streams as opposed to just the aggregate demand stream, as noted in [
1].
Although the retailer’s MSFE is never lower when forecasting using aggregated demand compared to the individual demand streams (this holds for the theoretical case when model coefficients are known and need not be estimated), there are cases when the individual streams do not reduce the MSFE. The primary situation where this occurs, as is discussed in the paper, is when various models generating the demand streams have identical ARMA parameter values. For the in-between case, our results demonstrate that the retailer’s MSFE under aggregate forecasting can be greatly reduced if the retailer forecasts various clusters of aggregated demand streams. We also show by example that clustering continues to perform well in the event that ARMA models are estimated for non-ARMA data.
In other words, retailers can make use of data mining and other clustering approaches in order to generate clusters of similar customers and their demand streams. We show that such clustering methods significantly enhance forecast accuracy. This is related to the study of telephone data in [
2], where the authors concluded that subaggregated data can be effective for improving forecast accuracy compared to aggregate data. They also note that data are often aggregated to the level that forecasts are required. We describe here ways in which subaggregated clusters can be selected to minimize forecast error. Several examples are mentioned in [
3] in the context of assigning demand allocation to different facilities.
Many researchers and practitioners focus on the need to determine clusters of similarly situated customers in order to create and provide customized and/or personalized products. This type of clustering is generally performed on specific characteristics that customers possess (see, for example, [
4] and the references within). On the other hand, our focus is on forecasting demand for a product by a firm’s customers, recognizing that these customers may have different preferences and hence differing demand. As we describe below, from the demand forecasting perspective, the information contained within the individual demand streams provides the optimal forecast (in terms of minimizing the MSFE and hence inventory related costs) for product demand. Nonetheless, there has been research on the use of clustering methods within a forecasting environment when customer demand data are high dimensional (see, for example, [
5]).
As opposed to generating clusters based upon customer preferences and customer demographics, we explain how clusters can be generated explicitly from the individual time series structure of the individual demand streams or customers. Even though it is always optimal from a forecasting perspective to use the individual streams, clusters of similar customer streams may be very helpful to the firm for other reasons as described above. Future empirical work would be necessary to investigate to what extent and in what contexts clusters generated based upon time series structure of the demand streams correlate to clusters based upon other customer preferences. In such a case where there exists such a relationship, firms could use clustering for simplifying their demand forecasting while identifying groups of customers to receive personalized products.
The purpose of this paper is to demonstrate that clustering based upon time series structure can be utilized within demand forecasting that is superior to forecasting aggregate demand and nearly as good as forecasting the individual demand streams. The structure of our paper is as follows. In the next section, we describe the demand framework and supply chain setting of our research problem as well as the way that theoretical MSFE computations are determined for the various forecasts (using aggregated demand processes) included herein. In
Section 3, we illustrate (through example) that there exists a particular set of subaggregated clusters which results in an MSFE that is close to the MSFE obtained from using disaggregated streams and much lower than the MSFE obtained from the fully aggregated sequence. In
Section 4, we describe how to cluster demand streams generated by ARMA models using Pivot Clustering and how this compares to other clustering methods. In
Section 5, we describe an objective function that can be minimized to obtain an optimal assignment of streams to clusters in terms of MSFE reduction. Finally, we obtain theoretical results on how demand streams produced by MA(1) models can be clustered in the most efficient way possible to reduce the resulting subaggregated MSFE in
Section 6.
2. Model Framework
We consider a retailer with possibly many large customers. In general, retailers forecast their aggregate demand stream since the forecasting of the individual customer demand streams is often thought of as being cumbersome and time consuming. We demonstrate that a retailer observing multiple streams of demand generated by ARMA models can drastically reduce its MSFE by forecasting the individual demand streams or aggregated clusters of similar demand streams. We limit the focus of this paper on ARMA models that describe stationary demand in order to keep the exposition as clear as possible. If we were to consider ARIMA (or seasonal ARIMA) models, then differencing (or seasonal differencing) would need to be carried out on the data to apply the methodology discussed here. We further note that even simple ARMA(1,1) models appearing in
Section 4 can have coefficients that produce seasonal patterns in demand realizations.
Hence, consider a retailer that observes multiple demand streams for a single product
. Each demand stream
is assumed to be generated by an ARMA model with respect to a sequence of shocks
given by
where
and
, such that
is invertible and causal with respect to
(see Brockwell and Davis, page 77 for a definition and discussion about causality and invertibility). We denote the variance of each shock sequence
. Furthermore, we note that the shock sequences are potentially contemporaneously correlated with
. In general, this set up guarantees that the shocks
are the retailer’s Wold shocks (see [
6] pp. 187–188 for a description of a Wold decomposition of a time series) and that the MSFE of one-step-ahead leadtime demand (when using the disaggregated (individual) streams) is the sum of the elements in the covariance matrix
where
such that
(see Equation (
7)).
The focus of this paper is evaluating the difference in one-step-ahead MSFEs at time
t when the forecast of leadtime demand, given by
, is based on the different series described below where
. Studying one-step-ahead MSFEs is mathematically simpler than those for general leadtimes since the former does not depend on model parameters.
| Disaggregated (individual) sequences | |
| Subaggregated (clustered) sequences | |
| Aggregated (full) sequence | |
Our problem is related to the one posed by [
7] where a two-stage supply chain was considered with the retailer observing two demand streams. The focus of that paper was in evaluating information sharing between the retailer and supplier in a situation where the retailer forecasts each demand stream separately. Here, we show the benefit to the retailer (the situation is really identical for any player in the supply chain that might be observing multiple demand streams, where information sharing does not take place) in determining the separate forecasts while considering the existence of (possibly) more than two demand streams. Kohn [
1] was the first to identify conditions under which using the individual demand streams leads to a better forecast than using the aggregated sequence; however, he did not determine the MSFE in the two cases. The same conditions can be used to show that if streams are subaggregated into clusters where optimal clusters are always used, then the MSFE of the forecast decreases as the number of clusters increases. Our aim is to determine the optimal cluster assignment based on a predetermined choice of the number of clusters. The number of clusters can be based on the level of detailed data available to a firm or based on the tradeoff from lowering MSFE and increasing the complexity of the model when increasing the amount of clusters used.
In this paper, we extend the results of [
7] by providing formulas for computing MSFEs under the possibility of more than two streams and a general leadtime in the situation where a player’s (retailer’s) forecast can only be based on their Wold shocks. We also describe how a retailer would forecast its demand by identifying clusters of similar demand streams and then forecasting each cluster after it is aggregated. We provide a pivot algorithm, which we call Pivot Clustering, for identifying a locally optimal assignment of streams into a fixed number of clusters. The algorithm will often find the best possible assignment. We also describe a fast clustering algorithm which results in a globally optimal assignment when demand streams are generated by independent MA(1) models. Our results show that after the algorithms are carried out, much of the benefit of forecasting individual streams can be obtained by forecasting the aggregated clusters.
2.1. Forecasting Using the Disaggregated (Individual) Sequences
In this section we are interested in forecasting
when the forecast is based on the diaggregated individual sequences as discussed in the previous section. The forecasting contained here is a textbook multivariate time-series result along with the propagation described in [
8] as seen in (
5). Thus, we consider processes
such that
generated by ARMA models given by
with
.
In this case, the disaggregated MSFE given by
where
is the best linear forecast of leadtime demand at time
t for stream
based on (
2). We note that
such that
with
is the
ith coefficient appearing in the MA(
∞) representation of
with respect to
(see [
8] for details). That is,
and
such that
.
Thus, the MSFE of the best linear forecast (BLF) of leadtime demand when using the individual sequences
is given by
We note that the one-step-ahead (
) disaggregated MSFE is given by
. Thus, we can compare (
7) with (
26) below to determine the reduction in MSFE when using the individual sequences as opposed to the aggregated sequence.
2.2. ARMA Representation of a Summed Sequence
In this subsection, we determine the ARMA representation of a series with respect to a series of Wold shocks, where is the sum of several ARMA-generated streams given by . Furthermore, we determine the variance of the Wold shocks appearing in this representation. This will allow us to determine the MSFE when forecasts are based on the fully aggregated series as well as when the forecasts are based on subaggregated clusters. In order to obtain the ARMA representation, we first need to obtain the spectral density and the covariance generating function of .
Proposition 1. Let . The spectral density of is given bywhere the cross-spectrum is defined with and . Proof. We will prove this by induction. Note that when
,
is given by
Noting that
, we see that
which matches representation (
8). □
Now suppose (
8) holds for
processes. Thus,
Consider
. Since
follows and ARMA model, we observe that
Note that starting with the definition of
,
Thus, from (
12),
or equivalently
which can be simply written as
and the result is proved. □
Now, consider the covariance generating function
of
. Here, we use the equivalence
and note the following:
Thus, from Proposition 1 we observe that
As described in Theorem 5 of [
7], the covariance generating function
can be factorized as the ratio
where
,
and
are Laurent polynomials, with
having all its roots on the unit circle and
and
having no roots on the unit circle. This result follows from the fact that each additive term in (
76) is a ratio of Laurent polynomials and the fact that for any Laurent polynomial
, both
and
will be Laurent polynomials. Furthermore, if
and
are Laurent polynomials then
and
will be Laurent polynomials as well.
We can now use the factorization provided in [
9] and described in [
7] to obtain the ARMA representation of
with respect to the Wold shocks
(appearing in its Wold representation). It should be noted that Remark 1 is simply a restatement of Theorem 5 of [
7] with the slight addition of determining the polynomials appearing in the ARMA representation of the aggregate sequence
.
Remark 1. can be represented with respect to shocks using the ARMA modelwhere where are the roots of on or inside the unit circle and where are the roots of inside the unit circle. Furthermore,where is the coefficient of in and is the coefficient of in . 2.3. Forecasting Using the Fully Aggregated Sequence for a General Leadtime
We note that Remark 1 can be used to obtain the ARMA representation of
with respect to its Wold shocks
as well as
. We can therefore use Lemma 1 of [
8] and its proof to determine the BLF of
and its MSFE when forecasting using the infinite past of
up to time
t, namely
. That is, if we consider the MA(
∞) representation of
with respect to
given by
where
, then the MSFE of the BLF when using
is
where
We note that .
2.4. Forecasting Using Subaggregated Sequences
In this section we use the results in the previous section to create a forecast and compute its MSFE when some of the individual streams are subaggregated. That is, for , let cluster consist of streams such that . We are interested in the forecast and MSFE based on .
Section 2.2 describes how we can obtain the ARMA representation and variance of the Wold shocks appearing in the Wold representation for each sequence
. This can then be used to create a forecast from each subaggregated sequence, the sum of which can be taken as the forecast for
. The one-step ahead MSFE of this forecast is the sum of the entries of the covariance matrix of the Wold shocks appearing in the Wold representation of
. Equation (
7) describes how we can also use the covariance matrix of the shocks of
to obtain the MSFE for multi-step ahead forecasts. The remainder of this section will focus on obtaining this covariance matrix.
Without loss of generality, consider two subaggregated series
and
with ARMA representations
where
and
are the shocks appearing in the Wold representation of
and
, respectively. We note that the variances of
and
can be obtained using Remark 1. To obtain the covariance
consider the following.
We can rewrite the ARMA representations above as
The ARMA representations of
can also be rewritten as
Based on the definition of
and
we observe that
To obtain
we need to compute the expectation of the the product of the right-hand-sides of these two equations. Thus, we need to consider the sum of terms such as
Note that we can write
and
where
and
can be obtained in the same way as the MA(
∞) coefficients in (
27). Hence, the term in Equation (
35) can be rewritten as
Since the shock sequences are not correlated across time by assumption, this is equivalent to
or equivalently
Adding up these terms as required would yield the covariance. Hence
We note that this methodology can easily be extended to obtain any of the covariances in the covariance matrix
We will use the previous methodology for all theoretical MSFE computations found in this paper. In the next subsection, we provide an example describing the importance of forecasting leadtime demand based upon the individual sequences.
2.5. Example
Consider a retailer that observes aggregate demand
where each individual demand stream is generated by one of the following ARMA models:
where the shock covariance matrix is given by
We use the results described in
Section 2.1 and
Section 2.2 to compare the MSFE of the forecasts of leadtime demand
when using the individual sequences
versus when using the aggregate sequence
.
The covariance generating function of
is given by
and the ARMA representation of
is given by
where
. We can check that the ARMA representation of
and its covariance generating function match up by noting that
with
and
being the MA and AR polynomials appearing in the ARMA representation of
as defined in Remark 1.
We note that the one-step ahead forecast then has a MSFE = 5.629561 and a two-step-ahead forecast (of ) has an MSFE = 11.44056.
Using Equation (
7) and noting that
in Equation (
5), we can obtain the MSFE of the forecast based on the individual demand streams. In this case, the MSFE is 1.5, which is 4.129561 (73.3%) lower that the forecast error when using the aggregated series. We can likewise compute the elements
when forecasting
. In this case,
and
,
, and
. From (
7) this implies that the MSFE = 7.311, which is also 4.129561 (36.1%) lower (In this case, the reduction in MSFE appears the same, regardless of leadtime; however, this is due to the series being generated by MA(1) models. For higher order ARMA models, the reduction in MSFE may be dependent on leadtime.) than the forecast error when using the aggregated series. In the next section we demonstrate, with example, the benefit of forecasting using subaggregated clusters (which would have been identified using a suitable technique).
3. The Benefit of Forecasting Using Subaggregated Clusters
In this section, we consider a retailer that has ten demand streams that aggregate into three clusters consisting of similar streams. The models generating these streams are specifically chosen to provide a clear separation between “good” clusters leading to low MSFE and “bad” clusters leading to high MSFE. Intuition gleaned from
Section 6 and
Section 7 hint that streams generated from ARMA models with similar coefficients should be clustered together. Hence, for our example we consider three groups of models having similar sets of coefficients within each group. Later, in
Section 4, we will randomly assign coefficients to streams and still observe a sharp drop in MSFE when streams are clustered to minimize MSFE.
Suppose the retailer observes aggregate demand
where each individual demand stream is generated by one of the following ARMA processes:
where the shock covariance matrix is given by
Consider the three natural clusters in the above ten demand streams, namely, streams 1–3, 4–6, and 7–10. It can be shown that, indeed, this grouping is optimal out of any other possible choice of three clusters simply by looking at all possible combinations and computing their MSFEs. Our analysis of the MA(1) case in
Section 6 also points to these being the correct clusters based on the proximity of the ARMA coefficients of the models generating the demand streams. We demonstrate that, even though the best the retailer can achieve in such a situation is forecast all ten streams individually, if the retailer correctly clusters the demand streams as mentioned, the results will be similar. All MSFEs stated in this section are obtained using the methods described in
Section 2.
Specifically in this case, if the retailer were to forecast the individual streams, its one-step ahead theoretical MSFE would be 21.64. If the retailer were to consider the subaggregated processes consisting of the correct clusters and forecast these separately, then the MSFE would be 21.74. This is in stark contrast to an MSFE of 61.39 when forecasting using the aggregate process of all ten streams. In other words, it is sufficient to determine clusters of similar customers as opposed to forecasting each individual stream in order to keep inventory-related costs down.
To see the impact of choosing the correct clusters, we consider the case that the retailer incorrectly clusters the streams as 1–2, 3–5, and 6–10. In this case, the MSFE rises to 33.4. Similarly, if the clusters chosen are
, and 6–10, then the MSFE is 45.04. Assigning streams randomly to three clusters consisting of three, two, and five streams yields
Table 1.
We note that there could be substantial reduction in MSFE even when multiple streams are clustered incorrectly. In the next section, we demonstrate how a retailer would be able to generate clusters of its individual demand streams using Pivot Clustering.
4. TS Clustering Algorithms and Pivot Clustering; Empirical Evaluation
We have shown that the when the retailer forecasts using clusters of its demand streams as opposed to the individual streams, its MSFE can vary greatly from close to the optimal value (when forecasting using the individual streams) to close to the MSFE of a forecast based on the aggregate of all the streams. Hence, if the retailer wishes to forecast using clusters of its demand streams, the selection of the clusters is important. In general, a retailer might have customer-related information that could be used to generate the clusters. The benefit of generating the clusters and forecasting them is that there could be situations where it would be cumbersome for the retailer to collect the individual demand streams and service them individually. Forecasting clusters would therefore be a second-best option.
We propose Pivot Clustering for determining clusters which usually result in a relatively low MSFE among all choices of streams to clusters. We consider two ways to obtain the subaggregated MSFE based on some clustering assignment. The first is to use the individual ARMA demand models appearing in (
2) to compute the subaggregated theoretical MSFE as per
Section 2.2,
Section 2.3 and
Section 2.4. We note that if there is only one cluster, then the MSFE is the one computed for a forecast based on the aggregate of the all the streams, while if the number of clusters is equal to the number of streams, the MSFE is for a forecast based on the disaggregated (individual) sequences. We also estimate the MSFE by generating demand realizations for each stream based on (
2). Once demand realizations are simulated for each stream, we subaggregate the realizations based on our choice of clusters. So, if some cluster is made up of streams
and
, we say that the cluster has realization
. We then estimate an ARMA(5,5) (the AR and MA degrees were chosen with the understanding that these degrees increase with the number of streams subaggregated into a particular cluster while trying to limit the complexity of the models being estimated) model using each cluster’s realization. Finally, we use the estimated models to obtain in-sample forecast errors and compute the covariance matrix of these forecast errors to estimate the MSFE for a particular assignment of streams to clusters. In the analysis below we see that the estimated MSFEs are close to theoretical ones and often lead to similar choices of clusters. Based on a predetermined number of clusters
n, Pivot Clustering works as follows.
For each stream, randomly assign it to a cluster.
For each cluster:
For each stream in the cluster, compute or estimate the MSFE for the current assignment along with the resulting MSFEs if the stream was moved to each of the other clusters.
The MSFE can be either estimated based on realizations of the demand streams or computed using Equations (
28), (
29), (
41) and (
42).
Move each stream in the cluster to a cluster which leads to the largest overall MSFE reduction among all choices of clusters.
In the remainder of this section, we perform various simulations to assess the efficacy of Pivot Clustering. We focus on ARMA(1,1) models as these do not require too much runtime for Pivot Clustering based on theoretical MSFE and are complex enough to describe demand data such as in [
10]. Additionally, forecasting an aggregate of ARMA(1,1) demand sequence has been studied by [
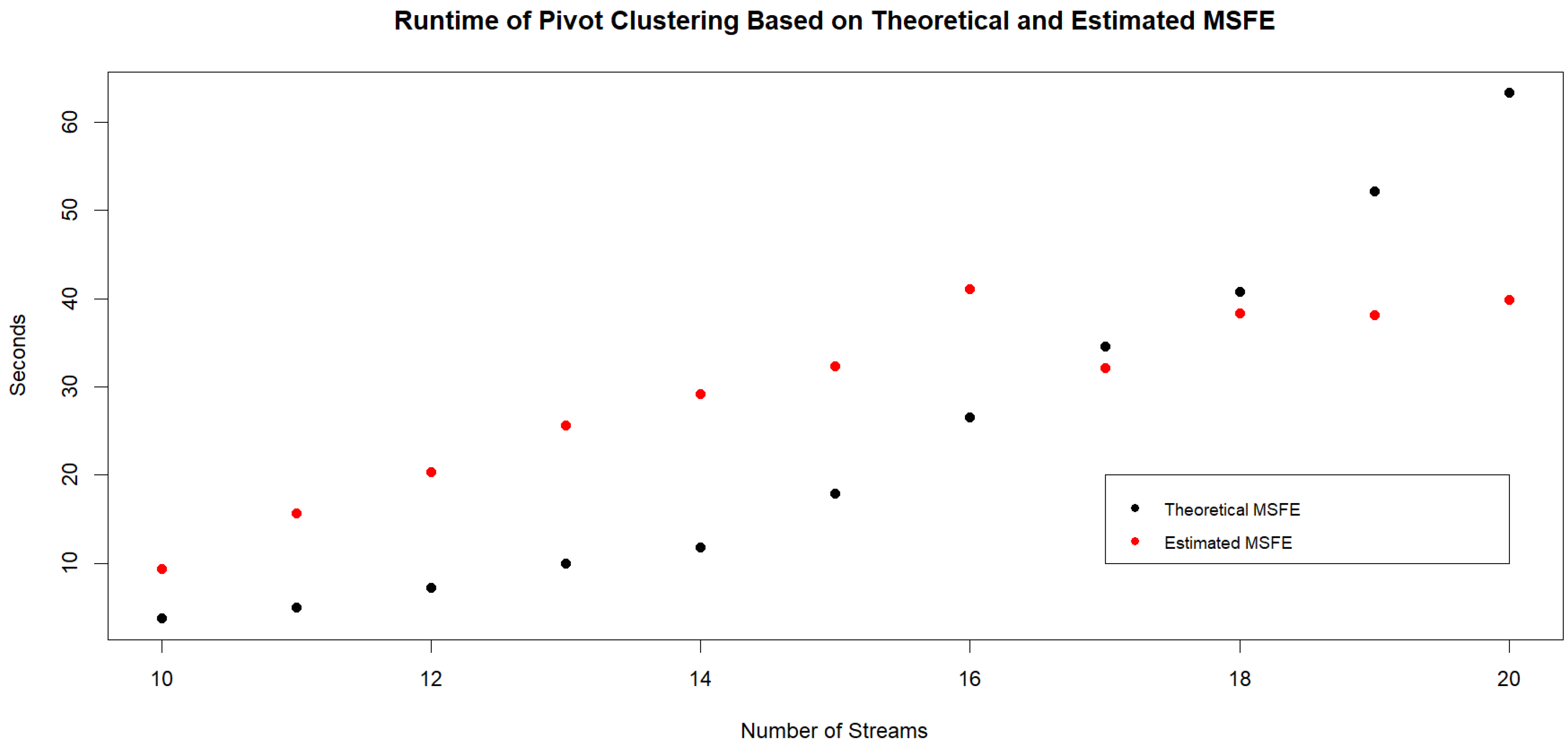
11], where forecasts were based on exponential smoothing. The methods herein are generally applicable, however, to higher-order ARMA models. From a computational standpoint, it is possible to determine theoretical MSFE based on the aggregate of up to twenty demand streams generated by ARMA(1,1) models. The burden lies in having to find roots of large degree polynomials in order to determine the ARMA model and shock variance that describes the aggregated sequence. To understand the computational requirements, we check the runtimes of Pivot Clustering when determining theoretical and estimated MSFEs. Based on a given number of streams (between 10 and 20), we carry out Pivot Clustering for twenty different combinations of ARMA(1,1) models and plot the average of the runtimes in
Figure 1 in assigning the streams to four clusters. If using estimated MSFE, then many more streams can be clustered, and Pivot Clustering has faster runtimes for larger amounts of streams. Upon checking, Pivot Clustering with estimated MSFEs for 200 streams takes approximately 20 min.
We can check the efficacy of Pivot Clustering through simulation. We begin by randomly assigning coefficients to twenty ARMA(1,1) models to produce twenty demand streams as well as the covariance matrix of the shock sequences. We make sure that each assignment results in causal and invertible demand with respect to the shocks and that the resulting covariance matrix is positive definite. The AR and MA coefficients and covariance matrix can be found under “Models.csv” and “covarmat.csv” in our Github location [
12].
After randomly assigning streams to one of four cluster’s we compute both the estimated and theoretical one-step-ahead MSFEs based on this random assignment and use it to start Pivot Clustering. We output the clusters found by Pivot Clustering as well as the MSFE of the forecast based on this set of clusters. We iterate this procedure 50 times to study how much the MSFE improves based on Pivot Clustering for the starting allocations. The MSFEs of the final clusters and random clusters can be found under “MSFEresults.csv” in our Github link [
12]. These can also be compared with the MSFEs of the forecast based on the individual (disaggregated) demand streams and the forecast based on fully aggregating the streams.
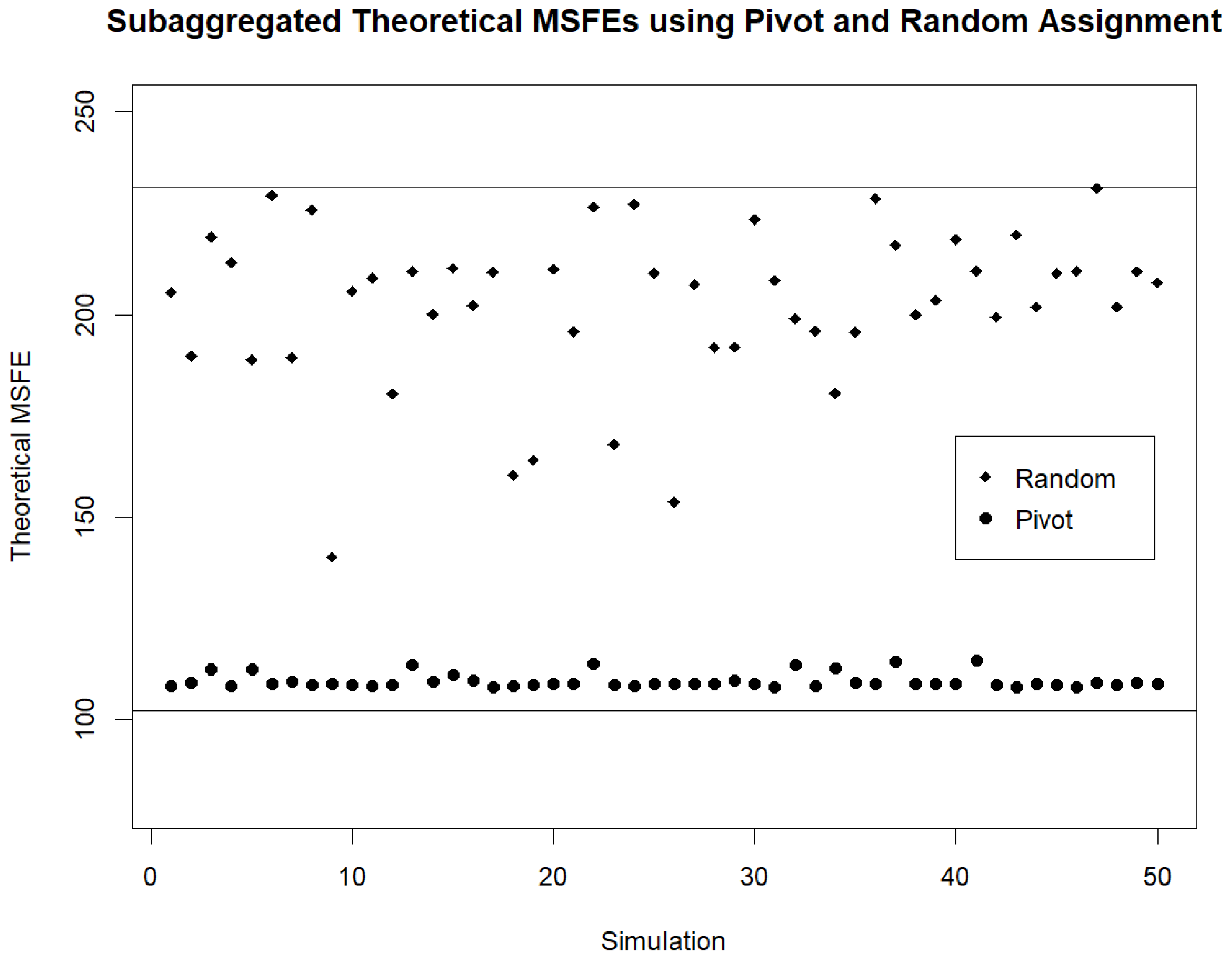
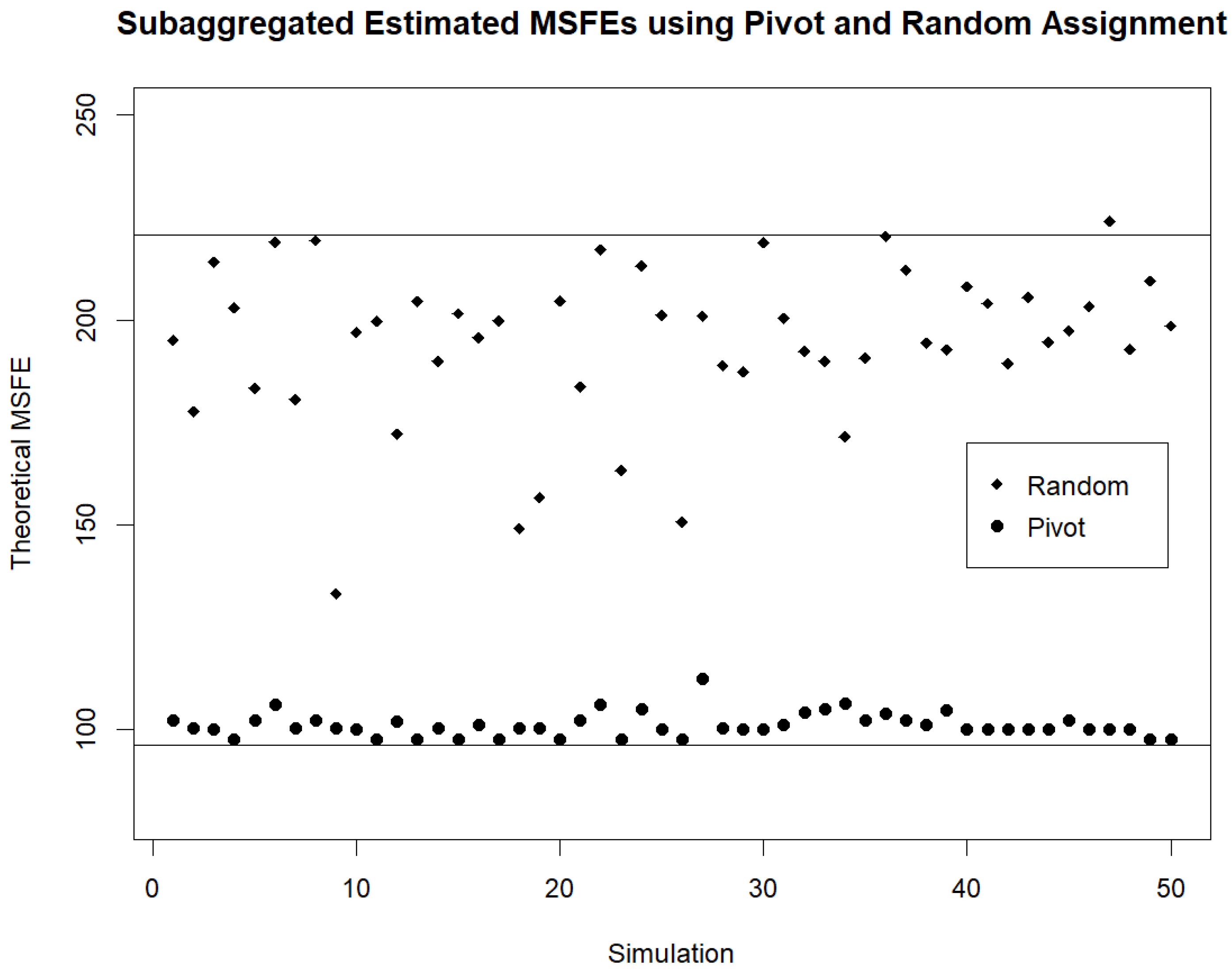
For the twenty demand streams and models used, the theoretical and estimated MSFEs when forecasting based on individual (disaggregated) streams are 102.1 and 96.2. The theoretical and estimated MSFEs when forecasting based on the fully aggregated streams are 231.3 and 220.6. For the 50 simulations of assigning streams to random clusters (used in the initialization step of Pivot Clustering) the average of the theoretical and estimated MSFEs based on the subaggregated random clusters are 202.2 and 194.2. After Pivot Clustering is carried out to obtain a better set of subaggregated clusters in each of the 50 simulations, the averages of the theoretical and estimated MSFEs are 109.4 and 101.0. The various theoretical and estimated MSFEs for the different initializations are provided in
Figure 2 and
Figure 3. We note that regardless of the initial random assignment of streams to clusters, Pivot Clustering leads to the clustering of streams such that the subaggregated MSFE is very low. In fact, typically, Pivot Clustering results in clusters for which the subaggregated MSFE ends up very close to the MSFE obtained when forecasts are based on the individual (disaggregated) streams.
We can compare our results with existing time-series clustering methods. Two distance measures that can be computed for time-series realizations are available in the TSclust package for R, namely AR.PIC and AR.LPC.CEPS. These distances can be used to perform hierarchical clustering such as average-linkage clustering. The final groups determined by these methods lead to MSFEs of 123.4 and 108.8, respectively, higher than those found by Pivot Clustering starting from random assignments. We note that the cluster assignments found by these methods can also be used in the initialization of Pivot Clustering, potentially leading to even better clusters.
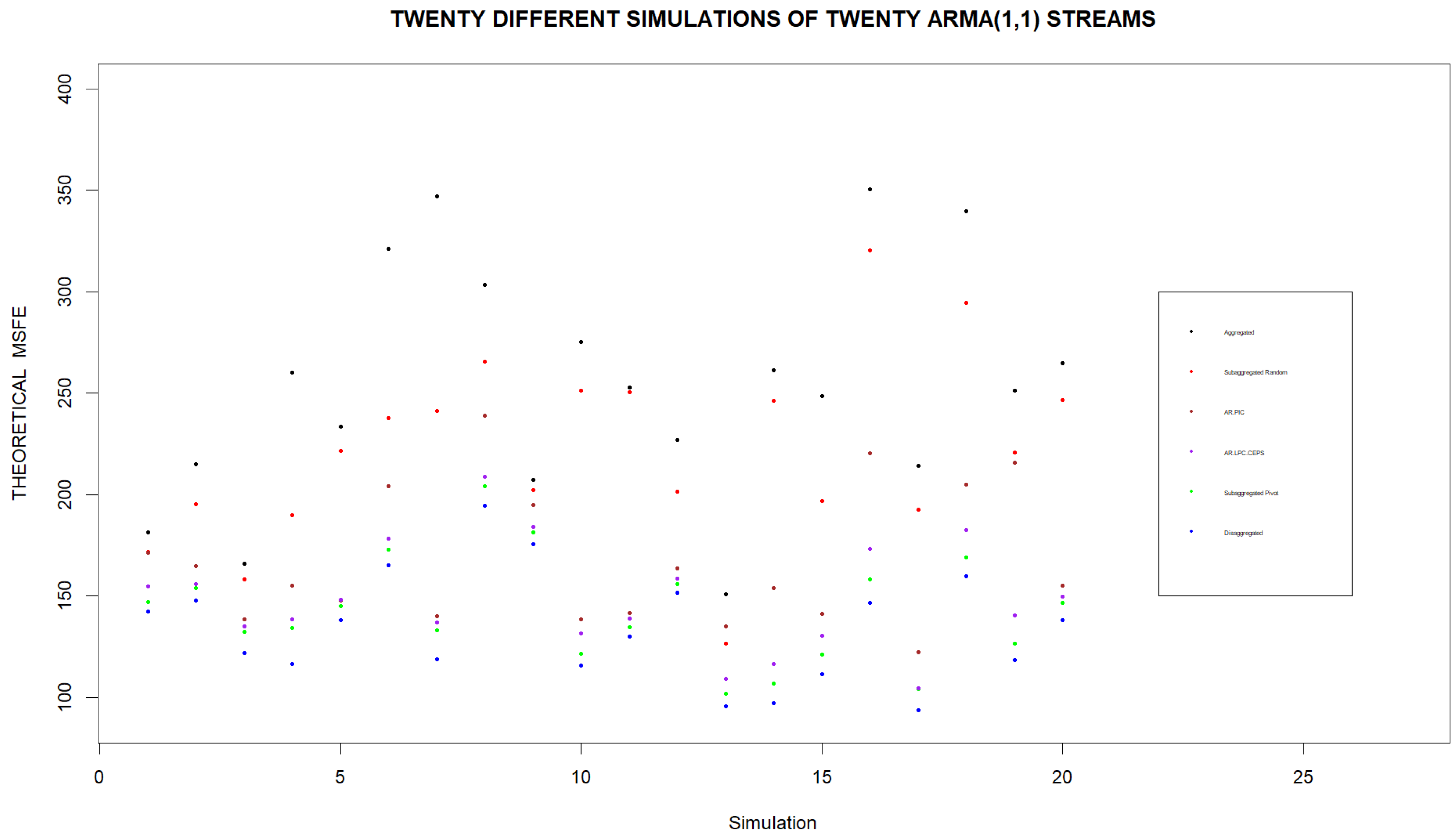
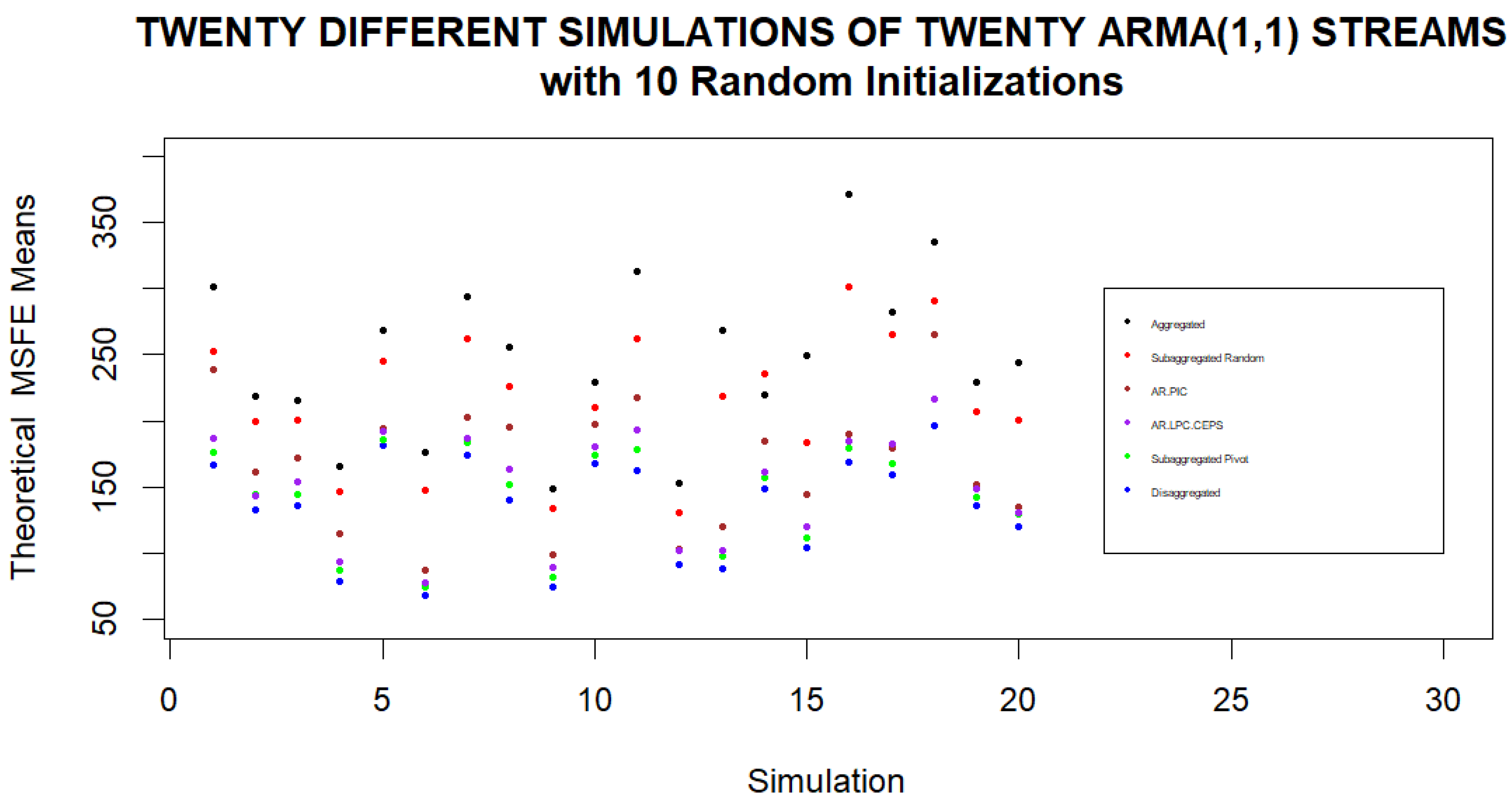
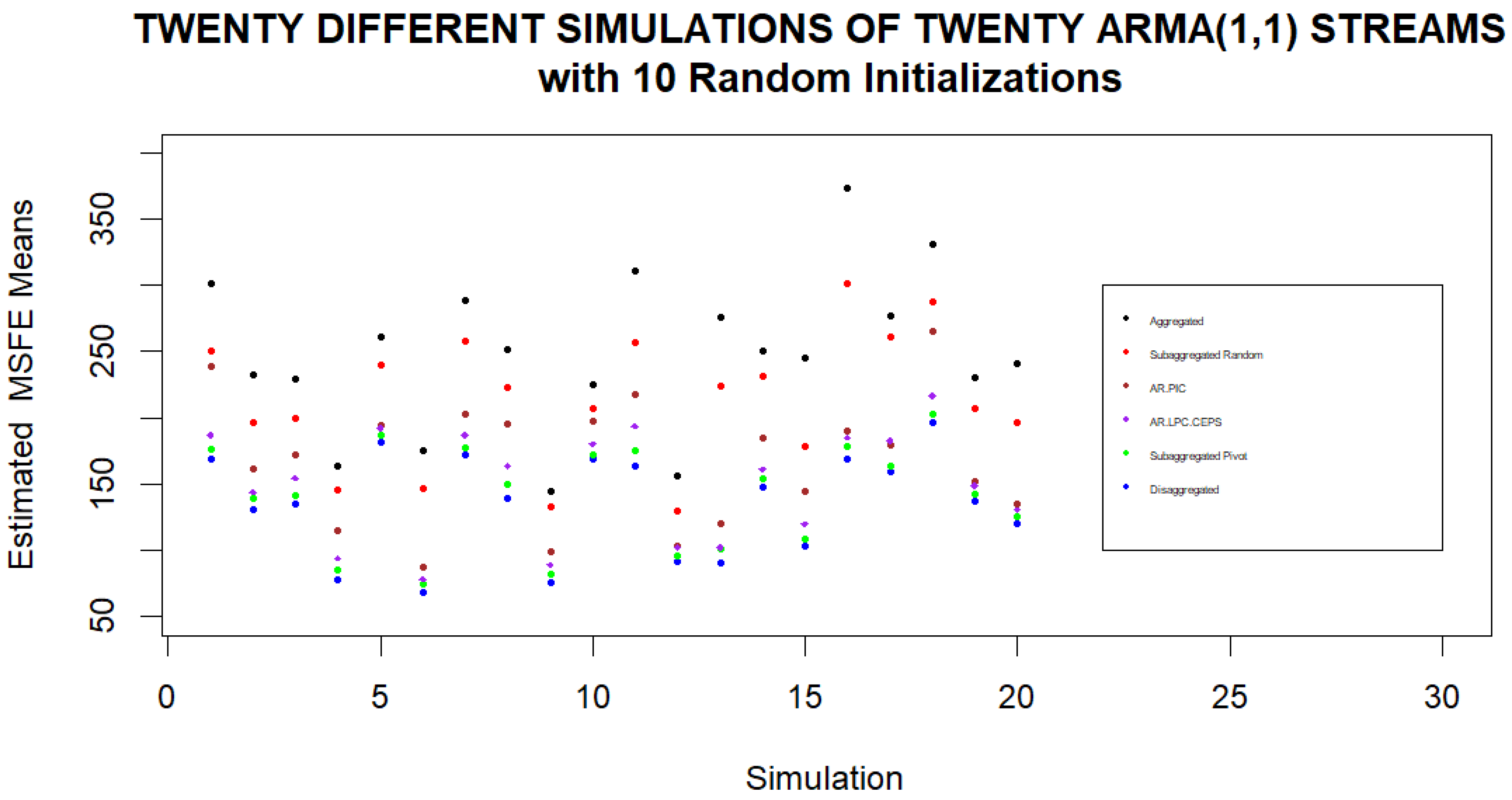
Since the previous simulations were carried out on only one set of twenty ARMA(1,1) demand models, we should also check the efficacy of Pivot Clustering for other sets of models as well. As such, we consider twenty simulations where within each simulation a new set of twenty demand models is considered. We compare the estimated and theoretical MSFEs of one random assignment of streams to four clusters with the estimated and theoretical MSFEs of the four clusters obtained by Pivot Clustering. In each simulation, we also compute the MSFEs that would be found when fully aggregating the streams or when considering forecasts based on individual streams as well as the MSFEs that would be found using the AR.PIC and AR.LPC.CEPS distances for hierarchical clustering streams into four clusters. The results of these simulations are displayed in
Figure 4 and
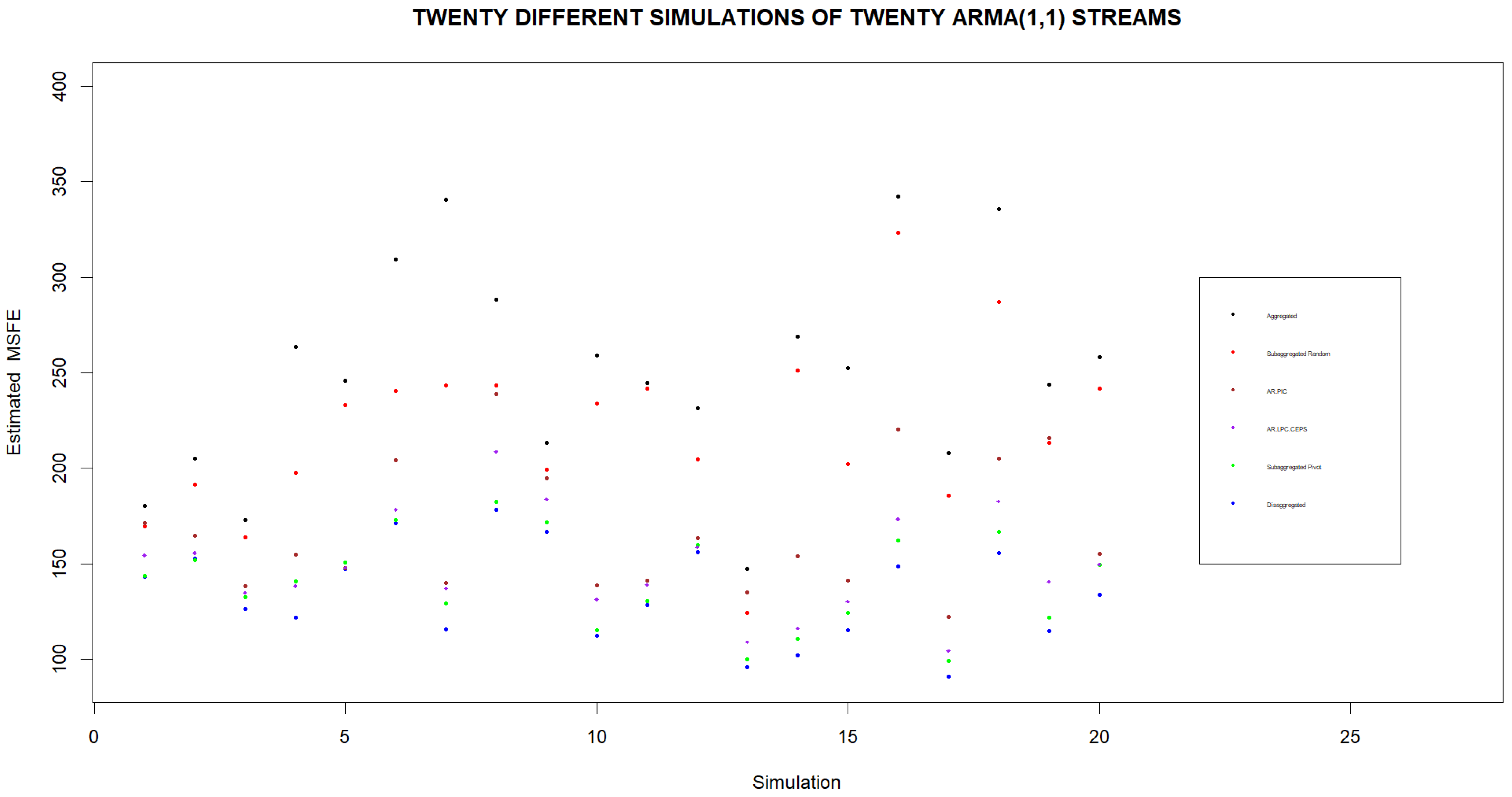
Figure 5. We note that if forecasts are to be based on four clusters, the lowest MSFEs are obtained when clusters are formed using Pivot Clustering. Furthermore, Pivot Clustering leads to forecasts whose MSFE is very close to the MSFE of the forecast based on the individual streams in every simulation.
We continue with twenty simulations where in each simulation we consider a separate set of 20 streams being subaggregated into four clusters with 10 random initializations of Pivot Clustering. The means of the various theoretical and estimated MSFEs under different clustering approaches are displayed in
Figure 6 and
Figure 7. We note again that in every set of twenty streams, the averaged subaggregated MSFEs are very close to the disaggregated MSFEs when averaged for different initial random assignments of streams to clusters.
We continue by assessing how well Pivot Clustering performs when compared against an exhaustive algorithm which checks all possible assignments of streams to clusters using theoretical MSFE calculations. To achieve this, we consider twenty simulations where within each simulation we randomly generate 10 ARMA(1,1) streams (We reduced the number of streams and clusters here due to the fact that an exhaustive algorithm requires
iterative steps to check all possible cluster assignments where
k is the number of clusters and
N is the number of streams. We note that Pivot Clustering has a complexity of
in the event that each stream is only allowed to change clusters once.) and compute the lowest MSFE possible among all choices of streams to three clusters. Furthermore, we consider 10 random initializations of Pivot Clustering each time new streams are considered. The results are displayed in
Table 2. For the first simulation of twenty streams (described by the first row of the table), 8 out of 10 initializations of our algorithm led Pivot Clustering to find the optimal solution. Among the two initializations that did not lead to the optimal solution, the ratio of optimal MSFE to the MSFE of the grouping found by pivot is 96.81%. The median was 96.81%, while the minimum ratio was 96.24%. In some instances Pivot Clustering never found an optimal solution (such as in the sixth simulation); however, the average MSFE of the optimal solution was around 99.6% of the MSFE of the groupings found by Pivot Clustering. In the worst performance, of Pivot Clustering (simulation 15), the best possible grouping led to an MSFE that was 80.27464% lower than the MSFE found by Pivot Clustering.
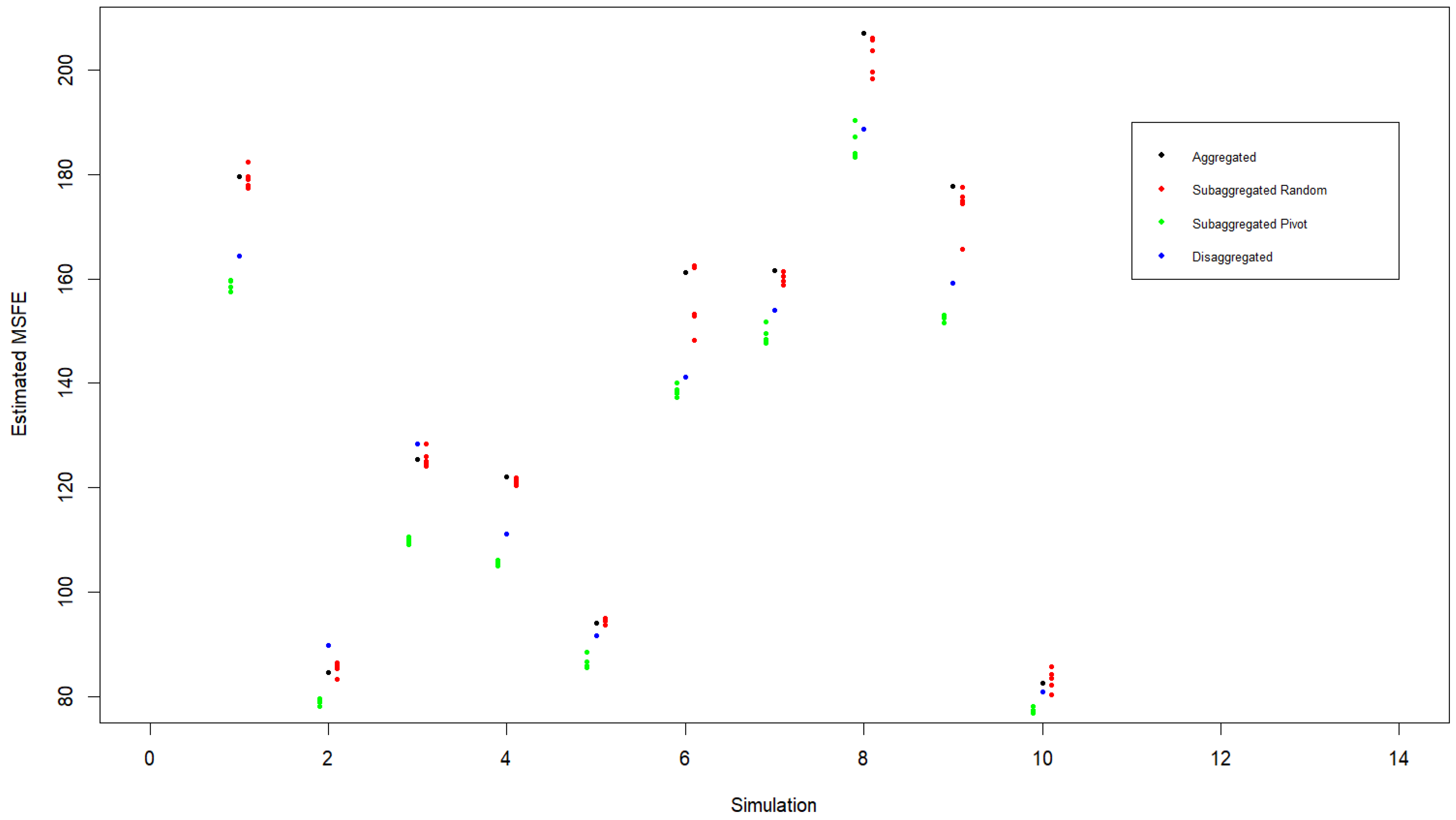
Finally, we consider the robustness of the Pivot Clustering algorithm to cases where the data generation process is not ARMA. To accomplish this, we perform ten simulations where in each simulation we simulate twenty demand stream realizations such that stream
follows an ARFIMA(
) model given by
where
and
may be nonzero. Each realization, consisting of 1500 time periods, is used to fit an ARMA(5,5) model to compute an estimated one-step-ahead MSFE for the disaggregated series (appearing as a blue dot in
Figure 8). Summing the realizations together to fit an ARMA(5,5) model yields an estimated MSFE for the aggregated series (appearing as a black dot in
Figure 8). Finally, the Pivot Clustering algorithm is carried out using five different random initializations of assigning streams to one of four clusters. The MSFEs for the subaggregated random clusters and pivot clusters appear as red and green dots in
Figure 8. We note that in the subaggregated case the number of ARMA models that needs to be estimated is equal to the number of clusters.
As before, we note that Pivot Clustering provides a sharp reduction in MSFE compared to random cluster assignments as well as compared to the aggregated case. We also observe that when fitting ARMA models to non-ARMA data, it is possible for Pivot Clustering to yield clusters which lead to a subaggregated MSFE that is lower than the MSFE using the individual (disaggregated) series. The exact cause of this is unclear; however, it is possible it has to do with the extra number of misspecified ARMA models that are fit in the disaggregated case.
6. MA(1) Streams
In this section, we consider the case that the demand streams being considered are independent MA(1). As we demonstrate below, this leads to a simpler objective function. We will use this fact to show how we can use non-linear optimization to assign clusters to streams and to come up with an efficient way to cluster independent MA(1) streams based on segmenting the coefficient space into intervals. The focus on MA(1) streams here allows us to observe that streams with their MA coefficients close to each other should be clustered together. At the end of the section, we provide a lemma on aggregating streams produced by models having identical ARMA coefficients.
Lemma 2. Suppose are MA(1) with MA coefficients . Optimal clusters can be found by assigning as an indicator variable for stream being in cluster such that we minimizewhereand Alternatively, the objective function (77) can be written as Proof. Suppose
are MA(1) with MA coefficients
. Suppose cluster
consists of streams
. The covariance generating function of
simplifies to
In order to determine the variance of the shocks of
, we need to find the roots of Equation (
81). Note that it can be rewritten as
We can find the roots of Equation (
82) using the quadratic formula
where
We note that one roots
will be outside the unit circle and from Remark 1 that the variance of the shocks of
is equal to
. Since
, the variance is then given by
Thus, if we are subaggregating into
n clusters, the MSFE is given by
Since
will be the same regardless of choice of clusters, we are minimizing the objective function given by
where
and
where
is an indicator variable for stream
being in cluster
.
The objective function can also be rewritten as
□
We have results (not shown here) where we use Equation (92) in a non-linear optimization algorithm to come up with clusters. When using 10 streams with three clusters, the approach actually leads to a globally optimal solution almost every time.
We note that Equation (92) can also be rewritten as
where the inner sum is taken over all pairs of streams in each cluster, including pairs of streams with themselves.
If stream
is moved from cluster
k to cluster
, then the change in the objective function is
which provides an alternative way to cluster streams by identifying and moving the stream from one cluster to another, which yields the largest drop in the objective function.
Aggregate of Two MA(1) Streams
In this subsection, we consider two MA(1) streams whose variance of shocks is unitary. We demonstrate that the MA coefficient (The aggregate of two MA(1) streams is always MA(1)) of their aggregate process is always between the two MA coefficients of the individual streams. Furthermore, we show that as the two coefficients of the two MA(1) streams are moved further apart from each other, the variance of the shocks appearing in the aggregated process increases. These two facts imply that if we are studying N individual MA(1) streams (with unit shock variance) and would like to cluster them into n clusters, then the globally optimal clustering assignment will cluster the streams along intervals. That is, the assignment will have split the clusters into groups of streams whose MA coefficients are next to each other in a sorted arrangement. This implies that an efficient algorithm for obtaining a globally optimal cluster assignment consists of arranging the MA coefficients in increasing order and checking all possible “interval” clusters, without worrying that if two streams are clustered together, another stream with an MA coefficient between the two is assigned to a different cluster. This algorithm would need to check possible cluster assignments to find the globally optimal arrangement.
Theorem 1. Consider two streams whose ARMA representations are given bywith and and . Note that and are allowed to equal 0. The aggregated process is described by the MA(1) modelsuch that . Proof. Note that the covariance generating function of the aggregate process is
As long as (if , then and the result still holds), this polynomial has roots and . Suppose is inside the unit circle, then according to Remark 1, and .
We can note that the Laurent polynomial in Equation (
95) has roots given by
In the remainder of this section, we will prove that
Suppose first that .
Then, we can rewrite Equation (
99) as
or equivalently,
or
Noting that the left and right-hand sides of the inequality are always larger than zero, (
102) holds if and only if the following inequality holds as well:
Labeling the three sides of this inequality as
, we observe that
Removing equivalent terms and combining like terms, we observe
which can be rewritten as
Noting that the left and right-hand sides of this inequality are additive inverses, we see that this inequality holds (the given direction of the inequalities must hold, otherwise
in (
99)) and therefore inequality (
99) holds.
Finally, if
in (
99), then the direction of the inequalities is reversed in (
100) and a similar sequence of steps would lead us to observe
and by the same argument, we see that (
99) holds and the theorem is proved. □
Theorem 2. Consider two streams whose ARMA representations are given bywith and and . Note that and may be 0. As the distance between and increases, increases.
Proof. From Equation (
95) we see that the root
of
, which is outside the unit circle, is given by
Since
, we have
To show that this is increasing in
, consider the derivative of the above with respect to
:
We need to show that (
109) is larger than zero, thus consider
or equivalently
which simplifies to
or
We will refer to the left and right hand sides of the inequality in (
113) as
and
. Note that squaring both yields,
Suppose first that
. Note that (
113) reduces to
, which holds, and therefore (
110) holds as well.
Next, suppose that
. Note that (
113) reduces to
which holds as well since the left-hand side is negative in this case.
In the remainder of the proof, we assume that
and
. Consider the case that
. Note that this implies that
>0 (since
) and that (
115) is less than zero. Thus, in this case
and
in (
113). Therefore, (
110) holds in this case as well.
Now, suppose that
and that
. The former implies that
and the latter implies that
. Therefore
and therefore
. Therefore, (
110) holds in this case as well.
Finally, suppose that
and that
. The former again implies that
, while the latter implies that
. Therefore,
and (
110) holds in all cases. □



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}