
Computationally Efficient Poisson Time-Varying Autoregressive Models through Bayesian Lattice Filters

Abstract
:1. Introduction
2. Methodology
2.1. TV-Pois-AR(P) Model
2.2. Bayesian Lattice Filter for the TV-AR Process
2.3. Model Specification and Bayesian Inference
2.4. Model Selection
2.5. Forecasting
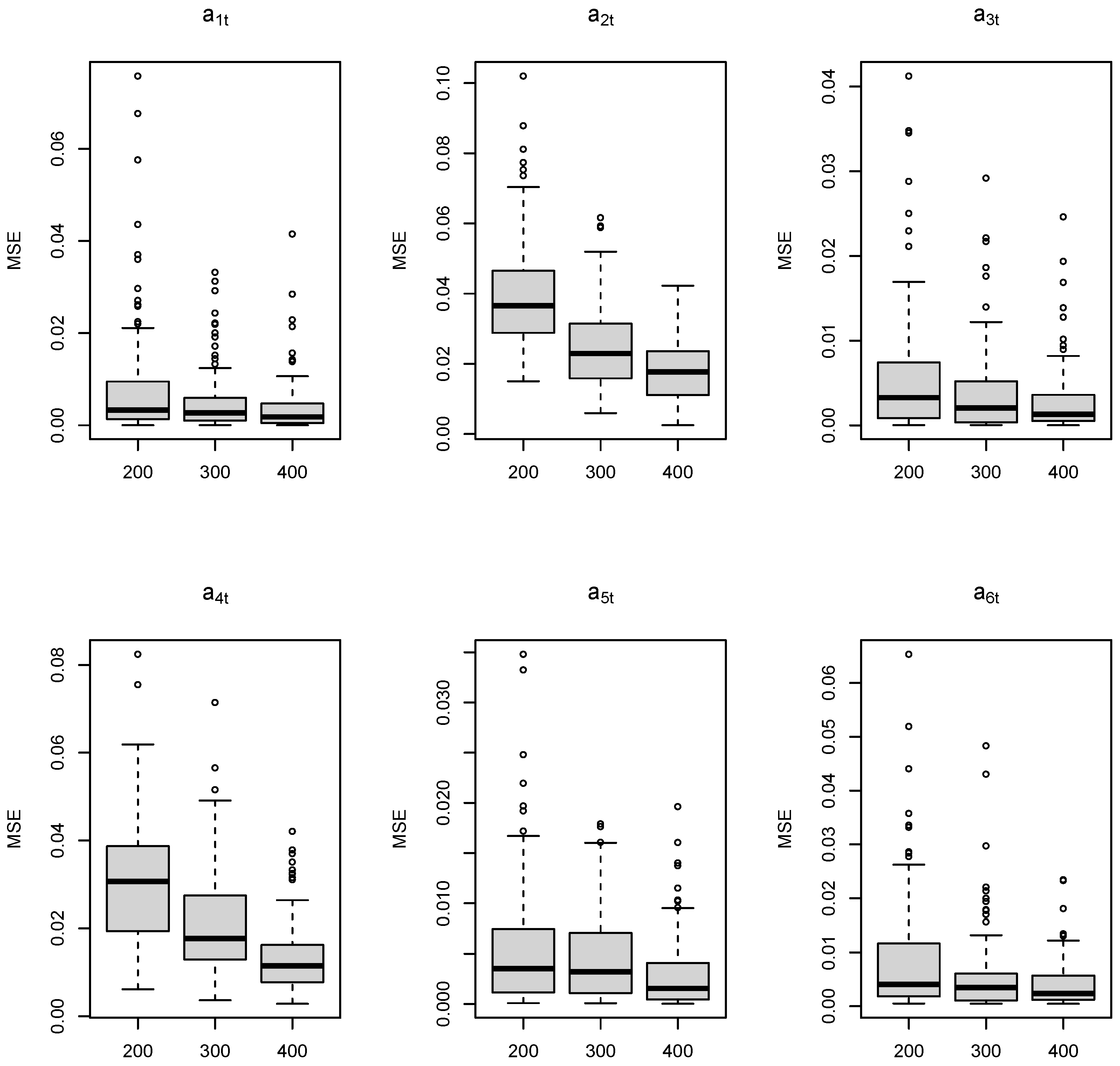
3. Simulation Study
3.1. Simulation 1
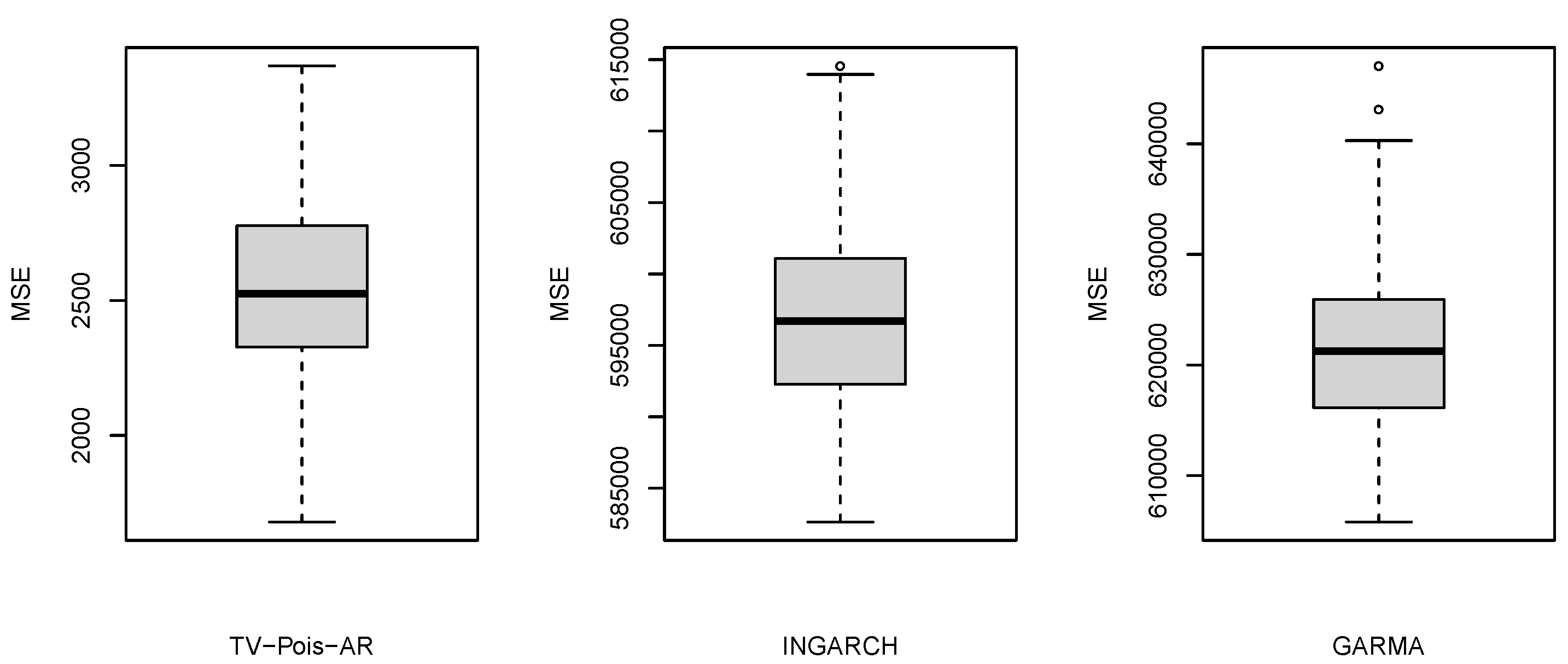
3.2. Simulation 2—An Empirical Simulation
4. Case Studies
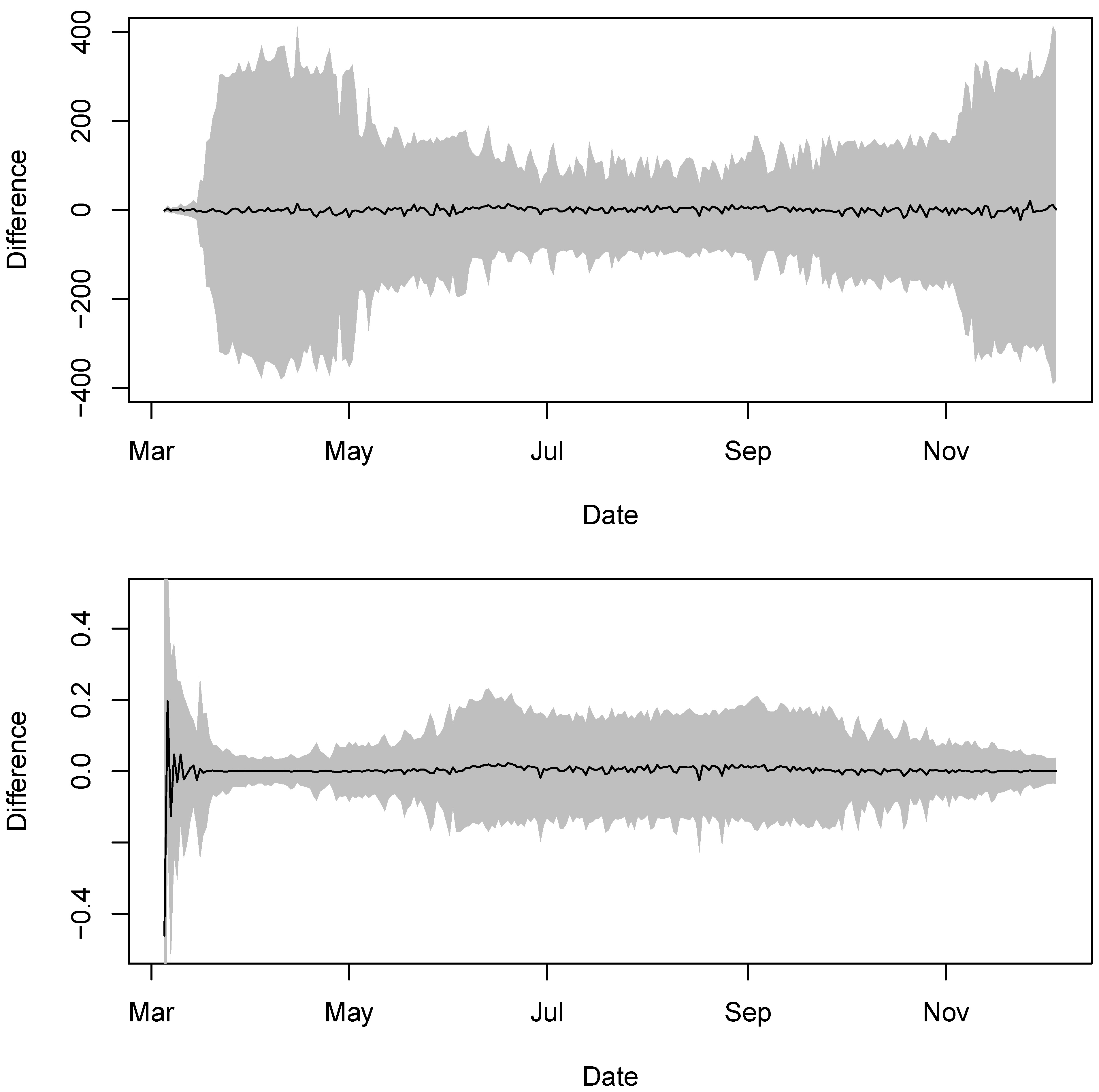
4.1. Case Study 1: COVID-19 in New York State
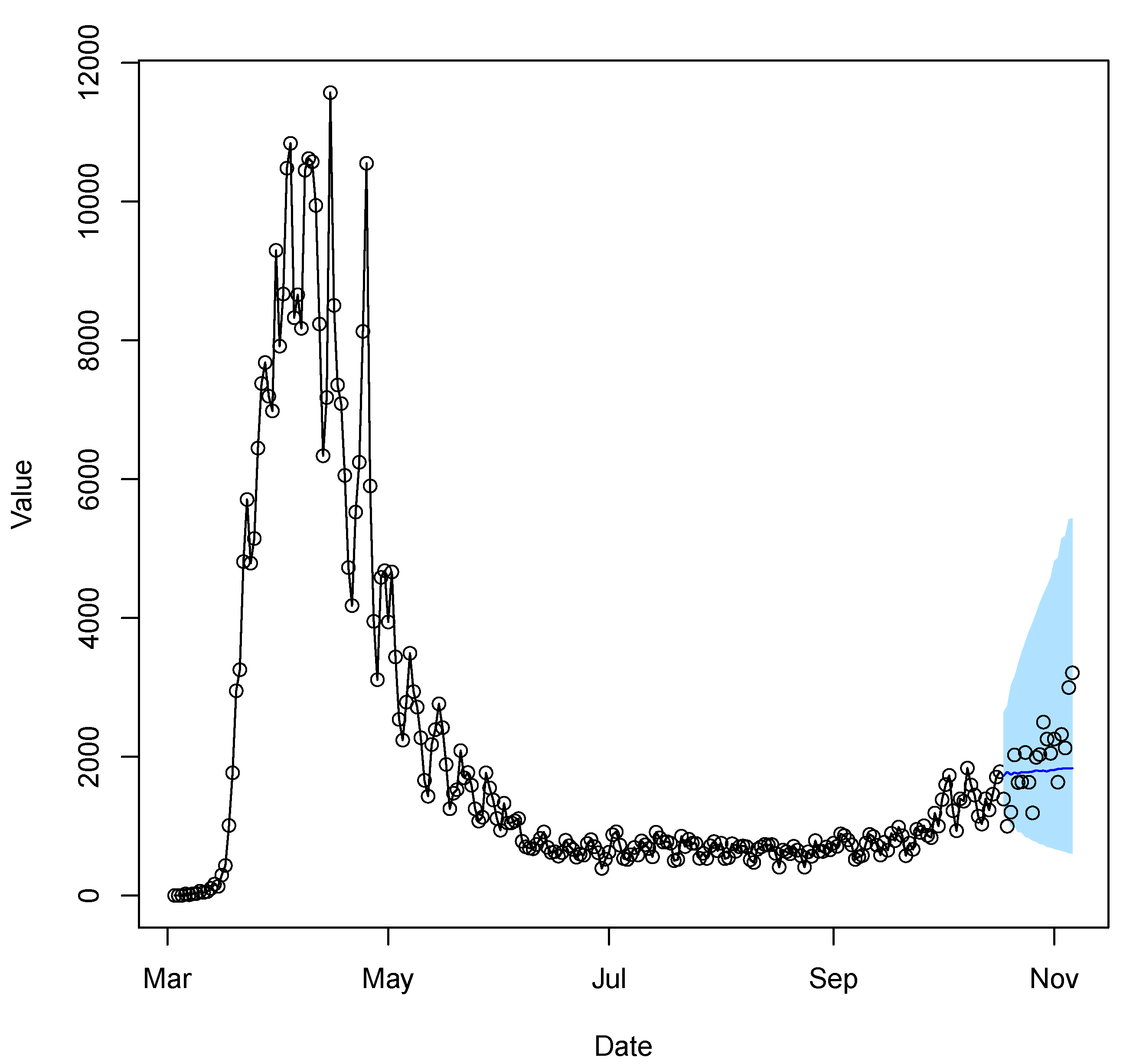
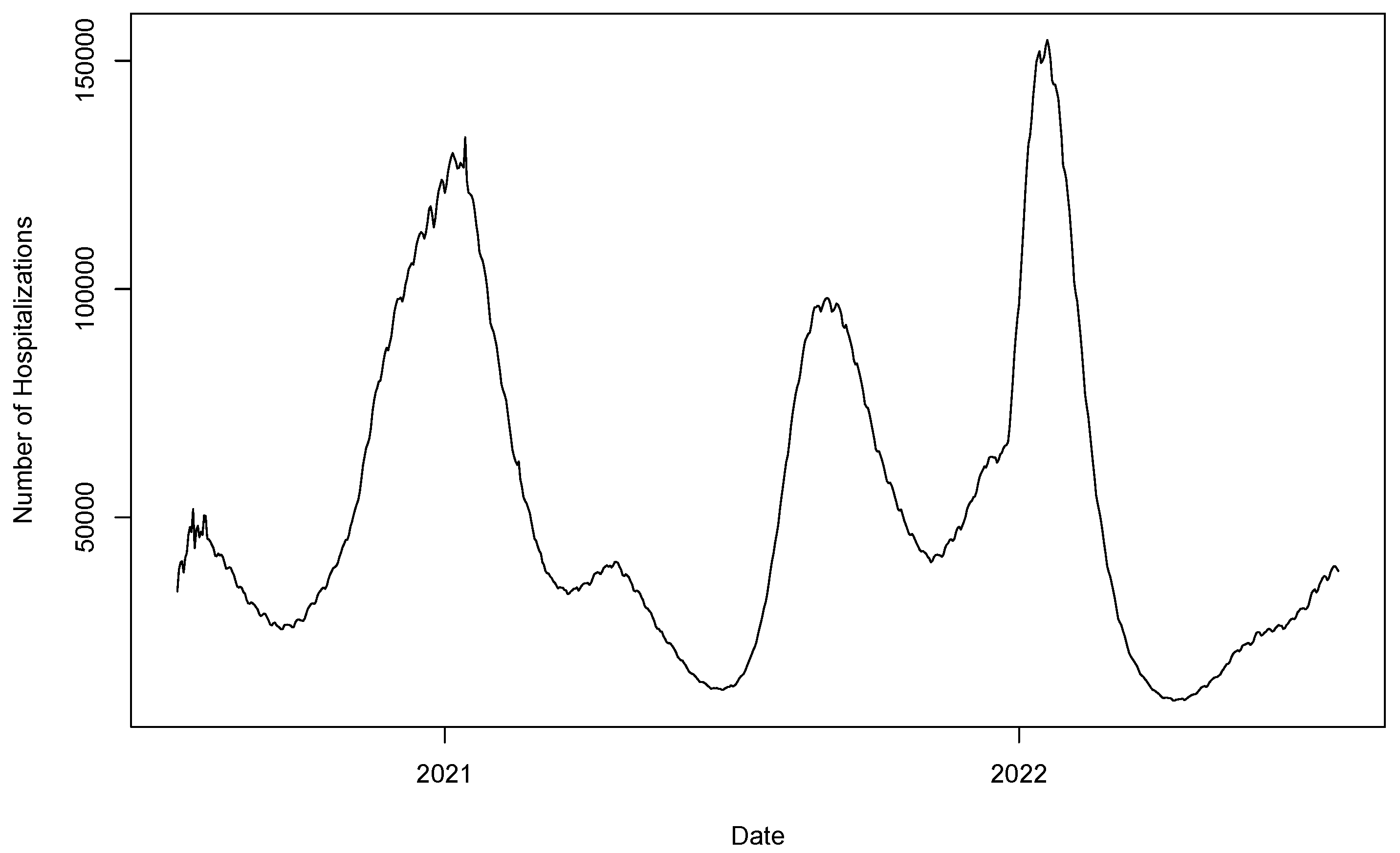
4.2. Case Study 2: COVID-19 hospitalization in the U.S.
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Algorithm of Fitting Poisson TV-AR Time Series
- Use the posterior means of and obtained from the BLF (see Appendix B) as samples, where and ;
- Draw samples of from the full conditional distribution using a a no-U-turn sampler.
Appendix B. Bayesian Lattice Filter
- Step 1. Repeat Step 2 for stage ;
- Step 2. Apply the sequential filtering and smoothing algorithm (see Appendix C) to the prediction errors of last stage, and , to obtain and of the forward and backward equations, and the forward and backward prediction errors, and , for ;
- Step 3. The posterior mean of and are and obtained from the Pth stage Step 2.
Appendix C. Sequential Filtering and Smoothing Algorithm
Appendix D. Forecasting
- For stage p, compute the h-step-ahead predictive distribution of the PARCOR coefficients following [26] where and with ;
- Draw J samples of from their predictive distribution;
- For stage p, compute the h-step-ahead predictive distribution of innovation variance following [26]: , where and ;
- For stage p, draw J samples of from its predictive distribution;
- Compute the samples of the AR coefficients through the Durbin–Levinson algorithm from the samples of ;
- The samples of are generated from its predictive distribution, such thatwhere if ;
- With the samples of from its posterior distribution, the samples of the h-step-ahead forecast are drawn as
- We use the posterior median of obtained through the samples in (A1) as the h-step-ahead forecast.
References
- Cox, D.R.; Gudmundsson, G.; Lindgren, G.; Bondesson, L.; Harsaae, E.; Laake, P.; Juselius, K.; Lauritzen, S.L. Statistical analysis of time series: Some recent developments [with discussion and reply]. Scand. J. Stat. 1981, 8, 93–115. [Google Scholar]
- Koopman, S.J.; Lucas, A.; Scharth, M. Predicting time-varying parameters with parameter-driven and observation-driven models. Rev. Econ. Stat. 2016, 98, 97–110. [Google Scholar] [CrossRef]
- Ferland, R.; Latour, A.; Oraichi, D. Integer-valued GARCH process. J. Time Ser. Anal. 2006, 27, 923–942. [Google Scholar] [CrossRef]
- Fokianos, K.; Rahbek, A.; Tjøstheim, D. Poisson autoregression. J. Am. Stat. Assoc. 2009, 104, 1430–1439. [Google Scholar] [CrossRef]
- Al-Osh, M.; Alzaid, A.A. First-order integer-valued autoregressive (INAR (1)) process. J. Time Ser. Anal. 1987, 8, 261–275. [Google Scholar] [CrossRef]
- Zeger, S.L. A regression model for time series of counts. Biometrika 1988, 75, 621–629. [Google Scholar] [CrossRef]
- Dunsmuir, W.T. Generalized Linear Autoregressive Moving Average Models. In Handbook of Discrete-Valued Time Series; Chapman & Hall/CRC: Boca Raton, FL, USA, 2016; p. 51. [Google Scholar]
- Brandt, P.T.; Williams, J.T. A linear Poisson autoregressive model: The Poisson AR (p) model. Political Anal. 2001, 9, 164–184. [Google Scholar] [CrossRef]
- Davis, R.A.; Holan, S.H.; Lund, R.; Ravishanker, N. (Eds.) Handbook of Discrete-Valued Time Series; Chapman & Hall/CRC: Boca Raton, FL, USA, 2016. [Google Scholar]
- Davis, R.A.; Fokianos, K.; Holan, S.H.; Joe, H.; Livsey, J.; Lund, R.; Pipiras, V.; Ravishanker, N. Count time series: A methodological review. J. Am. Stat. Assoc. 2021, 116, 1533–1547. [Google Scholar] [CrossRef]
- Smith, R.; Miller, J. A non-Gaussian state space model and application to prediction of records. J. R. Stat. Soc. Ser. B (Methodol.) 1986, 48, 79–88. [Google Scholar] [CrossRef]
- Brandt, P.T.; Williams, J.T.; Fordham, B.O.; Pollins, B. Dynamic modeling for persistent event-count time series. Am. J. Political Sci. 2000, 44, 823–843. [Google Scholar] [CrossRef]
- Berry, L.R.; West, M. Bayesian forecasting of many count-valued time series. J. Bus. Econ. Stat. 2019, 38, 872–887. [Google Scholar] [CrossRef]
- Bradley, J.R.; Holan, S.H.; Wikle, C.K. Computationally efficient multivariate spatio-temporal models for high-dimensional count-valued data (with discussion). Bayesian Anal. 2018, 13, 253–310. [Google Scholar] [CrossRef]
- Bradley, J.R.; Holan, S.H.; Wikle, C.K. Bayesian hierarchical models with conjugate full-conditional distributions for dependent data from the natural exponential family. J. Am. Stat. Assoc. 2020, 115, 2037–2052. [Google Scholar] [CrossRef]
- Yang, W.H.; Holan, S.H.; Wikle, C.K. Bayesian lattice filters for time–varying autoregression and time–frequency analysis. Bayesian Anal. 2016, 11, 977–1003. [Google Scholar] [CrossRef]
- Hoffman, M.D.; Gelman, A. The No-U-Turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo. J. Mach. Learn. Res. 2014, 15, 1593–1623. [Google Scholar]
- Märtens, K. HMC No-U-Turn Sampler (NUTS) Implementation in R. 2017. Available online: https://github.com/kasparmartens/NUTS (accessed on 27 July 2020).
- Neal, R.M. An improved acceptance procedure for the hybrid Monte Carlo algorithm. J. Comput. Phys. 1994, 111, 194–203. [Google Scholar] [CrossRef]
- Neal, R.M. MCMC using Hamiltonian dynamics. In Handbook of Markov Chain Monte Carlo; Chapman & Hall/CRC: Boca Raton, FL, USA, 2011; Volume 2, p. 2. [Google Scholar]
- Duane, S.; Kennedy, A.D.; Pendleton, B.J.; Roweth, D. Hybrid Monte Carlo. Phys. Lett. B 1987, 195, 216–222. [Google Scholar] [CrossRef]
- Martino, L.; Yang, H.; Luengo, D.; Kanniainen, J.; Corander, J. A fast universal self-tuned sampler within Gibbs sampling. Digit. Signal Process. 2015, 47, 68–83. [Google Scholar] [CrossRef]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Kitagawa, G. Introduction to Time Series Modeling; Chapman & Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- Hayes, M.H. Statistical Digital Signal Processing and Modeling; John Wiley & Sons: Hoboken, NJ, USA, 1996. [Google Scholar]
- West, M.; Harrison, J. Bayesian Forecasting and Dynamic Models, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Spiegelhalter, D.J.; Best, N.G.; Carlin, B.P.; Van Der Linde, A. Bayesian measures of model complexity and fit. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2002, 64, 583–639. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; Chapman & Hall/CRC: Boca Raton, FL, USA, 2013. [Google Scholar]
- Watanabe, S. Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory. J. Mach. Learn. Res. 2010, 11, 3571–3594. [Google Scholar]
- Watanabe, S. A widely applicable Bayesian information criterion. J. Mach. Learn. Res. 2013, 14, 867–897. [Google Scholar]
- Rosen, O.; Stoffer, D.S.; Wood, S. Local spectral analysis via a Bayesian mixture of smoothing splines. J. Am. Stat. Assoc. 2009, 104, 249–262. [Google Scholar] [CrossRef]
- Pan, W. Akaike’s information criterion in generalized estimating equations. Biometrics 2001, 57, 120–125. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average of MSEs (s.d. of MSEs) | |||
|---|---|---|---|
| 200 | 300 | 400 | |
| 0.0086 (0.0136) | 0.0055 (0.0070) | 0.0040 (0.0063) | |
| 0.0404 (0.0165) | 0.0254 (0.0119) | 0.0183 (0.0083) | |
| 0.0061 (0.0080) | 0.0039 (0.0052) | 0.0030 (0.0042) | |
| 0.0307 (0.0139) | 0.0212 (0.0121) | 0.0136 (0.0086) | |
| 0.0058 (0.0068) | 0.0047 (0.0047) | 0.0031 (0.0039) | |
| 0.0091 (0.0117) | 0.0058 (0.0081) | 0.0044 (0.0049) | |
| Model | INGARCH | GLARMA | TV-Pois-AR |
|---|---|---|---|
| AMSE | 597,041.3 | 621,732.5 | 2568.6 |
| P | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| DIC | 1738.540 | 1735.748 | 1783.484 | 1779.946 | 1796.255 |
| WAIC | 303.004 | 295.531 | 317.326 | 316.626 | 320.476 |
| Model | MPSE |
|---|---|
| TV-Pois-AR(2) | 2.277 × 10 |
| GLARMA(6,2) | 2.363 × 10 |
| INGARCH(1,0) | 2.675 × 10 |
| Naive | 2.286 × 10 |
| P | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| DIC | 24,481.39 | 23,898.07 | 23,248.08 | 22,726.58 | 23,278.76 |
| WAIC | 6518.81 | 6190.746 | 5863.422 | 5612.337 | 5881.701 |
| Model | MSPE |
|---|---|
| Pois-TVAR | 1.51 × 10 |
| GLARMA(6,2) | 16.00 × 10 |
| INGARCH(1,0) | 11.10 × 10 |
| Naive | 3.20 × 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sui, Y.; Holan, S.H.; Yang, W.-H. Computationally Efficient Poisson Time-Varying Autoregressive Models through Bayesian Lattice Filters. Stats 2023, 6, 1037-1052. https://doi.org/10.3390/stats6040065
Sui Y, Holan SH, Yang W-H. Computationally Efficient Poisson Time-Varying Autoregressive Models through Bayesian Lattice Filters. Stats. 2023; 6(4):1037-1052. https://doi.org/10.3390/stats6040065
Chicago/Turabian StyleSui, Yuelei, Scott H. Holan, and Wen-Hsi Yang. 2023. "Computationally Efficient Poisson Time-Varying Autoregressive Models through Bayesian Lattice Filters" Stats 6, no. 4: 1037-1052. https://doi.org/10.3390/stats6040065
APA StyleSui, Y., Holan, S. H., & Yang, W.-H. (2023). Computationally Efficient Poisson Time-Varying Autoregressive Models through Bayesian Lattice Filters. Stats, 6(4), 1037-1052. https://doi.org/10.3390/stats6040065