
Unsupervised Feature Selection for Histogram-Valued Symbolic Data Using Hierarchical Conceptual Clustering


Abstract
:1. Introduction
- (1)
- How to evaluate the similarity between objects and/or clusters under the given feature subset;
- (2)
- How to evaluate the quality of clusters under the given feature subset;
- (3)
- How to evaluate the effectiveness of the given feature subset; and
- (4)
- How to search the most robustly informative feature subset from the whole feature set.
2. Representation of Objects by Bin-Rectangles
2.1. Histogram-Valued Feature
2.2. Histogram Representation of Other Feature Types
2.2.1. Categorical Multi-Valued Feature
2.2.2. Modal Multi-Valued Feature
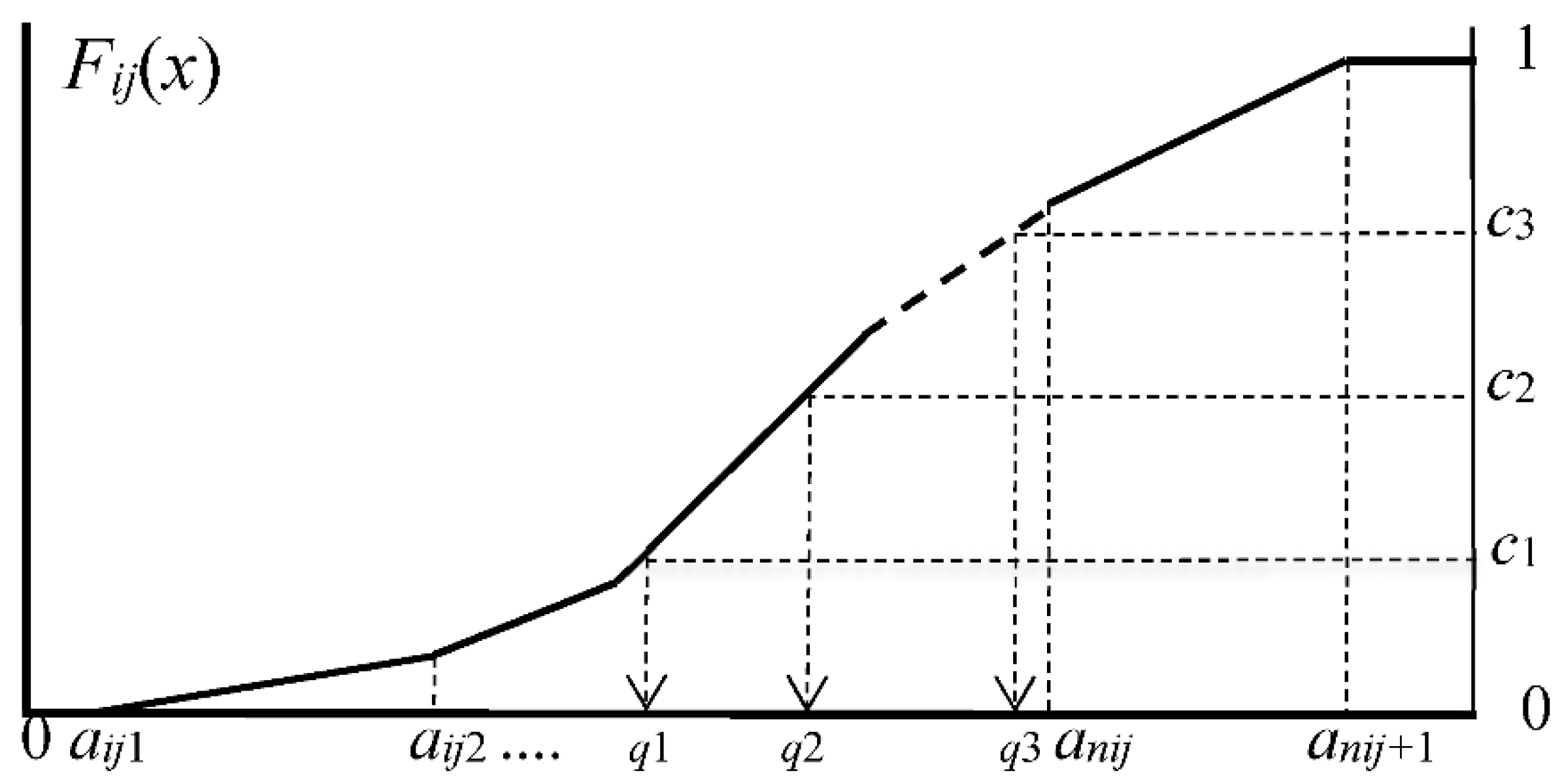
2.3. Representation of Histograms by Common Number of Quantiles
Fij(x) = pij1(x − aij1)/(aij2 − aij1) for aij1 ≤ x < aij2
Fij(x) = F(aij1) + pij2(x − aij2)/(aij3 − aij2) for aij2 ≤ x < aij3
⋯⋯
Fij(x) = F(anij−1) + pijnij(x − anij)/(anij+1 − anij) for anij ≤ x < anij+1
Fij(x) = 1 for anij+1 ≤ x.
- (1)
- We choose common number m of quantiles.
- (2)
- Let c1, c2,…, cm−1 be preselected cut points dividing the range of the distribution function Fij(x) into continuous intervals, i.e., bins, with preselected probabilities associated with m cut points. For example, in the quartile case we use three cut points, c1 = 1/4, c2 = 2/4, and c3 = 3/4, to have four bins with the same probability 1/4. However, we can choose different cut points, for example, c1 = 1/10, c2 = 5/10, and c3 = 9/10, to have four bins with probabilities 1/10, 4/10, 4/10, and 1/10, respectively.
- (3)
- For the given cut points c1, c2,…, cm−1, we have the corresponding quantiles by solving the following equations:
Fij(xij1) = c1, Fij(xij2) = c2,…, Fij(xij(m−1)) = cm−1, and
Fij(xijm) = 1, (i.e., xijm = aijnij+1).
2.4. Quantile Vectors and Bin-Rectangles
= [xi1k, xi1(k+1)] × [xi2k, xi2(k+1)] × ⋅⋅⋅ × [xipk, xip(k+1)], k = 0, 1,…, m−1,
2.5. Concept Size of Bin-Rectangles
+ (cm−1 − cm−2)(xij(m−1) − xij(m−2)) + (1 − cm−1)(xijm − xij(m−1))}/|Dj|,
= {c1|xij0⊕xij1| + (c2 − c1)|xij1⊕xij2| + ⋅⋅⋅ + (ck + c(k−1))|xij(k−1)⊕xijk| + ⋯
+ (cm−1 − cm−2)|xij(m−1)⊕xij(m−2)| + (1 − cm−1)|xijm⊕xij(m−1)|}/|Dj|, j = 1, 2,…, p,
- (1)
- When Eij is a histogram with a single bin, the concept size is P(Eij) = (xij1 − xij0)/|Dj|
- (2)
- When Eij is a histogram with four bins with equal probabilities, i.e., a quartile case, the average concept size of four bins is P(Eij) = (xij4 − xij0)/(4|Dj|).
- (3)
- When Eij is a histogram with four bins with cut points c1 = 1/10, c2 = 5/10, and c3 = 9/10, the average concept size of four bins isP(Eij) = {(xij1 − xij0)/10 + 4(xij2 − xij1)/10 + 4(xij3 − xij2)/10 + (xij4 − xij3)/10}/|Dj|= (xij4 + 3xij3 − 3xij1 − xij0)/(10|Dj|)
- (4)
- In the Hardwood data (seeSection 4.4), seven quantile values for five cut point probabilities, c1 = 1/10, c2 = 1/4, c3 = 1/2, c4 = 3/4, and c5 = 9/10, describe each histogram for Eij. Then, the average concept size of six bins becomes:P(Eij) = {(10(xij1 − xij0)/100 + 15(xij2 − xij1)/100 + 25(xij3 − xij2)/100 + 25(xij4 − xij3)/100
+ 15(xij5 − xij4)/100 + 10(xij6 − xij5)/100}/|Dj|
= {10xij6 + 5xij5 + 10xij4 − 10xij2 − 5xij1 −10xij0}/(100|Dj|)
= {2xij6 + xij5 + 2xij4 − 2xij2 − xij1 − 2xij0}/(20|Dj|)
- (1)
- When m bin probabilities are the same, the average concept size of m bins is reduced to the form:P(Eij) = (xijm − xij0)/(m|Dj|), j = 1, 2,…, p
- (2)
- When m bin-widths are the same size wij, we have:P(Eij) = wij/|Dj|, j = 1, 2,…, p,
- (3)
- It is clear that:wij = (xijm − xij0)/m.
3. Concept Size of the Cartesian Join of Objects and the Compactness
3.1. Concept Size of the Cartesian Join of Objects
+ (cm−1 − cm−2)(x(i+l)j(m−1) − x(i+l)j(m−2)) + (1 − cm−1)(x(i+l)jm − x(i+l)j(m−1))}/|Dj|,
= {c1|x(i+l)j0⊕x(i+l)j1| + (c2 − c1)|x(i+l)j1⊕x(i+l)j2| + …
+ (cm−1 − cm−2)|x(i+l)j(m−2)⊕x(i+l)j(m−1)| + (1 − cm−1)|x(i+l)j(m−1)⊕x(i+l)jm|}/|Dj|, j = 1, 2,…, p.
3.2. Compactness and Its Properties
- (1)
- 0 ≤ C(ωi, ωl) ≤ 1
- (2)
- C(ωi, ωl) = 0 iff Ei≡El and has null size (P(Ei) = 0)
- (3)
- C(ωi, ωi), C(ωl, ωl) ≤ C(ωi, ωl)
- (4)
- C(ωi, ωl) = C(ωl, ωi)
- (5)
- C(ωi, ωr) ≤ C(ωi, ωl) + C(ωl, ωr) may not hold in general.
4. Exploratory Hierarchical Concept Analysis
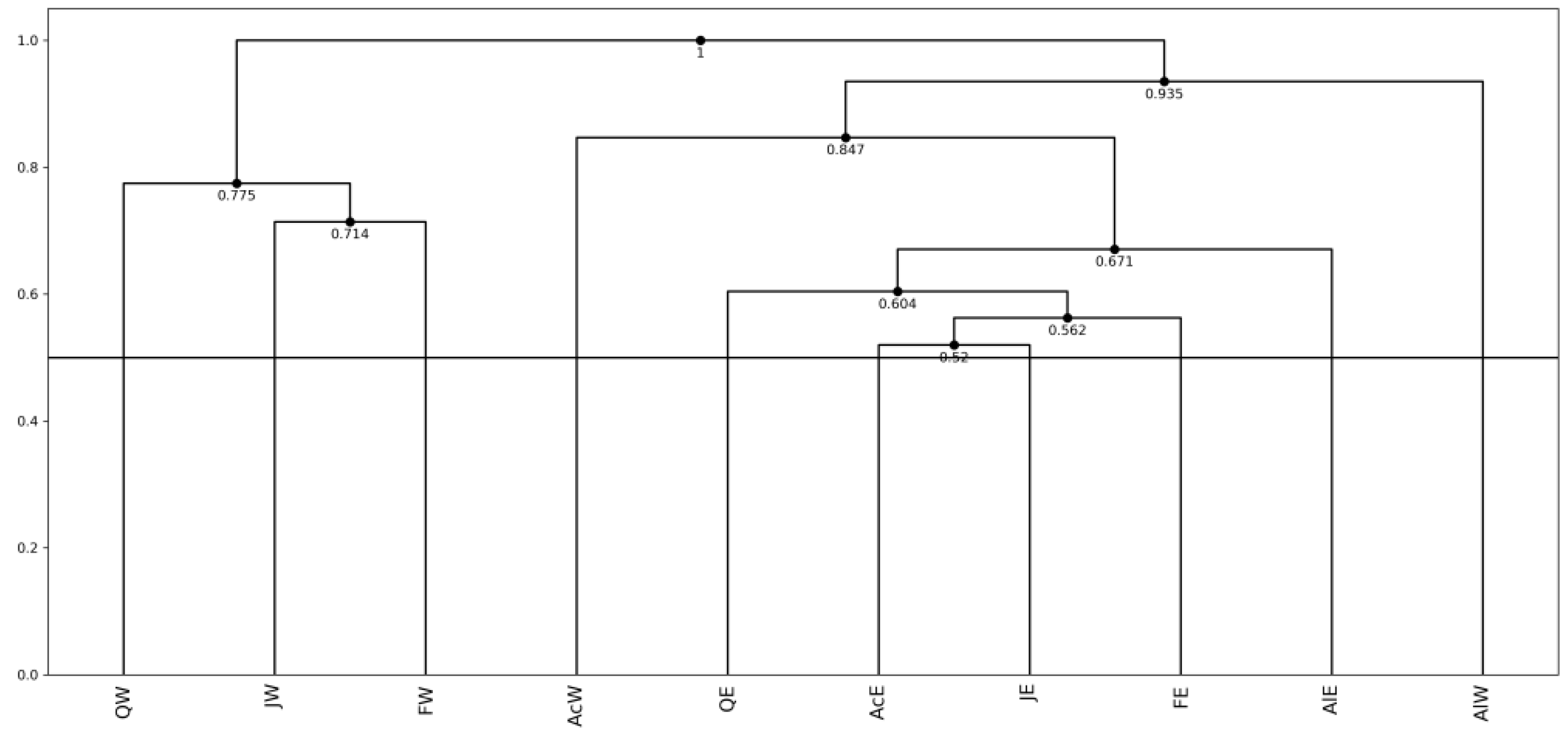
4.1. Hierarchical Conceptual Clustering
- Algorithm (Hierarchical Conceptual Clustering (HCC)
- Step 1: For each pair of objects ωi and ωl in U, evaluate the compactness C(ωi, ωl) and find the pair ωq and ωr that minimizes the compactness.
- Step 2: Add the merged concept ωqr = {ωq, ωr} to U and delete ωq and ωr from U, where the representation of ωqr follows to the Cartesian join in Definition 4 under the assumption of m quantiles and the equal bin probabilities.
- Step 3: Repeat Step 1 and Step 2 until U includes only one concept, i.e., the whole concept.
4.2. An Exploratory Method of Feature Selection
4.2.1. Artificial Data
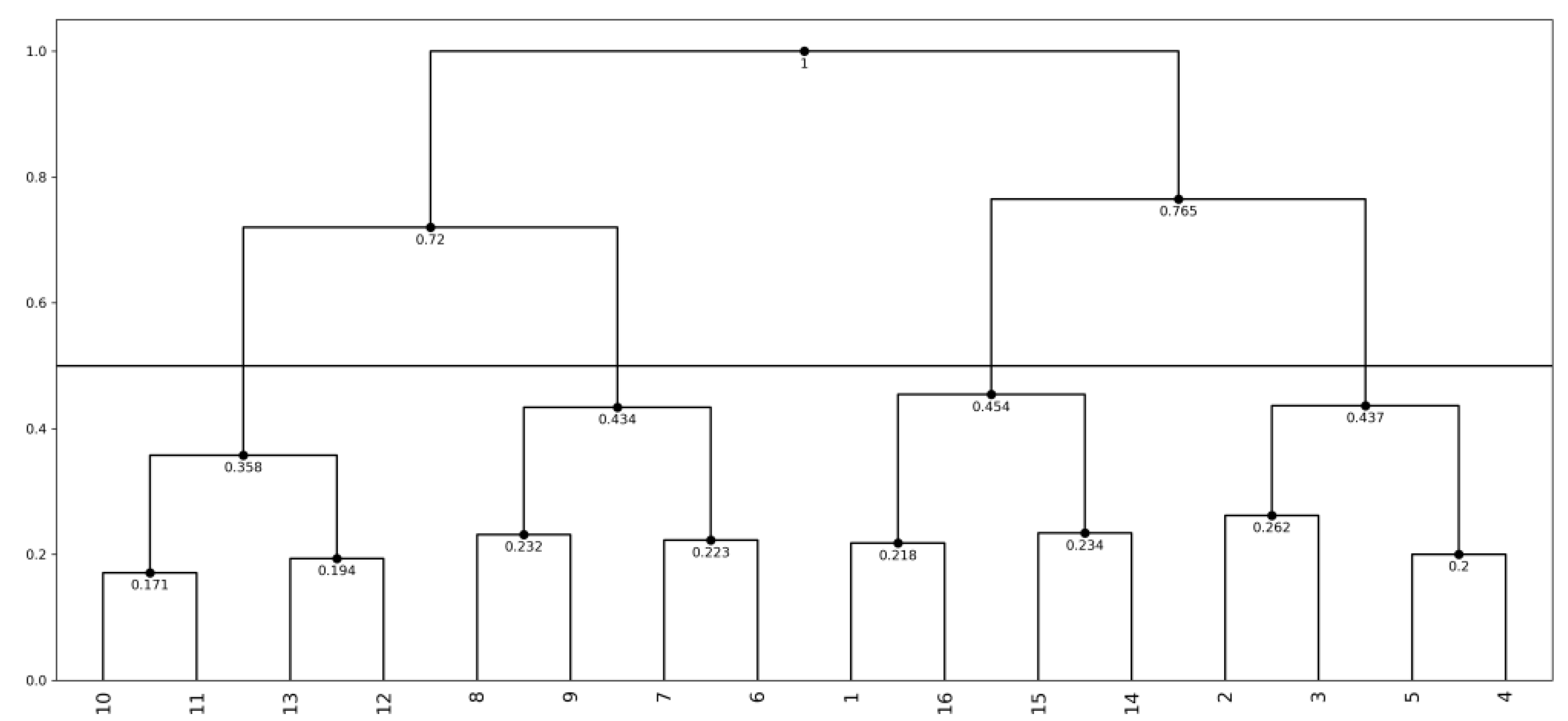
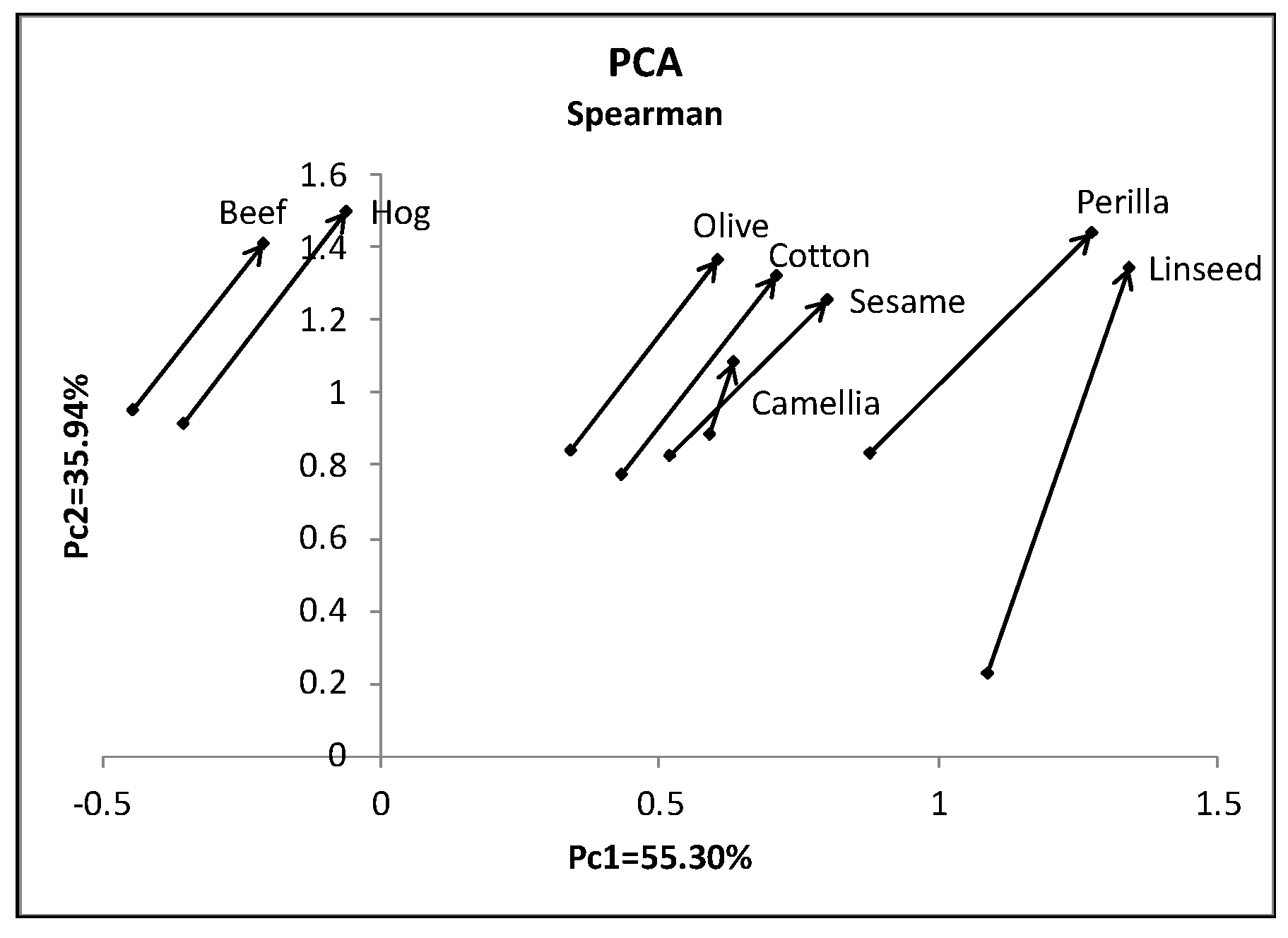
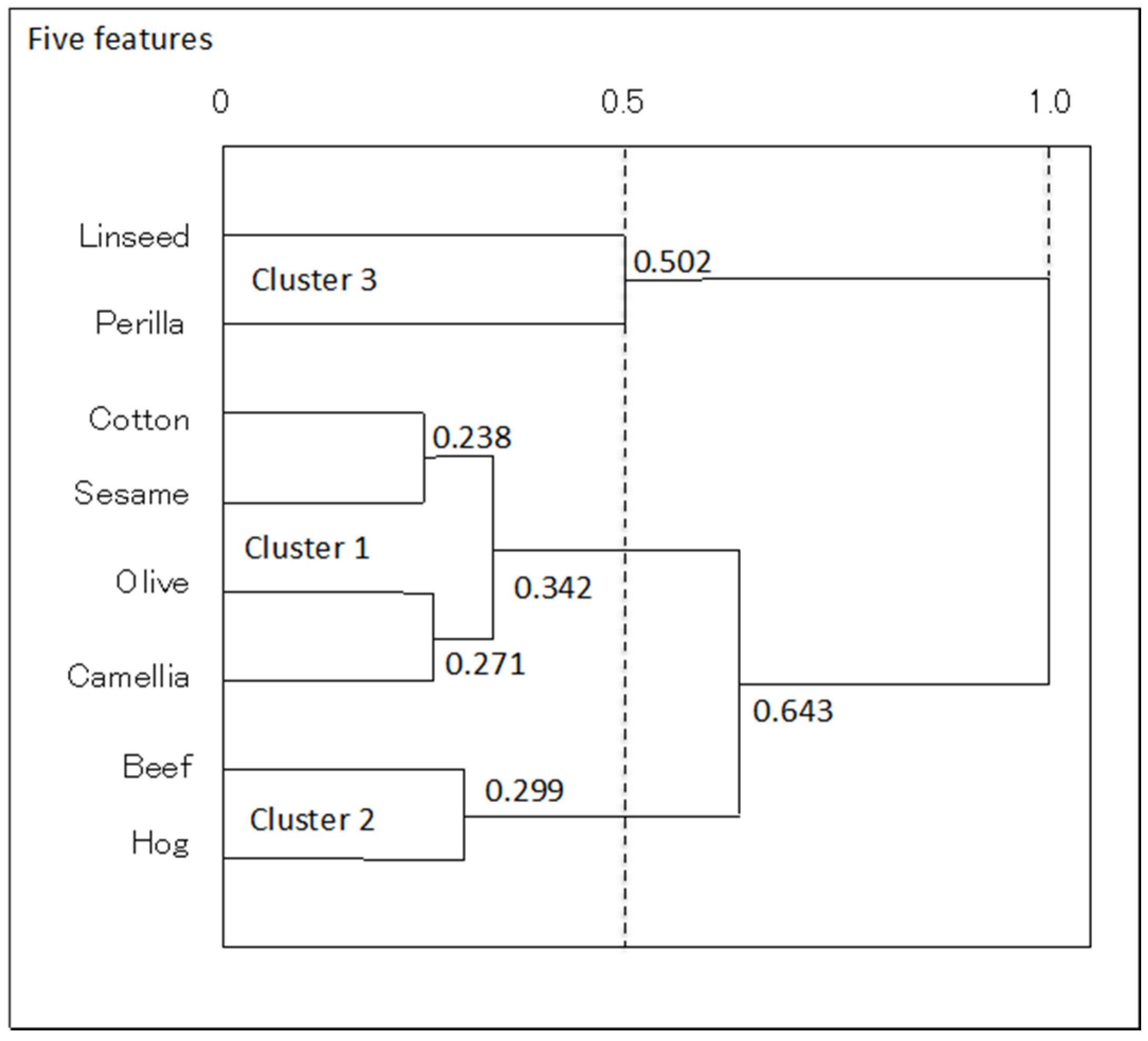
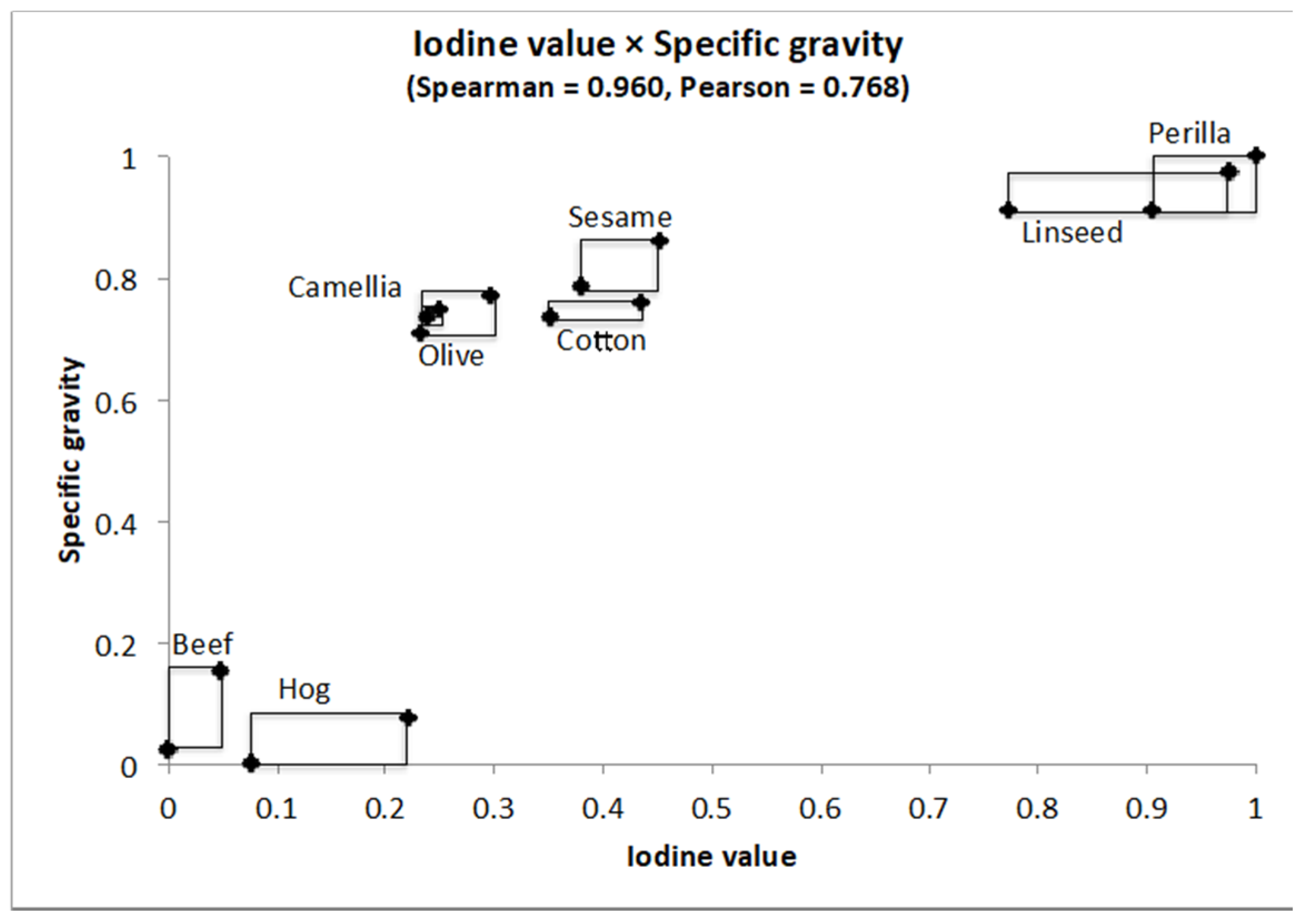
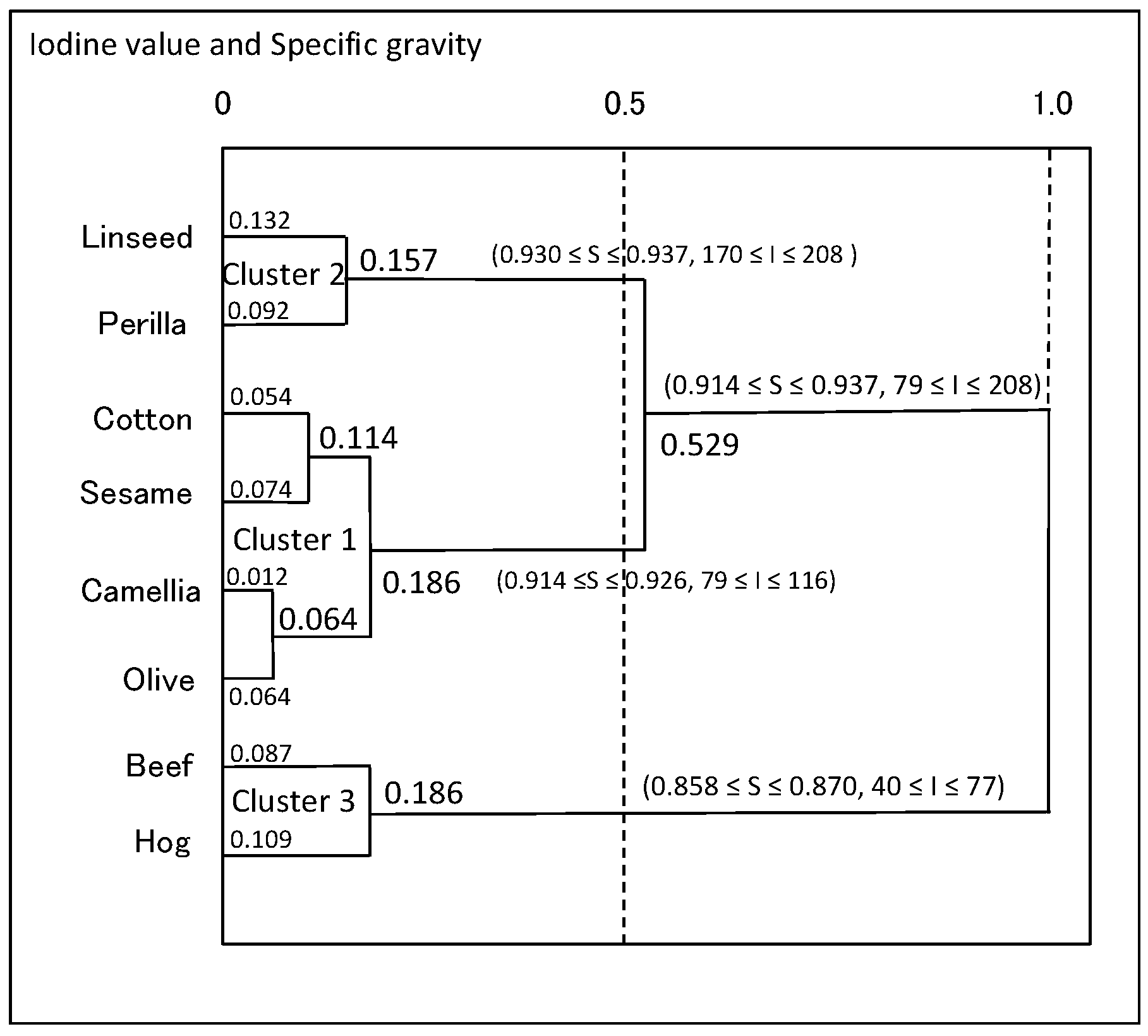
4.2.2. Oils Data
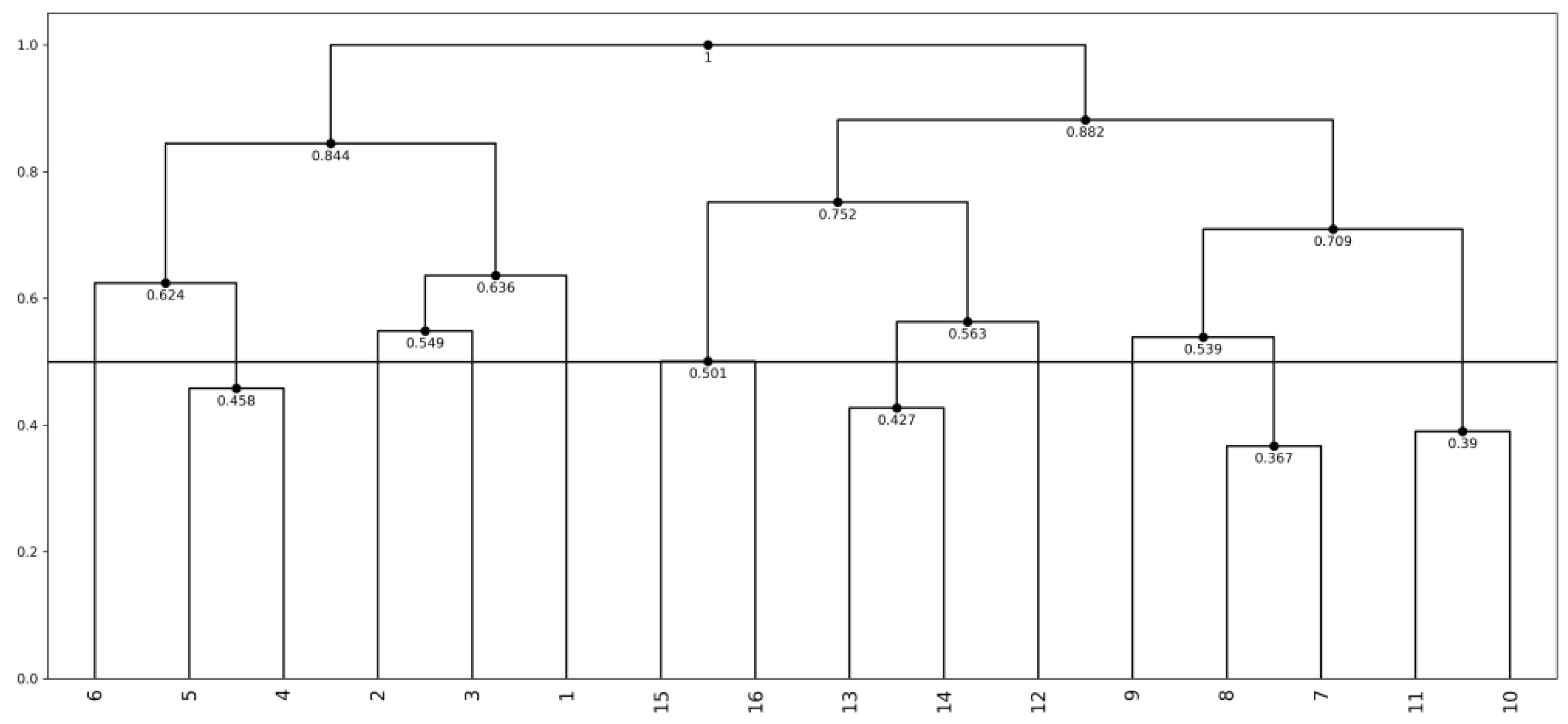
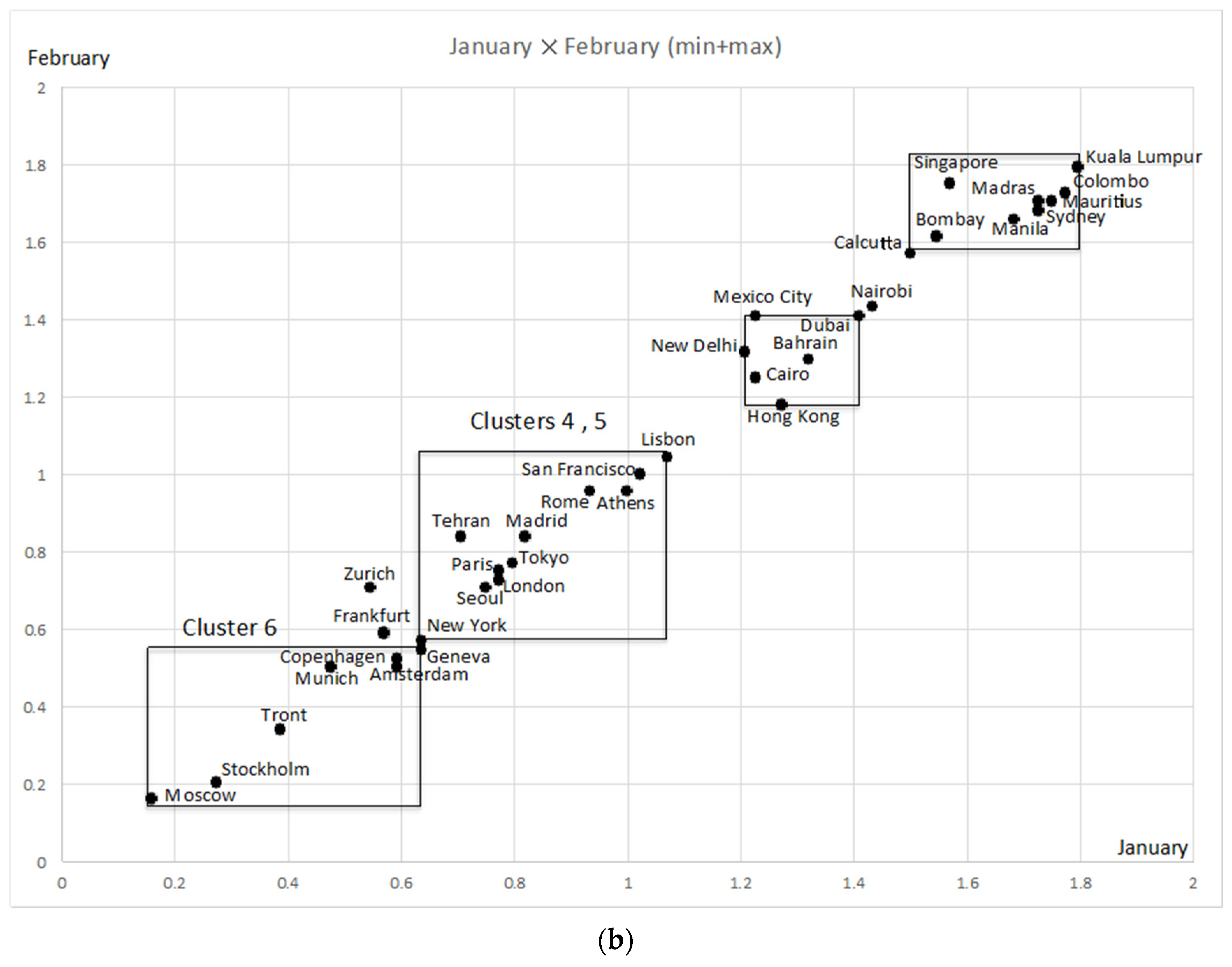
4.3. Analysis of City Temperature Data
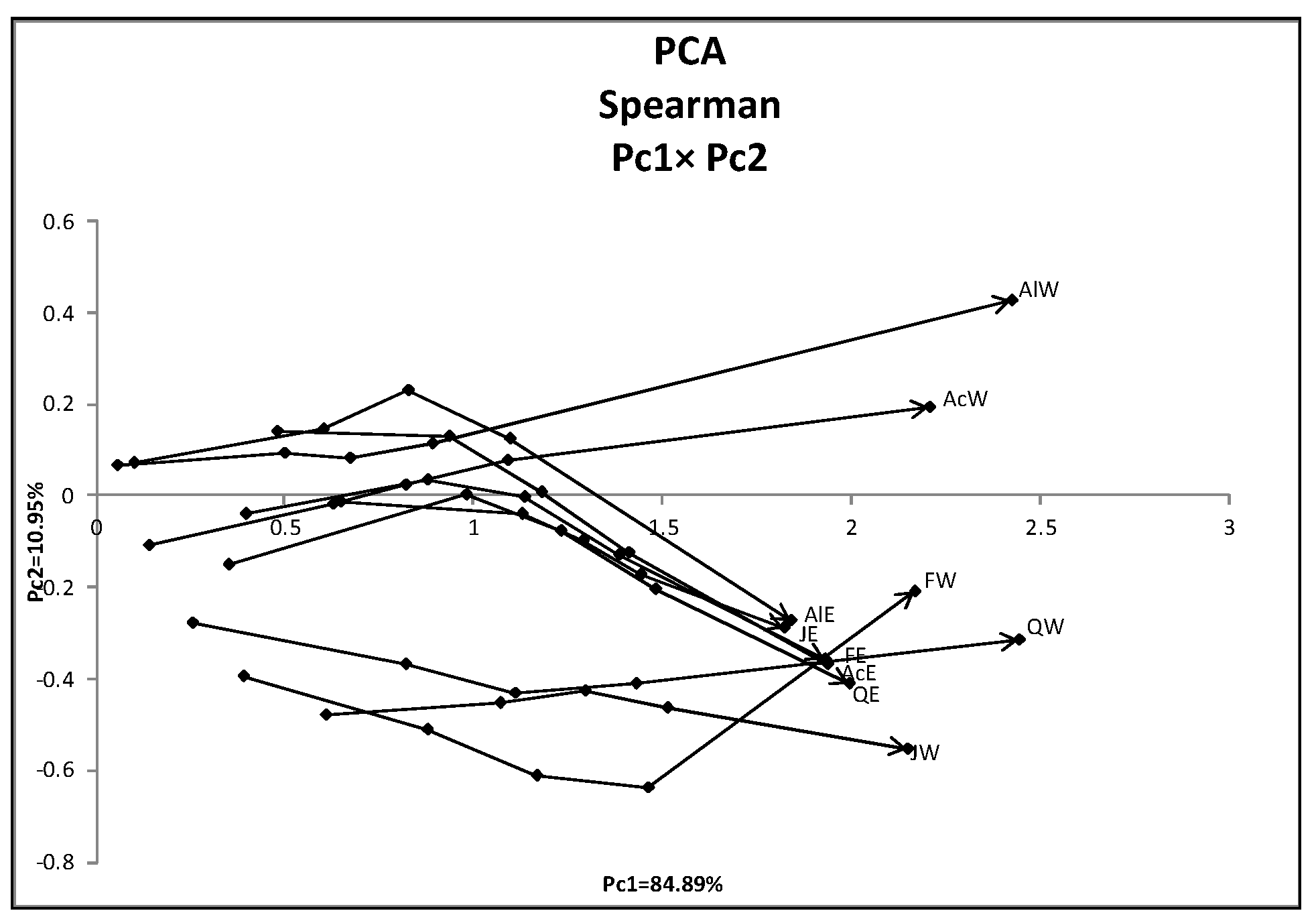
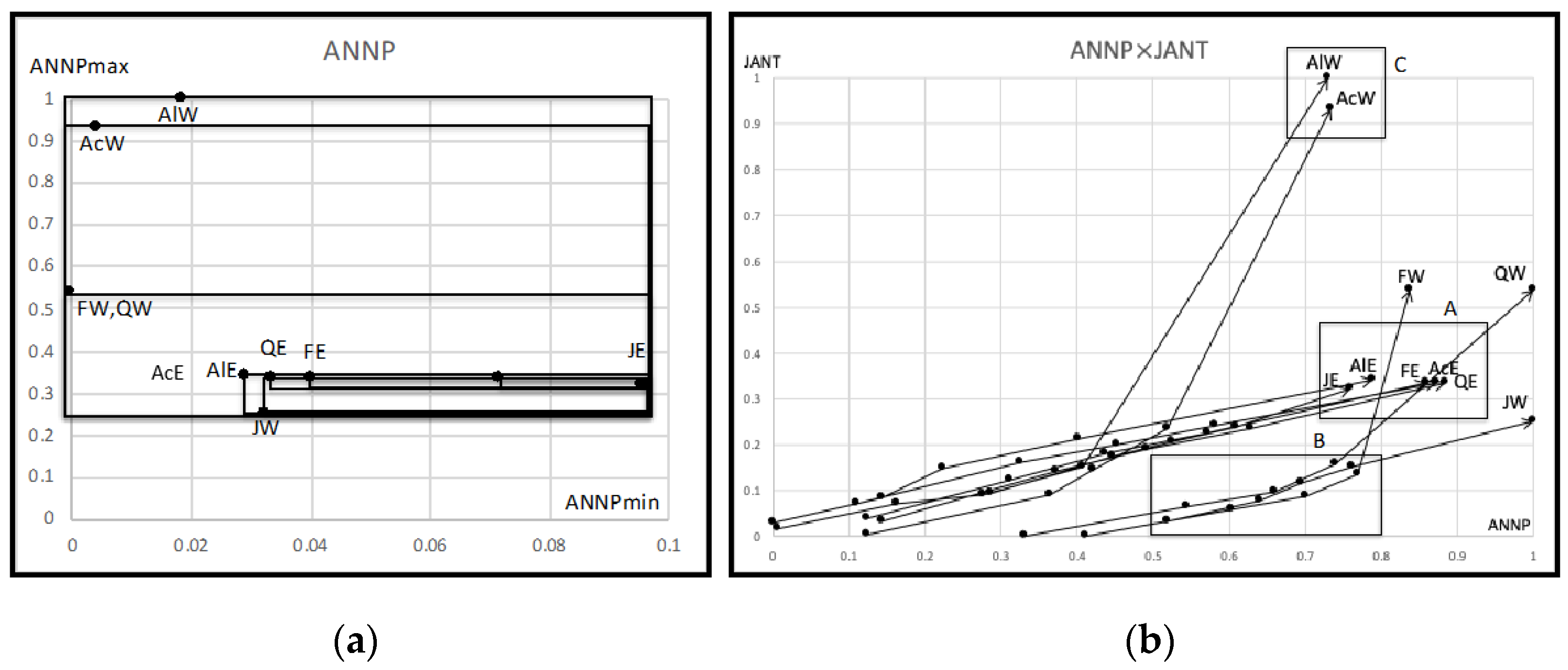
4.4. Analysis of the Hardwood Data
- F1: Annual Temperature (ANNT) (°C);
- F2: January Temperature (JANT) (°C);
- F3: July Temperature (JULT) (°C);
- F4: Annual Precipitation (ANNP) (mm);
- F5: January Precipitation (JANP) (mm);
- F6: July Precipitation (JULP) (mm);
- F7: Growing Degree Days on 5 °C base ×1000 (GDC5);
- F8: Moisture Index (MITM).
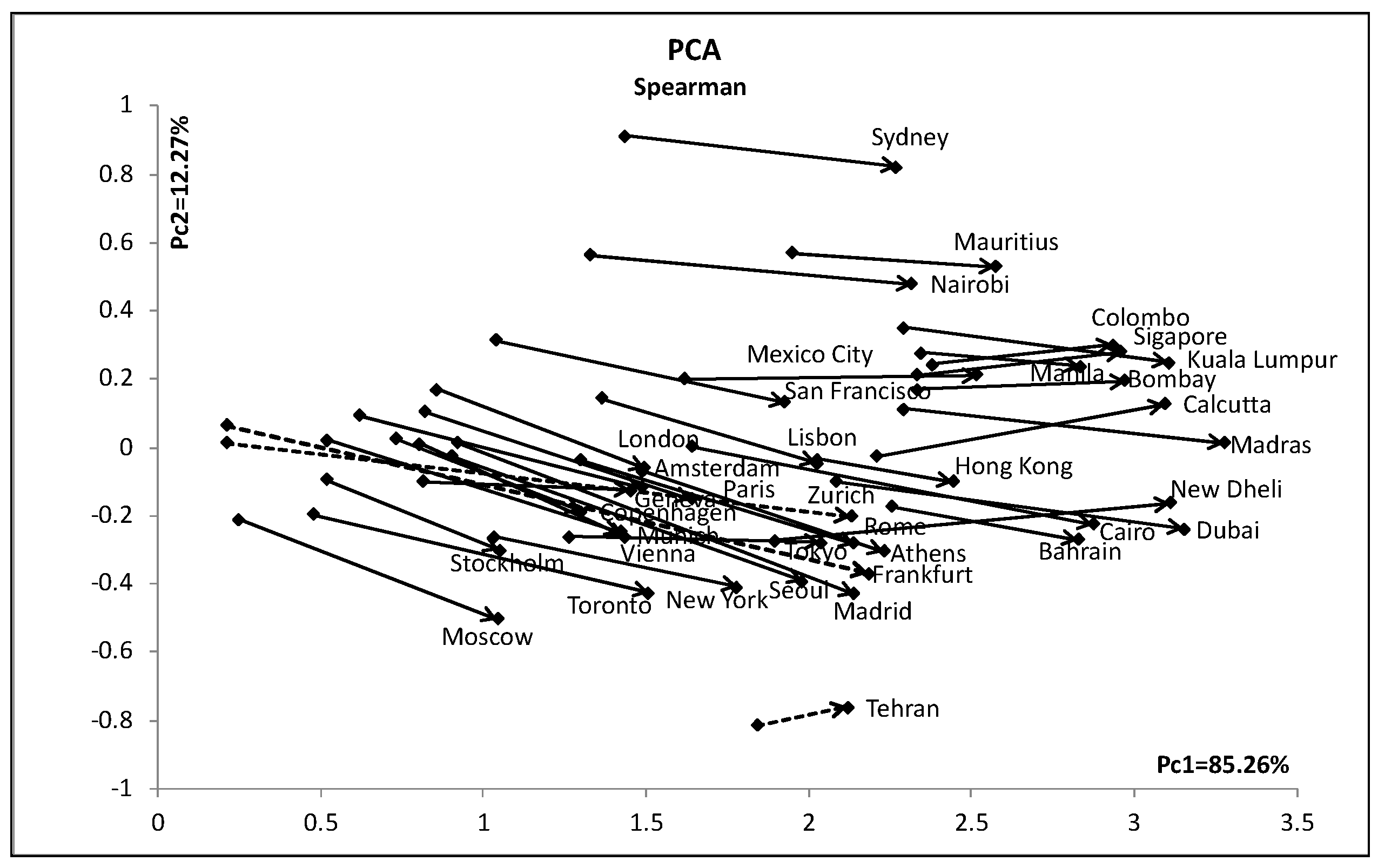
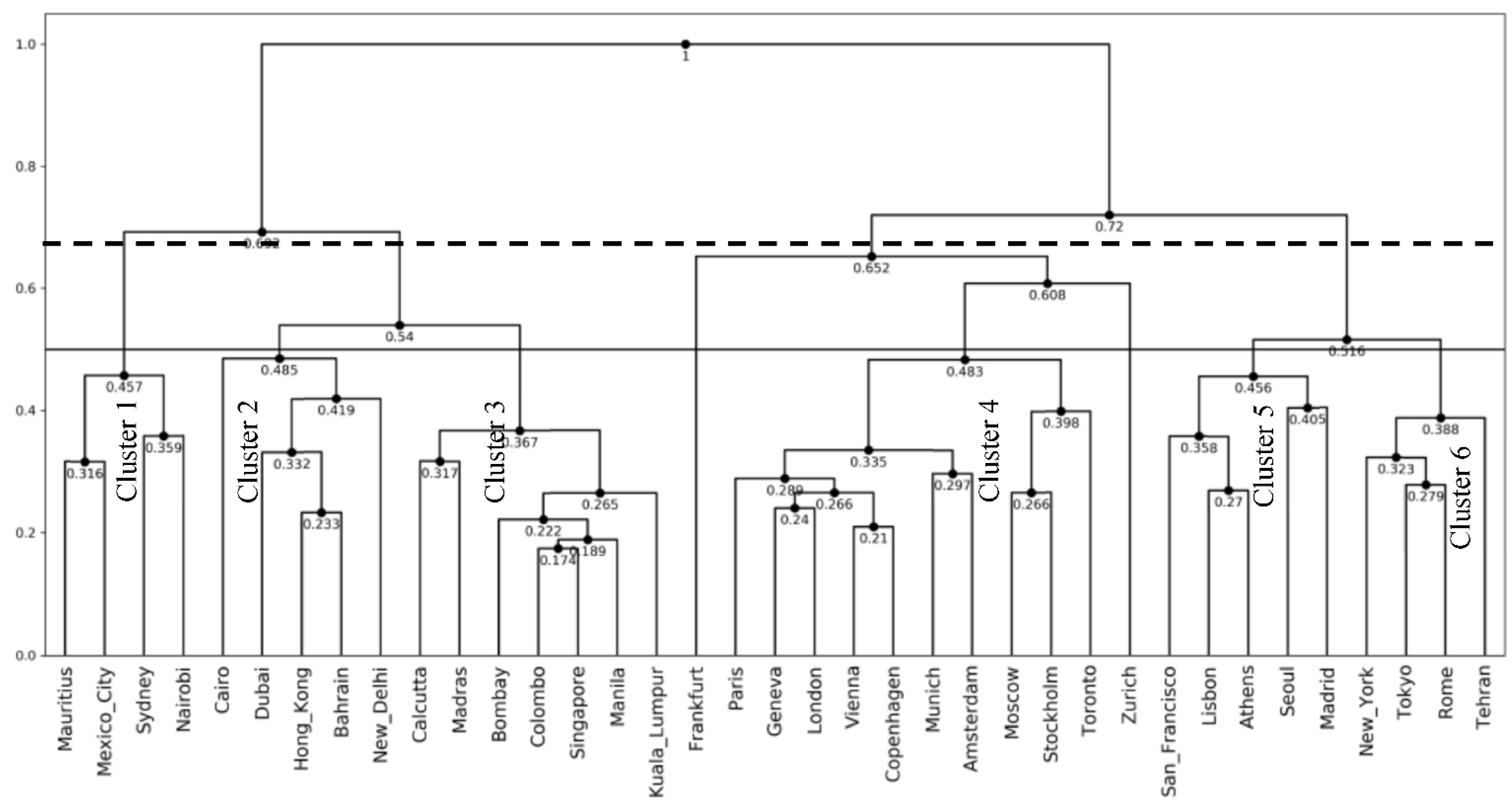
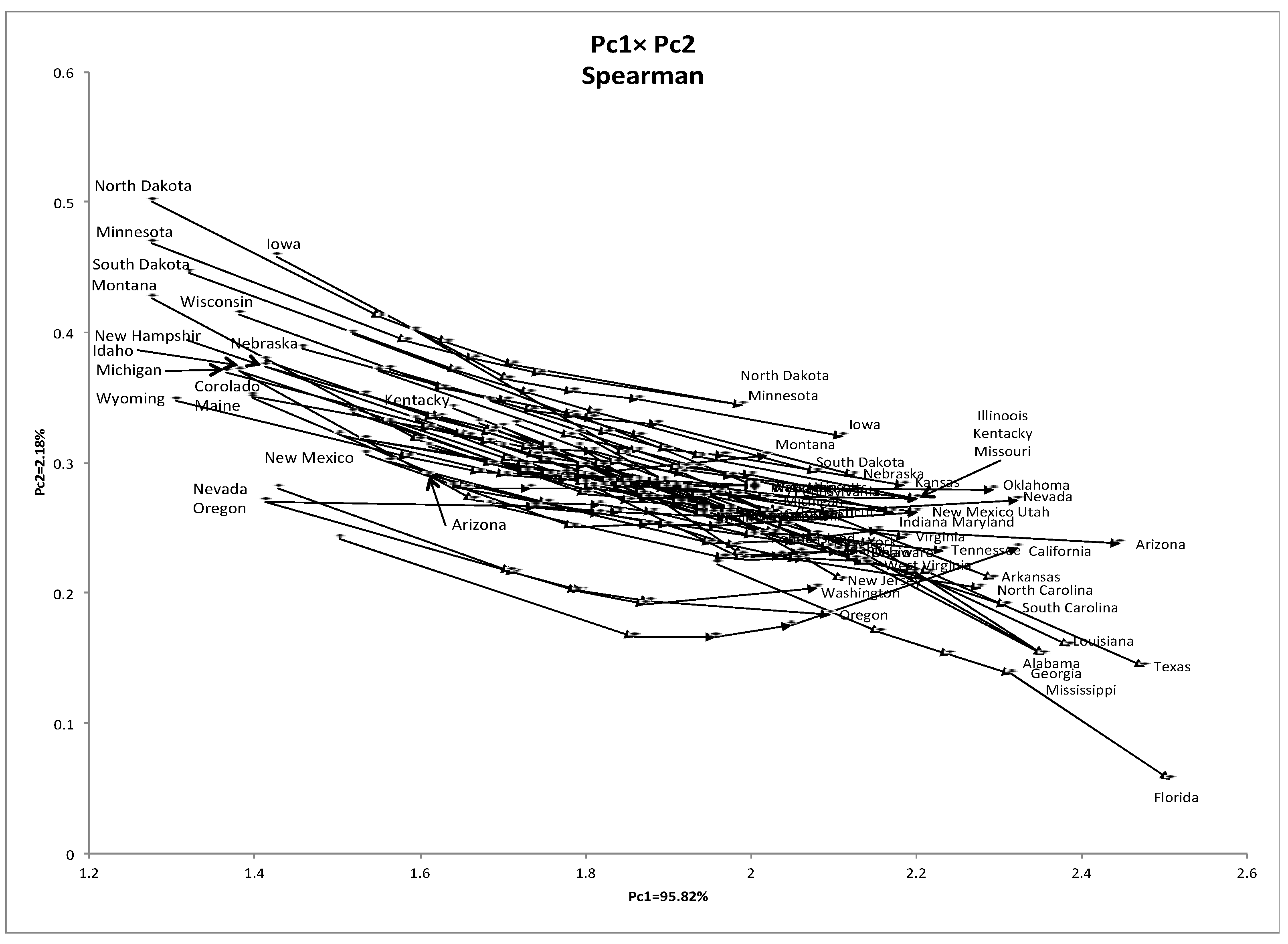
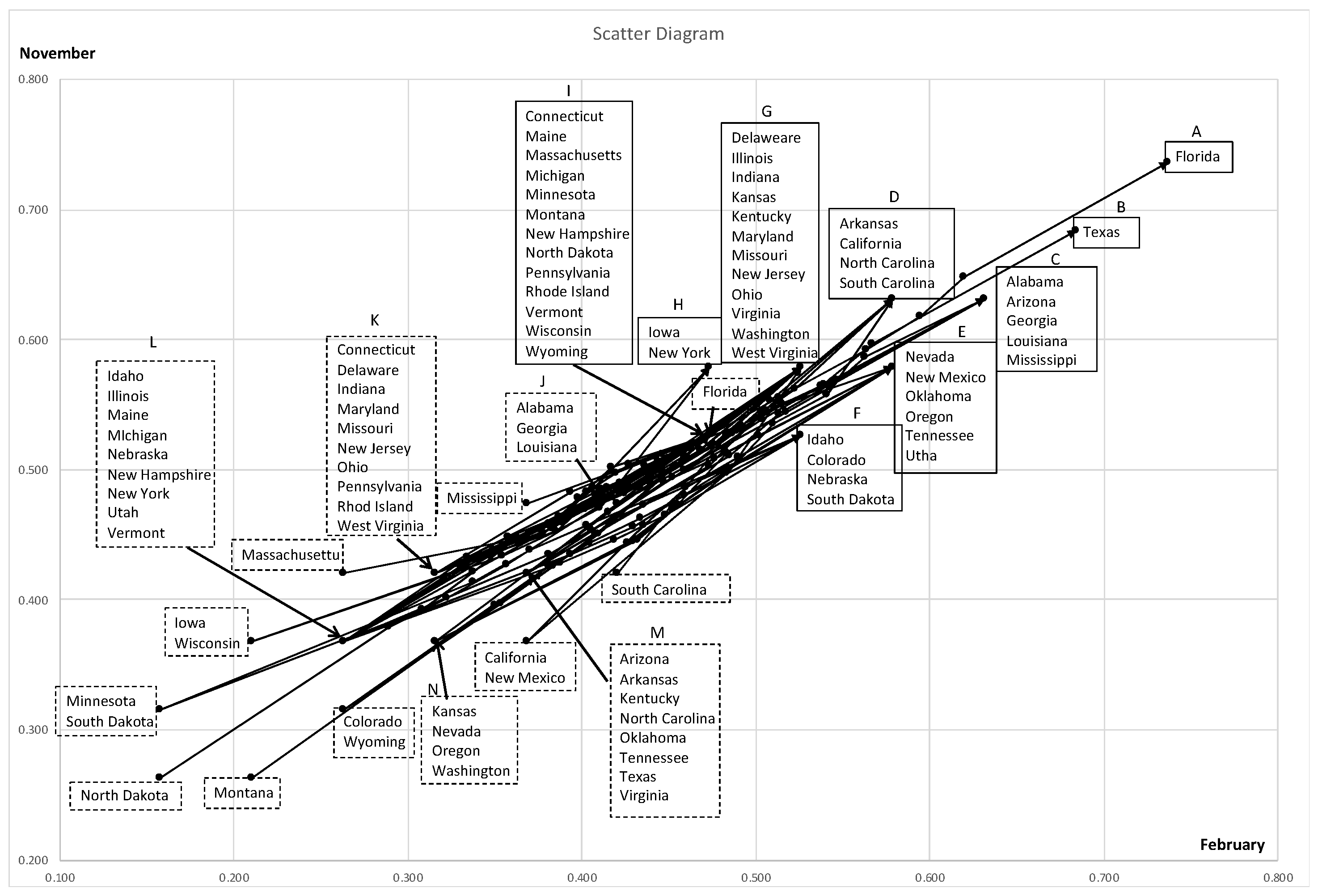
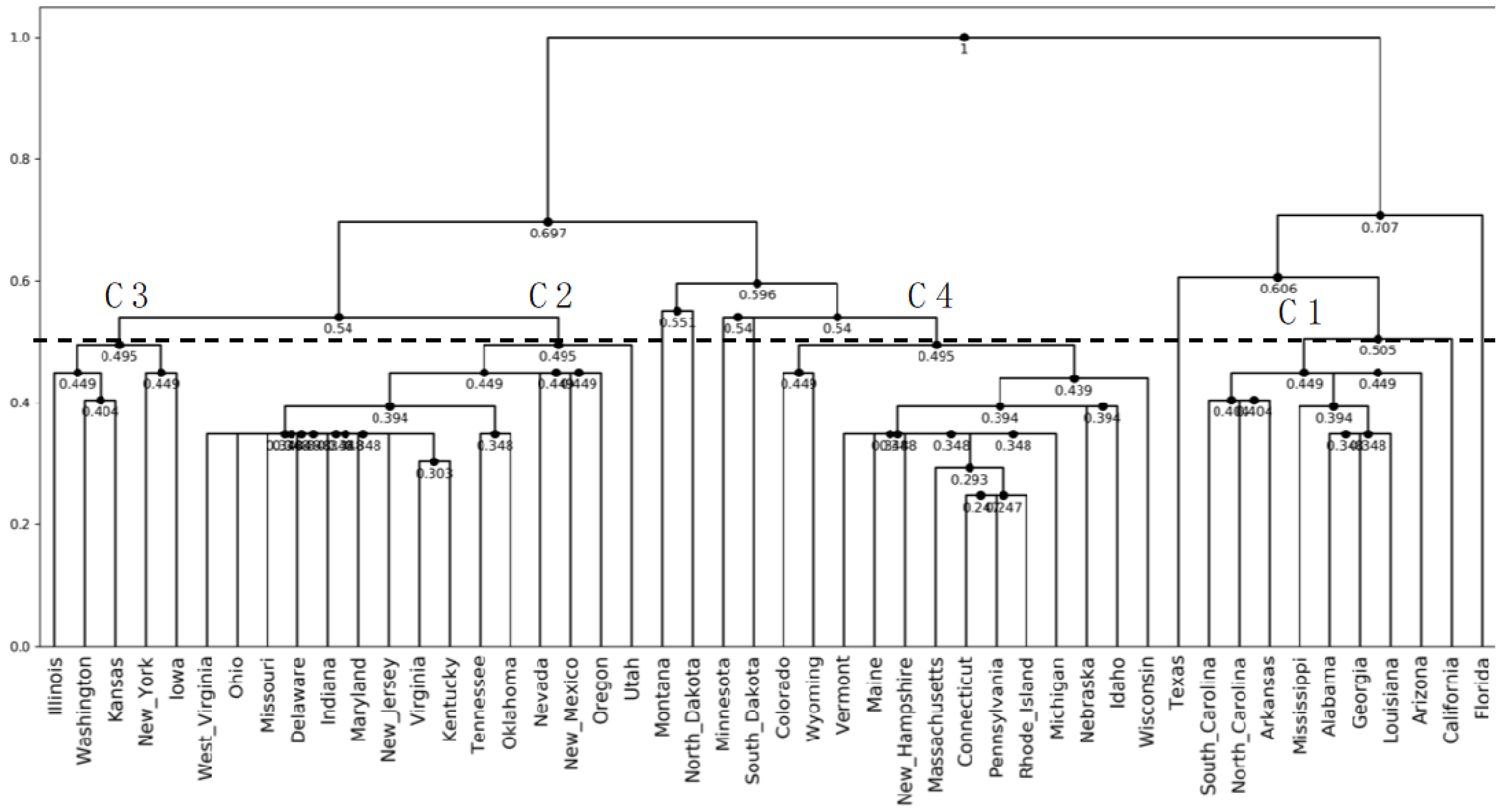
4.5. Analysis of the US Weather Data
- (1)
- Alabama, Mississippi, Georgia, and Louisiana;
- (2)
- Connecticut, Rhode Island, Massachusetts, Pennsylvania, Delaware, New Jersey, and Ohio;
- (3)
- Indiana, West Virginia, and Virginia:
- (4)
- Kentucky, Tennessee, and Missouri;
- (5)
- Arkansas and South Carolina;
- (6)
- Maine, New Hampshire, and Vermont.
5. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Dy, J.G.; Brodley, C.E. Feature selection for unsupervised learning. J. Mach. Learn. Res. 2004, 5, 845–889. [Google Scholar]
- Liu, H.; Motoda, H. Computational Methods of Feature Selection; CRC Press: London, UK, 2007. [Google Scholar]
- Miao, J.; Niu, L. A survey on feature selection. Procedia Comput. Sci. 2016, 91, 919–926. [Google Scholar]
- Solorio-Fernández, S.; Martínez-Trinidad, J.F.; Carrasco-Ochoa, J.A. A review of unsupervised feature selection methods. Artif. Intell. Rev. 2020, 53, 907–948. [Google Scholar] [CrossRef]
- Bock, H.-H.; Diday, E. Analysis of Symbolic Data; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Billard, L.; Diday, E. Symbolic Data Analysis: Conceptual Statistics and Data Mining; Wiley: Chichester, UK, 2007. [Google Scholar]
- Diday, E. Thinking by classes in data science: The symbolic data analysis paradigm. WIREs Comput. Stat. 2016, 8, 172–205. [Google Scholar] [CrossRef]
- Billard, L.; Diday, E. Clustering Methodology for Symbolic Data; Wiley: Chichester, UK, 2020. [Google Scholar]
- Irpino, A.; Verde, R. A new Wasserstein based distance for the hierarchical clustering of histogram symbolic data. In Data Science and Classification; Springer: Berlin/Heidelberg, Germany, 2006; pp. 185–192. [Google Scholar]
- de Carvalho, F.d.A.T.; De Souza, M.C.R. Unsupervised pattern recognition models for mixed feature-type data. Pattern Recognit. Lett. 2010, 31, 430–443. [Google Scholar] [CrossRef]
- Ichino, M.; Yaguchi, H. Generalized Minkowski metrics for mixed feature-type data analysis. IEEE Trans. Syst. Man Cybern. 1994, 24, 698–708. [Google Scholar] [CrossRef]
- Ono, Y.; Ichino, M. A new feature selection method based on geometrical thickness. In Proceedings of the KESDA’98, Luxembourg, 27–28 April 1998; Volume 1, pp. 19–38. [Google Scholar]
- Ichino, M. The quantile method of symbolic principal component analysis. Stat. Anal. Data Min. 2011, 4, 184–198. [Google Scholar] [CrossRef]
- Histogram Data by the U.S. Geological Survey, Climate-Vegetation Atlas of North America. Available online: http://pubs.usgs.gov/pp/p1650-b/ (accessed on 11 November 2010).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
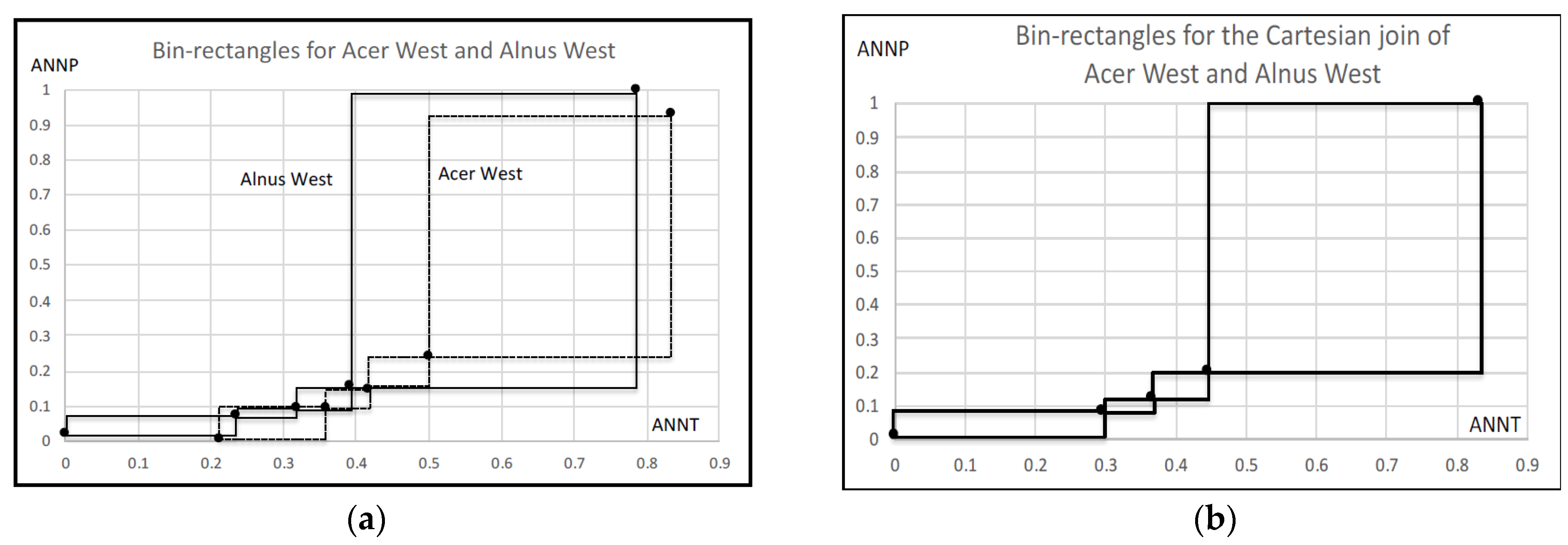
| Quantiles | ANNT | ANNP |
|---|---|---|
| Acer West 0 | 0.211 | 0.004 |
| 1 | 0.358 | 0.091 |
| 2 | 0.416 | 0.145 |
| 3 | 0.500 | 0.237 |
| 4 | 0.832 | 0.932 |
| Alnus West 0 | 0.000 | 0.018 |
| 1 | 0.234 | 0.071 |
| 2 | 0.317 | 0.092 |
| 3 | 0.391 | 0.153 |
| 4 | 0.784 | 1.000 |
| Concept Size | ANNT | ANNP | Average |
|---|---|---|---|
| Acer West | 0.155 | 0.232 | 0.194 |
| Alnus West | 0.196 | 0.245 | 0.221 |
| Cartesian join | 0.208 | 0.249 | 0.229 |
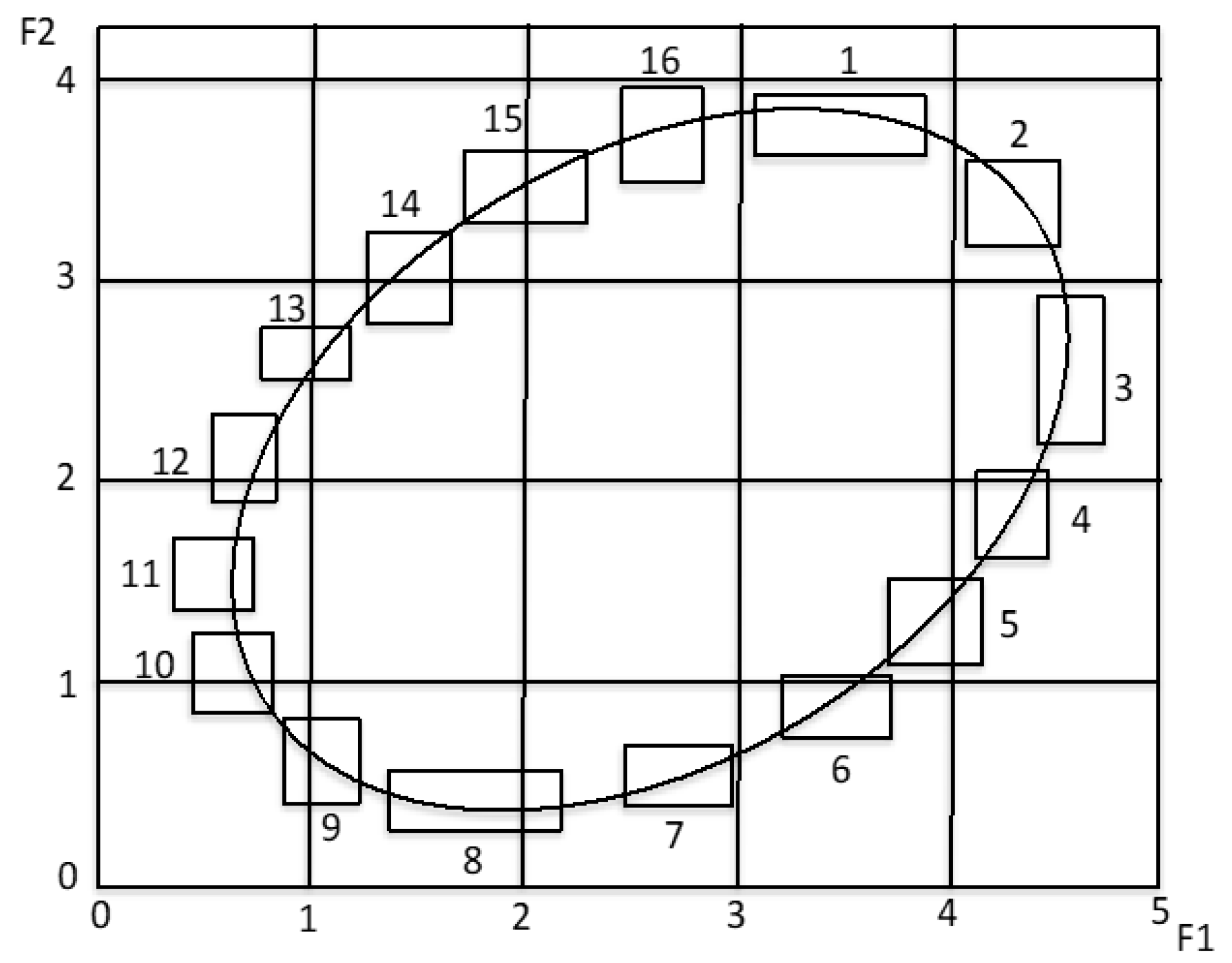
| F1 | F2 | F3 | F4 | F5 | Concept Size | ||
|---|---|---|---|---|---|---|---|
| 1 | [0.629, 0.798] | [0.905, 0.986] | [0.000, 0.982] | [0.002, 0.883] | [0.360, 0.380] | 0.427 | |
| 2 | [0.854, 0.955] | [0.797, 0.905] | [0.002, 0.421] | [0.573, 1.000] | [0.754, 0.761] | 0.212 | |
| 3 | [0.921, 1.000] | [0.527, 0.716] | [0.193, 0.934] | [0.035, 0.477] | [0.406, 0.587] | 0.326 | |
| 4 | [0.865, 0.933] | [0.378, 0.500] | [0.452, 0.854] | [0.213, 0.604] | [0.000, 0.074] | 0.211 | |
| 5 | [0.775, 0.876] | [0.257, 0.338] | [0.300, 0.614] | [0.425, 0.979] | [0.217, 0.568] | 0.280 | |
| 6 | [0.663, 0.764] | [0.135, 0.216] | [0.712, 1.000] | [0.904, 0.968] | [0.103, 0.950] | 0.276 | |
| 7 | [0.494, 0.596] | [0.041, 0.122] | [0.293, 0.470] | [0.023, 0.086] | [0.765, 0.902] | 0.112 | |
| 8 | [0.225, 0.427] | [0.000, 0.081] | [0.633, 0.872] | [0.000, 0.582] | [0.719, 0.852] | 0.247 | |
| 9 | [0.112, 0.213] | [0.041, 0.149] | [0.167, 0.802] | [0.056, 0.129] | [0.124, 0.642] | 0.287 | |
| 10 | [0.022, 0.112] | [0.162, 0.270] | [0.026, 0.718] | [0.418, 0.851] | [0.549, 0.853] | 0.325 | |
| 11 | [0.000, 0.090] | [0.297, 0.392] | [0.096, 0.759] | [0.438, 0.938] | [0.495, 0.760] | 0.323 | |
| 12 | [0.045,0.112] | [0.446, 0.554] | [0.826, 0.962] | [0.230, 0.755] | [0.104, 0.189] | 0.184 | |
| 13 | [0.101, 0.202] | [0.608, 0.676] | [0.367, 0.570] | [0.236, 0.684] | [0.683, 0.930] | 0.213 | |
| 14 | [0.213, 0.292] | [0.676, 0.811] | [0.371, 0.381] | [0.086, 0.305] | [0.009, 1.000] | 0.287 | |
| 15 | [0.315, 0.438] | [0.811, 0.919] | [0.049, 0.585] | [0.056, 0.891] | [0.528, 0.881] | 0.391 | |
| 16 | [0.483, 0.562] | [0.878, 1.000] | [0.402, 0.609] | [0.150, 0.769] | [0.207, 0.732] | 0.310 | |
| Average CS | 0.103 | 0.105 | 0.415 | 0.441 | 0.315 | 0.276 | |
| Clustering Step | Average Compactness | ||||
|---|---|---|---|---|---|
| F1 | F2 | F3 | F4 | F5 | |
| 0 | 0.103 | 0.105 | 0.415 | 0.441 | 0.315 |
| 1 | 0.115 | 0.109 | 0.454 | 0.466 | 0.330 |
| 2 | 0.118 | 0.119 | 0.442 | 0.470 | 0.338 |
| 3 | 0.128 | 0.128 | 0.475 | 0.501 | 0.345 |
| 4 | 0.138 | 0.142 | 0.501 | 0.528 | 0.386 |
| 5 | 0.154 | 0.151 | 0.530 | 0.519 | 0.403 |
| 6 | 0.171 | 0.158 | 0.532 | 0.564 | 0.451 |
| 7 | 0.186 | 0.185 | 0.566 | 0.637 | 0.519 |
| 8 | 0.208 | 0.215 | 0.669 | 0.660 | 0.574 |
| 9 | 0.239 | 0.251 | 0.744 | 0.744 | 0.589 |
| 10 | 0.288 | 0.293 | 0.712 | 0.727 | 0.692 |
| 11 | 0.346 | 0.354 | 0.736 | 0.839 | 0.759 |
| 12 | 0.438 | 0.443 | 0.860 | 0.882 | 0.780 |
| 13 | 0.494 | 0.599 | 0.919 | 0.924 | 0.906 |
| 14 | 0.483 | 0.926 | 0.967 | 0.968 | 0.971 |
| 15 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Specific Gravity | Freezing Point | Iodine Value | Saponification v. | Major Acids | ||
|---|---|---|---|---|---|---|
| Linseed | [0.930, 0.935] | [−27, −18] | [170, 204] | [118, 196] | [1.75, 4.81] | |
| Perilla | [0.930, 0.937] | [−5, −4] | [192, 208] | [188, 197] | [0.77, 4.85] | |
| Cotton | [0.916, 0.918] | [−6, −1] | [99, 113] | [189, 198] | [0.42, 3.84] | |
| Sesame | [0.920, 0.926] | [−6,−4] | [104, 116] | [187, 193] | [0.91, 3.77] | |
| Camellia | [0.916, 0.917] | [−21, −15] | [80, 82] | [189, 193] | [2.00, 2.98] | |
| Olive | [0.914, 0.919] | [0, 6] | [79, 90] | [187, 196] | [0.83, 4.02] | |
| Beef | [0.860, 0.870] | [30, 38] | [40, 48] | [190, 199] | [0.31, 2.89] | |
| Hog | [0.858, 0.864] | [22, 32] | [53, 77] | [190, 202] | [0.37, 3.65] | |
| Feature | Average Compactness for Each Clustering Step | |||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| Specific gravity | 0.066 | 0.080 | 0.091 | 0.099 | 0.114 | 0.131 | 0.475 | 1.000 |
| Freezing point | 0.090 | 0.099 | 0.154 | 0.178 | 0.204 | 0.338 | 0.631 | 1.000 |
| Iodine value | 0.090 | 0.095 | 0.109 | 0.137 | 0.185 | 0.222 | 0.339 | 1.000 |
| Saponification value | 0.202 | 0.224 | 0.254 | 0.283 | 0.327 | 0.405 | 0.560 | 1.000 |
| Major acids | 0.646 | 0.648 | 0.720 | 0.753 | 0.775 | 0.809 | 0.856 | 1.000 |
| Steps | Average Compactness for Several Clustering Steps | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jan. | Feb. | Mar. | Apr. | May | Jun. | Jul. | Aug. | Sept. | Oct. | Nov. | Dec. | |
| 0 | 0.195 | 0.194 | 0.224 | 0.265 | 0.217 | 0.281 | 0.305 | 0.286 | 0.289 | 0.266 | 0.233 | 0.194 |
| 25 | 0.360 | 0.345 | 0.363 | 0.406 | 0.361 | 0.461 | 0.519 | 0.484 | 0.466 | 0.422 | 0.410 | 0.375 |
| 29 | 0.409 | 0.389 | 0.426 | 0.490 | 0.414 | 0.544 | 0.609 | 0.555 | 0.516 | 0.456 | 0.443 | 0.429 |
| 31 | 0.466 | 0.443 | 0.476 | 0.500 | 0.451 | 0.593 | 0.667 | 0.609 | 0.568 | 0.515 | 0.486 | 0.476 |
| 33 | 0.489 | 0.477 | 0.476 | 0.500 | 0.464 | 0.618 | 0.694 | 0.664 | 0.586 | 0.522 | 0.500 | 0.512 |
| 35 | 0.580 | 0.568 | 0.583 | 0.645 | 0.656 | 0.853 | 0.984 | 0.969 | 0.797 | 0.662 | 0.608 | 0.583 |
| Taxon Name | Mean Annual Temperature (℃) | ||||||
|---|---|---|---|---|---|---|---|
| 0% | 10% | 25% | 50% | 75% | 90% | 100% | |
| ACER EAST | −2.3 | 0.6 | 3.8 | 9.2 | 14.4 | 17.9 | 24 |
| ACER WEST | −3.9 | 0.2 | 1.9 | 4.2 | 7.5 | 10.3 | 21 |
| ALNUS EAST | −10 | −4.4 | −2.3 | 0.6 | 6.1 | 15.0 | 21 |
| ALNUS WEST | −12 | −4.6 | −3.0 | 0.3 | 3.2 | 7.6 | 19 |
| FRAXINUS EAST | −2.3 | 1.4 | 4.3 | 8.6 | 14.1 | 17.9 | 23 |
| FRAXINUS WEST | 2.6 | 9.4 | 11.5 | 17.2 | 21.2 | 22.7 | 24 |
| JAGLANS EAST | 1.3 | 6.9 | 9.1 | 12.4 | 15.5 | 17.6 | 21 |
| JAGLANS WEST | 7.3 | 12.6 | 14.1 | 16.3 | 19.4 | 22.7 | 27 |
| QUERCUS EAST | −1.5 | 3.4 | 6.3 | 11.2 | 16.4 | 19.1 | 24 |
| QUERCUS WEST | −1.5 | 6.0 | 9.5 | 14.6 | 17.9 | 19.9 | 27 |
| Taxon Name | F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 |
|---|---|---|---|---|---|---|---|---|
| ACER EAST 0 | 0.251 | 0.110 | 0.165 | 0.072 | 0.014 | 0.124 | 0.048 | 0.587 |
| 1 | 0.406 | 0.326 | 0.416 | 0.163 | 0.059 | 0.197 | 0.167 | 0.935 |
| 2 | 0.543 | 0.452 | 0.566 | 0.201 | 0.102 | 0.221 | 0.286 | 0.967 |
| 3 | 0.675 | 0.581 | 0.700 | 0.242 | 0.143 | 0.250 | 0.417 | 0.989 |
| 4 | 0.914 | 0.872 | 0.813 | 0.336 | 0.248 | 0.491 | 0.798 | 1.000 |
| ACER WEST 0 | 0.211 | 0.124 | 0.000 | 0.004 | 0.006 | 0.000 | 0.000 | 0.065 |
| 1 | 0.358 | 0.364 | 0.213 | 0.091 | 0.080 | 0.051 | 0.071 | 0.576 |
| 2 | 0.416 | 0.420 | 0.292 | 0.145 | 0.137 | 0.084 | 0.119 | 0.728 |
| 3 | 0.500 | 0.518 | 0.393 | 0.237 | 0.263 | 0.115 | 0.179 | 0.902 |
| 4 | 0.832 | 0.734 | 0.828 | 0.932 | 0.923 | 0.354 | 0.655 | 1.000 |
| Step | Average Compactness of Each Feature | |||||||
|---|---|---|---|---|---|---|---|---|
| ANNT | JANT | JULT | ANNP | JANP | JULP | GDC5 | MITM | |
| 0 | 0.161 | 0.160 | 0.178 | 0.115 | 0.113 | 0.133 | 0.180 | 0.196 |
| 1 | 0.220 | 0.228 | 0.239 | 0.144 | 0.140 | 0.172 | 0.246 | 0.242 |
| 2 | 0.229 | 0.234 | 0.268 | 0.186 | 0.197 | 0.191 | 0.256 | 0.323 |
| 3 | 0.238 | 0.243 | 0.282 | 0.202 | 0.217 | 0.203 | 0.268 | 0.338 |
| 4 | 0.279 | 0.269 | 0.322 | 0.223 | 0.243 | 0.220 | 0.292 | 0.358 |
| 5 | 0.404 | 0.395 | 0.475 | 0.337 | 0.372 | 0.350 | 0.455 | 0.541 |
| 6 | 0.490 | 0.472 | 0.570 | 0.388 | 0.428 | 0.401 | 0.525 | 0.614 |
| 7 | 0.601 | 0.578 | 0.692 | 0.571 | 0.595 | 0.505 | 0.646 | 0.739 |
| 8 | 0.829 | 0.777 | 0.938 | 0.768 | 0.810 | 0.887 | 0.899 | 1.000 |
| Step | Average Compactness of Each Feature in Selected Clustering Steps | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jan | Feb | Mar | Apr | May | June | July | Aug | Sept | Oct | Nov | Dec | |
| 0 | 0.460 | 0.396 | 0.516 | 0.452 | 0.528 | 0.486 | 0.558 | 0.571 | 0.500 | 0.455 | 0.384 | 0.447 |
| 5 | 0.470 | 0.404 | 0.529 | 0.462 | 0.543 | 0.500 | 0.581 | 0.591 | 0.512 | 0.468 | 0.395 | 0.455 |
| 10 | 0.482 | 0.411 | 0.539 | 0.477 | 0.561 | 0.518 | 0.600 | 0.605 | 0.522 | 0.477 | 0.404 | 0.462 |
| 15 | 0.494 | 0.433 | 0.545 | 0.489 | 0.576 | 0.530 | 0.624 | 0.618 | 0.535 | 0.485 | 0.418 | 0.471 |
| 20 | 0.507 | 0.445 | 0.554 | 0.495 | 0.589 | 0.548 | 0.643 | 0.621 | 0.548 | 0.495 | 0.433 | 0.476 |
| 25 | 0.526 | 0.462 | 0.571 | 0.516 | 0.616 | 0.551 | 0.661 | 0.635 | 0.565 | 0.509 | 0.449 | 0.488 |
| 30 | 0.544 | 0.480 | 0.576 | 0.516 | 0.630 | 0.574 | 0.689 | 0.644 | 0.583 | 0.524 | 0.457 | 0.500 |
| 35 | 0.562 | 0.503 | 0.596 | 0.527 | 0.654 | 0.590 | 0.723 | 0.662 | 0.615 | 0.549 | 0.479 | 0.513 |
| 40 | 0.612 | 0.545 | 0.641 | 0.607 | 0.750 | 0.667 | 0.775 | 0.750 | 0.688 | 0.589 | 0.528 | 0.542 |
| 41 | 0.629 | 0.545 | 0.643 | 0.612 | 0.762 | 0.667 | 0.800 | 0.771 | 0.714 | 0.612 | 0.540 | 0.556 |
| 42 | 0.650 | 0.576 | 0.646 | 0.619 | 0.778 | 0.667 | 0.833 | 0.767 | 0.722 | 0.619 | 0.537 | 0.574 |
| 43 | 0.660 | 0.600 | 0.650 | 0.629 | 0.800 | 0.700 | 0.880 | 0.800 | 0.767 | 0.629 | 0.556 | 0.600 |
| 44 | 0.700 | 0.614 | 0.688 | 0.643 | 0.833 | 0.708 | 0.900 | 0.800 | 0.792 | 0.679 | 0.583 | 0.639 |
| 45 | 0.733 | 0.667 | 0.708 | 0.667 | 0.889 | 0.722 | 0.867 | 0.800 | 0.778 | 0.667 | 0.630 | 0.667 |
| 46 | 0.800 | 0.682 | 0.750 | 0.786 | 0.917 | 0.750 | 0.900 | 0.900 | 0.833 | 0.786 | 0.722 | 0.722 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ichino, M.; Umbleja, K.; Yaguchi, H. Unsupervised Feature Selection for Histogram-Valued Symbolic Data Using Hierarchical Conceptual Clustering. Stats 2021, 4, 359-384. https://doi.org/10.3390/stats4020024
Ichino M, Umbleja K, Yaguchi H. Unsupervised Feature Selection for Histogram-Valued Symbolic Data Using Hierarchical Conceptual Clustering. Stats. 2021; 4(2):359-384. https://doi.org/10.3390/stats4020024
Chicago/Turabian StyleIchino, Manabu, Kadri Umbleja, and Hiroyuki Yaguchi. 2021. "Unsupervised Feature Selection for Histogram-Valued Symbolic Data Using Hierarchical Conceptual Clustering" Stats 4, no. 2: 359-384. https://doi.org/10.3390/stats4020024
APA StyleIchino, M., Umbleja, K., & Yaguchi, H. (2021). Unsupervised Feature Selection for Histogram-Valued Symbolic Data Using Hierarchical Conceptual Clustering. Stats, 4(2), 359-384. https://doi.org/10.3390/stats4020024