Kolmogorov-Arnold Networks for Interpretable Analysis of Water Quality Time-Series Data




Abstract
1. Introduction
2. Material and Methods
2.1. Dataset Description
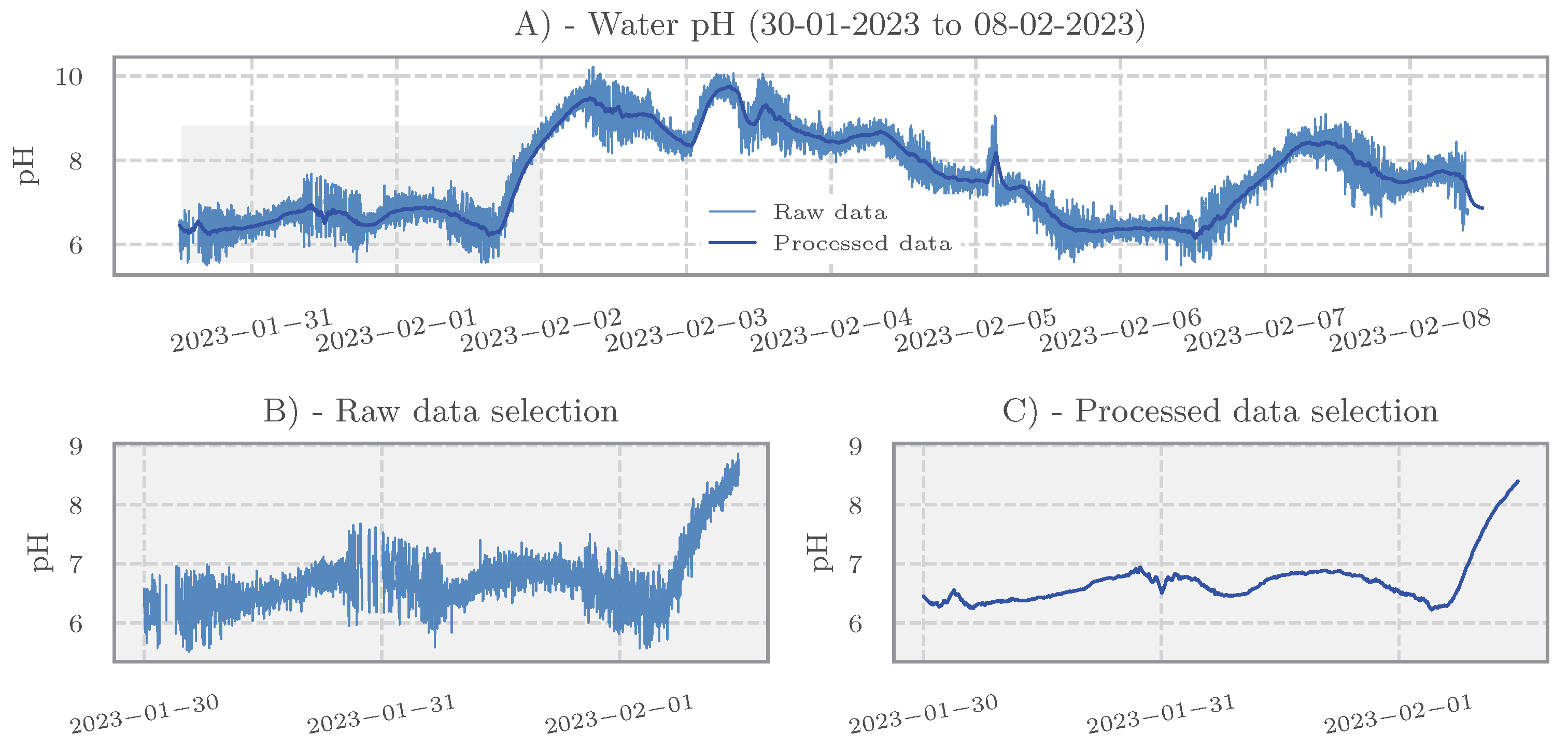
Data Cleaning and Preprocessing
2.2. WA-WQI and WQM-WQI Case Study Formulations
- is the sub-index quality rating (scaled between 0 and 100),
- is the weight assigned to each variable.
2.2.1. Quality Rating Calculation
pH Quality Rating (), Equation (3)
- = observed pH value
- Ideal pH = 7.0 (neutral)
- Standard maximum = 8.5
Inverse Scaled TDS Quality Rating (), Equation (4)
- = observed TDS value
- Ideal TDS = 0 mg/L
- Standard maximum = 500 mg/L
- Higher TDS indicates worse quality (inverse scaling)
Temperature Quality Rating (), Equation (5)
- = observed water temperature
- Ideal temperature = 26 °C
- Acceptable range = 24–27 °C
- Deviation from 26 °C results in a penalty
2.2.2. Weight Calculation
- = standard limit for each variable
- k = proportionality constant (set to 1 for simplicity)
- (deviation range from 26 °C)
2.3. Kolmogorov–Arnold Networks: Theoretical Foundations
- —the target multivariate function to approximate.
- —the p-th input variable.
- —continuous univariate inner functions, applied to each input variable.
- —continuous univariate outer functions, combining the intermediate results.
- n—the dimensionality of the input space.
2.4. KAN Implementation Details
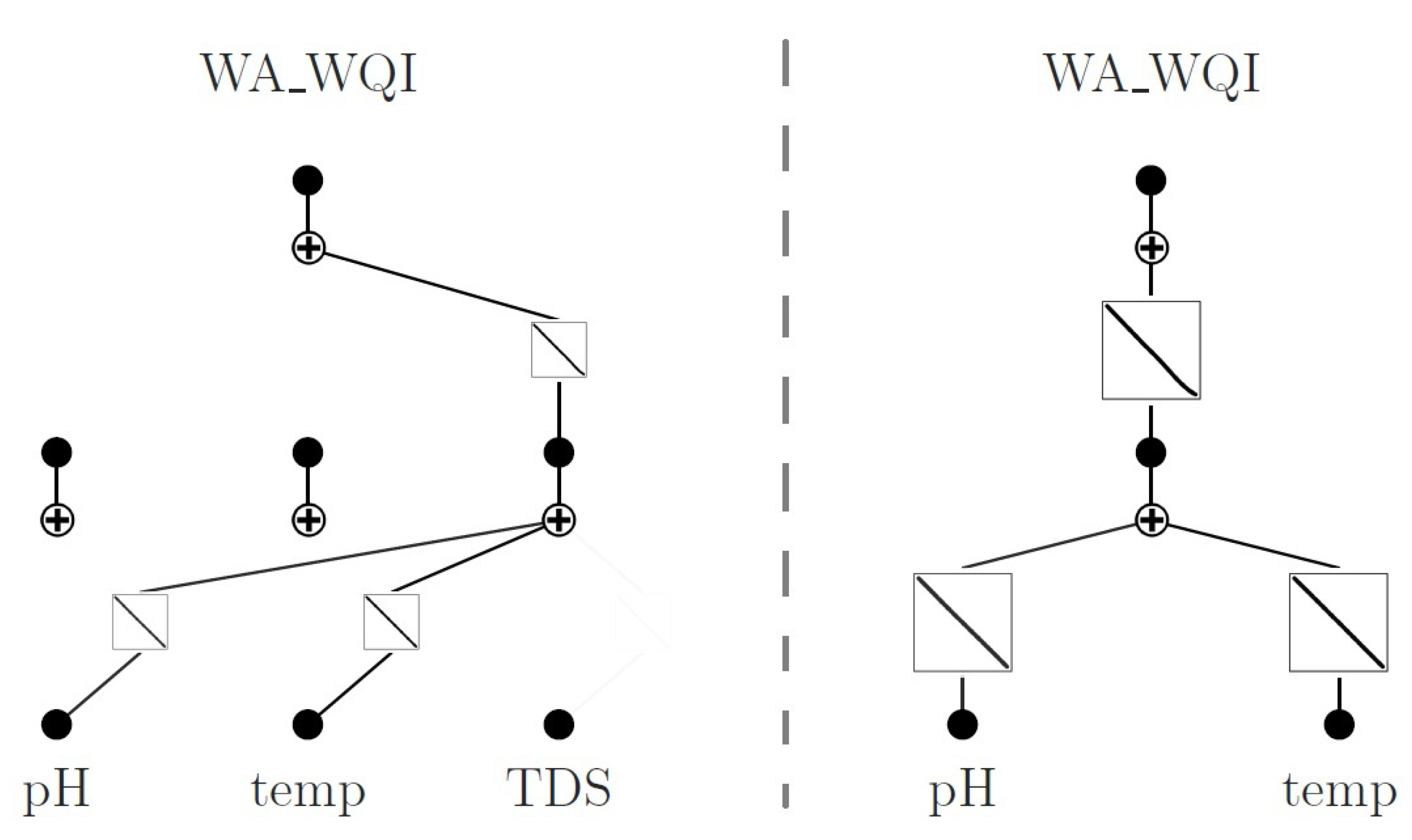
Motivation and Feasibility of Model Pruning
- Original model (KAN): Two layers configured as , , using all three input variables (pH, TDS, temperature).
- Pruned model (KAN′): Two layers configured as , , using only pH and temperature after feature sparsification.
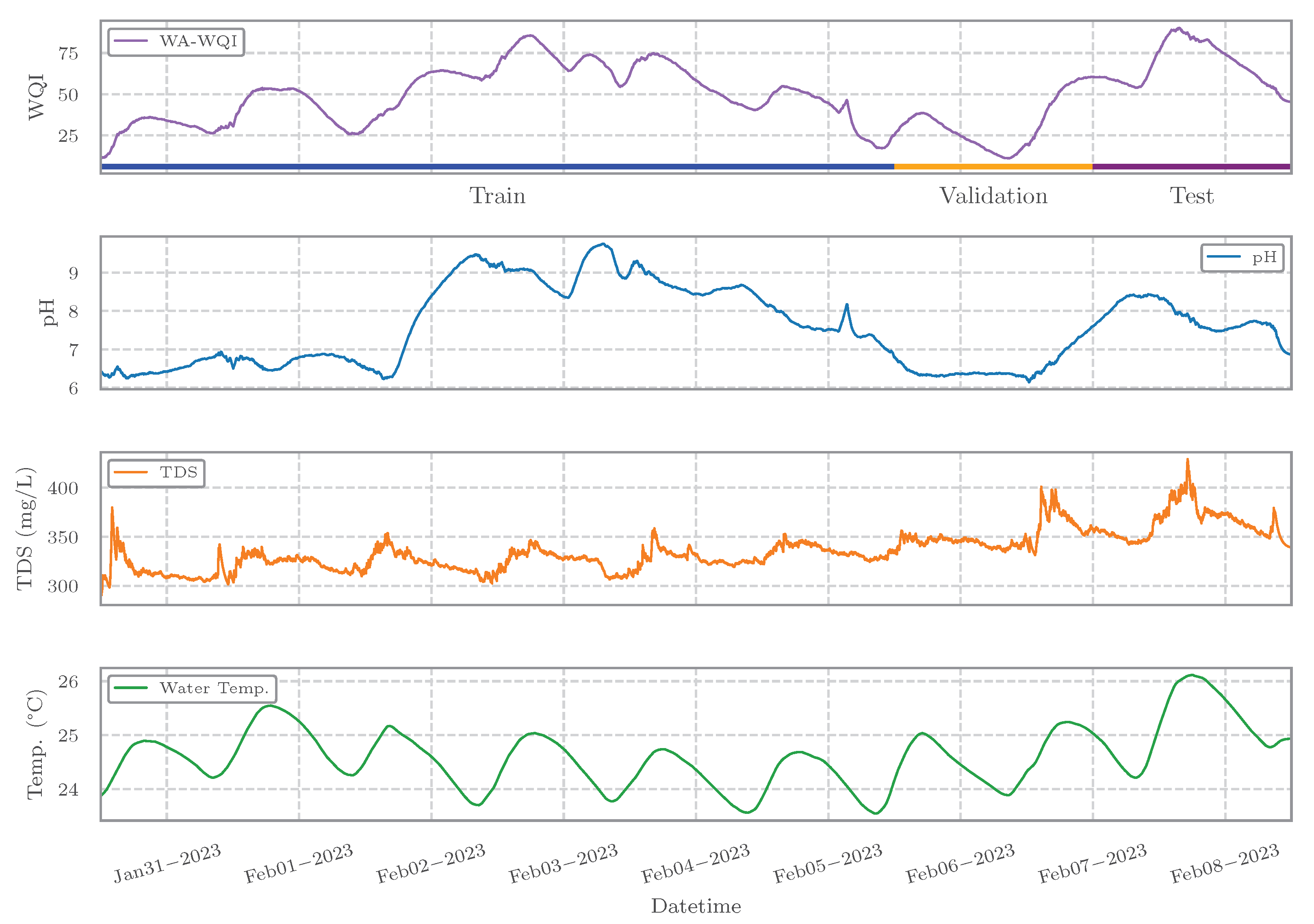
2.5. Data Split and Evaluation Protocols
2.5.1. Hold-Out Cross-Validation: Study Case 1
- Training set: 6 full days (∼8640 samples), covering the period from 2023-01-30 12:00 to 2023-02-05 12:00.
- Validation set: 1.5 days (∼2160 samples), immediately following the training set.
- Test set: 1.5 days (∼2160 samples), immediately following the validation set.
2.5.2. Temporal Cross-Validation: Study Case 2
- Training set: 6 full days (∼8640 samples), covering the same period used for Study Case 1.
- Validation set: 3 full days (∼4320 samples), immediately following the training set.
- Test set: 3.5 days (∼5040 samples), covering the period from 2023-03-04 00:00 to 2023-03-07 08:00.
2.6. Baseline Models for Comparative Evaluation
2.7. Overview of the Methodological Pipeline
3. Results and Discussion
3.1. Effectiveness of Data Preprocessing
3.2. Architectures of the Original and Pruned KAN Models
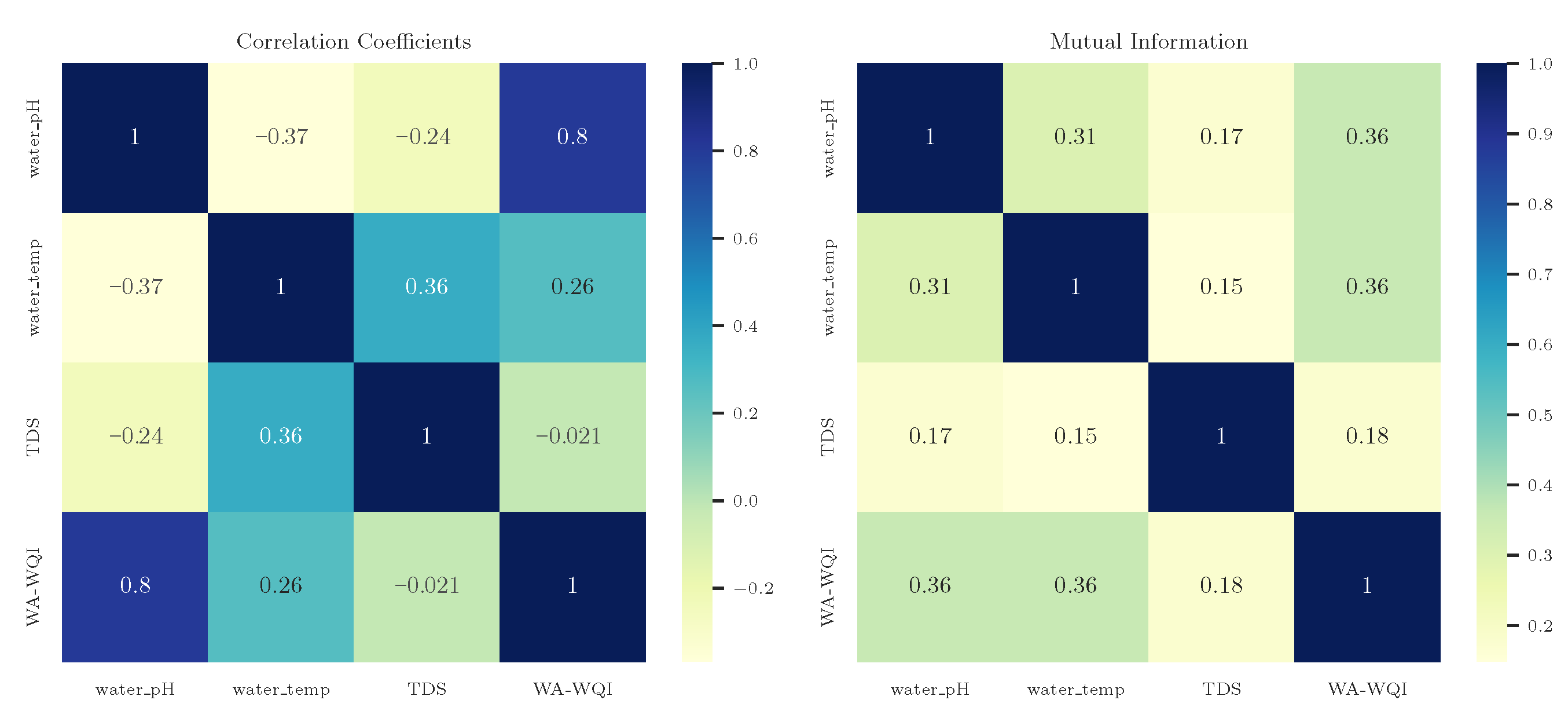
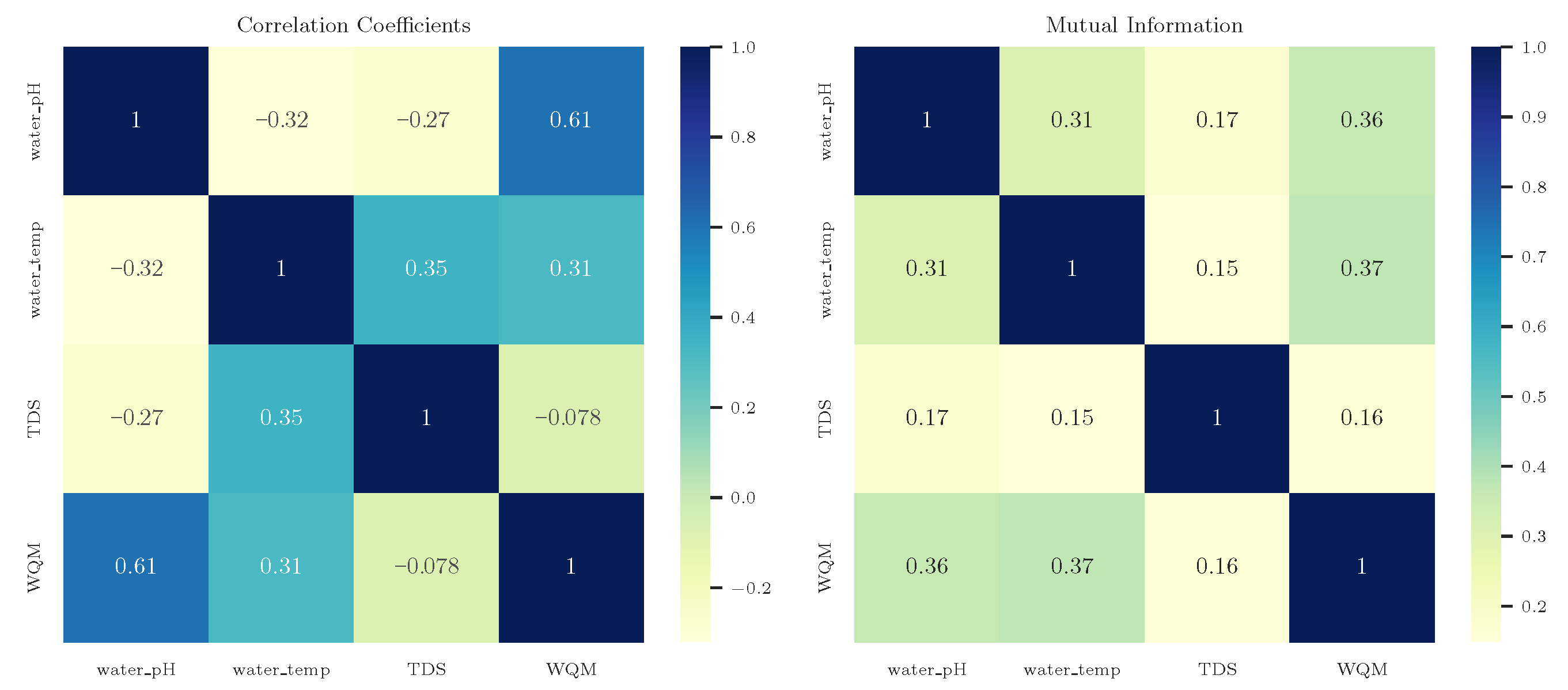
Exploratory Analysis of Variable Relationships
3.3. Model Inference and Symbolic Expression Evaluation
3.3.1. Symbolic Formulas
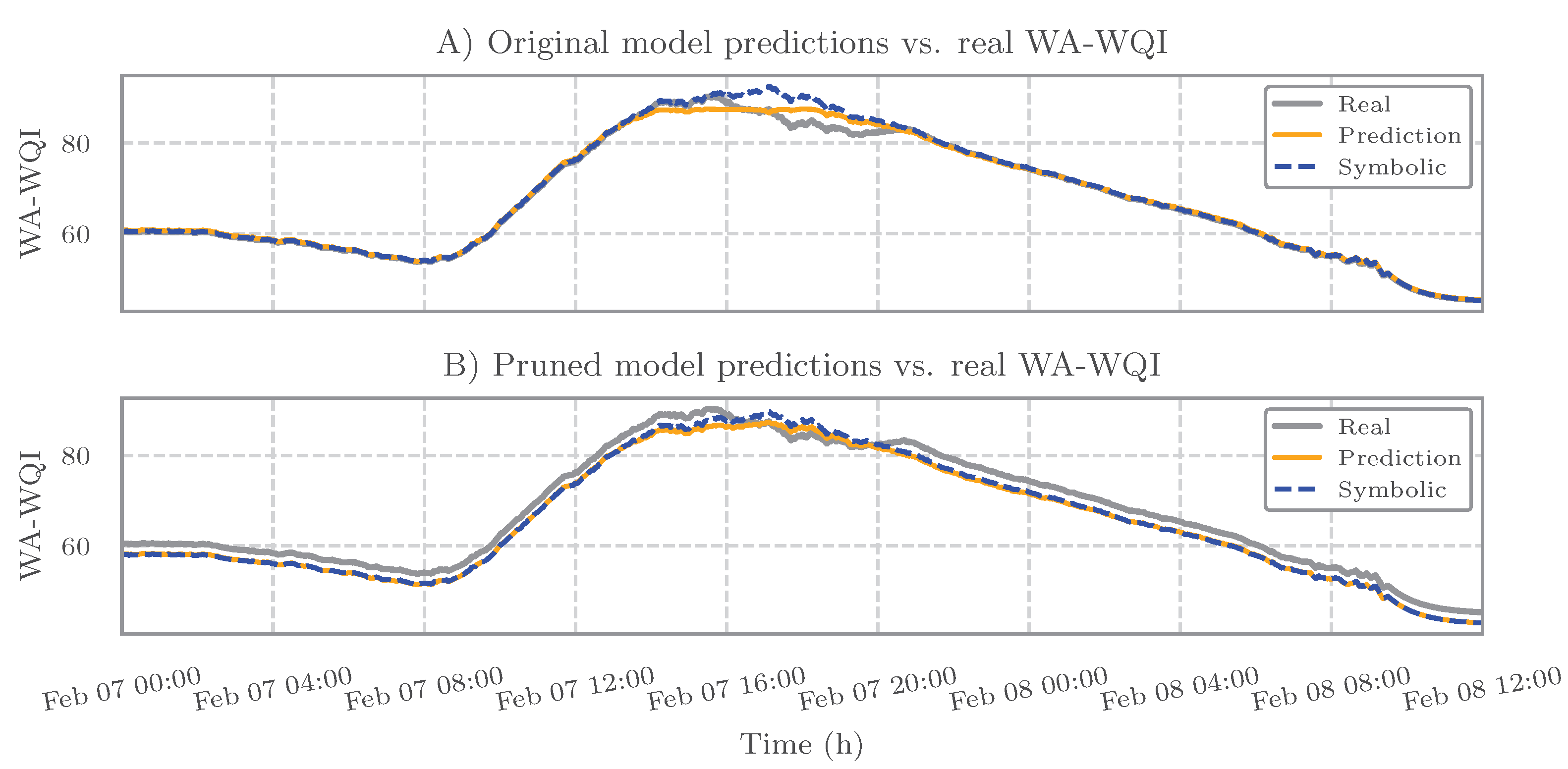
3.3.2. Performance Evaluation
Results for the WA-WQI Case Study
Results for the WQM-WQI Case Study
3.4. General Considerations
3.5. KAN Limitations and Challenges
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. KAN: Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2404.19756. [Google Scholar] [CrossRef]
- Liu, Z.; Ma, P.; Wang, Y.; Matusik, W.; Tegmark, M. KAN 2.0: Kolmogorov-Arnold Networks Meet Science. arXiv 2024, arXiv:2408.10205. [Google Scholar] [CrossRef]
- Ji, T.; Hou, Y.; Zhang, D. A Comprehensive Survey on Kolmogorov Arnold Networks (KAN). arXiv 2024, arXiv:2407.11075. [Google Scholar] [CrossRef]
- Gilbert Zequera, R.A.; Rassõlkin, A.; Vaimann, T.; Kallaste, A. Kolmogorov-Arnold networks for algorithm design in battery energy storage system applications. Energy Rep. 2025, 13, 2664–2677. [Google Scholar] [CrossRef]
- Huang, Y.; Li, B.; Wu, Z.; Liu, W. Symbolic Regression Based on Kolmogorov–Arnold Networks for Gray-Box Simulation Program with Integrated Circuit Emphasis Model of Generic Transistors. Electronics 2025, 14, 1161. [Google Scholar] [CrossRef]
- Siswanto, B.; Dani, Y.; Morika, D.; Mardiyana, B. A simple dataset of water quality on aquaponic fish ponds based on an internet of things measurement device. Data Brief 2023, 48, 109248. [Google Scholar] [CrossRef]
- Uddin, M.G.; Nash, S.; Olbert, A.I. A review of water quality index models and their use for assessing surface water quality. Ecol. Indic. 2021, 122, 107218. [Google Scholar] [CrossRef]
- Chidiac, S.; El Najjar, P.; Ouaini, N.; El Rayess, Y.; El Azzi, D. A comprehensive review of water quality indices (WQIs): History, models, attempts and perspectives. Rev. Environ. Sci. Bio/Technol. 2023, 22, 349–395. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Krishnamurthi, R.; Kumar, A.; Gopinathan, D.; Nayyar, A.; Qureshi, B. An Overview of IoT Sensor Data Processing, Fusion, and Analysis Techniques. Sensors 2020, 20, 6076. [Google Scholar] [CrossRef]
- Liu, Y.; Dillon, T.; Yu, W.; Rahayu, W.; Mostafa, F. Missing Value Imputation for Industrial IoT Sensor Data with Large Gaps. IEEE Internet Things J. 2020, 7, 6855–6867. [Google Scholar] [CrossRef]
- França, C.M.; Couto, R.S.; Velloso, P.B. Missing Data Imputation in Internet of Things Gateways. Information 2021, 12, 425. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R.; Taylor, J. Resampling Methods. In An Introduction to Statistical Learning; Springer International Publishing: Berlin/Heidelberg, Germany, 2023; pp. 201–228. [Google Scholar] [CrossRef]
- Xu, Y.; Goodacre, R. On Splitting Training and Validation Set: A Comparative Study of Cross-Validation, Bootstrap and Systematic Sampling for Estimating the Generalization Performance of Supervised Learning. J. Anal. Test. 2018, 2, 249–262. [Google Scholar] [CrossRef] [PubMed]
- Cao, L. Practical Issues in Implementing a Single-Pole Low-Pass IIR Filter [Applications Corner]. IEEE Signal Process. Mag. 2010, 27, 114–117. [Google Scholar] [CrossRef]
- Uddin, M.G.; Nash, S.; Rahman, A.; Olbert, A.I. A comprehensive method for improvement of water quality index (WQI) models for coastal water quality assessment. Water Res. 2022, 219, 118532. [Google Scholar] [CrossRef]
- Patel, D.D.; Mehta, D.J.; Azamathulla, H.M.; Shaikh, M.M.; Jha, S.; Rathnayake, U. Application of the Weighted Arithmetic Water Quality Index in Assessing Groundwater Quality: A Case Study of the South Gujarat Region. Water 2023, 15, 3512. [Google Scholar] [CrossRef]
- Abdolazizi, K.P.; Aydin, R.C.; Cyron, C.J.; Linka, K. Constitutive Kolmogorov–Arnold Networks (CKANs): Combining accuracy and interpretability in data-driven material modeling. J. Mech. Phys. Solids 2025, 203, 106212. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Leshno, M.; Lin, V.Y.; Pinkus, A.; Schocken, S. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Netw. 1993, 6, 861–867. [Google Scholar] [CrossRef]
- Schmidt-Hieber, J. The Kolmogorov–Arnold representation theorem revisited. Neural Netw. 2021, 137, 119–126. [Google Scholar] [CrossRef]
- Vaca-Rubio, C.J.; Blanco, L.; Pereira, R.; Caus, M. Kolmogorov-Arnold Networks (KANs) for Time Series Analysis. arXiv 2024, arXiv:2405.08790. [Google Scholar] [CrossRef]
- Abueidda, D.W.; Pantidis, P.; Mobasher, M.E. DeepOKAN: Deep operator network based on Kolmogorov Arnold networks for mechanics problems. Comput. Methods Appl. Mech. Eng. 2025, 436, 117699. [Google Scholar] [CrossRef]
- Perperoglou, A.; Sauerbrei, W.; Abrahamowicz, M.; Schmid, M. A review of spline function procedures in R. BMC Med. Res. Methodol. 2019, 19, 46. [Google Scholar] [CrossRef] [PubMed]
- Hasan, M.S.; Alam, M.N.; Fayz-Al-Asad, M.; Muhammad, N.; Tunç, C. B-spline curve theory: An overview and applications in real life. Nonlinear Eng. 2024, 13, 20240054. [Google Scholar] [CrossRef]
- Joseph, V.R. Optimal ratio for data splitting. Stat. Anal. Data Mining Asa Data Sci. J. 2022, 15, 531–538. [Google Scholar] [CrossRef]
- Kapoor, S.; Narayanan, A. Leakage and the reproducibility crisis in machine-learning-based science. Patterns 2023, 4, 100804. [Google Scholar] [CrossRef]
- Goap, A.; Sarkar, S.; Roy, A.; Krishna, C.R.; Kumar, S. An IoT-Based Architectural Framework for Earthquake Warning System Using Low-cost Heterogeneous Seismic Sensors. Arab. J. Sci. Eng. 2025, 1–16. [Google Scholar] [CrossRef]
- Eldin Rashed, A.E.; Elmorsy, A.M.; Mansour Atwa, A.E. Comparative evaluation of automated machine learning techniques for breast cancer diagnosis. Biomed. Signal Process. Control. 2023, 86, 105016. [Google Scholar] [CrossRef]
- Salehin, I.; Islam, M.S.; Saha, P.; Noman, S.; Tuni, A.; Hasan, M.M.; Baten, M.A. AutoML: A systematic review on automated machine learning with neural architecture search. J. Inf. Intell. 2024, 2, 52–81. [Google Scholar] [CrossRef]
- LazyPredict Python Library. Available online: https://lazypredict.readthedocs.io/en/latest/ (accessed on 25 June 2025).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R.; Taylor, J. Linear Regression. In An Introduction to Statistical Learning; Springer International Publishing: Berlin/Heidelberg, Germany, 2023; pp. 69–134. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R.; Taylor, J. Tree-Based Methods. In An Introduction to Statistical Learning; Springer International Publishing: Berlin/Heidelberg, Germany, 2023; pp. 331–366. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, J.; Shen, W. A Review of Ensemble Learning Algorithms Used in Remote Sensing Applications. Appl. Sci. 2022, 12, 8654. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Sanchez-Castillo, M.; Chica-Olmo, M.; Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 2015, 71, 804–818. [Google Scholar] [CrossRef]
- Sanyal, S.; Zhang, P. Improving Quality of Data: IoT Data Aggregation Using Device to Device Communications. IEEE Access 2018, 6, 67830–67840. [Google Scholar] [CrossRef]
- Herrera, M.; Sasidharan, M.; Merino, J.; Parlikad, A.K. Handling Irregularly Sampled IoT Time Series to Inform Infrastructure Asset Management. IFAC-PapersOnLine 2022, 55, 241–245. [Google Scholar] [CrossRef]
- Harker, M.; Rath, G. System Identification with Non-Uniformly Sampled and Intermittent Data in the Internet of Things. In Proceedings of the 2023 International Conference on Applied Electronics (AE), Pilsen, Czech Republic, 6–8 September 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Alotaibi, O.; Pardede, E.; Tomy, S. Cleaning Big Data Streams: A Systematic Literature Review. Technologies 2023, 11, 101. [Google Scholar] [CrossRef]
- Hu, H.; Huang, S. A Kalman Filtering and Least Absolute Residuals based Time Series Data Reconstruction Strategy for Structural Health Monitoring. In Proceedings of the 2024 IEEE 10th World Forum on Internet of Things (WF-IoT), Ottawa, QC, Canada, 10–13 November 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, X.; Zhu, R. Feature selection based on mutual information with correlation coefficient. Appl. Intell. 2022, 52, 5457–5474. [Google Scholar] [CrossRef]
- N., G.; Jain, P.; Choudhury, A.; Dutta, P.; Kalita, K.; Barsocchi, P. Random Forest Regression-Based Machine Learning Model for Accurate Estimation of Fluid Flow in Curved Pipes. Processes 2021, 9, 2095. [Google Scholar] [CrossRef]
- Do, D.D.; Le, A.H.; Vu, V.V.; Le, D.A.N.; Bui, H.M. Evaluation of water quality and key factors influencing water quality in intensive shrimp farming systems using principal component analysis-fuzzy approach. Desalin. Water Treat. 2025, 321, 101002. [Google Scholar] [CrossRef]
- Ferreira, N.; Bonetti, C.; Seiffert, W. Hydrological and Water Quality Indices as management tools in marine shrimp culture. Aquaculture 2011, 318, 425–433. [Google Scholar] [CrossRef]
- Tallar, R.Y.; Suen, J.P. Aquaculture Water Quality Index: A low-cost index to accelerate aquaculture development in Indonesia. Aquac. Int. 2015, 24, 295–312. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, Y.; Hu, F.; He, M.; Mao, Z.; Huang, X.; Ding, J. Predictive modeling of flexible EHD pumps using Kolmogorov–Arnold Networks. Biomim. Intell. Robot. 2024, 4, 100184. [Google Scholar] [CrossRef]
- Somvanshi, S.; Javed, S.A.; Islam, M.M.; Pandit, D.; Das, S. A Survey on Kolmogorov-Arnold Network; ACM Computing Surveys: New York, NY, USA, 2025. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; KDD’16. ACM Computing Surveys: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; NIPS’17. Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4768–4777. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Units |
|---|---|
| Timestamp recorded | Date Time |
| Water pH | pH units |
| TDS concentration | mg/L (ppm) |
| Water temperature | °C (Celsius) |
| Fold | Start Date & Time | End Date & Time | Duration |
|---|---|---|---|
| 1 | 2023-03-04 00:00 | 2023-03-06 00:00 | 2 days |
| 2 | 2023-03-04 08:00 | 2023-03-06 08:00 | 2 days |
| 3 | 2023-03-04 16:00 | 2023-03-06 16:00 | 2 days |
| 4 | 2023-03-05 00:00 | 2023-03-07 00:00 | 2 days |
| 5 | 2023-03-05 08:00 | 2023-03-07 08:00 | 2 days |
| 1. | LinearRegression | 9. | ExtraTreesRegressor |
| 2. | Ridge | 10. | ExtraTreeRegressor |
| 3. | Lasso | 11. | GradientBoostingRegressor |
| 4. | ElasticNet | 12. | BaggingRegressor |
| 5. | SVR | 13. | HistGradientBoostingRegressor |
| 6. | LinearSVR | 14. | DecisionTreeRegressor |
| 7. | KNeighborsRegressor | 15. | MLPRegressor |
| 8. | RandomForestRegressor |
| Model | R² | MAE | RMSE |
|---|---|---|---|
| KAN (full) inference | 0.994 | 0.526 | 0.948 |
| Symbolic (full) | 0.986 | 0.627 | 1.538 |
| KAN (pruned) inference | 0.965 | 2.322 | 2.408 |
| Symbolic (pruned) | 0.967 | 2.291 | 2.330 |
| Model | R² | MAE | RMSE |
|---|---|---|---|
| KAN (full) inference | 0.9149 | 1.7273 | 2.9471 |
| Symbolic (full) | 0.9012 | 2.0898 | 3.1761 |
| KAN (pruned) inference | 0.9847 | 0.5848 | 1.2496 |
| Symbolic (pruned) | 0.9997 | 0.1525 | 0.1845 |
| MLPRegressor | 0.9980 | 0.2410 | 0.4530 |
| RandomForestRegressor | 0.8820 | 2.0710 | 3.4640 |
| BaggingRegressor | 0.8800 | 2.1150 | 3.4990 |
| Model | R² | MAE | RMSE |
|---|---|---|---|
| Symbolic (pruned) | |||
| MLPRegressor | |||
| KAN (pruned) inference | |||
| RandomForestRegressor | |||
| BaggingRegressor |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sánchez-Gendriz, I.; Silva, I.; Guedes, L.A. Kolmogorov-Arnold Networks for Interpretable Analysis of Water Quality Time-Series Data. J 2025, 8, 24. https://doi.org/10.3390/j8030024
Sánchez-Gendriz I, Silva I, Guedes LA. Kolmogorov-Arnold Networks for Interpretable Analysis of Water Quality Time-Series Data. J. 2025; 8(3):24. https://doi.org/10.3390/j8030024
Chicago/Turabian StyleSánchez-Gendriz, Ignacio, Ivanovitch Silva, and Luiz Affonso Guedes. 2025. "Kolmogorov-Arnold Networks for Interpretable Analysis of Water Quality Time-Series Data" J 8, no. 3: 24. https://doi.org/10.3390/j8030024
APA StyleSánchez-Gendriz, I., Silva, I., & Guedes, L. A. (2025). Kolmogorov-Arnold Networks for Interpretable Analysis of Water Quality Time-Series Data. J, 8(3), 24. https://doi.org/10.3390/j8030024