1. Introduction
The viruses of the family Coronaviridae are so-called because of their peculiar crown-shaped surface (or spike) protein—see
Figure 1 for the genomic structure of a coronavirus, which includes the spike region. Coronaviruses cause a variety of known respiratory infections [
1], including SARS (SARS-CoV), Middle-Eastern Respiratory Syndrome (MERS-CoV), and, of course, SARS-CoV-2, which is responsible for the ongoing COVID-19 global pandemic. Many of the Coronaviridae affect a wide variety of hosts, and often spill over to other hosts [
2]. SARS-CoV was believed to have jumped to humans via palm civets and horseshoe bats [
3], MERS-CoV from dromedary camels [
4], whereas SARS-CoV-2 likely originated from bats [
5].
Our understanding of the mechanisms that could allow different viruses to spill over from one host to another is continuously updating as the viruses evolve and we gather more sequencing data. Here, we considered
information gain (IG) [
7] for explaining host specificity, something that is convenient in light of the constant accumulation of new sequencing data, since the IG computation only requires a multiple alignment of a set of sequences.
Definition 1 (Information Gain).
Information gain is a measure of how much information a feature provides about a target class [7]. Given a protein sequence, the IG of an amino acid site in terms of a host is the following:wherewhere H(C) is the entropy of category C, the notation C represents the host/site, and is the probability of element i of category C. Intuitively, the information gain of a given amino acid site is how much information this site provides for deciding the host, e.g., whether the sequence is of a virus that infects bats, humans, or camels. Such a measure, while simple to compute, has the potential to capture important trends when the number of sequences analyzed is sufficiently large.
Since it is the portion(s) of the surface protein responsible for fusing to the host cell membrane that determines host specificity [
8], one might expect information gain to be enriched for sites corresponding to solvent-exposed extracellular residues. For this reason, we performed solvent accessibility prediction for sequences in several different major subgenera (Sarbecovirus, Merbecovirus, etc.), and then demonstrated higher IG in solvent-exposed sites on the spike protein sequence.
The Coronaviridae are a family of enveloped, positive-sense single-stranded RNA viruses that can cause respiratory [
9], gastrointestinal [
10], liver [
11], and neurological diseases [
12] in humans and animals. The viral envelope, which is composed of a lipid bi-layer, is essential for survival and replication [
13], as it protects the viral genome and mediates interactions with host cells. The solvent exposure of the virus determines the stability of the viral envelope and affects its interactions with host cells and the environment [
14]. The spike proteins on the surface of the envelope are particularly sensitive to solvent exposure [
15], and changes in solvent exposure can cause structural changes in these proteins, which can affect their function [
16]. Therefore, the solvent exposure of the Coronaviridae is an important factor to consider when studying the biology and pathogenesis of these viruses. The advantages of studying solvent exposure in the spike protein of Coronaviridae include
Understanding protein stability: Solvent exposure can provide insights into the stability and conformational changes in the spike protein, which are critical for its function and viral infectivity [
17].
Drug discovery: Knowledge of the solvent exposure of the spike protein can aid in the discovery of drugs that target the virus by disrupting the protein’s stability or function [
18].
Vaccine design: Studying solvent exposure can inform the design of vaccines that elicit an immune response against the spike protein, which is a crucial target for neutralizing antibodies [
19].
Mechanism of action: Understanding the solvent exposure of the spike protein can provide insights into the mechanism of action of the virus and how it enters host cells [
16].
Evolution: Studying solvent exposure can also provide information on how the virus evolves and adapts to changing environments, which can inform the development of strategies to control the spread of the virus [
17].
Recently, as the amount of sequencing data becomes large enough, some efforts have been made to study families of viruses using machine learning approaches. These methods apply some form of classification [
20] or clustering [
21]. One way to improve the performance of these machine learning methods is to make use of biological domain knowledge [
22]. Using statistical analysis is another method that could be used to improve the performance of underlying machine learning models (as suggested by Ali et al. in [
20]). In this work, we studied the relationship between specific amino acid sites (within MSA) and the solvent accessibility of the surface (or spike) protein of different Coronaviridae. While we applied this study to the family Coronaviridae as a proof of concept, one could apply this to newer families of lesser-known viruses in the hopes of better understanding how protein structure affects their host specificity. Our contributions in this paper are the following:
We used information gain (IG) to evaluate the importance of amino acid sites of the spike sequence, which could be used to study the behavior of the virus.
Obtaining structural information about the spike protein, namely solvent accessibility, we evaluated if there is any relationship between this and IG.
We show that there is such a connection between IG and solvent accessibility, the latter requiring much more time to compute.
We performed several case studies to show the biological relevance of the relationship between solvent accessibility and IG.
The rest of the paper is organized as follows.
Section 2 contains the detail on the data collection and statistics.
Section 3 contains the study that shows a connection between information gain and solvent accessibility.
Section 4 provides some case studies on regions and pairs of hosts of interest. Finally, we conclude our paper in
Section 5.
2. Data Collection and Statistics
In this section, we first discuss details on the collection of the sequence data using different sources. We then provide some descriptive statistics of this data, and some visualization of the data using the t-distributed stochastic neighborhood embedding (t-SNE) method.
2.1. Data Collection
Virus Pathogen Resource(ViPR):
Data were obtained from ViPR (
https://www.viprbrc.org) on 9 February 2022. We downloaded all 1,441,773 unaligned complete S protein sequences of the family Coronaviridae for host “All”. Because this database is overwhelmed with SARS-CoV-2 sequences due to the COVID-19 pandemic, and the ViPR search utility is such that hosts can only be specified but not filtered (as far as we know), we downloaded all 1,439,557 such sequences for all hosts and the dataset for host “human” was excluded, resulting in a remaining 2216 sequences. Note that some of the sequences with no host label (according to ViPR) might still pertain to a human host. We then queried the National Center for Biotechnology Information (NCBI) resource (since the sequences from ViPR are annotated with NCBI IDs) to obtain the taxonomic and host information of these 2216 sequences. Of these, 14 sequences were from the Piscanivirinae, Serpentovirinae, and Torovirinae subfamilies, which were previously part of the Coronaviridae family but were re-classed to the Tobaniviridae family in 2018 [
23]. We removed these 14, resulting in a remaining 2202 sequences, which are distributed across different taxa as given in
Table 1.
Global Initiative on Sharing All Influenza Data (GISAID):
Data were also obtained from GISAID (
https://www.gisaid.org) on 9 February 2022. We downloaded all 7,940,305 unaligned S (spike) protein sequences of SARS-CoV-2 from GISAID. We then filtered out the 7,935,111 sequences tagged with host “Human” (or “Hombre”), resulting in a remaining 5194 sequences for all hosts except for “Human”. Since there was no way to restrict the search to complete sequences (like with ViPR, or as far as we know), we removed 59 sequences that were more than three standard deviations (
) shorter than the mean (
) sequence length, resulting in a remaining 5135 sequences with lengths ranging from 1128 to 1276. Since these were all SARS-CoV-2 sequences, they were all of the subgenus Sarbecovirus (genus Betacoronavirus).
Data Integration:
We then combined these two datasets into a single dataset of
sequences, and then added 2663 randomly selected sequences from the
sequences for host “Human” downloaded from ViPR (above) for an even
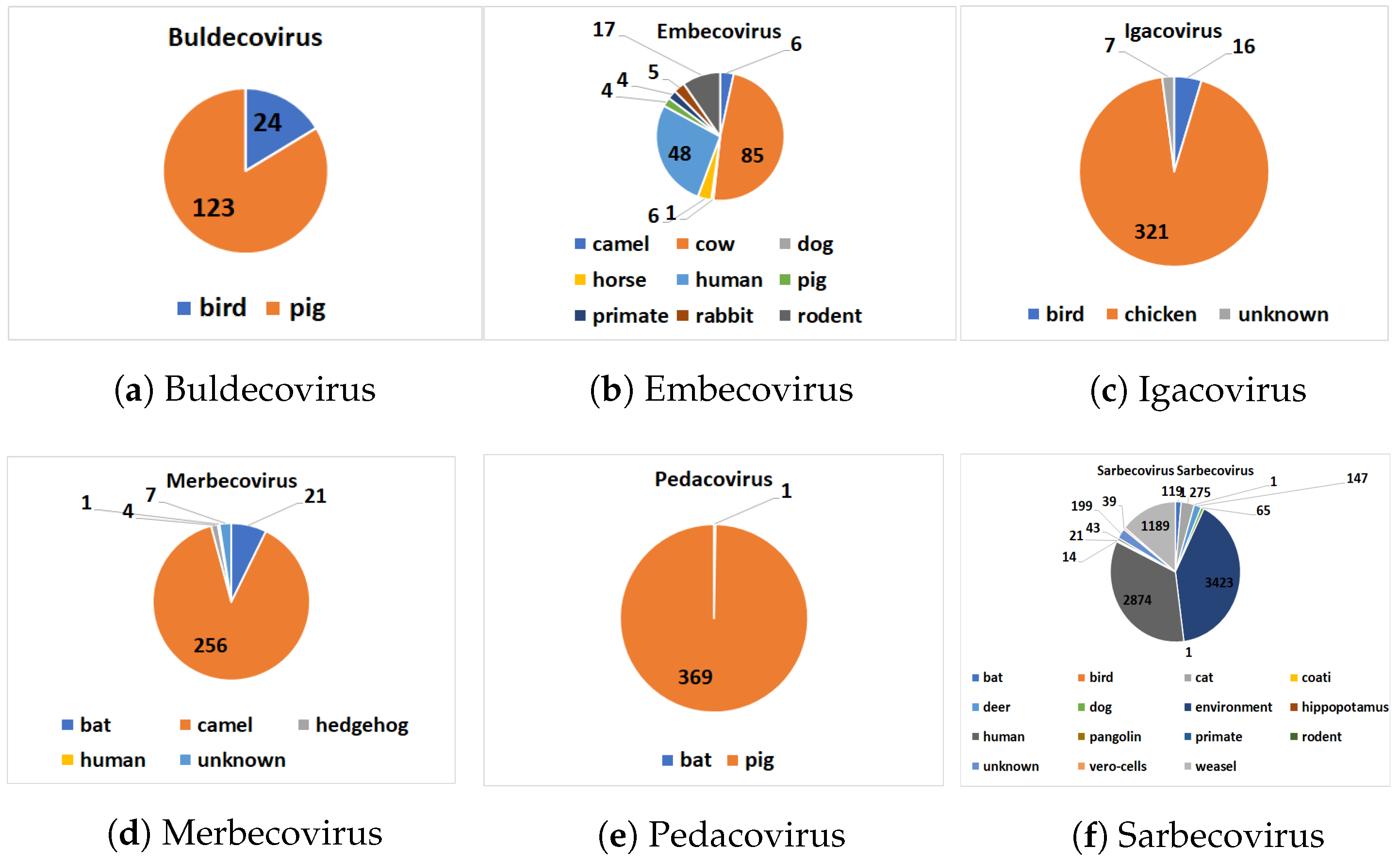
sequences. All but one of these 2663 sequences were of the subgenus Sarbecovirus, that one being of subgenus Embecovirus (genus Betacoronavirus). In the end, the “major” subgenera and hosts were considered, those represented by more than 100 sequences, and are depicted in
Table 2 and
Table 3.
Data Processing:
For each of the sets of sequences, represented by the subgenera and hosts, we performed a multiple alignment with Mafft (
https://mafft.cbrc.jp/alignment/software/) (accessed on 9 February 2022) using default parameters. We then removed from this alignment any position (column) containing only
X and
-, since they are a “wildcard” character and a gap, respectively. This is preferable to removing all
X characters from the sequences beforehand, because it allows the aligner to decide what each
X means, rather than making an irreversible decision. Since we are only interested in host specificity (not subgenus specificity), we computed the information gain of each site of the alignment for each subgenus of
Table 2 only. Note that, while some subgenera have many more sequences than others (
Table 2). The Host-based grouping of sequences is also reported in
Table 3. The length statistics for different subgenera and hosts are reported in
Table 4 and
Table 5, respectively. In
Table 2, most notable subgenus is Sarbecovirus, we studied the host specificity within each subgenus, independent of the others. Still, what this means is that the results will be more reliable for subgenera with a larger number of sequences—for example, in
Table 6, Sarbecovirus has a notably stronger correlation value and smaller
p-value—something we discuss more in
Section 3 below. The information of the spike protein was predicted using the SCRATCH Protein Predictor by taking protein sequences as the input (
http://scratch.proteomics.ics.uci.edu/) (accessed on 9 February 2022), classifying the sites as being solvent-exposed on a scale of 1 to 20. We provide more statistics and visualization of these data in the subsequent sections.
2.2. Dataset Statistics
We first give some statistics on the average sequence length and standard deviation (SD) of the length distribution for the major subgenera and hosts in
Table 4 and
Table 5, respectively. The last column of both tables shows the length of the alignment template. Note that this length tends to grow larger than the average length as both the number of sequences and standard deviation grow, which is to be expected.
The distribution of hosts within each subgenus is given in
Figure 2. Our pre-processed dataset is available online (
https://github.com/sarwanpasha/Comparative_Genomics) (accessed on 9 February 2022). Note that some subgenera, in particular Embecovirus and Sarbecovirus, have a much more widespread diversity of hosts than others. We note that host label (
Table 3 and
Figure 2) are discrete, when, in reality, the sequences exhibit a spectrum of host specificity; here, we just chose the most common host for each sequence from the records (NCBI, etc.) above. With a large enough number of sequences (e.g., Sarbecovirus,
Table 2), overall trends in host specificity should have a clear signal.
2.3. Visualization with t-SNE
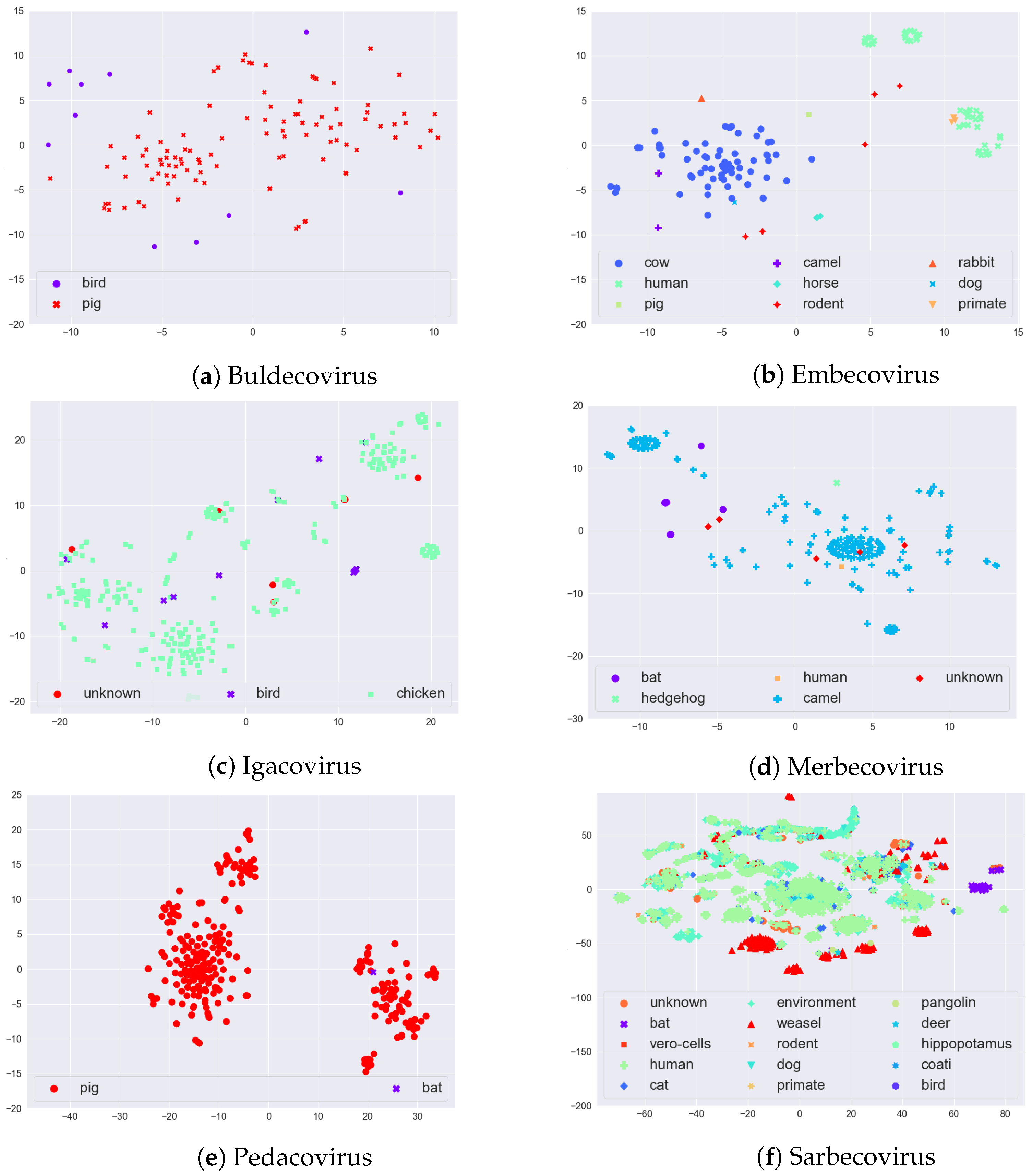
In order to visually evaluate if there is any (hidden) clustering in the sequences, we used the t-distributed stochastic neighbor embedding (t-SNE) [
24] method. The t-SNE method maps input data to 2D real vectors, which can then be visualized as a scatter plot. Since t-SNE takes numerical vectors as input, we obtained a numerical representation of the sequences of each subgenus using a feature vector generation called Spike2Vec [
20].
Given some sequence on alphabet , Spike2Vec generates substrings (also called mers) of length k, i.e., k-mers. In , we have the following 20 characters (amino acids): “ACDEFGHIKLMNPQRSTVWY”. From a sequence, k-mers are generated by applying a sliding window of size k over the sequences. Given a sequence of length N, the total number of k-mers that could be generated is .
After generating the
k-mers, Spike2Vec creates a feature vector
(a frequency vector), which contains the frequency (count) of each
k-mer occurring in the sequence. The length of the feature vector
is
. Since we worked with spike protein (amino acid) sequences and took
in our experiments, the feature vector length that we used was
. This feature vector can be used as the input for t-SNE plots. The t-SNE plots of the sequences of each of the six major subgenera, colored by host, are given in
Figure 3. In Embecovirus, we note that the two major groups, Cow and Human, are well separated. In Merbecovirus, there is some grouping for the Camel host. Interestingly, in the Pedacovirus, there seem to be two distinct groups of sequences that both affect the Pig (or Swine). Finally, in Sarbecovirus, there is some grouping of Humans, Weasel, and Bat. While these t-SNE plots capture sequence variability, this may or may not be related to information gain, since only a few such sites in the sequence might be important for specifying the host—something we explored in the case studies in
Section 4 below.
3. Information Gain and Solvent Accessibility
For each major subgenus (of
Table 2), we computed the information gain (IG) of each site in its alignment, according to Equation (
1), and extracted the solvent-accessible positions. We achieved this using the SCRATCH Protein Predictor, which uses ACCpro for predicting the relative solvent accessibility of protein residues [
25,
26,
27]. The ACCpro predictor is based on one-dimensional recursive neural networks (1D-RNNs), with each amino acid residue predicted as buried or exposed from a scale of 1 to 20.
Given the solvent accessibility and IG for each site of a spike protein of a coronavirus, the Spearman rank correlation coefficient () and Kendall rank correlation coefficient () were then calculated for each subgenus according to the following definitions.
Definition 2 (Spearman Rank Correlation).
The Spearman rank correlation coefficient measures the degree of association between two variables, where both variables are ordinal. The can be calculated as:where is the difference in the rank of and , and n is the number of observations. Definition 3 (Kendall Rank Correlation).
The Kendall rank correlation coefficient τ is a measure of the concordance between two variables, where both variables are ordinal or categorical. The τ can be calculated as:where c is the number of concordant pairs, d is the number of discordant pairs, and n is the number of observations. The values of these coefficients range from −1 to 1, where −1 represents a perfect negative correlation, 0 represents no correlation, and 1 represents a perfect positive correlation. The rank correlation between IG values and the average rank of each site is given in
Table 6 using the Spearman and Kendall rank correlation.
The results show that there is a moderate to strong positive correlation between the solvent accessibility of different sites on the spike protein and their information gain for each subgenera. This implies that the sites of the spike protein that are more solvent accessible (i.e., exposed) also have higher information gain, indicating that they are more informative about the host. The p-value of all of the viruses is very low, which means that the correlation is statistically significant at the level of 0.05 or less, indicating that the observed correlation is unlikely to be due to chance. The notably strongest correlation is viewed in Sarbecovirus, which has many more hosts than the other subgenera, which is likely due to its disproportionately many (≈8K) sequences compared to the other subgenera (due to the fact that it contains SARS-CoV-2); hence, we would expect the same trend in a stronger correlation as the number of sequences of subgenera increases.
The information gain of a site can be interpreted as the reduction in uncertainty or disorder of the host variable given that site. Therefore, if a site has a high information gain, it means that it provides a large amount of information about the host, and if a site has a low information gain, it means that it provides very little information about the host. Hence, since we can observe in
Table 6 that solvent accessibility is positively correlated with information gain, this implies that the sites of the spike protein that are more solvent-accessible (i.e., exposed) are also more informative about the host; that is, IG can be used as a proxy for solvent accessibility. This is desirable, given that it is much more computationally expensive (in terms of runtime and memory usage) to infer solvent accessibility (with SCRATCH) than to compute information gain (see
Table 7).
Although the study of solvent exposure comes with many advantages, such as providing direct information about the exposure of residues in the spike protein to the outside environment, which can directly impact its stability, function, and interactions with other molecules, its main disadvantage is the time it takes to compute its values when they are not known previously (see
Table 7). Now that the number of sequences for viruses such as the Coronaviridae is larger, we can use the much more easy-to-compute information gain as a proxy. While, e.g., SARS-CoV-2, is a fairly well-studied virus by now, much is known about the spike protein structure and its solvent accessibility [
16]; however, this proof of concept that information gain can be used as a proxy for solvent accessibility could be used for other lesser-known families of viruses, where one would need to first compute or infer solvent accessibility.
5. Conclusions
In this work, we studied information gain (IG) as a source of information to explain host specificity. Such an approach is flexible to the continuously updating sequence information since it just requires a multiple-sequence alignment. We showed a connection between high IG and solvent accessibility, suggesting that proteins exposed to (solvents in) the outside environment are more responsible for host specificity. We also performed a visualization of the sequences to see some trends between different hosts in a given viral subgenus, performing some case studies on some regions and pairs of hosts of interest.
Future work includes more measures of host specificity beyond solvent accessibility. Since we considered spike protein (amino acid) sequences in this study, we could not perform this; however, if given nucleotide sequences, it would be interesting to see if there are sites that are positively or negatively selected (via an analysis of, e.g., dN/dS) for IG, solvent accessibility, etc. Finally, some subgenera have many more sequences or a wider diversity of hosts than others. Exploring the effects of this, but also of imperfect labeling (e.g., many viral sequences have a spectrum of hosts, even though only one is specified in the data), is another future direction—perhaps a more phylogeny-aware analysis could correct for some of this. Connecting other proteomic features or aspects of the protein structure, such as a secondary and possibly tertiary structure, is another interesting line of future work. Finally, using this idea to obtain domain knowledge for other studies, as a basis for further investigation, or to improve the performance of machine learning models could be other interesting future directions.








{kind=link}
{kind=link}
{kind=link}
{kind=link}