
COVID-19 Mortality in English Neighborhoods: The Relative Role of Socioeconomic and Environmental Factors


Abstract
1. Introduction
2. Previous Research on Ecological Risk Factors for COVID Mortality
3. Materials and Methods
3.1. Sources of Data on Mortality and Predictors
3.2. Scaling of Predictors in Regression
3.3. Estimation and Goodness of Fit
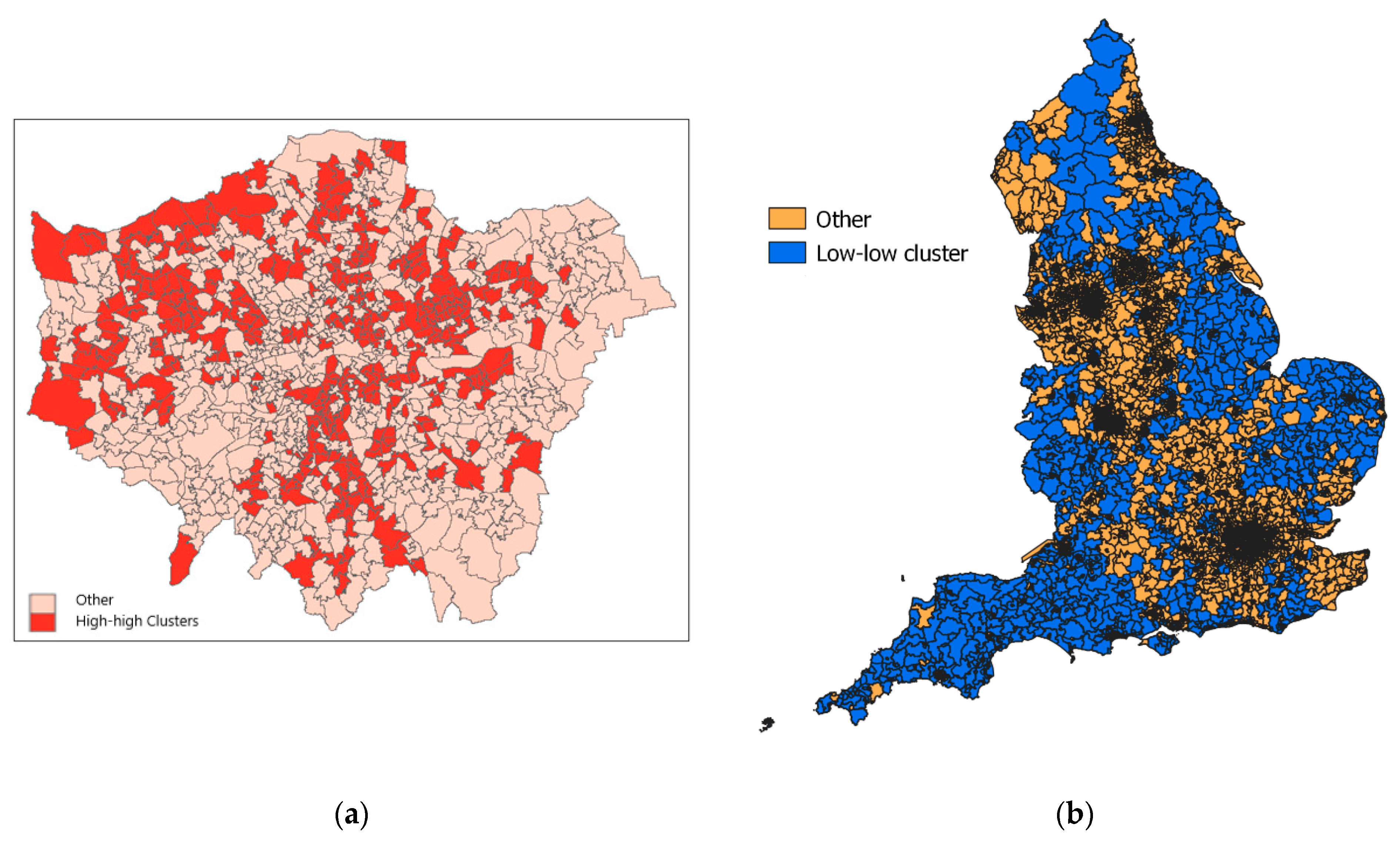
3.4. Spatial Clustering of High and Low Risk
4. Results
4.1. Mortality Gradients
4.2. Regression Analysis.
4.3. Spatial Clustering
5. Discussion
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Office of National Statistics. Deaths Involving COVID-19 by Local Area and Socioeconomic Deprivation: Deaths Occurring between 1 March 2020 and 31 July 2020; Statistical Bulletin, ONS: London, UK, 2020. Available online: https://www.ons.gov.uk/ (accessed on 5 December 2020).
- Public Health England. Disparities in the Risk and Outcomes of COVID-19; PHE: London, UK, 2020. [Google Scholar]
- Correa-Agudelo, E.; Mersha, T.; Branscum, A.; MacKinnon, N.; Cuadros, D. Identification of vulnerable populations and areas at higher risk of Covid-19-related mortality during the early stage of the epidemic in the United States. Int. J. Environ. Res. Public Health 2021, 18, 4021. [Google Scholar] [CrossRef]
- Baker, P. Men, deprivation and COVID-19. Trends Urol. Men’s Health 2021, 12, 22–25. [Google Scholar] [CrossRef]
- Public Health Scotland (PHS). What Explains the Spatial Variation in COVID-19 Mortality across Scotland? PHS: Edinburgh, Scotland, 2020. [Google Scholar]
- Rose, T.; Mason, K.; Pennington, A.; McHale, P.; Taylor-Robinson, D.; Barr, B. Inequalities in COVID19 mortality related to ethnicity and socioeconomic deprivation. MedRxiv 2020. Available online: https://www.medrxiv.org/content/10.1101/2020.04.25.20079491v2 (accessed on 10 April 2021).
- Quinio, V. Have UK Cities Been Hotbeds of the Covid-19 Pandemic? Centre for Cities. Available online: https://www.centreforcities.org/blog/have-uk-cities-been-hotbeds-of-covid-19-pandemic (accessed on 15 December 2020).
- Ali, N.; Islam, F. The effects of air pollution on Covid-19 infection and mortality—A review on recent evidence. Front. Public Health 2020, 8, 580057. [Google Scholar] [CrossRef]
- Diez Roux, A. Investigating neighborhood and area effects on health. Am. J. Public Health 2001, 91, 1783–1789. [Google Scholar] [CrossRef] [PubMed]
- Cordes, J.; Castro, M. Spatial analysis of COVID-19 clusters and contextual factors in New York City. Spat. Spatio-Temporal Epidemiol. 2020, 34, 100355. [Google Scholar] [CrossRef]
- Thompson Coon, J.; Boddy, K.; Stein, K.; Whear, R.; Barton, J.; Depledge, M. Does participating in physical activity in outdoor natural environments have a greater effect on physical and mental wellbeing than physical activity indoors? A systematic review. Environ. Sci. Technol. 2011, 45, 1761–1772. [Google Scholar] [CrossRef]
- Macintyre, S. Deprivation amplification revisited; or, is it always true that poorer places have poorer access to resources for healthy diets and physical activity? Int. J. Behav. Nutr. Phys. 2007, 4, 32. [Google Scholar] [CrossRef] [PubMed]
- White, K.; Borrell, L. Racial/ethnic residential segregation: Framing the context of health risk and health disparities. Health Place 2011, 17, 438–448. [Google Scholar] [CrossRef] [PubMed]
- Darlington-Pollock, F.; Norman, P. Examining ethnic inequalities in health and tenure in England: A repeated cross-sectional analysis. Health Place 2017, 46, 82–90. [Google Scholar] [CrossRef] [PubMed]
- Phillips, D. Black minority ethnic concentration, segregation and dispersal in Britain. Urban Stud. 1998, 35, 1681–1702. [Google Scholar] [CrossRef]
- Mitchell, G.; Dorling, D. An environmental justice analysis of British air quality. Environ. Plan. A 2003, 35, 909–929. [Google Scholar] [CrossRef]
- Mitchell, G. The Messy Challenge of Environmental Justice in the UK: Evolution, Status and Prospects; Natural England Commissioned Report NECR273; Natural England: London, UK, 2019. [Google Scholar]
- Liang, D.; Shi, L.; Zhao, J.; Liu, P.; Sarnat, J.; Gao, S.; Schwartz, J.; Liu, Y.; Ebelt, S.; Scovronick, N.; et al. Urban Air Pollution May Enhance COVID-19 Case-Fatality and Mortality Rates in the United States. Innovation 2020, 1, 100047. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Nethery, R.; Sabath, M.; Braun, D.; Dominici, F. Air pollution and COVID-19 mortality in the United States: Strengths and limitations of an ecological regression analysis. Sci. Adv. 2020, 6, eabd4049. [Google Scholar] [CrossRef]
- Dobricic, S.; Pisoni, E.; Pozzoli, L.; Van Dingenen, R.; Lettieri, T.; Wilson, J.; Vignati, E. Do Environmental Factors such as Weather Conditions and Air Pollution Influence COVID-19 Outbreaks; EUR 30376 EN; Publications Office of the European Union: Luxembourg, 2020. [Google Scholar]
- Heederik, D.; Smit, L.; Vermeulen, R. Go slow to go fast: A plea for sustained scientific rigour in air pollution research during the COVID-19 pandemic. Eur. Respir. J. 2020, 56, 2001361. [Google Scholar] [CrossRef] [PubMed]
- Evans, G.; Kantrowitz, E. Socioeconomic status and health: The potential role of environmental risk exposure. Annu. Rev. Public Health 2002, 23, 303–331. [Google Scholar] [CrossRef] [PubMed]
- Erqou, S.; Clougherty, J.; Olafiranye, O.; Magnani, J.; Aiyer, A.; Tripathy, S.; Kinnee, E.; Kip, K.; Reis, S. Particulate matter air pollution and racial differences in cardiovascular disease risk. Arterioscler. Thromb. Vasc. Biol. 2018, 38, 935–942. [Google Scholar] [CrossRef] [PubMed]
- Babyak, M. Understanding confounding and mediation. Evid. Based Ment. Health 2009, 12, 68–71. [Google Scholar] [CrossRef] [PubMed]
- Pearce, N. The ecological fallacy strikes back. J. Epidemiol. Community Health 2000, 54, 326–327. [Google Scholar] [CrossRef]
- Pinzari, L.; Mazumdar, S.; Girosi, F. A framework for the identification and classification of homogeneous socioeconomic areas in the analysis of health care variation. Int. J. Health Geogr. 2018, 17, 42. [Google Scholar] [CrossRef]
- Kang, S.; Cramb, S.; White, N.; Ball, S.; Mengersen, K. Making the most of spatial information in health: A tutorial in Bayesian disease mapping for areal data. Geospat. Health 2016, 11, 190–198. [Google Scholar] [CrossRef]
- Bell, D.; Comas-Herrera, A.; Henderson, D.; Jones, S.; Lemmon, E.; Moro, M.; Murphy, S.; O’Reilly, D.; Patrignani, P. COVID-19 Mortality and Long-Term Care: A UK Comparison. International Long-Term Care Policy Network, CPEC-LSE. Available online: https://ltccovid.org/2020/08/28/covid-19-mortality-and-long-term-care-a-uk-comparison/ (accessed on 16 January 2021).
- Ssentongo, P.; Ssentongo, A.; Heilbrunn, E.; Ba, D.; Chinchilli, V. Association of cardiovascular disease and 10 other pre-existing comorbidities with COVID-19 mortality: A systematic review and meta-analysis. PLoS ONE 2020, 15, e0238215. [Google Scholar] [CrossRef] [PubMed]
- Dutton, A. Coronavirus (COVID-19) Related Mortality Rates and the Effects of Air Pollution in England; Office of National Statistics: London, UK, 2020. [Google Scholar]
- Aldridge, R.; Lewer, D.; Katikireddi, S.; Mathur, R.; Pathak, N.; Burns, R.; Fragaszy, E.; Johnson, A.; Devakumar, D.; Abubakar, I.; et al. Black, Asian and Minority Ethnic groups in England are at increased risk of death from COVID-19: Indirect standardisation of NHS mortality data. Wellcome Open Res. 2020, 5, 88. [Google Scholar] [CrossRef] [PubMed]
- Office for National Statistics. Which Occupations Have the Highest Potential Exposure to the Coronavirus (COVID-19)? ONS: London, UK, 2020. [Google Scholar]
- Sun, Y.; Hu, X.; Xie, J. Spatial inequalities of COVID-19 mortality rate in relation to socioeconomic and environmental factors across England. Sci. Total Environ. 2020, 13, 143595. [Google Scholar] [CrossRef]
- Baena-Díez, J.; Barroso, M.; Cordeiro-Coelho, S.I.; Díaz, J.; Grau, M. Impact of COVID-19 outbreak by income: Hitting hardest the most deprived. J. Public Health 2020, 42, 698–703. [Google Scholar] [CrossRef]
- Pozzer, A.; Dominici, F.; Haines, A.; Witt, C.; Münzel, T.; Lelieveld, J. Regional and global contributions of air pollution to risk of death from COVID-19. Cardiovasc. Res. 2020, 116, cvaa288. [Google Scholar] [CrossRef]
- Bray, I.; Gibson, A.; White, J. Coronavirus disease 2019 mortality: A multivariate ecological analysis in relation to ethnicity, population density, obesity, deprivation and pollution. Public Health 2020, 185, 261–263. [Google Scholar] [CrossRef]
- Matheson, J.; Nathan, M.; Pickard, H.; Vanino, E. Why Has Coronavirus Affected Cities More Than Rural Areas? Economics Observatory. Available online: https://www.coronavirusandtheeconomy.com (accessed on 10 February 2021).
- Rojas-Rueda, D.; Nieuwenhuijsen, M.; Gascon, M.; Perez-Leon, D.; Mudu, P. Green spaces and mortality: A systematic review and meta-analysis of cohort studies. Lancet Planet. Health 2019, 3, e469–e477. [Google Scholar] [CrossRef]
- Gladwell, V.; Brown, D.; Wood, C.; Sandercock, G.; Barton, J. The great outdoors: How a green exercise environment can benefit all. Extrem. Physiol. Med. 2013, 2, 1–7. [Google Scholar] [CrossRef]
- American Association for the Advancement of Science (AAAS). COVID-19: Exercise May Protect against Deadly Complication, 15-04-2020. Available online: https://www.eurekalert.org/pub_releases/2020-04/uovh-cem041520.php (accessed on 12 December 2020).
- Ferguson, M.; Roberts, H.; McEachan, R.; Dallimer, M. Contrasting distributions of urban green infrastructure across social and ethno-racial groups. Landsc. Urban Plan. 2018, 175, 136–148. [Google Scholar] [CrossRef]
- Harris, R. Exploring the neighborhood-level correlates of Covid-19 deaths in London using a difference across spatial boundaries method. Health Place 2020, 66, 102446. [Google Scholar] [CrossRef] [PubMed]
- Kulu, H.; Dorey, P. Infection rates from COVID-19 in Great Britain by geographical units: A model-based estimation from mortality data. Health Place 2020, 66, 102460. [Google Scholar] [CrossRef] [PubMed]
- Sun, F.; Matthews, S.; Yang, T.; Hu, M. A spatial analysis of the COVID-19 period prevalence in US counties through June 28, 2020: Where geography matters? Ann. Epidemiol. 2020. epub ahead of print. [Google Scholar] [CrossRef]
- Huang, G.; Brown, P. Population-weighted exposure to air pollution and COVID-19 incidence in Germany. Spat. Stat. 2021, 41, 100480. [Google Scholar] [CrossRef] [PubMed]
- Hoeting, J. The importance of accounting for spatial and temporal correlation in analyses of ecological data. Ecol. Appl. 2009, 19, 574–577. [Google Scholar] [CrossRef] [PubMed]
- Beale, C.; Lennon, J.; Yearsley, J.; Brewer, M.; Elston, D. Regression analysis of spatial data. Ecol. Lett. 2010, 13, 246–264. [Google Scholar] [CrossRef] [PubMed]
- Cuzick, J. A Wilcoxon-type test for trend. Stat. Med. 1985, 4, 87–89. [Google Scholar] [CrossRef] [PubMed]
- Lawson, A.; Lee, D. Bayesian Disease Mapping for Public Health; Chapter 16 in Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2017; Volume 36, pp. 443–481. [Google Scholar]
- Waller, L.; Carlin, B. Disease mapping. In Chapter 14 in Chapman Hall/CRC Handbook of Modern Statistical Methods; CRC: Boca Raton, FL, USA, 2010; pp. 217–243. [Google Scholar]
- Leroux, B.; Lei, X.; Breslow, N. Estimation of disease rates in small areas: A new mixed model for spatial dependence. In Statistical Models in Epidemiology, the Environment and Clinical Trials; Halloran, M., Berry, D., Eds.; Springer: New York, NY, USA, 1999; pp. 135–178. [Google Scholar]
- Richardson, S.; Thomson, A.; Best, N.; Elliott, P. Interpreting posterior relative risk estimates in disease-mapping studies. Environ. Health Perspect. 2004, 112, 1016–1025. [Google Scholar] [CrossRef]
- Office of National Statistics (ONS). Deaths Involving COVID-19 by Local Area and Socioeconomic Deprivation: Deaths Occurring between 1 March and 31 July 2020; Statistical Bulletin, ONS: London, UK, 2020. [Google Scholar]
- Ministry of Housing, Communities and Local Government (MHCLG). English Indices of Deprivation 2019; MHCLG: London, UK, 2019. [Google Scholar]
- Ministry of Housing, Communities and Local Government (MHCLG). English Indices of Deprivation 2019; Technical Report; MHCLG: London, UK, 2019. [Google Scholar]
- Lieberson, S. An Asymmetrical Approach to Segregation. In Ethnic Segregation in Cities; Peach, C., Robinson, V., Smith, S., Eds.; Croom Helm: London, UK, 1981; pp. 61–82. [Google Scholar]
- Green, M.; Daras, K.; Davies, A.; Barr, B.; Singleton, A. Developing an openly accessible multi-dimensional small area index of ‘Access to Healthy Assets and Hazards’ for Great Britain. Health Place 2018, 54, 11–19. [Google Scholar] [CrossRef]
- Brookes, D.; Stedman, J.; Kent, A.; Whiting, S.; Rose, R.; Williams, C.; Pugsley, K. UK Supplementary Assessment under the Air Quality Directive (2008/50/EC), the Air Quality Framework Directive (96/62/EC) and Fourth Daughter Directive (2004/107/EC) for 2018; Technical Report; DEFRA: London, UK, 2020. Available online: https://uk-air.defra.gov.uk/library/reports?report_id=993 (accessed on 7 May 2021).
- Trust for London. Access to Healthy Assets and Hazards Index (Rebased for London) (2019). Available online: https://www.trustforlondon.org.uk/data/access-healthy-assets-and-hazards/ (accessed on 6 May 2021).
- Daras, K.; Green, M.; Davies, A.; Barr, B.; Singleton, A. Open data on health-related neighborhood features in Great Britain. Nat. Sci. Data 2019, 6, 107. [Google Scholar] [CrossRef]
- Office of National Statistics. Access to Gardens and Public Green Space in Great Britain. Available online: https://www.ons.gov.uk/economy/environmentalaccounts/datasets/accesstogardensandpublicgreenspaceingreatbritain (accessed on 6 May 2021).
- When and Why to Standardize Your Data? Available online: https://builtin.com/data-science/when-and-why-standardize-your-data (accessed on 3 May 2021).
- Available online: https://www.listendata.com/2017/04/how-to-standardize-variable-in-regression.html (accessed on 3 May 2021).
- Reich, B.; Fuentes, M.; Dunson, D. Bayesian spatial quantile regression. J. Am. Stat. Assoc. 2011, 106, 6–20. [Google Scholar] [CrossRef]
- Lunn, D.; Spiegelhalter, D.; Thomas, A.; Best, N. The BUGS project: Evolution, critique and future directions. Stat. Med. 2009, 28, 3049–3067. [Google Scholar] [CrossRef]
- Brooks, S.; Gelman, A. General methods for monitoring convergence of iterative simulations. J. Comput. Graph. Stat. 1998, 7, 434–455. [Google Scholar]
- Spiegelhalter, D.; Best, N.; Carlin, B.; van der Linde, A. Bayesian measures of model complexity and fit. J. R. Stat. Soc. Ser. B 2002, 64, 583–639. [Google Scholar]
- Lunn, D.; Jackson, C.; Best, N.; Thomas, A.; Spiegelhalter, D. The BUGS book. In A Practical Introduction to Bayesian Analysis; Chapman Hall: London, UK, 2013. [Google Scholar]
- Watanabe, S. Asymptotic Equivalence of Bayes Cross Validation and Widely Applicable Information Criterion in Singular Learning Theory. J. Mach. Learn. Res. 2010, 11, 3571–3594. [Google Scholar]
- Anselin, L.; Syabri, I.; Kho, Y. GeoDa: An introduction to spatial data analysis. Geogr. Anal. 2006, 38, 5–22. [Google Scholar] [CrossRef]
- Moraga, P.; Montes, F. Detection of spatial disease clusters with LISA functions. Stat. Med. 2011, 30, 1057–1071. [Google Scholar] [CrossRef] [PubMed]
- Bibby, P.; Brindley, P. The 2011 Rural-Urban Classification for Small Area Geographies: A User Guide and Frequently Asked Questions; Office for National Statistics: London, UK, 2013. [Google Scholar]
- Ogen, Y. Assessing nitrogen dioxide (NO2) levels as a contributing factor to coronavirus (COVID-19) fatality. Sci. Total Environ. 2020, 726, 138605. [Google Scholar] [CrossRef] [PubMed]
- Copat, C.; Cristaldi, A.; Fiore, M.; Grasso, A.; Zuccarello, P.; Santo Signorelli, S.; Conti, G.O.; Ferrante, M. The role of air pollution (PM and NO2) in COVID-19 spread and lethality: A systematic review. Environ. Res. 2020, 191, 110129. [Google Scholar] [CrossRef]
- Mele, M.; Magazzino, C.; Schneider, N.; Strezov, V. NO2 levels as a contributing factor to COVID-19 deaths: The first empirical estimate of threshold values. Environ. Res. 2021, 194, 110663. [Google Scholar] [CrossRef]
- Gurdasani, D.; Bear, L.; Bogaert, D.; Burgess, R.A.; Busse, R.; Cacciola, R.; Charpak, Y.; Colbourn, T.; Drury, J.; Friston, K.; et al. The UK needs a sustainable strategy for COVID-19. Lancet 2020, 396, 1800–1801. [Google Scholar] [CrossRef]
- Travaglio, M.; Yu, Y.; Popovic, R.; Selley, L.; Leal, N.; Martins, L. Links between air pollution and COVID-19 in England. Environ. Pollut. 2021, 268, 115859. [Google Scholar] [CrossRef]
- Anderson, G.; Frank, J.; Naylor, C.D.; Wodchis, W.; Feng, P. Using socioeconomics to counter health disparities arising from the covid-19 pandemic. Br. Med. J. 2020, 369, m2149. [Google Scholar] [CrossRef] [PubMed]
- Brandt, E.; Beck, A.; Mersha, T. Air pollution, racial disparities, and COVID-19 mortality. J. Allergy Clin. Immunol. 2020, 146, 61–63. [Google Scholar] [CrossRef]
- Washington, H. How environmental racism is fuelling the coronavirus pandemic. Nature 2020, 581, 241. [Google Scholar] [CrossRef] [PubMed]
- Soltan, M.; Crowley, L.; Melville, C.; Varney, J.; Cassidy, S.; Mahida, R.; Grudzinska, F.; Parekh, D.; Dosanjh, D.; Thickett, D. To what extent are social determinants of health, including household overcrowding, air pollution and housing quality deprivation, modulators of presentation, ITU admission and outcomes among patients with SARS-COV-2 infection in an urban catchment area in Birmingham, United Kingdom? Thorax 2021, 76, A237–A238. [Google Scholar]
- Carrington, D. Omission of Air Pollution from Report on Covid-19 and Race ‘Astonishing’; The Guardian: London, UK, 2020. [Google Scholar]
- Shen, Y.; Lung, S. Mediation pathways and effects of green structures on respiratory mortality via reducing air pollution. Sci. Rep. 2017, 7, 1–9. [Google Scholar] [CrossRef]
- Buchan, I.; Kontopantelis, E.; Sperrin, M.; Chandola, T.; Doran, T. North-South disparities in English mortality 1965–2015: Longitudinal population study. J. Epidemiol. Community Health 2017, 71, 928–936. [Google Scholar] [CrossRef] [PubMed]
- Mathur, R.; Rentsch, C.; Morton, C.; Hulme, W.; Schultze, A.; MacKenna, B.; Eggo, R.; Bhaskaran, K.; Wong, A.; Williamson, E.; et al. Ethnic differences in SARS-CoV-2 infection and COVID-19-related hospitalisation, intensive care unit admission, and death in 17 million adults in England: An observational cohort study using the OpenSAFELY platform. Lancet 2021, 397, 1711–1724. [Google Scholar] [CrossRef]
- Duncan, C.; Jones, K.; Moon, G. Context, composition and heterogeneity: Using multilevel models in health research. Soc. Sci. Med. 1998, 46, 97–117. [Google Scholar] [CrossRef]


{kind=link}
| Risk Variable | Mean | Median | 95th Percentile | 5th Percentile | Maximum | Minimum | InterQuartile Range |
|---|---|---|---|---|---|---|---|
| Income Deprivation | 0.128 | 0.106 | 0.289 | 0.04 | 0.490 | 0.010 | 0.103 |
| Health Deprivation and Disability | −0.008 | −0.0306 | 1.268 | −1.22 | 2.868 | −3.045 | 1.084 |
| BAME, % in MSOA population | 13.7 | 5.3 | 56.8 | 1.2 | 94.4 | 0.4 | 14.6 |
| BAME Isolation Index | 0.148 | 0.061 | 0.584 | 0.014 | 0.946 | 0.005 | 0.160 |
| Nursing Home Location, % | 3.49 | 2.70 | 9.61 | 0.00 | 41.07 | 0.00 | 3.47 |
| Active Green Space Index (CDRC) | 0.60 | 0.50 | 1.28 | 0.27 | 6.91 | 0.10 | 0.28 |
| % Private Outdoor Space | 89 | 92 | 98 | 72 | 100 | 2 | 8 |
| Overall Greenspace Access | 0.0 | −0.1 | 1.7 | −1.4 | 6.7 | −11.8 | 0.8 |
| NO2 | 12.6 | 12.0 | 21.5 | 6.1 | 28.5 | 3.3 | 4.8 |
| PM10 | 13.5 | 13.8 | 16.8 | 10.1 | 17.5 | 7.6 | 3.7 |
| SO2 | 1.22 | 1.2 | 1.8 | 0.8 | 2.7 | 0.4 | 0.4 |
| Overall Air Quality (Higher for Worse) | 26.1 | 20.5 | 67.9 | 4.5 | 99.7 | 0.4 | 24.3 |
| Socio-Demographic | |||||||
| Income Deprivation | Health Deprivation and Disability | BAME, % in MSOA Population | BAME Isolation Index | Nursing Home Location | |||
| Decile 1 | 0.60 | 0.81 | 0.65 | 0.66 | 0.87 | ||
| Decile 2 | 0.76 | 0.83 | 0.72 | 0.74 | 0.88 | ||
| Decile 3 | 0.84 | 0.83 | 0.79 | 0.80 | 0.94 | ||
| Decile 4 | 0.83 | 0.88 | 0.92 | 0.89 | 0.93 | ||
| Decile 5 | 0.90 | 0.90 | 0.88 | 0.90 | 0.94 | ||
| Decile 6 | 1.03 | 0.99 | 0.99 | 0.97 | 0.91 | ||
| Decile 7 | 1.18 | 1.04 | 1.11 | 1.09 | 1.09 | ||
| Decile 8 | 1.28 | 1.14 | 1.19 | 1.21 | 1.04 | ||
| Decile 9 | 1.42 | 1.33 | 1.41 | 1.40 | 1.14 | ||
| Decile 10 | 1.71 | 1.51 | 2.02 | 2.02 | 1.23 | ||
| All Neighborhoods | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | ||
| Environmental | |||||||
| Active Green Space Access * | % Private Outdoor Space * | Overall Greenspace Access * | NO2 | PM10 | SO2 | Overall Air Quality (Higher for Worse) | |
| Decile 1 | 0.64 | 0.96 | 0.67 | 0.55 | 0.97 | 0.55 | 0.60 |
| Decile 2 | 0.84 | 0.96 | 0.83 | 0.74 | 1.08 | 0.76 | 0.76 |
| Decile 3 | 0.94 | 0.98 | 0.87 | 0.74 | 1.00 | 0.83 | 0.84 |
| Decile 4 | 0.97 | 0.94 | 0.97 | 0.93 | 0.75 | 0.91 | 0.83 |
| Decile 5 | 0.98 | 0.91 | 0.96 | 0.97 | 0.92 | 1.02 | 0.90 |
| Decile 6 | 1.08 | 0.92 | 1.08 | 1.04 | 0.97 | 1.09 | 1.03 |
| Decile 7 | 1.13 | 0.89 | 1.10 | 1.20 | 0.84 | 1.24 | 1.18 |
| Decile 8 | 1.15 | 1.01 | 1.13 | 1.26 | 0.90 | 1.32 | 1.28 |
| Decile 9 | 1.18 | 1.13 | 1.22 | 1.47 | 1.17 | 1.27 | 1.42 |
| Decile 10 | 1.37 | 1.41 | 1.43 | 1.70 | 1.67 | 1.41 | 1.70 |
| All Neighborhoods | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Model 1 | Model 2 | |||
|---|---|---|---|---|
| Regression Coefficient 1 | Implied Relative Risk 2,3 | Regression Coefficient 1 | Implied Relative Risk 2,3 | |
| Income Deprivation (ID) | 0.153 | 1.085 | 0.140 | 1.077 |
| BAME | 0.856 | 1.616 | ||
| BAME Isolation | 0.828 | 1.604 | ||
| Nursing Homes | 1.143 | 1.301 | 1.142 | 1.301 |
| Health Deprivation (HDD Domain) | 1.150 | 1.625 | 1.164 | 1.635 |
| Poor Green Space Access | 0.134 | 1.119 | 0.075 | 1.072 |
| Poor Air Quality | 0.841 | 1.714 | 0.860 | 1.735 |
| Fit Measures | ||||
| DIC | 38139 | 37945 | ||
| WAIC | 38140 | 37950 | ||
| Numbers of MSOAs by Region and Urban Level | |||||||||
| Region | Rural & Dispersed (Sparse Setting) | Rural & Dispersed | Rural Town/Fringe (Sparse Setting) | Rural Town & Fringe | Urban City & Town (Sparse Setting) | Urban City & Town | Urban Minor Conurbation | Urban Major Conurbation | Total |
| East Midlands | 2 | 66 | 1 | 78 | 2 | 318 | 102 | 4 | 573 |
| East of England | 2 | 104 | 5 | 113 | 433 | 79 | 736 | ||
| London | 1 | 2 | 980 | 983 | |||||
| North East | 7 | 5 | 2 | 43 | 2 | 131 | 150 | 340 | |
| North West | 6 | 35 | 4 | 47 | 2 | 313 | 517 | 924 | |
| South East | 108 | 116 | 785 | 99 | 1108 | ||||
| South West | 14 | 125 | 5 | 81 | 4 | 471 | 700 | ||
| West Midlands | 7 | 58 | 41 | 1 | 290 | 338 | 735 | ||
| Yorkshire/Humber | 7 | 38 | 3 | 68 | 2 | 195 | 147 | 232 | 692 |
| Total | 45 | 539 | 20 | 588 | 13 | 2938 | 249 | 2399 | 6791 |
| High Mortality Clusters by Region and Urban Level | |||||||||
| Region | Rural/Dispersed (Sparse Setting) | Rural & Dispersed | Rural Town/Fringe (Sparse Setting) | Rural Town & Fringe | Urban City & Town (Sparse Setting) | Urban City & Town | Urban Minor Conurbation | Urban Major Conurbation | Total |
| East Midlands | 0 | 0 | 0 | 0 | 0 | 25 | 5 | 0 | 30 |
| East of England | 0 | 1 | 0 | 1 | 20 | 17 | 39 | ||
| London | 1 | 0 | 362 | 363 | |||||
| North East | 0 | 0 | 0 | 1 | 0 | 23 | 18 | 42 | |
| North West | 0 | 1 | 0 | 1 | 0 | 14 | 146 | 162 | |
| South East | 0 | 0 | 18 | 4 | 22 | ||||
| South West | 0 | 0 | 0 | 0 | 0 | 4 | 4 | ||
| West Midlands | 0 | 0 | 0 | 0 | 12 | 88 | 100 | ||
| Yorkshire/Humber | 0 | 0 | 0 | 0 | 0 | 7 | 14 | 41 | 62 |
| Total | 0 | 2 | 0 | 4 | 0 | 123 | 19 | 676 | 824 |
| Low mortality clusters by Region and Urban Level | |||||||||
| Region | Rural/Dispersed (Sparse Setting) | Rural & Dispersed | Rural Town/Fringe (Sparse Setting) | Rural Town & Fringe | Urban City & Town (Sparse Setting) | Urban City & Town | Urban Minor Conurbation | Urban Major Conurbation | Total |
| East Midlands | 2 | 43 | 1 | 23 | 1 | 59 | 5 | 0 | 134 |
| East of England | 2 | 66 | 5 | 49 | 101 | 1 | 224 | ||
| London | 0 | 0 | 6 | 6 | |||||
| North East | 6 | 3 | 1 | 2 | 2 | 6 | 9 | 29 | |
| North West | 5 | 9 | 1 | 10 | 1 | 18 | 0 | 44 | |
| South East | 43 | 50 | 160 | 3 | 256 | ||||
| South West | 13 | 104 | 5 | 69 | 4 | 280 | 475 | ||
| West Midlands | 7 | 30 | 13 | 1 | 31 | 1 | 83 | ||
| Yorkshire/Humber | 6 | 23 | 1 | 27 | 2 | 36 | 7 | 14 | 116 |
| Total | 41 | 321 | 14 | 243 | 11 | 691 | 12 | 34 | 1367 |
| HDD Score | Air Pollution | % BAME | BAME Isolation Index | |
|---|---|---|---|---|
| Rural & Dispersed (Sparse Setting) | 0.42 | 2.7 | 1.2 | 0.014 |
| Rural & Dispersed | 0.38 | 10.3 | 2.2 | 0.030 |
| Rural Town & Fringe (Sparse Setting) | 0.47 | 4.5 | 1.8 | 0.022 |
| Rural Town & Fringe | 0.43 | 13.2 | 2.8 | 0.034 |
| Urban City & Town (Sparse Setting) | 0.53 | 4.0 | 1.6 | 0.018 |
| Urban City & Town | 0.49 | 18.8 | 8.6 | 0.096 |
| Urban Minor Conurbation | 0.56 | 29.9 | 11.4 | 0.124 |
| Urban Major Conurbation | 0.52 | 42.1 | 25.8 | 0.272 |
| Neighbourhoods by Income Deprivation Decile | Average HDD | Neighbourhoods by % BAME Decile | Average HDD |
| 1 | −0.99 | 1 | −0.05 |
| 2 | −0.72 | 2 | −0.01 |
| 3 | −0.52 | 3 | 0.00 |
| 4 | −0.31 | 4 | −0.07 |
| 5 | −0.14 | 5 | −0.06 |
| 6 | 0.00 | 6 | −0.05 |
| 7 | 0.23 | 7 | −0.08 |
| 8 | 0.46 | 8 | 0.00 |
| 9 | 0.71 | 9 | 0.06 |
| 10 | 1.20 | 10 | 0.19 |
| All Neighborhoods | −0.01 | All Neighborhoods | −0.01 |
| Neighbourhoods by Income Deprivation Decile | Average Air Quality (Higher Scores for Worse Air Quality) | Neighbourhoods by % BAME Decile | Average Air Quality (Higher Scores for Worse Air Quality) |
| 1 | 20.7 | 1 | 9.8 |
| 2 | 19.0 | 2 | 13.3 |
| 3 | 20.2 | 3 | 16.0 |
| 4 | 21.6 | 4 | 17.1 |
| 5 | 22.6 | 5 | 19.3 |
| 6 | 27.1 | 6 | 22.6 |
| 7 | 30.0 | 7 | 27.2 |
| 8 | 33.5 | 8 | 33.3 |
| 9 | 34.0 | 9 | 46.5 |
| 10 | 32.4 | 10 | 55.8 |
| All Neighborhoods | 26.1 | All Neighborhoods | 26.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Congdon, P. COVID-19 Mortality in English Neighborhoods: The Relative Role of Socioeconomic and Environmental Factors. J 2021, 4, 131-146. https://doi.org/10.3390/j4020011
Congdon P. COVID-19 Mortality in English Neighborhoods: The Relative Role of Socioeconomic and Environmental Factors. J. 2021; 4(2):131-146. https://doi.org/10.3390/j4020011
Chicago/Turabian StyleCongdon, Peter. 2021. "COVID-19 Mortality in English Neighborhoods: The Relative Role of Socioeconomic and Environmental Factors" J 4, no. 2: 131-146. https://doi.org/10.3390/j4020011
APA StyleCongdon, P. (2021). COVID-19 Mortality in English Neighborhoods: The Relative Role of Socioeconomic and Environmental Factors. J, 4(2), 131-146. https://doi.org/10.3390/j4020011