Abstract
X-ray fluorescence (XRF) core scanners are commonly used for fine-scale geochemical analysis in sediment studies, but data are semi-quantitative and require calibration to convert geochemical element counts to concentrations. Application of XRF core scanning in soil science remains largely untapped. This study employed an ITRAX core scanner to scan grassland soil cores and developed a novel calibration method based on a chemometric approach to characterise soil geochemistry. As soil samples are collected based on depth sampling, this study investigated whether higher resolution element concentrations could be inferred from lower resolution reference samples and if regression models from multiple cores could apply to a new core at the same resolution. Reference concentrations were obtained for all cores at 10 cm intervals, with validation conducted at 1 cm for a single core. Two calibration curve types were proposed: one based on the single core’s 10 cm data to validate references at 1 cm intervals; and another using all cores, with each core serving as a test item after exclusion from the training set. Various preprocessing measures and feature selection techniques were tested. Results showed successful calibration for elements Ca, P, Zn, Sr, and S, with high values of 0.94, 0.93, 0.93, 0.92 and 0.91, respectively. The study presents a novel method for calibrating XRF core scanning element counts, demonstrating its potential for high-resolution soil analysis.
1. Introduction
In recent years, the development of rapid-response and high-precision ecological and agricultural management practices created an increasing demand for fast and low-cost acquisition of fine-scale chemical and physical data. X-ray fluorescence (XRF) core scanning is a rapid non-destructive method to acquire semi-quantitative information on the chemical properties of sediment cores [1]. Initially, XRF core scanners were developed for onboard geochemical high resolution data acquisition from sediment cores in sea expeditions [2], but with the advent of calibration of semi-quantitative counts to quantitative concentrations [3], they have attracted the attention of many fields such as archaeology [4], food science [5], forensic science [6], geoscience [7], and geomorphology [8]. Accordingly, there has been a simultaneous growth in the use of wave dispersive X-ray fluorescence scanning (WD-XRFS), portable (pXRF), and XRF core scanning in soil science to predict soil geochemical and physical properties in the past decade and efforts were made to predict geochemical properties such as pH, element concentrations, total nitrogen and carbon, organic carbon, and soil texture [9,10,11,12,13].
The semi-quantitative nature of count data measured by XRF, and the scanning method itself creates a few challenges, namely poorly constraint measurement geometry, non-independence between and within element counts and a large number of zero counts [3,14,15]. Some of these were addressed [3,15] by using a logarithmic ratio calibration based on the treatment of compositional data [16]. Another challenge in modelling semi-quantitative data that arises from the noisy nature of spectroscopic data and count noise. The signal-to-noise ratio for XRF core scanner counts can be as high as 100 for some elements and as low as 18 for others under the optimum measurement conditions [17]. Efforts have been made to characterise this noise and approximate the noise free data by Bloemsma and Weltje [18], but this method requires replicates that are often not carried out by labs to speed up the throughput of cores. Furthermore, it has been demonstrated that XRF core scanning has a very poor reproducibility at high resolution even for element ratios, and no more than trends in data can be reproduced when scanning and calibrating the same cores in varying conditions [19]. Thus, it is not known how much of the higher resolution calibrated data are actual signal rather than noise.
Another issue is with anomalous counts that arise because of stones and the uneven surface of the split soil cores used in analysis. Typically, datapoints with these characteristics are discarded by lengthy visual inspections of the RGB image, which can be subjective to some extent. It is ideal that this step is replaced with an automatic anomaly detection step. Isolation Forest [20] is an algorithm that can detect anomalies in data by isolating observations in a dataset by recursively partitioning them using random feature splits. The main idea behind Isolation Forest is that anomalies are typically far fewer in number and have different characteristics compared to regular data points, which can be used as features in an anomaly detection model. This is particularly useful to XRF core scanning because non-anomalous counts are likely to fall outside of the distribution profile and wrongly be detected as anomalies because they are statistical outliers. The anomalies detected by this algorithm can be replaced using a multivariate imputation algorithm [21] in order to not lose rows of data. For noise reduction, since both the inputs and outputs are on a highly autocorrelated continuous depth profile, Savitsky–Golay smoothing [22] can be implemented for both inputs and outputs, but choosing an objective smoothing strength for Savitsky–Golay can be challenging. In addition, in studies on cores, random cross validation is frequently used which is not the appropriate validation scheme for spatially autocorrelated data [23]. To address these issues, here, we propose (i) additional discrete sample scanning for feature selection and processing of the raw counts and calibrated values, (ii) multi-scale reference concentration measurement, and (iii) using all samples on an individual core as a cross-validation fold rather than random cross-validation for all the samples.
With the aim of determining the effectiveness of XRF core scanning for obtaining high resolution concentrations of elements of interest in agricultural soils, this study investigates (i) whether calibration regression curves obtained with reference concentrations at 10 cm intervals can be validated with reference concentrations at 1 cm intervals and (ii) whether calibration regression curves at 10 cm intervals can be validated with a new core at 10 cm intervals. Both approaches incorporate an assessment of whether pre-treatments and feature selection based on discrete pellets enhance the performance of these calibration regression curves.
2. Materials and Methods
2.1. Data Acquisition and Preparation
2.1.1. Soil Core Sampling
Nine soil cores were gathered from UCD Lyons Research Farm in Co. Kildare, Ireland, encompassing three distinct soil types: Brown Earth (BE), Grey Brown Podzolic (P), and low-humic Gley (G). The Brown Earth soil arises from a combination of Silurian rock, limestone drift, and Old Red Sandstone. The Podzolic soil originates from a thin layer of glacial limestone drift overlaying limestone rock, while the Gley soil is derived from unstratified calcareous drift parent material situated on decalcified and decalcifying Calp limestone [24]. All sampling locations were managed as a perennial ryegrass (Lolium perenne) pasture under rotational grazing, with reseeding occurring approximately every eight years. Soil cores, measuring 50 mm in diameter and up to 1000 mm in length, were extracted using a percussion drill (Eijkelkamp, Giesbeek, The Netherlands) equipped with uPVC core liners. These cores were then split lengthwise into halves using a mechanical saw to divide the uPVC liners and a fine-toothed single-handed saw to separate the soil within. No soil surface cleaning was conducted to minimise surface disruption. Cores were dried in a forced draft oven at 30 °C for 48 h prior to scanning. A subset of 10 cm intervals of the other split-core was ground, dried, and milled to <100 µm resulting in 53 samples. For each sample, 4 g of milled soil was pressed into a pellet using a manual arbour press with a force indicator at constant force of 400 N applied for 10 s.
2.1.2. XRF Count Data Acquisition
An energy dispersive X-ray fluorescence (ED-XRF) core scanner for measurement of intact split cores and pellets (ITRAX™ X-ray core-scanner, Cox Analytical Systems, MöIndal, Sweden) was used to collect high resolution XRF measurements. The instrument consists of a motorised flat-bed that moves the core under a measurement tower containing the X-ray source and XRF and auxiliary sensors. Soil cores and pellets were scanned using a 3 kW molybdenum target tube operating at 30 kV and 50 mA with an incremental step size of 200 µm and a 20 s exposure time, following the settings outlined in O’Rourke et al. [25] for soils. The data output consists of XRF counts for 22 elements (5000 measurements per 1 m split core). A surface RGB image with 100 µm pixel size was captured by an optical-line camera and laser triangulation system. If the distance between the XRF detector and sample surface exceeded the standard deviation of mean surface height (set at 0.5 mm in this case), the acquired XRF data were labelled as invalid and subsequently removed in data analysis. The reference pellets were positioned on the sample rail and scanned using the same settings.
2.1.3. Laboratory Reference Data Acquisition
Macro samples were collected from the opposite half of the split core for the reference geochemical measurement. The split cores were destructively sampled at 10 cm increments for 9 soil cores and to a further 1 cm increments in the BE core. All soil samples were analysed for total element concentrations by inductively coupled plasma-mass spectrometry (ICP-MS, Nexion300D, PerkinElmer, Waltham, Massachusetts, USA) for As, Ba, Bi, Cd, Ce, Co, Cr, Cu, Ga, Ge, La, Mn, Ni, Pb, Rb, Sc, Se, Sn, U, V, Y, Zn, Zr, and inductively coupled plasma-optical emission spectrometry (ICP-OES, Optima 7300DV, PerkinElmer, Waltham, Massachusetts, USA) for Al, Ca, Fe, K, Mg, P, S and Sr. This resulted in a reference soil geochemical dataset of 31 elements with 87 datapoints for 9 soil cores at 10 cm increments and 88 datapoints for 1 soil core at 1 cm increments.
2.2. Statistical Analysis
2.2.1. Pre-Processing
To normalise counts, each row of element counts was divided by total counts detected by the XRF core scanner at that row; herein, these normalised counts are called counts for simplicity. Anomalous datapoints arising due to stone content or soil cracks on each core were detected using Isolation Forest [20] as implemented in Scikit-learn v1.3. [26], with the degree of contamination automatically detected by the algorithm. Isolation Forest finds anomalies based on the principle that if the data are to be classified to leaves of decision trees in an unsupervised fashion, anomalous data become isolated with far fewer splits in the decision tree. These anomalous data points were imputed using multivariate imputation [21] as implemented in Scikit-learn [26]. This algorithm, in a scheme known as round-robin, uses other features as predictors for the feature to be imputed and regresses a line to predict the missing values. This is especially useful in datasets with high multicollinearity. The signal for each element in the cores was smoothed using Savitsky–Golay smoothing [22] with power of 2. The window width was determined by selection of a relatively uniform section of the core for the corresponding element, smoothing it at different windows (101, 201, 401, 501, and 801 points, which are situated at approximately 2.02, 4.02, 8.02, 10.02, and 16.02 cm on all cores), transforming the counts to Fourier space and plotting their power spectrums [27]. The width with the least fluctuation in the power spectrum were selected as the best performing width. The median of counts were calculated at 10 cm and 1 cm intervals to be used for analysis. Principal Components Analysis (PCA) plots, correlation plots and boxplots were generated for visualisation of the XRF count data and element concentrations.
2.2.2. Feature Selection
Feature selection, the process of isolating the most consistent, non-redundant, and relevant features for model construction, was used to determine suitable features (element variables) for model calibration. Correlation between element counts in cores and pellets were calculated and only the element counts with r > 0.6 were used as features. Next, in order to handle the multicollinearity in the dataset, variance inflation factors (VIF) [28] were calculated to discard elements with redundant information (VIF > 100).
2.2.3. Calibration
For calibration, a partial least squares regression [29] was used. Features selected from the previous step were used as inputs and each element reference concentration as output. The number of principal components was optimised based on the best performing validation s. To avoid negative values, any value predicted below zero was replaced by the limit of detection for concentration of that element. Two calibration approaches were tested as follows:
- To determine if higher resolution absolute concentrations can be obtained from calibration on lower resolution data, a single core calibration regression was performed with the 10 cm reference concentrations and counts as the training set and 1 cm element reference concentrations and counts for the same BE core as the validation set. The predicted results for the 1 cm intervals were smoothed using Savitsky–Golay filtering using the window widths described and a power of 2.
- To determine if the calibration curve obtained in (i) can be used on a new core to avoid overfitting caused by autocorrelation with depth, a complete dataset calibration regression was performed with 10 cm reference concentrations and counts for all cores and a systematic 9-fold cross-validation, with each core left out as validation.
Within each calibration approach, the use of pretreatments and feature selection based on discrete pellets was tested to identify an element variable input to enhance the performance of the calibration regression curves. All of the analysis and plot outputs were completed in Python v3.11.4.
3. Results
3.1. Data Description
Of the 31 elements that reference concentrations were obtained for, 17 were directly measured in XRF core scanning. These 17 elements had somewhat good agreement with their corresponding counts (on average r = 0.56), with Ca reporting the highest r = 0.97 and Cu with the lowest r = 0.10. The precision of measurement (%CV) was 7.0% on average, ranging from 22.11% (Sn) to 3.12% (Fe). Precision of measurement is not correlated with either mean element concentrations or dispersal (standard deviation divided by mean) of concentrations (Table 1).

Table 1.
Descriptive statistics (mean, 1st, and 3rd quantiles) and measurement precision for element reference concentration (%CV) and correlation with corresponding core element counts. Std. dev., standard deviation; Disp., dispersal (standard deviation divided by mean); %CV, % coefficient of variation; Corr. Coef., correlation coefficient.
PCA on element reference concentrations show that 84% of the variability in concentrations can be explained by the first five-most-important principal components. The degree of clustering for soil types is lower than in element counts, and reference concentrations are not distinguishable by soil type in the first three most important principal components (Figure 1).
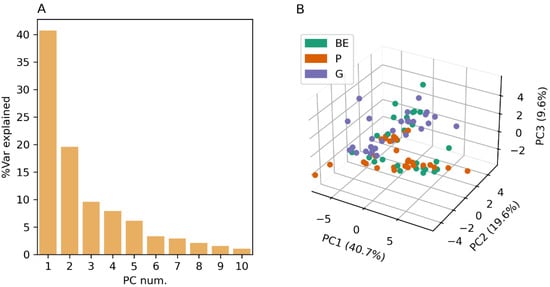
Figure 1.
(A) Variance explained by each PC and (B) scatter plot for PC1, PC2, and PC3 for element reference concentrations.
Variability of reference concentrations between each core follows a different pattern. For example, for Ca and Sr, cores of soil types BE and G have almost the same mean and range, but cores of soil type P have much wider range and higher Ca and Sr concentration. For phosphorus, soil cores with BE soil have a higher and wider range compared to soil cores with P and G soils. For S, nearly all the cores have the same range and mean (Figure 2).
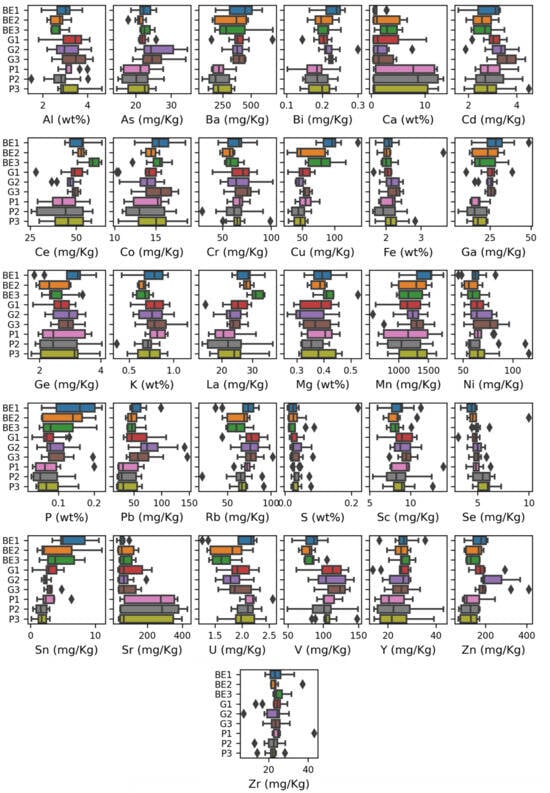
Figure 2.
Boxplots for element reference concentrations in different cores.
The element reference concentrations have an average absolute correlation coefficient of 0.38 with standard deviation of 0.08, comparable to absolute correlation coefficients of element counts, with Ge having the highest average absolute correlation of 0.51 and S the lowest average absolute correlation of 0.21. Ca and Sr show the most correlated element counts with r = 0.98. Measured element counts show good reliability with a mean correlation coefficient of 0.63 between pellet and core counts (Table 2). A wide range in correlation coefficient exists (r = 0.97 to 0.14) with a small number of elements <0.60 (Al, Ar, Ba, Ce, Cl, Cu). These correlations reflect the correlation coefficient of element reference concentrations to their corresponding counts (r = 0.75, p < 0.01). The precision error of measurements (%CV) is 23% on average and ranges from %CV = 2.90% to 211%. Measurement precision is not correlated with mean element counts but is highly correlated with dispersal (standard deviation divided by mean) of counts (r = 0.78, p < 0.01).
Table 2.
Descriptive statistics (mean, standard deviation, 1st, and 3rd quantiles) and measurement precision (% coefficient of variation) for core element counts and correlation coefficient between core and pellet element counts. Std. dev., standard deviation; Disp., dispersal (standard deviation divided by mean); %CV, % coefficient of variation; Corr. Coef., correlation coefficient. Counts are normalised.
The element counts have an average absolute correlation coefficient of 0.37 with standard deviation of 0.25. Sr and Ti report the highest average absolute correlation of 0.54 with all other elements and Cl the lowest average absolute correlation of 0.08 with all other elements. Ca and Sr as the most correlated element counts with r = 0.95.
Noise removal of the final features used for the calibration noise reduction was performed at different regions. S, Sr, and As had the most noise reduction at the window width 16.02 cm, Ba, Mn, and Ca at 8.02 cm and Zn at 4.02 cm.
3.2. Feature Selection
Elements were selected based on their correlation coefficient between counts of the pellets and the cores at a r = 0.60 threshold (Figure 3) and based on their variance inflation factor at a VIF of 100 (Figure 4). Final elements retained as input features for calibration were S, Zn, Ca, Mn, Sr, As, and Ba.
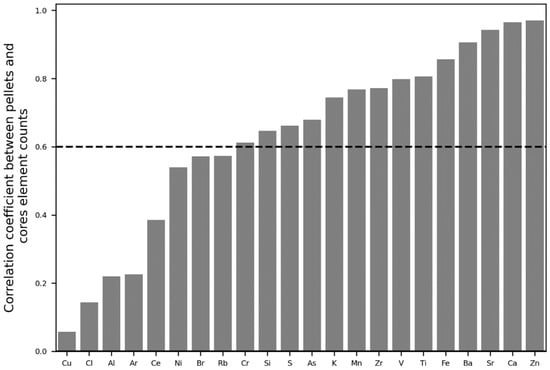
Figure 3.
Correlation coefficient between pellets and core element counts and 0.6 threshold for keeping the element for calibration input.
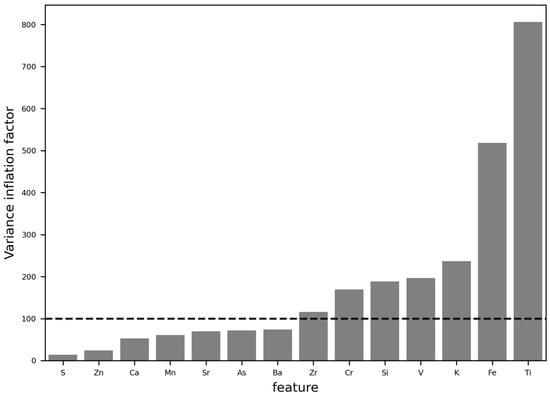
Figure 4.
Variance inflation factor for element counts with correlations stronger than r = 0.6 between pellets and cores and threshold of 100 for keeping the element for the calibration input.
3.3. Single Core Calibration
Single core calibration (Table 3) had an average validation of 0.67 with standard deviation of 0.20. Ca, P, Zn, Sr, and S have the best performing s of 0.94, 0.93, 0.93, 0.92, and 0.91, respectively. Most elements had the strongest validation s with five principal components. No correlation was found to exist between core and pellet counts’ correlation coefficients and s, indicating core and pellet element counts do not determine goodness-of-fit for calibration. In addition, no correlation was found between element concentration measurement precision (%CV) and validation s, indicating the level of the reference measurement does not determine goodness-of-fit for calibration. Similarly, there was no correlation found between the correlation coefficients of reference concentrations and counts, and validation s, for the reference elements that were directly measured by XRF core scanning. No relationship was found between the dispersal of reference concentrations (standard deviation divided by mean) and validation s. When Savitsky–Golay filtering on the output and Isolation Forest are not used for the calibration curves, the average s drops to 0.54 (19% reduction), and s for Ca, P, Zn, Sr, and S drop to 0.92, 0.92, 0.90, 0.89, and 0.81, respectively.
Table 3.
PLS results for the training set of 10 cm references for core BE2 and the validation set of 1 cm references from the same core (NC = not computed, regression failed; bold text indicates validation s above 0.6).
The predicted concentrations for Ca, P, and S at 1 cm were plotted for visual inspection (Figure 5), and it has been shown that some trends on 1 cm reference data that were not present in 10 cm reference data could be detected on the predicted concentrations. The trends observed in the first 10 cm section, the section of 30 to 40 cm, and in the last 20 cm section of 1 cm references for Ca were captured by the calibrated concentrations. This did not happen as precisely for P and S, as some trends are missing from calibrated concentrations. Consequently, it appears that while some higher resolution information is recovered from calibrating element counts, this information is only qualitatively accurate.
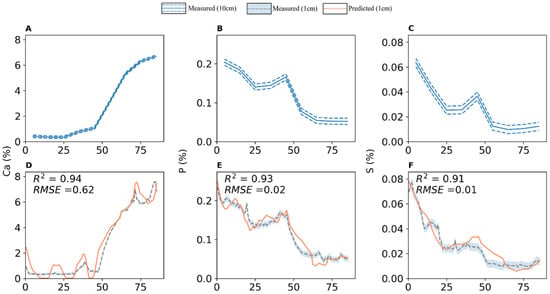
Figure 5.
Measured reference concentrations at 10 cm (A–C) and measured and predicted concentrations at 1 cm (D–F) for Ca, P, and S in a Brown Earth soil core.
3.4. Complete Dataset Calibration
Complete dataset calibration regressions (Table 4) had a mean validation of 0.33 with a standard deviation of 0.31 for cores and a mean validation of 0.46 with a standard deviation of 0.27 for pellets. Ca, Sr, and Zn had the best validation s of 0.94, 0.93, and 0.93 for cores and Sr, Ca, and Zn with validation s of 0.97, 0.95, and 0.93 for pellets. Fe had the most difference in validation with = 0.25 for cores and = 0.58 for pellets. P and S were not predicted adequately in either case with s of 0.37 and 0.06 for cores and 0.46 and 0.31 for pellets, respectively. There was a strong correlation between the correlation coefficients of reference concentrations and element counts and validation s for the reference elements that were directly measured by XRF core scanning both for cores and pellets (r = 0.78 and p < 0.01). No relationship was found between the dispersal of reference concentrations (standard deviation divided by mean) or measurement precision of references (%CV) and validation s. Isolation Forest and Savitsky–Golay filtering had no meaningful impact on the validation s. It has been shown that validation s can vary for the same element between each core, but even when validation is as low as 0.63, it is possible to detect patterns of change, as in the case of Ca for one of the G cores (Figure 6). Overall, it seems that the generalisably of calibration models for new cores can vary greatly depending on the target element and the new core’s similarity to the training dataset and is dependent on the correlation of element counts and reference concentrations. However, even when this is not strong, it might be possible to derive qualitative information from calibrated concentrations.
Table 4.
Regression results for all cores, with each core set out as cross-validation set (NC = not computed, regression failed; bold text has validation s above 0.6).
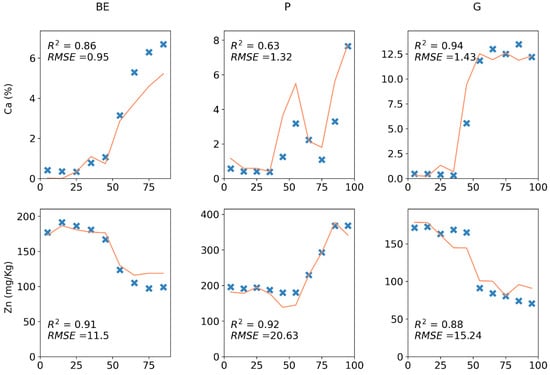
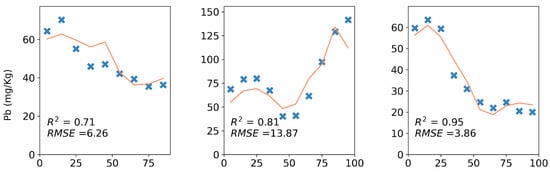
Figure 6.
Ca, Zn, and Pb, 10 cm validation predictions (orange lines) and reference concentrations (blue cross marks) on three sample cores from three soil types.
4. Discussion
4.1. Statistical Aspects of Calibration
Weltje and Tjallingii [3] asserted that to create a calibration curve for XRF counts to references concentrations, logarithmic ratios of both counts and elements should be used. Several reasons were put forward for this approach derived from the work by Aitchison [16] on compositional data analysis. The first argument in favor of using logarithmic ratios on both input and output of calibration is that compositional data are constrained, usually from 0 to 1, but this does not cover the whole Euclidean real sample space Rn. However, Euclidean geometry is not an assumption of linear regression [30]. Another justification provided is that logarithmic ratios often follow a normal distribution. In addition to the fact that this was not true for the soil dataset in this study, the fact that linear regression does not assume a normal distribution for the data, but rather a normal distribution for the residuals of the regression should be considered. In addition, the choice of logarithmic ratios was justified by asserting that predictions should not be negative for concentrations, but this can be addressed, as dealt with here, by replacing 50% or 100% of limit of detection for any predicted value below the limit of detection (including zero) [31]. Most crucially, using additive logarithmic ratios of both counts and concentrations means that after predicting a new value, it is not possible to derive the absolute concentrations. Weltje et al. [15] attempts to solve this issue by introducing an additional variable, “Undef”, which is 1 minus the sum of all the other element concentrations for each row of data and using centred logarithmic ratios instead of additive logarithmic ratios. While these two implementations will solve the problem of absolute concentrations, it also essentially ties the errors of measurement for different elements together, both via centred logarithm ratios and the ‘Undef’ variable, and since these errors can be very low or very high for different elements as seen here, this will affect the calibration performance of more accurately measured elements negatively and ultimately lead to the loss of fine scale information. In fact, when the logarithmic calibration method was used in the current study dataset in a preliminary investigation, the calibration curves could not predict any fine scale information at all, results for the 1 cm validation data had an average of = 0.29 and at best = 0.70 for Sr. Moreover, the use of PLS regression as in the case with Weltje et al. [15], implies no assumptions about the samples, which renders some of the points from earlier work null, yet the same logarithmic calibration methodology continues to be used throughout the literature. Although it has been demonstrated in Weltje et al. [15] that their method has better validation s than simple direct regression, there are some problems with the methodology. Firstly, a more justified use of logarithmic ratios in the case of calibrating XRF is using it only for the predictors, since some of the noise, non-linearity, and errors might be cancelled by the division of two variables to avoid creating problems in prediction of absolute concentrations. This has not been tested. Secondly, no degree of data pre-treatment, feature selection, and feature optimisation for PLS has been implemented to address the noise issue with XRF counts, causing inherent disadvantage for direct regression. Thirdly, a leave-one-out cross-validation (LOOCV) was used on a single core, which is highly biased in autocorrelated datasets such as a single core like this case which can potentially lead to data leakage because of the dependence of adjacent datapoints [23,32]. The difference in performance between direct and logarithmic ratios calibration might only be a product of worsening of this bias by logarithmic ratios or lack of pre-treatment in the case of direct calibration. Overall, it has been demonstrated here that a direct regression has more potential to reveal high resolution information if proper feature selection and pre-treatment is implemented.
4.2. Information in Higher Resolution
It has been shown here that some degree of higher resolution information in 1 cm intervals can be derived from calibration curves based on 10 cm references. However, this was limited to a few elements with many datapoints not equal to references at those points, and this casts some doubt on the “high-resolution” capabilities of XRF core scanning as it seems that quantitatively speaking, the XRF core scanning’s resolution is as good as its reference resolution at 1 cm, at least in the case of this study. However, as suggested by Larson et al. [33], it might be more practical to preserve high resolution characteristics of XRF core scanning by using its outputs as inputs for classification models of intensity intervals for chemicals rather than regression models of quantified exact concentrations. It can be suggested that the element counts with high noise or too many zero datapoints be converted into categorical variables of intensity intervals or presence/absence. This can potentially be used alongside continuous counts in regression models that can handle categorical and continuous inputs simultaneously, such as random forest [34], to maximise information preservation. To the author’s knowledge, the only study that directly addresses this question shows that for artificially produced laminated sediments, it is possible to obtain sub-cm or mm resolution [35]. However, this was undertaken using a pure molybdenum, vanadium, and calcite mixture with resin. It remains to be seen what the results of such future experiments are with reference soils for elements of interest in calibrating element concentrations.
4.3. Generalisability of the Calibration Models
Not many studies have investigated calibration performance results of XRF core scanning counts to concentrations in a soil context. An important issue with these studies is that they only reported on correlation coefficients of ICP measured references and XRF counts which can be misleading. Statistically extreme values of counts, which often occur in soil cores, can artificially exaggerate insignificant correlation coefficients (Mukaka 2012). Such a correlation has been reported in Longman et al. [36] for Fe ( = 0.78) and in Kern et al. [37] for silicon ( = 0.91), based on the inclusion of three extreme values. Both correlations are essentially reduced to two-point calibration because of the extreme distance between the two regions of the datapoints, which theoretically always yields a correlation coefficient of 1.0. Another reason for a weak calibration curve can be the high errors of measurement for references as is the case for K in the current study; however, these errors are often not reported.
A comparison of the results of this study with its sediment equivalents is difficult even without considering the difference in geochemical compositions of sediments and soils. Firstly, sediment cores can be longer than 1 m sometimes up to 5 m in length, and many of these studies are carried out on a single core, and secondly, many of these studies lack validation, and when they do include validation, it is usually on the same core. For example, Poto et al. [38] carried out a calibration between XRF core scanner counts and ICP concentrations on a single 7 m sediment core; however, it is not apparent whether a validation method was used. Even without a validation step, it seems that s are incomparable since Ca, which is very reliable in the current study, was poorly calibrated ( = 0.54).
Although the results of the current study are not comparable with the original work of Weltje and Tjallingii [3] because of s being reported for only logarithmic ratios, the former study [39] on the same sediment core GeoB7920, with a direct calibration, shows a strong correlation for Ca with = 0.97, however without validation. In the subsequent study [15], individual results for elements are not reported; although, some conclusions may be drawn from the predicted versus actual concentrations plots for validation sets. Firstly, parameter “Undef” is very poorly predicted for the core GeoB7920, which could potentially be a problem with the dataset in the current study, leading to loss of higher resolution information. Secondly, it seems that Ca and Sr are well predicted like the current study, but Fe and Al are also well predicted, while the ranges for these two elements are quite dissimilar and much wider compared to the current study. Fe in the current study is around 2 wt.% both between the cores and within each core profile, and this lack of variation makes the correlation curve fail because even the best prediction is still close to the average value which brings close to zero.
In addition, the current study shows that the generalizability of regression curves for an element in a newly acquired core is highly dependent on the correlation strength of that element’s concentration with its measured XRF counts, and the regression calibration performance for pressed pellets and cores are not radically different. This confirms the conclusion of Dunlea et al. [19] that many features on cores are not reproducible with XRF core scanning, and this is not necessarily because of the soil matrix or sample geometry effects. However, larger and more varied datasets should be experimented with to confirm the generalizability of calibration regression curves.
5. Conclusions
This study shows that calibration regression curves on soil cores can reveal some level of finer detail on geochemical concentrations, but this is dependent on proper pre-treatment and feature selection steps. The current study moves beyond the established logarithmic ratio calibration method to obtain high resolution calibrated concentrations to demonstrate that a direct regression with feature selection based on discrete pellets and pre-processing can yield accurate fine scale results. Furthermore, it has been shown that the generalisability of calibration regression curves to newly acquired cores is dependent on the degree of reliability of XRF count measurement of a specific element rather than a matrix or sample geometry effects, but larger datasets are needed to further confirm this. More accurate reference taking methods and larger datasets can improve calibration curves for elements of interest in agriculture such as K and Fe. Based on the findings of this study, it is suggested that specific experiments with proper validation schemes are conducted to further investigate the high-resolution capabilities of XRF core scanning in agricultural soil and other contexts.
Author Contributions
Conceptualisation, S.K. and S.M.O.; methodology, S.K., J.N.T. and S.M.O.; software, S.K.; validation, R.P.F., J.N.T. and S.M.O.; formal analysis, S.K.; investigation, S.K.; resources, N.M.H., J.N.T. and S.M.O.; data curation, S.K. and S.M.O.; writing—original draft preparation, S.K.; writing—review and editing, R.P.F., J.N.T. and S.M.O.; visualisation, S.K.; supervision, N.M.H. and S.M.O.; project administration, N.M.H. and S.M.O.; funding acquisition, S.M.O. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Irish Research Council [grant numbers IRCLA/2017/137].
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset and code used for models and plots in this study are available at GitHub via https://doi.org/10.5281/zenodo.10956953 [40] (accessed on 10 April 2024) with MIT licensing.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Croudace, I.; Rindby, A.; Rothwell, R. ITRAX: Description and Evaluation of a New Multi-Function X-ray Core Scanner. Geol. Soc. London Spec. Publ. 2006, 267, 51–63. [Google Scholar] [CrossRef]
- Jansen, J.H.F.; Van der Gaast, S.J.; Koster, B.; Vaars, A.J. CORTEX, a shipboard XRF-scanner for element analyses in split sediment cores. Mar. Geol. 1998, 151, 143–153. [Google Scholar] [CrossRef]
- Weltje, G.J.; Tjallingii, R. Calibration of XRF core scanners for quantitative geochemical logging of sediment cores: Theory and application. Earth Planet. Sci. Lett. 2008, 274, 423–438. [Google Scholar] [CrossRef]
- Kulkova, M.; Mazurkevich, A.; Dolbunova, E. Paste recipes and raw material sources for pottery-making in hunter-gatherer communities in the forest zone of Eastern Europe (Dnepr-Dvina region, 7–6th millennia BC). J. Archaeol. Sci. Rep. 2018, 21, 962–972. [Google Scholar] [CrossRef]
- Rajapaksha, D.; Waduge, V.; Padilla-Alvarez, R.; Kalpage, M.; Rathnayake, R.M.N.P.; Migliori, A.; Frew, R.; Abeysinghe, S.; Abrahim, A.; Amarakoon, T. XRF to support food traceability studies: Classification of Sri Lankan tea based on their region of origin. X-ray Spectrom. 2017, 46, 220–224. [Google Scholar] [CrossRef]
- Shand, C.A.; Wendler, R.; Dawson, L.; Yates, K.; Stephenson, H. Multivariate analysis of Scotch whisky by total reflection X-ray fluorescence and chemometric methods: A potential tool in the identification of counterfeits. Anal. Chim. Acta 2017, 976, 14–24. [Google Scholar] [CrossRef] [PubMed]
- Hussain, A.; Haughton, P.D.W.; Shannon, P.M.; Turner, J.N.; Pierce, C.S.; Obradors-Latre, A.; Barker, S.P.; Martinsen, O.J. High-resolution X-ray fluorescence profiling of hybrid event beds: Implications for sediment gravity flow behaviour and deposit structure. Sedimentology 2020, 67, 2850–2882. [Google Scholar] [CrossRef]
- Flood, R.P.; Bloemsma, M.R.; Weltje, G.J.; Barr, I.D.; O’Rourke, S.M.; Turner, J.N.; Orford, J.D. Compositional data analysis of Holocene sediments from the West Bengal Sundarbans, India: Geochemical proxies for grain-size variability in a delta environment. Appl. Geochem. 2016, 75, 222–235. [Google Scholar] [CrossRef]
- Albanese, S.; Sadeghi, M.; Lima, A.; Cicchella, D.; Dinelli, E.; Valera, P.; Falconi, M.; Demetriades, A.; De Vivo, B. GEMAS: Cobalt, Cr, Cu and Ni distribution in agricultural and grazing land soil of Europe. J. Geochem. Explor. 2015, 154, 81–93. [Google Scholar] [CrossRef]
- O’Rourke, S.; Minasny, B.; Holden, N.; McBratney, A. Synergistic Use of Vis-NIR, MIR, and XRF Spectroscopy for the Determination of Soil Geochemistry. Soil Sci. Soc. Am. J. 2016, 80, 888–899. [Google Scholar] [CrossRef]
- Zhang, Y.; Hartemink, A.E. Data fusion of vis–NIR and PXRF spectra to predict soil physical and chemical properties. Eur. J. Soil Sci. 2020, 71, 316–333. [Google Scholar] [CrossRef]
- Benedet, L.; Acuña-Guzman, S.F.; Faria, W.M.; Silva, S.H.G.; Mancini, M.; Teixeira, A.F.d.S.; Pierangeli, L.M.P.; Acerbi Júnior, F.W.; Gomide, L.R.; Pádua Júnior, A.L.; et al. Rapid soil fertility prediction using X-ray fluorescence data and machine learning algorithms. Catena 2021, 197, 105003. [Google Scholar] [CrossRef]
- John, K.; Kebonye, N.M.; Agyeman, P.C.; Ahado, S.K. Comparison of Cubist models for soil organic carbon prediction via portable XRF measured data. Environ. Monit. Assess. 2021, 193, 197. [Google Scholar] [CrossRef]
- Ranganathan, Y.; Borges, R.M. Reducing the babel in plant volatile communication: Using the forest to see the trees. Plant Biol. 2010, 12, 735–742. [Google Scholar] [CrossRef] [PubMed]
- Weltje, G.J.; Bloemsma, M.R.; Tjallingii, R.; Heslop, D.; Röhl, U.; Croudace, I.W. Prediction of Geochemical Composition from XRF Core Scanner Data: A New Multivariate Approach Including Automatic Selection of Calibration Samples and Quantification of Uncertainties. In Micro-XRF Studies of Sediment Cores: Applications of a Non-Destructive Tool for the Environmental Sciences; Croudace, I.W., Rothwell, R.G., Eds.; Springer: Dordrecht, The Netherlands, 2015; pp. 507–534. [Google Scholar] [CrossRef]
- Aitchison, J. The Statistical Analysis of Compositional Data. J. R. Stat. Society. Ser. B 1982, 44, 139–177. [Google Scholar] [CrossRef]
- Jones, A.F.; Turner, J.N.; Daly, J.S.; Francus, P.; Edwards, R.J. Signal-to-noise ratios, instrument parameters and repeatability of Itrax XRF core scan measurements of floodplain sediments. Quat. Int. 2019, 514, 44–54. [Google Scholar] [CrossRef]
- Bloemsma, M.R.; Weltje, G.J. Reduced-rank approximations to spectroscopic and compositional data: A universal framework based on log-ratios and counting statistics. Chemom. Intell. Lab. Syst. 2015, 142, 206–218. [Google Scholar] [CrossRef]
- Dunlea, A.G.; Murray, R.W.; Tada, R.; Alvarez-Zarikian, C.A.; Anderson, C.H.; Gilli, A.; Giosan, L.; Gorgas, T.; Hennekam, R.; Irino, T.; et al. Intercomparison of XRF Core Scanning Results from Seven Labs and Approaches to Practical Calibration. Geochem. Geophys. Geosyst. 2020, 21, e2020GC009248. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- van Buuren, S.; Groothuis-Oudshoorn, K. mice: Multivariate Imputation by Chained Equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Meyer, H.; Reudenbach, C.; Wöllauer, S.; Nauss, T. Importance of spatial predictor variable selection in machine learning applications—Moving from data reproduction to spatial prediction. Ecol. Model. 2019, 411, 108815. [Google Scholar] [CrossRef]
- Collins, J.F.; Brickley, W. Soils of Lyons Estate Celbridge, Co. Kildare: (University College Dublin, Farm); Soil Science Department, University College Dublin: Dublin, Ireland, 1970. [Google Scholar]
- O’Rourke, S.M.; Turner, J.N.; Holden, N.M. Estimating Fine Resolution Carbon Concentration in an Intact Soil Profile by X-ray Fluorescence Scanning. In Soil Carbon; Hartemink, A.E., McSweeney, K., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 179–187. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Pelliccia, D. Choosing the Optimal Parameters for a Savitzky–Golay Smoothing Filter. Available online: https://nirpyresearch.com/choosing-optimal-parameters-savitzky-golay-smoothing-filter (accessed on 5 February 2024).
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis, 5th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Wold, S.; Martens, H.; Wold, H. The Multivariate Calibration Problem in Chemistry Solved by the PLS Method; Springer: Berlin/Heidelberg, Germany, 1982; pp. 286–293. [Google Scholar]
- Urdan, T.C. Statistics in Plain English, 3rd ed.; Routledge: New York, NY, USA, 2010. [Google Scholar]
- Sanford, R.F.; Pierson, C.T.; Crovelli, R.A. An objective replacement method for censored geochemical data. Math. Geol. 1993, 25, 59–80. [Google Scholar] [CrossRef]
- Kaufman, S.; Rosset, S.; Perlich, C.; Stitelman, O. Leakage in data mining: Formulation, detection, and avoidance. ACM Trans. Knowl. Discov. Data 2012, 6, 15. [Google Scholar] [CrossRef]
- Larson, T.E.; Loucks, R.G.; Sivil, J.E.; Hattori, K.E.; Zahm, C.K. Machine learning classification of Austin Chalk chemofacies from high-resolution x-ray fluorescence core characterization. AAPG Bull. 2023, 107, 907–927. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by RandomForest. Forest 2001, 23, 18–22. [Google Scholar]
- Hennekam, R.; Sweere, T.; Tjallingii, R.; de Lange, G.J.; Reichart, G.J. Trace metal analysis of sediment cores using a novel X-ray fluorescence core scanning method. Quat. Int. 2019, 514, 55–67. [Google Scholar] [CrossRef]
- Longman, J.; Veres, D.; Wennrich, V. Utilisation of XRF core scanning on peat and other highly organic sediments. Quat. Int. 2019, 514, 85–96. [Google Scholar] [CrossRef]
- Kern, O.A.; Koutsodendris, A.; Mächtle, B.; Christanis, K.; Schukraft, G.; Scholz, C.; Kotthoff, U.; Pross, J. XRF core scanning yields reliable semiquantitative data on the elemental composition of highly organic-rich sediments: Evidence from the Füramoos peat bog (Southern Germany). Sci. Total Environ. 2019, 697, 134110. [Google Scholar] [CrossRef]
- Poto, L.; Gabrieli, J.; Crowhurst, S.; Agostinelli, C.; Spolaor, A.; Cairns, W.R.L.; Cozzi, G.; Barbante, C. Cross calibration between XRF and ICP-MS for high spatial resolution analysis of ombrotrophic peat cores for palaeoclimatic studies. Anal. Bioanal. Chem. 2015, 407, 379–385. [Google Scholar] [CrossRef]
- Tjallingii, R.; Röhl, U.; Kölling, M.; Bickert, T. Influence of the water content on X-ray fluorescence core-scanning measurements in soft marine sediments. Geochem. Geophys. Geosyst. 2007, 8. [Google Scholar] [CrossRef]
- Kabiri, S.; Holden, N.; Flood, R.; Turner, J.; O’Rourke, S. Grassland Soil XRF Dataset. Available online: https://zenodo.org/records/10956953 (accessed on 10 April 2024).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).