Accurate and Precise Prediction of Soil Properties from a Large Mid-Infrared Spectral Library


Abstract
1. Introduction
2. Materials and Methods
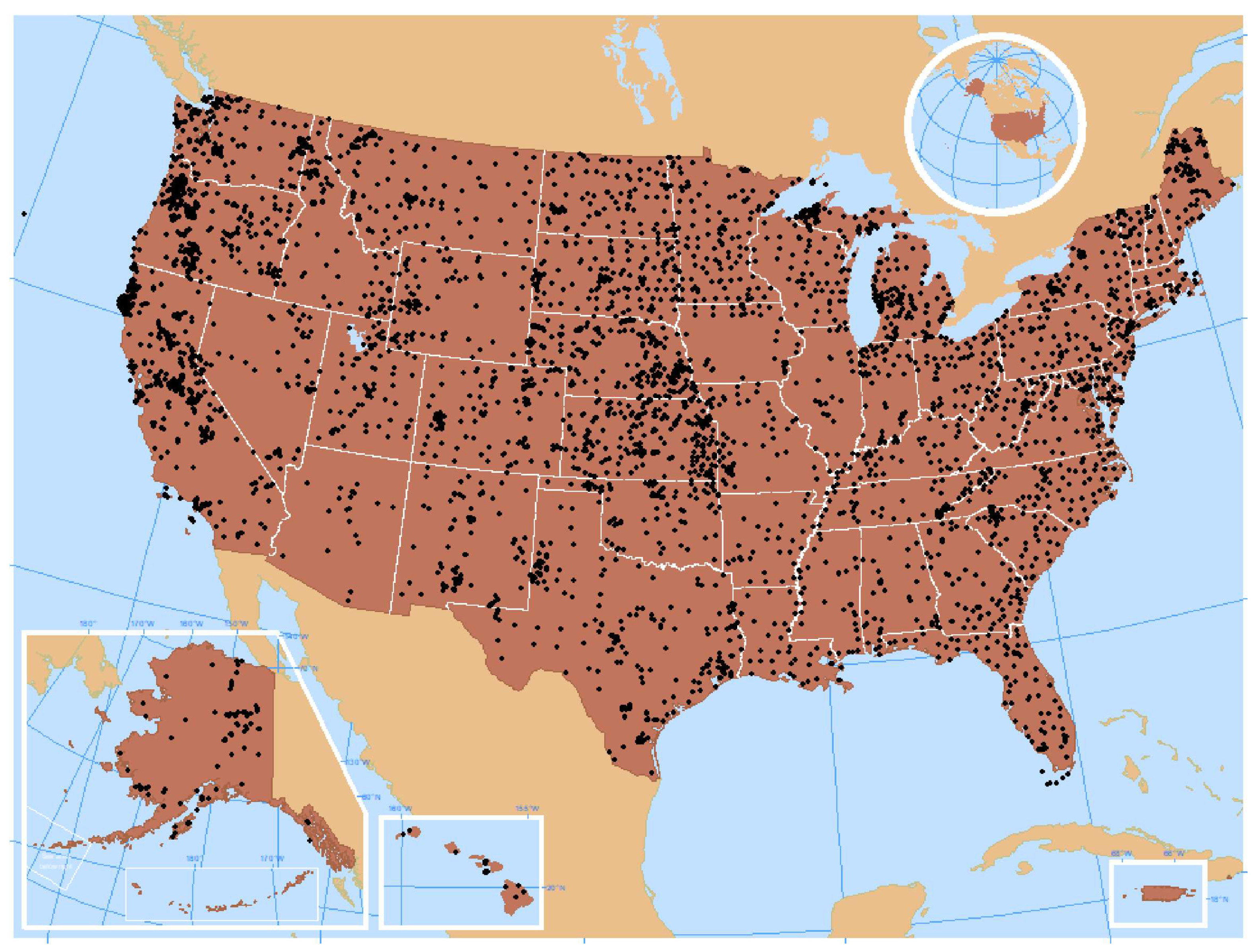
2.1. The NSSC-KSSL Spectral Library
2.2. Pre-Processing of MIR Spectra and Analytical Data
2.3. Sample Selection, Outlier Detection and Model Performance Assessment
2.4. Spectral Modeling
2.4.1. Partial Least Squares Regression (PLSR)
2.4.2. Memory-Based Learning (MBL)
2.4.3. Random Forest (RF)
2.4.4. Cubist
2.5. Assessment of Model and Individual Prediction Performance
2.5.1. Model Performance
2.5.2. Individual Prediction Uncertainty
2.5.3. Trustworthiness of New Predictions
3. Results
3.1. Exploratory Analysis of the KSSL MIR Library
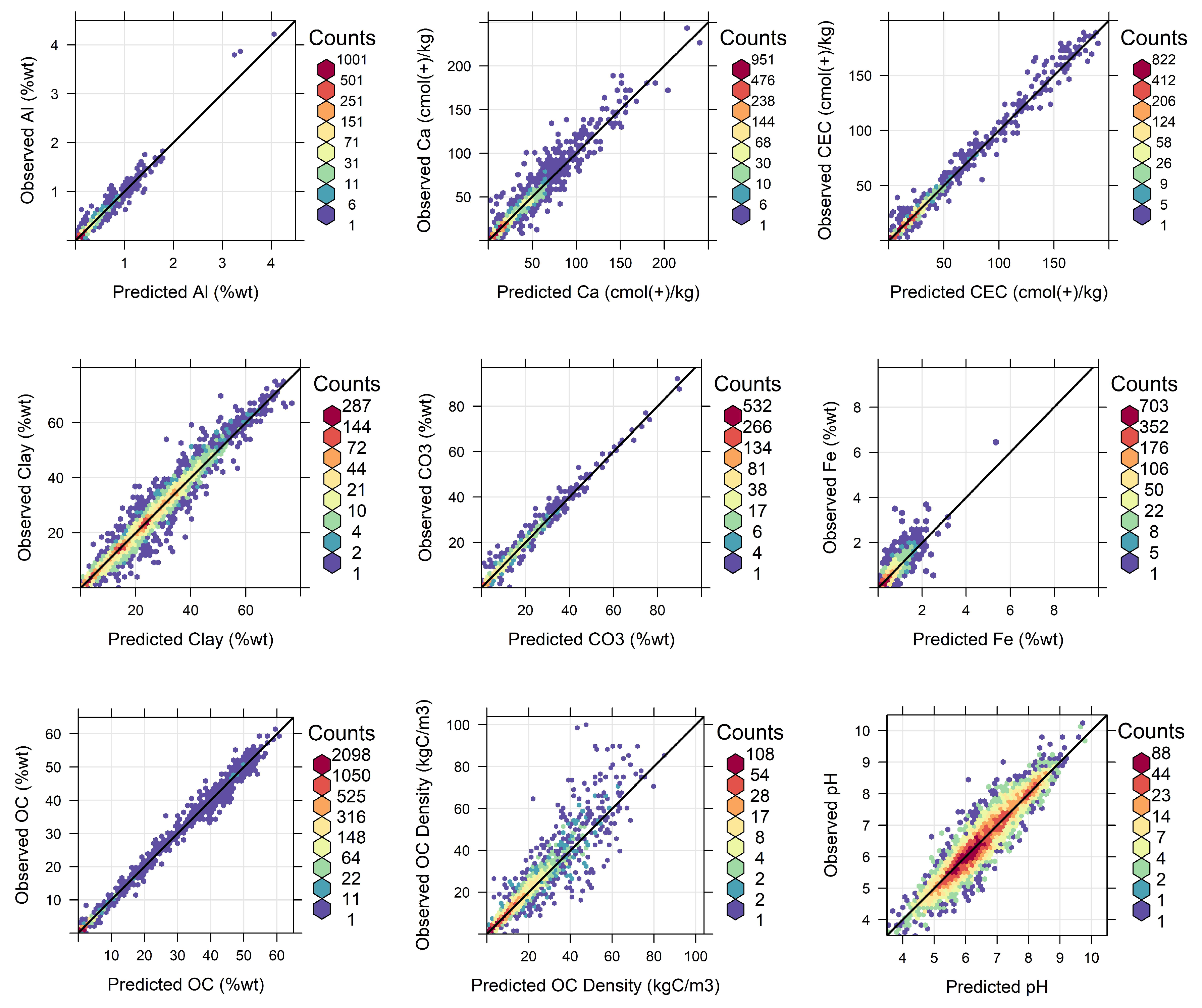
3.2. Overall Model Performance
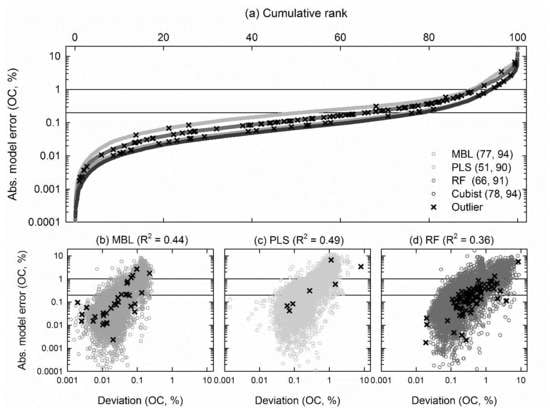
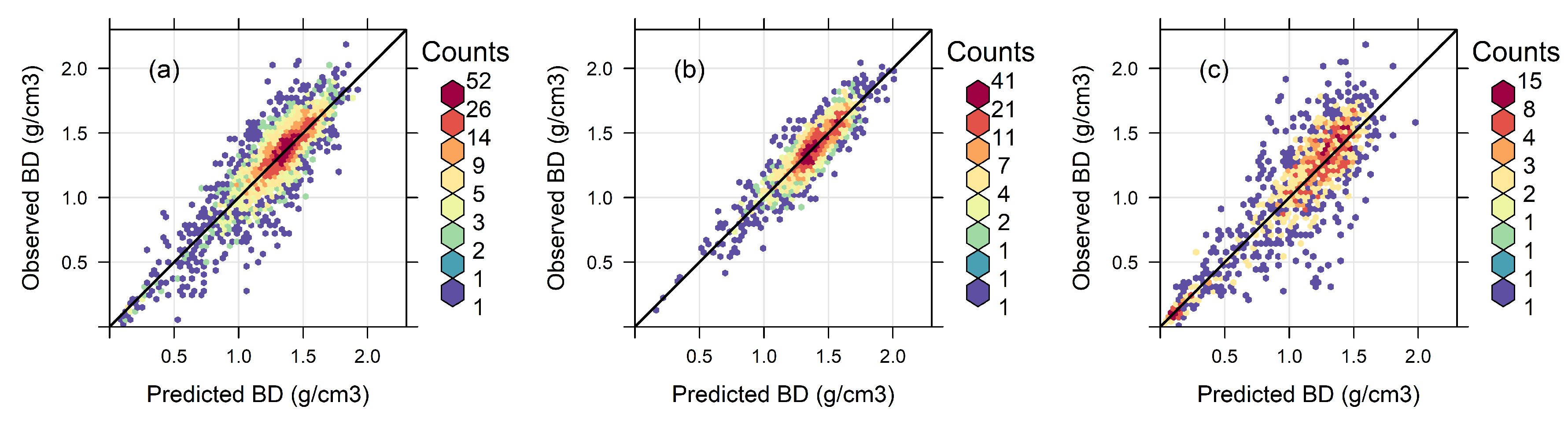
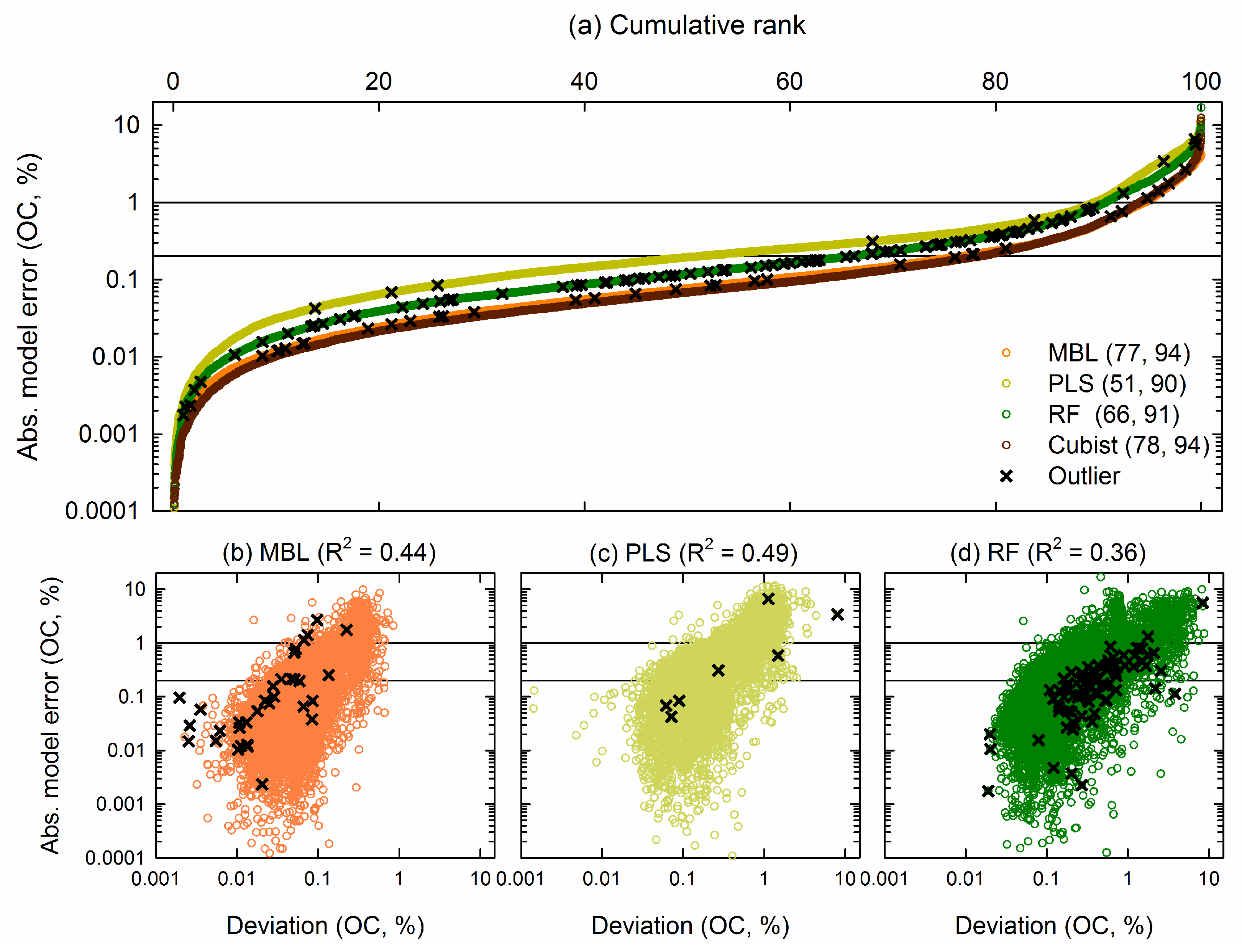
3.3. Absolute Model Error and Prediction Uncertainty
4. Discussion
4.1. KSSL MIR Library and Its Non-Normal Distribution
4.2. Model Performance for a Range of Soil Properties
4.3. The Importance of Estimating Prediction Uncertainty
4.4. Best Model Performance
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Schmidt, M.W.; Torn, M.S.; Abiven, S.; Dittmar, T.; Guggenberger, G.; Janssens, I.A.; Kleber, M.; Kögel-Knabner, I.; Lehmann, J.; Manning, D.A. Persistence of soil organic matter as an ecosystem property. Nature 2011, 478, 49. [Google Scholar] [CrossRef] [PubMed]
- Tiessen, H.; Cuevas, E.; Chacon, P. The role of soil organic matter in sustaining soil fertility. Nature 1994, 371, 783–785. [Google Scholar] [CrossRef]
- Foley, J.A.; DeFries, R.; Asner, G.P.; Barford, C.; Bonan, G.; Carpenter, S.R.; Chapin, F.S.; Coe, M.T.; Daily, G.C.; Gibbs, H.K. Global consequences of land use. Science 2005, 309, 570–574. [Google Scholar] [CrossRef] [PubMed]
- Sanderman, J.; Hengl, T.; Fiske, G.J. Soil carbon debt of 12,000 years of human land use. Proc. Natl. Acad. Sci. USA 2017, 114, 9575–9580. [Google Scholar] [CrossRef]
- Brown, D.J.; Shepherd, K.D.; Walsh, M.G.; Mays, M.D.; Reinsch, T.G. Global soil characterization with VNIR diffuse reflectance spectroscopy. Geoderma 2006, 132, 273–290. [Google Scholar] [CrossRef]
- Soriano-Disla, J.M.; Janik, L.J.; Viscarra Rossel, R.A.; Macdonald, L.M.; McLaughlin, M.J. The performance of visible, near-, and mid-infrared reflectance spectroscopy for prediction of soil physical, chemical, and biological properties. Appl. Spectrosc. Rev. 2014, 49, 139–186. [Google Scholar] [CrossRef]
- Rossel, R.V.; Walvoort, D.J.J.; McBratney, A.B.; Janik, L.J.; Skjemstad, J.O. Visible, near infrared, mid infrared or combined diffuse reflectance spectroscopy for simultaneous assessment of various soil properties. Geoderma 2006, 131, 59–75. [Google Scholar] [CrossRef]
- Terhoeven-Urselmans, T.; Vagen, T.G.; Spaargaren, O.; Shepherd, K.D. Prediction of soil fertility properties from a globally distributed soil mid-infrared spectral library. Soil Sci. Soc. Am. J. 2010, 74, 1792–1799. [Google Scholar] [CrossRef]
- Reeves, J.B., III; Smith, D.B. The potential of mid-and near-infrared diffuse reflectance spectroscopy for determining major-and trace-element concentrations in soils from a geochemical survey of North America. Appl. Geochem. 2009, 24, 1472–1481. [Google Scholar] [CrossRef]
- Stevens, A.; Nocita, M.; Tóth, G.; Montanarella, L.; van Wesemael, B. Prediction of soil organic carbon at the European scale by visible and near infrared reflectance spectroscopy. PLoS ONE 2013, 8, e66409. [Google Scholar] [CrossRef]
- Baldock, J.A.; Hawke, B.; Sanderman, J.; Macdonald, L.M. Predicting contents of carbon and its component fractions in Australian soils from diffuse reflectance mid-infrared spectra. Soil Res. 2014, 51, 577–595. [Google Scholar] [CrossRef]
- Shi, Z.; Ji, W.; Viscarra Rossel, R.A.; Chen, S.; Zhou, Y. Prediction of soil organic matter using a spatially constrained local partial least squares regression and the C hinese vis–NIR spectral library. Eur. J. Soil Sci. 2015, 66, 679–687. [Google Scholar] [CrossRef]
- Kuang, B.; Mouazen, A.M. Influence of the number of samples on prediction error of visible and near infrared spectroscopy of selected soil properties at the farm scale. Eur. J. Soil Sci. 2012, 63, 421–429. [Google Scholar] [CrossRef]
- Stenberg, B.; Rossel, R.A.V.; Mouazen, A.M.; Wetterlind, J. Visible and near infrared spectroscopy in soil science. In Advances in Agronomy; Elsevier: Burlington, MA, USA, 2010; Volume 107, pp. 163–215. [Google Scholar]
- McCarty, G.W.; Reeves, J.B.; Reeves, V.B.; Follett, R.F.; Kimble, J.M. Mid-infrared and near-infrared diffuse reflectance spectroscopy for soil carbon measurement. Soil Sci. Soc. Am. J. 2002, 66, 640–646. [Google Scholar]
- Wijewardane, N.K.; Ge, Y.; Wills, S.; Libohova, Z. Predicting Physical and Chemical Properties of US Soils with a Mid-Infrared Reflectance Spectral Library. Soil Sci. Soc. Am. J. 2018, 82, 722. [Google Scholar] [CrossRef]
- Bellon-Maurel, V.; Fernandez-Ahumada, E.; Palagos, B.; Roger, J.M.; McBratney, A. Critical review of chemometric indicators commonly used for assessing the quality of the prediction of soil attributes by NIR spectroscopy. TrAC Trends Anal. Chem. 2010, 29, 1073–1081. [Google Scholar] [CrossRef]
- Abdi, H. Partial least squares regression and projection on latent structure regression (PLS Regression). Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 97–106. [Google Scholar] [CrossRef]
- Mouazen, A.M.; Kuang, B.; De Baerdemaeker, J.; Ramon, H. Comparison among principal component, partial least squares and back propagation neural network analyses for accuracy of measurement of selected soil properties with visible and near infrared spectroscopy. Geoderma 2010, 158, 23–31. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Vohland, M.; Besold, J.; Hill, J.; Fründ, H.C. Comparing different multivariate calibration methods for the determination of soil organic carbon pools with visible to near infrared spectroscopy. Geoderma 2011, 166, 198–205. [Google Scholar] [CrossRef]
- Brown, D.J.; Bricklemyer, R.S.; Miller, P.R. Validation requirements for diffuse reflectance soil characterization models with a case study of VNIR soil C prediction in Montana. Geoderma 2005, 129, 251–267. [Google Scholar] [CrossRef]
- Bellon-Maurel, V.; McBratney, A. Near-infrared (NIR) and mid-infrared (MIR) spectroscopic techniques for assessing the amount of carbon stock in soils–Critical review and research perspectives. Soil Biol. Biochem. 2011, 43, 1398–1410. [Google Scholar] [CrossRef]
- Ramirez-Lopez, L.; Behrens, T.; Schmidt, K.; Stevens, A.; Demattê, J.A.M.; Scholten, T. The spectrum-based learner: A new local approach for modeling soil vis–NIR spectra of complex datasets. Geoderma 2013, 195, 268–279. [Google Scholar] [CrossRef]
- Clairotte, M.; Grinand, C.; Kouakoua, E.; Thébault, A.; Saby, N.P.; Bernoux, M.; Barthès, B.G. National calibration of soil organic carbon concentration using diffuse infrared reflectance spectroscopy. Geoderma 2016, 276, 41–52. [Google Scholar] [CrossRef]
- Gogé, F.; Gomez, C.; Jolivet, C.; Joffre, R. Which strategy is best to predict soil properties of a local site from a national Vis–NIR database? Geoderma 2014, 213, 1–9. [Google Scholar] [CrossRef]
- Guerrero, C.; Zornoza, R.; Gómez, I.; Mataix-Beneyto, J. Spiking of NIR regional models using samples from target sites: Effect of model size on prediction accuracy. Geoderma 2010, 158, 66–77. [Google Scholar] [CrossRef]
- Sankey, J.B.; Brown, D.J.; Bernard, M.L.; Lawrence, R.L. Comparing local vs. global visible and near-infrared (VisNIR) diffuse reflectance spectroscopy (DRS) calibrations for the prediction of soil clay, organic C and inorganic C. Geoderma 2008, 148, 149–158. [Google Scholar] [CrossRef]
- Wetterlind, J.; Stenberg, B. Near-infrared spectroscopy for within-field soil characterization: small local calibrations compared with national libraries spiked with local samples. Eur. J. Soil Sci. 2010, 61, 823–843. [Google Scholar] [CrossRef]
- Vasques, G.M.; Grunwald, S.; Sickman, J.O. Comparison of multivariate methods for inferential modeling of soil carbon using visible/near-infrared spectra. Geoderma 2008, 146, 14–25. [Google Scholar] [CrossRef]
- Ji, W.; Viscarra Rossel, R.A.; Shi, Z. Accounting for the effects of water and the environment on proximally sensed vis–NIR soil spectra and their calibrations. Eur. J. Soil Sci. 2015, 66, 555–565. [Google Scholar] [CrossRef]
- Guy, A.L.; Siciliano, S.D.; Lamb, E.G. Spiking regional vis-NIR calibration models with local samples to predict soil organic carbon in two High Arctic polar deserts using a vis-NIR probe. Can. J. Soil Sci. 2015, 95, 237–249. [Google Scholar] [CrossRef]
- Hengl, T.; de Jesus, J.M.; MacMillan, R.A.; Batjes, N.H.; Heuvelink, G.B.; Ribeiro, E.; Samuel-Rosa, A.; Kempen, B.; Leenaars, J.G.; Walsh, M.G. SoilGrids1km—Global soil information based on automated mapping. PLoS ONE 2014, 9, e105992. [Google Scholar] [CrossRef] [PubMed]
- Kuang, B.; Tekin, Y.; Mouazen, A.M. Comparison between artificial neural network and partial least squares for on-line visible and near infrared spectroscopy measurement of soil organic carbon, pH and clay content. Soil Tillage Res. 2015, 146, 243–252. [Google Scholar] [CrossRef]
- Morellos, A.; Pantazi, X.E.; Moshou, D.; Alexandridis, T.; Whetton, R.; Tziotzios, G.; Wiebensohn, J.; Bill, R.; Mouazen, A.M. Machine learning based prediction of soil total nitrogen, organic carbon and moisture content by using VIS-NIR spectroscopy. Biosyst. Eng. 2016, 152, 104–116. [Google Scholar] [CrossRef]
- Rossel, R.V.; Behrens, T.; Ben-Dor, E.; Brown, D.J.; Demattê, J.A.M.; Shepherd, K.D.; Shi, Z.; Stenberg, B.; Stevens, A.; Adamchuk, V. A global spectral library to characterize the world’s soil. Earth-Sci. Rev. 2016, 155, 198–230. [Google Scholar] [CrossRef]
- Rossel, R.V.; Behrens, T. Using data mining to model and interpret soil diffuse reflectance spectra. Geoderma 2010, 158, 46–54. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B. Regression rules as a tool for predicting soil properties from infrared reflectance spectroscopy. Chemom. Intell. Lab. Syst. 2008, 94, 72–79. [Google Scholar] [CrossRef]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer Science & Business Media: New York City, NY, USA, 2008. [Google Scholar]
- Dayhoff, J.E.; DeLeo, J.M. Artificial neural networks: Opening the black box. Cancer Interdiscip. Int. J. Am. Cancer Soc. 2001, 91, 1615–1635. [Google Scholar] [CrossRef]
- Ng, W.; Minasny, B.; Malone, B.; Filippi, P. In search of an optimum sampling algorithm for prediction of soil properties from infrared spectra. PeerJ 2018, 6, e5722. [Google Scholar] [CrossRef] [PubMed]
- Kang, P.; Cho, S. Locally linear reconstruction for instance-based learning. Pattern Recognit. 2008, 41, 3507–3518. [Google Scholar] [CrossRef]
- Tekin, Y.; Tümsavas, Z.; Mouazen, A.M. Comparing the artificial neural network with parcial least squares for prediction of soil organic carbon and pH at different moisture content levels using visible and near-infrared spectroscopy. Revista Brasileira de Ciência do Solo 2014, 38, 1794–1804. [Google Scholar] [CrossRef]
- Madari, B.E.; Reeves, J.B., III; Machado, P.L.; Guimarães, C.M.; Torres, E.; McCarty, G.W. Mid-and near-infrared spectroscopic assessment of soil compositional parameters and structural indices in two Ferralsols. Geoderma 2006, 136, 245–259. [Google Scholar] [CrossRef]
- Shepherd, K.D.; Walsh, M.G. Development of reflectance spectral libraries for characterization of soil properties. Soil Sci. Soc. Am. J. 2002, 66, 988–998. [Google Scholar] [CrossRef]
- Bro, R.; Rinnan, Å.; Faber, N.K.M. Standard error of prediction for multilinear PLS: 2. Practical implementation in fluorescence spectroscopy. Chemom. Intell. Lab. Syst. 2005, 75, 69–76. [Google Scholar]
- Bradford, M.A.; Wieder, W.R.; Bonan, G.B.; Fierer, N.; Raymond, P.A.; Crowther, T.W. Managing uncertainty in soil carbon feedbacks to climate change. Nat. Clim. Chang. 2016, 6, 751. [Google Scholar] [CrossRef]
- Martens, H.; Martens, M. Modified Jack-knife estimation of parameter uncertainty in bilinear modelling by partial least squares regression (PLSR). Food Qual. Preference 2000, 11, 5–16. [Google Scholar] [CrossRef]
- Bouckaert, R.R.; Frank, E.; Holmes, G.; Fletcher, D. A comparison of methods for estimating prediction intervals in NIR spectroscopy: Size matters. Chemom. Intell. Lab. Syst. 2011, 109, 139–145. [Google Scholar] [CrossRef]
- De Vries, S.; Ter Braak, C.J. Prediction error in partial least squares regression: A critique on the deviation used in The Unscrambler. Chemom. Intell. Lab. Syst. 1995, 30, 239–245. [Google Scholar] [CrossRef]
- Efron, B.; Gong, G. A leisurely look at the bootstrap, the jackknife, and cross-validation. Am. Stat. 1983, 37, 36–48. [Google Scholar]
- Ismartini, P.; Sunaryo, S.; Setiawan, S. The Jackknife Interval Estimation of Parametersin Partial Least Squares Regression Modelfor Poverty Data Analysis. IPTEK J. Technol. Sci. 2010, 21, 118–123. [Google Scholar] [CrossRef]
- Meinshausen, N. Quantile regression forests. J. Mach. Learn. Res. 2006, 7, 983–999. [Google Scholar]
- Soil Survey Staff. Kellogg Soil Survey Laboratory Methods Manual; Burt, R., Soil Survey Staff, Eds.; Soil Survey Investigations Report No. 42, Version 5.0.; U.S. Department of Agriculture, Natural Resources Conservation Service: Washington, DC, USA, 2014.
- Blake, G.R.; Hartge, K.H. Bulk Density 1. In Methods of Soil Analysis: Part 1—Physical and Mineralogical Methods; American Society of Agronomy—Soil Science Society of America: Madison, WI, USA, 1986; pp. 363–375. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Chalmers, J.M. Mid-Infrared Spectroscopy: Anomalies, Artifacts and Common Errors. In Handbook of Vibrational Spectroscopy; Chalmers, J.M., Ed.; John Wiley & Sons, Ltd.: New York City, NY, USA, 2006. [Google Scholar]
- Kennard, R.W.; Stone, L.A. Computer aided design of experiments. Technometrics 1969, 11, 137–148. [Google Scholar] [CrossRef]
- Mevik, B.H.; Wehrens, R.; Liland, K.H. pls: Partial Least Squares and Principal Component Regression, R Package Version 2.4-3.; Available online: https://cran.r-project.org/web/packages/pls/index.html (accessed on 28 January 2019).
- Trevor, H.; Robert, T.; JH, F. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Ramirez-Lopez, L.; Wadoux, A.C.; Franceschini, M.H.D.; Terra, F.S.; Marques, K.P.P.; Sayão, V.M.; Demattê, J.A.M. Robust soil mapping at the farm scale with vis–NIR spectroscopy. Eur. J. Soil Sci. 2019. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Classification and Regression Trees; Routledge: New York City, NY, USA, 2017. [Google Scholar]
- Wright, M.N.; Ziegler, A. Ranger: A fast implementation of random forests for high dimensional data in C++ and R. arXiv, 2015; arXiv:1508.04409. [Google Scholar]
- Hengl, T.; de Jesus, J.M.; Heuvelink, G.B.; Gonzalez, M.R.; Kilibarda, M.; Blagotić, A.; Shangguan, W.; Wright, M.N.; Geng, X.; Bauer-Marschallinger, B. SoilGrids250m: Global gridded soil information based on machine learning. PLoS ONE 2017, 12, e0169748. [Google Scholar] [CrossRef] [PubMed]
- Doetterl, S.; Stevens, A.; Six, J.; Merckx, R.; Van Oost, K.; Pinto, M.C.; Casanova-Katny, A.; Muñoz, C.; Boudin, M.; Venegas, E.Z. Soil carbon storage controlled by interactions between geochemistry and climate. Nat. Geosci. 2015, 8, 780. [Google Scholar] [CrossRef]
- Kuhn, M.; Weston, S.; Keefer, C.; Coulter, N.; Quinlan, R. Cubist: Rule- and Instance-Based Regression Modeling, R Package Version 0.0.13; Available online: https://cran.r-project.org/web/packages/Cubist/index.html (accessed on 28 January 2019).
- Henderson, B.; Bui, E.; Moran, C.; Simon, D.; Carlile, P. ASRIS: Continental-Scale Soil Property Predictions from Point Data; CSIRO Land and Water: Canberra, Australia, 2001. [Google Scholar]
- Chang, C.W.; Laird, D.A.; Mausbach, M.J.; Hurburgh, C.R. Near-infrared reflectance spectroscopy–principal components regression analyses of soil properties. Soil Sci. Soc. Am. J. 2001, 65, 480–490. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A. Why you don’t need to use RPD. Pedometron 2013, 33, 14–15. [Google Scholar]
- Meyer, J.S.; Ingersoll, C.G.; McDonald, L.L.; Boyce, M.S. Estimating uncertainty in population growth rates: Jackknife vs. bootstrap techniques. Ecology 1986, 67, 1156–1166. [Google Scholar] [CrossRef]
- Wager, S.; Hastie, T.; Efron, B. Confidence intervals for random forests: The jackknife and the infinitesimal jackknife. J. Mach. Learn. Res. 2014, 15, 1625–1651. [Google Scholar]
- Efron, B. Estimation and accuracy after model selection. J. Am. Stat. Assoc. 2014, 109, 991–1007. [Google Scholar] [CrossRef] [PubMed]
- Hicks, W.; Rossel, R.V.; Tuomi, S. Developing the Australian mid-infrared spectroscopic database using data from the Australian Soil Resource Information System. Soil Res. 2015, 53, 922–931. [Google Scholar] [CrossRef]
- Bruker. Opus Spectroscopy Software Version 7, Quant User Manual; BRUKER OPTIK: Ettlingen, Germany, 2011. [Google Scholar]
- Lobsey, C.R.; Viscarra Rossel, R.A.; Roudier, P.; Hedley, C.B. rs-local data-mines information from spectral libraries to improve local calibrations. Eur. J. Soil Sci. 2017, 68, 840–852. [Google Scholar]
- Waruru, B.K.; Shepherd, K.D.; Ndegwa, G.M.; Kamoni, P.T.; Sila, A.M. Rapid estimation of soil engineering properties using diffuse reflectance near infrared spectroscopy. Biosyst. Eng. 2014, 121, 177–185. [Google Scholar] [CrossRef]
- Sila, A.M.; Shepherd, K.D.; Pokhariyal, G.P. Evaluating the utility of mid-infrared spectral subspaces for predicting soil properties. Chemom. Intell. Lab. Syst. 2016, 153, 92–105. [Google Scholar] [CrossRef] [PubMed]
- Grinand, C.; Barthes, B.G.; Brunet, D.; Kouakoua, E.; Arrouays, D.; Jolivet, C.; Caria, G.; Bernoux, M. Prediction of soil organic and inorganic carbon contents at a national scale (France) using mid-infrared reflectance spectroscopy (MIRS). Eur. J. Soil Sci. 2012, 63, 141–151. [Google Scholar] [CrossRef]
- Naes, T.; Isaksson, T.; Kowalski, B. Locally weighted regression and scatter correction for near-infrared reflectance data. Anal. Chem. 1990, 62, 664–673. [Google Scholar] [CrossRef]
- Viscarra Rossel, R.A.; Webster, R.; Bui, E.N.; Baldock, J.A. Baseline map of organic carbon in Australian soil to support national carbon accounting and monitoring under climate change. Glob. Chang. Biol. 2014, 20, 2953–2970. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B.; Pichon, L.; Sun, W.; Short, M.G. Evaluating near infrared spectroscopy for field prediction of soil properties. Soil Res. 2009, 47, 664–673. [Google Scholar] [CrossRef]
- Farris, J.S.; Albert, V.A.; Källersjö, M.; Lipscomb, D.; Kluge, A.G. Parsimony jackknifing outperforms neighbor-joining. Cladistics 1996, 12, 99–124. [Google Scholar]
- Westad, F.; Kermit, M. Cross validation and uncertainty estimates in independent component analysis. Anal. Chim. Acta 2003, 490, 341–354. [Google Scholar] [CrossRef]
- Efron, B.; Stein, C. The jackknife estimate of variance. Ann. Stat. 1981, 9, 586–596. [Google Scholar] [CrossRef]
- Savvides, A.; Corstanje, R.; Baxter, S.J.; Rawlins, B.G.; Lark, R.M. The relationship between diffuse spectral reflectance of the soil and its cation exchange capacity is scale-dependent. Geoderma 2010, 154, 353–358. [Google Scholar] [CrossRef]
- Nocita, M.; Stevens, A.; Toth, G.; Panagos, P.; van Wesemael, B.; Montanarella, L. Prediction of soil organic carbon content by diffuse reflectance spectroscopy using a local partial least square regression approach. Soil Biol. Biochem. 2014, 68, 337–347. [Google Scholar] [CrossRef]
- Sorenson, P.T.; Small, C.; Tappert, M.C.; Quideau, S.A.; Drozdowski, B.; Underwood, A.; Janz, A. Monitoring organic carbon, total nitrogen, and pH for reclaimed soils using field reflectance spectroscopy. Can. J. Soil Sci. 2017, 97, 241–248. [Google Scholar] [CrossRef]
- Ramirez-Lopez, L.; Stevens, A. Resemble: Regression and Similarity Evaluation for Memory-Based Learning in Spectral Chemometrics, R Package Version 1.2.2.; Available online: https://cran.r-project.org/web/packages/resemble/ (accessed on 28 January 2019).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Soil | Units | Ntotal | Noutlier | Mean | Median | SD | Q25 | Q75 | Skew | Kurt |
|---|---|---|---|---|---|---|---|---|---|---|
| Al | wt % | 23,121 | 229 | 0.19 | 0.10 | 0.32 | 0.04 | 0.21 | 8.52 | 143.13 |
| BDclod | g cm | 10,653 | 100 | 1.35 | 1.38 | 0.27 | 1.22 | 1.52 | −1.05 | 5.34 |
| BDcore | g cm | 7071 | 68 | 0.93 | 1.01 | 0.50 | 0.51 | 1.30 | 0.21 | 7.94 |
| BDall | g cm | 17,488 | 173 | 1.18 | 1.29 | 0.43 | 1.00 | 1.47 | −0.73 | 7.02 |
| Ca | cmol(+) kg | 36,854 | 368 | 23.09 | 12.30 | 34.43 | 3.69 | 28.65 | 4.15 | 28.18 |
| CEC | cmol(+) kg | 36,936 | 349 | 22.81 | 16.58 | 25.73 | 8.47 | 26.10 | 3.64 | 27.25 |
| Clay | wt % | 33,156 | 313 | 22.44 | 20.49 | 15.92 | 9.39 | 32.36 | 0.80 | 3.40 |
| CO3 | wt % | 12205 | 120 | 6.92 | 1.00 | 12.05 | 0.21 | 9.24 | 2.98 | 14.73 |
| Fe | wt % | 21,530 | 212 | 0.44 | 0.26 | 0.63 | 0.10 | 0.57 | 8.84 | 191.11 |
| OC | wt % | 42,893 | 404 | 7.72 | 1.33 | 14.15 | 0.42 | 4.95 | 2.14 | 6.28 |
| OCD | kg m | 15,812 | 158 | 19.84 | 12.25 | 24.72 | 4.62 | 26.37 | 5.39 | 87.29 |
| pH | NA | 35,297 | 348 | 6.42 | 6.26 | 1.30 | 5.43 | 7.56 | 0.12 | 2.25 |
| Soil Horizons | ||||||||
|---|---|---|---|---|---|---|---|---|
| Order | O | A | E | B | C | R | Undefined | Total |
| Alfisols | 65 | 727 | 195 | 1918 | 216 | 1 | 289 | 3411 |
| Andisols | 157 | 368 | 13 | 616 | 116 | 2 | 20 | 1292 |
| Aridsols | 0 | 222 | 4 | 674 | 155 | 0 | 46 | 1101 |
| Entisols | 52 | 380 | 61 | 238 | 631 | 0 | 289 | 1651 |
| Gelisols | 72 | 13 | 0 | 32 | 59 | 0 | 38 | 214 |
| Histosols | 507 | 9 | 4 | 10 | 114 | 0 | 80 | 724 |
| Inceptisols | 191 | 729 | 42 | 1229 | 618 | 4 | 332 | 3145 |
| Mollisols | 47 | 2571 | 59 | 3608 | 823 | 0 | 1010 | 8118 |
| Oxisols | 0 | 1 | 0 | 5 | 0 | 0 | 0 | 6 |
| Spodosols | 129 | 116 | 212 | 744 | 221 | 1 | 20 | 1443 |
| Ultisols | 55 | 409 | 85 | 1002 | 130 | 0 | 235 | 1916 |
| Vertisols | 0 | 72 | 1 | 275 | 37 | 0 | 133 | 518 |
| Undefined | 514 | 1023 | 58 | 1243 | 371 | 0 | 24,145 | 27,354 |
| Total | 1789 | 6640 | 734 | 11,594 | 3491 | 8 | 26,637 | 50,893 |
| Soil Property | Method | Calibration | Validation | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | Bias | R2 | RPD | RMSE | N | Bias | R2 | RPD | RMSE | MeanDev | ||
| OC | Cubist | 33,991 | 0 | 1.0 | 16.9 | 0.85 | 8498 | 0.01 | 1.0 | 16.9 | 0.69 | |
| MBL | 0.03 | 1.0 | 18.2 | 0.64 | 0.08 | |||||||
| PLSR | 0.05 | 0.98 | 8.0 | 1.8 | 0.12 | 0.99 | 9.8 | 1.19 | 0.26 | |||
| RF | 0.05 | 1.0 | 20.7 | 0.69 | 0.11 | 0.99 | 12.5 | 0.93 | 0.39 | |||
| CO3 | Cubist | 9668 | 0.04 | 0.99 | 11.1 | 1.18 | 2417 | −0.01 | 0.98 | 8.0 | 1.35 | |
| MBL | 0.14 | 0.98 | 7.6 | 1.41 | 0.33 | |||||||
| PLSR | 0.09 | 0.97 | 6.1 | 2.17 | 0.04 | 0.97 | 5.9 | 1.81 | 0.70 | |||
| RF | 0.17 | 1.0 | 15.3 | 0.86 | 0.36 | 0.97 | 5.9 | 1.82 | 0.64 | |||
| CEC | Cubist | 29,270 | 0.16 | 0.98 | 7.3 | 3.45 | 7317 | 0.24 | 0.99 | 8.3 | 2.38 | |
| MBL | 0.07 | 0.99 | 8.6 | 2.3 | 0.33 | |||||||
| PLSR | 0.25 | 0.94 | 4.1 | 6.1 | 0.45 | 0.96 | 4.9 | 4.02 | 1.38 | |||
| RF | 0.26 | 0.99 | 10.2 | 2.48 | 0.51 | 0.97 | 5.8 | 3.44 | 1.52 | |||
| Clay | Cubist | 26,274 | 0.07 | 0.97 | 5.5 | 2.92 | 6569 | 0 | 0.96 | 5.1 | 2.69 | |
| MBL | 0.03 | 0.97 | 5.5 | 2.47 | 0.41 | |||||||
| PLSR | 0.34 | 0.89 | 3.0 | 5.43 | −0.24 | 0.92 | 3.5 | 3.95 | 1.86 | |||
| RF | 0.41 | 0.98 | 7.2 | 2.25 | 0.2 | 0.93 | 3.8 | 3.57 | 3.79 | |||
| Ca | Cubist | 29,189 | 0.34 | 0.96 | 5.2 | 5.65 | 7297 | 0.27 | 0.95 | 4.7 | 4.41 | |
| MBL | 0.12 | 0.95 | 4.6 | 4.49 | 0.47 | |||||||
| PLSR | 0.68 | 0.86 | 2.7 | 10.79 | 0.64 | 0.89 | 3.0 | 6.85 | 2.07 | |||
| RF | 0.69 | 0.98 | 7.2 | 4.03 | 0.67 | 0.93 | 3.8 | 5.43 | 4.06 | |||
| Al | Cubist | 18,314 | 0 | 0.95 | 4.7 | 0.05 | 4578 | 0 | 0.9 | 3.1 | 0.08 | |
| MBL | 0 | 0.97 | 5.4 | 0.04 | 0.01 | |||||||
| PLSR | 0.01 | 0.83 | 2.5 | 0.1 | 0.01 | 0.85 | 2.6 | 0.09 | 0.03 | |||
| RF | 0.01 | 0.97 | 5.9 | 0.04 | 0.02 | 0.83 | 2.4 | 0.1 | 0.03 | |||
| OCD | Cubist | 12,523 | 0.42 | 0.89 | 3 | 6.2 | 3131 | 0.39 | 0.89 | 3.0 | 5.23 | |
| MBL | 0.95 | 0.89 | 3.0 | 5.17 | 0.61 | |||||||
| PLSR | 0.49 | 0.82 | 2.3 | 8.09 | 1.19 | 0.86 | 2.6 | 5.93 | 1.96 | |||
| RF | 0.42 | 0.97 | 6.0 | 3.13 | 0.8 | 0.87 | 2.8 | 5.6 | 1.66 | |||
| pH | Cubist | 27,959 | 0 | 0.95 | 4.4 | 0.31 | 6990 | 0.01 | 0.88 | 2.9 | 0.36 | |
| MBL | 0 | 0.89 | 3.1 | 0.34 | 0.05 | |||||||
| PLSR | 0.01 | 0.8 | 2.3 | 0.59 | 0.04 | 0.74 | 1.9 | 0.54 | 0.27 | |||
| RF | 0.01 | 0.98 | 6.4 | 0.21 | 0 | 0.82 | 2.4 | 0.45 | 0.21 | |||
| Fe | Cubist | 17,054 | 0.02 | 0.88 | 2.9 | 0.18 | 4264 | 0.01 | 0.71 | 1.9 | 0.27 | |
| MBL | 0.02 | 0.81 | 2.3 | 0.22 | 0.02 | |||||||
| PLSR | 0.04 | 0.58 | 1.5 | 0.34 | 0.03 | 0.66 | 1.7 | 0.29 | 0.09 | |||
| RF | 0.03 | 0.95 | 4.4 | 0.12 | 0.04 | 0.69 | 1.8 | 0.28 | 0.06 | |||
| Soil Property | Method | Calibration | Validation | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | Bias | R2 | RPD | RMSE | N | Bias | R2 | RPD | RMSE | MeanDev | ||
| BDclod | Cubist | 8442 | 0 | 0.88 | 2.9 | 0.1 | 2111 | −0.01 | 0.75 | 2.0 | 0.11 | |
| MBL | 0 | 0.81 | 2.3 | 0.1 | 0.01 | |||||||
| PLSR | 0 | 0.77 | 2.1 | 0.14 | 0.01 | 0.71 | 1.8 | 0.12 | 0.05 | |||
| RF | 0 | 0.97 | 5.7 | 0.05 | 0 | 0.78 | 2.1 | 0.1 | 0.04 | |||
| BDcore | Cubist | 5602 | 0 | 0.87 | 2.8 | 0.17 | 1401 | 0.02 | 0.78 | 2.1 | 0.21 | |
| MBL | 0.02 | 0.79 | 2.2 | 0.21 | 0.02 | |||||||
| PLSR | 0.01 | 0.82 | 2.4 | 0.21 | 0.06 | 0.77 | 2.1 | 0.22 | 0.1 | |||
| RF | 0.01 | 0.97 | 5.9 | 0.08 | 0.05 | 0.79 | 2.2 | 0.21 | 0.06 | |||
| BDall | Cubist | 13,852 | 0 | 0.88 | 2.9 | 0.16 | 3463 | 0 | 0.67 | 1.8 | 0.16 | |
| MBL | 0.01 | 0.76 | 2.0 | 0.14 | 0.02 | |||||||
| PLSR | 0.01 | 0.81 | 2.3 | 0.19 | 0.02 | 0.64 | 1.7 | 0.17 | 0.08 | |||
| RF | 0.01 | 0.97 | 6.0 | 0.07 | 0.03 | 0.72 | 1.9 | 0.15 | 0.08 | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dangal, S.R.S.; Sanderman, J.; Wills, S.; Ramirez-Lopez, L. Accurate and Precise Prediction of Soil Properties from a Large Mid-Infrared Spectral Library. Soil Syst. 2019, 3, 11. https://doi.org/10.3390/soilsystems3010011
Dangal SRS, Sanderman J, Wills S, Ramirez-Lopez L. Accurate and Precise Prediction of Soil Properties from a Large Mid-Infrared Spectral Library. Soil Systems. 2019; 3(1):11. https://doi.org/10.3390/soilsystems3010011
Chicago/Turabian StyleDangal, Shree R. S., Jonathan Sanderman, Skye Wills, and Leonardo Ramirez-Lopez. 2019. "Accurate and Precise Prediction of Soil Properties from a Large Mid-Infrared Spectral Library" Soil Systems 3, no. 1: 11. https://doi.org/10.3390/soilsystems3010011
APA StyleDangal, S. R. S., Sanderman, J., Wills, S., & Ramirez-Lopez, L. (2019). Accurate and Precise Prediction of Soil Properties from a Large Mid-Infrared Spectral Library. Soil Systems, 3(1), 11. https://doi.org/10.3390/soilsystems3010011