


FireCLIP: Enhancing Forest Fire Detection with Multimodal Prompt Tuning and Vision-Language Understanding



Abstract
1. Introduction
- Identification of dual challenges in forest fire detection: pseudo-smoke false positives and regional data imbalance.
- Empirical validation of vision-language prompt learning’s effectiveness in addressing these challenges through adaptive feature extraction and cross-modal understanding.
- Contribution of a novel smoke recognition benchmark dataset featuring high inter-class confusion, specifically designed to evaluate model robustness against pseudo-smoke phenomena.
2. Materials and Methods
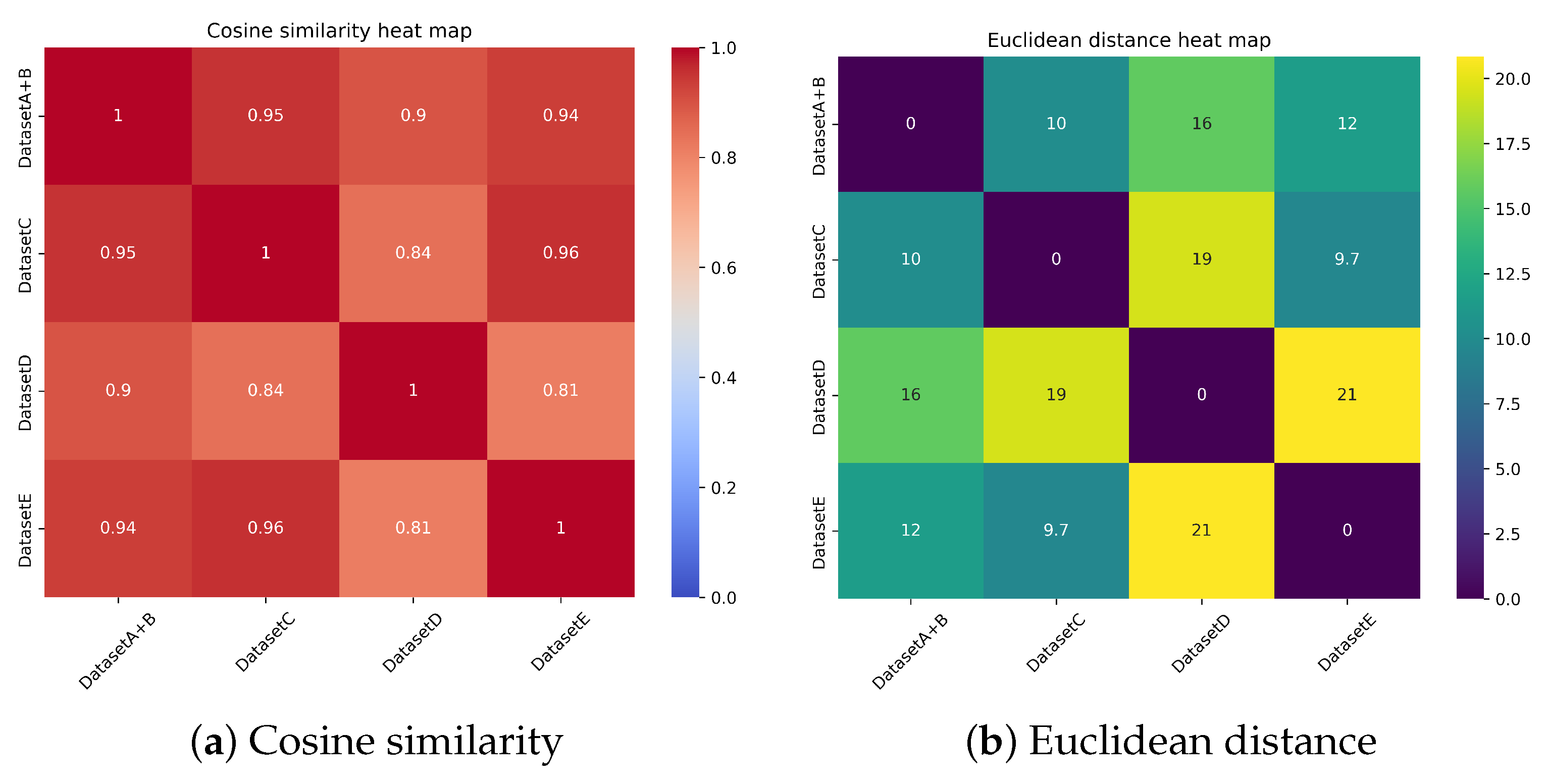
2.1. Wildland–Urban Interface Smoke Alarm Dataset (WUISAD)
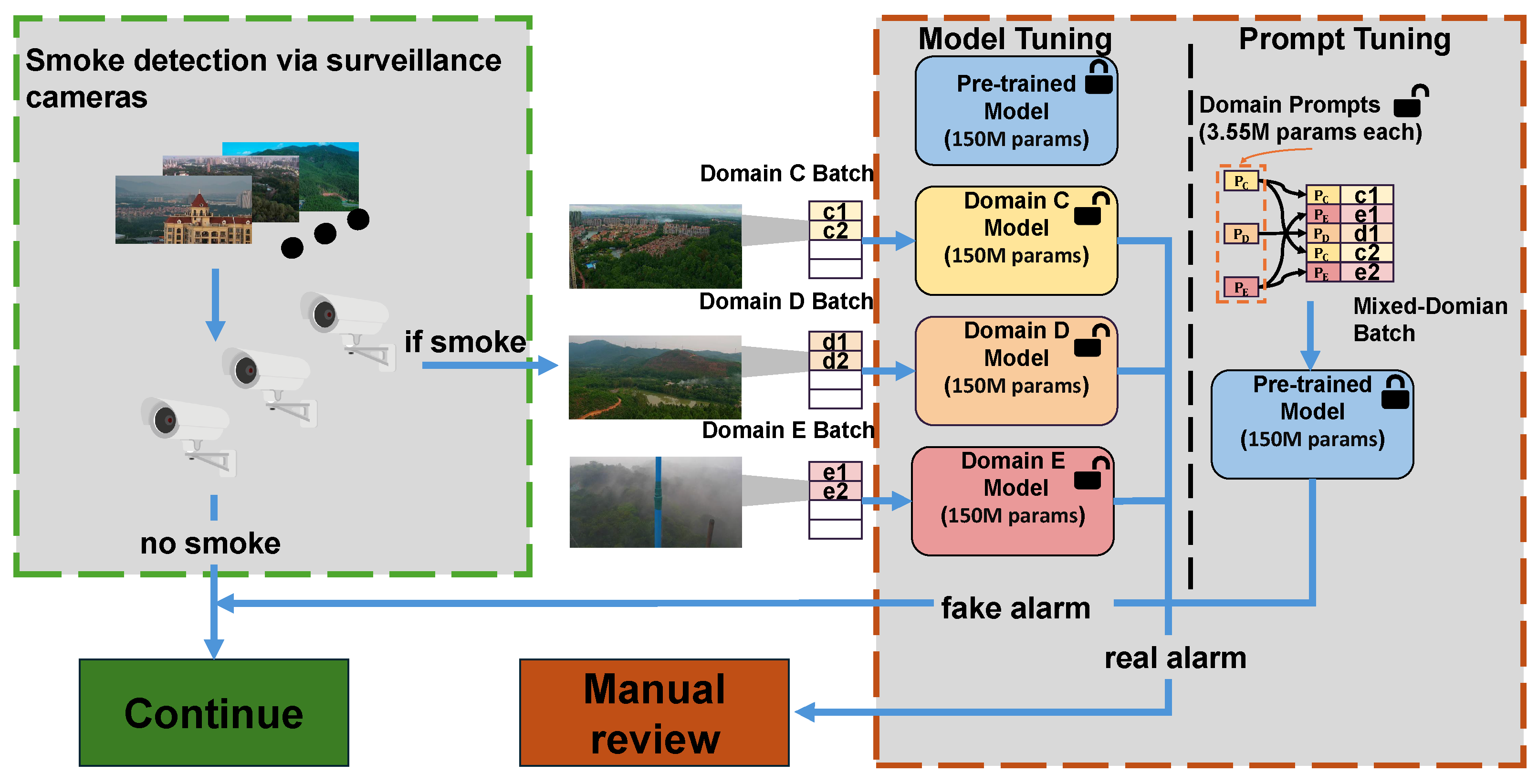
2.2. Forest Fire Detection System
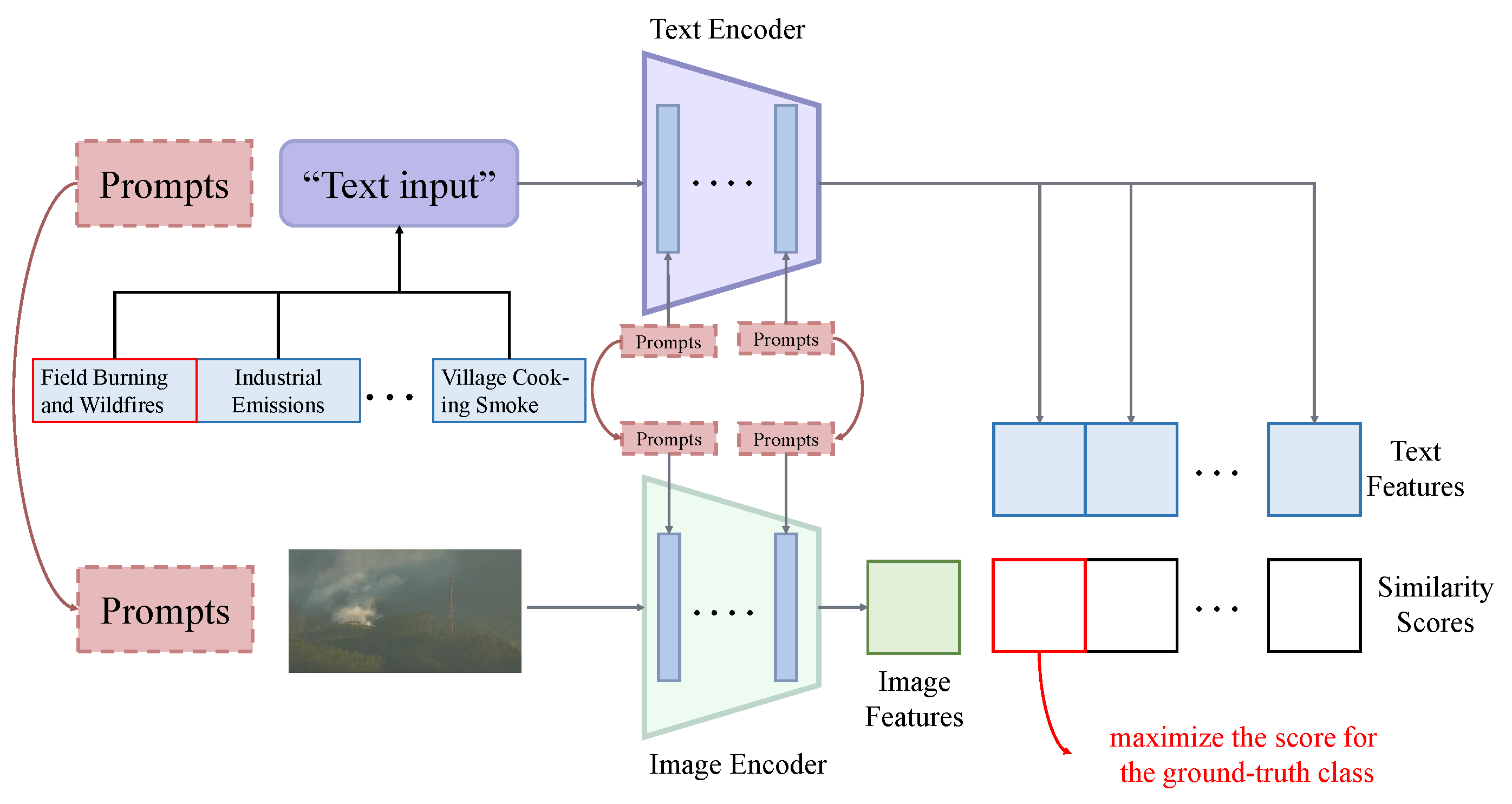
2.3. Multi-Modal Prompt Tuning (MaPLe)
3. Results
3.1. Benchmark Setting
- Pre-training: We deployed the baseline models on a pre-training dataset for pre-training, and compared the performance and efficiency of the baseline models versus FireCLIP.
- Zero-shot Transfer: We directly applied the pre-trained model to the dataset of a downstream task to observe the differences in generalization ability between baselines and FireCLIP methods.
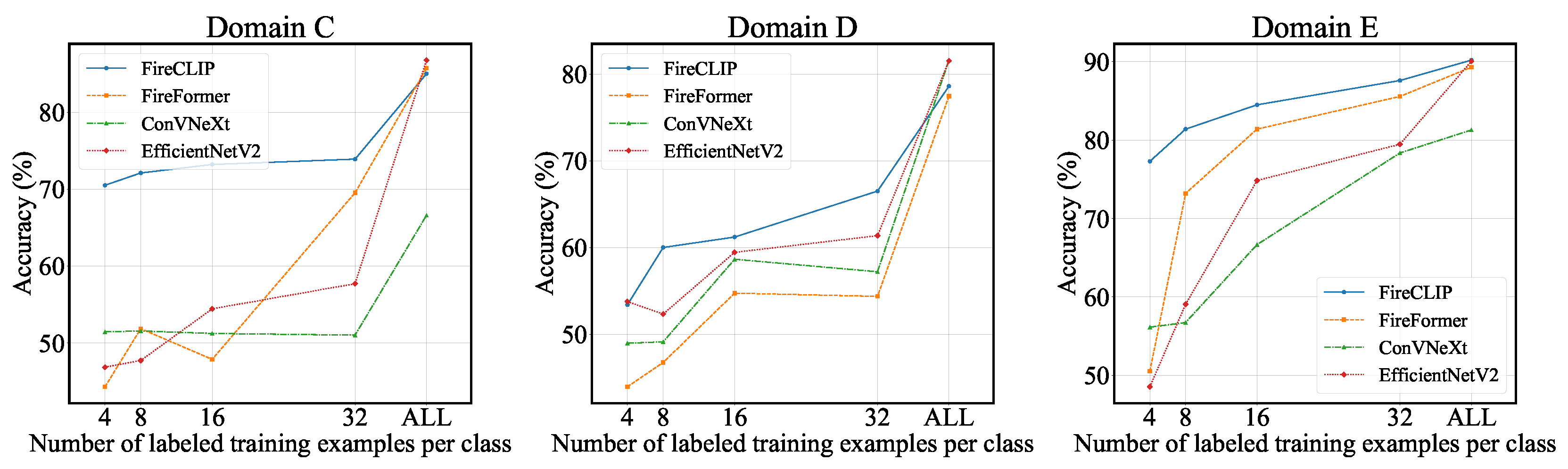
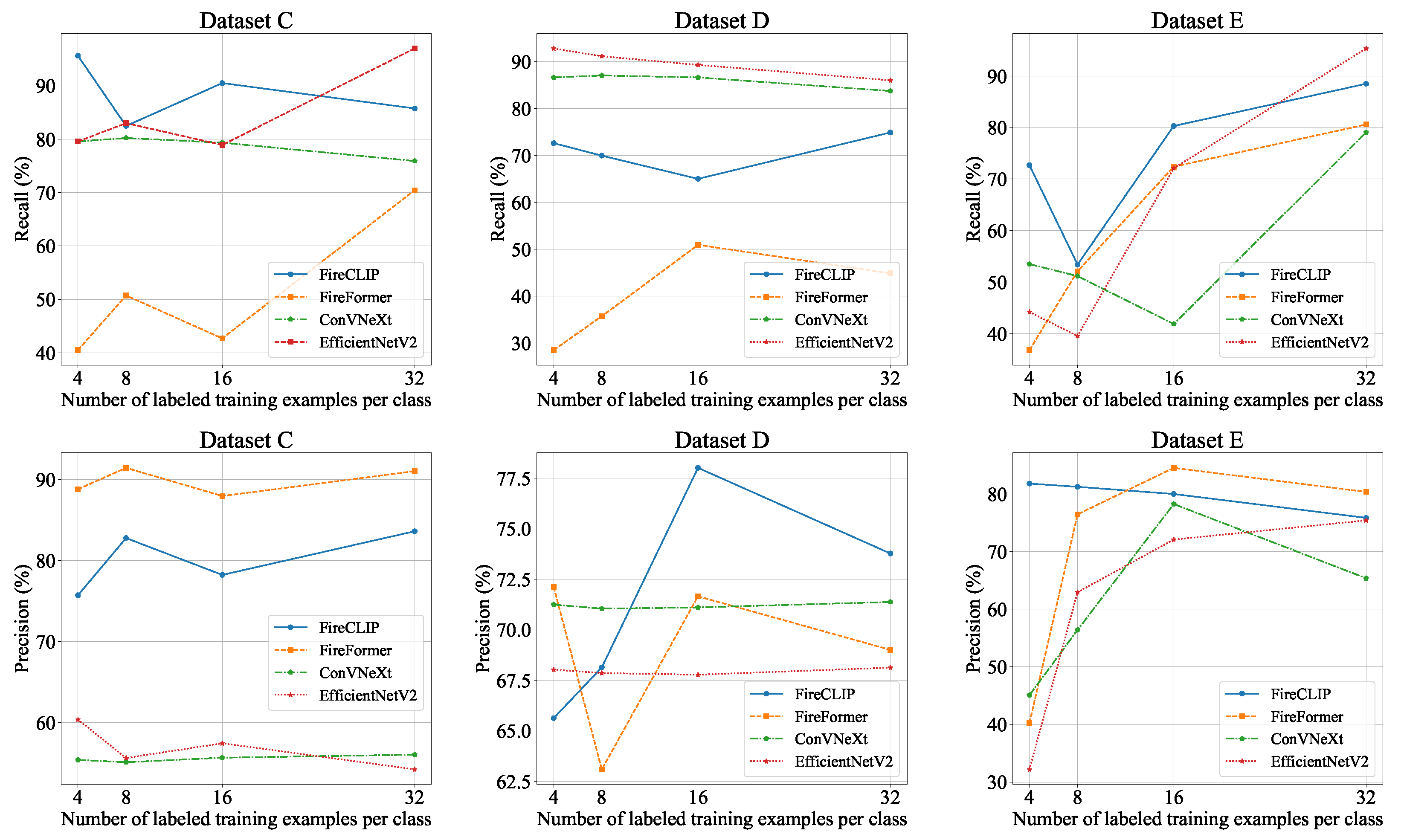
- Few-shot Learning: We conducted few-shot learning with the pre-trained model on the dataset of a downstream task. The learned model was then tested on both the pre-training dataset and the downstream task dataset to assess the performance of baselines and FireCLIP in 4-, 8-, 16-, and 32-shot settings.
3.2. Evaluation Setting
3.3. Implementation Details
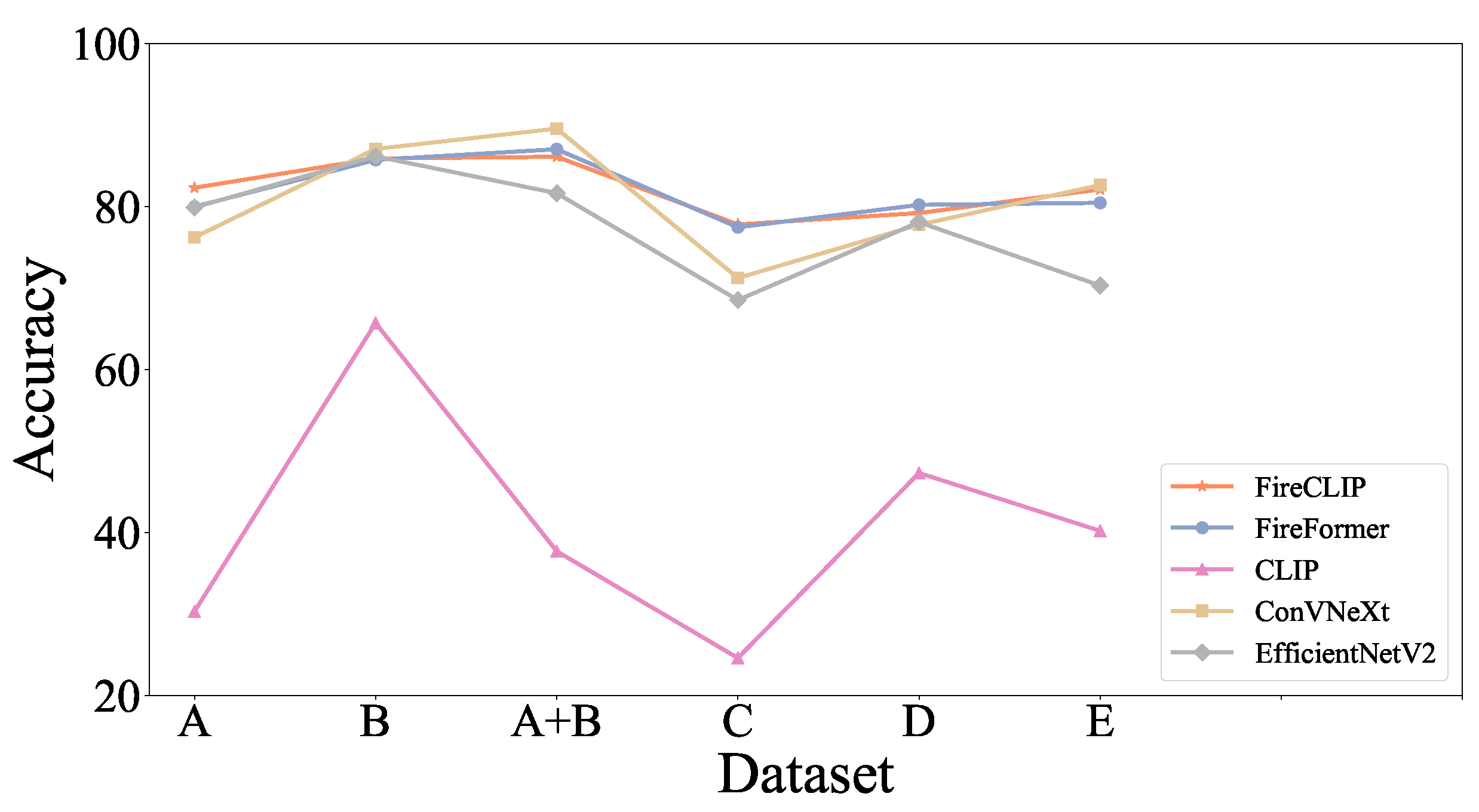
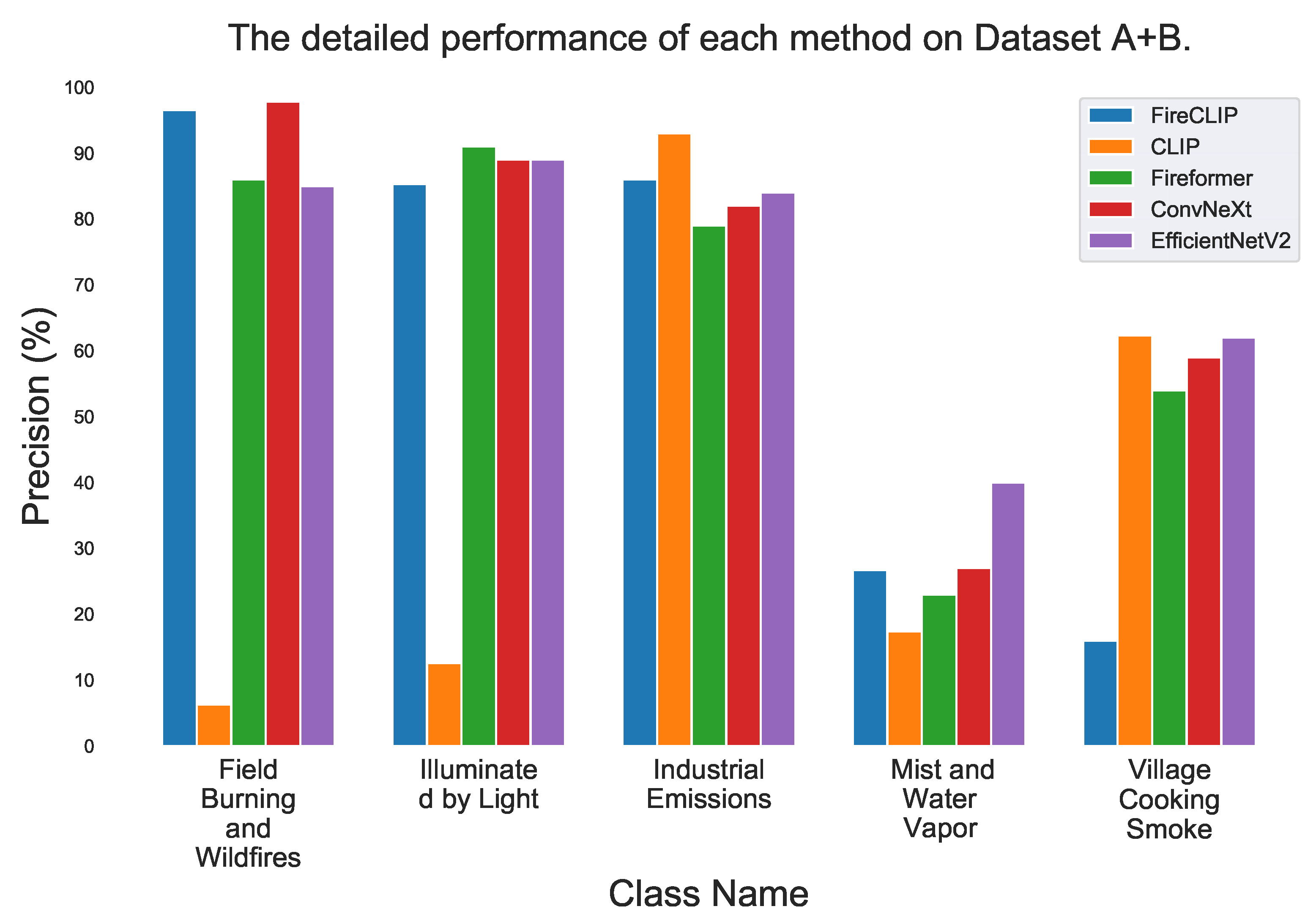
3.4. Performance Comparison
3.4.1. Pre-Training
3.4.2. Zero-Shot Transfer on WUISAD
3.4.3. Few-Shot Learning
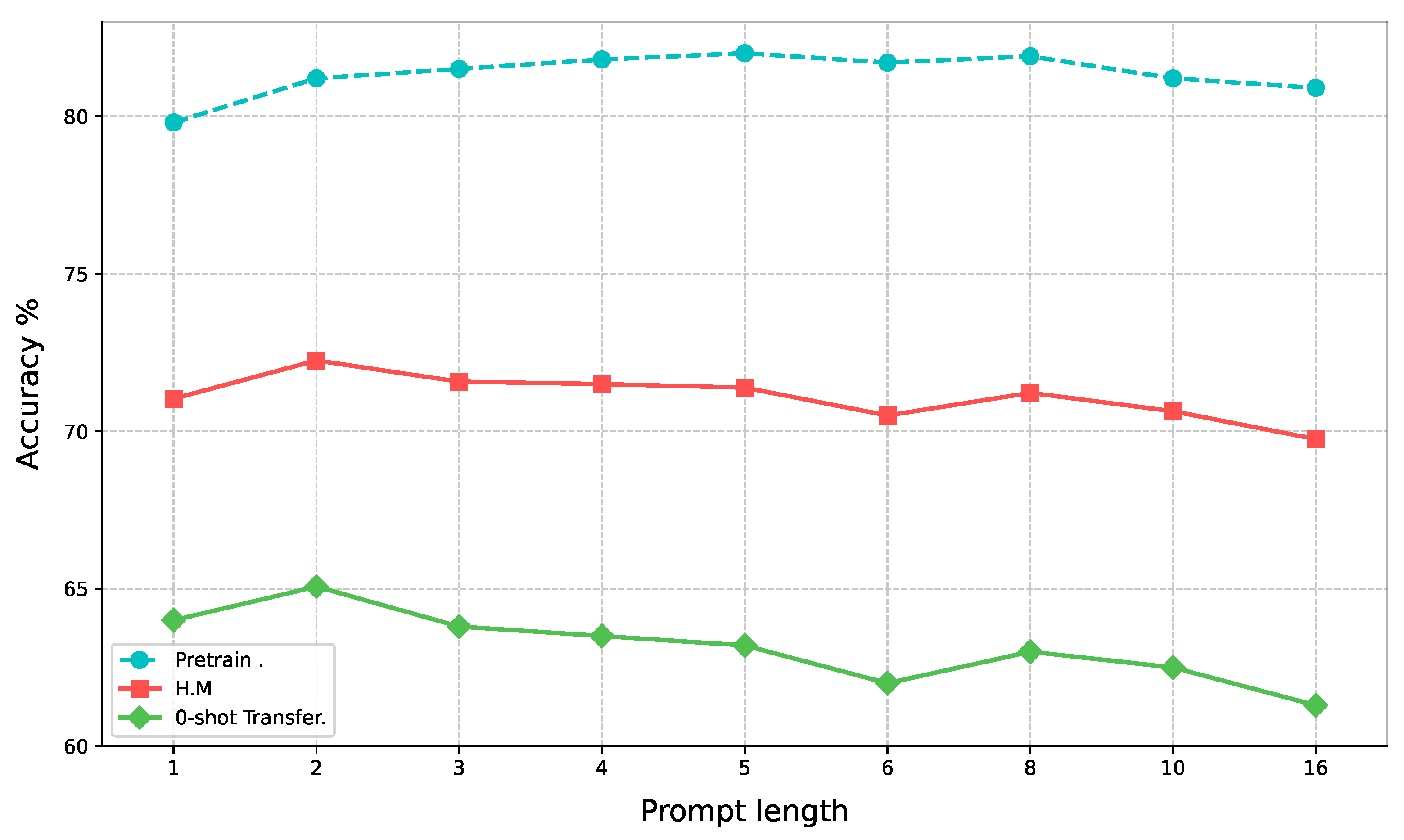
3.4.4. Ablation Experiments
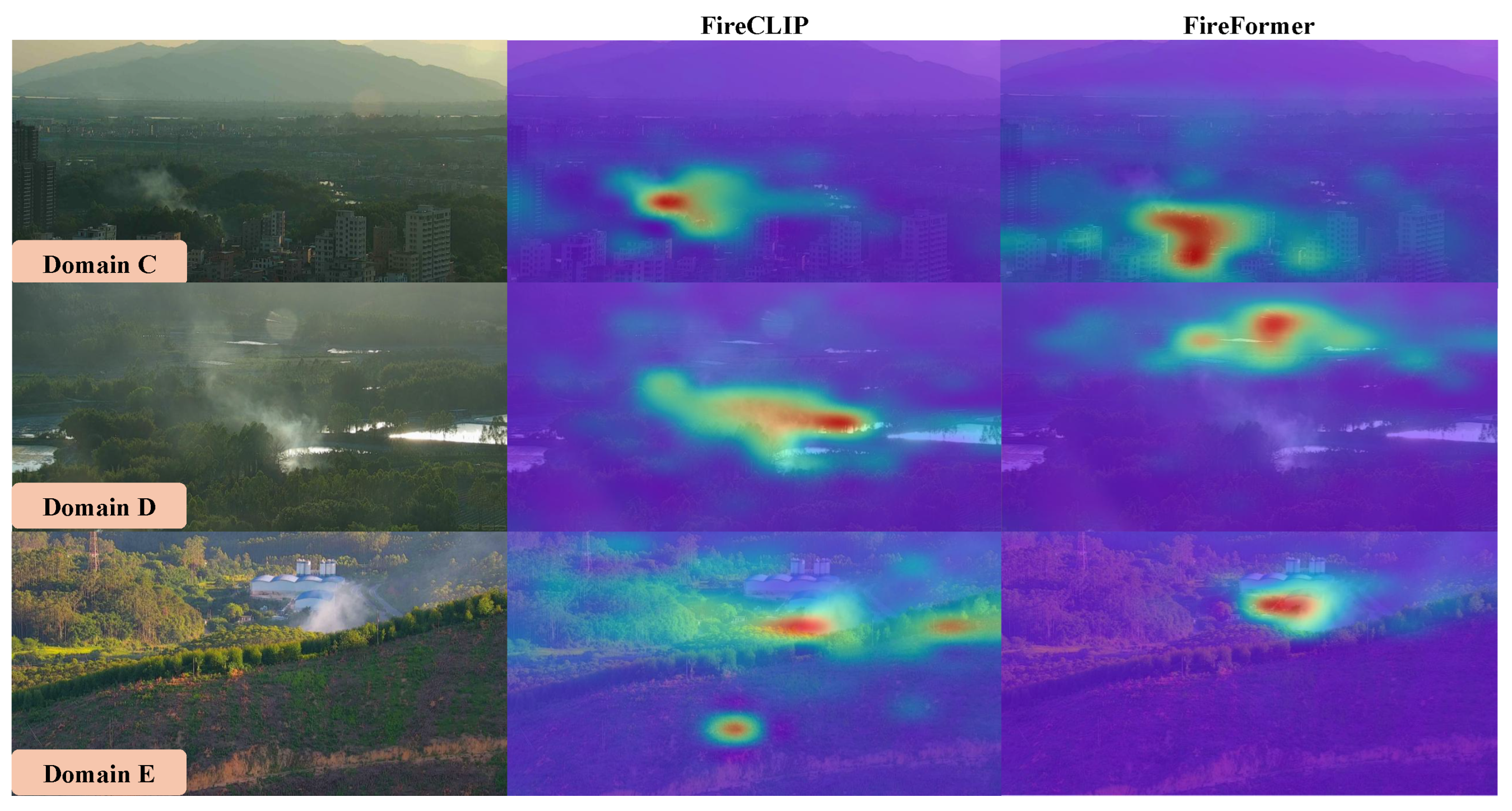
3.4.5. Visualization
4. Discussion
5. Conclusions
- Vision-Aware Dynamic Prompting: While the current prompt templates primarily rely on static textual descriptions, incorporating fine-grained visual semantics specific to the content of the current input image presents a promising future direction. Static prompts inherently struggle to adapt to the diverse visual manifestations of smoke. Future works can focus on developing mechanisms to dynamically inject image-specific visual features or semantic descriptions into the prompt template generation process. Successfully integrating these dynamic, vision-guided elements with static contextual knowledge has the potential to significantly refine the model’s ability to recognize subtle smoke characteristics, leading to enhanced generalization and robustness across varied environmental scenes.
- Environmental and Seasonal Variability: In addition to the challenges of large and diverse negative samples and regional data imbalance discussed in the present work, it is important to consider the influence of environmental changes and seasonal variations. Forest fire detection models may be sensitive to factors such as varying vegetation, weather conditions, and seasonal changes, which could impact model performance. Future research should explore how to adapt and optimize detection systems for different environmental contexts and seasons to ensure consistent performance year-round.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Goodrick, S.; Heilman, W. Wildland fire emissions, carbon, and climate: Wildfire–climate interactions. For. Ecol. Manag. 2014, 317, 80–96. [Google Scholar] [CrossRef]
- Jiang, W.; Qiao, Y.; Su, G.; Li, X.; Meng, Q.; Wu, H.; Quan, W.; Wang, J.; Wang, F. WFNet: A hierarchical convolutional neural network for wildfire spread prediction. Environ. Model. Softw. 2023, 170, 105841. [Google Scholar] [CrossRef]
- Lüthi, S.; Aznar-Siguan, G.; Fairless, C.; Bresch, D.N. Globally consistent assessment of economic impacts of wildfires in CLIMADA v2. 2. Geosci. Model Dev. 2021, 14, 7175–7187. [Google Scholar] [CrossRef]
- Politoski, D.; Dittrich, R.; Nielsen-Pincus, M. Assessing the absorption and economic impact of suppression and repair spending of the 2017 eagle creek fire, Oregon. J. For. 2022, 120, 491–503. [Google Scholar] [CrossRef]
- Diakakis, M.; Xanthopoulos, G.; Gregos, L. Analysis of forest fire fatalities in Greece: 1977–2013. Int. J. Wildland Fire 2016, 25, 797–809. [Google Scholar] [CrossRef]
- Jiang, W.; Qiao, Y.; Zheng, X.; Zhou, J.; Jiang, J.; Meng, Q.; Su, G.; Zhong, S.; Wang, F. Wildfire risk assessment using deep learning in Guangdong Province, China. Int. J. Appl. Earth Obs. Geoinf. 2024, 128, 103750. [Google Scholar] [CrossRef]
- Truong, T.X.; Kim, J.M. Fire flame detection in video sequences using multi-stage pattern recognition techniques. Eng. Appl. Artif. Intell. 2012, 25, 1365–1372. [Google Scholar] [CrossRef]
- Sakr, G.E.; Elhajj, I.H.; Mitri, G. Efficient forest fire occurrence prediction for developing countries using two weather parameters. Eng. Appl. Artif. Intell. 2011, 24, 888–894. [Google Scholar] [CrossRef]
- Fernández-Berni, J.; Carmona-Galán, R.; Martínez-Carmona, J.F.; Rodríguez-Vázquez, Á. Early forest fire detection by vision-enabled wireless sensor networks. Int. J. Wildland Fire 2012, 21, 938–949. [Google Scholar] [CrossRef]
- Wang, S.; Xiao, X.; Deng, T.; Chen, A.; Zhu, M. A Sauter mean diameter sensor for fire smoke detection. Sensors Actuators B Chem. 2019, 281, 920–932. [Google Scholar] [CrossRef]
- Gutmacher, D.; Hoefer, U.; Wöllenstein, J. Gas sensor technologies for fire detection. Sensors Actuators B Chem. 2012, 175, 40–45. [Google Scholar] [CrossRef]
- Song, L.; Wang, B.; Zhou, Z.; Wang, H.; Wu, S. The research of real-time forest fire alarm algorithm based on video. In Proceedings of the 2014 Sixth International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2014; IEEE: Piscataway, NJ, USA, 2014; Volume 1, pp. 106–109. [Google Scholar]
- Tomkins, L.; Benzeroual, T.; Milner, A.; Zacher, J.; Ballagh, M.; McAlpine, R.; Doig, T.; Jennings, S.; Craig, G.; Allison, R. Use of night vision goggles for aerial forest fire detection. Int. J. Wildland Fire 2014, 23, 678–685. [Google Scholar] [CrossRef]
- Zhou, Z.; Shi, Y.; Gao, Z.; Li, S. Wildfire smoke detection based on local extremal region segmentation and surveillance. Fire Saf. J. 2016, 85, 50–58. [Google Scholar] [CrossRef]
- Kaur, P.; Kaur, K.; Singh, K.; Kim, S. Early forest fire detection using a protocol for energy-efficient clustering with weighted-based optimization in wireless sensor networks. Appl. Sci. 2023, 13, 3048. [Google Scholar] [CrossRef]
- Khan, S.; Muhammad, K.; Hussain, T.; Del Ser, J.; Cuzzolin, F.; Bhattacharyya, S.; Akhtar, Z.; de Albuquerque, V.H.C. Deepsmoke: Deep learning model for smoke detection and segmentation in outdoor environments. Expert Syst. Appl. 2021, 182, 115125. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Y.; Zhang, Q.; Lin, G.; Wang, Z.; Jia, Y.; Wang, J. Video smoke detection based on deep saliency network. Fire Saf. J. 2019, 105, 277–285. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Xia, X.; Huang, Q.; Li, X. A wave-shaped deep neural network for smoke density estimation. IEEE Trans. Image Process. 2019, 29, 2301–2313. [Google Scholar] [CrossRef]
- Azim, M.R.; Keskin, M.; Do, N.; Gül, M. Automated classification of fuel types using roadside images via deep learning. Int. J. Wildland Fire 2022, 31, 982–987. [Google Scholar] [CrossRef]
- Qiang, X.; Zhou, G.; Chen, A.; Zhang, X.; Zhang, W. Forest fire smoke detection under complex backgrounds using TRPCA and TSVB. Int. J. Wildland Fire 2021, 30, 329–350. [Google Scholar] [CrossRef]
- Guede-Fernández, F.; Martins, L.; de Almeida, R.V.; Gamboa, H.; Vieira, P. A deep learning based object identification system for forest fire detection. Fire 2021, 4, 75. [Google Scholar] [CrossRef]
- Qiao, Y.; Jiang, W.; Wang, F.; Su, G.; Li, X.; Jiang, J. FireFormer: An efficient Transformer to identify forest fire from surveillance cameras. Int. J. Wildland Fire 2023, 32, 1364–1380. [Google Scholar] [CrossRef]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- Shahid, M.; Chien, I.F.; Sarapugdi, W.; Miao, L.; Hua, K.L. Deep spatial-temporal networks for flame detection. Multimed. Tools Appl. 2021, 80, 35297–35318. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Bari, A.; Saini, T.; Kumar, A. Fire detection using deep transfer learning on surveillance videos. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1061–1067. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Song, Y.; Wang, T.; Cai, P.; Mondal, S.K.; Sahoo, J.P. A comprehensive survey of few-shot learning: Evolution, applications, challenges, and opportunities. ACM Comput. Surv. 2023, 55, 1–40. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Zhang, Z.; Zhang, A.; Li, M.; Smola, A. Automatic Chain of Thought Prompting in Large Language Models. In Proceedings of the Eleventh International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Virtual, 7–11 November 2021; pp. 3045–3059. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to prompt for vision-language models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]
- Khattak, M.U.; Rasheed, H.; Maaz, M.; Khan, S.; Khan, F.S. Maple: Multi-modal prompt learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19113–19122. [Google Scholar]
- Khattak, M.U.; Wasim, S.T.; Naseer, M.; Khan, S.; Yang, M.H.; Khan, F.S. Self-regulating prompts: Foundational model adaptation without forgetting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 15190–15200. [Google Scholar]
- Park, J.; Ko, J.; Kim, H.J. Prompt Learning via Meta-Regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 26940–26950. [Google Scholar]
- Zhang, J.; Wu, S.; Gao, L.; Shen, H.T.; Song, J. Dept: Decoupled prompt tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 12924–12933. [Google Scholar]
- Zhao, C.; Wang, Y.; Jiang, X.; Shen, Y.; Song, K.; Li, D.; Miao, D. Learning domain invariant prompt for vision-language models. IEEE Trans. Image Process. 2024, 33, 1348–1360. [Google Scholar] [CrossRef]
- Xu, L.; Xie, H.; Qin, S.Z.J.; Tao, X.; Wang, F.L. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment. arXiv 2023, arXiv:2312.12148. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Wang, M.; Yue, P.; Jiang, L.; Yu, D.; Tuo, T.; Li, J. An open flame and smoke detection dataset for deep learning in remote sensing based fire detection. Geo-Spat. Inf. Sci. 2024, 1–16. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field Burning and Wildfires | Illuminated by Light | Industrial Emissions | Mist and Water Vapor | Village Cooking Smoke |
|---|---|---|---|---|
 |  |  |  |  |
| Dataset | Location | Field Burning and Wildfires | Illuminated by Light | Industrial Emissions | Mist and Water Vapor | Village Cooking Smoke |
|---|---|---|---|---|---|---|
| A | Yanghe Town | 5689 | 432 | 257 | 136 | 1435 |
| B | Mingcheng Town | 2037 | 204 | 3880 | 210 | 73 |
| C | Sanshui District | 728 | 20 | 418 | 128 | 171 |
| D | Genglou Town | 760 | 8 | 0 | 108 | 100 |
| E | Sanshan Forest Park | 68 | 14 | 38 | 127 | 21 |
| Model | Variant | Params | FPS |
|---|---|---|---|
| FireCLIP | ViT-B/16 | 154 M | 91 |
| Fireformer | Swin-L | 197 M | 58 |
| ConvNeXt | ConvNeXt-L | 198 M | 58 |
| EfficientNetV2 | EffNetV2-L | 119.5 M | 101 |
| Dataset | FireCLIP | Fireformer | ConvNeXt | EfficientNetV2 |
|---|---|---|---|---|
| FASDDCV | 99.52 | 98.51 | 98.64 | 97.82 |
| FASDDUAV | 93.56 | 91.75 | 91.93 | 92.96 |
| Source | Target | ||||
|---|---|---|---|---|---|
| Domain A + B | Domain C | Domain D | Domain E | Average | |
| FireFormer | 87.30 | 66.51 | 50.17 | 41.18 | 52.62 |
| ConvNeXt | 89.56 | 51.65 | 58.96 | 26.32 | 45.64 |
| EfficientNetV2 | 81.63 | 47.81 | 52.32 | 26.90 | 42.34 |
| FireCLIP | 86.10 | 70.24 | 58.24 | 66.73 | 65.07 |
| FireCLIP | Fireformer | ConvNeXt | EfficientNetV2 | |
|---|---|---|---|---|
| 4-shot | 98.33 | 83.62 | 81.04 | 80.61 |
| 8-shot | 98.43 | 84.51 | 85.67 | 80.83 |
| 16-shot | 98.51 | 85.42 | 86.27 | 82.00 |
| 32-shot | 98.56 | 87.23 | 88.60 | 82.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Qiao, Y.; He, S.; Zhou, J.; Wang, Z.; Li, X.; Wang, F. FireCLIP: Enhancing Forest Fire Detection with Multimodal Prompt Tuning and Vision-Language Understanding. Fire 2025, 8, 237. https://doi.org/10.3390/fire8060237
Wu S, Qiao Y, He S, Zhou J, Wang Z, Li X, Wang F. FireCLIP: Enhancing Forest Fire Detection with Multimodal Prompt Tuning and Vision-Language Understanding. Fire. 2025; 8(6):237. https://doi.org/10.3390/fire8060237
Chicago/Turabian StyleWu, Shanjunxia, Yuming Qiao, Sen He, Jiahao Zhou, Zhi Wang, Xin Li, and Fei Wang. 2025. "FireCLIP: Enhancing Forest Fire Detection with Multimodal Prompt Tuning and Vision-Language Understanding" Fire 8, no. 6: 237. https://doi.org/10.3390/fire8060237
APA StyleWu, S., Qiao, Y., He, S., Zhou, J., Wang, Z., Li, X., & Wang, F. (2025). FireCLIP: Enhancing Forest Fire Detection with Multimodal Prompt Tuning and Vision-Language Understanding. Fire, 8(6), 237. https://doi.org/10.3390/fire8060237