1. Introduction
The transportation infrastructure in China has undergone significant expansion in recent years, particularly in highway and tunnel construction. Statistical data reveal a consistent increase in total highway and tunnel mileage, where tunnel construction plays a pivotal role in enhancing road network efficiency by improving technical specifications, reducing travel distances, and increasing transport capacity [
1]. However, this rapid expansion has been accompanied by an increased frequency of road tunnel fire incidents. Road tunnel fires present unique challenges compared to conventional fire scenarios, characterized by their rapid development and propagation within confined spaces [
2]. These incidents often lead to severe consequences, including potential explosions of transported goods and the generation of high-temperature toxic fumes. Such characteristics significantly increase the risks to both infrastructure and human safety. Consequently, the development of reliable fire detection systems for tunnels has become crucial for effective fire prevention and control. Advanced detection mechanisms not only enhance the safety of tunnel operations but also contribute to the overall reliability of highway transportation systems, making them an essential component of modern infrastructure management [
3].
The conventional approach to tunnel fire detection relies on sensors to identify smoke, temperature fluctuations, and gas compounds generated by fires. However, this method exhibits several limitations, including restricted detection area coverage, susceptibility to environmental factors that compromise detection speed and accuracy, and an inability to provide critical information regarding fire size, location, and progression [
4]. With the rapid advancements in machine vision and deep learning, target detection algorithms utilizing convolutional neural networks (CNNs) have emerged as a pivotal tool for identifying flames or smoke in tunnel surveillance imagery [
5]. These algorithms offer numerous advantages, such as enhanced intelligence, cost-effective deployment, simplified operation and maintenance, and ease of functional expansion. Moreover, they enable the precise localization of tunnel fires, facilitating more timely and accurate detection and early warning systems [
6].
Recent advancements in deep learning (DL)-based fire detection algorithms have demonstrated significant progress. Boroujeni et al. [
7] proposed a novel DL framework utilizing improved conditional generative adversarial networks (IC-GANs) to convert RGB images into infrared images, enabling the capture of temperature information from forest fires using unmanned aerial vehicles (UAVs) for wildland fire management. Cao et al. [
8] introduced an enhanced forest fire detection algorithm based on YOLOv5, incorporating a global attention mechanism, BiFPN, and a reparameterized convolution module, which improved detection accuracy by 3.8%. Similarly, Wang et al. [
9] developed a YOLO-based forest fire detection model by designing the LEIEM information extraction module and the DF dynamic fusion module for YOLOv8, achieving a 2.9% increase in detection accuracy.
Despite these advancements, the high computational demands of deep learning result in large model sizes and complexity, posing challenges for deployment on resource-constrained mobile devices. To address this, researchers have focused on developing lightweight algorithms. Xiao et al. [
10] proposed EMG-YOLO, a fire detection algorithm tailored for embedded devices, which integrates a multiscale attention module (MAM) and an efficient multiscale convolution module (EMCM). By pruning YOLOv8n using a thinning algorithm, the improved algorithm reduces the number of parameters by 53.5% and the computational load by 49.8%. Zhou et al. [
11] introduced a lightweight fire detection model for UAV-based wildfire monitoring, leveraging MobileNetV3 as the backbone network for YOLOv5 and employing semi-supervised knowledge distillation (SSLD) for training, resulting in a compact model size of 6.3 MB. Additionally, Wang et al. [
12] proposed an improved YOLOv5-based forest fire detection model, incorporating DSConv, C2f-Light, and C3CIB modules, which enhanced inference speed by 19.3%.
While the aforementioned methods have optimized fire detection algorithms to some extent, achieving a balance between detection accuracy and computational resource consumption remains challenging, hindering their practical application. Furthermore, research on fire detection algorithms tailored for highway tunnel scenarios is limited. The presence of lighting and moving vehicles in such environments often degrades the detection accuracy of existing algorithms. To address these issues, this paper enhances the YOLOv8s baseline model for fire detection in road tunnel scenarios and proposes a lightweight fire detection algorithm, FIRE-YOLOv8s. The primary contributions of this work are as follows:
- (1)
A novel feature extraction module, P-C2f, is designed to extract fire features from images. The ADown module is employed for downsampling, significantly reducing the model’s parameter count and computational requirements, making it suitable for deployment on robotic platforms. The feature fusion network is redesigned using the CCFF module to further lightweight the model and enable effective multi-scale feature fusion. The dynamic head detection head is introduced to enhance the model’s capability to detect multi-scale fire targets in the complex environments of highway tunnels, effectively reducing missed detections and false alarms.
- (2)
Ablation and comparison experiments were conducted on a self-constructed tunnel fire dataset, and generalization experiments were performed on a public dataset. The results demonstrate that, compared to the baseline model, FIRE-YOLOv8s reduces the number of parameters and the computational load by 52.2% and 47.9%, respectively, while decreasing the model size by 50%. Additionally, the mAP@0.5 improves by 1.7%, achieving higher detection accuracy alongside lightweighting and exhibiting superior generalization capabilities.
- (3)
To validate the effectiveness of the proposed algorithm, a comprehensive experimental evaluation was conducted. A fire simulation scenario was constructed in a tunnel laboratory, and the algorithm was deployed on a tunnel emergency firefighting robot platform. Experimental results demonstrate that the proposed algorithm achieves a detection frame rate of 28.13 FPS on the robot platform, exhibiting robust detection performance for multi-scale fire targets. These findings indicate that the algorithm meets the engineering application requirements for highway tunnel scenarios.
The remainder of this paper is organized as follows:
Section 2 presents a comprehensive review of related work.
Section 3 begins with an overview of the evolution of the YOLO family of algorithms, including the rationale for selecting YOLOv8s as the baseline model, followed by a detailed introduction to the proposed FIRE-YOLOv8s model.
Section 4 elaborates on the experimental design, case studies, and a discussion of the results. Finally,
Section 5 concludes the paper and outlines potential directions for future research.
3. Materials and Methods
3.1. Introduction of YOLOv8s
The core idea of the YOLO-series algorithms is to treat target detection as a single regression problem, directly mapping image pixels to bounding box coordinates and class probabilities. This approach results in a relatively simple model structure with fewer parameters, enabling high-speed target detection while maintaining high accuracy. As a result, YOLO algorithms have been widely adopted in real-time processing scenarios [
28]. Since the introduction of YOLOv1, the series has evolved through continuous improvements, culminating in YOLOv11.
YOLOv1, the pioneering model in the series, was the first to frame target detection as a single regression problem, enabling end-to-end training. YOLOv2 built upon YOLOv1 by incorporating batch normalization, multi-scale training, and anchor frames, significantly enhancing model performance. YOLOv3 introduced a deeper network and multi-scale prediction to improve the detection of objects of varying sizes. YOLOv5 gained widespread adoption, particularly in industrial applications, due to its lightweight design. YOLOv7 further advanced the series with an updated network architecture, optimizing both inference speed and accuracy.
YOLOv8 (2023) represents a convergence and refinement of previous YOLO models. For the first time, Ultralytics designed it as a versatile algorithmic framework library, supporting not only the YOLO family but also non-YOLO models and a wide range of vision tasks, including classification, segmentation, and pose estimation, making it highly extensible. YOLOv10 (2024) and YOLOv11 (2024) further optimized the network structure based on YOLOv8s, achieving higher detection accuracy while maintaining high-speed operation. However, these advancements come with increased model complexity.
YOLOv8 represents one of the latest advancements in the YOLO series of target detection algorithms, integrating the strengths of its predecessors while introducing new features and improvements. It offers a range of model sizes (n/s/m/l/x) based on scaling factors, catering to diverse application requirements. Given its scalability, ease of development and deployment, and consideration of the hardware limitations of emergency tunnel firefighting robots, YOLOv8s is selected as the baseline model. YOLOv8s strikes an optimal balance between model size and accuracy, making it well suited for real-time applications.
The architecture of YOLOv8s extends the network structure of YOLOv5 and comprises three main components: the backbone, neck, and head. The backbone and neck components incorporate the ELAN design concept from YOLOv7. The backbone is primarily responsible for feature extraction and introduces a novel C2f module (CSPLayer_2Conv), which leverages residual connections and a bottleneck structure to enhance feature extraction performance. The neck component focuses on multi-scale feature fusion, utilizing the PAN-FPN (path aggregation network with feature pyramid network) architecture to effectively aggregate and fuse features across different scales. The head component processes the feature maps and generates prediction results. It employs a decoupled head structure, which includes three detection heads. This design allows for greater flexibility in adapting to feature maps of varying sizes, thereby improving detection accuracy.
3.2. Improvement of YOLOv8s Model: FIRE-YOLOv8s
In this paper, the final optimized network model is named FIRE-YOLOv8s, and its architecture is illustrated in
Figure 1. FIRE-YOLOv8s retains the three primary components: backbone, neck, and head. The backbone incorporates the enhanced P-C2f module for feature extraction and introduces the ADown module for downsampling, significantly reducing the model’s parameter count and computational requirements. The neck employs a redesigned feature fusion network structure with additional layer connections, which not only decreases the computational load but also enhances the efficiency of multi-scale feature fusion. The head utilizes the dynamic head structure, integrating multiple attention mechanisms to improve the model’s detection performance in complex backgrounds.
3.3. P-C2f Module
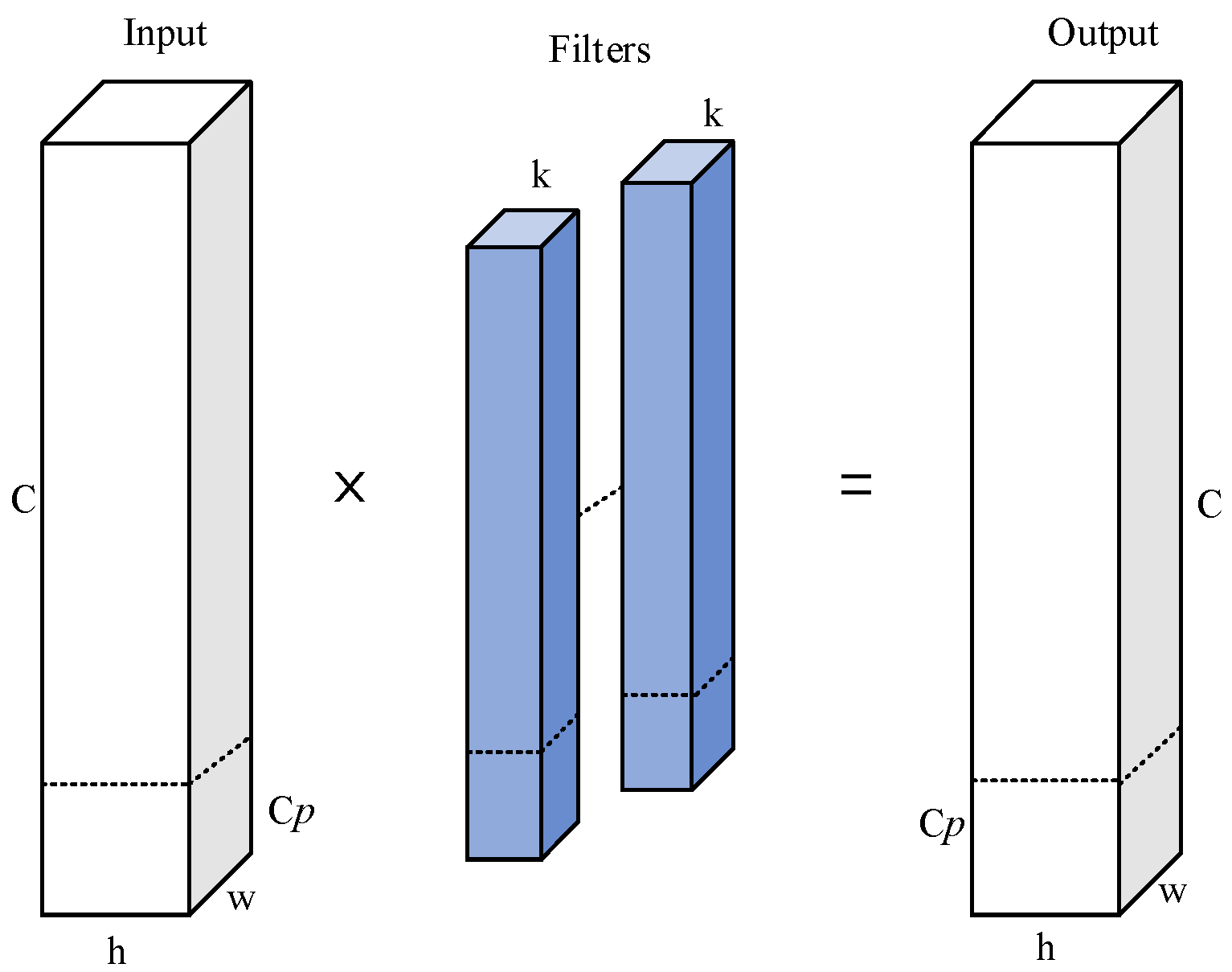
The C2f module in YOLOv8s comprises a DarknetBottleneck module, a 1 × 1 convolutional kernel, and a residual connection. This module integrates high-level features and contextual information, enabling richer gradient flow but at the cost of increased computational complexity. To ensure the improved model is more lightweight than the original, making it suitable for deployment on small embedded devices such as robots, and to allow for future enhancements to improve model accuracy, the backbone feature extraction network requires optimization for lightweighting.
Existing studies often employ lightweight convolutions, such as depthwise convolution (DWConv) [
29] and group convolution (GConv) [
30], to replace standard convolutions for feature extraction. However, these methods can lead to increased memory access, thereby prolonging computation time. To address this issue, this paper proposes a novel feature extraction module, P-C2f, utilizing partial convolution (PConv) [
31]. The structure of P-C2f is illustrated in
Figure 2.
The P-C2f module consists of
n PConv convolutions and two 1 × 1 convolution kernels. The feature map is initially processed by a 1 × 1 convolution kernel to reduce the number of input channels. Feature information is then extracted using multiple PConvs. Residual connections are employed to directly add the inputs to the outputs, forming a cross-layer connection that enables more accurate representation of deeper features. Finally, the number of channels in the feature map is restored through processing by another 1 × 1 convolution kernel. Unlike conventional convolution, PConv utilizes the redundancy in the feature map and flexibly applies conventional convolution to only a portion of the input channels for feature extraction while keeping the rest of the channels unchanged, which significantly reduces computational redundancy as well as memory accesses, and its working principle is shown in
Figure 3. For a given feature map input
, the computational cost and memory access for a single convolution operation are calculated as shown in Equations (1) and (2):
where
h and
w are the height and width of the feature map,
k is the kernel size, and
c is the number of channels. When the channel ratio of partial convolution (PConv) to conventional convolution satisfies
c/
= 1/4, the computational cost of PConv is reduced to 1/16 of that of conventional convolution, while the memory access requirement is only 1/4 of that of conventional convolution.
In this study, we propose a novel feature extraction module, termed P-C2f, which leverages PConv to enhance computational efficiency. The proposed module significantly reduces both the computational complexity and the number of model parameters. However, since PConv performs feature extraction only on a subset of input channels, it may introduce a certain degree of degradation in detection accuracy.
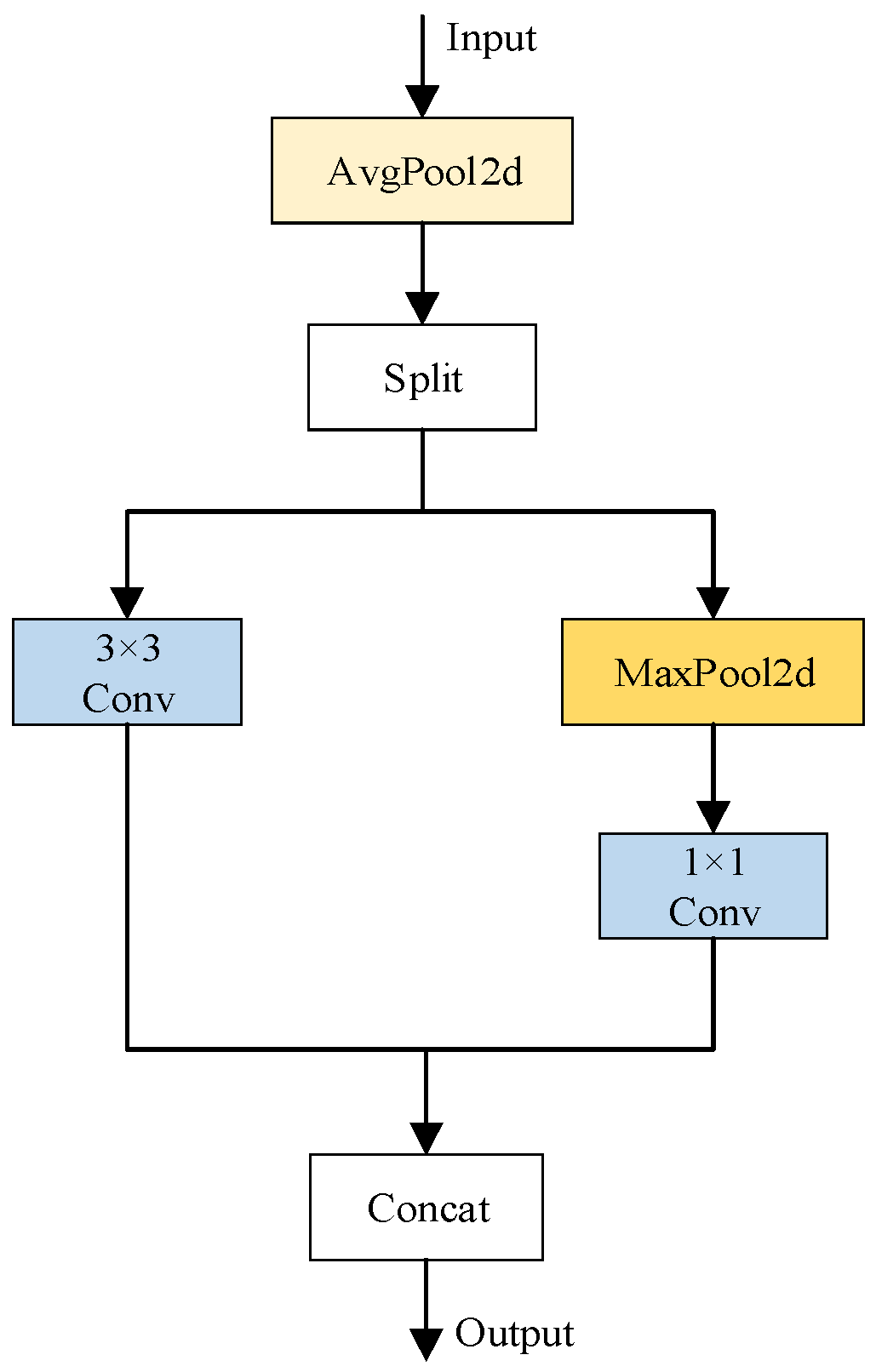
3.4. ADown Module
In the YOLOv8s feature extraction network, the downsampling operation is primarily performed using a conventional convolution module, which consists of a 3 × 3 convolution kernel, batch normalization, and a SiLU activation function. This module reduces the spatial dimensions of the feature maps. However, due to the information bottleneck phenomenon, the input feature map may lose a significant amount of information during the layer-by-layer feature extraction and spatial transformation processes. This information loss leads to the diminished salience or dilution of features corresponding to small flame targets during downsampling, making it challenging for the model to effectively recognize these targets in subsequent layers. Addressing the information loss problem is particularly critical for lightweight algorithms, which are typically under-parameterized and prone to substantial information loss during the feed-forward process.
To mitigate these issues, this study introduces the ADown module as a replacement for the conventional convolution module in downsampling. The ADown module, proposed by Wang et al. [
32], is a lightweight convolutional module designed to enhance inter-layer information interactions through a branching architecture. It effectively aggregates network information and reduces information loss during propagation. As illustrated in
Figure 4, the input feature map first undergoes average pooling (AvgPool) to capture global information and reduce the feature map size. Subsequently, the feature map is split into two sub-feature maps along the channel dimension. One sub-feature map is processed using a 3 × 3 convolutional kernel, while the other undergoes maximum pooling (MaxPool2d) followed by a 1 × 1 convolutional kernel. Finally, the outputs of the two branches are concatenated to produce the final output. This hybrid pooling strategy is designed to extract important information, discard less relevant details, reduce computational costs, and retain critical features. Notably, average pooling is more sensitive to global information, whereas maximum pooling excels at capturing finer details.
In this study, the ADown module is integrated into the downsampling operation of YOLOv8s. This integration reduces the model’s parameter count and computational load while maintaining accuracy by effectively decreasing the data size of the input feature maps. Furthermore, in deep networks, the ADown downsampling mechanism facilitates the abstraction of high-level features from low-level details, thereby preserving as much image information as possible and mitigating significant information loss.
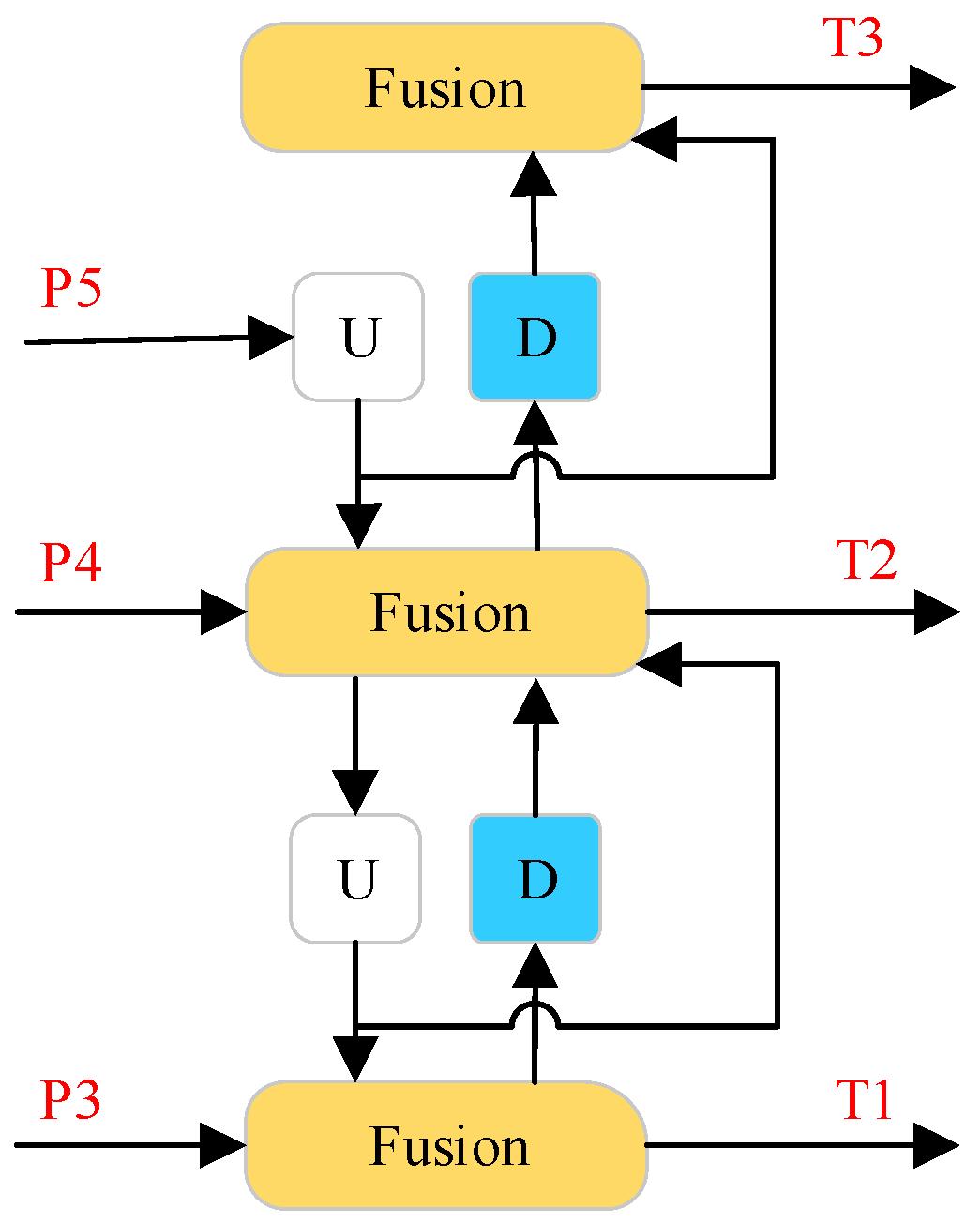
3.5. Enhancement of the Feature Fusion Network Using the CCFF Module
The neck component of YOLOv8s plays a critical role in the model, as it processes and fuses feature maps from the backbone at multiple scales to capture feature information across different resolutions. The neck adopts the PAN-FPN architecture [
33], which primarily consists of multiple C2f modules, regular convolutional modules, and top-down and bottom-up sampling and connection operations. However, this architecture tends to lose some important feature information obtained from the backbone during the feature fusion process, resulting in suboptimal fusion quality. To address these limitations and further reduce the model’s complexity, this study redesigns the feature fusion network by incorporating the lightweight cross-scale feature fusion (CCFF) module.
The CCFF module, proposed by Zhao et al. [
34], is a lightweight cross-scale feature fusion module based on convolutional neural networks (CNNs). As illustrated in
Figure 5, the CCFF module consists of up-sampling (U), down-sampling (D), and a fusion block. The fusion block employs a 1 × 1 convolutional kernel and RepConv [
35] with residual connections to fuse features from two adjacent scales into a new feature representation. The key advantage of CCFF lies in its use of lightweight operations for cross-scale feature fusion. Specifically, it utilizes a 1 × 1 convolutional kernel to reduce the resolution of feature maps, rearranges pixels to adjust the size and structure of the feature maps, and retains essential details without directly processing high-resolution features. This approach significantly reduces computational requirements. Additionally, the fusion block, integrated into the fusion path, leverages residual connections and convolutional operations to enhance the model’s feature representation capability, particularly for small target detection. By effectively fusing multi-level feature information and minimizing the interference of redundant features, the CCFF module improves both the efficiency and the accuracy of the feature fusion process.
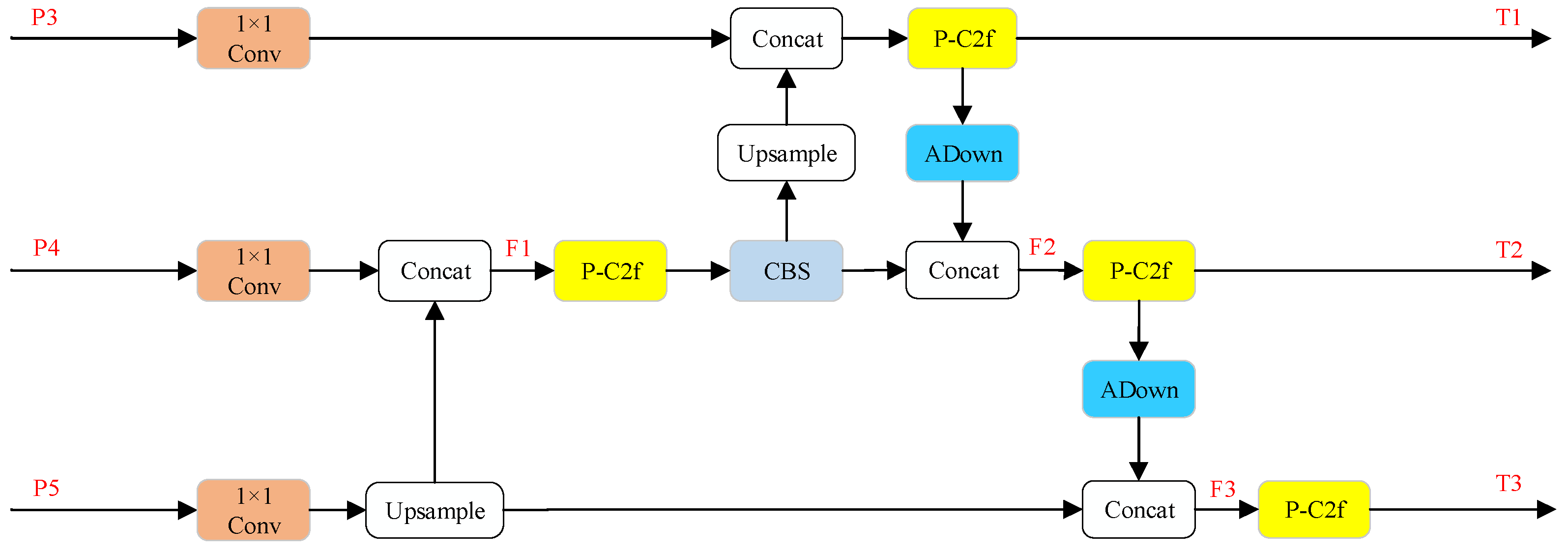
In this study, the neck feature fusion network is redesigned by incorporating the CCFF module, splitting the fusion block, and introducing the P-C2f and ADown modules. This reconstruction significantly reduces the computational cost and parameter count of the model while maintaining its performance. The structure of the redesigned network is illustrated in
Figure 6. Specifically, feature maps P3, P4, and P5 at different scales undergo resolution reduction via a 1 × 1 convolutional kernel. Subsequently, through a series of up-sampling, down-sampling, and convolutional layers, the feature representation capability is enhanced, enabling effective horizontal fusion of multi-scale feature maps. Finally, the processed feature maps (T1, T2, T3) are forwarded to the detection head for prediction. By reconfiguring the feature fusion network, the inter-layer connections are strengthened, and the efficiency of feature fusion is improved. This design leverages the spatial information from high-resolution feature maps and the rich semantic information from low-resolution feature maps, thereby enhancing the model’s ability to detect small targets. Furthermore, the redesigned network is more lightweight, with reduced computational and parametric complexity compared to the original architecture.
3.6. Dynamic Head
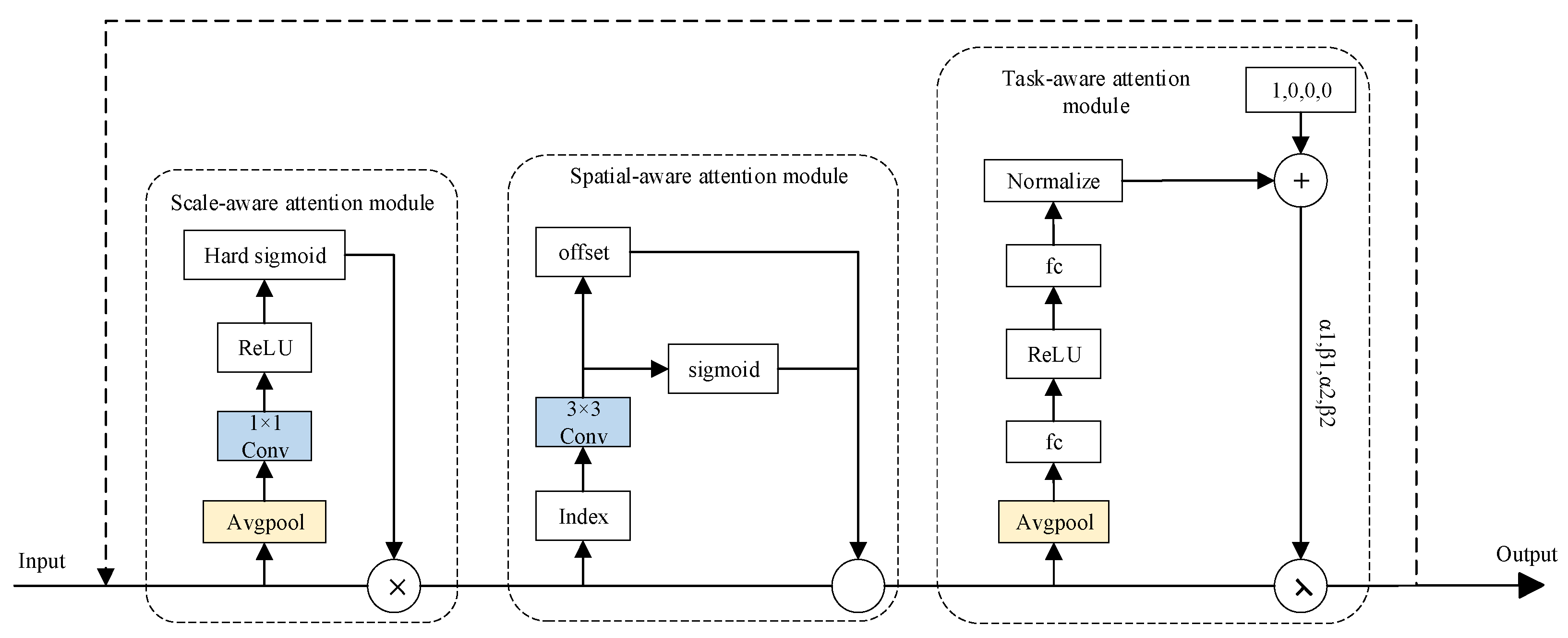
The head component of YOLOv8s is responsible for processing feature maps derived from the three layers of the neck network to generate the model’s outputs. It comprises a 3 × 3 convolution, a 1 × 1 convolution kernel, and a loss function. However, in tunnel fire scenarios, multiple fire targets often appear simultaneously at varying scales, and factors such as tunnel lighting, dust, and vehicle taillights can introduce significant interference in fire detection. Additionally, the shape, rotation angle, and position of fire targets in captured images can vary considerably when an emergency tunnel firefighting robot is in motion. To address these challenges and enhance the accuracy of fire target localization, this study proposes the integration of the dynamic head (DyHead) [
36] as a replacement for the original detector head in YOLOv8s, with further optimization to adapt it for fire detection tasks. The structure of DyHead is illustrated in
Figure 7. DyHead coherently integrates three attention mechanisms and deploys them across the three dimensions of the input feature map
I (i.e., scale, spatial, and channel). This design enables more effective fusion of contextual information and improved recognition of multi-scale targets. The mathematical formulation of DyHead can be expressed as follows:
where
,
, and
represent three distinct attention functions applied to the horizontal, spatial, and channel dimensions, respectively. Specifically, the scale-aware attention module comprises global pooling, a 1 × 1 convolution, a ReLU activation function, and a hard sigmoid activation function. The spatially aware attention module primarily incorporates deformable convolution V2, which includes offset learning and feature amplitude modulation. The task-aware attention module consists of a fully connected layer, a ReLU activation function, and a normalization operation. When a feature map passes through the scale-aware attention module, it becomes more sensitive to scale variations in the target. Subsequently, after processing by the spatially aware attention module, the feature map becomes sparser and focuses on discriminative spatial locations of the target. Finally, the task-aware attention module refines the feature map with task-specific activations, enabling it to adapt to different downstream tasks.
In this study, we propose the integration of the DyHead detection module as a replacement for the conventional detection head in tunnel fire detection systems. The DyHead module enhances the model’s capability to process multi-scale target features while simultaneously improving task-specific and spatial awareness. This enhancement significantly boosts the model’s performance in fire detection within the complex environments of road tunnels, leading to improved accuracy and robustness. Nevertheless, the implementation of multiple attention mechanisms within DyHead inevitably increases the computational overhead of the model to some extent.
4. Experiments and Analysis
4.1. Dataset
Due to the absence of publicly available datasets for tunnel fire detection, this study utilizes a proprietary dataset constructed by China Merchants Chongqing Transportation Research and Design Institute Co., Ltd, located in Chongqing, China. The dataset comprises multiple sources, including: (1) online images of actual tunnel fire incidents, (2) video frames extracted from tunnel fire drills conducted in various cities across China, and (3) experimental fire scenarios captured in the State Key Tunnel Laboratory and the Huayan Tunnel of Chongqing Municipality. To enhance the dataset’s diversity and robustness, additional highway fire images were incorporated, and artificial variations were introduced through brightness adjustments and blurring noise to simulate challenging illumination conditions in tunnel environments.
The final dataset consists of approximately 6000 images, exclusively containing fire-related instances. These images were systematically partitioned into training (70%), validation (10%), and test sets (20%) to ensure proper model evaluation. The dataset encompasses diverse environmental conditions, including varying fire scales (large and small) and complex scenarios with vehicle occlusions. For precise annotation, fire regions in all images were manually labeled using Labelme3.16.2 software, with annotations initially stored in XML format and subsequently converted to TXT format for compatibility with our detection framework. Representative samples from the dataset are illustrated in
Figure 8.
4.2. Experimental Environment
To validate the effectiveness of the proposed algorithm, we constructed a dedicated experimental platform. The experimental setup comprises a Windows 10 Professional 64-bit operating system, with detailed hardware specifications and software configurations systematically documented in
Table 1. For model training and algorithm implementation, we employed the PyTorch 2.2.2 deep learning framework, which provides comprehensive support for neural network development and optimization.
To maintain consistency across experiments, we adopted identical hyperparameter configurations for all training processes. The specific settings were as follows: the model was trained for 253 epochs with a batch size of 128, utilizing the Stochastic Gradient Descent (SGD) optimization algorithm. The initial learning rate was set to 0.01, accompanied by a weight decay coefficient of 0.0005 to prevent overfitting. All input images were uniformly resized to 640 × 640 pixels to ensure dimensional consistency. To guarantee the fairness and reliability of experimental comparisons, we intentionally avoided using any pre-trained weights from official sources, ensuring that all network trainings were conducted from scratch under identical initialization conditions.
4.3. Model Evaluation Indicators
The model’s performance was comprehensively evaluated using multiple quantitative metrics, including precision (P), recall (R), F1 score, mean average precision at 0.5 IoU threshold (mAP@0.5), model size (weight size), computational complexity measured in floating point operations (FLOPs), parameter count (Params), and inference speed measured in frames per second (FPS). These metrics were calculated according to the following formulations:
where true positive (
TP) represents the number of correctly identified positive samples, false positive (
FP) indicates the number of incorrectly classified negative samples as positive, and false negative (
FN) corresponds to the number of undetected positive samples. Additionally,
N denotes the total number of distinct categories within the dataset.
Precision (P) quantifies the proportion of correctly identified positive instances among all predicted positive samples, reflecting the model’s capability to accurately distinguish fire occurrences from non-fire scenarios. Recall (R) measures the ratio of correctly detected positive samples to the total number of actual positive instances, indicating the model’s effectiveness in identifying fire incidents. The F1 score, serving as the harmonic mean of precision and recall, provides a balanced evaluation metric, where higher values indicate more robust model performance. The mean average precision at 0.5 IoU threshold (mAP@0.5) integrates precision and recall across all N categories in the dataset, offering a comprehensive assessment of the model’s detection capability. Model size (weight size) reflects the memory footprint of the model, with smaller values indicating more efficient memory utilization. Computational complexity, measured in floating point operations (FLOPs), represents the model’s computational requirements, where lower FLOP values correspond to reduced computational overhead. The parameter count (Params) indicates the model’s architectural complexity, with fewer parameters generally suggesting a more lightweight architecture. Finally, inference speed, measured in frames per second (FPS), characterizes the model’s real-time processing capability, where higher FPS values denote faster detection performance.
4.4. Ablation Experiment
To systematically validate the effectiveness of our proposed improvement strategy, we conducted comprehensive ablation studies to evaluate the individual and combined contributions of each enhancement to the YOLOv8s model’s performance. The experimental design incorporates four key modifications: (1) implementation of a novel feature extraction module (P-C2f) for enhanced feature representation, (2) adoption of the ADown module for optimized downsampling operations, (3) integration of the CCFF module to refine the neck architecture, and (4) utilization of the dynamic head detector for final prediction processing and output generation. The experimental outcomes, presented in
Table 2, employ the symbol “✓” to denote the incorporation of each respective improvement method.
As evidenced by the experimental results in
Table 2, compared to the original YOLOv8s, the introduction of the P-C2f module reduced mAP@0.5 by 0.5%, but it also decreased the number of parameters by 32.4% and the computational load by 30.7%. This indicates that P-C2f significantly reduces model complexity while achieving lightweighting. However, since PConv extracts features from only a subset of input channels, it results in a slight degradation in accuracy and average precision. After incorporating the ADown module for downsampling, mAP@0.5 improved by 1%. This suggests that ADown mitigates information loss to some extent, and its lightweight design further reduces the model’s parameters and computational requirements. The use of the CCFF module to enhance the neck structure improved accuracy by 0.2% and recall by 0.3%. This indicates that the improved neck network enhances the model’s ability to detect small targets while further reducing parameters and computational load, providing room for subsequent precision improvements. The introduction of the dynamic head led to a 1.6% increase in mAP@0.5, a 2% improvement in accuracy, and a 1.7% boost in recall, with only a minor increase in parameters and computational cost. This demonstrates that dynamic head enhances the model’s ability to detect multi-scale fire targets in complex highway tunnel environments through the deployment of multiple attention mechanisms.
By incrementally adding the proposed improvement strategies, the experiments demonstrated that each enhancement contributed to the model’s performance. Specifically, P-C2f, ADown, and CCFF effectively reduced the model’s parameters and computational complexity, while the dynamic head significantly improved accuracy, recall, and average precision. Compared to YOLOv8s, FIRE-YOLOv8s reduced Params and FLOPs by 52.2% and 47.9%, respectively, while improving mAP@0.5 by 1.7%. These results indicate that the four improvement strategies successfully achieve lightweighting without compromising detection accuracy, making the model more suitable for resource-constrained tunnel scenarios.
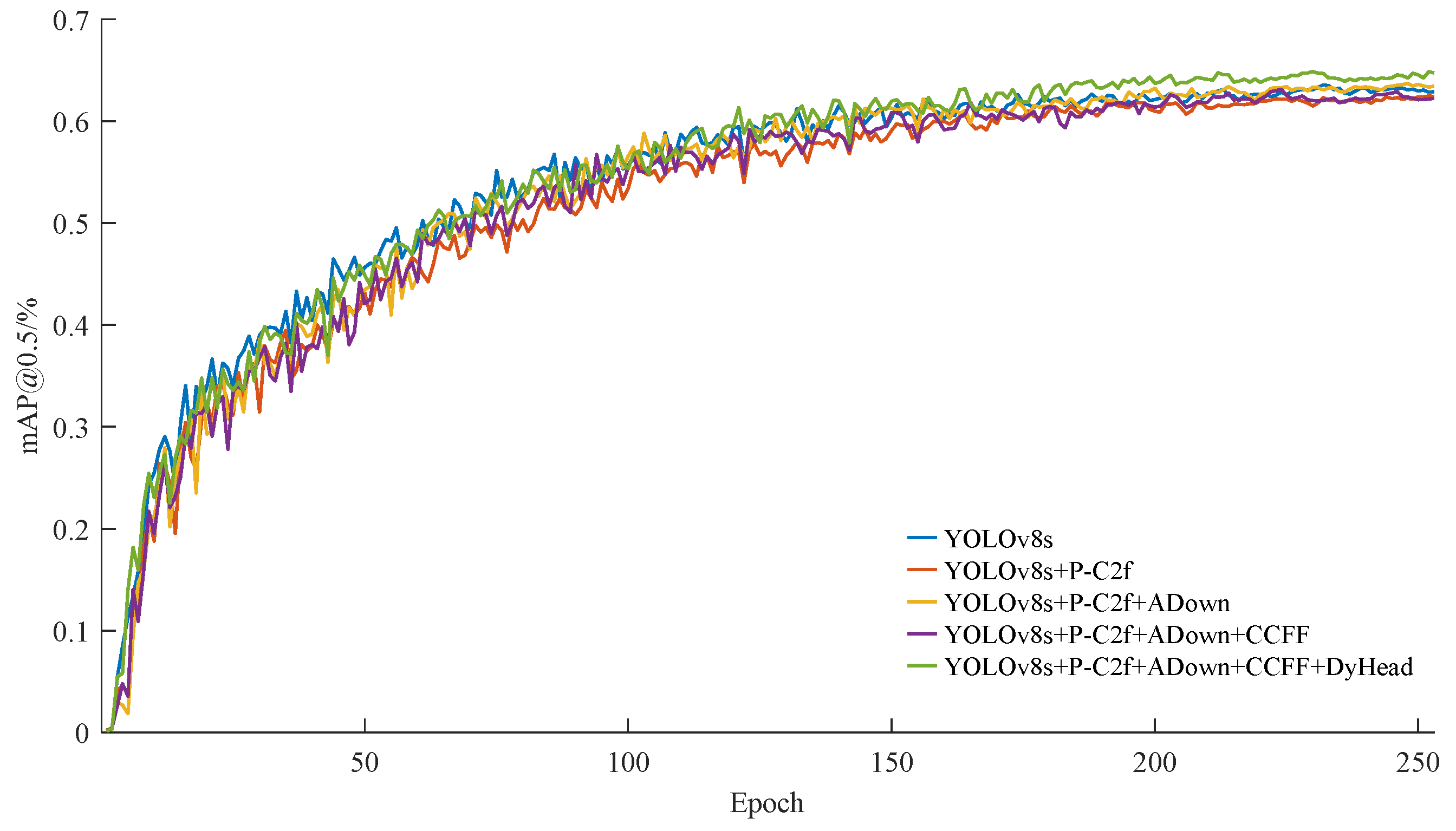
To visualize the impact of the improvement strategies on model accuracy,
Figure 9 presents the mAP@0.5 curves for the ablation experiments involving a series of models. As illustrated in the figure, the final improved model achieves a higher mAP@0.5 compared to the other models after approximately 150 epochs.
4.5. Comparison Experiment
To further evaluate the performance of FIRE-YOLOv8s, comparative experiments were conducted under identical experimental conditions with other mainstream models. The models included in the experiments were the two-stage model Faster R-CNN, the single-stage model SSD, lightweight YOLO series models (YOLOv5s, YOLOv6s, YOLOv7-tiny, YOLOv8s, YOLOv10s, and YOLOv11s), the proposed FIRE-YOLOv8s, and tunnel fire detection algorithms from the literature [
24,
25]. The experimental results are summarized in
Table 3.
As shown in
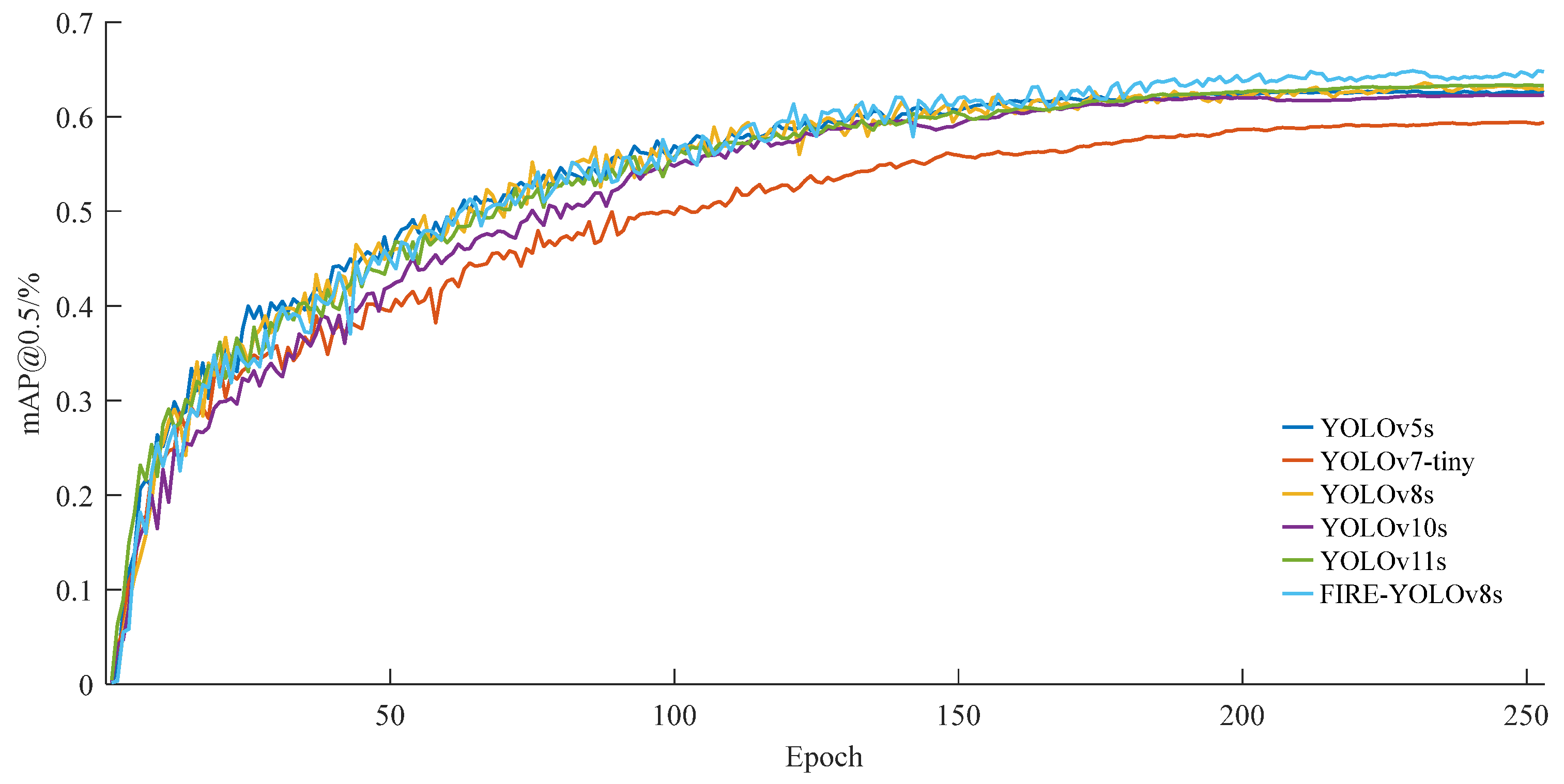
Table 3, FIRE-YOLOv8s achieved an accuracy of 78.3% and an mAP@0.5 of 64.5%, significantly outperforming Faster R-CNN and SSD, as well as other lightweight YOLO series models. These results indicate that FIRE-YOLOv8s is highly suitable for accurate fire detection tasks in tunnel environments. To visualize its performance,
Figure 10 compares the mAP@0.5 curves of FIRE-YOLOv8s with other models, demonstrating that FIRE-YOLOv8s consistently achieves higher average accuracy.
In terms of model lightweighting, computational complexity, and size, FIRE-YOLOv8s exhibited superior performance. It had the smallest memory usage (10.3 MB), the fewest parameters (5.3 M), and a computational load of 14.9 G, which was only slightly higher than that of YOLOv7-tiny. However, FIRE-YOLOv8s outperformed YOLOv7-tiny in both average precision and accuracy. These attributes enable FIRE-YOLOv8s to significantly reduce computational complexity and model size, making it highly suitable for deployment on robotic platforms.
FIRE-YOLOv8s achieved a detection speed of 120.7 FPS, meeting real-time detection requirements and surpassing most models in speed, with only SSD being faster. However, SSD’s average accuracy was considerably lower than that of FIRE-YOLOv8s, highlighting the latter’s superior balance of speed and precision.
When compared to other tunnel fire detection algorithms, FIRE-YOLOv8s demonstrates clear advantages. For instance, the method proposed in [
25] enhances YOLOv5’s accuracy by incorporating the CBAM attention mechanism and RFB module without increasing computational load. However, it employs a multi-model predictive inference approach, resulting in a larger model size, slower detection speed, and lower accuracy compared to FIRE-YOLOv8s. Similarly, the approach in [
24] uses K-means to recalculate anchor frame sizes, integrates the CBAM module and gradient equalization mechanism into YOLOv5s, and combines it with the SRGAN model. While this improves small target detection accuracy, it also increases computational load and degrades real-time performance.
Comparative experimental results indicate that FIRE-YOLOv8s offers significant advantages in detection accuracy and lightweighting compared to both mainstream lightweight target detection algorithms and state-of-the-art tunnel fire detection algorithms. Its ability to balance accuracy, computational efficiency, and real-time performance makes it a highly effective solution for fire detection in tunnel environments.
4.6. Visualization and Analysis of Tunnel Fire Detection
To evaluate the detection performance of FIRE-YOLOv8s more comprehensively, a subset of images from the dataset was selected for comparative analysis with several mainstream models. These images included scenarios with regular fire targets, small targets, and multiple targets.
The detection results for a single regular-sized fire target are shown in
Figure 11. Most models accurately detected the fire, with only YOLOv7-tiny and Faster R-CNN producing false detections. Among the models, FIRE-YOLOv8s and YOLOv5s demonstrated higher overall detection accuracy.
The detection results for a small fire target are shown in
Figure 12. YOLOv8s and SSD exhibited significant missed detections, while Faster R-CNN, YOLOv6s, and YOLOv7-tiny produced varying degrees of misdetections, mistakenly identifying vehicle taillights as fires. Faster R-CNN performed the worst, with overlapping bounding boxes. In contrast, FIRE-YOLOv8s, YOLOv5s, and YOLOv11s performed well, with no missed detections or false alarms. Notably, FIRE-YOLOv8s predicted bounding boxes more accurately than YOLOv5s and YOLOv11s, achieving approximately 70% precision.
The detection results for multiple fire targets are shown in
Figure 13. FIRE-YOLOv8s effectively identified all targets with high accuracy. YOLOv8s and SSD exhibited varying degrees of under-detection, YOLOv5s and YOLOv11s produced overlapping bounding boxes, and Faster R-CNN and YOLOv6s generated some misdetections. Although YOLOv7-tiny detected all targets, its accuracy was low. Overall, FIRE-YOLOv8s outperformed the other models, producing more accurate bounding boxes in multi-target scenarios.
The combined experimental results across different scenarios demonstrate that FIRE-YOLOv8s achieves higher detection accuracy, lower rates of missed and false detections, and stronger multi-scale target detection capabilities compared to other models. In conclusion, the visualization experiments validate the effectiveness of the proposed improvements, significantly enhancing the model’s ability to detect tunnel fire targets.
4.7. Generalisation Experiments
To further evaluate the performance of FIRE-YOLOv8s, the publicly available dataset M4SFWD [
37] was selected for comparison with the aforementioned models. M4SFWD utilizes Unreal Engine 5 to simulate real forest fire scenarios with aerial views, covering eight different terrains, four weather conditions (sunny, foggy, rainy, snowy), and three times of day (morning, evening, night). Each scene is configured with three scenarios: no target, single target, and multiple targets, aiming to create a comprehensive forest fire dataset. The dataset includes 3974 images, divided into training, validation, and test sets in a 7:1:2 ratio. The experimental parameters were consistent with those described in
Section 4.2.
The experimental results, as shown in
Table 4, demonstrate that FIRE-YOLOv8s achieved an accuracy of 89.7% and an mAP@0.5 of 75.2% on the M4SFWD dataset. This represents a 3.3% improvement over the baseline model YOLOv8s and significantly outperformed other models. The number of parameters, computational load, and model size remained largely unchanged, while the detection speed was only slightly lower than that of SSD. These results indicate that FIRE-YOLOv8s maintains strong generalization capabilities and can be effectively applied to fire detection in diverse scenarios beyond tunnels.
4.8. Algorithm Validation and Application
4.8.1. Introduction to Robotics Platform
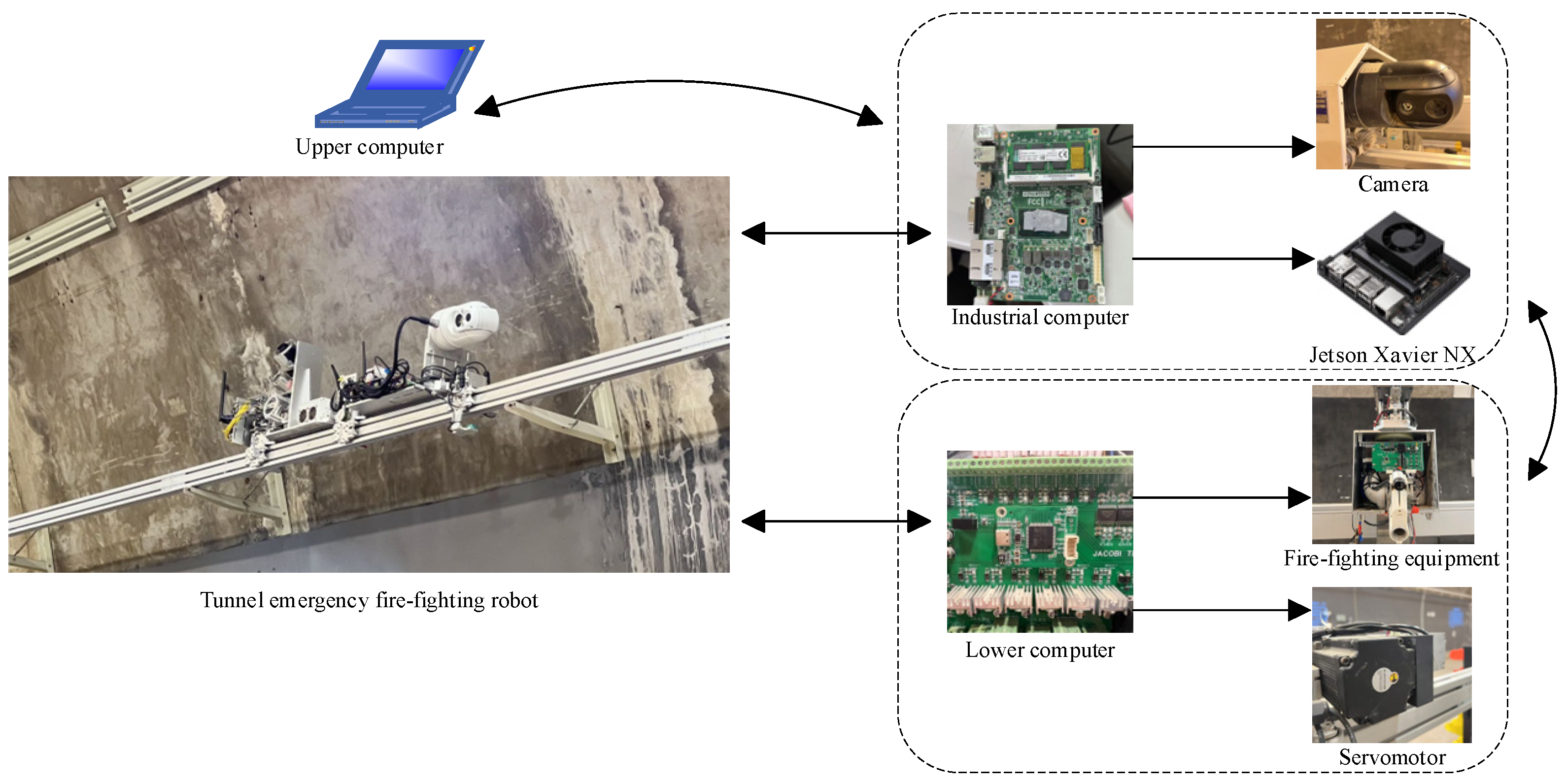
The overall structure and control system of the robot are illustrated in
Figure 14. The hardware control scheme consists of three main components: an upper computer, an industrial computer, and a lower-level controller.
The lower-level controller is based on the STM32F407VGT6 microcontroller and is responsible for managing the electrical drive control module (e.g., servo motors, LEDs, fire extinguishing equipment) and the data acquisition module (e.g., RFID module, motor encoder, temperature and humidity sensors). The industrial computer communicates with the lower-level controller via a 485 bus, enabling manual control of motor operations and real-time acquisition of motor speed and position data. Additionally, the industrial computer interfaces with a dual-spectrum camera and an edge AI device. The edge AI device processes video image data in real time by deploying the fire detection algorithm, enabling efficient and accurate fire detection. The upper computer communicates with the industrial computer wirelessly and provides a user interface (UI) for real-time monitoring of tunnel video images and robot position coordinates.
This integrated control system ensures efficient operation, real-time data processing, and effective fire detection capabilities, making the robot well suited for tunnel emergency scenarios.
4.8.2. Algorithm Deployment Experiment
To validate the computational efficiency and practical applicability of the proposed algorithm on resource-constrained embedded systems, we implemented the algorithm on a rail-mounted tunnel firefighting robot platform. This robotic system, operating along the tunnel ceiling, performs real-time fire monitoring through its integrated vision system. The experimental platform utilizes an NVIDIA Jetson Xavier NX module, offering a computational capacity of 21 TOPS, with the following technical specifications:
Hardware configuration:
Software environment:
This experimental setup was specifically designed to evaluate the algorithm’s performance under realistic operational constraints, particularly in terms of computational efficiency and real-time processing capabilities on embedded hardware platforms.
The implementation process begins with the deployment of FIRE-YOLOv8s on the NVIDIA Jetson Xavier NX embedded platform. The trained model files are converted into TensorRT-compatible format using the tensorrtx tool, enabling inference acceleration through TensorRT optimization. Additionally, model quantization with FP16 precision is implemented to enhance computational efficiency. This configuration allows real-time processing of video streams captured by the robot’s integrated camera system for fire detection.
Experimental validation was conducted in the State Key Tunnel Laboratory of China Merchants Chongqing Transportation Research and Design Institute, with the experimental setup illustrated in
Figure 15. The evaluation results demonstrate that the proposed algorithm achieved:
Real-time tunnel fire detection capability;
Robust multi-scale fire target recognition;
A zero false alarm rate, with no target omissions;
Sustained detection frame rate of 28.13 FPS.
These experimental outcomes, with representative results shown in
Figure 16, confirm the algorithm’s strong applicability for tunnel fire detection scenarios under computational resource constraints. The system’s performance metrics validate its effectiveness in real-time operational environments.
5. Conclusions
This paper proposes a lightweight tunnel fire detection algorithm, FIRE-YOLOv8s, to address the challenges of high computational complexity and low accuracy in existing fire detection algorithms when applied to highway tunnel scenarios. The algorithm enhances the YOLOv8s model by improving its backbone, neck, and head components: a novel feature extraction module (P-C2f) is introduced to significantly reduce the number of parameters and computational complexity, the lightweight ADown module is employed to minimize information loss while reducing computational load, the CCFF module is used to improve feature fusion efficiency and further lightweight the model, and the dynamic head detection head, combined with attention mechanisms, enhances the model’s performance in complex tunnel environments.
The experimental results demonstrate that FIRE-YOLOv8s achieves a 1.7% improvement in average accuracy (mAP@0.5), reduces the number of parameters by 52.2%, decreases computational load by 47.9%, and reduces the model size to 50% of the original YOLOv8s. Compared to other lightweight models, FIRE-YOLOv8s achieves the highest detection accuracy with the smallest model size and the fewest parameters, while maintaining computational requirements only slightly higher than those of YOLOv7-tiny. These results highlight the algorithm’s ability to balance detection accuracy and computational efficiency, making it highly suitable for real-time fire detection in tunnel scenarios.
Despite its advantages, FIRE-YOLOv8s has areas for improvement. The P-C2f module’s feature extraction from only a subset of input channels results in a slight decrease in accuracy and average precision. The deployment of multiple attention mechanisms in the dynamic head increases the computational load. Additionally, the lack of publicly available tunnel fire datasets restricts the validation of the model’s generalization ability. Future work will focus on optimizing computational resource consumption while maintaining detection accuracy, expanding the dataset to include more diverse tunnel fire images, and improving the model’s generalization and stability. Integrating the algorithm with fire extinguishing equipment on tunnel emergency firefighting robots could enable precise fire suppression, providing a more reliable and efficient solution for tunnel safety operations.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}