

Reliable Indoor Fire Detection Using Attention-Based 3D CNNs: A Fire Safety Engineering Perspective



Abstract
1. Introduction
- Development of a novel indoor fire video dataset, compiled from real-world CCTV footage across diverse residential environments.
- Design of an enhanced fire detection model, based on the mixed convolution ResNets (MC3_18) architecture augmented with Convolutional Block Attention Modules (CBAM), to improve early-stage fire recognition by emphasizing salient spatiotemporal features.
- Introduction of an indoor fire detection benchmark, constructed from realistic surveillance footage and focused explicitly on early-stage events, providing a reproducible evaluation framework for future 3D CNN-based research.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Approach | Training Dataset Type | Result |
|---|---|---|---|
| Pincott et al. [19] | Flame/smoke object detection | Indoor | Accuracy, precision, recall |
| Yusun et al. [20] | Smoke/flame object detection | Indoor | Precision, recall, mAP0.5, detection time |
| Khan et al. [17] | Flame object detection and segmentation | Multiple scenes of fires | Accuracy, F-measure, precision, recall |
| Arpit et al. [18] | Flame recognition | Multiple scenes of fires | Accuracy, F-measure, precision, recall |
| Wu et al. [21] | Flame object detection | Outdoor | Detection rate and speed |
| Khan et al. [15] | Smoke/flame recognition | Multiple scenes of fires | Accuracy, F-measure, precision, recall |
| Yuan et al. [22] | Smoke segmentation | Complex scenes | Intersection over Union and Mean Square Error |
| Tao et al. [23] | Smoke recognition | Real surveillance scenes | Detection rate, false alarm rate, and F1-score |
| Majid et al. [24] | Flame recognition | Multiple scenes of fires | Accuracy, F-measure, precision, recall |
| Chaoxia et al. [25] | Flame object detection | Multiple scenes of fires | Accuracy, F-measure, precision, recall |
| Li et al. [26] | Smoke/flame object detection | Multiple scenes of fires | Detection speed, Precision |
| This study | Smoke/flame recognition | Indoor | Accuracy, F-measure precision, recall |
2. Related Work
- Late-Stage Combustion Bias: Many datasets, including DFAN, BoWFire (Chino’s), and non-public collections like Pincott’s, predominantly feature images or video clips of fully developed flames (See Figure 1). While such vivid fire scenes enhance detection rates in later stages, they offer minimal training data for early fire detection, particularly pre-flashover fires, which are crucial for timely warnings.
- Smoke Frames Labeled as Non-Fire: Foggia’s dataset explicitly treats all smoke frames—including those from genuine early-stage fires—as non-fire, conflating smoke-only events with background and undermining a model’s ability to learn true flame signatures.
- Low Intra-Video Diversity: Datasets with large frame counts often derive many of their images from a handful of video sources, leading to near-duplicate frames that lack sufficient scene diversity for robust training. For example, Foggia’s dataset comprises 31 raw videos, from which over 57,000 frames are extracted, but the majority are temporally adjacent and visually redundant, limiting the model’s ability to generalize beyond a few camera angles and lighting conditions.
- Smoke-Based Detection Focus: A subset of datasets (e.g., VSD, Smoke100k) emphasizes smoke rather than flame features. However, certain fire types (e.g., electrical faults, gas leaks, and chemical reactions) produce little or no visible smoke, rendering smoke-centric classifiers ineffective in those scenarios.
| Dataset Name | Description and Volume | Environment | Usage Count † |
|---|---|---|---|
| Töreyin [30] | 11 videos: 5 genuine fire scenes (e.g., garden, fireplace, box fire) and 6 fire-like scenarios (e.g., red clothing, vehicles, crowds). | Indoor and outdoor | 910 |
| Foggia’s [16] | 31 videos: 13 fire, 16 non-fire, 2 mixed. 57,800 total frames (6311 fire; 51,489 non-fire). Smoke is labeled as non-fire. | Indoor and outdoor | 454 |
| FireSense [31] | 49 videos: flame detection (11 positive, 16 negative), smoke detection (13 positive, 9 negative). | Indoor and outdoor | 233 |
| BoWFire (Chino’s) [11] | 226 images: 119 real fire, 107 fire-colored distractors (e.g., sunsets, clothing, lights). | Indoor and outdoor | 234 |
| VSD Dataset [32] | 6 videos converted into 4 image sets (e.g., leaf, cotton, wood fires). | Outdoor fire | 242 |
| FD Dataset [33] | Aggregated from Foggia and BoWFire. | Indoor and outdoor | 100 |
| Smoke100k [34] | 100,000 synthetic images across smoke levels: low (33 k), medium (36 k), high (33 k). | Synthetic images | 7 |
| VisiFire [35] | 57 videos: 13 fire, 21 urban smoke, 21 forest smoke, 2 other. | Outdoor/forest | -- |
| DFAN (Yar’s) [36] | 3403 fire images distributed across 12 classes: boat fire (338), building fire (305), bus fire (400), car fire (579), cargo fire (207), electric pole fire (300), forest fire (480), pickup fire (257), SUV fire (240), train fire (300), van fire (300), and 97 normal (non-fire) images. | Outdoor | 79 |
| Pincott’s [19] | 600 images covering all fire development stages, from ignition to spread. | Indoor | Private dataset |
| Ahn’s [20] | 10,163 indoor images; 514 for false positive scenarios (e.g., welding sparks, light reflections). | Indoor | Private dataset |
| Our Dataset | 1108 indoor videos, described in detail in this section. | Indoor | N/A |

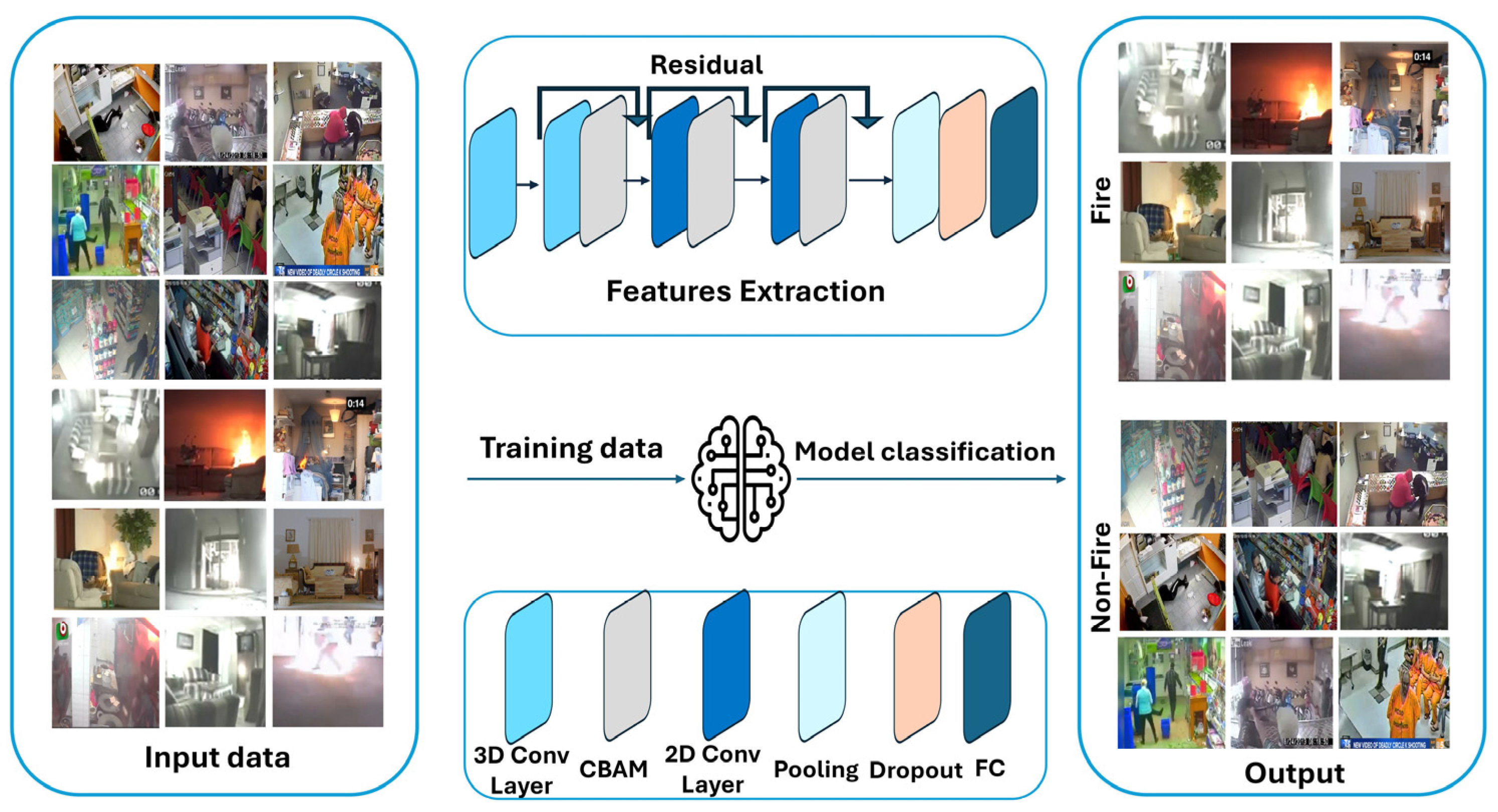
3. Proposed Framework
3.1. Dataset
- Early-Stage Focus and Broad Scenario Coverage. All the clips are limited to the fire flashover, ensuring that the flames remain physically small and challenging to detect. The videos encompass a wide variety of residential fire types—wall fires, sofa ignitions, cupboard blazes, and attic fires—as well as horizontal and vertical ventilation conditions, supporting robust generalization across household layouts. We collected real fire scenarios from credible and publicly available sources such as the Fire Safety Research Institute [37] to ensure the dataset accurately reflects authentic fire incidents.
- Diverse Environmental Conditions. We vary the camera-to-fire distances, incorporate common indoor backgrounds featuring fire-colored objects, and capture across different lighting regimes to mimic real-world surveillance footage [38]. Additionally, the dataset includes occlusion cases, where flames are partially obscured by furniture or structural elements (e.g., table edges, sofa backs), and multi-view scenes from different camera angles, simulating realistic variations in fixed surveillance deployments.
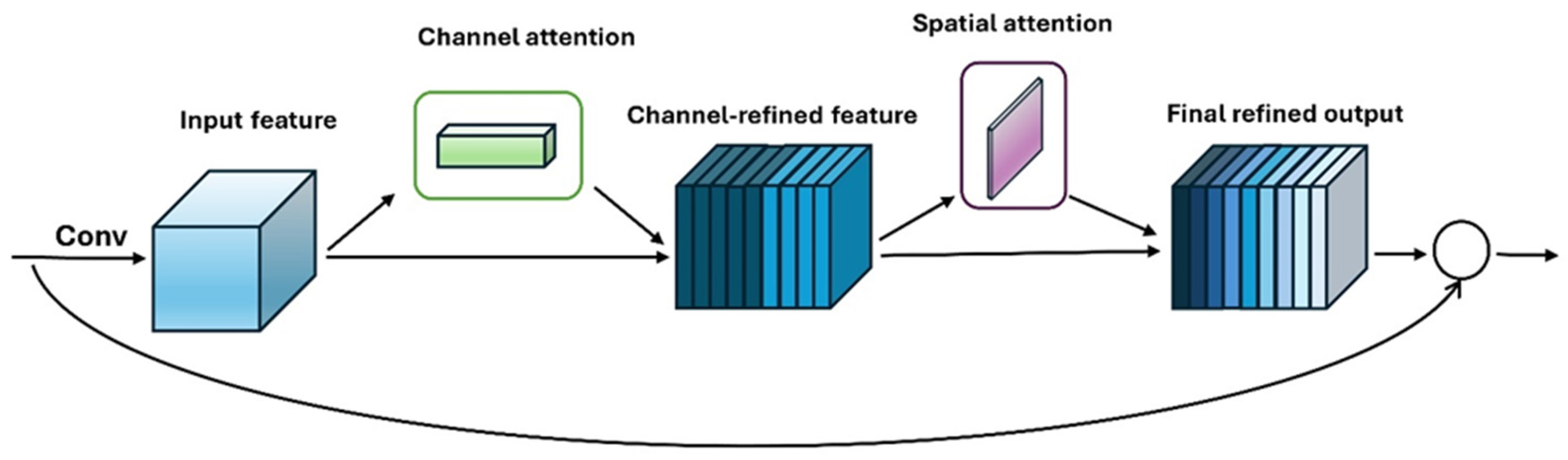
3.2. Proposed Model
3.3. Preprocessing and Hyperparameters
4. Experimental Results
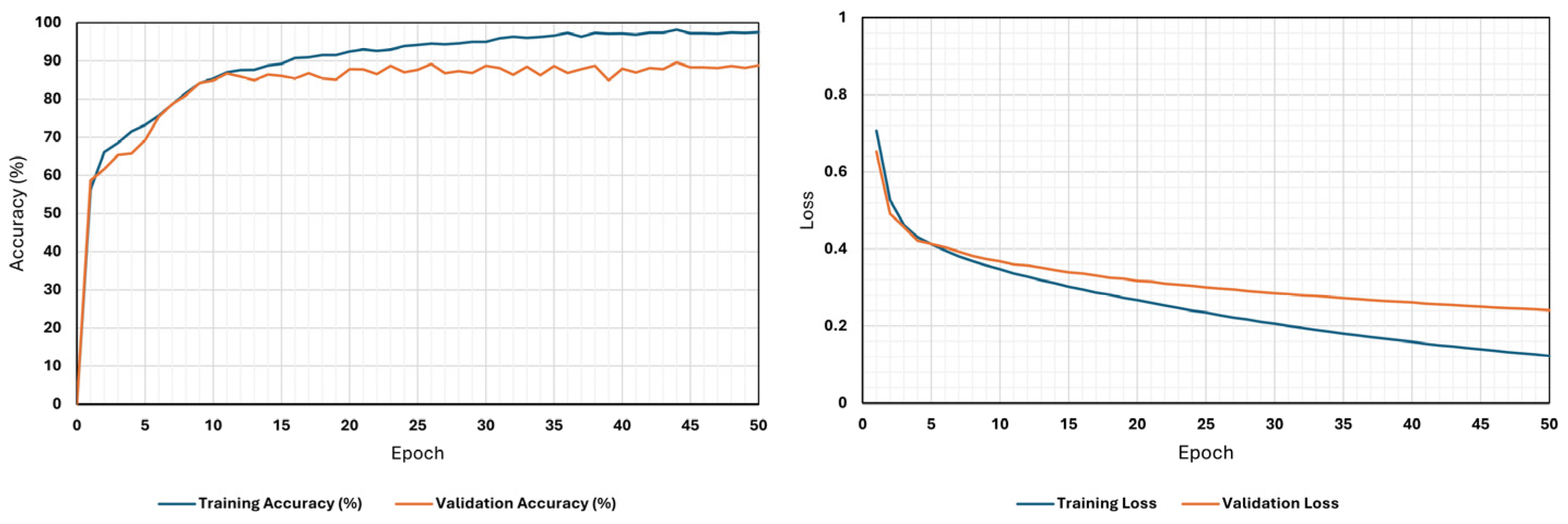
4.1. Performance Matrix and Assessment
4.2. Performance Comparison with Earlier Approaches
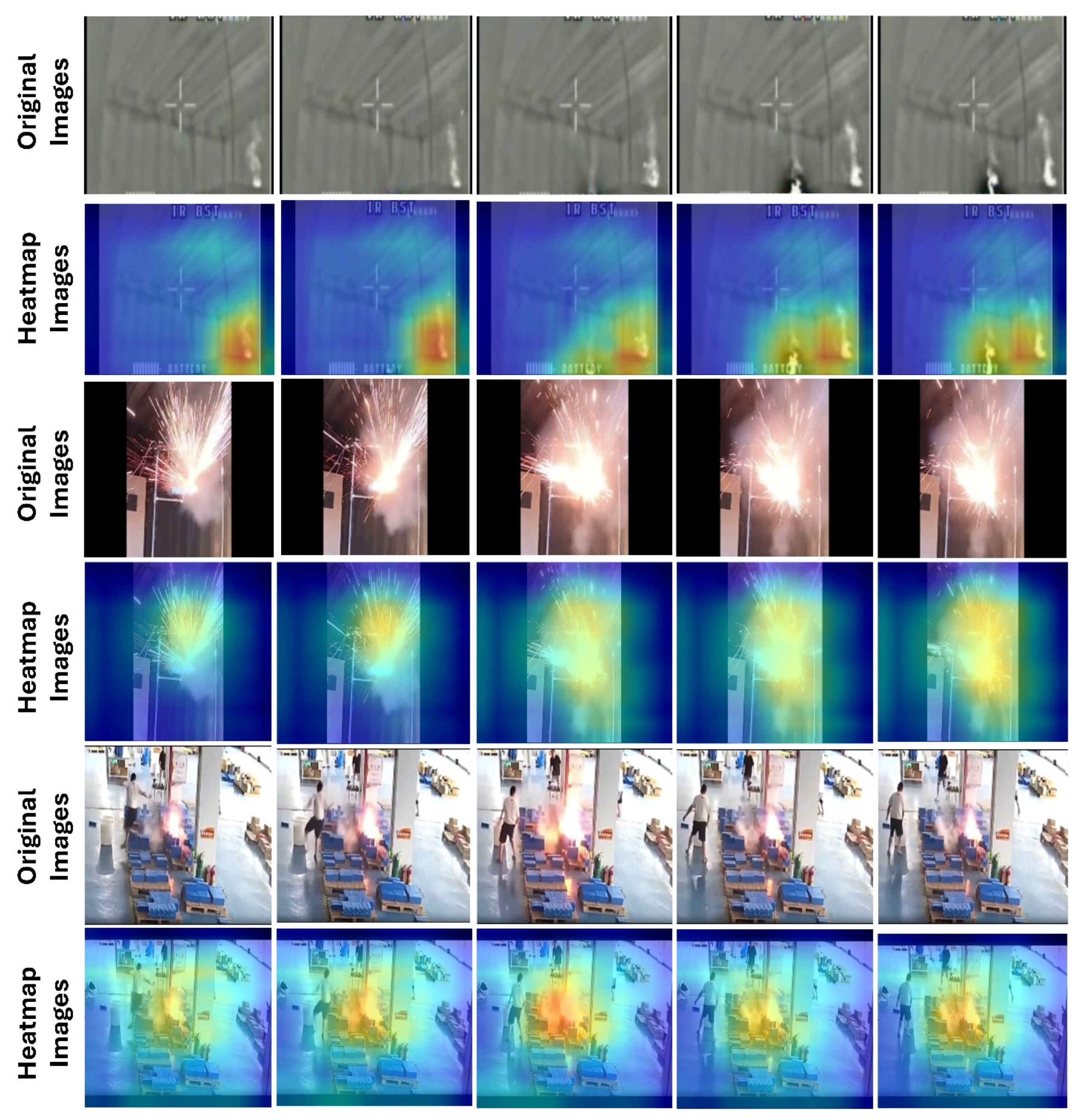
4.3. Grad-CAM++ Visualization and Interpretation
4.4. Model Efficiency and Real-Time Inference Capability
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ghassempour, N.; Tannous, W.K.; Agho, K.E.; Avsar, G.; Harvey, L.A. Comparison of causes, characteristics and consequences of residential fires in social and non-social housing dwellings in New South Wales, Australia. Prev. Med. Rep. 2022, 28, 101860. [Google Scholar] [CrossRef] [PubMed]
- Dinaburg, J.; Gottuk, D. Smoke alarm nuisance source characterization: Review and recommendations. Fire Technol. 2016, 52, 1197–1233. [Google Scholar] [CrossRef]
- Mailstop, F.; Prevention, A.F.; Grants, S. Global Concepts in Residential Fire Safety Part 3–Best Practices from Canada, Puerto Rico, Mexico, and Dominican Republic; System Planning Corporation: Arlington, VA, USA, 2009. [Google Scholar]
- Coates, L.; Kaandorp, G.; Harris, J.; Van Leeuwen, J.; Avci, A.; Evans, J.; George, S.; Gissing, A.; van den Honert, R.; Haynes, K. Preventable Residential Fire Fatalities in Australia July 2003 to June 2017; Bushfire and Natural Hazards CRC: Melbourne, Australia, 2019. [Google Scholar]
- Liu, G.; Yuan, H.; Huang, L. A fire alarm judgment method using multiple smoke alarms based on Bayesian estimation. Fire Saf. J. 2023, 136, 103733. [Google Scholar] [CrossRef]
- Khan, F.; Xu, Z.; Sun, J.; Khan, F.M.; Ahmed, A.; Zhao, Y. Recent advances in sensors for fire detection. Sensors 2022, 22, 3310. [Google Scholar] [CrossRef] [PubMed]
- Gaur, A.; Singh, A.; Kumar, A.; Kulkarni, K.S.; Lala, S.; Kapoor, K.; Srivastava, V.; Kumar, A.; Mukhopadhyay, S.C. Fire sensing technologies: A review. IEEE Sens. J. 2019, 19, 3191–3202. [Google Scholar] [CrossRef]
- Smoke Alarms Fail in a Third of House Fires. Available online: https://www.bbc.co.uk/news/uk-england-50598387 (accessed on 30 April 2025).
- Jin, C.; Wang, T.; Alhusaini, N.; Zhao, S.; Liu, H.; Xu, K.; Zhang, J. Video Fire Detection Methods Based on Deep Learning: Datasets, Methods, and Future Directions. Fire 2023, 6, 315. [Google Scholar] [CrossRef]
- Xu, F.; Zhang, X.; Deng, T.; Xu, W. An image-based fire monitoring algorithm resistant to fire-like objects. Fire 2023, 7, 3. [Google Scholar] [CrossRef]
- Chino, D.Y.; Avalhais, L.P.; Rodrigues, J.F.; Traina, A.J. Bowfire: Detection of fire in still images by integrating pixel color and texture analysis. In Proceedings of the 2015 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, Brazil, 26–29 August 2015; pp. 95–102. [Google Scholar]
- Ahmad, N.; Akbar, M.; Alkhammash, E.H.; Jamjoom, M.M. CN2VF-Net: A Hybrid Convolutional Neural Network and Vision Transformer Framework for Multi-Scale Fire Detection in Complex Environments. Fire 2025, 8, 211. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Umirzakova, S.; Tashev, K.; Sevinov, J.; Temirov, Z.; Muminov, B.; Buriboev, A.; Safarova Ulmasovna, L.; Lee, C. AI-Driven Boost in Detection Accuracy for Agricultural Fire Monitoring. Fire 2025, 8, 205. [Google Scholar] [CrossRef]
- Safarov, F.; Muksimova, S.; Kamoliddin, M.; Cho, Y.I. Fire and Smoke Detection in Complex Environments. Fire 2024, 7, 389. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Baik, S.W. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2018, 288, 30–42. [Google Scholar] [CrossRef]
- Foggia, P.; Saggese, A.; Vento, M. Real-time fire detection for video-surveillance applications using a combination of experts based on color, shape, and motion. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1545–1556. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient deep CNN-based fire detection and localization in video surveillance applications. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 1419–1434. [Google Scholar] [CrossRef]
- Jadon, A.; Varshney, A.; Ansari, M.S. Low-complexity high-performance deep learning model for real-time low-cost embedded fire detection systems. Procedia Comput. Sci. 2020, 171, 418–426. [Google Scholar] [CrossRef]
- Pincott, J.; Tien, P.W.; Wei, S.; Calautit, J.K. Indoor fire detection utilizing computer vision-based strategies. J. Build. Eng. 2022, 61, 105154. [Google Scholar] [CrossRef]
- Ahn, Y.; Choi, H.; Kim, B.S. Development of early fire detection model for buildings using computer vision-based CCTV. J. Build. Eng. 2023, 65, 105647. [Google Scholar] [CrossRef]
- Wu, H.; Wu, D.; Zhao, J. An intelligent fire detection approach through cameras based on computer vision methods. Process Saf. Environ. Prot. 2019, 127, 245–256. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Xia, X.; Huang, Q.; Li, X. A gated recurrent network with dual classification assistance for smoke semantic segmentation. IEEE Trans. Image Process. 2021, 30, 4409–4422. [Google Scholar] [CrossRef] [PubMed]
- Tao, H.; Duan, Q. An adaptive frame selection network with enhanced dilated convolution for video smoke recognition. Expert Syst. Appl. 2023, 215, 119371. [Google Scholar] [CrossRef]
- Majid, S.; Alenezi, F.; Masood, S.; Ahmad, M.; Gündüz, E.S.; Polat, K. Attention based CNN model for fire detection and localization in real-world images. Expert Syst. Appl. 2022, 189, 116114. [Google Scholar] [CrossRef]
- Chaoxia, C.; Shang, W.; Zhang, F. Information-guided flame detection based on faster R-CNN. IEEE Access 2020, 8, 58923–58932. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, W.; Liu, Y.; Jing, R.; Liu, C. An efficient fire and smoke detection algorithm based on an end-to-end structured network. Eng. Appl. Artif. Intell. 2022, 116, 105492. [Google Scholar] [CrossRef]
- Huang, L.; Liu, G.; Wang, Y.; Yuan, H.; Chen, T. Fire detection in video surveillances using convolutional neural networks and wavelet transform. Eng. Appl. Artif. Intell. 2022, 110, 104737. [Google Scholar] [CrossRef]
- Zheng, S.; Gao, P.; Wang, W.; Zou, X. A highly accurate forest fire prediction model based on an improved dynamic convolutional neural network. Appl. Sci. 2022, 12, 6721. [Google Scholar] [CrossRef]
- Muhammad, K.; Khan, S.; Palade, V.; Mehmood, I.; De Albuquerque, V.H.C. Edge intelligence-assisted smoke detection in foggy surveillance environments. IEEE Trans. Ind. Inform. 2019, 16, 1067–1075. [Google Scholar] [CrossRef]
- Töreyin, B.U.; Dedeoğlu, Y.; Güdükbay, U.; Cetin, A.E. Computer vision based method for real-time fire and flame detection. Pattern Recognit. Lett. 2006, 27, 49–58. [Google Scholar] [CrossRef]
- Dimitropoulos, K.; Barmpoutis, P.; Grammalidis, N. Spatio-temporal flame modeling and dynamic texture analysis for automatic video-based fire detection. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 339–351. [Google Scholar] [CrossRef]
- Yuan, F. Video-based smoke detection with histogram sequence of LBP and LBPV pyramids. Fire Saf. J. 2011, 46, 132–139. [Google Scholar] [CrossRef]
- Li, S.; Yan, Q.; Liu, P. An efficient fire detection method based on multiscale feature extraction, implicit deep supervision and channel attention mechanism. IEEE Trans. Image Process. 2020, 29, 8467–8475. [Google Scholar] [CrossRef] [PubMed]
- Cheng, H.-Y.; Yin, J.-L.; Chen, B.-H.; Yu, Z.-M. Smoke 100k: A database for smoke detection. In Proceedings of the 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; pp. 596–597. [Google Scholar]
- Cetin, A.E. Computer Vision Based Fire Detection Dataset. 2024. Available online: http://signal.ee.bilkent.edu.tr/VisiFire/ (accessed on 26 January 2025).
- Yar, H.; Hussain, T.; Agarwal, M.; Khan, Z.A.; Gupta, S.K.; Baik, S.W. Optimized dual fire attention network and medium-scale fire classification benchmark. IEEE Trans. Image Process. 2022, 31, 6331–6343. [Google Scholar] [CrossRef] [PubMed]
- Fire Safety Research Institute. Available online: https://www.youtube.com/@FireSafetyResearchInstitute (accessed on 26 January 2025).
- Oh, S.; Hoogs, A.; Perera, A.; Cuntoor, N.; Chen, C.-C.; Lee, J.T.; Mukherjee, S.; Aggarwal, J.K.; Lee, H.; Davis, L. A large-scale benchmark dataset for event recognition in surveillance video. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3153–3160. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Tang, J.; Shu, X.; Yan, R.; Zhang, L. Coherence constrained graph LSTM for group activity recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 44, 636–647. [Google Scholar] [CrossRef] [PubMed]
- Yar, H.; Khan, Z.A.; Rida, I.; Ullah, W.; Kim, M.J.; Baik, S.W. An efficient deep learning architecture for effective fire detection in smart surveillance. Image Vis. Comput. 2024, 145, 104989. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Khan, R.U.; Wong, W.S.; Ullah, I.; Algarni, F.; Haq, U.; Inam, M.; bin Barawi, M.H.; Khan, M.A. Evaluating the Efficiency of CBAM-Resnet Using Malaysian Sign Language. Comput. Mater. Contin. 2022, 71, 2755–2772. [Google Scholar] [CrossRef]
- Yar, H.; Ullah, W.; Khan, Z.A.; Baik, S.W. An effective attention-based CNN model for fire detection in adverse weather conditions. ISPRS J. Photogramm. Remote Sens. 2023, 206, 335–346. [Google Scholar] [CrossRef]
- Sharma, J.; Granmo, O.-C.; Goodwin, M.; Fidje, J.T. Deep convolutional neural networks for fire detection in images. In Proceedings of the Engineering Applications of Neural Networks: 18th International Conference, EANN 2017, Athens, Greece, 25–27 August 2017; pp. 183–193. [Google Scholar]

| Fire | Non-Fire | |
|---|---|---|
| Training | 337 | 357 |
| Validation | 114 | 120 |
| Test | 86 | 94 |
| Total | 537 | 571 |
| 1108 | ||
| Network | Number of Parameters | Recognition Accuracy |
|---|---|---|
| R3D | 33.4 M | 64.2 |
| R(2+1)D | 33.3 M | 68.0 |
| rMC3 | 33.0 M | 65.0 |
| R2D | 11.4 M | 58.9 |
| MC3 | 11.7 M | 64.7 |
| Layer Name | Output Size | MC3_18 Configuration |
|---|---|---|
| conv1 | L × 112 × 112 | 3 × 7 × 7, 64, stride 1 × 2 × 2, padding 1 × 3 × 3 |
| conv2_x | L × 56 × 56 | [3D block: 3 × 3 × 3, 64] × 2 |
| conv3_x | L × 28 × 28 | [2D block: 3 × 3, 128] × 2, stride 2 × 2 |
| conv4_x | L × 14 × 14 | [2D block: 3 × 3, 256] × 2, stride 2 × 2 |
| conv5_x | L × 7 × 7 | [2D block: 3 × 3, 512] × 2, stride 2 × 2 |
| pool | 1 × 1 × 1 | Global average pooling |
| fc | 1 × 1 × 1 | Fully connected (512 → 1 classes) |
| Ref | Dataset | Classes | False Positives | False Negatives | Accuracy |
|---|---|---|---|---|---|
| [36] | DFAN | Outdoor: boat, car, forest, etc. | - | - | 88.00% |
| [41] | Custom dataset | Outdoor/forest fires vs. non-fire | - | - | 93.50% |
| [44] | Custom dataset | Outdoor/forest fires vs. non-fire | - | - | 98.75% |
| [15] | Foggia’s & Chino’s Smoke instances are labeled as non-fire. | Outdoor/forest fires vs. non-fire | 9.07 | 2.13 | 94.39 |
| [27] | Corsican, Foggia, Chino | Indoor and outdoor fires vs. non-fire | 0.64% | 1.13% | 98.26% |
| [19] | Custom dataset | Indoor smoke, flame, non-fire | 72.00% | 10.67% | 82.63% |
| This work | Our new dataset (Realistic, Early-Stage) | Indoor fires vs. non-fire | 11.63% | 15.96% | 86.11% |
| Ref | Dataset | Classes | Recall | Precision | F-Measure |
|---|---|---|---|---|---|
| [36] | DFAN | Outdoor: boat, car, forest, etc. | 88.00% | 88.00% | 87.00% |
| [41] | Custom dataset | Outdoor/forest fires vs. non-fire | 93.51% | 93.57% | 93.51% |
| [44] | Custom dataset | Outdoor/forest fires vs. non-fire | 98.70% | 98.82% | 98.74% |
| [15] | Foggia’s & Chino’s smoke instances are labeled as non-fire. | Outdoor/forest fires vs. non-fire | 98.00% | 82.00% | 89.00% |
| [27] | Corsican, Foggia, Chino | Indoor and outdoor fires vs. non-fire | 96.09% | 97.65% | 96.86% |
| [19] | Custom dataset | Indoor smoke, flame, non-fire | 88.21% | 83.21% | 84.79% |
| This work | Our new dataset (realistic, early-stage) | Indoor fires vs. non-fire | 84.04 | 88.76% | 86.34% |
| Model | FPS | Model Size (MB) | Parameters (Millions) | System Specification |
|---|---|---|---|---|
| Our model | 47.6 | 44.18 | 11.58 | NVIDIA GPU RTX 4090 24 GB GPU |
| ResNet50 [27] | 112 | 97.6 | 25.6 | - |
| DFAN [36] | 70.55 | 83.63 | 23.9 | NVIDIA GPU 2070 12 GB GPU |
| 12.90 | Intel Core i9, 3,60 GHz CPU | |||
| MSAM [41] | 75.15 | 25.20 | 3.17 | NVIDIA GPU 2070 12 GB GPU |
| MobileNet_V2 [29] | 39.78 | 13.23 | - | NVIDIA GPU TITAN X (Pascal) 12 GB GPU |
| ResNetFire [45] | 57.3 | 98.0 | 25.6 | NVIDIA 12 GB GPU |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, M.M.E.H.; Ghodrat, M. Reliable Indoor Fire Detection Using Attention-Based 3D CNNs: A Fire Safety Engineering Perspective. Fire 2025, 8, 285. https://doi.org/10.3390/fire8070285
Ali MMEH, Ghodrat M. Reliable Indoor Fire Detection Using Attention-Based 3D CNNs: A Fire Safety Engineering Perspective. Fire. 2025; 8(7):285. https://doi.org/10.3390/fire8070285
Chicago/Turabian StyleAli, Mostafa M. E. H., and Maryam Ghodrat. 2025. "Reliable Indoor Fire Detection Using Attention-Based 3D CNNs: A Fire Safety Engineering Perspective" Fire 8, no. 7: 285. https://doi.org/10.3390/fire8070285
APA StyleAli, M. M. E. H., & Ghodrat, M. (2025). Reliable Indoor Fire Detection Using Attention-Based 3D CNNs: A Fire Safety Engineering Perspective. Fire, 8(7), 285. https://doi.org/10.3390/fire8070285