

Wildfire Susceptibility Prediction Based on a CA-Based CCNN with Active Learning Optimization

Abstract
1. Introduction
- In order to capture the spatial distribution characteristics of pixels and the correlation between local regions in the fire-influencing factor raster map, we embed the CA module into the feature extraction network of CCNN in order to aggregate different location information into channels and thereby model the global information of the fire-influencing factor raster map;
- We adopt an active learning approach based on two types of complementary learning strategies in order to improve the network’s discriminative performance by prioritizing the selection of fire-influencing factor patches with high confidence. Compared with traditional learning methods, the model can achieve a balance of high prediction accuracy and low annotation cost;
- We adopt the CA-based CCNN to output the fire probability of fire-influencing factor raster patches. Instead of fixed input patches used in CNN, the proposed method allows different patch sizes without changing the structural parameters of the model, which contributes to improving the application flexibility of the wildfire susceptibility prediction model in different scenes.
2. Study Area and Data Sources
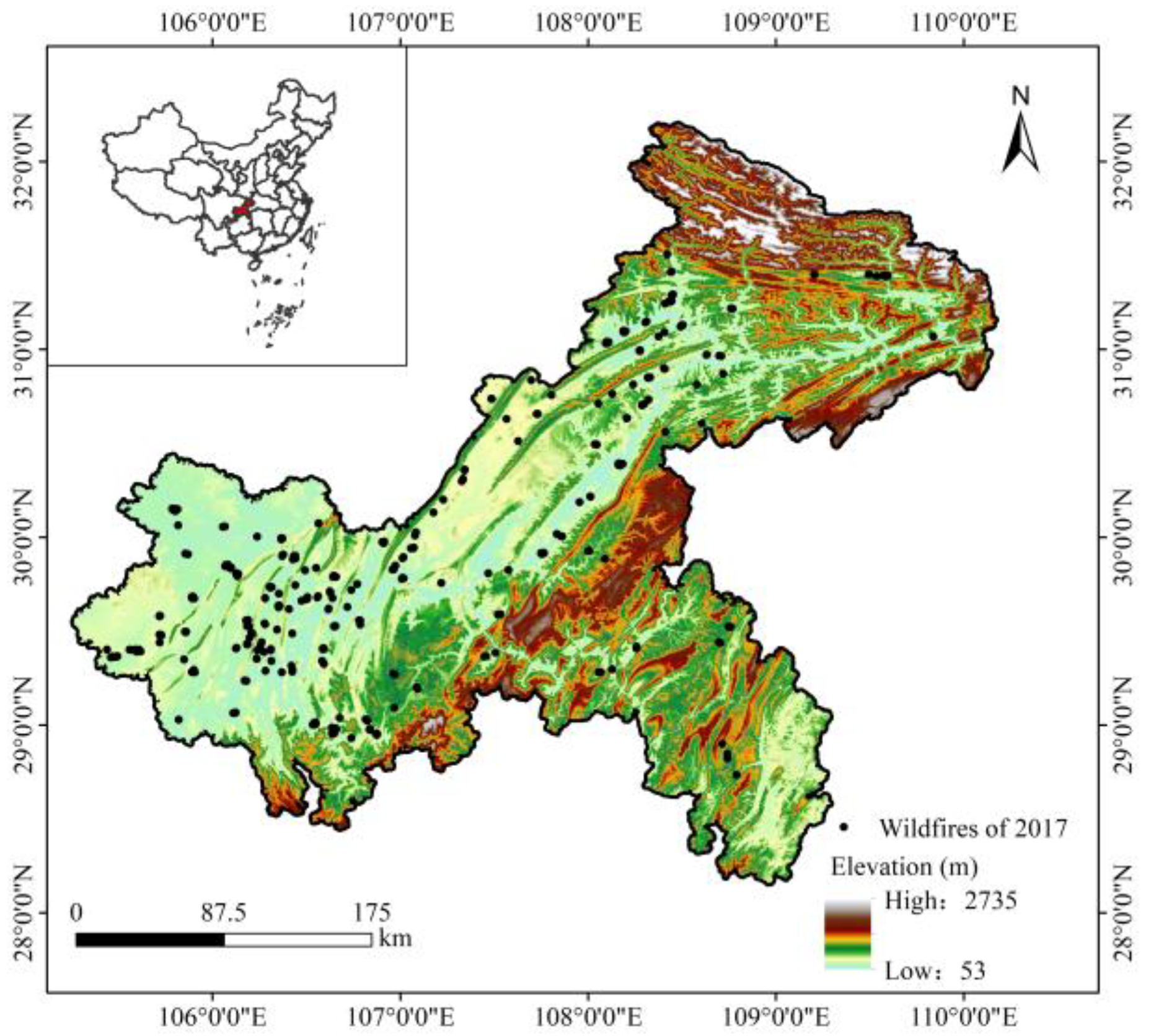
2.1. Study Area
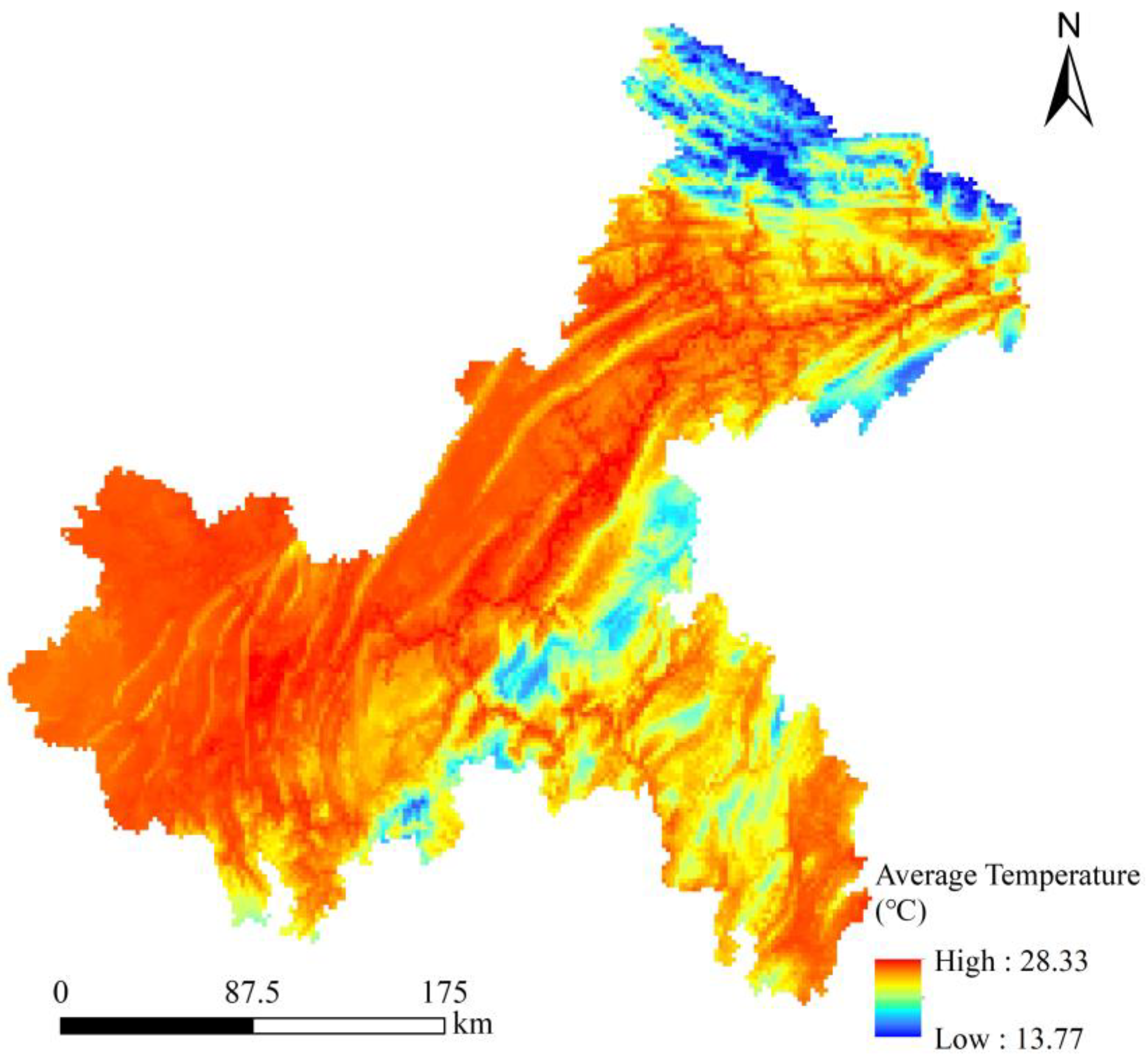
2.2. Data Sources
3. Methods
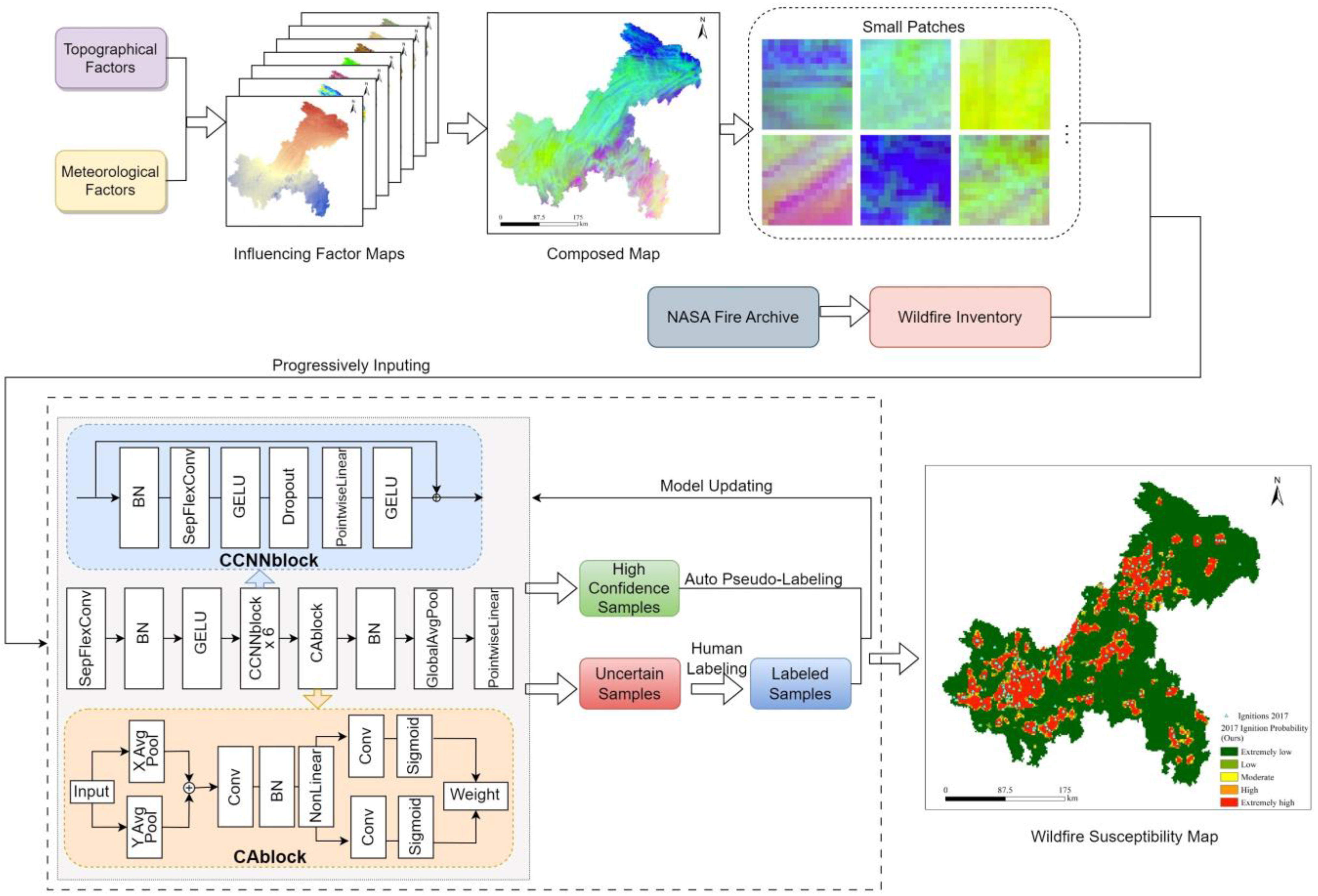
3.1. Generation of Fire-Influencing Factor Raster Maps
3.2. The Model Input
3.3. The Structure of the CA-Based CCNN Model
3.4. Active Learning Training Strategy
4. Experiments
4.1. Implement Details
4.2. Metrics
5. Results
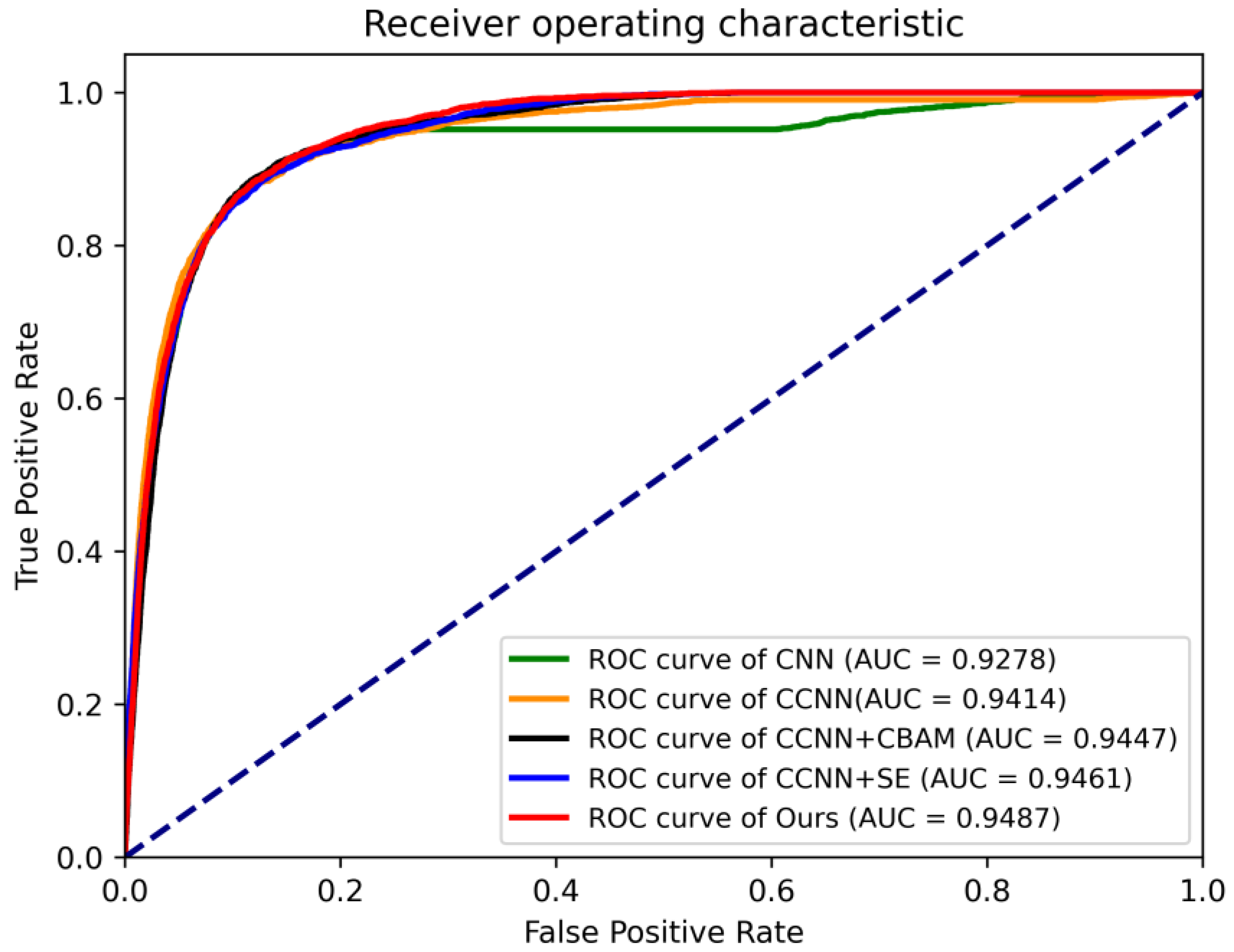
5.1. Ablation Study
5.2. Comparison with State-of-the-Art Machine Learning Methods
5.3. Wildfire Susceptibility Maps
5.4. Verification of Training Efficiency of Two Types of Complementary Learning Strategy
6. Discussions
6.1. Fire-Influencing Factors and Fire Susceptibility Prediction
6.2. Advantages of CCNN
6.3. The Basis for CA Module Selection
6.4. Labeling Cost
6.5. Wildfire Susceptibility Map
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bui, D.T.; Le, H.V.; Hoang, N.D. GIS-based spatial prediction of tropical forest fire danger using a new hybrid machine learning method. Ecol. Inform. 2018, 48, 104–116. [Google Scholar] [CrossRef]
- Sachdeva, S.; Bhatia, T.; Verma, A.K. GIS-based evolutionary optimized Gradient Boosted Decision Trees for forest fire susceptibility mapping. Nat. Hazards 2018, 92, 1399–1418. [Google Scholar] [CrossRef]
- Razavi-Termeh, S.V.; Sadeghi-Niaraki, A.; Choi, S.M. Ubiquitous GIS-Based Forest Fire Susceptibility Mapping Using Artificial Intelligence Methods. Remote Sens. 2020, 12, 1689. [Google Scholar] [CrossRef]
- McEvoy, A.; Nielsen-Pincus, M.; Holz, A.; Catalano, A.J.; Gleason, K.E. Projected Impact of Mid-21st Century Climate Change on Wildfire Hazard in a Major Urban Watershed outside Portland, Oregon USA. Fire 2020, 3, 70. [Google Scholar] [CrossRef]
- Nguyen, N.T.; Dang, B.T.N.; Pham, X.C.; Nguyen, H.T.; Bui, H.T.; Hoang, N.D.; Bui, D.T. Spatial pattern assessment of tropical forest fire danger at Thuan Chau area (Vietnam) using GIS-based advanced machine learning algorithms: A comparative study. Ecol. Inform. 2018, 46, 74–85. [Google Scholar] [CrossRef]
- Cicione, A.; Gibson, L.; Wade, C.; Spearpoint, M.; Walls, R.; Rush, D. Towards the Development of a Probabilistic Approach to Informal Settlement Fire Spread Using Ignition Modelling and Spatial Metrics. Fire 2020, 3, 67. [Google Scholar] [CrossRef]
- Maeda, E.E.; Formaggio, A.R.; Shimabukuro, Y.E.; Arcoverde, G.F.B.; Hansen, M.C. Predicting forest fire in the Brazilian Amazon using MODIS imagery and artificial neural networks. Int. J. Appl. Earth Obs. Geoinf. 2009, 11, 265–272. [Google Scholar] [CrossRef]
- Mohajane, M.; Costache, R.; Karimi, F.; Pham, Q.B.; Essahlaoui, A.; Nguyen, H.; Laneve, G.; Oudija, F. Application of remote sensing and machine learning algorithms for forest fire mapping in a Mediterranean area. Ecol. Indic. 2021, 129, 107869. [Google Scholar] [CrossRef]
- Bui, D.T.; Bui, Q.T.; Nguyen, Q.P.; Pradhan, B.; Nampak, H.; Trinh, P.T. A hybrid artificial intelligence approach using GIS-based neural-fuzzy inference system and particle swarm optimization for forest fire susceptibility modeling at a tropical area. Agr. Forest Meteorol. 2017, 233, 32–44. [Google Scholar] [CrossRef]
- Sivrikaya, F.; Küçük, O. Modeling forest fire risk based on GIS-based analytical hierarchy process and statistical analysis in Mediterranean region. Ecol. Inform. 2022, 68, 15. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Aretano, R.; Semeraro, T. Investigation of general indicators influencing on forest fire and its susceptibility modeling using different data mining techniques. Ecol. Indic. 2016, 64, 72–84. [Google Scholar] [CrossRef]
- Bui, D.T.; Le, K.T.T.; Nguyen, V.C.; Le, H.D.; Revhaug, I. Tropical Forest Fire Susceptibility Mapping at the Cat Ba National Park Area, Hai Phong City, Vietnam, Using GIS-Based Kernel Logistic Regression. Remote Sens. 2016, 8, 347. [Google Scholar] [CrossRef]
- Vasconcelos, M.J.P.D.; Silva, S.; Tome, M.; Alvim, M.; Pereira, J.M.C. Spatial prediction of fire ignition probabilities: Comparing logistic regression and neural networks. Photogramm. Eng. Remote Sens. 2001, 67, 73–81. [Google Scholar]
- Dimuccio, L.A.; Ferreira, R.; Cunha, L.; de Almeida, A.C. Regional forest-fire susceptibility analysis in central Portugal using a probabilistic ratings procedure and artificial neural network weights assignment. Int. J. Wildland Fire 2011, 20, 776–791. [Google Scholar] [CrossRef]
- Satir, O.; Berberoglu, S.; Donmez, C. Mapping regional forest fire probability using artificial neural network model in a Mediterranean forest ecosystem. Geomat. Nat. Hazards Risk 2016, 7, 1645–1658. [Google Scholar] [CrossRef]
- Dong, Z.; Pei, M.T.; He, Y.; Liu, T.; Dong, Y.M.; Jia, Y.D. Vehicle Type Classification Using Unsupervised Convolutional Neural Network. In Proceedings of the 22nd International Conference on Pattern Recognition (ICPR), Swedish Soc Automated Image Anal, Stockholm, Sweden, 24–28 August 2014; pp. 172–177. [Google Scholar]
- Yan, X.; Liu, Y.; Xu, Y.; Jia, M. Multistep forecasting for diurnal wind speed based on hybrid deep learning model with improved singular spectrum decomposition. Energy Convers. Manag. 2020, 225, 113456. [Google Scholar] [CrossRef]
- Zhang, G.L.; Wang, M.; Liu, K. Forest Fire Susceptibility Modeling Using a Convolutional Neural Network for Yunnan Province of China. Int. J. Disaster Risk Sci. 2019, 10, 386–403. [Google Scholar] [CrossRef]
- Huang, Z.; Zhu, T.; Li, Z.; Ni, C. Non-Destructive Testing of Moisture and Nitrogen Content in Pinus Massoniana Seedling Leaves with NIRS Based on MS-SC-CNN. Appl. Sci. 2021, 11, 2754. [Google Scholar] [CrossRef]
- Knigge, D.M.; Romero, D.W.; Gu, A.; Gavves, E.; Bekkers, E.; Tomczak, J.M.; Hoogendoorn, M.; Sonke, J. Modelling Long Range Dependencies in N-D: From Task-Specific to a General Purpose CNN. arxiv 2023, arXiv:2301.10540. [Google Scholar]
- Romero, D.W.; Kuzina, A.; Bekkers, E.J.; Tomczak, J.M.; Hoogendoorn, M. CKConv: Continuous Kernel Convolution For Sequential Data. arxiv 2021, arXiv:2102.02611. [Google Scholar]
- Romero, D.W.; Bruintjes, R.J.; Tomczak, J.M.; Bekkers, E.J.; Hoogendoorn, M.; Gemert, J.C.V. FlexConv: Continuous Kernel Convolutions with Differentiable Kernel Sizes. arxiv 2021, arXiv:2110.08059. [Google Scholar]
- Fathony, R.; Sahu, A.K.; Willmott, D.; Kolter, J.Z. Multiplicative filter networks. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 165–174. [Google Scholar]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Virtual, 19–25 June 2021; pp. 13708–13717. [Google Scholar]
- Wang, K.Z.; Zhang, D.Y.; Li, Y.; Zhang, R.M.; Lin, L. Cost-Effective Active Learning for Deep Image Classification. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 2591–2600. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arxiv 2017, arXiv:1711.05101. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arxiv 2016, arXiv:1608.03983. [Google Scholar]
- Cao, Y.X.; Wang, M.; Liu, K. Wildfire Susceptibility Assessment in Southern China: A Comparison of Multiple Methods. Int. J. Disaster Risk Sci. 2017, 8, 164–181. [Google Scholar] [CrossRef]
- Fadhillah, M.F.; Lee, S.; Lee, C.W.; Park, Y.C. Application of Support Vector Regression and Metaheuristic Optimization Algorithms for Groundwater Potential Mapping in Gangneung-si, South Korea. Remote Sens. 2021, 13, 1196. [Google Scholar] [CrossRef]
- Hakim, W.L.; Achmad, A.R.; Lee, C.W. Land Subsidence Susceptibility Mapping in Jakarta Using Functional and Meta-Ensemble Machine Learning Algorithm Based on Time-Series InSAR Data. Remote Sens. 2020, 12, 3627. [Google Scholar] [CrossRef]
- Han, J.; Nur, A.S.; Syifa, M.; Ha, M.; Lee, C.W.; Lee, K.Y. Improvement of Earthquake Risk Awareness and Seismic Literacy of Korean Citizens through Earthquake Vulnerability Map from the 2017 Pohang Earthquake, South Korea. Remote Sens. 2021, 13, 1365. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression, 3rd ed.; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Demir, B.; Bruzzone, L. A Novel Active Learning Method in Relevance Feedback for Content-Based Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2323–2334. [Google Scholar] [CrossRef]
- Wang, H.; Zhu, Y.; Green, B.; Adam, H.; Yuille, A.; Chen, L.C. Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation. arxiv 2020, arXiv:2003.07853. [Google Scholar]
- Hou, Q.B.; Zhang, L.; Cheng, M.M.; Feng, J.S. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Seattle, WA, USA, 14–19 June 2020; pp. 4002–4011. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Size | 15 × 15 | 25 × 25 | 35 × 35 | |
|---|---|---|---|---|
| Training | TP | 2005 | 2005 | 2000 |
| TN | 1992 | 1993 | 1988 | |
| FP | 2 | 1 | 6 | |
| FN | 1 | 1 | 6 | |
| Sensitivity (%) | 99.95 | 99.95 | 99.70 | |
| Specificity (%) | 99.90 | 99.95 | 99.70 | |
| PPV (%) | 99.90 | 99.95 | 99.70 | |
| NPV (%) | 99.95 | 99.95 | 99.70 | |
| Accuracy (%) | 99.93 | 99.95 | 99.70 | |
| Validating | TP | 466 | 468 | 472 |
| TN | 447 | 449 | 440 | |
| FP | 59 | 57 | 66 | |
| FN | 28 | 26 | 22 | |
| Sensitivity (%) | 94.33 | 94.74 | 95.55 | |
| Specificity (%) | 88.34 | 88.74 | 86.96 | |
| PPV (%) | 88.76 | 89.14 | 87.73 | |
| NPV (%) | 94.11 | 94.53 | 95.24 | |
| Accuracy (%) | 91.30 | 91.70 | 91.20 |
| Models | Ours | CNN-Based Method [18] | CCNN | CCNN + SE | CCNN + CBAM | |
|---|---|---|---|---|---|---|
| Training | TP | 2005 | 1992 | 2001 | 2000 | 1997 |
| TN | 1993 | 1918 | 1978 | 1984 | 1983 | |
| FP | 1 | 71 | 16 | 10 | 11 | |
| FN | 1 | 19 | 5 | 6 | 9 | |
| Sensitivity (%) | 99.95 | 99.06 | 99.75 | 99.70 | 99.55 | |
| Specificity (%) | 99.95 | 96.43 | 99.20 | 99.50 | 99.45 | |
| PPV (%) | 99.95 | 96.56 | 99.21 | 99.50 | 99.45 | |
| NPV (%) | 99.95 | 99.02 | 99.75 | 99.70 | 99.55 | |
| Accuracy (%) | 99.95 | 97.75 | 99.48 | 99.60 | 99.50 | |
| Validating | TP | 468 | 437 | 464 | 463 | 460 |
| TN | 449 | 429 | 436 | 448 | 444 | |
| FP | 57 | 82 | 70 | 58 | 62 | |
| FN | 26 | 52 | 30 | 31 | 34 | |
| Sensitivity (%) | 94.74 | 89.37 | 93.93 | 93.72 | 93.12 | |
| Specificity (%) | 88.74 | 83.95 | 86.17 | 88.54 | 87.75 | |
| PPV (%) | 89.14 | 84.2 | 86.89 | 88.87 | 88.12 | |
| NPV (%) | 94.53 | 89.19 | 93.56 | 93.53 | 92.89 | |
| Accuracy (%) | 91.70 | 86.60 | 90.00 | 91.10 | 90.40 |
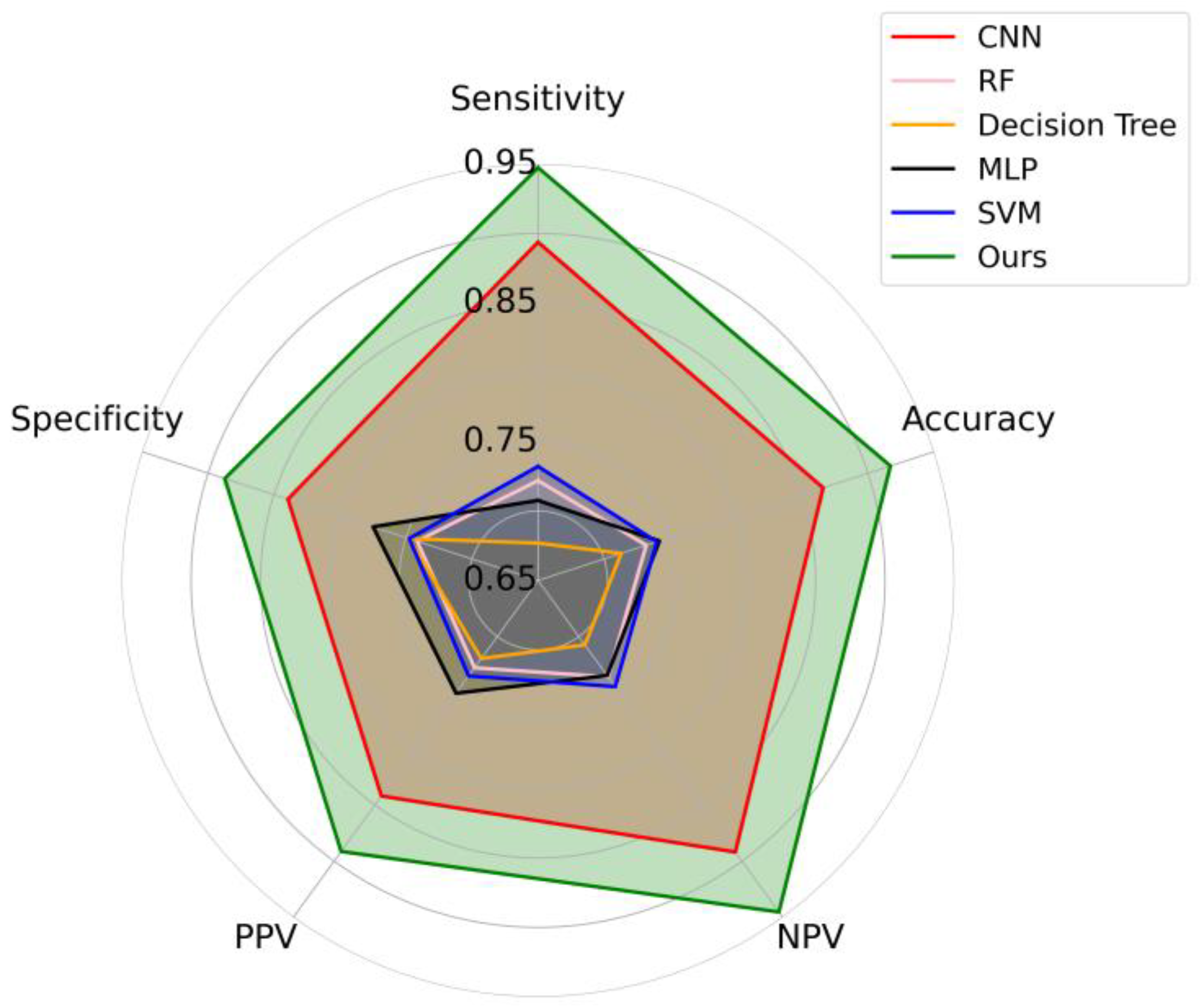
| Models | Ours | CNN | RF | Decision Tree | MLP | SVM | |
|---|---|---|---|---|---|---|---|
| Training | TP | 2005 | 1992 | 2003 | 1695 | 1530 | 1611 |
| TN | 1993 | 1918 | 1985 | 1742 | 1555 | 1558 | |
| FP | 1 | 71 | 4 | 247 | 434 | 431 | |
| FN | 1 | 19 | 8 | 316 | 481 | 400 | |
| Sensitivity (%) | 99.95 | 99.06 | 99.60 | 84.29 | 76.08 | 80.11 | |
| Specificity (%) | 99.95 | 96.43 | 99.80 | 87.58 | 78.18 | 78.33 | |
| PPV (%) | 99.95 | 96.56 | 99.80 | 87.28 | 77.90 | 78.89 | |
| NPV (%) | 99.95 | 99.02 | 99.60 | 84.65 | 76.38 | 79.57 | |
| Accuracy (%) | 99.95 | 97.75 | 99.70 | 85.93 | 77.13 | 79.23 | |
| Validating | TP | 468 | 437 | 353 | 331 | 346 | 358 |
| TN | 449 | 429 | 379 | 382 | 396 | 382 | |
| FP | 57 | 82 | 132 | 129 | 115 | 129 | |
| FN | 26 | 52 | 136 | 158 | 143 | 131 | |
| Sensitivity (%) | 94.74 | 89.37 | 72.19 | 67.69 | 70.76 | 73.21 | |
| Specificity (%) | 88.74 | 83.95 | 74.17 | 74.76 | 77.50 | 74.76 | |
| PPV (%) | 89.14 | 84.2 | 72.78 | 71.96 | 75.05 | 73.51 | |
| NPV (%) | 94.53 | 89.19 | 73.59 | 70.74 | 73.47 | 74.46 | |
| Accuracy (%) | 91.70 | 86.60 | 73.20 | 71.30 | 74.20 | 74.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Q.; Zhao, Y.; Yin, Z.; Xu, Z. Wildfire Susceptibility Prediction Based on a CA-Based CCNN with Active Learning Optimization. Fire 2024, 7, 201. https://doi.org/10.3390/fire7060201
Yu Q, Zhao Y, Yin Z, Xu Z. Wildfire Susceptibility Prediction Based on a CA-Based CCNN with Active Learning Optimization. Fire. 2024; 7(6):201. https://doi.org/10.3390/fire7060201
Chicago/Turabian StyleYu, Qiuping, Yaqin Zhao, Zixuan Yin, and Zhihao Xu. 2024. "Wildfire Susceptibility Prediction Based on a CA-Based CCNN with Active Learning Optimization" Fire 7, no. 6: 201. https://doi.org/10.3390/fire7060201
APA StyleYu, Q., Zhao, Y., Yin, Z., & Xu, Z. (2024). Wildfire Susceptibility Prediction Based on a CA-Based CCNN with Active Learning Optimization. Fire, 7(6), 201. https://doi.org/10.3390/fire7060201