
Comparing Accuracy of Wildfire Spread Prediction Models under Different Data Deficiency Conditions



Abstract
1. Introduction
- We assessed the impact of missing data (e.g., topographic, fuel, and weather items) on the accuracy of wildfire spread models, visualized the final results, and quantified the prediction errors;
- Based on the assessment results, we analyzed the potential causes of the decline in accuracy and evaluation metrics, providing new insights for the development of universally applicable prediction models in the future.
2. Materials and Methods
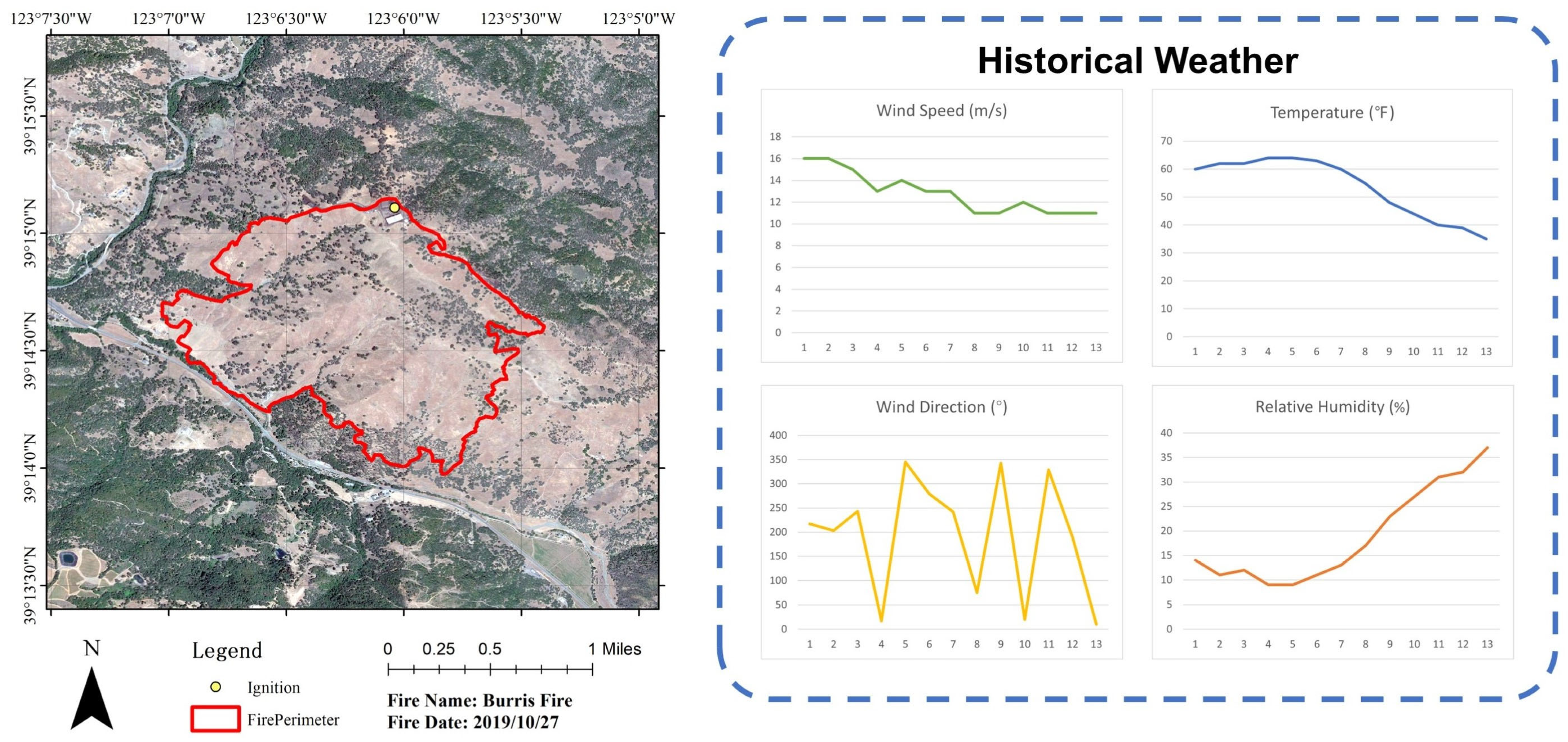
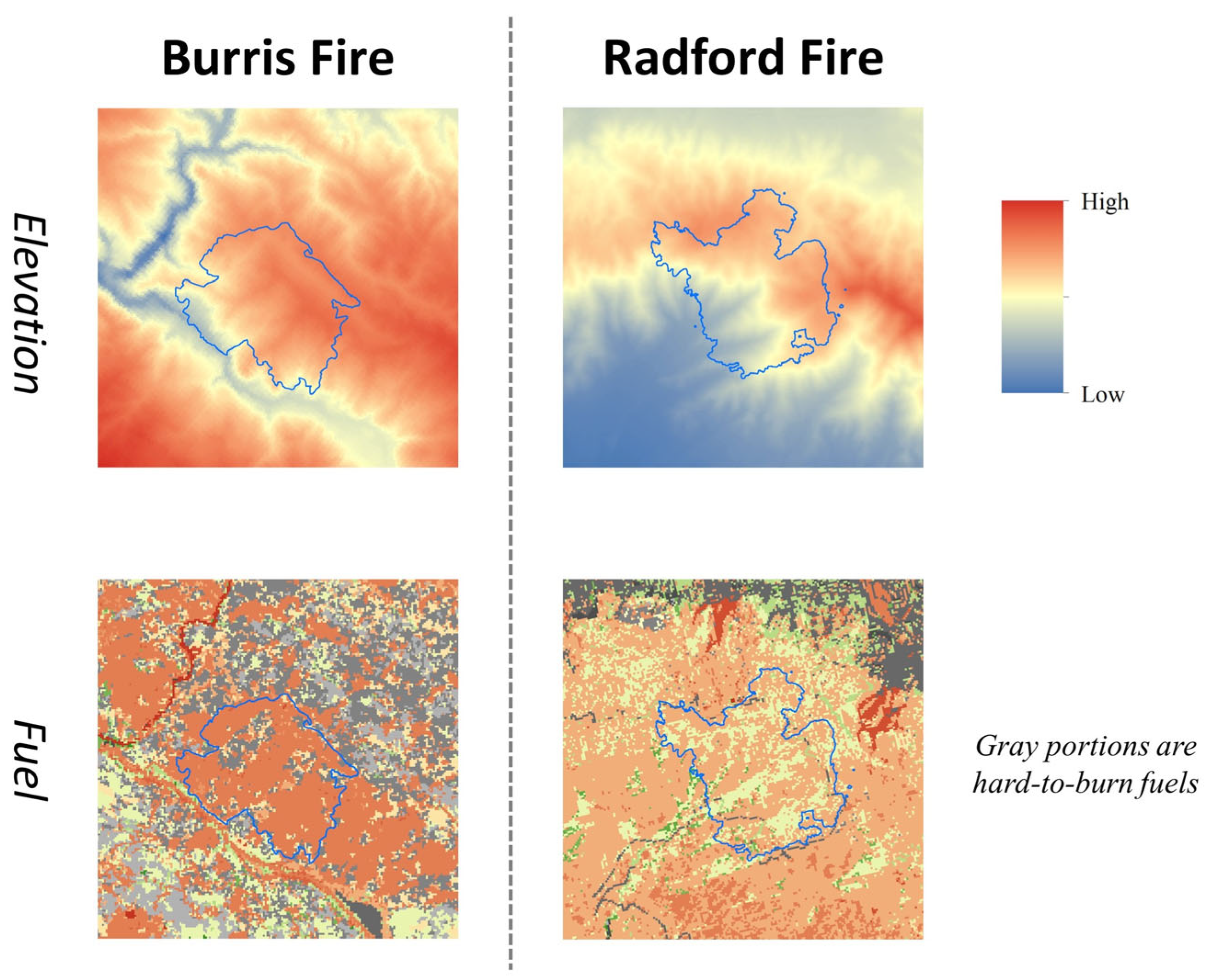
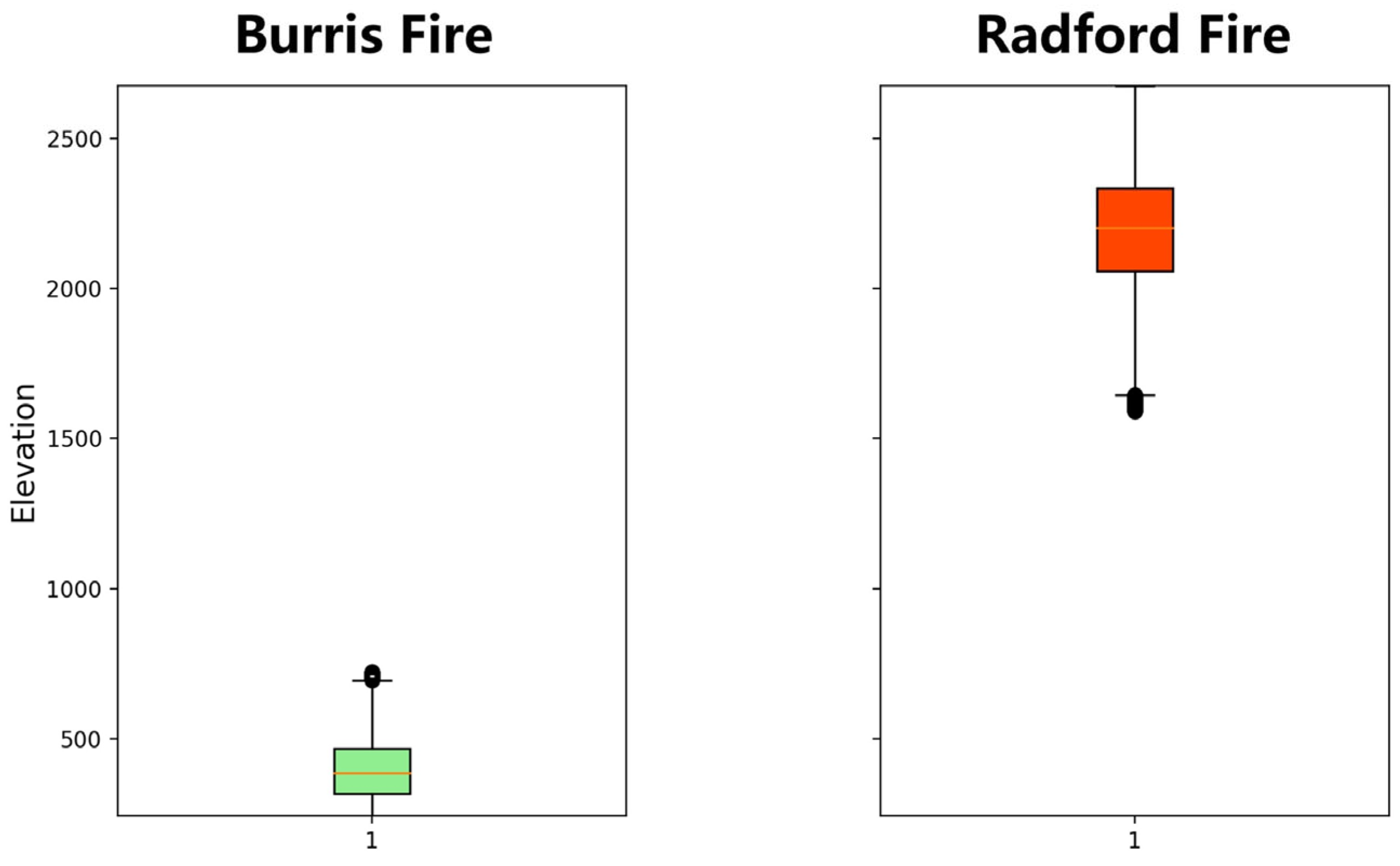
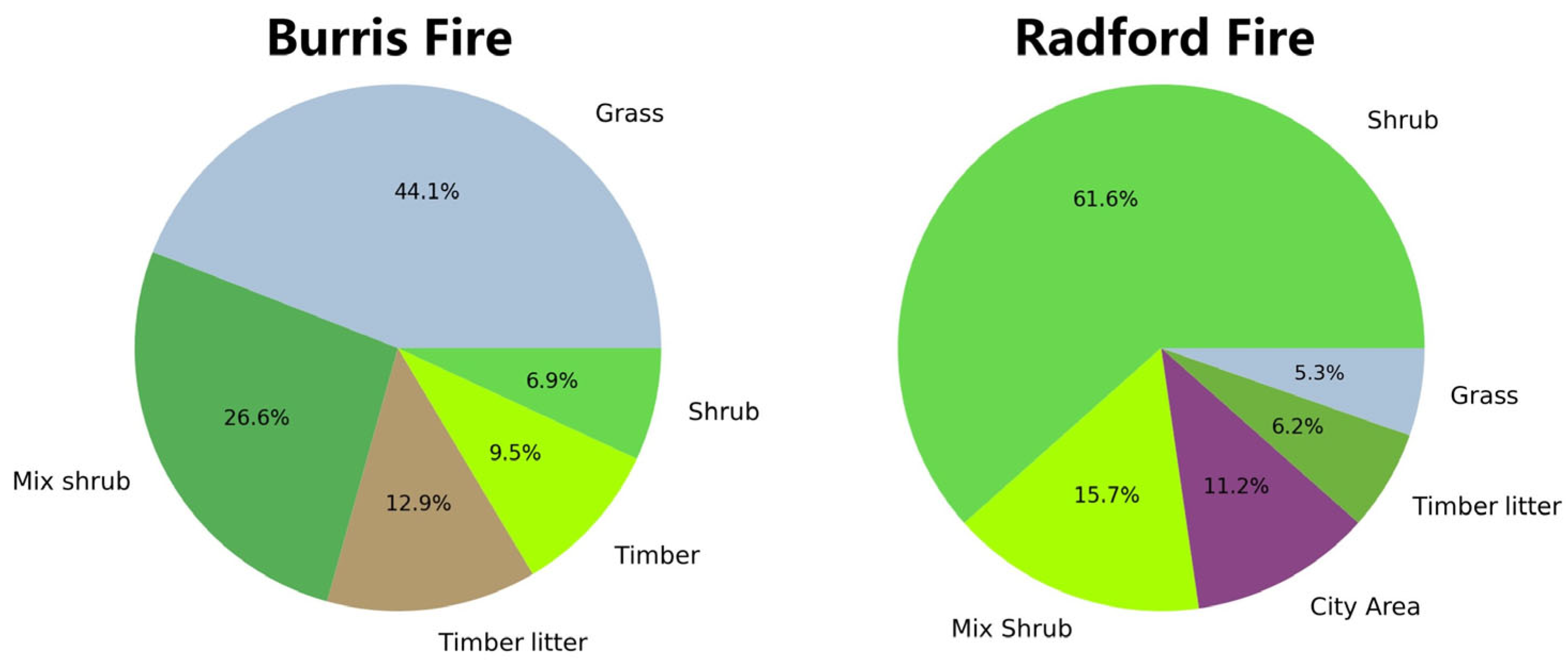
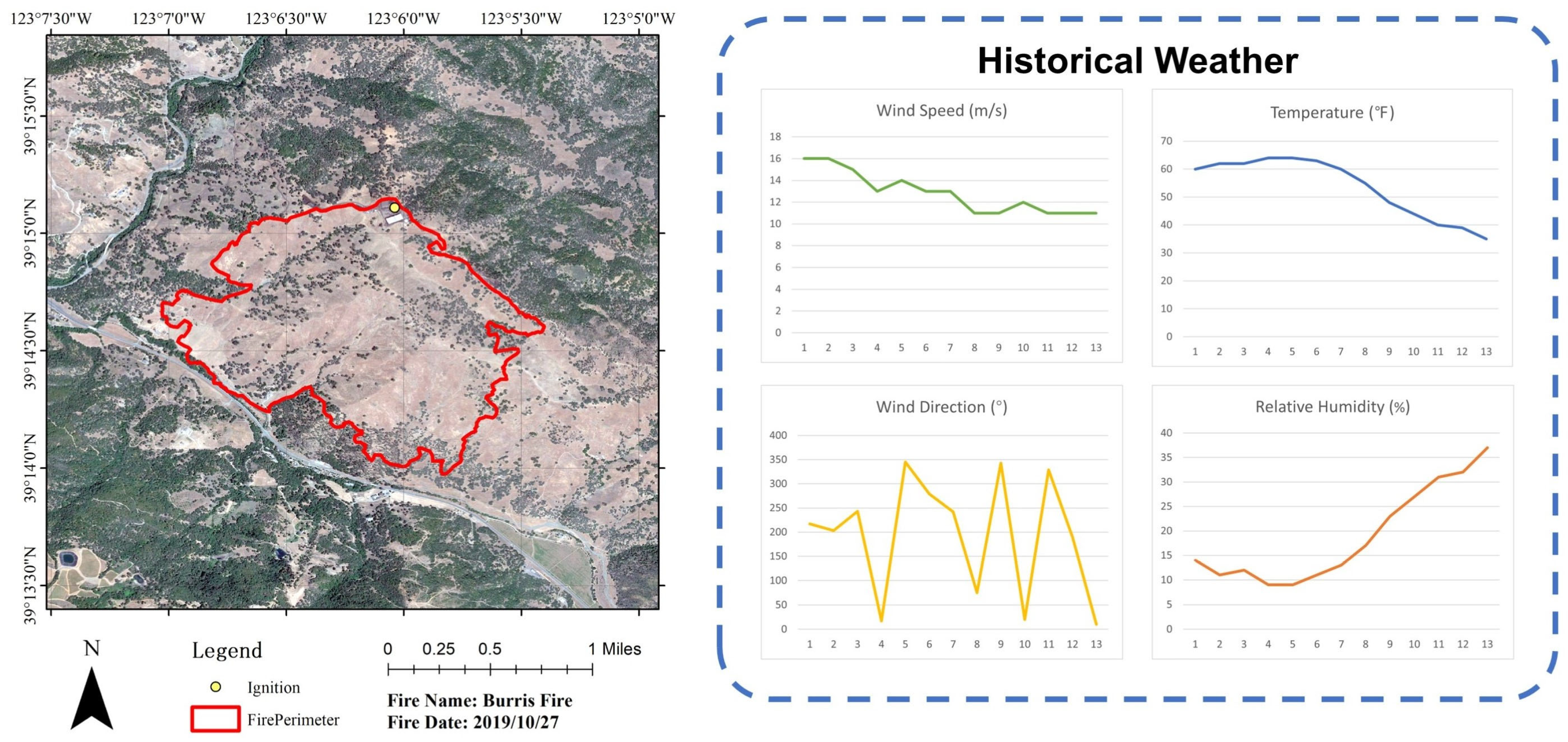
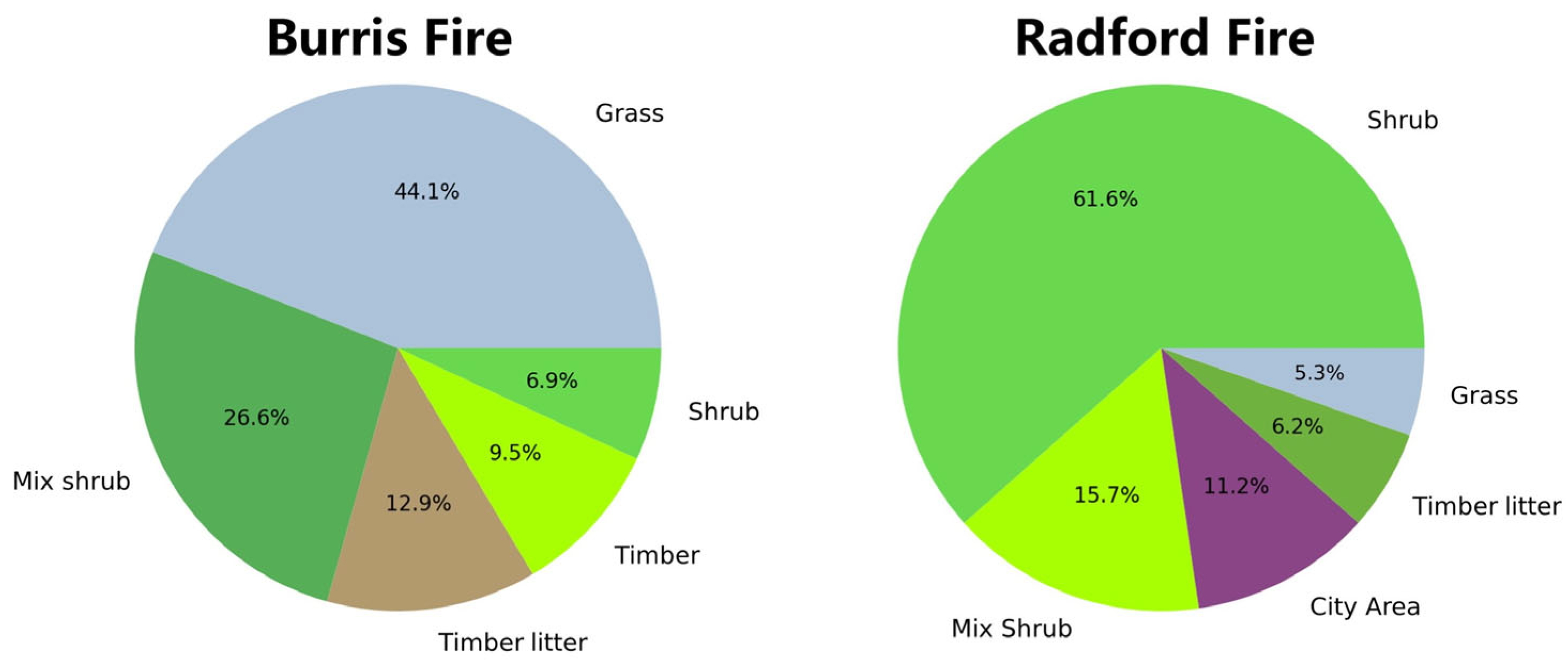
2.1. Experimental Area
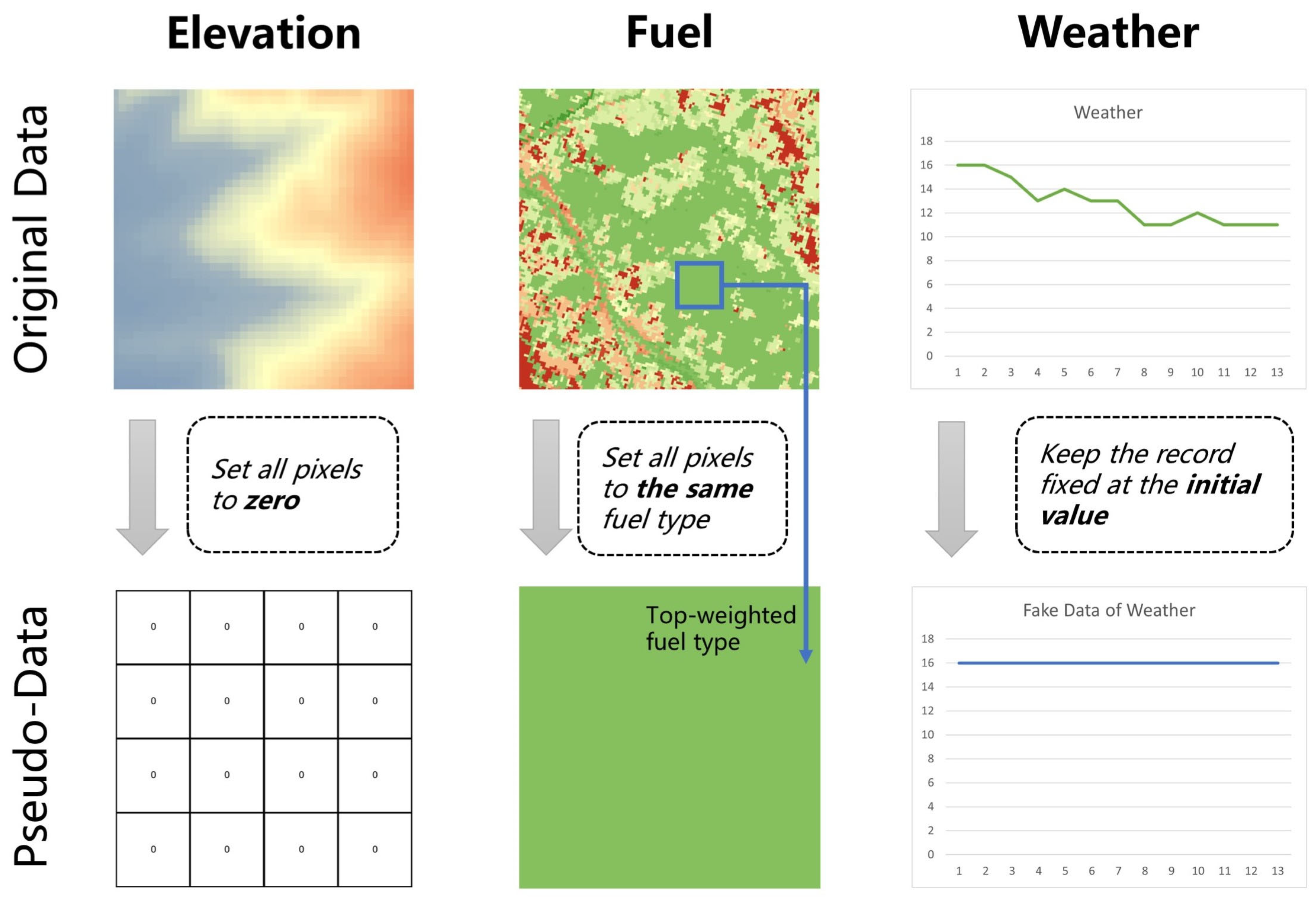
2.2. Pseudo-Data Generation
- Elevation data: Raster data with all pixels set to zero were generated according to the original data range and resolution to simulate unknown elevation conditions;
- Fuel model: Based on the most prevalent type of fuel in the burning area, raster data with all pixels set to the same fuel type were also created according to the original data range and resolution;
- Weather data: It was assumed that all weather elements remained constant from the start of the fire, and from this, pseudo-weather data were generated.
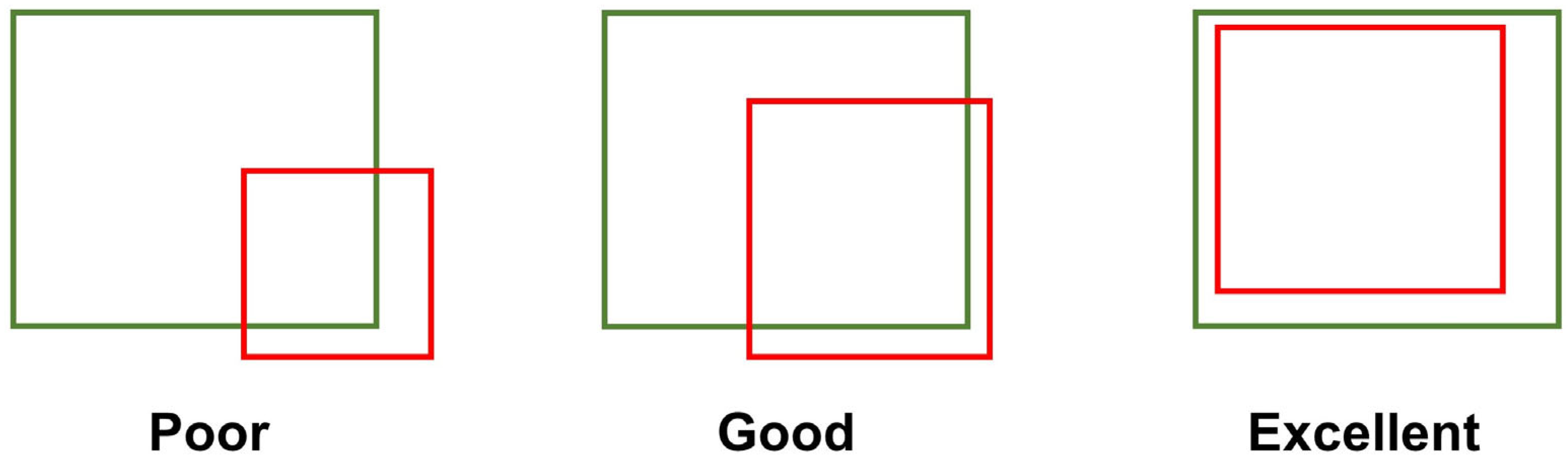
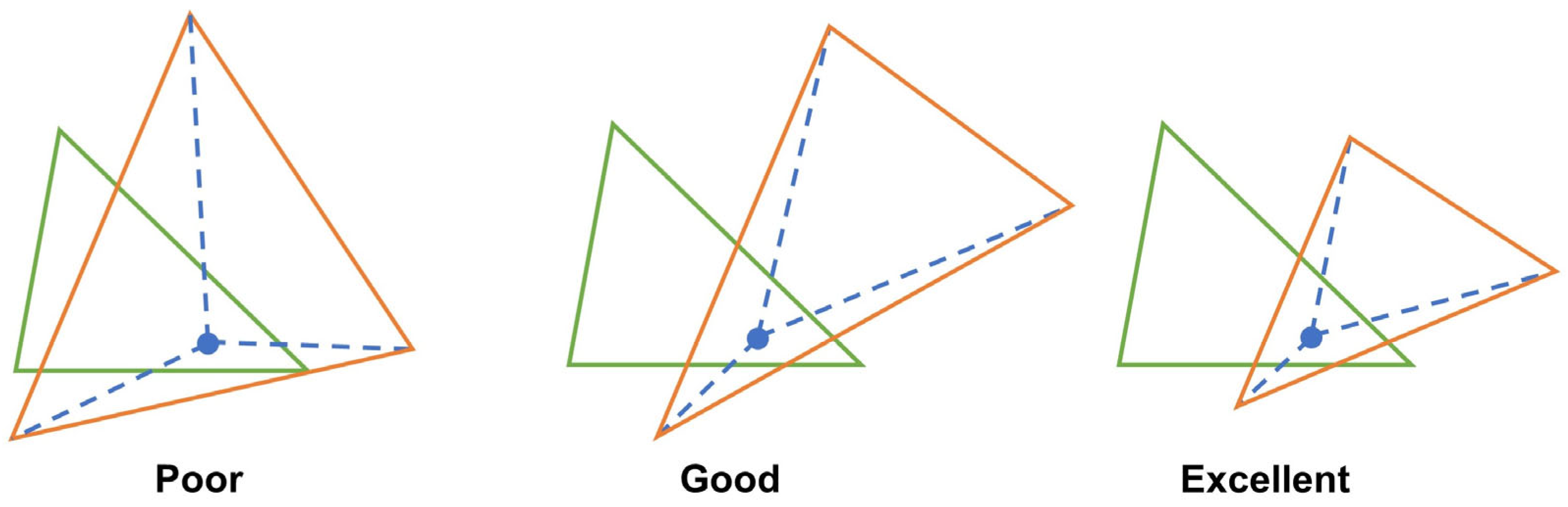
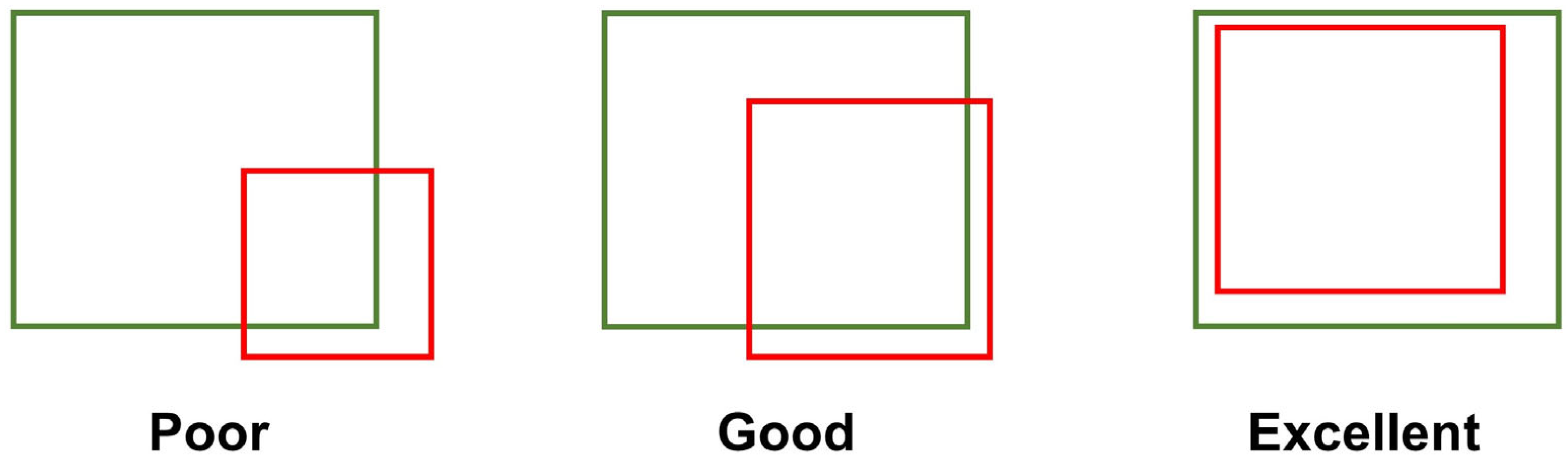
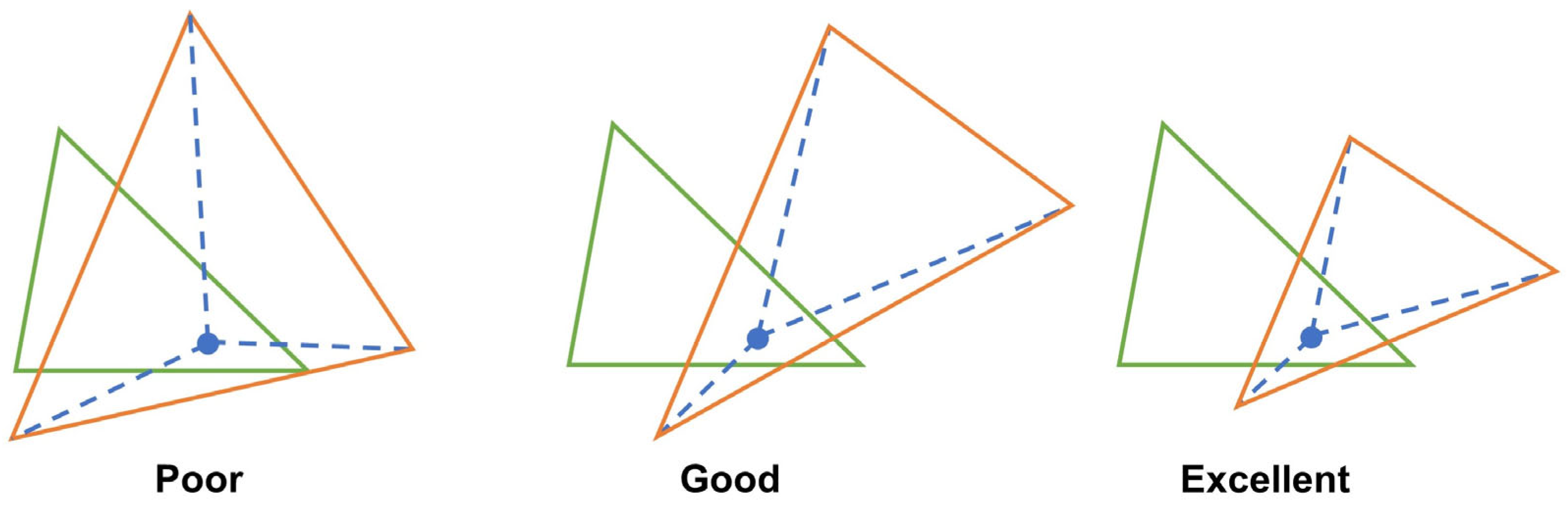
2.3. Evaluation Metrics
3. Experiment Results
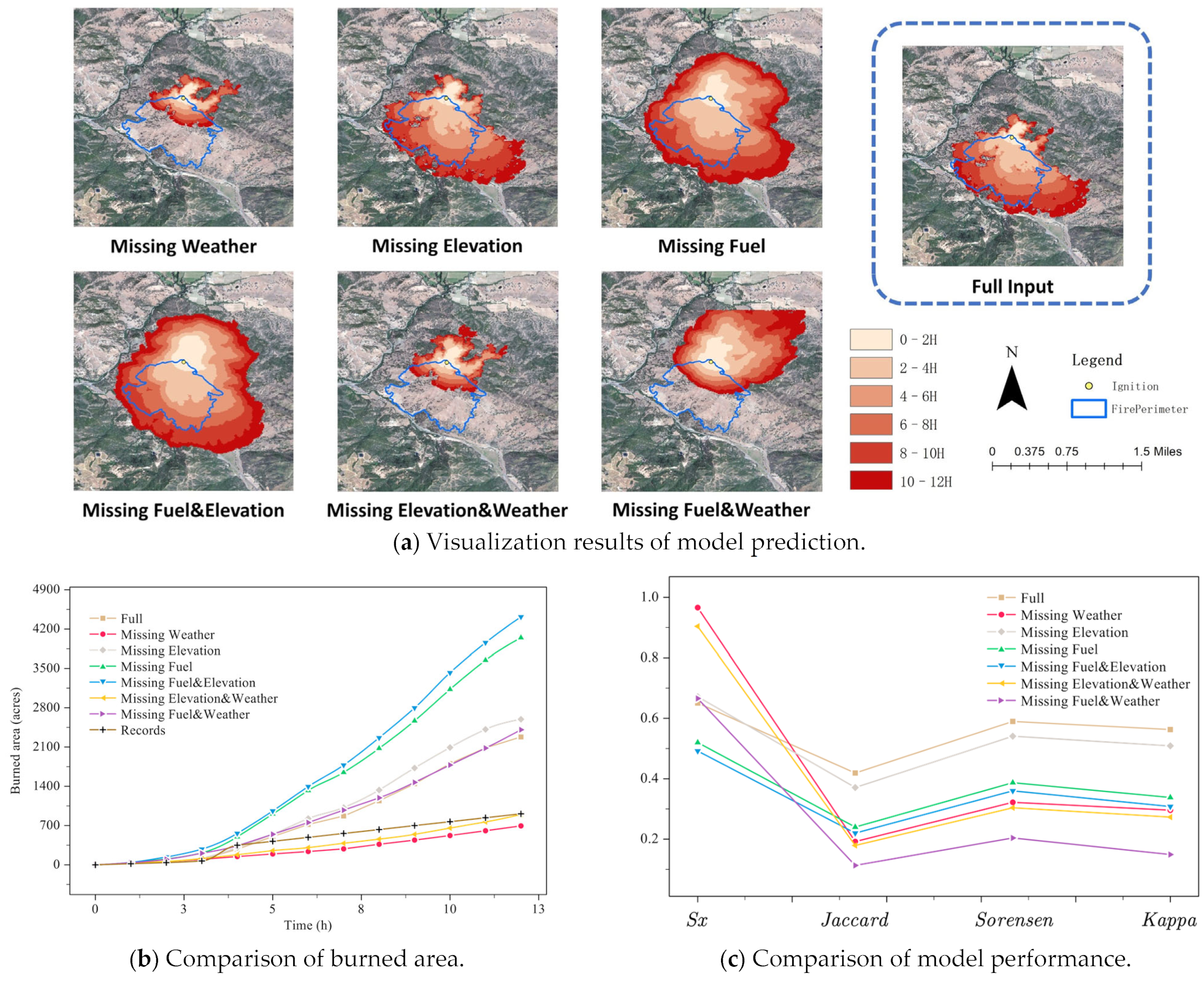
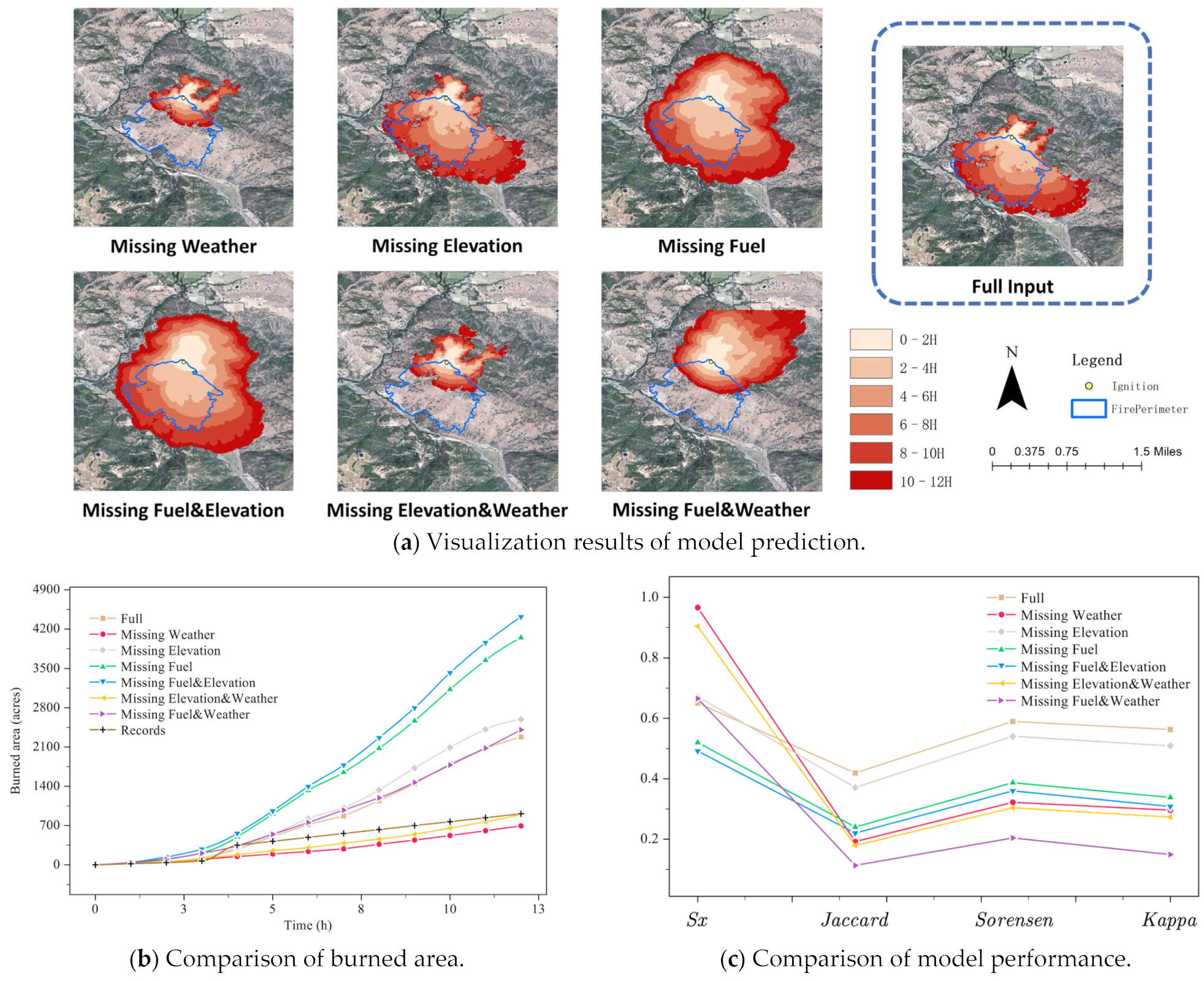
3.1. Results on Burris Fire
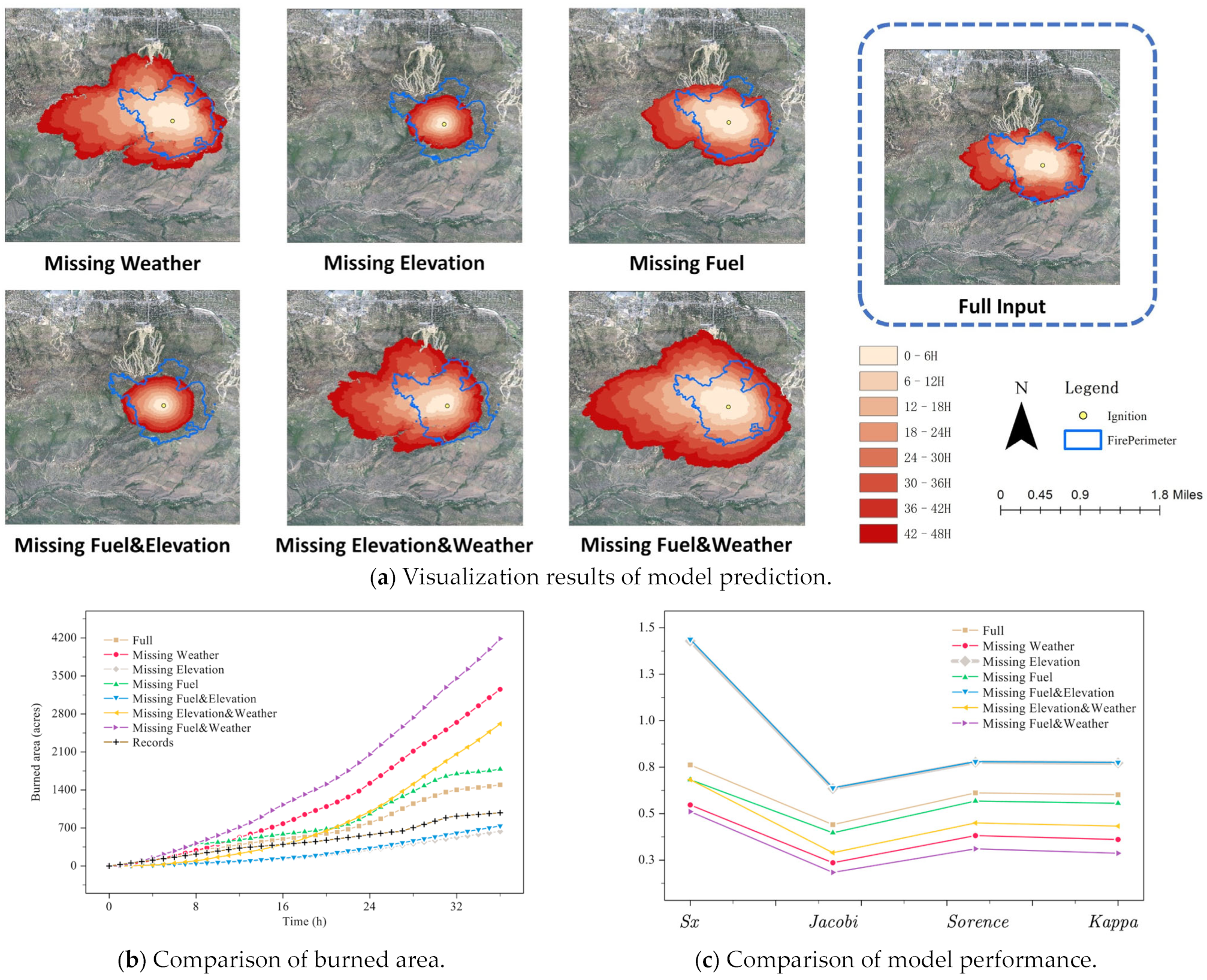
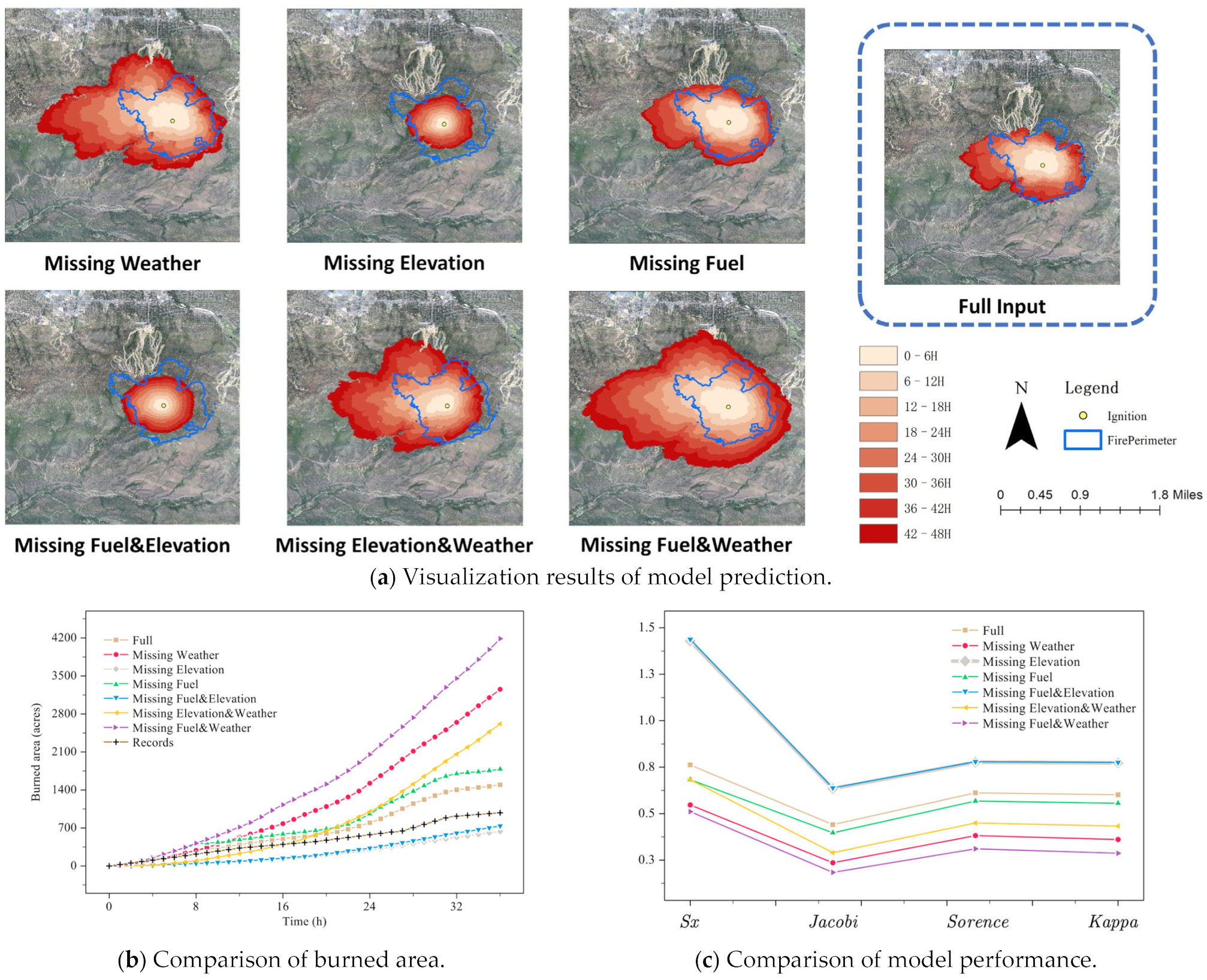
3.2. Results on Radford Fire
4. Discussion
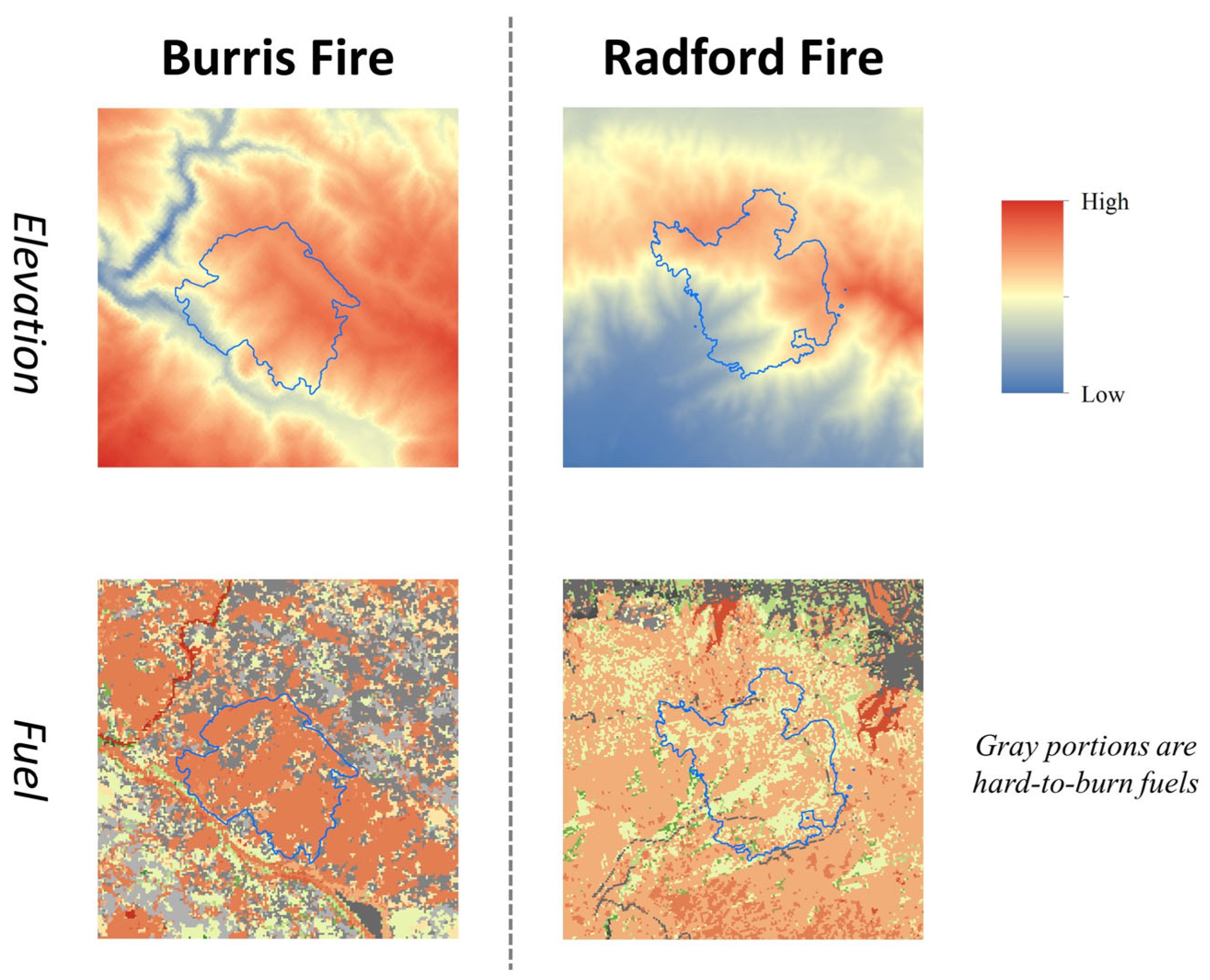
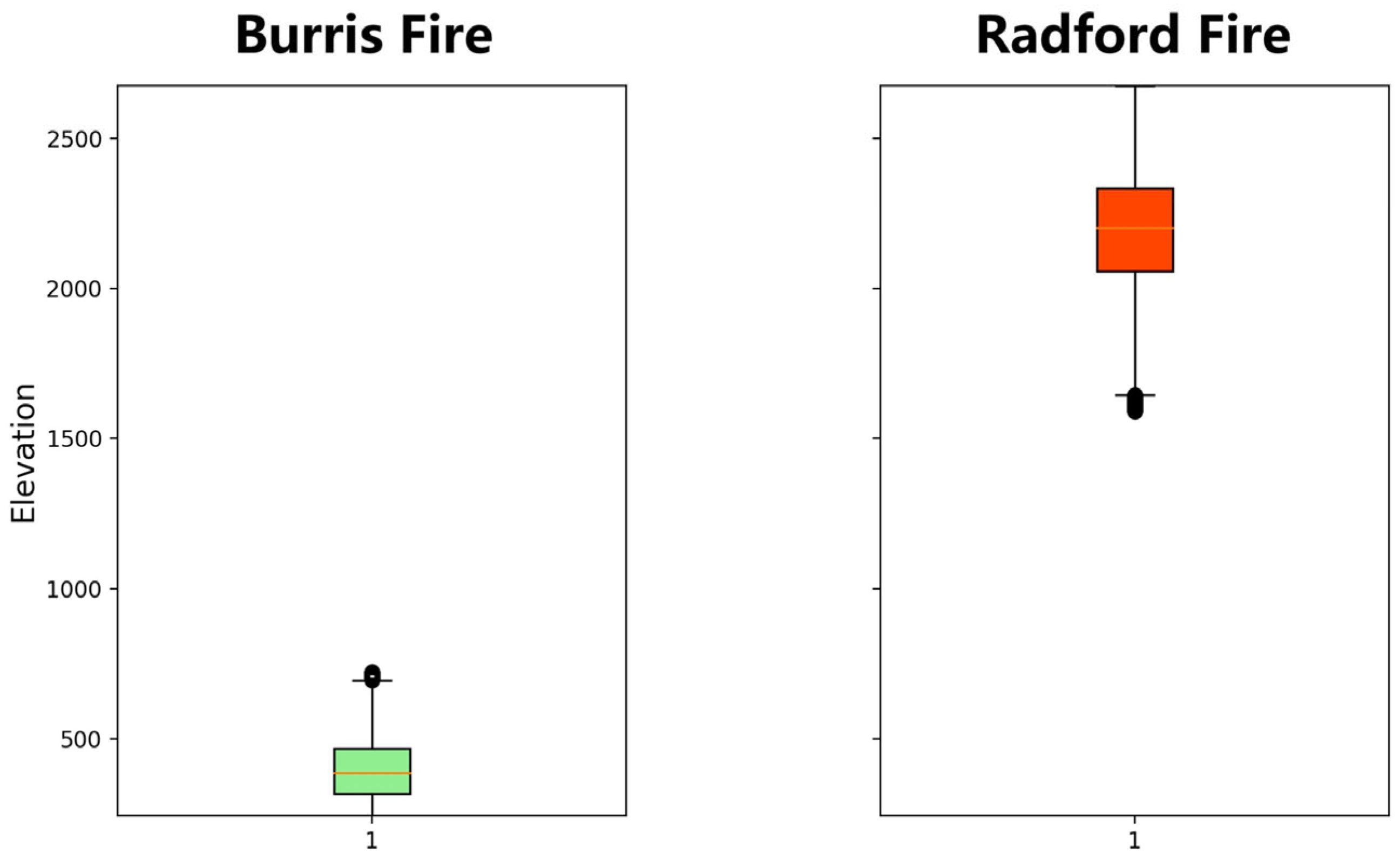
4.1. Comparison of Experimental Areas
4.2. Bias of Evaluation Metrics
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Van der Werf, G.R.; Randerson, J.T.; Giglio, L.; van Leeuwen, T.T.; Chen, Y.; Rogers, B.M.; Mu, M.; van Marle, M.J.E.; Morton, D.C.; Collatz, G.J.; et al. Global Fire Emissions Estimates during 1997–2016. Earth Syst. Sci. Data 2017, 9, 697–720. [Google Scholar] [CrossRef]
- Homepage|CIFFC. Available online: https://ciffc.ca/ (accessed on 21 March 2024).
- Farsite, F.M. Fire Area Simulator-Model Development and Evaluation; Research Paper RMRS-RP-4 Revised; US Department of Agriculture, Forest Service, Rocky Mountain Research Station: Ogden, UT, USA, 2004. [Google Scholar]
- Andrews, P.L.; Bevins, C.D.; Seli, R.C. BehavePlus Fire Modeling System, Version 4.0: User’s Guide; Gen. Tech. Rep. RMRS-GTR-106 Revised; Department of Agriculture, Forest Service, Rocky Mountain Research Station: Ogden, UT, USA, 2005; Volume 106, 132p. [Google Scholar]
- Mandel, J.; Beezley, J.D.; Kochanski, A.K. Coupled Atmosphere-Wildland Fire Modeling with WRF 3.3 and SFIRE 2011. Geosci. Model Dev. 2011, 4, 591–610. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, F.; Fang, L.; Zheng, X.; Qiao, X.; Li, Z.; Meng, Q. Modelling of Wildland-Urban Interface Fire Spread with the Heterogeneous Cellular Automata Model. Environ. Model. Softw. 2021, 135, 104895. [Google Scholar] [CrossRef]
- Jiang, W.; Qiao, Y.; Su, G.; Li, X.; Meng, Q.; Wu, H.; Quan, W.; Wang, J.; Wang, F. WFNet: A Hierarchical Convolutional Neural Network for Wildfire Spread Prediction. Environ. Model. Softw. 2023, 170, 105841. [Google Scholar] [CrossRef]
- Benali, A.; Ervilha, A.R.; Sá, A.C.L.; Fernandes, P.M.; Pinto, R.M.S.; Trigo, R.M.; Pereira, J.M.C. Deciphering the Impact of Uncertainty on the Accuracy of Large Wildfire Spread Simulations. Sci. Total Environ. 2016, 569–570, 73–85. [Google Scholar] [CrossRef]
- Cardil, A.; Monedero, S.; SeLegue, P.; Navarrete, M.Á.; de-Miguel, S.; Purdy, S.; Marshall, G.; Chavez, T.; Allison, K.; Quilez, R.; et al. Performance of Operational Fire Spread Models in California. Int. J. Wildland Fire 2023, 32, 1492–1502. [Google Scholar] [CrossRef]
- Beven, K.; Binley, A. The Future of Distributed Models: Model Calibration and Uncertainty Prediction. Hydrol. Process. 1992, 6, 279–298. [Google Scholar] [CrossRef]
- Thompson, M.P.; Calkin, D.E. Uncertainty and Risk in Wildland Fire Management: A Review. J. Environ. Manag. 2011, 92, 1895–1909. [Google Scholar] [CrossRef] [PubMed]
- Yuan, X.; Liu, N.; Xie, X.; Viegas, D.X. Physical Model of Wildland Fire Spread: Parametric Uncertainty Analysis. Combust. Flame 2020, 217, 285–293. [Google Scholar] [CrossRef]
- Cai, L.; He, H.S.; Liang, Y.; Wu, Z.; Huang, C. Analysis of the Uncertainty of Fuel Model Parameters in Wildland Fire Modelling of a Boreal Forest in North-East China. Int. J. Wildland Fire 2019, 28, 205–215. [Google Scholar] [CrossRef]
- DeCastro, A.; Siems-Anderson, A.; Smith, E.; Knievel, J.C.; Kosović, B.; Brown, B.G.; Balch, J.K. Weather Research and Forecasting—Fire Simulated Burned Area and Propagation Direction Sensitivity to Initiation Point Location and Time. Fire 2022, 5, 58. [Google Scholar] [CrossRef]
- Valero, M.M.; Jofre, L.; Torres, R. Multifidelity Prediction in Wildfire Spread Simulation: Modeling, Uncertainty Quantification and Sensitivity Analysis. Environ. Model. Softw. 2021, 141, 105050. [Google Scholar] [CrossRef]
- Ciri, U.; Garimella, M.M.; Bernardoni, F.; Bennett, R.L.; Leonardi, S. Uncertainty Quantification of Forecast Error in Coupled Fire–Atmosphere Wildfire Spread Simulations: Sensitivity to the Spatial Resolution. Int. J. Wildland Fire 2021, 30, 790–806. [Google Scholar] [CrossRef]
- GeoMAC Wildfire Application. Available online: https://wildfire.usgs.gov/geomac/GeoMACTransition.shtml (accessed on 20 December 2023).
- LANDFIRE Program: Home. Available online: https://www.landfire.gov/ (accessed on 20 December 2023).
- MesoWest Data. Available online: https://mesowest.utah.edu/ (accessed on 20 December 2023).
- Radford Fire: 1088 Acres, 40% Contained. All Evacuation Orders Downgraded to Warnings—KESQ. Available online: https://kesq.com/news/2022/09/05/radford-fire-1088-acres-40-contained-all-evacuation-orders-downgraded-to-warnings/ (accessed on 20 December 2023).
- You Searched for Burris Fire. The Mendocino Voice|Mendocino County, CA. Available online: https://mendovoice.com/search/burrisfire/ (accessed on 20 December 2023).
- Lake County News, California—Search. Available online: https://lakeconews.com/component/%20search/ (accessed on 20 December 2023).
- Arca, B.; Duce, P.; Laconi, M.; Pellizzaro, G.; Salis, M.; Spano, D. Evaluation of FARSITE Simulator in Mediterranean Maquis. Int. J. Wildland Fire 2007, 16, 563–572. [Google Scholar] [CrossRef]
- Andrews, P.L. The Rothermel Surface Fire Spread Model and Associated Developments: A Comprehensive Explanation; United States Department of Agriculture, Rocky Mountain Research Station: Ogden, UT, USA, 2018. [Google Scholar]
- Alexander, M.E.; Cruz, M.G. Evaluating a Model for Predicting Active Crown Fire Rate of Spread Using Wildfire Observations. Can. J. For. Res. 2006, 36, 3015–3028. [Google Scholar] [CrossRef]
- Hao, Y. California Wildfire Spread Prediction Using FARSITE and the Comparison with the Actual Wildfire Maps Using Statistical Methods; University of California: Los Angeles, CA, USA, 2018. [Google Scholar]
- Duff, T.J.; Chong, D.M.; Tolhurst, K.G. Indices for the Evaluation of Wildfire Spread Simulations Using Contemporaneous Predictions and Observations of Burnt Area. Environ. Model. Softw 2016, 83, 276–285. [Google Scholar] [CrossRef]
- Duff, T.J.; Chong, D.M.; Taylor, P.; Tolhurst, K.G. Procrustes Based Metrics for Spatial Validation and Calibration of Two-Dimensional Perimeter Spread Models: A Case Study Considering Fire. Agric. For. Meteorol. 2012, 160, 110–117. [Google Scholar] [CrossRef]
- Filippi, J.-B.; Mallet, V.; Nader, B. Representation and Evaluation of Wildfire Propagation Simulations. Int. J. Wildland Fire 2013, 23, 46–57. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Date | Duration (h) | Location | Burned Area (Acre) | Fuel |
|---|---|---|---|---|---|
| Burris Fire | 28 October 2019 01:34 | 10 | 34.096° N 118.481° W | 704 | Grass |
| Radford Fire | 5 September 2022 12:00 | 50 | 34.177° N 116.882° W | 1100 | Forest |
| Missing Item | Sx | Jaccard | Sorensen | Kappa |
|---|---|---|---|---|
| Full input | 0.651 | 0.419 | 0.590 | 0.563 |
| Missing weather | 0.966 | 0.192 | 0.322 | 0.296 |
| Missing elevation | 0.672 | 0.371 | 0.541 | 0.509 |
| Missing fuel | 0.520 | 0.240 | 0.387 | 0.338 |
| Missing fuel and elevation | 0.492 | 0.220 | 0.360 | 0.309 |
| Missing elevation and weather | 0.904 | 0.179 | 0.304 | 0.273 |
| Missing fuel and weather | 0.666 | 0.113 | 0.204 | 0.149 |
| Missing Item | Sx | Jaccard | Sorensen | Kappa |
|---|---|---|---|---|
| Full input | 0.762 | 0.441 | 0.612 | 0.602 |
| Missing weather | 0.547 | 0.236 | 0.382 | 0.361 |
| Missing elevation | 1.429 | 0.635 | 0.777 | 0.773 |
| Missing fuel | 0.683 | 0.397 | 0.568 | 0.556 |
| Missing fuel and elevation | 1.438 | 0.639 | 0.780 | 0.776 |
| Missing elevation and weather | 0.683 | 0.290 | 0.450 | 0.433 |
| Missing fuel and weather | 0.511 | 0.184 | 0.311 | 0.287 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Jiang, W.; Wang, F.; Qiao, Y.; Meng, Q. Comparing Accuracy of Wildfire Spread Prediction Models under Different Data Deficiency Conditions. Fire 2024, 7, 141. https://doi.org/10.3390/fire7040141
Zhou J, Jiang W, Wang F, Qiao Y, Meng Q. Comparing Accuracy of Wildfire Spread Prediction Models under Different Data Deficiency Conditions. Fire. 2024; 7(4):141. https://doi.org/10.3390/fire7040141
Chicago/Turabian StyleZhou, Jiahao, Wenyu Jiang, Fei Wang, Yuming Qiao, and Qingxiang Meng. 2024. "Comparing Accuracy of Wildfire Spread Prediction Models under Different Data Deficiency Conditions" Fire 7, no. 4: 141. https://doi.org/10.3390/fire7040141
APA StyleZhou, J., Jiang, W., Wang, F., Qiao, Y., & Meng, Q. (2024). Comparing Accuracy of Wildfire Spread Prediction Models under Different Data Deficiency Conditions. Fire, 7(4), 141. https://doi.org/10.3390/fire7040141