Abstract
Privacy-preserving record linkage (PPRL) aims to link records from different data sources while ensuring sensitive information is not disclosed. Utilizing blockchain as a trusted third party is an effective strategy for enhancing transparency and auditability in PPRL. However, to ensure data privacy during computation, such approaches often require computationally intensive cryptographic techniques. This can introduce significant computational overhead, limiting the method’s efficiency and scalability. To address this performance bottleneck, we combine blockchain with the distributed computation of secret sharing to propose a PPRL method based on blockchain-coordinated distributed computation. At its core, the approach utilizes Bloom filters to encode data and employs Boolean and arithmetic secret sharing to decompose the data into secret shares, which are uploaded to the InterPlanetary File System (IPFS). Combined with masking and random permutation mechanisms, it enhances privacy protection. Computing nodes perform similarity calculations locally, interacting with IPFS only a limited number of times, effectively reducing communication overhead. Furthermore, blockchain manages the entire computation process through smart contracts, ensuring transparency and correctness of the computation, achieving efficient and secure record linkage. Experimental results demonstrate that this method effectively safeguards data privacy while exhibiting high linkage quality and scalability.
1. Introduction
In the era of big data, cross-institutional data sharing and integration have become key drivers in advancing fields such as medical research, financial analysis, and government decision-making. Record linkage (RL), as a core technology, aims to identify and match records representing the same entity across multiple data sources, providing critical support for data integration and value extraction [1,2]. However, with the exponential growth of data volumes and increasingly stringent privacy regulations, traditional methods face significant challenges when handling sensitive data. Direct sharing of raw data risks exposing personal information, limiting its widespread use. To address this, privacy-preserving record linkage (PPRL) has emerged, focusing on achieving efficient and accurate record matching without disclosing raw data [3]. For instance, in public health, PPRL can securely link records from different hospitals, transportation systems, or communities for infectious disease contact tracing [4]. While ensuring privacy, it effectively identifies transmission chains and informs containment strategies, complying with relevant data protection regulations.
Researchers have proposed various methods for PPRL, most of which are built on the “honest but curious” model [3,5,6]. This model assumes that participants strictly follow the protocol but may attempt to infer additional information from received data. Such methods typically rely on a semi-trusted third party (STTP) for similarity computation or direct collaborative computation among participants. The former approach risks data privacy leakage due to STTP’s potential untrustworthiness, while the latter incurs significant communication overhead and struggles to prevent malicious collusion among participants, posing threats to data security. Some researchers suggest introducing blockchain technology to record and verify the actions of all participants and third parties in the PPRL process, enhancing overall transparency and traceability [7]. While this strategy improves data security to some extent, it still cannot fully prevent collusion among malicious participants [8]. Therefore, cryptographic techniques such as secure multi-party computation and homomorphic encryption are still needed to achieve higher levels of privacy protection [9]. However, these encryption methods often involve significant communication and computational overhead, presenting a trade-off between efficiency and security in practical deployment. In our prior work, we employed a method based on homomorphic encryption to enhance security, but its high computational cost also confirmed this trade-off between efficiency and security [10].
To specifically address this performance bottleneck, we propose a novel PPRL architecture that deeply integrates blockchain with the distributed computation model of secret sharing, offering a more efficient alternative to computationally intensive homomorphic encryption schemes. In this architecture, we first encode data using Bloom filters, then leverage secret sharing to securely decompose computational tasks across multiple distributed nodes. The blockchain acts as a decentralized coordinator and auditor, managing task allocation, data flow (via IPFS), and result verification through smart contracts, while masking and random permutation mechanisms enhance privacy. This architecture allows most computations to be performed locally on the nodes, thereby minimizing inter-node communication and significantly improving overall efficiency.
The main contributions are as follows:
- (1)
- We apply secret sharing techniques to data encoded with Bloom filters, introducing masking and random permutation to decompose similarity computations into basic operations that each computation node can independently perform locally. Only a single interaction involving the sharing of masked differences is required between nodes, significantly reducing the communication and computational overhead compared to computationally intensive approaches like those based on homomorphic encryption and effectively enhancing resilience against collusion attacks.
- (2)
- Addressing the trust issues of third parties and participants in existing PPRL methods, we utilize blockchain smart contracts to manage the entire PPRL process (including verifiable mask generation, task allocation, and node management) and enable trusted auditing. Combined with IPFS for efficient data storage and distribution, the use of tamper-proof records and automated rule execution enhances process transparency and the trustworthiness of computation nodes.
- (3)
- Through theoretical analysis and experimental validation, we demonstrate that this method ensures data privacy and security while achieving high linkage quality and good scalability, making it suitable for large-scale multi-party collaboration scenarios.
The structure of this paper is organized as follows: Section 2 reviews related work, analyzing existing technologies in the PPRL domain and their limitations. Section 3 introduces the background knowledge and techniques involved in this method. Section 4 elaborates on the proposed PPRL method based on secret sharing and blockchain. Section 5 analyzes the method’s security, computational complexity, and resilience against collusion attacks. Section 6 validates the effectiveness of the method through experiments. Section 7 summarizes the research findings and discusses future directions.
2. Related Works
In recent years, research on PPRL methods has primarily focused on privacy protection while also considering linkage quality and computational efficiency [3,5,6,8]. Among these, Bloom filters have been widely adopted in PPRL due to their excellent space efficiency and fast query capabilities, enabling the encoding of identifiers for similarity matching [11]. However, standard Bloom filters are vulnerable to frequency attacks and cryptanalysis, offering relatively limited privacy protection [6]. To enhance security, researchers have proposed various improved encoding techniques, such as adjacent bit encoding [12], to bolster resistance against attacks. While these encoding methods are generally efficient, they may still leak sensitive information in certain scenarios. In contrast, methods based on secure multi-party computation provide stronger privacy guarantees, allowing matching computations without revealing raw data. Homomorphic encryption enables computations directly on encrypted data, mitigating the risk of plaintext exposure [9]. Laud et al. demonstrated a large-scale PPRL instance using secret sharing on the Sharemind platform [13]. Despite the significant privacy advantages of MPC methods, their high computational and communication overheads pose efficiency bottlenecks for large-scale data applications. To enhance system trustworthiness and auditability, particularly in multi-party collaborative environments lacking trust, blockchain technology has also been applied to PPRL. Nóbrega et al. proposed a blockchain-based PPRL method that leverages smart contracts as a STTP to manage computational tasks during linkage [7]. However, this approach was later criticized for potentially exposing sensitive information during the exchange of Bloom filter segments [8]. To address these security concerns, our prior work [10] explored a different direction, integrating homomorphic encryption with a consortium blockchain framework to enable secure, parallel computation. While this approach successfully enhanced security against malicious adversaries, it also highlighted a critical trade-off: the significant computational overhead inherent to homomorphic encryption remained a primary obstacle to scalability and practical deployment. This challenge underscores a gap in the literature for a solution that can retain the trust and auditability benefits of blockchain while utilizing a more lightweight cryptographic primitive to achieve higher efficiency.
To improve computational efficiency, researchers have explored various optimization techniques, including partitioning, distributed computing, and parallel computing [14]. Partitioning techniques, such as random blocking based on Locality-Sensitive Hashing, can effectively identify similar record pairs while ensuring theoretical correctness, significantly reducing computational load during matching [15,16]. Distributed computing frameworks, such as Apache Flink, support large-scale data processing, enhancing the scalability of PPRL when handling massive datasets [16]. Furthermore, parallel computing methods, by integrating technologies like MapReduce, enable efficient data matching and comparison [10], further improving computational efficiency and reducing processing time. This allows PPRL to operate more effectively in large-scale, multi-party environments.
In terms of linkage quality, researchers have optimized the accuracy and reliability of record linkage from multiple perspectives. For instance, Vaiwsri et al. proposed a novel Bloom filter method for databases with missing values [17]. This approach uses a missing pattern lattice structure to group records and assigns different weights to non-missing attributes to optimize similarity calculations, thereby improving matching accuracy. Additionally, Florens Rohde developed a multi-layer active learning protocol that integrates human review mechanisms to dynamically optimize the matching process [18]. Through iterative learning, this protocol continuously refines matching strategies, minimizing human intervention while maximizing the accuracy and robustness of matches, thus further enhancing linkage quality.
3. Preliminaries and Background
To facilitate understanding of our proposed method, this section provides a detailed explanation of the relevant background knowledge and technical principles.
3.1. Blockchain
Blockchain is a distributed, tamper-resistant ledger technology. In this paper, it serves as a decentralized coordinator, trust anchor, and audit log, leveraging its transparency, immutability, and traceability to provide a highly trusted environment for multi-party collaboration without relying on traditional trusted third parties. The blockchain is primarily responsible for securely storing critical metadata, such as content identifiers (CIDs) for data on IPFS, access rules, task allocation indices, and reputation records of computational nodes [19].
3.2. Smart Contracts
Smart contracts are self-executing code protocols deployed on the blockchain that automatically enforce predefined rules [20]. They are the core mechanism for automating and enforcing the protocol processes of this method, handling specific operational logic, including implementing fine-grained role definitions and data access control policies, coordinating the storage and distribution of secret shares and masked data on IPFS to computational nodes, and managing the audit and verification of final results, as well as dynamically updating the reputation scores of computational nodes.
3.3. InterPlanetary File System
To avoid the high storage costs of blockchain, this method employs IPFS as a distributed file system to store large-scale data, such as Bloom filter shares, masks, and intermediate results. The blockchain only records the unique CIDs of these data. Computational nodes or participants, upon authorization via smart contracts, retrieve the required data directly from IPFS using the CIDs [21]. This strategy of combining on-chain metadata with off-chain data leverages IPFS’s content addressing and distributed storage capabilities, significantly enhancing the system’s scalability [22].
3.4. Bloom Filters
Bloom filters are efficient probabilistic data structures used to represent sets and support membership queries. In privacy-preserving record linkage, they are commonly employed to encode quasi-identifiers (QIDs; such as names or addresses). The specific approach involves decomposing a QID value into q-grams, mapping them to a bit array of length m using k hash functions, and setting the corresponding k bits to 1. This encoding supports approximate matching while providing a degree of privacy protection through the one-way nature of hashing and collision properties.
3.5. Secret Sharing
Secret sharing is a key cryptographic technique for secure multi-party computation, particularly suitable for distributed computing environments [23]. It involves decomposing Bloom filter bits and computational masks into shares and distributing them across multiple computational nodes, ensuring that no single node holds complete information, thereby protecting data privacy in a distributed setting. To support different operations, this method adopts two types of secret sharing schemes:
Boolean Secret Sharing: Primarily based on XOR operations, it is used to securely handle the bits of Bloom filters, enabling computational nodes to compute Boolean shares of the difference between two corresponding bits without revealing the original bit values, denoted as .
Arithmetic Secret Sharing: Based on modular addition, it is used for numerical computations. It securely distributes arithmetic shares of random masks and constants required for Boolean-to-arithmetic conversion protocols and supports secure additive aggregation of arithmetic difference shares obtained from Boolean secret sharing, i.e., computing , to derive partial shares of the final Hamming distance [24].
Through the synergistic application of these two secret sharing techniques, this method establishes a foundation for securely and efficiently computing the Hamming distance between records without revealing the specific contents of Bloom filters.
3.6. Hamming Distance
Hamming distance is a metric for measuring the difference between two strings of equal length. For binary strings and of length , it is defined as the total number of positions where the corresponding bits differ. Hamming distance can be computed through simple additive aggregation (summing bit differences), which, in a secret sharing framework, is more efficient than computing Dice/Jaccard similarity functions that require secure intersection operations (typically involving complex or high overhead secure multiplications).
4. Methods
The privacy-preserving record linkage method based on secret sharing and blockchain (SSB-PPRL) integrates technologies such as secret sharing, Bloom filters, blockchain, and IPFS to achieve secure matching of multi-party data records. Its core components include the system architecture and three main modules: the data preparation and generation module, the approximate matching module, and the output and audit module. The system architecture leverages the synergy of blockchain and IPFS, using smart contracts to manage data distribution, computation, and verification processes, ensuring both privacy protection and efficiency. The data preparation and generation module are responsible for encoding raw data and decomposing it into distributed shares. The approximate matching module performs secure similarity computations, while the output and audit module verify results and provide traceability.
4.1. System Architecture
To implement the SSB-PPRL method, we propose a system architecture integrating blockchain and IPFS. The architecture comprises five components, participants, computational nodes, verification nodes, blockchain, and IPFS, with multiple smart contracts collaboratively managing data distribution, computation, and verification processes [19].
The specific roles in the system are defined as follows:
Participants: Data owners who encode quasi-identifiers into Bloom filters, decompose them into shares using Boolean secret sharing and upload them to IPFS. They only access their own data CIDs and the final results.
Computational Nodes: Off-chain entities that retrieve secret shares and masks from IPFS perform local similarity computations and are restricted to accessing assigned data.
Verification Nodes: On-chain supervisors that audit computation results, update node reputation scores and access output results without interacting with raw data.
Role assignments and data access control are implemented through smart contracts deployed on the blockchain. These contracts define role identities (participants, computational nodes, verification nodes), assign data access permissions, and enforce strict access control logic to ensure sensitive data is only accessed within authorized scopes. The data access control mechanism is designed as follows:
Permission Definition and Negotiation: After participants upload data to IPFS and generate CIDs, they negotiate access permissions with the system through an on-chain mechanism. Metadata associated with each CID is stored in the blockchain’s “data record mapping” in the form of a data structure, including the CID (pointing to Bloom filter shares on IPFS), the data owner’s address, an access permission list (specifying authorized roles or addresses), and an expiration time (defining the validity period of the permission). For example, a participant may propose authorizing a specific computational node to access a particular CID. The system verifies this based on predefined rules (e.g., reputation thresholds) and updates the access permission list upon confirmation.
Access Verification and Time Window: The smart contract provides an access permission verification function. Callers must pass two checks: the current time must be less than or equal to the expiration time, and the caller’s address must be included in the access permission list. Only upon passing these checks can the caller retrieve the CID from the data record mapping and download the data from IPFS. Expired permissions automatically become invalid, preventing unauthorized long-term access.
Dynamic Management and Security: Data owners can revoke or modify permissions at any time. Change requests are validated by the contract for consistency before updating state variables (e.g., the access permission list). To prevent inference attacks, CID distribution is strictly controlled by the contract, ensuring that unauthorized roles cannot directly query the data record mapping. The time window design, combined with on-chain verification, ensures data access remains controllable within the authorized period, enhancing security.
Collaborative Support: The access control contract shares role mappings and reputation information with the computational node selection contract, synchronizes permission states (e.g., expiration) with the audit and verification contract, and provides CIDs and permission rules to the data distribution contract, ensuring compliance in computation and verification processes. Sensitive data is stored on IPFS, with only metadata recorded on the blockchain, making permission negotiation and verification fully transparent and auditable.
The overall system architecture is illustrated in Figure 1.
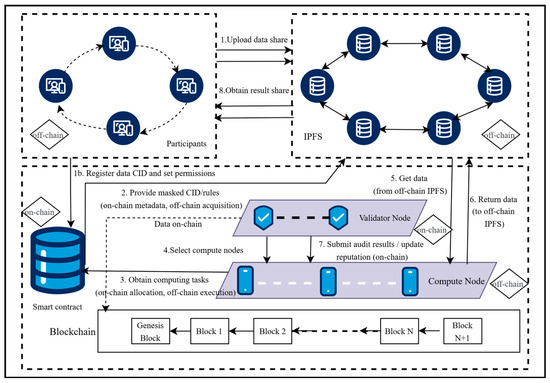
Figure 1.
The overall process of multi-party PPRL.
The system operates in stages: Participants preprocess data, encode it into Bloom filters, split it into secret shares, and upload them to IPFS, generating CIDs. The role and data access control smart contracts negotiate permissions, logging CIDs and permissions on the blockchain. A node selection smart contract chooses computing nodes based on reputation data from an audit verification contract. A data distribution smart contract assigns shares and masks, creating an on-chain index table. Computing nodes download data from IPFS, perform local computations, and upload results to IPFS. The audit verification smart contract inspects results, updates reputation, and syncs permission states. Participants reconstruct the Hamming distance as the outcome. Blockchain records metadata, IPFS stores data, and smart contracts orchestrate the process, ensuring privacy, efficiency, and auditability.
4.2. Data Preparation and Generation Module
The data preparation and generation module is the foundation of the SSB-PPRL method, a privacy-preserving record linkage approach based on secret sharing and blockchain. It transforms raw records into a distributed computing format and generates masks via smart contracts for matching and auditing. The module includes data encoding, Boolean secret sharing generation, mask generation, computing node selection, and data distribution. Data is split into distributed shares and managed by blockchain and IPFS, as shown in Figure 2.
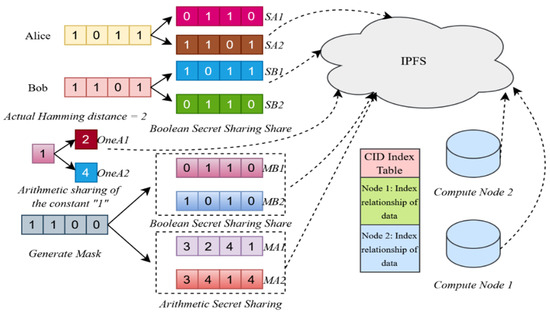
Figure 2.
The data processing flow of data preparation and generation module.
4.2.1. Data Encoding
Participants negotiate preprocessing parameters via smart contracts to standardize data formats and provide initial privacy protection, ensuring consistency for subsequent processing. Quasi-identifier attributes are then encoded into Bloom filters to efficiently match similarity while preserving ambiguity for enhanced privacy protection. Consider a dataset , where each record has a set of quasi-identifier attributes . All participants negotiate Bloom filter parameters—bit length and number of hash functions —through a blockchain smart contract, with results recorded on-chain to ensure consistency and transparency. For example, Alice maps the quasi-identifiers of record to a Bloom filter () using hash functions. Bob performs the same operation for record , generating . Parameter selection must balance security and efficiency: a larger and appropriate reduce false positives and enhance privacy, but excessively large values decrease the efficiency of Boolean secret sharing decomposition and matching. Thus, parameters are chosen to optimize both aspects.
4.2.2. Share Generation of Boolean Secret Sharing
Bloom filters enable fast queries while preserving privacy but are vulnerable to frequency attacks. To mitigate this, participants split each bit into Boolean secret shares and generate masks via smart contracts, distributing them to different computing nodes to ensure no single node accesses complete data, enhancing distributed privacy protection [25].
For the -th bit of Alice’s Bloom filter , Boolean secret sharing generates shares , satisfying
Similarly, the -th bit of Bob’s follows the same condition. Here, denotes the XOR operation, which ensures that all shares are required for reconstruction, with fewer than shares revealing no information about the original value, and randomness obscures frequency patterns.
The generation steps, using Alice’s and Bob’s as examples, are as follows:
- Determine shares (a system parameter, e.g., ), randomly generating the first shares and adjusting the last to satisfy the XOR condition.
- For to , randomly generate uniformly distributed , introducing randomness to conceal frequency patterns.
- For Alice, set (same for Bob), ensuring the XOR result is correct.
- The generated shares form and , which are uploaded to IPFS, with CIDs stored on the blockchain.
4.2.3. Mask Generation and Data Distribution
In distributed computing, nodes compute the difference between two Bloom filters using the XOR operation (), generating Boolean-shared differences. These are converted to arithmetic shares using masks () to support additive aggregation for Hamming distance, ensuring computational security and privacy of results.
Masks are designed to match the structure of Bloom filters and are generated per quasi-identifier attribute. The dataset contains attributes, each encoded as a Bloom filter of length , with a corresponding mask (length ). Each mask is decomposed into the following: Boolean shares: is split into Boolean shares, satisfying the following: Arithmetic shares: is split into arithmetic shares, satisfying
where is a large prime.
To improve efficiency and reduce the number of masks, record pairs are grouped and sets of masks are generated. Each set is assigned to a group of record pairs rather than generating unique masks for each pair. The value of balances efficiency and security: a smaller reduces computational and storage overhead but increases the risk of collusion inference; a larger reduces the number of record pairs sharing masks, enhancing resistance to collusion but increasing costs. The value of can be dynamically adjusted based on the total number of record pairs and system resources.
Mask Generation Process (Managed by Blockchain Smart Contracts):
- Record Pair Grouping: The total number of record pairs () is divided into groups (, e.g., or a fixed value like ) using deterministic hashing, balancing security and efficiency.
- Mask Generation: For each group () and attribute (), a mask of length is generated using a Verifiable Random Function (VRF) with and as inputs, ensuring randomness and fairness.
- Share Decomposition: Boolean shares: is decomposed into shares. Generate random Boolean shares , and compute: Arithmetic shares: is decomposed into shares. Generate random arithmetic shares , and compute: Constant 1 Shares: To support Boolean-to-arithmetic (B2A) conversion, generate arithmetic shares , satisfying by randomly generating shares and computing .
- Storage and Management: The generated Boolean shares , arithmetic shares , and constant 1 shares are uploaded to IPFS, obtaining CIDs. These CIDs, along with the CIDs of secret shares uploaded during the data preparation phase, are recorded and managed by smart contracts (e.g., mask management or data distribution contracts) to ensure efficient and secure data distribution.
4.2.4. Compute Node Selection
After masks and secret shares are uploaded to IPFS, the blockchain triggers the compute node selection smart contract to choose a suitable set of nodes for executing record linkage tasks efficiently and securely [26].
A reputation-based evaluation mechanism is executed by on-chain validation nodes. From candidate nodes, nodes () are selected, with determined through negotiation by the task requester. Validation nodes assess each node based on three key metrics: reputation score , indicating trustworthiness; computational power , normalized to reflect hardware performance; and task completion rate , representing the proportion of successfully completed tasks, measuring execution stability. New nodes, lacking historical data, start with , , . The selection results are synchronized on the blockchain via a consensus mechanism (e.g., PBFT), ensuring consistency and transparency [10].
An audit verification contract dynamically updates and stores node parameters , , and . New nodes begin with , , , and the contract periodically updates these based on task execution logs (e.g., completion time, result accuracy), ensuring parameters accurately reflect node performance and provide a reliable basis for selection.
- Selection Process:
- Weighted Scoring: The task requester specifies the number of nodes and security level (corresponding to high, medium, or low security requirements). Validation nodes compute each node’s weighted score:where weights are (reputation), (computational power), (completion rate), satisfying . Weights can be adjusted through participant negotiation.
- Random Adjustment: To ensure new nodes () have a chance to participate, a Verifiable Random Function (VRF) adjusts scores:where is collectively generated by validation nodes to ensure fairness, and controls the random offset magnitude.
- Grouping and Selection: Nodes are divided into four groups based on :
- ○
- (high reputation);
- ○
- (medium reputation);
- ○
- (low reputation);
- ○
- (new nodes). Proportions are set based on , e.g., for (high security): , , , . Calculate group sizes:
- If the total is less than , increase . After verifying node availability, select nodes from each group in descending order of adjusted scores , ensuring the total number of nodes is .
4.2.5. Data Distribution
After compute nodes are selected, the blockchain triggers the data distribution smart contract to coordinate the allocation of data shares stored on IPFS, preparing for approximate matching computations. The core process includes record pair grouping, compute node assignment, random permutation, and data index table generation.
Record Pair Grouping and Input Preparation: The contract retrieves CIDs for task-required data, including Boolean secret shares of Bloom filters uploaded by participants; system-generated mask Boolean shares, mask arithmetic shares, and arithmetic shares of the constant 1; list of selected compute nodes; system parameters: number of mask groups , number of compute nodes/shares per record pair , and total selected nodes . To improve efficiency and enable mask reuse, the contract divides record pairs into groups using a deterministic hash function, with all pairs in the same group sharing the same mask set.
Compute Node Assignment and Random Permutation: For a record pair , assumed to belong to group , the contract assigns compute nodes to process its secret shares. Using a Verifiable Random Function (VRF) with seed , it randomly selects nodes from , denoted as . To prevent collusion attacks among nodes, a random permutation mechanism is introduced to obfuscate the logical numbering of shares, breaking their direct association with original data. For each selected node (), the contract generates a unique permutation using VRF with seed , reordering the set . For example, when , might be . When node processes logical share (), it retrieves the physical share index:
For instance, if , logical share corresponds to physical share 2, to physical share 3, and to physical share 1. Random permutation, by generating a unique mapping for each node, disrupts fixed share assignments, significantly reducing the risk of colluding nodes inferring original data. The permutation process, driven by VRF, ensures randomness and verifiability, guaranteeing fair and auditable allocation while maintaining computational efficiency, as it only involves index remapping without requiring additional cryptographic operations. The random permutation algorithm process is shown in the following Figure 3:
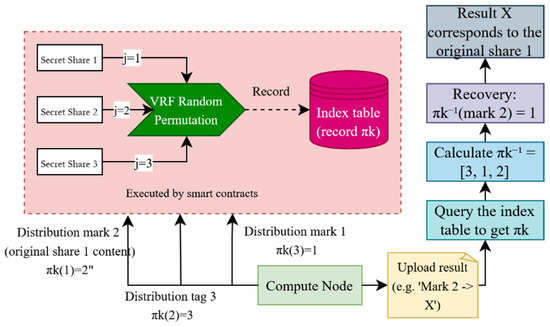
Figure 3.
The process of random permutation.
Data Index Table Generation: One of the core tasks of data distribution is generating an index table and storing it on the blockchain. This index table precisely records the allocation details for each computational task, specifying which computing node is responsible for processing which logical share of which record pair, along with the specific data required to complete the task. The index table is typically a key–value store, with keys defined as the tuple , where is the mask group number for the record pair, is the record pair identifier, identifies the compute node , and is the logical share index (from 1 to ). The value contains the CIDs of all data required to complete task , along with the node’s permutation information. Specifically, it includes the following: : CID of the -th Boolean secret share of ; : CID of the -th Boolean secret share of ; : CID of the -th Boolean share of the -th mask group; : CID of the -th arithmetic share of the -th mask group; : CID of the -th arithmetic share of the constant “1”; : the complete random permutation function corresponding to compute node .
The smart contract iterates through all record pairs to be processed, the compute nodes assigned to each pair, and the logical share indices for each node. It computes the mapped physical index , retrieves or combines the corresponding CIDs, and stores this information as key–value pairs in the index table. The algorithm for data distribution is described in pseudocode as Algorithm 1.
| Algorithm 1 Data Distribution Algorithm |
| Input: record_pairs: List of record pairs to be processed; k: Number of mask groups; n: Number of computation nodes per record pair; total_nodes: Total selected computation nodes Output: index_table: Mapping of tasks to computation nodes with CIDs and permutations 1: for each record_pair in record_pairs do 2: group_id ← DeterministicHash(record_pair) mod k 3: selected_nodes ← VRFSelectNodes(total_nodes, n) 4: for each node in selected_nodes do 5: perm ← VRFGeneratePermutation(n, seed = (record_pair, node)) 6: physical_share ← perm(1) 7: task_key ← (group_id, record_pair, node, 1) 8: task_value ← (GetCIDs(record_pair, group_id, physical_share), perm) 9: index_table[task_key] ← task_value 10: end for 11: end for 12: StoreIndexTableToBlockchain(index_table) 13: return index_table |
In Algorithm 1, lines 1–3 iterate through record pairs, group them via hashing, and randomly select computing nodes for each pair. Lines 4–9 generate a random permutation for each node, compute physical share indices, create task key–value pairs, and populate the index table. Lines 10–13 store the index table on the blockchain and return.
4.3. Approximate Matching Module
The core task of the approximate matching module is to securely and efficiently compute the similarity between records in a distributed environment, using secret shares and masked data generated by the data preparation and generation module, with hamming distance as the metric. The main process includes data acquisition, local difference computation, Boolean-to-arithmetic share conversion, and the generation of partial Hamming distance results. The module relies on local collaboration among multiple computing nodes to perform matching computations, optimizing storage and distribution efficiency through the collaboration of blockchain and IPFS [27]. The data processing of this module is illustrated in Figure 4, taking the processing of a single computing node as an example:
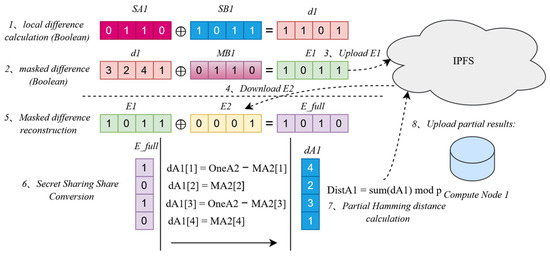
Figure 4.
The data processing of the approximate matching module.
The index table generated by the data distribution smart contract is recorded on the blockchain. This action ensures the transparency, immutability, and auditability of the data distribution process. Based on the assigned task , computing node queries the index table on the blockchain to obtain the CIDs of the data shares required to complete its task, along with its own random permutation . Subsequently, the computing node can asynchronously download these data shares from IPFS to prepare for approximate matching computations. To enhance security and resistance to collusion, this module adopts a multi-node decentralized strategy, with the number of computing nodes significantly exceeding the number of shares. The data distribution smart contract randomly allocates data based on participants, records, and attributes, ensuring high data dispersion. Even if some nodes collude, it is difficult to gather enough shares to reconstruct the original information.
The computation process centers on localized operations. After downloading data based on the index table, each computing node independently performs local difference calculations, Boolean-to-arithmetic share conversions, and partial Hamming distance result generation. For a pair of records , the node processes each bit ( from 1 to ) using obfuscated Boolean shares and to compute the local difference . Through a modified B2A protocol, is converted to an arithmetic share , which is accumulated to generate the partial Hamming distance share . The random permutation mechanism is applied throughout the process to ensure data privacy. The specific steps are as follows.
4.3.1. Local Difference Calculation and Masked Difference Vector Generation
The computation of the approximate matching module begins with the Boolean shares of local differences. Each computing node performs an XOR operation for each bit (where ranges from 1 to ) to calculate the Boolean share of the local difference. The computation formula is as follows:
Due to the random permutation introduced in data distribution, the node processes obfuscated Boolean shares. However, the properties of the XOR operation ensure that the result is independent of the order, and the shares from all nodes satisfy
Subsequently, node uses pre-generated Boolean mask shares (corresponding to group ) to compute the masked difference vector for all bits. The masked difference for each bit is defined as follows:
The permutation mechanism ensures that the masks correctly correspond to the Boolean shares, thereby guaranteeing the correctness of the computation results while protecting data privacy.
4.3.2. Batch Interaction and Data Sharing
Nodes share masked difference vectors in batches. Node uploads its vector (a Boolean sequence of length ) to IPFS, obtaining the content identifier . It then submits the task identifier and to the smart contract to record the upload. The smart contract logs these submissions and, once all nodes have submitted, notifies relevant nodes by triggering an event (containing the task identifier, node identifiers, and corresponding content identifier list) or updating the task status [28]. Node monitors blockchain events or queries the task status to confirm that all nodes have completed submissions. Upon confirmation, it retrieves the content identifiers of the other nodes (e.g., ) from the smart contract and downloads the corresponding vectors via IPFS. The random permutation , recorded in the index table, allows the node to restore the correct order of downloaded data, ensuring consistency.
4.3.3. Masked Difference Reconstruction and Conversion
After obtaining the masked difference vectors from all nodes, node performs local reconstruction and Boolean-to-arithmetic share conversion. Using its own vector and the downloaded vectors, the node computes the complete masked difference vector , where
Based on , the node ensures that corresponds to the correct index. The XOR property guarantees the following:
Here, the randomness of protects from being exposed. Next, node uses , the arithmetic mask share , and the arithmetic share of the constant 1, , to compute the arithmetic share for each bit . The results are as follows:
If (i.e., )
If (i.e., )
The permutation mechanism ensures consistency, and the shares from all nodes satisfy
The algorithm for batch interaction and masked difference reconstruction is described in pseudocode as shown in Algorithm 2.
| Algorithm 2 Share And Reconstruct Masked Diff Algorithm |
| Input: masked_diff: Masked difference vector; n: Number of computation nodes; perm: Permutation function for data reordering Output: full_masked_diff: Fully reconstructed masked difference 1: cid_masked_diff ← UploadToIPFS(masked_diff) 2: SubmitToSmartContract(task_id, node_id, cid_masked_diff) 3: WaitForAllNodes(task_id, n) 4: other_cids ← GetOtherNodesCIDs(task_id, n) 5: other_masked_diffs ← [DownloadFromIPFS(cid) for cid in other_cids] 6: Reorder(other_masked_diffs, perm) 7: full_masked_diff ← masked_diff 8: for j ← 1 to n − 1 do 9: for i ← 1 to m do 10: full_masked_diff[i] ← full_masked_diff[i] XOR other_masked_diffs[j][i] 11: end for 12: end for 13: return full_masked_diff |
In Algorithm 2, lines 1–6 handle uploading the local masked difference to IPFS and submitting it to the smart contract, then wait for all nodes to submit, download other nodes’ masked differences, and reorder them using the permutation function. Lines 7–13 aggregate the local and other nodes’ masked differences through bitwise XOR operations, generating and returning the complete masked difference vector for subsequent processing.
4.3.4. Hamming Distance Calculation and Result Upload
Finally, node calculates the partial Hamming distance and uploads the result. It locally sums the arithmetic shares for all bits to generate the partial Hamming distance share:
Subsequently, the node uploads along with the obfuscated index to IPFS, generating a CID and recording it via the smart contract. Batch interaction reduces communication frequency [29], and the random permutation mechanism enhances privacy protection, ensuring the computation process is both efficient and secure.
The algorithm for masked difference conversion and Hamming distance calculation is described in pseudocode as shown in Algorithm 3.
| Algorithm 3 B2A conversion And Hamming Distance Algorithm |
| Input: full_masked_diff: Fully reconstructed masked difference; mask_arith_share: Arithmetic mask share; const_one_share: Arithmetic share of constant one; m: Length of Bloom filter Output: partial_hamming_share: Partial Hamming distance share 1: arith_diff ← [] 2: for i ← 1 to m do 3: if full_masked_diff[i] = 0 then 4: arith_diff.append(mask_arith_share[i]) 5: else 6: arith_diff.append(const_one_share[i] - mask_arith_share[i]) 7: end if 8: end for 9: partial_hamming_share ← 0 10: for i ← 1 to m do 11: partial_hamming_share ← partial_hamming_share + arith_diff[i] 12: end for 13: return partial_hamming_share |
In Algorithm 3, lines 1–8 convert each bit of the fully reconstructed masked difference into an arithmetic share vector using the arithmetic mask share and the arithmetic share of constant one, achieving a Boolean-to-arithmetic conversion. Lines 9–13 sum the arithmetic share vector to generate the partial Hamming distance share, which is uploaded to IPFS, submitted to the smart contract, and returned for final result aggregation.
4.4. Output and Audit Module
The output and audit module are the final component of this method, handling the Hamming distance result shares from the approximate matching module, aggregating them to produce the matching results, and ensuring computational correctness and security through audit verification via smart contracts and validation nodes. Blockchain and IPFS are utilized to achieve output and traceability, allowing participants to access only the final results without exposure to masks or intermediate data, with masks generated by the mask distribution contract. Validation nodes randomly sample and recompute results to maintain credibility and node reputation. All actions and data are recorded on the blockchain and stored on IPFS, ensuring security, efficiency, and transparency.
4.4.1. Result Aggregation and Output
After completing the approximate matching tasks, computing nodes upload their partial hamming distance shares to IPFS and record the corresponding CIDs on the blockchain via smart contracts [30]. Participants query the blockchain using the task identifier to obtain the CIDs of the shares () for record pair . They download the shares from IPFS, restore the original order using the index table (), and reconstruct the Hamming distance with the following formula:
Participants only obtain , without access to intermediate values or original Bloom filters, ensuring privacy. The Hamming distance can be directly output or further processed, such as applying thresholds to filter similar record pairs.
4.4.2. Audit and Verification
To ensure the integrity and accuracy of computing nodes’ results, the audit verification contract coordinates validation nodes to perform the audit process.
- Trigger and Sampling: Upon activation, validation nodes use a Verifiable Random Function to randomly select a portion of the result shares for verification.
- Data Retrieval: For sampled shares , validation nodes query the blockchain’s index table to obtain CIDs and download from IPFS: the sampled share , corresponding Bloom filter boolean shares and , mask boolean shares , mask arithmetic shares , constant “1” arithmetic shares , and permutation data .
- Recomputation: Using the retrieved input and mask shares, validation nodes independently recompute the core steps of the approximate matching module to generate a reference value, denoted .
- Verification: Validation nodes compare the uploaded share with the recomputed reference . If they satisfy , the share passes verification; otherwise, it is marked as incorrect. The trustworthiness of a computing node’s task execution is determined based on the verification results of all sampled shares [31].
4.4.3. Reputation Management
Reputation management, a core function of the audit verification contract, ensures node parameters reflect true performance, guiding the node selection contract.
- Reputation Score Update: , initialized at 0, is updated based on task outcomes:Correct task: . Incorrect task: . Severe malicious behavior (e.g., data tampering): . Incentives for consistency: Three consecutive correct tasks: ; two consecutive incorrect tasks: .
- Computing Power Update: , initialized at 0, is periodically updated via off-chain tests (e.g., benchmarks), increasing with hardware performance.
- Task Completion Rate Update: , initialized at 0, reflects historical reliability, calculated as follows:
Updated in real-time by the audit verification contract based on task logs.
New nodes start with , , . The contract optimizes these parameters over time and shares them with the node selection contract. The latter computes a weighted score from , , and , adding a verifiable random offset to yield the final score . This balances opportunities for new nodes while prioritizing high-reputation ones, ensuring dynamic and accurate node selection.
4.4.4. Record Keeping and Provenance
To ensure traceability and transparency in the audit process, the blockchain records all critical data and computing node actions, including CIDs of Boolean shares , , masks and from the data preparation module, and from the approximate matching phase, managed by the data distribution smart contract to maintain clear mappings between matching pairs and masks. Audit verification contract uses on-chain index tables and IPFS data to conduct periodic or on-demand audits, verifying task assignment consistency and ensuring recomputed shares match uploaded ones.
Immutable audit logs on the blockchain capture node reputation changes, anomalies, and verification outcomes, providing a reliable foundation for long-term system operation. If participants question the results, they can request an audit via the verification contract, obtaining a report to confirm result validity. The process operates autonomously, with blockchain and IPFS collaboration ensuring efficient and fair audits.
The algorithm for masked difference conversion and Hamming distance calculation is described in pseudocode as shown in Algorithm 4.
| Algorithm 4 Audit And Reputation Management Algorithm |
| Input: task_id: Task identifier; sample_rate: Proportion of results to audit; index_table: Index table with CIDs; node_performance: Node historical performance data Output: audit_results: Audit results with verification outcomes; updated_reputation: Updated reputation scores; blockchain_records: Stored records on blockchain 1: sampled_shares ← RandomSample(partial_hamming_shares, sample_rate) 2: for each share in sampled_shares do 3: task_data ← GetTaskData(index_table, share) 4: reference_share ← RecomputeShare(task_data) 5: if reference_share == share then 6: audit_results[share] ← “Verified” 7: UpdateNodeReputation(node, outcome = “Success”) 8: else 9: audit_results[share] ← “Failed” 10: UpdateNodeReputation(node, outcome = “Failure”) 11: end if 12: end for 13: cid_audit, cid_reputation ← UploadResultsToIPFS(audit_results, up_reputation) 14: cid_reputation ← UploadToIPFS(updated_reputation) 15: return audit_results, up_reputation, StoreToBlockchain(cid_audit, cid_reputation) |
In Algorithm 4, lines 1–4: Randomly sample a portion of the computation result shares and prepare for verification by recalculating. Lines 5–11: Compare the recalculated results with the submitted results, record the audit outcome (“Verified” or “Failed”) accordingly, and update the reputation values of the corresponding computation nodes. Lines 12–15: After the loop, upload the final audit results and updated reputation data to IPFS, store the address (CID) on the blockchain, and return the audit results and reputation data.
5. Method Analysis
5.1. Complexity Analysis
The computational and communication complexity analysis of this method is as follows. Assume there are participants, each participant possesses records, and let . The Bloom filter length is , using hash functions, with quasi-identifier attributes generating an average of q-grams. The secret sharing threshold is , meaning each Bloom filter bit is split into shares processed by computing nodes. The system selects computing nodes to form a node pool. The total number of record pairs to be matched is , distributed across mask groups, with an audit sampling rate of .
In the data preparation and generation module, parameter negotiation among participants involves on-chain computation and communication costs, with complexity depending on the consensus mechanism and the number of participants , denoted as [32]. Data encoding is a local operation, with computational complexity for each participant as , and the total across all participants is . Boolean secret share generation is also local, with computational complexity , totaling ; this step also involves uploading shares to IPFS (communication cost ) and recording CIDs on the blockchain (on-chain write cost ). Mask generation is executed by smart contracts, with on-chain computational complexity approximately , accompanied by IPFS uploads (cost ) and on-chain CID recording (cost ). The computational complexity of node selection on-chain is denoted as . In the data distribution phase, the smart contract processes record pairs, involving grouping, node selection, permutation generation, and index creation, with on-chain computational complexity approximately , and requires writing index records to the blockchain (cost ).
In the approximate matching module, processing is performed for record pairs, each handled by computing nodes in parallel. For each pair, data retrieval involves each node querying the blockchain (total cost ) and downloading data from IPFS (total cost ). The total computational complexity for local difference computation and masking is . In the batch interaction phase, nodes exchange masked difference vectors via IPFS and blockchain, with total communication cost approximately . Reconstruction and B2A conversion are computational bottlenecks, with total computational complexity . The final Hamming distance partial sum has computational complexity , requiring result uploads to IPFS (total cost ) and CID submission to the blockchain (total cost ). Thus, the total computational complexity for the approximate matching phase across all pairs is approximately , with IPFS communication complexity approximately , and blockchain communication complexity approximately .
In the output and audit module, the computational complexity for participants aggregating results is , with communication costs approximately . The audit verification process involves recomputing shares, with total audit computational complexity approximately , and communication complexity approximately . The on-chain computation and write costs for reputation management are approximately and . Record keeping and provenance involve additional IPFS and blockchain write costs.
The method’s computation is primarily driven by the approximate matching phase’s and the audit phase’s , proportional to the number of record pairs , higher powers of the secret sharing threshold , and Bloom filter length , but the tasks are highly parallelizable. Communication bottlenecks stem mainly from IPFS data transfers (especially ) and blockchain interactions (where throughput and transaction costs are critical) [33].
5.2. Privacy Analysis
This method establishes multi-layered privacy protection under the “honest-but-curious” model, with considerations extended to stronger malicious models and extreme scenarios such as large-scale node compromise. During the data preparation phase, raw data remains local to participants; only their Bloom filter encodings are processed and decomposed into t Boolean secret shares, which are then distributed to t different computation nodes selected from a larger pool [34]. This highly dispersed sharing ensures that a single computation node (even if malicious and logging/analyzing its shares) can only access 1/t of the fragmented information, making it extremely difficult to infer useful content or launch effective attacks. These shares are stored on IPFS, their CIDs are recorded on the blockchain, and access to data on IPFS is strictly managed by access control smart contracts.
In the approximate matching phase, computation nodes retrieve authorized data from IPFS via CIDs. The core masking technique ensures that nodes operate on obfuscated shares (e.g., shares of d ⊕ r) that are unrelated to the true difference d, meaning that even if t nodes (including Byzantine ones) collude, they cannot recover d. The B2A conversion similarly relies on secret-shared masks and the constant “1” to protect intermediate results. Masked difference vectors exchanged between nodes also do not leak d. Furthermore, the random permutation π mechanism, executed by the data distribution smart contract, further shuffles the logical order of shares, increasing inference difficulty. Malicious nodes submitting tampered data would face verification coordinated by the audit verification smart contract and penalties from the reputation management smart contract.
Regarding potential collusion attacks, an adversary must first identify and organize the specific computation nodes holding all t shares for the same record—a task already made difficult by the fact that the total number of nodes is far greater than t and task assignment is handled by the data distribution smart contract (potentially incorporating randomization and reputation). Even if shares are successfully collected, the random permutation mechanism forces attackers to face t! permutations. Experiments show that even with 80% node collusion, the reconstruction success rate is below . The entire process is coordinated by multiple smart contracts on the blockchain, ensuring transparency, enforcement, and auditability.
Nevertheless, this method has limitations in certain extreme threat scenarios. Regarding Byzantine behavior, the sampling audit driven by the audit verification smart contract may not capture all malicious acts, and the system relies on the honesty of verification nodes. Concerning DoS attacks, while underlying platforms (blockchain consensus, IPFS distributed nature) offer some protection, large-scale attacks could still impact the system (e.g., if IPFS nodes are attacked, preventing smart contracts from effectively retrieving data via CIDs) or computation nodes (the node selection smart contract filters by reputation, but widespread unavailability remains an issue). As for observable patterns, strong adversaries might still infer information from metadata (like CIDs or task assignment indices on the blockchain), network traffic, or IPFS access timings as side-channels.
Further considering extreme scenarios where a majority of nodes are compromised:
- If a majority of computation nodes are compromised: On the privacy front, an attacker’s chances of collecting all t shares for a record increase, but they still face the t! complexity from random permutation. In terms of result integrity, if most computation nodes in a specific task are malicious, they could collude to submit erroneous results, relying on verification node sampling audit as the main check.
- If a majority of validation nodes are compromised: This would destroy the system’s core trust mechanism, as the audit and reputation systems (maintained by the audit verification and reputation management smart contracts) would fail.
- If both types of nodes are compromised on a large scale: This is a catastrophic scenario. Attackers could submit malicious data and have it “legitimized” by compromised validation nodes, causing the defense system built by various smart contracts and IPFS to face systemic failure. The immutability of the blockchain would only preserve a trace for post-mortem analysis.
Regarding Bloom filters, while they might have risks if used in isolation (especially when facing malicious attackers), in SSB-PPRL, they primarily serve as an encoding tool. Their privacy is ensured by subsequent steps strictly orchestrated and enforced by various smart contracts, such as secret sharing (shares stored on IPFS), mask computation, and random permutation, which largely mitigate their inherent weaknesses. However, to further strengthen against complex malicious attacks that directly analyze or crack Bloom filters encoding themselves, future introduction of techniques like salted hashing or noise injection would be a very valuable supplement.
In the output and audit phase, participants only receive the aggregated Hamming distance . Audit verification nodes access data from IPFS as authorized by smart contracts for recomputation. All critical operations and metadata are recorded on the blockchain, ensuring transparency and traceability.
In summary, this method integrates various techniques, including blockchain smart contract-driven access control and process management, alongside IPFS distributed storage. Information available to a single node is limited, and the system is designed to resist collusion by t − 1 nodes. However, primary risks and trust requirements shift to node behavioral security and underlying technology robustness. Therefore, the security and correctness of various smart contracts, the effectiveness of node selection and reputation mechanisms, the secret sharing threshold t, and IPFS data guarantees are crucial for maintaining system privacy and usability in complex adversarial environments.
5.3. Linkage Quality Analysis
This method achieves approximate matching by computing the Hamming distance between Bloom filters, a technique that effectively handles data errors and variations, offering broader applicability compared to methods limited to exact matching. The Hamming distance reflects the similarity of original records based on q-grams. Linkage quality significantly depends on the choice of Bloom filter parameters (length m, number of hash functions k, q-gram length q). These parameters determine the precision of representation and the false positive rate f, directly impacting linkage accuracy. Parameter settings require a trade-off between linkage quality, privacy protection, and system overhead. This method adopts Hamming distance as the similarity metric; it is sensitive to differences in all bit positions, distinguishing it from metrics like the Dice coefficient which focus on shared features. Consequently, its matching performance may vary compared to other metrics under different data characteristics (e.g., sparsity) or application scenarios, necessitating practical evaluation. Subsequent processes, including secret sharing, mask computation, B2A conversion, and final Hamming distance aggregation, are designed to precisely compute the Hamming distance determined by Bloom filter representation, assuming no computational errors or malicious behavior. These cryptographic operations should theoretically not introduce additional loss in linkage quality. Thus, the primary factors affecting linkage quality remain the Bloom filter encoding strategy and its parameter settings in the initial stage.
Beyond the encoding strategy itself, the robustness of the Hamming distance computation process during actual operation critically affects final linkage quality, particularly false positive/negative (FP/FN) rates. Instances where computation nodes fail, do not successfully upload their shares, or (under a malicious model) submit inconsistent or tampered shares, can all impair Hamming distance accuracy.
Partial computation node failure or share loss can lead to inaccurate Hamming distance reconstruction, as aggregating all (t) partial shares submitted by computation nodes is required. This primarily increases False Negatives (reducing recall), as true matches might be missed due to inability to compute an accurate similarity score. While the system’s reputation mechanism penalizes failing nodes, thereby indirectly promoting reliability, unaddressed real-time share loss can still negatively affect judgments for specific linkage pairs.
Similarly, if computation nodes upload inconsistent or erroneous shares (due to unintentional error or Byzantine behavior) that are not captured by the sampling audit mechanism of verification nodes (driven by the audit verification smart contract), the final aggregated Hamming distance will deviate from the true value. An incorrectly calculated Hamming distance might cause dissimilar records to appear similar (leading to false positives, reducing precision) or similar records to appear dissimilar (leading to False Negatives, reducing recall). The current design relies on sampling audits and the reputation system to deter and detect such issues, but the non-comprehensive nature of sampling audits means some erroneous shares might still affect calculations.
In summary, while this method’s cryptographic design aims for accurate Hamming distance computation (making linkage quality primarily dependent on the encoding strategy), practical operational factors like computation node reliability, honesty, and network stability can, if not fully mitigated by existing fault tolerance and error correction mechanisms (e.g., reputation management, sampling audits), indirectly affect Hamming distance accuracy. This, in turn, can adversely impact FP/FN rates. Therefore, further enhancing the fault tolerance of the Hamming distance computation process against such node failures and data inconsistencies is an important aspect for improving overall linkage quality stability.
6. Experimental Results
6.1. Experiment Preparation
In this section, we evaluate the proposed SSB-PPRL method’s performance in three aspects—scalability, linkage quality, and security—through experiments, comparing it with three related methods by Han et al. [10], Vatsalan et al. [35], and Yao et al. [36]. Han et al.’s MP-PPRL-CBT uses a consortium blockchain instead of a semi-trusted third party, integrating homomorphic encryption and MapReduce for secure and efficient multi-party linkage. Vatsalan et al.’s method employs segmented Bloom filters and distributed secure computation for efficient multi-party approximate matching. Yao et al.’s approach introduces twin neural networks to PPRL for adaptive matching via feature learning and proposes a composite Bloom filter to enhance encoding security.
The experimental environment consisted of several high-performance servers, each equipped with an AMD EPYC 7763 CPU (64 cores/128 threads, ~2.45 GHz base frequency), 128 GB DDR4 RAM, high-speed NVMe storage, and Ubuntu 20.04 LTS. The core SSB-PPRL algorithm was implemented in Python 3.8, with cryptographic operations utilizing the PyCryptodome library. Blockchain functionalities were supported by a private Ethereum test network based on Ganache CLI v7.7.0, with smart contracts written in Solidity v0.8.17 and managed by Truffle Suite. For IPFS storage, multiple Kubo v0.18.1 nodes were deployed. These nodes, along with the SSB-PPRL application modules, were containerized using Docker and run in a local high-speed network environment. Interaction with the blockchain was handled via the Web3.py library, and communication with IPFS used the ipfshttpclient library.
The datasets used in this study include the North Carolina Voter Registration List (NCVR), the DBLP-Scholar dataset, and the DBLP-ACM dataset. All three datasets are publicly available and widely used in privacy-preserving record linkage research.
The independent variables in the experiments include the size of the data source, the number of participating parties, and the perturbation ratio. We extracted 5 K, 10 K, 50 K, 100 K, and 500 K records from the datasets. The number of participating parties was set to 3, 5, 7, and 9, respectively.
To more accurately reflect real-world data errors, we applied perturbation processing to the original datasets, generating datasets with different noise levels. Specifically, we created three perturbed versions, introducing spelling errors, semantic changes, and structural adjustments. The perturbation operations included character deletion, random replacement, word order adjustment, and character insertion. To maintain control over the perturbations, we defined three error levels: Mod-1, where each record has at most one error; Mod-2, where each record has at most two errors; and Mod-3, where each record has at most three errors. Through this design, the datasets better align with real-world scenarios, providing effective support for evaluating the robustness and matching capabilities of privacy-preserving record linkage methods under different noise environments.
We adopt five key metrics to evaluate the overall scalability, linkage quality, and security of the proposed method: runtime, precision, recall, F-score, and reconstruction rate. Among them, precision measures the proportion of actual matching record pairs in the total number of candidate record pairs, reflecting the method’s accuracy; recall represents the proportion of actual matching record pairs relative to all true matching record pairs, indicating the method’s coverage capability. The F-score, as a comprehensive metric combining precision and recall, is calculated using the following formula:
The reconstruction rate is a metric used to assess an attacker’s ability to recover original data. It measures the extent to which an attacker, by controlling a subset of computation nodes, successfully reconstructs the information in Bloom filters. Suppose there are M Bloom filter pairs, each decomposed into t shares, randomly distributed to t nodes among N nodes [37]. Randomly select c colluding nodes from the N nodes and check how many Bloom filters have all t shares controlled by the colluding nodes.
Theoretically, considering the impact of permutations, the reconstruction rate (i.e., the probability that an attacker successfully obtains all t shares for a specific Bloom filter and guesses its correct permutation) is calculated as follows:
6.2. Experimental Results and Analysis
6.2.1. Scalability Assessment
In evaluating scalability, we primarily use runtime as the key metric to analyze the system’s performance under different data sizes and computational node configurations.
To ensure security, our method employs secret sharing techniques and smart contract management, which significantly reduce the method’s efficiency. Therefore, we use multi-node distributed computing and attribute-based partitioning methods to accelerate this process. When the number of participating parties is 3, the perturbation ratio is 30%, the number of secret shares is 5, and the number of masks is 5 sets, the runtime of the proposed method (in the approximate matching phase and the audit verification phase) varies with increasing data source size, as shown in Figure 5.
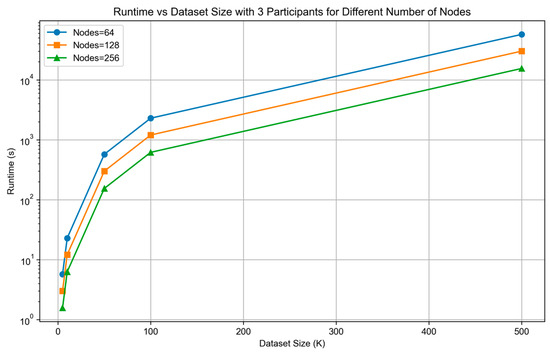
Figure 5.
The runtime of the proposed method varies with increasing data source size.
As the dataset size increases, the specific runtime for different numbers of nodes is shown in Table 1.

Table 1.
The runtime performance for varying node counts with growing dataset size.
When the data size is 50 k, the perturbation ratio is 30%, the number of secret shares is 5, and the number of masks is 5 sets, the running time of the proposed method (for the approximate matching phase and the audit verification phase) varies with the increase in the number of participants, as shown Figure 6.
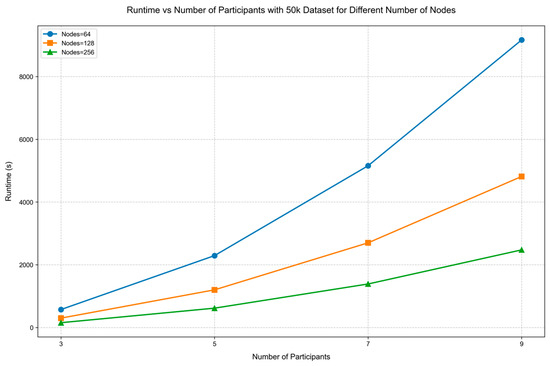
Figure 6.
The runtime performance for varying node counts with increasing participant numbers.
As the number of participants increases, the specific runtime for different numbers of nodes is shown in Table 2.
Table 2.
The runtime performance for varying node counts with increasing participant numbers.
6.2.2. Method Performance Evaluation
To comprehensively evaluate the linkage quality of the proposed method, we assessed the SSB-PPRL method in terms of precision, recall, and F-score. The evaluation examined how these three metrics vary with an increasing number of participants, given a fixed data size, across datasets with three different levels of perturbation.
Under datasets with 20,000 records perturbed to varying degrees (Mod-1 to Mod-3), the precision of all methods decreases as the number of participants and data error rates increase, with the most significant decline observed under high error rates (Mod-3). Benefiting from its neural network matching mechanism, the Yao method achieves the highest prediction precision and robust performance. The Vatsalan method, relying on precise privacy-preserving computation, is primarily constrained by the performance of its Bloom filter and Dice similarity function. Our proposed method, based on accurate secret sharing computation, incurs no additional precision loss and demonstrates precision comparable to the Vatsalan method. Notably, under complex conditions with a high number of participants and elevated error rates, our method outperforms Han, exhibiting a clear advantage in precision. This avoids the potential negative impact of the binary tree structure on matching accuracy observed in the Han method. The precision variation with the number of participants in the three perturbed datasets is shown in Figure 7.
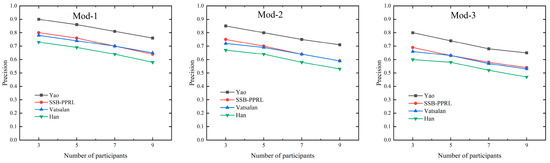
Figure 7.
The precision variation with the number of participants in the three perturbed datasets.
The specific precision values for the three perturbed datasets as the number of participants varies are shown in Table 3.
Table 3.
Precision values for three perturbed datasets changing with participant numbers.
As the number of participants and perturbation levels increase, the recall rates of all methods show a downward trend. Notably, the decline in recall from Mod-1 to Mod-2 is particularly significant. The Yao method stands out, maintaining the highest recall across all test conditions. Additionally, the Vatsalan method and our proposed SSB-PPRL method also sustain relatively high recall rates, outperforming the Han method, which aligns with their core privacy-preserving mechanisms that theoretically introduce no additional False Negatives. The recall variation with the number of participants in the three perturbed datasets is shown in Figure 8.
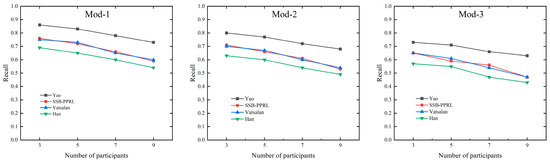
Figure 8.
The recall variation with the number of participants in the three perturbed datasets.
The specific recall values for the three perturbed datasets as the number of participants varies are shown in Table 4.
Table 4.
Recalling values for three perturbed datasets changing with participant numbers.
Under varying numbers of participants and perturbation levels, the Yao method achieves the highest F-score and strong anti-interference capability, benefiting from improvements in its linkage approach. Our proposed method and the Vatsalan method, however, are primarily influenced by the Bloom filter and similarity metric functions in terms of linkage quality. The Han method improves data structure for better efficiency but experiences a slight decline in linkage quality. The F-score variation with the number of participants in the three perturbed datasets is shown in Figure 9.
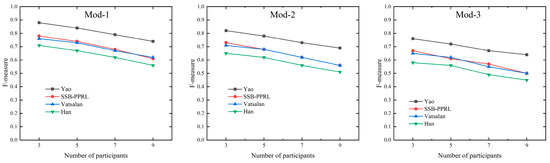
Figure 9.
The F-score variation with the number of participants in the three perturbed datasets.
The specific F-score values for the three perturbed datasets as the number of participants varies are shown in Table 5.
Table 5.
F-score values for three perturbed datasets changing with participant numbers.
6.2.3. Security Evaluation
In this section, we set the number of secret shares t = 10, meaning each Bloom filter is decomposed into 10 Boolean shares, distributed across 10 computing nodes. We evaluated the ability of colluding nodes to reconstruct the Bloom filter by varying the total number of nodes N (50, 100, 200) and the number of colluding nodes c (starting from 10 and increasing to 0.8 × N). The experimental results are shown in Table 6 below.
Table 6.
Comparison of theoretical and experimental reconstruction rates under different collusion scenarios.
The experimental results demonstrate how the total number of nodes and the number of colluding nodes affect the reconstruction rate under a fixed number of secret shares . The reconstruction rate, defined as the probability of colluding nodes recovering a Bloom filter, depends on the likelihood of collecting all shares and guessing the correct permutation. The theoretical reconstruction rate is given by
When c < t, the reconstruction rate is 0, as insufficient shares are collected. In the experiments, t = 10, with permutation possibilities t! = 3,628,800, significantly reducing the attack success rate. When c = t = 10 (i.e., the number of colluding nodes equals the number of secret shares), the theoretical rate is extremely low (e.g., for N = 50). Experimental values are 0, which is consistent with such a low theoretical probability of successful reconstruction. When c ≥ t, the theoretical reconstruction rate increases with c. However, it remains very small for lower c values and becomes more significant (though still low) for higher c values (e.g., 80% node collusion). For example, for N = 50, c = 40 (80% collusion), the corrected theoretical rate is , with an experimental value of 2 × . For N = 200, c = 160 (80% collusion), the corrected theoretical rate is , with an experimental value of 1 × . Permutation difficulty ensures security.
Increasing N (total nodes) reduces the theoretical reconstruction rate, e.g., for c = 40, the rate drops from at N = 50 to at N = 200, due to lower collection probability. Increasing c (colluding nodes) raises the theoretical rate. The permutation factor t! ensures these theoretical rates remain very low (e.g., in the order of or lower for the parameters tested). The experimental rates observed are in the order of for high collusion scenarios.
The experimental reconstruction rates in high collusion scenarios (e.g., 2 × for N = 50, c = 40) are observed to be higher than the recalculated theoretical rates (e.g., 2.274 × for N = 50, c = 40). This difference might be attributed to factors in the experimental setup or inherent randomness. However, both theoretical (recalculated) and experimental rates are extremely low, and the general trends (effect of N and c) align.
The results show that even with 80% node collusion, the t = 10 configuration results in experimentally observed reconstruction rates around 1–2 × . This is an extremely low rate. To put this into perspective, a reconstruction rate of 1−2× signifies approximately one to two successful reconstructions per ten million attempts, making the orders of magnitude rarer than one successful reconstruction per thousand. The dual protection of secret sharing and permutation confirms SBB-PPRL’s strong privacy protection under high collusion scenarios.
7. Conclusions
We propose a privacy-preserving record linkage method based on secret sharing and blockchain (SSB-PPRL), designed for secure and efficient record linkage across multiple data sources. By leveraging secret sharing, blockchain coordination, and IPFS storage, the method enhances privacy, scalability, and fault tolerance. Experimental results demonstrate that it maintains high linkage quality and scalability while ensuring data privacy.
Nevertheless, there is room for improvement in computational efficiency, protocol optimization, and resilience against extreme attack scenarios. Future research will focus on advancing the following key directions: Firstly, efforts will continue to optimize system performance and efficiency, including refining blockchain–IPFS interactions and enhancing node scheduling and core computation strategies managed by smart contracts. Secondly, work will aim to enhance overall system security and robustness, with a focus on researching stronger Byzantine fault-tolerant mechanisms for critical coordination and verification stages (potentially involving new smart contract designs), advanced collusion-resistant techniques, dynamic trust models, and comprehensive defenses and emergency response protocols against various DoS attacks, to effectively address extreme situations of large-scale computation and validation node failures or malicious behavior [38]. Furthermore, attention will be given to ensuring linkage quality under non-ideal conditions, particularly by investigating more fault-tolerant secret sharing aggregation algorithms and computation result consistency verification techniques to stabilize and control false positive/negative rates that may arise from partial node failures or data inconsistencies. Lastly, the integration and advancement of cutting-edge privacy-preserving technologies will be deepened, for instance, by hardening initial encoding stages like Bloom filters through salting or noise injection to defend against direct data analysis attacks [39], and by combining differential privacy and access pattern obfuscation to reduce potential side-channel leakage, ensuring high-level privacy in complex adversarial environments [40].
Through continued exploration in these areas, we expect to further elevate the comprehensive performance of the SSB-PPRL method, enabling it to better serve real-world data sharing requirements.
Author Contributions
Conceptualization, S.H., Z.W., and Q.Z.; methodology, S.H., Z.W., and Q.Z.; software, S.H., Z.W., and Y.X.; validation, S.H., Z.W., and Q.Z.; formal analysis, S.H., Q.Z., D.S., and C.W.; investigation, S.H., Q.Z., D.S., and C.W.; resources, S.H. and Z.W.; data curation, S.H., Z.W., and Y.X.; writing—original draft preparation, S.H. and Z.W.; writing—review and editing, S.H., Z.W., and Q.Z.; visualization, S.H., Z.W., and D.S.; supervision, S.H. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by the National Natural Science Foundation of China (62172082) and the Education Department of Liaoning Province, Youth Project (LJKQZ20222440).
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Sayers, A.; Ben-Shlomo, Y.; Blom, A.W.; Steele, F. Probabilistic Record Linkage. Int. J. Epidemiol. 2016, 45, 954–964. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Gu, Y.; Zhou, X.; Ma, Q.; Yu, G. An Effective and Efficient Truth Discovery Framework over Data Streams. In Proceedings of the EDBT, Venice, Italy, 21–24 March 2017; pp. 180–191. [Google Scholar]
- Vatsalan, D.; Christen, P.; Verykios, V.S. A Taxonomy of Privacy-Preserving Record Linkage Techniques. Inf. Syst. 2013, 38, 946–969. [Google Scholar] [CrossRef]
- Pathak, A.; Serrer, L.; Zapata, D.; King, R.; Mirel, L.B.; Sukalac, T.; Srinivasan, A.; Baier, P.; Bhalla, M.; David-Ferdon, C.; et al. Privacy Preserving Record Linkage for Public Health Action: Opportunities and Challenges. J. Am. Med. Inf. Assoc. 2024, 31, 2605–2612. [Google Scholar] [CrossRef]
- Gkoulalas-Divanis, A.; Vatsalan, D.; Karapiperis, D.; Kantarcioglu, M. Modern Privacy-Preserving Record Linkage Techniques: An Overview. IEEE Trans. Inform. Forensic Secur. 2021, 16, 4966–4987. [Google Scholar] [CrossRef]
- Vidanage, A.; Ranbaduge, T.; Christen, P.; Schnell, R. A Taxonomy of Attacks on Privacy-Preserving Record Linkage. J. Priv. Confidentiality 2022, 12, 1. [Google Scholar] [CrossRef]
- Nóbrega, T.; Pires, C.E.S.; Nascimento, D.C. Blockchain-Based Privacy-Preserving Record Linkage: Enhancing Data Privacy in an Untrusted Environment. Inf. Syst. 2021, 102, 101826. [Google Scholar] [CrossRef]
- Christen, P.; Schnell, R.; Ranbaduge, T.; Vidanage, A. A Critique and Attack on “Blockchain-Based Privacy-Preserving Record Linkage”. Inf. Syst. 2022, 108, 101930. [Google Scholar] [CrossRef]
- Randall, S.M.; Brown, A.P.; Ferrante, A.M.; Boyd, J.H.; Semmens, J.B. Privacy Preserving Record Linkage Using Homomorphic Encryption. In Proceedings of the First International Workshop on Population Informatics for Big Data, Sydney, Australia, 13 April 2015; Volume 10. [Google Scholar]
- Han, S.; Wang, Z.; Shen, D.; Wang, C. A Parallel Multi-Party Privacy-Preserving Record Linkage Method Based on a Consortium Blockchain. Mathematics 2024, 12, 1854. [Google Scholar] [CrossRef]
- Schnell, R.; Bachteler, T.; Reiher, J. Privacy-Preserving Record Linkage Using Bloom Filters. BMC Med. Inf. Decis. Making 2009, 9, 41. [Google Scholar] [CrossRef]
- Vatsalan, D.; Yu, J.; Henecka, W.; Thorne, B. Fairness-Aware Privacy-Preserving Record Linkage. In Proceedings of the International Workshop on Data Privacy Management, Surrey, UK, 17–18 September 2020; pp. 3–18. [Google Scholar]
- Laud, P.; Pankova, A. Privacy-Preserving Record Linkage in Large Databases Using Secure Multiparty Computation. BMC Med. Genomics 2018, 11, 84. [Google Scholar] [CrossRef]
- Han, S.; Shen, D.; Nie, T.; Kou, Y.; Yu, G. Private Blocking Technique for Multi-Party Privacy-Preserving Record Linkage. Data Sci. Eng. 2017, 2, 187–196. [Google Scholar] [CrossRef]
- Wu, J.; Li, T.; Chen, L.; Gao, Y.; Wei, Z. SEA: A Scalable Entity Alignment System. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, 23–27 July 2023; pp. 3175–3179. [Google Scholar]
- Karapiperis, D.; Verykios, V.S. A Distributed Framework for Scaling up LSH-Based Computations in Privacy Preserving Record Linkage. In Proceedings of the 6th Balkan Conference in Informatics, Thessaloniki, Greece, 19–21 September 2013; pp. 102–109. [Google Scholar]
- Vaiwsri, S.; Ranbaduge, T.; Christen, P.; Schnell, R. Accurate Privacy-Preserving Record Linkage for Databases with Missing Values. Inf. Syst. 2022, 106, 101959. [Google Scholar] [CrossRef]
- Rohde, F.; Christen, V.; Franke, M.; Rahm, E. Multi-Layer Privacy-Preserving Record Linkage with Clerical Review Based on Gradual Information Disclosure. arXiv 2024, arXiv:2412.04178. [Google Scholar]
- Lu, K.; Zhang, C. Blockchain-Based Multiparty Computation System. In Proceedings of the 2020 IEEE 11th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 16 October 2020; pp. 28–31. [Google Scholar]
- Sanchez-Gomez, N.; Torres-Valderrama, J.; Mejias Risoto, M.; Garrido, A. Blockchain Smart Contract Meta-Modeling. J. Web Eng. 2021, 20, 2059–2079. [Google Scholar] [CrossRef]
- Kumar, R.; Tripathi, R. Implementation of Distributed File Storage and Access Framework Using IPFS and Blockchain. In Proceedings of the 2019 Fifth International Conference on Image Information Processing (ICIIP), Shimla, India, 15–17 November 2019; pp. 246–251. [Google Scholar]
- Kang, P.; Yang, W.; Zheng, J. Blockchain Private File Storage-Sharing Method Based on IPFS. Sensors 2022, 22, 5100. [Google Scholar] [CrossRef]
- Chattopadhyay, A.K.; Saha, S.; Nag, A.; Nandi, S. Secret Sharing: A Comprehensive Survey, Taxonomy and Applications. Comput. Sci. Rev. 2024, 51, 100608. [Google Scholar] [CrossRef]
- Cheng, N.; Zhang, F.; Mitrokotsa, A. Efficient Three-Party Boolean-to-Arithmetic Share Conversion. In Proceedings of the 2023 20th Annual International Conference on Privacy, Security and Trust (PST), Copenhagen, Denmark, 21–23 August 2023; pp. 1–6. [Google Scholar]
- Dehkordi, M.H.; Mashhadi, S.; Farahi, S.T.; Noorallahzadeh, M.H. Changeable Essential Threshold Secret Image Sharing Scheme with Verifiability Using Bloom Filter. Multimed. Tools Appl. 2023, 83, 1–37. [Google Scholar] [CrossRef]
- Maskey, S.R.; Badsha, S.; Sengupta, S.; Khalil, I. Reputation-Based Miner Node Selection in Blockchain-Based Vehicular Edge Computing. IEEE Consum. Electron. Mag. 2021, 10, 14–22. [Google Scholar] [CrossRef]
- Zhang, X.; He, M. Collusion Attack Resistance and Practice-Oriented Threshold Changeable Secret Sharing Schemes. In Proceedings of the 2010 24th IEEE International Conference on Advanced Information Networking and Applications, Perth, Australia, 20–23 April 2010; pp. 745–752. [Google Scholar]
- Mukhedkar, M.; Kote, P.; Zonde, M.; Jadhav, O.; Bhasme, V.; Dawande, N.A. Advanced and Secure Data Sharing Scheme with Blockchain and IPFS: A Brief Review. In Proceedings of the 2024 15th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kamand, India, 24–28 June 2024; pp. 1–5. [Google Scholar]
- Liu, S.; Li, Y.; Guan, P.; Li, T.; Yu, J.; Taherkordi, A.; Jensen, C.S. FedAGL: A Communication-Efficient Federated Vehicular Network. IEEE Trans. Telligent Veh. 2024, 9, 3704–3720. [Google Scholar] [CrossRef]
- Davidson, A.; Snyder, P.; Quirk, E.B.; Genereux, J.; Livshits, B.; Haddadi, H. Star: Secret Sharing for Private Threshold Aggregation Reporting. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, Los Angeles, CA, USA, 7–11 November 2022; pp. 697–710. [Google Scholar]
- Chen, L.; Fu, Q.; Mu, Y.; Zeng, L.; Rezaeibagha, F.; Hwang, M.-S. Blockchain-Based Random Auditor Committee for Integrity Verification. Future Gener. Comput. Syst. 2022, 131, 183–193. [Google Scholar] [CrossRef]
- Eren, H.; Karaduman, O.; Gencoglu, M.T. Security Challenges and Performance Trade-Offs in On-Chain and Off-Chain Blockchain Storage: A Comprehensive Review. Appl. Sci. 2025, 15, 3225. [Google Scholar] [CrossRef]
- Wei, Y.; Trautwein, D.; Psaras, Y.; Castro, I.; Scott, W.; Raman, A.; Tyson, G. The Eternal Tussle: Exploring the Role of Centralization in {IPFS}. In Proceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), Santa Clara, CA, USA, 16–18 April 2024; pp. 441–454. [Google Scholar]
- Järvinen, K.; Leppäkoski, H.; Lohan, E.-S.; Richter, P.; Schneider, T.; Tkachenko, O.; Yang, Z. PILOT: Practical Privacy-Preserving Indoor Localization Using Outsourcing. In Proceedings of the 2019 IEEE European Symposium on Security and Privacy (EuroS&P), Stockholm, Sweden, 17–19 June 2019; pp. 448–463. [Google Scholar]
- Vatsalan, D.; Christen, P. Multi-Party Privacy-Preserving Record Linkage Using Bloom Filters. arXiv 2016, arXiv:1612.08835. [Google Scholar]
- Yao, S.; Ren, Y.; Wang, D.; Wang, Y.; Yin, W.; Yuan, L. SNN-PPRL: A Secure Record Matching Scheme Based on Siamese Neural Network. J. Inf. Secur. Appl. 2023, 76, 103529. [Google Scholar] [CrossRef]
- Luo, L.; Guo, D.; Ma, R.T.B.; Rottenstreich, O.; Luo, X. Optimizing Bloom Filter: Challenges, Solutions, and Comparisons. IEEE Commun. Surv. Tutor. 2019, 21, 1912–1949. [Google Scholar] [CrossRef]
- Song, Y.; Gu, Y.; Li, T.; Qi, J.; Liu, Z.; Jensen, C.S.; Yu, G. CHGNN: A Semi-Supervised Contrastive Hypergraph Learning Network. IEEE Trans. Knowl. Data Eng. 2024, 36, 4515–4530. [Google Scholar] [CrossRef]
- Ke, Y.; Liang, Y.; Sha, Z.; Shi, Z.; Song, Z. DPBloomfilter: Securing Bloom Filters with Differential Privacy. arXiv 2025, arXiv:2502.00693. [Google Scholar]
- Huang, C.; Yao, Y.; Zhang, X. Robust Privacy-Preserving Aggregation against Poisoning Attacks for Secure Distributed Data Fusion. Inf. Fusion 2025, 122, 103223. [Google Scholar] [CrossRef]
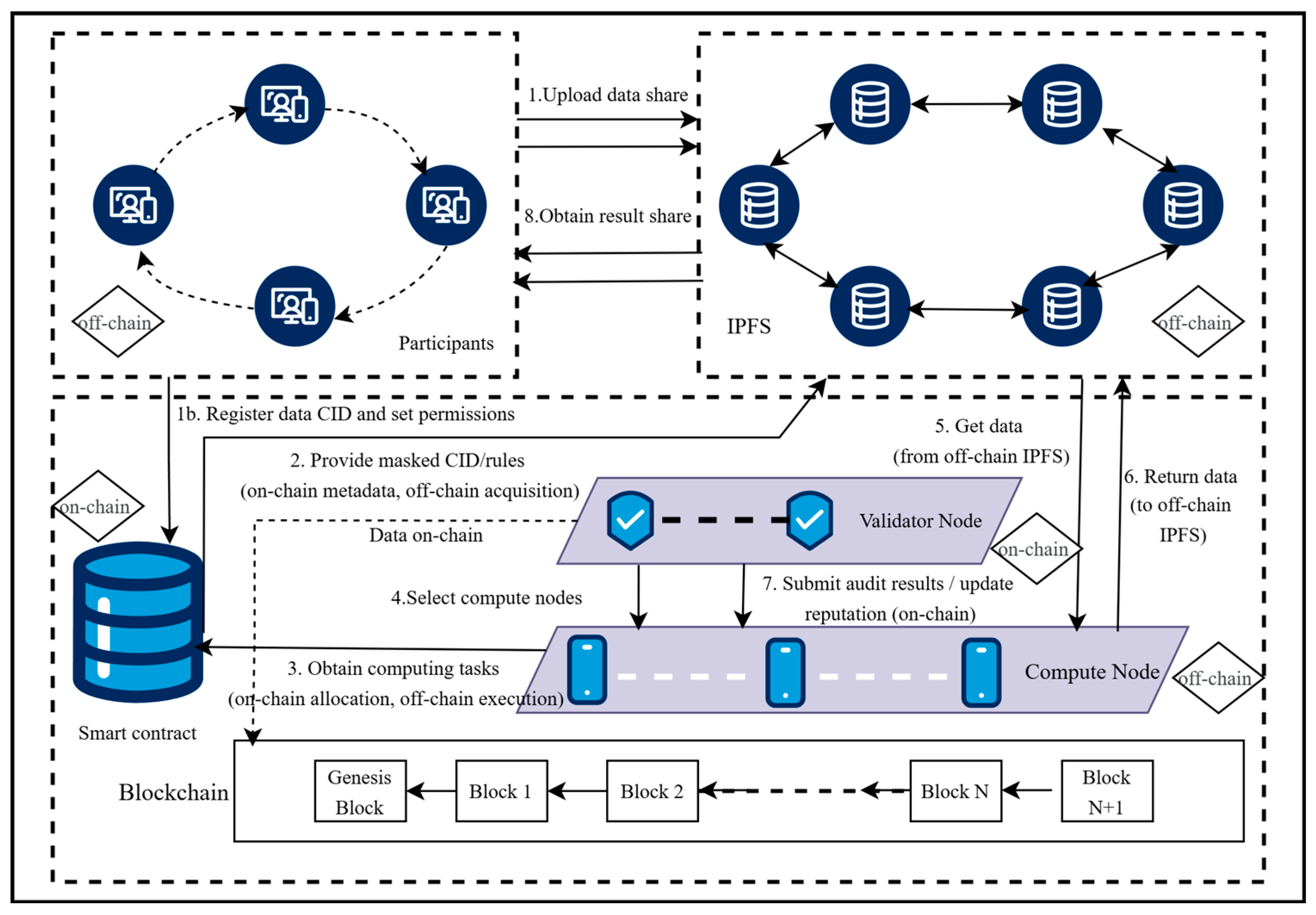
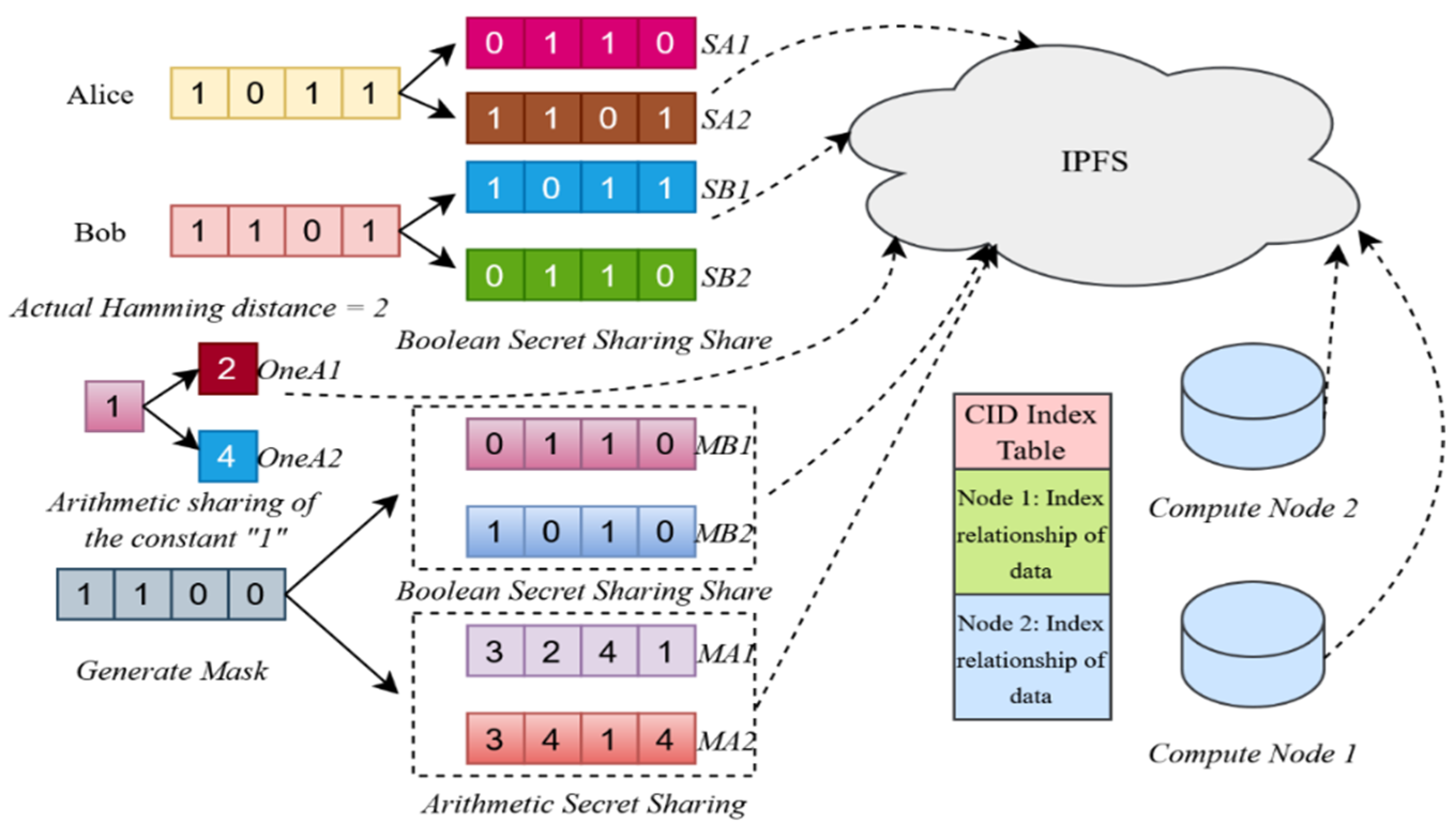
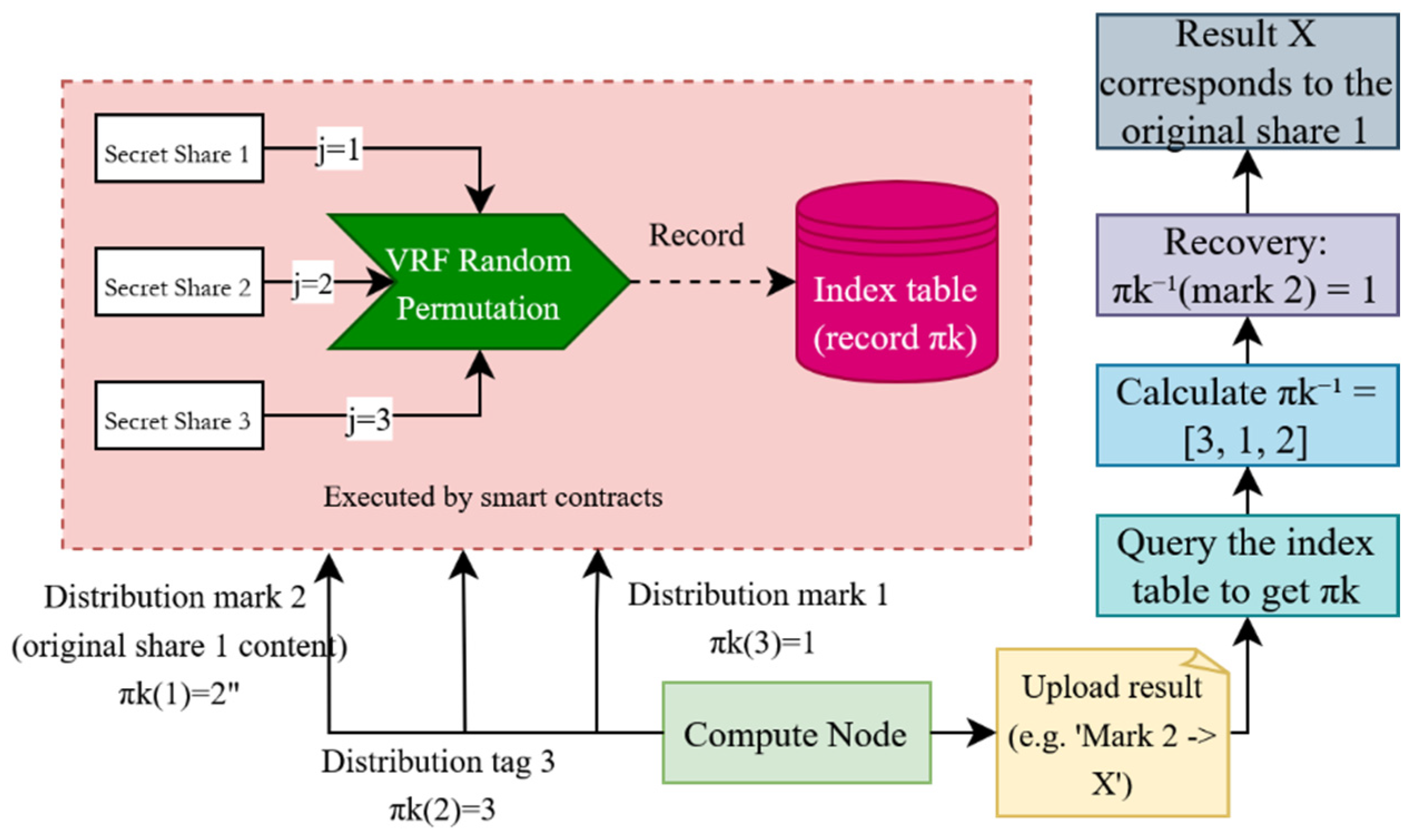
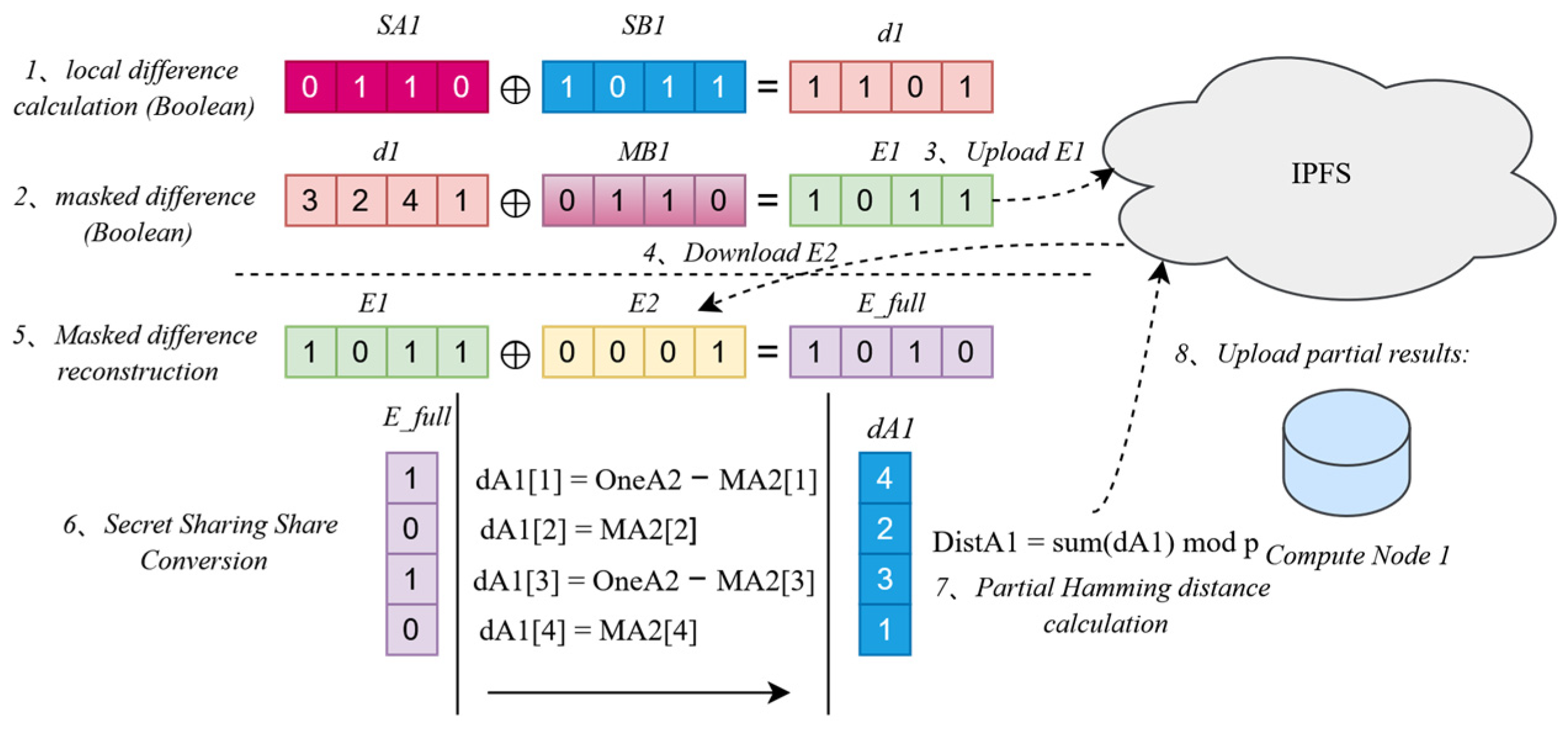
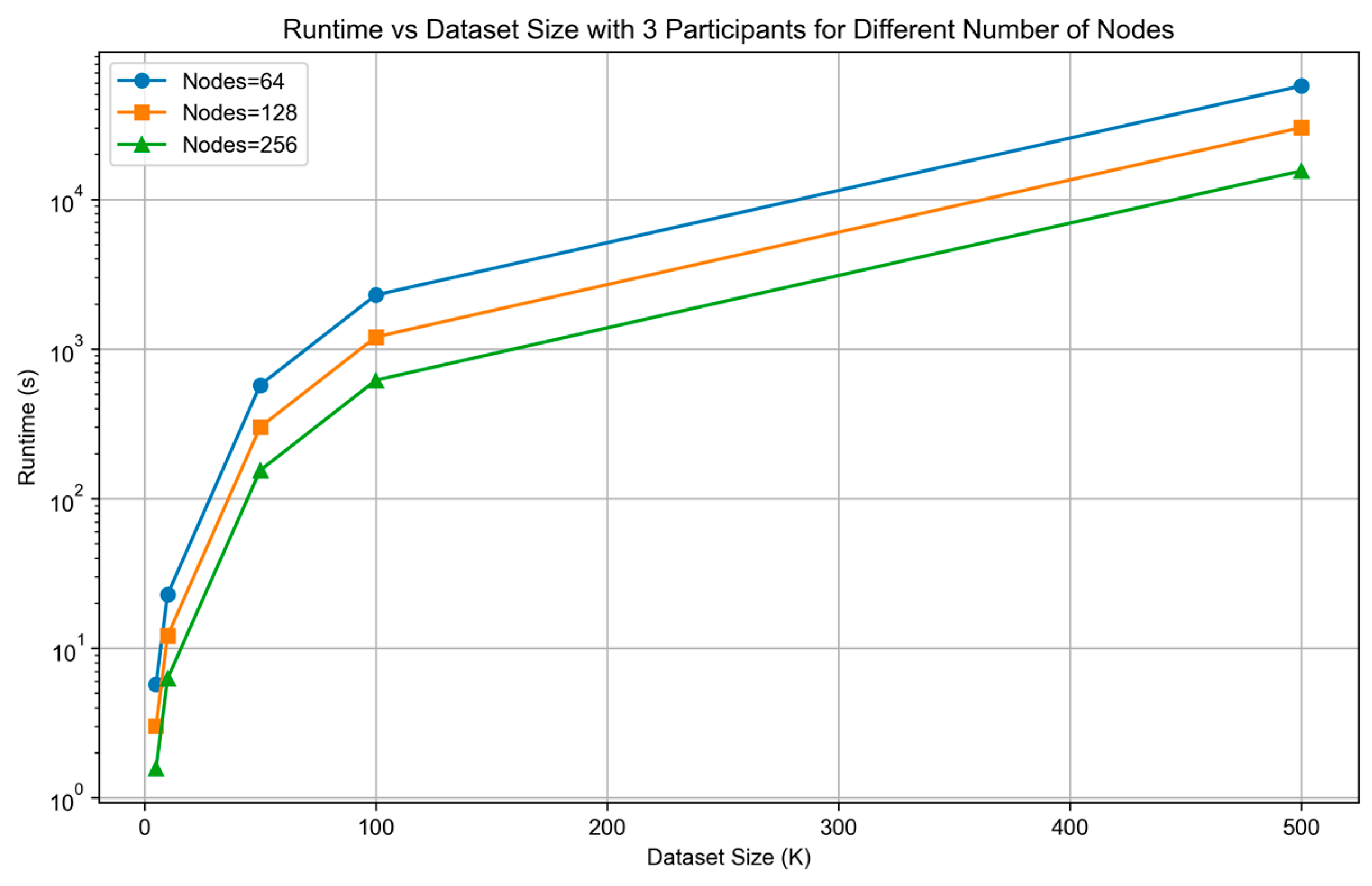
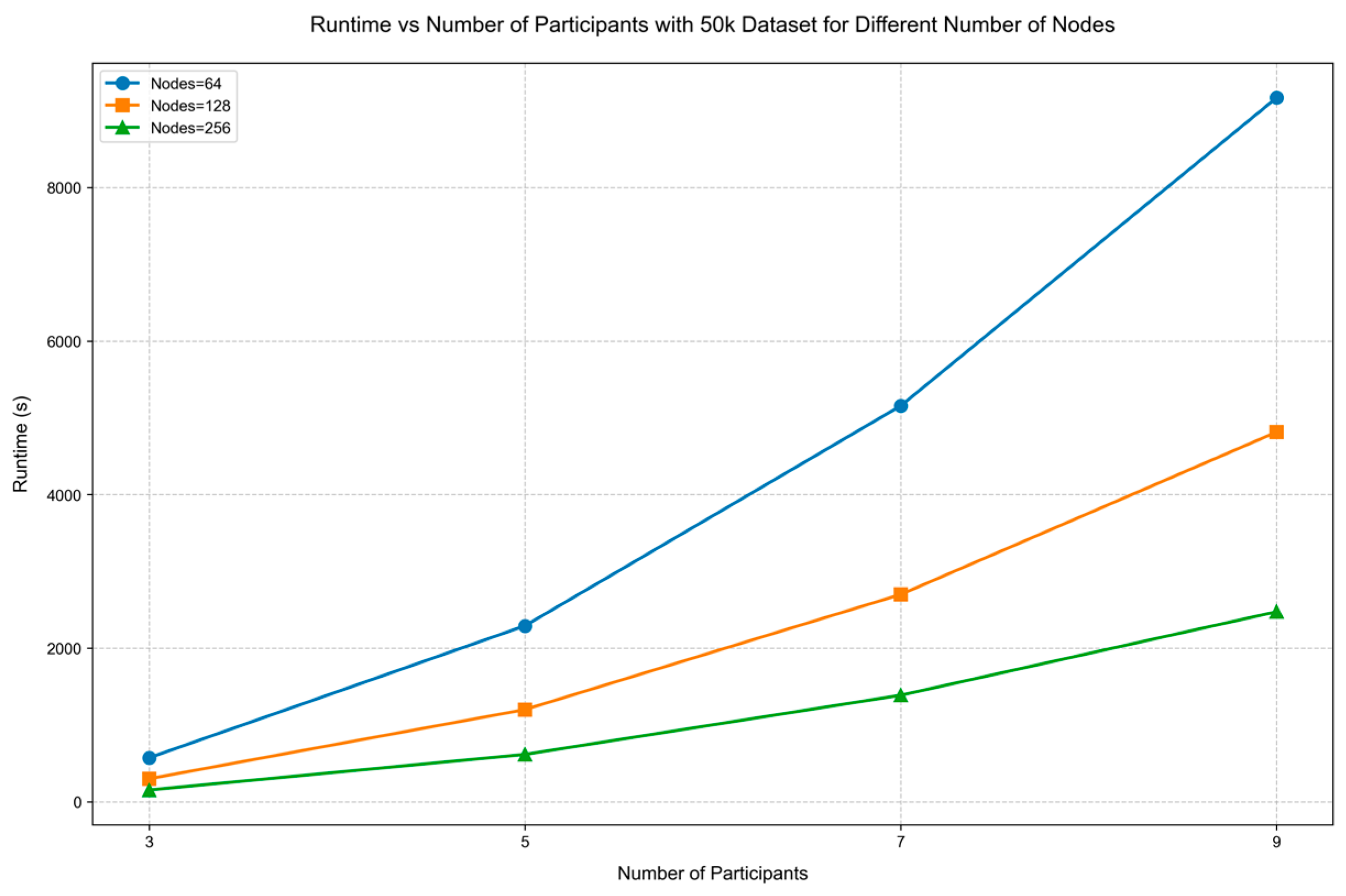
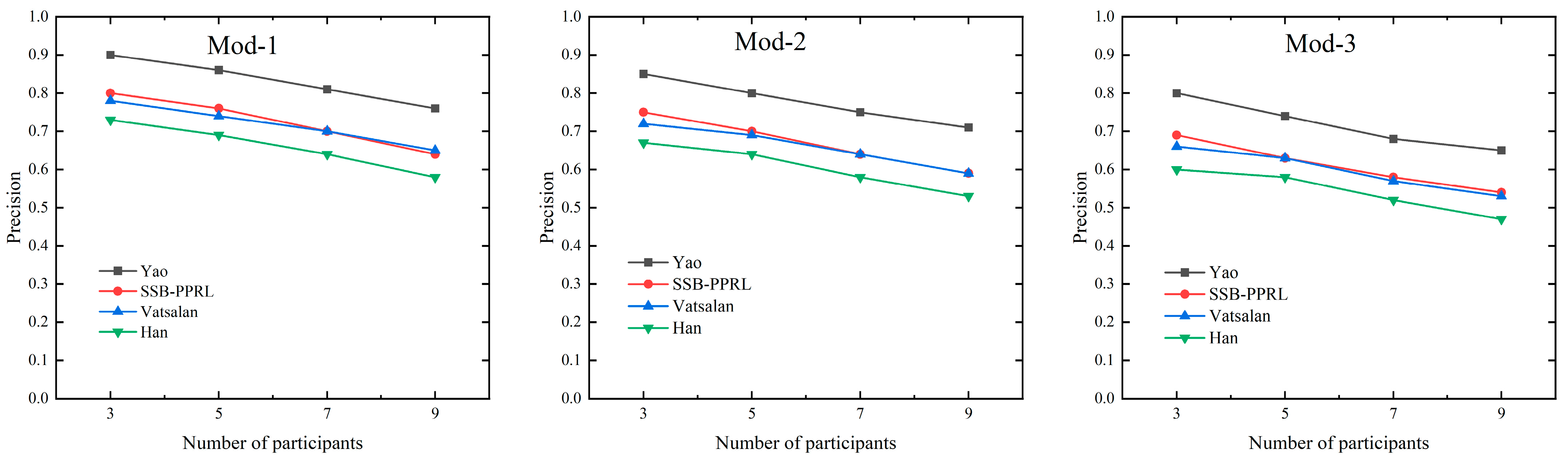
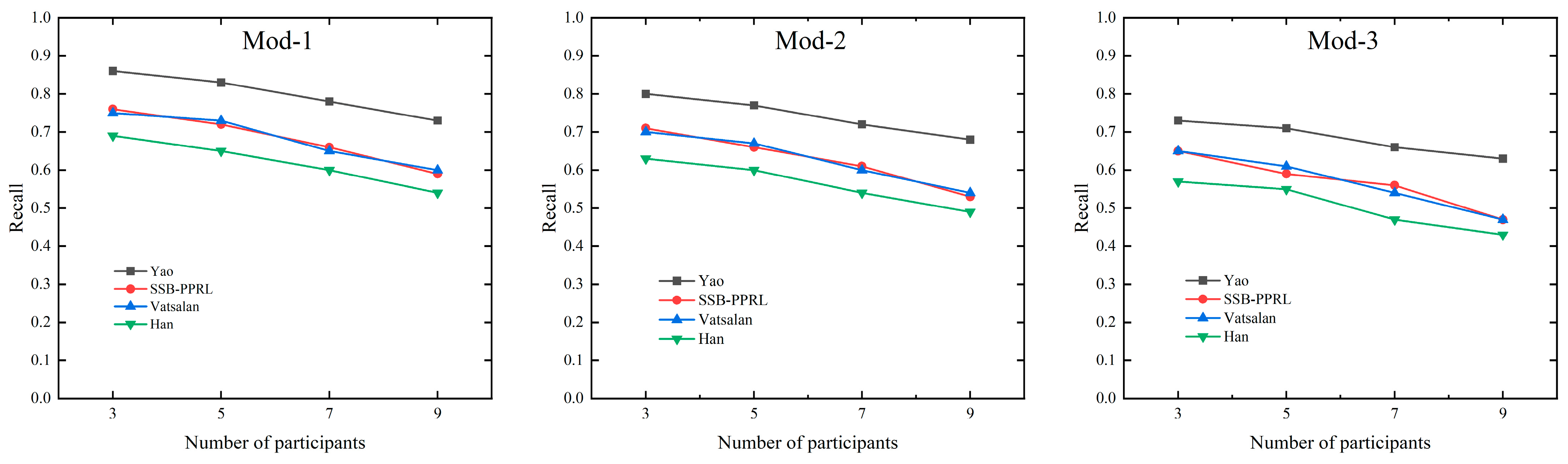
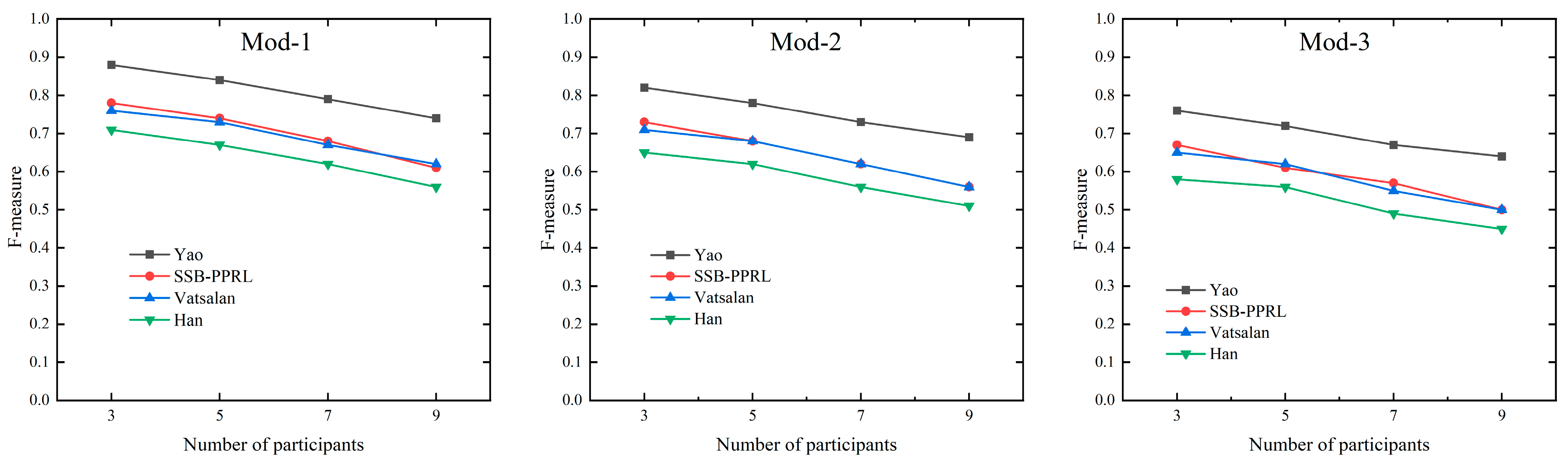
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Institute of Knowledge Innovation and Invention. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).