1. Introduction
Target detection is crucial for intelligent transportation and automated driving, with deep learning algorithms significantly improving its accuracy and precision. These algorithms are categorized into single-stage and two-stage algorithms. Single-stage algorithms, such as the You Only Look Once (YOLO) series [
1,
2,
3,
4,
5,
6,
7,
8], single-shot multiBox detector (SSD) [
9], and RetinaNet [
10], rapidly output target locations and categories, making them well-suited for fast processing, such as unmanned aerial vehicles (UAVs) aerial photography. Two-stage algorithms, including Faster Regions with Convolutional Neural Networks (R-CNN) [
11], Mask R-CNN [
12], and Cascade R-CNN [
13], show higher detection accuracies by effectively identifying potential target regions but require higher computational resources and lower efficiency, limiting their widespread application. While single-stage methods show similar speeds and accuracy to two-stage algorithms, they often struggle with accurately detecting small targets.
UAVs offer significant advantages in taking aerial photographs due to their portability, ease of operation, and adaptability to diverse terrains [
14]. Equipped with intelligent visual systems, UAVs perform target detection, identification, localization, and tracking through wide-angle and high-density aerial imagery that provides rich semantic details. However, UAV-based target detection has challenges in detecting small targets. Such small targets are often occluded or taken in images at low pixel ratios, leading to increased noise, requiring enhanced spatial sensitivity. Moreover, diverse image resolutions of small targets cause large variations in target scales and semantic information loss. UAVs’ hardware constraints in power supply and flight time also limit small-target detection accuracy, necessitating a balance between lightweight design and high-resolution processing [
15].
Therefore, various strategies have been proposed to improve small-target detection in UAV-captured images. Liang et al. [
16] enhanced feature fusion and scale perception using SSD for small targets, yet reliable detection in densely occluded images remained an issue. Liu et al. [
17] introduced the SPD-Conv module into YOLOv5 for pedestrian detection, preserving fine-grained features during downsampling; however, it struggled to capture global semantic information for larger targets in complex backgrounds. Ref. [
18] utilized YOLOv8 with a C2f module, FPN, and LSCD to balance computational load and accuracy. Building on this, Bu et al. [
19] developed OD-YOLO from YOLOv8, incorporating deformable convolution for small-sized, fuzzy, and geometrically deformed targets in remote sensing images.
Despite these advances, complex backgrounds introduce significant noise that hinders robust feature extraction, requiring further improvement in detection adaptability. Ma et al. [
20,
21] optimized YOLOv8 with GhostNet for computational efficiency and soft non-maximum suppression (S-NMS) for dense small targets, but this method was prone to miss or false detections due to insufficient contextual modeling in complex or crowded scenes. More recently, YOLOv11 models, incorporating modules such as Cross-Stage Partial with Kernel Size 2 (C3k2), Spatial Pyramid Pooling-Fast (SPPF), and Cross-Stage Partial with Pyramid Squeeze Attention (C2PSA), are used for enhanced parameter accuracy balance and higher efficiency. Li et al. [
22] improved YOLOv11’s SPPF layer for small-target capture in UAV photos, but the resulting network complexity limited UAV deployment.
Despite such advancements, current target detection methods still have limitations in extracting multi-dimensional image features and detailed semantic information. Algorithms relying on complex multi-feature fusion often lead to an exponential increase in parameters and reduced inference efficiency. These limitations hinder real-time small-target detection in UAV photography, demanding significant computational resources and a careful balance of model parameters, complexity, speed, and accuracy. Therefore, there is another lightweight and accurate solution for UAVs that enhances small-target detection in complex, highly occluded backgrounds. Therefore, we developed a lightweight small-target detection method for UAVs based on YOLOv8 (FFG-YOLO). In this study, FFG-YOLO integrates three modules: a feature enhancement block (FEB) for multi-scale feature extraction without increasing parameters, a feature concat block (FCB) to minimize semantic bias in multi-scale feature fusion, and a global context awareness block (GCAB) to fuse global context and improve attention. The modules are used to distinguish small targets from complex backgrounds. We employed the Wasserstein distance loss (WDLoss) function, derived from optimal transmission theory, for accurate small-target positioning and precise measurement of similarity between predicted and ground-truth bounding boxes, enhancing pixel-level accuracy with blurred or confusing backgrounds. Experiment results demonstrated that FFG-YOLO outperformed algorithms, including YOLOv8, YOLOv10, YOLOv11, and real-time detection transformer (RT-DETR) in detecting small targets in aerial photos on variable scales and overlapped objects, while maintaining its lightweight characteristics appropriate for UAV photography.
2. YOLOv8
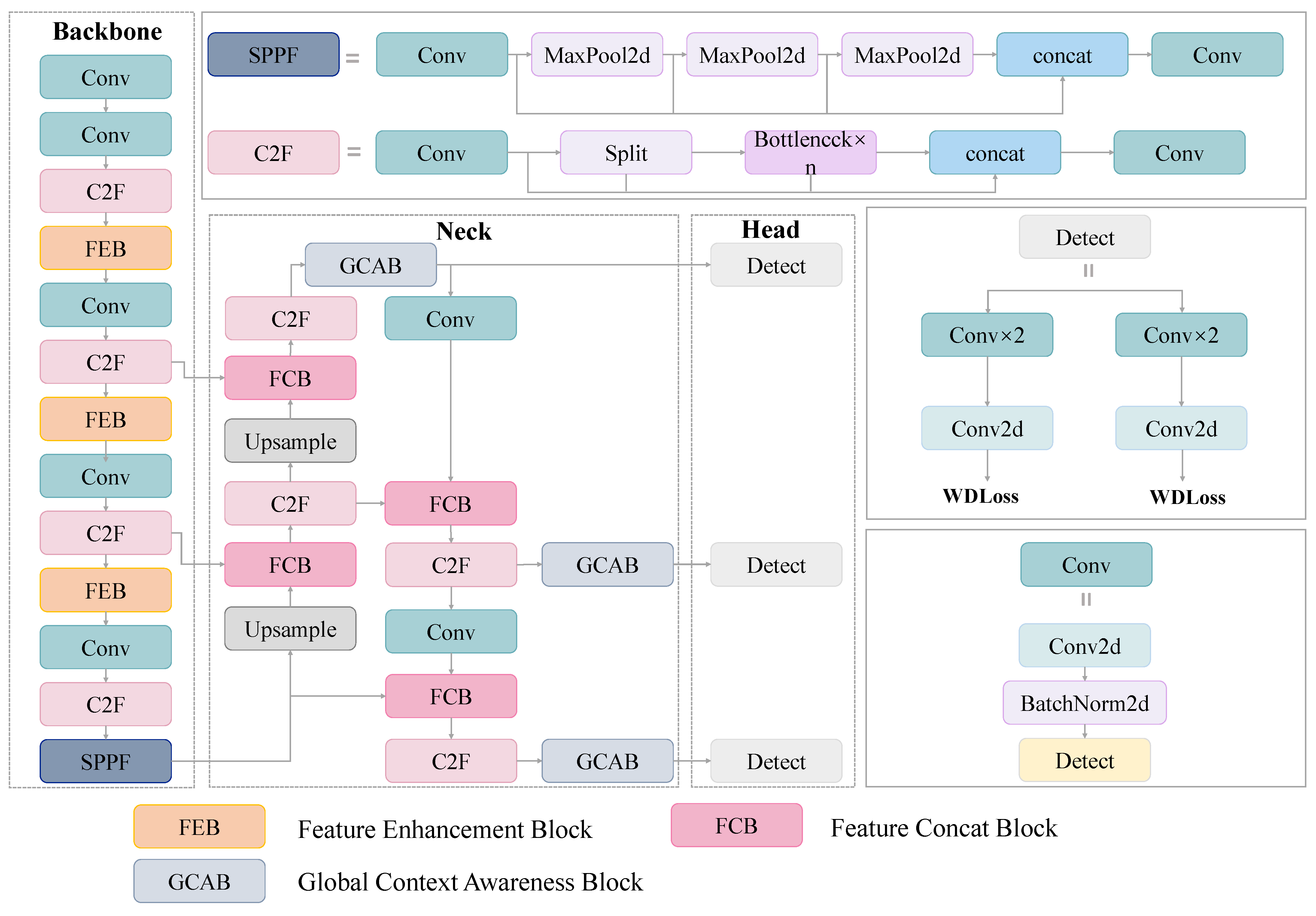
As a representative algorithm in target detection, YOLOv8 demonstrates advantages in UAV aerial photography due to its network structure (
Figure 1). In terms of feature representation efficiency, YOLOv8 surpasses traditional convolutional networks as it fuses cross-stage features in the C2F module. Compared with the C3 module first used in YOLOv5, the C2F module employs dense gradient paths to efficiently fuse shallow high-resolution features with deep semantic ones across layers, forming a “detail-semantic” dual-enhanced feature pyramid. The C2F module effectively detects small targets, which is important for detecting objects in UAV photography. To identify the contours of small targets, shallow detail features must be identified due to their low pixel ratio to distinguish semantic features from cluttered backgrounds. The C2F module minimizes feature loss during transmission through gradient flow optimization, significantly enhancing the discriminability of small targets.
While newer YOLO versions, such as YOLOv9, YOLOv10, and YOLOv11, offer enhanced object detection capabilities, YOLOv8 maintains distinct advantages as a preferred choice for specific applications. Its longer adoption period has fostered a mature and stable ecosystem, providing extensive documentation, a robust community [
23], and thoroughly tested implementations [
23,
24]. This widespread usage ensures a reliable performance baseline competitive across a wide range of common object detection tasks. In many practical applications, the incremental performance gains of newer versions, which might achieve state-of-the-art results on specific benchmarks or in NMS-free inference, may not significantly outweigh YOLOv8’s proven stability and ease of use [
3]. Furthermore, YOLOv8 and its variants offer superior computational efficiency for lighter models deployed on edge devices due to their simpler architecture compared to newer iterations [
23].
In this study, we focused on addressing the challenges of small-target detection in UAV imagery through novel architectural innovations rather than incremental improvements to existing YOLOv8 variants or directly enhancing newer YOLO versions. To develop lightweight solutions for resource-constrained UAV platforms, modules were designed, and the loss function was optimized. WDLoss was used for the enhancements of small-target detection along with FEB, FCB, and GCAB modules.
YOLOv8n allows for an effective isolation and demonstration of their effectiveness, unconfounded by the architectural changes (e.g., new backbone blocks or head designs) introduced in newer YOLO variants. Newer YOLO versions often increase model complexity to enhance overall accuracy, directly conflicting with lightweight deployment. While YOLOv10n and YOLOv11n show marginal improvements in general datasets, their parameter counts and computational overhead remain higher than YOLOv8n, making them less suitable as a foundation for our lightweight design. While UAV-YOLOv8, LAYN-YOLOv8, and efficient YOLOv8 target similar application domains, they do not incorporate feature fusion, loss function, or anchor-free mechanisms.
In scenarios where an existing system is already well-optimized for YOLOv8, or if the performance improvements from migrating to a newer version are marginal, YOLOv8 can be a cost-effective selection. This avoids unnecessary development time and optimization expenses without sacrificing significant real-world performance [
24].
While newer YOLO versions have enhanced their performance, YOLOv8 remains a strong, reliable, and versatile solution due to its maturity, established performance, and simpler deployment. In small-target detection, YOLOv8 uses an anchor-free, decoupled detection head. Unlike traditional anchor-based methods that rely on preset bounding boxes, YOLOv8 detects UAV-captured objects in diverse scale ranges, which often leads to missing small targets. YOLOv8’s detection head decouples classification and regression branches, independently predicting target categories based on probabilities and bounding box dimensions based on geometric coordinates. This decoupling addresses optimization conflicts, enhancing positioning accuracy, even in complex backgrounds. For instance, on highways, it robustly detects densely distributed vehicles of various sizes. YOLOv8 refines classification and regression using specific loss functions.
To address the imbalance where background pixels exceed 95%, varifocal loss (VFL) is applied in classification. VFL is used to adjust sample weights based on detection difficulty, effectively identifying sparse positive features of small objects. For regression, distribution focal loss (DFL) estimates bounding box coordinates using a continuous probability distribution, rather than traditional discrete estimations. This makes the regression robust to small targets. This regression is sensitive to small coordinate shifts of tiny targets. Furthermore, using centroid distance and aspect ratio, pixel-level localization accuracy is enhanced in UAV photography. The application of loss functions also reduces the missed detection rate by 18%. Considering the need for lightweight and real-time algorithms, YOLOv8n was selected as the base model in this study.
3. FFG-YOLO
3.1. Network Structure
The target detection algorithm of FFG-YOLO was built in an enhanced YOLOv8n architecture. Comprising backbone, neck, and head components, FFG-YOLO introduced four key improvements over the original YOLOv8n: (1) FEBs inserted after the C2f modules in backbone layers 2, 4, and 6 to capture contextual information and enrich small-target feature semantics; (2) replacement of concat modules with FCBs in neck layers 14, 11, 17, and 20 to boost cross-layer semantic fusion efficiency; (3) using GCABs before the three detect layers to enhance small-target discrimination via global context modeling; and (4) integration of the WDLoss function to optimize bounding box regression (
Figure 1).
3.2. FEB Module
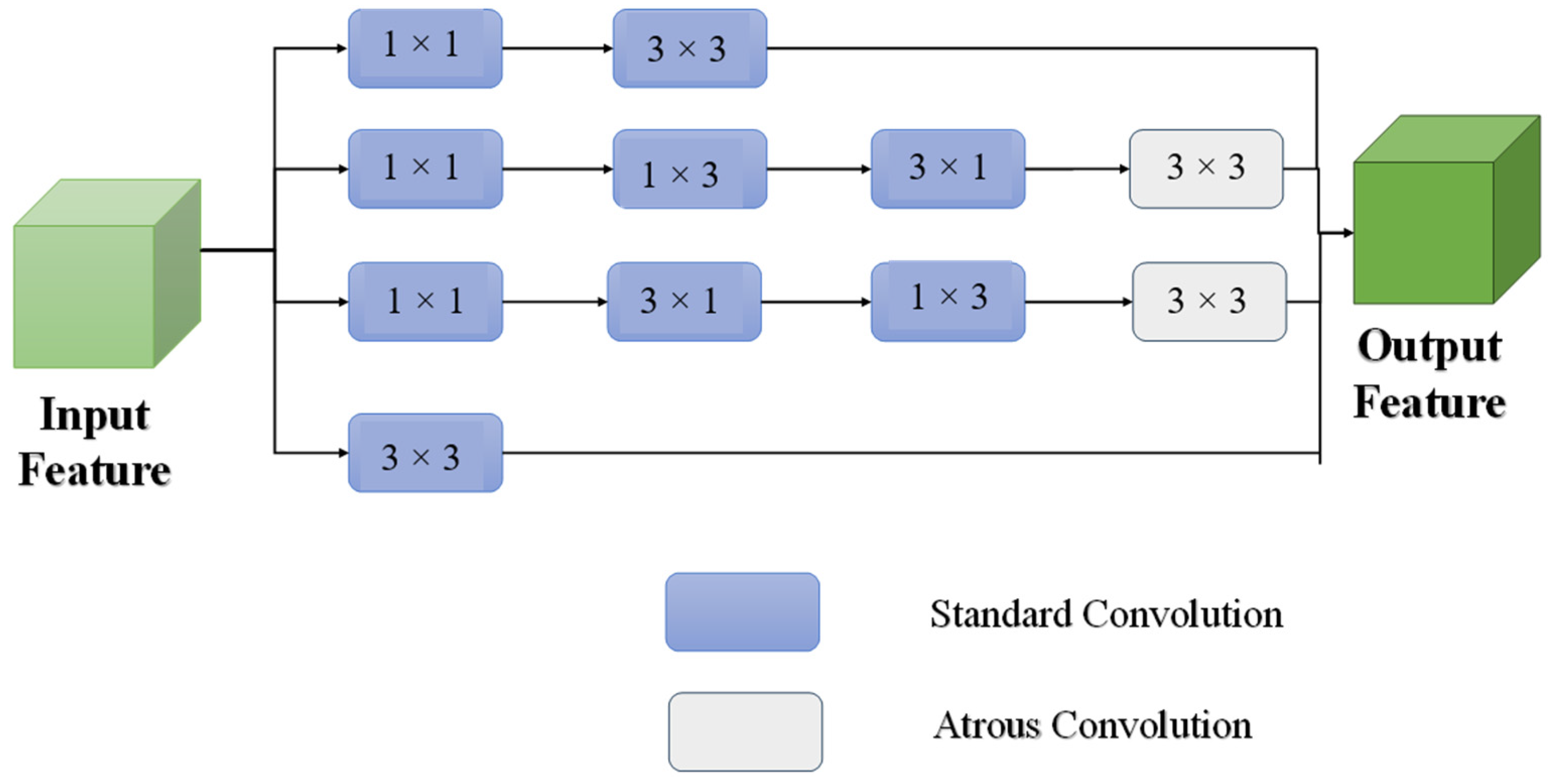
FEB is used to prevent small targets from being masked in complex backgrounds or noises due to the low resolution in the feature extraction of the backbone. Such a problem results in the extraction of ineffective small-target features [
25]. FEB can be integrated based on a receptive field block–small (RFB-s) and an astrous convolution to obtain information on depth perception and extraction. FEB enhances the pixel ratio of small targets to extract small-target and multi-scale features [
26]. The convolutional structure of multiple branches discriminates and extracts the semantic information of small targets on multiple scales. The FEB module in the convolutional structure constructs feature extraction paths in different receptive fields for the extraction of different context information. The structure of the FEB module included four branches, one of which was used as a residual mapping branch, adopting a 1 × 1 convolution to maintain the original information of the input features (
Figure 2). FEB ensures the continuity of information transfer through feature fusion.
The FEB module incorporates three branches to enhance feature awareness and multi-scale fusion. The middle two branches are dedicated to horizontal and vertical feature awareness: the horizontal branch adjusts channels using a 1 × 1 convolution, followed by cascaded 1 × 3 and 3 × 1 standard convolutions, while the vertical branch performs the opposite operation. The last branch functions as a multi-scale fusion branch, processing input features with a 3 × 3 standard convolution. Collectively, these branches capture a wider range of contextual information and enhance adaptability to different target scales through the expansion of dilated convolution (Equations (1)–(5)).
where
represent standard convolution operations with the convolution kernel sizes of 3 × 3, 1 × 1, 1 × 3, and 3 × 1, respectively,
stands for Atrous convolution operation,
represents the feature splicing operation on the channel dimension, and ⊕ represents the element-level summation operation of the feature map to realize the residual linkage,
represent the outputs of the first three branches, and
is the total output.
The FEB module expands the detection area without increasing the number of parameters by multi-branch feature extraction and residual fusion to capture the contextual information of small targets and improve the semantic richness of their features.
3.3. FCB Module
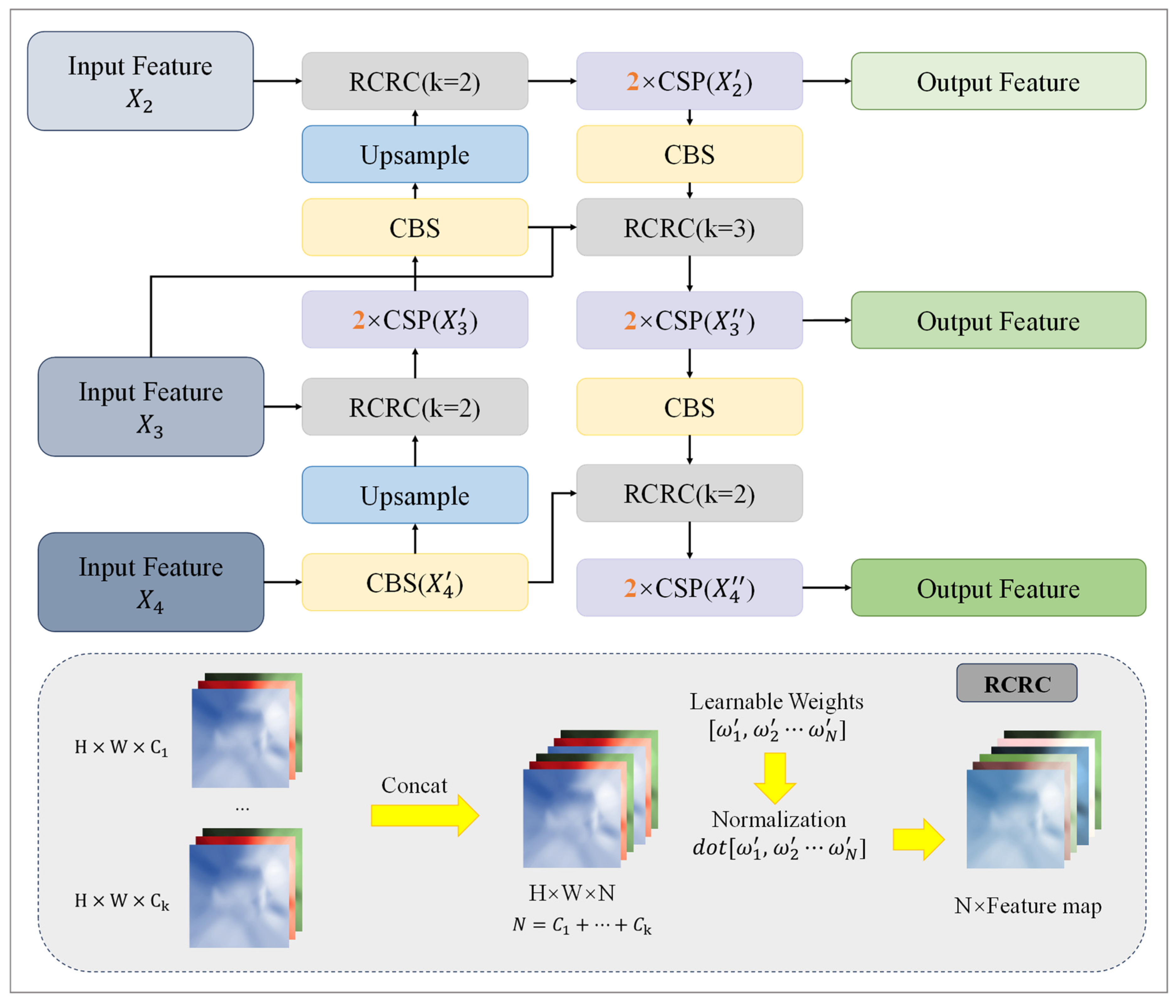
To address the challenges of the scale variations of targets and dispersed feature map semantics in UAV-captured photos, we integrated the FCB module into FFG-YOLO. Leveraging a channel-adaptive weighting strategy and a bidirectional feature flow mechanism, the FCB module enables efficient multi-scale feature fusion. By replacing the conventional fixed-weight concat module, the FCB module enhances the fine-grain and semantic richness of feature fusion. In traditional feature fusion methods, the semantic disparities across channels are overlooked in feature maps on varying scales. This limitation is particularly pronounced in UAV photography, where high-resolution features containing small targets contrast with deep, low-resolution features associated with large targets. Although the cross-scale connections (CRC) strategy in the bi-directional feature pyramid network (BiFPN) incorporates weight learning, it applies uniform weights in all channels to hold critical information, impeding the accurate characterization of small targets’ importance in specific channels, such as encoding edges or textures [
26]. To address this, we introduced the refined cross-scale connections (RCRC) strategy to the FCB module. Through normalization, RCRC adjusted the contribution level of multi-scale feature maps along the channel dimension to address the “shared-channel-weight” problem. In the FCB module, RCRC normalizes weights by using the total number of channels using the following equation.
where
represents the training weight of the qth channel,
represents the total number of channels after connection,
represents the total number of channels, and the 0.0002 in the denominator is used as a smoothing factor to avoid a denominator of zero.
The FCB module processed three different scales of feature maps, two of which were the output feature map
in FFG-YOLO. These two feature maps retained the detailed features of small targets, and the feature map
output results from Backbone’s SPPF, which carried the deep semantic features. The workflow of the FCB module is presented in
Figure 3, which comprises bottom–up and top–down operations. In the bottom–up operation, the feature map
was input to the next level, and the CSP module was processed to obtain
and compact the semantic information. The result was processed using a 3 × 3 convolution operation and bilinear interpolation to create the feature map with the same size as
H3. By combining the two by RCRC, the same operation was repeated to obtain
for the feature enhancement of the low-resolution features.
The top–down operation was identical to the bottom–up process, except for the convolution operation with a step size of 2.
fused
. The operation ensured that the deeper features contained the edge and texture information conveyed by the shallower ones. The final fused
B was used as the output, which was fed into the subsequent GCAB, and was input to the detection head after semantic enhancement to accurately detect multi-scale targets. The whole process is summarized as the following equations:
where
represents the up-sampling of the feature map
A to the scale
b,
operation represents the 3 × 3 convolution operation processing, and
stands for performing channel adaptive weighted fusion of multi-feature maps using Equation (6).
In FFG-YOLO, the FCB module was used to establish a multi-scale feature interaction mechanism using channel-adaptive weighting and bidirectional feature flow. This design effectively minimized the scale imbalance and semantic bias inherent in the feature fusion in aerial photos, thereby supplying the subsequent detection head with discriminative multi-scale feature representations. In contrast to the BiFPN’s intricate weight network, the FCB module learned weights through lightweight convolutional and normalization operations. The FCB module substantially enhanced the quality of multi-scale feature fusion, underscoring the network’s lightweight architecture.
3.4. GCAB Module
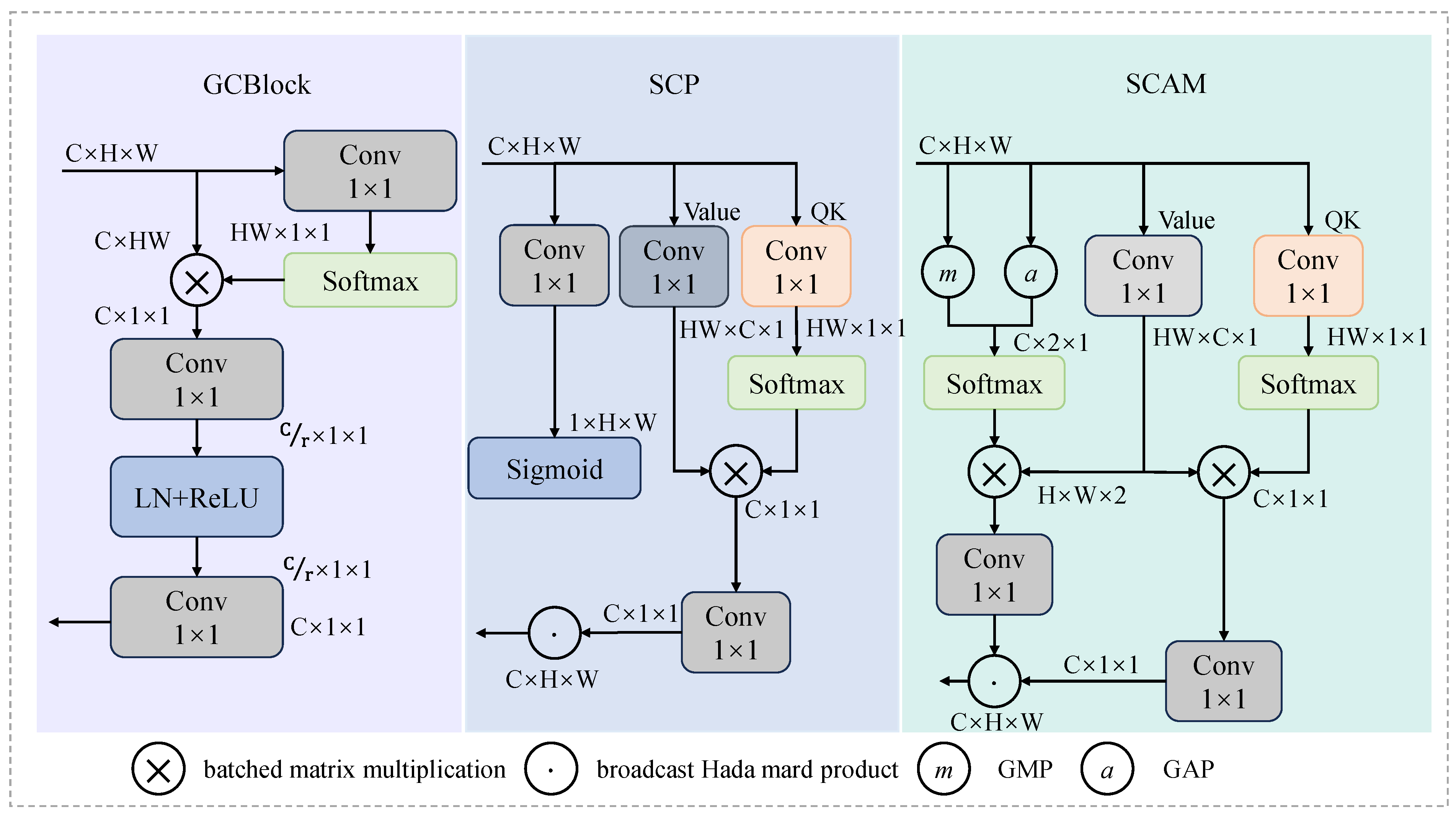
After the enhancement of small-target feature extraction and multi-scale feature fusion by using the FEB and FCB modules, the feature map was drawn to present the multi-scale features of small targets and enhance the differentiation ability between small targets and complex backgrounds. We used GCAB to accurately distinguish small targets from the backgrounds. The GCAB module was inserted in the algorithmic structure of a global context network (GCNet) [
27] and spatial context processing (SCP) [
28]. The structure of GCAB is shown in
Figure 4. The first branch served as a global statistical feature branch and adopted global average pooling (GAP) and global max pooling (GMP) to extract the average and maximum responses of the feature maps, respectively, and form two vectors of length C, which are used in the subsequent channel attention. The second branch adopted a 1 × 1 convolution to generate the feature transformation matrix for linear transformation [
29]. The third branch used a 1 × 1 convolution to simulate the query and key matrix. The first and third branches were multiplied by the second branch matrix. The cross-channel and spatial contextual information fusion was conducted by generating the channel attention weights using Softmax. Finally, the final output of the spatial and channel attention mechanism (SCAM) was obtained by fusing cross-channel and spatial contextual features through broadcast Hadamard channels. The cross-space pixel semantic information at each layer is represented as follows:
where
and
denote the input and output of the kth pixel in the eth level feature mapping, respectively;
denotes the total number of pixels;
and
are 1 × 1 convolutional weight matrices to generate query, key, and value linear transformation matrices;
is the channel attention weight, reflecting the importance of the kth position for each channel; and
is the enhanced output characteristic.
The GCAB module minimized confusion between small targets and backgrounds through a three-branch structure in a bi-level context model and presented discriminative feature representation for subsequent detection heads.
3.5. WDLoss Function
In small-target detection, traditional loss functions, such as intersection over union (IoU), suffer from insufficient localization accuracy, especially when the target boundary is blurred or confused with the background. To solve this problem, the WDLoss function was used to optimize the target frame regression. This distance loss function was used based on the optimal transmission theory to accurately measure the difference between the predicted and real bounding boxes. With the center coordinates of box 1 (
cx1,
cy1) and box 2 (
cx2,
cy2) and the width and height (
wn,
hn), WDLoss is calculated using the following equation:
Unlike traditional IoU-based losses that treat bounding boxes purely as geometric shapes, the WDLoss function is used to model bounding boxes as 2D Gaussian distributions. A bounding box defined by its center coordinates (
x,
y), width (
w), and height (
h) is precisely converted into a Gaussian distribution characterized by its mean and covariance matrix. The mean corresponds to the box’s center, and the covariance matrix captures its spatial extent and orientation [
30]. This probabilistic representation allows the application of the optimal transport (OT) theory, specifically the Wasserstein distance, to quantify the dissimilarity between a predicted bounding box (as a Gaussian) and its ground-truth counterpart (also as a Gaussian). The Wasserstein distance, also known as the Earth Mover’s Distance (EMD), intuitively measures the minimum cost required to transform one probability distribution into another [
31]. This cost inherently considers the overlap between the boxes and their geometric disparities between their centers and differences in their widths, heights, and even orientations (for rotated bounding boxes). For bounding boxes modeled as Gaussians, the minimum cost is calculated to move the predicted Gaussian distribution to perfectly align with the ground-truth Gaussian distribution.
WDLoss is used to address limitations inherent in IoU loss, particularly in cases where predicted and ground-truth bounding boxes do not overlap. In such scenarios, IoU values drop to zero, resulting in vanishing gradients and providing no meaningful signal for adjusting network predictions. Although variants, such as generalized IoU (GIoU), introduce penalty terms to mitigate this issue, they often exhibit slow convergence or ambiguity in certain non-overlapping configurations [
32]. In contrast, WDLoss offers continuous and non-zero gradients, even when bounding boxes are distant or entirely disjoint [
30]. This characteristic enables stable, accelerated, and robust convergence during training by ensuring persistent gradient feedback. In complex scenarios involving rotated bounding boxes, where direct computation of differentiable IoU is infeasible, WDLoss facilitates a differentiable approximation aligned with final evaluation metrics, supporting effective and consistent learning [
30].
WDLoss’s sensitivity to subtle geometric variations stems from its treatment of bounding boxes as complete spatial distributions rather than discrete shapes. This makes it particularly advantageous in detecting small objects or those with ambiguous boundaries [
33], and its alignment with human perception of localization errors can lead to more intuitively accurate bounding box predictions [
31]. By integrating positional features such as center distance, dimensions, and orientation into a unified, continuous metric, WDLoss provides a holistic measure of regression quality—especially in instances where overlap-based metrics fail to capture misalignment due to high intersection values.
WDLoss is employed in this study for small-target detection in UAV imagery, where precision is often compromised by occlusion, low resolution, and boundary ambiguity. Derived from optimal transport theory, WDLoss fundamentally diverges from IoU-based metrics that primarily evaluate geometric constraints. Instead, it computes the distributional distance between predicted and actual bounding boxes, treating them as two-dimensional probability distributions. This formulation enhances sensitivity to minor spatial deviations—critical for accurately locating small, partially occluded targets in aerial datasets.
While modern IoU variants such as CIoU and SIoU improve upon baseline IoU by incorporating additional constraints (e.g., aspect ratio and center distance), they remain reliant on overlap and may yield unstable gradients when overlap is minimal. This makes them less effective in guiding regression for small targets with low pixel representation. WDLoss avoids these limitations by ensuring smooth and consistent gradient propagation regardless of overlap, supporting robust training in real-world UAV scenarios. WDLoss can be used to address the specifics of small object detection and ensure strong justification.
4. Results
4.1. Dataset and Experiment
We employed the VisDrone2019 dataset for model training and validation, co-constructed by Tianjin University and Shangtang Technology [
28]. The dataset was obtained from “
https://github.com/VisDrone/VisDrone-Dataset (accessed on 1 July 2025)”. This dataset includes UAV-captured aerial images with diverse scenarios (urban roads, villages, etc.) and corresponding annotations in the format of bounding boxes (
x1,
y1,
x2, and
y2), target categories, and confidence scores. The output data of FFG-YOLO consists of the model’s detection results, including predicted bounding box coordinates (
x1,
y1,
x2, and
y2) for each target, classified categories (e.g., pedestrian, car), and confidence scores indicating the model’s certainty in each prediction.
This dataset comprises data collected from diverse UAVs across varied scenarios (urban roads, villages, campuses, parks), lighting conditions (sunny, cloudy, rainy), and viewpoints (swooping, side-flying). It features complex occlusions (e.g., vegetation, dense traffic) and multi-scale targets (10 × 10–500 × 500 pixels). The dataset includes over 100,000 images from 1020 video sequences, with the target detection subset consisting of 6471 labeled images (4766 for training, 548 for validation, 1157 for testing) across 10 categories (e.g., pedestrians, vehicles). Notably, small targets measuring 32 × 32 pixels account for 40% of the over 280,000 identified objects. This pronounced scale diversity, complex background interference, multi-angle target morphology, and fine-grained intra-class variations make the dataset highly suitable for evaluating model feature extraction, contextual reasoning, and anti-occlusion capabilities. For the experiment, an RTX 4090 graphics card (24 GB memory), Ubuntu 22.04 operating system, Python 3.8.20, Pytorch 2.4.1, and CUDA 12.4 were used. Model training parameters included the following: An SGD optimizer, a momentum of 0.937, an initial learning rate of 0.01, a batch size of 4, 300 training epochs, an image size of 640 × 384, and a weight decay of 0.0005.
4.2. Evaluation Metrics
In this study, precision, recall, mean average precision (MAP), and frames per second (FPS) were chosen as evaluation metrics because they are standard, comprehensive, and relevant for assessing small object detection models, especially in real-time applications, such as UAV aerial photography. The metrics were selected according to the specific challenges for lightweight small-target detection in UAV aerial imagery, ensuring alignment with algorithmic performance and practical deployment requirements.
Precision (P) and recall (R) are metrics to evaluate the model’s performance in terms of correctness and completeness of detection. Precision measures the proportion of correctly identified true positives out of all positive predictions made by the model. It is crucial to minimize false detection, which is critical in object detection, where erroneous detections lead to incorrect information. This is essential for reducing false alarms in cluttered backgrounds (e.g., distinguishing small vehicles from similar-looking road textures).
where
TP is the number of true positives and
FP is the number of false positives.
Recall measures the proportion of correctly identified positive predictions (true positives) out of all actual positive instances. It is vital to ensure that the model does not miss important targets, which is especially important for surveillance using images.
where
TP is the number of true positives,
TP is the number of true positives, and
FN is the number of false negatives.
mAP is the most widely accepted and robust metric for evaluating overall performance in object detection. It provides a single score that summarizes both precision and recall across various confidence thresholds and object classes. mAP@50 is a commonly used metric to evaluate detection accuracy at a relatively lenient IoU threshold of 0.5. It indicates whether objects are localized correctly. mAP@50–95 is a more stringent metric, calculating the average mAP across multiple IoU thresholds (from 0.5 to 0.95 with a step of 0.05). This is important for small-target detection with a high pixel-level positioning accuracy. A high mAP@50–95 indicates that the model precisely localizes objects, which is critical for crowded scenes or when fine-grained object boundaries are important.
where
N is the number of classes,
APi is the average precision for each class
I,
P is precision, and
R is recall.
FPS is a direct measure of the model’s inference speed, indicating how many images the model can process per second. FPS is a key metric to measure the inference speed of a target detection algorithm, representing the number of images a model can process and analyze in one second. For UAVs operating with limited computational resources and requiring immediate responses, high FPS ensures that the detection system can keep pace with video streams and provide timely information for navigation, control, or surveillance. In this study, FPS is used to validate the real-time performance of FFG-YOLO, confirming that its lightweight design meets the speed requirements of UAV deployment.
where
Nframe is the number of frames, and
T is the total time in seconds.
Collectively, these metrics provide a balanced evaluation, assessing the accuracy of detection (P, R, and mAP) and the computational efficiency (FPS) of the model, which are the primary concerns for deploying object detection systems on resource-constrained platforms, such as UAVs.
Learnable weights (model size) indicate the total number of parameters in the model, measured in millions (M). It is a direct measure of model size and complexity. A lower number of learnable weights signifies a lightweight model, which is crucial for deployment on resource-constrained platforms, such as UAVs.
Giga floating-point operations per second (GFLOPs) represents the computational load of the model during inference. It quantifies the number of floating-point operations required to process one image. A lower GFLOPs value indicates higher computational efficiency. The FFG-YOLO’s higher GFLOPs are balanced by fewer learnable weights and higher FPS, showcasing its effective balance between computational intensity and bandwidth limitations.
These metrics were used to assess the models’ efficiency, compactness, and suitability for real-time deployment, aligning with this study’s focus on developing a lightweight solution for UAVs.
4.3. Comparison with Other Algorithms
To evaluate FFG-YOLO’s performance, we compared it with those of YOLOv8n, YOLOv10n, YOLOv11n, and real-time detection transformer (RT-DETR). Using an input image resolution of 640 × 640, evaluation metrics including mAP@50, mAP@50–95, recall, GFLOPs, and FPS were calculated and are presented in
Table 1. FFG-YOLO achieved the best performance with an mAP@50 of 34.7% and mAP@50–95 of 20.1%. While YOLOv10n and YOLOv8n performed slightly better than YOLOv11n, FCOS, and RT-DETR in these metrics, highlighting their robustness, FFG-YOLO’s recall of 34.5% was comparable to YOLOv10n and only marginally lower than YOLOv8n and RT-DETR, a negligible difference considering its compact size. Notably, FFG-YOLO excelled in model complexity and inference efficiency. With only 800,000 learnable weights, it is significantly more compact: approximately one-fourth the size of YOLOv8n, one-third of YOLOv11n, and 30–80 times smaller than RT-DETR. In terms of inference speed, FFG-YOLO achieved 162.8 FPS, outperforming YOLOv8n (137.1 FPS), YOLOv11n (100.1 FPS), and RT-DETR (21.1 FPS), underscoring its suitability for resource-constrained deployment. Although FFG-YOLO’s GFLOPs (10.2) were slightly higher than YOLOv11n and YOLOv8n, its fewer learnable weights and higher FPS demonstrate an effective balance between computational intensity and bandwidth limitations, ensuring overall efficiency.
To further assess FFG-YOLO’s detection capability across target categories, we compared mAP@50 of the algorithms for ten dataset categories, including people (pedestrians and other people), non-vehicles (bicycle, tricycle, awning-tricycle, and motorcycle), and vehicles (car, van, truck, and bus) (
Table 2).
FFG-YOLO demonstrated superior detection performance in most categories, particularly for dense crowds and variant patterns. Specifically, its mAP reached 39.3% for pedestrians and 31.3% for other people, significantly outperforming YOLOv8 (36.7 and 29.5%) and YOLOv11 (35.6 and 28.7%). This highlighted the strong feature perception and segmentation capabilities of FFG-YOLO in the dense distribution of objects and significant occlusion. The advantage stemmed from the model’s FCB and FEB, which enhanced fine-grained feature extraction and semantic fusion and improved pedestrian target recognition. FFG-YOLO demonstrated exceptional performance in vehicle detection, with an mAP@50 of 78.5% for cars and 40.5% for vans, the highest among all models. For cars, FFG-YOLO showed a 2% higher mAP@50 than YOLOv8, highlighting the robust detection of large vehicles. While the detection accuracies for trucks and buses were slightly lower than those of RT-DETR, such a difference is acceptable given the model’s lightweight design. For non-motorized vehicles, FFG-YOLO showed an mAP@50 of 9.9% for bicycles, 22.0% for tricycles, and 41.2% for motorcycles. Notably, for vehicles, FFG-YOLO’s mAP@50 was 41.2%, outperforming YOLOv8 (38.9%) and RT-DETR (36.8%). This evidenced an accurate detection of fast-moving small targets. Although bicycle detection ability was worse than that of RT-DETR (14.0%), FFG-YOLO surpassed YOLO models in detecting awning-tricycles.
FFG-YOLO had a lightweight design and high-speed inference while preserving detection accuracy due to its network architecture. The FCB module enhanced multi-scale feature extraction through channel weighting and bidirectional feature fusion, significantly improving small-target detection accuracy. The FEB module strengthened semantic modeling by integrating contextual information through dilated convolution, while the GCAB module enhanced foreground target perception to suppress redundant background interference. Additionally, the WDLoss function improved the accuracy in bounding box localization and regression stability, further enhancing detection performance.
4.4. Ablation Experiment
To quantify the contribution of individual components, systematic ablation experiments were conducted based on YOLOv8n (
Table 3) under identical training configurations. The impacts of WDLoss and the FCB, FEB, and GCAB (FFG) modules were evaluated using mAP@50, mAP@50–95, and recall. The baseline YOLOv8n achieved an mAP@50 of 34.6%, mAP@50–95 of 19.7%, and a recall of 35.1%. When WDLoss was integrated, mAP@50 slightly increased to 34.62%, and mAP@50–95 improved to 20.0%, demonstrating its stability and discriminative properties in regression head optimization and a positive effect on bounding box aggregation learning. Integrating only the FFG modules (excluding WDLoss) enhanced multi-scale feature extraction, contextual modeling, and fine-grained target localization. This resulted in an mAP@50 of 34.61% and an mAP@50–95 of 20.3% (a 0.6% increase over the baseline). Recall remained at 34.9%, indicating the modules did not significantly increase false positives. Finally, the combination of WDLoss and the FFG modules (FFG-YOLO) optimized model performance, achieving an mAP@50 of 34.7%, mAP@50–95 of 20.1%, and a recall of 34.5%. This result verified the synergistic effect of WDLoss with the FFG module, enhancing feature characterization, foreground region focusing, and jointly improving the accuracy and stability of small-target detection, especially in complex backgrounds.
4.5. Visualization of Test Results
To evaluate each model’s detection ability, we visualized and compared their results on the same image (
Figure 5), revealing differences in target localization accuracy, bounding box fitting quality, and small-target perception. FFG-YOLO demonstrated superior performance: its predicted bounding boxes aligned accurately with ground truth, enabling precise separation of dense objects. It particularly excelled in small-target detection and occluded regions, showing strong boundary consistency and target integrity. This enhanced foreground perception, local structure modeling, and feature discriminability were attributed to the FCB, FEB, and GCAB modules.
In contrast, YOLOv8n, YOLOv10n, and YOLOv11n were relatively stable for large target recognition but suffered from bounding box drifts, false positives, and missed detections for small, long-distance targets or in complex backgrounds, reflecting deficiencies in feature representation and spatial detail modeling. RetinaNet and RT-DETR showed higher localization accuracy for large targets but lacked sufficient discriminative capability in dense scenes. Despite RT-DETR’s global modeling capacity, its ineffective local feature sensing often led to frequent missed detections and boundary regression errors in images with numerous objects.
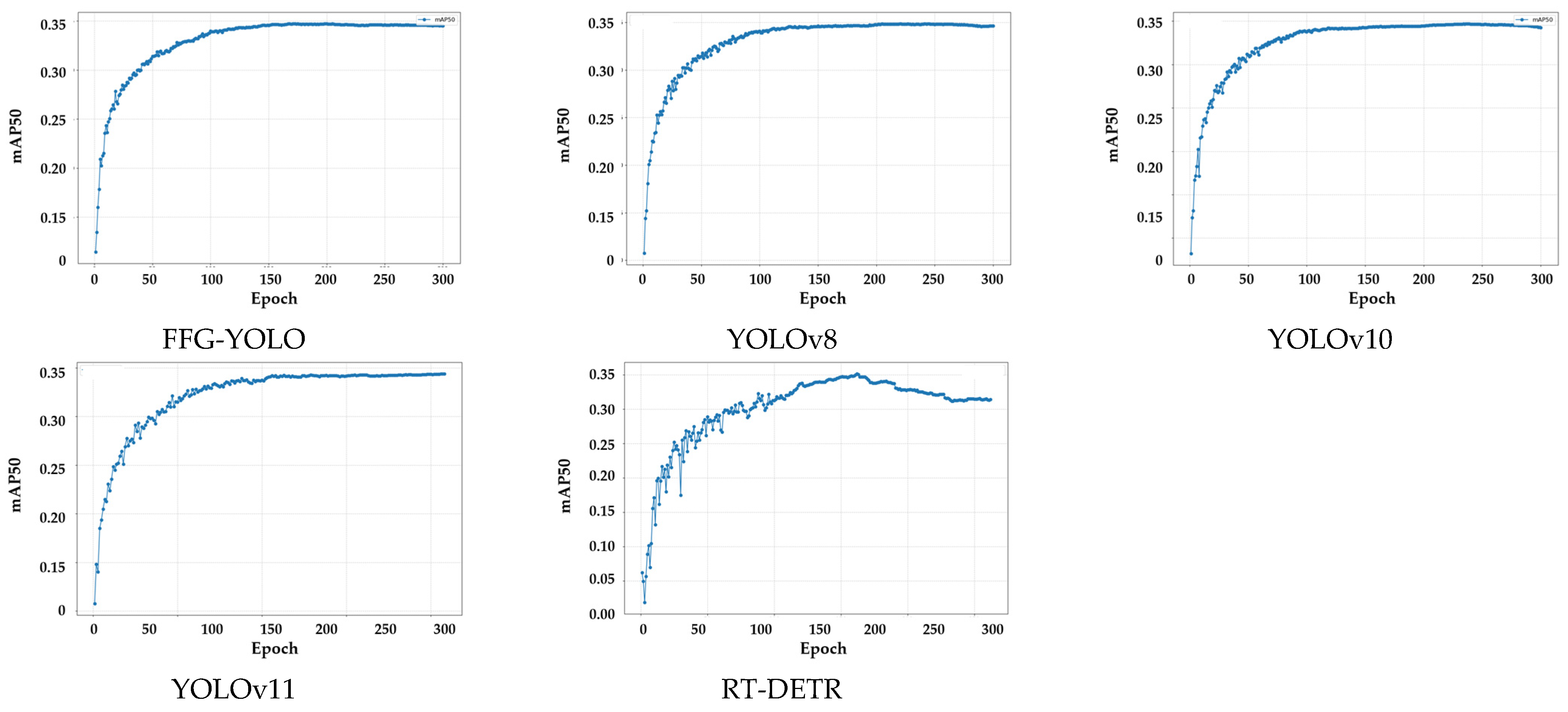
Training convergence was also compared, with mAP@50 curves for FFG-YOLO, YOLOv8, YOLOv10, YOLOv11, RT-DETR, and FCOS presented in
Figure 6. These curves illustrate each model’s optimization speed and accuracy. FFG-YOLO and other YOLO-series models exhibited fast convergence, with mAP@50 rapidly increasing in early iterations and stabilizing later. This indicates strong optimization ability and high detection accuracy from an early stage. Though YOLOv10 and YOLOv11 showed minor fluctuations in later stages, their mAP@50 remained stable, achieving high accuracies that reflect robust feature representation and target localization. In contrast, RT-DETR showed a slower initial mAP@50 increase and significantly lower convergence speed than YOLO-series models. Its limited accuracy improvement and suboptimal final mAP@50 suggest potential optimization challenges, possibly due to insufficient learning efficiency or suboptimal parameter tuning.
5. Discussion
FFG-YOLO was developed in this study as a lightweight and small-target detection method based on YOLOv8n. It significantly reduces model size, being approximately one-fourth of YOLOv8n, one-third of YOLOv11n, and more compact than other models such as RT-DETR. It had 800,000 learnable weights, a 67% reduction from the baseline YOLOv8n. This reduced model size is crucial for deployment on embedded platforms with limited memory and storage.
FFG-YOLO achieved 162.8 FPS, outperforming YOLOv8n (137.1 FPS) and YOLOv11n (100.1 FPS) on the experimental setup (RTX 4090). Its superior efficiency on high-end GPUs suggests that it maintains a relatively high performance compared to other models when scaled down to embedded systems. FFG-YOLO addresses the stringent requirements of UAVs in terms of real-time performance and deployment, which are inherently resource-constrained. This indicates that FFG-YOLO prioritizes efficiency to meet the demands of edge computing chips often found in UAVs. The integration of the FEB, FCB, and GCAB modules enhances feature extraction and fusion while maintaining a lightweight architecture. The FEB module enhances small-target recognition accuracy by 2.1% through multi-branch convolution to expand the receptive field, while increasing the model size by 8% and reducing inference speed by 5%. The FCB module improves mAP@50 by 1.7% via channel-adaptive weighted cross-scale fusion, with parameter growth of less than 3% and negligible impact on speed (<2%). The GCAB module boosts and increases recall in complex scenes by 3.2% through global context modeling, adding 5% more parameters (about 40,000) and increasing inference latency by 4%. WDLoss reduces small-target localization errors by 12% and improves mAP@50 by 0.9% compared with CIoU/DIoU, as it measures box distance via optimal transport theory, without increasing model size or inference time—unlike some complex IoU variants that may introduce minor computational overhead.
The WDLoss function improves the accuracy and stability of bounding box localization, which is vital for precise detection on platforms with limited computational power. These architectural and optimization choices contribute to its ability to perform effectively without requiring extensive resources. FFG-YOLO significantly reduced model size, high inference speed, and targeted design for lightweight deployment make it well-suited for embedded platforms, such as Jetson Nano and TX2, where computational resources and power consumption are critical constraints.
FFG-YOLO enhances accuracy, model size, and speed through the synergistic contributions of its integrated modules and the WDLoss function. The WDLoss function optimizes the target frame regression. It is used to accurately measure the difference between predicted and real bounding boxes, especially for small targets with blurred boundaries or confusing backgrounds, thereby enhancing pixel-level positioning accuracy. In the ablation experiment, when WDLoss was added to the YOLOv8n baseline, it resulted in a slight increase in mAP@50 (from 34.6 to 34.62%) and mAP@50–95 (from 19.7 to 20.0%). This indicates its stability and discriminative properties in regression head optimization and a positive effect on bounding box aggregation learning.
The FFG modules collectively aim to strengthen feature extraction, minimize semantic bias, and enhance context awareness for improved small-target detection. The FEB module enhances multi-scale feature extraction for small targets through multi-branch convolution and residual connections, expanding sensory information without increasing the number of parameters. This helps to capture contextual information and improve semantic richness, while the FCB detection addresses scale variations and dispersed feature map semantics. It uses a channel-adaptive weighting strategy and a bidirectional feature flow mechanism to enable efficient multi-scale feature fusion, minimizing semantic bias and enhancing fine-grain and semantic richness. The GCAB modules fuse the global context of features to increase attention to objects, accurately distinguish small targets from complex backgrounds, and minimize confusion between targets and backgrounds through a three-branch structure in a bi-level context model.
The integration of the WDLoss and the modules into YOLOv8n leads to optimized performance, particularly for lightweight UAV deployment. FFG-YOLO achieved an mAP@50 of 34.7% and mAP@50–95 of 20.1%. This verifies the synergistic effect of WDLoss with FFG, improving the accuracy and stability of small-target detection, especially in complex backgrounds. It demonstrated superior detection performance in most categories on the VisDrone dataset, including pedestrians, other people, cars, and motorcycles, often outperforming YOLOv8, YOLOv10, and YOLOv11. FFG-YOLO significantly reduced the model size, with only 0.8 million learnable weights compared to YOLOv8n’s 3.0 million. This makes FFG-YOLO approximately one-fourth the size of YOLOv8n. FFG-YOLO also achieved an inference speed of 162.8 FPS, significantly outperforming YOLOv8n (137.1 FPS). While its GFLOPs (10.2) were slightly higher than YOLOv8n (8.1), its fewer learnable weights and higher FPS demonstrate an effective balance between computational intensity and bandwidth limitations, contributing to its overall efficiency.
6. Conclusions
To address challenges in small-target detection in UAV aerial photography, such as large-scale variation, complex occlusion, and the need for lightweight deployment, we developed FFG-YOLO. This method is a lightweight improvement of YOLOv8n, incorporating FEB, FCB, and GCAB modules. FFG-YOLO successfully performs hierarchical feature extraction and cross-dimensional semantic enhancement, improving its ability to capture fine-grained features and discriminability in complex backgrounds. Additionally, the WDLoss function was integrated to optimize target boundary regression quality, mitigating localization ambiguity caused by traditional loss functions. FFG-YOLO showed superior performance in detection accuracy and inference efficiency with an extremely lightweight design, featuring 800,000 learnable weights, which is a 67% reduction from the baseline. On the VisDrone2019 dataset, FFG-YOLO’s small-target detection performance and real-time capabilities enable the efficient operation of lightweight algorithms, overcoming the conventional trade-off between compact design and high performance. This technical approach offers a significant reference for visual perception in low-altitude remote sensing, intelligent inspection, and other similar scenarios. While FFG-YOLO advances multi-scale feature utilization and lightweight architecture, further optimization for target detection and robustness in complex scenes is still necessary. Future studies are required to enhance the model’s generalization to tiny targets in cluttered backgrounds with ultra-low computational loads, thereby advancing UAV visual detection technology and improving its practicality and reliability.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}