1. Introduction
Over the years, forensic computing has evolved from being an auxiliary discipline to becoming a relevant and crucial pillar in the digital field since it not only combines computer science and forensic sciences to collect legally admissible digital evidence in criminal and civil cases, but also provides essential evidence to determine the what, how, when, and where of events [
1] through scientific techniques that allow the identification of malicious manipulations in systems, files, or data during the different phases of an investigation [
2]. In essence, it seeks to guarantee the authenticity, originality, sameness, and integrity of digital evidence.
Steganography has emerged as a significant challenge in forensic analysis due to its ability to hide information without perceptibly altering the carrier files. Thanks to this ability, it is a tool that can be misused to hide illicit communications or manipulate digital evidence [
3,
4,
5,
6], which poses a risk, since the chain of custody can be affected, and it can even induce judicial errors and compromise decisions based on apparently legitimate evidence [
7].
Adopting advanced technological approaches to address these threats is essential as investigations become more complex. Steganography based on the least significant bit (LSB) method is particularly difficult to detect as the alterations it introduces in digital images are minimal and practically imperceptible to the naked eye.
Faced with this problem, the need arises to implement a variety of techniques ranging from pixel-to-pixel comparison to the use of convolutional neural networks (CNNs), whose implementation has shown significant results since, with the application of deep learning, these networks are capable of identifying complex patterns and subtle characteristics in digital images, allowing the detection of imperceptible modifications and, consequently, the presence of hidden messages with high precision [
3,
6,
8].
From the above, the development of a CNN-based model is proposed for the detection of hidden messages in grayscale digital images (PNG type) affected by the least significant bit (LSB) steganographic method to find out with certainty whether the images are genuine or not and, at the same time, a semantic validation process for the extracted message is integrated using natural language processing (NLP) techniques, to verify if the hidden message has linguistic coherence in the Spanish language.
1.1. Background and Advances in Steganography with CNN
Steganography, a discipline within image processing, focuses on concealing information within digital files, such as images, audio, or videos. Although its origin dates back to ancient practices, such as the tattooing of messages on the scalp in ancient Greece in the 5th century BC [
9], in the digital age, it has evolved into much more sophisticated methods that allow information to be hidden quickly and efficiently [
10,
11].
Unlike cryptography, which protects content through encryption, steganography aims to conceal the existence of the message. This characteristic makes it a helpful tool in contexts where monitoring or detection mechanisms are desired, as it allows confidential data to be transmitted covertly [
7,
12,
13]. Currently, its application extends to artistic, activist, and even criminal spheres, which has prompted the development of multiple methods for its detection [
14,
15].
Among the most widely used methods is the LSB technique, which alters the lowest-order bit of each pixel, generating changes imperceptible to the naked eye [
16,
17]. However, if the process is not performed correctly, visual artifacts or statistical patterns can be generated that compromise the invisibility of the message.
To address this issue, detection tools have been developed, initially based on statistical methods such as Rich Models (RM) and Subtractive Residual Models (SRM), which, although useful in certain contexts, have limitations when trained from images with compression, noise, or natural variations [
4,
14].
In response to these limitations, deep learning-based techniques have emerged, which have proven effective in steganalysis tasks due to their ability to identify complex image patterns [
18,
19]. In particular, CNNs excel in terms of their hierarchical architecture, which enables the extraction of features at different levels of abstraction, thereby facilitating the detection of subtle differences between images with and without steganography [
20,
21].
Among the most relevant models designed specifically for this task are Xu-Net, Yedroudj-Net, and SRNet, which incorporate preprocessing stages to amplify the LSB residual. Other notable works include that of Linga Murthy et al. [
22], who implemented transfer learning by pretraining the inputs before fine-tuning the network to optimize detection. Similarly, Kich et al. [
23] structured their proposal in three stages, input preparation, pretraining, and binary classification using CNNs, achieving superior results compared to traditional methodologies.
While these models may present certain biases, they have demonstrated improvements over common algorithms. Other notable contributions include the work of Ke et al. [
24], who developed a network with multiple filter sizes (
,
,
, and
) to adapt to different resolutions without losing accuracy, and that of Ker [
25], who explored the modification of the two least significant bits per pixel, a technique that, although more visually risky, can evade some detection algorithms focused only on the first bit.
Similarly, Kim et al. [
26] proposed a dual neural network that applies specialized preprocessing filters to each convolutional branch. This design enhances detection performance by identifying complementary features in parallel; however, utilizing two streams can lead to ambiguity in the outputs, potentially affecting model stability.
Although progress in detection has been significant, most research focuses solely on confirming the presence of steganography without delving into the content or its semantic validity. In this regard, works such as that of Vijjapu et al. [
27] have explored message extraction in various formats, but their experimental tests were limited to BMP images, which limits the generalizability of their conclusions.
1.2. Paper Approach and Organization
Contemporary approaches to steganalysis primarily focus on detecting statistical patterns, often overlooking the semantic coherence of the extracted content. However, this issue is critical in forensic scenarios, where the volume of digital evidence is substantial, and progressive analysis demands prioritizing semantically relevant messages by minimizing irrelevant data, particularly by reducing false positives. While numerous tools are available for digital evidence processing, few integrate steganalytic capabilities, and, to date, none has incorporated post-detection linguistic validation. In response to this gap, the model proposed in this study is designed to perform efficient steganalysis on digital images subjected to LSB steganography and subsequently evaluate the semantic coherence of the recovered message, thereby enhancing the interpretability and evidentiary value of the extracted information.
The document is organized as follows: First,
Section 2 introduces the methodology employed, while
Section 3 presents the CNN-NLP architecture design for LSB steganography detection.
Section 4 details the results and comparison with existing models. Finally, the discussion and conclusions are presented in
Section 5 and
Section 6.
2. Methodology
This paper proposes a hybrid model-based methodology that combines convolutional neural networks and natural language processing techniques to detect the least significant bit (LSB)-based steganography in digital images. The research is based on a labeled dataset composed of both clean and steganographic images, where the hidden data consist of Spanish-language texts generated or selected from standardized linguistic corpora. These images were labeled to facilitate supervised training of the model. It is relevant to mention that the image datasets were created from real-world urban and rural photographs, which include a wide variety of scenes with vegetation, buildings, roads, fields, and vehicles. These natural images contain diverse textures and structures, providing a realistic basis for training and evaluating the model.
The dataset was built using images from an open-access database, which were extracted and processed locally. Steganographic images were generated through controlled LSB insertion. Each stego-image included a hidden message composed of variable-length text containing complete syntactic structures and semantically coherent content.
The neural network was trained using MATLAB R2024b with the Deep Learning Toolbox for building and tuning the CNN architecture. Meanwhile, linguistic analysis was performed in Python 3.11, using the spaCy library (v3.7) along with the es_core_news_md model to validate the semantic coherence of the hidden messages extracted. The integration between both environments was handled through MATLAB’s Pyenv function and auxiliary scripts responsible for communication and result transfer.
The simulations were carried out on a desktop with an AMD Ryzen 7 5800X 8-core processor, 32 GB of RAM, and an NVIDIA GeForce RTX 3070 Ti GPU with 6 GB of memory. Training was accelerated on the GPU to optimize computation time, particularly when working with large datasets of up to 25,000 images.
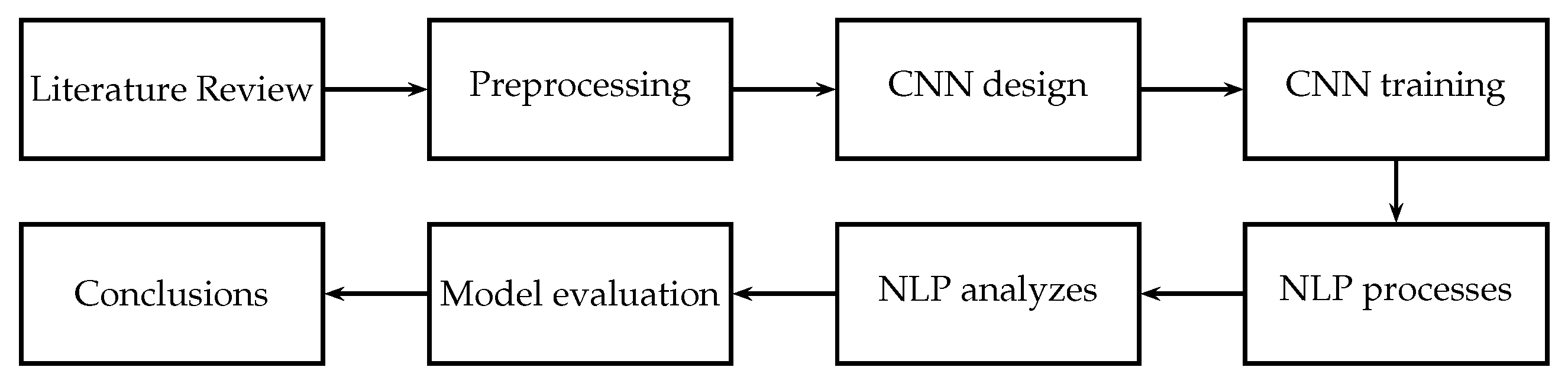
Figure 1 illustrates the methodology employed in the development of this work. First, a documentary review was conducted on the current state of research on steganography detection using convolutional neural networks, revealing various developments (as discussed in the introduction). However, the previous research has not explored in-depth improvements to this process using natural language processing. Consequently, the next stage of the research approach was defined, which involved designing a hybrid CNN-NLP model to detect LSB steganography in digital images.
During the preprocessing stage, the original grayscale images (with a resolution of 640 × 640 pixels) were resized to 150 × 150 pixels using nearest-neighbor interpolation, which preserves pixel-level integrity and avoids introducing interpolated artifacts that could distort LSB patterns. All images were required to be in PNG format; images in other formats were converted using lossless compression tools to maintain the integrity of the embedded bits.
A Laplacian-based enhancement filter was applied to each image to compute a residual channel emphasizing local intensity variations. This residual was normalized to the range [0, 1] using Min–Max scaling. Simultaneously, the first four least significant bit planes were extracted using the “bitget” function. These five components (one residual and four LSB planes) were stacked into a 5-channel input tensor, serving as input to the CNN. This preprocessing scheme increased the capability of the model to capture subtle distortions indicative of steganographic content while maintaining consistency across the dataset.
The CNN component was responsible for extracting discriminative visual features from the processed images [
28]. Its output was passed through dense layers and finalized by a binary classification layer, which determined whether the image contains steganographic content. The model was trained employing the Adam optimizer and a cross-entropy loss function with an 80–20% training–validation split. This decision was based on three factors: the large size of the dataset, the high computational cost of retraining CNN models in multiple folds, and consistency with protocols followed in benchmark architectures such as Xu-Net [
11], Yedroudj-Net [
27], and SRNet [
29].
The selection of training hyper-parameters was guided by an empirical tuning strategy informed by previous research in CNN-based steganalysis [
11,
27,
29]. Initial values were chosen based on their reported stability in similar tasks and refined through pilot experiments conducted on a stratified validation subset. Specifically, the learning rate was set to
with a piecewise decay schedule (drop factor of 0.5 every 5 epochs), and the batch size was fixed at 64 to balance GPU memory usage and convergence behavior. The dropout rate (0.5) and
regularization factor (
) were selected to improve generalization and prevent overfitting. This configuration was found to provide consistent and robust performance across different dataset sizes, without the need for exhaustive hyper-parameter search frameworks.
After classification, the hidden message was decoded from the LSBs and analyzed using the NLP module. This module evaluated grammatical structure, named entities, and lexical patterns to validate the semantic coherence of the message and reduce false positives.
Next, the hidden texts were extracted using LSB decoding techniques and were subjected to NLP processes [
30]. This process made it possible to leverage both visual and linguistic cues to improve steganography detection, allowing for the capture of relevant linguistic features that could reveal unusual patterns derived from concealment [
31].
Linguistic coherence was assessed using semantic similarity scores calculated with the spaCy library. This produced a cosine similarity between the extracted message embedding and the Spanish reference texts. Then, from this base, a minimum threshold of 0.65 was established, meaning that only messages with a semantic similarity greater than or equal to this value were considered valid and meaningful (true positives). This threshold was selected by experimentally evaluating 100 extracted messages and analyzing their interpretability and linguistic fluency. Consequently, the value of 0.65 provided the best balance between detecting hidden but coherent messages and avoiding the meaningless or random sequences that can arise from false positives.
To further analyze the impact of the coherence threshold on the performance of the semantic validation stage, multiple similarity thresholds ranging from 0.50 to 0.90 were explored. A receiver operating characteristic (ROC) curve was generated to visualize the trade-off between the true-positive rate and the false-positive rate at each threshold. As expected, lower thresholds increased recall by admitting more messages, but at the expense of precision, as more incoherent sequences were incorrectly accepted. Conversely, higher thresholds reduced false positives but also excluded valid messages. The area under the curve (AUC) calculated was superior to 0.95, indicating that the NLP module exhibited strong discriminative capability in separating meaningful from meaningless messages across a wide range of similarity values.
Evaluation was performed using metrics such as accuracy, precision, recall, F1-score, and the confusion matrix to measure not only the overall accuracy of the system but also its ability to identify false positives and negatives. After obtaining the results, a comparison was made with other models used for image detection with stenography [
32].
3. CNN-NLP Architecture Design for LSB Steganography Detection
The proposed model integrates two main components, a CNN specialized in steganography detection using the LSB method [
22,
23,
26] and a semantic validation module implemented via NLP. This combination enables the classification of images as containing steganography, and also the verification of whether the extracted hidden content is linguistically consistent in Spanish, thereby increasing the system’s reliability in forensic contexts. The model consists of four main stages, described below.
3.1. Preprocessing
Each image in the dataset is grayscale and resized. A Laplacian filter is then applied to obtain a residual channel highlighting local intensity differences. The four least significant bit planes (LSBs) are extracted, producing a 5-channel input tensor (1 residual + 4 LSBs) designed to highlight subtle alterations introduced by masking techniques. For this case, the kernel is defined as follows:
This filter analyzes each pixel by comparing it to its eight neighbors and highlights points where the intensity changes abruptly, which may indicate the presence of a steganographic pattern. Applying the kernel generates the residual channel presented in Equation (
2):
Then, the first four bit planes of each pixel are extracted using Equation (
3) to isolate the lowest weighted bits of each intensity value:
Finally, the residual channel obtained in the previous stage and the four extracted bit planes are combined to form a three-dimensional tensor, where each of the five channels represents a distinct feature of the processed image. The tensor constitutes the direct input to the CNN and is defined as follows:
Here, represents the characteristic vector corresponding to the spatial position of the input three-dimensional tensor. The operator indicates that all channels at that location are considered. The notation refers to the k-th least significant bit extracted from the intensity value of the pixel at position .
3.2. CNN Architecture
The three-dimensional tensor resulting from the image preprocessing stage serves as the input to the proposed CNN architecture. The network consists of three convolutional blocks with residual connections, followed by a global average pooling (GAP) layer, a fully connected dense layer with 128 units (using 50% dropout) with the activation function, and, finally, a “Softmax” layer utilized for binary classification.
Each residual convolutional block receives as input a three-dimensional tensor
(see Equation (
4)), which, as described above, is composed of a normalized residual image and four bit planes corresponding to the extracted LSBs. The residually connected convolutional blocks
are defined as follows:
where a series of sequential operations is applied to
, and ∗ corresponds to the convolution operator. First, a two-dimensional convolution operation is performed with a set of filters
and a bias
. Next, the result of this operation is normalized using BN, which is batch normalization. Then, the
activation function is applied, which allows the passage of negative values, improving the gradient flow and preventing the deactivation of neurons.
The intermediate output
is then processed by a second convolutional layer, which applies a new set of filters
and a bias
, followed again by batch normalization and a
activation, resulting in
, as expressed in Equation (
6):
Subsequently, as seen in Equation (
7), a residual connection
is implemented summing the output
with the original input of the block
, which allows the input information to be preserved throughout the block, facilitating the training of deep networks. Finally, a spatial reduction with a window of
and stride 2 is applied, which reduces the spatial dimensions of the activation map.
On the other hand, it is worth noting that
is the activation function used in all convolutional blocks, which allows the passage of gradients even when the activation is negative, thereby mitigating the problem of gradient flow and preventing neurons from becoming inactive during training, a common issue with
. The activation function used for this case is defined in Equation (
8):
All of the above makes the block residual and allows some of the original information to flow unaffected by the convolutions, improving learning and preventing the gradient from fading.
Once the three residual convolutional blocks have processed the input tensor, the resulting activation map passes through a GAP layer, which allows all the spatial information learned by the filters to be condensed into a feature vector
by calculating the average of each channel (or filter) over the entire resulting image. The mathematical operation to generate this vector is shown in Equation (
9):
The dimensions H and W correspond to the spatial height and width of the output of the last convolutional block. In the case of the proposed model, after applying three “Max-Pooling” layers with stride 2, the final dimensions are and , resulting in a global feature vector of a size equal to the number of filters ().
The resulting feature vector
, obtained from the GAP layer as described in Equation (
9), is then passed through a fully connected layer with 128 neurons. For this layer, a dropout process with a rate of
is applied, which helps reduce overfitting by preventing the co-adaptation of neurons during training. Finally, the result passes through the “Softmax” layer, which transforms the vector of raw outputs (logits) into a probability distribution according to the two classes present in this model. This results in a probability vector (see Equation (
10)) associated with an input image belonging to class
c where
represents the probability of belonging to each class,
With-Steganography or
Without-Steganography, and
is the value of the
function (output without activating for class
c).
Then, from the resulting probability,
is compared with the true label, and the weighted cross-entropy loss function is used to quantify the error committed. The loss function is expressed in Equation (
11):
Finally, it should be noted that the model was trained using the Adam optimizer, with an initial learning rate of , which was progressively reduced every 5 epochs (factor ). Likewise, to avoid overfitting, regularization with a coefficient was employed, and the early stopping mechanism was also utilized, which terminated the training when no improvements were observed in the validation metric over 10 consecutive iterations.
3.3. Message Classification and Extraction
After classification, if an image is identified as containing steganography, the hidden message is extracted from the LSBs of each pixel. The message is reconstructed by converting binary to text via ASCII encoding using Equation (
12), where
denotes each bit sequentially extracted from the image:
3.4. Semantic Validation with NLP
The extracted message is processed using the spaCy library to validate its linguistic coherence in Spanish and to determine whether it aligns with the expression in Equation (
13), where
T represents the message extracted from the image.
Subsequently, the grammatical structure, the presence of named entities, and the frequency of words are analyzed according to a reference dictionary. To consider the message as valid
, the following condition must be met:
where
denotes the minimum linguistic validity threshold required to consider a message as meaningful. In this work, it was set to
. This evaluation considers features such as the presence of structured sentences (
), named entities (
), and the frequency of Spanish words (
), verified through natural language processing techniques.
The choice of was determined by preliminary evaluations of a sample of 100 messages extracted from steganographic images. Several threshold values ranging from 0.1 to 0.6 were tested, and this value yielded the best trade-off between accepting coherent messages and filtering out semantically meaningless content. Messages classified as valid under this criterion showed consistent grammatical structure, named entities, and dictionary-based word frequency, with minimal inclusion of random or truncated strings. While this threshold is task-specific, it proved effective in reducing false positives during the semantic validation stage.
Additionally, based on experimental observations during the validation process, it was noted that messages shorter than 10 characters generally lacked sufficient syntactic structure or semantic content to be reliably validated. Therefore, this value can be considered a practical lower bound for the minimum detectable message length in the current CNN-NLP configuration. Messages below this threshold frequently failed to meet the combined linguistic criteria shown in Equation (
14) and were classified as incoherent or invalid.
In brief, the developed model implements a specialized architecture for detecting LSB steganography in digital images, combining image processing techniques, deep convolutional neural networks, and semantic validation through natural language processing.
3.5. Model Summary
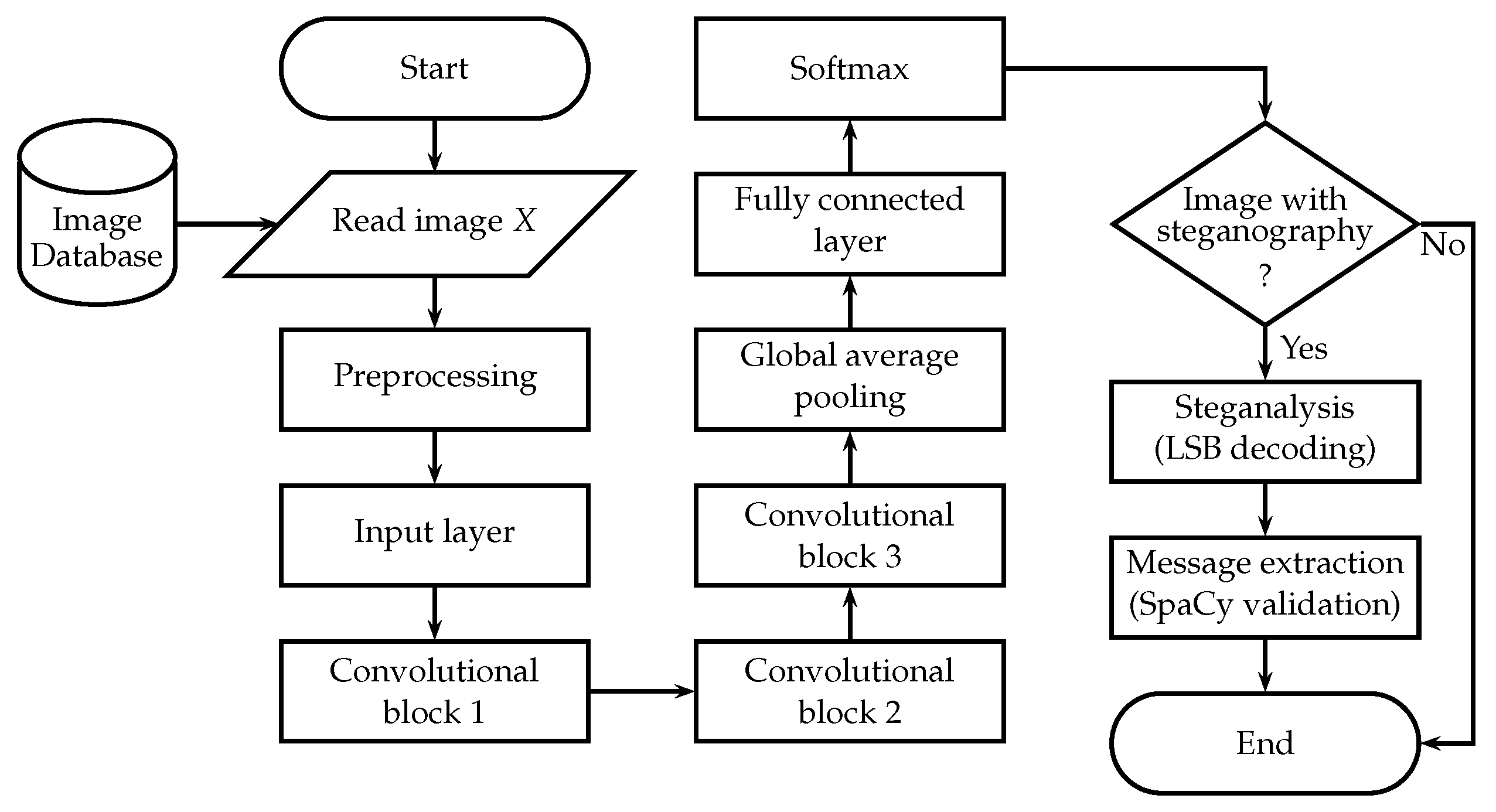
After training the convolutional neural network, the process displayed in
Figure 2 is employed for a suspicious image. As observed, the procedure begins with retrieving the image from a database. Once obtained, the image is subjected to a preprocessing stage, during which it is transformed to meet the input requirements of the convolutional neural network. This preprocessing involves resizing and normalization operations to ensure compatibility with the model and optimize its performance.
Following this stage, the preprocessed image is fed into the CNN, which has been specifically trained to detect the presence of steganography—namely, the intentional concealment of information within digital images. The convolutional neural network analyzes the image and outputs a classification result indicating whether or not a hidden message is embedded in the image.
The CNN receives the preprocessed image (as a tensor) as input and processes it through an input layer followed by three convolutional blocks with residual connections. After these stages, a GAP layer is applied, which computes the spatial average of each feature map to produce a compact feature vector. This vector is then passed through a fully connected dense layer with 128 neurons. The final classification is obtained by applying the “Softmax” layer, which transforms the vector of raw outputs into a probability distribution for the two defined classes.
If the network determines that the image does contain hidden information (referred to as the With-Steganography case), the system proceeds to extract or decode the concealed message. However, the validity of the extracted message is not assumed by default. To ensure its linguistic coherence and meaningfulness, the message is subsequently analyzed using the spaCy library, a powerful tool for natural language processing in Python. This step helps verify that the message is not only structurally well-formed but also semantically coherent, thereby reducing the likelihood of false positives caused by noise or model inaccuracies.
This multi-stage architecture provides a robust and interpretable pipeline for detecting and validating hidden messages in images. By integrating advanced techniques from computer vision and natural language processing, the model ensures not only high classification accuracy but also semantic validation of the extracted message, reinforcing the forensic reliability of the detection process.
4. Results and Comparison with Existing Models
This section presents the main findings obtained after implementing and evaluating the CNN-NLP model. First, the experimental results derived from different dataset sizes are analyzed, including their impact on commonly used metrics. Furthermore, the model’s behavior during training is examined, with a focus on its stability and convergence capacity. Second, a comparison with representative models is conducted to assess the performance of the proposed approach in quantitative terms.
4.1. Evaluation of the Proposed Model
To evaluate the performance of the proposed CNN-NLP model, multiple experiments were conducted using data subsets of 5000, 7000, 9000, 10,000, and 12,500 images per class (With-Steganography and Without-Steganography). In all cases, of the images were used for training and the remaining for validation, ensuring a stratified and random distribution.
As an initial part of the performance analysis,
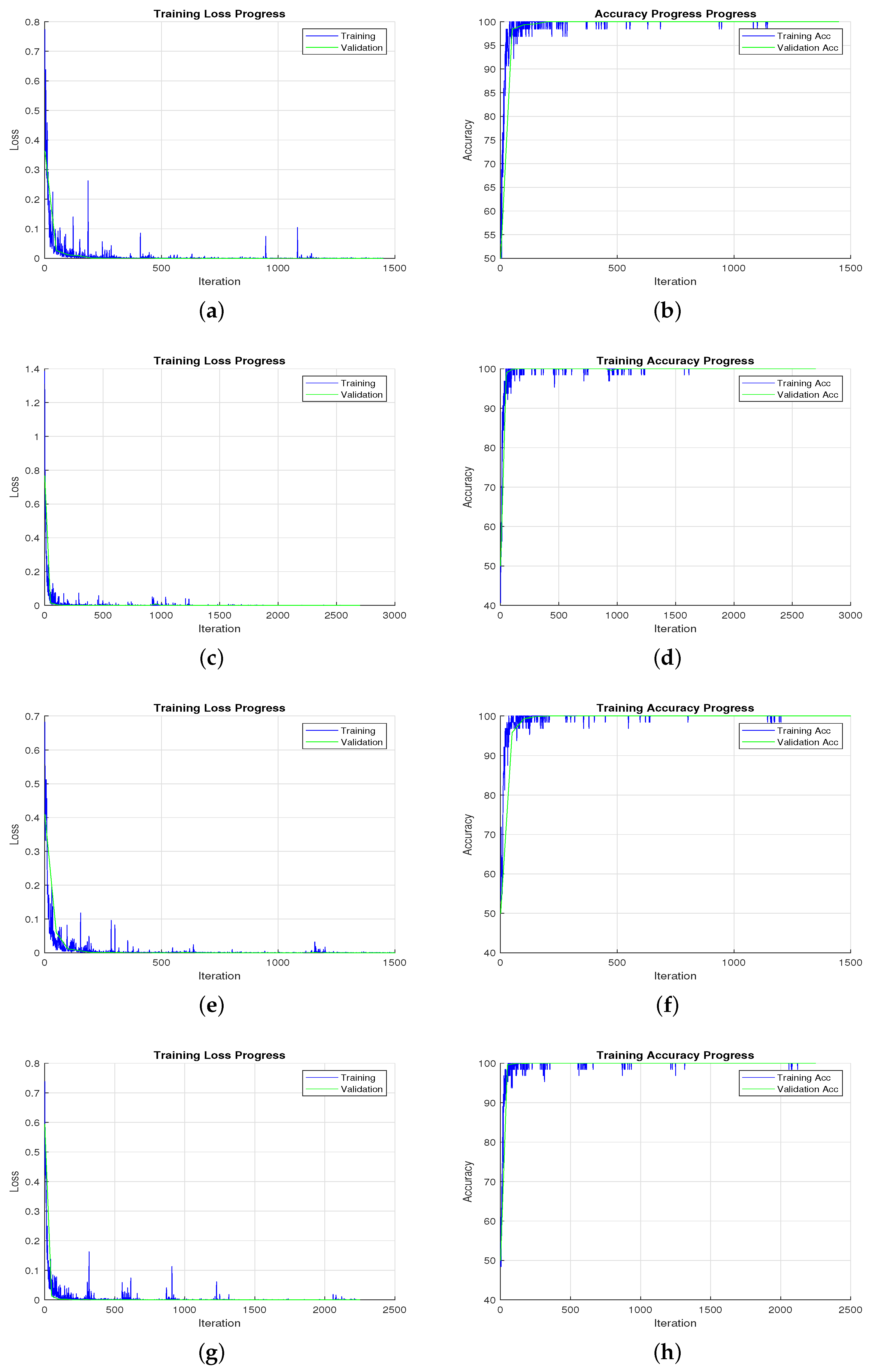
Figure 3 presents the evolution of accuracy and the loss function over the training epochs, corresponding to the experiments with 7000, 9000, 10,000, and 12,500 images per class. This graph illustrates how, with a larger dataset, the model exhibits more progressive and stable convergence, characterized by noticeably smoother curves and fewer oscillations.
This behavior confirms that a larger volume of data significantly contributes to improving the robustness and stability of the learning process and the generalization capacity of the model.
Performance evaluation was carried out using classic binary classification metrics: accuracy corresponds to the proportion of correctly classified images out of the total evaluated; precision indicates how many of the images were correctly predicted to be
With-Steganography, reducing false positives; recall reflects the model’s ability to identify all true cases, avoiding false negatives; and F1-score balances precision and sensitivity, representing an integrated performance measure, especially useful in balanced sets. Their definitions are presented in Equations (15)–(18).
In Equations (15)–(18),
represents the true positives,
the true negatives,
the false positives, and
the false negatives.
Table 1 presents the average results obtained for each experiment based on the number of images per class employed.
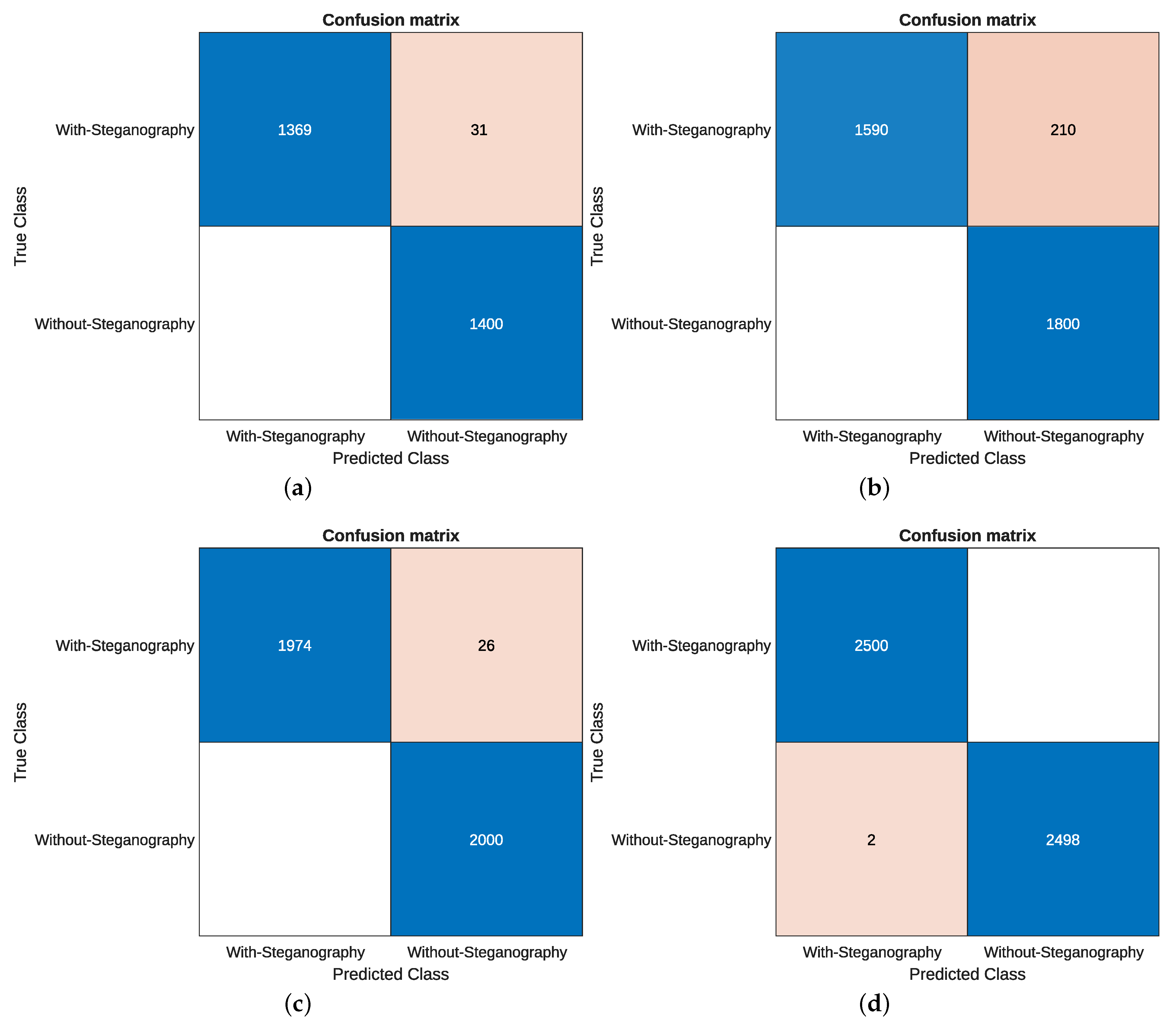
Figure 4 shows the confusion matrix obtained corresponding to the experiments with 7000, 9000, 10,000, and 12,500 images per class.
For the 5000-image dataset, the model achieved an accuracy of 98.20%, with 98.20% precision and an F1-score of 98.20%. Although the classification results were already solid, some variability in the training curves suggests the model was still learning to generalize under limited-data conditions.
In the 7000-image experiment, performance improved significantly: the model achieved an accuracy of 98.89%, with 98.93% precision and an F1-score of 99.12%. This suggests a more robust learning process with reduced error rates and earlier convergence.
In the case with 9000 images per class, the performance decreased slightly. This drop may be attributed to class imbalance or an increased sample diversity not fully captured during training, highlighting the importance of controlled dataset composition.
With 10,000 images per class, the model regained stability and delivered 99.35% accuracy, 99.35% precision, and an F1-score of 99.35%, supported by smooth learning curves and a notable reduction in classification errors across both classes.
Finally, for the largest set (12,500 images per class), a high-accuracy performance and 2500 hits per class were observed, with only two false positives and no false negatives, thus consolidating the highest accuracy value (99.96%), reflecting not only an excellent learning capacity but also robust behavior in large-scale conditions. These results confirm that increasing the volume of training data improves not only the precision but also the stability of the training process, as observed in the smoother loss and accuracy curves.
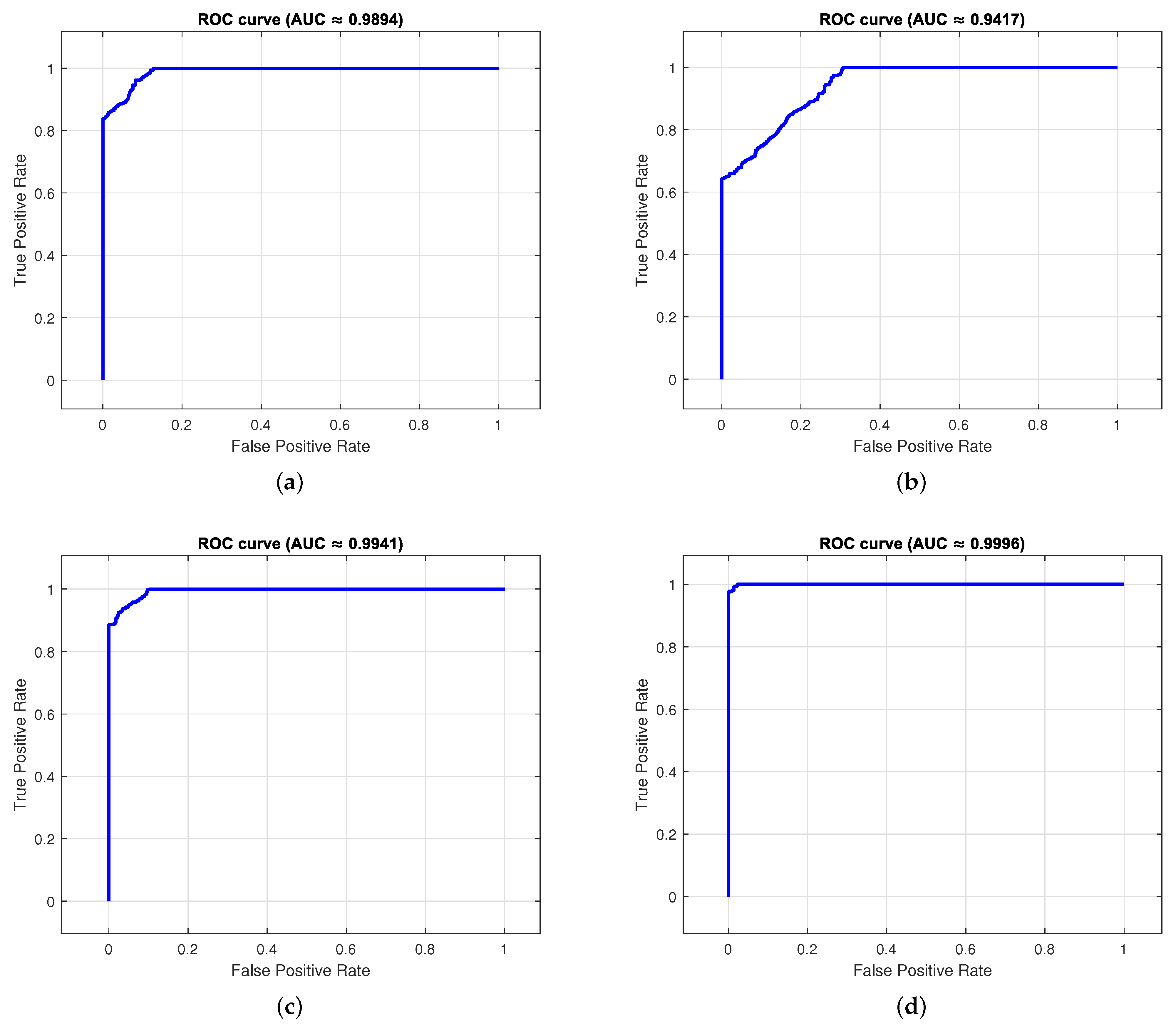
In addition to these classic metrics, the receiver operating characteristic (ROC) curves were analyzed to evaluate the discriminative capacity of the model under different decision thresholds (see
Figure 5). An ROC curve plots the true-positive rate against the false-positive rate, and the area under the curve (AUC) quantifies the overall classification quality.
For the dataset with 5000 images per class, the AUC reached 0.9894, indicating a strong separation ability even with a moderate training volume. With 7000 and 10,000 images, the AUC values improved to 0.9941 and 0.9996, respectively, demonstrating greater robustness and convergence. Interestingly, the experiment with 9000 images showed a temporary drop in performance, yielding an AUC of 0.9417. This behavior may be attributed to variance in the validation subset or suboptimal tuning during training. Nevertheless, the best results were obtained with 12,500 images, where the AUC peaked at 0.9996, reflecting near-perfect separation between classes.
Overall, the high AUC values across the experiments reaffirm the model’s ability to distinguish between steganographic and non-steganographic images, complementing the precision and F1-scores obtained in earlier analyses.
In
Figure 5 the result of the ROC curve shows the effect of varying this threshold on the true-positive rate and the false-positive rate. In all cases, the area under the curve value was above 0.94, which implies that the model performed with high efficiency in terms of its ability to discriminate messages with grammatical meaning.
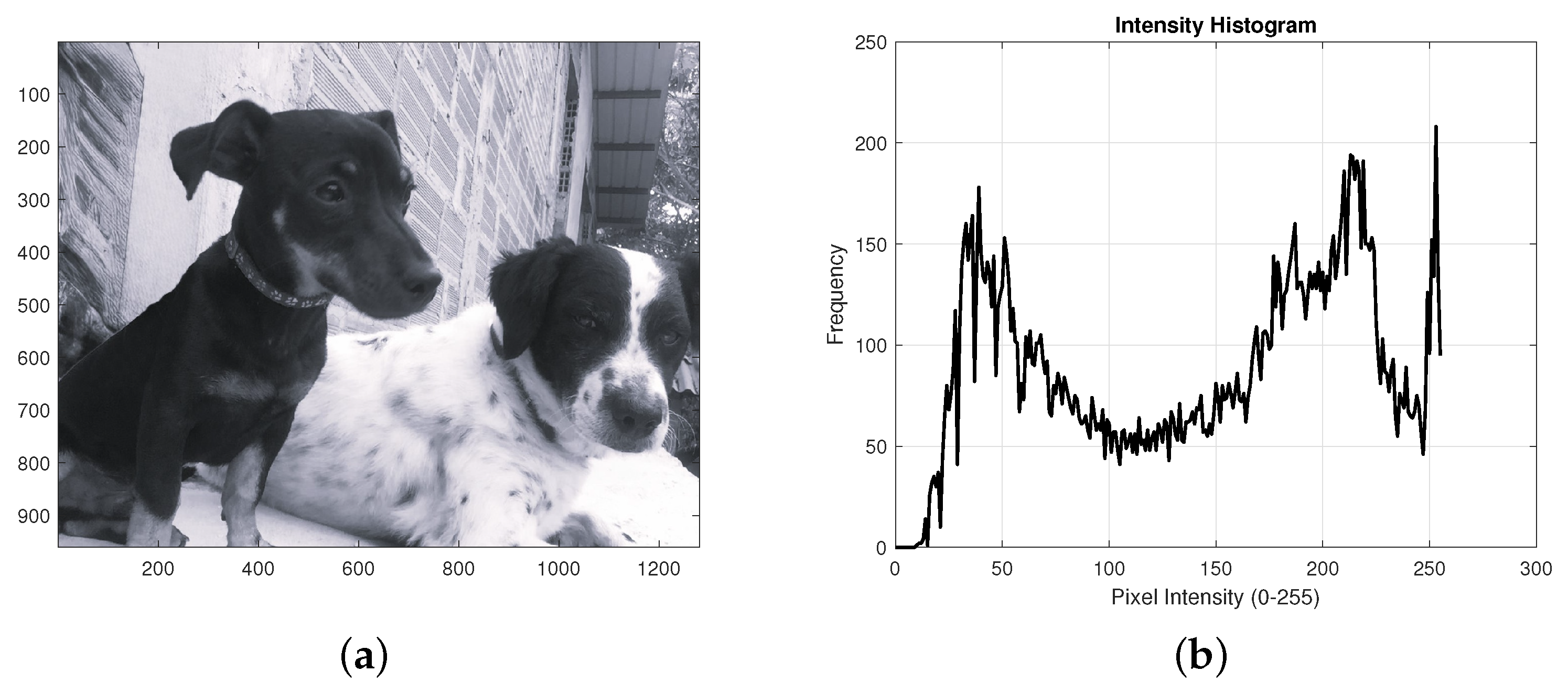
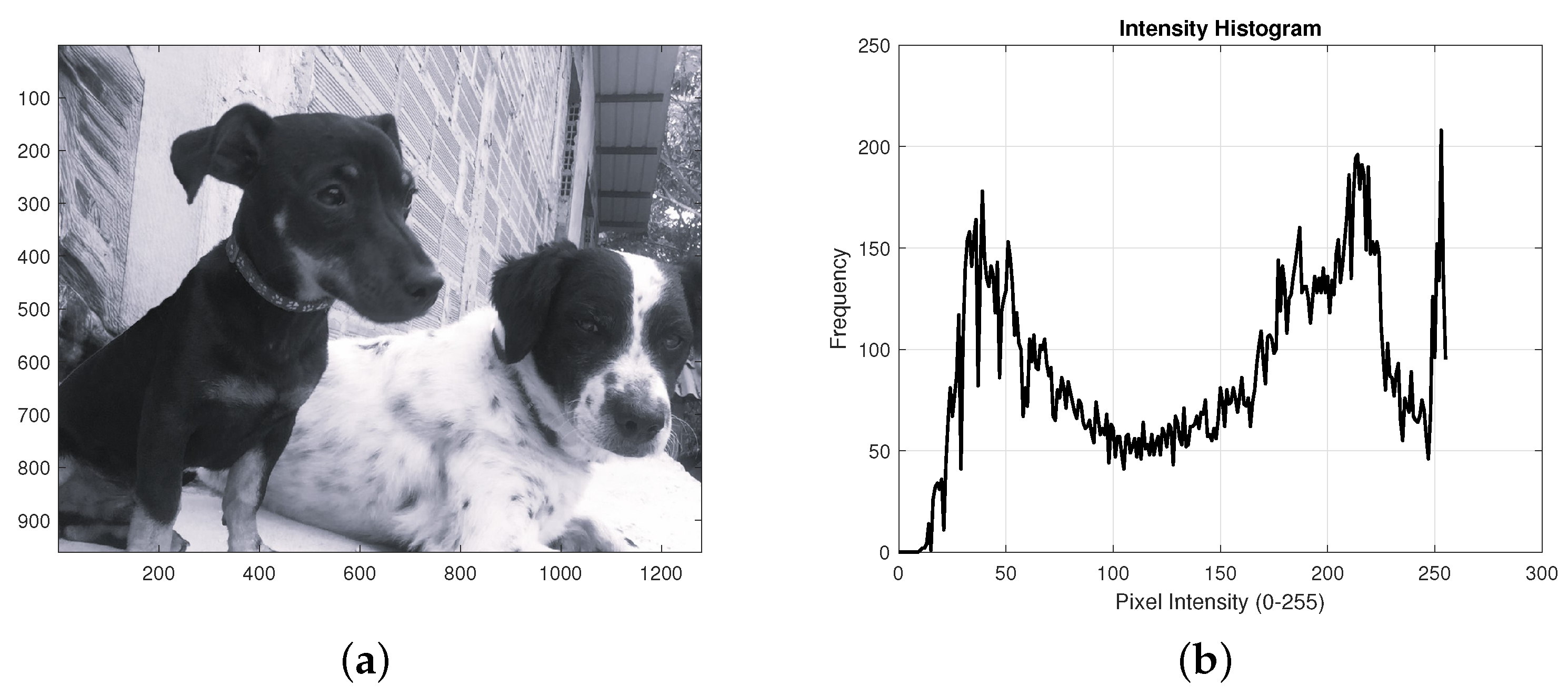
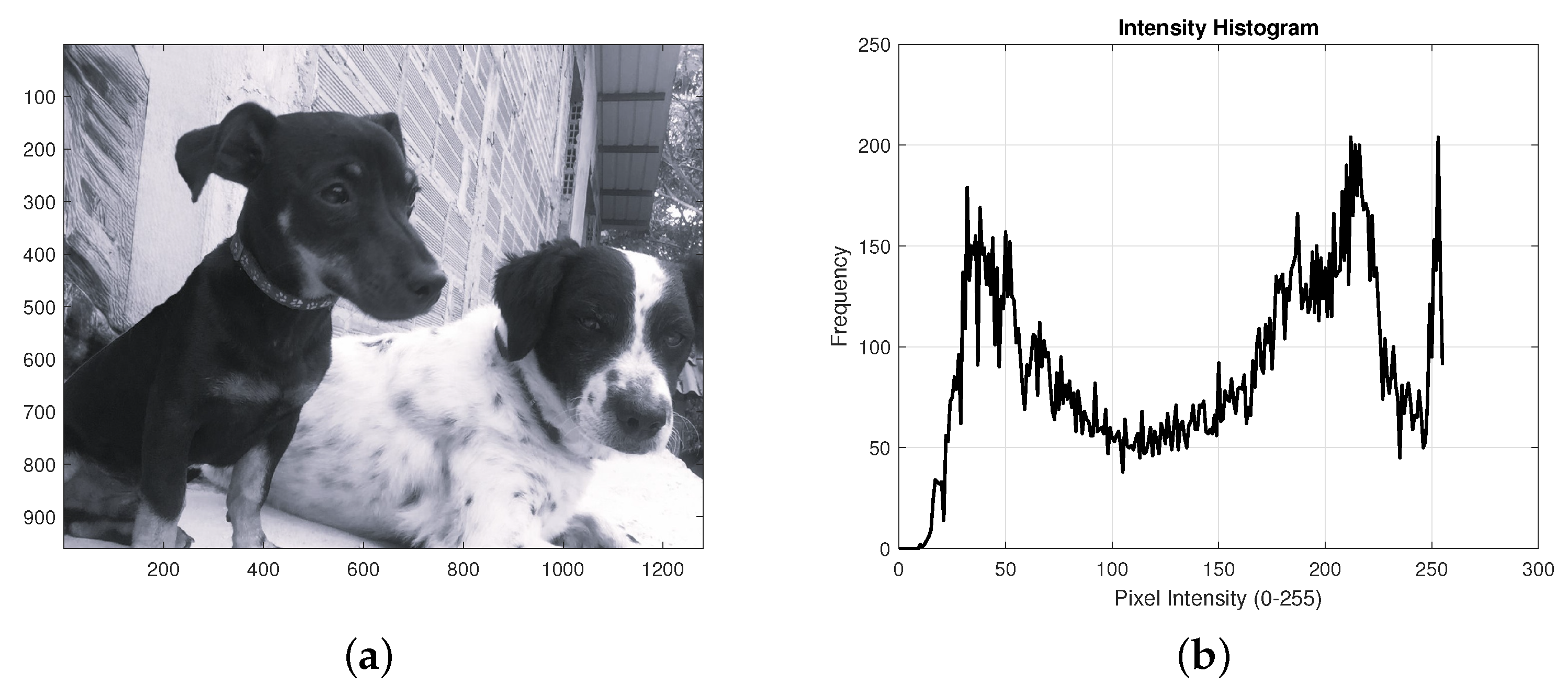
Additionally,
Figure 6,
Figure 7 and
Figure 8 display examples of the semantic validation process applied to messages extracted from images classified as
With-steganography. In these cases, the model correctly identified the presence of steganography and evaluated whether the retrieved message made sense in Spanish. This evaluation was performed using natural language processing techniques, and only those messages that exceeded a minimum threshold of linguistic coherence were considered true positives.
4.2. Model Comparison
To validate the effectiveness of the proposed CNN-NLP model, a comparison was made with benchmark models in the field of steganalysis, including Xu-Net, Yedroudj-Net, and SRNet. These models have been specifically designed for image steganography detection and have been trained on databases such as BOSSbase. Xu-Net, for example, includes an initial convolution layer with fixed filters; Yedroudj-Net extends the architecture with additional layers and early batch normalization; and SRNet proposes a deeper network without pooling convolutions to preserve low-frequency information. The comparison focuses on three key aspects: accuracy, F1-score, and semantic validation capability.
As shown in
Table 2, the proposed CNN-NLP model outperforms the traditional architectures in all performance metrics. In terms of accuracy, Xu-Net reaches 87.75%, Yedroudj-Net reaches 90.10%, and SRNet reaches 92.60%. In contrast, the CNN-NLP model achieves an accuracy of 99.96%, which represents an improvement of 7.36% compared to the best of the compared models (SRNet). This implies that most of the cases that it detects as carrying steganography effectively are carrying steganography, which significantly reduces false positives and strengthens the reliability of the system, a key aspect in forensic analysis.
The differences are also notable in terms of accuracy: the proposed model achieves 99.96%, representing an improvement of more than six percentage points compared to the best performer (93.80% with SRNet). This indicates that the proposed model not only accurately identifies altered images but also avoids misclassifying authentic images as manipulated, thus improving the overall accuracy of the system.
These results are due not only to the architectural design and the residual preprocessing applied, but also to the inclusion of semantic validation, which allows verification of whether the hidden message is consistent in Spanish. With additional validation and the absence of traditional models, false positives can be ruled out. Although they exhibit statistical patterns similar to those of a hidden message, they do not contain linguistically valid content. This enhances the utility of CNN-NLP, particularly in legal and forensic contexts where the content of the message is as crucial as its detection.
5. Discussion
The hybrid CNN-NLP model proposed for detecting LSB steganography in digital images demonstrated strong performance in controlled experimental settings, particularly in scenarios with well-preprocessed grayscale images and known encoding patterns. However, several significant limitations must be addressed before deploying the system in real-world conditions.
It is essential to point out that the comparison with models such as Xu-Net, Yedroudj-Net, and SRNet was based on different datasets, as these models were initially trained and evaluated on BOSSbase. While this limits direct equivalence in the performance metrics, the comparison still offers valuable insight into architectural differences and the potential impact of semantic validation. As a future line of research, it would be relevant to retrain the proposed CNN-NLP model using the BOSSbase dataset or similar standardized corpora, to conduct experiments under equivalent conditions and evaluate the generalizability of the model across diverse image sources.
One of the primary limitations is the reliance of the model on synthetically generated grayscale PNG datasets under idealized conditions. Although these datasets allow controlled experimentation and initial validation, they do not fully capture the variability and unpredictability of real-world steganographic cases, including JPEG compression distortions, color image variability, adversarial noise, or alternative embedding schemes. This limits the generalizability of the model to more diverse formats and practical forensic applications.
Specifically, JPEG images pose a unique challenge, as the lossy compression process tends to eliminate or distort the subtle bit-level patterns targeted by LSB-based steganography detection. Similarly, RGB color images introduce additional complexity due to inter-channel correlations and color-space transformations, requiring a different preprocessing pipeline (e.g., extraction of LSB planes from each RGB channel or transformation to the YCbCr color space). While the current model is optimized for grayscale PNGs to maximize LSB fidelity, adapting it to these other formats is a crucial direction for future work.
Another challenge concerns the computational cost of the hybrid architecture. The combination of a deep convolutional network with semantic analysis introduces a heavier inference load, making the system less suitable for deployment on low-power devices or in time-constrained environments. Additionally, while the NLP component significantly improves interpretability and semantic validation, its performance depends on the accurate recovery of the hidden message. Any distortion, truncation, or decoding error can compromise the text evaluation phase, leading to false negatives or overlooked threats.
An important limitation of the current semantic validation approach arises when the hidden messages are encrypted using ciphers such as Vigenère or other classical encryption schemes. In such cases, the extracted text lacks natural language structure, and the NLP module would correctly classify it as semantically invalid. While this behavior helps prevent false positives from random bit noise, it also implies that the system may fail to detect encrypted stego-content, resulting in false negatives.
This design choice is justified by the specific goal of identifying steganographic messages not only present but also interpretable in the linguistic domain, particularly relevant in forensic contexts where message content matters. Nevertheless, detecting encrypted payloads remains an open challenge. Future work could incorporate statistical text analysis (e.g., entropy estimation, n-gram frequency analysis, or cryptographic feature extraction) as a preliminary filter before NLP validation. Such enhancements could increase the capability of the system to flag hidden encrypted messages, even if their semantic content cannot be directly interpreted.
In the case where the method is applied to non-grayscale images (such as images in RGB or YCbCr formats), the computational complexity would increase substantially due to the need to process three color channels instead of one. Specifically, the preprocessing pipeline would need to extract residuals and bit planes from each channel (i.e., R, G, and B), resulting in a fifteen-channel tensor instead of the current five-channel input (one residual + four LSBs per channel). This would affect both memory usage and training time. The convolutional layers in the CNN would require additional parameters and operations in the first layers to handle the increased input dimensionality. Furthermore, training on color images would require larger batch sizes and longer convergence times to capture inter-channel dependencies.
While feasible, this extension would multiply the cost of forward and backward passes by approximately to , depending on the architecture depth and number of filters. Additional complexity would also arise in tuning the preprocessing logic and validating semantic consistency in more visually complex contexts. Despite this, the model’s architecture is modular and could be adapted to color image inputs by adjusting the input layer and increasing the CNN capacity. Future work could explore this direction using optimized color-specific representations such as YCbCr or residual-based fusion strategies.
Additionally, although the NLP component is currently configured for Spanish using the spaCy model “es_core_news_md”, the modular nature of the system allows for seamless integration of other language models. By switching to language-specific pipelines (e.g., English, French, or Portuguese), the system can adapt to different linguistic environments. This multilingual potential extends the applicability of the proposed architecture to international forensic scenarios, provided that reliable language models and linguistic resources are available.
Despite these challenges, the results suggest several promising directions for future research. An essential area is the construction and use of more datasets and realistic datasets, including color and compressed formats, and potentially real-world stego-content captured from forensic case samples. Improving the robustness of text extraction would also enhance the system’s adaptability. Furthermore, integrating explainable AI techniques could enable the system to highlight or visualize regions suspected of concealing information, thereby increasing transparency in forensic analyses.
Lastly, optimizing the architecture for resource-constrained environments remains a priority. Exploring lightweight CNN backbones, quantization strategies, or hybrid architectures that selectively activate the NLP module only under certain confidence thresholds could make the system more scalable and efficient.
6. Conclusions
This work presented a hybrid approach based on convolutional neural networks and natural language processing to detect LSB steganography in digital images. The combination of visual and linguistic analyses allowed the development of a system capable of identifying semantic patterns in image content and hidden data, overcoming the limitations of traditional unimodal approaches. The results obtained in experimental settings indicate that integrating both branches can significantly improve detection capacity, especially when the embedded messages have textual coherence.
The CNN-NLP model developed in this work achieves efficient metrics and redefines the traditional approach to digital steganalysis by integrating a semantic validation layer for the hidden message. Unlike the architectures evaluated, which focus solely on binary detection, the CNN-NLP enables the verification of whether the extracted content is linguistically coherent, thus elevating the analysis from a technical to an interpretive perspective.
Likewise, the inclusion of the NLP module allows the filtering of statistical false positives, providing a second line of verification based on natural language processing. The progressive analysis with different dataset sizes showed that the proposed architecture maintains stability, generalization capacity, and a low error rate, even in scenarios with visual noise or highly complex messages, making it a robust, replicable, and scalable alternative for detecting steganography in digital images.
Significant challenges were identified, such as the need for more realistic data, the computational complexity of the model, and limitations in accurately extracting hidden text. These aspects unlock new opportunities for future research aimed at improving the system’s robustness, efficiency, and applicability.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}