




Optimizing Sentiment Analysis in Multilingual Balanced Datasets: A New Comparative Approach to Enhancing Feature Extraction Performance with ML and DL Classifiers

 ,
,
Abstract
1. Introduction
- Use balanced multilingual datasets to ensure comparability across English, French, and Arabic;
- Apply three categories of feature extraction methods and combine them with both traditional and deep learning classification models;
- Evaluate model performance across several metrics, including a novel consideration of execution time during embedding generation, allowing us to examine the relationship between vectorization method, classifier, dataset type, and computational efficiency;
- Provide practical guidance for selecting the most appropriate embedding and classification techniques for multilingual sentiment analysis tasks.
2. Literature Review
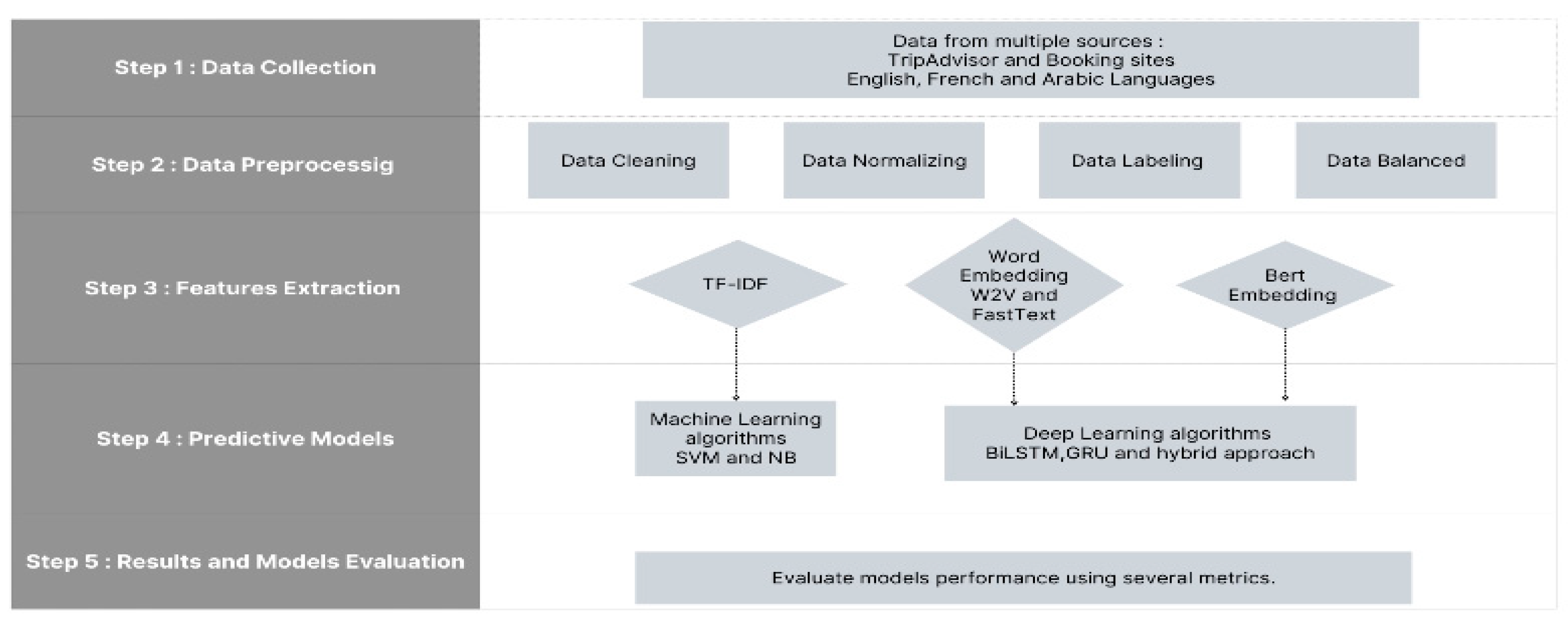
3. Methodology
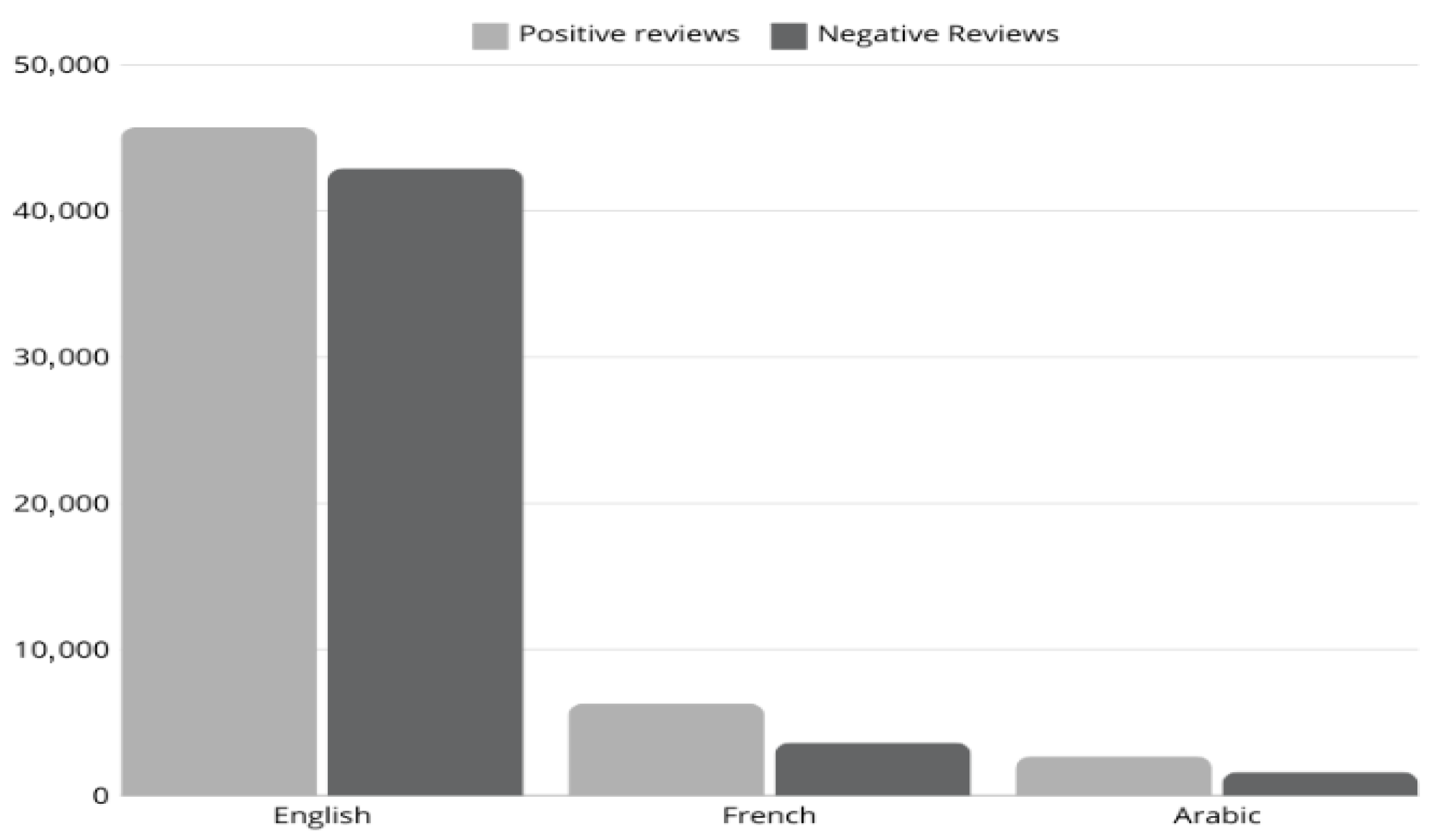
3.1. Data Collection
3.1.1. English Dataset
3.1.2. French Dataset
3.1.3. Arabic Dataset
3.2. Data Processing
3.3. Data Labeling
3.4. Feature Extraction
3.4.1. TF-IDF
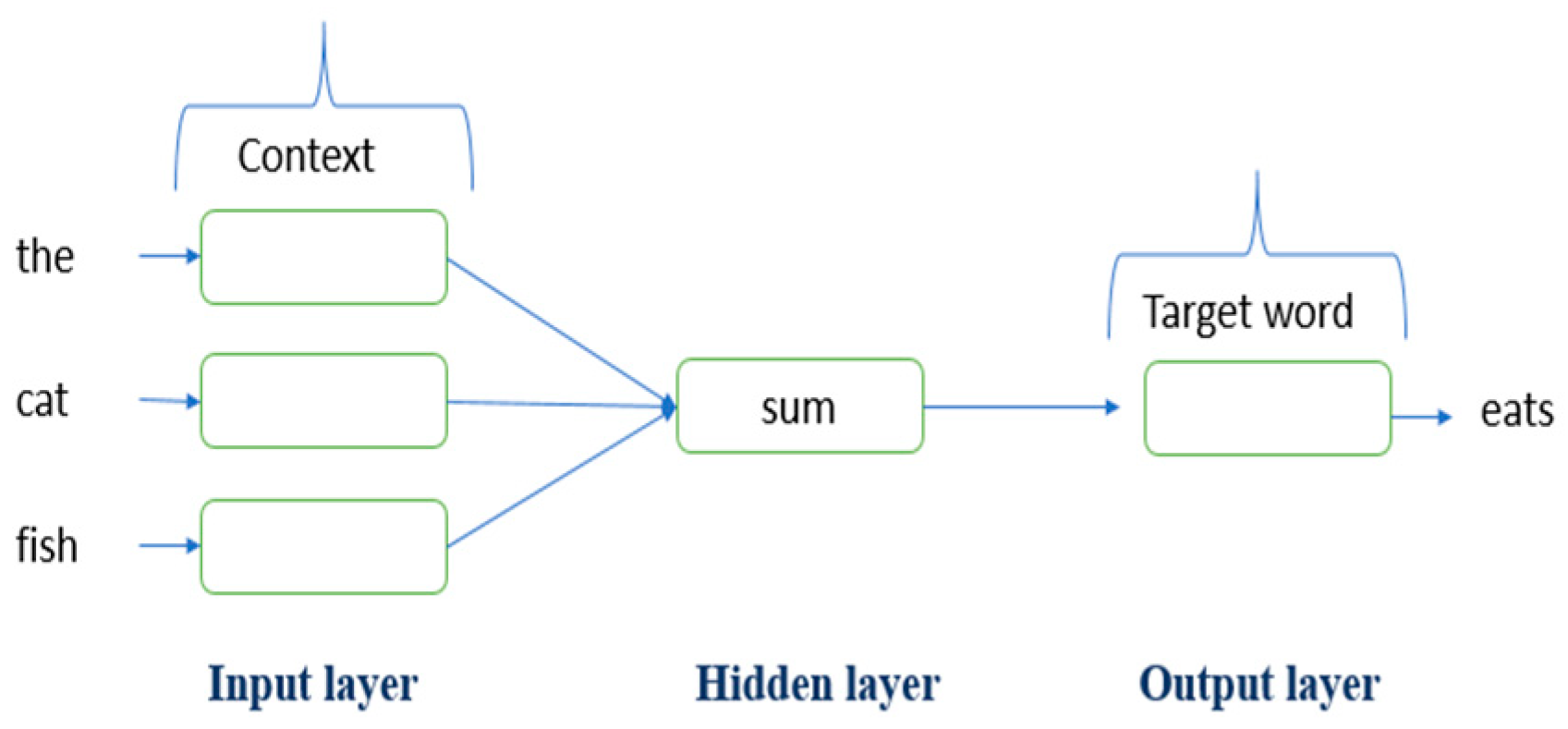
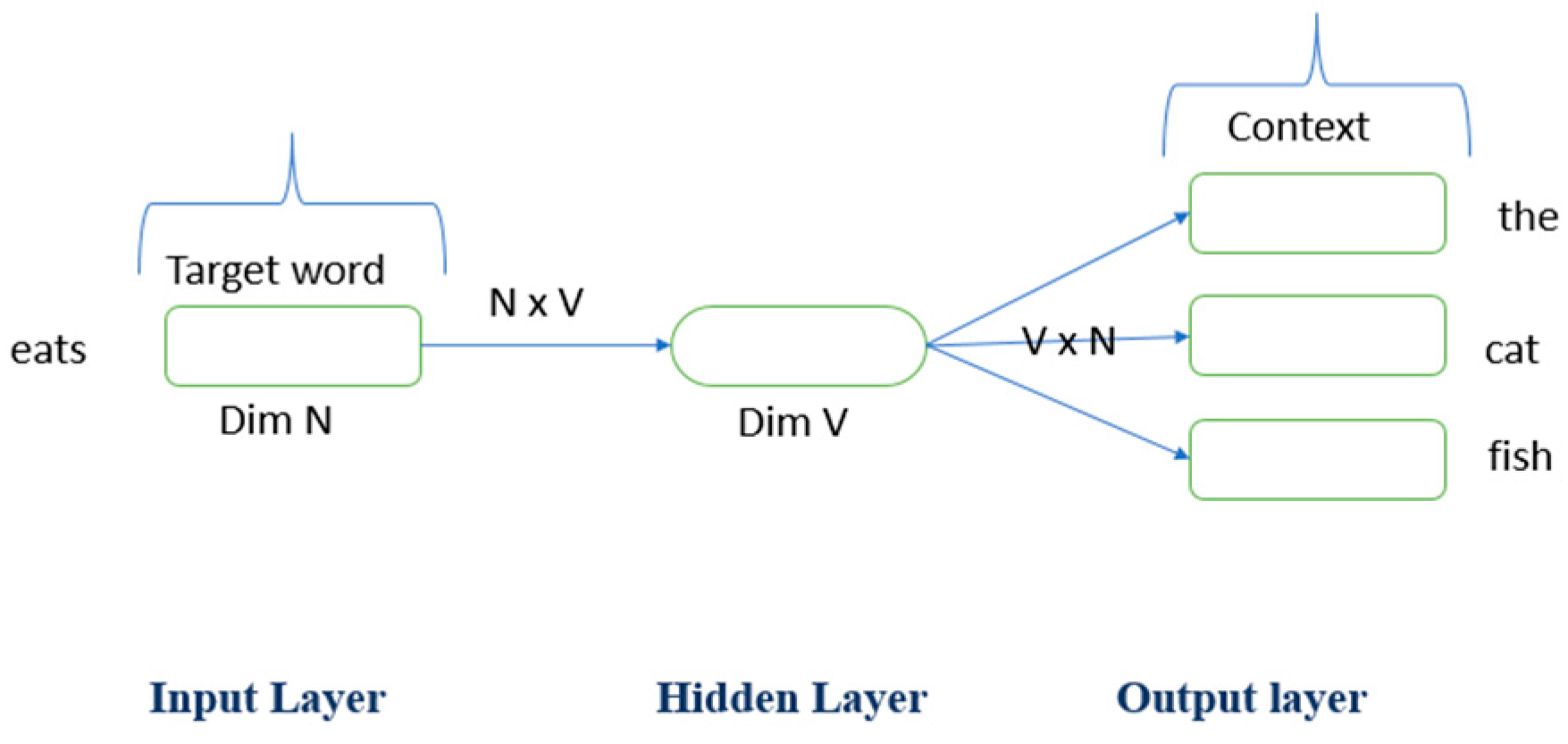
3.4.2. Word Embedding
Word2Vec
FastText
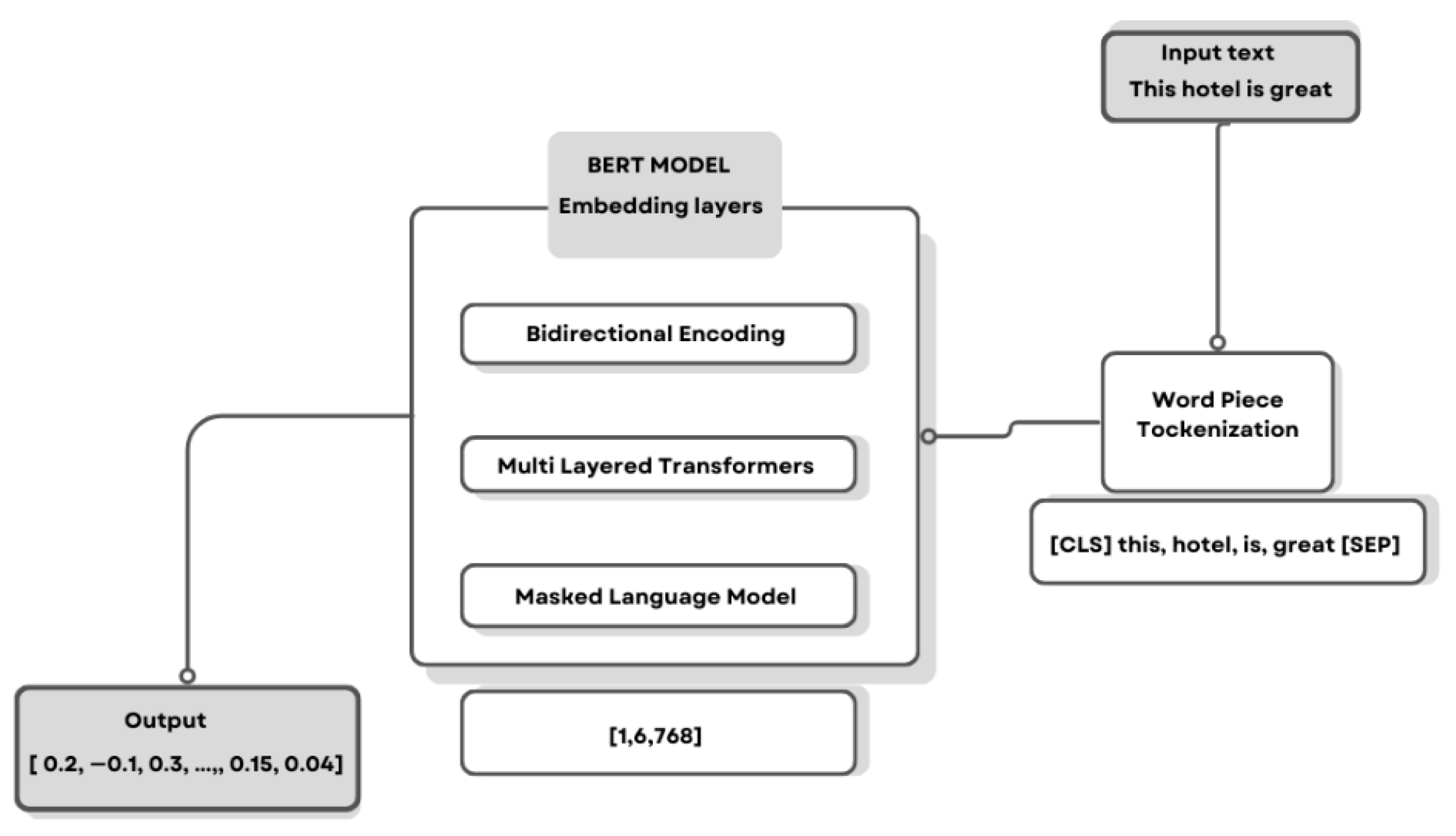
3.4.3. BERT Embedding
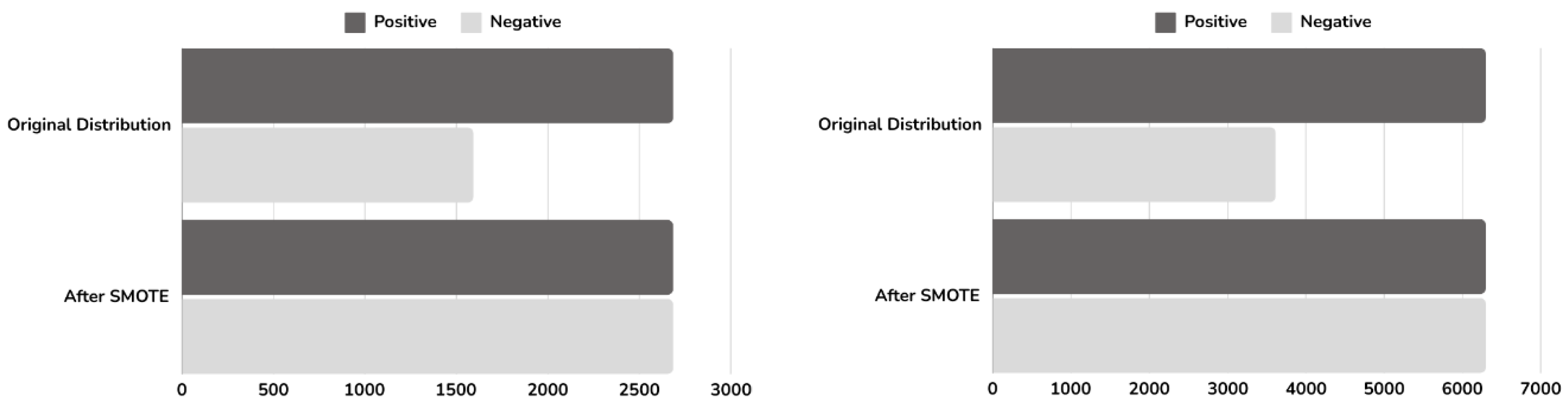
3.5. Data Balancing
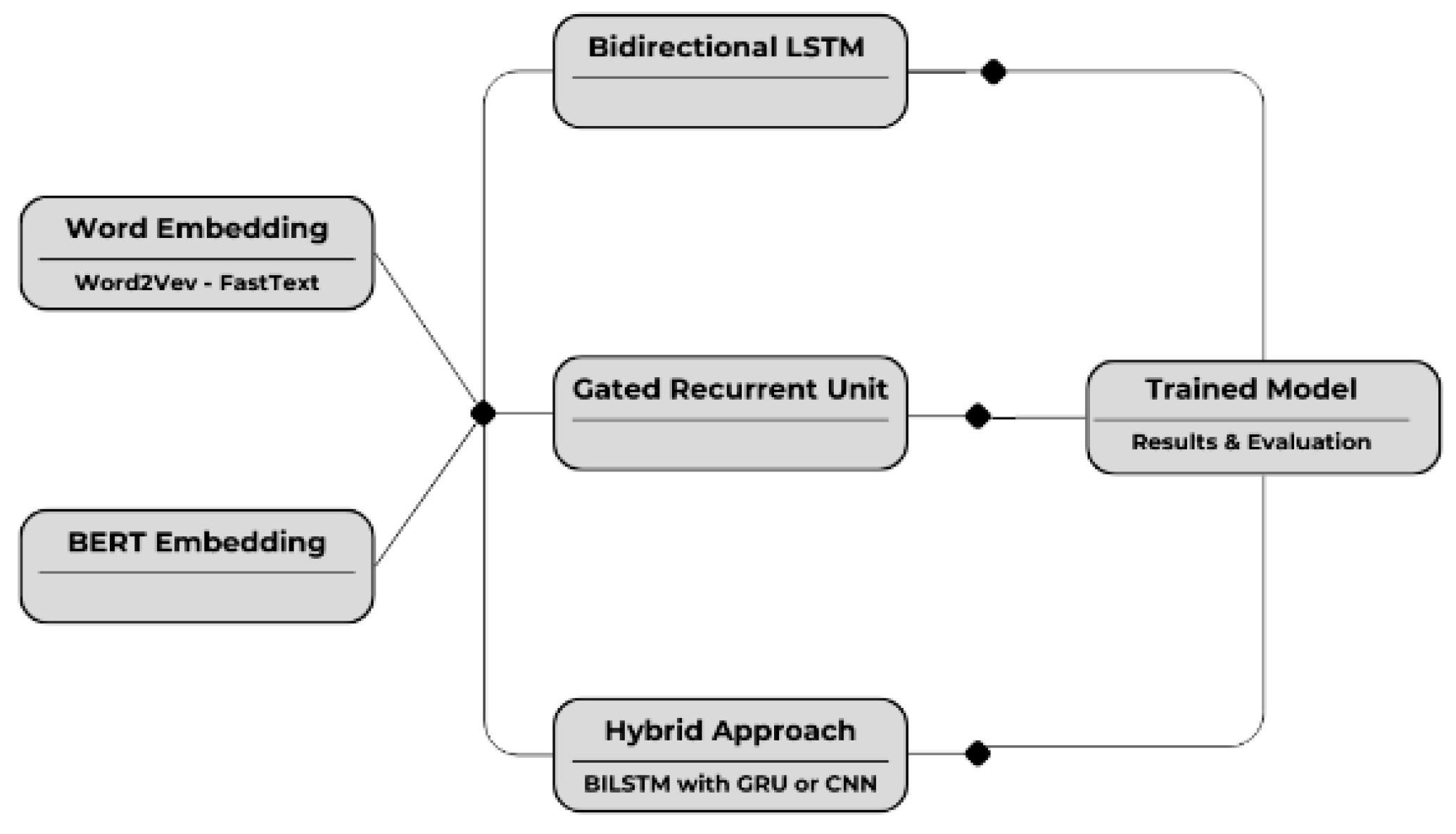
3.6. Machine and Deep Learning Algorithms
4. Results and Discussion
4.1. Evaluation Metrics
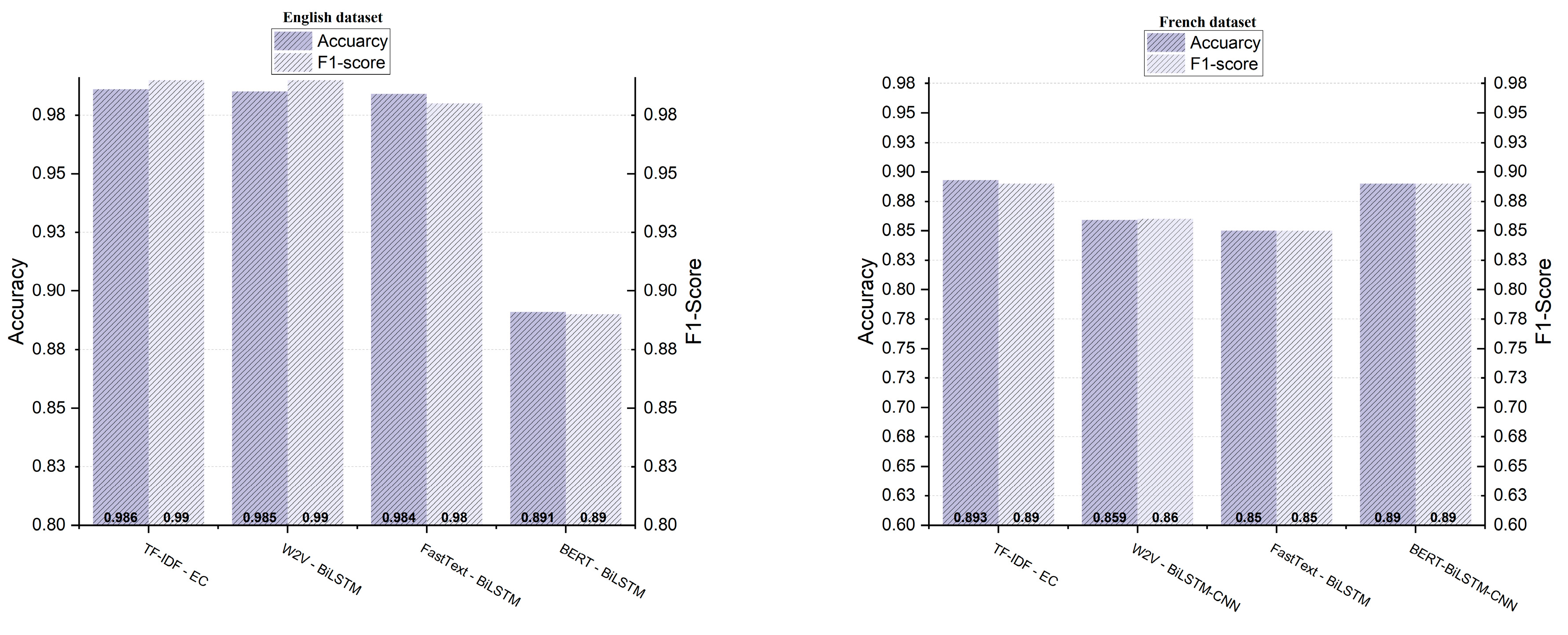
4.2. Experimental Findings
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lareyre, F.; Nasr, B.; Chaudhuri, A.; Di Lorenzo, G.; Carlier, M.; Raffort, J. Comprehensive Review of Natural Language Processing (NLP) in Vascular Surgery. EJVES Vasc. Forum. 2023, 60, 57–63. [Google Scholar] [CrossRef]
- Mukherjee, P.; Badr, Y.; Doppalapudi, S.; Srinivasan, S.M.; Sangwan, R.S.; Sharma, R. Effect of Negation in Sentences on Sentiment Analysis and Polarity Detection. Procedia Comput. Sci. 2021, 185, 370–379. [Google Scholar] [CrossRef]
- Haris, N.A.K.M.; Mutalib, S.; Malik, A.M.A.; Abdul-Rahman, S.; Kamarudin, S.N.K. Sentiment classification from reviews for tourism analytics. Int. J. Adv. Intell Inform. 2023, 9, 108. [Google Scholar] [CrossRef]
- Albahli, S. Twitter sentiment analysis: An Arabic text mining approach based on COVID-19. Front. Public Health 2022, 10, 966779. [Google Scholar] [CrossRef] [PubMed]
- Muhammad, P.F.; Kusumaningrum, R.; Wibowo, A. Sentiment Analysis Using Word2vec and Long Short-Term Memory (LSTM) For Indonesian Hotel Reviews. Procedia Comput. Sci. 2021, 179, 728–735. [Google Scholar] [CrossRef]
- Alharbi, A.; Kalkatawi, M.; Taileb, M. Arabic Sentiment Analysis Using Deep Learning and Ensemble Methods. Arab. J. Sci. Eng. 2021, 46, 8913–8923. [Google Scholar] [CrossRef]
- Talaat, A.S. Sentiment analysis classification system using hybrid BERT models. J. Big Data 2023, 10, 110. [Google Scholar] [CrossRef]
- Murfi, H.; Syamsyuriani Gowandi, T.; Ardaneswari, G.; Nurrohmah, S. BERT-based combination of convolutional and recurrent neural network for indonesian sentiment analysis. Appl. Soft Comput. 2024, 151, 111112. [Google Scholar] [CrossRef]
- Ahmed, J.; Ahmed, M. Classification, detection and sentiment analysis using machine learning over next generation communication platforms. Microprocessors and Microsystems. Microprocess. Microsyst. 2023, 98, 104795. [Google Scholar] [CrossRef]
- Qi, Y.; Shabrina, Z. Sentiment analysis using Twitter data: A comparative application of lexicon- and machine-learning-based approach. Soc. Netw Anal Min. 2023, 13, 31. [Google Scholar] [CrossRef]
- Bello, A.; Ng, S.C.; Leung, M.F. A BERT Framework to Sentiment Analysis of Tweets. Sensors 2023, 23, 506. [Google Scholar] [CrossRef] [PubMed]
- Kasri, M.; Birjali, M.; Beni-Hssane, A. A Comparison of Features Extraction Methods for Arabic Sentiment Analysis. In Proceedings of the 4th International Conference on Big Data and Internet of Things, Rabat, Morocco, 23–24 October 2019; ACM: New York, NY, USA, 2019; pp. 1–6. Available online: https://dl.acm.org/doi/10.1145/3372938.3372998 (accessed on 6 November 2024).
- Kaibi, I.; Nfaoui, E.H.; Satori, H. A Comparative Evaluation of Word Embeddings Techniques for Twitter Sentiment Analysis. In Proceedings of the 2019 International Conference on Wireless Technologies, Embedded and Intelligent Systems (WITS), Fez, Morocco, 3–4 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. Available online: https://ieeexplore.ieee.org/document/8723864/ (accessed on 6 November 2024).
- Hadwan, M.; AAl-Hagery, M.; Al-Sarem, M.; Saeed, F. Arabic Sentiment Analysis of Users’ Opinions of Governmental Mobile Applications. Comput. Mater. Contin. 2022, 72, 4675–4689. [Google Scholar] [CrossRef]
- Hicham, N.; Karim, S.; Habbat, N. An Efficient Approach for Improving Customer Sentiment Analysis in the Arabic Language Using an Ensemble Machine Learning Technique. In Proceedings of the 2022 5th International Conference on Advanced Communication Technologies and Networking (CommNet), Marrakech, Morocco, 12–14 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. Available online: https://ieeexplore.ieee.org/document/9993924/ (accessed on 6 November 2024).
- Mboungou, M.M.B.; Yamin, I.; Zhang, S.; Iqbal, A. Sentiment Analysis of Client Reviews on a French E-Commerce Platform. In Proceedings of the 2023 International Conference on Ambient Intelligence, Knowledge Informatics and Industrial Electronics (AIKIIE), Ballari, India, 2–3 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. Available online: https://ieeexplore.ieee.org/document/10390055/ (accessed on 8 November 2024).
- Essebbar, A.; Kane, B.; Guinaudeau, O.; Chiesa, V.; Quénel, I.; Chau, S. Aspect Based Sentiment Analysis using French Pre-Trained Models. In Proceedings of the 13th International Conference on Agents and Artificial Intelligence, Vienna, Austria, 4–6 February 2021; SCITEPRESS—Science and Technology Publications: Setúbal, Portugal, 2021; pp. 519–525. Available online: https://www.scitepress.org/DigitalLibrary/Link.aspx?doi=10.5220/0010382705190525 (accessed on 8 November 2024).
- Mas Diyasa, I.G.S.; Marini Mandenni, N.M.I.; Fachrurrozi, M.I.; Pradika, S.I.; Nur Manab, K.R.; Sasmita, N.R. Twitter Sentiment Analysis as an Evaluation and Service Base on Python Textblob. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1125, 012034. [Google Scholar] [CrossRef]
- Zhou, J.; Ye, Z.; Zhang, S.; Geng, Z.; Han, N.; Yang, T. Investigating response behavior through TF-IDF and Word2vec text analysis: A case study of PISA 2012 problem-solving process data. Heliyon 2024, 10, e35945. [Google Scholar] [CrossRef]
- Rezaeinia, S.M.; Rahmani, R.; Ghodsi, A.; Veisi, H. Sentiment analysis based on improved pre-trained word embeddings. Expert Syst. Appl. Mars. 2019, 117, 139–147. [Google Scholar] [CrossRef]
- Nawangsari, R.P.; Kusumaningrum, R.; Wibowo, A. Word2Vec for Indonesian Sentiment Analysis towards Hotel Reviews: An Evaluation Study. Procedia Comput. Sci. 2019, 157, 360–366. [Google Scholar] [CrossRef]
- Fouad, M.M.; Mahany, A.; Aljohani, N.; Abbasi, R.A.; Hassan, S.U. ArWordVec: Efficient word embedding models for Arabic tweets. Soft Comput. 2020, 24, 8061–8068. [Google Scholar] [CrossRef]
- Abdelhady, N.; Hassan ASoliman, T.; Farghally, M. Stacked-CNN-BiLSTM-COVID: An effective stacked ensemble deep learning framework for sentiment analysis of Arabic COVID-19 tweets. J. Cloud Comp. 2024, 13, 85. [Google Scholar] [CrossRef]
- Gomes, L.; Da Silva Torres, R.; Côrtes, M.L. BERT- and TF-IDF-based feature extraction for long-lived bug prediction in FLOSS: A comparative study. Inf. Softw. Technol. 2023, 160, 107217. [Google Scholar] [CrossRef]
- Mohammed, R.; Rawashdeh, J.; Abdullah, M. Machine Learning with Oversampling and Undersampling Techniques: Overview Study and Experimental Results. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; IEEE: Piscataway, NJ, USA; 2020; pp. 243–248. Available online: https://ieeexplore.ieee.org/document/9078901/ (accessed on 26 November 2024).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Çakir, M.; Yilmaz, M.; Oral, M.A.; Kazanci, H.Ö.; Oral, O. Accuracy assessment of RFerns, NB, SVM, and kNN machine learning classifiers in aquaculture. J. King Saud Univ. Sci. 2023, 35, 102754. [Google Scholar] [CrossRef]
- Islam, M.Z.; Liu, J.; Li, J.; Liu, L.; Kang, W. A Semantics Aware Random Forest for Text Classification. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; ACM: New York, NY, USA, 2019; pp. 1061–1070. Available online: https://dl.acm.org/doi/10.1145/3357384.3357891 (accessed on 21 November 2024).
- Ghasemieh, A.; Lloyed, A.; Bahrami, P.; Vajar, P.; Kashef, R. A novel machine learning model with Stacking Ensemble Learner for predicting emergency readmission of heart-disease patients. Decis. Anal. J. 2023, 7, 100242. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, S.; Wang, D.; Zhang, Y.; Yu, G. Context-Aware Chinese Microblog Sentiment Classification with Bidirectional LSTM; Li, F., Shim, K., Zheng, K., Liu, G., Eds.; Web Technologies and Applications; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9931, pp. 594–606. Available online: http://link.springer.com/10.1007/978-3-319-45814-4_48 (accessed on 31 October 2024).
- Bibi, I.; Akhunzada, A.; Malik, J.; Iqbal, J.; Musaddiq, A.; Kim, S. A Dynamic DL-Driven Architecture to Combat Sophisticated Android Malware. IEEE Access 2020, 8, 129600–129612. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Dataset | Resampling Techniques | Feature Extraction | Classifiers | Results |
|---|---|---|---|---|---|
| [9] | A dataset of English news articles | No | TF-IDF | NB, logistic regression (LR), linear SVC, gradient boosting | Best model = NB Accuracy = 89.02% |
| [10] | A dataset of English tweets related to COVID-19 | No | Bag of words (BoW), TF-IDF, Word2Vec | RB, multinomial NB, SVC | Best model = TF-IDF with SVM Accuracy = 71% |
| [11] | Six English datasets combined from Kaggle | No | Word2Vec, BERT | CNN, RNN, BiLSTM | Best model = BERT with CNN, RNN and BiLSTM Accuracy = 93% |
| [12] | A combination of six English datasets from Kaggle | No | BoW, TF-IDF, AraVec | LR, RF, Extra Trees (ETrees), linear SVM, SVM RBF | Best model = TF-IDF with LR Accuracy = 82.10% |
| [13] | Arabic dataset of Twitter comments | No | Word2Vec, Glove, FastText | Gaussian NB, linear SVC, NuSVC, LR, SGD, RF | Best model = FastText with NuSVC Accuracy = 84.89% |
| [14] | An Arabic dataset of user opinions on a mobile application | No | Supervised lexicon weights, TDM, TFM | Decision tree (DT), KNN, SVM, NB | Best model = hybrid (Supervised lexicon weights, TDM, TFM) with KNN Accuracy = 78.46 |
| [15] | Arabic datasets of hotel reviews (Datasets A and C) | No | TF-IDF | Adaboost, KNN, DT, maximum entropy (ME), SVM, ensemble classifier (EC) | Best model = TF-IDF with EC Accuracy = 89.2% |
| [16] | A dataset of customer reviews from a French e-commerce platform | No | TF-IDF | RNN, LSTM | Precision metric between 73% and 77% |
| [17] | SemEval2016 French dataset, including restaurant and museum reviews | No | BERT’s variants | Conventional methods like LSTM Fine-tuned models using FC, SPC, and AEN approaches | Best model = FlauBERT with a pretrained fully connected model (PTM-FC) Best accuracy = 84.68% |
| Text | Language | Text Cleaning |
|---|---|---|
| Room was very well appointed and facilities were good | English | room well appoint facil good |
| Large queues for breakfast Room was very crammed booked a room for 2 adults and 2 children no space to go in with a pushchair Not enough lifts to cater for guests at times it took us 10 min to go down to the lobby restaurant\r | English | larg queue breakfast room cram book room adult children space go pushchair enough lift cater guest time took us minut go lobbi restaur |
| Were staying in london for just one night and the location was perfect we paid around 200 for one night for a family suite and it was very well worth the money\r | English | stay london one night locat perfect paid around one night famili suit well worth money |
| Chambre de petite taille Le petit-déjeuner à améliorer Manque d’équipement | French | chambr petit taill petit-déjeun amélior manqu d’équipement |
| Le service, le personnel et la propreté des lieux. | French | servic personnel propreté lieux |
| Hôtel de qualité à proximité immédiate de la gare. | French | Hôtel qualité proximité immédiat gare |
| Text | Text in English | Text Cleaning | Tashaphyne Stemmer | ISRI Stemmer |
|---|---|---|---|---|
| لم يعجبني اي شيء، حجزنا في الصور شيء لكن في الحقيقة هذا المكان حتى الكلاب لا تستطيع ان تقعد فيه ، رائحة الجيفة في كل مكان الذباب و الناموس و التعامل 0 و صاحب الفندق رجل لا يمكن وصفه إلا بأنه نصاب ، دفعنا ف بوكينج و لما وصلنا للمكان الدي يوجد في قرية نائية و الفندق لا توجد فيه حتى قنينة ماء ، | I didn’t like anything. What we booked in the pictures was one thing, but in reality, this place is so bad that not even dogs can sit there. The smell of rotting flesh is everywhere, flies and mosquitoes are all over, the service is zero, and the hotel owner is nothing but a scammer... | لم يعجبني اي شيء حجزنا الصور شيء الحقيقه المكان حتي الكلاب لا تستطيع ان تقعد رايحه الجيفه مكان الذباب الناموس التعامل 0 صاحب الفندق رجل لا يمكن وصفه الا بانه نصاب دفعنا بوكينج وصلنا لمكان الدي يوجد قريه نايه الفندق لا توجد حتي قنينه ماء | لم عجب اي شيء حجز صور شيء حقيقه مك حت كلاب لا تستطيع ان قعد رايح جيفه مك ذباب ناموس تعامل 0 صاحب فندق رجل لا مك صف لا ان صاب دفع وكينج صل مكا دي وجد قر نا فندق لا وجد حت قني ماء | لم عجب اي شيء حجز صور شيء حقق كان حتي كلب لا تطع ان قعد ريح جيف كان ذبب نمس عمل 0 صحب ندق رجل لا يمكن وصف الا بنه نصب دفع كينج وصل لمك الد وجد قره نيه ندق لا وجد حتي قنن ماء |
| Models | English Word Embedding | French Word Embedding | Arabic Word Embedding | ||||
|---|---|---|---|---|---|---|---|
| Configuration | Word2Vec | FastText | frWac2Vec | FastText | ArWordVec | FastText | |
| Vector size | 300 | 300 | 200 | 300 | 300 | 300 | |
| Approaches | CBOW | CBOW | CBOW | CBOW | CBOW | CBOW | |
| Window size | 5 | 5 | Not Specified | 5 | 3 | 5 | |
| English Dataset | French Dataset | Arabic Dataset | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Training | Validation | Testing | Training | Validation | Testing | Training | Validation | Testing | |
| ML classifiers | 70,911 | - | 17,727 | 10,084 | - | 2520 | 4298 | - | 1074 |
| DL Classifiers | 56,729 | 14,182 | 17,727 | 9662 | 1074 | 1890 | 3868 | 430 | 1074 |
| Classifiers | English Dataset | French Dataset | Arabic Dataset | |
|---|---|---|---|---|
| SVM | C | 1 | 10 | 10 |
| Kernel | RBF | RBF | RBF | |
| Degree, Gamma | 3.1 | 2.1 | 2.1 | |
| RF | N_estimators | 200 | 200 | 200 |
| min_samples_split | 5 | 5 | 2 | |
| EC | SVM | C = 10; Kernel = RBF; Gamma = 1 | ||
| KNN | N estimators = 200; min samples split = 5 | |||
| MLP | Hidden layers = 50; max iterations = 1000 | |||
| Parameters | Values |
|---|---|
| Learning rate | 1 × 10−3; 5 × 10−4; 1 × 10−4 |
| Epoch | 10 |
| Optimizer | Adam; RMSprop |
| Batch size | 64;32;16 |
| Activation | Relu; Softmax |
| Models | English Dataset | French Dataset | Arabic Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| TF-IDF | ||||||||||||
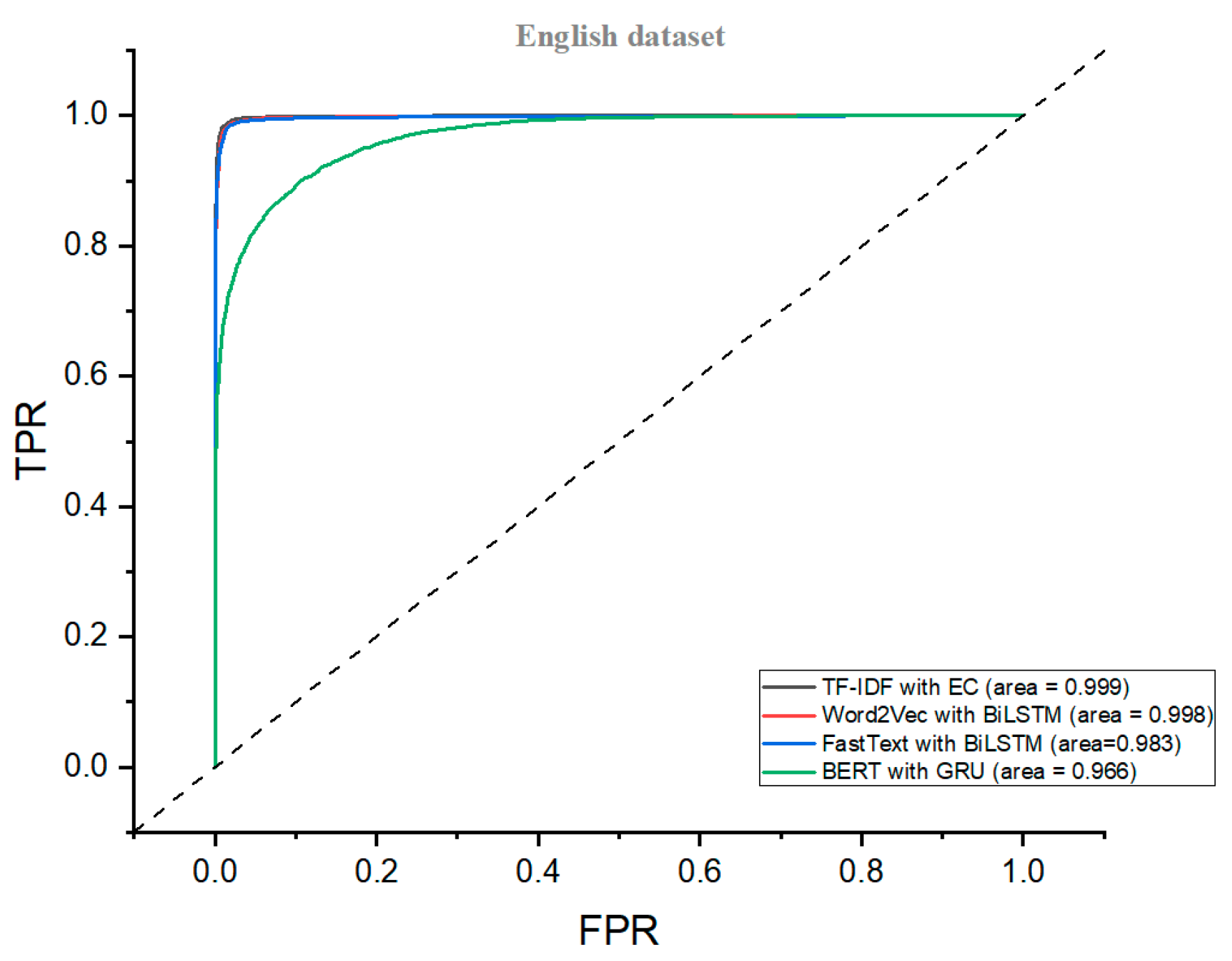
| SVM | 0.978 | 0.98 | 0.98 | 0.98 | 0.893 | 0.90 | 0.89 | 0.89 | 0.938 | 0.94 | 0.94 | 0.94 |
| RF | 0.962 | 0.96 | 0.96 | 0.96 | 0.888 | 0.89 | 0.89 | 0.89 | 0.933 | 0.94 | 0.93 | 0.93 |
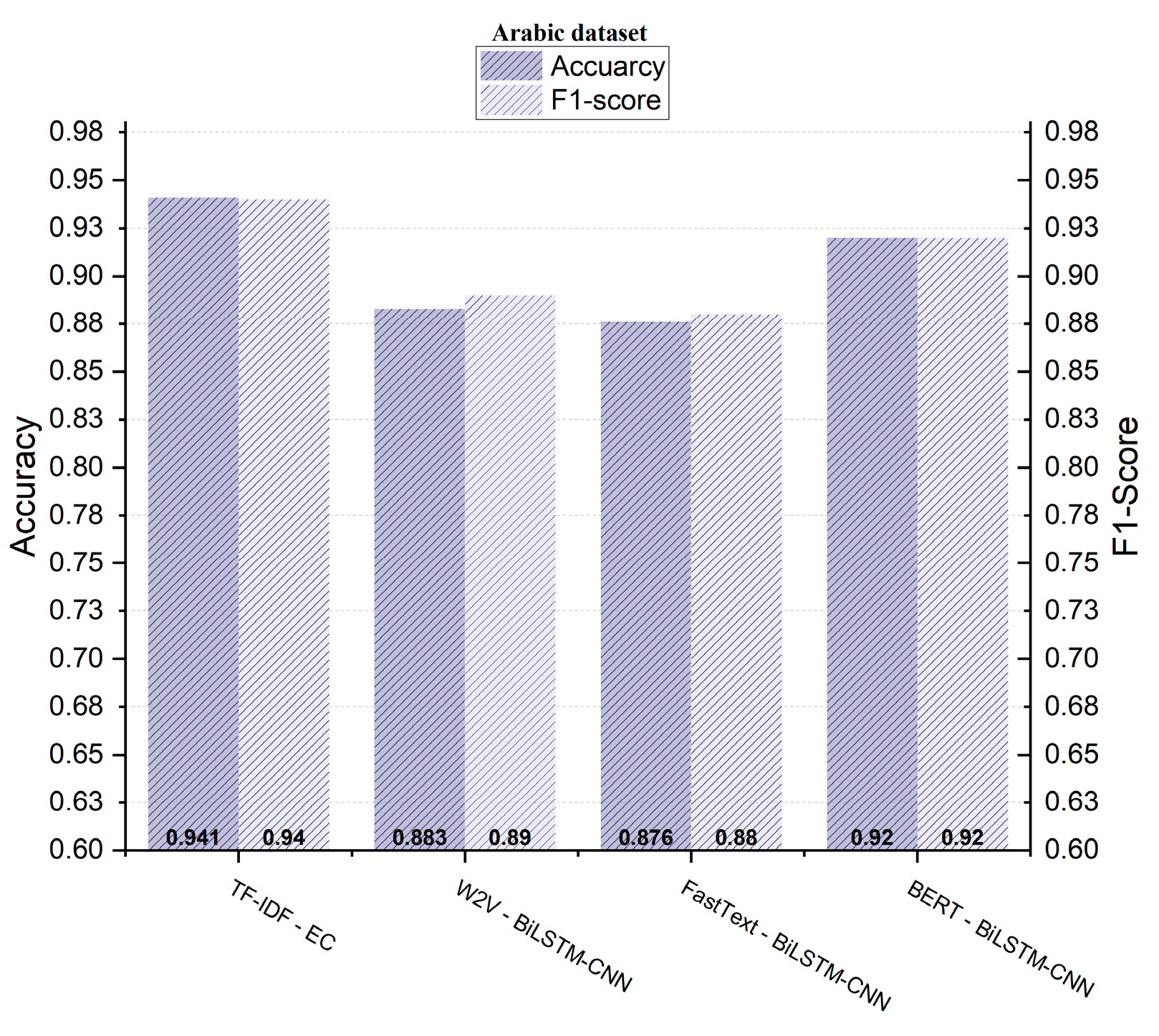
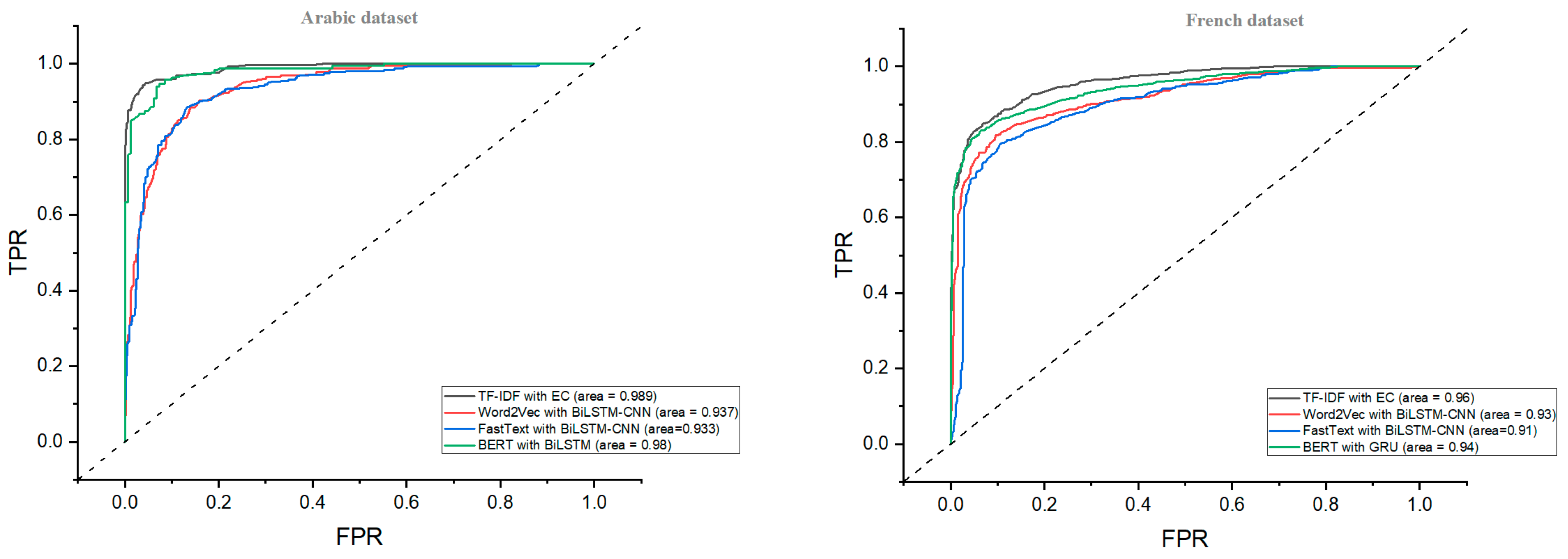
| EC | 0.986 | 0.99 | 0.99 | 0.99 | 0.892 | 0.90 | 0.89 | 0.89 | 0.941 | 0.94 | 0.94 | 0.94 |
| Models | English Dataset | French Dataset | Arabic Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| Word2Vec | ||||||||||||
| BiLSTM | 0.985 | 0.99 | 0.99 | 0.99 | 0.848 | 0.85 | 0.85 | 0.85 | 0.872 | 0.87 | 0.87 | 0.87 |
| GRU | 0.983 | 0.98 | 0.98 | 0.98 | 0.847 | 0.85 | 0.85 | 0.85 | 0.866 | 0.87 | 0.87 | 0.87 |
| BiLSTM- CNN | 0.983 | 0.98 | 0.98 | 0.98 | 0.859 | 0.86 | 0.86 | 0.86 | 0.883 | 0.89 | 0.89 | 0.89 |
| FastText | ||||||||||||
| BiLSTM | 0.984 | 0.98 | 0.98 | 0.98 | 0.840 | 0.84 | 0.84 | 0.84 | 0.859 | 0.86 | 0.86 | 0.86 |
| GRU | 0.980 | 0.98 | 0.98 | 0.98 | 0.830 | 0.83 | 0.83 | 0.83 | 0.862 | 0.86 | 0.86 | 0.86 |
| BiLSTM–CNN | 0.983 | 0.98 | 0.98 | 0.98 | 0.850 | 0.85 | 0.85 | 0.85 | 0.876 | 0.88 | 0.88 | 0.88 |
| Models | English Dataset | French Dataset | Arabic Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| BERT | ||||||||||||
| BiLSTM | 0.893 | 0.890 | 0.890 | 0.890 | 0.870 | 0.870 | 0.870 | 0.870 | 0.911 | 0.920 | 0.910 | 0.910 |
| GRU | 0.892 | 0.890 | 0.890 | 0.890 | 0.868 | 0.870 | 0.870 | 0.870 | 0.906 | 0.910 | 0.910 | 0.910 |
| BiLSTM–CNN | 0.891 | 0.890 | 0.890 | 0.890 | 0.871 | 0.880 | 0.870 | 0.870 | 0.920 | 0.920 | 0.920 | 0.920 |
| Time Execution of Vectorization | ||||
|---|---|---|---|---|
| Vectorization Techniques | English Dataset | French Dataset | Arabic Dataset | |
| MX330 GPU | TF-IDF | 2.919 s | 0.159 s | 0.142 s |
| Word2Vec | 47.679 s | 1.597 s | 1.229 s | |
| FastText | 15.188 s | 39.534 s | 13.332 s | |
| A100 GPU | BERT | 1029.873 s | 470.829 s | 106.331 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Institute of Knowledge Innovation and Invention. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jakha, H.; El Houssaini, S.; El Houssaini, M.-A.; Ajjaj, S.; Hadir, A. Optimizing Sentiment Analysis in Multilingual Balanced Datasets: A New Comparative Approach to Enhancing Feature Extraction Performance with ML and DL Classifiers. Appl. Syst. Innov. 2025, 8, 104. https://doi.org/10.3390/asi8040104
Jakha H, El Houssaini S, El Houssaini M-A, Ajjaj S, Hadir A. Optimizing Sentiment Analysis in Multilingual Balanced Datasets: A New Comparative Approach to Enhancing Feature Extraction Performance with ML and DL Classifiers. Applied System Innovation. 2025; 8(4):104. https://doi.org/10.3390/asi8040104
Chicago/Turabian StyleJakha, Hamza, Souad El Houssaini, Mohammed-Alamine El Houssaini, Souad Ajjaj, and Abdelali Hadir. 2025. "Optimizing Sentiment Analysis in Multilingual Balanced Datasets: A New Comparative Approach to Enhancing Feature Extraction Performance with ML and DL Classifiers" Applied System Innovation 8, no. 4: 104. https://doi.org/10.3390/asi8040104
APA StyleJakha, H., El Houssaini, S., El Houssaini, M.-A., Ajjaj, S., & Hadir, A. (2025). Optimizing Sentiment Analysis in Multilingual Balanced Datasets: A New Comparative Approach to Enhancing Feature Extraction Performance with ML and DL Classifiers. Applied System Innovation, 8(4), 104. https://doi.org/10.3390/asi8040104