
Options for Performing DNN-Based Causal Speech Denoising Using the U-Net Architecture †


Abstract
1. Introduction
2. Related Works and Research Planning
3. Speech Denoising
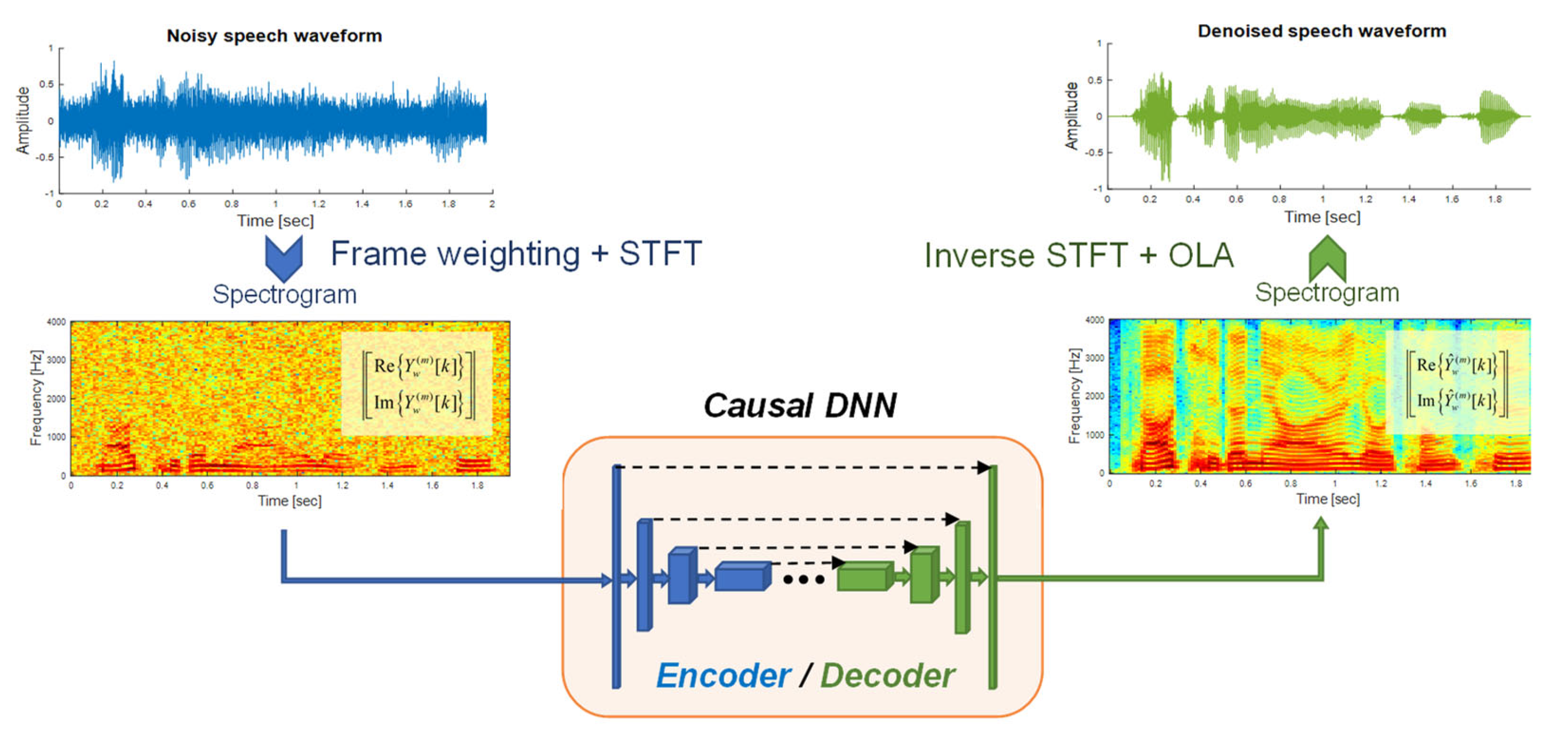
3.1. Processing Framework
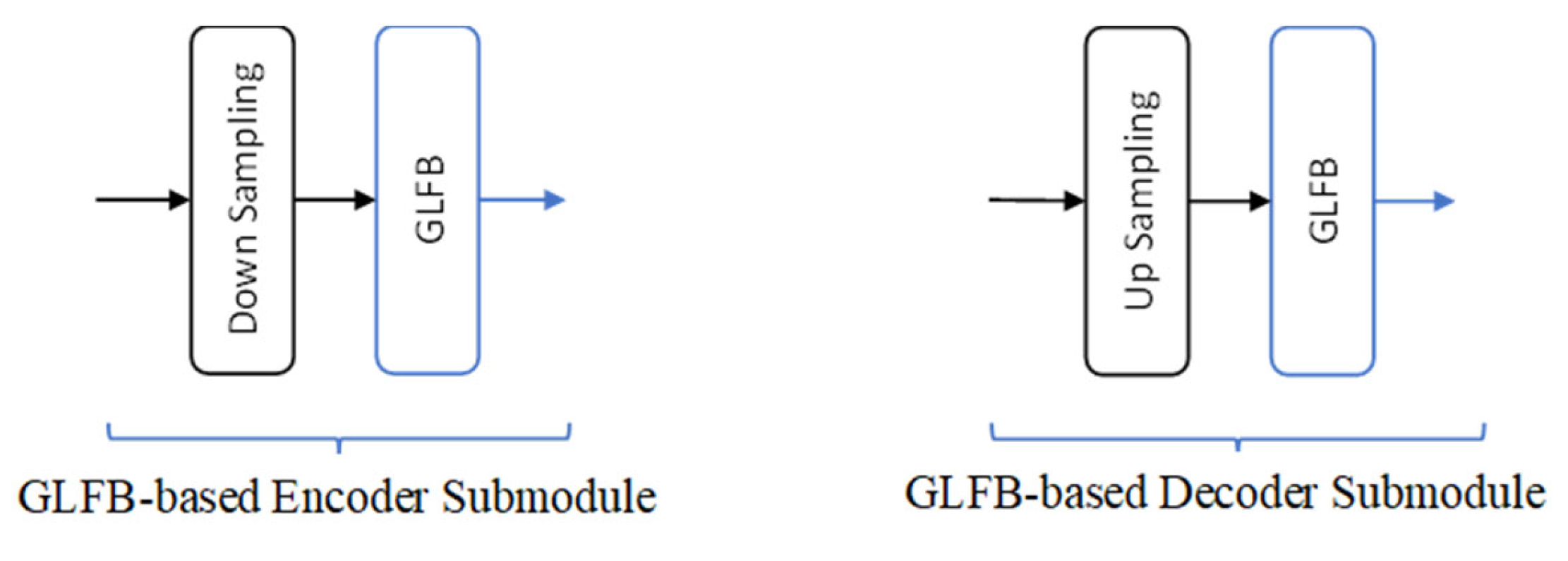
3.2. DNN Architecture
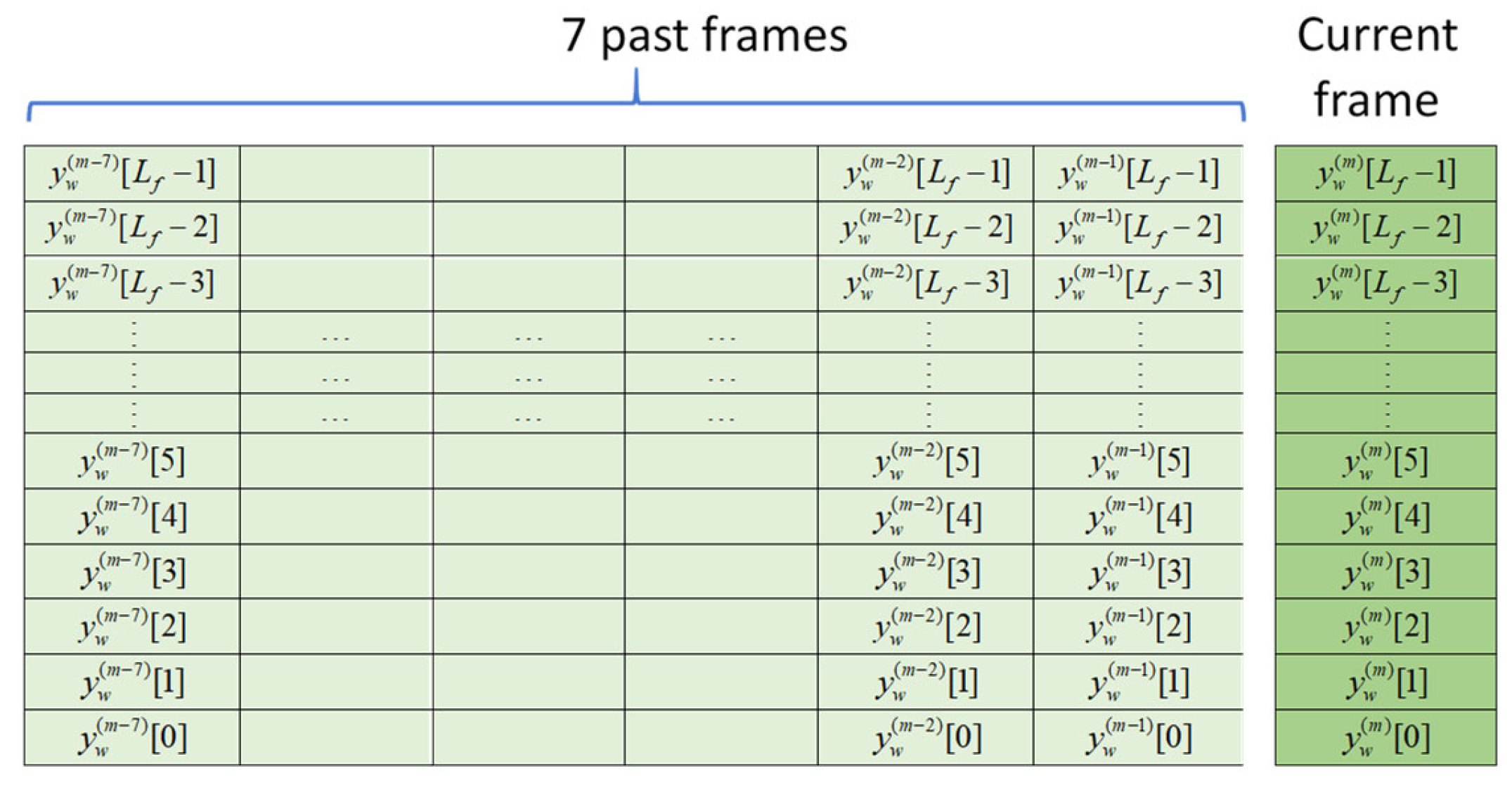
3.3. Input Arrangements
3.4. Loss Functions
4. Experiment and Performance Evaluation
4.1. Datasets for Model Training
4.2. Performance Evaluation
4.3. Further Considerations of Loss Function in the STFT and STDCT Domains
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, Y.; Wang, W.; Chambers, J.A.; Naqvi, S.M. Enhanced Time-Frequency Masking by Using Neural Networks for Monaural Source Separation in Reverberant Room Environments. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1647–1651. [Google Scholar]
- Choi, H.-S.; Heo, H.; Lee, J.H.; Lee, K. Phase-aware Single-stage Speech Denoising and Dereverberation with U-Net. arXiv 2020, arXiv:2006.00687. [Google Scholar]
- Sarker, I.H. Deep Learning: A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Tan, K.; Wang, D. Learning Complex Spectral Mapping With Gated Convolutional Recurrent Networks for Monaural Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 380–390. [Google Scholar] [CrossRef]
- Choi, H.-S.; Kim, J.-H.; Huh, J.; Kim, A.; Ha, J.-W.; Lee, K. Phase-aware Speech Enhancement with Deep Complex U-Net. arXiv 2019, arXiv:1903.03107. [Google Scholar]
- Li, A.; Liu, W.; Zheng, C.; Fan, C.; Li, X. Two Heads are Better Than One: A Two-Stage Complex Spectral Mapping Approach for Monaural Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1829–1843. [Google Scholar] [CrossRef]
- Yuan, W. A time–frequency smoothing neural network for speech enhancement. Speech Commun. 2020, 124, 75–84. [Google Scholar] [CrossRef]
- Kang, Z.; Huang, Z.; Lu, C. Speech Enhancement Using U-Net with Compressed Sensing. Appl. Sci. 2022, 12, 4161. [Google Scholar] [CrossRef]
- Luo, X.; Zheng, C.; Li, A.; Ke, Y.; Li, X. Analysis of trade-offs between magnitude and phase estimation in loss functions for speech denoising and dereverberation. Speech Commun. 2022, 145, 71–87. [Google Scholar] [CrossRef]
- Azarang, A.; Kehtarnavaz, N. A review of multi-objective deep learning speech denoising methods. Speech Commun. 2020, 122, 1–10. [Google Scholar] [CrossRef]
- Pandey, A.; Wang, D. Dense CNN With Self-Attention for Time-Domain Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 29, 1270–1279. [Google Scholar] [CrossRef] [PubMed]
- Défossez, A.; Synnaeve, G.; Adi, Y. Real Time Speech Enhancement in the Waveform Domain. arXiv 2020, arXiv:2006.12847. [Google Scholar]
- Germain, F.G.; Chen, Q.; Koltun, V. Speech Denoising with Deep Feature Losses. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Erdogan, H.; Hershey, J.R.; Watanabe, S.; Roux, J.L. Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 708–712. [Google Scholar]
- Kulmer, J.; Mahale, P.M.B. Phase Estimation in Single Channel Speech Enhancement Using Phase Decomposition. IEEE Signal Process. Lett. 2015, 22, 598–602. [Google Scholar] [CrossRef]
- Lu, X.; Tsao, Y.; Matsuda, S.; Hori, C. Speech enhancement based on deep denoising autoencoder. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013. [Google Scholar]
- Zhao, H.; Zarar, S.; Tashev, I.; Lee, C.H. Convolutional-Recurrent Neural Networks for Speech Enhancement. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2401–2405. [Google Scholar]
- Tan, K.; Wang, D. A Convolutional Recurrent Neural Network for Real-Time Speech Enhancement. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 3229–3233. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Mirsamadi, S.; Tashev, I.J. Causal Speech Enhancement Combining Data-Driven Learning and Suppression Rule Estimation. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Park, S.R.; Lee, J. A Fully Convolutional Neural Network for Speech Enhancement. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 1993–1997. [Google Scholar]
- Li, A.; Zheng, C.; Peng, R.; Li, X. On the importance of power compression and phase estimation in monaural speech dereverberation. JASA Express Lett. 2021, 1, 014802. [Google Scholar] [CrossRef]
- Liu, L.; Guan, H.; Ma, J.; Dai, W.; Wang, G.-Y.; Ding, S. A Mask Free Neural Network for Monaural Speech Enhancement. arXiv 2023, arXiv:2306.04286. [Google Scholar]
- Ba, J.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Maas, A.L. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Hu, H.-T.; Tsai, H.-H.; Lee, T.-T. Suitable domains for causal speech denoising using DNN with U-Net architecture. In Proceedings of the 7th International Conference on Knowledge Innovation and Invention 2024 (ICKII 2024), Nagoya, Japan, 16–18 August 2024. [Google Scholar]
- Oppenheim, A.V.; Willsky, A.S.; Nawab, S.H. Signals & Systems, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 1997. [Google Scholar]
- Valentini-Botinhao, C.; Wang, X.; Takaki, S.; Yamagishi, J. Investigating RNN-based speech enhancement methods for noise-robust Text-to-Speech. In Proceedings of the Speech Synthesis Workshop, Sunnyvale, CA, USA, 13–15 September 2016. [Google Scholar]
- Thiemann, J.; Ito, N.; Vincent, E. The Diverse Environments Multi-channel Acoustic Noise Database (DEMAND): A database of multichannel environmental noise recordings. J. Acoust. Soc. Am. 2013, 133, 3591. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Hu, Y.; Loizou, P.C. Evaluation of Objective Quality Measures for Speech Enhancement. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 229–238. [Google Scholar] [CrossRef]
- International Telecommunications Union. ITU-T Recommendation P.800: Methods for Subjective Determination of Transmission Quality; International Telecommunications Union: Geneva, Switzerland, 1996. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An Algorithm for Intelligibility Prediction of Time–Frequency Weighted Noisy Speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. MetaFormer is Actually What You Need for Vision. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10809–10819. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Type | Initial SNR | Classical U-Net with CCABs | Advanced U-Net with GLFBs | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Resulting SNR (dB) | CSIG | CBAK | COVL | PESQ | STOI (%) | Resulting SNR (dB) | CSIG | CBAK | COVL | PESQ | STOI (%) | ||
| STFT-RI sequences | –2.5 dB | 12.97 | 3.460 | 3.055 | 3.091 | 2.811 | 80.59 | 13.73 | 3.495 | 3.114 | 3.132 | 2.851 | 81.69 |
| 2.5 dB | 15.96 | 3.941 | 3.372 | 3.496 | 3.097 | 85.69 | 16.51 | 3.948 | 3.410 | 3.515 | 3.123 | 86.39 | |
| 7.5 dB | 18.37 | 4.322 | 3.624 | 3.814 | 3.323 | 89.03 | 18.75 | 4.334 | 3.660 | 3.838 | 3.355 | 89.65 | |
| 12.5 dB | 20.45 | 4.618 | 3.854 | 4.072 | 3.518 | 91.45 | 20.69 | 4.632 | 3.887 | 4.097 | 3.549 | 91.99 | |
| Average | 16.94 | 4.085 | 3.476 | 3.618 | 3.187 | 86.69 | 17.42 | 4.102 | 3.518 | 3.646 | 3.220 | 87.43 | |
| STDCT sequences | –2.5 dB | 13.04 | 3.458 | 3.062 | 3.096 | 2.821 | 80.85 | 13.79 | 3.506 | 3.122 | 3.149 | 2.878 | 81.95 |
| 2.5 dB | 16.04 | 3.940 | 3.375 | 3.498 | 3.102 | 85.81 | 16.53 | 3.964 | 3.421 | 3.533 | 3.145 | 86.53 | |
| 7.5 dB | 18.38 | 4.345 | 3.626 | 3.830 | 3.332 | 89.14 | 18.66 | 4.358 | 3.666 | 3.858 | 3.370 | 89.68 | |
| 12.5 dB | 20.50 | 4.661 | 3.861 | 4.101 | 3.535 | 91.61 | 20.67 | 4.660 | 3.890 | 4.116 | 3.562 | 92.00 | |
| Average | 16.99 | 4.101 | 3.481 | 3.631 | 3.198 | 86.85 | 17.41 | 4.122 | 3.525 | 3.664 | 3.239 | 87.54 | |
| Waveform sequences | –2.5 dB | 13.40 | 3.338 | 3.014 | 2.996 | 2.739 | 81.18 | 13.45 | 3.313 | 3.009 | 2.980 | 2.734 | 81.13 |
| 2.5 dB | 15.96 | 3.784 | 3.297 | 3.364 | 2.992 | 85.61 | 16.17 | 3.761 | 3.306 | 3.355 | 3.000 | 85.81 | |
| 7.5 dB | 18.21 | 4.178 | 3.547 | 3.690 | 3.218 | 88.80 | 18.30 | 4.152 | 3.543 | 3.673 | 3.218 | 88.88 | |
| 12.5 dB | 20.05 | 4.492 | 3.771 | 3.958 | 3.418 | 91.13 | 20.13 | 4.469 | 3.761 | 3.942 | 3.418 | 91.06 | |
| Average | 16.90 | 3.948 | 3.407 | 3.502 | 3.092 | 86.68 | 17.01 | 3.924 | 3.405 | 3.487 | 3.092 | 86.72 | |
| Loss Function | Initial SNR | Classical U-Net with CCABs | Advanced U-Net with GLFBs | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Resulting SNR (dB) | CSIG | CBAK | COVL | PESQ | STOI (%) | Resulting SNR (dB) | CSIG | CBAK | COVL | PESQ | STOI (%) | ||
| (0, 1) | –2.5 dB | 12.97 | 3.460 | 3.055 | 3.091 | 2.811 | 80.59 | 13.73 | 3.495 | 3.114 | 3.132 | 2.851 | 81.69 |
| 2.5 dB | 15.96 | 3.941 | 3.372 | 3.496 | 3.097 | 85.69 | 16.51 | 3.948 | 3.410 | 3.515 | 3.123 | 86.39 | |
| 7.5 dB | 18.37 | 4.322 | 3.624 | 3.814 | 3.323 | 89.03 | 18.75 | 4.334 | 3.660 | 3.838 | 3.355 | 89.65 | |
| 12.5 dB | 20.45 | 4.618 | 3.854 | 4.072 | 3.518 | 91.45 | 20.69 | 4.632 | 3.887 | 4.097 | 3.549 | 91.99 | |
| Average | 16.94 | 4.085 | 3.476 | 3.618 | 3.187 | 86.69 | 17.42 | 4.102 | 3.518 | 3.646 | 3.220 | 87.43 | |
| (0.5, 1) | –2.5 dB | 12.75 | 3.638 | 3.053 | 3.190 | 2.809 | 81.02 | 13.58 | 3.737 | 3.125 | 3.277 | 2.876 | 82.41 |
| 2.5 dB | 15.65 | 4.052 | 3.349 | 3.548 | 3.076 | 85.82 | 16.23 | 4.110 | 3.399 | 3.604 | 3.126 | 86.83 | |
| 7.5 dB | 18.00 | 4.388 | 3.600 | 3.843 | 3.305 | 89.21 | 18.46 | 4.424 | 3.635 | 3.880 | 3.339 | 89.91 | |
| 12.5 dB | 20.15 | 4.655 | 3.834 | 4.085 | 3.499 | 91.65 | 20.44 | 4.675 | 3.859 | 4.109 | 3.526 | 92.07 | |
| Average | 16.64 | 4.183 | 3.459 | 3.666 | 3.172 | 86.92 | 17.18 | 4.237 | 3.504 | 3.718 | 3.217 | 87.81 | |
| (0, 0.5) | –2.5 dB | 13.30 | 3.298 | 3.024 | 2.973 | 2.758 | 80.37 | 13.82 | 3.397 | 3.098 | 3.062 | 2.821 | 81.36 |
| 2.5 dB | 16.27 | 3.837 | 3.375 | 3.442 | 3.107 | 85.67 | 16.63 | 3.930 | 3.427 | 3.517 | 3.153 | 86.30 | |
| 7.5 dB | 18.63 | 4.318 | 3.666 | 3.844 | 3.396 | 89.25 | 18.84 | 4.389 | 3.701 | 3.903 | 3.434 | 89.58 | |
| 12.5 dB | 20.52 | 4.679 | 3.912 | 4.156 | 3.627 | 91.70 | 20.72 | 4.739 | 3.944 | 4.207 | 3.666 | 92.02 | |
| Average | 17.18 | 4.033 | 3.494 | 3.604 | 3.222 | 86.75 | 17.50 | 4.114 | 3.542 | 3.672 | 3.269 | 87.32 | |
| (0.5, 0.5) | –2.5 dB | 13.08 | 3.750 | 3.120 | 3.267 | 2.844 | 81.14 | 13.93 | 3.901 | 3.222 | 3.402 | 2.949 | 82.65 |
| 2.5 dB | 16.04 | 4.206 | 3.448 | 3.677 | 3.171 | 86.25 | 16.66 | 4.312 | 3.520 | 3.777 | 3.259 | 87.24 | |
| 7.5 dB | 18.44 | 4.569 | 3.715 | 4.007 | 3.442 | 89.74 | 18.89 | 4.639 | 3.769 | 4.078 | 3.509 | 90.30 | |
| 12.5 dB | 20.50 | 4.848 | 3.954 | 4.268 | 3.663 | 92.18 | 20.90 | 4.907 | 4.004 | 4.331 | 3.727 | 92.67 | |
| Average | 17.01 | 4.343 | 3.559 | 3.805 | 3.280 | 87.32 | 17.59 | 4.440 | 3.629 | 3.897 | 3.361 | 88.21 | |
| Loss Function | Initial SNR | Classical U-Net with CCABs | Advanced U-Net with GLFBs | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Resulting SNR (dB) | CSIG | CBAK | COVL | PESQ | STOI (%) | Resulting SNR (dB) | CSIG | CBAK | COVL | PESQ | STOI (%) | ||
| (0, 1) | –2.5 dB | 13.04 | 3.458 | 3.062 | 3.096 | 2.821 | 80.85 | 13.79 | 3.506 | 3.122 | 3.149 | 2.878 | 81.95 |
| 2.5 dB | 16.04 | 3.940 | 3.375 | 3.498 | 3.102 | 85.81 | 16.53 | 3.964 | 3.421 | 3.533 | 3.145 | 86.53 | |
| 7.5 dB | 18.38 | 4.345 | 3.626 | 3.830 | 3.332 | 89.14 | 18.66 | 4.358 | 3.666 | 3.858 | 3.370 | 89.68 | |
| 12.5 dB | 20.50 | 4.661 | 3.861 | 4.101 | 3.535 | 91.61 | 20.67 | 4.660 | 3.890 | 4.116 | 3.562 | 92.00 | |
| Average | 16.99 | 4.101 | 3.481 | 3.631 | 3.198 | 86.85 | 17.41 | 4.122 | 3.525 | 3.664 | 3.239 | 87.54 | |
| (0.5, 1) | –2.5 dB | 12.91 | 3.642 | 3.077 | 3.206 | 2.837 | 81.28 | 13.19 | 3.700 | 3.103 | 3.245 | 2.857 | 81.79 |
| 2.5 dB | 15.92 | 4.077 | 3.385 | 3.580 | 3.114 | 86.27 | 16.10 | 4.090 | 3.395 | 3.591 | 3.123 | 86.50 | |
| 7.5 dB | 18.26 | 4.412 | 3.627 | 3.870 | 3.334 | 89.48 | 18.38 | 4.407 | 3.632 | 3.871 | 3.341 | 89.67 | |
| 12.5 dB | 20.30 | 4.676 | 3.852 | 4.108 | 3.524 | 91.68 | 20.41 | 4.667 | 3.857 | 4.105 | 3.528 | 91.99 | |
| Average | 16.85 | 4.202 | 3.485 | 3.691 | 3.202 | 87.18 | 17.02 | 4.216 | 3.497 | 3.703 | 3.212 | 87.48 | |
| (0, 0.5) | –2.5 dB | 13.09 | 3.345 | 3.035 | 3.008 | 2.776 | 80.32 | 13.79 | 3.401 | 3.099 | 3.065 | 2.828 | 81.41 |
| 2.5 dB | 16.06 | 3.845 | 3.376 | 3.448 | 3.107 | 85.60 | 16.55 | 3.913 | 3.420 | 3.506 | 3.155 | 86.25 | |
| 7.5 dB | 18.43 | 4.314 | 3.658 | 3.841 | 3.390 | 89.10 | 18.84 | 4.384 | 3.703 | 3.902 | 3.440 | 89.58 | |
| 12.5 dB | 20.42 | 4.687 | 3.908 | 4.160 | 3.626 | 91.67 | 20.68 | 4.740 | 3.943 | 4.209 | 3.670 | 91.98 | |
| Average | 17.00 | 4.048 | 3.494 | 3.614 | 3.225 | 86.67 | 17.47 | 4.109 | 3.541 | 3.670 | 3.273 | 87.30 | |
| (0.5, 0.5) | –2.5 dB | 13.23 | 3.792 | 3.141 | 3.303 | 2.877 | 81.48 | 13.80 | 3.889 | 3.208 | 3.386 | 2.934 | 82.40 |
| 2.5 dB | 16.03 | 4.229 | 3.452 | 3.695 | 3.188 | 86.34 | 16.63 | 4.313 | 3.516 | 3.774 | 3.254 | 87.06 | |
| 7.5 dB | 18.52 | 4.591 | 3.726 | 4.026 | 3.460 | 89.73 | 18.86 | 4.636 | 3.764 | 4.072 | 3.503 | 90.13 | |
| 12.5 dB | 20.48 | 4.862 | 3.957 | 4.280 | 3.674 | 92.08 | 20.87 | 4.903 | 4.000 | 4.324 | 3.720 | 92.52 | |
| Average | 17.07 | 4.368 | 3.569 | 3.826 | 3.300 | 87.40 | 17.54 | 4.435 | 3.622 | 3.889 | 3.353 | 88.03 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Published by MDPI on behalf of the International Institute of Knowledge Innovation and Invention. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, H.-T.; Lee, T.-T. Options for Performing DNN-Based Causal Speech Denoising Using the U-Net Architecture. Appl. Syst. Innov. 2024, 7, 120. https://doi.org/10.3390/asi7060120
Hu H-T, Lee T-T. Options for Performing DNN-Based Causal Speech Denoising Using the U-Net Architecture. Applied System Innovation. 2024; 7(6):120. https://doi.org/10.3390/asi7060120
Chicago/Turabian StyleHu, Hwai-Tsu, and Tung-Tsun Lee. 2024. "Options for Performing DNN-Based Causal Speech Denoising Using the U-Net Architecture" Applied System Innovation 7, no. 6: 120. https://doi.org/10.3390/asi7060120
APA StyleHu, H.-T., & Lee, T.-T. (2024). Options for Performing DNN-Based Causal Speech Denoising Using the U-Net Architecture. Applied System Innovation, 7(6), 120. https://doi.org/10.3390/asi7060120