Web Scraping Scientific Repositories for Augmented Relevant Literature Search Using CRISP-DM


Abstract
1. Introduction
- Lack of consistency in the reported results
- Potential towards uncovering flaws within previous research (based on design, data collection instruments, sampling, interpretation, etc.)
- Research may have been conducted on different data populations, which could lead to uncertainty about interpretation of previous studies’ findings
- Etc.
- Breadth and Depth of Knowledge
- Rigor and Consistency of Comprehension & Application
- Clarity and Brevity of Analysis, Synthesis & Evaluation
2. Research Motivation & Questions
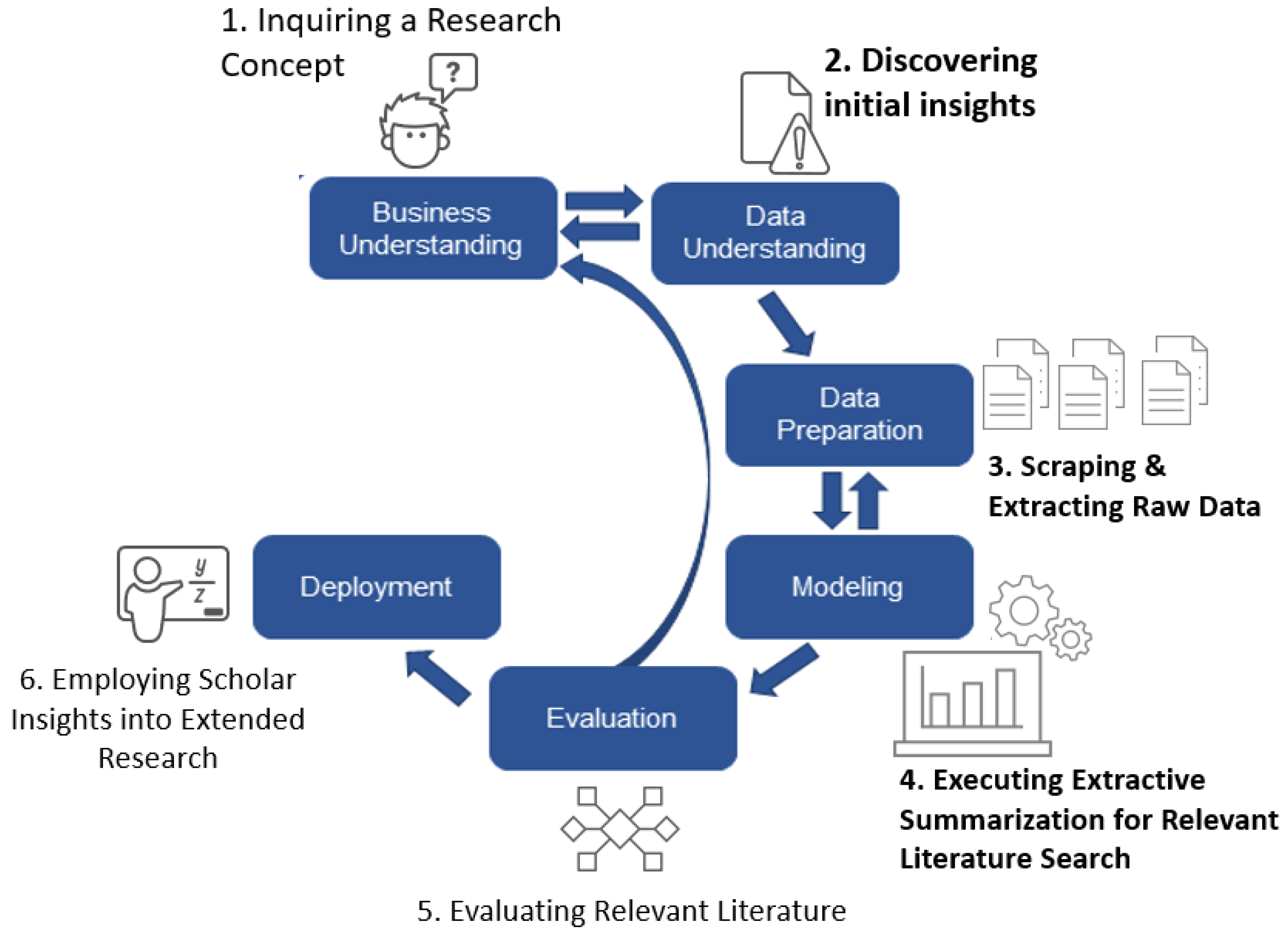
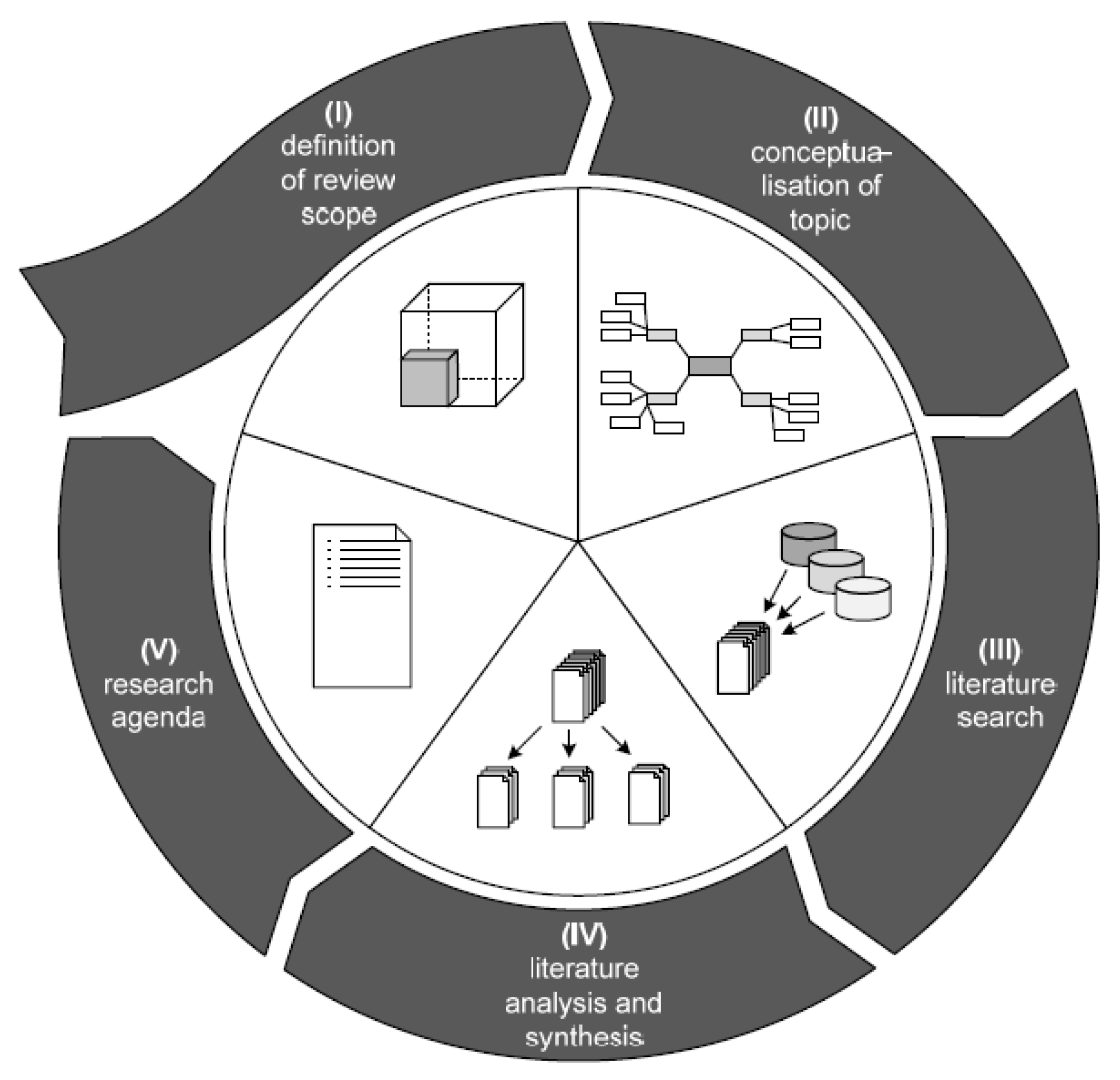
3. Research Methodology
4. Research Methods
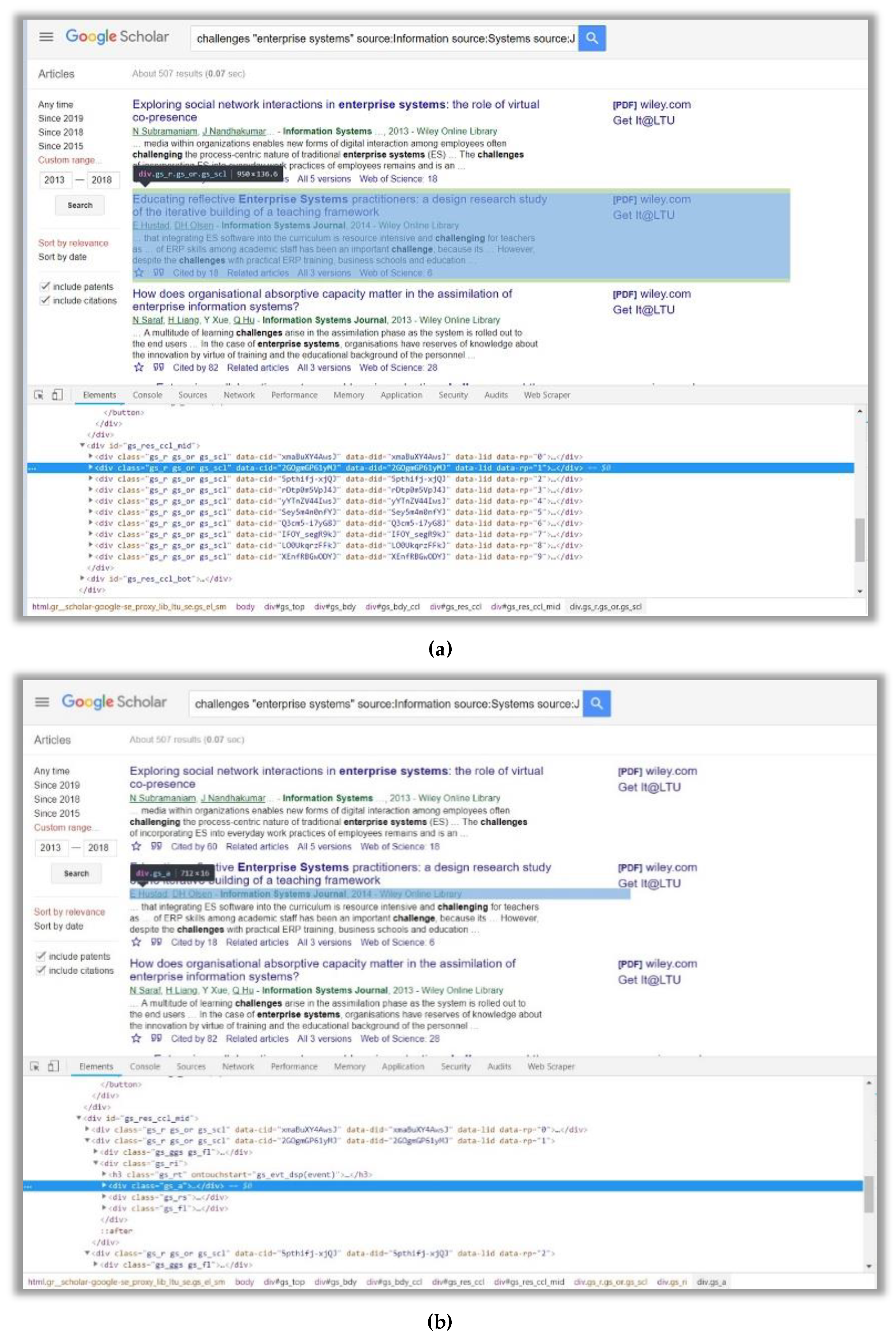
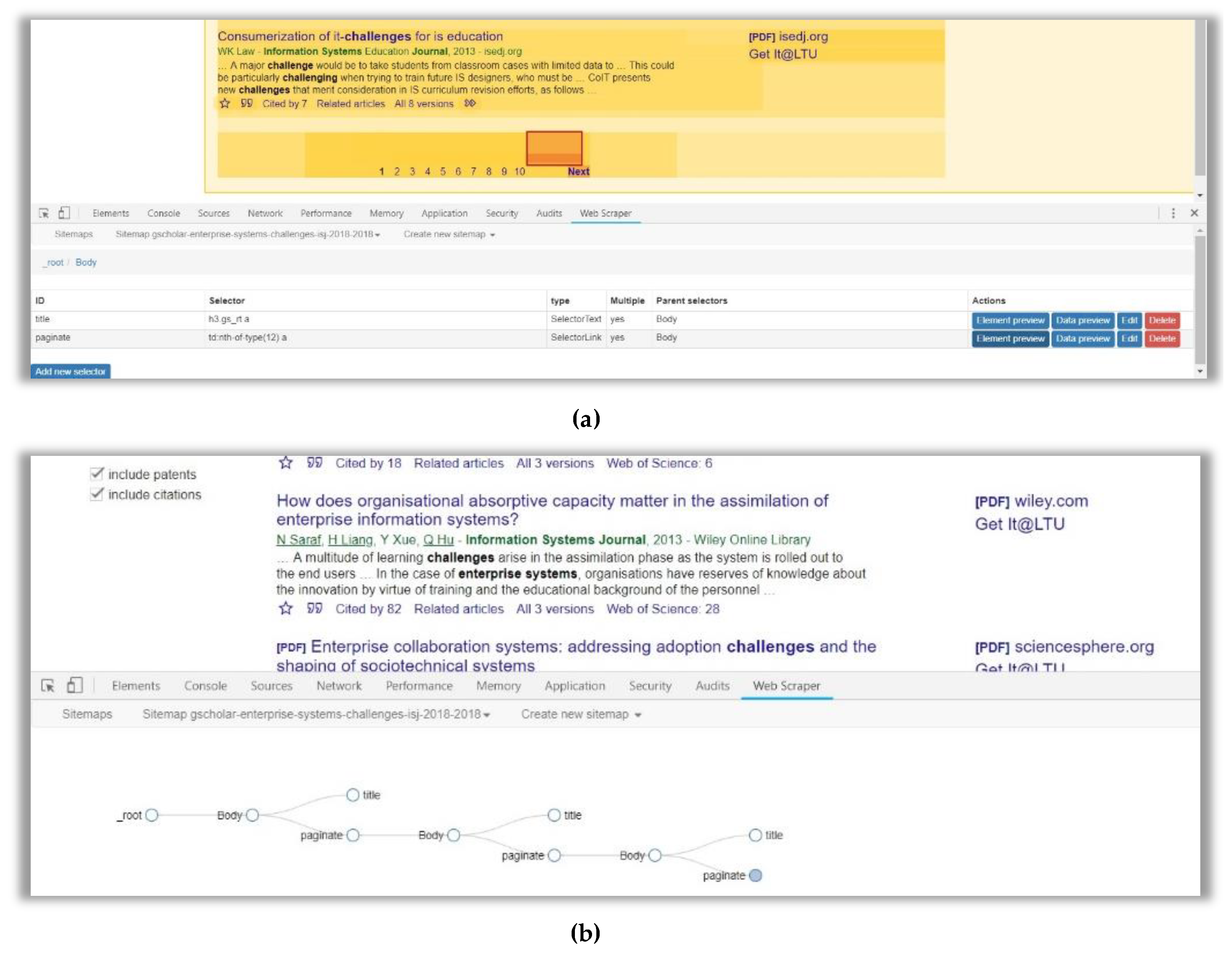
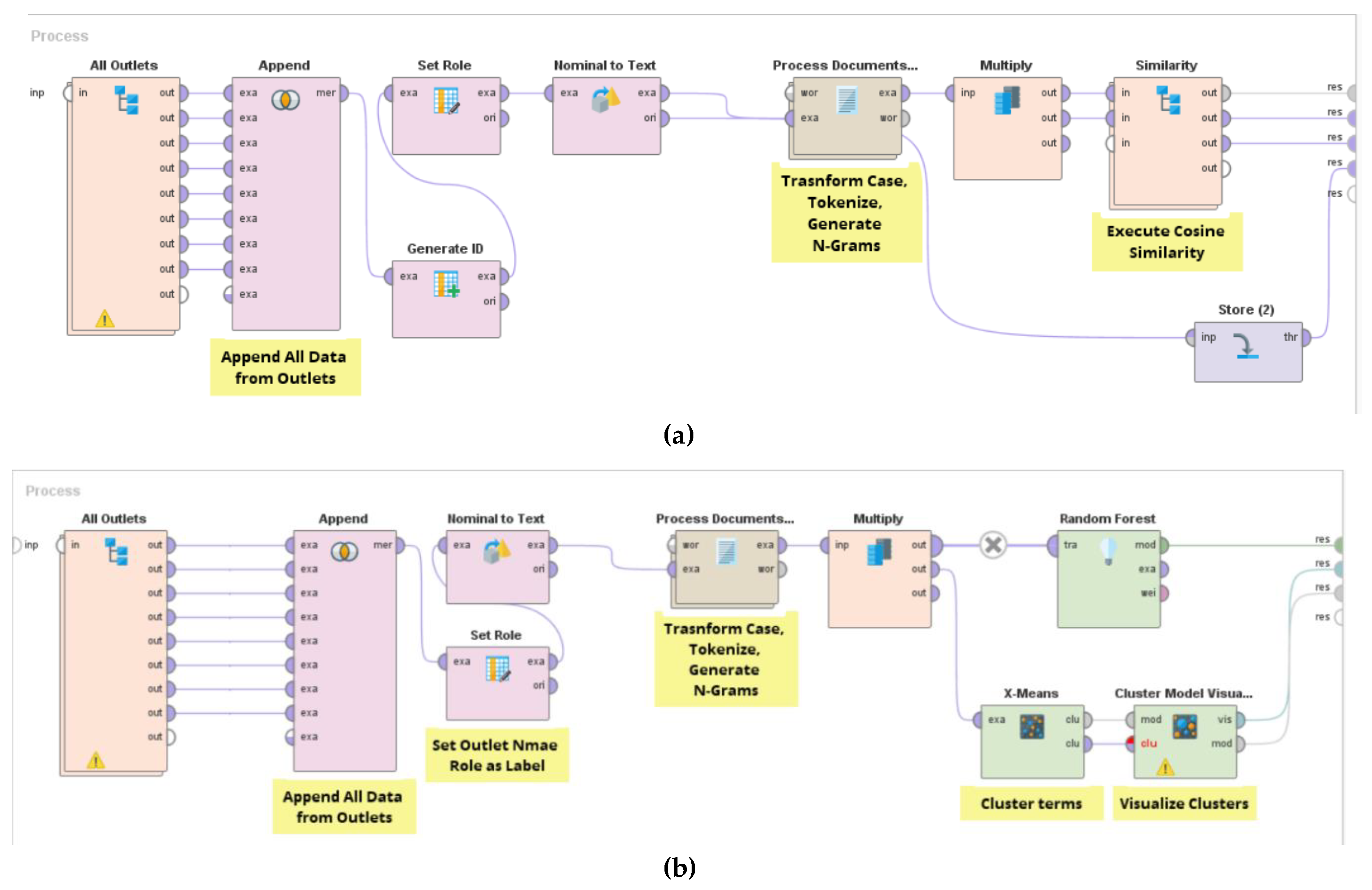
4.1. Web Scraping (Data Understanding & Preparation)
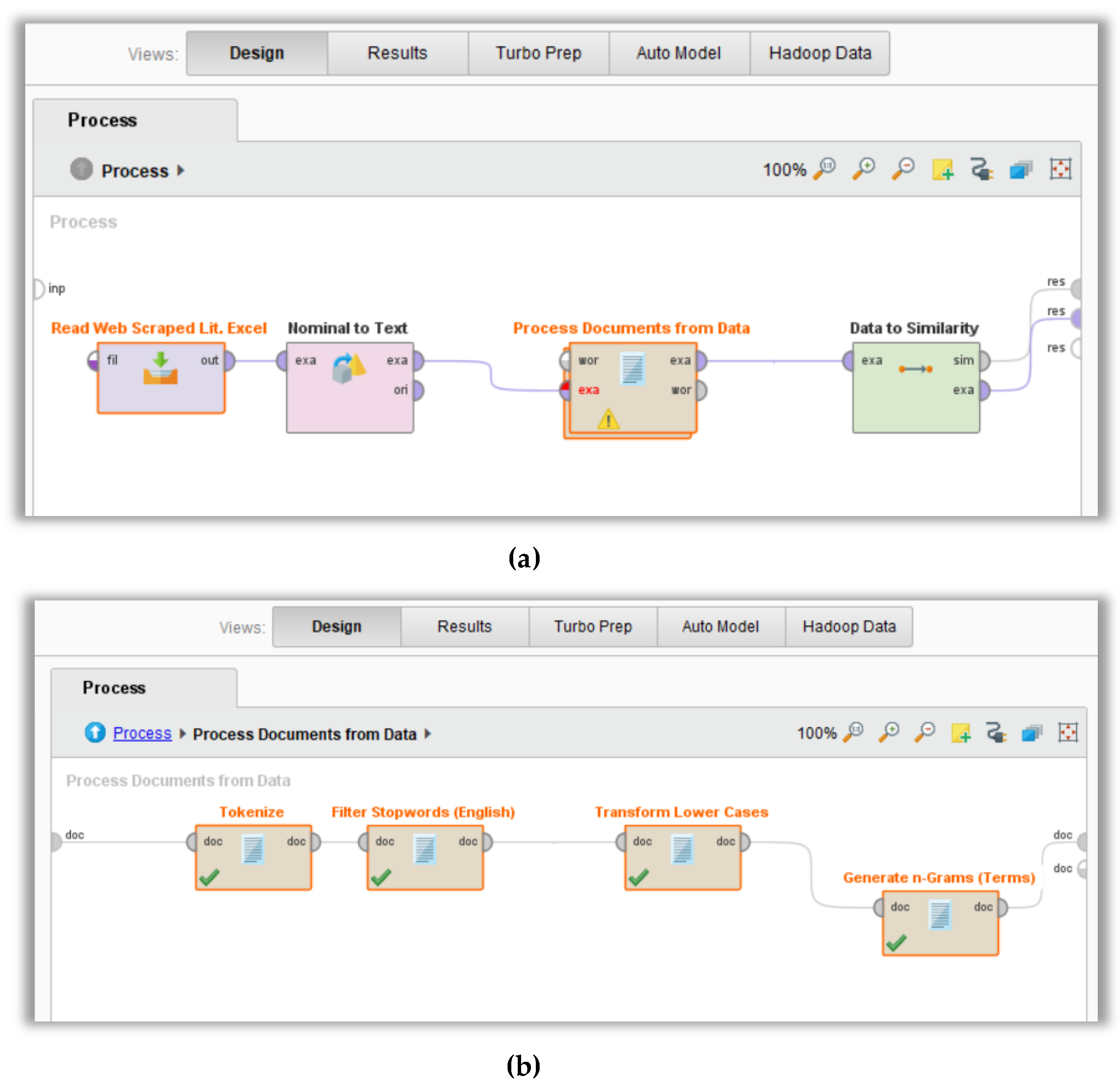
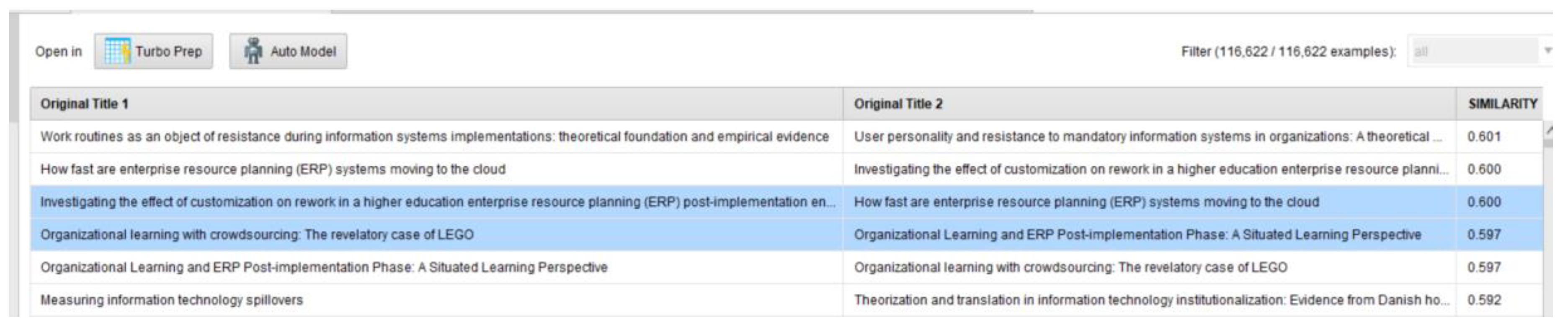
4.2. Mining & Analyzing the Relevance of Literature (Modeling)
5. Case Study
ERP systems have been criticized for not maintaining the Return-on-Investments (RoI) promised. Sykes et al. claims that 80% of ERP implementations fails [21]. Also, 90% of large companies implementing ERP-systems failed in their first trial [22]. It has also been reported that between 50%–75% of US firms experience some degree of failure. Additionally, 65% of executives believe ERP implementation has at least a moderate chance of hurting business [23].
Three quarters of ERP projects are considered failures and many ERP Projects ended catastrophically [24]. Failure rates estimated to be as high as 50% of all ERP implementations [25]. And as much as 70% of ERP implementations fail to deliver anticipated benefits [26]. Still many ERP systems still face resistance and ultimately failure [27,28]. That been said, there are two main critical phases that might lead to the failure of an ERP project. The Implementation as well as the post-implementation phases marks to two main phases in a given ERP lifecycle where many of the organizations might experience failure. The two phases include similar activities and involve similar stakeholders.
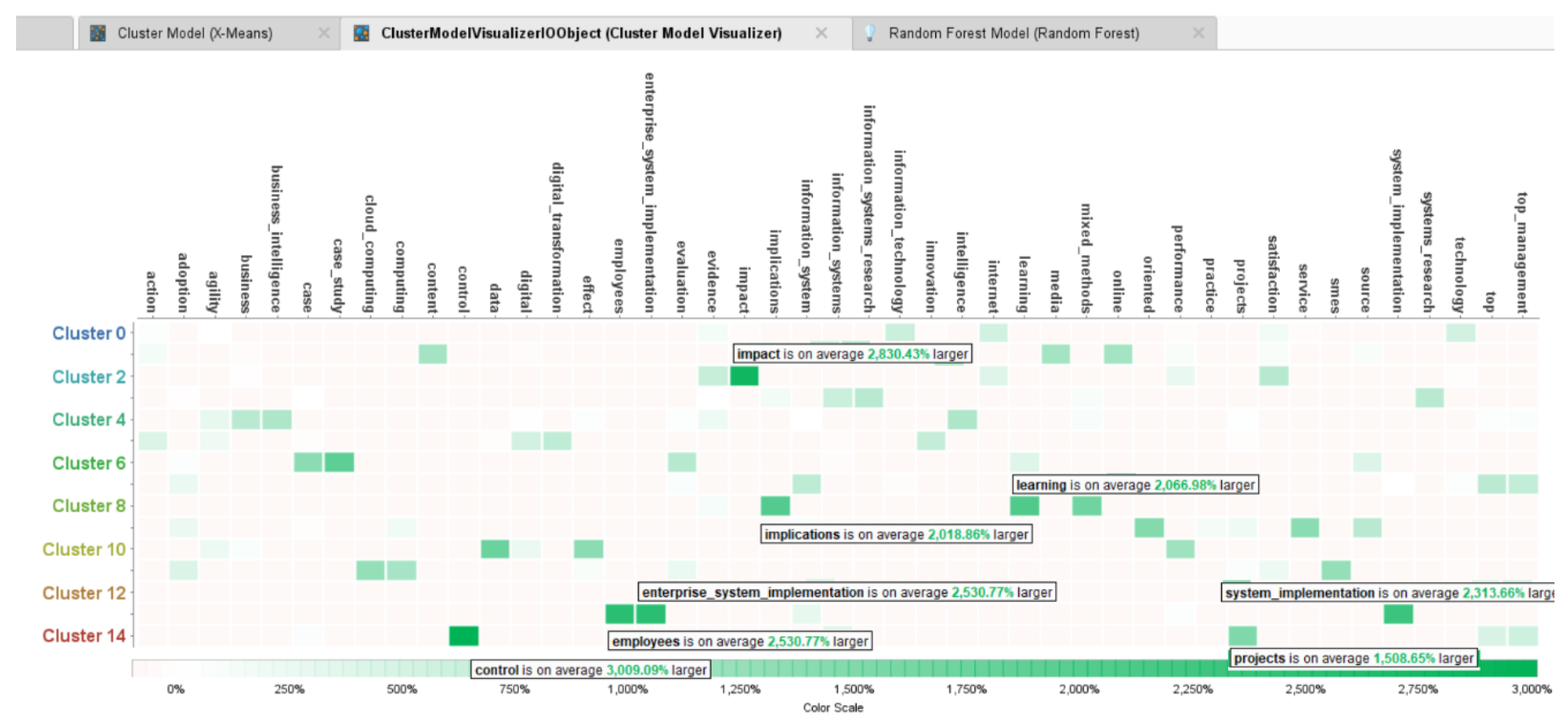
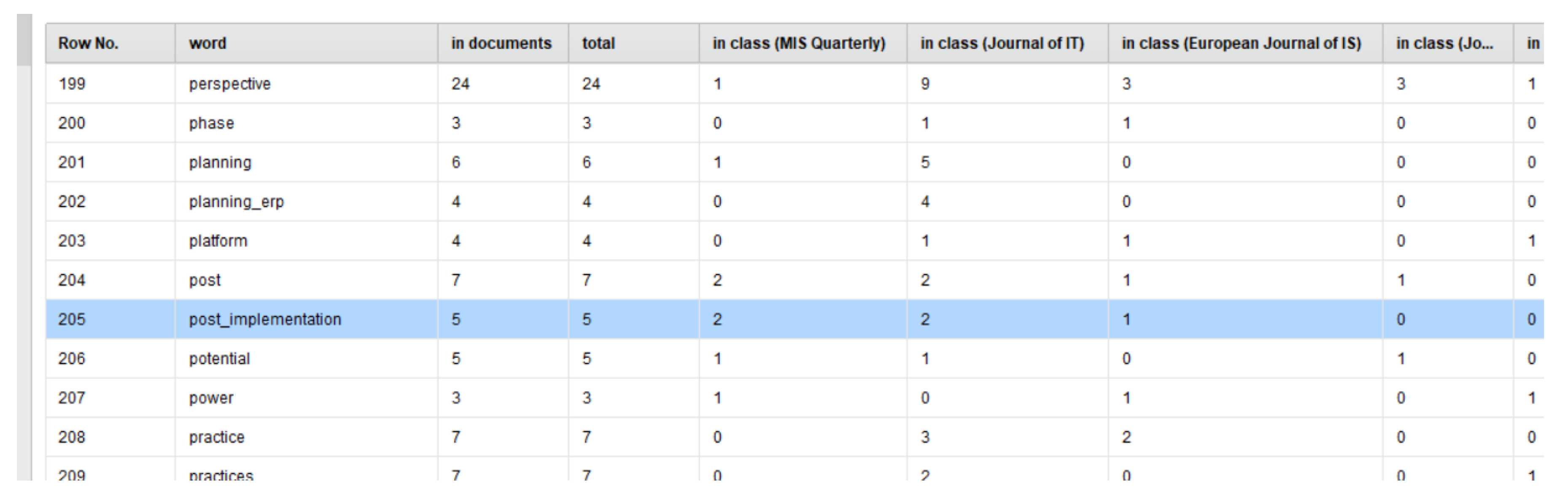
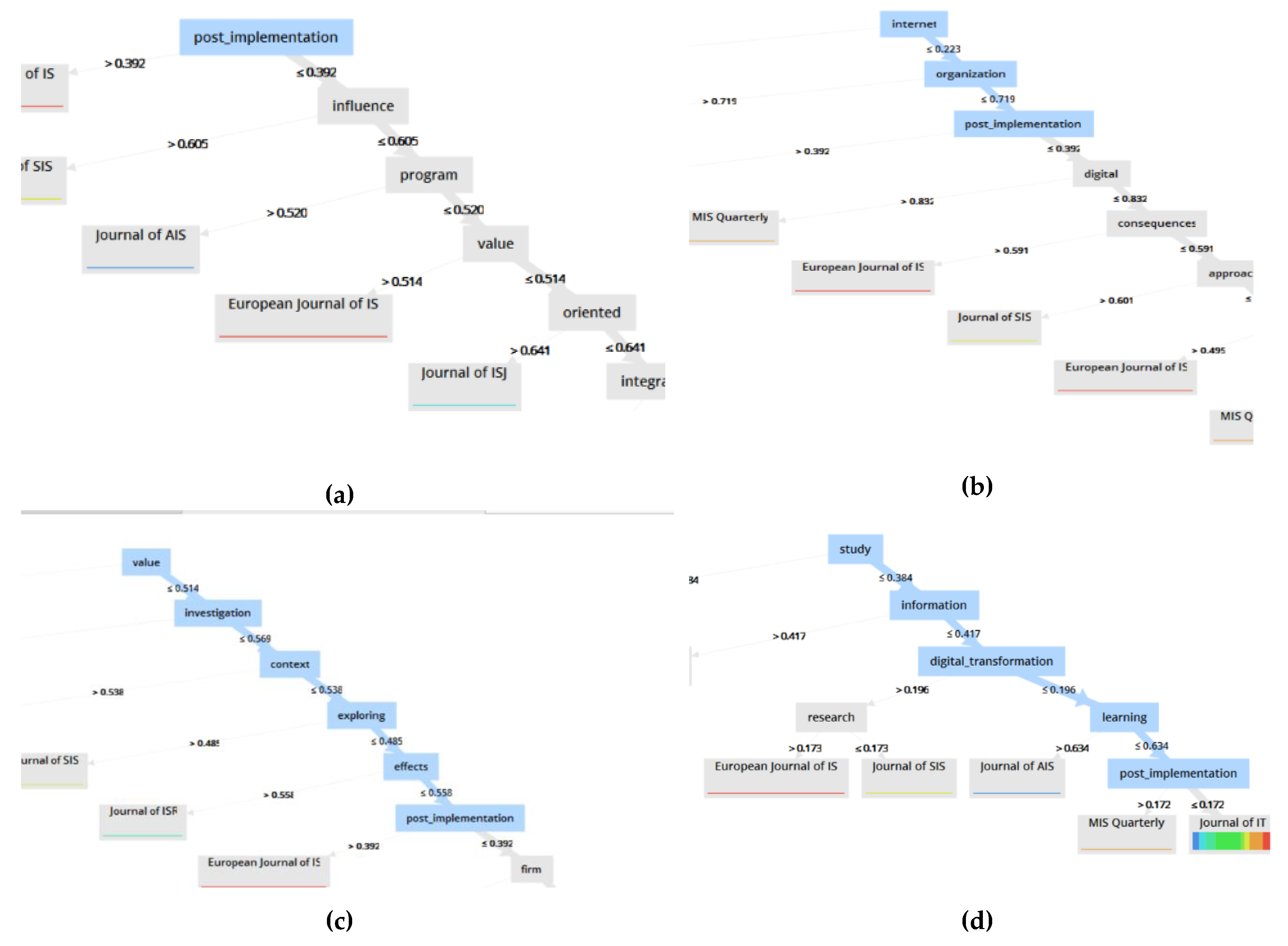
Results
- The “impact” and “implications” of “enterprise_system_implementation” “projects” and “post_implementation” phases on organizational “control”, “employees” and “learning”.
6. Scientometric Relatedness
- Framework Focus:
- ◦
- Scale focus of the framework; Micro or Macro.
- Ease of Use:
- ◦
- User friendliness
- Flexibility
- ◦
- Enabling cross-functional, multidimensional and multi-algorithmic analysis
- Reproducibility
- ◦
- Ability for users to obtain the same results using authors’ own analyzed data
- Replicability
- ◦
- Ability for users to obtain substantially similar results by applying the same steps in a different context with different data
- Reach
- ◦
- Ability for users to include other data sources
- Data Preparation Need
- ◦
- Requirement for users to thoroughly prepare datasets to conduct the analysis exercise
- Visual Capability
- ◦
- Users ability to visualize the analyzed citation data
7. Future Work and Limitations
8. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Semantic Scholar Open Research & Corpus Download Examples:
- REST API: wget –I, Available online: https://s3-us-west-2.amazonaws.com/ai2-s2-research-public/open-corpus/manifest.txt (accessed on 3 December 2019);
- AWS CLI: aws s3 cp –recursive, Available online: s3://ai2-s2-research-public/open-corpus/destinationPath (accessed on 3 December 2019).
Appendix A.2. xPath:
- XPath is defined as XML path. It is a syntax or language for finding any element on the web page using XML path expression. XPath is used to find the location of any element on a webpage using HTML Document Object Model (DOM) structure
Appendix A.3. Web Scraper:
- Web Scraper Web Site, Available online: https://www.webscraper.io/ (accessed on 3 December 2019);
- Google Chrome Extension: Web Scraper, Available online: https://goo.gl/QuUdHu (accessed on 3 December 2019).
Appendix A.4. Association of Information Systems Journals Basket:
- European Journal of Information Systems
- Information Systems Journal
- Information Systems Research
- Journal of AIS
- Journal of Information Technology
- Journal of MIS
- Journal of Strategic Information Systems
- MIS Quarterly
Appendix A.5. Git Repository Location- CRISP-DM for Augmented Literature Search:
Appendix B

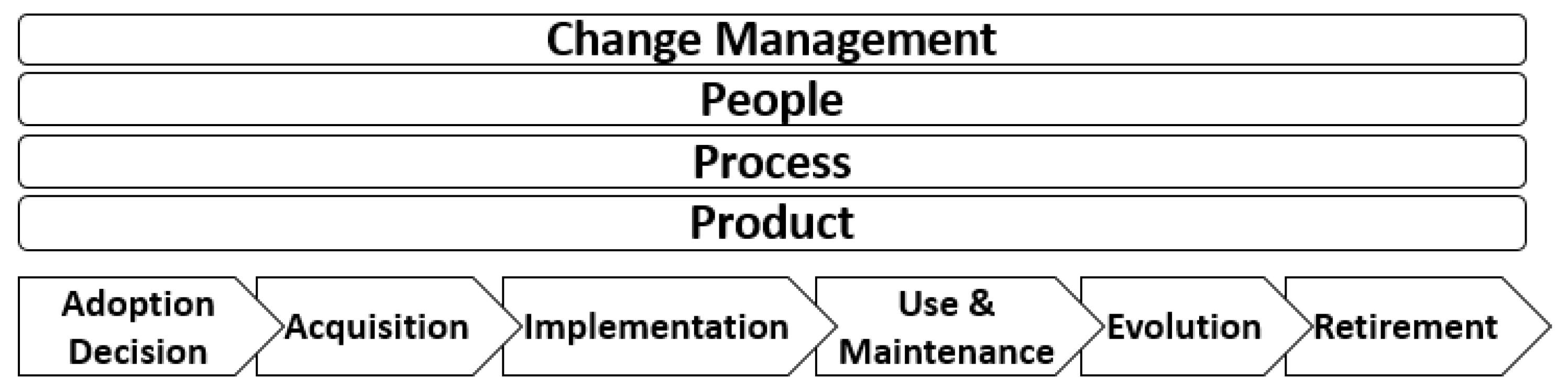
- Stages:
- ◦
- Adoption Decision
- ◦
- Acquisition
- ◦
- Implementation
- ◦
- Use and Maintenance
- ◦
- Evolution
- ◦
- Retirement
- Dimensions:
- ◦
- People
- ◦
- Process
- ◦
- Product
- ◦
- Change Management


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Outlet | Reference | Adoption | Acquisition | Implementation | Use & Maintenance | Evolution | Retirement | Change Management | People | Process | Product |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | JAIS | [40] | XX | XX | XX | XX | ||||||
| 2 | JAIS | [41] | XX | XX | XX | |||||||
| 3 | JAIS | [42] | XX | XX | XX | XX | ||||||
| 4 | JAIS | [43] | XX | XX | XX | XX | ||||||
| 5 | JAIS | [44] | XX | XX | XX | |||||||
| 6 | JAIS | [45] | XX | XX | ||||||||
| 7 | ISJ | [46] | XX | XX | XX | |||||||
| 8 | ISJ | [47] | XX | |||||||||
| 9 | ISJ | [48] | XX | XX | XX | |||||||
| 10 | ISJ | [49] | XX | XX | XX | |||||||
| 11 | ISJ | [50] | XX | XX | XX | |||||||
| 12 | ISR | [51] | XX | XX | ||||||||
| 13 | ISR | [52] | XX | XX | XX | |||||||
| 14 | ISR | [53] | XX | XX | XX | |||||||
| 15 | ISR | [54] | XX | XX | XX | |||||||
| 16 | JIT | [55] | XX | XX | XX | |||||||
| 17 | JIT | [56] | XX | XX | XX | |||||||
| 18 | JIT | [57] | XX | XX | ||||||||
| 19 | JIT | [58] | XX | XX | XX | |||||||
| 20 | JIT | [59] | XX | XX | ||||||||
| 21 | JIT | [60] | XX | XX | XX | XX | ||||||
| 22 | JMIS | [61] | XX | XX | XX | |||||||
| 23 | JMIS | [62] | XX | XX | XX | |||||||
| 24 | JSIS | [63] | XX | XX | XX | XX | ||||||
| 25 | JSIS | [64] | XX | XX | XX | |||||||
| 26 | JSIS | [65] | XX | XX | ||||||||
| 27 | MISQ | [66] | XX | XX | XX | |||||||
| 28 | MISQ | [21] | XX | XX | XX | |||||||
| 29 | MISQ | [67] | XX | XX | ||||||||
| 30 | MISQ | [68] | XX | XX | XX | |||||||
| 31 | MISQ | [69] | XX | XX | XX | |||||||
| 32 | MISQ | [70] | XX | XX | XX | |||||||
| 33 | EJIS | [71] | XX | XX | XX | |||||||
| 34 | EJIS | [72] | XX | XX |
References
- Von Brocke, J.; Simons, A.; Niehaves, B.; Riemer, K.; Plattfaut, R.; Cleven, A. Reconstructing the Giant: On the Importance of Rigour in Documenting the Literature Search Process. In Proceedings of the 17th European Conference on Information Systems (ECIS 2009), Verona, Italy, 8–10 June 2009; Volume 9, pp. 2206–2217. [Google Scholar]
- Webster, J.; Watson, R.T. Analyzing the Past to Prepare for the Future: Writing a Literature Review. MIS Q. 2002, 26, 13–23. [Google Scholar]
- Cooper, H.M. Organizing knowledge syntheses: A taxonomy of literature reviews. Knowl. Soc. 1988, 1, 104–126. [Google Scholar] [CrossRef]
- Nakano, D.; Muniz, J., Jr. Writing the literature review for empirical papers. Production 2018, 28. [Google Scholar] [CrossRef]
- Levy, Y.; Ellis, T.J. Towards a Framework of Literature Review Process in Support of Information Systems Research. InSITE 2006, 6. [Google Scholar] [CrossRef]
- Synnestvedt, M.B.; Chen, C.; Holmes, J.H. CiteSpace II: Visualization and knowledge discovery in bibliographic databases. AMIA Annu. Symp. Proc. 2005, 2005, 724–728. [Google Scholar]
- Hutton, B.; Catalá-López, F.; Moher, D. The PRISMA statement extension for systematic reviews incorporating network meta-analysis: PRISMA-NMA. Med. Clin. 2016, 147, 262–266. [Google Scholar] [CrossRef]
- Phongwattana, T.; Chan, J.H. A Combination of Text Mining Techniques for Relevant Literature Search and Extractive Summarization. In Proceedings of the 2nd International Conference on Natural Language Processing and Information Retrieval, Bangkok, Thailand, 7–9 September 2018; pp. 7–11. [Google Scholar]
- Chen, C. CiteSpace: A Practical Guide for Mapping Scientific Literature; Nova Science Publishers, Inc.: New York, NY, USA, 2017; ISBN 9781536102956. [Google Scholar]
- Wirth, R.; Hipp, J. CRISP-DM: Towards a Standard Process Model for Data Mining. In Proceedings of the Fourth International Conference on the Practical, New York, NY, USA, 27–31 August 1998. [Google Scholar]
- Goyal, V.K. A Comparative Study of Classification Methods in Data Mining using RapidMiner Studio. Int. J. Innov. Res. Sci. Eng. 2014, 4, 28–30. [Google Scholar]
- Liao, S.; Chu, P.; Hsiao, P. Data mining techniques and applications—A decade review from 2000 to 2011. Expert Syst. Appl. 2012, 39, 11303–11311. [Google Scholar] [CrossRef]
- Eaton, E. Teaching Integrated AI through Interdisciplinary Project-Driven Courses. AI Mag. 2017, 38, 13. [Google Scholar] [CrossRef]
- Tang, J.; Zhang, J.; Yao, L.; Li, J.; Zhang, L.; Su, Z. ArnetMiner: Extraction and Mining of Academic Social Networks. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’08), Las Vegas, ND, USA, 24–27 August 2008; ACM: New York, NY, USA, 2008; pp. 990–998. [Google Scholar] [CrossRef]
- Haddaway, R.N. The Use of Web-scraping Software in Searching for Grey Literature. Grey J. 2015, 11, 186–190. [Google Scholar]
- Meschenmoser, P.; Meuschke, N.; Hotz, M.; Gipp, B. Scientific Web Repositories: Challenges and Solutions for Automated Content Extraction. D-Lib Magazine 2016, 22, 9–10. [Google Scholar] [CrossRef]
- Glez-Peña, D.; Lourenço, A.; López-Fernández, H.; Reboiro-Jato, M.; Fdez-Riverola, F. Web scraping technologies in an API world. Brief Bioinform. 2013, 15, 788–797. [Google Scholar] [CrossRef] [PubMed]
- Berglund, A.; Wg, X.S.L.; Boag, S.; Wg, X.S.L.; Chamberlin, D.; Wg, X.M.L.Q.; Almaden, I.B.M.; Fern, M.F.; Wg, X.M.L.Q.; Kay, M.; et al. XML Path Language (XPath) 2.0; W3C. 2010. Available online: https://www.w3.org/TR/xpath20/ (accessed on 5 December 2019).
- Dwivedi, S. Comprehensive Study of Data Analytics Tools. In Proceedings of the 2016 Symposium on Colossal Data Analysis and Networking (CDAN), Indore, India, 18–19 March 2016. [Google Scholar] [CrossRef]
- Van Der Blonk, H. Writing case studies in information systems research. Formul. Res. Methods Inf. Syst. 2003, 2, 255–270. [Google Scholar] [CrossRef]
- Sykes, T.A.; Venkatesh, V.; Johnson, J.L. Enterprise system implementation and employee job performance: Understanding the role of advice networks. MIS Q. 2014, 38, 51–72. [Google Scholar] [CrossRef]
- Donovan, R.M. Successful ERP Implementation the First Time. Midrange ERP 2001. Available online: http://www.midrangeerp.com (accessed on 5 December 2019).
- Umble, E.J.; Umble, M.M. Avoiding ERP implementation failure. Ind. Manag. 2000, 44, 25–33. [Google Scholar]
- Rasmy, M.; Tharwat, A.; Ashraf, S. Enterprise resource planning (ERP) implementation in the Egyptian organizational context. Eur. Mediterr. Conf. Inf. Syst. EMCIS 2005, 2005, 1–13. [Google Scholar]
- Muscatello, J.R.; Parente, D.H. Enterprise Resource Planning (ERP): A Postimplementation Cross-Case Analysis. Inf. Resour. Manag. J. 2006, 19, 20. [Google Scholar] [CrossRef]
- Wang, E.T.G.; Chia-Lin Lin, C.; Jiang, J.J.; Klein, G. Improving enterprise resource planning (ERP) fit to organizational process through knowledge transfer. Int. J. Inf. Manage. 2007, 27, 200–212. [Google Scholar] [CrossRef]
- Osnes, K.B.; Olsen, J.R.; Vassilakopoulou, P.; Hustad, E. ERP Systems in Multinational Enterprises: A literature Review of Post-implementation Challenges. Procedia Comput. Sci. 2018, 138, 541–548. [Google Scholar] [CrossRef]
- Chatterjee, S. ERP Failure in Developing Countries: A Case Study in India.
- Vijay Gaikwad, S.; Chaugule, A.; Patil, P.; Y Patil, P.D.; Patil, P. Text Mining Methods and Techniques. Int. J. Comput. Appl. 2014, 85, 975–8887. [Google Scholar]
- Lin, Y.S.; Jiang, J.Y.; Lee, S.J. A similarity measure for text classification and clustering. IEEE Trans. Knowl. Data Eng. 2014, 26, 1575–1590. [Google Scholar] [CrossRef]
- Ishioka, T. An Expansion of X-Means for Automatically Determining the Optimal Number of Clusters—Progressive Iterations of K-Means and Merging of the Clusters. Proceedings of International Conference on Computational Intelligence, Calgary, Canada, 4–6 July 2005; Vlo. 2; pp. 91–96. [Google Scholar]
- Hirsch, J.E. An index to quantify an individual’s scientific research output. Proc. Natl. Acad. Sci. USA. 2005, 102, 16569–16572. [Google Scholar] [CrossRef] [PubMed]
- Eggue, L. Theory and practise of the g-index. Scientometrics 2006, 69, 131–152. [Google Scholar] [CrossRef]
- Leydesdorff, L.; Milojević, S. Scientometrics. International Encyclopedia of Social and Behavioral Sciences; Elsevier: Amsterdam, The Netherlands, 2015; pp. 1–18. [Google Scholar]
- Harzing, A.W. Publish or Perish Available online:. Available online: https://harzing.com/resources/publish-or-perish (accessed on 3 December 2019).
- Damasevicius, R. Automatic Generation of Concept Taxonomies from Web Search Data Using Support Vector Machine. In Proceedings of the Fifth International Conference on Web Information Systems and Technologies, Lisbon, Portugal, 23–26 March 2009. [Google Scholar]
- Damasevicius, R. Automatic generation of part-whole hierarchies for domain ontologies using web search data. In Proceedings of the 32nd International Convention Proceedings: Computers in Technical Systems and Intelligent Systems (MIPRO 2009), Opatija, Croatia, 25–29 March 2009; pp. 215–220. [Google Scholar]
- Grimm, S.; Abecker, A.; Vo, J. Handbook of Semantic Web Technologies; Springer: Berlin/Heidelberg, Germany, 2011; ISBN 9783540929130. [Google Scholar]
- Esteves, J.M.J.; Pastor, J.A. An ERP Life-Cycle-Based Research Agenda. In Proceedings of the 1st International Workshop in Enterprise Management & Resource Planning: Methods, Tools and Architectures (EMRPS’99), Venice, Italy, 25–27 November 1999; pp. 359–371. [Google Scholar]
- Cram, W.A.; Brohman, K.; Gallupe, R.B. Information Systems Control: A Review and Framework for Emerging Information Systems Processes. J. Assoc. Inf. Syst. 2018, 17, 216–266. [Google Scholar] [CrossRef]
- Kulkarni, U.; Robles-Flores, J.; Popovič, A. Business Intelligence Capability: The Effect of Top Management and the Mediating Roles of User Participation and Analytical Decision Making Orientation. J. Assoc. Inf. Syst. 2018, 18, 516–541. [Google Scholar] [CrossRef]
- Bagayogo, F.F. Enhanced Use of IT: A New Perspective on Post- Adoption. J. Assoc. Inf. Syst. 2014, 15, 361–387. [Google Scholar] [CrossRef]
- Liu, G.; Wang, E.; Chua, C. Leveraging Social Capital to Obtain Top Management Support in Complex, Cross-Functional IT Projects. J. Assoc. Inf. Syst. 2018, 16, 707–737. [Google Scholar] [CrossRef]
- Lin, T.; Huang, S.; Chiang, S.-C. User Resistance to the Implementation of Information Systems: A Psychological Contract Breach Perspective. J. Assoc. Inf. Syst. 2018, 19, 306–332. [Google Scholar] [CrossRef]
- Vessey, I.; Vessey, I. The Dynamics of Sustainable IS Alignment: The Case for IS Adaptivity. J. Assoc. Inf. Syst. 2016, 14, 2. [Google Scholar] [CrossRef]
- Bala, H.; Bhagwatwar, A. Employee dispositions to job and organization as antecedents and consequences of information systems use. Inf. Syst. J. 2018, 28, 650–683. [Google Scholar] [CrossRef]
- Shollo, A.; Galliers, R.D. Towards an understanding of the role of business intelligence systems in organisational knowing. Inf. Syst. J. 2016, 26, 339–367. [Google Scholar] [CrossRef]
- Van Beijsterveld, J.A.A.; van Groenendaal, W.J.H. Solving misfits in ERP implementations by SMEs. Inf. Syst. J. 2016, 26, 369–393. [Google Scholar] [CrossRef]
- Seddon, P.B.; Constantinidis, D.; Tamm, T.; Dod, H. How does business analytics contribute to business value? Inf. Syst. J. 2017, 27, 237–269. [Google Scholar] [CrossRef]
- Deng, X.N.; Wang, T.; Galliers, R.D. More than providing “solutions”: Towards an understanding of customer-Oriented citizenship behaviours of IS professionals. Inf. Syst. J. 2015, 25, 489–530. [Google Scholar] [CrossRef]
- Li, X.; Po-An Hsieh, J.J.; Rai, A. Motivational differences across post-acceptance information system usage behaviors: An investigation in the business intelligence systems context. Inf. Syst. Res. 2013, 24, 659–682. [Google Scholar] [CrossRef]
- Liang, H.; Xue, Y.; Wu, L. Ensuring employees’ IT compliance: Carrot or stick? Inf. Syst. Res. 2013, 24, 279–294. [Google Scholar] [CrossRef]
- Tong, Y.; Tan, S.S.-L.; Teo, H.-H. The Road to Early Success: Impact of System Use in the Swift Response Phase. Inf. Syst. Res. 2015, 26, 418–436. [Google Scholar] [CrossRef]
- Windeler, J.B.; Maruping, L.; Venkatesh, V. Technical systems development risk factors: The role of empowering leadership in lowering developers’ stress. Inf. Syst. Res. 2017, 28, 775–796. [Google Scholar] [CrossRef]
- Fryling, M. Investigating the Effect of Customization on Rework in a Higher Education Enterprise Resource Planning (ERP) Post-Implementation Environment: A System Dynamics Approach. J. Inf. Technol. Case Appl. Res. 2015, 17, 8–40. [Google Scholar] [CrossRef]
- Grainger, N.; McKay, J. The long and winding road of enterprise system implementation: Finding success or failure? J. Inf. Technol. Teach. Cases 2015, 5, 92–101. [Google Scholar] [CrossRef]
- Recker, J. Reasoning about Discontinuance of Information System Use. J. Inf. Technol. Theory Appl. 2016, 17, 41–66. [Google Scholar]
- Croasdell, D.; Kuechler, B.; Wawdo, S. Examining Resistance to Information System Implementation. J. Inf. Technol. Case Appl. Res. 2013, 15, 3–24. [Google Scholar] [CrossRef]
- Chadhar, M.; Daneshgar, F. Organizational Learning and ERP Post-implementation Phase: A Situated Learning Perspective. J. Inf. Technol. 2018, 19, 138–156. [Google Scholar]
- Lederman, R.; Kurnia, S.; Peng, F.; Dreyfus, S. Tick a box, any box: A case study on the unintended consequences of system misuse in a hospital emergency department. J. Inf. Technol. Teach. Cases 2015, 5, 74–83. [Google Scholar] [CrossRef]
- Müller, O.; Fay, M.; vom Brocke, J. The Effect of Big Data and Analytics on Firm Performance: An Econometric Analysis Considering Industry Characteristics. J. Manag. Inf. Syst. 2018, 35, 488–509. [Google Scholar] [CrossRef]
- Lai, V.S.; Lai, F.; Lowry, P.B. Technology Evaluation and Imitation: Do They Have Differential or Dichotomous Effects on ERP Adoption and Assimilation in China? J. Manag. Inf. Syst. 2016, 33, 1209–1251. [Google Scholar] [CrossRef]
- Arvidsson, V.; Holmström, J.; Lyytinen, K. Information systems use as strategy practice: A multi-dimensional view of strategic information system implementation and use. J. Strateg. Inf. Syst. 2014, 23, 45–61. [Google Scholar] [CrossRef]
- Leonard, J.; Higson, H. A strategic activity model of Enterprise System implementation and use: Scaffolding fluidity. J. Strateg. Inf. Syst. 2014, 23, 62–86. [Google Scholar] [CrossRef]
- Ravichandran, T. Exploring the relationships between IT competence, innovation capacity and organizational agility. J. Strateg. Inf. Syst. 2018, 27, 22–42. [Google Scholar] [CrossRef]
- Tian, F.; Xu, S.X. How Do Enterprise Resource Planning Systems Affect Firm Risk? Post-Implementation Impact. MIS Q. 2015, 39, 39–60. [Google Scholar] [CrossRef]
- Sykes, T.A. Support Structures and Their Impacts on Employee Outcomes: A Longitudinal Filed Study of an Enterprise System Implementation. MIS Q. 2015, 39, 473–495. [Google Scholar] [CrossRef]
- Venkatesh, V.; Morris, M.G.; Davis, G.B.; Davis, F.D. Changes in employees’ job characteristics during an enterprise system implementation: a latent growth modeling perspective. MIS Q. 2014, 27, 425–478. [Google Scholar] [CrossRef]
- Hsinchun, C.; Roger, H.L.; Chiang, V.C.S. Transformational Issues of Big Data And Analytics. Netw. Bus. 2018, 36, 1165–1188. [Google Scholar]
- Gust, G.; Flath, C.M.; Brandt, T.; Strohle, P.; Neumann, D. How a Traditional Company Seeded New Analytics Capabilities. MIS Q. Exec. 2017, 16, 10–13. [Google Scholar]
- Laumer, S.; Maier, C.; Eckhardt, A.; Weitzel, T. Work routines as an object of resistance during information systems implementations: Theoretical foundation and empirical evidence. Eur. J. Inf. Syst. 2016, 25, 317–343. [Google Scholar] [CrossRef]
- Laumer, S.; Maier, C.; Weitzel, T. Information quality, user satisfaction, and the manifestation of workarounds: A qualitative and quantitative study of enterprise content management system users. Eur. J. Inf. Syst. 2017, 26, 333–360. [Google Scholar] [CrossRef]










| No | Outlet/Journal Name | Search Hit Count |
|---|---|---|
| 1 | Journal of the Association of Information Systems | 34 |
| 2 | Information Systems Journal | 21 |
| 3 | Information Systems Research | 40 |
| 4 | Journal of Information Technology | 111 |
| 5 | Journal of Management Information Systems | 26 |
| 6 | Journal of Strategic Information Systems | 23 |
| 7 | Management Information Systems Quarterly | 61 |
| 8 | European Journal of Information Systems | 45 |
| Total | 361 |
| Adoption | Acquisition | Implementation | Use & Maintenance | Evolution | Retirement | Change Management | People | Process | Product | |
|---|---|---|---|---|---|---|---|---|---|---|
| Total Count | 3 | 0 | 17 | 23 | 1 | 1 | 5 | 30 | 16 | 2 |
| % of Total (out of 34 shortlisted articles based on content) | 9% | 0% | 49% | 66% | 3% | 3% | 14% | 86% | 46% | 6% |
| Criteria/Methodology | CRISP-DM | Harzing’s Publish or Perish (HPoP) |
|---|---|---|
| Framework Focus | Macro scale Conducts the analysis exercise on word level relations of the body of science | Micro scale Conducts the analysis over scientific discourse in relation to authors, journals and scientific citations |
| Ease of Use | High Depends on the user data science skills and understanding | High Ease of Use Educates users on the software use through user guides |
| Flexibility | High Data Mining software provides a plethora of algorithms to be conducted over multi-dimensional and cross functional data | Medium Bound by the features of the HPoP software |
| Reproducibility | High Models can be exported and shared with users easily | High Steps to reproduce the analysis can be easily followed using the software GUI |
| Replicability | Medium Ability to replicate models depends on users’ skills | High Steps to replicate the analysis can be easily followed using the software GUI |
| Reach | High Provides unlimited reach for users to further expand on the analysis of their data | Low Provides limited analysis channels (Google Scholar, Web of Science, Scopus, etc.) |
| Data Preparation Need | Low Requires the use of web scraping methods to extract and prepare data | High Does not posture any data preparation needs by the users |
| Visual Capabilities | High Data Science tools typically have a plethora of visualization tools enabling users to model understandable assessment visualizations | Low Requires use of additional components to produce visually meaningful diagrams (e.g., VOSViewer, CiteNetExplorer, etc.) |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassanien, H.E.-D. Web Scraping Scientific Repositories for Augmented Relevant Literature Search Using CRISP-DM. Appl. Syst. Innov. 2019, 2, 37. https://doi.org/10.3390/asi2040037
Hassanien HE-D. Web Scraping Scientific Repositories for Augmented Relevant Literature Search Using CRISP-DM. Applied System Innovation. 2019; 2(4):37. https://doi.org/10.3390/asi2040037
Chicago/Turabian StyleHassanien, Hossam El-Din. 2019. "Web Scraping Scientific Repositories for Augmented Relevant Literature Search Using CRISP-DM" Applied System Innovation 2, no. 4: 37. https://doi.org/10.3390/asi2040037
APA StyleHassanien, H. E.-D. (2019). Web Scraping Scientific Repositories for Augmented Relevant Literature Search Using CRISP-DM. Applied System Innovation, 2(4), 37. https://doi.org/10.3390/asi2040037