1. Introduction
Most human labor organizations emphasize control methods and optimization in order to achieve high standards of productivity. Considering only the physical aspects of labor routines (discrete variables) such as products properties or services quality, both identifiable with several methodologies nowadays [
1], organizations fail to find a solution to achieve high standards of productivity where continuous variables are also the main component of productivity. For this type of hybrid organization, where productivity is linked with human cognitive work (agents), machines and objects (environmental aspects), traditional methodologies of productivity do not express the possibilities of controlling events from a probabilistic perspective, of which events in this type of organizations occur. Nowadays, general and famous international industrial methods of workflows consider mostly discrete variables only as the basis of production. However, several other types of industries or labor activities demand continuous variables (cognitive domain) to be defined within a method. Following this path, this article considers productivity in modern and complex contexts of human labor interactions with non-physical environments [
1] or, in other words, hybrid organizations where non-physical information is the main component of productivity.
A large number of variables that constitute workflows are complex in nature [
2] as a complex adaptive system [
3]. Statistical analyses on the portion that occupies each category of information processing of a workflow on a scale of 0% to 100% is not recommended for analyzing how an organism process information due to the non-linear nature of the phenomena [
4,
5]. Since an individual might process information given in several different forms (ad hoc expressions), the complex adaptive system can reach a possible margin of work performances (index of performances). The non-linearity of the complex adaptive systems prevents the possibility of comparing a group of individuals with specific and indeterminate cognitive patterns naturally [
5,
6], and their forms of work, to generate patterns of execution in the workflows of linear or non-linear dimensions [
7,
8,
9,
10]. For this empirical limitation, in order to arrange the best productivity, theoretical control methods can be mandatory to conceive the phenomena in its complex nature.
If the only discrete input of information for producing a good or service are the variables that influence production, then the agents within the process maintains an impartial relationship with it not performing a higher degree of information processing in the event. Despite production with discrete variables present also a performance range [
6], many types of production where individual experience, knowledge and cognitive skills are necessary lead to a higher level of performance range, constituting a labor system where continuous variables are created continuously as a default pattern in relation to how to perform a given task. This non-discrete form of productivity might reach, commonly, due to its cognitive nature, a probability distribution composed of discrete and continuous forms of information and its processing. For this type of hybrid modelling, statistical analysis can give a performance indexes with distinct classification of how the system works for the discrete events. On the other hand, if an agent’s forms of processing information (continuous variable presence) consists in an inherent part of production, statistical methods cannot survey how an individual or a group of individuals might give a better performance compared with each other, since the nature of this variable in many cases cannot be identifiable and observable. In this sense, productivity elements such as time and resources, for example, are defined by the form of processing of the agents that produce, and likewise, the resources that will be needed for the extent of the possibility to optimize the continuous variables of the system, and for this case, the cognitive dimension of agents. Following this path, discrete and continuous variables are inputs in the state of correlation with the agent and its processing mode, and not an impartial relation to the agent’s processing mode (controller).
This brief description of a hybrid organization can be represented by
Figure 1, where a control method is proposed and presented.
For this kind of hybrid system workflow, it is necessary to realize that productivity will be optimized by a remodeling of the production algorithm, that is, new observations about the production parameter stages (
m index of performances), entropy states (outputs) and the heuristic processing of production (adaptive controller) (
Figure 1).
2. Method: Productivity Equation
The ergodicity of a system as common manufacturing plants workflows can present high optimization levels due to presence of discrete variable within the system and control methods over the agents. However, this situation is not a constant expression considering some real-life situations or hybrid organizations where the production line is composed of a human presence as a metric of productivity [
11,
12,
13]. Therefore, for the purpose of empirical investigation of these types of organizations, it is recommended starting from an analysis in which non-ergodicity is the a priori event, more present in the real world, where the distribution
m of labor performances expressed by an agent assumes various possible forms (derivations) [
13,
14,
15,
16,
17].
To understand the role of continuous variables within the productivity of a firm, or its importance as an artificial intelligence system, both approaches needs a formal description of the event concerning information processing (individual experience, cognitive skills, biological conditions, reasoning design, …), information availability and time. This description can be identified as the basis of a probabilistic equation, called a productivity equation. Since labor activities for hybrid contexts produce dynamics as a range of outputs as a result of information processing, the inputs and controller stages can also identify the chain of the event as a whole. However, this does not identify it as a mechanical process, but as an approach for non-linear dynamic metrics. Following the previous statements where hybrid organizations have no defined methods of analysis for workflows whose systems are in adaptive mode and present constant non-linear results of precision, then let us consider the probabilistic event i where the inputs and outputs of information and processing occurs when an agent () and a given information I must be processed generating a precision (P) for a default range of expected performances. These random variables of the system consisting of information (I), processing () and time (T), the event i can be predicted by the following mathematical framework. If a stream of information arises from an event i, where any individual (agent) X processes as an input state a given discrete information I generating time T and reaching precision P influenced by individual experience then there is a probabilistic event in which the event i, the probability of precision (P) can be defined as where for reaching an ideal precision constantly equal, the odds should be like . However, inversely, as T is defined by I given (data source) and is processed by individual X defining how information and time will be generated as an output like , the input values of I and (not defined in the previous equation) generates m distributions for I influenced by and for T also influenced by as a new output. can be defined as the ad hoc cognitive performances and previous experience of the individual in which represents a posterior processing stage of , being this first probability the first interactions between organism or a machine and the environment. In this sense, is the same event , but exponentially growth by individual experience , being also a cumulative self organized (adaptive) data set of events for precision-making. These cumulative trials and results are stored as i (events information) and in its turn i can be redefined by several other probabilities generated by the new interactions and iterations of the organism or machine and environment.
This equation of event
i as any event that considers information processing by an organism or machine giving
P, can be defined by,
In which
P assumes variations according to the probabilistic distribution of
I,
and
T, which in turn defines the information entropy of
P, hence, of the workflow (see
m distributions
Section 3). Also Equation (1) can be written in the same way as Equation (2) due to conceptual description mentioned before.
It is necessarily understood within the equation formulation that the time occurs only if the information is processed at first, so the probability of time is dependent on the probability distributions of the information and the processing. In this way, given information processing can result in several distinct outputs for time and for entropy if the processing variable has its own variance. Since the equation defines the controller as a complex adaptive agent, then as an empirical consequence, time and entropy outputs assume a range of possible performances. However, the probabilistic distributions of
I and
T assume behavior in a sample space that does not have fixed intervals, since they come from complex adaptive systems (
) [
2,
3,
4,
5,
6] and with a degree of freedom for any resultant that varies from individual to individual [
6]. In this way, it is possible to assume that every learning process as well cognitive processing derives not from a predefined sample understanding it as information that is fully objective for the controller (biological system or artificial intelligence) in its potential of apprehension. For this reason, it can be identified as a probabilistic event defined by the data source (
I), individual experience/processing performances (
) as input values and time of processing (
T) and resulting information (
I) as output values. Thus, it is not previously defined that there are probabilities of
I and
T, but that the probabilities are due to the dependence between these variables and their empirical expression, which identifies the phenomenon itself as the product of non-linear dynamics by cumulatively modifying their probabilistic distributions as the more complex adaptive systems interact with the environment.
If theoretically an information processed in
T time is set to defined variables and processing in
I, the precision is always given as 100%. But, if
influence the processing of
I, then
can influence the event to express monotone properties where
takes chance for lowering or rising
chances. Lowering means lower precision or time processing and rising means achieving new form of processing the formal way of dealing with
. This means in other words, improving the
default pattern of working. Consider for this a single example of empirical experiments of eye processing forms [
18], where statistical patterns are processed in the task of recognizing an individual’s own error of visual memory and learning. As different tasks are presented by the environment, the default pattern of information processing adapts itself to reach the ideal precision of the given task. This means clearly that an organism influences information and time-processing performance. The same way, information as it is given influences the organism to adapt itself in order to achieve specific goals. For this experiment, the chances of precision in the given events present lowering or rising effects. In other [
19] research, even if subjectivity of an individual is removed, empirically, the response of information processing can be changed from the neural perspective between individuals and also with specific processing capacities.
For the machine artificial intelligence, the same behavior present in biological systems are not available in full expression. Thou, the control theory presented in this article is suggested, as well as the mathematical framework making a comparison by analogy of information processing for an organism or a machine. This is recommended for the readers to take it into account when analyzing the inferences of this research. The organism–machine–environment interactions and iterations can be understood in the same framework of analysis for the specific problem formulation of productivity equation concerning discrete and continuous or discrete-continuous data processing.
3. Results: M Distributions of Information Processing in Workflows
The mathematical modelling that describes information flows in the workflows can be defined as a probability event when from a given event i by Equation (1) of the interaction between given discrete information variables (I), individual experience and defining the time T (discrete or continuous depending on the case) as a function of I for the execution of individual or group work/between agents/machines reaching precision (P), assumes for i 7 inductive derivations and 8 definitions, like:
A. Discrete Binomial Probability Distribution
Definition 1. For a single event and i.i.d (independent and identically distributed), in which P assumes variations according to the probabilistic distribution of I,and T, which in turn defines the information entropy of P, i assumes expressions like: Hence, T is the unique variable on system defined by successful p. Or, , Hence, decision making takes place in general defining T and I as, B. Discrete Probability Distribution
Definition 2. Otherwise, if m is a result of discrete variables, not binomial and information is processed constantly without imprecisions in the same properties as cognition processing, reachingor asprecision for any event then,where i is processed constantly without any oscillation, then, Hence,assumes the main role of processing as a defined precision given by an agent. Whereas the precision is not reached at 100%, indefinite probabilities occurs due to subjective nature of organism processing or machine-leaning environments, but as for an effort of reaching 100% precision, cumulative trials lead the event to the maximum information entropy where trials of learning process assumes also monotone properties as following items briefly describes.
Definition 3. If precision is lower than 100%, then, defined as the original equation form, C. Discrete Probability Distribution and Monotonically Decreasing
Defined by the equation from a discrete cumulative distribution function (CDF) in which the discrete and probabilistic function is discrete by the presence of pre-defined data, but with uncertain processing and/or temporality that assume in an adaptive system, the well-defined ad hoc mode of work is predictable. This type of distribution associated with adaptive systems does not represent an entropy of critical information, in which it is not possible to reach accuracies close to 100%. The monotonically decreasing function is presented by the high probability of accurate execution and low presence of information that generates randomness in the system. It is dependent on an ad hoc method to achieve an accuracy of 100% or close. Mathematically, it is not possible to obtain a CDF-like probability as described above as a function of the organic component of the system. Thus, the cumulative function of information as discrete values can of course be processed to the inverse of the manifestation itself in its physical nature or axiomatic origin of probabilities (a characteristic event of a non-adaptive system where ). Precisely the propositions of biological order can establish a function between precision and information of the type . Thus the probability of precision is strictly greater than that of information, the set of P contained in I being at the same time contained in another set of unknown dimensions (of individual experience), such as, , being the experience accumulated by the individual, or in other words, the accumulated information of n events i, which confer to the biological potential the possibility that . A cumulative function in an adaptive system assumes the biological form of the individual and breaks the axiom of probabilities, differentiating the axiom that applies to the physical world from the complex adaptive world.
Definition 4. On the other hand if, for any I given to prevent oscillations in a system resulting in, the probability of precision is thus strictly greater than that of information, the set of P contained in I being at the same time contained in another set of unknown dimension (of individual experience), such as, Hence, it confers to the biological potential the possibility, To add biological properties in the complex adaptive system, a learning process can be observed as a heuristic input and output of information of obscure probabilities. But for any given heuristic cognitive processing, weights can be strictly associated with an organism search for environment patterns and previous memory experiences.
Weights in this view are distributed and classified as cognitive modeling of cumulative experiencesas cognitive processing are indexed heuristically aswhereare weights associated with a given precision P. For each trial a pattern search is generated randomly, but just for representation (excluding order for real process) asand for reaching an interpolated information for P, a set of values and trials can be defined as consecutive events for reaching precision (and a function ofcan be defined as, And consecutively, the heuristic cognitive linear function searches for environment patterns coding of, As organism limitations to process environment patterns fail, it leads to the inverse phenomena of item C.
D. Discrete Probability Distribution and Monotonically Increasing
Definition 5. In the other hand if, but present definition with limits of, and cognitive system presents lower information processing skills, then, Thus, reducing time and pathways for reaching precision P of information given I. Or E. Continuous probability density function distribution and monotonically decreasing
Definition 6. Keeping T and processing of I unstable and unpredictable a priori. Following this path, ifunder high complexity of n-dimensions interactions/iterations, then m assumes distributions likeonly if the probabilistic densities have patterns like, where, F. Continuous Probability Density Function Distribution and Monotonically Increasing
Definition 7. Otherwise, if, then m expressfor n-dimensions, then, G. Joint Probability Density Function
Definition 8. Considering now n-dimensions of external source (, not only for an individual phenomenon but for a group of agents, m assumes distribution like,whereassumes notations of, Giving a new equation like, Or in the opposite direction, it can be defined as, It is worth mentioning that in time dependent systems, regularity allows the continuous flow of information and possible interruptions caused by the exchange of information between distinct systems generates deceleration of subsequent processes. In other words, the frequency with which activities are performed is dependent on continuous flows to avoid saturation of the work steps that do not have their finalization in the appropriate time. In large information flows, PDFs (probability density function) can be generated on account of chaotic profiles between time-controlled systems [20,21]. Summarizing all the definitions as the m index of performance (parameters) for information-processing in hybrid workflows regarding continuous or discrete-continuous variables iterations for organisms–machines–environment, the following derivations can be obtained: observe that only iteration process can develop into several probabilistic distributions originating from a single equation and modifying parameters.
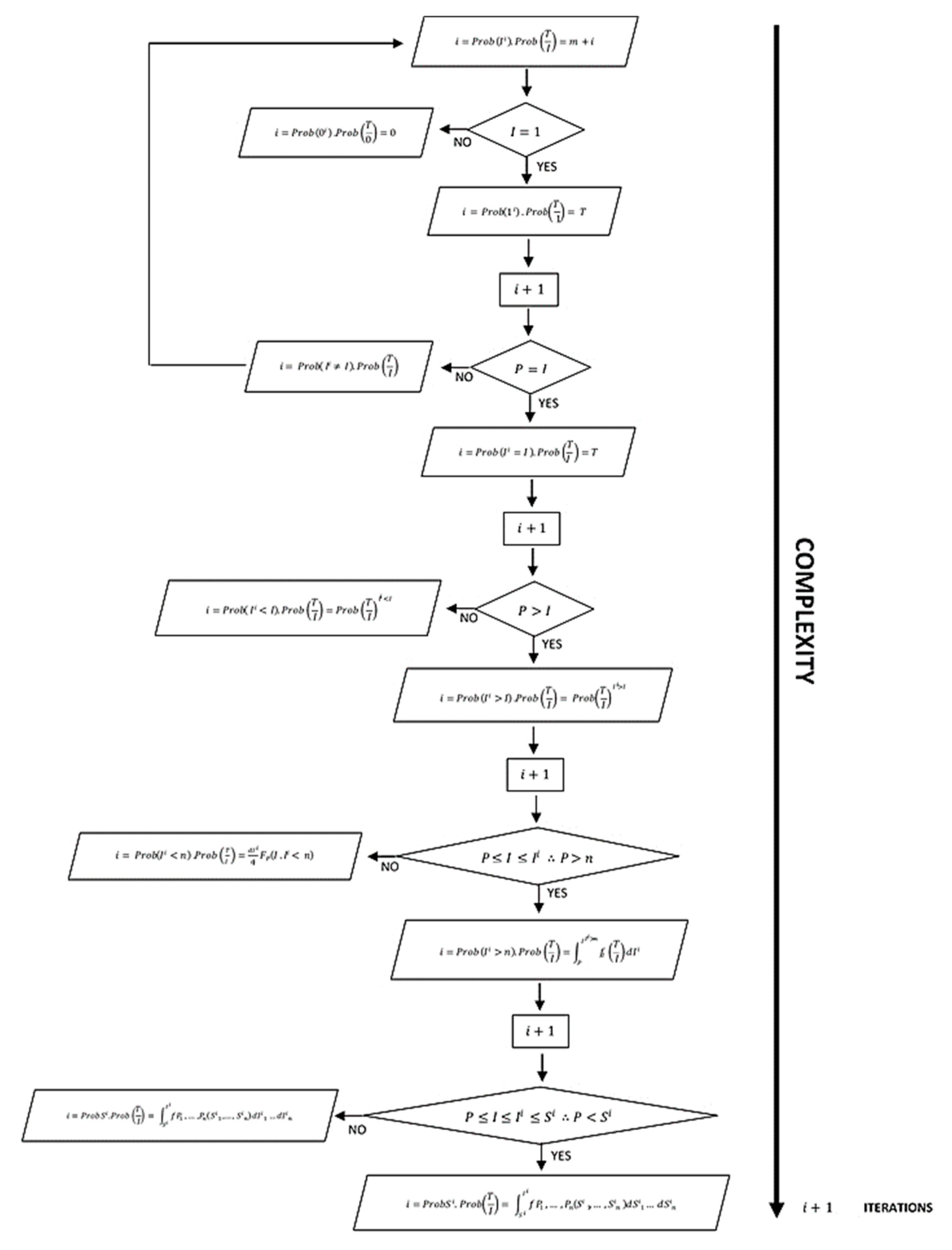
The
m index of performances can be extracted into an algorithm for information processing that can be seen in
Figure 2.
Definition 9. Let i be an event where all finite variables can iterate continuously. An adaptive controller can receive the same input with different parameters by iterations and the outputs can reach higher stages of complexity or states of entropy. Sequentially, this can be done to achieve disorder. Or inversely, this can go from disorder to the order, or a desired stages-states.
For the interactions aspects, an adaptive controller may arrange desired control by stating weights to any input and all parameters index, giving selective outputs as predicted.
High amount of information are constantly processed in natural phenomena or in brain–mind dimensions. The movement towards one or the other direction of complexity is much more dependent on the length of iterations or interactions than a specific linear path to the right desired position.
These theoretical views can be represented by an algorithm compiling all parameters and modifications from the single starting equation resulting into several sort of inputs and outputs of information processing (
Figure 2). Note that only iterations were analyzed and interactions effects of those parameters were not investigated so far. Further analysis and mathematical derivations are necessary to define the interactions’ new approaches. A flow diagram of
Figure 2 is showed in order to present how information flow through iteration processes, considering for it, the same input of information for all the flow given, and changing only the parameters in which information is processed. The flow diagram also presents several possible inputs and outputs of information, represented by the parallelograms and decision-making stages. Note that as an emergent phenomenon [
22], this bio-inspired computing algorithm can be arranged in a complex network of iterations and interactions not displaying a mandatory order of iterations or interactions from the lower to higher level of complexity or vice-versa. However, these proofs were not performed in this research. This issue needs further investigation. The emergent feature of this flowchart is addressed specifically to the parameters of the event. On this point, for every iteration or a possible interaction, a specific parameter might modify the local behavior into a new redesigned global behavior [
22].
4. Discussion
All the definitions, as a rule, are only theoretical and do not prove empirically for any agent or modes of production of a firm when always trying to reach 100% perfect precision, except for artificial intelligence. However, this example illustrates the ideal way of analyzing a workflow for hybrid organizational systems, where the production and precision are constantly modifying for qualitative and/or quantitative parameters in the sequence of events agent/information/processing/time sequence, which generates precision ideally for a single, a chain or web of events whose expression can be regulated as a mathematical modelling for any region of the system.
It is highly recommended for other researchers in this field or related fields to keep in the search of workflows modelling dynamics and algorithms with new properties of biological systems as an adaptive integration of multidimensional analysis and mathematical approaches.
This article was exclusively performed for the evaluation of qualitative mathematical purposes and not an in depth calculation analysis for each definition. Qualitative analysis can be applied to flowcharts or other qualitative methods of workflow and information processing analysis. Although, calculations can be useful for digital workflows, artificial intelligence and information processing, several approaches for theoretical and practical views can be implemented by using Equation (1) and the other derivations to achieve an automated or oriented algorithm. Also exploring the environment where hybrid variables are present can be a challenge purpose of this research when considering not organism–machine interactions but organism–environment and machine–environment specific dimensions. A very similar approach towards a quantitative method (full mathematical descriptive formulation) for objects-to-objects interaction and formal framework for probabilistic unclean databases (PUD) was proposed for data analysis in Ilyas et al. [
23]. A full description for structured predictions to achieve probabilistic modelling was developed [
23] and it is suggested as a tool of information processing as authors require for further investigations of this new techniques, programming parameters that considers biological empirical variances that can serve as input data and more descriptive performance of complex adaptive systems as this issue (quantitative descriptive methods) was not covered by this research.
Also, these articles discuss the event of human information processing in workflows as some emergent phenomena [
22,
24] where there are reasoning expressions and in turn it leads later to workflow expressions. It is not possible to observe the human work without prior concepts of mathematical, physical and biological nature, aside of the own work itself in terms of any field of knowledge.
The complex adaptive system performing the evolution of event as an emergent phenomenon reveals the phenomenological nature of human–object interactions [
25] where the small parts that compose the given event do not sum into their totality giving a linear calculus [
24]. In this sense, small parts do not reflect the whole and any expression (performance index) is possible to achieve with the same small parts. The high dimensionality of organisms and environment correlations cannot be measured in a steady-state method for a determinism view of nature, but can be observed and understood in a given real life events as simulations and experimentations within a control methodology and some mathematical tools that can be processed for quantitative or qualitative purposes. From another point of view, the remarks of Darley [
24] are very helpful to understand how simulation can also lead to a perfect way to understand cognition expression regarding artificial intelligence.
Simulations were not performed in this article. It is only a suggestion for future researchers towards some forms of analysis of the brain–mind emergent phenomenon of. For example, the body and brain search for stability and transformational patterns, mind (sensory cognition) inherent pattern of stability/transformational patterns, drugs administration/testing and information processing in terms of procedural patterns of stability/instability and reasoning/sensory input-output stability/transformational patterns.
Regarding simulations, they can be achieved by knowing or setting the initial stage of a process. Prediction is possible to achieve as the controller is the main key element for managing the system. In this view controller is the main agent-based element in which small parts are processed and present specific forms of expression. The prediction can be made through simulation, as far as controller initial condition can be determined. In real life, an organism can be predicted in a constant manner for some conditions or simulated experiments. Statistical analysis can give a glance in a given event, but not count for universal purpose regarding time and space aspects of the same event [
5,
24]. The main limitation of statistical analysis is the constant relevant index of performance (parameters) a cognitive system might set for itself. The fact that parameters of probability distributions exist in the natural world as an infrastructure of the universe does not mean an organism may process, consciously, information processing based on all of those parameters. It means in another words, the optimization for a default pattern of input and output of information processing is something produced by all organisms as an empirical fact (a constant organism oriented system task) and these phenomena can be regulated through an external controller within the system.
Following the arguments of the last paragraph, a steady state for the hybrid system could not be achieved without an index of performances to be reached. Since the nature of event is itself unstable, naturally organisms try to perform default patterns of recognition and activity execution for environmental tasks. This biological feature remains one of the main structures of brain–mind and body–environment designs to reach a possible steady state. Considering now the machine’s performance in the given productivity equation, a steady state as a bio-inspired system, can perform a desired task or measure if the index of performances can be programmed together with machine actions to perform and brain-inspired model for cognitive processing of information through a mathematical framework as it was suggested along this research (
Figure 2). This issue was not investigated further in this research and more development is needed to improve it.
Considering the arguments in this latter paragraph and artificial intelligence research, it is very important to address the use of an equation for information processing with the possibility of modifying pattern’s recognition as a probabilistic domain as can be seen in [
23]. However, conceiving a finite set of elements as possible to reach higher or lower levels of complexity can be challenging in terms of experimental design. It is not impossible in theory and mathematical description with further numerical exploration/examples to improve research results and empirical observations/experimentations.
5. Conclusions
Productivity is one of the most common human activities. Also, this concept applies vastly to an organism’s survivability and machine learning environments. Although it has been investigated for years how to achieve higher precision for discrete-based systems, (where an individual presence does not affect productivity in a wider range) modern life demands more hybrid systems as far as spread of knowledge and techniques of work requires more cognitive performance by the workforce. Following this path, this research proposed a mathematical approach method to identify, monitor and modify workflows for hybrid organizations towards the presence of discrete and discrete-continuous variables.
As continuous variables affect the system, as well adaptive control itself (controller), the functions and, therefore, the algorithm’s functions of a workflow change themselves. In turn, an organism’s interaction with the environment is transformed. An evolutional/transformational property is conferred to the system. The optimization process can be measured and designed as object-oriented metrics (i.e., the case of organizational routines or environment basis of analysis) or organism-oriented (i.e., individual performance within an organization; enhancements of individual performances for artistic or intellectual activities; biological aspects of self-organization and stability, machine learning tasks and development). In this sense, the equation of productivity and its derivations can be used as tools to understand the phenomena due to the overwhelming number of variables that affect the whole system and its parts and mainly for the presence of continuous variables as an auto-generating parameter of the adaptation algorithm for hybrid systems.
Also the use of this methodology can be carried out for real-life analysis or simulations in many fields of labor activities as well theoretical scientific purposes such as artificial intelligence, hybrid probabilistic systems, hybrid organizations, and other organism–machine–environment interactions.


{kind=link}
{kind=link}

