Abstract
In this study, we introduce an enhanced hybrid Autoencoder–Dense–Transformer Neural Network (AE-DTNN) model for developing an effective intrusion detection system (IDS) aimed at improving the performance and robustness of threat detection strategies within a rapidly changing and increasingly complex network landscape. The Autoencoder component restructures network traffic data, while a stack of Dense layers performs feature extraction to generate more meaningful representations. The Transformer network then facilitates highly precise and comprehensive classification. Our strategy incorporates adaptive synthetic sampling (ADASYN) for both binary and multi-class classification tasks, complemented by the edited nearest neighbors (ENN) technique and the use of class weights to mitigate class imbalance issues. In experiments conducted on the NF-BoT-IoT-v2 dataset, the AE-DTNN-based IDS achieved outstanding performance, with 99.98% accuracy in binary classification and 98.30% in multi-class classification. On the NSL-KDD dataset, the model reached 98.57% accuracy for binary classification and 97.50% for multi-class classification. Additionally, the model attained 99.92% and 99.78% accuracy in binary and multi-class classification, respectively, on the CSE-CIC-IDS2018 dataset. These results demonstrate the exceptional effectiveness of the proposed model in contrast to conventional approaches, highlighting its strong potential to detect a broad range of network intrusions with high reliability.
Keywords:
ADASYN; AE-DTNN; binary classification; deep learning; ENN; IDS; multi-class classification 1. Introduction
Networks are inherently exposed to a wide range of potential security threats, including unauthorized access attempts, penetration attacks, and other malicious intrusions from external or internal actors. While the primary purpose of a network is to facilitate the sharing of resources among legitimate users, it also becomes a target for unauthorized individuals seeking to exploit these resources for malicious purposes. Moreover, the development and implementation of comprehensive global security policies remain scarce and challenging. Security breaches are a grave concern for organizations, as they can lead to significant disruptions and damage. Given the critical nature of these risks, it is essential for organizations to devise robust preventive measures to protect their interests from the diverse spectrum of attacks to which they are vulnerable. According to Heady et al. [1], an intrusion is described as a series of actions aimed at compromising the integrity, confidentiality, or availability of an organization’s information resources.
Sophisticated defense strategies have been devised to enhance network security, with intrusion detection systems (IDSs) serving as a key safeguard [2]. These systems include Host-Based Intrusion Detection Systems (HIDS), which monitor activities on devices, and Network-Based Intrusion Detection Systems (NIDS) [3], which analyze traffic to identify threats.
The rapid identification of cyber threats is essential for maintaining the security and resilience of network infrastructures. Leveraging deep learning techniques has proven highly effective in the instantaneous analysis of network traffic, allowing for the swift detection of potential intrusions [4]. Advanced deep learning paradigms further enhance the adaptability of IDSs, equipping them with the capability to dynamically respond to evolving attack patterns [5]. Furthermore, embedding real-time processing functionalities within IDS frameworks significantly strengthens network defenses by facilitating immediate threat detection and proactive mitigation [6]. Beyond traditional IT environments, the advancement of IDS technologies holds significant promise in diverse sectors, including healthcare. For instance, securing internet of medical things (IoMT) infrastructures is becoming increasingly vital, as highlighted in Messinis et al. [7], where artificial intelligence-driven security mechanisms are explored to protect sensitive medical systems. The adaptable and high-performing nature of the proposed IDS model offers potential for integration into such critical domains, ensuring robust protection across a variety of application areas.
IDSs include Signature-Based IDS (SIDS) and Anomaly-Based IDS (AIDS). SIDS works by comparing incoming data with a predefined set of attack signatures, triggering alerts when a match is detected. AIDS, on the other hand, identifies potential intrusions by analyzing user behavior and raising alarms when significant deviations from normal activity are observed. While SIDS is effective at identifying known threats, AIDS is better at detecting new or unfamiliar attacks but tends to generate more false positives due to the variability in attacker tactics. Security breaches can be detected by reviewing system audit records for abnormal usage patterns [8].
This study directly supports the aims and thematic scope of Machine Learning and Knowledge Extraction (MAKE) by advancing intelligent information processing and cybersecurity through a deep learning-based IDS [9,10,11,12]. In response to the evolving landscape of cybersecurity threats, we propose an effective IDS framework based on a hybrid Autoencoder–Dense–Transformer Neural Network (AE-DTNN) model, which incorporates adaptive synthetic sampling (ADASYN), edited nearest neighbors (ENN), and class weights to mitigate class imbalance in both binary and multi-class classification challenges. The model achieved remarkable performance on the NF-BoT-IoT-v2 dataset, securing 99.98% accuracy for binary classification and 98.30% for multi-class classification. Additionally, it demonstrated strong results on the NSL-KDD dataset, with 98.57% accuracy in binary classification and 97.50% in multi-class classification. In addition, it achieves high performance with 99.92% accuracy in binary classification and 99.78% accuracy in multi-class classification on the CSE-CIC-IDS2018 dataset. These outcomes highlight the model’s robust capabilities across multiple datasets. The study’s key contributions are summarized below:
- Creating a highly sophisticated IDS utilizing the enhanced hybrid AE-DTNN model. The Autoencoder mechanism restructures and enhances network traffic patterns, while a stratified array of Dense layers executes feature extraction. The Transformer network subsequently enables exceptionally accurate and all-encompassing classification.
- A sophisticated data preprocessing pipeline is implemented, beginning with a hybrid outlier detection method using Z-score and local outlier factor (LOF) to identify and address anomalies, followed by feature selection based on correlation and the use of Principal Component Analysis (PCA) for dimensionality reduction. This structured methodology optimizes model inputs, enhancing performance and minimizing processing overhead.
- Employing ADASYN resampling for binary and multi-class classification, integrated with ENN and class weights, to proficiently resolve class imbalance and boost model efficacy.
- Assessment on the NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 datasets showcases the exceptional performance of the proposed model in comparison to leading-edge methods.
The paper is arranged as follows: Section 2 presents a thorough overview of pertinent literature. Section 3 explains the methodology utilized in this investigation. Section 4 showcases the experimental results, while Section 5 delivers an extensive analysis of the outcomes. Section 6 examines the limitations of the proposed strategy. Lastly, Section 7 wraps up the study by highlighting the core contributions, insights, and future work.
2. Related Work
This section reviews past research on intrusion detection systems, emphasizing advancements made using machine learning and deep learning. It highlights various methods developed to improve IDS performance, effectiveness, and robustness, evaluating the strengths and limitations of existing approaches while identifying emerging trends in the field.
2.1. Binary Classification
Several recent studies have explored advanced methods for binary classification in intrusion detection, as depicted in Table 1. In [13], the Near-Earth Spatio-Temporal Graph Attention Network (N-STGAT) model was applied to the NF-BoT-IoT-v2 dataset, achieving 97.88% accuracy, but suffered from limited dataset diversity, which hindered generalizability. Study [14] used a Graph Neural Network (GNN) on the same dataset and attained 99.64% accuracy; however, the absence of resampling introduced class imbalance, reducing its ability to detect rare threats. In [15], a Transformer–Convolutional Neural Network (CNN) architecture, supported by ADASYN, SMOTE, ENN, and class weighting, was applied to the NF-UNSW-NB15-v2 dataset, reaching 99.71% accuracy. Despite strong results, the model faced challenges in handling larger datasets and adapting to evolving threats. A CNN-Long Short-Term Memory (LSTM) hybrid was implemented in [16] on the ToN-IoT dataset, resulting in 98.75% accuracy, though scalability and performance trade-offs were noted due to computational limits. Study [17] introduced CNN with ADASYN and Tomek Links for the NSL-KDD dataset, achieving 93.3% accuracy, but was sensitive to noise and lacked robustness due to class imbalance. A comprehensive analysis in [18] using multiple traditional models (Logistic Regression (LR), K-Nearest Neighbors (KNN), Random Forest (RF), Decision Tree (DT), Multi-Layer Perceptron (MLP), LSTM) reported 97.8% accuracy on NSL-KDD but was impacted by noisy data and the absence of resampling. Two hybrid deep learning models, Autoencoder–CNN and Transformer–Deep Neural Network (DNN), were proposed in [19] for CICIDS2017, achieving 99.90% and 99.92% accuracy, respectively, yet they struggled with adapting to new threats and managing larger datasets. Another Transformer–CNN variant in [10] also attained 99.93% on CICIDS2017 using class rebalancing techniques but shared similar limitations. In [20], RF and Extra Trees (ET) models with stacking and PCA were applied to UNSW-NB15, yielding 99.59% accuracy; however, traditional ML models struggled with capturing complex patterns due to suboptimal parameter tuning. Study [21] reached 99% accuracy with RF on the same dataset but noted issues with outdated datasets and limited generalizability. A filtered classifier applied in [22] to the IoT-23 dataset achieved 99.2% accuracy, but the use of traditional models limited its ability to handle modern data complexities. Lastly, ref. [23] proposed a CNN–MLP hybrid for IoT-23, integrating ADASYN-synthetic minority over-sampling technique (SMOTE), ENN, and category-specific weighting and achieving 99.94% accuracy while facing limitations in scalability, dataset diversity, and adaptability to new attack patterns.

Table 1.
Literature review of binary classification.
2.2. Multi-Class Classification
Several recent studies have focused on improving multi-class intrusion detection using a variety of deep and machine learning techniques across diverse datasets, as illustrated in Table 2. The N-STGAT method applied to the NF-BoT-IoT-v2 dataset achieved 93% accuracy but faced limitations in generalizability due to limited dataset diversity [13]. A federated LSTM-based approach attained 94.61% accuracy on the same dataset, though its performance was constrained by trade-offs between speed and accuracy, affecting its ability to detect a broad range of attacks [24]. A Transformer–CNN model applied to the NF-UNSW-NB15-v2 dataset achieved 99.02% accuracy by incorporating ADASYN, SMOTE, ENN, and class weighting to address imbalance, though limitations in dataset diversity and scalability persisted [15]. A CNN with ADASYN-Tomek on NSL-KDD yielded 81.8% accuracy, limited by susceptibility to noise and poor rare-class detection due to insufficient resampling [17]. Another study using multiple models, including LR, KNN, RF, DT, MLP, and LSTM, achieved 93.4% accuracy but suffered from poor data quality and imbalance, leading to biased performance [18]. Two hybrid models, Autoencoder–CNN and Transformer–DNN, applied to the CICIDS2017 dataset achieved 99.95% and 99.96% accuracy, respectively, yet struggled with generalizability and performance on large or evolving datasets [19]. A Transformer–CNN model on the same dataset achieved 99.13% accuracy with similar limitations [10]. Another method using RF and ET with RO and PCA reached 99.59% on UNSW-NB15 but faced optimization and complexity limitations when modeling modern traffic patterns [20]. Similarly, a 99% accurate RF-based model on UNSW-NB15 highlighted issues with dataset diversity [21]. A filtered classifier on the IoT-23 dataset yielded 99.2% accuracy, but traditional machine learning limitations in modeling complex patterns and restricted dataset diversity hampered its effectiveness [22]. A CNN–MLP hybrid model achieved 99.94% accuracy on the same dataset by applying ADASYN, SMOTE, ENN, and class weighting, yet faced limitations in scalability and adaptability to new threats [23]. Finally, a study using AAE and BiGAN attained 99% accuracy but was constrained by limited dataset coverage, reducing generalization to varied attack types and environments [25]. In Ref. [26], the authors used an LSTM Autoencoder with an RF in Zeekflow+, achieving 99% accuracy, though its evaluation on a single dataset limits generalizability and scalability.
Table 2.
Literature review of multi-class classification.
2.3. Challenges and Contribution
IDSs utilizing deep learning face several critical challenges that impact their effectiveness and real-world deployment. These challenges stem from both intrinsic data issues and practical constraints in operational environments. Below, we analyze the key shortcomings observed in prior schemes and the underlying root causes.
- Achieving high performance in deep learning-based intrusion detection remains challenging, as models must accurately distinguish among multiple traffic classes, including benign and diverse attack types. The root cause of this difficulty lies in limited model selection, poor optimization, and inadequate preprocessing, which hinder robustness across diverse network conditions.
- Class imbalance is a prevalent issue in many intrusion detection datasets, often characterized by unequal distribution among different traffic classes. This imbalance often leads to inflated false-positive rates and diminished detection efficacy, as the model may struggle to effectively identify and classify rare anomalous or adversarial traffic. The root cause of this limitation is the insufficient use of resampling techniques to balance the dataset, which hampers the model’s ability to learn from minority classes effectively.
- The generalizability and adaptability of these models remain significant challenges, as their performance often declines when faced with variations in network parameters and diverse attack types. The root cause of this limitation is the insufficient testing and validation of models across multiple, diverse datasets, which restricts their ability to effectively generalize and adapt to dynamic, real-world network environments.
- Scalability remains a challenge for deep learning models, especially in large-scale, real-time applications where fast and efficient processing is critical. The root cause is due to inadequate model optimization for high-volume environments, including extended training times, high inference latency, and substantial memory requirements, which limit their practicality for deployment.
A comparison of related works with our work, as shown in Table 3, highlights the strengths and limitations of various models compared to our AE-DTNN approach.
Table 3.
Comparison of related works with our work.
The AE-DTNN model overcomes these challenges by optimizing class balance, computational efficiency, and adaptability while ensuring real-time deployment. These improvements enhance detection accuracy, reduce false alarms, and strengthen overall IDS performance. The strategies for addressing these challenges are outlined below.
- High performance: A high-performance IDS is developed using the hybrid AE-DTNN model, where the AE restructures network traffic data, Dense layers extract relevant features, and the Transformer network enables accurate classification. The data preprocessing pipeline includes hybrid outlier detection using Z-score and LOF, followed by feature selection based on correlation and PCA for dimensionality reduction, ensuring optimized feature extraction and minimized computational overhead for maximum efficiency.
- Class imbalance: ADASYN resampling is employed for both binary and multi-class classification, combined with ENN and class weights to effectively address class imbalance. This integrated approach enhances model performance by generating synthetic samples for underrepresented classes and refining the decision boundary, resulting in improved classification performance across imbalanced datasets.
- Generalization: The AE-DTNN model achieves robust generalizability by leveraging a hybrid architecture that excels at learning intricate traffic patterns. The Autoencoder’s data reshaping, the Dense layers’ feature extraction, and the Transformer’s classification capabilities enable the model to adapt to varying network conditions and identify novel attack types across diverse datasets, including NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018.
- Scalability: This is a key factor in deploying the AE-DTNN model in real-time IDS environments. In Section 4.8, we assess inference time, training time, and memory usage, with results demonstrating that the model performs efficiently across these metrics. The AE-DTNN model exhibits optimal resource utilization, providing fast inference and reasonable training times, making it highly scalable and suitable for handling large datasets in operational network environments where performance is critical.
- Reducing false-positive and false-negative rates: The AE-DTNN model demonstrates a substantial reduction in both false-positive and false-negative rates, as supported by the confusion matrix analysis presented in Section 5 (Discussion). It effectively distinguishes between benign traffic and diverse categories of malicious activities. This capability highlights the model’s robust classification performance and significantly enhances the accuracy and reliability of intrusion detection. As a result, the AE-DTNN model is well suited for real-world deployment in dynamic and complex network security environments.
3. Methodology
The AE-DTNN architecture emerged as the chosen solution following a thorough assessment of the limitations of traditional IDS techniques and a process of iterative model refinement. To achieve high detection performance, the model employs an enhanced data preprocessing pipeline in combination with an optimized hybrid AE-DTNN structure. Designed specifically to address the challenges posed by skewed class distributions in network traffic, the model mitigates class imbalance using an improved ADASYN technique for oversampling in both binary and multi-class classification tasks, while ENN is applied for undersampling to remove noisy or ambiguous samples. Additionally, class weighting ensures balanced representation during training. To assess its generalizability, the model was applied to the NF-BoT-IoT-v2 dataset and further evaluated on the NSL-KDD and CSE-CIC-IDS2018 datasets. Furthermore, by incorporating a Transformer module, the architecture offers scalability to handle large-scale datasets. From an inference time perspective, AE-DTNN demonstrates practical suitability for real-time deployment in operational environments. A visual representation of the proposed architecture, depicted in Figure 1, demonstrates its efficacy in both binary and multi-class classification within the NF-BoT-IoT-v2 dataset.

Figure 1.
Schematic representation of the architecture used for binary and multi-class classification on the NF-BoT-IoT-v2 dataset.
The proposed AE-DTNN architecture, as shown in Figure 2, is structured into three primary processing blocks: a feed-forward (vanilla) Autoencoder for traffic reshaping, Dense layers for hierarchical feature extraction, and a Transformer module for final classification. The Autoencoder, selected for its simplicity, low computational cost, and effectiveness in learning compressed representations of high-dimensional input data, initially transforms the raw traffic by encoding and reconstructing key patterns. The output is then passed through Dense layers that abstract higher-level features for improved representation. These features are subsequently processed by the Transformer, which consists of a Transformer encoder followed by a classification layer. The Transformer encoder itself is composed of two main components: a multi-head attention (MHA) mechanism that captures contextual relationships among features and a feed-forward network (FFN) that further refines the attended outputs. This architecture enables the model to combine spatial compression, feature abstraction, and temporal/contextual learning to enhance detection accuracy across both binary and multi-class classification tasks.
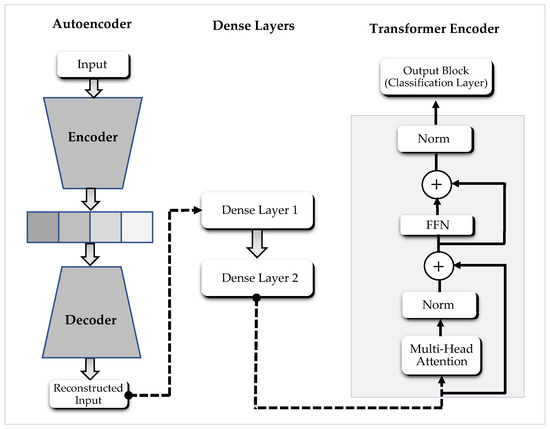
Figure 2.
Proposed AE-DTNN model architecture.
3.1. Dataset Description
A collection of network traffic data tailored for internet of things (IoT) devices and using NetFlow records was generated by expanding upon the existing NF-BoT-IoT dataset. Characteristics were derived from publicly accessible network packet capture (pcap) files, and the network communication sequences (flows) were marked with labels indicating their corresponding threat types. The entire set comprises 37,763,497 network communication instances. Of these, 37,628,460, representing 99.64%, were identified as malicious, while 135,037, or 0.36%, were classified as benign [27,28]. The data is divided into five distinct classes: one representing safe activity and four denoting separate attack classifications. A detailed categorization of class types is provided, emphasizing their unique attributes and potential impacts, as illustrated in Table 4.
Table 4.
NF-BoT-IoT-v2 dataset classes.
3.2. Data Preprocessing
Data preparation constitutes a foundational phase within data analysis and machine learning pipelines, encompassing the careful conversion of unprocessed, rough data into a consistent, organized format suitable for sophisticated examination and the creation of robust predictive systems, as shown in Figure 1. This process entails multiple phases, such as addressing absent values, eliminating redundant entries, discarding extraneous information or anomalies, pinpointing crucial characteristics, and executing scaling or standardization on numerical attributes. Additionally, techniques for modifying category distribution are utilized to rectify disparities among categories. Efficient preparation not only enhances the overall quality of the data but also diminishes interference, boosting the efficacy of machine learning systems in learning from the refined data. The preparation protocols can differ depending on the dataset, and for the NF-BoT-IoT-v2 dataset, the initial action involves managing any missing or null values, which are immediately discarded. Redundancies are then removed, followed by anomaly detection and removal using a combination of Z-Score and LOF techniques. A relationship-based attribute selection method is employed to lessen dimensionality, and numerical attributes are scaled using MinMaxScaler to ensure uniform data depiction. PCA is utilized to reduce dimensionality in the case of two-category classification and single-stage multi-category classification (including the standard category) to preserve the most impactful features and minimize data duplication. Following the execution of these steps, the dataset is divided into training and testing portions, followed by merging, at which point the ADASYN approach is applied to the combined data to produce artificial samples. These artificial samples are incorporated into the dataset, after which the training and testing sets are divided again, preserving the test set unchanged. This enhanced training set improves the system’s capacity to learn more effectively, resolving category imbalances and improving the system’s accuracy and overall performance. To further balance the dataset, the ENN method is used for downsampling, and class weights are adjusted during the system training phase. These comprehensive preparation methods ensure that the dataset is optimally formatted for machine learning, promoting effective system development and enhancing its ability to accurately identify and classify irregularities.
3.2.1. Outlier Removal Using Combined Z-Score and LOF
A dual-stage strategy was employed to refine the NF-BoT-IoT-v2 dataset and eliminate anomalous points, thereby enhancing its reliability for both binary and multi-class classification. Initially, the Z-score method was used to detect significant variations, with a threshold of 5 set to identify and discard any sample exhibiting a Z-score above this value in any feature. Subsequently, the LOF method was applied using 20 nearest neighbors and an anomaly percentage of 0.1, where entries labeled with −1 were considered outliers and removed, while entries labeled with 1 were retained. This combined approach effectively improved data quality by reducing the impact of anomalies and ensuring more robust model performance. For binary classification, the dataset was reduced from 41,596 benign, 64,100 reconnaissance, 89,736 DDoS, 79,770 DoS, and 1460 theft samples to 25,792 benign, 56,942 reconnaissance, 85,653 DDoS, 71,830 DoS, and 1012 theft samples, as shown in Table 5. For multi-class classification, the original distribution of 41,507 benign, 64,121 reconnaissance, 89,719 DDoS, 79,778 DoS, and 1452 theft samples was refined to 26,150 benign, 56,760 reconnaissance, 85,713 DDoS, 71,717 DoS, and 991 theft samples, as illustrated in Table 5.
Table 5.
Binary and multi-class classification sample counts for the NF-BoT-IoT-v2 dataset before and after Z-score and LOF outlier removal.
3.2.2. Feature Selection Based on Correlation
Relevance of attributes is determined by calculating the connection between each attribute and the target outcome. Attributes surpassing a defined absolute correlation threshold (0.01) are maintained. To mitigate multicollinearity, attributes with high inter-correlation (correlation > 0.9) are identified and eliminated. This approach ensures that the selected attributes are both significant to the target outcome and mutually independent, thereby enhancing model performance. The correlation technique was employed to select features for binary classification within the NF-BoT-IoT-v2 dataset, as depicted in Table 6. This method identified significant network traffic characteristics, notably FLOW_DURATION_MILLISECONDS, IN_BYTES, OUT_PKTS, TCP_FLAGS, and L7_PROTO, crucial for distinguishing varied traffic patterns. Table 6 details the selected features, encompassing packet size, duration, data transfer rate, and protocol-specific aspects, ensuring only the most relevant attributes are maintained for optimal classification.
Table 6.
Binary classification feature selection for the NF-BoT-IoT-v2 dataset, utilizing correlation.
The NF-BoT-IoT-v2 dataset underwent correlation analysis to determine the most significant features for multi-class classification. Table 7 lists the selected attributes, including network flow properties such as FLOW_DURATION_MILLISECONDS, IN_BYTES, OUT_PKTS, and TCP_WIN_MAX_IN, alongside protocol-specific details like L7_PROTO, DNS_QUERY_TYPE, and ICMP_TYPE. These features capture vital information regarding packet size, duration, data transmission speed, and transport-layer actions, thus refining the classification process.
Table 7.
Multi-class classification feature selection for the NF-BoT-IoT-v2 dataset, utilizing correlation.
3.2.3. Normalization
Data scaling is a critical preprocessing step in machine and deep learning that enhances model performance by standardizing feature values. In this work, the MinMaxScaler from the scikit-learn library was employed to normalize all input features, ensuring a consistent range across the dataset. This method transforms each feature to a [0, 1] scale. After evaluating several normalization techniques, MinMaxScaler was selected for its simplicity and effectiveness in improving model training. This method was applied to all features to ensure consistent scaling throughout the dataset.
3.2.4. Dimensionality Reduction Using PCA
PCA reduced the dimensions of the NF-BoT-IoT-v2 dataset, preserving maximal variance. For binary classification, PCA identified 19 principal components, retaining 99.98% of the dataset’s variance. Similarly, 18 principal components were selected for multi-class classification to maintain the same variance threshold. This dimensionality reduction increases computational efficiency while minimizing information loss, ensuring that the most significant features support the classification task.
3.2.5. Training and Testing Data Separation
A separation of the dataset into learning and testing segments was implemented, facilitating a strong assessment of the model’s performance. The learning segment allowed for pattern acquisition and model refinement, while the testing segment supplied an impartial valuation of its generalization proficiency. This split confirms the model’s applicability within authentic contexts. The NF-BoT-IoT-v2 dataset was split into training and testing sets for binary classification, distinguishing between safe and attack data. The training set comprised 24,520 safe and 204,647 attack entries, whereas the testing set contained 1272 safe and 10,790 attack entries. This breakdown, visually represented in Table 8, ensures sufficient examples for effective model development and performance measurement.
Table 8.
Distribution of samples in binary classification for NF-BoT-IoT-v2 dataset.
The NF-BoT-IoT-v2 dataset was prepared for multi-class classification, with data categorized into benign, reconnaissance, DDoS, DoS, and theft classes. The training set comprised 24,860 benign records, 53,918 reconnaissance instances, 81,432 DDoS attacks, 68,110 DoS attacks, and 944 theft cases. In the test set, there were 1290 benign samples, 2842 reconnaissance cases, 4281 DDoS attacks, 3607 DoS attacks, and 47 theft instances. As depicted in Table 9, this distribution provides a well-rounded representation of different categories, aiding in the development of a more effective classification model.
Table 9.
Distribution of samples in multi-class classification for NF-BoT-IoT-v2 dataset.
3.2.6. Class Balancing
Uneven class distribution presents a substantial obstacle within the NF-BoT-IoT-v2 dataset, potentially hindering the efficacy of machine learning algorithms. To alleviate this problem, a resilient class equalization method was deployed, utilizing a mix of augmentation and reduction procedures, established approaches for tackling class disparity [29]. Subsequently, the learning and assessment sets were joined, and ADASYN was utilized on the unified data. This method enhances learning by enabling the algorithm to profit from both training and evaluation data. Following the creation of simulated samples, the data collection was once again partitioned, with the revised learning set encompassing the initial training data coupled with the ADASYN-produced samples, while the assessment set remained unchanged. ADASYN was implemented to augment both two-category and multi-category classification tasks by fabricating artificial samples to bolster the presence of less frequent categories. This strategy boosts algorithm performance by enriching the data with extra samples. Additionally, ENN was applied to the learning data for reduction, eliminating disruptive or superfluous instances from the dominant category. Class weights were altered during algorithm training to balance the impact of each category, guaranteeing that the algorithms did not become prejudiced towards the majority category. By employing this combination of ADASYN for augmentation, ENN for reduction, and category weight adjustments, the algorithm’s capacity to precisely identify and categorize infrequent categories was considerably improved, resulting in superior performance and dependability. Nonetheless, despite attaining high precision, algorithms may still encounter the precision paradox, where infrequent category predictions are feeble [30]. To counteract this, an enhanced strategy, inspired by [31], was introduced, integrating ADASYN for augmentation, ENN for reduction, and class weights to furnish a more potent resolution to class disparity. This approach secures more uniform performance across all categories, ultimately enhancing the algorithm’s effectiveness in handling unbalanced data.
- ADASYN
A strategy to rectify class disparity involved the application of ADASYN. This technique generates synthetic data points for the minority class, following the data’s inherent distribution. The model’s aptitude for learning from sparsely populated instances is thereby improved, resulting in better classification performance. The focus on the minority class achieves a more equitable dataset, diminishing prejudice against majority classes and strengthening the model’s generalization across various classes. The NF-BoT-IoT-v2 dataset initially displayed a pronounced class imbalance in its binary classification setup, with 25,792 normal samples and 215,437 attack instances. To mitigate this imbalance, ADASYN resampling was employed once, generating additional synthetic samples for the minority class and bringing the normal sample count to 215,443. This process resulted in a more evenly distributed dataset, enhancing the model’s capacity to distinguish between normal and attack traffic. Table 10 presents the sample distribution before and after ADASYN resampling, demonstrating its effectiveness in addressing class imbalance and improving classification reliability.
Table 10.
Effect of ADASYN resampling on class distribution for binary classification of the NF-BoT-IoT-v2 dataset.
The NF-BoT-IoT-v2 dataset originally displayed a significant disparity in class distribution for multi-class classification, with the benign and theft categories containing notably fewer samples than other attack types. To rectify this imbalance, ADASYN resampling was utilized twice, synthesizing additional instances for the underrepresented classes. As a result, benign samples increased from 26,150 to 85,730, while theft cases rose from 991 to 85,722, creating a more evenly distributed dataset. This modification improves the model’s ability to identify patterns across all categories, reducing bias toward dominant classes. Table 11 illustrates the sample distribution before and after ADASYN resampling, highlighting its role in enhancing dataset balance and classification accuracy.
Table 11.
Effect of ADASYN resampling on class distribution for multi-class classification of the NF-BoT-IoT-v2 dataset.
- 2.
- ENN
The ENN method, using its default automatic sampling, was applied to refine the dataset by removing misclassified and unclear data points. This technique identifies and eliminates samples that deviate from the majority of their closest neighbors, thus improving the dataset’s quality. Reduction of noise and enhanced class separation result from this process. A more reliable training set is created by ENN, which ultimately contributes to improved model generalization and classification performance. The NF-BoT-IoT-v2 dataset underwent refinement of its class distribution for binary classification through the application of the ENN technique. Prior to ENN, the dataset comprised 214,171 normal samples and 204,647 attack samples. Post-resampling, a slight reduction in normal samples occurred, decreasing to 214,164, while the attack sample count remained constant. This minimal change suggests ENN primarily filtered out misclassified or ambiguous samples, enhancing dataset quality without substantially altering its overall balance. Table 12 visually represents the effect of ENN resampling, showcasing its contribution to improved data consistency for enhanced model training.
Table 12.
Effect of ENN resampling on class distribution for binary classification of the NF-BoT-IoT-v2 dataset.
The ENN method was applied to refine the NF-BoT-IoT-v2 dataset for multi-class classification by eliminating ambiguous or misclassified samples. Prior to ENN resampling, the dataset contained 84,440 benign instances, 53,918 reconnaissance samples, 81,432 DDoS attacks, 68,110 DoS attacks, and 85,675 theft cases. After applying ENN, the number of DDoS instances was reduced to 80,262, while DoS samples decreased to 63,186, with other classes remaining unchanged. This selective reduction helps improve data quality by removing potentially mislabeled or redundant samples, leading to better model generalization. Table 13 illustrates the impact of ENN on the dataset distribution.
Table 13.
Effect of ENN resampling on class distribution for multi-class classification of the NF-BoT-IoT-v2 dataset.
- 3.
- Class Weights
Uneven category representation was rectified through the deliberate calculation of category importance values, mirroring the spread of data points across the dataset. The overall data count and the presence of each category were leveraged to assign greater significance to less prevalent categories and diminished significance to more prevalent ones. These importance values were then organized into a structured collection, guaranteeing the model compensates for category differences during its learning phase. This strategy bolsters the model’s aptitude for identifying instances of underrepresented categories and forestalls partiality towards overrepresented categories. The disparity in quantity between typical and attack records in the NF-BoT-IoT-v2 dataset’s two-part sorting was managed using category-specific weighting. The assigned weights gave a slightly elevated importance to the attack category (1.0233) and a diminished importance to the typical category (0.9778). This weighting strategy prevents the model from favoring the more prevalent category while preserving a balanced learning process, as shown in Table 14. By adjusting how much each category affects the error rate, this method strengthens the model’s ability to accurately pinpoint attack records without harming overall effectiveness.
Table 14.
Assigned class weights on model training for binary classification of the NF-BoT-IoT-v2 dataset.
Category-specific weights were assigned to rectify the uneven distribution of class types in the NF-BoT-IoT-v2 dataset’s multi-class classification, as shown in Table 15. The benign and theft categories, due to their higher frequency, received lower weights (0.8704 and 0.8578, respectively). Conversely, the reconnaissance and DoS categories were assigned higher weights (1.3631 and 1.1632) to compensate for their lower occurrence. The DDoS category received a moderate weight of 0.9157. This adjustment of weights encouraged the model to treat underrepresented categories more equitably, improving its ability to correctly classify minority class instances while preventing bias towards majority classes.
Table 15.
Assigned class weights on model training for multi-class classification of the NF-BoT-IoT-v2 dataset.
3.3. Proposed Model
This section introduces the proposed AE-DTNN, a hybrid deep learning architecture designed for both binary and multi-class intrusion detection. The model integrates the feature extraction capabilities of Autoencoders, the representational strength of Dense layers, and the contextual learning power of Transformer blocks to enhance detection performance across diverse datasets.
Autoencoder–Dense–Transformer (AE-DTNN)
The proposed AE-DTNN model is trained and evaluated using the NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 datasets, where the input is the number of features. The model begins with a feed-forward (vanilla) Autoencoder, which consists of an input layer, a hidden encoder layer, and a decoder layer. The input layer receives the raw features, which are then passed to the encoder layer, a fully connected Dense layer that learns a compressed representation of the input data. The decoder layer reconstructs the input from the encoded representation, ensuring that the most significant features are retained. This type of Autoencoder was selected due to its simplicity, low computational cost, and strong capability in capturing the underlying structure of high-dimensional data without requiring complex architectural components. Its straightforward design makes it well suited for traffic reshaping in intrusion detection tasks, enabling efficient dimensionality reduction while preserving key information. The reconstructed inputs produced by the Autoencoder are used as input to the subsequent Dense layers. The Dense layers consist of multiple fully connected layers with activation functions, refining and transforming the feature representations for improved classification performance. The output of the Dense layers then serves as the input to the Transformer block, which captures long-range dependencies and contextual relationships within the data. The model adopts a Transformer architecture that includes a Transformer encoder, focusing solely on encoding input features for classification tasks. The Transformer encoder consists of two primary components. The first is the MHA mechanism, which enables the model to attend to different parts of the input simultaneously, thereby capturing complex feature interactions. This is followed by Layer Normalization and a residual connection to maintain uninterrupted information flow, mitigate the vanishing gradient problem, and stabilize training. The second component is a FFN, composed of two Dense layers: the first with ReLU activation and the second with no activation. This FFN processes each feature position independently to learn non-linear transformations. A residual connection and Layer Normalization are subsequently applied to the FFN output to enhance model stability and convergence. The output of the Transformer encoder is then flattened into a one-dimensional vector and passed to the output layer for final classification. For binary classification, a sigmoid activation function produces a single output neuron representing the probability of the instance belonging to class 1, while the probability of class 0 is computed as one minus this value. For multi-class classification, a softmax activation function generates output neurons corresponding to various class types.
The encoder layers progressively reduce the dimensionality of the input data, enabling the model to extract key features through Dense layers. This process of dimensionality reduction and feature extraction can be mathematically expressed as shown in Equation (1) [32].
Within this framework, signifies the output produced by the encoder layer l, while denotes the output of the prior layer, which acts as the input for the subsequent layer. The weight matrix corresponding to layer l is symbolized as , and the related bias vector is expressed as . The activation function f, applied in this scenario, is the ReLU function.
Within a typical self-encoding mechanism, the decoding stratum bears the duty of regenerating the initial entry from the condensed depiction crafted by the encoding unit. This act of rebuilding the entry from the encoded attributes can be numerically depicted within Formula (2) [32].
In this scenario, ά designates the reproduced output, whereas denotes the concluding output of the encoding stage. Within the decoder layer, its structure is determined by the corresponding weight matrix and symbolizing its corresponding bias vector. The activation function g, typically configured as a linear function, is utilized to assist in the rebuilding process.
Multi-head attention effectively discerns intricate connections within the entry information, as demonstrated by Formula (3) [33].
In this setting, Q stands for the query matrix, K indicates the key matrix, and V symbolizes the value matrix. The parameter indicates the size of the key vectors, which is essential for calculating the attention scores within the model.
The attention evaluation for each attention component operates in isolation, with the ensuing outcomes then being amalgamated, as per Equation (4) [33].
Within this framework, denotes the output weight matrix, which is employed to convert the previous layer’s output into the model’s final output.
As articulated in Formula (5) [34], Layer Normalization generates consistent output throughout every stratum.
In this setting, µ indicates the average of the inputs, while σ signifies their standard deviation. Additionally, γ and β are adjustable elements utilized for the normalization.
The FFN receives and processes the consequences of the attention mechanism, as depicted in Equation (6) [33].
In this scenario, and correspond to the weight matrices, while and signify the bias parameters associated with the layer operations.
- (i)
- Binary Classification
The proposed AE-DTNN, as shown in Table 16, is designed for binary classification using the NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 datasets, where the input dimensions are 19, 118, and 68, respectively. The model begins with an Autoencoder, which learns a compact representation of the input features by encoding them into a lower-dimensional space and then reconstructing them. The Autoencoder consists of an input layer corresponding to the number of features in the dataset, followed by an encoder layer with 64 neurons and ReLU activation. The decoder layer then reconstructs the input using a linear activation function, ensuring minimal reconstruction error. The reconstructed outputs generated by the Autoencoder are subsequently fed into the following Dense layers. This section comprises two fully connected layers with 256 and 128 neurons, respectively, both activated by ReLU. To enhance generalization and prevent overfitting, an extremely small Dropout value of 1 × 10−7 is applied after each Dense layer. Following the Dense layers, the Transformer block refines feature representation using the Transformer encoder architecture. The encoder begins with an MHA mechanism, which operates with 8 attention heads and a key dimension of 64, enabling the model to capture complex and diverse dependencies within the feature space. The output of the attention mechanism is normalized using Layer Normalization (ε = 1 × 10−6) and combined with the input to the attention layer through residual connection to preserve information flow and improve training stability. This is followed by a FFN consisting of two Dense layers, each with 128 neurons, where the first uses ReLU activation and the second has no activation. This structure further processes the attended features while preserving the original dimensionality. The output of the FFN is added back to the FFN input via another residual connection and then normalized using Layer Normalization (ε = 1 × 10−6). Finally, the processed features are flattened into a one-dimensional vector and passed to a Dense output layer with a single neuron activated by a sigmoid function for binary classification.
Table 16.
AE-DTNN model structure.
- (ii)
- Multi-Class Classification
The proposed AE-DTNN, as shown in Table 16, is designed for multi-class classification using the NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 datasets, where the input feature dimensions are 18, 118, and 68, respectively. The architecture begins with an Autoencoder, which extracts a compact feature representation by encoding the input into a lower-dimensional space and subsequently reconstructing it. The Autoencoder comprises an input layer matching the feature dimensions of the dataset, followed by an encoder with 64 neurons activated by ReLU. A decoder layer with a linear activation function reconstructs the input while minimizing the reconstruction error. The reconstructed outputs from the Autoencoder are then passed through the subsequent Dense layers for further processing. This module consists of two fully connected layers with 256 and 128 neurons, both using ReLU activation. To improve generalization and mitigate overfitting, an extremely small Dropout rate of 1 × 10−7 is applied after each Dense layer. Next, a Transformer block enhances the extracted features using the Transformer encoder architecture. The encoder starts with an MHA mechanism that employs 8 attention heads with a key dimension of 64, allowing the model to capture intricate dependencies across different parts of the feature space simultaneously. The output from the attention module is normalized using Layer Normalization (ε = 1 × 10−6) and combined with the original input to the attention layer via a residual connection, which help maintain smooth gradient flow and stable training. Next, a FFN is applied, comprising two Dense layers with 128 neurons each, the first utilizing ReLU activation and the second without activation. This network refines the attended features while maintaining the same dimensionality. A residual connection then adds the FFN’s output to its input, followed by Layer Normalization (ε = 1 × 10−6) to enhance stability and convergence. Finally, the processed features are flattened into a one-dimensional vector and passed to a Dense output layer using a softmax activation function for multi-class classification, with five neurons for the NF-BoT-IoT-v2 and NSL-KDD datasets, and fifteen neurons for the CSE-CIC-IDS2018 dataset.
- (iii)
- AE-DTNN Hyperparameters
The adjustable hyperparameters for the Autoencoder model are shown in Table 17. For both two-class and multi-class categorization endeavors, the model functions with a batch size of 64, defining the count of samples handled before the model modifies its internal parameters. The Adam optimization algorithm is employed with its standard learning rate of 0.001, guaranteeing productive and consistent convergence during training. The model utilizes mean squared error (MSE) as the error measure for both tasks.
Table 17.
Autoencoder hyperparameter values.
The DTNN hyperparameter configuration (Table 18) is precisely adjusted for dual-category and multi-category objectives. It implements a batch size of 128 and the Adam optimization technique. A variable learning rate, commencing at 0.001 and diminishing when validation error stabilizes, is utilized, with a lowest rate of 1 × 10−5. Dual-category tasks utilize binary cross-entropy as the error measurement, while multi-category tasks employ categorical cross-entropy. Accuracy serves as the performance indicator for both scenarios.
Table 18.
DTNN hyperparameter values.
4. Results and Experiments
This segment offers a thorough evaluation of the constructed irregularity identification systems, encompassing the CNN, Autoencoder, DNN, Transformer, and AE-DTNN. To optimize efficacy and address issues stemming from uneven data distribution, we employed refined data balancing methods alongside category importance adjustments on the challenging NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 datasets. The empirical outcomes demonstrate that our systems surpass current leading methods in abnormality detection precision. Specifically, the integration of advanced data preparation procedures and the novel frameworks presented in this investigation substantially elevate the systems’ abilities to discern complex and nuanced deviations, signifying a substantial progression within the domain.
4.1. Dataset Characteristics and Preprocessing Outline
This investigation employs the NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 data repositories, which are frequently acknowledged standards for IDS that document varied network behaviors and intrusion styles. Nevertheless, difficulties including absent entries, repetitive information, extreme values, and uneven category distribution demand meticulous preparatory steps. To improve information integrity, methods such as value replacement, duplicate removal, deviation management, and category equalization are implemented, guaranteeing dependable system assessment for both two-category and multiple-category categorization.
4.1.1. NF-BoT-IoT-v2 Dataset
The NF-BoT-IoT-v2 data corpus, detailed in Section 3.1, offers a detailed portrayal of network operations encapsulating both benign and adversarial traffic across a spectrum of attack vectors, thus serving as an indispensable asset for IDS investigations. Notwithstanding its intrinsic worth, the dataset presents complexities such as incomplete data points, redundant entries, and substantial disparities in class representation. These impediments underwent systematic resolution via the preprocessing protocols delineated in Section 3.2. The procedure encompassed the management of absent data through imputation, the elimination of duplicate records, and the application of advanced outlier identification methodologies, including a synergistic Z-score and LOF approach, coupled with feature selection via correlation analysis. Furthermore, numerical attributes were subjected to MinMaxScaler normalization to guarantee uniformity, followed by dimensionality reduction using PCA. To rectify class imbalance, sophisticated resampling strategies, such as an augmented ADASYN for oversampling in both binary and multi-class contexts and ENN for undersampling, were incorporated into the model training pipeline, alongside the implementation of class weighting. These exhaustive preparatory measures significantly fortified the dataset’s resilience and dependability for both two-category and multiple-category classification objectives.
4.1.2. NSL-KDD Dataset
The NSL-KDD data collection, first presented by M. Tavallaee in reference [35], represents an advancement over the KDD’99 data and functions as a standard for assessing intrusion detection techniques. It comprises KDDTrain and KDDTest, segmented by varying complexity. In contrast to KDD’99, it removes repetitive and identical entries, guaranteeing an equitable and trustworthy training phase while upholding proportional selection across difficulty tiers to uphold the original spread [35]. Furthermore, its reasonable size permits thorough experimentation without the need for random sampling, simplifying accurate comparisons between detection algorithms [35]. The dataset encompasses 41 features and a classification tag, classifying network traffic into five groups: standard activity; Denial of Service (DoS) attacks, which deplete system resources to interrupt services [36]; reconnaissance attacks (probe), which collect network information for exploitation [36]; remote to local (R2L) attacks, wherein a malicious actor obtains unauthorized network entry [36]; and user to root (U2R) attacks, where a user elevates permissions to administrative privileges [36]. Within the 41 features, 3 are qualitative, including the Protocol type with 3 options, Service with 70 options, and Flag with 11 options, while the remaining 38 features are quantitative [36]. These refinements establish NSL-KDD as a commonly utilized and well-organized data resource for intrusion detection studies. For the NSL-KDD data repository, the preparation stage commences with addressing absent information by eliminating partial entries, followed by the removal of identical records to eliminate repetition. Anomalous values are detected and managed via the Z-Score procedure to elevate data uniformity, while MinMaxScaler is employed to standardize quantitative attributes, and one-hot encoding is implemented to transform qualitative characteristics into a numerical configuration suitable for model instruction. In two-category classification, the data collection is initially partitioned into training and validation segments, which are subsequently joined temporarily to implement ADASYN, producing artificial instances to rectify category disparities within the five-category dataset. Following enhancement, the data collection is re-divided, ensuring the validation set remains unaltered, followed by ENN undersampling to filter out irregular or marginal cases from the training data. The training and validation segments are then reassembled, and ADASYN is re-applied for two-class binary classification. The data collection is subsequently split anew, with the validation set remaining constant, while ENN is once more utilized to refine the training set by removing supplementary irregular instances. Furthermore, class weights are incorporated during model training to further lessen any residual category imbalances. For multiple-category classification, a comparable approach is executed: the data collection is initially segmented, followed by the recombination of training and validation data for ADASYN augmentation, then re-separated while maintaining the integrity of the validation set. ENN undersampling is performed on the training data to improve its quality, and class weight adaptations are introduced to enhance model generalization. This systematic data preparation framework ensures a well-proportioned and superior-quality data resource, reinforcing the model’s dependability in irregularity identification and improving its efficacy in accurately categorizing network traffic.
4.1.3. CSE-CIC-IDS2018 Dataset
The CSE-CIC-IDS2018 dataset [37] emerged from a collaborative initiative between the communications security establishment (CSE) and the Canadian Institute for Cybersecurity (CIC), aimed at advancing the field of IDS research. Conceived as a comprehensive and high-fidelity resource, this dataset has evolved into a prominent benchmark for assessing the effectiveness of IDS methodologies. It was meticulously engineered to simulate authentic and diverse cyberattack scenarios within realistic network traffic, capturing the complex nature of modern threat landscapes. Its design reflects an intricate emulation of operational network environments, enabling researchers and security professionals to rigorously evaluate and enhance the robustness and adaptability of IDS solutions. Collected over a span of ten consecutive days, the dataset comprises 80 feature attributes and encompasses 15 distinct classes [38], offering a rich foundation for empirical analysis and performance benchmarking in cybersecurity research. The preprocessing of the CSE-CIC-IDS2018 dataset commenced with merging all ten CSV files, each representing a day’s network activity, into a single comprehensive dataset to facilitate thorough analysis. Features with only one distinct value across all entries were discarded, as they lacked predictive significance. To create a balanced and computationally feasible dataset, representative samples were selected. Outlier detection was conducted using both the LOF and Z-score techniques (with Z-score applied specifically to the Benign and Infiltration classes for further refinement) to identify and remove extreme values that might hinder model accuracy. The cleaned dataset was then divided into input features and target labels, and all numerical features were normalized using the MinMaxScaler to ensure uniform scaling. Lastly, the data were split into training and testing subsets, finalizing the preprocessing workflow and enabling the next phase of model development and validation.
4.2. Configuration Overview of the Compared Models
In this section, we present a configuration overview of the compared models: CNN, Autoencoder, DNN, and Transformer. These models were selected based on their demonstrated effectiveness across a range of performance metrics [39,40,41].
4.2.1. Convolutional Neural Network (CNN)
The input to the neural network corresponds to the number of features present in each dataset, which varies depending on the specific data source. The structure initiates with a data entry point, followed by three sets of convolutional operations, each comprising a convolutional level to derive attribute representations, Batch Normalization to maintain consistent training, a rectified linear unit (ReLU) to introduce non-linear processing, maximum pooling to lessen data size while keeping important traits, and Dropout (0.0000001) to prevent overfitting. Subsequent to the convolutional sets, the resultant attribute representations are transformed into a linear array and transmitted through three completely interconnected levels, which additionally refine the derived representations. Ultimately, the output layer is configured based on the classification task. For binary classification, it comprises a single node with a sigmoid activation function to produce a two-class prediction. For multi-class classification, the output layer contains five units for the NF-BoT-IoT-v2 and NSL-KDD datasets and fifteen units for the CSE-CIC-IDS2018 dataset, all using softmax activation to enable classification across multiple categories [32,42].
4.2.2. Autoencoder (AE)
The Autoencoder receives input based on the feature count of each dataset, which differs according to the specific data source. The Autoencoder consists of a compression and decompression unit, where the compression unit is composed of three densely connected stages with 128, 64, and 32 neurons, in that order, each employing the ReLU activation to progressively reduce the characteristic size while retaining key representations. The decompression unit symmetrically reconstructs the input using corresponding densely connected stages. Upon finalization of training, the compression unit is extracted to transform input data into a smaller-dimensional representation, while the decompression unit is discarded [43,44,45,46]. For binary classification tasks, a classification stage with a single output unit is appended to the encoder, utilizing a sigmoid activation function that outputs a probability score between zero and one. For multi-class classification, a sorting layer is added instead, employing a softmax activation function. The number of output units corresponds to the number of classes in each dataset: five units for the NF-BoT-IoT-v2 and NSL-KDD datasets and fifteen units for the CSE-CIC-IDS2018 dataset. This setup enables the model to output a probability distribution over all possible categories, with each unit representing the likelihood of a specific class [15,19,23].
4.2.3. Deep Neural Network (DNN)
The DNN model is engineered for both binary and multi-class classification tasks. The input to the neural network corresponds to the number of features present in each dataset, which varies depending on the specific data source. The framework comprises several Dense layers, each employing the ReLU activation function to identify intricate arrangements. The initial layer possesses 64 processing units, followed by Batch Normalization to stabilize outputs and Dropout (0.3) to lessen over-adaptation. The subsequent layer includes 32 processing units, and the third has 16 processing units, both integrating Batch Normalization and Dropout (0.3) to improve training consistency. For binary classification, the final Dense layer consists of a single processing unit with a sigmoid activation function, outputting a probability between 0 and 1. For multi-class classification, the concluding Dense layer employs a softmax activation function with five output neurons for the NF-BoT-IoT-v2 and NSL-KDD datasets and fifteen output neurons for the CSE-CIC-IDS2018 dataset, producing probability distributions across the respective class categories [32].
4.2.4. Transformer
This system employs a Transformer architecture, a type of artificial neural network, to perform both binary and multi-class classification. The input to the model consists of feature vectors, with the number of features varying depending on the dataset used. Each input is treated as a column vector and processed through a MHA mechanism, which operates across eight parallel attention heads, each focusing on different aspects of the feature space using a key dimension of 64. To ensure consistent behavior and improve training stability, Layer Normalization is applied, with a small constant added for numerical stability. To facilitate efficient learning, the system incorporates a shortcut connection, also known as a residual connection, which helps maintain strong signal flow during training. Following the attention mechanism, the data is processed by a FFN, which is a series of two fully connected layers, each containing 128 neurons [47], where the first uses ReLU activation and the second has no activation. Another residual connection and normalization step are then applied. The resulting data is flattened into a one-dimensional array before reaching the output layer. For binary classification, the final output layer consists of a single neuron with a sigmoid activation function producing a probability between 0 and 1. For multi-class classification, a softmax-activated output layer is used, with five neurons for the NF-BoT-IoT-v2 and NSL-KDD datasets and fifteen neurons for the CSE-CIC-IDS2018 dataset, providing a probability distribution over the possible classes [15,19,33].
Model Hyperparameters
Specific adjustable settings were implemented within the model to guarantee optimal functionality for both two-class and multiple-class categorization tasks after characteristic extraction. A consistent batch size of 128 was utilized, and the Adam optimization algorithm was chosen for its efficient parameter updates. The learning speed was dynamically regulated through a ReduceLROnPlateau scheduler, initiating at 0.001 and diminishing by a factor of 0.5 whenever the validation error reached a plateau, with a minimum speed of 1 × 10−5. The core distinction between two-class and multiple-class configurations resided in the error function: binary cross-entropy for two-class categorization and categorical cross-entropy for multiple-class categorization. Accuracy was the selected performance metric for both categorization types. This configurable parameter layout, reflecting the setups for the model, sought to optimize the model’s efficacy in learning and categorizing information.
4.3. Experiment’s Establishment
The algorithmic structures were developed using TensorFlow and Keras within the Kaggle environment. The experimental setup included hardware equipped with an Nvidia GeForce RTX 1050 graphics processing unit and the Windows 10 operating system. Throughout all data balancing procedures, only the training partition was modified. The validation dataset, preserved in its original state, was strictly reserved for evaluating the model’s effectiveness.
4.4. Evaluation Metrics
The confusion matrix is a widely recognized method for evaluating machine learning models. It compares the actual and predicted class labels within a structured grid, as documented in source [48]. This matrix allows for the calculation of several key performance metrics by clearly displaying the classification outcomes. Specifically, true positives (TPs) represent instances correctly identified as belonging to the positive class, while true negatives (TNs) refer to correctly identified negative instances. In contrast, false positives (FPs) occur when negative instances are mistakenly classified as positive, leading to false alarms, and false negatives (FNs) occur when positive instances are incorrectly classified as negative, potentially resulting in missed detections. These values are critical for assessing model performance, especially in scenarios where misclassifications can have significant consequences. The fundamental metric of accuracy, defined in Equation (7) [49], is calculated directly from the confusion matrix.
In addition to accuracy, it is essential to evaluate a model’s performance using other metrics, particularly when working with imbalanced datasets. Accordingly, the evaluation also includes recall, precision, and the F-score. Precision is the ratio of correctly predicted positive cases to the total number of cases predicted as positive, including both true and false positives. This metric, also known as the positive predictive value, is expressed in Equation (8) [49]. Recall, defined in Equation (9) [49], measures the proportion of actual positive cases that are correctly identified by the model. The F-score, shown in Equation (10) [50,51,52,53,54], is the harmonic mean of precision and recall and provides a balanced evaluation of both.
The primary objective is to maximize these evaluation metrics: accuracy, precision, recall, and F-score, in accordance with the prescribed performance assessment criteria.
4.5. Results
The evaluation of the proposed model with baseline models was conducted using the NF-BoT-IoT-v2 dataset for training and testing, with further assessments on the NSL-KDD and CSE-CIC-IDS2018 datasets to validate their generalizability. The study explored both binary and multi-class classification, assessing the influence of data resampling strategies and comparing performance with existing intrusion detection frameworks. Findings revealed that the AE-DTNN model demonstrated exceptional accuracy in identifying and categorizing attacks, while the CNN, Autoencoder, DNN, and Transformer models also yielded competitive results. These outcomes emphasize the efficiency of preprocessing methods and the resilience of the proposed model in tackling classification complexities. In this evaluation, accuracy refers to the overall classification accuracy, while precision, recall, and F1-score are reported as weighted averages to account for class imbalance across the datasets.
- (i)
- Binary Classification
The effectiveness of various deep learning models for binary classification is clearly demonstrated through their performance on the NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 datasets, as shown in Table 19. On the NF-BoT-IoT-v2 dataset, the CNN and Autoencoder performed equally well, achieving 99.97% in accuracy, precision, recall, and F-score. The DNN model exhibited slightly lower performance, recording 99.87% across all metrics, while the Transformer model followed closely with 99.96%. Our proposed AE-DTNN model demonstrated the best results, achieving the highest scores of 99.98% across all evaluation measures. For the NSL-KDD dataset, the CNN model achieved an accuracy of 97.34%, with a slightly higher precision of 97.40%, while recall and F-score remained at 97.34%. The Autoencoder model performed slightly better, attaining 98.54% in accuracy, recall, and F-score, with precision reaching 98.55%. The DNN model maintained consistent values of 98.46% across all metrics. Meanwhile, the Transformer model recorded 97.33% for accuracy, recall, and F-score, with a marginally higher precision of 97.34%. Our AE-DTNN model once again outperformed the other models, achieving the highest accuracy, precision, recall, and F-score of 98.57%, reinforcing its effectiveness in detecting network intrusions. For the CSE-CIC-IDS2018 dataset, the models maintained strong performance across all evaluation metrics. The CNN model achieved 99.88% in accuracy, precision, recall, and F-score, while the Autoencoder slightly outperformed in terms of accuracy and recall at 99.89%, with precision and F1-score remaining at 99.88%. The DNN model recorded consistent values of 99.86% across all measures. The Transformer model outperformed the previous models slightly, attaining 99.90% for all metrics. The AE-DTNN model delivered the best results, achieving the highest accuracy, precision, recall, and F-score of 99.92%. Each metric was computed independently and carefully validated to ensure correctness, and the uniformity of the results reflects the model’s ability to handle highly imbalanced binary network traffic with exceptional precision and consistency. These outcomes underscore the robustness and generalizability of the AE-DTNN model across diverse intrusion detection datasets. The superior performance of AE-DTNN can be attributed to its architectural synergy: the feed-forward (vanilla) Autoencoder effectively reduces noise and extracts compact, high-quality representations of network traffic, the Dense layers enhance hierarchical feature abstraction by capturing complex relationships within the reconstructed data, and the Transformer encoder captures long-range dependencies and contextual patterns critical for distinguishing between normal and anomalous behaviors.
Table 19.
Evaluation measures for binary classification models.
- (ii)
- Multi-Class Classification
The performance evaluation of multi-class classification models, as presented in Table 20, highlights the effectiveness of different architectures across the NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 datasets. On the NF-BoT-IoT-v2 dataset, the CNN model achieved an accuracy, recall, and F-score of 98.07%, with a slightly higher precision of 98.08%. The Autoencoder model demonstrated marginal improvement, reaching 98.08% in accuracy and recall, 98.07% in F-score, and 98.12% in precision. The DNN model exhibited stronger performance, with 98.14% across accuracy, recall, and F-score, and 98.19% in precision. The Transformer model displayed slightly lower results, recording 97.91% for accuracy, recall, and F-score, with precision at 97.96%. Our proposed AE-DTNN model outperformed all others, achieving the highest values across all metrics: 98.30% in accuracy, recall, and F-score, with 98.32% in precision. For the NSL-KDD dataset, the CNN model recorded an accuracy and recall of 97.38%, an F-score of 97.46%, and a slightly higher precision of 97.68%. The Autoencoder model performed similarly, attaining 97.33% in accuracy and recall, 97.47% in F-score, and 97.78% in precision. The DNN model demonstrated an improvement, reaching 97.47% in accuracy and recall, 97.76% in F-score, and 98.20% in precision. The Transformer model achieved 97.48% in accuracy and recall, 97.56% in F-score, and 97.76% in precision. Once again, our AE-DTNN model achieved the highest performance, with 97.50% in accuracy and recall, 97.82% in F-score, and 98.25% in precision. For the CSE-CIC-IDS2018 dataset, all models exhibited excellent performance. The CNN model achieved 99.76% across accuracy, precision, and recall, with an F-score of 99.75%. The Autoencoder model showed comparable results, attaining 99.73% in accuracy, precision, and recall, and 99.72% in F-score. The DNN model recorded slightly lower values, with 99.70% for accuracy and recall and 99.67% in precision and F-score. The Transformer model performed slightly better, achieving 99.76% in accuracy, recall, and F-score, and 99.77% in precision. The AE-DTNN model delivered the best performance across all metrics, reaching 99.78% in accuracy, precision, recall, and F-score. Each metric was computed independently and carefully validated to ensure correctness, and the uniformity of the results reflects the model’s ability to handle highly imbalanced yet structured network traffic with exceptional precision. These results reinforce the superiority of AE-DTNN in handling complex multi-class classification tasks across different datasets. These results reinforce the superiority of AE-DTNN in handling complex multi-class classification tasks across different datasets. The root cause of this enhanced performance lies in the model’s integrated architecture: the feed-forward (vanilla) Autoencoder reduces data dimensionality and filters noise, the Dense layers learn discriminative hierarchical features, and the Transformer encoder captures dependencies among feature dimensions, which is particularly beneficial for distinguishing closely related attack classes.
Table 20.
Evaluation measures for multi-class classification models.
4.6. Ablation Study on Component-Wise Enhancements in the AE-DTNN Model
The performance of the proposed hybrid AE-DTNN model shows notable improvements with the inclusion of each additional component across both binary and multi-class classification tasks, as shown in Table 21. In binary classification, for the NF-BoT-IoT-v2 dataset, the Autoencoder (AE) alone achieves an accuracy of 95.82%, which increases to 99.79% when Dense is added (AE + Dense) and further improves to 99.98% with the addition of the Transformer (AE + Dense + Transformer). Similarly, for the NSL-KDD dataset, AE achieves an accuracy of 96.55%, which is slightly improved to 98.01% with AE + Dense and further reaches 98.57% when the Transformer is incorporated into the model. The CSE-CIC-IDS2018 dataset follows a similar trend, where AE achieves 98.12%, AE + Dense increases accuracy to 99.77%, and the highest performance is reached with AE + Dense + Transformer at 99.92%. On the other hand, the model’s performance in multi-class classification shows considerable improvements with the inclusion of Dense and Transformer layers across different datasets. For the NF-BoT-IoT-v2 dataset, the AE model achieves an accuracy of 93.88%, which rises to 97.97% when Dense is added (AE + Dense) and further increases to 98.30% with the addition of the Transformer (AE + Dense + Transformer). In the case of the NSL-KDD dataset, AE performs at 93.78%, which is enhanced to 96.64% with AE + Dense and reaches 97.50% when the Transformer is incorporated. For the CSE-CIC-IDS2018 dataset, AE attains an accuracy of 94.04%, which improves to 99.51% with Dense (AE + Dense) and reaches 99.78% when both Dense and Transformer layers are added (AE + Dense + Transformer). These results demonstrate that while the inclusion of Dense and Transformer layers generally improves performance, the exact effect varies across datasets (NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018), with the AE + Dense + Transformer configuration often yielding the highest performance in both binary and multi-class classification.
Table 21.
Evaluation measures of individual components in the proposed hybrid AE-DTNN model.
4.7. Ablation Analysis of Preprocessing and Class Imbalance Mitigation Techniques in the Proposed Hybrid AE-DTNN Model
The ablation study presented in Table 22 highlights the progressive improvement in the AE-DTNN model’s performance as more advanced preprocessing and class imbalance mitigation strategies are applied for both binary and multi-class classification. Initial preprocessing using only Z-Score results in modest accuracy levels, with 81.24% for binary and 77.36% for multi-class classification. A gradual improvement is observed with the addition of LOF and feature selection. However, a significant boost in performance begins when normalization is introduced, raising accuracy to 99.49% for binary and 97.26% for multi-class classification. Further enhancement is achieved by incorporating PCA, followed by the application of resampling techniques such as ADASYN and ADASYN combined with edited nearest neighbors (ENN). The highest performance is observed when class weights are integrated with these resampling methods, resulting in near-perfect metrics reaching up to 99.98% accuracy for binary and 98.30% for multi-class classification. These findings underscore the critical role of normalization as a turning point in improving the model’s effectiveness and the importance of combining robust preprocessing with class imbalance mitigation strategies to maximize intrusion detection performance.
Table 22.
Ablation study on the effect of preprocessing and class imbalance mitigation strategies on AE-DTNN model performance for binary and multi-class classification.
4.8. Inference Time, Training Time, and Memory
The computational efficiency of deep learning models, including their training time, inference time, and memory usage, is a key factor in evaluating their practicality for real-world deployment. This section analyzes the resource consumption of the proposed AE-DTNN model in comparison with other models such as CNN, Autoencoder, DNN, and Transformer. Performance is assessed using the NF-BoT-IoT-v2 dataset across both binary and multi-class classification tasks to gauge the responsiveness and scalability of each model. Additionally, memory usage is evaluated to determine the operational footprint, highlighting the importance of balancing high detection performance with manageable computational costs. This analysis offers a comprehensive understanding of AE-DTNN’s resource requirements and the associated trade-offs when deploying deep learning-based intrusion detection systems in various computing environments.
- (i)
- Inference time
The inference time results demonstrate that the proposed AE-DTNN model achieves inference times that are very close to those of baseline models such as CNN, DNN, and Transformer while still remaining well within the acceptable threshold for real-time deployment. Specifically, the AE-DTNN records an inference time of approximately 0.9473 milliseconds (ms) per sample for binary classification and 0.9614 ms per sample for multi-class classification, as shown in Table 23. These figures indicate the model’s capability to handle high volumes of network traffic with minimal delay, making it well-suited for real-world environments where rapid intrusion detection is essential. The marginal increase in inference time is a reasonable trade-off for the model’s improved detection performance and robustness, ensuring effective and efficient anomaly detection without compromising performance.
Table 23.
Inference time.
- (ii)
- Training time
The training time analysis reveals that the proposed AE-DTNN model achieves training efficiency comparable to other deep learning models while delivering enhanced performance. For binary classification, the AE-DTNN model records a training time of approximately 0.9804 ms per sample, and 0.9870 ms per sample for multi-class classification, as depicted in Table 24. These values are closely aligned with the training times of the Autoencoder and only slightly higher than those of the CNN, DNN, and Transformer models. Despite the marginal increase, the training time remains efficient and manageable, especially considering the model’s improved detection capabilities. This balance between training overhead and performance gain indicates that the AE-DTNN model is not only effective but also practical for deployment in real-world scenarios, where both training time and detection performance are critical.
Table 24.
Training time.
- (iii)
- Memory consumption
The memory consumption analysis indicates that the proposed AE-DTNN model maintains a moderate memory footprint while offering superior detection performance. For binary and multi-class classification, the model consumes 1.63 MB and 1.67 MB of memory, respectively, as shown in Table 25. While this is higher than the memory usage of lightweight models such as DNN, Autoencoder, and Transformer, it remains significantly lower than that of CNN, which exceeds 3 MB in both tasks. This demonstrates that AE-DTNN strikes an effective balance between resource efficiency and model complexity. The relatively low memory requirements make the model suitable for deployment in environments with limited computational resources, such as edge devices, without compromising its capability to accurately detect anomalies in network traffic.
Table 25.
Memory consumption.
5. Discussion
This section assesses the AE-DTNN model by benchmarking its performance against CNN, Autoencoder, DNN, and Transformer in both binary and multi-class classification tasks. Utilizing confusion matrices and essential performance indicators, the study underscores the model’s strengths in identifying different attack types across the NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 datasets. The AE-DTNN model demonstrates superior detection capabilities due to its combination of Autoencoder, Dense layers, and Transformer, leading to improved classification performance. These results highlight the model’s efficiency in enhancing intrusion detection systems and fortifying cybersecurity by facilitating prompt threat identification and response.
5.1. Binary Classification
The AE-DTNN framework exhibits exceptional classification effectiveness across the NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 datasets, attaining nearly flawless values for accuracy, precision, recall, and F-score at 99.98%, 98.57%, and 99.92%, respectively. The confusion matrices offer a deeper examination of the system’s proficiency in differentiating between benign and malicious instances. Regarding the NF-BoT-IoT-v2 dataset, the model successfully identified 1272 benign samples and 10,788 attack cases, with merely two malicious events being mistakenly categorized as normal traffic, as illustrated in Figure 3a. This underscores the framework’s robust capability to detect cyber threats while minimizing false-negative occurrences. Conversely, in the NSL-KDD dataset, the model successfully identified 7669 normal instances and 8952 attack cases. However, it misclassified 111 normal instances as intrusions and incorrectly labeled 130 attack cases as benign, as shown in Figure 3b. Similarly, for the CSE-CIC-IDS2018 dataset, the model successfully identified 546 benign and 27,311 attack instances, with only 6 attacks misclassified as benign and 17 benign samples mistakenly flagged as malicious, as depicted in Figure 3c. These misclassifications highlight the challenges associated with imbalanced datasets, where underrepresented classes can affect the model’s learning process and overall detection performance. In practical cybersecurity applications, such misclassifications hold significant consequences. False-positive detections (genuine traffic incorrectly labeled as an attack) can result in an overwhelming volume of security notifications, straining analysts’ workload. Meanwhile, false-negative errors (threats mistakenly marked as normal) pose a critical risk, as undetected intrusions may jeopardize system integrity. The AE-DTNN model maintains an optimal equilibrium between precision and recall, effectively reducing these inaccuracies. However, for deployment in real-world environments, additional refinements are necessary to counteract class imbalance effects and improve the recognition of infrequent attack patterns, ensuring a fortified cybersecurity defense.
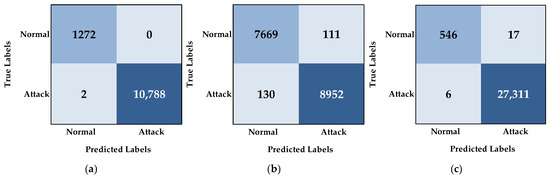
Figure 3.
Binary classification confusion matrix results for (a) NF-BoT-IoT-v2 dataset, (b) NSL-KDD dataset, and (c) CSE-CIC-IDS2018 dataset.
The class-wise assessment of AE-DTNN’s classification performance in binary classification, as detailed in Table 26, showcases its efficiency on the NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 datasets. For the NF-BoT-IoT-v2 dataset, AE-DTNN exhibited outstanding results, attaining 100% accuracy and recall for the normal class, with a precision of 99.84% and an F-score of 99.92%. In distinguishing attack instances, the model achieved an accuracy of 99.98%, a precision of 100%, a recall of 99.98%, and an F-score of 99.99%, affirming its robustness in differentiating normal from malicious traffic. On the NSL-KDD dataset, the model continued to perform reliably. For the normal class, AE-DTNN recorded 98.57% accuracy and recall, with 98.33% precision and an F-score of 98.45%. In detecting attack instances, it achieved 98.57% accuracy and recall, a precision of 98.78%, and an F-score of 98.67%, further demonstrating its effectiveness in identifying security threats. On the CSE-CIC-IDS2018 dataset, AE-DTNN demonstrated strong performance as well. For the normal class, the model achieved 96.98% accuracy and recall, with precision reaching 98.91% and an F-score of 97.94%. In identifying attack instances, AE-DTNN recorded 99.98% accuracy and recall, a precision of 99.94%, and an F-score of 99.96%. These findings highlight AE-DTNN’s ability to maintain high accuracy and balanced precision–recall trade-offs, ensuring reliable binary classification across different datasets.
Table 26.
AE-DTNN class performance in binary classification.
5.2. Multi-Class Classification
In multi-class classification, the AE-DTNN model exhibited excellent classification accuracy on the NF-BoT-IoT-v2 dataset, achieving 98.30%. It successfully identified all 1290 benign samples, 2732 reconnaissance attacks, 4249 DDoS attacks, 3544 DoS attacks, and all 47 theft-related instances, as illustrated in Figure 4. Although the model demonstrated high effectiveness, some misclassifications led to occasional false positives and false negatives across different attack types. Despite these minor inconsistencies, it remained highly dependable in detecting cyber threats. Impressive detection performance was also observed on the NSL-KDD dataset, where the AE-DTNN model attained an accuracy of 97.50%. It correctly classified 7616 normal traffic samples, 5666 DoS attacks, 1102 probe attacks, 29 U2R attacks, and 2027 L2R attacks, as depicted in Figure 5. While certain misclassifications resulted in some false positives and false negatives, the overall classification remained highly effective. The model consistently distinguished among diverse classes, including benign (normal) traffic and multiple attack types, reinforcing its applicability in real-world intrusion detection scenarios.

Figure 4.
Multi-class classification confusion matrix results for the NF-BoT-IoT-v2 dataset.
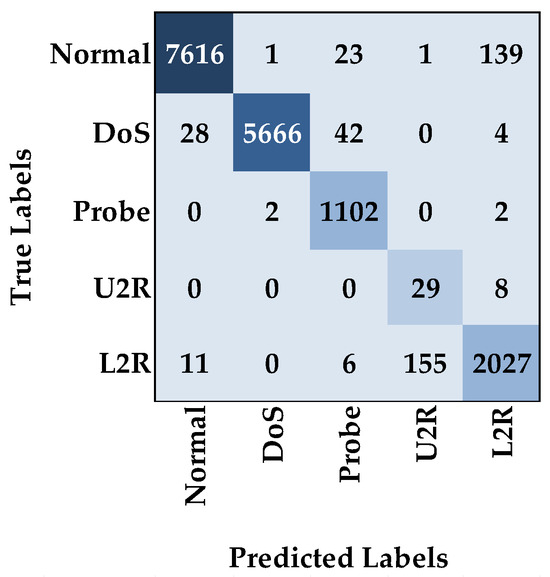
Figure 5.
Multi-class classification confusion matrix results for the NSL-KDD dataset.
The AE-DTNN model achieved an impressive accuracy of 99.78% on the CSE-CIC-IDS2018 dataset, demonstrating exceptional classification performance. It successfully identified a wide range of classes, including 481 benign samples, 5509 DDoS attacks-LOIC-HTTP, 4873 DDOS attack-HOIC, 4585 DoS attacks-Hulk, 4128 Bot-related incidents, and 897 infiltration attempts. Additionally, it accurately classified 3143 SSH-Bruteforce attacks, 2629 DoS attacks-GoldenEye, 1230 DoS attacks-Slowloris, and 232 DDOS attack-LOIC-UDP. The model also detected 72 instances of Brute Force-Web, 32 Brute Force-XSS attacks, 3 SQL injections, 1 DoS attacks-SlowHTTPTest, and 1 instance of FTP-BruteForce. Although the results are impressive, a few misclassifications were observed. These outcomes are depicted in the confusion matrix in Figure 6. The AE-DTNN model excels at differentiating among multiple traffic classes, including normal activity and various types of cyberattacks, highlighting its potential for practical use in intrusion detection systems.
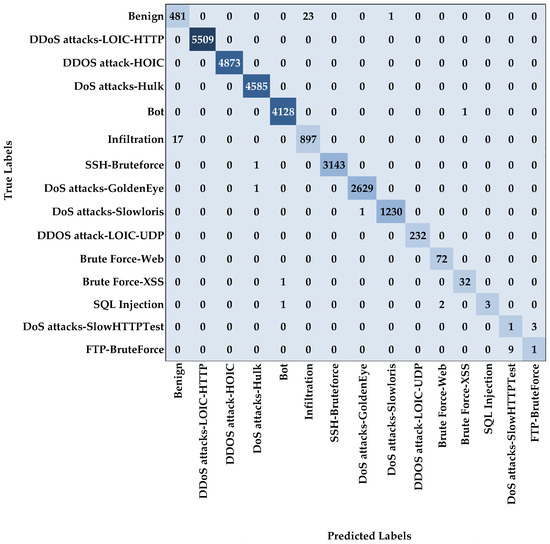
Figure 6.
Multi-class classification confusion matrix results for the CSE-CIC-IDS2018 dataset.
The class-wise performance assessment of AE-DTNN in multi-class classification, as detailed in Table 27, demonstrates its ability to accurately differentiate between various class types within the NF-BoT-IoT-v2 and NSL-KDD datasets. For the NF-BoT-IoT-v2 dataset, AE-DTNN exhibited exceptional accuracy in identifying benign and theft traffic, attaining 100% accuracy and recall, with precision scores of 99.85% and 100%, leading to F-scores of 99.92% and 100%, respectively. The model effectively detected reconnaissance attacks, achieving 96.13% accuracy and recall, with 98.66% precision and an F-score of 97.38%. DDoS attacks were classified with 99.25% accuracy and recall, supported by a 99.39% precision score and a 99.32% F-score. The DoS category was identified with 98.25% accuracy and recall, precision of 96.20%, and an F-score of 97.22%, reflecting the model’s strong detection capabilities across attack classes. For the NSL-KDD dataset, AE-DTNN demonstrated high accuracy in classifying normal traffic, achieving 97.89% accuracy and recall, with 99.49% precision and an F-score of 98.68%. The model efficiently recognized DoS threats, achieving 98.71% accuracy and recall, a precision of 99.95%, and an F-score of 99.33%. In identifying probe attacks, AE-DTNN attained 99.64% accuracy and recall, with a precision of 93.95% and an F-score of 96.71%. For the U2R class, the model achieved 78.38% accuracy and recall, with reasonable precision and F-score, indicating promising detection capability. The L2R category was detected with 92.18% accuracy and recall, 92.98% precision, and an F-score of 92.58%, underscoring the model’s proficiency in identifying network intrusions. These findings reaffirm AE-DTNN’s effectiveness in multi-class classification, delivering high accuracy and strong predictive capability across various class types.
Table 27.
AE-DTNN class performance in multi-class classification on NF-BoT-IoT-v2 and NSL-KDD datasets.
The class-wise performance of the AE-DTNN model in multi-class classification on the CSE-CIC-IDS2018 dataset demonstrates a varied level of success across different attack types and the benign class, as depicted in Table 28. Most attack categories, such as DDoS attacks-LOIC-HTTP, DDoS attack-HOIC, and DDOS attack-LOIC-UDP, achieved perfect results, with 100% accuracy, precision, recall, and F1-score, indicating the model’s excellent capability in detecting these threats. For the benign class, the model maintained a high performance with 95.25% accuracy, 96.59% precision, 95.25% recall, and F1-score of 95.91%. Additionally, the model performed notably well on other challenging attack types such as Bot, SSH-Bruteforce, DoS attacks-GoldenEye, DoS attacks-Slowloris, and Brute Force-Web, achieving high and balanced performance across evaluation metrics. These findings emphasize the model’s robustness in managing a variety of traffic classes, including both benign traffic and multiple intrusion types.
Table 28.
AE-DTNN class performance in multi-class classification on CSE-CIC-IDS2018 dataset.
6. Limitations
The AE-DTNN embodies sophisticated, combined deep learning frameworks, crafted to elevate efficacy in both two-category and multiple-category categorization endeavors. Although this strategy tackles critical obstacles within security breach detection systems, notably boosting performance and handling uneven class distributions, numerous constraints and hurdles still necessitate resolution:
- Scalability: The model’s computational requirements may escalate with larger datasets and more intricate network configurations, potentially hindering its efficiency and ability to adapt to extensive, real-world environments.
- Generalization: Although the model demonstrates strong performance on the NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 datasets, its ability to effectively handle a wider range of network traffic patterns and newly emerging cyber threats is not guaranteed. To ensure its robustness, further evaluation on diverse datasets such as UNSW-NB15, IoT23, CICIDS2017, NF-UNSW-NB15-v2, and NF-ToN-IoT-v2 is essential.
- Data Preprocessing: The model’s success is significantly contingent on the quality of data preprocessing. Accurate handling of missing values, appropriate encoding of categorical data, and effective normalization of numerical features are critical to achieving optimal performance.
- Model Adaptation: Tailoring the model for optimal performance across various datasets necessitates a thorough and iterative process of hyperparameter optimization, ensuring that the model is precisely aligned with the specific characteristics of each new dataset.
7. Conclusions
This research introduces an innovative approach to network intrusion detection by presenting the advanced hybrid AE-DTNN model. By incorporating techniques such as ADASYN, ENN, and class weights, we effectively tackle the prevalent challenge of class imbalance, which often degrades the performance of conventional intrusion detection systems. Evaluation across multiple datasets highlights the AE-DTNN model’s strong and consistent performance. On the NF-BoT-IoT-v2 dataset, the model achieved outstanding results, securing 99.98% accuracy in binary classification and 98.30% in multi-class classification. Similarly, on the NSL-KDD dataset, it attained 98.57% accuracy for binary classification and 97.50% for multi-class classification. Furthermore, on the CSE-CIC-IDS2018 dataset, the model demonstrated high effectiveness, with 99.92% accuracy in binary classification and 99.78% in multi-class classification. These results underscore the model’s robustness in detecting a wide range of network threats and affirm its suitability for practical deployment in real-world environments. To build upon this work, future research may explore the evaluation of the model on additional and more diverse datasets to further test its generalizability. Enhancing data preprocessing and optimizing hyperparameters for different environments can also lead to improved performance. Moreover, focusing on model scalability and computational efficiency will be crucial for real-time deployment in large-scale network systems.
Author Contributions
Conceptualization, H.K. and M.M.; Methodology, H.K. and M.M.; Software, H.K. and M.M.; Validation, H.K. and M.M.; Writing—original draft, H.K. and M.M.; Supervision, M.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The datasets used in our study, NF-BoT-IoT-v2, NSL-KDD, and CSE-CIC-IDS2018 are publicly available. Below are the URLs for the datasets:
- NF-BoT-IoT-v2: https://staff.itee.uq.edu.au/marius/NIDS_datasets/ (accessed on 21 June 2025)
- NSL-KDD: https://www.unb.ca/cic/datasets/nsl.html (accessed on 21 June 2025)
- CSE-CIC-IDS2018: https://www.unb.ca/cic/datasets/ids-2018.html (accessed on 21 June 2025)
Conflicts of Interest
The authors declare no conflict of interest.
References
- Heady, R.; Luger, G.; Maccabe, A.; Servilla, M. The Architecture of a Network Level Intrusion Detection System; Technical Report; U.S. Department of Energy: Washington, DC, USA, 1990.
- Mitchell, R.; Chen, R. A survey of intrusion detection in wireless network applications. Comput. Commun. 2014, 42, 1–23. [Google Scholar] [CrossRef]
- Hu, J.; Yu, X.; Qiu, D.; Chen, H.H. A simple and efficient hidden Markov model scheme for host-based anomaly intrusion detection. IEEE Netw. 2009, 23, 42–47. [Google Scholar] [CrossRef]
- Zhang, X.; Xie, J.; Huang, L. Real-Time Intrusion Detection Using Deep Learning Techniques. J. Netw. Comput. Appl. 2020, 140, 45–53. [Google Scholar]
- Kumar, S.; Kumar, R. A Review of Real-Time Intrusion Detection Systems Using Machine Learning Approaches. Comput. Secur. 2020, 95, 101944. [Google Scholar]
- Smith, A.; Jones, B.; Taylor, C. Enhancing Network Security with Real-Time Intrusion Detection Systems. Int. J. Inf. Secur. 2021, 21, 123–135. [Google Scholar]
- Messinis, S.; Temenos, N.; Protonotarios, N.E.; Rallis, I.; Kalogeras, D.; Doulamis, N. Enhancing Internet of Medical Things security with artificial intelligence: A comprehensive review. Comput. Biol. Med. 2024, 170, 108036. [Google Scholar] [CrossRef]
- Dorothy, E. An intrusion-detection model. IEEE Trans. Softw. Eng. 1987, 13, 222–232. [Google Scholar] [CrossRef]
- Tayeh, T.; Aburakhia, S.; Myers, R.; Shami, A. An attention-based ConvLSTM autoencoder with dynamic thresholding for unsupervised anomaly detection in multivariate time series. Mach. Learn. Knowl. Extr. 2022, 4, 350–370. [Google Scholar] [CrossRef]
- Strelcenia, E.; Prakoonwit, S. A survey on gan techniques for data augmentation to address the imbalanced data issues in credit card fraud detection. Mach. Learn. Knowl. Extr. 2023, 5, 304–329. [Google Scholar] [CrossRef]
- Lewandowski, B.; Paffenroth, R. Autoencoder Feature Residuals for Network Intrusion Detection: One-Class Pretraining for Improved Performance. Mach. Learn. Knowl. Extr. 2023, 5, 868–890. [Google Scholar] [CrossRef]
- Bacevicius, M.; Paulauskaite-Taraseviciene, A.; Zokaityte, G.; Kersys, L.; Moleikaityte, A.; Moleikaityte, A. Comparative analysis of perturbation techniques in LIME for intrusion detection enhancement. Mach. Learn. Knowl. Extr. 2025, 7, 1–8. [Google Scholar] [CrossRef]
- Wang, Y.; Li, J.; Zhao, W.; Han, Z.; Zhao, H.; Wang, L.; He, X. N-STGAT: Spatio-temporal graph neural network based network intrusion detection for near-earth remote sensing. Remote Sens. 2023, 15, 3611. [Google Scholar] [CrossRef]
- Xu, R.; Wu, G.; Wang, W.; Gao, X.; He, A.; Zhang, Z. Applying self-supervised learning to network intrusion detection for network flows with graph neural network. Comput. Netw. 2024, 248, 110495. [Google Scholar] [CrossRef]
- Kamal, H.; Mashaly, M. Advanced Hybrid Transformer-CNN Deep Learning Model for Effective Intrusion Detection Systems with Class Imbalance Mitigation Using Resampling Techniques. Future Internet 2024, 16, 481. [Google Scholar] [CrossRef]
- Yaras, S.; Dener, M. IoT-based intrusion detection system using new hybrid deep learning algorithm. Electronics 2024, 13, 1053. [Google Scholar] [CrossRef]
- Abdelkhalek, A.; Mashaly, M. Addressing the class imbalance problem in network intrusion detection systems using data resampling and deep learning. J. Supercomput. 2023, 79, 10611–10644. [Google Scholar] [CrossRef]
- Türk, F. Analysis of intrusion detection systems in UNSW-NB15 and NSL-KDD datasets with machine learning algorithms. Bitlis Eren Üniversitesi Fen Bilim. Dergisi. 2023, 12, 465–477. [Google Scholar] [CrossRef]
- Kamal, H.; Mashaly, M. Enhanced Hybrid Deep Learning Models-Based Anomaly Detection Method for Two-Stage Binary and Multi-Class Classification of Attacks in Intrusion Detection Systems. Algorithms 2025, 18, 69. [Google Scholar] [CrossRef]
- Talukder, M.A.; Islam, M.M.; Uddin, M.A.; Hasan, K.F.; Sharmin, S.; Alyami, S.A.; Moni, M.A. Machine learning-based network intrusion detection for big and imbalanced data using oversampling, stacking feature embedding and feature extraction. J. Big Data 2024, 11, 33. [Google Scholar] [CrossRef]
- Fathima, A.; Khan, A.; Uddin, M.F.; Waris, M.M.; Ahmad, S.; Sanin, C.; Szczerbicki, E. Performance evaluation and comparative analysis of machine learning models on the unsw-nb15 dataset: A contemporary approach to cyber threat detection. Cybern. Syst. 2023, 16, 1–7. [Google Scholar] [CrossRef]
- ElKashlan, M.; Elsayed, M.S.; Jurcut, A.D.; Azer, M. A machine learning-based intrusion detection system for IoT electric vehicle charging stations (EVCSs). Electronics 2023, 12, 1044. [Google Scholar] [CrossRef]
- Kamal, H.; Mashaly, M. Robust Intrusion Detection System Using an Improved Hybrid Deep Learning Model for Binary and Multi-Class Classification in IoT Networks. Technologies (2227-7080) 2025, 13, 102. [Google Scholar] [CrossRef]
- Sarhan, M.; Layeghy, S.; Moustafa, N.; Portmann, M. Cyber threat intelligence sharing scheme based on federated learning for network intrusion detection. J. Netw. Syst. Manag. 2023, 31, 3. [Google Scholar] [CrossRef]
- Abdalgawad, N.; Sajun, A.; Kaddoura, Y.; Zualkernan, I.A.; Aloul, F. Generative deep learning to detect cyberattacks for the IoT-23 dataset. IEEE Access 2021, 10, 6430–6441. [Google Scholar] [CrossRef]
- Arapidis, E.; Temenos, N.; Giagkos, D.; Rallis, I.; Kalogeras, D.; Papadakis, N.; Litke, A.; Messinis, C.; Zeekflow+, S. A Deep LSTM Autoencoder with Integrated Random Forest Classifier for Binary and Multi-class Classification in Network Traffic Data. In Proceedings of the 17th International Conference on PErvasive Technologies Related to Assistive Environments, Crete, Greece, 26–28 June 2024; pp. 613–618. [Google Scholar]
- Sarhan, M.; Layeghy, S.; Portmann, M. Towards a standard feature set for network intrusion detection system datasets. Mob. Netw. Appl. 2022, 27, 357–370. [Google Scholar] [CrossRef]
- Moustafa, N. Network Intrusion Detection System (NIDS) Datasets [Internet]. University of Queensland: Brisbane, Australia. Available online: https://staff.itee.uq.edu.au/marius/NIDS_datasets (accessed on 21 June 2025).
- Bagui, S.; Li, K. Resampling imbalanced data for network intrusion detection datasets. J. Big Data 2021, 8, 6. [Google Scholar] [CrossRef]
- Elmasry, W.; Akbulut, A.; Zaim, A.H. Empirical study on multiclass classification-based network intrusion detection. Comput. Intell. 2019, 35, 919–954. [Google Scholar] [CrossRef]
- Mbow, M.; Koide, H.; Sakurai, K. Handling class imbalance problem in intrusion detection system based on deep learning. Int. J. Netw. Comput. 2022, 12, 467–492. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; IEEE: New York, NY, USA, 2009; pp. 1–6. [Google Scholar]
- Dhanabal, L.; Shantharajah, S.P. A study on NSL-KDD dataset for intrusion detection system based on classification algorithms. Int. J. Adv. Res. Comput. Commun. Eng. 2015, 4, 446–452. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. CSE-CIC-IDS2018 Dataset. Fredericton (NB): Canadian Institute for Cybersecurity, University of New Brunswick; 2018. Available online: https://www.unb.ca/cic/datasets/ids-2018.html (accessed on 21 June 2025).
- Songma, S.; Sathuphan, T.; Pamutha, T. Optimizing intrusion detection systems in three phases on the CSE-CIC-IDS-2018 dataset. Computers 2023, 12, 245. [Google Scholar] [CrossRef]
- El-Habil, B.Y.; Abu-Naser, S.S. Global climate prediction using deep learning. J. Theor. Appl. Inf. Technol. 2022, 100, 4824–4838. [Google Scholar]
- Song, Z.; Ma, J. Deep learning-driven MIMO: Data encoding and processing mechanism. Phys. Commun. 2023, 57, 101976. [Google Scholar] [CrossRef]
- Zhou, X.; Zhao, C.; Sun, J.; Yao, K.; Xu, M. Detection of lead content in oilseed rape leaves and roots based on deep transfer learning and hyperspectral imaging technology. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2023, 290, 122288. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 2002, 86, 2278–2324. [Google Scholar] [CrossRef]
- Kunang, Y.N.; Nurmaini, S.; Stiawan, D.; Zarkasi, A. Automatic features extraction using autoencoder in intrusion detection system. In Proceedings of the International Conference on Electrical Engineering and Computer Science (ICECOS), Pangkal Pinang, Indonesia, 2–4 October 2018; IEEE: New York, NY, USA, 2018; pp. 219–224. [Google Scholar]
- Gogna, A.; Majumdar, A. Discriminative autoencoder for feature extraction: Application to character recognition. Neural Process. Lett. 2019, 49, 1723–1735. [Google Scholar] [CrossRef]
- Chen, X.; Ma, L.; Yang, X. Stacked denoise autoencoder based feature extraction and classification for hyperspectral images. J. Sens. 2016, 2016, 3632943. [Google Scholar]
- Michelucci, U. An introduction to autoencoders. arXiv 2022. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Veeramreddy, J.; Prasad, K. Anomaly-based intrusion detection system. In Anomaly Detection and Complex Network System; Alexandrov, A.A., Ed.; IntechOpen: London, UK, 2019. [Google Scholar] [CrossRef]
- Chen, C.; Song, Y.; Yue, S.; Xu, X.; Zhou, L.; Lv, Q.; Yang, L. Fcnn-se: An intrusion detection model based on a fusion CNN and stacked ensemble. Appl. Sci. 2022, 12, 8601. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020. [Google Scholar] [CrossRef]
- Kamal, H.; Mashaly, M. Improving Anomaly Detection in IDS with Hybrid Auto Encoder-SVM and Auto Encoder-LSTM Models Using Resampling Methods. In Proceedings of the 6th Novel Intelligent and Leading Emerging Sciences Conference (NILES), Giza, Egypt, 19–21 October 2024; IEEE: New York, NY, USA, 2024; pp. 34–39. [Google Scholar]
- Assy, A.T.; Mostafa, Y.; Abd El-khaleq, A.; Mashaly, M. Anomaly-based intrusion detection system using one-dimensional convolutional neural network. Procedia Comput. Sci. 2023, 220, 78–85. [Google Scholar] [CrossRef]
- Kamal, H.; Mashaly, M. Hybrid Deep Learning-Based Autoencoder-DNN Model for Intelligent Intrusion Detection System in IoT Networks. In Proceedings of the 15th International Conference on Electrical Engineering (ICEENG), Cairo, Egypt, 12–15 May 2025; IEEE: New York, NY, USA, 2025; pp. 1–6. [Google Scholar]
- Kamal, H.; Mashaly, M. Combined Dataset System Based on a Hybrid PCA–Transformer Model for Effective Intrusion Detection Systems. AI 2025, 6, 168. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).