Abstract
Applying language models (LMs) and generative artificial intelligence (GenAI) to the study of Ancient Greek offers promising opportunities. However, it faces substantial challenges due to the language’s morphological complexity and lack of annotated resources. Despite growing interest, no systematic overview of existing research currently exists. To address this gap, a systematic literature review was conducted following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 methodology. Twenty-seven peer-reviewed studies were identified and analyzed, focusing on application areas such as machine translation, morphological analysis, named entity recognition (NER), and emotion detection. The review reveals six key findings, highlighting both the technical advances and persistent limitations, particularly the scarcity of large, domain-specific corpora and the need for better integration into educational contexts. Future developments should focus on building richer resources and tailoring models to the unique features of Ancient Greek, thereby fully realizing the potential of these technologies in both research and teaching.
1. Introduction
The study of Ancient Greek plays a pivotal role in understanding both cultural heritage and the foundations of modern intellectual disciplines [1]. With its enduring legacy, Ancient Greek has contributed over 150,000 words to modern English and significantly influenced Romance languages via Latin [2]. Its impact reaches far beyond linguistics, underpinning essential fields such as philosophy, mathematics, and medicine [3]. Moreover, in a globalized and multicultural society, studying Ancient Greek fosters intercultural awareness and inclusivity [4].
Despite these contributions, the study of Ancient Greek has seen a marked decline in recent decades. Educational institutions in countries such as France [5], the United Kingdom [6], and even Greece [7] have reduced instructional hours or eliminated courses [8]. This downturn is primarily attributed to the inherent difficulties of the language—its intricate morphology and syntax, complex system of inflections, lack of native speakers, semantic ambiguities, and the fragmentary nature of ancient manuscripts—all of which require significant effort from both students and educators [9,10,11,12].
In response to these challenges, recent advances in Language Models (LMs) offer valuable tools for revitalizing Ancient Greek studies. These models can effectively analyze extensive, complex text collections, identify linguistic patterns, generate nuanced interpretations, and support personalized learning [13,14]. Their ability to manage complicated grammatical structures, reconstruct fragmented texts, and provide interactive language practice can lower entry barriers for learners and enhance research productivity [15].
However, although LMs have seen increasing success in areas such as machine translation, text analysis, and language pedagogy, no previous work has provided a systematic review of how these models have been explicitly applied to Ancient Greek. The existing literature is either scattered across various disciplines [16] or focuses on broader categories, such as Classical Studies or general linguistic applications [17,18], without a targeted assessment of Ancient Greek, and without a unified synthesis of technical and educational dimensions.
Given this, the present work constitutes the first systematic and focused review of transformer-based language models in this field. Our review is innovative in several respects:
- We synthesize fragmented literature across Natural Language Processing (NLP), digital humanities, and pedagogy to provide a unified and critical overview;
- We explicitly distinguish between general-purpose foundation LMs and domain-specific models trained for Ancient Greek, analyzing their strengths, limitations, and areas of application;
- We critically assess both technical advances and persistent challenges, and propose concrete future directions for integrating research and education.
Building on these contributions, we frame our review around the following research questions:
- In which domains have LMs been applied for the study of the Ancient Greek language?
- How effective are current LMs in the analysis and processing of Ancient Greek?
- What challenges and limitations have been identified in the application of LMs to Ancient Greek?
The remainder of the paper is structured as follows: Section 2 outlines the research methodology used to identify relevant studies. Section 3 presents the findings of the literature review, categorized by different research directions. Section 4 discusses these results, highlights the limitations of the current study, and proposes directions for future research. Finally, Section 5 summarizes the main conclusions.
2. Materials and Methods
This section outlines the procedures used to identify and select studies for review, including the development of eligibility criteria, search strategy, and screening process.
2.1. Study Design
The review was conducted by the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 standards [19], which provide a structured approach to reporting systematic reviews. As the topic lies outside the scope of health-related research, registration in PROSPERO was not applicable.
2.2. Eligibility Criteria
Eligibility criteria are essential in ensuring the validity, relevance, and focus of a systematic review [20]. In this study, we designed the exclusion criteria to be sequential: if the first exclusion condition disqualified an article, it was not further evaluated under subsequent criteria. To be included, a study had to meet all of the following conditions:
- IC-1: The study applies transformer-based LMs such as ChatGPT (3.5/4/4o), Bidirectional Encoder Representations from Transformers (BERT), LLaMA (2/3), Generative Pre-trained Transformer (GPT)-3/4, or similar to the analysis or teaching of Ancient Greek;
- IC-2: The study is a peer-reviewed journal article or conference proceeding;
- IC-3: The full text is available, and the article is written in English.
Conversely, articles were excluded if any of the following conditions applied (evaluated sequentially):
- EC-1: The study does not apply transformer-based LMs;
- EC-2: The focus is on languages other than Ancient Greek, with no meaningful reference to Ancient Greek;
- EC-3: The study is not peer-reviewed, or the full text is not accessible;
- EC-4: The article is written in a language other than English;
- EC-5: The study is purely theoretical or conceptual, without empirical application of an LM.
2.3. Search Strategy
The search strategy was designed to systematically identify peer-reviewed research at the intersection of three thematic areas:
- Transformer-based LMs;
- Education, pedagogy, and digital learning;
- The study and teaching of Ancient Greek.
To ensure broad and reliable coverage, three major academic databases were selected: Scopus, IEEE Xplore, and Web of Science. These platforms were chosen for their strong representation of high-impact research in artificial intelligence (AΙ), digital humanities, and educational technology.
The search was conducted on May 22, 2025, and employed a structured combination of keyword groups. Specifically, the following:
- LLM-related terms included: “large language models”, “generative AI”, “foundation models”, “ChatGPT”, “BERT”, “LLaMA”, “autoregressive models”, and similar.
- Education-related terms included: “pedagogy”, “education”, “digital humanities”, “instructional technology”, “e-learning”, and others.
- Ancient Greek-related terms included: “Ancient Greek”, “Classical Greek”, “Koine Greek”, “Homeric Greek”, and related historical variants.
Each query was adapted to the syntax requirements of the respective database to optimize relevance and retrieval accuracy. The complete search strings used for each platform are provided in Table 1.

Table 1.
Different Search strings per selected database.
2.4. Study Selection Process
The screening of records was performed independently by two reviewers, who first evaluated titles and abstracts for initial relevance. This was followed by a full-text screening phase, during which articles were assessed against the predefined eligibility criteria outlined in Section 2.1. In cases of disagreement regarding the inclusion or exclusion of a study, the reviewers discussed the content and its alignment with the review’s scope until a consensus was reached.
2.5. Data Collection Process and Categorization
The final pool of 27 studies, selected through the PRISMA screening process, was systematically reviewed in order to extract relevant data for analysis. For each survey, key information was collected, including:
- The year of publication;
- The corpus or dataset used;
- The type of language model (foundation or domain-specific);
- The primary NLP technique or approach employed;
- The specific application domain (e.g., translation, Named Entity Recognition (NER), etc.).
To facilitate meaningful comparison and synthesis, the studies were categorized based on their thematic focus and technical approach. Thematic categories were aligned with the primary linguistic and pedagogical functions relevant to the study of Ancient Greek, such as morphological analysis, translation, semantic modeling, and education. This categorization serves as the structural basis for Section 3, enabling a deeper understanding of how LMs have been applied across different dimensions of Ancient Greek research and instruction.
2.6. Risk of Bias
Although the study selection process followed systematic procedures, including independent screening by two reviewers and consensus-based inclusion decisions, several potential sources of bias may still persist. First, language bias may be present, as only English-language publications were included. Second, database bias is possible due to the reliance on three major academic databases (Scopus, Web of Science, and IEEE Xplore), which may have excluded relevant grey literature or non-indexed studies. Additionally, terminological bias could affect the completeness of the results, as some relevant studies may have used alternative terms not captured in the search queries despite iterative refinement.
Furthermore, in some cases, the type of LM used was not clearly defined, requiring interpretive judgment during inclusion decisions. While these risks were mitigated through predefined eligibility criteria, transparent documentation, and reviewer discussion, they cannot be eliminated due to the qualitative nature of the review.
3. Results
This section presents the results of the systematic review, beginning with the identification and selection of relevant studies. It then provides a descriptive overview of the included works and concludes with a thematic analysis covering key application areas where LMs have been applied to Ancient Greek.
3.1. Identification and Inclusion of Studies
The search strategy yielded a total of 46 articles across the three selected databases: 31 from Scopus, 9 from IEEE Xplore, and 6 from Web of Science. After removing duplicates, identified through metadata comparison, 11 records were excluded due to repetition across databases.
This resulted in a final pool of 35 unique articles. These were then screened in two phases: first by title and abstract and subsequently through full-text review, based on the eligibility criteria defined in Section 2.2. Studies that did not apply transformer-based LMs lacked direct relevance to Ancient Greek or were purely theoretical without empirical application were excluded.
A total of 27 studies met all inclusion criteria and were selected for full analysis. The complete selection process is illustrated in the PRISMA 2020 flow diagram (Figure 1):
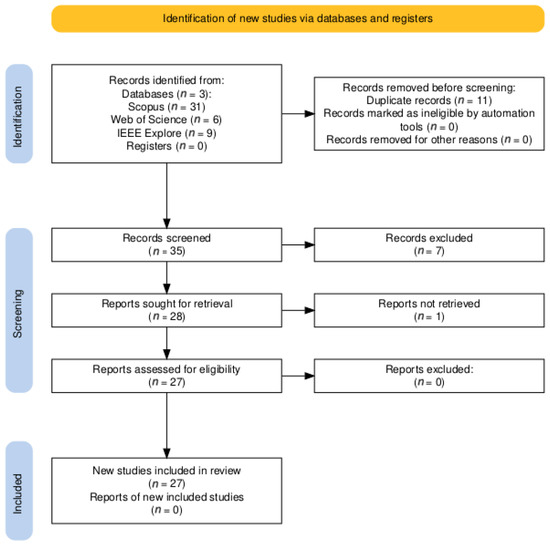
Figure 1.
PRISMA 2020 flow diagram.
3.2. Descriptive Overview of Included Studies
The 27 reviewed studies were analyzed, firstly, to provide a descriptive overview of recent research trends in language models and Ancient Greek. Specifically, we examine the distribution of studies by year of publication, publisher, and patterns of authorship.
In Figure 2, the temporal distribution of these publications indicates a steady increase in research activity over recent years, with a significant rise observed from 2023 onward. This trend highlights the growing academic interest in applying LMs, and more specifically, large language models (LLMs), to Ancient Greek studies.
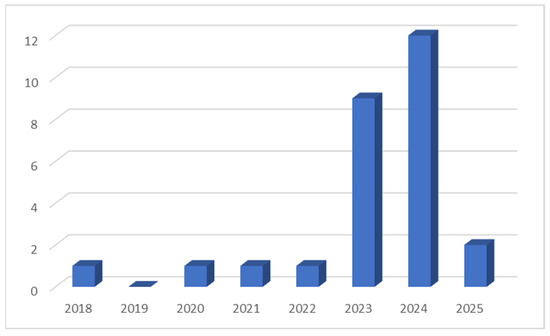
Figure 2.
Temporal distribution of publications on lm applications in Ancient Greek studies.
Regarding dissemination venues, Figure 3 shows that the Association for Computational Linguistics is the leading publisher, followed by IEEE and Cambridge University Press, reflecting the interdisciplinary nature of research at the intersection of computational linguistics and Ancient Greek language studies.
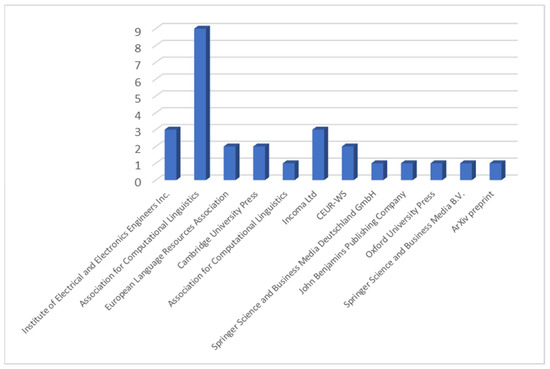
Figure 3.
Distribution of publications by publisher.
Lastly, regarding authorship patterns, Figure 4 illustrates that among 72 unique contributors, Pavlopoulos J. emerges as the most prolific author, with several others contributing multiple publications.
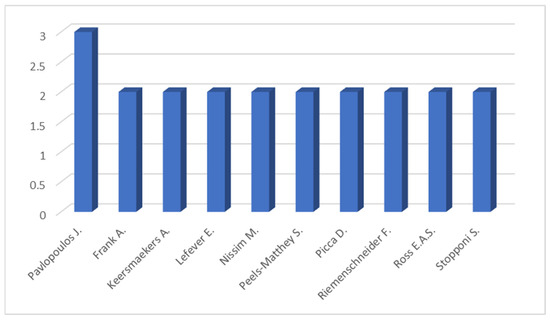
Figure 4.
Most frequent authors in LM research on Ancient Greek.
3.3. Thematic Analysis of Applications of LMs in Ancient Greek
To provide a deeper understanding of how LMs are employed in the study and teaching of Ancient Greek, the selected studies were analyzed and grouped into key application areas through an inductive qualitative synthesis. These categories reflect both the linguistic complexity of Ancient Greek, and the diversity of computational approaches applied to its analysis. The classification presented is an original contribution based on the patterns and themes identified across the reviewed studies.
In Figure 5, the most frequent areas of application are morphological and syntactic analysis, as well as NER, followed by growing interest in machine translation, semantic modeling, and intertextual analysis. More recent research has also begun to explore emotion analysis in Ancient Greek literature and pedagogical applications, such as the use of generative models in language instruction.
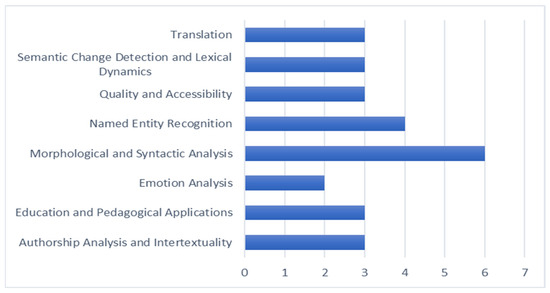
Figure 5.
Distribution of studies by key application areas in Ancient Greek language modeling.
Each of the following subsections explores these areas in turn, presenting the methodologies employed and summarizing key results. An overview of the selected articles is provided in Appendix A, Table A1.
3.3.1. Morphological and Syntactic Processing of Ancient Greek Using LMs
In this literature review, a significant area of research attention has been the application of LMs to the morphological and syntactic analysis of Ancient Greek. The studies reviewed here—including the works of Lim and Park [11], Singh et al. [21], Kostkan et al. [22], Riemenschneider and Frank [18], Keersmaekers and Mercelis [10], and Swaelens et al. [23]—demonstrate the methodological progression in this domain, from the adoption of general-purpose multilingual models to the development and optimization of domain-specific transformer architectures trained or fine-tuned on Ancient Greek corpora.
Early work by Lim and Park [11] demonstrated the use of pre-trained multilingual models such as Embeddings from Language Models (ELMo) and BERT, combined with a multiview learning framework that integrated character-based representations at both the word and sentence levels. Evaluated on the Universal Dependencies (UD) Conference on Computational Natural Language Learning (CoNLL) 2018 shared task dataset, this approach achieved an average improvement of 8.89 accuracy points over prior word-based models for Ancient Greek Part-of-Speech (POS) tagging.
Subsequent research has focused on models explicitly developed for the Ancient Greek language. Singh et al. [21] presented a subword-based BERT language model pre-trained on a combined corpus of Ancient, Medieval, and Modern Greek texts. The model achieved a perplexity of 4.9 on the development set and yielded fine-grained morphological analysis accuracies of 88.6% on Ancient Greek Dependency Treebank (AGDT), 92.9% on Pragmatic Resources in Old Indo-European Languages (PROIEL), and 91.9% on Gorman, with up to 97.4% accuracy for coarse-grained POS tagging. For Byzantine Greek, accuracy reached 86.9%. Kostkan et al. [22] developed the OdyCy pipeline using Ancient-Greek-BERT, which was jointly trained on the UD Perseus and UD PROIEL treebanks. OdyCyjoint achieved 95.39% POS tagging accuracy, 92.56% morphological analysis accuracy, 73.09% Labeled Attachment Score (LAS), and 83.20% lemmatization accuracy on UD Perseus, and 97.81% POS, 93.46% morphology, 79.03% LAS, and 94.41% lemmatization on UD PROIEL.
Riemenschneider and Frank [18] further expanded the modeling landscape by presenting GRεBERTA, GRεTA, PHILBERTA, and PHILTA, all of which were pre-trained in Ancient Greek, Latin, and English. On UD Perseus, GRεTA achieved 97.62% POS tagging accuracy, 93.19% morphological tagging, 79.91% LAS, and 96.07% lemmatization accuracy, while the multilingual PHILTA model obtained 97.46% POS tagging, 93.03% morphology, 79.47% LAS, and 95.88% lemmatization accuracy. Comparable results were obtained on UD PROIEL. Keersmaekers and Mercelis [10] utilized ELECTRA and LaBERTa models, which were trained on the Greek and Latin Annotated Universal Corpus (GLAUx) corpus for Ancient Greek. Their MultiTag approach achieved 96.3% accuracy without a lexicon, 96.9% with a lexicon, and 97.2% with both lexicon and tag constraints, with individual morphological feature accuracy reaching 0.999 for person and voice and 0.991 for case.
Swaelens et al. [23] lastly addressed the challenges of unnormalized Byzantine Greek by training BERT, ELECTRA, and RoBERTa models on a mix of Ancient, Byzantine, and Modern Greek texts. The best results, achieved with BERT trained on all available Greek data, yielded 82.76% accuracy for coarse POS tagging and 68.57% for full morphological analysis on a gold-standard test set of 10,000 tokens from Byzantine epigrams; the inter-annotator agreement was high at 89.83%.
3.3.2. NER in Ancient Greek with Language Model Technology
Building on the progress achieved in morphological and syntactic processing, a further line of research explores the application of LMs to NER in Ancient Greek. Approaches in this area range from models pre-trained specifically for Ancient Greek [24,25] to adaptations of general-purpose LLMs through prompting strategies [26,27].
Among the studies focused on models developed and supervised specifically for Ancient Greek, Gessler and Schneider [24] evaluated transformer architectures—such as SynCLM, SLA, and MicroBERT—using corpora including Ancient Greek Wikipedia and Universal Dependencies treebanks. For Ancient Greek NER on the WikiAnn dataset, the MicroBERT variant achieved an F1 score of 82.02. For syntactic parsing, labeled attachment scores for the top models were around 81.8. Across model variants and tasks, gains from syntactic bias methods typically ranged from 1 to 4 F1 points.
In a related line of inquiry, Beersmans et al. [25] evaluated four transformer-based NER models—AG_BERT, ELECTRA, GrεBerta, and UGARIT—trained and tested on harmonized datasets of Ancient Greek literature. On the main held-out test set, AG_BERT achieved F1 scores of 0.87 for person entities, 0.73 for locations, and 0.81 for groups, with a macro F1 score of 0.80. On the out-of-domain GLAUx TEST, macro F1 was 0.77. The incorporation of gazetteer and syntactic information yielded small gains, such as an increase in precision for person names from 0.84 to 0.90.
Complementing these domain-specific efforts, other researchers have explored the potential of general-purpose LLMs for NER tasks in Ancient Greek. González-Gallardo et al. [26,27] evaluated models such as ChatGPT-3.5, Llama-2, Llama-3, Mixtral-8 × 7B, and Zephyr-7B using datasets including the Ajax Multi-Commentary (AJMC), HIPE, and NewsEye. Using zero-shot and few-shot prompting, these models produced entity predictions for Ancient Greek text. For example, on the AJMC dataset, ChatGPT-3.5 achieved a strict F1-score of 23.8%. On Ancient Greek subsets of HIPE, F1-scores for instruction-tuned and commercial models generally remained below 40%.
3.3.3. Machine Translation of Ancient Greek Using LMs
An equally significant focus in the literature on the application of LMs to the study of Ancient Greek lies in the area of machine translation. Research efforts in this field—exemplified by the works of Lamar and Chambers [28], Wannaz and Miyagawa [29], and Rapacz and Smywiński-Pohl [30]—trace the evolution from early hybrid neural strategies to the implementation of general-purpose LLMs and the development of specialized neural architectures designed for Ancient Greek translation tasks.
The earliest of these studies, by Lamar and Chambers [28], addressed the challenge of translating Ancient Greek in a low-resource setting, using Plato’s Timaeus as a case study. The authors developed neural machine translation models based on 2-layer bidirectional Long Short-Term Memory (LSTM) architectures. They trained their Greek-to-English system on over 31,000 sentences from Plato’s works available in the Perseus Digital Library. Their approach included both a baseline model (trained solely on lines spoken by Socrates) and a “noisy” model (which included lines spoken by other characters) to assess not only translation accuracy but also the preservation of stylistic and rhetorical features of the Greek source, such as the persona of Socrates. Quantitatively, their Greek-to-English model achieved a Bilingual Evaluation Understudy (BLEU) score of 26.7 for the noisy model, demonstrating that even with heterogeneous training data, essential aspects of rhetorical style and vocabulary could be preserved in the English translations of ancient Greek texts.
A more recent direction in the field is represented by the evaluation of foundation and commercial LLMs, such as GPT-4o, Claude 3 Opus, and Gemini. Wannaz and Miyagawa [29] systematically compared nine LLMs, including both general-purpose and specialized models, on the translation of Ancient Greek ostraca into English. The study employed four Ancient Greek documentary texts, with expert-produced English reference translations, and evaluated model outputs using BLEU (SacreBLEU), Metric for Evaluation of Translation with Explicit ORdering (METEOR), Recall-Oriented Understudy for Gisting Evaluation (ROUGE), Translation Edit Rate (TER), Levenshtein distance, and a custom “school” metric. Among the foundation models, Claude 3 Opus and GPT-4o achieved the highest BLEU scores, up to 39.63, and also showed strong results in METEOR (up to 0.67) and ROUGE (up to 0.65). These models demonstrated lower rates of translation errors and consistently higher metric scores compared to translations from Coptic. The findings indicate that, even without task-specific fine-tuning on Ancient Greek, foundation LLMs can produce translations that align closely with expert references, as measured by standard NLP evaluation metrics.
The latest developments in the field focus on specialized transformer-based models and explicit integration of linguistic features for Ancient Greek translation. Rapacz and Smywiński-Pohl [30] conducted a comprehensive evaluation of four neural models, including two specialized for Ancient Greek (GreTa and PhilTa) and two general-purpose multilingual models (mT5-base and mT5-large), on the task of interlinear translation from Ancient Greek to English and Polish. Using a word-aligned, morphologically annotated parallel corpus of the Greek New Testament, they systematically tested 144 experimental configurations, varying preprocessing methods, and the encoding of morphological information. Results demonstrated that incorporating dedicated morphological embedding layers led to significant improvements: BLEU scores for English translations increased from 44.67 (baseline) to 60.40 (with morphological embeddings), and for Polish, from 42.92 to 59.33. The PhilTa model achieved the best performance for English, while mT5-large performed best for Polish. Notably, the PhilTa model maintained robust BLEU scores (36.20–43.52) even when trained on only 10% of the available data, highlighting its efficiency and stability in low-resource conditions.
3.3.4. LMs for Authorship Attribution and Intertextuality in Ancient Greek
Recent research has also leveraged LMs to address questions of authorship attribution and intertextuality within Ancient Greek texts. This area focuses on identifying distinct authorial signatures and detecting literary relationships, such as allusions or parallels, across works and languages. The reviewed studies illustrate a variety of modeling approaches—from the use of specialized sentence transformers [31] and transformer-based classifiers for author attribution [32] to the application of foundation LMs in expert-in-the-loop settings [33] —demonstrating the growing methodological sophistication in capturing stylistic and literary dynamics in Ancient Greek corpora.
A primary direction in this area has been the development and evaluation of specialized sentence transformer models tailored to classical languages. For example, Riemenschneider and Frank [31] introduced SPHILBERTA, a trilingual sentence transformer designed for Ancient Greek, Latin, and English. The model was trained using parallel corpora sourced from the Bible, the Perseus Digital Library, Open Parallel corpus (OPUS), and Rosenthal, with both automatically and manually aligned trilingual data. The methodology employed multilingual knowledge distillation to align sentence representations across languages using cosine similarity. SPHILBERTA was evaluated on translation retrieval tasks, achieving accuracy rates over 96% for both English–Latin and English–Greek and above 91% for Latin–Greek retrieval. The model was also applied to the identification of intertextual parallels between the Aeneid and the Odyssey, demonstrating its application in cross-lingual literary analysis.
Moving from multilingual to monolingual settings, authorship analysis has been another significant focus within this domain. Schmidt et al. [32] investigated the application of pre-trained and fine-tuned LMs for attributing authorship to texts of rhetorical theory from the Second Sophistic period, with particular attention to the Pseudo-Dionysian Ars Rhetorica. Their study employed three transformer models—GreBerta (a RoBERTa-sized model pre-trained on Ancient Greek), Ancient Greek BERT, and Modern Greek BERT—using a two-step process of masked language modeling fine-tuning followed by classifier training for sequence classification. The models were tested on a corpus of Greek rhetorical texts, with performance assessed using F1 score and accuracy. The GreBerta model, when further fine-tuned on the task-specific data, achieved the highest results (F1: 90.14%, Accuracy: 90.12%). A chapter-level analysis of Ars Rhetorica revealed stylistic divisions, with the first part of the treatise aligning with Menander Rhetor and later chapters indicating more heterogeneous or uncertain authorship.
In addition to domain-adapted and pre-trained transformer models, recent work has also evaluated the potential of foundation LLMs in intertextuality research. Umphrey et al. [33] assessed the application of Claude Opus, a commercial large language model, for identifying intertextual relationships—including quotations, allusions, and echoes—within biblical Koine Greek texts. The study adopted an expert-in-the-loop methodology, in which the outputs of the LLM were interpreted and scored by experts according to Hays’ intertextuality criteria, encompassing thematic, lexical, and structural alignment. Various test scenarios were included, using both known and hypothetical textual pairs. Unlike studies in other domains, such as NER or POS tagging, which typically report quantitative evaluation metrics, the assessment here was qualitative, relying on expert judgments rather than accuracy or F1 scores. Results indicated that the model could retrieve established intertextual links, generate novel connections, and suggest new candidates for scholarly investigation. Model performance was primarily discussed in terms of expert agreement and the plausibility of retrieved links rather than through standardized percentage-based measures.
3.3.5. Emotion Analysis in Ancient Greek Literature Using LMs
Following the exploration of authorship and intertextuality, recent research has turned to the application of LMs for emotion analysis in Ancient Greek literature. This emerging area investigates how computational methods can capture and classify emotional expression in ancient texts, with particular attention to epic poetry. Notably, studies by Pavlopoulos et al. [34] and Picca and Pavlopoulos [35] have introduced annotated datasets and evaluated a range of approaches—from lexicon-based methods to deep learning models—for detecting and modeling emotions in the Iliad.
The first of these studies, by Pavlopoulos et al. [35], addressed the lack of sentiment resources for ancient Greek texts by producing a sentiment-annotated dataset for the first Book of the Iliad. Native Greek speakers annotated the modern Greek translation of each verse, labeling perceived sentiment (positive, negative, neutral, or narrator) as well as associated emotions. The resulting dataset modeled perceived sentiment as a multivariate time series across the poem. For automatic sentiment prediction, the authors fine-tuned GreekBERT—a transformer model pre-trained on modern Greek—on the annotated dataset. The model achieved a macro-averaged mean squared error (MSE) of 0.063 and a mean absolute error (MAE) of 0.187. The study also reported inter-annotator agreement, with Krippendorff’s alpha of 0.39 for sentiment and 0.83 for narrator recognition, illustrating the degree of subjectivity and complexity in emotion annotation for literary texts.
In a subsequent study, Picca and Pavlopoulos [35] introduced a French-annotated dataset covering ten books of the Iliad, specifically targeting excerpts of direct speech for emotion recognition. The annotation taxonomy was based on Cambria’s Hourglass of Emotions model, allowing annotators to assign multiple emotions per excerpt. A total of 468 excerpts were annotated by up to four native French speakers each, with the inter-annotator agreement (Krippendorff’s alpha) varying across books and reflecting the complexity of consensus in nuanced emotional interpretation. The study evaluated two types of computational models: a lexicon-based classifier using the French expanded emotion lexicon (FEEL) and a fine-tuned Multilingual-BERT model. For Multilingual-BERT, macro-averaged MSE and MAE were reported at 0.101 and 0.188, respectively. Both studies noted specific challenges associated with certain emotion categories, such as “eagerness,” and observed variability in emotional perception depending on language, translation, and annotation protocol.
3.3.6. LMs for Semantic Change and Lexical Dynamics in Ancient Greek
In our review, we also identified a series of recent studies focusing on the application of LMs and distributional semantics to the detection of semantic change and the investigation of lexical dynamics in Ancient Greek. This line of research integrates multilingual embedding approaches, the development of new benchmarks, and comparative analyses of various semantic representation techniques.
Krahn et al. [36] developed BERT-based sentence embedding models for Ancient Greek using a multilingual knowledge distillation approach. The models were trained on a parallel corpus of approximately 380,000 Ancient Greek–English sentence pairs compiled from sources such as Perseus, First1KGreek, and OPUS. Evaluation of translation similarity search tasks revealed that the best Simple Contrastive Sentence Embeddings (SimCSE)-based model achieved an accuracy of 96.64%, while knowledge distillation models reached an accuracy of up to 91.6%. For semantic textual similarity, the highest Spearman correlation obtained was 86.84 (ρ × 100). In semantic retrieval tasks, the top-performing models achieved Recall@10 of 69.87% and mAP@20 of 53.00%.
Complementing these advances, Stopponi et al. [37] introduced Ancient Greek Relatedness Evaluation benchmark (AGREE), the first benchmark for the intrinsic evaluation of distributional semantic models of Ancient Greek, constructed using expert judgments on word similarity and relatedness. The AGREE dataset, based on the Diorisis Ancient Greek Corpus, comprises 150 target words and 600 word pairs, rated by five expert annotators using both relatedness questionnaires and pairwise comparison tasks. Inter-annotator agreement was measured with Krippendorff’s alpha (0.73 for relatedness and 0.68 for similarity). Using AGREE as a gold standard, the authors evaluated various semantic models, including count-based models, Word2Vec skip-gram, and Continuous Bag of Words (CBOW) embeddings, and reported their correlations with expert scores. The best-performing models achieved Spearman correlation coefficients up to 0.57 for relatedness and 0.56 for similarity.
In a broader comparative context, Stopponi et al. [38] evaluated three classes of LMs for semantic analysis in Ancient Greek: count-based models, Word2Vec embeddings, and syntactic (graph-based) embeddings. The models were trained on corpora such as Diorisis, PROIEL, and PapyGreek and assessed for their ability to represent semantic relationships and detect lexical-semantic change. Using the AGREE benchmark as a gold standard, performance was measured with cosine similarity, nearest neighbor analysis, and precision scores. For example, in evaluating the lemma ἐλεύθερος (‘free’), the count-based model achieved a precision of 0.8, and the Word2Vec model reached 0.2 when comparing the top five nearest neighbors against expert judgments. For another lemma, σῆμα (‘sign, mark’), both models had a precision of 0.0. The results showed that Word2Vec models provided denser and higher-quality representations, particularly for words that occur frequently. At the same time, syntactic embeddings captured functional similarity but tended to yield lower precision (e.g., 0.2) against topical benchmarks.
3.3.7. Improving Quality and Accessibility of Ancient Greek Texts with LMs
After addressing advances in semantic modeling and lexical dynamics, recent work has also focused on practical applications that enhance the accessibility and reliability of Ancient Greek texts. Researchers have employed LMs for tasks such as error detection in manuscript digitization and the standardization of educational materials. These efforts underscore the importance of reliable textual resources and demonstrate the increasing integration of language technologies into digital philology and the study of Ancient Greek.
The first significant contribution in this area comes from Pavlopoulos et al. [39], who addressed the challenge of detecting and correcting errors in Handwritten Text Recognition (HTR) outputs for Byzantine Greek manuscripts spanning the 10th to 16th centuries. The authors developed a large masked language model, GreekBERT, which was pre-trained on modern Greek and subsequently fine-tuned on Byzantine and Ancient Greek data. Their approach treated error detection as a text classification problem and benchmarked both classical machine learning and deep learning methods. The best-performing model—GreekBERT: M+A, which was pre-trained on both modern and ancient Greek—achieved an Average Precision of 97% and demonstrated a clear advantage in detecting errors, particularly in older manuscripts. The model’s application before neural post-correction of HTRed texts significantly reduced the rate of post-correction mistakes, indicating that language model-based error detection can effectively mitigate the introduction of adversarial errors in automated manuscript processing. The study also provided century-based and character error rate (CER)-based analyses, highlighting the importance of pre-training on both historical and modern language data to maximize performance across varied text types.
A complementary approach is offered by Cowen-Breen et al. [12], who introduced LOGION, a domain-specific BERT-based contextual language model trained on approximately 70 million words of premodern Greek. LOGION was designed to detect and correct scribal errors in ancient Greek philological texts. The system learns conditional word distributions from large corpora (including Perseus, First1KGreek, and Thesaurus Linguae Graecae/TLG), then identifies potential errors based on contextual likelihood and proposes emendations using model suggestions with high statistical confidence. In experiments on artificially generated errors, LOGION achieved 90.5% top-1 accuracy and 98.1% correction accuracy, with further expert validation of real detected errors in Byzantine authors such as Michael Psellus. The study showed that contextual LMs are capable of automatically identifying textual corruptions that might otherwise go unnoticed, providing a practical tool for philologists and textual scholars. Additionally, the authors made their trained model and code openly available, supporting transparency and enabling others to build on their work.
Beyond text correction, LMs have also been used to improve the quality and standardization of educational resources. Kasapakis and Morgado [40] explored the use of a custom ChatGPT assistant (the Immersive Learning Case Sheet/ILCS Assistant) to support the structured documentation of immersive learning cases in the context of ancient Greek technology. In their VRChat-based case study, the assistant guided a research team through the process of describing and standardizing an educational scenario involving ancient Greek technological artifacts in virtual reality. The assistant prompted the team for additional details, checked for alignment with established frameworks, and supported iterative revisions of the case description. As a result, the documentation became more consistent and analytically rigorous. The study illustrates how human–AI collaboration can contribute to more complete and reproducible reporting in qualitative educational research.
3.3.8. Educational and Pedagogical Applications of LMs in Ancient Greek
Lastly, complementing the previously discussed developments in linguistic analysis, text processing, and resource creation, recent research has increasingly explored the role of LLMs in supporting the teaching of Ancient Greek. Recent studies in this area explore not only the practical utility of LLMs for translation, grammar instruction, and interactive support but also their influence on educational practices and student engagement. Significant work by Ross [9], Abbondanza [41], and Ross and Baines [42] offers valuable perspectives on how general-purpose LLMs can be utilized in educational settings.
The earliest of these studies, by Ross [9], provided a detailed evaluation of ChatGPT 3.5 as a pedagogical tool for teaching ancient languages at the secondary and university levels. The study systematically examined ChatGPT’s ability to parse, translate, and explain grammatical structures in Ancient Greek, Latin, and Sanskrit using materials from the OCR curriculum and established textbooks. ChatGPT was found to be effective in providing grammatical explanations and translation support for Latin and Sanskrit, but its performance with Ancient Greek was markedly less reliable. Errors included inconsistent handling of accentuation, confusion between Ancient and Modern Greek forms, and occasional failure to produce correct grammatical examples. Manual comparisons with established tools, such as Perseus and Whitaker’s Words, revealed that while ChatGPT offered practical classroom applications—such as rephrasing explanations and generating practice exercises—its outputs required careful vetting by teachers and students to avoid misunderstandings.
Abbondanza [41] explored the adoption of GenAI, particularly ChatGPT 3.5, in Italian high school settings for Latin and Ancient Greek instruction. The study emphasized the contrasting attitudes of educators—some of whom resist AI use, while others seek to embrace it within a constructivist pedagogical framework. Using a range of classroom activities and example prompts, Abbondanza found that ChatGPT could assist with translation tasks, respond to questions about grammar and syntax, and participate in interactive discussions with students. The study also found that some responses were incomplete or superficial, suggesting that teacher supervision remains necessary. Overall, the results suggest that while ChatGPT is not a replacement for direct instruction, it can serve as a valuable tool for supporting independent learning and providing individualized assistance when carefully integrated into existing curricula.
The most recent developments are presented by Ross and Baines [42], who investigate the broader impact of LLMs—including ChatGPT 3.5/4, Bard, Claude, Bing Chat, and custom GPTs—on students’ attitudes toward AI in Ancient Greek pedagogy. Their study focused not only on the practical classroom use of GenAI, but also on its ethical, social, and environmental implications in higher education. Information sessions and surveys were conducted with Classics students at the University of Reading before and after AI ethics presentations. The study found that while most students were aware of AI tools, many were apprehensive or reluctant to use them for learning, particularly after being informed of the ethical and data concerns associated with them. Students acknowledged the practical potential of LLMs for grammar practice, translation feedback, and revision exercises but also noted persistent worries about accuracy, content policy restrictions, and the risks of over-reliance on AI-generated outputs.
As the preceding sections illustrate, research in this domain has progressed rapidly, spanning a diverse range of NLP tasks, model architecture, and evaluation protocols. While some studies have focused primarily on demonstrating technical feasibility and reporting performance metrics, others have begun to explore educational applications and assess impacts on student learning. To consolidate these findings and facilitate comparison across methodologies, Table 2 provides a benchmarking overview of language model performance in Ancient Greek studies, including key tasks, datasets, and reported metrics, along with an indication of whether each study represents exploratory work or includes validated educational outcomes.
Table 2.
Comparative benchmarking of LMs applied to Ancient Greek.
4. Discussion
This section addresses the main findings of the review about to the guiding research questions, focusing on the application and effectiveness of LMs for Ancient Greek as well as the challenges encountered. The discussion is structured in four parts: first, we identify the main trends emerging from the literature; second, we examine the practical implications for research and education; third, we outline directions for future research; and finally, we critically reflect on ethical considerations and biases inherent in current approaches.
4.1. Critical Analysis of Key Findings
The present systematic review highlights substantial advances in the application of LMs to Ancient Greek while also revealing essential distinctions in the performance, strengths, and weaknesses of different methodological approaches.
Particularly notable are transformer-based models such as Ancient-Greek-BERT [22], GRεBERTA, and PHILTA [18], which have been pre-trained or fine-tuned specifically for Ancient Greek. These models consistently outperform earlier architectures, including RNNs and general-purpose multilingual models, achieving high performance in tasks like part-of-speech tagging, lemmatization, and syntactic parsing. For instance, Ancient-Greek-BERT achieved POS tagging accuracy above 95% on specialized corpora [22], with OdyCyjoint and GRεTA models showing similarly strong results [18]. Their success can be attributed to the availability of high-quality, annotated datasets and the explicit integration of linguistic features during training. Nevertheless, transformer-based models encounter limitations when applied to fragmented, dialectally diverse, or low-resource texts. As demonstrated by Swaelens et al. [23], accuracy in morphological analysis declines significantly for unnormalized Byzantine Greek, underscoring challenges in generalizing across orthographic variation and data quality. Additionally, studies such as Riemenschneider and Frank [31] and Kostkan et al. [22] point to difficulties adapting these models to inscriptions, papyri, and non-canonical texts, where performance gaps remain substantial.
Morphology-aware and hybrid models have also garnered significant attention. By explicitly integrating linguistic features through specialized morphological embeddings or joint learning objectives, these models show notable improvements in translation and morphological tasks, even under low-resource conditions, as demonstrated by the works of Rapacz and Smywiński-Pohl [30] and Beersmans et al. [25]. For example, PhilTa maintained robust performance even when trained on limited data—a crucial advantage for less-documented subdomains. However, the development of such models demands substantial annotated resources and benefits from interdisciplinary collaboration between computational scientists and philologists, as underlined by Stopponi et al. [38].
In contrast, General-purpose LLMs, such as ChatGPT [9], Claude Opus [20], and GPT-4o [19], offer notable flexibility and accessibility, particularly for zero-shot or few-shot applications in translation and educational support. Studies like Ross [9], Abbondanza [41], and Wannaz and Miyagawa [29] highlight their capacity to generate translations and grammatical feedback, making them attractive tools for educational settings. However, without fine-tuning, these models demonstrate lower accuracy in specialized tasks; for example, González-Gallardo et al. [27] reported that NER performance with ChatGPT-3.5 remained below a 40% F1-score [26], significantly underperforming compared to dedicated models like AG_BERT and MicroBERT [24]. Furthermore, general-purpose LLMs are prone to issues such as inaccuracy, hallucination, and difficulty handling code-switching or rare linguistic phenomena.
Beyond performance considerations, the reviewed literature exhibits critical methodological weaknesses. The overwhelming reliance on BERT-like transformer architectures was evident across most studies (e.g., Singh et al. [21], Riemenschneider and Frank [31], Kostkan et al. [22]), potentially constraining the exploration of alternative modeling paradigms better suited to the morphological richness and orthographic diversity of Ancient Greek. This architectural homogeneity risks overlooking innovative approaches, such as graph-based or recurrent models (Schmidt et al. [32]; Pavlopoulos et al. [34]), that could better address certain linguistic challenges. Reproducibility also remains an underdeveloped aspect in much of the literature: only a limited subset of studies, notably Swaelens et al. [23] and Stopponi et al. [38], provide comprehensive details on training configurations, hyperparameters, or open-source implementations. The absence of standardized evaluation protocols and publicly available benchmarks further complicates the comparison of results and limits the transparency necessary for robust scientific progress.
Beyond the methodological considerations, however, it is essential to recognize how these developments—and their current limitations—are already shaping practical realities in both research and education.
4.2. Practical Implications
These developments are having a transformative impact on both the research and teaching of Ancient Greek.
In research, the automation of tasks such as lemmatization, syntactic analysis, and entity recognition improves workflows. It enhances methodological accuracy, facilitating the development of new tools and methods for text analysis. This shift enhances the productivity and methodological rigor of philological research, broadening the available tools and resources for classical studies.
In the educational domain, LLMs introduce new dynamics into the teaching of Ancient Greek. By providing immediate translations, grammatical feedback, and personalized support, these tools lower traditional barriers to learning a complex and highly inflected language, making Ancient Greek more accessible and less intimidating for students and independent learners.
Moreover, advancements in syntactic and semantic analysis facilitate the application of sophisticated techniques, such as sentiment analysis, in works like the Iliad, as well as the detection of intertextual relationships in ancient texts. These innovative approaches not only deepen engagement with classical literature but also highlight the potential of AI-driven tools to reshape interpretive methodologies.
Nevertheless, the full realization of these technologies requires the development of specialized corpora and the enhancement of digital literacy among philologists and researchers. Without these foundational infrastructures, the integration of LMs into research and teaching risks remaining fragmented and insufficient.
Consequently, a clear agenda is needed to guide future efforts in addressing these gaps and unlocking the full potential of language technologies. The following section synthesizes key directions that emerge from this review.
4.3. Synthesis and Future Research Directions
The synthesis of the findings from this review points to several critical directions for future research, which can be grouped into three main priorities:
4.3.1. Data Resources and Benchmarks
First and foremost, there is a critical need for the development and open sharing of large-scale, high-quality, and linguistically diverse corpora and annotated resources for Ancient Greek [10,22,25]. This need has already begun to be addressed by initiatives such as the AGREE benchmark [37], which aims to create standardized datasets for evaluating the processing of dialects and rare forms. Further efforts to expand and maintain openly accessible corpora will be essential to support both academic research and educational applications.
4.3.2. Modeling Approaches and Methodological Innovation
Building on the foundation of richer data, future research should focus on advancing modeling techniques that explicitly incorporate more profound linguistic knowledge. Models that integrate morphology- or syntax-enriched architectures have consistently demonstrated superior performance [22,27]. Exploring alternative modeling paradigms beyond BERT-like transformers, including graph-based, recurrent, or hybrid approaches, may help address current limitations such as overfitting, bias, and limited adaptability to underrepresented forms. Additionally, incorporating multimodal data (e.g., manuscript images or archaeological metadata) offers promising avenues to enhance contextual understanding and support new interpretive methods [19,24].
4.3.3. Pedagogical Integration and Ethical Evaluation
Alongside data and methodological advancements, the practical impact of LLMs in educational settings requires more rigorous and systematic evaluation. As demonstrated by Ross [9], Abbondanza [41], and Ross and Baines [42], while LLMs can support individualized learning and improve accessibility, further studies are needed to assess learning outcomes, student engagement, and the ethical implications of AI integration in classrooms. Particular attention should be given to issues of bias, transparency, and over-reliance on automated outputs. Developing clear guidelines and best practices will be crucial to ensuring the responsible and effective use of these technologies in teaching and learning.
Addressing these priorities will require sustained interdisciplinary collaboration among linguists, philologists, computer scientists, and educators. Indeed, some of the most promising advances identified in this review have resulted from teams that combine computational expertise with in-depth domain knowledge, as seen in projects such as LOGION [12] and OdyCy [22]. Moving forward, future work should prioritize open science, reproducibility, and the active involvement of end users to ensure that language technologies for Ancient Greek are both practical and ethically grounded.
At the same time, the adoption of these technologies brings to the forefront significant ethical considerations, which warrant careful reflection.
4.4. Ethical Considerations and Bias in Language Models
While recent advances in LLMs have opened new opportunities for studying Ancient Greek, they also raise significant ethical concerns regarding bias, fairness and transparency. These issues are not peripheral but intersect fundamentally with the methodological and pedagogical questions discussed in the previous sections.
Pretrained language models often inherit and amplify biases present in their training data, which, in the case of historical texts, may reflect outdated cultural, ideological, or social norms (Ross and Baines [42]; Abbondanza [41]). For example, models trained predominantly on ancient sources can reproduce gender hierarchies and ethnocentric stereotypes embedded in epic poetry and historiography. As Picca and Pavlopoulos [35] observe, sentiment analysis applied to the Iliad frequently reinforces martial and patriarchal perspectives while neglecting alternative interpretations.
Additionally, biases can arise from the uneven representation of dialects, genres, and authors in existing corpora. Swaelens et al. [23] highlight that many resources overrepresent Attic and Homeric Greek, leading to models that systematically underperform on Byzantine or Hellenistic texts. Such overrepresentation can lead models to favor specific linguistic registers or canonical texts while underestimating marginalized or less-documented material. In educational settings, uncritical reliance on biased outputs risks reinforcing historical hierarchies, misrepresenting culturally sensitive content, or discouraging inclusive pedagogical practices.
These challenges are further complicated by the limited availability of critical annotations and transparent reporting of data composition in many studies (Riemenschneider and Frank [31]; Stopponi et al. [38]). For instance, a few projects explicitly document how training corpora were selected, balanced, or preprocessed, limiting users’ ability to assess the biases embedded in model predictions.
Addressing these challenges requires deliberate mitigation strategies, such as curating more diverse and balanced training corpora, incorporating bias detection and correction techniques, and ensuring transparent documentation of model limitations. Some recent efforts, like the AGREE benchmark introduced by Stopponi et al. [38], are promising steps toward more representative evaluation datasets. Moreover, integrating critical perspectives and ethical awareness into the design and deployment of language technologies is crucial for supporting responsible use in both research and pedagogy. Collaborations with experts in gender studies, postcolonial studies, and cultural heritage can further enrich ethical frameworks and help ensure that AI applications in classical philology do not uncritically reproduce the ideological assumptions of their sources.
5. Conclusions
This review systematically assessed the application of LMs to the study and teaching of Ancient Greek. Analysis of 27 peer-reviewed studies revealed that transformer-based models fine-tuned specifically for Ancient Greek consistently outperform earlier architectures in tasks such as part-of-speech tagging, morphological analysis, syntactic parsing, and translation. These advances demonstrate the significant potential of domain-specific LMs in addressing the linguistic complexity of Ancient Greek.
However, the review also identified persistent limitations. Challenges include limited generalization across dialects; performance declines with fragmented or low-resource texts, and the continued reliance on small, specialized datasets. In educational contexts, general-purpose LLMs offer accessibility but exhibit lower accuracy without fine-tuning and remain prone to errors, such as hallucination and difficulties handling rare linguistic phenomena.
Overall, while language models have considerably advanced the computational study of Ancient Greek, significant barriers remain that must be addressed to realize their potential in both research and pedagogy fully.
Author Contributions
Conceptualization, D.T., L.T. and V.S.V.; methodology, D.T., L.T. and V.S.V.; software, D.T.; validation, L.T. and V.S.V.; formal analysis, D.T.; investigation, D.T.; resources, D.T.; data curation, D.T.; writing—original draft preparation, D.T.; writing—review and editing, L.T. and V.S.V.; visualization, D.T.; supervision, V.S.V.; project administration, V.S.V. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study is only contained in the article itself.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| AGDT | Ancient Greek Dependency Treebank |
| AGREE | Ancient Greek Relatedness Evaluation benchmark |
| AUC | Area Under the Curve |
| BLEU | Bilingual Evaluation Understudy |
| BERT | Bidirectional Encoder Representations from Transformers |
| CBOW | Continuous Bag of Words |
| CER | Character Error Rate |
| CLTK | Classical Language Toolkit |
| CoNLL | Conference on Computational Natural Language Learning |
| DBBE | Database of Byzantine Book Epigrams |
| ELMo | Embeddings from Language Models |
| F1-score | Harmonic mean of precision and recall |
| FEEL | French Expanded Emotion Lexicon |
| GenAI | Generative Artificial Intelligence |
| GLAUx | Greek and Latin Annotated Universal Corpus |
| GPT | Generative Pre-trained Transformer |
| GCSE | Greek General Certificate of Secondary Education |
| HTR | Handwritten Text Recognition |
| ILCS | Immersive Learning Case Sheet |
| LAS | Labeled Attachment Score |
| LLM | Large Language Model |
| LM | Language Model |
| LOGION | Language model for Greek Philology |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| METEOR | Metric for Evaluation of Translation with Explicit Ordering |
| MSE | Mean Squared Error |
| MT5 | Multilingual T5 Transformer Model |
| NER | Named Entity Recognition |
| NLP | Natural Language Processing |
| NMT | Neural Machine Translation |
| OCR | Oxford, Cambridge and RSA |
| OPUS | Open Parallel corpus |
| POS tagging | Part-of-Speech tagging |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| PROIEL | Pragmatic Resources in Old Indo-European Languages |
| RNN | Recurrent Neural Network |
| RoBERTa | Robustly Optimized BERT Pretraining Approach |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| SG | Skip-Gram |
| SimCSE | Simple Contrastive Sentence Embeddings |
| SOTA | State of the Art |
| T5 | Text-To-Text Transfer Transformer |
| TER | Translation Edit Rate |
| TLG | Thesaurus Linguae Graecae |
| UD | Universal Dependencies Treebank |
Appendix A
Table A1.
Overview of Selected Articles for the Literature Review on LMs and Ancient Greek, sorted by Publication Year.
Table A1.
Overview of Selected Articles for the Literature Review on LMs and Ancient Greek, sorted by Publication Year.
| # | Authors (Year) | Model(s) Used | Type of Model | Corpus/Dataset | NLP Task/Application | Main Contribution/Focus | Evaluation Method |
|---|---|---|---|---|---|---|---|
| 1 | Lamar and Chambers [28] | Encoder–decoder RNNs (OpenNMT-py, LSTM) | Task-specific NMT (custom-trained) | 16k Socratic + 15k non-Socratic Greek lines; 11k Cicero sentences (pivot via English) | Machine Translation (Ancient Greek → Latin) | Style-preserving NMT using pivot language in low-resource classical texts | BLEU scores, rhetorical feature retention |
| 2 | Lim and Park [11] | ELMo, BERT, Multi-view character-based models | Deep contextualized LMs and character-based representations | Universal Dependencies (UD) CoNLL 2018 Shared Task dataset | POS tagging | Introduced joint multiview learning combining sentence- and word-based character embeddings for better tagging in morphologically rich languages, including Ancient Greek | Accuracy metrics across multiple languages including Ancient Greek; ablation studies and model comparison |
| 3 | Singh et al. [21] | Expanded Ancient Greek BERT | Domain-specific (fine-tuned BERT) | AGDT, PROIEL, Gorman treebanks, Perseus, First1KGreek, DBBE | Morphological analysis, PoS tagging | Development of BERT-based model for Ancient/Byzantine Greek; fine-grained PoS tagging | Accuracy on validation/test sets; comparison with RNNTagger; Gold standard for DBBE |
| 4 | Pavlopoulos et al. [39] | GreekBERT (fine-tuned) | Pretrained Transformer (fine-tuned on emotion annotation) | Modern Greek translation of Book 1 of the Iliad | Sentiment analysis (perceived emotion labeling) | Annotated dataset + sentiment modeling for Homeric text using deep learning; multivariate emotion time-series | MSE, MAE, inter-annotator agreement |
| 5 | Ross [9] | ChatGPT 3.5 | Foundation model (LLM) | Ancient Greek GCSE materials; OCR curriculum texts | Translation, grammar explanation, pedagogical support | Evaluated ChatGPT’s ability to parse, translate, and explain Ancient Greek, Latin, and Sanskrit for pedagogical use in secondary and university-level education | Manual comparison with Perseus and Whitaker’s Words; qualitative analysis; practical classroom use cases |
| 6 | Kostkan et al. [22] | Ancient-Greek-BERT (odyCy) | Domain-specific (fine-tuned transformer) | UD Perseus Treebank and UD Proiel Treebank | POS tagging, morphological analysis, lemmatization, syntactic dependency parsing | Developed a modular spaCy-based NLP pipeline for Ancient Greek with improved generalizability and performance across dialects | Accuracy on individual tasks; comparison with CLTK, greCy, Stanza, UDPipe; joint and per-treebank models |
| 7 | Riemenschneider and Frank [18] | GRεBERTA, GRεTA, PHILBERTA, PHILTA | Encoder-only (RoBERTa), Encoder–decoder (T5), Monolingual and Multilingual | Open Greek and Latin, Greek Medieval Texts, Patrologia Graeca, Internet Archive (~185.1M tokens) | PoS tagging, lemmatization, dependency parsing, semantic probing | Created and benchmarked 4 LMs for Ancient Greek; evaluated architectural and multilingual impacts | Benchmarks on Perseus and PROIEL treebanks, semantic/world knowledge probing tasks |
| 8 | Pavlopoulos et al. [34] | GreekBERT:M, GreekBERT:M+A, MT5 | Pretrained LLMs, Transformer, Encoder–Decoder | HTREC2022 (Byzantine Greek manuscripts, 10th–16th c.) | Error detection and correction in HTR | Detecting and mitigating adversarial errors in post-correction of HTR outputs | Average Precision, AUC, F1 score, Century-based and CER-based analysis |
| 9 | Krahn et al. [36] | GRCmBERT, GRCXLM-R, SimCSE | Multilingual sentence embeddings via knowledge distillation and contrastive learning | 380k Ancient Greek–English parallel sentence pairs; Perseus, First1KGreek, OPUS | Semantic similarity, translation search, semantic retrieval | Developed sentence embedding models for Ancient Greek using cross-lingual knowledge distillation; created evaluation datasets | Translation similarity accuracy, semantic textual similarity (Spearman ρ), semantic retrieval (Recall@10, mAP@20), MRR for translation bias |
| 10 | Cowen-Breen et al. [12] | LOGION (BERT-based contextual model) | Domain-specific transformer model | ~70M words of premodern Greek (Perseus, First1KGreek, TLG, etc.) | Scribal error detection and correction in Ancient Greek | Introduced LOGION for automated error detection in philological texts using confidence-based statistical metrics | Top-1 accuracy (90.5%) on artificial errors; 98.1% correction accuracy; expert validation on real data |
| 11 | Riemenschneider and Frank [31] | SPHILBERTA | Multilingual Sentence Transformer | Parallel corpora from Bible, Perseus, OPUS, Rosenthal; English-Greek-Latin trilingual texts | Cross-lingual sentence embeddings; Intertextuality detection | Developed SPHILBERTA, a trilingual sentence transformer for Ancient Greek, Latin, and English to detect intertextual parallels | Translation accuracy using cosine similarity across test corpora; case study on Aeneid–Odyssey allusions |
| 12 | Gessler and Schneider [24] | SynCLM, SLA, MicroBERT | Transformer-based LMs with syntactic inductive bias | Ancient Greek Wikipedia (9M tokens), UD treebanks, WikiAnn, PrOnto benchmark | Syntactic parsing, NER, sequence classification | Assessed whether syntax-guided inductive biases improve performance of LMs for low-resource languages like Ancient Greek | LAS for parsing, F1 for NER, accuracy for PrOnto tasks; comparison across model variants |
| 13 | González-Gallardo et al. [26] | ChatGPT-3.5 | General-purpose instruction-tuned LLM | AJMC (historical commentaries on Sophocles’ Ajax, 19th c.); multilingual NER corpus | NER in historical and code-switched documents | Zero-shot NER performance evaluation of ChatGPT on historical texts involving Ancient Greek; discussed challenges of LLMs with multilingual and ancient code-switching | Token-level F1 score (strict and fuzzy); qualitative analysis of NER failures |
| 14 | Beersmans et al. [25] | AG_BERT, ELECTRA, GrεBerta, UGARIT | Transformer-based NER models with domain adaptation | OD, DEIPN, SB, PH, GLAUx corpus | NER for Ancient Greek, focus on personal names | Comparison of transformer models for NER; domain knowledge and syntactic information integration; focus on improving NER for personal names | F1-score on Held-out and GLAUx TEST sets; qualitative error analysis; comparison of rule-based vs. mask-based gazetteer methods |
| 15 | Picca and Pavlopoulos [35] | Multilingual-BERT; FEEL lexicon | Pretrained transformer model and lexicon-based classifier | 468 speech excerpts from Iliad (Books 1, 16–24) annotated in French | Emotion recognition in Ancient Greek literature | Introduced a French-annotated dataset of Iliad for emotion detection; evaluated lexicon-based vs. deep learning approaches | MSE, MAE; Inter-annotator agreement; qualitative comparison via confusion matrix |
| 16 | Wannaz and Miyagawa [29] | Claude Opus, GPT-4o, GPT-4, GPT-3.5, Claude Sonnet, Claude Haiku, Gemini, Gemini Advanced | General-purpose LLMs | 4 Ancient Greek ostraca from papyri.info (TM 817897, 89219, 89224, 42504) | Machine Translation (Ancient Greek → English) | Evaluation of 8 LLMs for Ancient Greek-English machine translation using 6 NLP metrics | Quantitative metrics: BLEU, TER, Levenshtein, METEOR, ROUGE, custom ‘school’ metric |
| 17 | Umphrey et al. [33] | Claude Opus | Foundation Model (LLM) | Biblical Koine Greek texts (e.g., Matthew, Clement, Sirach, Acts) | Intertextual analysis (quotations, allusions, echoes) | Evaluating LLMs in detecting intertextual patterns using an expert-in-the-loop method | Expert evaluation using Hays’ intertextuality criteria (thematic, lexical, structural alignment) |
| 18 | Abbondanza [41] | ChatGPT 3.5 | Foundation Model (LLM) | Educational prompts in Latin and Ancient Greek used by Italian high school students | Interactive educational support, translation, grammar and syntax evaluation | Exploration of ChatGPT’s role as a supportive tool in high school Latin and Greek education, including prompt-based evaluations | Qualitative assessment of ChatGPT’s responses to student-style questions; case-based analysis |
| 19 | Schmidt et al. [32] | GreBerta, Ancient Greek BERT, Modern Greek BERT | Fine-tuned transformer models (BERT/RoBERTa variants) | Greek rhetorical texts from the Second Sophistic period, including Pseudo-Dionysius’s Ars Rhetorica | Authorship attribution | Analysis of authorial identity in the Ars Rhetorica; identification of internal textual structure | F1 score, accuracy, comparison of attribution profiles, majority voting across text chunks |
| 20 | González-Gallardo et al. [27] | Llama-2-70B, Llama-3-70B, Mixtral-8 × 7B, Zephyr-7B | Open Instruct LLMs (Instruction-tuned) | AJMC, HIPE, NewsEye historical corpora (19th–20th c.), multilingual (with Ancient Greek code-switching) | NER | Assessed performance of open instruction-tuned LLMs for NER in historical documents using few-shot prompting | Precision, Recall, F1-score under strict and fuzzy boundary matching; comparison with SOTA benchmarks |
| 21 | Keersmaekers and Mercelis [10] | ELECTRA (electra-grc), LaBERTa (RoBERTa) | Transformer-based, domain-specific | GLAUx corpus (Greek, 1.46M tokens), PROIEL treebank (Latin, 205K tokens) | Morphological tagging | Systematic comparison of adaptations for transformer-based tagging in Ancient Greek and Latin | Accuracy scores; statistical tests (McNemar’s); error analysis (by feature, text type, lexicon use) |
| 22 | Ross and Baines [42] | ChatGPT 3.5/4, Bard AI, Claude-2, Bing Chat, custom GPTs | General-purpose LLMs (instruction-tuned) | Not applicable (evaluated user interaction in educational context) | Ethical education on AI; student attitudes toward AI in Ancient Greek pedagogy | Impact of AI ethics sessions on student perceptions and potential educational use of LLMs | Surveys before and after information sessions, qualitative analysis |
| 23 | Kasapakis and Morgado [40] | Custom ChatGPT Assistant (ILCS Assistant) | Customized LLM assistant for qualitative research | VRChat-based immersive learning case on Ancient Greek technology (Phyctories, Aeolosphere) | Standardization of case reporting; educational case support | Application of co-intelligent LLM to improve consistency and structure in immersive learning case documentation using ILCS methodology | Iterative human–AI co-authoring; framework alignment analysis |
| 24 | Stopponi et al. [37] | Word2Vec (SG and CBOW) | Distributional semantic embeddings | Diorisis Ancient Greek Corpus | Semantic similarity and relatedness | Developed AGREE, a benchmark for evaluating semantic models of Ancient Greek using expert-annotated word pairs | Expert judgment surveys, inter-rater agreement analysis, qualitative and quantitative validation of semantic scores |
| 25 | Stopponi et al. [38] | Count-based, Word2vec, Graph-based (Node2vec with syntax) | Count-based, Word Embeddings, Syntactic Embeddings | Diorisis Corpus, Treebanks (PROIEL, PapyGreek, etc.) | Semantic representation, semantic change detection | Comparison of model architectures for Ancient Greek semantic analysis; evaluation with AGREE benchmark | AGREE benchmark; cosine similarity; nearest neighbors; precision scores |
| 26 | Rapacz and Smywiński-Pohl [30] | GreTa, PhilTa, mT5-base, mT5-large | Transformer-based (T5 variants) | Greek New Testament (BibleHub and Oblubienica interlinear corpora) | Interlinear translation (Ancient Greek → English/Polish) | Introduced morphology-enhanced neural models for interlinear translation; showed large BLEU gains using morphological embeddings. | BLEU, SemScore (semantic similarity); 144 experimental setups; statistical significance via Mann–Whitney U tests |
| 27 | Swaelens et al. [23] | BERT, ELECTRA, RoBERTa | Transformer-based LMs (custom-trained) | DBBE, First1KGreek, Perseus, Trismegistos, Modern Greek Wikipedia, Rhoby epigrams | Fine-grained Part-of-Speech Tagging (Morphological Analysis) | Development of a POS tagger for unnormalized Byzantine Greek using newly trained LMs; evaluation across multiple architectures and datasets | Accuracy, Precision, Recall, F1-score; Inter-annotator agreement; Comparison with Morpheus and RNN Tagger |
References
- Carter, D. The influence of Ancient Greece: A historical and cultural analysis. Int. J. Sci. Soc. 2023, 5, 257–265. [Google Scholar] [CrossRef]
- Peraki, M.; Vougiouklaki, C. How Has Greek Influenced the English Language. British Council. Available online: https://www.britishcouncil.org/voices-magazine/how-has-greek-influenced-english-language (accessed on 25 April 2025).
- Di Gioia, I. I think learning ancient Greek via video game is…’: An online survey to understand perceptions of digital game-based learning for ancient Greek. J. Class. Teach. 2024, 25, 173–180. [Google Scholar] [CrossRef]
- Reggiani, N. Multicultural education in the ancient world: Dimensions of diversity in the first contacts between Greeks and Egyptians. In Multicultural Education: From Theory and Practice; Cambridge Scholars Publishing: Cambridge, UK, 2013. [Google Scholar]
- World Stock Market. France: Latin and Ancient Greek No Longer Excite Students. Available online: https://www.worldstockmarket.net/france-latin-and-ancient-greek-no-longer-excite-students/ (accessed on 10 March 2025).
- Hunt, S. Classical studies trends: Teaching classics in secondary schools in the UK. J. Class. Teach. 2024, 25, 198–214. [Google Scholar] [CrossRef]
- Le Hur, C. A new classical Greek qualification. J. Class. Teach. 2022, 23, 79–80. [Google Scholar] [CrossRef]
- Tzotzi, A. Ancient Greek and Language Policy 1830–2020, Reasons–Goals–Results. Master’s Thesis, Hellenic Open University, Patras, Greece, 2020. Available online: https://apothesis.eap.gr/archive/download/df8d7eb2-c928-402a-84d8-694485d2562c.pdf (accessed on 3 May 2025).
- Ross, E.A.S. A new frontier: AI and ancient language pedagogy. J. Class. Teach. 2023, 24, 143–161. [Google Scholar] [CrossRef]
- Keersmaekers, A.; Mercelis, W. Adapting transformer models to morphological tagging of two highly inflectional languages: A case study on Ancient Greek and Latin. In Proceedings of the 1st Workshop on Machine Learning for Ancient Languages (ML4AL 2024), Bangkok, Thailand, 15 August 2024; pp. 165–176. [Google Scholar]
- Lim, K.; Park, J. Part-of-speech tagging using multiview learning. IEEE Access 2020, 8, 195184–195196. [Google Scholar] [CrossRef]
- Cowen-Breen, C.; Brooks, C.; Graziosi, B.; Haubold, J. Logion: Machine-learning based detection and correction of textual errors in Greek philology. In Proceedings of the Ancient Language Processing Workshop (RANLP-ALP 2023), Varna, Bulgaria, 8 September 2023; pp. 170–178. Available online: https://aclanthology.org/2023.alp-1.20.pdf (accessed on 3 May 2025).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar] [CrossRef]
- Lampinen, A. Can language models handle recursively nested grammatical structures? A case study on comparing models and humans. Comput. Linguist. 2024, 50, 1441–1476. [Google Scholar] [CrossRef]
- Berti, M. (Ed.) Digital Classical Philology: Ancient Greek and Latin in the Digital Revolution; Walter de Gruyter GmbH & Co KG: Berlin, Germany, 2019; Volume 10. [Google Scholar]
- Sommerschield, T.; Assael, Y.; Pavlopoulos, J.; Stefanak, V.; Senior, A.; Dyer, C.; Bodel, J.; Prag, J.; Androutsopoulos, I.; De Freitas, N. Machine learning for ancient languages: A survey. Comput. Linguist. 2023, 49, 703–747. [Google Scholar] [CrossRef]
- Riemenschneider, F.; Frank, A. Exploring large language models for classical philology. arXiv 2023, arXiv:2305.13698. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef] [PubMed]
- Sohrabi, C.; Franchi, T.; Mathew, G.; Kerwan, A.; Nicola, M.; Griffin, M.; Agha, M.; Agha, R. PRISMA 2020 statement: What’s new and the importance of reporting guidelines. Int. J. Surg. 2021, 88, 105918. [Google Scholar] [CrossRef] [PubMed]
- Singh, P.; Rutten, G.; Lefever, E. A pilot study for BERT language modelling and morphological analysis for ancient and medieval Greek. In Proceedings of the 5th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, Punta Cana, Dominican Republic, 11 November 2021; pp. 128–137. [Google Scholar]
- Kostkan, J.; Kardos, M.; Mortensen, J.P.B.; Nielbo, K.L. OdyCy–A general-purpose NLP pipeline for Ancient Greek. In Proceedings of the 7th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (EACL 2023), Dubrovnik, Croatia, 5 May 2023; pp. 128–134. [Google Scholar]
- Swaelens, C.; De Vos, I.; Lefever, E. Linguistic annotation of Byzantine book epigrams. Lang. Resour. Eval. 2025, 1, 1–26. [Google Scholar] [CrossRef]
- Gessler, L.; Schneider, N. Syntactic inductive bias in transformer language models: Especially helpful for low-resource languages? arXiv 2023, arXiv:2311.00268. [Google Scholar] [CrossRef]
- Beersmans, M.; Keersmaekers, A.; Graaf, E.; Van de Cruys, T.; Depauw, M.; Fantoli, M. “Gotta catch ‘em all!”: Retrieving people in Ancient Greek texts combining transformer models and domain knowledge. In Proceedings of the 1st Workshop on Machine Learning for Ancient Languages (ML4AL 2024), Bangkok, Thailand, 15 August 2024; pp. 152–164. [Google Scholar]
- González-Gallardo, C.E.; Tran, H.T.H.; Hamdi, A.; Doucet, A. Leveraging open large language models for historical named entity recognition. In Proceedings of the 28th International Conference on Theory and Practice of Digital Libraries (TPDL 2024), Ljubljana, Slovenia, 24–27 September 2024; Springer Nature Switzerland: Cham, Switzerland, 2024; pp. 379–395. [Google Scholar]
- González-Gallardo, C.E.; Boros, E.; Girdhar, N.; Hamdi, A.; Moreno, J.G.; Doucet, A. Yes but… can ChatGPT identify entities in historical documents? In Proceedings of the 2023 ACM/IEEE Joint Conference on Digital Libraries (JCDL 2023), Santa Fe, NM, USA, 26–30 June 2023; IEEE: New York, NY, USA, 2023; pp. 184–189. [Google Scholar]
- Lamar, A.K.; Chambers, A. Preserving personality through a pivot language low-resource NMT of ancient languages. In Proceedings of the 2018 IEEE MIT Undergraduate Research Technology Conference (URTC 2018), Cambridge, MA, USA, 5–7 October 2018; IEEE: New York, NY, USA, 2018; pp. 1–4. [Google Scholar]
- Wannaz, A.C.; Miyagawa, S. Assessing large language models in translating Coptic and Ancient Greek ostraca. In Proceedings of the 4th International Conference on Natural Language Processing for Digital Humanities (NLP4DH 2024), Miami, FL, USA, 16 November 2024; pp. 463–471. [Google Scholar]
- Rapacz, M.; Smywiński-Pohl, A. Low-resource interlinear translation: Morphology-enhanced neural models for Ancient Greek. In Proceedings of the First Workshop on Language Models for Low-Resource Languages, Abu Dhabi, United Arab Emirates, 20 January 2025; pp. 145–165. Available online: https://aclanthology.org/2025.loreslm-1.11.pdf (accessed on 3 May 2025).
- Riemenschneider, F.; Frank, A. Graecia capta ferum victorem cepit: Detecting Latin allusions to ancient Greek literature. arXiv 2023, arXiv:2308.12008. [Google Scholar] [CrossRef]
- Schmidt, G.; Vybornaya, V.; Yamshchikov, I.P. Fine-tuning pre-trained language models for authorship attribution of the Pseudo-Dionysian Ars Rhetorica. In Proceedings of the Computational Humanities Research Conference (CHR 2024), Aarhus, Denmark, 4-6 December 2024; Available online: https://ceur-ws.org/Vol-3834/paper139.pdf (accessed on 3 May 2025).
- Umphrey, R.; Roberts, J.; Roberts, L. Investigating expert-in-the-loop LLM discourse patterns for ancient intertextual analysis. arXiv 2024, arXiv:2409.01882. [Google Scholar]
- Pavlopoulos, J.; Kougia, V.; Platanou, P.; Essler, H. Detecting erroneous handwritten Byzantine text recognition. In Findings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2023); Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; Available online: https://ipavlopoulos.github.io/files/pavlopoulos_etal_2023_htrec.pdf (accessed on 3 May 2025).
- Picca, D.; Pavlopoulos, J. Deciphering emotional landscapes in the Iliad: A novel French-annotated dataset for emotion recognition. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; pp. 4462–4467. Available online: https://aclanthology.org/2024.lrec-main.399.pdf (accessed on 3 May 2025).
- Krahn, K.; Tate, D.; Lamicela, A.C. Sentence embedding models for Ancient Greek using multilingual knowledge distillation. arXiv 2023, arXiv:2308.13116. [Google Scholar] [CrossRef]
- Stopponi, S.; Peels-Matthey, S.; Nissim, M. AGREE: A new benchmark for the evaluation of distributional semantic models of ancient Greek. Digit. Scholarsh. Humanit. 2024, 39, 373–392. [Google Scholar] [CrossRef]
- Stopponi, S.; Pedrazzini, N.; Peels-Matthey, S.; McGillivray, B.; Nissim, M. Natural language processing for Ancient Greek: Design, advantages and challenges of language models. Diachronica 2024, 41, 414–435. [Google Scholar] [CrossRef]
- Pavlopoulos, J.; Xenos, A.; Picca, D. Sentiment analysis of Homeric text: The 1st Book of the Iliad. In Proceedings of the Thirteenth Language Resources and Evaluation Conference (LREC 2022), Marseille, France, 20–25 June 2022; pp. 7071–7077. Available online: https://aclanthology.org/2022.lrec-1.765.pdf (accessed on 3 May 2025).
- Kasapakis, V.; Morgado, L. Ancient Greek technology: An immersive learning use case described using a co-intelligent custom ChatGPT assistant. In Proceedings of the 2024 IEEE 3rd International Conference on Intelligent Reality (ICIR 2024), Coimbra, Portugal, 5–6 December 2024; IEEE: New York, NY, USA, 2024; pp. 1–5. [Google Scholar]
- Abbondanza, C. Generative AI for teaching Latin and Greek in high school. In Proceedings of the Second International Workshop on Artificial Intelligence Systems in Education, Co-Located with the 23rd International Conference of the Italian Association for Artificial Intelligence (AIxIA 2024), Bolzano, Italy, 25–28 November 2024; CEUR Workshop Proceedings. Available online: https://ceur-ws.org/Vol-3879/AIxEDU2024_paper_11.pdf (accessed on 3 May 2025).
- Ross, E.A.; Baines, J. Treading water: New data on the impact of AI ethics information sessions in classics and ancient language pedagogy. J. Class. Teach. 2024, 25, 181–190. [Google Scholar] [CrossRef]
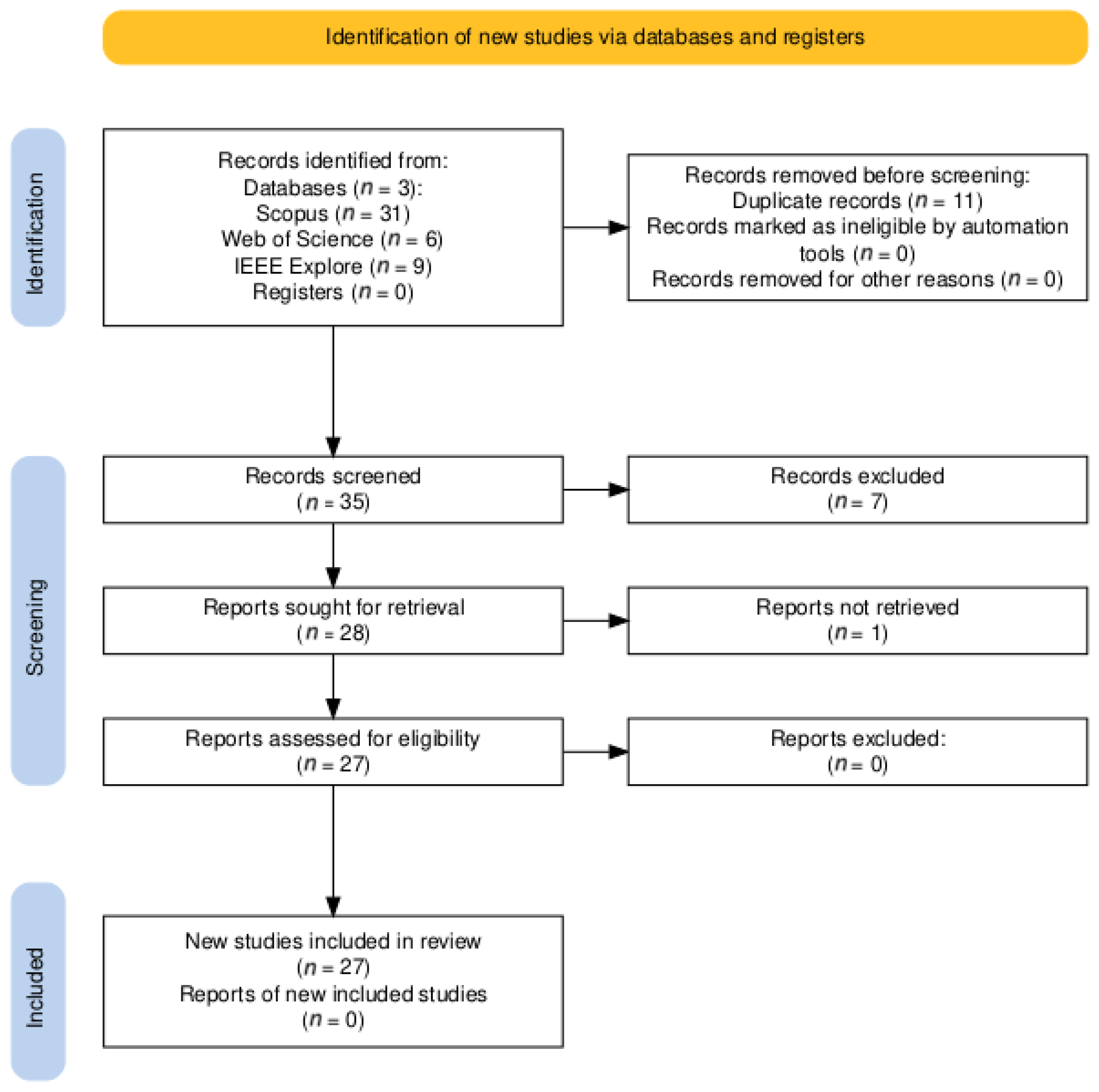
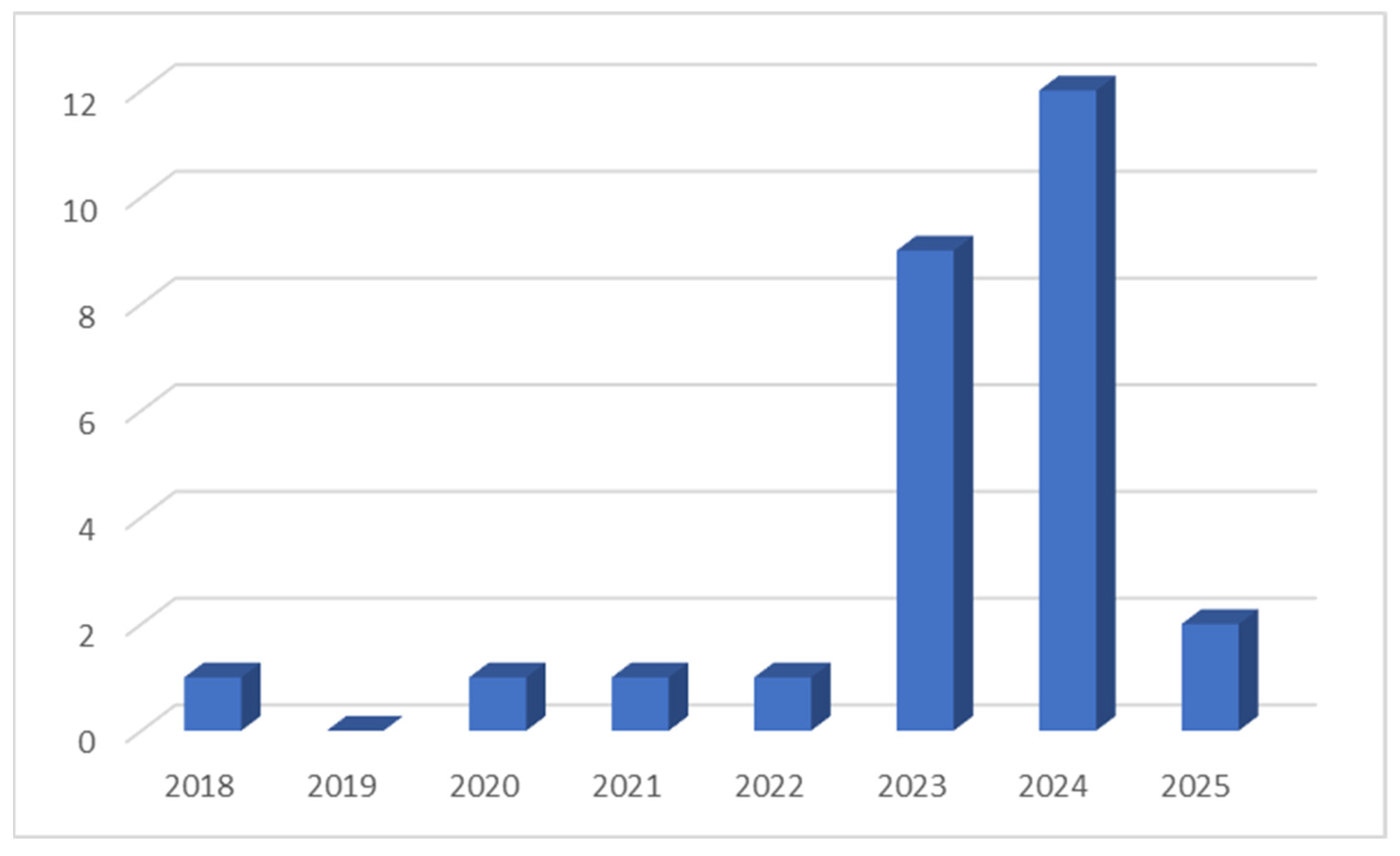
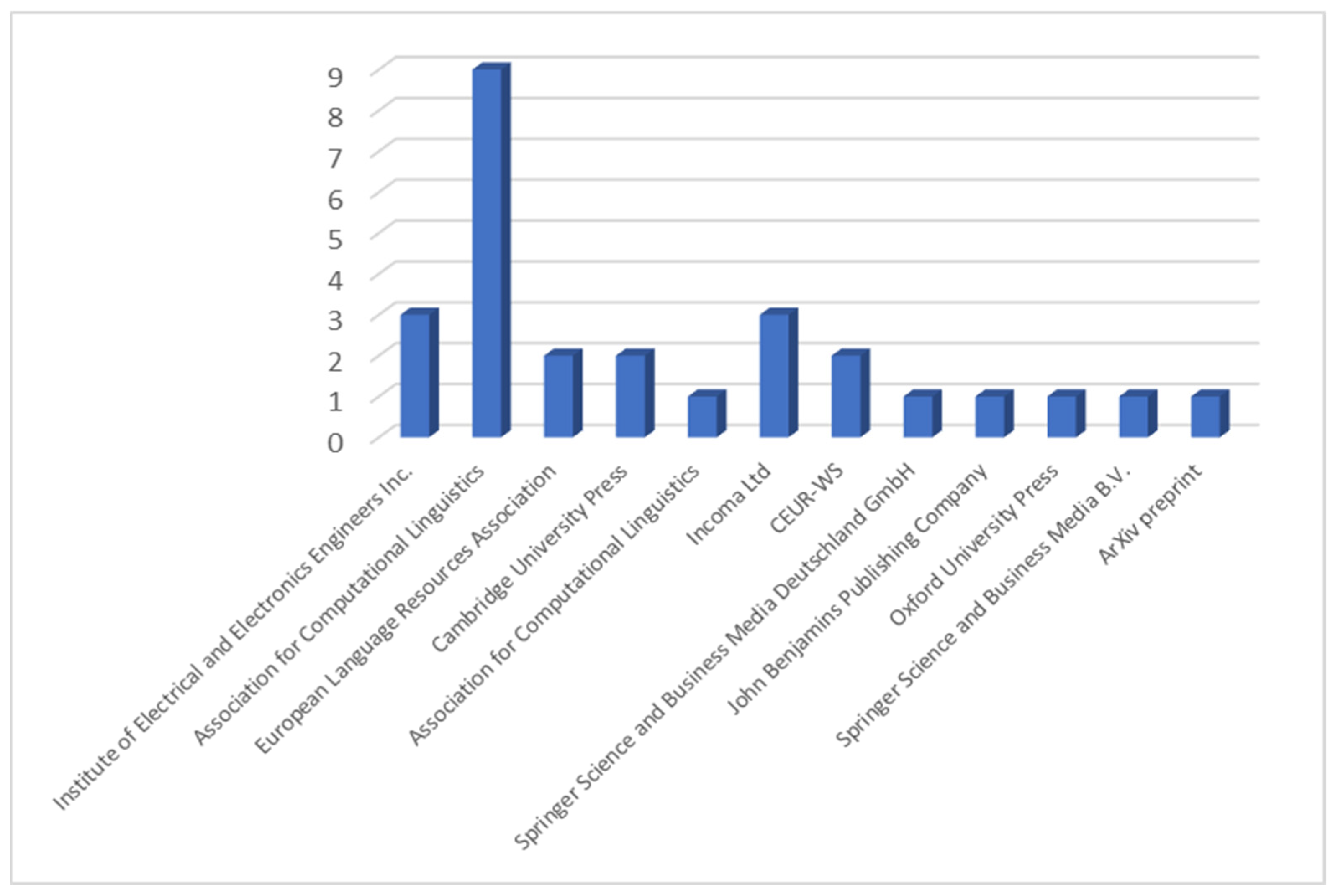
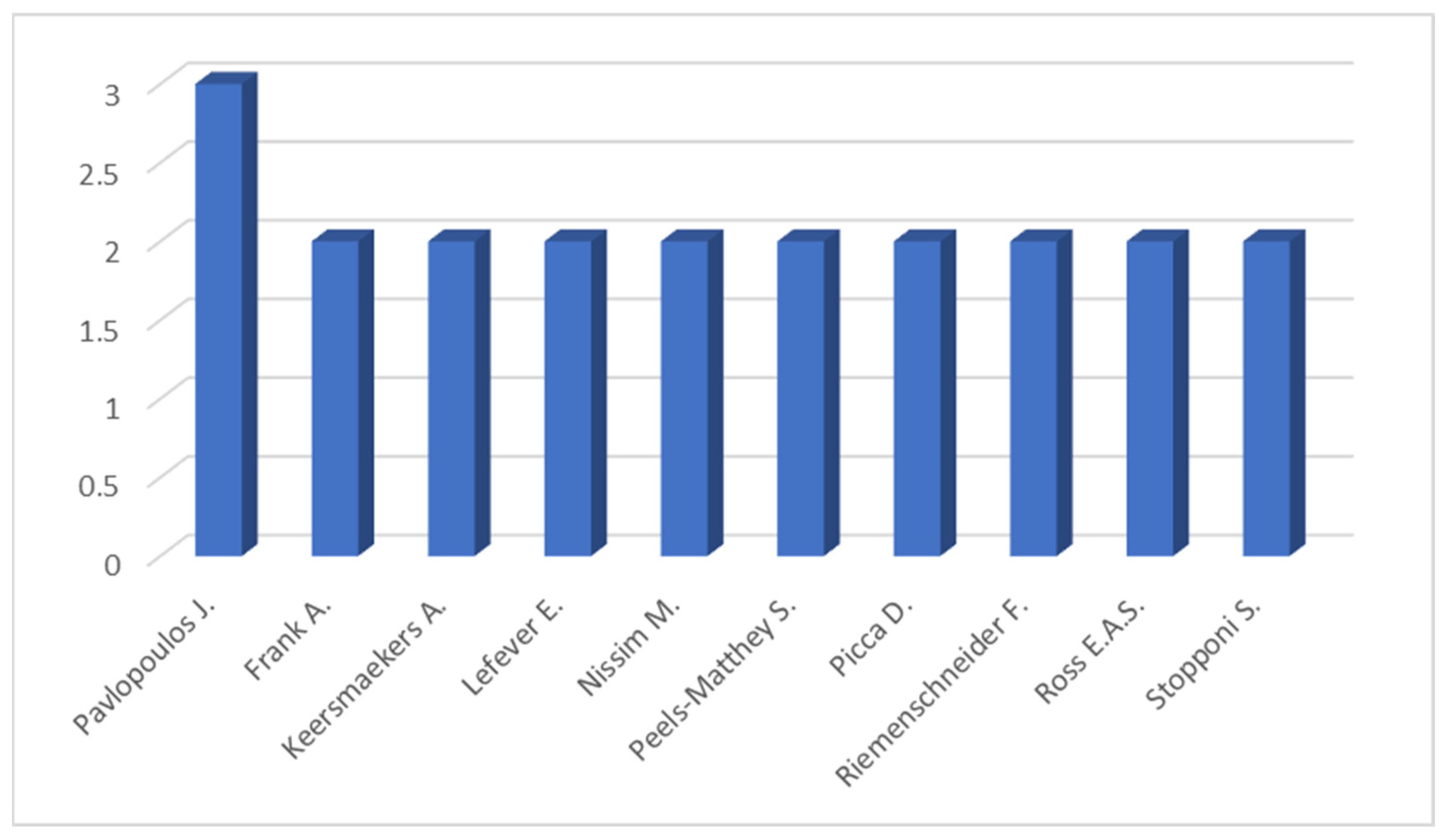
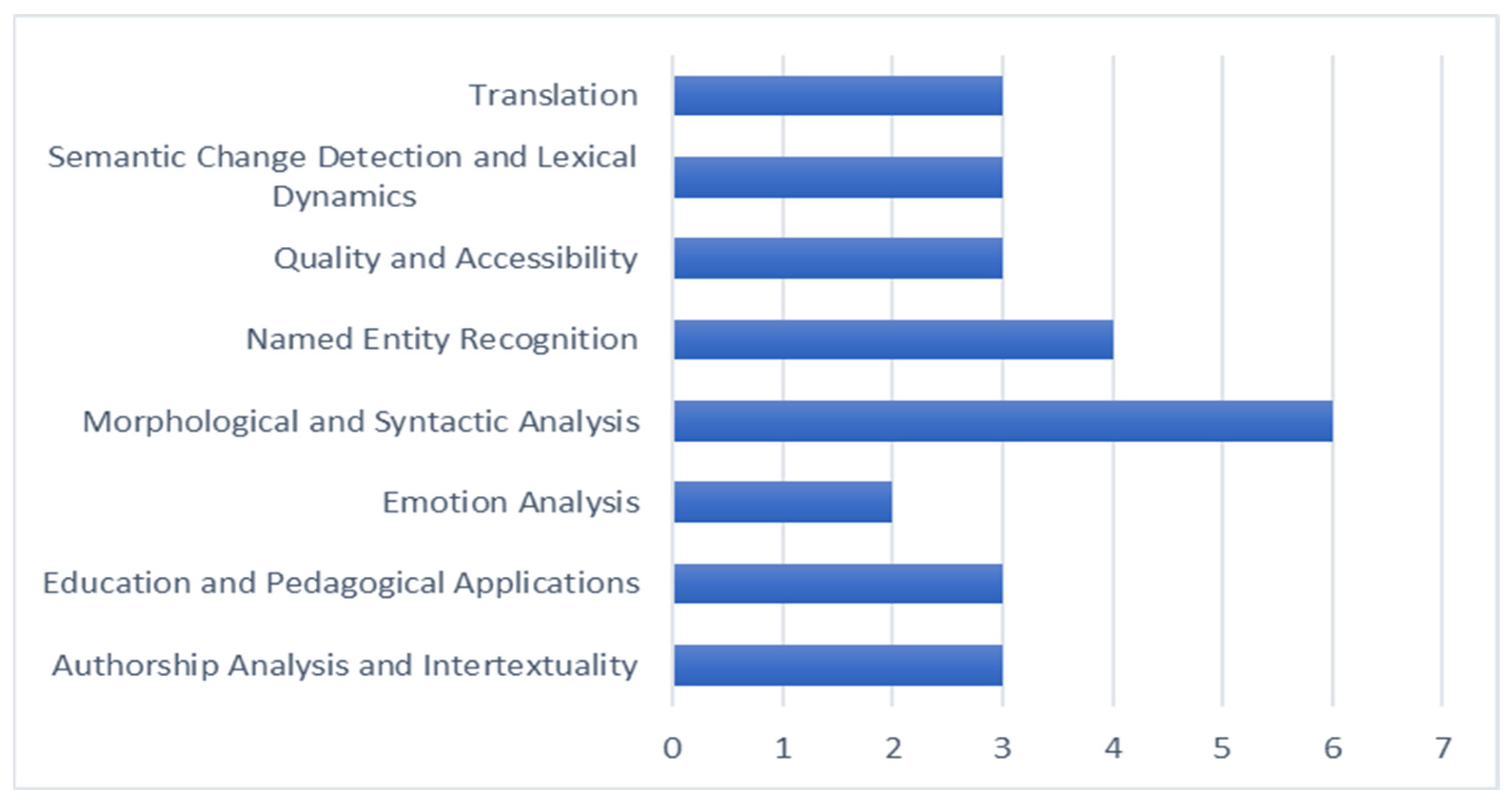
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).