1. Introduction
It is widely known that the performance of multiple combined classifiers far exceeds that of using any single classifier independently [
1]. Tree ensembles such as Random Forest (RF) [
2] have achieved impressive success across various classification and regression tasks. RF builds a number of decision trees in the training process, which contributes to the final outcome through an aggregation method known as bagging [
3]. Each decision tree is built using a bootstrap sample of the data and random subsets of features at each split. The predictions from decision trees are combined to produce the final output of RF, delivering high accuracy and robustness across different datasets and outperforming single classifiers, especially on complex predictive tasks [
4].
RF has established itself as an indispensable tool in data mining, with applications covering bioinformatics [
5], image processing [
6], financial analytics [
7], and natural language processing [
8]. However, traditional RF algorithms face substantial challenges when handling high-dimensional data or running on hardware-constrained devices such as smartphones and Internet-of-Things (IoT) systems [
9]. In these scenarios, the traditional algorithms often exhibit lower computational efficiency and reduced predictive accuracy. These limitations become even more pronounced due to the rapidly evolving computational landscape, where edge computing and IoT devices demand faster and more reliable algorithms [
10].
To address these computational demands, researchers have explored various optimization techniques, particularly those focusing on decision-tree construction [
11]. Decision trees represent the relationship between features and target variables through a hierarchical structure of conjunctive conditions, where each internal node corresponds to a feature and a threshold. In RF, finding the optimal split by identifying the best feature–threshold pair is crucial for both computational efficiency and predictive accuracy [
12]. Accordingly, optimizing the node splitting process can significantly improve the overall performance of RF [
13].
The traditional RF algorithms determine optimal splits by exhaustively searching through all possible splitting points, resulting in a computational complexity of
for each split, where
is the number of instances. They are computationally heavy and inefficient. To address this problem, algorithms like XGBoost [
14] and LightGBM [
15] have employed histogram-based techniques to reduce the complexity to
, where
, by grouping feature values into discrete bins. While histogram-based methods can substantially accelerate training, they remain wasteful because they allocate the same computational effort to all features, including those that are not particularly informative.
1.1. Related Works
In 2001, Breiman [
2] introduced the RF algorithm by combining the bagging technique, the random subspace method, and the Classification and Regression Trees (CART) algorithm. With the rapid growth of information technology, datasets have expanded dramatically in both size and complexity. Traditional RF algorithms face significant challenges meeting time and computational demands [
16]. Thus, enhancing RFs to handle large datasets has become a major focus in both research and industry [
17].
Recent advancements have emerged in algorithmic optimizations and parallel computing techniques. Yates and Islam [
9] developed FastForest, which incorporates Subbagging to reduce the size of bootstrap samples, Logarithmic Split-Point Sampling (LSPS) to decrease the computational cost of node splits, and Dynamic Restricted Subspacing (DRS) to adjust the feature subset size during feature selection. These optimizations collectively reduce the data processed by each tree, thereby accelerating node splitting. In the context of incremental learning, Domingos and Hulten [
18] introduced Hoeffding Tree (HT) in Very Fast Decision Tree (VFDT), which utilizes the Hoeffding Bound to guide the choice of decision nodes, ensuring a rapid and effective approximation of the optimal decision with limited samples. The Extremely Fast Decision Tree (EFDT) algorithm [
19] builds upon HT by introducing Hoeffding Anytime Tree (HATT), which continuously monitors and updates splits as more data becomes available. Both HT and HATT are incremental decision tree learning techniques, particularly suited for big data environments and data stream applications.
Parallel computing frameworks have also been leveraged to enhance decision tree algorithms. Mu et al. [
20] proposed a parallel decision tree algorithm based on MapReduce, using Pearson’s correlation coefficient for optimal split selection. Xu [
21] introduced an improved RF algorithm based on Spark, leveraging the Fayyad boundary point principle for efficient feature discretization. Yin et al. [
22] presented a fast parallel RF algorithm on Spark, integrating a modified Gini coefficient to reduce feature redundancy and applying an approximate equal-frequency binning method for split optimization.
Although these algorithms have sped up the training process for decision tree ensembles, most of them still rely on exhaustive searches to find the optimal split at each node, which can be costly for large datasets. MABSplit presents a cutting-edge solution to overcome this bottleneck [
23]. At its core, MABSplit treats each candidate feature–threshold pair as an arm in a multi-armed bandit (MAB) problem, aiming to efficiently identify the optimal split by estimating each candidate’s impurity reduction through sampling. Specifically, the algorithm iteratively samples batches of data points, updates confidence intervals of impurity reduction estimates for each candidate split, and eliminates splits whose lower confidence bound exceeds the upper confidence bound of the currently best-performing candidate. This adaptive procedure significantly reduces computational complexity from linear to logarithmic with respect to the number of samples, achieving substantial speed-ups without compromising predictive accuracy.
Despite its considerable strengths, MABSplit has certain aspects that could be further enhanced:
Lack of Memory Mechanism: MABSplit lacks some related mechanisms to leverage information gathered from previously explored splits. The valuable information from earlier computations is not utilized to improve subsequent split evaluations. Consequently, the exploration in the early phase would be less efficient.
Lower Efficiency for Similar Candidates: The computational efficiency of MABSplit relies on sufficient heterogeneity among the true impurity reductions of different feature–threshold pairs. When most splits have similar impurity reductions (as in highly symmetric datasets), MABSplit fails to achieve its promised logarithmic sample complexity and reduces to a batched version of the naïve approach, resulting in no significant speed advantage.
Reduced Accuracy with Limited Samples: MABSplit employs confidence intervals to estimate split quality, which are derived from some statistical properties of impurity measures such as Gini impurity and entropy. However, these estimates may become less reliable when sample sizes are small or probabilities approach extreme values.
1.2. Our Contributions
In this paper, we introduce BayesSplit, a novel node-splitting algorithm that extends MABSplit to improve the computational efficiency and predictive accuracy of RFs. BayesSplit treats the probability of impurity reduction as a Beta posterior distribution, which is iteratively refined based on batched observations. Based on this, posterior confidence intervals are used to adaptively select splits most likely to maximize impurity reduction, ensuring statistically robust and data-driven tree construction. Our key contributions include:
(1) A Novel Bayesian-Based Impurity Estimation Framework
A Bayesian framework is developed that treats each split’s impurity reduction as a random event with an unknown success probability. The framework initializes uninformative Beta priors that evolve into informative posteriors as observations accumulate. After each batch of samples is evaluated, the Beta parameters of candidate splits are updated according to the observed impurity reductions. These posterior distributions are used to derive confidence intervals that balance exploration of uncertain splits with exploitation of promising ones. By comparing the confidence bounds of each split across all candidates, BayesSplit eliminates suboptimal splits while allocating computational resources to the most promising candidates. This Bayesian-based Impurity Estimation Framework naturally accommodates prior knowledge and new data, enabling robust decision-making and faster convergence to optimal splits.
(2) Two Bayesian Optimization Strategies to Achieve High Computational Efficiency
Dynamic Posterior Parameter Refinement: Drawing inspiration from Thompson Sampling (TS), this strategy treats each split’s impurity reduction as a reward signal to update the parameters of Beta distributions. After a batch is sampled, whether each split reduced impurity is evaluated, is incremented when impurity decreases and when it does not. This process creates a memory mechanism to accumulate evidence across iterations.
Posterior-Derived Confidence Bounding: This strategy uses each split’s posterior Beta distribution to establish confidence intervals. Rather than relying on frequentist approximations, the confidence bounds are set directly from the posterior parameters, enabling more accurate uncertainty quantification across diverse data conditions.
Our experiment results demonstrate that BayesSplit further minimizes quantization errors and more accurately captures the underlying data distribution than existing approaches.
2. Algorithmic Background
To facilitate understanding of the subsequent technical content, we summarize the key notation used in this paper.
Table 1 provides a list of symbols and their meanings, serving as a reference for the algorithmic development and theoretical analysis of BayesSplit.
2.1. Node-Splitting Description in RFs and Decision Trees
An RF is composed of multiple classification or regression trees, where each treemaps the feature space to the response. Consider a datasetwithdata points , whereis the-th feature vector and is the corresponding target. Each tree in an RF is built independently on a bootstrapped dataset from the original data, while a random subset of featuresis considered at each node.
In the decision tree node-splitting process, let
represent the region in the feature space corresponding to node
(typically a hyper-rectangle) [
24]. Using the pair
to split node
,
is partitioned into two subregions
and
, corresponding to the left and right child nodes of node
. For a node
in decision tree
,
denotes the number of samples falling into
. Finding the optimal split, i.e., determining the best pair
to maximize node-splitting effectiveness, is accomplished by maximizing the reduction in label impurity:
where
and
represent the number of samples in the left and right child nodes, respectively,
represents the impurity measure, and
denotes the permissible thresholds for feature
. Popular impurity measures include the Gini index and entropy for classification, as well as the mean-squared error (MSE) for regression [
25]:
where
represents the no. of classes in the target variable,
is the proportion of samples at node belonging to class
, and
is calculated as
. In Equation (1),
denotes the impurity of node
before splitting and does not depend on the split feature
or threshold
. Since
does not affect the minimization process, we simplify Equations (1)–(5) for a direct evaluation of the split effect, written as follows:
We define as the optimization objective. Note that lower values of correspond to higher impurity reductions, while higher values of correspond to lower impurity reductions.
2.2. Confidence Interval Estimation in MABSplit
Since computing exactly requires a full pass over the data, MABSplit draws samples, , to construct point estimates and confidence intervals for impurity reduction. At the core of this approach is the delta method, which transforms the empirical estimates of class distributions into reliable estimates of impurity measures.
Let
and
represent the proportion of the full data points in class
and each of the two subsets created by the split
. For a given split
MABSplit constructs empirical estimates
and
represents the proportion of class
samples in the left and right child nodes based on the
subsamples, respectively:
These estimates jointly follow a multinomial distribution with parameters
, where
. By the Central Limit Theorem (CLT), we obtain the following:
where
and
.
is the corresponding covariance matrix. Specifically,
could be written in terms of
for the impurity metrics (e.g., Gini or entropy). Let
be the derivative of
with respect to
. Applying the delta method, we obtain the following:
This allows MABSplit to construct confidence intervals scale as , these confidence intervals are asymptotically valid as . In MABSplit, each batch of data points updates and , which in turn refine the point estimates and their corresponding confidence intervals.
While the delta method provides a theoretically sound framework for constructing confidence intervals, its practical reliability depends on the validity of asymptotic assumptions guaranteed by the CLT. Specifically, Equation (8) shows that the width of the confidence intervals depends on the sample size through ascaling. In the early stages of MABSplit, where only small batches of data are available, this approximation may break down. For example, when the class proportions approach 0, the derivative of impurity metrics such as entropy becomes unstable, leading to large variance and unreliable confidence intervals.
In summary, MABSplit exhibits reduced accuracy with limited samples, as statistical estimation under small-sample conditions can introduce substantial variance in impurity estimates.
3. BayesSplit: A Bayesian Node-Splitting Algorithm
3.1. Overview of the Framework
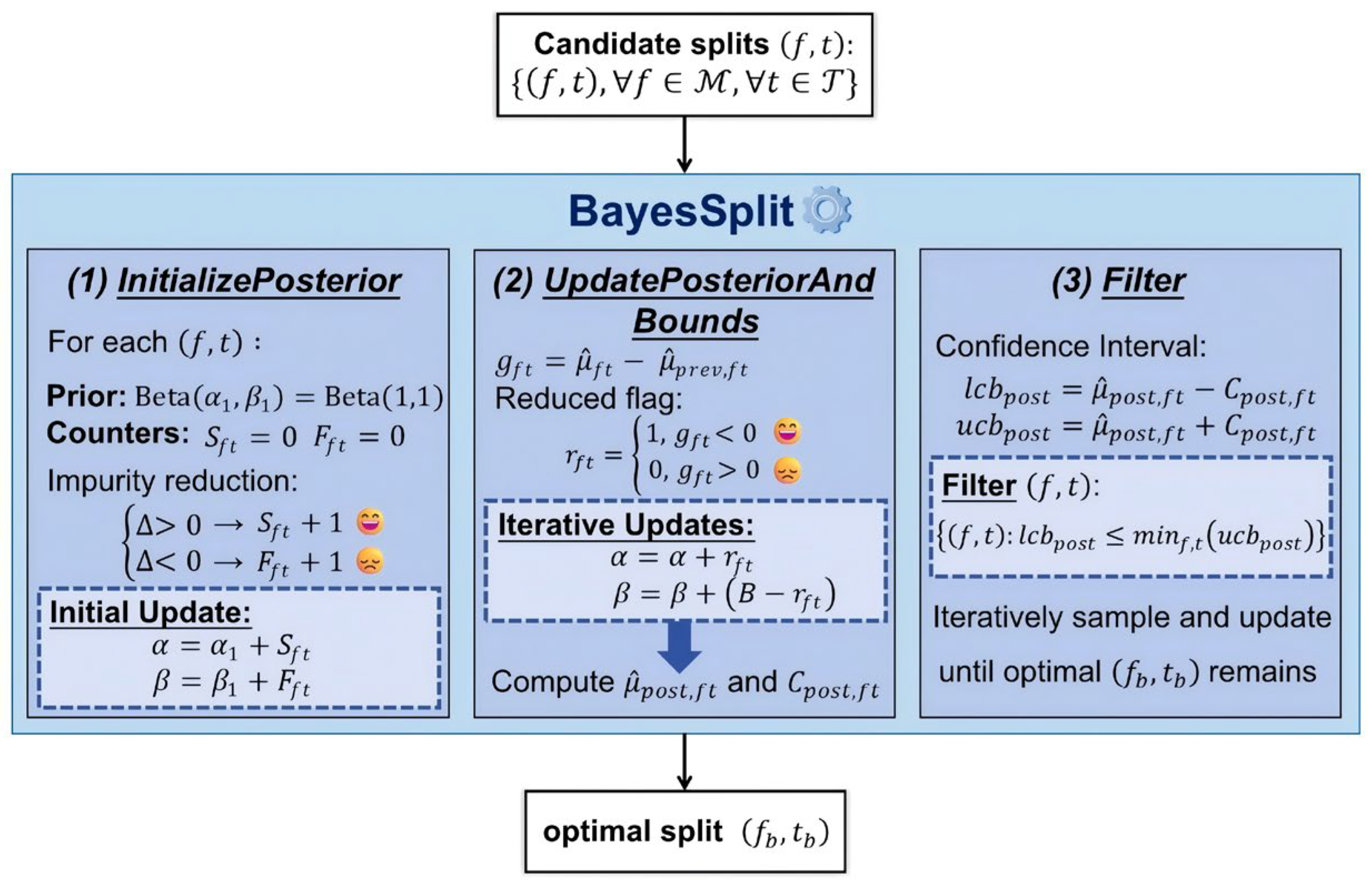
BayesSplit treats impurity reduction as a Bernoulli event with Beta-conjugate priors, as shown in
Figure 1. The framework begins with uninformative priors, which are gradually updated into informative posteriors as observations accumulate. After each batch of samples is evaluated, the Beta parameters of candidate splits are updated based on the observed impurity reductions.
The framework consists of three key components: (1) InitializePosterior establishes posterior distributions for each candidate split based on initial impurity evaluations; (2) UpdatePosteriorAndBounds implements the Dynamic Posterior Parameter Refinement strategy, updating beliefs about split effectiveness based on empirical observations; and (3) Filter uses Posterior-Derived Confidence Bounds to eliminate splits that are demonstrably suboptimal, focusing resources on promising candidates.
The precise splitting approach BayesSplit is outlined in Algorithm 1. We preprocess the input data to identify candidate splits
, or arms, for each feature
. All potential solutions to Equation (5) are tracked by maintaining a set
, which initially includes every candidate arm
.
| Algorithm 1 BayesSplit |
- 1:
// Set of potential solutions to Equation (5) - 2:
// Number of data points sampled - 3:
for all do - 4:
// Initialize mean and CI for each arm - 5:
end for - 6:
for all do - 7:
Create empty histogram with equally spaced bins - 8:
end for - 9:
InitializePosterior // Set up posterior distributions - 10:
while do - 11:
Draw a batch sample of size B with replacement from - 12:
for all unique f in Ssolution do - 13:
for all x in do - 14:
Insert xf into histogram hf // Update histograms with sampled data - 15:
end for - 16:
end for - 17:
for all do - 18:
Update based on histogram hf - 19:
end for - 20:
UpdatePosteriorAndBounds // Adjust posterior and refine bounds - 21:
// Retain promising splits - 22:
- 23:
end while - 24:
if then - 25:
return - 26:
else - 27:
Compute exactly for all - 28:
return
|
Algorithm 1, as depicted in
Figure 1, begins with candidate splits at the top and produces the optimal split
at the bottom. In each iteration, it samples a batch of data points and updates histograms to refine impurity estimates. When evaluating a candidate split, BayesSplit calculates the impurity gain
and updates the posterior Beta parameters, which are then used to compute confidence intervals for each split. The algorithm renews
until convergence by eliminating suboptimal splits.
This Bayesian framework fundamentally distinguishes BayesSplit from previous approaches by providing adaptive, accurate, and computationally efficient node-splitting decisions, thus enhancing both computational efficiency and predictive accuracy of RFs.
3.2. Dynamic Posterior Parameter Refinement
BayesSplit is inspired by TS, a seminal Bayesian heuristic for solving MAB problems [
26]. TS has shown robust performance compared to alternatives like Upper Confidence Bound (UCB) algorithms [
27]. It is widely applied in Bernoulli bandit problems, where rewards are binary, with a value of 1 for success and 0 for failure. In BayesSplit, “success” specifically corresponds to a split that successfully reduces node impurity. To clarify the application of TS within BayesSplit, we begin by briefly reviewing the Beta-Bernoulli Bandit.
Beta distributions serve as natural representations of uncertainty for Bernoulli trials due to their conjugacy properties, meaning that if the prior is Beta
, the posterior after observing outcomes from Bernoulli trials remains a Beta distribution with updated parameters. The probability density function (PDF) of the Beta distribution on the interval
is given by the following:
where
is the Beta function, defined as follows:
Here, denotes the gamma function, generalizing factorials.
Suppose there are
actions, and when an action
is played, it yields a reward of 1 with probability
and a reward of 0 with probability
[
28]. Each
represents the probability of success, or the mean reward. Once an action
is chosen, the resulting reward
is generated with success probability
. We assume an independent prior belief for each
, where these priors follow a Beta distribution with parameters
and
. For each action
, the prior PDF of
is calculated as follows:
If action
is chosen at step
, the parameters are updated based on the observed reward
. The posterior update for each action’s distribution follows the following simple rule:
Initially, BayesSplit assigns a non-informativeprior to each candidate split, representing uncertainty about split effectiveness. Before the main iterations begin, the algorithm performs a posterior initialization phase where each candidate split undergoes a preliminary impurity reduction evaluation. If this evaluation shows that a split reduces impurity (a success), its parameters update as ; otherwise (a failure), as . This initialization step provides an informed starting point for the posterior distributions, leveraging global data characteristics to guide early exploration (see Algorithm 2). It ensures that all candidate splits begin without bias and are immediately updated based on observed impurity reductions. As more batches are processed, the influence of the prior becomes negligible, and split selection is determined by empirical evidence.
In each subsequent iteration, BayesSplit samples a new batch of data
to evaluate all candidate splits
in
. This ongoing update process refines the value of
, which represents the mean objective estimate computed from histograms. Using the current estimate, BayesSplit calculates the impurity gain
between consecutive iterations. The posterior parameters are then updated based on this gain: specifically, when
, confidence increases by incrementing
; when
, confidence decreases by incrementing
. This dynamic mechanism actively accumulates evidence across iterations, enhancing convergence efficiency (see Algorithm 3).
| Algorithm 2 InitializePosterior |
Require: : input data; : list of histograms; impurity measure; non-informative prior parameters of Beta distribution
Ensure: initialized posterior parameters
- 1:
- 2:
for each feature f do // Iterate over all features - 3:
for each bin b in hf do // Iterate over bins in histogram - 4:
Compute impurity reduction Δ for splitting on bin b - 5:
if then // Check if split reduces impurity - 6:
- 7:
else - 8:
- 9:
end if - 10:
end for - 11:
end for - 12:
- 13:
return
|
3.3. Posterior-Derived Confidence Bounding
Unlike the classical TS, which selects arms based on posterior sampling alone, BayesSplit uses posterior distributions to construct explicit confidence intervals for impurity reductions. Arms whose confidence intervals indicate potential optimality are retained for further exploration; others are eliminated early.
Confidence intervals in BayesSplit are derived directly from the statistical properties of the Beta distribution posterior, providing a theoretically sound basis for uncertainty quantification. The moment-generating function (MGF) of the Beta distribution can be expressed through a confluent hypergeometric function, written as follows:
From this, the
raw moment of a Beta
random variable
is given by:
where
, known as the Pochhammer symbol or rising factorial. The mean and variance are defined as follows:
For each candidate split
with posterior parameters
and
, BayesSplit computes the posterior mean as
, which represents our current belief about the probability that the split reduces impurity based on all observed evidence. The half-width of the confidence interval
is based on the standard deviation
from the posterior Beta distribution,
, which naturally decreases as more samples are accumulated.
| Algorithm 3 UpdatePosteriorAndBounds |
- 1:
for all do - 2:
Compute impurity gain // Compute impurity gains from new batches - 3:
if then - 4:
Set reduced flag - 5:
else - 6:
Set reduced flag - 7:
end if - 8:
Update posterior parameters: - 9:
// Increase confidence if split reduced impurity - 10:
// Decrease confidence if split increased impurity - 11:
end for - 12:
Update - 13:
return Updated
|
At each iteration, BayesSplit implements a filtering mechanism by retaining only those splits whose posterior lower confidence bound falls below the upper confidence bound of the highest potential arm . This criterion ensures that only splits that are demonstrably suboptimal with high probability are removed from consideration. As sampling progresses, the confidence intervals narrow, enabling the algorithm to identify the optimal split while minimizing exploration of suboptimal splits. The iterative process continues until either a single optimal split remains or the algorithm reaches a predefined computational budget.
While both Dynamic Posterior Parameter Refinement and Posterior-Derived Confidence Bounding contribute to BayesSplit’s efficiency, their roles are complementary rather than independent. Dynamic Posterior Parameter Refinement is the primary driver of performance gains. It accumulates evidence across iterations to update split-quality estimates adaptively, addressing MABSplit’s lack of memory mechanism by leveraging historical data to inform future sampling. The accumulated evidence enables faster convergence to optimal splits, particularly when many feature–threshold pairs have similar impurity reductions, a scenario where MABSplit requires substantially more samples to distinguish among candidates. Posterior-Derived Confidence Bounding adds statistical robustness and accuracy under limited-sample conditions, since its confidence intervals are derived directly from the exact properties of the Beta distribution.
The synergy between the two strategies is crucial because the Dynamic Posterior Parameter Refinement provides increasingly informative posteriors that tighten confidence bounds, and the Posterior Derived Confidence Bounding ensures statistically sound elimination decisions, creating a feedback loop that focuses computational resources on the most competitive splits.
Implementation Details: In practice, sampling without replacement is utilized for efficiency, similar to MABSplit, achieving substantial computational savings without significantly impacting performance.
3.4. Convergence Analysis
In this section, we show that BayesSplit’s posterior estimation of impurity reduction for each feature–threshold pair converges to the true parameter as the number of observations increases. Based on these estimates, the algorithm eliminates suboptimal splits with high confidence, and the retained candidate converges to the optimal split with high probability. For any feature–threshold pair let denote the true probability that splitsuccessfully reduces node impurity. We treat the event of observing an impurity reduction as a Bernoulli trial with success probability .
We make the following standard assumptions for Bayesian consistency:
1. The Bernoulli likelihood is different for different parameter values.
2. The prior Beta distribution assigns non-zero density to the true parameter .
Lemma 1. For any feature–threshold pair given a sufficient number of samples, the posterior estimate in BayesSplit converges to the true impurity reduction probability . As, the posterior mean tends to , and the posterior distribution concentrates its mass at .
Proof. We use a conjugate Beta–Bernoulli model for inference. Suppose the prior for
is
. After observing
independent impurity-reduction outcomes
,
…,
for split
, where
and it indicates whether impurity is reduced
or not
, the posterior distribution is as follows:
with updated parameters, it is written as follows:
The posterior mean at this stage is
. We can rewrite the posterior mean as follows:
As grows large, the weight on the prior mean vanishes, while the weight on the sample mean approaches 1. By the Law of Large Numbers, the sample mean converges to . Therefore, as .
In the Beta–Bernoulli model, the posterior variance of the random variable
given
is written as follows:
Thus, as
increases, the posterior variance shrinks, and the distribution becomes increasingly concentrated around
. Another perspective uses the Kullback–Leibler (KL) divergence [
29]. For any candidate value
, the KL divergence between the Beta distributions with parameters
and
is written as follows:
By Gibbs’ inequality,
With i.i.d. observations, the average log-likelihood ratio converges to
, implying the following:
The likelihood of the data under any diminishes exponentially relative to the likelihood under. Consequently, the posterior probability of such a becomes negligible, and the posterior mass concentrates at as . □
The above analysis shows that BayesSplit’s posterior estimate converges to the true impurity reduction probability , and its uncertainty decreases as . Given enough sampling, the algorithm will, with high probability, correctly identify the optimal split.
3.5. Optimal Solution Regret Bound
BayesSplit’s multi-armed bandit formulation allows us to derive a finite-time regret guarantee for the node-splitting process. Consider a node with data points , features , and possible thresholds for each feature (). Assume that is the optimal feature–threshold pair that maximizes node-splitting effectiveness, i.e., . The following theorem provides an upper bound on the expected regret at total computation.
Theorem 1. FixFor the multi-armed bandit formulation of BayesSplit, the finite-time expected regret at total computation satisfies the following:where is the KL divergence between the probability of achieving impurity reduction of the optimal splitand that of any suboptimal split , defined as with .
A complete derivation and step-by-step proof of Theorem 1 can be found in
Appendix A. The proof follows standard multi-armed bandit analyses by bounding the number of times a suboptimal split
can be selected. The regret bound implies that BayesSplit rapidly converges on the optimal split when one is clearly superior. In scenarios where several splits exhibit comparable performance, the cumulative regret increases slightly, yet it remains sublinear overall.
4. Performance Analysis
To evaluate the effectiveness of BayesSplit, we conducted a series of experiments. Initially, the wall-clock training time and corresponding generalization performance of decision tree ensembles utilizing BayesSplit were measured. Subsequently, we assessed the computational efficiency and resulting generalization performance under a fixed computational budget. All experiments were performed on a ThinkPad T14 Gen 3 laptop, equipped with a 12th Generation Intel Core i7-1260P processor and 32 GB of RAM.
In these comparative experiments, we evaluated the histogrammed versions of three decision tree ensembles with and without BayesSplit: Random Forest (RF), ExtraTrees [
30], and Random Patches (RP) [
31]. Random Forest creates an ensemble of decision trees built on bootstrapped samples, while a random subset of features is considered at every node split to balance variance reduction and computational complexity. ExtraTrees further randomizes this process by randomly selecting split thresholds, reducing variance and training time but potentially increasing bias. Random Patches samples subsets of instances and features simultaneously for each tree, enhancing ensemble diversity and improving generalization, particularly for high-dimensional datasets.
We performed experiments using all datasets originally employed by MABSplit, supplemented with additional publicly available classification and regression datasets from the UCI Machine Learning Repository. This dataset selection ensured coverage of varying complexities and data characteristics, while consistent preprocessing and benchmarking allowed for a fair comparison of BayesSplit, MABSplit, and the naïve approach. In addition to these core experiments, we conducted additional experiments to evaluate BayesSplit’s sensitivity to hyperparameter settings and its performance on imbalanced datasets, with detailed results provided in
Appendix B.
4.1. Wall-Clock Time Comparisons
Classification: We assessed the performance of BayesSplit by comparing it with MABSplit and the baseline brute-force solver on several classification tasks, evaluating wall-clock training time, number of histogram insertions, and test accuracy. As shown in
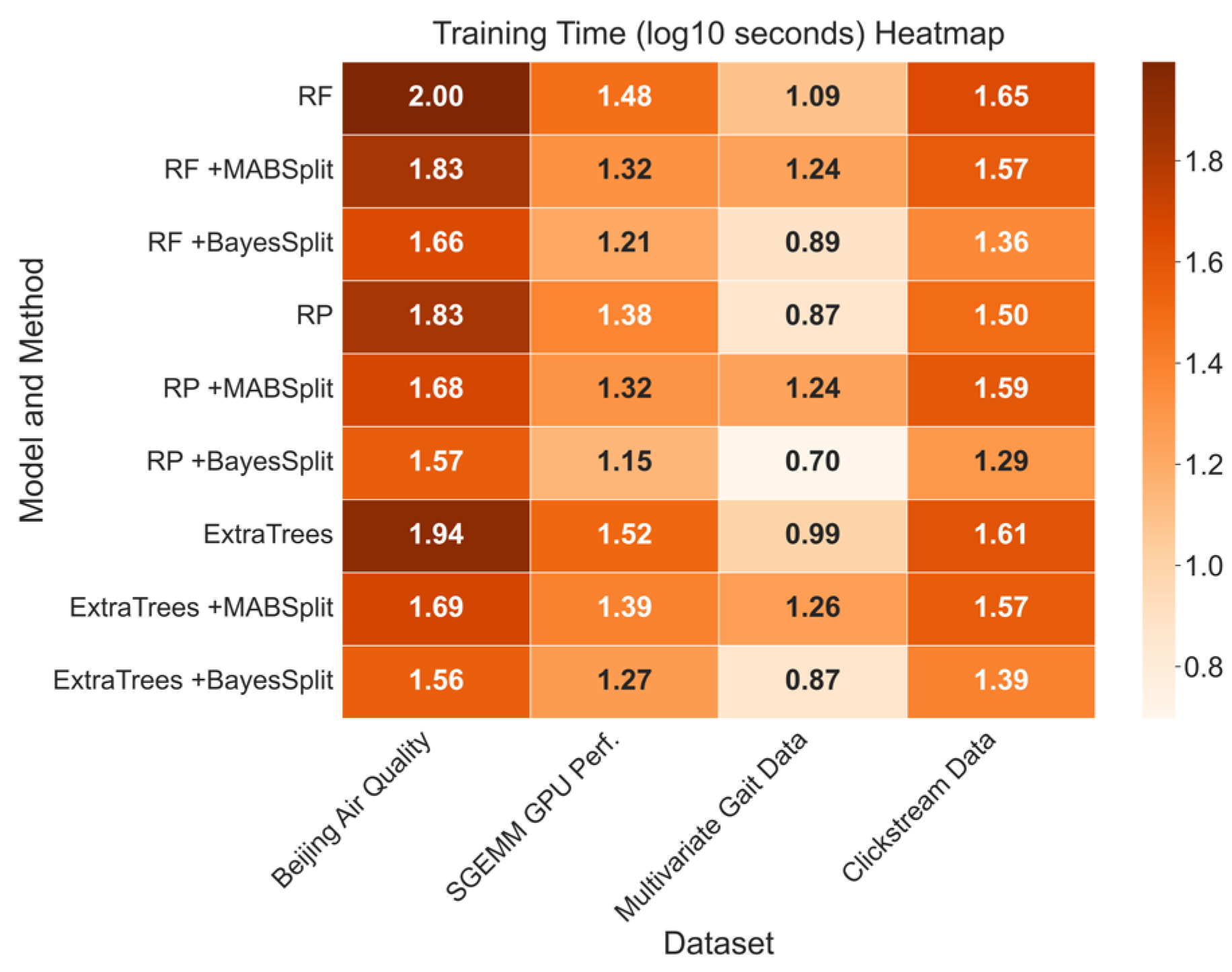
Figure 2, incorporating BayesSplit and MABSplit subroutines significantly reduces training time relative to the naïve approach, with BayesSplit providing up to a 95% reduction compared to baseline methods.
Table 2 further confirms their efficiency by showing fewer histogram insertions, with BayesSplit’s refined histogram-based splits providing additional computational savings to the ExtraTrees model. The identical insertion counts between BayesSplit and MABSplit for RF and RP models occur because both algorithms eliminate candidates at similar rates when significant differences in split quality are evident. Given the strong correlation between histogram insertions and training time, improving node-splitting by reducing sample complexity is clearly justified.
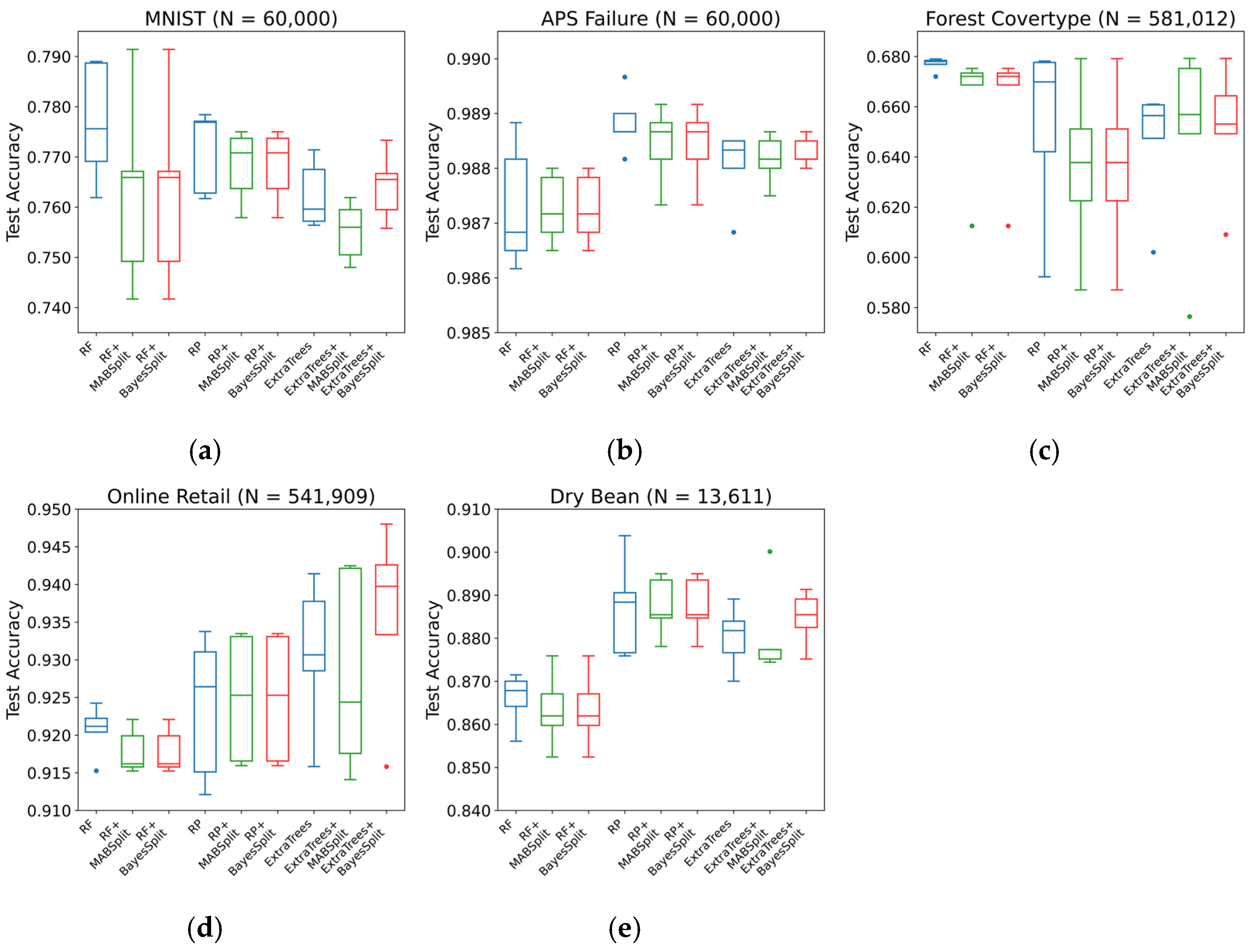
Figure 3 illustrates that integrating BayesSplit and MABSplit produces test accuracy comparable to that of the baseline models. Notably, BayesSplit provides significant advantages to the ExtraTrees model, which typically relies on random split thresholds that can lead to suboptimal decisions. Through Bayesian optimization, BayesSplit refines those random splits, resulting in more precise decision boundaries and improved accuracy.
Regression: Across four regression datasets with diverse characteristics, BayesSplit consistently reduces training time by 20–70% compared to MABSplit, as shown in
Figure 4. To ensure fairness given the varying histogram bin counts of the baseline regression models, we excluded the number of histogram insertions from our analysis.
Table 3 shows that using BayesSplit yields lower test MSEs than the naïve solver or MABSplit, and the improvement in generalization performance along with reduced training time highlights the effectiveness of Bayesian optimization in efficiently focusing on the most promising splits.
4.2. Fixed Budget Comparisons
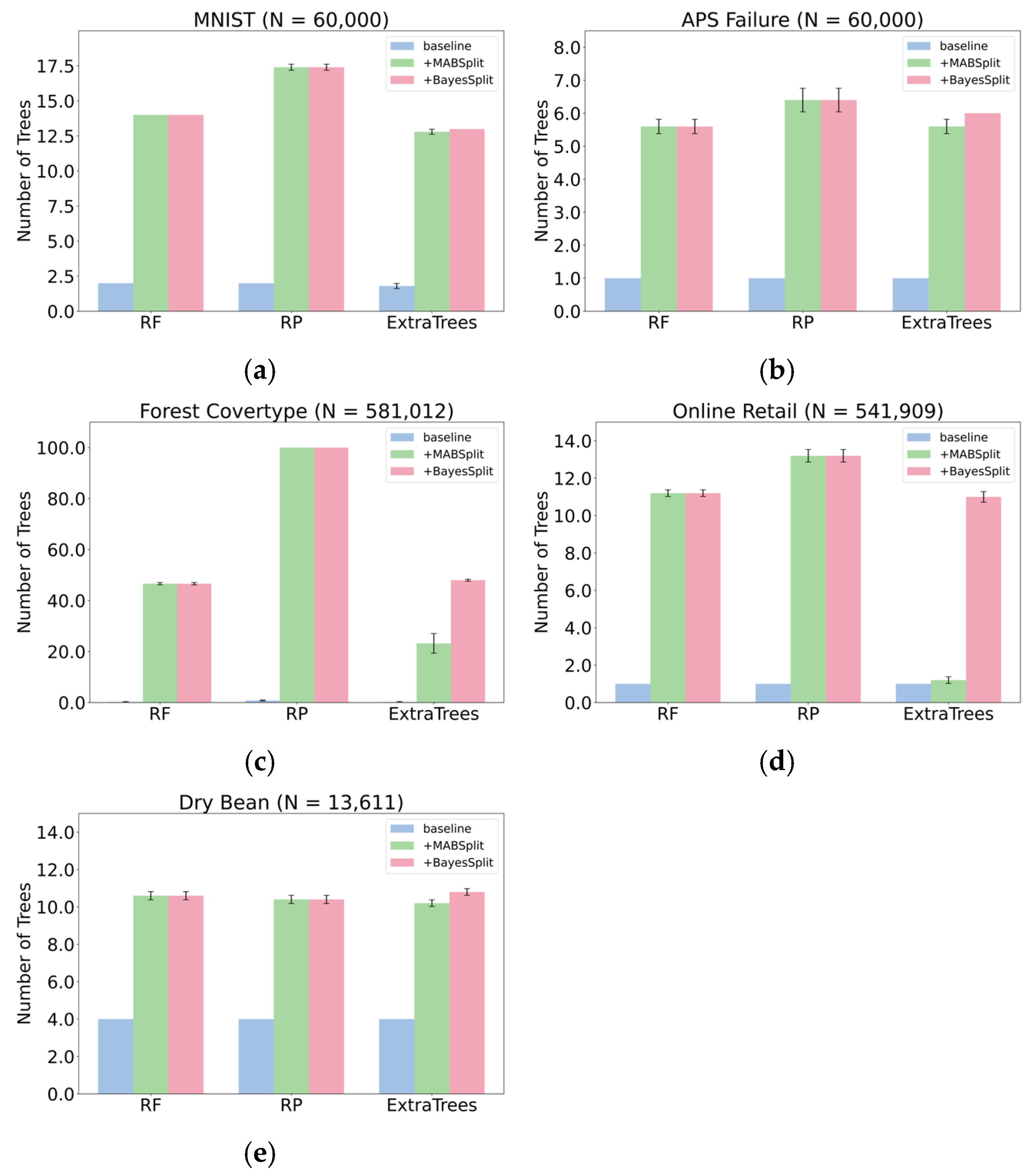
Classification: Under a fixed computational budget defined by a set number of histogram insertions, forests trained with BayesSplit split more nodes and require fewer data-point queries than those using the naïve solver. Consequently, these forests can accommodate more trees and achieve improved generalization.
Figure 5 compares the number of classification trees built under a fixed budget with test accuracies in
Table 4. For RF and RP, BayesSplit and MABSplit perform similarly across all five datasets. However, in ExtraTrees, BayesSplit surpasses MABSplit in both tree count and test accuracy, indicating that BayesSplit effectively captures and leverages the additional randomness in ExtraTrees’ split-selection process.
Regression: Under a fixed computational budget, integrating BayesSplit consistently outperforms both the naïve approach and MABSplit, allowing more trees to be trained and yielding lower test MSEs in all baseline models.
Figure 6 shows that BayesSplit supports additional regression trees within the same budget, and
Table 5 confirms notable improvements in predictive performance via reduced test MSEs. Notably, compared to MABSplit, BayesSplit can reduce the test MSEs by up to 25%.
BayesSplit proves particularly well-suited to regression tasks due to the continuous nature of the target variable, which enables more precise estimation of impurity reductions. This precision results in tighter confidence intervals within the Bayesian updating framework, allowing the algorithm to allocate more samples to regions of high uncertainty while limiting evaluations in low-variance segments. Consequently, BayesSplit converges more rapidly toward optimal splits, reducing unnecessary computations and enhancing overall efficiency.
4.3. Feature Stability Comparisons
Beyond predictive performance, Random Forests offer valuable insights into feature importance, thereby enhancing model explainability [
32]. We evaluate feature importance using two well-established metrics: Out-of-Bag Permutation Importance (OOB-PI) and Mean Decrease in Impurity (MDI). Specifically, OOB-PI quantifies the change in out-of-bag error when the values of a feature are shuffled, reflecting its contribution to predictive accuracy. On the other hand, MDI calculates the average reduction in impurity (e.g., Gini index or entropy for classification, MSE for regression) across all decision nodes where a given feature is used for splitting, indicating its effectiveness in reducing overall impurity within the model. To ensure robustness, the top
features identified by these metrics are further assessed for stability using standardized formulas [
33].
Table 6 shows that under a fixed computational budget, forests trained with BayesSplit achieve a 10–40% improvement in feature stability compared to MABSplit, corresponding to an average increase of approximately 30.28%. This improvement is particularly significant in resource-constrained environments, such as IoT and edge computing applications, where model interpretability and robustness are critical. By consistently identifying the most relevant features across multiple iterations, BayesSplit not only enhances predictive performance but also mitigates the risk of overfitting to irrelevant or noisy data.
5. Conclusions and Future Work
In this work, the BayesSplit algorithm was proposed as a Bayesian enhancement of MABSplit for decision-tree node splitting. While MABSplit introduces multi-armed bandit techniques with frequentist confidence intervals, BayesSplit advances this approach by developing a Bayesian-based impurity estimation framework where impurity reduction events are treated as Bernoulli trials. On the benchmark datasets, BayesSplit reduced wall-clock training time by 20–70% relative to MABSplit and by up to 95% relative to the naïve approach. Compared to MABSplit, it also lowered regression MSEs by as much as 25%.
Beyond computational efficiency, BayesSplit exhibits enhanced feature stability. Our experiments primarily focused on standard computing environments, making it an important future research direction to benchmark and optimize BayesSplit for resource-constrained devices such as smartphones and IoT platforms. Given the growing relevance of edge computing, which involves limited memory, power constraints, and specialized hardware architectures, dedicated optimizations and platform-specific considerations are critical. Future work could also extend BayesSplit to parallel frameworks such as Apache Spark, further broadening its applicability in large-scale real-time processing scenarios.
Finally, we note that gradient boosting decision tree (GBDT) frameworks such as XGBoost, LightGBM, and CatBoost remain strong baselines in predictive performance. These boosting algorithms often achieve higher accuracy than bagging-based methods on many tasks due to their sequential error-correcting training process. In contrast, our work focuses on the Random Forest framework, where trees are constructed in parallel, aiming to improve training efficiency without sacrificing accuracy. Nevertheless, integrating BayesSplit’s adaptive splitting strategy into boosting frameworks offers potential advantages, such as selectively updating the necessary data points’ residual targets rather than recomputing residuals for the entire dataset at each iteration. Although such integration presents practical and algorithmic challenges, it represents a promising direction for future research, as indicated by recent advances such as FastForest [
9]. Thus, our proposed approach complements rather than directly competes with optimized gradient boosting and hybrid methods. We intend to explore this topic in greater detail in future work.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}