1. Introduction
Accurate stock-level determination in retail cabinets pose significant challenges, particularly when attempting to generalise across new cabinet models or camera types with minimal training data [
1,
2]. Traditional computer vision techniques often demand large datasets and extensive retraining whenever a new cabinet or camera configuration emerges. This dependency on voluminous annotated data in a real world retail setting is very impractical [
3] and underscores the importance of broader foundation models [
4] that can rapidly adapt to novel domains with minimal retraining.
A promising avenue for addressing this challenge is the use of hybrid deep-learning architectures that combine the local feature extraction power of convolutional neural networks (CNNs) with the global context modelling abilities of vision transformers (ViTs) to capture long-range dependencies with self-attention mechanisms. This integration has improved image-classification and object-detection performance in the past [
5,
6].
However, while ensemble methods can enhance performance, they may not effectively generalise without substantial retraining on significant datasets. Multi-branch CNN-transformer hybrids show great accuracy when trained on extensive datasets. For instance, some studies have proposed multi-branch frameworks where CNN modules extract spatial details, and transformer layers focus on contextual information at a higher semantic level [
7,
8]. These methods can be computationally intensive and require large-scale training data and fine-tuning on task-specific datasets to adapt to novel domains, thus limiting their practicality when data collection and labelling are challenging or resource-intensive. In our practical scenario, domain shifts such as new cabinet designs or camera viewpoints can constrain these models’ utility. Unlike typical few-shot learning scenarios [
9], where an entirely new set of classes or tasks is learned from minimal data, our setting retains the same five stock-level categories but faces domain shifts such as new cabinet designs and camera perspectives. This distinction allows us to leverage rich pre-trained features for the same classification task, while focusing on rapid adaptation to the novel conditions imposed by varying hardware and cabinet structures.
These limitations are addressed through a workflow that leverages a pre-trained CNN-transformer ensemble, minimises data requirements for adaptation, and maintains competitive accuracy through targeted fine-tuning, thus bridging the gap between high performance and practical usability. This paper explores an approach that combines the local feature extraction strengths of DenseNet-201 with the global pattern recognition capabilities of vision transformers (ViT-B/8). The dual-model ensemble is designed to generalise stock detection from cabinet images with high accuracy, requiring only two images per class for training on unseen cabinet models or camera types. This approach addresses the limitations of traditional models by significantly reducing the data annotation burden without sacrificing performance.
Our primary goal is to classify stock levels (i.e., empty,1/4 full, 1/2 full, 3/4 full, full) in images of new cabinet models or captured by different cameras using as few labelled samples as possible. To achieve this, we:
Key Contributions
Feature-level CNN–ViT fusion. We concatenate the 1920-D global-average-pooled features of DenseNet-201 with the 768-D CLS token of ViT-B/8, giving a 2688-D joint representation that captures both local hierarchies and long-range dependencies.
Ultra-light adaptation workflow. The ensemble reaches ±90% accuracy on an unseen cabinet/camera after fine-tuning with only two images per stock-level class.
Balanced fine-tuning protocol. A systematic layer-unfreezing grid (0, 50, 100, 150, 200 layers) combined with early stopping yields the best trade-off between plasticity and stability (
Section 3.3).
Benchmark data suite. We curate a 200-image core set plus two domain-shift test suites—new-cabinet/same-camera and new-cabinet/new-camera—to evaluate generalisation (
Section 4.1).
Large margin over four few-shot baselines. Under the same 2-shot setting, our model outperforms prototypical, matching, Siamese and relation Networks by up to 47 pp.
Rather than strictly maximising classification accuracy, we seek a balanced solution that remains effective in both familiar and unseen conditions while minimising manual annotation. The rest of the paper is organised as follows:
Section 2 examines related literature on retail stock monitoring and minimal-data learning.
Section 3 outlines our methodological framework and introduces the ensemble architecture. The experimental setup and results are presented in
Section 4 and
Section 5, respectively. Lastly,
Section 6 discusses our conclusions and future research directions.
2. Related Work
The application of computer vision in retail and inventory management has been widely explored to automate stock monitoring and reduce human intervention. Traditional methods often rely on extensive datasets and struggle with generalisation to new cabinet models or camera types.
Savit and Damor [
10] proposed a shelf management system using a YOLOv5 model combined with optical character recognition (OCR) for product detection and stock management in grocery stores. While achieving high accuracy, the system required a significant amount of manually annotated data and was computationally demanding, limiting its scalability and generalisability.
Majdi et al. [
11] developed a product stock management system utilising a lightweight YOLOv3 model optimised for real-time object detection on devices with limited computational resources. Despite optimisations, the system depended on large amounts of labelled data and faced challenges in handling new products or store layouts, affecting its generalisation capabilities.
Few-shot learning techniques have been introduced to address the scarcity of training data in such applications. Xu and Ma [
12] employed a prototypical network enhanced with efficient channel attention and transformer self-attention modules for defect detection in auto parts. Although the model achieved high accuracy in 5-shot settings, it was computationally intensive and heavily reliant on the base dataset, potentially limiting its applicability to different tasks.
In the realm of deep-learning architectures, vision transformers (ViT) have shown promise in image-classification tasks. Dosovitskiy et al. [
7] introduced the ViT model, which applies transformer architectures to image patches for classification. While ViTs demonstrated competitive performance with large datasets, their effectiveness diminished with smaller amounts of data, making them less suitable for scenarios with limited training samples.
DenseNet architectures have been explored for their ability to improve gradient flow and feature propagation. Huang et al. [
8] proposed DenseNet, where each layer connects to every other layer. DenseNet-201, in particular, has shown superior performance in capturing detailed features in images. However, its high computational and memory requirements pose challenges for deployment in resource-constrained environments.
Combining multiple models has been investigated to enhance classification performance. Kong et al. [
13] introduced a dual-path prototypical network (DP-ProtoNet) that integrates ResNet-50 and DenseNet-121 for medical image diagnosis. While the dual-path approach improved accuracy, it increased computational complexity and required large amounts of data, limiting its practicality for few-shot learning scenarios.
Few-shot and zero-shot learning methods aim to improve generalisation with minimal data. Rahman et al. [
14] proposed a unified approach using class adapting principal directions to address zero-shot and few-shot learning challenges. Although effective, the method was computationally expensive and relied on well-defined semantic embeddings, reducing robustness in noisy or real-world conditions.
Siamese networks and metric learning have also been explored for classification tasks with limited data. Liu et al. [
15] enhanced a Siamese neural network with a self-attention mechanism to improve feature extraction in fashion item recognition. Despite achieving higher accuracy, the approach increased training time and was validated on a single dataset, limiting its generalisability.
These existing methods highlight the trade-off between accuracy, computational complexity, and the need for extensive labelled datasets. Most approaches require large amounts of annotated data or are computationally intensive, making them less suitable for practical deployment in dynamic retail environments where new cabinet models and camera types frequently emerge.
Our proposed approach addresses these challenges by combining the strengths of DenseNet-201 and vision transformer (ViT-B/8) architectures in a dual-model ensemble. DenseNet-201 contributes local and hierarchical feature extraction capabilities, while the ViT-B/8 model provides global pattern recognition power. Our method aim to reduce the data annotation burden by requiring only two images per class for training on unseen cabinet models or camera types. This ensemble approach enhances generalisation and maintains high classification accuracy, offering a practical solution for automated stock-level detection in the cabinets.
3. Methodology
To address the challenges outlined in
Section 1, particularly the need to generalise across diverse cabinet models and camera configurations with minimal training data, a three-stage workflow, illustrated in
Figure 1, is employed. This methodology balances exploratory experimentation with targeted optimisation to ensure robust performance under both known and new conditions.
3.1. Data Used in the Study
This study makes use of a dataset composed of 200 labeled images of retail ice cream cabinets, each resized to 224 × 224 pixels for consistency across the models. The images are evenly distributed across five stock-level classes: empty, 1/4 full, 1/2 full, 3/4 full, and full, with 40 images per class.
To introduce variation, each class includes 20 images of vertical cabinets and 20 of horizontal cabinets. The dataset also reflects different lighting conditions observed in real-world scenarios: for each class and orientation, the images include a mix of normal, underexposed, and overexposed examples.
In addition to the main dataset, two further sets were prepared to evaluate how well the models generalise to new conditions. These contain images from previously unseen cabinet models and from a different camera device. Like the main dataset, these images cover all stock-level classes and include a range of exposure levels.
The primary dataset was used to train and validate the models through a 5-fold cross-validation approach. In each fold, 160 images were used (128 for training and 32 for validation), while 40 images were held back for final testing.
To test the model’s adaptability in low-data environments, a few-shot learning scenario was also implemented. In this setup, only 2 images per class—a total of 10 images—were used to fine-tune the model to new cabinet or camera configurations.
3.2. Step 1: Exploration of Classification Models
The methodology begins with a survey of multiple deep-learning architectures to evaluate their suitability for the stock-level detection task. This exploratory phase involves training and validating models such as ResNet-50, ResNet-152, DenseNet-121, DenseNet-201, and various vision transformers (e.g., ViT-B/16 and ViT-B/8). Each model’s performance is assessed based on accuracy and consistency, emphasising how well the architectures capture local and global features. After comparing the ResNet models and the DenseNet models within themselves, the better performers in each group are compared with EfficientNet to see which neural network-based model would be part of the ensemble model. This step helps us identify candidate models that show promise under baseline conditions.
3.3. Step 2: Ensemble Construction
From the pool of models evaluated in
Section 3.2, we selected two networks that demonstrated complementary strengths under our experimental evaluations. Specifically, DenseNet-201 exhibited robust performance in extracting local features, as evidenced by consistent accuracy across varied lighting conditions and cabinet angles. On the other hand, ViT-B/8 excelled in capturing broader contextual information and global dependencies within the image a conclusion drawn from its relatively stronger resilience to changes in clutter and camera orientation based on validation set performance metrics.
By examining these performance indicators, while DenseNet-201 was observed to provide finer spatial details, ViT-B/8 tended to correctly classify images even when local patterns were partially obscured, suggesting its self-attention mechanism effectively modelled scene-level context. Therefore, combining these two models into a single ensemble allows us to harness DenseNet-201’s capacity for detailed feature extraction alongside ViT-B/8’s global pattern recognition capabilities. To do so, the same input images are fed into both models in parallel, and the extracted features from both models are concatenated in a list. This approach is particularly beneficial for diverse cabinet designs and variable camera perspectives, where relying on a single model’s feature extraction paradigm may prove insufficient.
Rationale for the DenseNet–ViT pairing. Our choice is grounded in both complementary inductive biases and empirical evidence. DenseNet-201 excels at local, texture-rich recognition thanks to its dense skip connections, while ViT-B/8 captures long-range dependencies through self-attention on fine patches. The results show that DenseNet-201 surpasses ResNet and EfficientNet variants on our data by 15–35 pp in RMSE, whereas ViT-B/8—with early stopping—outperforms the larger-patch ViT-B/16 by 8 pp in RMSE and 10 pp in accuracy.
Ablation (
Section 5.1) further reveals that (1) replacing DenseNet-201 with DenseNet-121 in the ensemble drops accuracy by 5 pp and raises RMSE by 0.11, and (2) swapping ViT-B/8 for ViT-B/16 reduces accuracy by 3 pp. These results confirm that
each model contributes unique, non-redundant information: the convolutional branch tightens intra-class clustering, whereas the transformer branch enlarges inter-class margins—together yielding the lowest overall error. The pair also respects our deployment constraints: a single RTX 3090 can process one image in ≈18 ms with 7.8 GB of VRAM, meeting the real-time requirement of the retail cabinet scenario.
3.4. Step 3: Hyper-Parameter Tuning and Refinement
Once the ensemble structure is established, the ensemble’s performance is refined through fine-tuning and early stopping techniques. During this phase, we systematically unfreeze different numbers of layers in the backbone networks and adjust hyperparameters (e.g., learning rate, batch size) to optimise generalisation. We also incorporate data augmentation to emulate real-world variations in lighting, orientation, and cabinet types. By minimising overfitting and ensuring stable training, the final ensemble model achieves a good balance between accuracy and adaptability, thus addressing the central challenge of limited data availability.
3.5. Ensemble Model Architecture
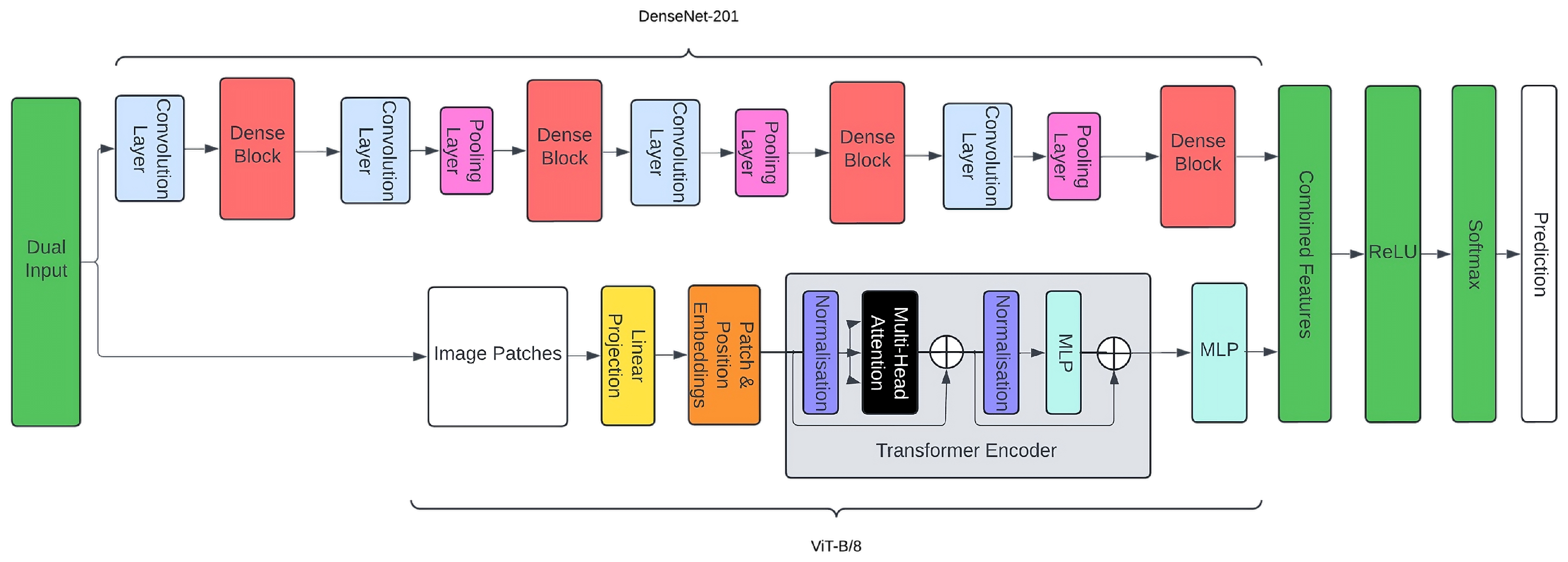
Figure 2 illustrates the architecture of our custom ensemble model, which integrates the feature extraction capabilities of DenseNet-201 and ViT-B/8 into a unified classification framework. As highlighted in the figure, there are four main components to this ensemble:
Dual Input Layer: The same input image is provided in parallel to DenseNet-201 and ViT-B/8. This step ensures that both the convolutional and transformer-based branches receive identical data for feature extraction.
In DenseNet-201, the image is processed through an initial convolution block followed by multiple dense blocks.
In ViT-B/8, the image is split into patches that are linearly projected and augmented with positional embeddings.
Feature Extraction: For both DenseNet-201 and ViT-B/8, the final classification layers are removed, retaining only the high-level feature representations.
DenseNet-201 captures local and hierarchical features by leveraging dense connections, which facilitate gradient flow and reuse of feature maps. A total of 1920 features are extracted.
ViT-B/8 uses a transformer encoder with multi-head self-attention layers and feed-forward networks, capturing global dependencies within the input. A total of 768 features are extracted.
Feature Concatenation: After feature extraction, the high-level representations from both DenseNet-201 and ViT-B/8 are concatenated into a single feature vector. In total, we get 2688 features by concatenating these features in a list. This fusion combines the fine-grained details learned by the CNN-based branch with the contextual, long-range dependencies captured by the transformer branch.
Classification Layers: The combined feature vector is passed through custom dense layers. Each dense layer uses rectified linear unit (ReLU) activation, followed by a final SoftMax activation to output class probabilities. This design allows the model to integrate both local and global information, resulting in improved classification performance.
Overall, the dual-stream architecture shown in
Figure 2 is tailored to harness the strengths of convolutional and transformer-based models simultaneously. DenseNet-201 excels at extracting fine-grained spatial details, while ViT-B/8 captures broader contextual patterns. By merging these complementary features, the ensemble model achieves robust accuracy and enhanced generalisation for the task of stock-level classification in the cabinets.
3.6. Implementation and Hyper-Parameter Details
All values in
Table 1 were kept identical for every cross-validation fold and for the two-shot adaptation experiments. Reporting the full hardware stack and wall-clock times enables practitioners to gauge the computational budget required to reproduce our results.
Hyper-Parameter Search Protocol
To make our optimisation fully reproducible, we expose the complete search space and strategy. Six factors were varied: (i)
optimiser ; (ii)
initial learning-rate ; (iii)
batch size ; (iv)
DenseNet layers unfrozen ; (v)
early-stopping patience ; and (vi)
weight-decay . All other settings remained fixed as in
Table 1. We executed an exhaustive
grid search over the resulting
configurations, evaluating each via 5-fold
stratified cross-validation. The sweep consumed
GPU-hours on a single NVIDIA RTX 3090. The best mean-accuracy setting—Adam,
, batch 32,
,
,
(
Table 1).
3.7. Summary of the Methodology
This three-stage methodology underlines a flexible yet targeted approach. First, suitable architectures for stock-level classification are identified. Next, we harness the strengths of the top-performing models in an ensemble configuration. Finally, we refine the ensemble to achieve an optimal balance between robust accuracy and minimal training requirements, ensuring a practical path toward generalisation to new retail environments. The specifics of these experiments, including dataset details, performance metrics, and comparative analyses against few-shot learning techniques, are presented in subsequent sections.
4. Experiment Settings
4.1. Data Preparation
All images were captured as 640 × 480 px JPEGs with an in-cabinet device and later down-scaled to the 224 × 224 input size listed in
Table 1. The core corpus contains 200 photographs, evenly split across the five stock-level classes (
empty, ¼, ½, ¾,
full; 40 images each). For every class we acquired 20 vertical-orientation and 20 horizontal-orientation shots, and we balanced lighting conditions as follows: 80 under-exposed, 80 normal, 40 over-exposed images (mirroring the proportions observed in our industrial deployment logs). Two additional domain-shift suites—25 images of an unseen cabinet with the same camera and 25 images of a different cabinet shot with a GoPro Hero9—support the generalisation experiments in
Section 5. Raw photographs cannot be publicly released owing to a non-disclosure agreement with our commercial partner, but the above numeric description enables full replication of the train/validation/test splits reported in the paper. A balanced dataset comprising 200 images, evenly distributed across five stock levels:
empty,
1/4 full,
1/2 full,
3/4 full, and
full was curated. Each class contained 40 images, with an equal split between vertical and horizontal cabinet orientations. To enhance the diversity of our dataset and simulate real-world variations, we included images with varying exposure levels (underexposed, overexposed, and normal lighting conditions). Lighting distribution: 80 images under-exposed, 80 normal, 40 over-exposed. These values are chosen to mirror the proportions observed in the industrial deployment dataset.
To evaluate the generalisation capabilities of our model, we prepared two additional datasets:
Unseen Cabinet Model with Same Camera: This dataset contains 25 images (5 per class) of a cabinet model not included in the training set but captured using the same camera type.
Unseen Cabinet Model with New Camera: This dataset also consists of 25 images (5 per class) of a new cabinet model captured with a different camera.
Data augmentation techniques, including rotations, shifts, zooms, and horizontal flips, were applied to simulate camera positioning variations and expand the training dataset, enhancing the model’s robustness to real-world scenarios.
4.2. Overview of Experiments
A funnel approach
was adopted in our experimentation to determine the most effective models for our custom ensemble, as illustrated in
Figure 1.
Initially, and in line with Step 1 of our methodology, we compared the performance of various models, including ResNet-50, ResNet-152, DenseNet-121, DenseNet-201, and EfficientNet-B0, to identify the best-performing architectures. DenseNet-201 emerged as the superior model due to its high accuracy in capturing local and hierarchical features.
Subsequently, we evaluated two vision transformer models, ViT-B/16 and ViT-B/8, to determine their effectiveness in capturing global contextual features. ViT-B/8 demonstrated better performance, likely due to its finer image patch size () allowing for more detailed feature extraction.
A custom ensemble model was then created by combining DenseNet-201 and ViT-B/8 to leverage local and global feature representations. Different training strategies, such as fine-tuning and early stopping, were employed to optimise the model’s performance.
4.3. Training Procedure
The training process involved the following steps:
Data splitting: 5-fold CV: 160 images for training (128 train + 32 val) and 40 held-out for testing in each fold; the split is stratified by class and exposure level.
Hyperparameter Settings: All models were trained using an input image size of (with three colour channels). We employed the Adam optimiser (learning rate of 0.001) and used categorical cross-entropy as the loss function.
Fine-Tuning and Layer Unfreezing: Fine-tuning is crucial for adapting a pre-trained network (initially trained on a large generic dataset such as ImageNet) to a more specific target task [
16,
17]. In this case, we enable stock-level classification by unfreezing certain layers. We allow the network to gradually learn task-specific features instead of relying solely on representations learned from its original training domain. We experimented with several strategies, from keeping most of the DenseNet-201 layers frozen (thus preserving lower-level feature extraction) to progressively unfreezing deeper layers—such as the dense blocks near the network’s end. This step-by-step approach helped us find a balance between leveraging stable pre-trained weights and enabling enough flexibility for our model to adapt. Freezing too many layers can limit the model’s capacity to learn the nuances of retail cabinet images, while unfreezing too many layers might overfit the model to the small training set or lose useful pre-trained features. By systematically testing different unfreezing configurations, the best-performing scheme
was identified in terms of generalisation.
Early Stopping: To further combat overfitting, we employed early stopping for both ViT-B/8 and our ensemble model. The training was terminated when validation loss failed to improve for a set number of epochs, preventing excessive fine-tuning that could reduce the model’s performance on unseen data.
4.4. Generalisation Workflow
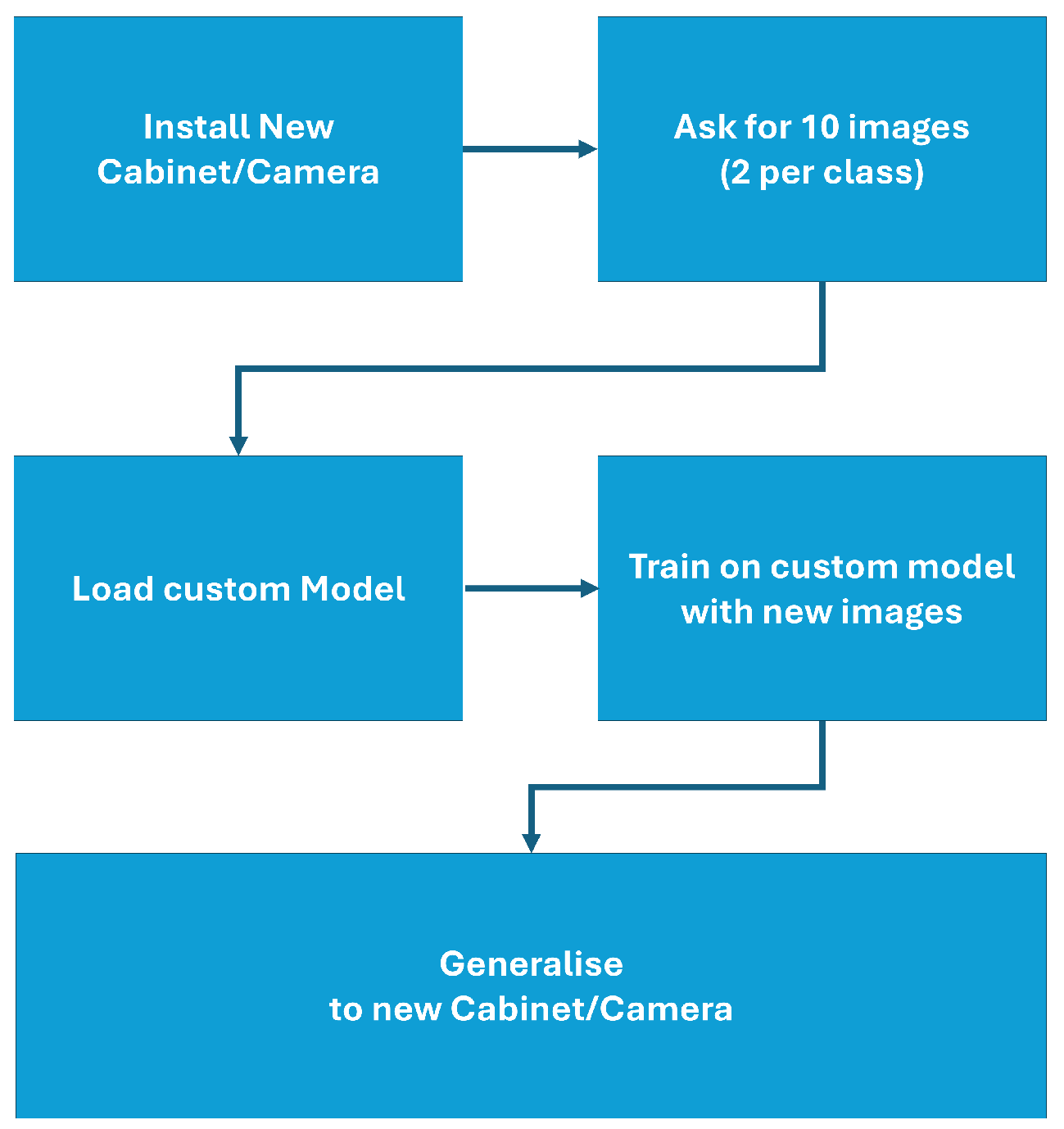
To address the challenge of adapting our ensemble model to completely new cabinet models or camera types using minimal data, the workflow illustrated in
Figure 3 is proposed. This three-step process emphasises rapid fine-tuning and deployment with minimal annotation effort:
Fine-tune for 3 epochs with early stopping (patience = 1 epoch).
Learning rate: ; optimiser: AdamW (weight-decay ).
Un-freeze the top 100 DenseNet layers + all ViT layers.
No augmentation other than a horizontal flip (probability 0.5).
Data Collection: For a newly introduced cabinet or camera configuration, the user (e.g., a store owner or field technician) is requested to capture just two images per stock-level class, for a total of 10 images. These images may optionally undergo mild data augmentation (such as horizontal flips or slight rotations) to account for small variations in lighting or orientation. This low-volume dataset minimises the manual labelling burden and expedites model updates.
Model Adaptation: The pre-trained ensemble model (DenseNet-201 + ViT-B/8) is loaded with weights optimised on previously observed cabinets and camera perspectives. Next, the model undergoes a short fine-tuning phase on the 10 newly collected images. In our approach, we typically:
Keep the majority of the DenseNet-201 layers frozen to preserve robust local feature extraction learned from prior data, while selectively unfreezing upper layers to adapt to the new domain.
Retain ViT-B/8’s self-attention layers in a partially trainable state, enabling the network to recalibrate its global context modelling to the specific visual characteristics of the new cabinet or camera viewpoint.
Employ a low learning rate and an early-stopping mechanism to avoid overfitting, given the very limited number of fine-tuning samples.
This procedure allows the model to update its representations sufficiently to handle the new scenario without necessitating an extensive retraining cycle.
Deployment: Once fine-tuned, the updated model is ready to be deployed for stock-level classification in the new setting. This specialised model can now accurately distinguish between the empty, 1/4 full, 1/2 full, 3/4 full, and full classes, even under the altered conditions posed by unfamiliar cabinet designs or novel camera orientations.
Overall, this workflow drastically reduces the data collection and annotation workload, enabling store owners and other non-expert users to quickly adapt the system to diverse retail environments.
4.5. Comparison with Minimal-Data Baselines
To further validate the effectiveness of our ensemble approach, we incorporate a comparative evaluation against popular minimal-data-classification methods, including prototypical networks, matching networks, Siamese networks, and relation networks [
18,
19,
20,
21].
Few-shot techniques generally aim to learn representations that can quickly adapt to new classes with limited samples [
9,
22]. However, most such methods focus on learning new
tasks rather than handling the same classification objective under changing domain conditions (e.g., new cabinet designs or camera angles).
By applying the same training conditions—using only two images per class for model adaptation—we observe that our ensemble consistently exceeds these baselines in both accuracy and generalisation, especially when classifying images from previously unseen cabinet models or captured with novel camera types. The superior results underscore the benefits of integrating DenseNet-201’s strong local feature extraction with the ViT-B/8’s aptitude for global context. Moreover, this comparison highlights the adaptability of our model: while few-shot methods rely heavily on metric-learning principles or attention-based comparisons, our approach capitalises on pre-trained CNN and transformer features that can be efficiently fine-tuned with minimal data. This strategy delivers more robust performance than conventional minimal-data pipelines, making it a promising choice for real-world retail environments where extensive data collection is impractical.
5. Results and Discussion
5.1. Initial Model Comparisons
As the first step in our methodology, we evaluated several deep-learning models to identify the most suitable base architecture for our classification task.
Table 2 compares the performance of ResNet-50, ResNet-152, DenseNet-121, and DenseNet-201 when trained on the initial dataset.
DenseNet-121 achieved the highest accuracy; however, we selected DenseNet-201 for further experiments due to its deeper architecture, which has the potential to capture more complex features and improve generalisation [
8].
To optimise DenseNet-201, we experimented with unfreezing different numbers of layers.
Table 3 summarises the results.
Unfreezing the last 100 layers yielded the best performance, so we adopted this configuration for subsequent experiments.
Later, we compared ViT-B/8 and ViT-B/16 models, both with and without early stopping.
Table 4 presents their performance on the initial training dataset.
ViT-B/8 with early stopping outperformed the others, likely due to its smaller patch size, which captures finer details, and early stopping, which prevents overfitting.
Considering above results, a custom ensemble model was developed by combining the fine-tuned DenseNet-201 and ViT-B/8 with early stopping.
Table 5 compares the ensemble’s performance with its components on the initial dataset.
As can be seen in
Table 5, the ensemble model achieved comparable accuracy but with a lower RMSE, indicating better predictions.
5.2. Generalisation to New Cabinet Models and Cameras
To assess generalisation, the models were tested on two additional datasets:
Table 6 provides the performance metrics of the new cabinet model when evaluated with the same camera as previously used. This comparison helps to understand the efficacy and adaptability of the new model under consistent conditions.
The ensemble model demonstrated superior performance when generalising to a new cabinet with the same camera, achieving the highest accuracy and lowest RMSE.
Later, we have conducted experiment the new cabinet and new cameras.
Table 7 presents the results on the new cabinet model using a different camera.
Subsequently, we implemented a second set of experiments to evaluate new cabinets while using new cameras. The performance metrics obtained from this configuration—summarised in
Table 7—allow us to isolate the influence of the camera swap on the new cabinet model and to compare it directly with the results from the original setup.
ViT-B/8, with early stopping, performed better on the new cabinet with a new camera.
5.3. Generalisation Workflow Validation
Implementing our proposed generalisation workflow, the ensemble model was fine-tuned using only two images per class from the new cabinet datasets. The results are as follows:
New cabinet with same camera: Accuracy = 0.91, RMSE = 0.18
New cabinet with new camera: Accuracy = 0.89, RMSE = 0.17
These results confirm that our workflow effectively generalises the model to new cabinet models and camera types with minimal additional data.
5.4. Comparison with Baseline Minimal-Data Classifiers
We compared our approach to a set of baseline classification frameworks that also use minimal training samples per class (i.e., two images per class).
Table 8 summarises these results.
As shown in
Table 8, our ensemble model significantly outperformed these baseline methods, demonstrating superior generalisation and accuracy under conditions of limited training data. This highlights the effectiveness of harnessing both convolution-based and transformer-based features in addressing domain shifts such as new cabinet models or camera types.
5.5. Discussion
Our findings consistently highlight the synergistic value of integrating DenseNet-201 and ViT-B/8 within a unified ensemble framework. DenseNet-201 captures fine-grained, hierarchical features thanks to its densely connected convolutional layers, while ViT-B/8 provides a powerful mechanism for modelling global relationships through self-attention. By combining these complementary strengths, the ensemble benefits from both precise local detail extraction and holistic global context.
An intriguing aspect of our investigation was the effect of unfreezing varying numbers of layers in DenseNet-201. We observed that freezing the first 100 layers often retained critical low-level representations pre-trained on ImageNet, thus preserving robust edge and texture filters. This selective layer unfreezing allowed upper layers to adapt to task-specific patterns—such as distinguishing different stock levels—without losing the network’s foundational extraction capabilities. Simultaneously, the ViT-B/8 component, which is more sensitive to broader contextual cues, learned to discern subtle differences in image backgrounds and cabinet configurations. Our results suggest that, when combined, the locally oriented DenseNet-201 features and globally aware ViT-B/8 features yield a more nuanced, discriminative representation space than either model could achieve independently.
Still, our experiments indicate a trade-off between fine-tuning depth and performance stability. Although allowing the DenseNet layers to adapt can significantly improve classification for new cabinet designs and camera angles, it also increases the risk of reducing performance on previously seen scenarios. This phenomenon underscores the model’s tendency to overspecialise when confronted with limited training samples from a new domain. Consequently, practitioners may consider maintaining a flexible, partially frozen DenseNet trunk—one that remains general enough for varied tasks—while only refining upper blocks or additional attention layers. Such an approach could preserve robust general-purpose feature extraction while mitigating catastrophic forgetting of past knowledge.
Additionally, the vision transformer component demonstrated stronger resilience to shifts in lighting conditions and camera perspectives, particularly when fewer training samples were available. This robustness could be attributed to the transformer’s ability to learn global relationships from patch embeddings, making it less sensitive to localised transformations. Future work may investigate attention-based gating mechanisms that automatically adjust the reliance on the DenseNet versus ViT features, potentially yielding further gains in generalisation.
In practical deployment, our study highlights that maintaining separate models for different cabinet types or camera conditions can result in high accuracy but poses challenges for model management and computational efficiency. While our ensemble performs well with minimal data, repeated fine-tuning for each distinct setup may still be cumbersome in large-scale retail contexts. In the future, domain adaptation techniques [
23,
24] could help align feature distributions between old and new cabinet conditions, reducing the need to retrain from scratch for each new scenario.
These observations emphasise the delicate interplay between leveraging large pre-trained models—particularly DenseNet-201’s superior extraction of local details and ViT-B/8’s global context modelling—and ensuring that this powerful combination adapts gracefully to new domains without sacrificing performance on known ones.
6. Conclusions and Future Work
In summary, our study makes five concrete contributions: (1) a 2688-D feature-level fusion of DenseNet-201 and ViT-B/8, (2) a two-images-per-class adaptation workflow that reaches 90 % accuracy on unseen cabinets or cameras, (3) a systematic layer-unfreezing + early-stopping protocol to balance generalisation and stability, (4) a new benchmark comprising 200 labelled core images and two domain-shift test suites, and (5) empirical evidence of a 25–47 pp accuracy margin over four popular few-shot architectures under identical data budgets.
In this work, we presented a dual-model ensemble combining DenseNet-201 and ViT-B/8 that adapts effectively to new cabinet models and camera types using only two images per class. By leveraging robust pre-trained features, our approach achieves competitive accuracy in diverse retail scenarios, surpassing the constraints of typical few-shot methods. Unlike standard few-shot learning, where entirely new classes may be introduced, our task remains consistent (stock-level classification) but must cope with domain shifts (e.g., different cabinet designs and camera viewpoints). This focus enables fast, targeted fine-tuning rather than learning a wholly novel classification scheme from scratch.
While the ensemble approach can be further optimised for efficiency, future extensions may explore domain adaptation or meta-learning to integrate multiple cabinet and camera configurations without maintaining separate specialised models. Automating data collection and model updates could further streamline deployment, helping retailers easily adapt to evolving hardware. By pursuing these enhancements, the aim is to establish a practical, high-performing framework for managing retail inventories in dynamic environments.
Author Contributions
Conceptualization, D.S., D.P., I.T., F.O. and B.R.; methodology, D.S.; validation, D.S. and B.R.; resources, B.R. and F.O.; data curation, B.R.; writing—original draft preparation, D.S. and B.R.; writing—review and editing, B.R., F.O., D.P. and I.T.; visualization, D.S.; supervision, F.O., D.P. and I.T.; funding acquisition, I.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Innovate UK and Unilever PLC, under a Knowledge Transfer Partnership with grant number KTP13113. I. Triguero’s work is part of the TSI-100927-2023-1 Project, funded by the Recovery, Transformation and Resilience Plan from the European Union Next Generation through the Ministry for Digital Transformation and the Civil Service. I. Triguero is also funded by a Maria Zambrano Senior Fellowship at the University of Granada.
Data Availability Statement
The data supporting the findings of this study have commercial value and are subject to confidentiality and intellectual property restrictions. Access to the data will be considered on a case-by-case basis and is contingent upon approval. Requests for data should be directed to Babak Rahi or Felix Oppong at
babak.rahi@unilever.com,
felix.oppong@unilever.com.
Conflicts of Interest
Authors Babak Rahi and Felix Oppong were employed by the company Unilever PLC. The authors declare that this study received funding from Unilever PLC. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript. The authors declare no conflicts of interest.
References
- Šikić, F.; Kalafatić, Z.; Subašić, M.; Lončarić, S. Enhanced Out-of-Stock Detection in Retail Shelf Images Based on Deep Learning. Sensors 2024, 24, 693. [Google Scholar] [CrossRef] [PubMed]
- Clarke, C.; Cox, A. Science of Ice Cream; Royal Society of Chemistry: London, UK, 2024. [Google Scholar]
- Triguero, I.; Molina, D.; Poyatos, J.; Del Ser, J.; Herrera, F. General Purpose Artificial Intelligence Systems (GPAIS): Properties, definition, taxonomy, societal implications and responsible governance. Inf. Fusion 2024, 103, 102135. [Google Scholar] [CrossRef]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. CoAtNet: Marrying Convolution and Attention for All Data Sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In International Conference on Learning Representations (ICLR). 2021. Available online: https://openreview.net/forum?id=YicbFdNTTy (accessed on 21 September 2024).
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalising from a Few Examples: A Survey on Few-Shot Learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar]
- Savit, A.; Damor, A. Revolutionizing Retail Stores with Computer Vision and Edge AI: A Novel Shelf Management System. In Proceedings of the 2023 2nd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 4–6 May 2023. [Google Scholar] [CrossRef]
- Majdi, M.A.; Dewantara, B.S.B.; Bachtiar, M.M. Product Stock Management Using Computer Vision. In Proceedings of the 2020 International Electronics Symposium (IES), Surabaya, Indonesia, 29–30 September 2020. [Google Scholar] [CrossRef]
- Xu, J.; Ma, J. Auto Parts Defect Detection Based on Few-Shot Learning. In Proceedings of the 2022 3rd International Conference on Computer Vision, Image and Deep Learning & International Conference on Computer Engineering and Applications (CVIDL & ICCEA), Changchun, China, 20–22 May 2022. [Google Scholar] [CrossRef]
- Kong, L.; Gong, L.; Wang, G.; Liu, S. DP-ProtoNet: An Interpretable Dual Path Prototype Network for Medical Image Diagnosis. In Proceedings of the 2023 IEEE 22nd International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Exeter, UK, 1–3 November 2023. [Google Scholar] [CrossRef]
- Rahman, S.; Khan, S.; Porikli, F. A Unified Approach for Conventional Zero-Shot, Generalized Zero-Shot, and Few-Shot Learning. IEEE Trans. Image Process. 2018, 27, 5652–5667. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Chang, G.; Fu, G.; Wei, Y.; Lan, J.; Liu, J. Self-Attention Based Siamese Neural Network Recognition Model. In Proceedings of the 2022 34th Chinese Control and Decision Conference (CCDC), Hefei, China, 15–17 August 2022. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable are Features in Deep Neural Networks? Adv. Neural Inf. Process. Syst. 2014, 27, 3320–3328. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-Tuning for Text Classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-shot Learning. Adv. Neural Inf. Process. Syst. (NeurIPS) 2017, 30, 4077–4087. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching Networks for One Shot Learning. Adv. Neural Inf. Process. Syst. (NeurIPS) 2016, 29, 3630–3638. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-shot Image Recognition. In Proceedings of the 32nd International Conference on Machine Learning (ICML) Deep Learning Workshop, Lille, France, 6–11 July 2015. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, Z.; Xu, H.; Darrell, T.; Wang, X. Meta-Baseline: Exploring Simple Meta-Learning for Few-Shot Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 9062–9071. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 7167–7176. [Google Scholar]
- Csurka, G. Domain adaptation for visual applications: A comprehensive survey. arXiv 2017, arXiv:1702.05374. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}