1. Introduction
Machine Learning (ML) has become a cornerstone of modern technology, finding applications across diverse domains such as predictive analytics, anomaly detection, and decision-making [
1,
2]. Many ML applications address similar underlying tasks, presenting significant potential for systematically reusing core assets. Despite this, existing reuse practices in ML are often fragmented, limited in scope, and conducted on an ad hoc basis. Efforts typically focus on isolated components like pretrained models, datasets, or pipelines, without providing a cohesive framework that supports large-scale reuse across systems and projects. This lack of systematic reuse leads to inefficiencies, duplicated efforts, and challenges in scaling ML development for complex applications.
In traditional engineering, Product Line Engineering (PLE) offers a well-established methodology for achieving large-scale systematic reuse [
3,
4,
5]. By managing shared core assets—such as requirements, models, and code—PLE enables the efficient development of product families, reducing redundancy and improving consistency. However, conventional PLE processes are not designed to address the unique characteristics of ML systems. Unlike traditional systems, ML systems rely heavily on data as a core asset, involve iterative workflows, and exhibit variability in datasets, models, and pipelines. These differences necessitate the adaptation of PLE principles to accommodate the specific needs of ML systems.
To address this gap, we propose Machine Learning Product Line Engineering (ML PLE), a novel framework that extends PLE principles to ML systems. ML PLE systematically manages ML-specific core assets, such as datasets, feature pipelines, models, and hyperparameters, while aligning with the dynamic, data-driven nature of ML workflows. The proposed framework introduces key requirements for adapting PLE to ML and outlines a lifecycle process tailored to machine-learning-intensive systems. This approach enables systematic reuse, efficient variability management, and enhanced scalability for ML development.
To validate the applicability and effectiveness of ML PLE, we applied the framework to an industrial case study in the context of space systems. The case study focuses on data analytics for satellite missions, demonstrating how ML PLE can address challenges such as managing variability in telemetry data, evolving datasets, and adapting workflows to mission-specific requirements. The results highlight the potential of ML PLE to improve reuse, scalability, and efficiency in ML-enabled space systems.
The remainder of this paper is organized as follows.
Section 2 provides background and reviews related work, including existing reuse practices in machine learning and their limitations.
Section 3 describes the motivating space systems case study and illustrates the need for systematic ML reuse.
Section 4 describes the requirements for adopting PLE for ML.
Section 5 introduces the ML PLE framework, outlining its key concepts, ML Domain Engineering process, ML Application Engineering, and the integrated ML PLE process.
Section 6 presents a qualitative evaluation based on the case study. Finally,
Section 7 concludes the paper.
2. Background and Related Work
2.1. Machine Learning
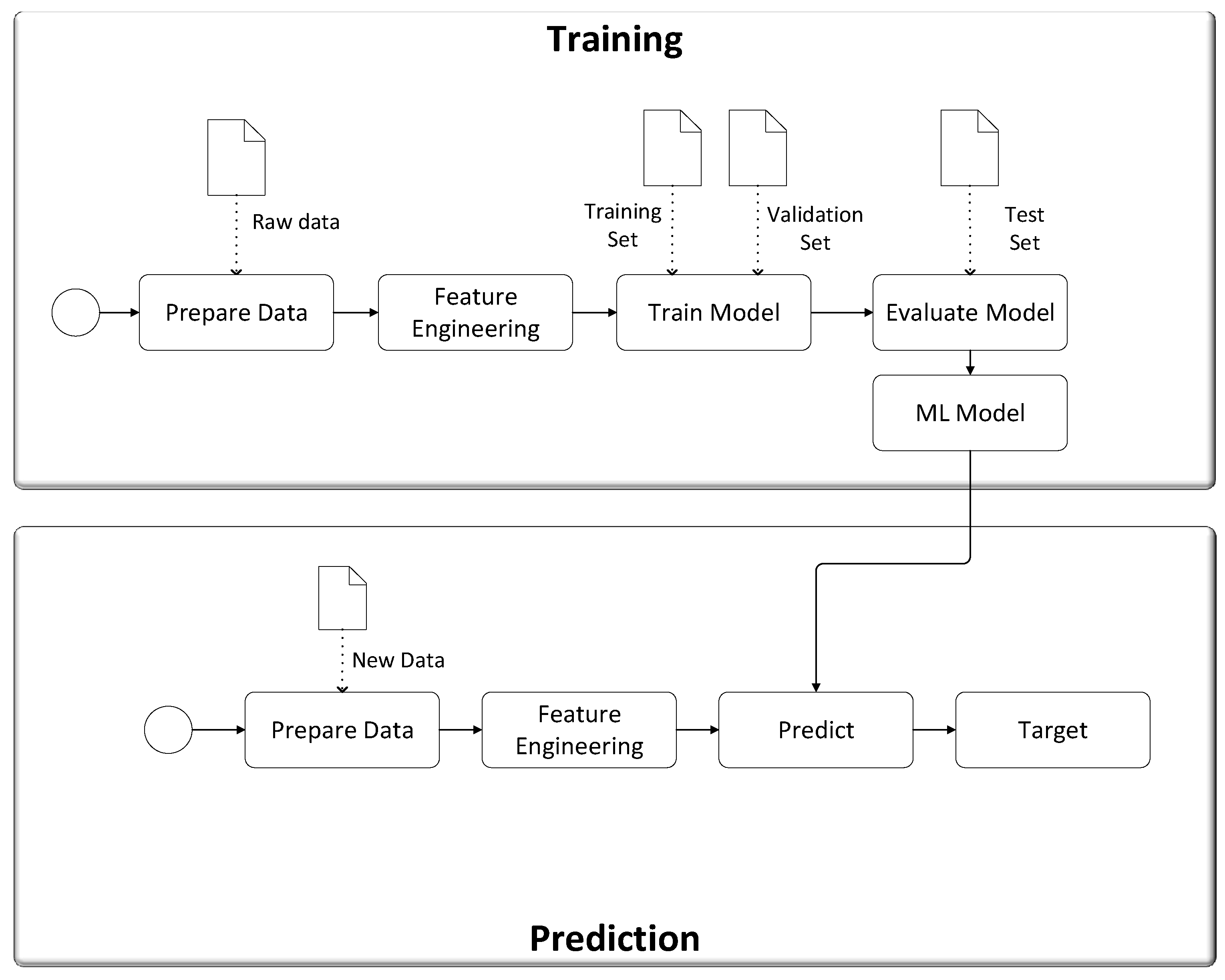
To identify the needs for machine learning in a general context, it is essential to understand the conventional ML process and its relationship with data science. While data science focuses on obtaining raw data and transforming it into useful information for decision-making, ML builds on this foundation by using data to develop predictive models that automate complex tasks such as classification, regression, diagnosis, planning, and recognition. The ML process offers a structured and repeatable approach for extracting patterns and insights from data, enabling applications across a wide range of domains. The ML process typically involves two primary activities: training and prediction, including data collection, preprocessing, and feature extraction (
Figure 1). Data collection is the initial step, where raw data is systematically gathered from various sources to ensure it adequately represents the problem space. This data must then undergo preprocessing to address issues such as missing values, duplicates, noise, or inconsistencies. Preprocessing also involves transforming the data into a usable format (e.g., normalization or scaling) and reducing its complexity through dimensionality reduction techniques. In the training phase, the preprocessed data is used to build a model capable of learning from historical patterns. The data is typically divided into subsets, including a training set for fitting the model and a validation set for tuning its hyperparameters. Feature extraction plays a significant role here, as it focuses on identifying and selecting the most relevant variables (features) for analysis, allowing the model to concentrate on meaningful correlations. The training phase concludes with an evaluation of the model using a separate test dataset to measure its performance and generalizability, resulting in the creation of the final ML model.
In the prediction phase, the trained ML model is deployed to process new data and make predictions. Similar to the training phase, new data must be preprocessed, and relevant features must be extracted before being fed into the model. The model then outputs predictions or classifications that support decision-making and enable automated responses to various tasks or problems.
Figure 1 illustrates this traditional ML workflow, emphasizing the iterative nature of the training and prediction activities.
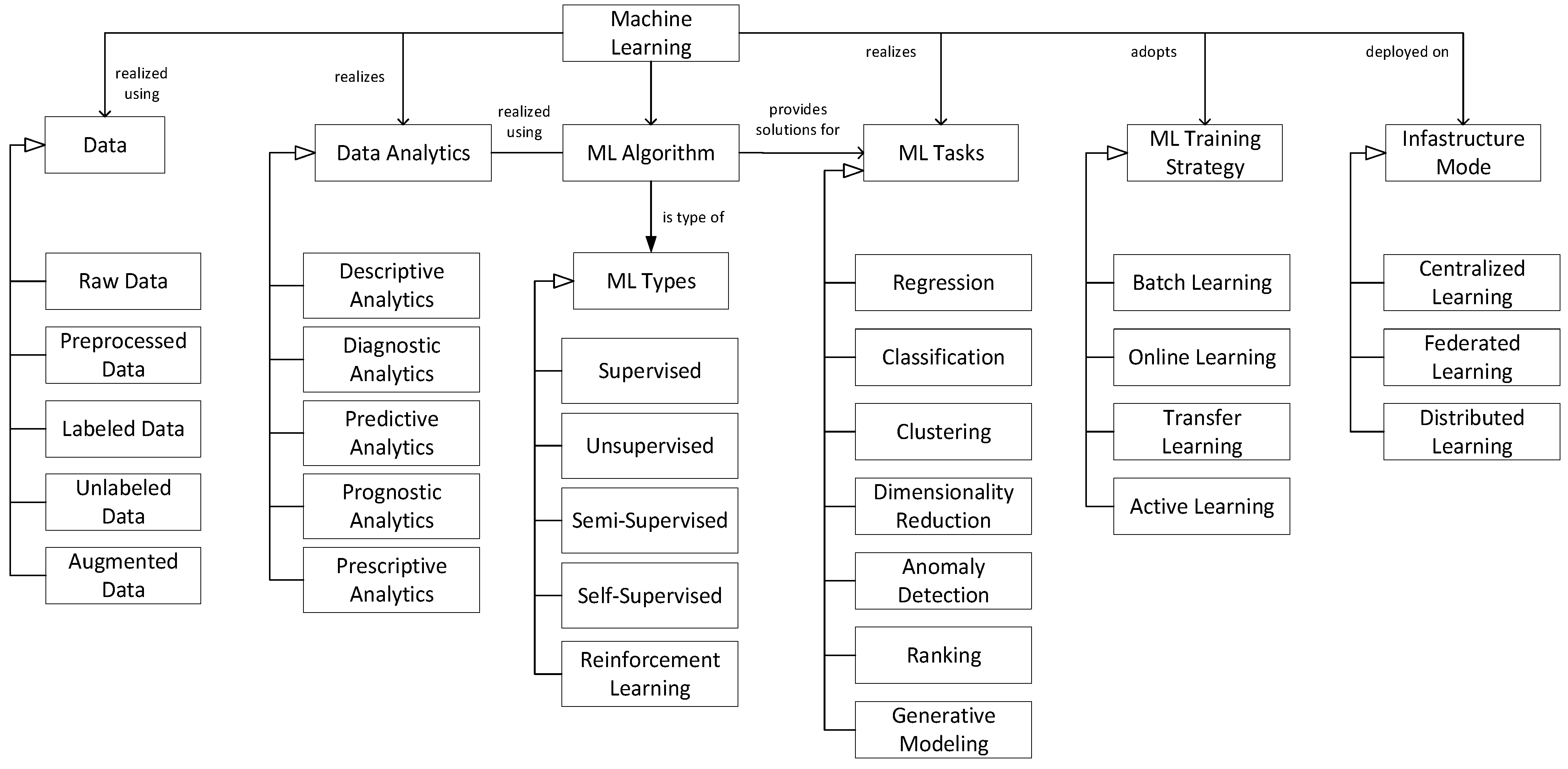
The key concepts of machine learning are shown in
Figure 2. The model distinguishes between different dataset forms including raw, preprocessed, labeled, unlabeled, and augmented data, which represent essential building blocks across the ML lifecycle. Different types of analytics can be distinguished, including descriptive analytics (what happened), diagnostic analytics (why it happened), predictive analytics (what is likely to happen), prognostic analytics (what will happen if trends continue), and prescriptive analytics (what should be done). Data analytics is performed using ML algorithms. Different types of ML can be distinguished based on how they learn from data including Supervised Learning, Unsupervised Learning, Semi-Supervised Learning, Self-Supervised, and Reinforcement Learning. ML techniques are applied to a variety of tasks across numerous fields. Different ML tasks include Regression, Classification, Clustering, Dimensionality Reduction, Anomaly Detection, Ranking, and Generative Modeling. ML training strategy refers to how a model learns from data, such as in batch mode (training on the full dataset), online mode (incrementally updating with new data), transfer learning (adapting a pretrained model to a new task), and active learning (where the model selectively queries the most informative data points to optimize learning efficiency with minimal labeled data). Infrastructure mode describes where and how training occurs—centrally on a single server, distributed across multiple machines, or in federated setups where training happens locally on devices without sharing raw data.
This metamodel in
Figure 2 captures essential concepts in machine learning and serves as a foundation for analyzing and structuring ML core assets within the ML PLE framework. While it does not aim to exhaustively cover all ML paradigms or configurations, it reflects a representative set of widely used and practically relevant concepts.
2.2. Product Line Engineering
Compared to single-system development, adopting a PLE approach requires an upfront investment in establishing reusable platforms, feature models, and supporting processes. However, this investment typically pays off after developing more than one product, as the cumulative benefits increase with each additional product. The point at which these investments are recovered is called the breakeven point. Beyond this point, PLE enables organizations to achieve a significant return on investment (ROI), particularly in terms of scalability and efficiency compared to developing each product independently. As shown in
Figure 3, the PLE process is structured around two complementary lifecycle activities: domain engineering and application engineering. In domain engineering, the focus is on creating reusable platforms, product line architectures, and variability models that define the commonalities and variabilities across the product family. These assets are then used in application engineering, where individual products are developed by selecting and configuring features based on specific requirements. These lifecycles are supported by a management process that addresses technical and organizational aspects, ensuring alignment with business goals and the effective execution of PLE practices.
PLE is used extensively in software engineering, where shared codebases, libraries, and architectures form the foundation for reusable platforms. However, its principles are equally applicable to systems engineering, where reusable hardware components, interfaces, and subsystems play a similar role. This dual applicability makes PLE a powerful approach for managing variability and achieving reuse across diverse domains, from software-intensive systems to integrated hardware–software solutions.
2.3. Related Work
Reuse in AI and ML has been a relevant attention point aimed at reducing duplication of effort and enhancing scalability across projects and domains [
6,
7,
8,
9]. While a full systematic literature review of machine learning reuse techniques is beyond the scope of this paper, we acknowledge its importance and intend to address it in a dedicated follow-up study. In this work, we provide a focused overview of representative reuse techniques to frame the relevance and motivation for the ML PLE framework. The number of key reuse approaches that were identified is described below.
Reusable datasets form the basis of many ML systems, particularly for supervised learning tasks where data collection and labeling are expensive [
10,
11]. Publicly available datasets provide a starting point for training and benchmarking models. Enhancements like data versioning, augmentation, and traceability enable datasets to be adapted for new tasks while maintaining reproducibility.
Code reuse is widely facilitated using ML frameworks such as TensorFlow, PyTorch, and Scikit-learn. These tools provide modular implementations of training routines, model architectures, evaluation metrics, and loss functions, enabling developers to build upon proven components and maintain uniform development practices [
12].
Pretrained models and transfer learning build on these foundational components, offering reusable, general-purpose models trained on large datasets, such as BERT, ResNet, and GPT [
13,
14,
15,
16]. Transfer learning allows developers to adapt these pretrained models for new tasks by fine-tuning only specific layers, significantly reducing training time and computational costs. Pretrained models are especially powerful when combined with reusable datasets and feature pipelines, creating a comprehensive foundation for ML development.
Another reuse approach in ML involves the development and deployment of feature engineering pipelines [
17,
18,
19]. These modular workflows are designed to extract, transform, and select features from raw data in a standardized manner. A well-designed preprocessing pipeline can often be reused across multiple datasets or tasks—for example, adapting a time-series transformation pipeline for various anomaly detection applications with only minor adjustments.
Reusable hyperparameter tuning strategies address the optimization phase by defining configurable parameter ranges that can be applied across different models and tasks [
20,
21]. Tools like Optuna and Ray Tune automate the search for optimal configurations, reducing duplication of effort and improving efficiency.
Reusable evaluation metrics and benchmarks are essential for enabling systematic reuse in machine learning. Standard metrics such as accuracy, F1-score, and mean squared error can be applied consistently across different models and tasks, supporting uniform evaluation practices. Benchmarks like General Language Understanding Evaluation (GLUE) for NLP [
15], and DAWNBench, a benchmark suite for end-to-end deep learning training and inference [
22], provide shared protocols and datasets that facilitate reproducibility and comparability. Within an ML PLE context, these reusable evaluation components help ensure consistent quality across product variants, reduce redundancy in evaluation design, and enhance traceability throughout the lifecycle. As such, they are key elements in supporting scalable and reliable ML reuse.
2.4. Limitations of Existing ML Reuse Approaches and the Motivation for ML PLE
Despite existing and ongoing efforts, significant limitations remain in achieving systematic and large-scale reuse in machine learning. Existing approaches typically emphasize isolated components such as models, datasets, or individual pipelines, without integrating them into a cohesive framework that spans the complete machine learning lifecycle. This narrow focus and the fragmentation of current reuse strategies often lead to inefficiencies in managing interdependencies. Common issues include misalignment between preprocessing components and model expectations, as well as compatibility challenges between retrained models and deployment environments. In addition, feedback mechanisms are frequently implemented manually and are unstructured, making it difficult to maintain traceability and consistency across iterative development cycles.
A prominent class of recent solutions to improve ML development and deployment is MLOps (Machine Learning Operations). MLOps platforms such as MLflow, Kubeflow, and TFX are designed to support the operational lifecycle of machine learning, offering automation, orchestration, and continuous integration and delivery (CI/CD) [
6,
11,
17]. These tools help manage training, deployment, and monitoring of models in production settings and are effective at enabling reproducibility and traceability at the level of individual pipelines. However, MLOps does not address reuse at a strategic, system level across families of ML-enabled products. It primarily focuses on the operationalization of single ML solutions, and does not include concepts such as variability modeling, asset readiness classification, or coordinated management of reusable core assets like datasets, models, and pipelines. To clarify the distinction between these paradigms,
Table 1 presents a comparative overview of MLOps and the proposed ML PLE approach.
These limitations and the lack of a holistic and systematic reuse point to the need for a unified reuse framework that integrates traceability, supports structured variability management, and promotes automation across the machine learning lifecycle. In contrast to the current approaches, the proposed ML PLE framework introduces a comprehensive, system-level approach to reuse that is inspired by principles from PLE. ML PLE organizes machine learning development around reusable core assets, including datasets, models, pipelines, and hyperparameters. It provides explicit support for managing variability and configuring reusable components across a family of machine-learning-enabled products. The originality of ML PLE lies thus in essence in its holistic adaptation of PLE concepts to the domain of machine learning. This includes both technical elements such as asset modularization, reusable pipelines, and asset readiness classification, as well as a structured methodology consisting of dedicated domain engineering and application engineering phases tailored to machine learning workflows. In this way, ML PLE offers a strategic extension to conventional reuse practices in machine learning. It bridges the gap between high-level planning for product families and the concrete execution of machine learning workflows, an area that is not fully addressed by current lifecycle management platforms. We further elaborate on the theoretical positioning of ML PLE in
Section 6.1, where we explicitly compare it with major ML reuse paradigms.
Based on the above comparison, we can thus conclude that while MLOps is vital for operationalizing ML solutions, ML PLE complements it by focusing on managing variability, large-scale and systematic reuse, and traceability across multiple ML systems. MLOps focuses on the execution and automation of pipelines, whereas ML PLE governs the structured reuse of the underlying assets and configurations at scale.
3. Case Study—Space Systems
In this section, we present an industrial case study in the domain of space systems, which serves both to motivate the need for systematic reuse of machine learning components and to illustrate the practical application of the ML PLE framework. The case involves a company that has developed a family of space systems for multiple satellite missions. These systems are highly data-intensive and apply machine learning techniques to a variety of critical tasks, including telemetry analysis, anomaly detection, trajectory optimization, and payload data interpretation [
22,
23,
24,
25].
Despite the widespread use of machine learning across these systems, we observed that the reuse of machine learning assets such as datasets, models, feature pipelines, and training workflows was minimal [
24]. Most machine learning solutions were developed independently for each mission, leading to redundancy, inconsistencies, and additional development effort. This observation highlighted the need for a structured approach to reuse, and served as the motivation for applying the ML PLE framework.
Space systems and machine learning systems share several important characteristics. Both involve complex modular architectures, exhibit variability across deployments, and operate within iterative and data-driven environments. They also require rigorous traceability, validation, and adaptability in response to changing operational demands. These commonalities provide a strong rationale for using the space systems domain to demonstrate the relevance and effectiveness of product line engineering principles in the context of machine learning.
Figure 4 presents a conceptual model of a typical space system, composed of four main segments: Launch Segment, Ground Segment, Space Segment, and User Segment. These segments are common to nearly all space missions, including both commercial and scientific applications. They may be co-located or geographically distributed and are often operated by different organizations. Each segment functions as a complex system that integrates hardware, software, and data.
The Launch Segment includes the launch vehicle and associated facilities for integration and testing prior to launch. The Space Segment comprises the satellite itself, including the satellite bus, payload management systems, command and data handling units, telemetry tracking and command modules, onboard software, and communication antennas. The Ground Segment is essential for mission control and data processing, integrating systems for mission planning, command and control, flight dynamics, and analytics.
Mission planning ensures conflict-free and resource-efficient operations. Command and control monitors satellite status and transmits operational commands. Flight dynamics handles satellite stability, orbit determination, trajectory optimization, and collision avoidance. Through radiofrequency links, the ground segment sends telecommands to the satellite—typically asynchronous data packets received by the satellite’s central computer—to initiate specific behaviors or override internal onboard decisions. Depending on the mission profile, the satellite-ground link may be continuous or only available during specific orbital windows.
In return, the satellite transmits data to the ground segment, which generally falls into two categories: payload data and telemetry (or housekeeping) data. Payload data consists of mission-related outputs such as images or measurements, while telemetry data provides insights into the satellite’s operational health and status.
Space systems are characterized by the generation of large volumes of spatio-temporal data, often collected at high frequency and transmitted to a distributed network of ground stations for archiving and processing. This data is then made available to end-users through the User Segment. In addition to storage and dissemination, ground systems increasingly apply data analytics and machine learning techniques to derive actionable insights from both telemetry and payload data. These insights support decision-making in areas such as satellite health monitoring, anomaly detection, trend analysis, and predictive maintenance, helping to ensure mission success and continuity. Payload data is further processed to produce mission-specific outputs, which may feed into downstream applications or be shared with external stakeholders.
To illustrate the diversity and shared structure within a typical product family of space systems,
Table 2 presents five satellite-based systems developed under a common architectural framework. Each of these systems has a distinct mission focus—ranging from earth observation to disaster response—but all rely on machine learning capabilities to analyze data, guide operations, or deliver downstream services. Despite their common needs for image classification, anomaly detection, or predictive modeling, we observed that the machine learning assets—such as datasets, pretrained models, and processing pipelines—were developed and maintained independently for each system.
This absence of structured reuse in the development and evolution of machine learning components reflects a broader gap in current Product Line Engineering (PLE) practices. While traditional core assets like requirements, design models, and source code are often reused across system variants, assets related to machine learning are rarely integrated into the core asset base. As a result, machine learning development remains siloed and uncoordinated, leading to duplicated effort, inconsistent performance, and limited traceability across products. These observations motivate the need for a dedicated framework—Machine Learning Product Line Engineering—that can systematize reuse, variation management, and lifecycle integration of machine learning assets across space system product lines.
Need for Systematic Reuse of ML for Space Systems
Machine Learning is used extensively in space systems, supporting critical tasks such as telemetry analysis, trajectory optimization, and payload data processing. These systems rely on ML to enable advanced capabilities in data-driven decision-making and operational efficiency. Given the increasing complexity of space missions, ML has become a key enabler of automation and analytics in both ground and space segments. Despite the diverse nature of tasks performed using ML in space systems, many of these tasks share similar underlying requirements and processes. For instance, anomaly detection in telemetry, path optimization for satellite control, and data preprocessing for payload analysis often involve comparable datasets, models, and workflows. This similarity presents a significant opportunity for reuse, as developing generic, reusable ML components could dramatically reduce development effort, costs, and time for new missions. However, reuse in ML for space systems is currently ad hoc and fragmented. Most developments focus on isolated projects without systematic reuse of datasets, models, or pipelines. This lack of a comprehensive approach leads to duplicated effort, inconsistencies, and inefficiencies when deploying ML solutions across missions. Without a structured framework, scaling and adapting ML-enabled capabilities for new missions becomes resource-intensive and prone to errors.
A more systematic and comprehensive approach to reuse in ML is needed to address these challenges. This case study illustrates how space systems highlight the need for structured reuse practices. Variability in ML assets, such as differing telemetry formats, model architectures, and operational requirements, complicates reuse further. For instance, telemetry data across satellites often varies in format and frequency, necessitating mission-specific preprocessing. Similarly, the choice of ML algorithms and hyperparameters is influenced by mission goals, such as optimizing real-time decision-making or achieving high accuracy in anomaly detection. Additionally, the dynamic and iterative nature of ML workflows introduces further complexities. Models must frequently be retrained or updated to adapt to changes in data distributions, mission objectives, and operational environments. Maintaining consistency and traceability across multiple missions or iterations becomes challenging, especially when coupled with the rigorous testing and validation required for critical space operations.
Given these observations, a more systematic and integrated reuse approach is essential to address the challenges of managing variability, scalability, and adaptability in ML-enabled space systems. By leveraging PLE principles and the process, organizations can develop a structured framework for systematically managing core ML assets such as datasets, models, and pipelines. We will elaborate on this in the following sections.
While the case study focuses on space systems, the ML PLE framework is designed to be general and domain-agnostic. Its principles, such as large-scale systematic reuse, asset modularization, configuration variability, and lifecycle traceability, apply equally to sectors like industrial automation, financial risk modeling, and smart agriculture. For example, in agriculture, datasets from sensor networks and weather stations can be reused across farms, while configurable pipelines can be adapted for crop yield prediction or disease detection.
4. Requirements for Product Line Engineering for Machine Learning
Given the benefits of PLE, we could try to adopt the PLE lifecycle process as it is currently defined. Yet, this conventional process cannot be adopted as-is for ML due to the different and unique characteristics and lifecycle of ML systems. While the core principles of PLE—such as defining core assets, managing variability, and separating domain and application engineering—are relevant, several requirements must be addressed:
PLE must expand its scope to treat ML core assets as fundamental components of the product line, alongside traditional software components and architectures. This includes systematic management of ML-specific assets such as datasets, model architectures, feature pipelines, and hyperparameters. Processes must account for the iterative nature of these assets, ensuring traceability and version control to handle updates effectively. Comprehensive management of variability, configurations, and dependencies across these assets is essential to maintaining consistency, enabling reuse, and supporting the dynamic and evolving requirements of ML systems.
- 2.
Supporting Dynamic Evolution
While traditional SE PLE assets, such as requirements, architecture models, and test cases, are inherently dynamic and subject to change over time, ML-specific assets such as datasets, trained models, and hyperparameters can often evolve with even greater frequency. This is primarily due to ongoing data acquisition, shifting distributions, and feedback-driven retraining cycles intrinsic to many ML applications. SE assets typically evolve due to changes in stakeholder needs or system requirements, whereas the dynamics of the data and model performance feedback drive ML assets. The ML PLE framework needs to account for both types of evolution by supporting traceability and reuse across interdependent assets.
- 3.
Incorporating Feedback Loops
PLE for ML must integrate continuous feedback mechanisms from deployed systems into its lifecycle. Feedback loops are vital for capturing real-world performance data, identifying issues such as concept drift, and triggering updates to datasets, models, and pipelines. These feedback-driven updates ensure that the product line evolves in response to operational needs and maintains optimal performance.
- 4.
Enabling Pipeline-Centric Workflows
PLE processes must adapt to the pipeline-centric nature of ML development. Automated workflows for data preprocessing, model training, evaluation, and deployment must be treated as modular and configurable assets. The PLE framework should support the design, reuse, and customization of these pipelines to streamline development and deployment across the product line. Modularity and automation in pipeline management are essential to reducing manual effort and enhancing scalability.
- 5.
Addressing Testing and Validation Complexity
PLE for ML must expand testing and validation processes to include the unique complexities of ML systems. This involves testing not only software functionality but also data quality, model performance, and pipeline correctness. The inherent uncertainties in data and algorithms require rigorous validation protocols, including checks for data consistency, model robustness, and the integrity of automated workflows. These processes must ensure that product variants meet their requirements and perform reliably in real-world conditions.
- 6.
Adjusting the Production Plan for ML
A dynamic production plan is required to accommodate the iterative and evolving nature of ML systems. This includes continuous data collection, preprocessing, and augmentation to support retraining and updates. Retraining workflows should be triggered by feedback loops or changes in data distributions. Flexible pipeline infrastructures must enable updates without disrupting production systems. Continuous monitoring systems should be integrated to detect performance degradation, initiate updates, and maintain the reliability of deployed ML solutions.
- 7.
Incorporating FAIR Principles
To ensure that data, models, and workflows are Findable, Accessible, Interoperable, and Reusable (FAIR), the PLE framework must enforce metadata-driven cataloging for datasets and standardized data formats [
25]. APIs should be designed for accessibility, and versioning of models and data must ensure reusability. Transparent lineage and provenance of datasets and models should be maintained, supporting interoperability and reproducibility. By integrating FAIR principles, PLE for ML can facilitate collaboration, scalability, and innovation across the product line.
5. ML PLE Framework
In this section, we present the ML PLE framework that includes a metamodel representing the key concepts for ML PLE and the lifecycle process for ML PLE. The ML PLE framework presented in this work is conceived as an extension of the conventional PLE process. Hence, it builds upon it by integrating the additional concerns of machine learning systems. The ML PLE that we will present preserves the key principles of the conventional PLE, including domain engineering, core asset management, and application engineering, while expanding the core asset base and lifecycle considerations to accommodate the unique characteristics of ML workflows. The following subsections will clarify this further and describe the ML PLE metamodel and process in detail.
5.1. Metamodel
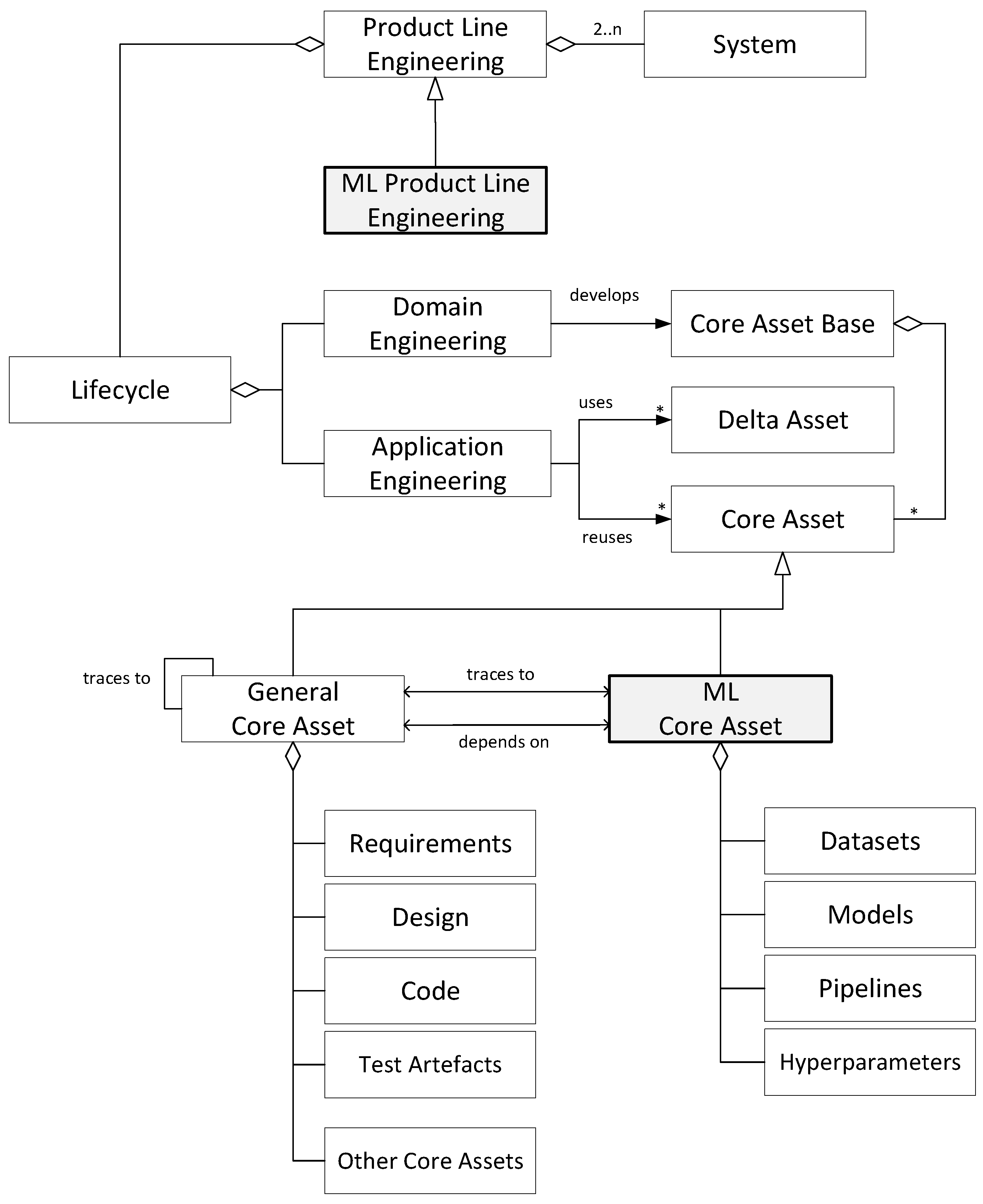
The metamodel that illustrates the concepts for this mapping is displayed in
Figure 5. The adopted notation is based on UML. A product line is defined as a set of products developed using a two-phase lifecycle process: domain engineering and application engineering. The domain engineering process results in a core asset base that consists of different core assets. A core asset is a reusable artifact or component systematically developed to serve as the foundation for creating a family of related products. The application engineering process focuses on the development of a single product and reuses the core asset base. In addition, unanticipated assets that do not reside in the core asset base—the delta assets—can be used.
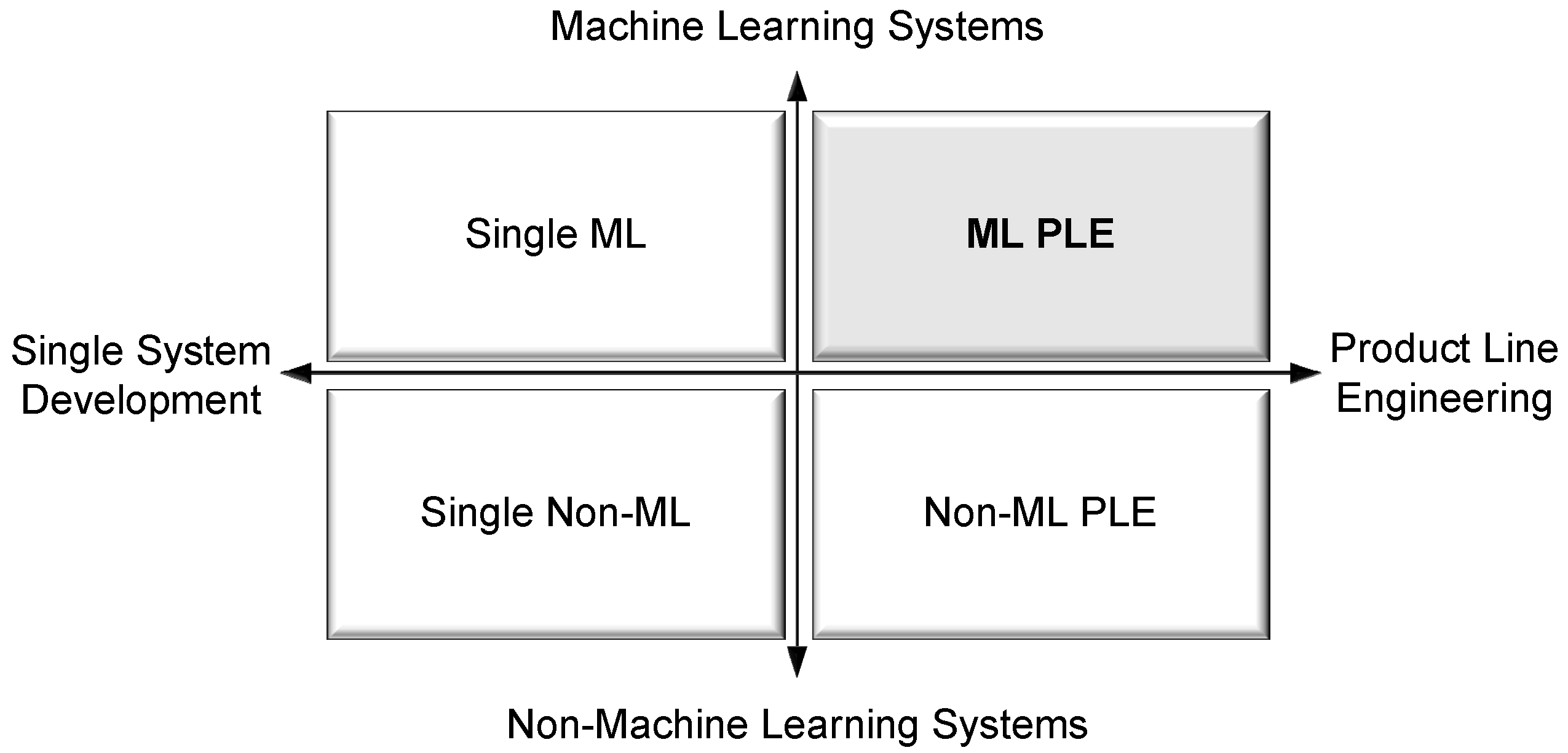
When examining the intersection of ML and PLE, system development can be categorized into four distinct approaches, as illustrated in
Figure 6. The first category, Single Non-ML, refers to the development of individual systems that do not incorporate ML and are not designed with reuse or product family considerations. The second category, Single ML, involves the development of individual systems that include ML components, but similarly lack a reuse-oriented or product line perspective. The third category, Non-ML PLE, represents traditional PLE approaches applied to conventional software systems without ML. The fourth and final focus of this study, ML PLE, involves the development of ML-enabled systems within a product family, guided by principles of systematic reuse, variability management, and coordinated lifecycle engineering. This last category forms the foundation of the ML PLE framework proposed in this paper.
When we consider ML PLE, new concepts and definitions need to be introduced:
Machine Learning Product Line (ML PL) is defined as a family of related ML-enabled products that share common core assets, such as datasets, models, feature pipelines, and training workflows, while differing in specific configurations or functionalities to meet diverse application requirements. ML PL focuses on systematic reuse and variability management to facilitate efficient development, deployment, and maintenance across various domains.
Machine Learning Product Line Engineering (ML PLE) is defined as a systematic approach to developing and managing a family of ML-enabled systems by applying PLE principles. It emphasizes maximizing reuse, managing variability, and ensuring scalability by treating datasets, models, pipelines, and hyperparameters as configurable and reusable core assets.
Machine Learning Core Asset (ML Core Asset) is defined as a reusable and configurable component that can be used as a building block for developing ML-enabled systems within a product line. Core assets in traditional software engineering—such as requirements, architecture models, and test artifacts—often trace to and depend on ML core assets like datasets, models, and pipelines when ML components are integrated into a system. Conversely, ML core assets also depend on SE assets for structural guidance, functional constraints, and validation strategies. This bidirectional relationship ensures alignment and traceability across the full system lifecycle.
In principle, as derived from the above matrix in
Figure 6, a product line focused exclusively on ML could be developed, emphasizing the large-scale, systematic reuse of ML capabilities within a defined product line scope. Alternatively, ML could serve as a component within a broader, conventional product line that focuses on the development of complete systems or products. In such cases, we can distinguish between two categories of core assets: General Core Assets and ML Core Assets. General Core Assets represent the traditional engineering lifecycle assets typically associated with PLE. These include requirements models, feature models, design models, code, and test artifacts. ML Core Assets, on the other hand, are specific to the ML domain. In addition to these general core assets, we have identified four different types of ML Core Assets, which are listed below:
- 1.
Datasets
Datasets are foundational to ML systems, as models learn from historical data to make predictions. Core dataset assets include the following:
Raw Datasets: collected from diverse sources unprocessed data.
Labeled Datasets: annotated data for supervised learning.
Preprocessed Datasets: cleaned, normalized, and transformed datasets prepared for specific tasks, such as removing outliers or scaling features.
Augmented Data Variants: variations generated through augmentation techniques, such as flipping, cropping, or noise addition, to improve model generalization.
Metadata and Documentation: information about data sources, labeling processes, and preprocessing steps to ensure traceability and reproducibility.
- 2.
Models
Models represent the algorithms and architectures used to solve ML problems. Core model assets include the following:
Reusable Architectures: standardized designs for ML models, such as convolutional neural networks (CNNs) for image processing, recurrent neural networks (RNNs) for sequence data, or transformers for natural language tasks.
Pretrained Models: general-purpose models trained on large datasets (e.g., ResNet, BERT, GPT) that can be fine-tuned for specific tasks, significantly reducing training time and data requirements.
Model Templates: configurable model blueprints that support different hyperparameters, layer sizes, or activation functions for customization.
Model Versions: trained and validated models stored with metadata, such as training dataset, performance metrics, and parameter settings.
Explainability Modules: components to interpret model predictions, essential for domains requiring transparency (e.g., healthcare, finance).
- 3.
Pipelines
Pipelines automate the end-to-end ML workflow, ensuring consistency and efficiency. Core pipeline assets include the following:
Data Processing Pipelines: workflows for cleaning, transforming, and augmenting raw data, adaptable for different datasets or domains.
Training Pipelines: automated processes for training models, including dataset splitting (training, validation, test), batching, and distributed training.
Inference Pipelines: deployment workflows that include preprocessing input data, running model predictions, and post-processing outputs.
Evaluation Pipelines: configurable workflows to assess model performance using metrics such as accuracy, F1-score, precision, recall, or mean squared error.
Monitoring Pipelines: tools to track deployed model performance, detect drift in data distributions, and trigger retraining when necessary.
- 4.
Hyperparameters
Hyperparameters are settings that influence how ML models learn during training [
20]. Core hyperparameter assets include the following:
Default Hyperparameter Configurations: predefined settings for common ML models, such as learning rate, batch size, and number of epochs.
Tunable Ranges: variability definitions for hyperparameters, enabling systematic exploration through grid search, random search, or Bayesian optimization.
Hyperparameter Templates: task-specific configurations for optimizing performance, such as low-latency setups for real-time applications or high-accuracy settings for critical tasks.
Optimization Records: documentation of past experiments, including tested hyperparameter values and their corresponding model performance metrics, to guide future tuning efforts.
Within the ML PLE process, reuse techniques such as transfer learning, modular feature pipelines, and architectural patterns (e.g., encoder-decoder backbones) are thus also treated as reusable core assets. These can be captured in the core asset base and systematically managed through variability models and asset readiness levels, enabling the structured reuse of assets across multiple ML product variants. These ML Core Assets can exist at different levels of reuse, ranging from raw data and initial model architectures to fully preprocessed datasets, fine-tuned models, and automated pipelines. To distinguish the different readiness levels, we introduce the following definition:
Asset Readiness Level (ARL) refers to the degree of preparation or maturity of a core asset, indicating how readily it can be reused or integrated into a specific application with minimal additional effort. ARL measures the work required during application engineering to adapt an asset for its intended use, ranging from raw, unprocessed components to fully configured, task-specific solutions.
Table 3 shows the ARLs for the ML Core Assets.
Asset reuse is thus operationalized through the development of a modular core asset base, including the datasets, configurable model templates, data preprocessing pipelines, and hyperparameter configurations. These assets are annotated with metadata and readiness levels to facilitate their selection and adaptation across product variants.
5.2. ML Domain Engineering Process
The domain engineering process in ML PLE focuses on defining, developing, and managing reusable ML core assets while systematically addressing variability. This phase ensures these assets can effectively create diverse ML product variants during application engineering. Below is a description of the key stages in the ML PLE domain engineering process:
The process begins by defining the scope of the ML product line and identifying reusable core assets. This includes determining common tasks (e.g., classification, regression, anomaly detection) and capturing variability in datasets, models, pipelines, and hyperparameters. The variability space is defined by identifying configurable features, such as data sources, preprocessing techniques, and model architectures. The output of this stage is a clear understanding of shared and variable elements within the product line.
- 2.
Variability Modeling
Once the scope is defined, variability is modeled to capture differences across core assets. Variability models for ML include options for datasets (e.g., formats, augmentation strategies), model configurations (e.g., neural network architectures, hyperparameters), and pipeline workflows (e.g., preprocessing, training, and inference steps). These models provide a blueprint for systematically managing and reusing ML assets.
- 3.
Core Asset Development
This stage involves creating reusable ML core assets that form the foundation of the product line, and which have been described in the previous section.
- 4.
Traceability Establishment
Traceability enables systematic updates and ensures consistency throughout the lifecycle. It is supported by establishing explicit links between requirements, core assets, and their configurations using a combination of metadata tagging, feature models, and version control systems. Tools such as Enterprise Architect and IBM DOORS are employed to define and maintain these links at both system and ML-specific levels. Additionally, integration with versioned repositories and model registries (e.g., Git, MLflow) ensures that changes in datasets, models, or pipelines can be traced back to feature selections and system-level requirements. This bidirectional traceability supports impact analysis, facilitates audits, and improves maintainability across evolving ML product lines.
- 5.
Testing and Validation
Core assets are rigorously tested to ensure quality, robustness, and reusability. Datasets are validated for completeness, accuracy, and representativeness, while models are evaluated for baseline performance. Pipelines are tested for correctness and modularity, ensuring they can handle variability and scale effectively. Standardized benchmarks and metrics are used to guide testing.
- 6.
Documentation and Guidelines
Comprehensive documentation is developed to support the reuse of core assets during application engineering. This includes configuration instructions for datasets, models, and pipelines, as well as best practices for adapting or extending assets. Metadata is recorded for all core assets to ensure traceability and reproducibility.
- 7.
Maintenance and Evolution
Domain engineering is an iterative process. As new requirements emerge or feedback from deployed systems is received, core assets and variability models are updated to remain relevant and aligned with the product line’s goals. This ensures the product line evolves dynamically with changing data, technology, and operational needs.
5.3. ML Application Engineering Process
The application engineering process in ML PLE focuses on creating specific ML-enabled products by systematically reusing and configuring core assets developed during domain engineering. This process customizes reusable datasets, models, pipelines, and other components to meet the unique requirements of each product variant while maintaining consistency and efficiency.
The application engineering process begins with selecting and configuring core assets to develop ML product variants tailored to specific requirements. Using variability models as a guide, datasets, model architectures, pipelines, and hyperparameters are customized to align with the product’s domain, operational environment, and performance objectives. For example, in a space system, telemetry data analysis pipelines might be adapted to handle different satellite subsystems or orbital configurations.
- 2.
Integration of Core Assets
Once configured, core assets are integrated to form an end-to-end ML solution. This includes combining datasets, feature pipelines, models, and workflows into a cohesive system. For instance, a satellite anomaly detection system may involve integrating a telemetry preprocessing pipeline with an anomaly detection model and a real-time monitoring dashboard.
- 3.
Testing and Validation of Product Variants
After integration, product variants undergo rigorous testing and validation to ensure they meet functional and performance requirements. Testing focuses on evaluating data quality, model accuracy, pipeline reliability, and overall system performance under the intended operational conditions. For example, an Earth observation satellite’s ML variant would be tested for the accuracy of image classification models and the reliability of image preprocessing pipelines.
- 4.
Deployment
Validated product variants are deployed to their target environments. Deployment involves preparing and transferring configured pipelines and models to operational systems, such as ground stations or onboard satellite platforms. Deployment pipelines ensure compatibility with the operational context and may include mechanisms for resource optimization and system monitoring.
- 5.
Feedback and Continuous Improvement
A key aspect of application engineering in ML PLE is the incorporation of feedback from deployed systems. Feedback loops are implemented using automated monitoring pipelines that track performance indicators such as prediction accuracy, data drift, latency, and failure rates. These pipelines trigger alerts or initiate retraining workflows when thresholds are breached. Monitoring tools (e.g., Prometheus, MLflow) can be integrated to visualize and analyze real-time model behavior. Collected feedback is systematically linked to specific core assets, such as the pipeline variant or dataset version in use, enabling traceable refinement of configurations.
- 6.
Automation and Scalability
Automation plays a critical role in application engineering by enabling efficient configuration, testing, deployment, and monitoring of ML variants. CI/CD pipelines are tailored for ML automate repetitive tasks, such as retraining models or updating pipelines, ensuring consistency across product variants and reducing manual effort. Automation enhances scalability, allowing organizations to handle a growing number of product variants with minimal additional resources.
5.4. ML PLE Process
As stated before, integrating ML PLE requires a redefined lifecycle process to address the dynamic, iterative, and data-driven nature of ML systems. This lifecycle incorporates traditional PLE principles while adapting them to ML-specific workflows and assets.
Figure 7 shows the ML PLE lifecycle process with the enhanced Domain Engineering and Application Engineering processes.
The ML Domain Engineering process results in a ML Core Asset base with the ML Core assets that we have described before. Each of these assets can be at different readiness level. The higher the readiness level, the less additional effort is needed when these are reused in the application engineering process to implement a machine learning problem.
To align the ML PLE process with established PLE practices, we adopt the conventional structure used in both domain and application engineering: product management, requirements engineering, design, implementation, and testing. Hereby,
Table 4 and
Table 5 present a structured mapping of ML-specific activities to each of these phases, capturing the adaptations needed to address the distinct characteristics of ML development, such as data-driven requirements, reusable model pipelines, configuration variability, and iterative feedback. This mapping enables the integration of machine learning into the broader PLE process, promoting consistency, traceability, and systematic reuse across product lines.
The ML domain engineering process begins with scoping, where the product line’s scope is defined by identifying commonalities and variability in datasets, models, pipelines, and tasks. Reusable assets such as datasets, feature extraction pipelines, model architectures, training workflows, and hyperparameters are then identified, with an emphasis on configurability. Variability modeling captures differences and options for datasets, preprocessing techniques, model configurations, and pipelines. Core asset development focuses on creating modular and reusable ML assets, including labeled datasets, feature engineering workflows, model templates, and automated pipelines. Traceability links are established between requirements, core assets, and variability models to ensure consistency and systematic updates. Testing and validation confirm the quality and reusability of core assets, while comprehensive documentation ensures traceability and reproducibility. Finally, core assets and variability models are continuously maintained and updated based on feedback and evolving requirements.
The ML application engineering process involves configuring and customizing reusable core assets to derive specific ML-enabled products. Datasets, models, and pipelines are selected and adapted to meet the target application’s requirements, guided by variability models. Application-specific training and fine-tuning align the models with task-specific goals, such as optimizing for accuracy or latency. Configured pipelines are validated to ensure performance and reliability, followed by deployment into production. Monitoring pipelines are implemented to track performance, detect drift, and enable retraining as needed. Feedback from deployment informs updates to core assets and variability models, enabling continuous improvement. This iterative process ensures efficient derivation of ML-enabled products while leveraging the systematic reuse established during domain engineering.
6. Qualitative Evaluation
To assess the scientific validity and practical utility of the proposed ML PLE framework, we conducted both theoretical and empirical evaluations based on case study research. The goal of this evaluation is twofold: first, to position ML PLE within the broader landscape of machine learning reuse techniques and highlight its conceptual innovations; and second, to demonstrate its practical applicability and benefits through an industrial case study. In the following,
Section 6.1 presents a theoretical analysis comparing ML PLE with existing state-of-the-art ML reuse methodologies, while
Section 6.2 elaborates on our case study in the space systems domain, illustrating the operational deployment and qualitative impact of the framework.
6.1. Theoretical Evaluation
ML PLE makes novel theoretical and practical contributions to the domain of ML reuse by extending the principles of variability management, systematic reuse, and lifecycle traceability into machine-learning-intensive systems. As discussed in
Section 2.4, existing reuse approaches often lack systematic support for managing asset variability, traceability, and configuration across a family of systems. Here, we further position ML PLE within the broader landscape of reuse-oriented ML methodologies, including transfer learning, meta-learning, multi-task learning, foundation model fine-tuning, neural architecture search, and knowledge distillation. These techniques, while widely adopted, primarily focus on improving efficiency or performance in specific stages of the ML pipeline, most notably training. For instance, transfer learning and fine-tuning enable model reuse across tasks, meta-learning focuses on learning to learn, and NAS optimizes architectures. However, they do not provide a coherent, lifecycle-based, and variability-aware approach to reuse across a family of ML-enabled systems. In contrast, ML PLE provides a reusable infrastructure for orchestrating these techniques in a coherent, lifecycle-aware manner. It elevates reuse from a model-centric to a system-centric paradigm and aligns reuse strategies with formal product derivation processes.
Table 6 summarizes the conceptual differences between ML PLE and key ML reuse paradigms.
ML PLE thus contributes to the theory and methodology of ML reuse by elevating reuse from individual model-centric operations to a system-level configuration of ML-enabled product lines. Beyond small-scale, ad-hoc reuse focused on traditional lifecycle assets, it enables a large-scale systematic lifecycle-wide reuse by integrating variability management of the traditional and the ML core assets, including datasets, preprocessing pipelines, training routines, and deployment workflows.
6.2. Implementation of ML PLE
The implementation of ML PLE relies on a suite of specialized tools that support different stages of the machine learning product line lifecycle. At the foundation, Feature IDE is used to define feature models that capture variability across ML datasets, model architectures, pipelines, and hyperparameter strategies. These models guide the systematic selection and instantiation of core ML assets for different product variants. System-level traceability is achieved through the integration of Enterprise Architect for architecture modeling and IBM DOORS for linking system-level and ML-specific requirements to reusable artifacts. This toolchain enables bi-directional traceability between high-level system goals and the concrete ML components reused across downstream products. To operationalize configured ML pipelines, Hydra and PyTorch Lightning are employed to instantiate parameterized workflows. MLflow is used to manage model and dataset versions, performance metrics, and experiment tracking, facilitating governance and reuse across variants. JIRA supports project coordination and alignment between domain and application engineering. CI/CD pipelines (e.g., GitLab or Jenkins) automate pipeline instantiation, validation, and deployment, including retraining triggers based on data drift or feature changes. These and other tools in the integrated tooling infrastructure supports consistent, scalable, and traceable reuse of ML components across a family of products. While not all implementation details can be disclosed due to confidentiality constraints, the current integration of these tools remains an ongoing research effort and is outside the scope of this paper.
6.3. Case Study Evaluation
In the industrial case study involving a family of space systems, the ML PLE framework was applied to guide the development of machine learning components across multiple satellite missions. These systems, characterized by their data-intensive and mission-critical nature, presented a suitable context for exploring the applicability of systematic reuse in machine learning development. The framework supported the reuse of core assets such as preprocessing pipelines, data transformation workflows, and model templates, while allowing for their adaptation to the specific operational requirements and constraints of each mission.
The structured approach provided by ML PLE—particularly in terms of asset modularization, variability management, and lifecycle traceability—enabled a more consistent, transparent, and maintainable development process. Teams were able to more easily identify and reuse recurring components, reduce redundancy in the design of data pipelines, and maintain clearer mappings between reusable assets and mission-specific configurations.
To assess the feasibility of applying PLE principles, a feasibility analysis was conducted for software artefacts, which evaluated the potential for systematic reuse, cost savings, and scalability in the context of software components. Given the similarities in reuse objectives, the feasibility analysis for machine learning artefacts was extrapolated from the software PLE analysis, adapting it to account for the data-centric and iterative nature of ML workflows. This extrapolation considered factors such as data pipeline modularity, model adaptability, and the complexity of ML-specific variability management.
To compare the development approaches, we consider the general cost model for establishing a software product line as defined by Pohl et al. [
5]. The total cost C for developing a set of n products p is expressed in Equation (1):
These parameters represent the cost of adapting the software reuse approach for the organization (COrg), the cost to define the asset base (CCab), the cost for developing unique products (CUnique), and the cost of reusing core assets (CReuse). Different formulas for different strategies based on Equation (1).
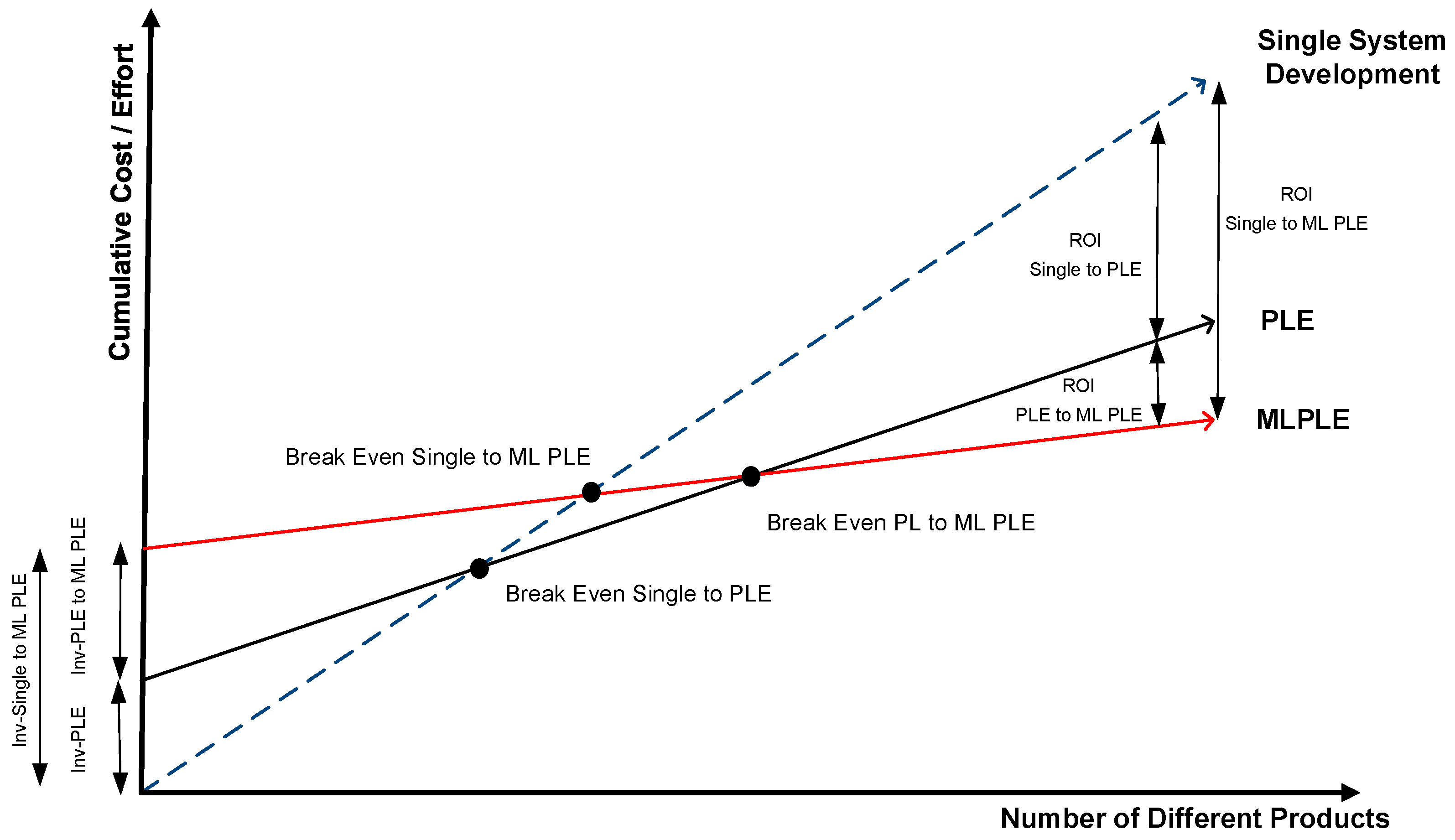
We illustrate the comparison in
Figure 8, which contrasts three approaches to system development: single-system development, conventional PLE, and ML PLE. We distinguish between three types of initial investment: the investment required to move from single-system development to conventional PLE (Inv-PL), the investment required to move directly from single-system development to ML PLE (Inv-ML PLE), and the incremental investment needed to extend a conventional PLE approach to an ML PLE strategy (Inv-PL to ML PLE).
Correspondingly, we identify three types of return on investment (ROI): the ROI of adopting conventional PLE over single-system development, the ROI of adopting ML PLE directly over single-system development, and the ROI gained from extending conventional PLE with machine learning capabilities.
Each of these approaches also presents a different breakeven point, depending on the number of products and the extent of reuse achieved. As shown in
Figure 8, ML PLE requires the highest upfront investment due to the complexity of managing data-centric, iterative ML workflows. However, it also offers the highest long-term returns when reuse of ML assets is frequent and critical. Conventional PLE sits between ML PLE and single-system development in both investment and benefit, offering strong reuse potential without the added complexity of ML. Overall, ML PLE extends the advantages of conventional PLE by incorporating reusable ML-specific components, making it particularly valuable in data-intensive and ML-driven domains.
Although a fully controlled experimental evaluation was beyond the scope of this industrial collaboration, the case study offered valuable qualitative insights into the practical benefits and feasibility of the ML PLE framework. These insights indicate that ML PLE can play a significant role in improving the scalability, maintainability, and traceability of machine learning solutions, especially in complex, high-dependence domains such as space systems.
A more rigorous empirical evaluation, including controlled benchmarks, quantitative reuse metrics, and comparative baselines with conventional ML development approaches, will be pursued in future work. This next phase of research aims to systematically assess the effectiveness and generalizability of ML PLE across different application domains and organizational settings.
7. Conclusions
Reuse in machine learning (ML) is critical for improving efficiency and scalability, yet current reuse practices remain fragmented and ad hoc. To address this, we have proposed Machine Learning Product Line Engineering (ML PLE), a systematic reuse framework that extends traditional Product Line Engineering (PLE) principles to ML-enabled systems. The framework introduces a structured approach to managing core ML assets, such as datasets, models, pipelines, and hyperparameters, while addressing variability and scalability challenges. Unlike existing reuse strategies that focus on isolated ML components, ML PLE introduces a structured reuse methodology at the system family level, enabling traceability, configurability, and reuse across the full ML lifecycle. By integrating domain engineering and application engineering processes, ML PLE facilitates systematic reuse and the efficient derivation of ML solutions tailored to diverse application needs.
The novelty of this study lies in two complementary perspectives. From the PLE perspective, this is the first approach to systematically integrate ML-specific core assets into a product line engineering framework. Prior PLE efforts have largely excluded the data-driven and iterative nature of ML development. From the ML perspective, ML PLE introduces a methodology for large-scale, systematic reuse across ML product families, going beyond the current landscape of isolated reuse techniques such as transfer learning or fine-tuning.
To validate the framework, we applied it to a real industrial case study in the space systems domain. As such, the insights are grounded in real-world practice. While the standard ROI equation has been applied and used qualitatively to compare development strategies, our future work will include a quantitative evaluation. This will involve instantiating the model with empirical data across benchmark tasks to assess reuse effort, variability management, and return on investment under ML PLE versus baseline approaches. A broader empirical validation would be beneficial to confirm generalizability. Moreover, certain aspects such as asset variability modeling and integration with MLOps pipelines require further elaboration and refinement as the framework evolves.
Several important future research directions emerge from the findings of this study. A key priority is to advance the ML PLE framework to support emerging machine learning paradigms such as federated learning, edge deployment, and real-time adaptive systems. We also aim to further explore the automated management of ML asset variability, assess the scalability of reuse strategies in high-dimensional and multi-modal pipelines, and strengthen the alignment of ML PLE with the principles of responsible AI, particularly transparency, traceability, and compliance with evolving data governance standards.
In addition to conventional PLE metrics, we will develop quantitative measures specifically tailored to the ML PLE context, focusing on reuse effectiveness, configuration effort, and lifecycle traceability across ML core assets. These metrics are intended to support rigorous empirical validation and enable comparative benchmarking with alternative reuse strategies. As part of our future work, we plan to conduct controlled evaluations using standardized benchmarks and task suites. Key evaluation indicators will include reuse effort, time-to-deployment, asset utilization coverage, and configuration complexity. These studies will be conducted across diverse domains, such as precision agriculture, industrial automation, and smart manufacturing, to systematically assess the scalability and generalizability of the ML PLE framework.
Furthermore, we intend to extend the integration of supporting tools, with a focus on improving interoperability between feature modeling environments, configuration management systems, CI/CD pipelines, and MLOps platforms. This will facilitate the seamless instantiation, monitoring, and evolution of reusable ML artifacts at scale.
Finally, although this study focused on a space systems case study, we are actively exploring applications of ML PLE in other industrial domains, including smart agriculture, industrial automation, and energy systems. These efforts aim to further validate the generalizability of the framework and will be reported in future work.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}