
Knowledge Bases and Representation Learning Towards Bug Triaging

 ,
,
Abstract
1. Introduction
- An automatic bug-triaging method based on knowledge base and link prediction is developed. To the best of our knowledge, our study is the first one to apply a knowledge base and link prediction to bug triaging.
- Knowledge bases are constructed for three projects by extracting both structured and textual information from bug repository. Hopefully, the constructed knowledge bases can provide insight into solutions of other software engineering issues, e.g., duplicate bug report detection.
- A new model PTITransE is proposed, specializing for learning the representation of knowledge base with both structured information and partial entities’ textual information. When it is applied to bug triaging, the model can make full use of the interactions between bug reports and other entities such as developers, components and products in the historical activities and bug-tracking process.
- The cold start issue on bug triaging, which is not well studied in the previous literature by leveraging the semantic feature of textual information learnt from the deep-learning-based model, is analyzed in this paper, and the results support that the proposed framework can mitigate the cold-start problem for new fixer recommendations.
- An extensive set of experiments using three real-world large-scale datasets are performed, and the experimental results show the effectiveness of the proposed method over the state-of-the-art methods by a significantly large margin.
2. Related Work
2.1. Automated Bug Triaging
2.2. Knowledge Bases for the Software Engineering Domain
3. Background and Motivation
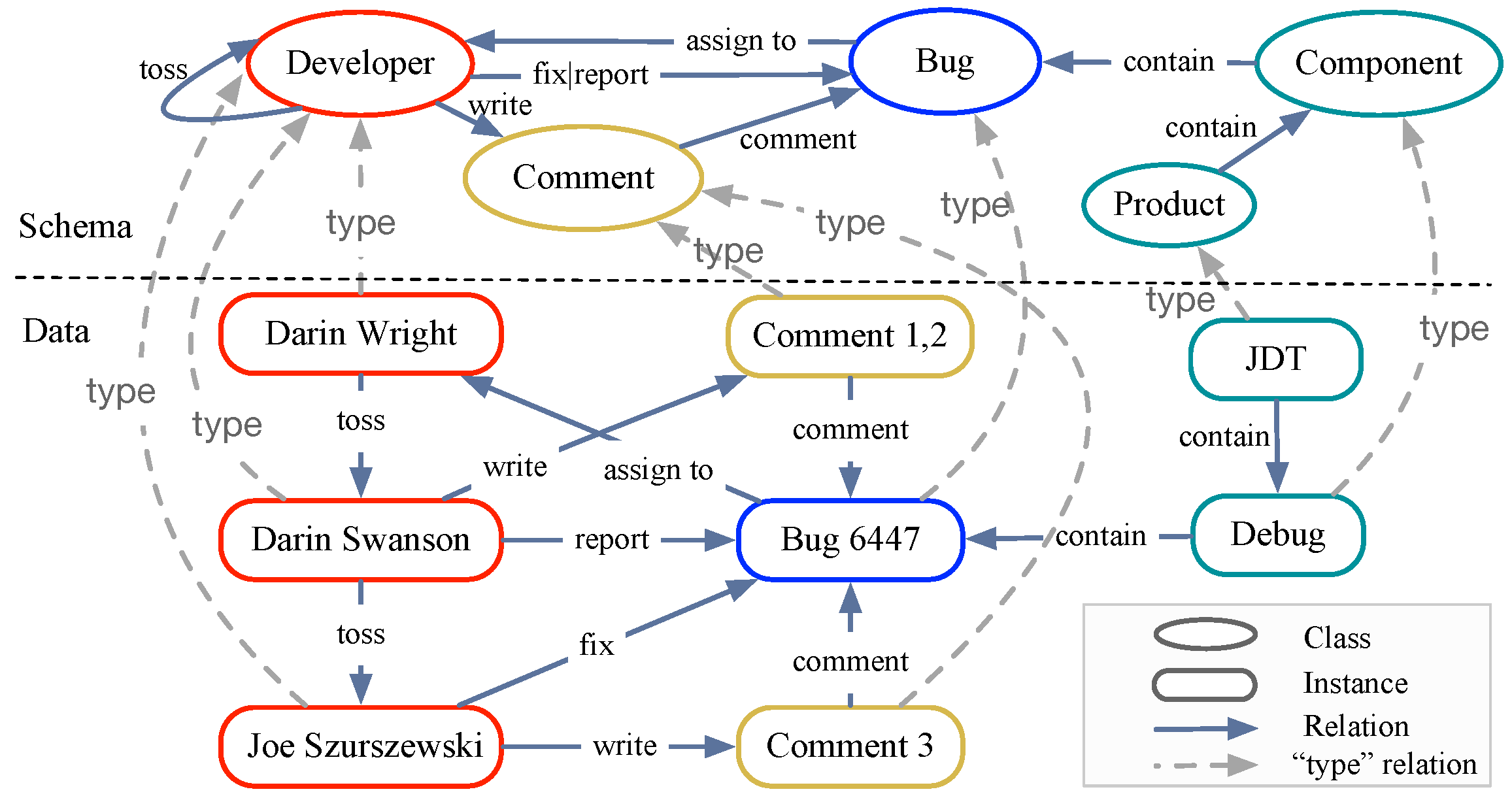
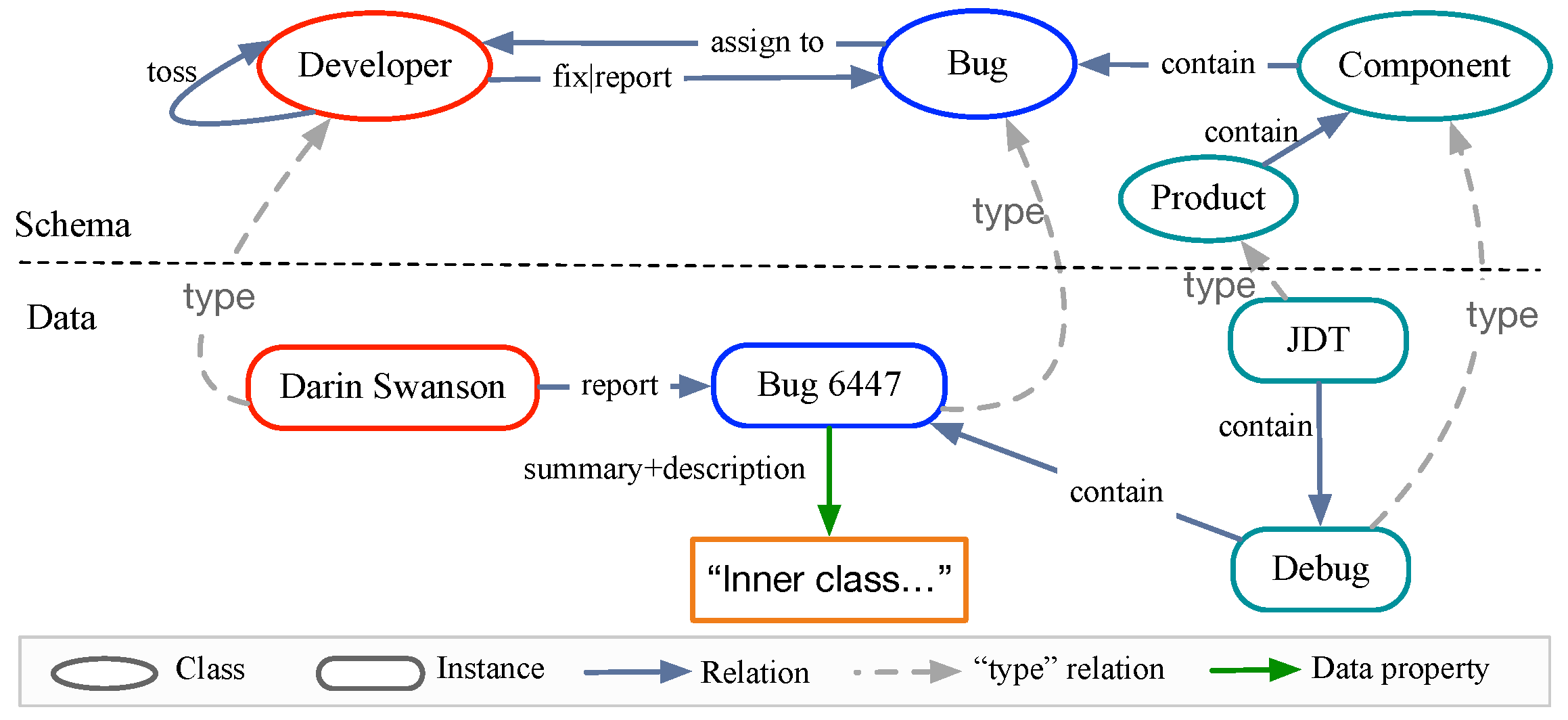
3.1. Motivation Example
3.2. Knowledge Bases
3.3. Knowledge Base Embedding
- TransE [14] learns the embeddings of h, r, t that satisfy the constraint when (h, r, t) holds. The scoring function of TransE to measure the plausibility of the triplet is defined aswhere h, r and t are the embeddings of h, r and t, respectively.
- TransH [43] projects the embeddings of entities onto a hyperplane determined by relation r before translation, which overcomes the flaws of TransE in dealing with reflexive/one-to-many/many-to-one/many-to-many relations [43]. The scoring function iswhere and are the projections of h and r on the hyperplane, which are expected to be connected by the translation vector of r with low error.
- TransR [44] projects the embeddings of entities from entity space to corresponding relation space and then builds translations between projected embeddings. The difference with TransH is the projection operator is a matrix that is more general than an orthogonal projection to a hyperplane [46]. The scoring function iswhere and are projections of h and r by multiplying a projection matrix.
- TransD [45] improves the projection operation of TransR by replacing the projection matrix with the inner product of two distinct vectors of entity–relation pairs.
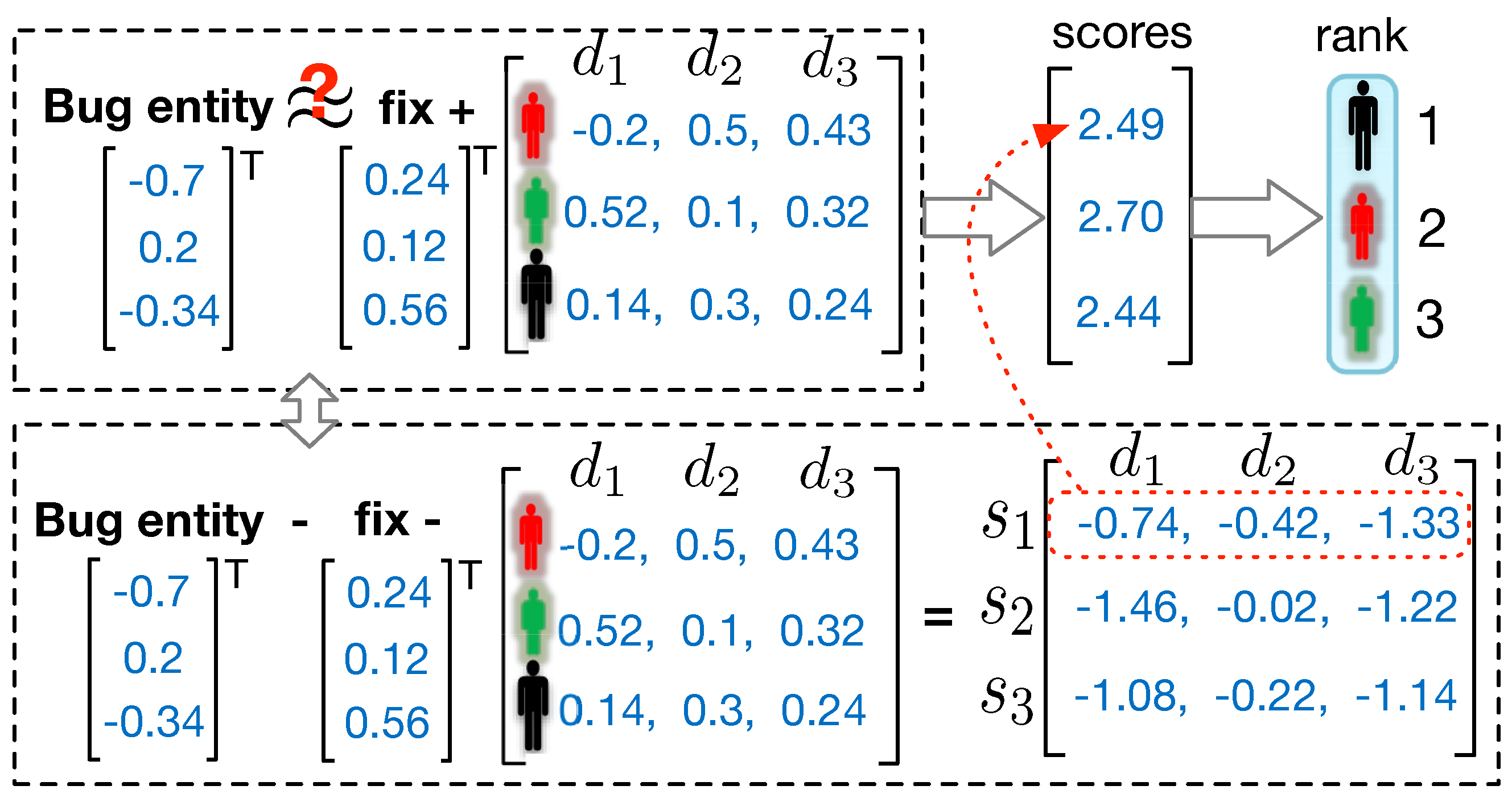
3.4. Link Prediction
3.5. Continuous Bag-of-Words Encoder
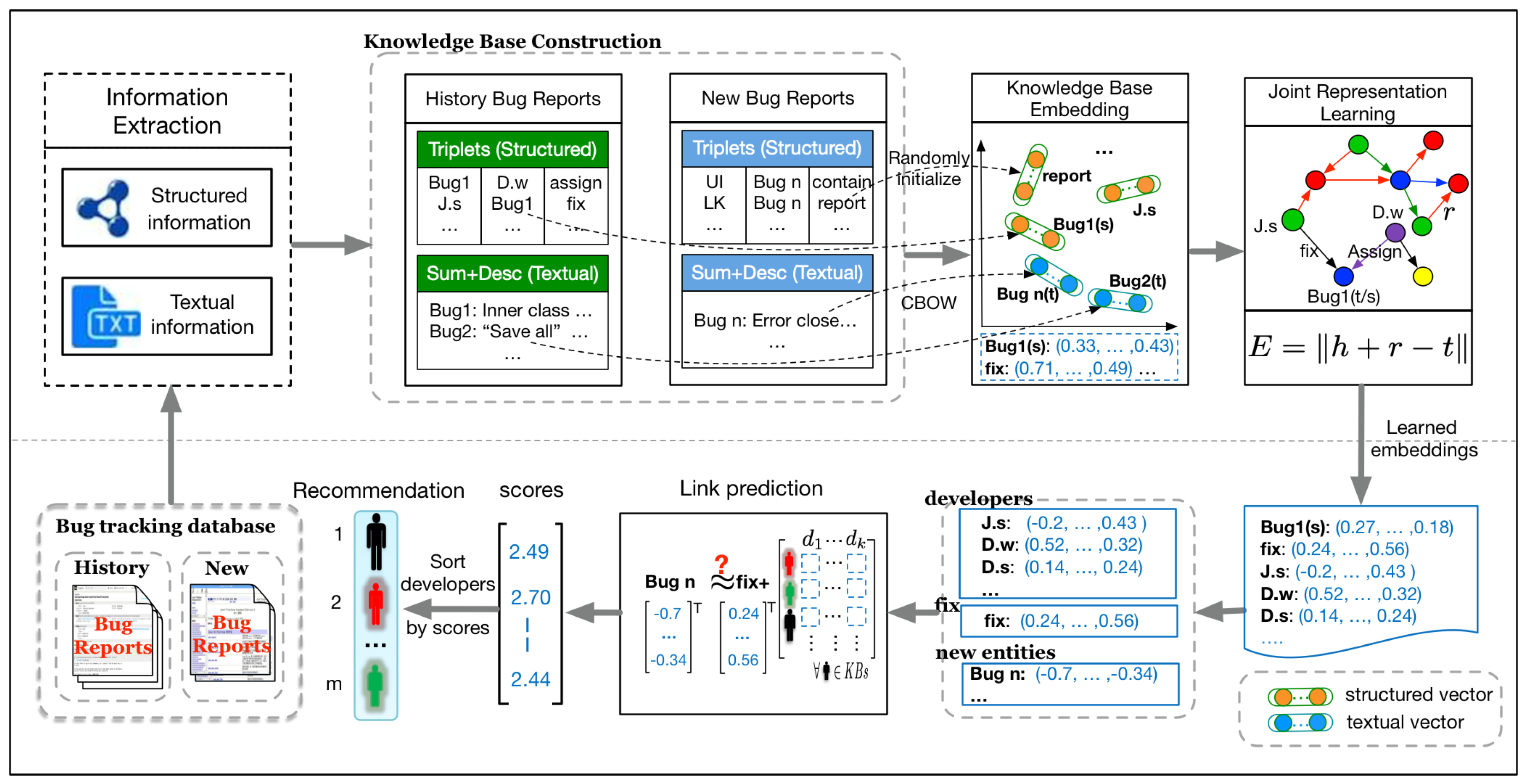
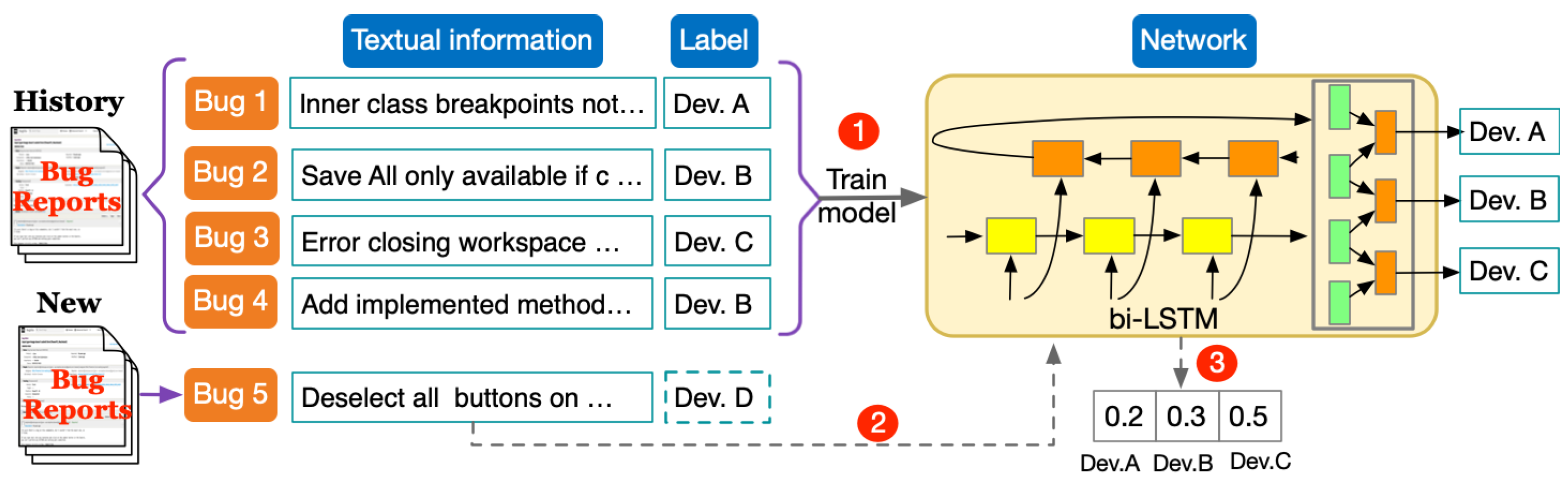
4. The Overall Framework
4.1. Information Extraction and Knowledge Base Construction
4.2. Knowledge Base Embedding
4.3. Joint Representation Learning
4.4. Fixer Recommendation
5. Our Approach
5.1. Knowledge Base Construction
5.2. Knowledge Base Embedding
5.3. Joint Representation Learning
5.4. Link Prediction
| Algorithm 1: PTITransE |
 |
5.5. Bug Triaging Details Using PTITransE
| Algorithm 2: Bug Triaging Process |
 |
6. Cold-Start in Bug Triaging
6.1. Problem Statement
6.2. Alleviating Cold-Start Using PTITransE
7. Experiments
7.1. Datasets
7.2. Evaluation Metric
- Recall@k: the ratio of bug reports whose fixers are successfully detected in the recommended top-k developers () among all bug reports () in testing dataset.
- MR (Mean Rank): The mean rank of correct entities.
- Hits@1: the strict metric that validates the accuracy of picking only the first predicted entity in the ranked list. The higher its value, the more effective the recommendation system [59].
- MRR (Mean Reciprocal Rank): The average of the reciprocal ranks of results for a set of queries (new bug reports). If the first returned result is relevant, MRR is 1.0. Otherwise, it is smaller than 1.0 [39]. Here, MRR is defined as follows:
7.3. Experiment Setting
7.4. RQ1: Whether PTITransE Is Superior to Other Representation Learning Models for the Issue of Bug Triaging?
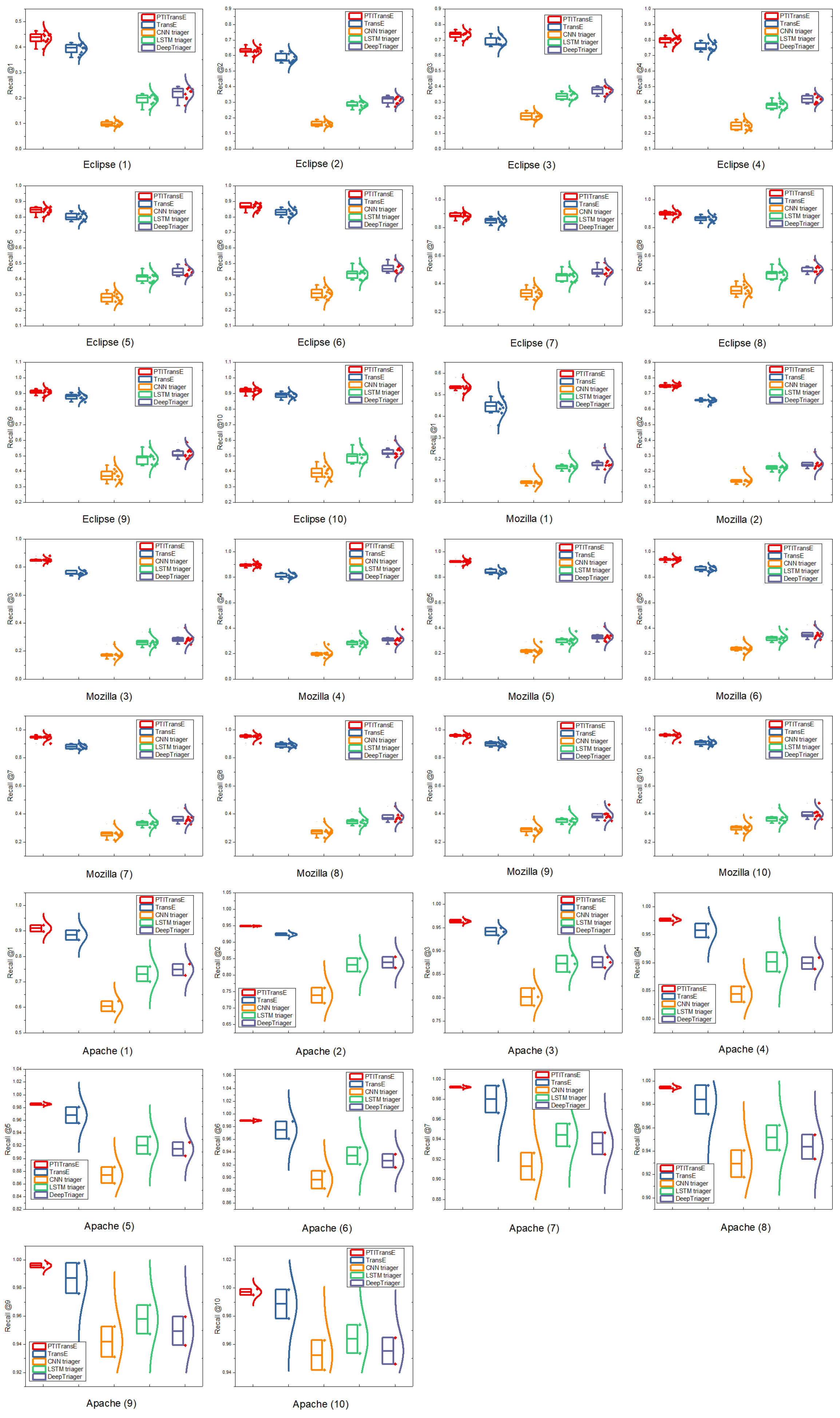
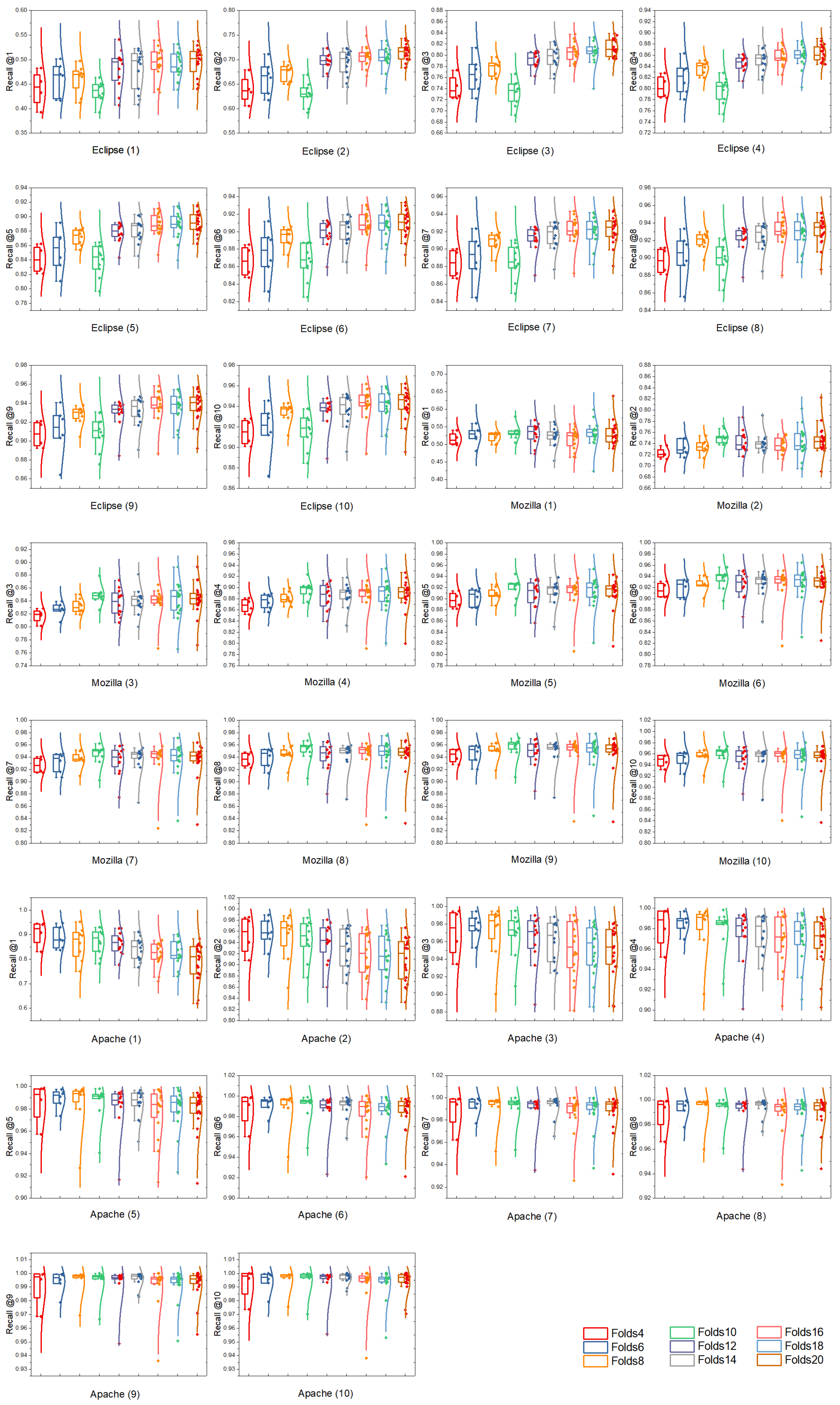
- Approach. To evaluate our proposed method PTITransE at bug triaging, we perform experiments on three real-world datasets and compare with other representation learning models. As described in Section 3.4, we treat bug triaging as a link prediction task. But unlike the previous link prediction, we only treat head entity in the unseen triplets as target entity rather than both of head and tail entities for the bug-triaging task. Thus, the developer in the triplet of (developer, fix, bug) is the target entity to be predicted by the representation learning model.Results. The experiments are performed using cross-validation (i.e., 10-fold CV), and the results are averaged. Table 6 illustrates the averaged experimental results of different representation-learning-based approaches on link prediction metrics (i.e., MR, Hits@1 and MRR) for bug triaging. Additionally, considering varying numbers of developers used for training and testing across the cross-validation (CV) sets, i.e., the bug-triaging model is trained on different folds with different number of developers, taking the averaged performance values (i.e., the results in Table 6) would only provide a statistical estimate of the model performance and is not accurately interpretable [11]. It is, therefore, necessary to report the top-k accuracy of each cross-validation set to compare the variance among different approaches introduced in the model training. In this section, the top-k accuracy results of each cross-validation set on different projects are bucketed and plotted as boxplots [66,67], as shown in Figure 6, where k is in the range of [0, 10] in our experimental setting. From Table 6 and Figure 6, we can draw the following conclusions:
- (1)
- All typical representation learning models (i.e., TransE, TransD and TransH) use only structured information of bug reports in the bug-triaging task and achieve promising results on all projects. The results indicate that structured information can reflect the process of historical fixing activities of developers and provide valuable information to improve the performance of automatic bug triaging.
- (2)
- The performance of TransE is superior to that of the improved representation learning models for bug triaging, such as TransD and TransH, when using widely accepted metrics MR and Hits@1 as well as MRR as our evaluation metrics, as shown in Table 6. This is due to the fact that the fixer is a specific one-to-one relationship between developer and the given bug entity, which can be solved more effectively by the TransE model. In addition, more sophisticated representation learning models, e.g., TransH and TransD, need to learn more parameters that may lead to the model overfitting. However, from Figure 6, we found that in some cases, i.e., recommending top-2 ∼ top-10 developers for bug reports in Eclipse project, the performances of TransH and TransD are higher than that of TransE, although they are still significantly lower than that of the proposed method PTITransE. This provides supporting evidence that the improved representation learning models (i.e., TransD and TransH) may perform better than TransE for this purpose in recommending multiple (i.e., top-k, where ) developers for bug reports in some projects like Eclipse.
- (3)
- PTITransE provides further improvement compared with the TransE model because the TransE model only utilizes the structured information and ignores another type of important information, i.e., the textual information of bug reports. It has been proved that the textual information is very useful for bug triaging in traditional methods [10,11,12], which are mostly based on the fact that a developer can resolve the bug reports with a similar textual description since the bug reports with high textual similarity often correspond to the same type of bugs. Therefore, PTITransE can improve the performance of the representation learning model by combining this textual information with structured information.
- (4)
- The superiority of PTITransE’s performance is more obvious on the Apache project than that on Eclipse and Mozilla projects. The reason is that the number of developers (i.e., 24) in Apache is much smaller than that of the Eclipse (i.e., 1833) and Mozilla (i.e., 2948) as described in Table 4. The larger the number of developers, the greater the chance to make errors is. This is also consistent with previous works [10,13].
7.5. RQ2: How Does Our Proposed Method Perform Compared with the State-of-the-Art Bug-Triaging Methods Under the Stringent Assumption? And Which of the Textual and Structured Information Is the More Important Factor That Determines the Quality of Bug Triaging?
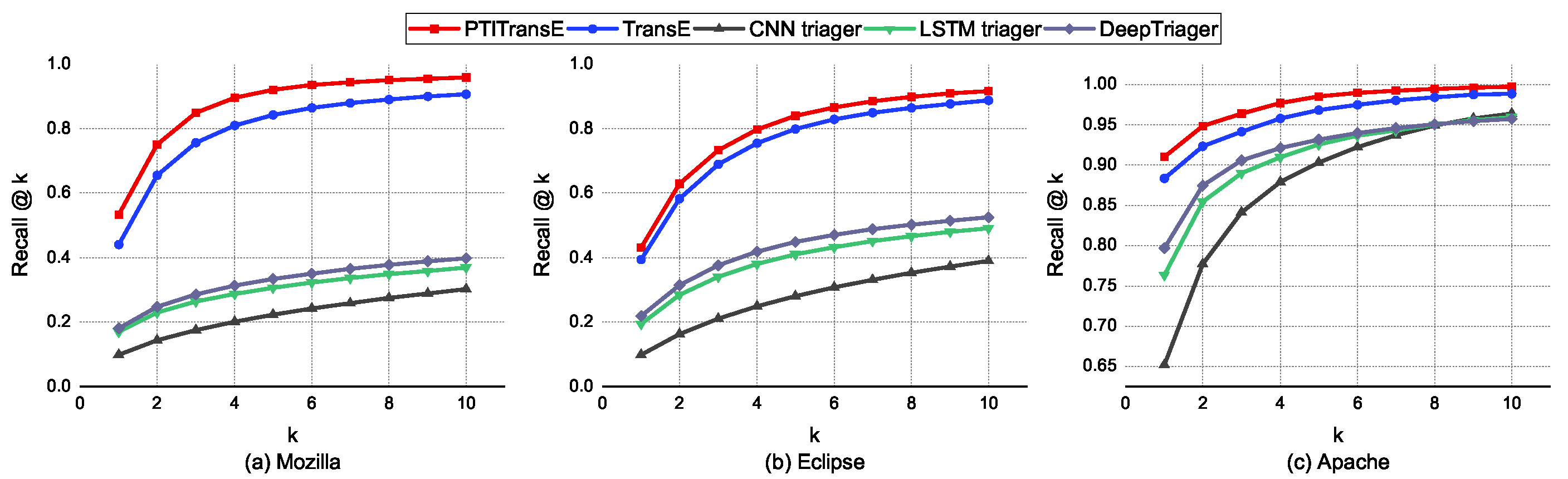
- Approach. The deep-learning-based bug-triaging methods, including CNN triager, LSTM triager and DeepTriager, predict suitable developers to fix the given bug by analyzing the content patterns of previously resolved bug reports, while our method recommends the best fixer for the given bug by using the knowledge learned from both the structured and textual features. To better demonstrate the superiority of our method under the assumption of stringent evaluation criterion (i.e., only the developer who really fixed the bug is treated as ground truth), we conduct experiments to compare the proposed with the existing state-of-the-art deep-learning-based bug-triaging methods via 10-fold validation experiments on three datasets. In addition, we would also like to investigate which of the textual and structured properties is the more important factor that determines the quality of bug triaging. Therefore, we compare the TransE method only based on structured features with the textual-classification-based methods. Our experiments recommend different numbers of developers so as to make a more comprehensive comparison with other methods. The number of developers recommended, denoted as k, ranges from 1 to 10.
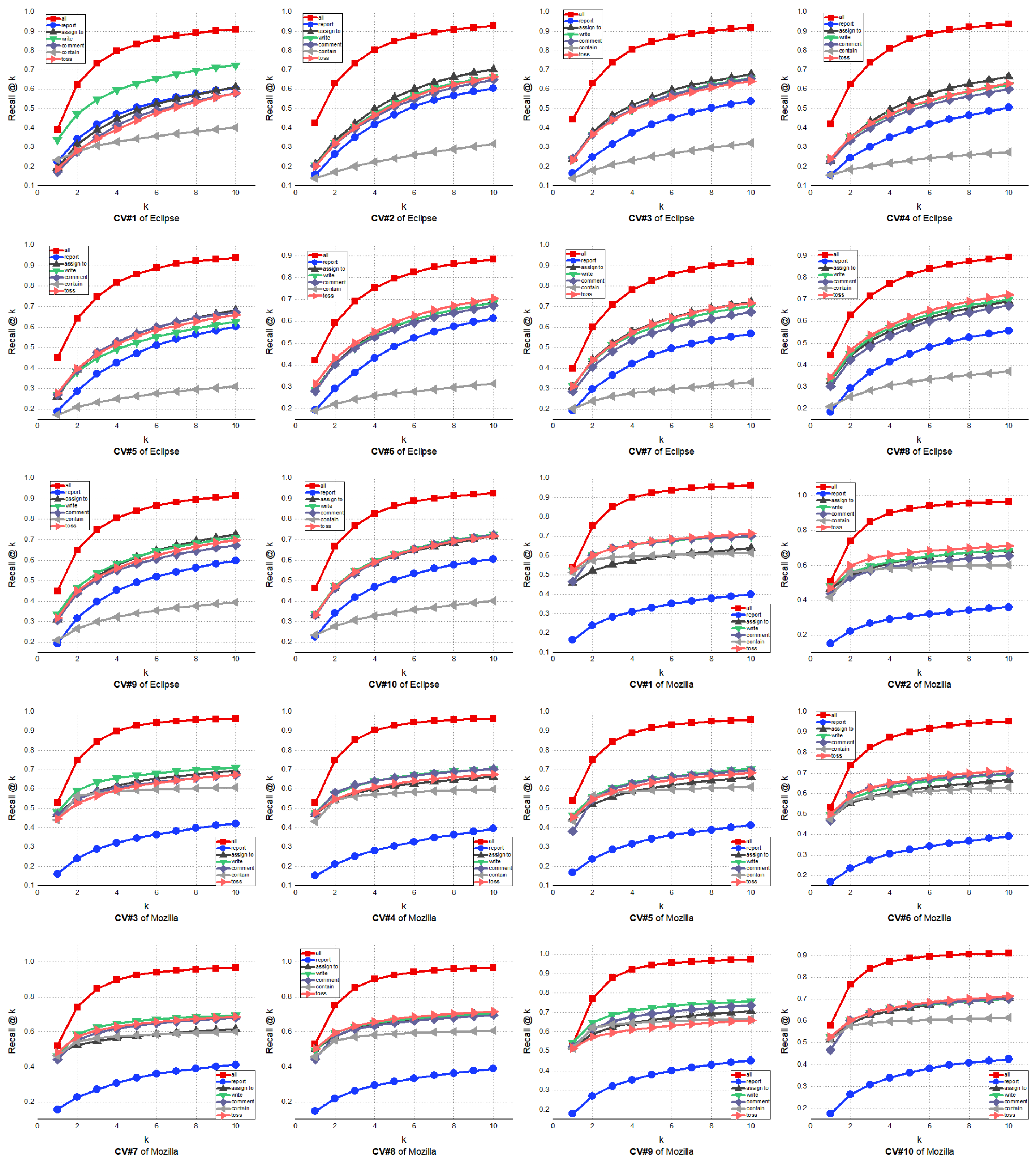
- Results. Figure 7 shows the averaged performance (i.e., Recall@k) of different deep-learning-based and representation-learning-based bug-triaging methods in recommending top-k developers on 10-fold cross-validation experiments for three open source projects including Eclipse, Mozilla and Apache. Furthermore, we report the top-k accuracy (i.e., Recall@k) for each cross-validation set, as shown in Figure 8, to understand the variance between different methods introduced in the training phase considering that it provides more accurate interpretation than the averaged performance values, as detailed in Section 7.4. From Figure 7 and Figure 8, we can obtain the following conclusions:
- (1)
- PTITransE outperforms the deep-learning-based bug-triaging methods by a great margin on all projects. This could be due to the fact that PTITransE can correctly learn the vector representations for all entities and relations by taking into account both structured and textual information of bug reports. However, deep-learning-based bug-triaging methods make fixer prediction only according to the textual content of bug reports, which may cause great inaccuracy due to the lack of structured information. Additionally, this also demonstrates the effectiveness of applying knowledge bases and representation learning to bug triaging.
- (2)
- The performance of TransE based on structured features is superior to that of textual-based deep learning methods, which indicates that structured features of bug reports are the more important factor that determines the quality of bug triaging. This could be due to the fact that the structured information is critical as it reflects the developers’ behavior in their previous bug-fixing activities, which can help to accurately analyze the developers’ experience so that the most appropriate developers are recommended to fix the new bug reports.
- (3)
- For the Apache project, the deep-learning-based methods also achieved good results due to the lesser number of fixers, which indicates that these methods are more suitable for the projects with a small number of candidate developers. The main reason is that, for deep-learning-based models, the number of nodes of their output layer is determined by the number of developers, i.e., (the # of unique fixers) in Table 4, and the greater the number of output nodes, the more complex the deep-learning-based model. This means that given a fixed amount of data, a greater number of output nodes usually leads to poorer results. However, our proposed method performs well in all projects, which demonstrates the robustness and generalization of our method in terms of the scale of developers. This is because our method relies on a reduced set of parameters as it learns only a dense low-dimensional vector for each entity and each relationship.
- (4)
- From the obtained results of Figure 8, it can be clearly observed that the deep-learning-based bug-triaging methods produce larger variance than the proposed methods on N-fold cross-validation results, especially for the Apache project. Again, this is due to the fact that the deep-learning-based methods may be sensitive to the text quality of bug reports. Additionally, the bug reporters may have different writing styles and diction for describing bugs [68]; hence, there are possibly notable differences in the text quality across the cross-validation (CV) sets. However, our proposed approach is not restricted to a specific type of information (i.e., the textual information or structured information) of bug reports by jointly learning latent representations of both of them using PTITransE. Therefore, the effects (i.e., high variance) resulted from large differences in text quality across the CV sets can be alleviated by incorporating structured information about the developers and bug reports into the recommendation process.
7.6. RQ3: How Does Our Method Perform Compared with the Existing Bug-Triaging Methods Under the Weak Assumption?
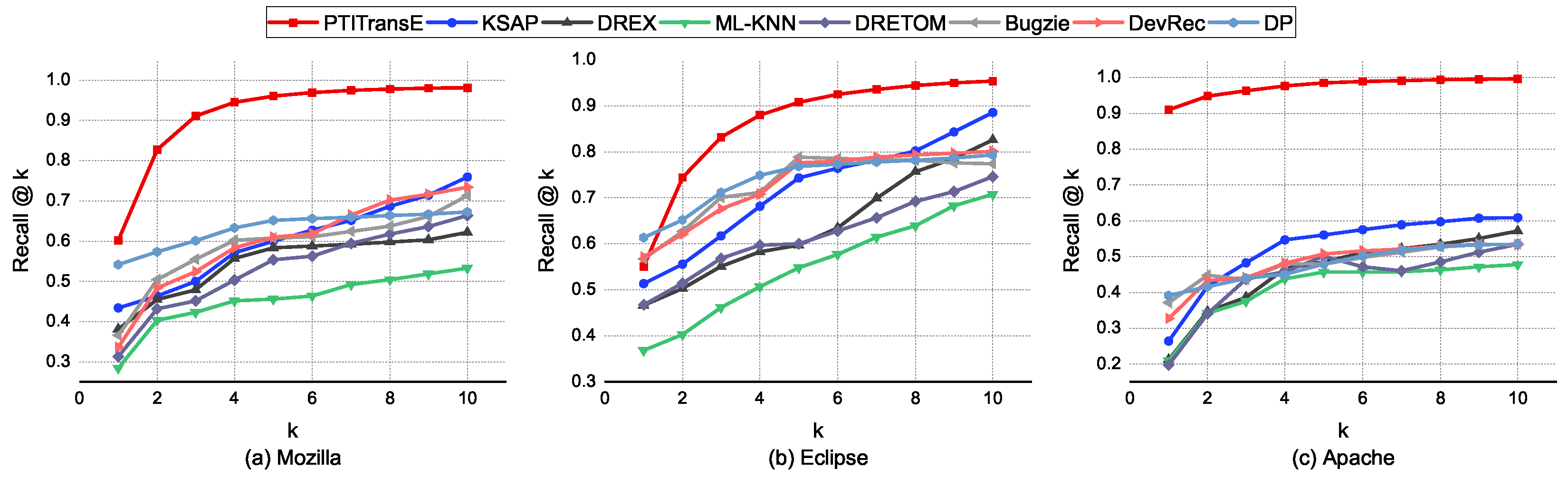
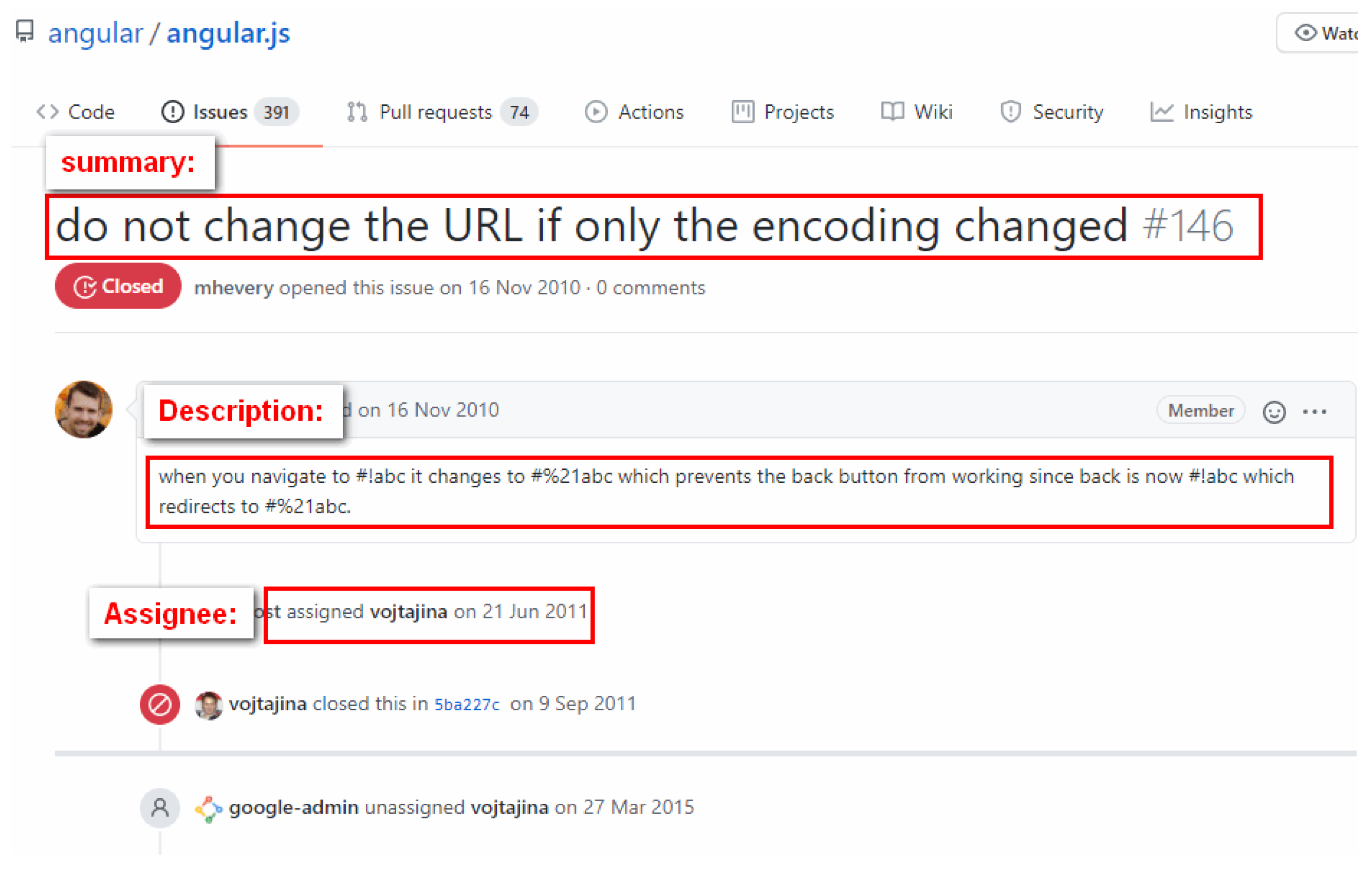
- Approach. As detailed in Section 7.3, these bug-triaging methods under the weak hypothesis assume that a bug is collaboratively resolved by a set of developers, not merely one fixer. That means the ground truth consists of these developers who participated in and contributed to resolving the bug. Taking the bug report #6447 from the Eclipse project as an example, the developers involved in “tossed|fix|assign to” relations include “Joe Szurszewski”, “Darin Wright” and “Darin Swanson”, who are regarded as ground truth for this bug report. Obviously, if the developers who participated in a bug resolution are treated as the ground truth as well, the hit rate of recommendation will increase. Therefore, we conducted further experiments to compare the performance of the proposed method with the existing methods under the weak hypothesis. Similar to RQ2, we set the number of recommended developers (i.e., k) to a value in the range [1, 10] to make a more comprehensive comparison.
- Results. The averaged values of Recall@k on 10-fold cross-validation experiments for three projects are shown in Figure 9. Additionally, for this RQ, we did not report the top-k accuracy of each cross-validation set to compare the variance between different methods considering the fact that the original experimental results of each cross-validation set for the compared methods are difficult to obtain, which is one of the most challenging problems in the bug-triaging field [11] and will be further discussed in the following analysis and also in the discussion Section (i.e., Section 8). Through Figure 9, we draw three interesting conclusions:
- (1)
- The highest recall among different methods is derived by PTITransE when top 2∼10 developers are recommended for different projects. PTITransE achieves more than 95% in recall metric when top-10 developers are recommended for different projects, which is significantly better than traditional methods.
- (2)
- For our proposed method PTITransE, the recall curve of Eclipse has the same trend with that of Mozilla. Even if only a small number of developers are recommended, PTITransE still achieves the same desired results for all projects. This indicates that our method has strong robustness.
- (3)
- For Apache project, PTITransE achieves the best result in recall@k (i.e., 1.0) once k is equal to or greater than 6. This means the top-6 recommended developers in the ranked list contain ground truth for all new bug reports in the testing set.
7.7. RQ4: How Much Does the Prediction Rely on Each Textual Field (e.g., Summary and Description) of Bug Reports, and How Much Does It Rely on Other Relationships Except for the “Fix” Relationship?
- The top-k accuracy of each cross-validation set (i.e., Recall@k where k is from 1 to 10) shows that, by further incorporating textual information regardless of whether it is from singular fields that contain only summary or description, or the merged text combining both of fields, PTITransE can perform substantially better than that without considering textual information in the bug-triaging task. This fact agrees with the claim made in RQ1, which, yet again, demonstrates the effectiveness of our method by making full use of both structured and textual information of bug reports.
- Different textual fields of bug reports (e.g., summary and description) have quite different levels of importance for effective training representation-learning-based models and making accurate recommendations. For the Eclipse project, we found that using either only the summary or only the description performs better than that using both of summary and description. This could be due to the fact that we employ the CBOW model (see Section 3.5) to encode the semantic information of textual fields of bug reports, which is calculated by averaging the vectors of all words present in textual fields to produce a single feature vector. Although it is an effective approach, when there is a long sequence of words in textual fields, this method may no longer easily memorize all of them and thus results in the loss of valuable information about the contents of the bug. However, for the Mozilla project, the average sequence length of textual information is 41.5, much shorter than that of the Eclipse project, which is 119.6. Therefore, the aforementioned problem has a slightly negative effect on prediction performance. Additionally, using only the description produces larger variance than that using either summary or the merged text for Mozilla project. This is because the text quality of the description of bug reports varies greatly, and the low-quality description of bug reports will adversely affect the performance of prediction models.
- Using the merged text can help improve the performance of traditional representation learning methods (e.g., TransE) based only on the structured information and thus serves as a simple and fast strategy of combining textual information with structured information for the bug-triaging task since it does not require additional experiment to judge which of two textual fields of bug reports is more important; however, it may or may not be the best option to achieve the best performance for different projects.
- In the case that all the relationships in the knowledge bases are considered, the proposed approach achieves better results than the other six cases without considering one of relationships on all projects. This demonstrates the effectiveness of considering all relationships among different entities for the bug-triaging task.
- Different relationships in the knowledge bases have different importance, which affects the performance of the developer recommendation. For the Eclipse project, among six relationships, the contain has the most influence on the efforts for recommending suitable developers. This is because, as a result of removing the contain relationship from knowledge bases, it is possible that the affinity information of the fixer will be lost since developers often specialized in some products and components. This is consistent with previous work [10], which finds that using the product–component combination as the input feature can further improve the accuracy of the LDA-based bug-triaging methods. For the Mozilla project, the report relationship is more important than the other five relationships in deriving the high performance of bug triaging. This could be due to the fact that it is possible to find the most relevant developers to fix this bug report only by the reporter entity of the bug reports.
- Except for the contain and report relationships, the other four relationships, i.e., assign to, write, comment and toss, have shown a similar influence on bug-triaging performance for both projects. These relationships may shadow the similar parts of the developer communities, which represents that the removal of one of them in knowledge bases will reduce the complex sets of the relationships between the developer members of the software systems. Therefore, the learned representation in such four cases captures fewer intrinsic characteristics of the developers than that learned on knowledge bases with all relationships.
7.8. RQ5: How Well Does the Training Size Affect the Prediction Performance on Bug Triaging?
- (1)
- For the Eclipse and Mozilla projects, when the training model using N-fold cross-validation with N is greater than 10, the performance of bug triaging is higher than that with N smaller than 10. That means the performance decreases, although smoothly, as the size of training data increases in most of these results, which is not consistent with the fact that the previous deep-learning-based models with a large number of the learning parameters require a large number of data to adequately train [70]. This is because the proposed representation-learning-based method learns only dense low-dimensional vectors for each entity and each relationship based on their surrounding context, without learning any additional parameters that commonly exist in deep-learning-based models, e.g., network parameters. Therefore, our method does not need a large amount of well-labeled training data compared with deep-learning-based methods. In addition, augmenting the training data by reducing the number of folds will lead to the accumulation of noise and, hence, will show no improvement or even cause a decline in the effectiveness of bug triaging. Furthermore, increasing the number of training instances to cover a longer time period will inevitably introduce more developer candidates, which makes the task more difficult, as we discussed in Section 7.4.
- (2)
- For the Apache project, the performance of PTITransE decreases as the number of folds increases, which means the top-k accuracy decreases when reducing the sizes of the training dataset. This is because, when applying the N-fold cross-validation setting with a greater N value on the Apache dataset, each fold used for the training model is too small to efficiently improve the discriminability of the learned features for each entity and relationship, which exerts a negative impact on the performance of bug triaging. In addition, as shown in Figure 12 (Apache (1) ∼ Apache (10)), we found that, with a smaller number of developers (e.g., 1∼4) to recommend, the performance differences caused by the size of the training dataset are larger than that recommending a larger number of developers (e.g., 5∼10). This is due to the fact that, although, for various number of folds, the learned embeddings for entities have large differences in capturing the semantic information of these relations, it is more likely that the recommender can make a correct top-k recommendation (e.g., k is from 5 to 10) when the total number of candidates is small.
- (3)
- Since the number of data instances required in the training phase depends on the project and different projects vary greatly in both complexity and size, especially in the number of developers, it may not help or make sense to give an exact integer number of training instances for different projects. However, across the ten figures for Eclipse and Mozilla projects in Figure 12, PTITransE achieves optimal and stable results on bug triaging when the number of folds is within the specific range of 16∼20. We believe it could serve as a useful guide for training the PTITransE model on similar projects to achieve satisfactory results.
7.9. RQ6: Can PTITransE Help to Alleviate the Cold-Start Problem?
- Approach. In this section, we aim to demonstrate whether the proposed approach can effectively alleviate the cold-start problem compared to previous deep-learning-based methods. From the description of cold-start problem in Section 6, we can see that, given the same testing dataset, the fewer bug reports that are removed, the better a bug-triaging approach works in terms of alleviating the cold-start problem. Therefore, for each cross-validation set, we compute the number of removed bug reports (i.e., the # of removed reports) that cannot be easily handled by various approaches to verify that the proposed method works for alleviating this problem as intended. Additionally, we are also interested in examining the performance of the proposed method on these bug reports, which are fixed by a minority of developers who have no experience in resolving similar bugs earlier and thus cannot be recommended by deep-learning-based methods.
- Results. As evidence, Table 9 shows the statistical results of the number of bug reports removed from each testing fold by a variety of bug-triaging methods (i.e., RL-based and DL-based methods) in three projects, where the bold ones indicate a fewer number of removed bug reports on each testing dataset. In addition, Figure 13 shows the performance differences of the proposed method PTITransE over the full testing datasets (i.e., “PTITransE tested on all datasets”) or only over the testing bug reports removed by DL-based methods (“PTITransE tested on removed datasets by DL”). From these results, we can observe four notable points.
- (1)
- The fewer number of removed bug reports for different projects are all achieved by representation-learning-based methods as shown in Table 9, which demonstrates that the representation-learning-based method can alleviate the cold-start problem.
- (2)
- Since the removed bug reports from each testing fold cannot be recommended by deep-learning-based methods as their true fixers do not equip with the historical experience in resolving similar bugs earlier (i.e., their fixers did n-t appear in the training set) as we described in Section 6, the accuracy of the deep-learning-based methods in recommending top-1∼top-10 developers (i.e., Recall@1∼Recall@10) over those testing bug reports is 0, as shown in Figure 13.
- (3)
- The performance of the proposed method in recommending top-1∼top-10 developers (i.e., Recall@1∼Recall@10) over each full testing fold (i.e., “PTITransE tested on all datasets” in Figure 13) is significantly better than that only over the data instances that cannot be recommended by deep-learning-based methods (i.e., “PTITransE tested on removed datasets by DL” in Figure 13). We believe this can be explained by the fact that the removed testing bug reports by deep-learning-based methods are the most difficult to assign among the full testing datasets due to lack of historical experience of their true fixers. Nevertheless, our method still achieves promising results and leads competitors (i.e., deep-learning-based methods) by a large margin. This is because the proposed method can assign the new bug report to a “young" or “new" developer who has no fixing experience in historical bug reports but has participated in the bug resolution activity. This means that our method relaxes the restriction that all developers, who can be recommended by the prediction model, must resolve a number of bug reports in the training dataset. Therefore, we can claim that our approach is effective in alleviating the cold-start problem of bug triaging.
- (4)
- In particular, the effectiveness of representation-learning-based methods on the Apache project is significantly better than that on other projects in alleviating the cold-start problem. That is because the Apache project has less numbers of fixers, one of whom may affect many bug reports in the testing set. Therefore, for deep-learning-based methods, many bug reports in the testing set will be removed in evaluation as long as the ground truth (i.e., developers) of them does not fix any bug reports in the training set. However, as shown in Table 9 and Figure 13, the cold-start problem has less influence on the performance of the proposed method. This may be due to the fact that most of the developers participated in the bug resolution activity, which also provides evidence that the representation-learning-based methods are more appropriate to organizations with less numbers of developers.
8. Discussion
8.1. How to Choose the Best One Between Two Hypotheses for Your Project
8.2. Which Scenarios Are Well Suitable for the Proposed Approach?
8.3. Threats to Validity
9. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| PTITransE | Combining Partial entities’ Textual Information with TransE |
| VSM | Vector Space Model |
| KBs | Knowledge bases |
| IR | Information retrieval |
| RL | Representation learning |
| NLP | Natural language processing |
| CBOW | Continuous bag-of-words encoder |
| HBRs | Historical bug reports |
| CV | Cross-validation |
| MR | Mean Rank |
| MRR | Mean Reciprocal Rank |
| CNN | Convolution neural network |
| LSTM | Long short-term memory |
References
- Foundation, M. Bugzilla Bug Tracking System. 1998. Available online: https://www.bugzilla.org/ (accessed on 1 June 2025).
- Atlassian. JIRA Issue Tracking System. 2002. Available online: https://www.atlassian.com/software/jira (accessed on 1 June 2025).
- GNATS Project. GNATS Bug Tracking System. 1992. Available online: https://www.gnu.org/software/gnats/ (accessed on 1 June 2025).
- Wu, W.; Zhang, W.; Yang, Y.; Wang, Q. Drex: Developer recommendation with k-nearest-neighbor search and expertise ranking. In Proceedings of the 2011 18th Asia-Pacific Software Engineering Conference, Washington, DC, USA, 5–8 December 2011; pp. 389–396. [Google Scholar]
- Anvik, J.; Hiew, L.; Murphy, G.C. Who should fix this bug? In Proceedings of the 28th international conference on Software Engineering, Shanghai, China, 20–28 May 2006; pp. 361–370. [Google Scholar]
- Murphy, G.; Cubranic, D. Automatic bug triage using text categorization. In Proceedings of the Sixteenth International Conference on Software Engineering & Knowledge Engineering, Banff, AB, Canada, 20–24 June 2004. [Google Scholar]
- Ahsan, S.N.; Ferzund, J.; Wotawa, F. Automatic software bug triage system (bts) based on latent semantic indexing and support vector machine. In Proceedings of the 2009 Fourth International Conference on Software Engineering Advances, Porto, Portugal, 20–25 September 2009; pp. 216–221. [Google Scholar]
- Tamrawi, A.; Nguyen, T.T.; Al-Kofahi, J.M.; Nguyen, T.N. Fuzzy set and cache-based approach for bug triaging. In Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering, Szeged, Hungary, 5–9 September 2011; pp. 365–375. [Google Scholar]
- Salton, G. Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer; Addison-Wesley: Reading, UK, 1989; Volume 169. [Google Scholar]
- Xia, X.; Lo, D.; Ding, Y.; Al-Kofahi, J.M.; Nguyen, T.N.; Wang, X. Improving automated bug triaging with specialized topic model. IEEE Trans. Softw. Eng. 2016, 43, 272–297. [Google Scholar] [CrossRef]
- Mani, S.; Sankaran, A.; Aralikatte, R. Deeptriage: Exploring the effectiveness of deep learning for bug triaging. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data, Kolkata, India, 3–5 January 2019; pp. 171–179. [Google Scholar]
- Lee, S.R.; Heo, M.J.; Lee, C.G.; Kim, M.; Jeong, G. Applying deep learning based automatic bug triager to industrial projects. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, Paderborn, Germany, 4–8 September 2017; pp. 926–931. [Google Scholar]
- Zhang, W.; Wang, S.; Wang, Q. KSAP: An approach to bug report assignment using KNN search and heterogeneous proximity. Inf. Softw. Technol. 2016, 70, 68–84. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the Advances in Neural Information Processing systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 2787–2795. [Google Scholar]
- Xia, X.; Lo, D.; Wang, X.; Zhou, B. Accurate developer recommendation for bug resolution. In Proceedings of the 2013 20th Working Conference on Reverse Engineering (WCRE), Koblenz, Germany, 14–17 October 2013; pp. 72–81. [Google Scholar]
- Xuan, J.; Jiang, H.; Ren, Z.; Yan, J.; Luo, Z. Automatic bug triage using semi-supervised text classification. arXiv 2017, arXiv:1704.04769. [Google Scholar]
- Naguib, H.; Narayan, N.; Brügge, B.; Helal, D. Bug report assignee recommendation using activity profiles. In Proceedings of the 2013 10th Working Conference on Mining Software Repositories (MSR), San Francisco, CA, USA, 18–19 May 2013; pp. 22–30. [Google Scholar]
- Zhang, T.; Lee, B. A hybrid bug triage algorithm for developer recommendation. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, Coimbra, Portugal, 18–22 March 2013; pp. 1088–1094. [Google Scholar]
- Xie, X.; Zhang, W.; Yang, Y.; Wang, Q. Dretom: Developer recommendation based on topic models for bug resolution. In Proceedings of the 8th International Conference on Predictive Models in Software Engineering, Lund, Sweden, 21–22 September 2012; pp. 19–28. [Google Scholar]
- Hu, H.; Zhang, H.; Xuan, J.; Sun, W. Effective bug triage based on historical bug-fix information. In Proceedings of the 2014 IEEE 25th International Symposium on Software Reliability Engineering, Naples, Italy, 3–6 November 2014; pp. 122–132. [Google Scholar]
- Shokripour, R.; Anvik, J.; Kasirun, Z.M.; Zamani, S. Why so complicated? Simple term filtering and weighting for location-based bug report assignment recommendation. In Proceedings of the 2013 10th Working Conference on Mining Software Repositories (MSR), San Francisco, CA, USA, 18–19 May 2013; pp. 2–11. [Google Scholar]
- Matter, D.; Kuhn, A.; Nierstrasz, O. Assigning bug reports using a vocabulary-based expertise model of developers. In Proceedings of the 2009 6th IEEE International Working Conference on Mining Software Repositories, Vancouver, BC, Canada, 16–17 May 2009; pp. 131–140. [Google Scholar]
- Badashian, A.S.; Hindle, A.; Stroulia, E. Crowdsourced bug triaging. In Proceedings of the 2015 IEEE International Conference on Software Maintenance and Evolution (ICSME), Bremen, Germany, 29 September–1 October 2015; pp. 506–510. [Google Scholar]
- Kagdi, H.; Gethers, M.; Poshyvanyk, D.; Hammad, M. Assigning change requests to software developers. J. Softw. Evol. Process 2012, 24, 3–33. [Google Scholar] [CrossRef]
- Linares-Vásquez, M.; Hossen, K.; Dang, H.; Kagdi, H.; Gethers, M.; Poshyvanyk, D. Triaging incoming change requests: Bug or commit history, or code authorship? In Proceedings of the 2012 28th IEEE International Conference on Software Maintenance (ICSM), Trento, Italy, 23–28 September 2012; pp. 451–460. [Google Scholar]
- Jeong, G.; Kim, S.; Zimmermann, T. Improving bug triage with bug tossing graphs. In Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on The Foundations of Software Engineering, Amsterdam, The Netherlands, 24–28 August 2009; pp. 111–120. [Google Scholar]
- Zhang, J.; Xie, R.; Ye, W.; Zhang, Y.; Zhang, S. Exploiting Code Knowledge Graph for Bug Localization via Bi-directional Attention. In Proceedings of the 28th International Conference on Program Comprehension, Seoul, Republic of Korea, 13–15 July 2020; pp. 219–229. [Google Scholar]
- Xie, R.; Chen, L.; Ye, W.; Li, Z.; Hu, T.; Du, D.; Zhang, S. DeepLink: A code knowledge graph based deep learning approach for issue-commit link recovery. In Proceedings of the 2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER), Hangzhou, China, 24–27 February 2019; pp. 434–444. [Google Scholar]
- Liu, M.; Peng, X.; Marcus, A.; Xing, Z.; Xie, W.; Xing, S.; Liu, Y. Generating query-specific class API summaries. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Tallinn, Estonia, 26–30 August 2019; pp. 120–130. [Google Scholar]
- Zhou, C. Intelligent bug fixing with software bug knowledge graph. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Lake Buena Vista, FL, USA, 4–9 November 2018; pp. 944–947. [Google Scholar]
- Lin, Z.Q.; Xie, B.; Zou, Y.Z.; Zhao, J.F.; Li, X.D.; Wei, J.; Sun, H.L.; Yin, G. Intelligent development environment and software knowledge graph. J. Comput. Sci. Technol. 2017, 32, 242–249. [Google Scholar] [CrossRef]
- Abal, I.; Melo, J.; Stănciulescu, Ş.; Brabrand, C.; Ribeiro, M.; Wasowski, A. Variability bugs in highly configurable systems: A qualitative analysis. Acm Trans. Softw. Eng. Methodol. TOSEM 2018, 26, 1–34. [Google Scholar] [CrossRef]
- Szurszewski, J. Bug 6447-Inner Class Breakpoints Are not Triggered. 2001. Available online: https://bugs.eclipse.org/bugs/show_bug.cgi?id=6447 (accessed on 1 June 2025).
- Szurszewski, J. Bug 7004-Removed Specified Step Filters when Deselecting All Buttons on Preference Page. 2001. Available online: https://bugs.eclipse.org/bugs/show_bug.cgi?id=7004 (accessed on 1 June 2025).
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In The Semantic Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Fabian, M.; Gjergji, K.; Gerhard, W. Yago: A core of semantic knowledge unifying wordnet and wikipedia. In Proceedings of the 16th International World Wide Web Conference, WWW, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Lao, N.; Mitchell, T.; Cohen, W.W. Random walk inference and learning in a large scale knowledge base. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 529–539. [Google Scholar]
- Xie, R.; Liu, Z.; Sun, M. Representation Learning of Knowledge Graphs with Hierarchical Types. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence IJCAI, New York, NY, USA, 9–15 July 2016; pp. 2965–2971. [Google Scholar]
- Yang, B.; Yih, W.t.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Neelakantan, A.; Roth, B.; McCallum, A. Compositional vector space models for knowledge base completion. arXiv 2015, arXiv:1504.06662. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- García-Durán, A.; Bordes, A.; Usunier, N.; Grandvalet, Y. Combining two and three-way embedding models for link prediction in knowledge bases. J. Artif. Intell. Res. 2016, 55, 715–742. [Google Scholar] [CrossRef]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef]
- Getoor, L.; Diehl, C.P. Link mining: A survey. Acm Sigkdd Explor. Newsl. 2005, 7, 3–12. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Yang, X.; Lo, D.; Xia, X.; Bao, L.; Sun, J. Combining Word Embedding with Information Retrieval to Recommend Similar Bug Reports. In Proceedings of the 2016 IEEE 27th International Symposium on Software Reliability Engineering (ISSRE), Ottawa, ON, Canada, 23–27 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 127–137. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Jiang, Y.; Lu, P.; Su, X.; Wang, T. LTRWES: A new framework for security bug report detection. Inf. Softw. Technol. 2020, 106314. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Xie, R.; Liu, Z.; Jia, J.; Luan, H.; Sun, M. Representation learning of knowledge graphs with entity descriptions. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Xu, J.; Chen, K.; Qiu, X.; Huang, X. Knowledge graph representation with jointly structural and textual encoding. arXiv 2016, arXiv:1611.08661. [Google Scholar]
- Nasim, S.; Razzaq, S.; Ferzund, J. Automated change request triage using alpha frequency matrix. In Proceedings of the 2011 Frontiers of Information Technology, Islamabad, Pakistan, 19–21 December 2011; pp. 298–302. [Google Scholar]
- Ye, X.; Bunescu, R.; Liu, C. Learning to rank relevant files for bug reports using domain knowledge. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, Hong Kong, China, 16–21 November 2014; pp. 689–699. [Google Scholar]
- Fan, M.; Cao, K.; He, Y.; Grishman, R. Jointly embedding relations and mentions for knowledge population. arXiv 2015, arXiv:1504.01683. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Xuan, J.; Jiang, H.; Ren, Z.; Zou, W. Developer prioritization in bug repositories. In Proceedings of the 2012 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, 2–9 June 2012; pp. 25–35. [Google Scholar]
- Schein, A.I.; Popescul, A.; Ungar, L.H.; Pennock, D.M. Methods and metrics for cold-start recommendations. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Tampere, Finland, 11–15 August 2002; pp. 253–260. [Google Scholar]
- Williamson, D.F.; Parker, R.A.; Kendrick, J.S. The box plot: A simple visual method to interpret data. Ann. Intern. Med. 1989, 110, 916–921. [Google Scholar] [CrossRef] [PubMed]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence IJCAI, Montreal, QC, Canada, 20–25 August 1995; Volume 14, pp. 1137–1145. [Google Scholar]
- Gegick, M.; Rotella, P.; Xie, T. Identifying security bug reports via text mining: An industrial case study. In Proceedings of the 2010 7th IEEE Working Conference on Mining Software Repositories (MSR 2010), Cape Town, South Africa, 2–3 May 2010; pp. 11–20. [Google Scholar]
- Bhattacharya, P.; Neamtiu, I. Fine-grained incremental learning and multi-feature tossing graphs to improve bug triaging. In Proceedings of the 2010 IEEE International Conference on Software Maintenance, Timioara, Romania, 12–18 September 2010; pp. 1–10. [Google Scholar]
- Lei, C.; Liu, D.; Li, W.; Zha, Z.J.; Li, H. Comparative deep learning of hybrid representations for image recommendations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2545–2553. [Google Scholar]
- Wijayasekara, D.; Manic, M.; Wright, J.L.; McQueen, M. Mining bug databases for unidentified software vulnerabilities. In Proceedings of the 2012 5th International Conference on Human System Interactions, Perth, Australia, 6–8 June 2012; pp. 89–96. [Google Scholar]
- Banerjee, S.; Syed, Z.; Helmick, J.; Culp, M.; Ryan, K.; Cukic, B. Automated triaging of very large bug repositories. Inf. Softw. Technol. 2017, 89, 1–13. [Google Scholar] [CrossRef]
- Badashian, A.S.; Hindle, A.; Stroulia, E. Crowdsourced bug triaging: Leveraging q&a platforms for bug assignment. In Proceedings of the International Conference on Fundamental Approaches to Software Engineering, Eindhoven, The Netherlands, 4–7 April 2016; pp. 231–248. [Google Scholar]
- Sajedi-Badashian, A.; Stroulia, E. Guidelines for evaluating bug-assignment research. J. Softw. Evol. Process 2020, 32, e2250. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Bug Report 1 [33] | Bug Report 2 [34] |
|---|---|---|
| Bug_id | 6447 | 7004 |
| Summary | Inner class breakpoints not hit | DCR: Deselect All button on step filter preference page |
| Description | From the newsgroup: I just tried it on 1127, and it wouldn’t break for me. I tested the following code: … | It would be nice to have a deselect all button that would not remove specified step filters, but would deselect all of them |
| Reporter | Darin Swanson | Darin Swanson |
| Product | JDT | JDT |
| Component | Debug | Debug |
| Bug severity | Critical | Normal |
| Fixer | Joe Szurszewski | Joe Szurszewski |
| Who | When | What | Removed | Added |
|---|---|---|---|---|
| darin eclipse | 2001/11/29 | Severity | normal | critical |
| 18:24:32 | Priority | P3 | P1 | |
| pilf_b | 2001/11/29 | CC | pilf_b | |
| 18:24:32 | ||||
| Darin Swanson | 2001/11/30 | Assignee | Darin Wright | Darin Swanson |
| 12:31:36 | ||||
| Darin Swanson | 2001/11/30 | Status | New | Assign |
| 12:31:44 | ||||
| Darin Swanson | 2001/11/30 | Assignee | Darin Swanson | Joe Szurszewski |
| 15:58:13 |
| Types of Relation | Description | Cardinality |
|---|---|---|
| report | a developer can find more than one (n) bugs and give reports | 1:n |
| assign to | a bug is assigned to a developer | 1:1 |
| fix | a developer fixes a bug | 1:1 |
| write | a developer can write more than one (n) comments | 1:n |
| comment | one or more comments are written to comment a bug | n:1 |
| contain | a component can contain one or more bugs | 1:n |
| a product can contain one or more components | 1:n | |
| toss | a developer tosses a bug to another developer | 1:1 |
| Project | # of Bug Reports | # of Unique Developers | # of Unique Fixers | # of Bug Reporters | # of Component | # of Products | Time Duration |
|---|---|---|---|---|---|---|---|
| Eclipse | 149,390 | 14,633 | 1833 | 10,344 | 463 | 98 | 2001/10/10– 2017/10/25 |
| Mozilla | 149,909 | 8120 | 2948 | 4786 | 1196 | 117 | 2015/01/15– 2018/08/16 |
| Apache | 21,221 | 9546 | 24 | 7472 | 309 | 34 | 2001/01/08– 2018/08/16 |
| Project | Size | CV#1 | CV#2 | CV#3 | CV#4 | CV#5 | CV#6 | CV#7 | CV#8 | CV#9 | CV#10 | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Eclipse | # of train set | 13,590 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,581.3 |
| # of test set | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | |
| # of entities | 31,208 | 31,893 | 32,040 | 31,909 | 31,998 | 32,147 | 32,357 | 32,533 | 32,548 | 32,430 | 32,106.3 | |
| # of triplets | 158,403 | 161,800 | 163,413 | 163,377 | 166,085 | 166,679 | 162,942 | 160,508 | 157,468 | 155,546 | 161,622.1 | |
| Mozilla | # of train set | 13,629 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628.1 |
| # of test set | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | |
| # of entities | 35,078 | 34,927 | 33,727 | 32,190 | 32,018 | 31,840 | 31,187 | 31,083 | 30,385 | 30,028 | 32,246.3 | |
| # of triplets | 202,837 | 203,581 | 203,754 | 206,636 | 209,767 | 212,157 | 211,967 | 214,144 | 204,746 | 196,720 | 206,630.9 | |
| Apache | # of train set | 7075 | 7073 | - | - | - | - | - | - | - | - | 7074 |
| # of test set | 7073 | 7073 | - | - | - | - | - | - | - | - | 77, 073 | |
| # of entities | 19,617 | 19,919 | - | - | - | - | - | - | - | - | 19,768.0 | |
| # of triplets | 63,216 | 60,541 | - | - | - | - | - | - | - | - | 61,878.5 |
| Project | Mozilla | Eclipse | Apache | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Metirc | MRR | MR | Hits@1 | MRR | MR | Hits@1 | MRR | MR | Hits@1 |
| TransH | 0.569 | 52.314 | 0.411 | 0.578 | 25.64 | 0.393 | 0.513 | 26.272 | 0.369 |
| TransD | 0.571 | 36.938 | 0.407 | 0.577 | 25.32 | 0.389 | 0.610 | 17.62 | 0.496 |
| TransE | 0.613 | 16.714 | 0.440 | 0.566 | 11.806 | 0.394 | 0.919 | 1.504 | 0.883 |
| PTITransE | 0.698 | 8.903 | 0.505 | 0.604 | 8.547 | 0.431 | 0.941 | 1.258 | 0.909 |
| Project | Mozilla | Eclipse | Apache |
|---|---|---|---|
| CNN triager | 0.098 | 0.099 | 0.652 |
| LSTM triager | 0.169 | 0.195 | 0.763 |
| DeepTriager | 0.181 | 0.219 | 0.797 |
| PTITransE | 0.698 | 0.604 | 0.941 |
| Metric | MRR | MAP | ||||
|---|---|---|---|---|---|---|
| Project | Mozilla | Eclipse | Apache | Mozilla | Eclipse | Apache |
| DP | 0.113 | 0.085 | 0.169 | 0.220 | 0.207 | 0.172 |
| DevRec | 0.134 | 0.151 | 0.170 | 0.232 | 0.289 | 0.173 |
| Bugzie | 0.246 | 0.261 | 0.187 | 0.374 | 0.425 | 0.211 |
| KSAP | 0.278 | 0.280 | 0.347 | 0.445 | 0.564 | 0.365 |
| PTITransE | 0.758 | 0.703 | 0.941 | 0.672 | 0.584 | 0.937 |
| Project | Size | CV#1 | CV#2 | CV#3 | CV#4 | CV#5 | CV#6 | CV#7 | CV#8 | CV#9 | CV#10 | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Eclipse | # of test set | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 | 13,580 |
| # of removed reports by DL | 1225 | 858 | 1505 | 1285 | 1698 | 1379 | 789 | 1127 | 739 | 625 | 1123 | |
| # of removed reports by RL | 772 | 459 | 999 | 773 | 1117 | 918 | 432 | 639 | 241 | 331 | 668.1 | |
| Mozilla | # of test set | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 | 13,628 |
| # of removed reports by DL | 895 | 740 | 722 | 777 | 808 | 655 | 2730 | 816 | 760 | 1601 | 1050.4 | |
| # of removed reports by RL | 287 | 261 | 292 | 283 | 337 | 224 | 223 | 402 | 315 | 319 | 294.3 | |
| Apache | # of test set | 7073 | 7073 | - | - | - | - | - | - | - | - | 7073 |
| # of removed reports by DL | 435 | 602 | - | - | - | - | - | - | - | - | 518.5 | |
| # of removed reports by RL | 10 | 84 | - | - | - | - | - | - | - | - | 47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Yan, W.; Li, Y.; Ge, Y.; Liu, Y.; Yin, P.; Tan, S. Knowledge Bases and Representation Learning Towards Bug Triaging. Mach. Learn. Knowl. Extr. 2025, 7, 57. https://doi.org/10.3390/make7020057
Wang Q, Yan W, Li Y, Ge Y, Liu Y, Yin P, Tan S. Knowledge Bases and Representation Learning Towards Bug Triaging. Machine Learning and Knowledge Extraction. 2025; 7(2):57. https://doi.org/10.3390/make7020057
Chicago/Turabian StyleWang, Qi, Weihao Yan, Yanlong Li, Yizheng Ge, Yiwei Liu, Peng Yin, and Shuai Tan. 2025. "Knowledge Bases and Representation Learning Towards Bug Triaging" Machine Learning and Knowledge Extraction 7, no. 2: 57. https://doi.org/10.3390/make7020057
APA StyleWang, Q., Yan, W., Li, Y., Ge, Y., Liu, Y., Yin, P., & Tan, S. (2025). Knowledge Bases and Representation Learning Towards Bug Triaging. Machine Learning and Knowledge Extraction, 7(2), 57. https://doi.org/10.3390/make7020057