
Membership Inference Attacks Fueled by Few-Shot Learning to Detect Privacy Leakage and Address Data Integrity

 ,
,  and
and 
Abstract

1. Introduction
- (1)
- to overcome the computational time and data availability limitations presented in the field of MIAs applied to deep learning models and
- (2)
- to provide an insightful view of the data integrity of a deep learning model, regardless of the MIA and victim model.
- The incorporation of a new MIA model based on few-shot learning due to its simplicity and effectiveness, named the FeS-MIA model, to significantly reduce the number of resources required to measure the privacy breach of a deep learning model. This enables the assessment of the integrity of the training data and provides a membership inference scenario with fewer data and a shorter computational time. More specifically, we do not assume access to the training data of the target model, and we limit ourselves to a small support set—reflecting a ‘few-shot’ regime. We argue that membership inference techniques should require no more data, or significantly more computation, than what was needed to train the victim model itself. Therefore, while computational efficiency is not a direct design goal in our approach, it emerges naturally from our low-data assumptions. This distinction is important to highlight, as our aim is not to optimize the runtime but to demonstrate the feasibility of data integrity assessment in scenarios of restricted access. We note that few-shot learning tackles the problem of performing a classification task on unseen classes with as few data as possible. Moreover, we incorporate multiple implementations of FeS-MIA models with the aim of showing the flexibility of this conceptual framework.
- A privacy evaluation measure, the Log-MIA measure, which changes the scale and proportion of the reported metrics to further boost the assessment of the data integrity, leading to a reinterpretation of state-of-the-art MIAs. Log-MIA is a proposal to help identify the extent of a privacy leakage and raises awareness of the data integrity risks present in deep learning models. The proposed measure is not only quantitatively more reasonable but also easier to interpret.
- Jointly, the contributions of this work provide tools to measure the privacy leaks of deep learning models, enabling us to reinterpret and compare the state-of-the-art results and experimentally assess whether it is possible to achieve a significant privacy leakage with as few resources as possible.
2. Background and Related Works
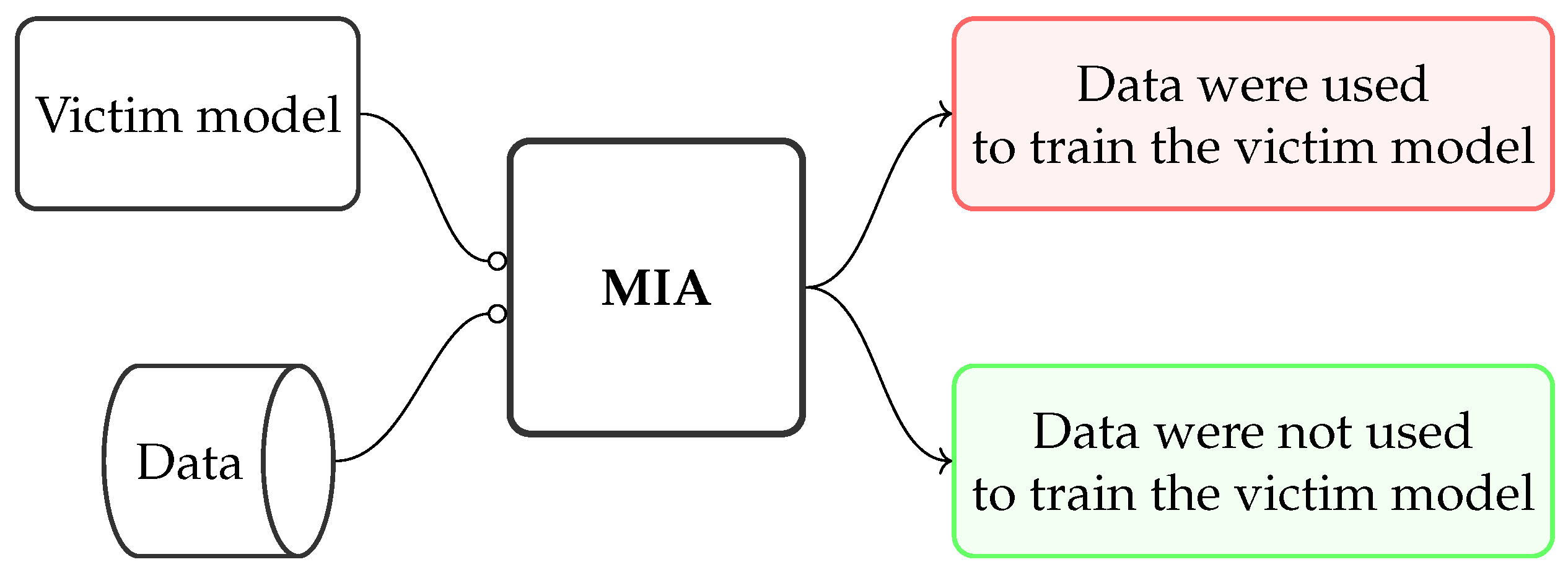
2.1. Membership Inference Attacks
2.1.1. Data and Computational Resource Requirements
2.1.2. Evaluation
2.2. Few-Shot Learning
3. Few-Shot Learning MIA Model
- (1)
- evaluating the privacy leakage of a model should not be more resource-intensive than training the victim model itself, and
- (2)
- MIAs should require fewer data than those used to train the victim model.
3.1. FeS-MIA Transductive Tuning (FeS-MIA TT)
3.2. FeS-MIA Simple-Shot (FeS-MIA SS)
3.3. FeS-MIA Laplacian-Shot (FeS-MIA LS)
4. Towards the New Privacy Evaluation Log-MIA Measure
4.1. The Lack of Interpretability of the TPR at Low FPR
- On the CIFAR datasets, 0.001% and 0.1% are 0 and 25 FP, respectively. The test dataset for the MIA has 50,000 items.
- On the WikiText103 dataset, 0.001% and 0.1% are 0 and 50 FP, respectively. The test dataset for the MIA has 1,000,000 items.
- With the FeS-MIA model, 0.001% and 0.1% are 0 FP because of the small test set; this is an intrinsic limitation when using few-shot techniques. We note that our test dataset has 30 items.
- CIFAR-10: a TPR at 0.001% FPR equal to 2.2% means 550 true positives (TP) and a TPR at 0.1% FPR equal to 8.4% means 2100 TP.
- CIFAR-100: a TRP at 0.001% FPR equal to 11.2% means 2800 TP and a TPR at 0.1% FPR equal to 27.6% means 6900 TP.
- WikiText103: a TPR at 0.001% FPR equal to 0.09% means 450 TP and a TPR at 0.1% FPR equal to 1.40% means 7000 TP.
- (1)
- the meaning of a low FPR is ambiguous and changes for each dataset, and
- (2)
- the TPR values can be misleading if the test dataset is too large.
4.2. Rethinking the Low FPR
- For the CIFAR datasets, with a test dataset of 50,000 items, log(50,000) ≈ 10.
- For WikiText-103, with a test dataset of 100,000 items, log(100,000) ≈ 11.
- For the FeS-MIA model, with a test dataset of 30 items, .
4.3. A More Intuitive Alternative to the TPR
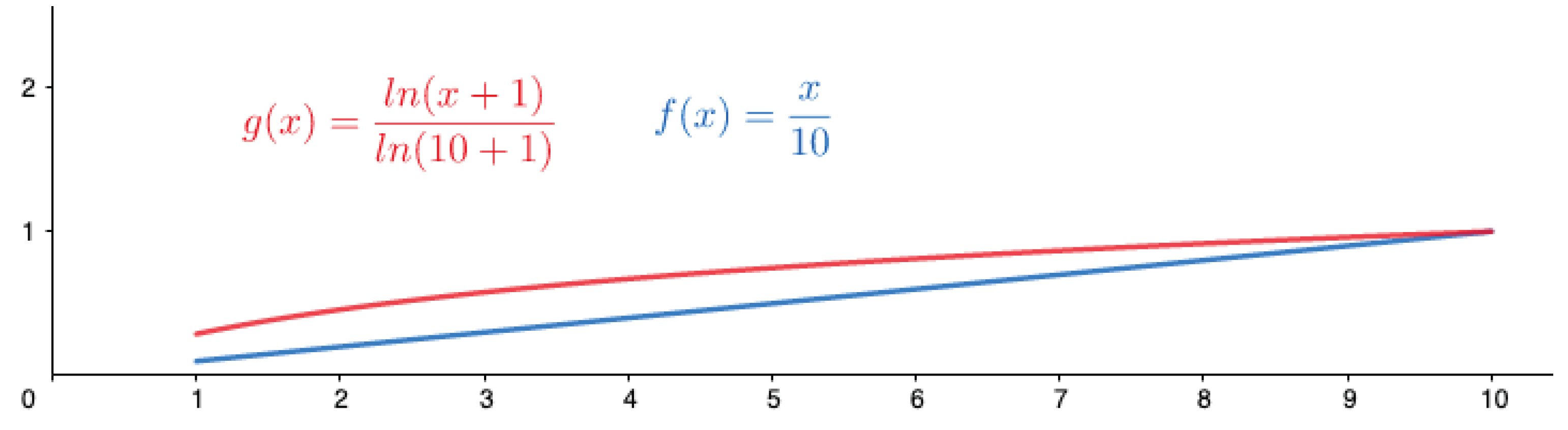
- It grows faster than the TPR, even with small values, representing the idea that there is no negligible privacy leakage. Figure 2 illustrates the effect of this property.
- The non-zero value closest to 0 that the TP log-ratio can report is . That is, any value smaller than means that there is no privacy leakage, whereas any value greater than or equal to indicates a privacy leakage. It is important to note that this value also exists for the TPR metric, i.e., . However, can be much smaller than , especially with large test sizes. This fact is supported by the inequality , where x is the size of the positive class. Figure 3 shows this behavior.
4.4. Log-MIA: A New Privacy Evaluation Measure
- Regime A: We report the TP log-ratio at . In this regime, the reported value must be greater than or equal to to indicate a severe privacy leakage. Otherwise, we can state that the victim model is private.
- Regime B: We report the TP log-ratio at . In this regime, we can establish further severity levels for the privacy leakage.
- If the reported value is greater than or equal tothen a severe privacy leakage can be declared. The attacker can flawlessly infer the positive membership of some data used to train the victim model.
- If the reported value is in the interval , then there is a moderate privacy leakage. The attacker can reveal the membership of some data. However, at best, it is paired with the same number of FP, i.e., false memberships.
- Otherwise, there is no privacy leakage. The attacker cannot infer the membership of any data used to train the victim model.
4.5. Reevaluating the Privacy Leakage of the State of the Art with the Log-MIA Measure
- It adapts the interpretation of a low FPR to the MIA problem;
- It considers that any TPR>0 indicates a non-negligible privacy leakage;
- It allows for the qualitative comparison of privacy leakages when different test sizes are used.
5. Experimental Analysis of the FeS-MIA Model
5.1. Experimental Setup
5.1.1. Victim Model and Training Datasets
- CIFAR-10 and CIFAR-100 [57]. The CIFAR-10 dataset consists of 60,000 32 × 32 color images in 10 classes, with 6000 images per class. There are 50,000 training images and 10,000 test images. CIFAR-100 is an extension of the CIFAR-10 dataset, with 100 classes containing 600 images each. There are 500 training images and 100 testing images per class. Both datasets are approached with a Wide ResNet [54] model, WRN-28-2, with a depth of 28 layers and a widening factor of 2. The model is trained on half of the dataset until 60% accuracy is reached.
- WikiText-103 [32]. The WikiText-103 language modeling dataset is a collection of over 100 million tokens extracted from the set of verified Good and Featured articles on Wikipedia, tackled with the smallest GPT-2 [58] model (124M parameters). The model is trained on half of the dataset for 20 epochs.
5.1.2. FeS-MIA Model Experimental Setup
5.2. Regime A: Results and Analysis
5.3. Regime B: Results and Analysis
6. Conclusions
- The FeS-MIA model proposes a new set of MIAs based on few-shot learning techniques and significantly reduces the resources required to evaluate the data integrity of a deep learning model. These techniques make the assessment of the training data’s integrity more feasible by requiring fewer data and less computational time, thus facilitating the proposition and evaluation of a wider range of membership inference scenarios. The impact of our model’s contribution is heightened by its ability to demonstrate significant privacy leakages with only minimal data and computational resources. Although efficiency was not a primary design goal, it emerges as a positive consequence of our few-shot approach, reinforcing the applicability of our method in constrained environments.
- The Log-MIA measure further boosts the interpretability of MIA privacy risks, leading to the reinterpretation of state-of-the-art MIA metrics. The proposed metric verifies that almost all MIAs are capable of achieving a significant privacy leakage.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rodríguez-Barroso, N.; Jiménez-López, D.; Luzón, M.V.; Herrera, F.; Martínez-Cámara, E. Survey on federated learning threats: Concepts, taxonomy on attacks and defences, experimental study and challenges. Inf. Fusion 2023, 90, 148–173. [Google Scholar] [CrossRef]
- Long, T.; Gao, Q.; Xu, L.; Zhou, Z. A survey on adversarial attacks in computer vision: Taxonomy, visualization and future directions. Comput. Secur. 2022, 121, 102847. [Google Scholar] [CrossRef]
- Ganju, K.; Wang, Q.; Yang, W.; Gunter, C.A.; Borisov, N. Property Inference Attacks on Fully Connected Neural Networks Using Permutation Invariant Representations. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; Association for Computing Machinery (ACM): New York, NY, USA, 2018; pp. 619–633. [Google Scholar]
- Salem, A.; Bhattacharya, A.; Backes, M.; Fritz, M.; Zhang, Y. Updates-Leak: Data Set Inference and Reconstruction Attacks in Online Learning. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Berkeley, CA, USA, 12–14 August 2020; USENIX Association: Berkeley, CA, USA, 2020; pp. 1291–1308. [Google Scholar]
- Wu, D.; Qi, S.; Qi, Y.; Li, Q.; Cai, B.; Guo, Q.; Cheng, J. Understanding and defending against White-box membership inference attack in deep learning. Knowl.-Based Syst. 2023, 259, 110014. [Google Scholar] [CrossRef]
- Manzonelli, N.; Zhang, W.; Vadhan, S. Membership Inference Attacks and Privacy in Topic Modeling. arXiv 2024, arXiv:2403.04451. [Google Scholar]
- European Commission. High-level expert group on artificial intelligence. In Ethics Guidelines for Trustworthy AI; European Union: Maastricht, The Netherlands, 2019. [Google Scholar]
- Li, M.; Ye, Z.; Li, Y.; Song, A.; Zhang, G.; Liu, F. Membership Inference Attack Should Move On to Distributional Statistics for Distilled Generative Models. arXiv 2025, arXiv:2502.02970. [Google Scholar]
- Zhu, G.; Li, D.; Gu, H.; Yao, Y.; Fan, L.; Han, Y. FedMIA: An Effective Membership Inference Attack Exploiting “All for One” Principle in Federated Learning. arXiv 2024, arXiv:2402.06289. [Google Scholar]
- Liu, X.; Zheng, Y.; Yuan, X.; Yi, X. Securely Outsourcing Neural Network Inference to the Cloud with Lightweight Techniques. IEEE Trans. Dependable Secur. Comput. 2023, 20, 620–636. [Google Scholar] [CrossRef]
- Ruan, W.; Xu, M.; Fang, W.; Wang, L.; Wang, L.; Han, W. Private, Efficient, and Accurate: Protecting Models Trained by Multi-party Learning with Differential Privacy. In Proceedings of the 2023 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–25 May 2023; pp. 1926–1943. [Google Scholar]
- Dealcala, D.; Mancera, G.; Morales, A.; Fierrez, J.; Tolosana, R.; Ortega-Garcia, J. A Comprehensive Analysis of Factors Impacting Membership Inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 17–21 June 2024; pp. 3585–3593. [Google Scholar]
- Landau, O.; Cohen, A.; Gordon, S.; Nissim, N. Mind your privacy: Privacy leakage through BCI applications using machine learning methods. Knowl.-Based Syst. 2020, 198, 105932. [Google Scholar] [CrossRef]
- Carlini, N.; Chien, S.; Nasr, M.; Song, S.; Terzis, A.; Tramèr, F. Membership Inference Attacks From First Principles. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 23–25 May 2022; pp. 1897–1914. [Google Scholar]
- Ho, G.; Sharma, A.; Javed, M.; Paxson, V.; Wagner, D. Detecting Credential Spearphishing in Enterprise Settings. In Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Vancouver, BC, Canada, 16–18 August 2017; USENIX Association: Berkeley, CA, USA, 2017; pp. 469–485. [Google Scholar]
- Kantchelian, A.; Tschantz, M.C.; Afroz, S.; Miller, B.; Shankar, V.; Bachwani, R.; Joseph, A.D.; Tygar, J.D. Better Malware Ground Truth: Techniques for Weighting Anti-Virus Vendor Labels. In Proceedings of the 8th ACM Workshop on Artificial Intelligence and Security. Association for Computing Machinery (ACM), Denver, CO, USA, 16 October 2015; pp. 45–56. [Google Scholar]
- Lazarevic, A.; Ertöz, L.; Kumar, V.; Ozgur, A.; Srivastava, J. A Comparative Study of Anomaly Detection Schemes in Network Intrusion Detection. In Proceedings of the SIAM International Conference on Data Mining (SDM), San Francisco, CA, USA, 1–3 May 2003; pp. 25–36. [Google Scholar]
- Bagdasaryan, E.; Poursaeed, O.; Shmatikov, V. Differential Privacy has disparate impact on model accuracy. Adv. Neural Inf. Process. Syst. 2019, 32, 15479–15488. [Google Scholar]
- Gao, L.; Biderman, S.; Black, S.; Golding, L.; Hoppe, T.; Foster, C.; Phang, J.; He, H.; Thite, A.; Nabeshima, N.; et al. The Pile: An 800GB Dataset of Diverse Text for Language Modelling. arXiv 2020, arXiv:2101.00027. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership Inference Attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- Yeom, S.; Giacomelli, I.; Fredrikson, M.; Jha, S. Privacy risk in Machine Learning: Analyzing the connection to overfitting. In Proceedings of the 2018 IEEE 31st Computer Security Foundations Symposium (CSF), Oxford, UK, 9–12 July 2018; pp. 268–282. [Google Scholar]
- Sablayrolles, A.; Douze, M.; Schmid, C.; Ollivier, Y.; Jégou, H. White-box vs Black-box: Bayes Optimal Strategies for Membership Inference. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Birmingham, UK, 2019; Volume 97, pp. 5558–5567. [Google Scholar]
- Jayaraman, B.; Wang, L.; Knipmeyer, K.; Gu, Q.; Evans, D. Revisiting Membership Inference Under Realistic Assumptions. Priv. Enhancing Technol. 2020, 2021, 348–368. [Google Scholar] [CrossRef]
- Song, L.; Mittal, P. Systematic Evaluation of Privacy Risks of Machine Learning Models. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Vancouver, BC, Canada, 11–13 August 2021; USENIX Association: Berkeley, CA, USA, 2021; pp. 2615–2632. [Google Scholar]
- Long, Y.; Wang, L.; Bu, D.; Bindschaedler, V.; Wang, X.; Tang, H.; Gunter, C.A.; Chen, K. A Pragmatic Approach to Membership Inferences on Machine Learning Models. In Proceedings of the 5th IEEE European Symposium on Security and Privacy, Euro S and P, Genoa, Italy, 7–11 September 2020; pp. 521–534. [Google Scholar]
- Watson, L.; Guo, C.; Cormode, G.; Sablayrolles, A. On the Importance of Difficulty Calibration in Membership Inference Attacks. arXiv 2022, arXiv:2111.08440. [Google Scholar]
- Ye, J.; Maddi, A.; Murakonda, S.K.; Bindschaedler, V.; Shokri, R. Enhanced Membership Inference Attacks against Machine Learning Models. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, Los Angeles, CA, USA, 7–11 November 2022; Association for Computing Machinery (ACM): New York, NY, USA, 2022; pp. 3093–3106. [Google Scholar]
- Zarifzadeh, S.; Liu, P.; Shokri, R. Low-Cost High-Power Membership Inference Attacks. Int. Conf. Mach. Learn. (ICML) 2024, 2403, 39. [Google Scholar]
- Bertran, M.; Tang, S.; Kearns, M.; Morgenstern, J.; Roth, A.; Wu, Z.S. Scalable membership inference attacks via quantile regression. In Proceedings of the 37th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024. NIPS ’23. [Google Scholar]
- Merity, S.; Xiong, C.; Bradbury, J.; Socher, R. Pointer Sentinel Mixture Models. arXiv 2017, arXiv:1609.07843. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Rezaei, S.; Liu, X. On the Difficulty of Membership Inference Attacks. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 7888–7896. [Google Scholar]
- Dhillon, G.S.; Chaudhari, P.; Ravichandran, A.; Soatto, S. A Baseline for Few-Shot Image Classification. arXiv 2020, arXiv:1909.02729. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Schwartz, E.; Karlinsky, L.; Shtok, J.; Harary, S.; Marder, M.; Kumar, A.; Feris, R.; Giryes, R.; Bronstein, A. Delta-encoder: An effective sample synthesis method for few-shot object recognition. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Hariharan, B.; Girshick, R. Low-Shot Visual Recognition by Shrinking and Hallucinating Features. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3037–3046. [Google Scholar]
- Ye, H.J.; Hu, H.; Zhan, D.C.; Sha, F. Few-Shot Learning via Embedding Adaptation with Set-to-Set Functions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8805–8814. [Google Scholar]
- Liu, J.; Song, L.; Qin, Y. Prototype Rectification for Few-Shot Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Ziko, I.M.; Dolz, J.; Granger, É.; Ayed, I.B. Laplacian Regularized Few-Shot Learning. arXiv 2020, arXiv:2006.15486. [Google Scholar]
- Boudiaf, M.; Ziko, I.; Rony, J.; Dolz, J.; Piantanida, P.; Ayed, I. Information Maximization for Few-Shot Learning. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 2445–2457. [Google Scholar]
- Hu, H.; Salcic, Z.; Sun, L.; Dobbie, G.; Yu, P.S.; Zhang, X. Membership Inference Attacks on Machine Learning: A Survey. ACM Comput. Surv. 2022, 54, 37. [Google Scholar] [CrossRef]
- Tang, J.; Korolova, A.; Bai, X.; Wang, X.; Wang, X. Privacy Loss in Apple’s Implementation of Differential Privacy on MacOS 10.12. arXiv 2017, arXiv:1709.02753. [Google Scholar]
- Garfinkel, S.; Abowd, J.M.; Martindale, C. Understanding database reconstruction attacks on public data. Commun. ACM 2019, 62, 46–53. [Google Scholar] [CrossRef]
- Bertran, M.; Tang, S.; Kearns, M.; Morgenstern, J.; Roth, A.; Wu, Z.S. Reconstruction Attacks on Machine Unlearning: Simple Models are Vulnerable. In Advances in Neural Information Processing Systems; Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2024; Volume 37, pp. 104995–105016. [Google Scholar]
- Panchendrarajan, R.; Bhoi, S. Dataset reconstruction attack against language models. In Proceedings of the CEUR Workshop, Online, 13–15 December 2021. [Google Scholar]
- Carlini, N.; Tramer, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; Roberts, A.; Brown, T.; Song, D.; Erlingsson, U.; et al. Extracting training data from large language models. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Vancouver, BC, Canada, 11–13 August 2021; pp. 2633–2650. [Google Scholar]
- Wang, Y.; Chao, W.L.; Weinberger, K.Q.; Van Der Maaten, L. Simpleshot: Revisiting nearest-neighbor classification for few-shot learning. arXiv 2019, arXiv:1911.04623. [Google Scholar]
- Tramèr, F.; Shokri, R.; San Joaquin, A.; Le, H.; Jagielski, M.; Hong, S.; Carlini, N. Truth Serum: Poisoning Machine Learning Models to Reveal Their Secrets. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, Los Angeles, CA, USA, 7–11 November 2022; pp. 2779–2792. [Google Scholar]
- Carlini, N.; Tramèr, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; Roberts, A.; Brown, T.B.; Song, D.X.; Erlingsson, Ú.; et al. Extracting Training Data from Large Language Models. In Proceedings of the USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Metsis, V.; Androutsopoulos, I.; Paliouras, G. Spam filtering with naive bayes-which naive bayes? In Proceedings of the Conference on Email and Anti-Spam, Mountain View, CA, USA, 27–28 July 2006; Volume 17, pp. 28–69. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features From Tiny Images; Technical report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Solaiman, I.; Brundage, M.; Clark, J.; Askell, A.; Herbert-Voss, A.; Wu, J.; Radford, A.; Krueger, G.; Kim, J.W.; Kreps, S.; et al. Release strategies and the social impacts of language models. arXiv 2019, arXiv:1908.09203. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TPR at 0.001% FPR | TPR at 0.1% FPR | |||||
|---|---|---|---|---|---|---|
| Method | C-10 | C-100 | WT103 | C-10 | C-100 | WT103 |
| Yeom et al. [23] | 0% | 0% | 0% | 0% | 0% | 0% |
| Shokri et al. [22] | 0% | 0% | - | 0.3% | 1.6% | - |
| Jayaraman et al. [25] | 0% | 0% | - | 0% | 0% | - |
| Song and Mitall [26] | 0% | 0% | - | 0.1% | 1.4% | - |
| Sablayrolles et al. [24] | 0.1% | 0.8% | 0.01% | 1.7% | 7.4% | 1% |
| Long et al. [27] | 0% | 0% | - | 2.2% | 4.7% | - |
| Watson et al. [28] | 0.1% | 0.9% | 0.02% | 1.3% | 5.4% | 1.10% |
| Carlini et al. [14] | 2.2% | 11.2% | 0.09% | 8.4% | 27.6% | 1.40% |
 ; otherwise, there is no privacy leakage. For the CIFAR datasets (C-10 and C-100), the smallest non-zero value in the TP log-ratio is = 0.07, and, for WikiText (WT-103), it is = 0.06. Note that, in these datasets, 0.001% FPR is the same as 0 FP. Missing values mean that the attack cannot be applied.
; otherwise, there is no privacy leakage. For the CIFAR datasets (C-10 and C-100), the smallest non-zero value in the TP log-ratio is = 0.07, and, for WikiText (WT-103), it is = 0.06. Note that, in these datasets, 0.001% FPR is the same as 0 FP. Missing values mean that the attack cannot be applied.
; otherwise, there is no privacy leakage. For the CIFAR datasets (C-10 and C-100), the smallest non-zero value in the TP log-ratio is = 0.07, and, for WikiText (WT-103), it is = 0.06. Note that, in these datasets, 0.001% FPR is the same as 0 FP. Missing values mean that the attack cannot be applied.
; otherwise, there is no privacy leakage. For the CIFAR datasets (C-10 and C-100), the smallest non-zero value in the TP log-ratio is = 0.07, and, for WikiText (WT-103), it is = 0.06. Note that, in these datasets, 0.001% FPR is the same as 0 FP. Missing values mean that the attack cannot be applied.| TPR at 0.001% FPR | Regime A | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | C-10 | C-100 | WT103 | C-10 | C-100 | WT103 | |||
| Yeom et al. [23] | 0.0% | 0.0% | 0.00% | 0.00 | 0.00 | 0.00 | |||
| Shokri et al. [22] | 0.0% | 0.0% | - | 0.00 | 0.00 | - | |||
| Jayaraman et al. [25] | 0.0% | 0.0% | - | 0.00 | 0.00 | - | |||
| Song and Mitall [26] | 0.0% | 0.0% | - | 0.00 | 0.00 | - | |||
| Sablayrolles et al. [24] | 0.1% | 0.8% | 0.01% | | 0.32 | | 0.52 | | 0.17 |
| Long et al. [27] | 0.0% | 0.0% | - | 0.00 | 0.00 | - | |||
| Watson et al. [28] | 0.1% | 0.9% | 0.02% | | 0.32 | | 0.54 | | 0.22 |
| Carlini et al. [14] | 2.2% | 11.2% | 0.09% | | 0.62 | | 0.78 | | 0.35 |
, and moderate privacy leakages are marked with  ; otherwise, there is no privacy leakage. For the CIFAR datasets (C-10 and C-100), the Regime B interval is [ = 0.068, = 0.245), and, for WikiText (WT-103), it is [ = 0.053, = 0.211). Missing values mean that the attack cannot be applied.
, and moderate privacy leakages are marked with ; otherwise, there is no privacy leakage. For the CIFAR datasets (C-10 and C-100), the Regime B interval is [ = 0.068, = 0.245), and, for WikiText (WT-103), it is [ = 0.053, = 0.211). Missing values mean that the attack cannot be applied.
; otherwise, there is no privacy leakage. For the CIFAR datasets (C-10 and C-100), the Regime B interval is [ = 0.068, = 0.245), and, for WikiText (WT-103), it is [ = 0.053, = 0.211). Missing values mean that the attack cannot be applied.
, and moderate privacy leakages are marked with ; otherwise, there is no privacy leakage. For the CIFAR datasets (C-10 and C-100), the Regime B interval is [ = 0.068, = 0.245), and, for WikiText (WT-103), it is [ = 0.053, = 0.211). Missing values mean that the attack cannot be applied.| TPR at 0.1% FPR | Regime B | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | C-10 | C-100 | WT103 | C-10 | C-100 | WT103 | |||
| Yeom et al. [23] | 0.0% | 0.0% | 0.1% | 0.000 | 0.000 | | 0.206 | ||
| Shokri et al. [22] | 0.3% | 1.6% | - | | 0.339 | | 0.502 | - | |
| Jayaraman et al. [25] | 0.0% | 0.0% | - | 0.000 | 0.000 | - | |||
| Song and Mitall [26] | 0.1% | 1.5% | - | | 0.237 | | 0.495 | - | |
| Sablayrolles et al. [24] | 1.7% | 7.4% | 1.0% | | 0.516 | | 0.667 | | 0.400 |
| Long et al. [27] | 2.2% | 4.7% | - | | 0.533 | | 0.608 | - | |
| Watson et al. [28] | 1.3% | 5.4% | 1.1% | | 0.492 | | 0.643 | | 0.421 |
| Carlini et al. [14] | 8.4% | 27.6% | 1.4% | | 0.698 | | 0.829 | | 0.492 |
; otherwise, there is no privacy leakage. For our attacks, the smallest non-zero value in the TP log-ratio is = 0.25 for all datasets. For other attacks, on the CIFAR datasets (C-10 and C-100), it is = 0.07, and, on WikiText (WT-103), it is = 0.06.
; otherwise, there is no privacy leakage. For our attacks, the smallest non-zero value in the TP log-ratio is = 0.25 for all datasets. For other attacks, on the CIFAR datasets (C-10 and C-100), it is = 0.07, and, on WikiText (WT-103), it is = 0.06.| Regime A | ||||||
|---|---|---|---|---|---|---|
| Method | C-10 | C-100 | WT103 | |||
| Sablayrolles et al. [24] | | 0.32 | | 0.52 | | 0.17 |
| Watson et al. [28] | | 0.32 | | 0.54 | | 0.22 |
| Carlini et al. [14] | | 0.62 | | 0.78 | | 0.35 |
| FeS-MIA TT 1-shot | 0.17 ± 0.02 | 0.16 ± 0.02 | 0.18 ± 0.02 | |||
| FeS-MIA TT 5-shots | 0.18 ± 0.02 | 0.17 ± 0.02 | 0.19 ± 0.02 | |||
| FeS-MIA TT 10-shots | 0.18 ± 0.02 | 0.18 ± 0.02 | 0.19 ± 0.02 | |||
| FeS-MIA SS 1-shot | 0.00 ± 0.00 | 0.00 ± 0.00 | 0.00 ± 0.00 | |||
| FeS-MIA SS 5-shots | 0.18 ± 0.02 | 0.17 ± 0.02 | 0.17 ± 0.02 | |||
| FeS-MIA SS 10-shots | 0.18 ± 0.02 | 0.18 ± 0.02 | 0.18 ± 0.02 | |||
| FeS-MIA LS 1-shot | 0.13 ± 0.02 | 0.12 ± 0.02 | 0.00 ± 0.00 | |||
| FeS-MIA LS 5-shots | 0.15 ± 0.02 | 0.14 ± 0.02 | 0.00 ± 0.00 | |||
| FeS-MIA LS 10-shots | 0.16 ± 0.03 | 0.14 ± 0.03 | 0.00 ± 0.00 | |||
, and moderate privacy leakages are marked with ; otherwise, there is no privacy leakage. For our attacks, the Regime B interval is [ = 0.25, = 0.58) for all datasets. For other attacks, the interval on the CIFAR datasets (C-10 and C-100) is [ = 0.068, = 0.245), and, on WikiText (WT-103), it is [ = 0.053, = 0.211).
, and moderate privacy leakages are marked with ; otherwise, there is no privacy leakage. For our attacks, the Regime B interval is [ = 0.25, = 0.58) for all datasets. For other attacks, the interval on the CIFAR datasets (C-10 and C-100) is [ = 0.068, = 0.245), and, on WikiText (WT-103), it is [ = 0.053, = 0.211).| Regime B | ||||||
|---|---|---|---|---|---|---|
| Method | C-10 | C-100 | WT103 | |||
| Sablayrolles et al. [24] | | 0.516 | | 0.667 | | 0.400 |
| Watson et al. [28] | | 0.492 | | 0.643 | | 0.421 |
| Carlini et al. [14] | | 0.698 | | 0.829 | | 0.492 |
| FeS-MIA TT 1-shot | | 0.59 ± 0.01 | | 0.58 ± 0.02 | | 0.58 ± 0.02 |
| FeS-MIA TT 5-shot | | 0.60 ± 0.01 | | 0.59 ± 0.02 | | 0.59 ± 0.02 |
| FeS-MIA TT 10-shot | | 0.59 ± 0.02 | | 0.58 ± 0.02 | | 0.60 ± 0.02 |
| FeS-MIA SS 1-shot | 0.00 ± 0.00 | 0.00 ± 0.00 | 0.00 ± 0.00 | |||
| FeS-MIA SS 5-shot | | 0.59 ± 0.02 | | 0.58 ± 0.02 | | 0.57 ± 0.02 |
| FeS-MIA SS 10-shot | | 0.60 ± 0.02 | | 0.59 ± 0.02 | | 0.58 ± 0.02 |
| FeS-MIA LS 1-shot | | 0.44 ± 0.03 | | 0.44 ± 0.03 | 0.00 ± 0.00 | |
| FeS-MIA LS 5-shot | | 0.52 ± 0.02 | | 0.47 ± 0.02 | 0.00 ± 0.00 | |
| FeS-MIA LS 10-shot | | 0.54 ± 0.02 | | 0.45 ± 0.03 | 0.00 ± 0.00 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiménez-López, D.; Rodríguez-Barroso, N.; Luzón, M.V.; Del Ser, J.; Herrera, F. Membership Inference Attacks Fueled by Few-Shot Learning to Detect Privacy Leakage and Address Data Integrity. Mach. Learn. Knowl. Extr. 2025, 7, 43. https://doi.org/10.3390/make7020043
Jiménez-López D, Rodríguez-Barroso N, Luzón MV, Del Ser J, Herrera F. Membership Inference Attacks Fueled by Few-Shot Learning to Detect Privacy Leakage and Address Data Integrity. Machine Learning and Knowledge Extraction. 2025; 7(2):43. https://doi.org/10.3390/make7020043
Chicago/Turabian StyleJiménez-López, Daniel, Nuria Rodríguez-Barroso, M. Victoria Luzón, Javier Del Ser, and Francisco Herrera. 2025. "Membership Inference Attacks Fueled by Few-Shot Learning to Detect Privacy Leakage and Address Data Integrity" Machine Learning and Knowledge Extraction 7, no. 2: 43. https://doi.org/10.3390/make7020043
APA StyleJiménez-López, D., Rodríguez-Barroso, N., Luzón, M. V., Del Ser, J., & Herrera, F. (2025). Membership Inference Attacks Fueled by Few-Shot Learning to Detect Privacy Leakage and Address Data Integrity. Machine Learning and Knowledge Extraction, 7(2), 43. https://doi.org/10.3390/make7020043