1. Introduction
The widespread impact of language models is undeniable. The surge in popularity of models such as GPT (Generative Pre-trained Transformer) was notably driven by the launch of ChatGPT-3.5 in November 2022, based on the GPT-3 and subsequently GPT-4 models. Within a few months, major technology companies introduced their own applications: Microsoft Copilot, Google Bard, and Meta’s Llama (used across Facebook, Instagram, etc.). These NLP models are trained on millions of texts available online. Despite their impressive generalization capabilities, their use has certain technical limitations [
1]. The possibilities for industrial applications are numerous, and the need for such tools for Industry 4.0/5.0 is clear. The ability to process and analyze technical texts efficiently is fundamental to these applications. However, adapting NLP techniques to deal with texts that often deviate from the syntactic and semantic rules of standard language presents significant challenges. This research addresses these issues by integrating NLP methodologies with reliability engineering techniques, particularly FMEA [
2], to develop a robust methodology to train a NER model. The aim is to accurately identify and classify equipment, components, failure modes, and degradation mechanisms in maintenance work orders to improve the automation and reliability of information extraction in industrial contexts. In many organizations, maintenance data, particularly work orders, are recorded in Enterprise Resource Planning (ERP) systems. The quality of maintenance data is often challenged [
3,
4] and its validation primarily relies on the extraction of text fields describing the observed issues and the repairs performed. These descriptions are often jargon-rich, sometimes specific to language and regionalism, and therefore depart from standard linguistic conventions. Unlike natural language, technical texts often contain irregular sentence structures, abbreviations, acronyms, and domain-specific terminology. These characteristics pose major obstacles for conventional NLP techniques. However, FMEA is a well-established systematic approach commonly used in engineering to identify potential failure modes within a system and assess their impact. Many asset-intensive companies have long utilized FMEA techniques, making relevant data readily available. By integrating the principles of FMEA with NLP techniques, there is an opportunity to take advantage of domain-specific knowledge and improve the accuracy and relevance of text analysis in industrial environments.
Despite the growing interest in NLP applications, limited research has been conducted to develop methodologies specifically tailored for the handling of technical texts within industrial contexts. Existing models often struggle to handle the peculiarities of technical language, leading to suboptimal performance and restricted real-world applicability. In addition, annotation remains costly and inconsistent due to domain-specific terminology and a lack of labeled data. At the same time, organizations often maintain structured expert knowledge in the form of FMEA tables. Despite this, such information is rarely used to support or automate NLP annotation tasks. This represents a critical and underexplored opportunity to reduce manual effort and improve consistency in industrial NER tasks, especially in safety-critical or large-scale maintenance contexts. This study seeks to address these issues through the following methods:
Using real maintenance data from an electrical utility.
Investigating the linguistic characteristics of maintenance texts in power systems.
Proposing a new methodology that combines FMEA knowledge with state-of-the-art NLP techniques to improve the identification and classification of components and failure modes in technical documents.
Developing and evaluating a specialized NER model trained on annotated datasets sourced from industrial contexts.
The proposition of this research is that by integrating reliability engineering principles with advanced NLP techniques, a robust and efficient methodology can be developed to adapt NER models to recognize and classify components and failure modes in technical texts. This work significantly improves the automation and accuracy of information extraction processes that are essential to guarantee the reliability and safety of industrial operations.
Section 2 presents a brief review of the literature and describes NLP techniques and tasks.
Section 3 describes the methodology developed in this work and
Section 4 and
Section 5 present, respectively, the case study and a discussion of the results obtained from the analysis, followed by a conclusion in
Section 6.
3. Methodological Approach
The previous sections introduced the applications and methods used to develop a NLP model. First, this section explains how the model is implemented and validated for the following case study. Then, it presents the step-by-step process to develop a custom NER model, exploring how it can benefit from using FMEA documentation.
3.1. Implementation and Validation
This section outlines the experimental framework, including the tools used, the selection of metrics for evaluation, and the validation procedures. By carefully defining our experimental setup, we intend to provide reproducible and meaningful information about the capabilities and limitations of our approach. The development was carried out on the Azure DataBricks platform, a cloud-based analytics solution that combines Apache Spark-based processing with Azure cloud services. Programming is carried out using PySpark, the Python API for Spark. The library used for modeling is Spark NLP, and the Spacy and NLTK libraries were used primarily for preprocessing and exploratory analysis. The modeling and validation results were recorded using ML Flow. Versions of the tools used during the experiments are as follow:
Model training and validation are generated directly in the Spark NLP pipeline. The hyperparameters controlled are as follows:
The training and validation log records the number of true positives, false positives, false negatives, precision, recall, and F1 score for each of the entities identified. In summary, precision is the proportion of true positives over all positive instances, while recall is the proportion of true positives over all correctly classified instances. The F1 score is simply the armonic mean of precision and recall. The program also stores overall values and the macro- and micro-averages. These measurements are available for the training sample and the validation sample for each epoch.
3.2. General Methodology Overview
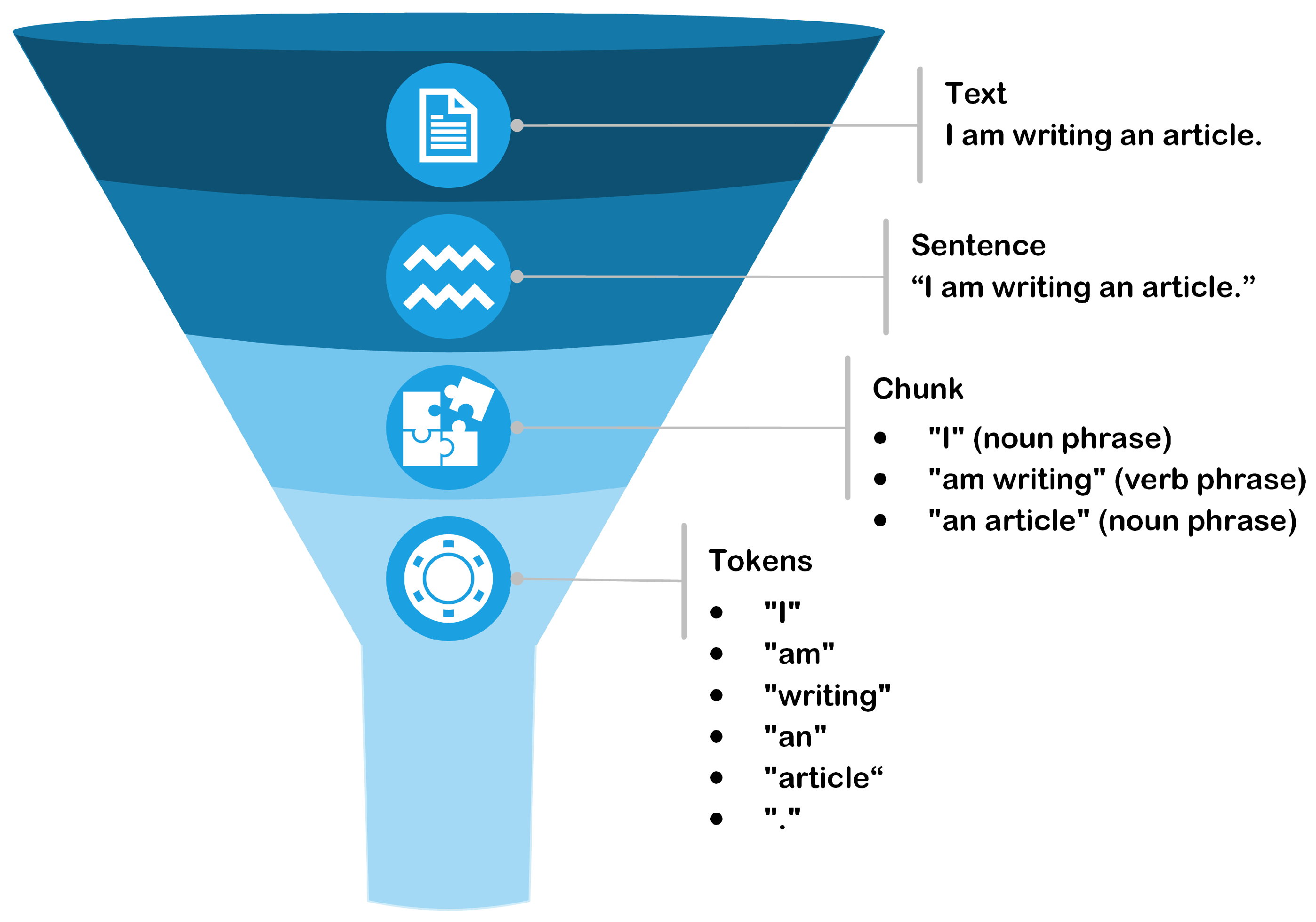
Developing a custom NER model is very similar to developing a standard supervised learning model. The first step is to gather a labeled dataset. In this case, this requires an annotated dataset; that is, text instances where the entities are already correctly identified. In the case of Spark NLP, the training data must be in CoNLL-2003 format. Then, as mentioned above, the dataset is separated into training and validation samples.
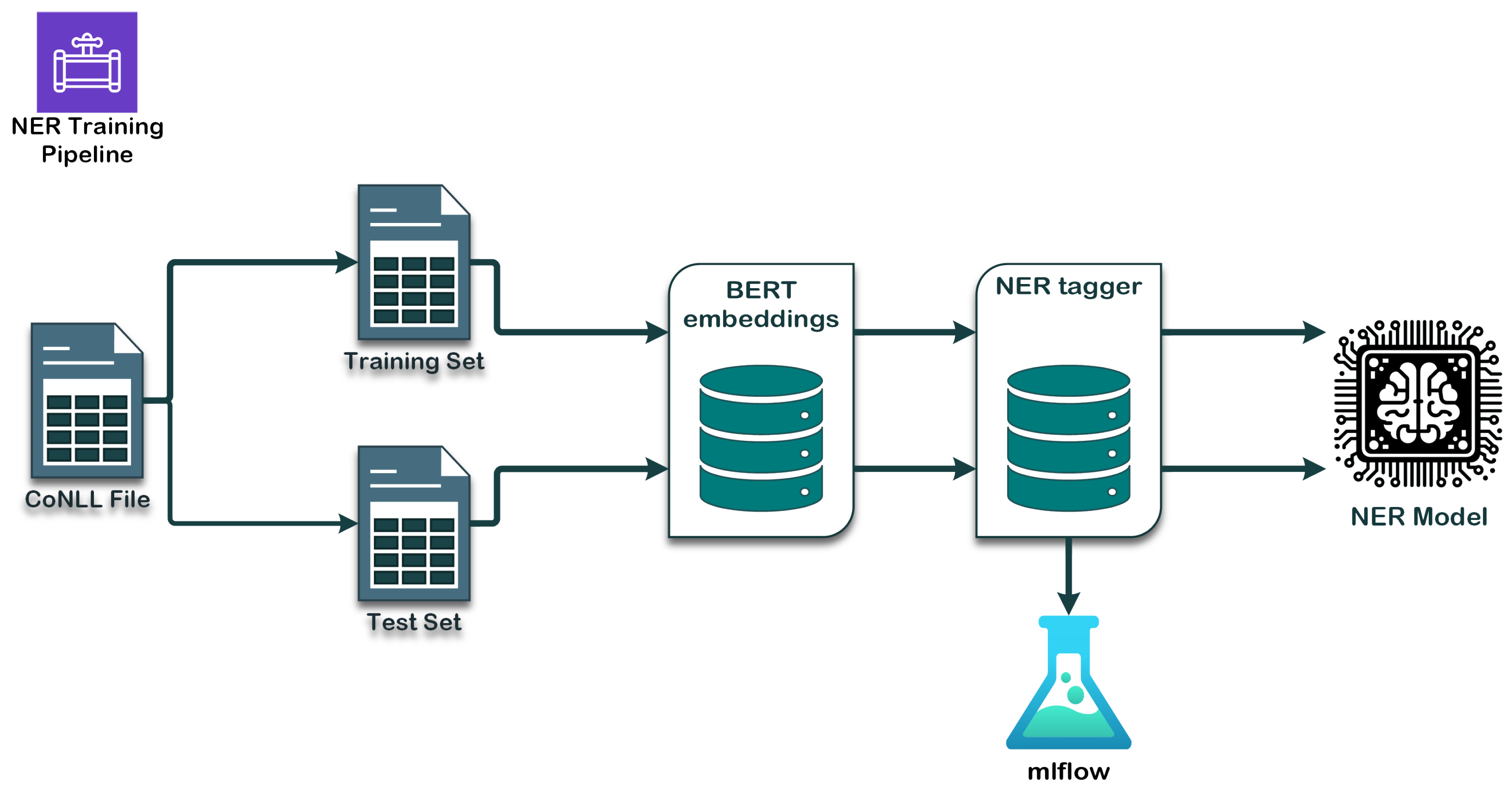
Figure 2 details the general approach:
The training and validation sets pass through a BERT component, which enables all the preprocessing (tokenization, word embedding, etc.) to be carried out directly, and then the vectors are pushed into a NER tagger. In Spark NLP, this is referred to as an NER annotator, and the one used in this project is the NerDL Approach. This annotator has a neural network architecture of Char CNNs- BiLSTM-CRF, which stands for Character-level Convolutional Neural Networks, Bidirectional Long Short-Term Memory, and Conditional Random Field. It combines several neural network structures, making learning easier in tasks such as entity recognition. In summary, the NER annotator is used to identify and classify entities (equipment, components, failure modes, etc.) in the text, and uses a deep learning framework to learn from the examples sent. These simple steps make it easy to define and evaluate a NER model that can be reused for other NLP applications, such as information extraction or text classification. With this framework, entity classification is context sensitive, meaning that a single term can be assigned different labels based on its usage within a sentence. This is mainly due to the use of contextualized embeddings, in this case a French BERT model, and the quality of the training data. Accurate labeling relies on both the richness of the training data and the use of BIO (Beginning, Inside, Outside) tagging in the CoNLL format, which allows the model to learn both single- and multi-token entities. For example, in the phrase ‘The power transformer is an asset’, the model tags ‘power’ as B-EQUIPMENT and ‘transformer’ as I-EQUIPMENT, allowing recognition of ‘power transformer’ as a complete entity. The model performs well when trained on diverse, well-annotated examples but struggles with unseen or infrequent terms.
3.3. FMEA for Token Classification
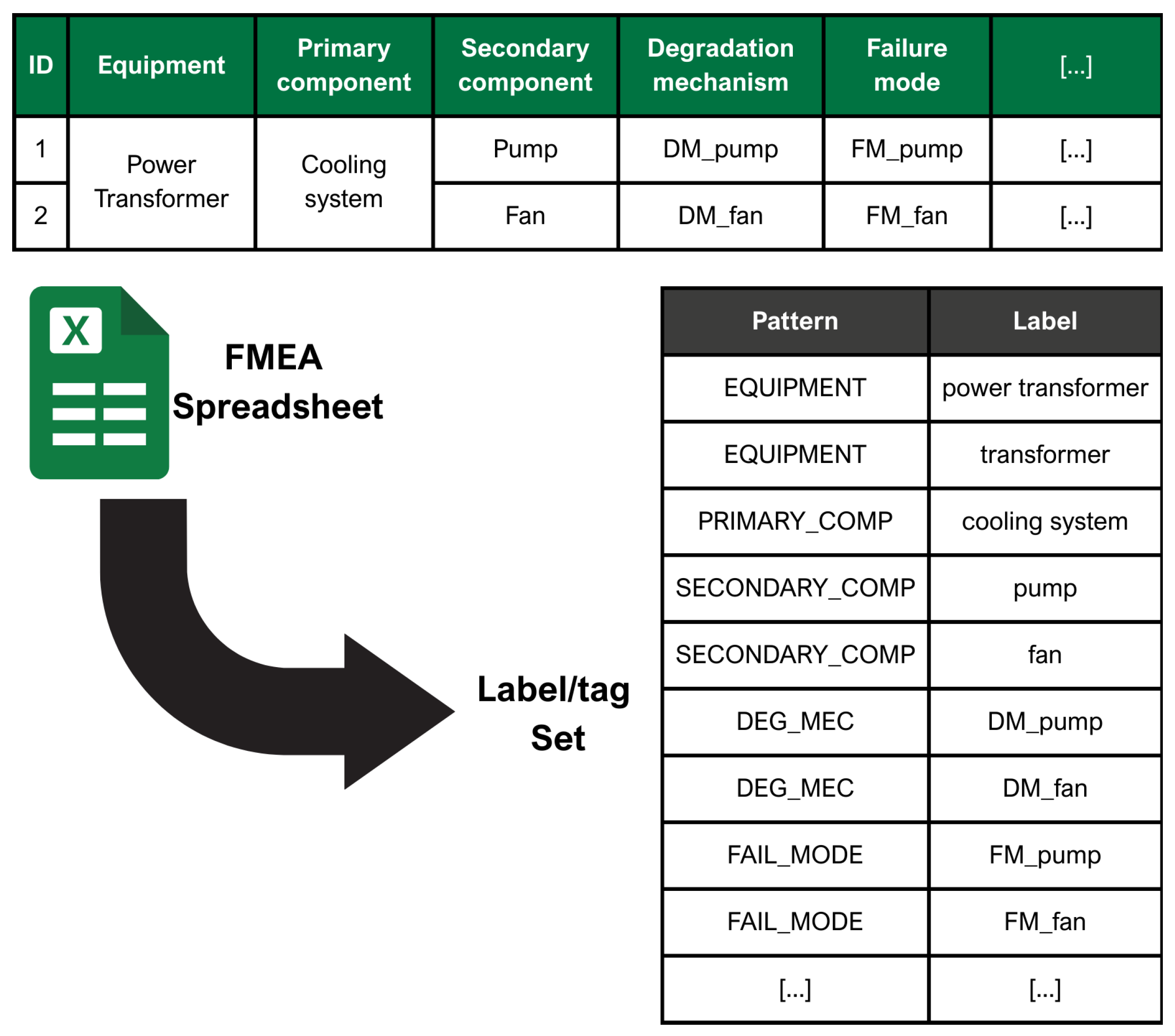
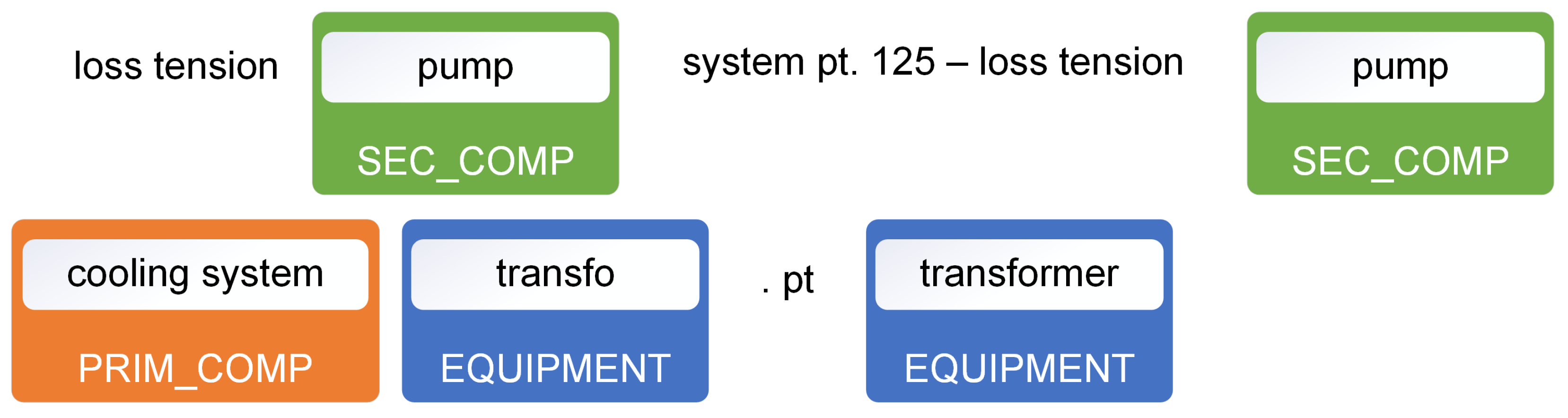
As mentioned in the previous section, modeling requires a labeled dataset. There are several sources for finding this kind of dataset, but they are generally adapted to generic entity types (e.g., location, company name, date, etc.). For this project, it was therefore necessary to generate a context-specific dataset. The first step was to collect the data from the FMEA and to extract their general structure for the target equipment, as shown in
Figure 3.
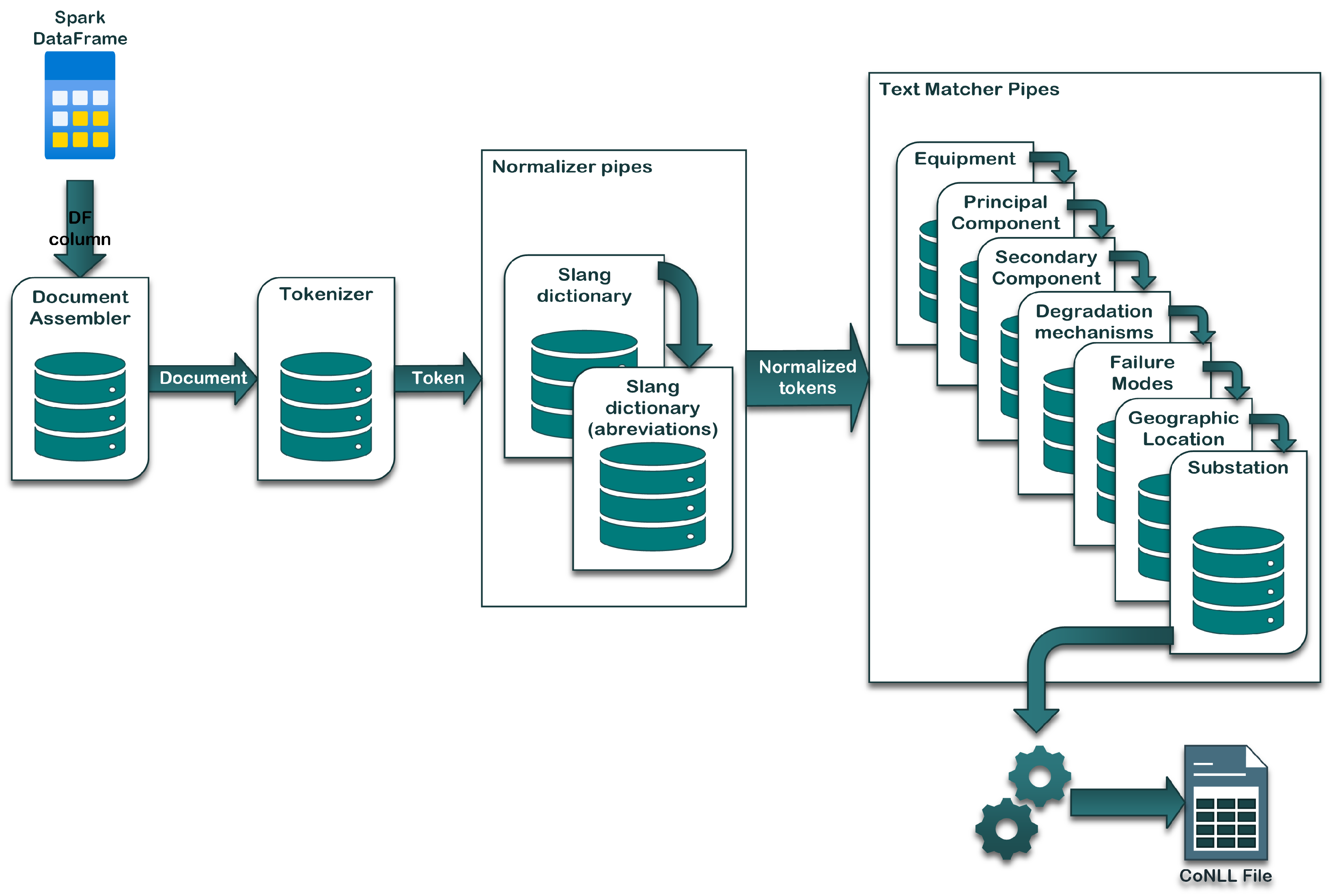
The FMEA for each asset is developed and periodically reviewed by expert committees in accordance with IEC standards, using technical specifications and equipment documentation. The structure of the FMEA aligns with the component hierarchies, degradation mechanisms, and failure modes defined within the proprietary catalogs of the organization’s maintenance ERP system. These catalogs also provide default classifications for failures of unknown origin or cases that cannot be precisely categorized. Maintenance technicians document work activities through structured forms that include both predefined fields (e.g., drop-down menus) and unstructured free text entries. Through straightforward operations, the information from the FMEA spreadsheets can be utilized to construct a table that links all maintenance-related terms with a list of entities. The maintenance work order texts can now be annotated with pattern-matching techniques using this table. In practice, this means finding an exact correspondance of the terms within the list, e.g., ‘transformer’, and assigning it a label, in this case ‘EQUIPMENT’. In this way, terms are identified and classified according to the same groupings as in the FMEA.
5. Results and Discussion
This section presents the results of the case study, applying the methodology introduced earlier. Using data from substation equipment and its FMEA, the study analyzes model training and validation, showcasing entity recognition in maintenance data to highlight model robustness. The study aims to develop and test a text annotation methodology based on FMEA, demonstrating its relevance and effectiveness. The model was trained on maintenance orders from 2010 to 2017, a range selected to support future analyses while keeping the data current. The work orders were filtered for uniqueness and textual completeness. The dataset includes over 15,000 work orders, with 30% used for testing. In total, more than 50,000 examples were used for training, with 20% reserved for validation.
Figure 5 shows an example of a maintenance text that has been annotated using the NER model.
Figure 6 shows the evolution of the macromean recall over training cycles, for the validation and test sample. The analysis of the curves shows that average recall increases rapidly over the first few training cycles and, after around five cycles, performance begins to stabilize. This indicates convergence of the model. The performance observed on the test sample indicates an excellent ability to generalize to new data. In the case of overlearning, a decrease in performance on the validation set would have been observed, which is not the case here. Furthermore, this chart demonstrates the model’s good performance, both in training and on new data.
Once training, validation, and testing had been completed, the results were analyzed to determine whether the model had a good ability to identify and classify entities in the text.
Table 6 presents the overall results of the performance of the model after 10 epochs.
Initially, the entity recognition model generally demonstrates excellent performance, as shown by the high micro-average statistics for the F1 score, recall, and accuracy. However, the macro-average shows that there seems to be an imbalance between precision and recall, indicating that there may be some variability in performance between classes (entities). Looking at the detailed statistics for each class, we can see that the entities corresponding to geographical location and electrical substation (location), as well as degradation mechanisms, are the categories with the lowest scores. However, the results concerning the location class still show that the model is performing really well, with an F1 score of 0.86, with good balance between precision and recall.
Table 7 shows the detailed statistics for the test sample and for each type of entity.
For degradation mechanisms, precision is relatively low, as is recall. This class is also underrepresented compared to the other entities in the training and test samples, which probably explains its poor performance. This result suggests that the accuracy of the model could be improved by working on this class. There are several ways that could be employed to achieve better results: adding synonyms or different formulations used to define degradation mechanisms would be a good starting point. Another iteration of improving the dictionaries, with a particular focus on these terms, would also be an interesting avenue. Alternatively, it would also be beneficial to resample to increase the dataset so that it contains a higher proportion of text containing this type of entity, or simply by extending the analysis range over a few more years. In the event that these options do not work, this class could also be removed from the NER model, as its precision is highly unreliable at 50%. Apart from the poor results for the degradation mechanism class, the rest of the entities are generally well classified, and the model’s performance is excellent.
Thus, it is clear that with this annotation method, the ability of NLP models to understand technical texts is increased. As mentioned in the literature, applying NLP techniques without adapting them to the context leads to doubtful results. The methodology developed enables the extraction of information in a reliable and rigorous way by reusing knowledge sources already available within the organization. One of the challenges in applying ML techniques to such data is the quality and quantity of available data. With this new annotation technique, the process of creating a dataset, and therefore NLP models, is simplified. The use of existing expertise is not limited to FMEAs, but the methodology can be extended to other analysis techniques that aim to decompose a system and its relationships. However, there are some limitations; as the case study demonstrated, some entities may not be sufficiently referenced in the text, making it difficult to obtain a reliable model to discriminate between them. In addition, when extracting the data, a difference in notation and writing has been noticed, particularly when changes have been made to the company’s IT systems; this can result in the use of acronyms that have changed over time, or references to a codification that is not cataloged in any accessible documentation.
Ultimately, the models generated from the methodology will provide a means of including these elements in much more complex NLP pipelines. In fact, NER models are essential components in understanding text for many NLP applications. These models would thus benefit from being employed to perform text classification, for example, to classify the types of activity that have been carried out on a particular equipment item, to extract knowledge from the text by listing the components and equipment involved in a maintenance job, and much more.
Implications and Generalization
While this methodology was developed within the context of electrical utility maintenance, its core principles of leveraging structured documentation (FMEA) for text annotation can be extended to other technical domains. These include the following:
Aviation: Maintenance logs or incident reports could be analyzed using fault tree or root cause analyses.
Automotive: Vehicle diagnostics or warranty claim data annotated from repair manuals.
Oil and Gas: Risk assessments or pipeline inspection reports leveraging hazard analysis methods (e.g., HAZOP).
These documents often contain detailed information about components, failure modes, and operational conditions, which can be transformed into annotated datasets, similarly to FMEA. The adaptability of the approach suggests a potential for broader application, particularly in industries that rely on structured data and unstructured maintenance records.
6. Conclusions
This study presents a novel methodology that integrates FMEA with NLP to improve the processing and analysis of technical maintenance texts. By extracting structured engineering knowledge from FMEA, a key challenge in industrial NLP applications was addressed: the lack of annotated data and the complexity of domain-specific terminology. Our approach enables the efficient creation of a custom NER model capable of accurately identifying and classifying entities such as equipment, components, failure modes, and degradation mechanisms within maintenance work orders. This FMEA-informed annotation process significantly reduces reliance on manual annotation while ensuring greater consistency and contextual relevance. A case study using substation equipment maintenance data from the Hydro-Québec transmission network (2010–2017) validated the methodology. The results show a strong model performance in the recognition of critical entities, demonstrating the practical benefits of combining reliability engineering tools with NLP. The method proved particularly effective in processing technical texts that deviate from standard linguistic norms, common in industrial contexts, thus reinforcing the importance of adapting NLP models to their operational environment. The key contributions of this research include the following:
Domain-Specific NLP Adaptation: A tailored approach for processing technical maintenance texts, often overlooked in standard NLP models.
Efficient Annotation Workflow: A scalable method for generating annotated datasets using existing documentation, improving speed and accuracy.
Improved Maintenance Data Quality: Enhanced extraction of structured insights from maintenance data, supporting better asset management decisions.
Cross-Disciplinary Innovation: A bridge between reliability engineering and AI, demonstrating how domain knowledge can enrich NLP applications.
Despite these strengths, a limitation remains in the ability to generate enough training data for the modeling process. In fact, even though there was a considerable amount of data, the texts themselves did not contain enough examples for some entity classes to provide adequate results. Furthermore, while the methodology is designed to be adaptable to other technical domains, its generalizability beyond the electrical utilities sector has not yet been tested. This should be addressed in future work, along with scaling up annotated datasets and exploring transfer learning to further improve model performance. Ultimately, this research lays the foundation for broader applications of NLP in industrial maintenance contexts. In fact, the advantage of developing annotated models adapted to technical texts is that they can be reused in more advanced use cases like text classification, information extractions, etc.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}