1. Introduction
Non-negative Matrix Factorization (NMF) is a clustering and dimension reduction method that approximates a matrix as a product of two nonnegative components [
1]. Unlike similar techniques, NMF allows only additive combinations, leading to a parts-based representation. NMF has gained increasing attention due to its unique capability to provide interpretable results that are nonnegative, distinguishing it from other conventional subspace learning algorithms [
2]. This characteristic enables NMF to effectively capture the essence of intelligent data representation [
2]. While other dimension-reduction techniques like Singular Value Decomposition (SVD) [
3], Principal Component Analysis (PCA) [
4], and Independent Component Analysis (ICA) [
5] have been widely used, few of them offer a clear physical interpretation of their decomposition results. Studies suggest that human perception relies on interpreting objects as compositions of their fundamental additive parts [
6], aligning with NMF’s approach. However, traditional NMF methods struggle in the presence of noise, outliers, or when the underlying manifold structure of the data is ignored [
7].
To overcome the last problem, traditional linear subspace methods, such as PCA and Linear Discriminant Analysis (LDA), rely on Euclidean distance to measure similarities between samples. However, in datasets like the classic ‘Swiss roll’, Euclidean distance fails to capture the intrinsic data structure, providing misleading ‘shortcuts’ across the manifold. Instead, geodesic distance, which measures the shortest path along the manifold surface, offers a more accurate representation of pairwise relationships [
8]. Nonlinear techniques, like ISOMAP, Locally Linear Embedding (LLE), and Laplacian Eigenmap (LE), which use geodesic distance, assume an Euclidean embedding, resulting in a better similarity/distance calculation. Now consider a different curved manifold, the data placed on the surface of a sphere. They must be stretched to map onto a plane. There are two problems; first, we might still hope to find Euclidean embedding space, and, second, we can never find a distortion-free Euclidean embedding (in the sense that the distances will always have errors).
To address these limitations, researchers have integrated manifold learning into NMF by encoding data samples using graph structures, leading to improved data representation [
9]. Manifold learning assumes data exist within a complex structure, making traditional linear subspace methods ineffective for highly nonlinear datasets. To capture the local geometric information of the original data, Cai et al. [
10] introduced a graph regularization NMF (GNMF) approach. GNMF utilizes a nearest neighbor graph to represent the data’s geometric structure in a lower dimensional space and constructs a Laplacian graph to encode the local manifold structure of the data. This method has been used in almost all NMF methods to identify the intrinsic geometry of manifolds [
7,
10,
11].
Another constraint used in most NMF methods is the orthogonality of the basis vectors [
12]. This constraint also reduces redundancy [
13], enhances interpretability [
14], and improves discrimination representation [
15]. By imposing orthogonality on the basis vector, they are more likely to capture distinct and independent patterns while minimizing overlap in the information they represent. This results in learned components that are distinct, non-redundant, and better suited for separating different classes or categories in applications such as classification. Additionally, orthogonality provides a more compact and efficient representation of the data, making them easier to understand and interpret and useful for feature extraction or data compression.
Orthogonality constraints can also indirectly promote sparsity in the representation. When combined with non-negativity, the resulting components tend to have sparse and informative activations, leading to a more efficient and meaningful representation. However, the benefits of orthogonality constraints may vary depending on the specific problem and dataset.
Recently, data clustering has shifted from traditional centroid-based methods [
16] to subspace clustering [
17], where data points are grouped based on their tendency to form subspace structures [
18]. This approach is widely used in fields like computer vision, pattern recognition [
18], and bioinformatics [
19]. The goal is to transform high-dimensional data into a lower-dimensional space while preserving the maximum amount of information present in the original dataset. Typically, input data are represented in the form of vectors, matrices, or tensors. Subspace learning involves identifying an optimal transformation, whether linear or nonlinear, to project the input data into a lower-dimensional space.
To model data on curved manifolds in high-dimensional space, Riemannian manifold methods are used to capture complex nonlinear relationships. A Riemannian manifold is a differentiable manifold equipped with a Riemannian metric [
18], which defines smoothly varying inner products within the tangent spaces on the manifold. Therefore, in contrast to Euclidean distance, the Riemannian distance considers the curved path (geodesic) on the manifold itself, which depends on the Riemannian metric that defines the geometry of the manifold [
18,
20,
21,
22]. Two key manifolds in this framework are the Stiefel manifold and the Grassmann manifold. The Stiefel manifold St (D, d) consists of all D×d matrices with orthonormal columns (U ∈ R
D×d|U
TU = I
d) [
23]. This orthogonality minimizes redundancy, ensuring efficient subspace representation. The Stiefel manifold, as a Riemannian manifold, is widely used in spectral clustering, matrix factorization, and neural network training; preserving intrinsic high-dimensional data relationships is essential in various application areas, such as social networks and recommender systems.
Riemannian optimization provides an effective framework for solving nonlinear problems with structural constraints. By embedding properties like orthonormality, low-rankness, and positivity into the manifold’s geometry, it enables efficient enforcement of these constraints, which is difficult with classical methods. Unlike traditional optimization techniques (e.g., Alternating Least Squares (ALS) [
24], Multi-User Resource Scheduling (MURs) [
16], Alternating Direction Method of Multipliers (ADMM) [
25]), which may become trapped in local minima, Riemannian optimization offers better convergence guarantees.
Over the past two decades, various methods have been developed for manifold optimization. A notable instance is the work presented in [
23], which introduces a framework for optimizing functions on different matrix manifolds. Commonly employed algorithms include the Riemannian gradient descent and the Riemannian trust region. The trust-region method can linearly approximate local solutions in the tangent space at each iteration and, ultimately, converge to a globally nonlinear solution, often resulting in superior performance compared to the traditional Euclidean-based methods. These algorithms methods have been implemented in Python (version 3.11) as the “Pymanopt” (
https://pymanopt.org/) package and in MATLAB (R2015a) as the “ManOpt” (
https://www.manopt.org/) toolbox.
In this paper, we aim to develop a better representation of the original data and use it to infer a more accurate affinity/similarity matrix for the NMF decomposition algorithm. To achieve this, a strategy is employed that involves the transformation of the data from its original space to a Stiefel manifold space. By choosing this manifold, the basis vectors in the new subspace become orthonormal. This transformation is subsequently subjected to Riemannian manifold optimization. Naturally, Riemannian manifold optimization can reveal the nonlinear geometric structures of the high-dimensional data. This approach moves away from the traditional flat Euclidean space paradigm and instead formulates the optimization problem directly on the intricate curved manifold.
Subsequently, this methodology is extended to address low-rank nonnegative matrix factorization, leveraging the inherent low-rank structure of the transformed data. This transformation results in the data being expressed through a Frobenius norm computed from latent factors. Additionally, graph-based smoothness constraints are incorporated into the coefficient matrix to enhance robustness. This novel approach optimizes data representation on the Stiefel manifold, integrates low-rank structures, and reinforces stability using graph-based constraints.
The main contributions of this work are summarized as follows:
Learning improved representations of the original data and leveraging them to derive a more accurate affinity or similarity matrix. This is achieved by transforming the data from its original space into a Stiefel manifold orthonormal space and applying Riemannian manifold optimization to uncover the nonlinear geometric structures of the high-dimensional data that enable the extraction of more meaningful structural relationships.
Using the transformed Euclidean data matrix under the new subspace to identify the inherent geometric structure of the data, rather than deriving it directly from the original data, for use in NMF decomposition.
Numerous experiments on different datasets demonstrate that this method can enhance the clustering efficiency compared to the traditional NMF-based method.
However, in addition to the contributions of the proposed approach, the experiments indicate that it experiences a slightly longer execution time compared to previous methods.
Since the proposed approach applies Subspace Graph Regularization and a Riemannian-based trust region algorithm within the Non-negative Matrix Factorization framework, we have selected the abbreviated name SGRiT for this approach throughout this article. The remainder of this paper is structured as follows:
Section 2 provides a summary of related works,
Section 3 explains the SGRiT approach,
Section 4 discusses the experimental results, and
Section 5 presents conclusions and directions for future research
2. Related Work
To significantly enhance the performance of traditional Non-negative Matrix Factorization (NMF) methods, numerous algorithms have been proposed that incorporate additional constraints into the objective function. To ensure accurate orthogonality, Zhang et al. [
26] leverage the sparsity of non-negative orthogonal solutions. They decompose the overall problem into a series of local optimizations, effectively simplifying the process. Other algorithms, such as Orthogonal Non-negative Matrix Factorization (ONMF) [
27,
28,
29], reduce redundancy in data representation by imposing orthogonality constraints on the factor matrices.
The orthogonality constraints effectively define a specific subset within a larger space known as the Stiefel manifold. Choi et al. [
30,
31] utilize the natural gradient method within this Stiefel submanifold to enhance computational efficiency in implementing ONMF. Robust NMF (RNMF), for example, operates under the assumption that corrupted data entries are sparsely distributed and impose sparsity constraints on the residual matrix. Building on RNMF, Févotte et al. [
32] incorporate a group-sparse outlier residual term to address potential nonlinear effects, resulting in Group Robust Non-negative Matrix Factorization (GRNMF).
As the concept of Semi-NMF gains popularity, Zhang et al. [
33] relax the non-negativity constraints on the basis matrix. This leads to the development of an efficient orthogonal Semi-NMF algorithm that continues to operate within the context of the Stiefel manifold. A significant amount of research has been dedicated to enhancing clustering performance through the derivation of improved data representations. One notable example is Spectral Clustering [
20], an influential technique that relies on spectral decomposition to obtain a low-dimensional data embedding, which then serves as input for fundamental clustering procedures.
Within the realm of spectral clustering methods, two prominent contenders for learning similarity or affinity matrices are Sparse Subspace Clustering (SSubC) [
34] and Low-Rank Representation (LRR) [
24]. Both methods leverage the self-expressive property within a linear space [
34], where each data point in a union of subspaces can be efficiently approximated as a linear combination of other points in the dataset. While SSubC enhances sparsity by independently exploiting the l1 Subspace Detection Property, the LRR model adopts a more comprehensive approach by considering the intrinsic relationships among data objects through a low-rank constraint. Notably, the LRR method has demonstrated its ability to uncover a union of multiple subspaces within a dataset, effectively facilitating subspace clustering when such a structure is present [
25]. The self-expressive property is grounded in linear relationships among the data.
To extend these insights and exploit the nonlinear information inherent in manifold structures, particularly in manifold-valued data, several researchers have begun leveraging the self-expressive property within the context of manifold geometry. This has led to the adaptation of LRR to accommodate manifold scenarios such as Stiefel manifolds [
35], Grassmann manifolds [
36], and positive definite manifolds [
37]. Additionally, a second paradigm is emerging, where researchers approach the problem as a means to learn informative latent representations. A recent example is Sparse Spectral Clustering (SSC), introduced by Lu et al. [
38], which incorporates a sparsity-induced penalty to enhance the discovery of cluster-favoring latent representations. The introduction of non-Frobenius norm constraints in this context separates the solution from eigenvectors, allowing the latent representation to be derived through a subsequent stage.
In reference [
20], a direct solution is presented that involves resolving a novel Grassmann optimization problem. This approach incorporates the calculation of latent embeddings as part of manifold-based optimization. Importantly, the new features learned through these methods not only significantly enhance clustering effectiveness but also provide more intuitive and effective visualizations following dimensionality reduction. In reference [
3], a pioneering approach is introduced, presenting a novel low-rank Non-negative Matrix Factorization learning method known as Low-rank Nonnegative Matrix Factorization on the Stiefel Manifold (LNMFS). This method introduces three additional constraints to the conventional NMF framework. Firstly, LNMFS incorporates a low-rank constraint on the intrinsic data. This is achieved by penalizing the nuclear norm of the intrinsic data matrix. To streamline the optimization process, the nuclear norm of the intrinsic data matrix is transformed into a convex Frobenius norm of the latent factors, leveraging a well-established theorem [
39]. Secondly, with the aim of generating distinctive patterns for simplified interpretation, LNMFS posits that the basis matrix resides on a Stiefel manifold. This assumption ensures that different factors are orthogonal to one another. Thirdly, LNMFS takes measures to enhance the data’s robustness within a manifold structure. This is realized by integrating the graph smoothness constraint of the coefficient matrix.
Many algorithms based on Euclidean discriminant analysis are prone to quickly converging to misleading local minima, often lacking a definitive and unique solution [
40]. It is essential to recognize that the trust-region approach can linearly approximate local solutions in the tangent space throughout iterations, ultimately converging to a globally nonlinear solution [
41]. To address this issue, a method called Riemannian-based Discriminant Analysis (RDA) is introduced [
18]. This method transforms conventional Euclidean techniques into the framework of Riemannian manifold space. RDA utilizes the second-order geometry inherent in trust-region methods to effectively learn the bases for discrimination.
Addressing the issues of noise, outliers, and unaccounted manifold structures in data, reference [
7] introduces an innovative technique called correntropy-based hypergraph regularized non-negative matrix factorization (CHNMF). In CHNMF, the conventional Euclidean norm in the loss term is replaced with correntropy, which enhances the algorithm’s robustness. Additionally, the objective function is augmented with hypergraph regularization, allowing for the exploration of high-order geometric information across multiple sample points.
However, the classical NMF algorithm primarily operates as an unsupervised learning method, which may overlook the spatial structural information present in the original data. This oversight can lead to suboptimal clustering performance within the subspace. To address these challenges, reference [
6] introduces a semi-supervised NMF algorithm known as Semi-supervised Dual Graph Regularized NMF with Biorthogonal Constraints (SDGNMF-BO). This innovative technique employs a three-factor decomposition model based on a dual graph framework that encompasses both the data space and the feature space of the original dataset. Such an approach significantly enhances the algorithm’s learning capacity within the subspace. Furthermore, the integration of biorthogonal constraint conditions during the decomposition process improves local representation, notably reducing the inconsistency between the original matrix and the fundamental vectors.
3. The SGRiT Algorithm
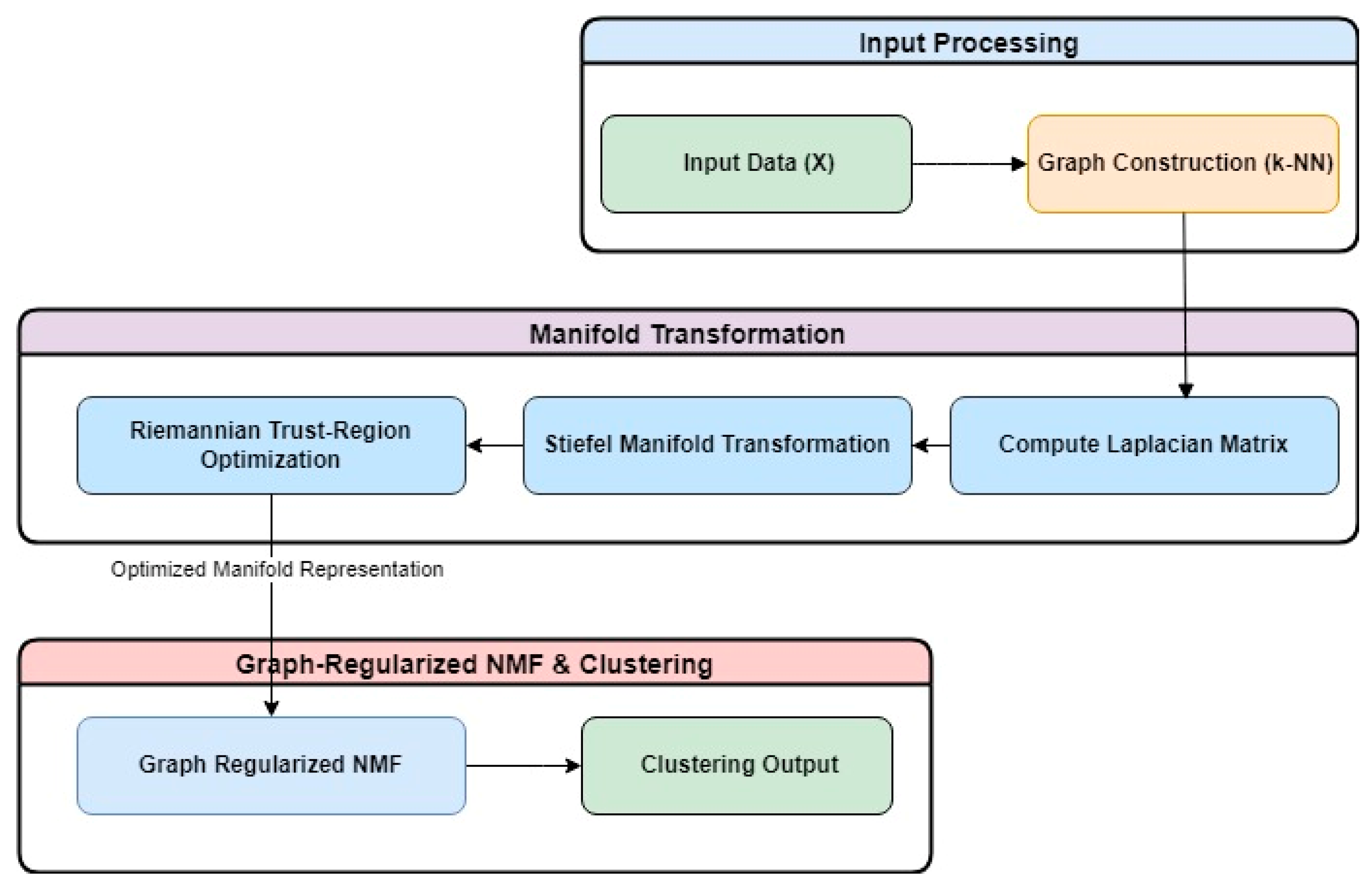
In this work, we present a novel algorithm that introduces constraints to enhance the standard NMF framework. This algorithm operates within the Stiefel manifold and an orthogonal subspace by leveraging the Riemannian trust region algorithm. Our approach combines a low-rank constraint on the transferred data, sparsity, and a graph smoothness constraint on the coefficient matrix. The workflow of the SGRiT approach is illustrated in
Figure 1.
Let the data matrix be denoted as X = [x
1, x
2, …, x
N] ∈ R
N×M, where x
i,j ≥ 0. The widely used Spectral Clustering (SC) [
20] technique involves the following steps to create a new representation of data:
where D is the diagonal matrix with the following:
- 3.
The optimization problem for computing Y ∈ RN×d, d << M is as follows:
where Y is the d-dimensional new representation in new subspace of M-dimensional original data X in original subspace and
denotes the inner product which generalizes the standard dot product to matrices. The definition of Stiefel manifold that consist of all the orthogonal column matrix is as follows:
By comparing relations (1) and (2), it is clear that problem (1) is an unconstrained manifold optimization problem on the Stiefel manifold S(d,N). Thus, the unconstrained manifold optimization problem (1) on the Stiefel manifold can be written as follows:
The Riemannian trust-region algorithm is employed on the Stiefel manifold optimization Equation (3), yielding a new representation data matrix Y. This involves using the pymanopt (
https://pymanopt.org/) package in the python programming language to convert the original data space to a new orthogonal subspace through the largest k eigenvectors corresponding to the top k eigenvalues of W.
Subsequently, the nearest neighborhood graph is recreated from new representation data matrix Y with the improved-weighted matrix W. This new matrix W and new subspace representation of data is employed in the NMF process, incorporating the graph smoothness and sparsity constraint to partition data into clusters.
The NMF decomposes each observed data point X into two nonnegative matrices U ϵ
and V ϵ
. U acts as the coefficient matrix, and V serves as the basis matrix in tasks like clustering. The core objective is to minimize the square of the Euclidean distance under non-negativity constraints:
Orthogonal Non-negative Matrix Factorization (ONMF) models can impose orthogonality on the basis matrices for parts-based interpretation.
When the SGRiT algorithm transfers original data into a subspace on Stiefel manifold with orthogonal vectors, it disregards the orthogonality of basis matrix V and writes the optimization equation accordingly.
The algorithm enhances sparsity by introducing an independent penalty term, making the basis vectors sparser:
To maintain the local geometric structure of the data manifold, it incorporates the graph smoothness regularization term into the objective function. However, instead of using the Laplacian matrix, which is made from the similarity matrix of the original data, it uses the Laplacian matrix, which is made from the transferred data under the Stiefel manifold and with the help of Riemannian optimization. This ensures that the geometric structure of the data is preserved better, leading to more accurate clustering results.
Finally, the parameters α and β control the weight of the graph smoothness and sparsity regularization terms, respectively.
Optimization
To minimize the objective function presented in Equation (4), the algorithm calculates the derivatives of this function with respect to U while keeping V fixed and with respect to V while keeping U fixed in the Euclidean space.
where L is replaced with L = D − W.
Using the KKT condition and KKT complementary slackness, which is as follows:
The symbols ⊙ and the fraction line (
) indicate element-wise matrix product and division, respectively. According to the above equations, the multiplicative update rules for U and V are given by the following:
Therefore, the whole above process can be implemented in the form of Algorithm 1. The SGRiT method is expressed as an optimization problem that is resolved through an iterative multiplicative algorithm.
| Algorithm 1: The SGRiT Algorithm |
Input:
Output:
Steps: |
| | - 3.
Utilize the pymanopt library to project the original data X onto a Stiefel manifold subspace Y with Euclidean distances based of relation (3) - 4.
Compute the (weighted) graph W and the diagonal matrix D based on the new data in the newly formed subspace. - 5.
repeat
, until the convergence criterion is satisfied
- 6.
apply kmeans to Ut+1 - 7.
return Ut+1
|
4. Experiments and Analysis
In this section, a series of experiments have been conducted to validate and analyze the algorithm’s performance across various dimensions. These experiments include algorithm parameter selection analysis as well as clustering effect comparison. To ensure comprehensive validation, the outcomes of the SGRiT algorithm have been compared against those of other Non-negative Matrix Factorization (NMF) algorithms.
4.1. Datasets
Clustering experiments are executed on ten distinct datasets, for which the statistical information is presented in
Table 1.
4.2. Compared Algorithms
To ensure a fair and rigorous comparison of the SGRiT algorithm’s performance, it has been benchmarked against six other classic NMF algorithms. Below, a comprehensive description of each of these comparison algorithms is provided.
NMF: The classic Non-negative Matrix Factorization algorithm that enforces non-negativity constraints on the two factor matrices produced during decomposition.
SNMF: The Sparse Non-negative Matrix Factorization (SNMF) algorithm incorporates sparsity constraints into the standard NMF framework to improve parts-based learning. These constraints significantly enhance the discriminative power of the learned components. Additionally, SNMF introduces a more streamlined representation approach.
RNMF: Robust Non-negative Matrix Factorization (RNMF) is a variant of the NMF algorithm specifically designed to manage datasets that may contain outliers or noise. RNMF addresses these challenges by introducing sparsity constraints on the residual matrix. The concept of sparsity in RNMF is grounded in the understanding that noise or outliers are typically sparse and affect only a limited number of data points. By incorporating these sparsity constraints, RNMF effectively separates the clean data components from the corrupted ones, resulting in more accurate factorization outcomes.
PNMF: Probabilistic Non-negative Matrix Factorization (PNMF) employs variational Bayesian inference to achieve deterministic convergence to the solution of NMF, moving away from dependence on random sampling.
ONMF: Orthogonal Non-negative Matrix Factorization (ONMF) is based on the principles of standard NMF. Ref. [
42] introduced ONMF models that incorporate orthogonality constraints on both the basis and coefficient matrices.
GNMF: Graph Regularized Non-negative Matrix Factorization (GNMF) constructs the local geometric structure of the original data space and incorporates it into the classic NMF algorithm as constraints, effectively utilizing it as a regularization term.
LNMFS: The Low-Rank NMF on the Stiefel Manifold (LNMFS) algorithm, as proposed by [
7], utilizes the low-rank structure of intrinsic data and represents it in a Frobenius norm format using latent factors. Additionally, it maintains orthogonality among the factors by ensuring that the basis matrix lies on a Stiefel manifold. Furthermore, it incorporates a graph smoothness constraint on the coefficient matrix.
4.3. Parameter Analysis
In this analysis, specific parameters were evaluated to understand their influence on the algorithm’s performance. Reference [
7] demonstrated that an increase in embedding dimension does not necessarily lead to improved clustering performance. Instead, optimal or nearly optimal clustering performance is typically achieved when the embedding dimension aligns with the number of clusters. This observation can be attributed to the fact that matching the embedding dimension with the rank of the intrinsic data allows for the maximal utilization of the low-rank regularization term. Therefore, for each dataset, the dimension of the matrix decomposition’s embedding was set as equal to the number of clusters, ensuring that each dimension of the latent feature space corresponds to a distinct cluster.
Three parameters in the algorithm under evaluation need to be adjusted. First, the square root of the number of samples per cluster is used to define the parameter ’k’, which is employed to calculate the graph of k-nearest neighbors within the k-NN algorithm. To create a binary adjacency matrix that captures the relationships between data items based on their shared nearest neighbors, 0/1 neighbor graphs are constructed. The adjacency matrix is denoted as W, where each element wij indicates the connection strength between the ith and jth data points.
Given that the SGRiT algorithm and LNMFS operate under the assumption that the basis vectors are orthogonal during the decomposition procedure, a specific initialization strategy is employed. Specifically, the V matrix is initialized by generating a random orthogonal matrix, while the U matrix is initialized using random values. This approach allows for flexibility in the initial configuration of U while still adhering to the requirements of the optimization process’s requirements. The orthogonal initialization of V and the randomized initialization of U collectively enhance the algorithm’s capacity to converge towards a solution that conforms to the orthogonal basis vector assumption and effectively approximates the original data matrix.
The optimal values for the coefficients ‘α’ and ‘β’, which, respectively, represent the weights of the geometric structure and sparsity terms in the objective function, were identified through experimentation on diverse datasets. Values ranging from 10−5 to 10+5 were examined in intervals of 100.5. The average purity attained for different ‘α’ and ‘β’ values across various datasets was computed, and the maximum of these averages was deemed the suitable ‘α’ and ‘β’ for the algorithm. For the LNMFS algorithm, the optimal values were found to be α = 1 and β = 102.5, while, for the SGRiT algorithm, the values were α = 0.1 and β = 103.5. α and β are parameters that influence the smoothness and sparsity of the data in relation to the value derived from the Frobenius norm. Our results indicate that, although these parameters exhibit some dependence on the data, they can be assigned values that produce acceptable outputs across all datasets. All datasets have been normalized by dividing by the maximum of each column so that different features have the same weight in the evaluation algorithms.
4.4. Evaluation Metrics
To evaluate the performance of the SGRiT algorithm in comparison to the other selected algorithms, four key assessment criteria are utilized: Purity, Normalized Mutual Information (NMI), Rand Index, and algorithm execution time.
Purity: Purity is a straightforward and transparent evaluation metric, especially in the context of unsupervised machine learning. It involves assigning each cluster to the class that is most prevalent within that cluster. The accuracy of this assignment is calculated by dividing the number of correctly assigned objects by the total number of objects in the dataset. High purity values indicate effective clustering, with perfect clustering achieving a purity of 1, while poor clustering results in purity values close to 0. However, it is important to note that high purity can be easily achieved when the number of clusters is large; therefore, purity alone may not be the best metric for balancing clustering quality against the number of clusters.
The purity of a clustering result is calculated using the following equation:
where:
N is the total number of data points.
K is the number of clusters in the clustering result.
Ci is the set of data points in cluster i.
Lj is the set of data points in class j according to the ground-truth labels.
The purity is calculated by summing over each cluster i and finding the maximum overlap between that cluster and any class j based on ground-truth labels. The result is normalized by dividing by the total number of data points N.
Normalized Mutual Information (NMI): NMI allows us to strike a balance between clustering quality and the number of clusters, as it is independent of the cluster count. It can be information-theoretically interpreted and quantifies the average mutual information between each pair of clusters and classes, while also considering the normalization factors to make it a value between 0 and 1.
The formula for NMI is as follows:
where
I(C; L) is the mutual information between the clustering C and the reference labels L.
H(C) is the entropy of the clustering C.
H(L) is the entropy of the reference labels L.
Rand Index (RI): Rand Index (RI) is a metric used to measure the similarity between two data clustering. It takes into account both false positive (FP) and false negative (FN) decisions during clustering evaluation. It measures the percentage of decisions that are correct (true positives + true negatives) out of the total decisions. It provides a value between 0 and 1, where higher values indicate greater similarity between the clustering.
These evaluation criteria collectively provide a comprehensive understanding of the performance of the SGRiT algorithm compared to other algorithms. In such cases, optimizing for accuracy alone may not provide a clear picture of model performance, as a classifier can achieve high accuracy by simply predicting the majority class for all instances.
4.5. Clustering Results Analysis
To evaluate the clustering results of NMF, SNMF, RNMF, PNMF, ONMF, GNMF, LNMFS, and the SGRiT algorithm, the five previously mentioned evaluation criteria have been employed. The implementations of NMF, SNMF, RNMF, PNMF, and ONMF are sourced from NMF library packages
https://github.com/hiroyuki-kasai/NMFLibrary (accessed on 10 March 2025), while the code for LNMFS and the SGRiT algorithm is developed within the Python environment. To ensure reliable results, each algorithm is executed ten times, and the average value of the criteria, along with their standard deviation, is computed. Instances where an algorithm fails to produce clustering results are indicated by NA.
The results presented in
Table 2 clearly demonstrate that the SGRiT algorithm exhibits the highest purity across most datasets when compared to various other algorithms. With the exception of the Ecoli dataset, which is ranked third, the SGRiT method consistently secures the top position in all other instances. Ecoli is a relatively simple dataset characterized by low dimensionality, a limited number of samples, and five classes. This simplicity makes the dataset more amenable to less complex approaches, while the SGRiT method excels on more complex datasets that feature higher dimensionality and a greater number of classes. For instance, as illustrated in the results, the SGRiT approach significantly outperforms other methods on high-dimensional datasets such as Yale, Coil24, and ORL. A similar trend is observed in larger datasets with more instances and classes, including Isolet, CNAE, and USPS. Notably, in the case of the Pendigit dataset, the performance difference between SGRiT and the next-best algorithm reaches approximately 0.11. This indicates that the SGRiT algorithm achieves superior clustering performance in terms of the purity metric across a variety of datasets.
The standard deviations (SDs) of the experiments for the SGRiT approach are relatively low, indicating a high probability of convergence. In contrast to the mean performance, which was significantly better on more complex datasets, the SD is lower (i.e., nearly zero) for simpler datasets such as Breat and Pendigit. This observation suggests that the approach is both robust and stable; however, its stability diminishes as the complexity of the data increases. The NMI criterion quantifies the amount of information shared between two clustering results while accounting for random chance agreement. A higher NMI value indicates that the clusters produced by the algorithm correspond more closely with the true underlying structure or ground truth. The results of the tests concerning the NMI criterion, as presented in
Table 3, demonstrate the superiority of the SGRiT algorithm across all selected datasets.
The observations presented in
Table 2 are reiterated here, with the notable exception that the approach has excelled across all datasets.
Table 2 indicates that SGRiT consistently outperforms other algorithms, achieving the highest NMI scores across all datasets, such as 0.809281 for the Breast dataset and 0.97892 for CNAE. In contrast, PNMF generally exhibits the poorest performance, with significantly low scores. Most algorithms, including GNMF and LNMFS, demonstrate competitive results, with GNMF particularly excelling on datasets such as Optdigit (0.8450) and ORL (0.8514). Overall, SGRiT showcases superior clustering accuracy and stability, as evidenced by its high NMI scores and relatively low standard deviations.
As observed, the margin of performance improvement based on the NMI criterion is notably higher in this context. For instance, on the Pendigit dataset, the improvement margin is 0.19; on the Ecoli and CANE datasets, the NMI improves by 0.09; on the USPS dataset, a 0.1 improvement is recorded. Referring to
Table 1, both CANE and USPS are classified as complex datasets, and this performance enhancement further underscores the effectiveness of the SGRiT approach. The Rand Index (RI), a metric used to evaluate the similarity between two clustering or partitioning results, quantifies the agreement between the clustering assignments of elements within a dataset. It takes into account both pairs of elements that are correctly grouped together and pairs that are accurately placed in separate clusters.
As shown in
Table 4, with the exception of the Isolet dataset, where the SGRiT algorithm ranks lower (sixth place), the algorithm consistently achieves either first or second place in the remaining cases. Notably, SGRiT attains the highest Rand Index scores, such as 0.99123 for CNAE and 0.98473 for ORL, indicating superior clustering accuracy. In contrast, PNMF generally performs the worst, with particularly low scores of 0.6661 for Ecoli and 0.8630 for breast cancer. Most algorithms, including GNMF and LNMFS, yield competitive results, with GNMF performing exceptionally well on datasets like Optdigit (0.9498) and ORL (0.9784). Overall, SGRiT demonstrates the best performance, with high Rand Index values and relatively low standard deviations, underscoring its robustness and effectiveness. This performance may be attributed to the presence of negative data in the dataset. To align with the principles of the NMF algorithm, the SGRiT algorithm adds the minimum value of the data to all entries, ensuring that the resulting matrix is positive and suitable for NMF implementation. This observation suggests that, for the majority of datasets, the proposed clustering algorithm exhibits satisfactory performance in terms of the Rand Index criterion. Additionally, the standard deviation of the resulting Rand Index reflects the stability and robustness of the approach across different learning subsets.
Time complexity analysis in NMF is crucial, as the algorithms can be computationally intensive, particularly when handling large datasets. Analyzing time complexity aids in selecting or designing algorithms that can efficiently factorize matrices, thereby conserving computational resources. Furthermore, understanding time complexity enables researchers and practitioners to evaluate the scalability of NMF algorithms, which is essential when working with large datasets or high-dimensional matrices. Therefore, a run-time analysis is performed and reported in this section. Experiments involving SGRiT and LNMFS algorithms were conducted using PyCharm version 2021.3.1 with Python version 3.11. For the other methods, MATLAB R2015a was employed. The experiments were carried out on a server equipped with an Intel Xeon E7530 processor operating at 1.87 GHz (56 processors) and 16 GB of RAM. To accurately measure the algorithm’s runtime, it was executed 10 times, and the average execution time for each algorithm was recorded in the table. As seen in
Table 5, the proposed algorithm takes a lot of time to transfer the data from the main space to a subspace with smaller dimensions; this problem causes a significant increase in the execution time of this algorithm compared to other algorithms, as in the practical test of all the data.
The experimental results clearly demonstrate that SGRiT consistently outperforms seven representative NMF-based algorithms; however, it is less efficient in terms of execution time for clustering tasks across a diverse range of real-world datasets. While SGRiT may exhibit longer execution times in certain scenarios, the additional computational cost is warranted by our primary objective of enhancing clustering performance. For applications where accuracy is prioritized over speed, the SGRiT algorithm focuses on achieving superior feature extraction and clustering quality. Moreover, NMF can be executed offline, mitigating the impact of prolonged execution times. Additionally, optimizations such as parallelization and approximation can be implemented to reduce computational costs when runtime efficiency is critical.





{kind=link}