
Explainable Artificial Intelligence Using Expressive Boolean Formulas
 , , , ,
, , , ,
Abstract
:1. Introduction
- Improved and expanded Integer Linear Programming (ILP) formulations and respective Quadratic Unconstrained Binary Optimization (QUBO) formulations for finding depth-one rules.
- A native local solver for determining expressive Boolean formulas.
- The addition of non-local moves, powered by the above ILP/QUBO formulations (or, potentially, other formulations).
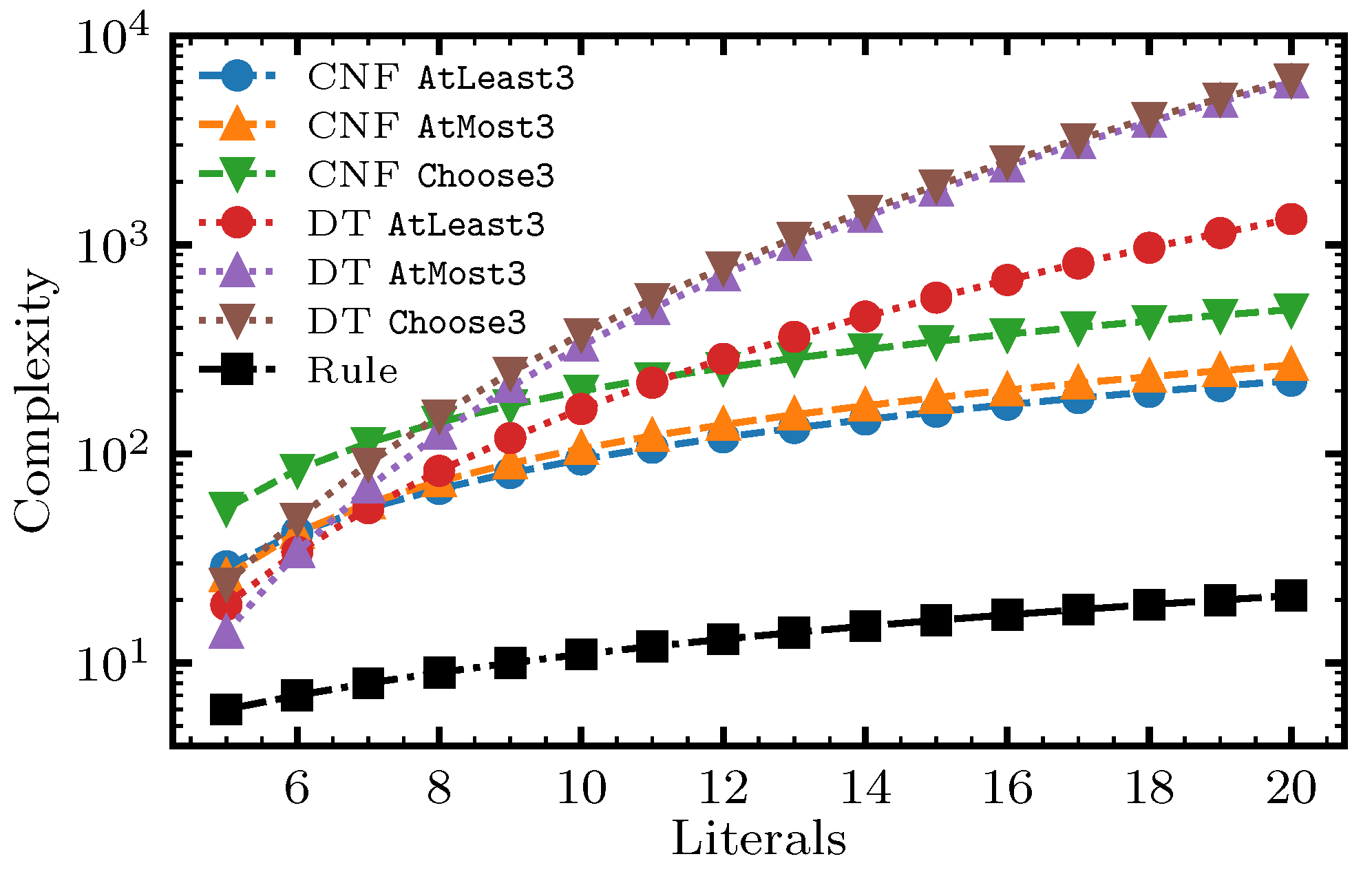
- Expressive Boolean formulas provide a more compact representation than decision trees and conjunctive normal form (CNF) rules for various examples.
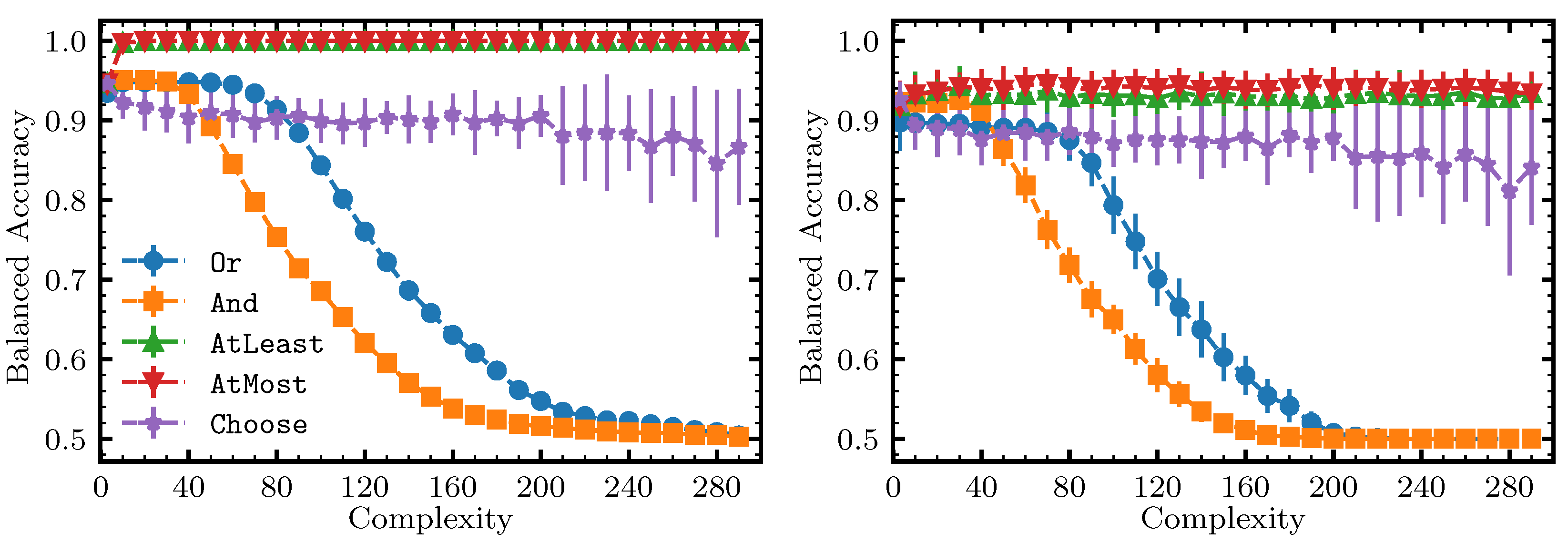
- Parameterized operators such as AtLeast are more expressive than non-parameterized operators such as Or.
- The native local rule classifier is competitive with the well-known alternatives considered in this work.
- The addition of non-local moves achieves similar results with fewer iterations. Therefore, using specialized or quantum hardware could lead to a significant speedup through the rapid proposal of non-local moves.
2. Related Works
3. Research Methodology
3.1. Problem Definition
3.2. Objectives
- Combining multiple objectives into one—introducing a new parameter that controls the relative importance of the complexity (and, therefore, interpretability). The parameter quantifies the drop in the score we are willing to accept to decrease the complexity by one. Higher values of generally result in less complex models. We then solve a single-objective optimization problem with the objective function , which combines both objectives into one hybrid objective controlled by the (use-specific) parameter .
- Constraining one of the objectives—introducing the maximum allowed complexity (also referred to as max_complexity) and then varying to achieve the desired result.
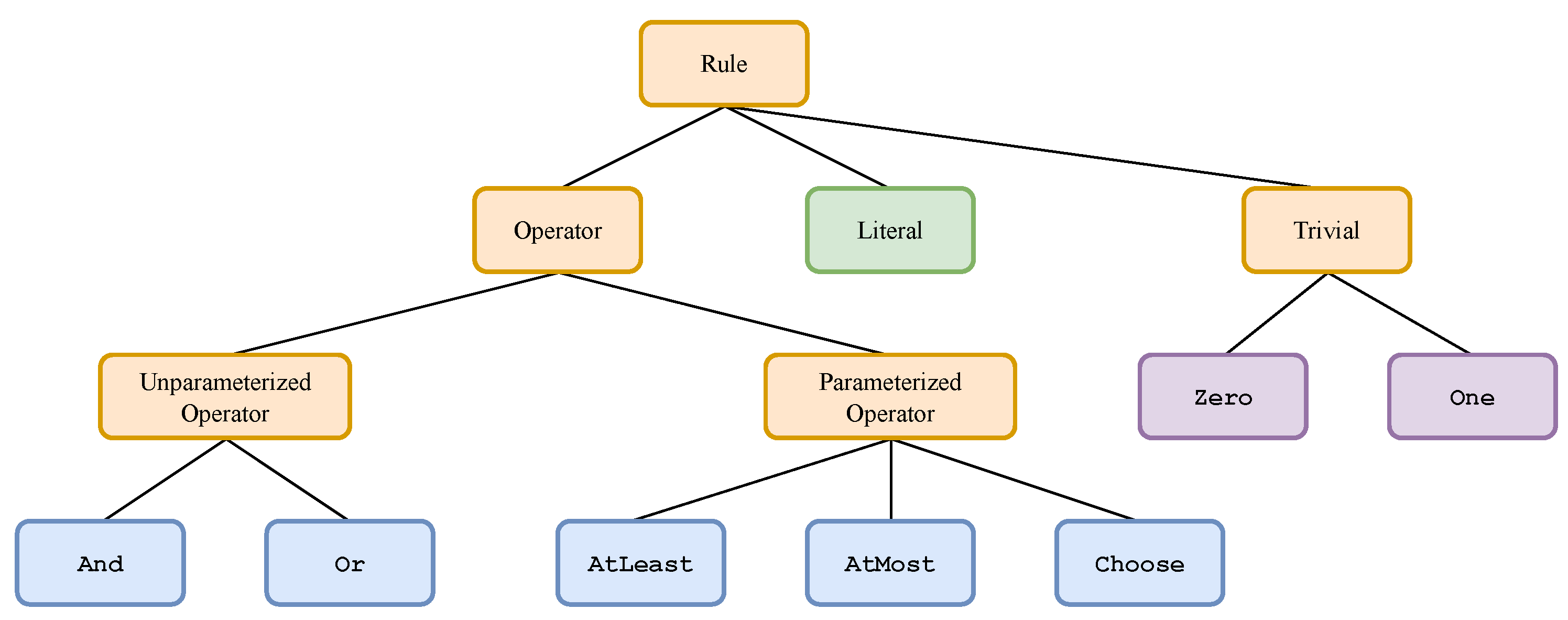
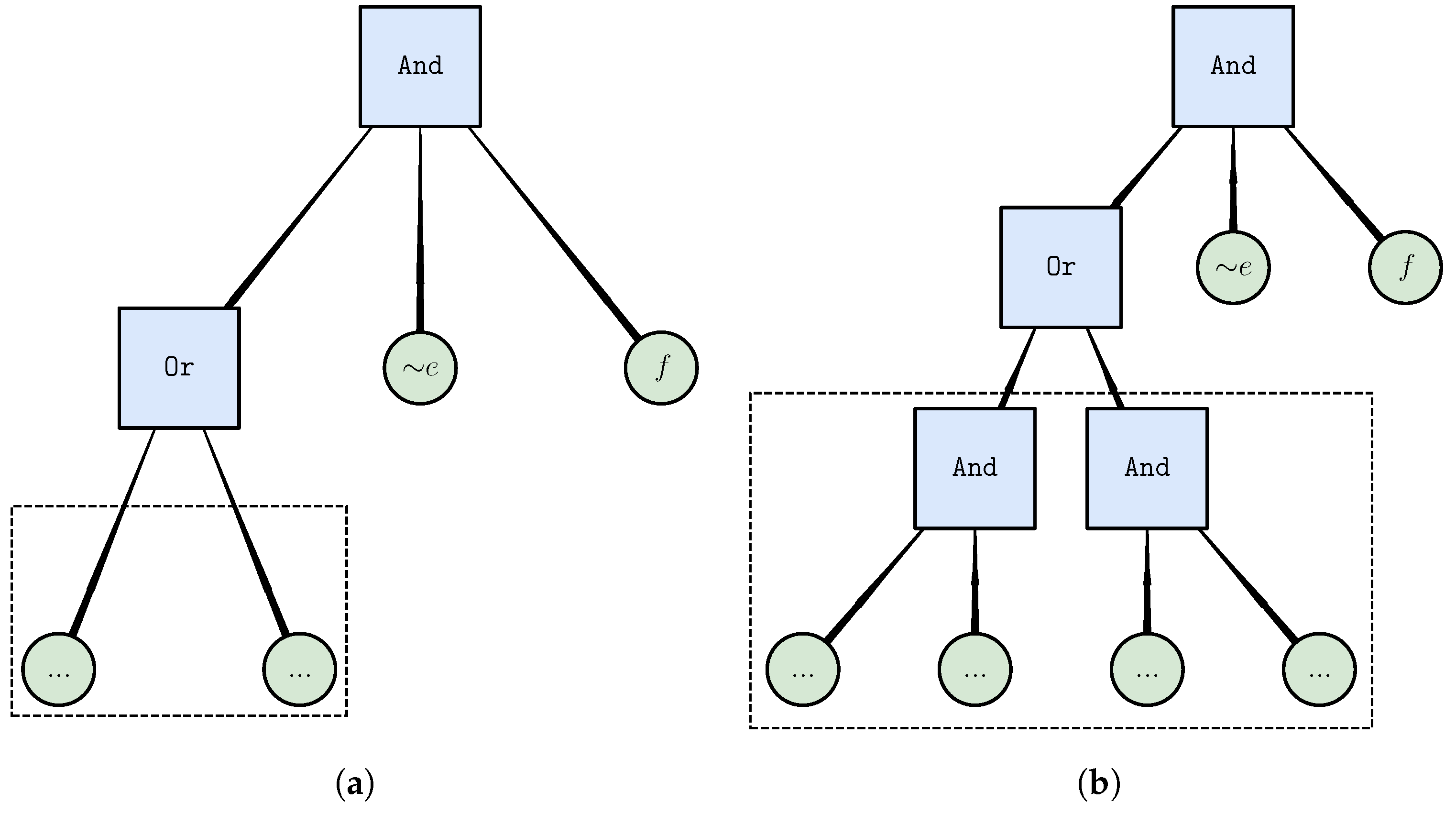
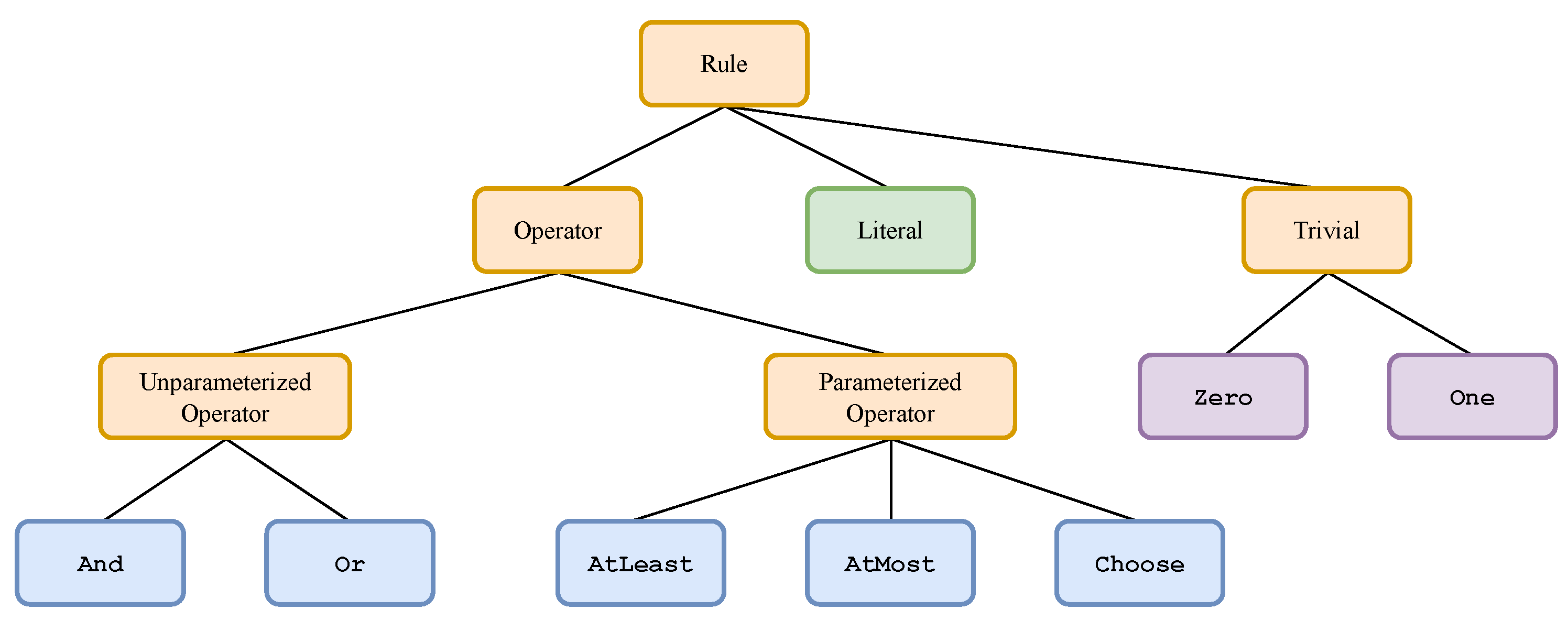
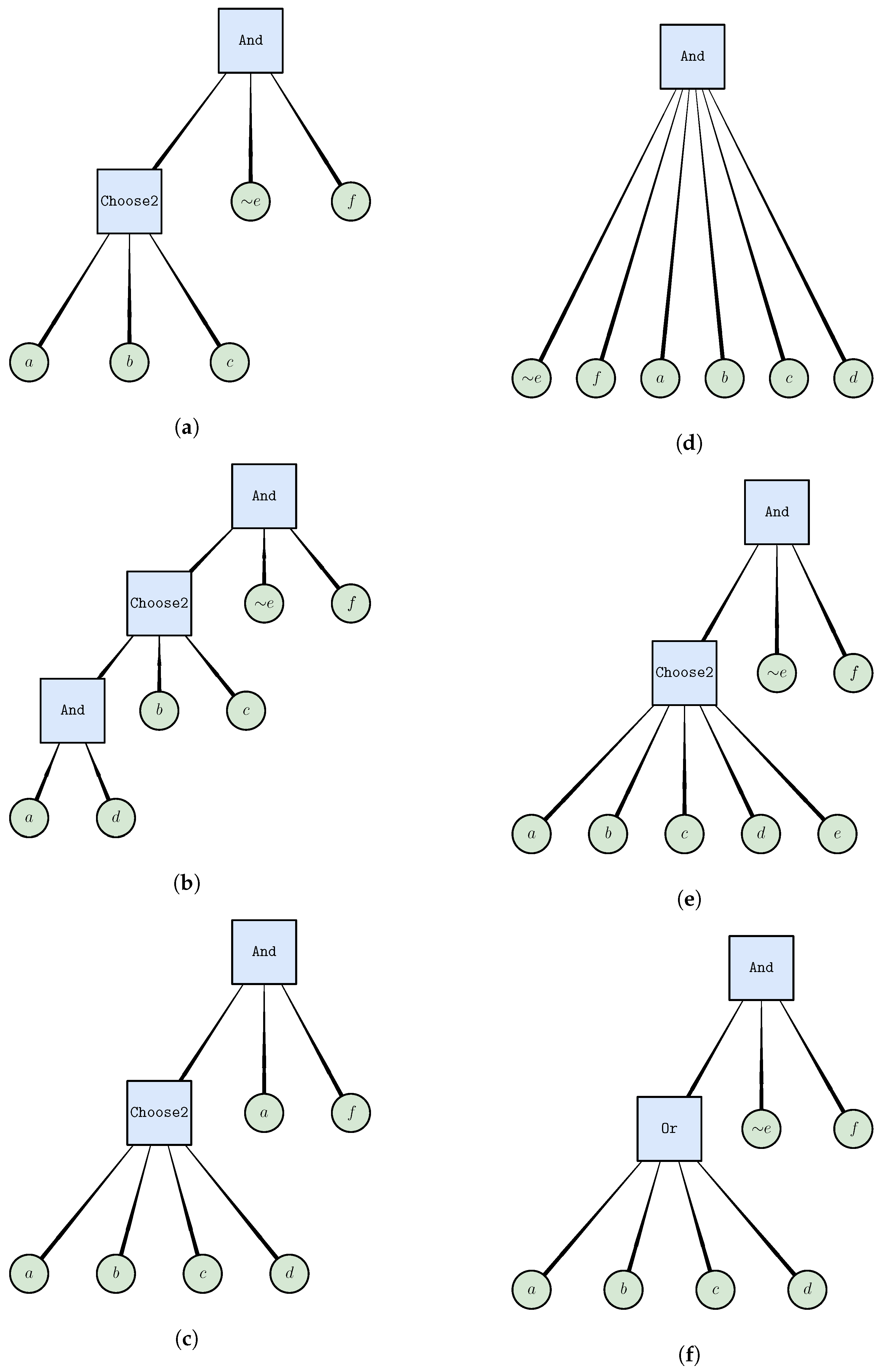
3.3. Rules as Expressive Boolean Formulas
3.4. Motivation
4. The Components of the Solver
4.1. Constraints and Search Space
4.2. Generating Initial Rules
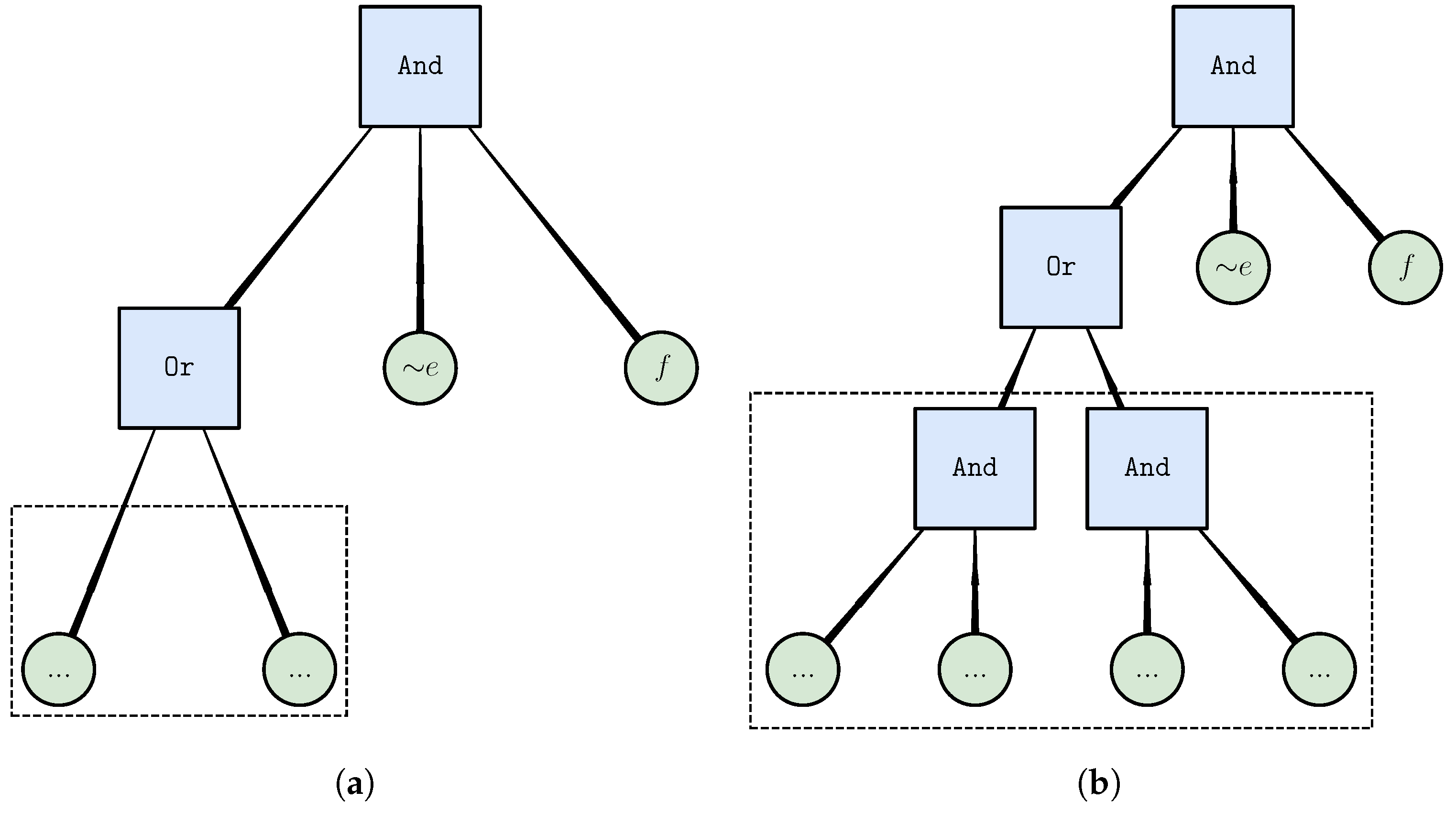
4.3. Generating Local Moves
| Algorithm 1 The function that proposes local moves—propose_local_move(). This function selects a node (an operator or a literal) randomly while cycling through the move types and then attempts to find a valid local move for that node and move type. The process is restarted if needed until a valid local move is found, a process that is referred to as “rejection sampling”. |
literal_move_types=cycle({"remove_literal","expand_literal_to_operator", "swap_literal"}) operator_move_types=cycle({"remove_operator","add_literal","swap_operator"}) def propose_local_move(current_rule): all_operators_and_literals = current_rule.flatten() proposed_move = None while proposed_move is None: target = random.choice(all_operators_and_literals) if isinstance(target, Literal): move_type = next(literal_move_types) else: move_type = next(operator_move_types) proposed_move = get_random_move(move_type, target) return proposed_move |
- Remove literal—removes the chosen literal but only if the parent operator would not end up with fewer than two subrules. If the parent is a parameterized operator, it adjusts the parameter down (if needed) so that it remains valid after the removal of the chosen literal.
- Expand literal to operator—expands a chosen literal to an operator, moving a randomly chosen sibling literal to that new operator. It proceeds only if the parent operator includes at least one more literal. If the parent is a parameterized operator, it adjusts the parameter down (if needed) so that it remains valid after the removal of the chosen literal and the sibling literal.
- Swap literal—replaces the chosen literal with a random literal that is either the negation of the current literal or is a (possibly negated) literal that is not already included under the parent operator.

- Remove operator—removes an operator and any operators and literals under it. It only proceeds if the operator has a parent (i.e., it is not the root) and if the parent operator has at least three subrules, such that the rule is still valid after the move has been applied.
- Add literal to operator—adds a random literal (possibly negated) to a given operator, but only if that variable is not already included in the parent operator.
- Swap operator—swaps an operator for a randomly selected operator and a randomly selected parameter (if the new operator is parameterized). It proceeds only if the new operator type is different or if the parameter is different.
4.4. Evaluation of Rules
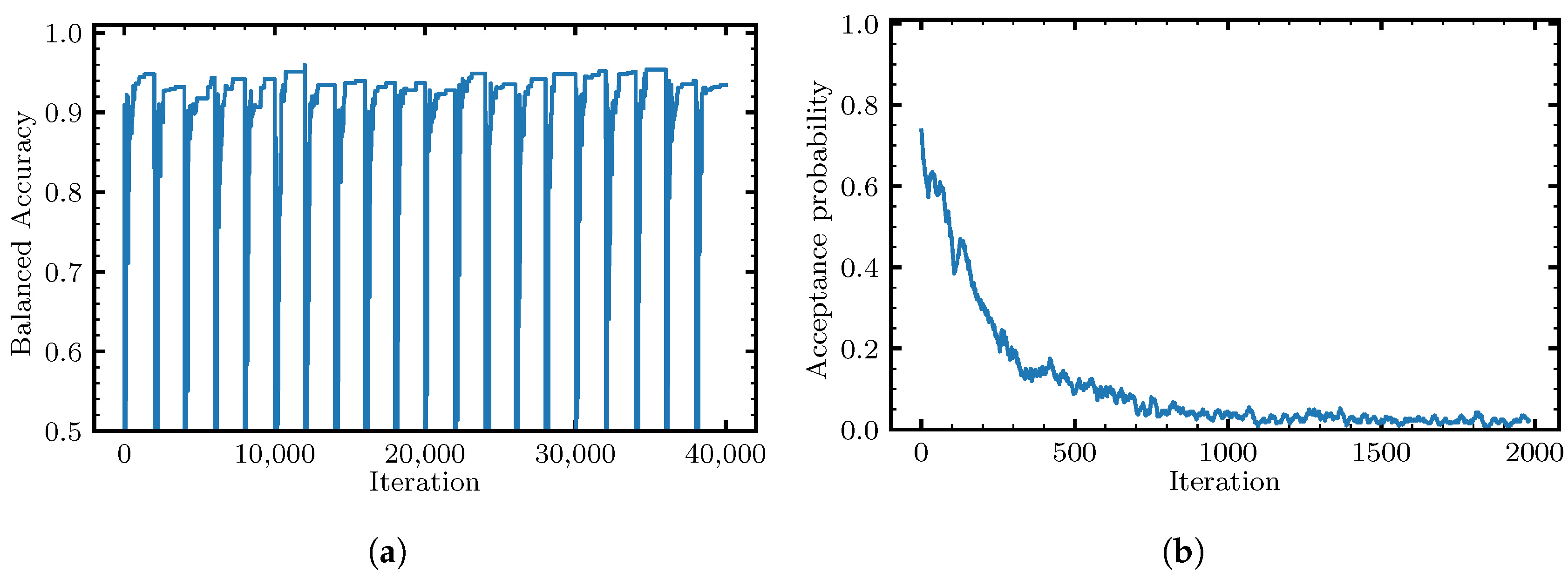
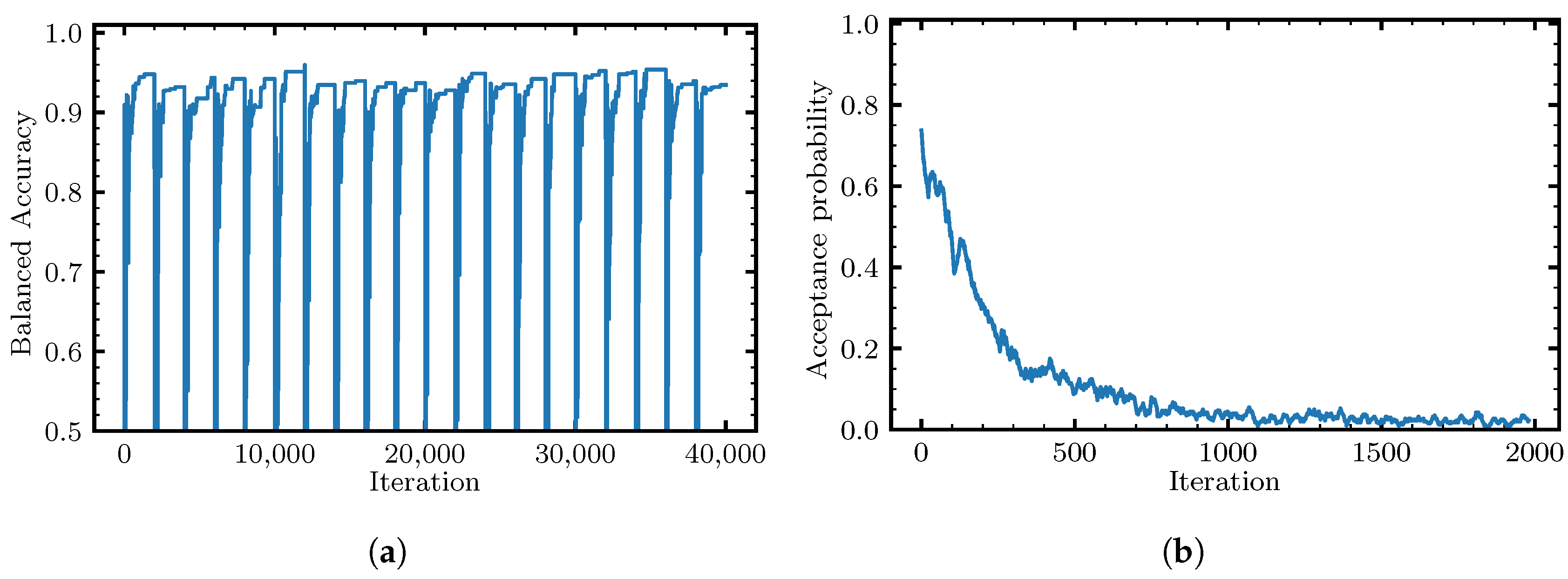
4.5. The Native Local Solver
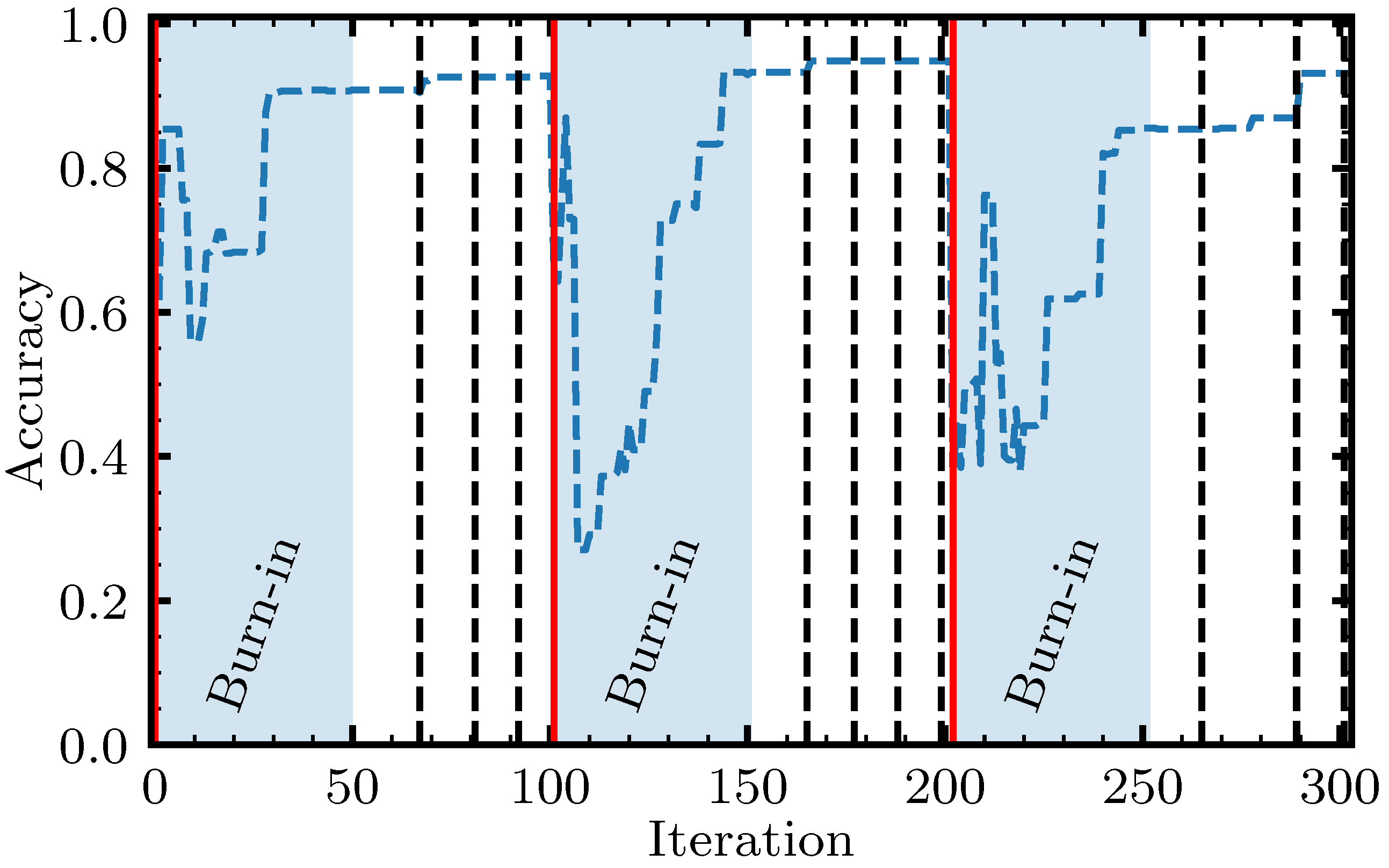
4.6. Non-Local Moves
4.7. Putting It All Together
| Algorithm 2 The pseudo-code for our native local solver with non-local moves. The solver executes num_starts starts, each with num_iterations iterations. In each start, a random initial rule is constructed and then a series of local (see Algorithm 1) and non-local moves (see Section 4.6) are proposed and accepted based on the Metropolis criterion. Non-local moves are introduced only after initial num_iterations_burn_in iterations and only if there have been no improvements over patience iterations. Both the initial rule and the proposed moves are constructed so that the current rule is always feasible and, in particular, has a complexity no higher than max_complexity. Non-local moves replace an existing literal or operator with a subtree, optimized over a randomly selected subset of the data of size max_samples. The solver returns the best rule found. Some details are omitted due to a lack of space. |
def solve(X, y, max_complexity, num_starts, num_iterations, num_iterations_burn_in, patience): best_score = -inf best_rule = None for start in range(num_starts): is_patience_exceeded = False current_rule = generate_initial_rule(X, max_complexity) current_score = score(current_rule, X, y) for iteration in range(num_iterations): T = update_temperature() if iteration > num_iterations_burn_in and is_patience_exceeded: proposed_move = propose_non_local_move(current_rule, max_samples) else: proposed_move = propose_local_move(current_rule) proposed_move_score = score(proposed_move, X, y) dE = proposed_move_score - current_score accept = dE >= 0 or random.random() < exp(dE/T) if accept: current_score = proposed_move_score current_rule = proposed_move if current_score > best_score: best_score = current_score best_rule = deepcopy(current_rule) is_patience_exceeded = update_patience_exceeded(patience) return best_rule |
5. Depth-One ILP and QUBO Formulations
- The addition of negated features.
- Design of even-handed formulations (unbiased toward positive/negative samples) and the addition of class weights.
- Correction of the original formulation for AtLeast and generalizations to the AtMost and Choose operators.
- Direct control over the score/complexity tradeoff by constraining the number of literals.
5.1. Formulating the Or Rule as an ILP
5.2. Formulating the And Rule as an ILP
5.3. Extending the ILP Formulation to Parameterized Operators
5.4. Converting the ILPs to QUBO Problems
- Assume we have a problem in canonical ILP form:
- Convert the inequality constraints to the equivalent equality constraints with the addition of slack variables:where we have adopted, without loss of generality, the “from above” formulation.
- Convert to a QUBO:where we have dropped a constant, and is a square matrix with on the diagonal.
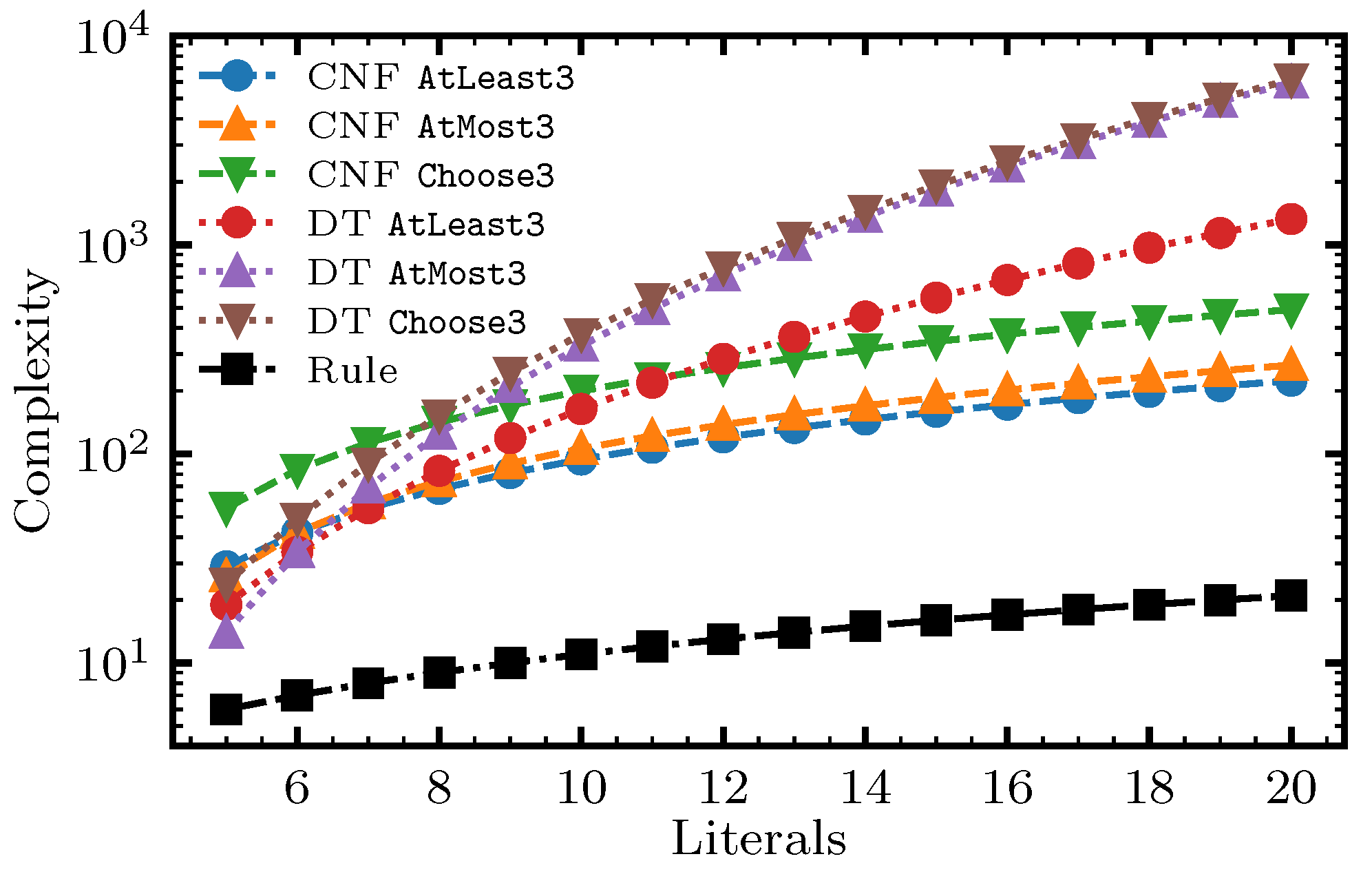
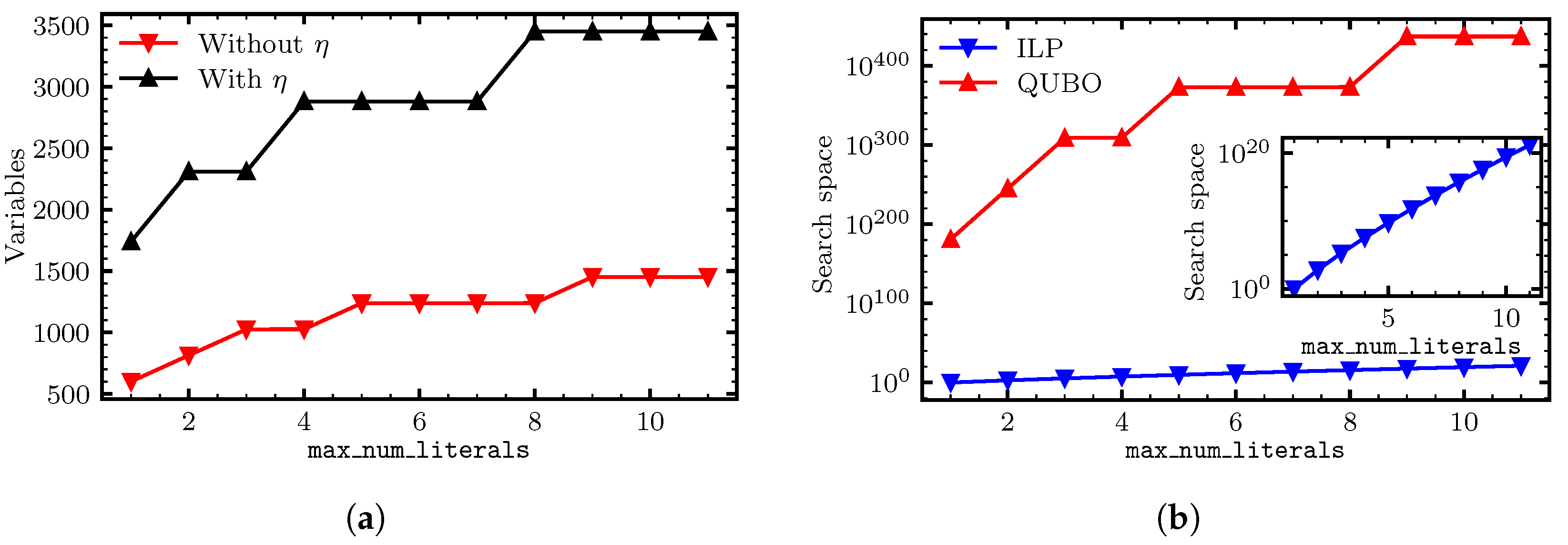
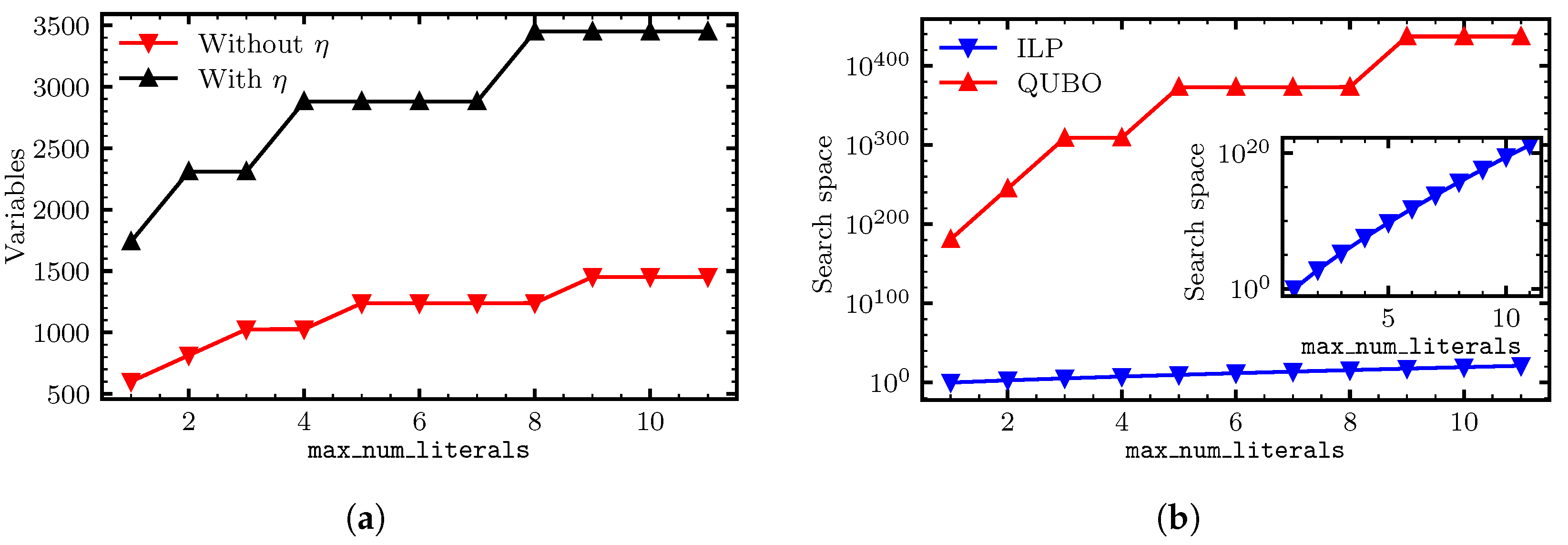
5.5. Reducing the Number of Variables
5.6. Number of Variables and the Nature of the Search Space
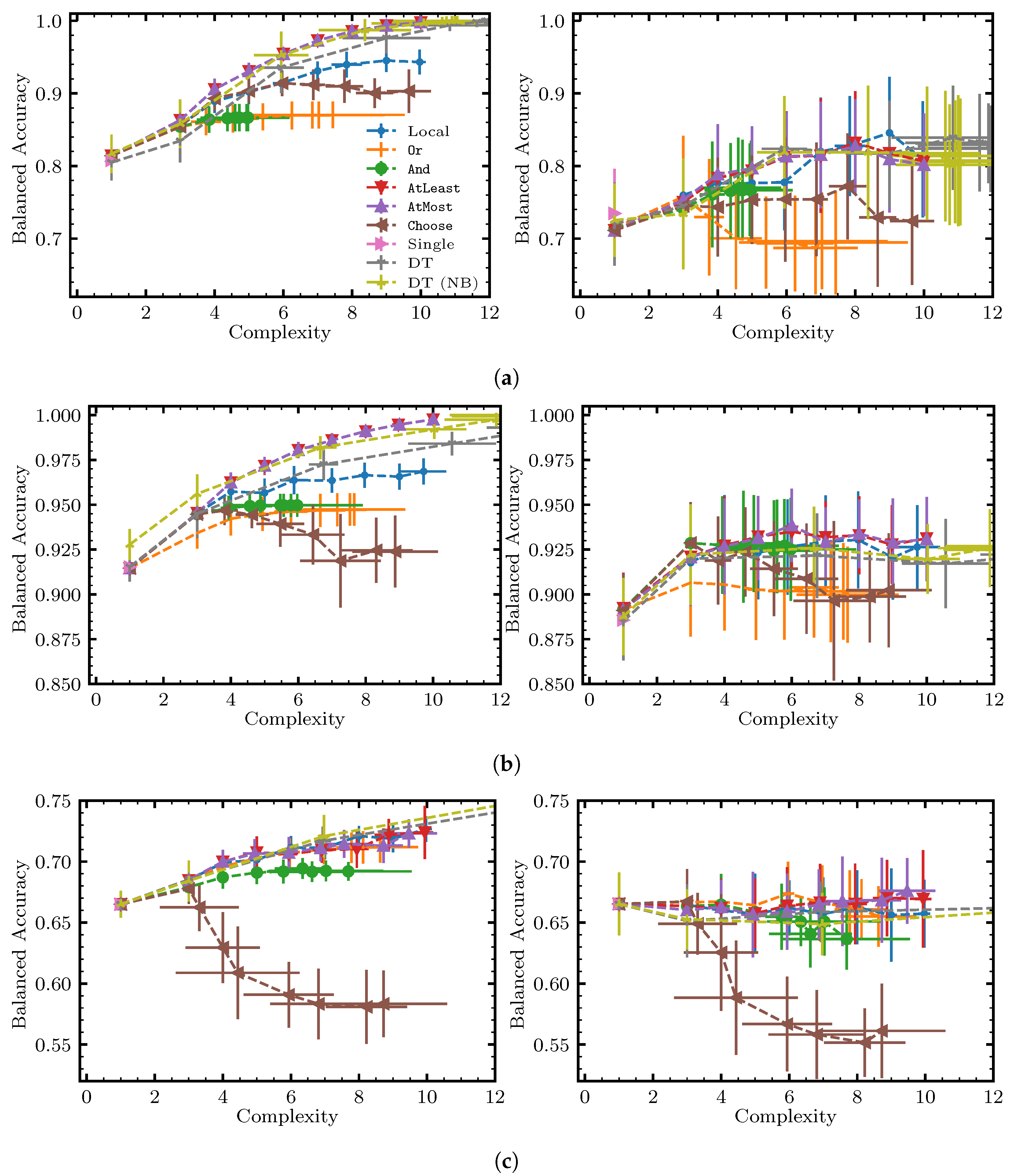
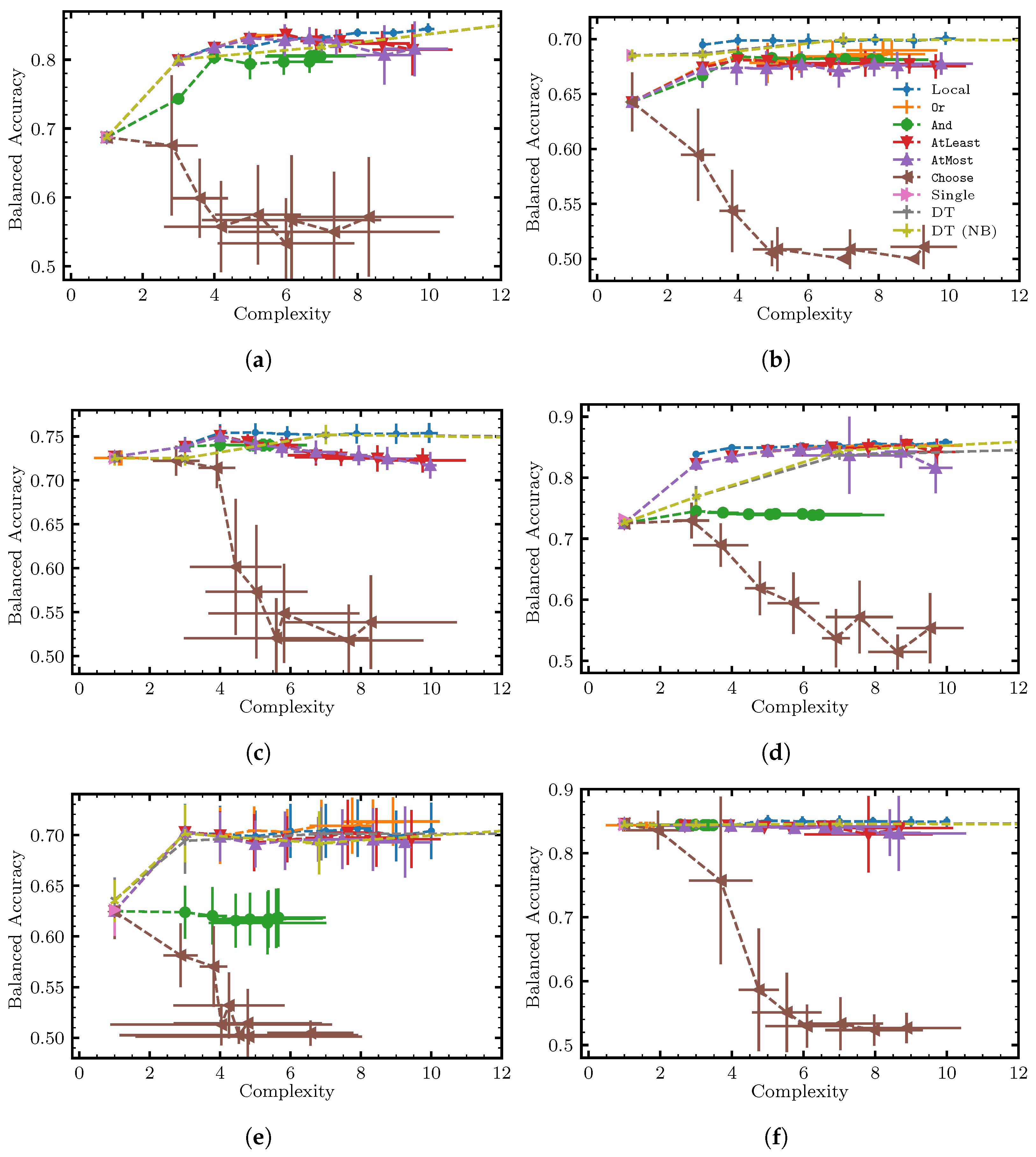
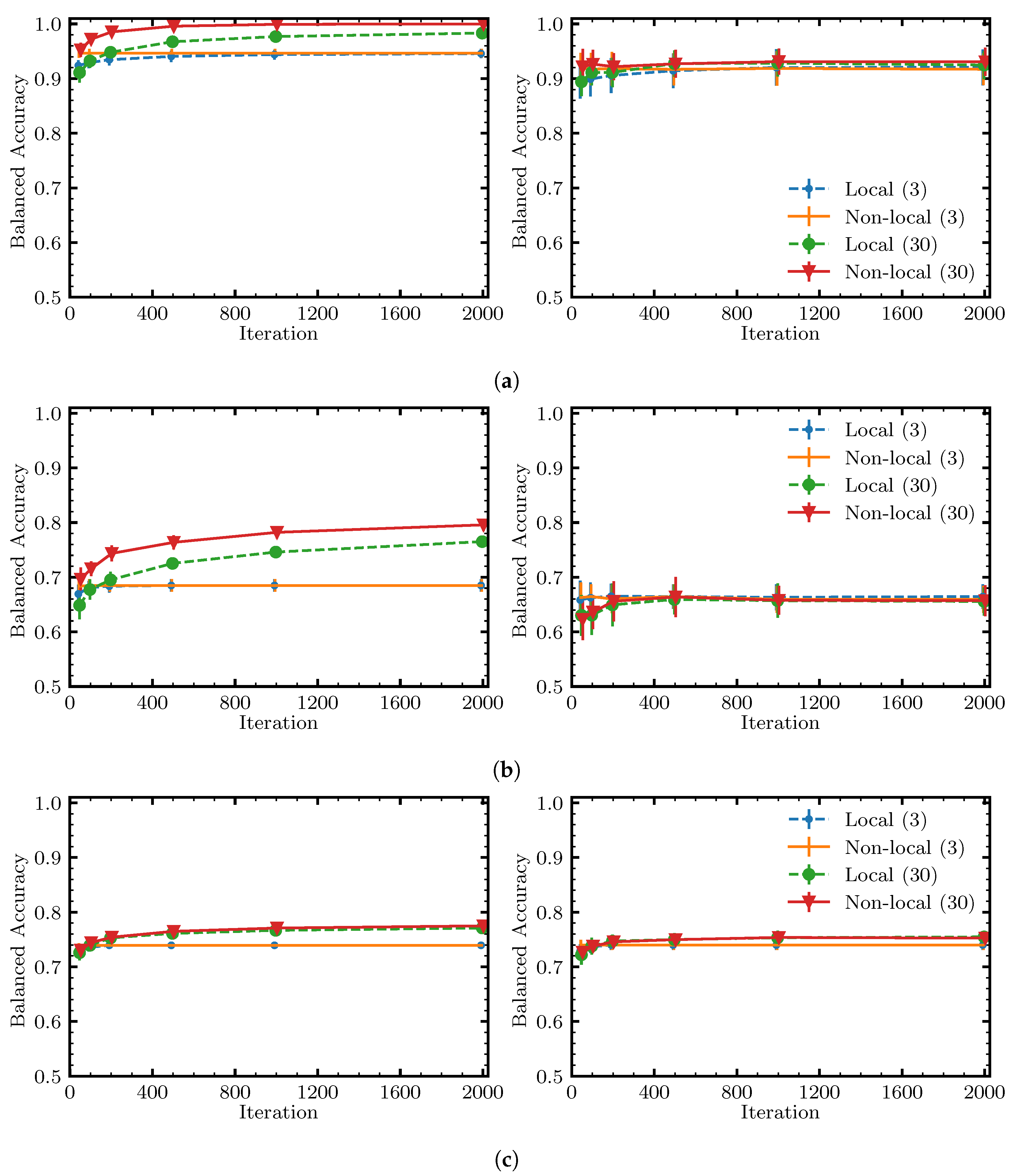
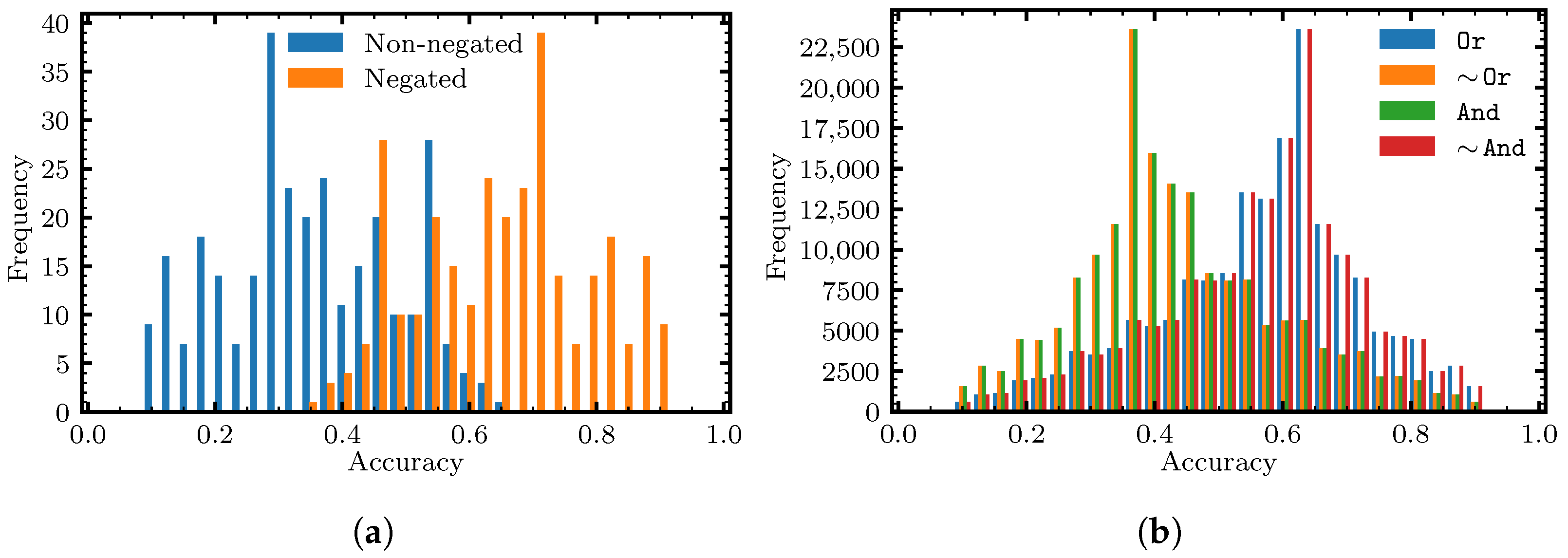
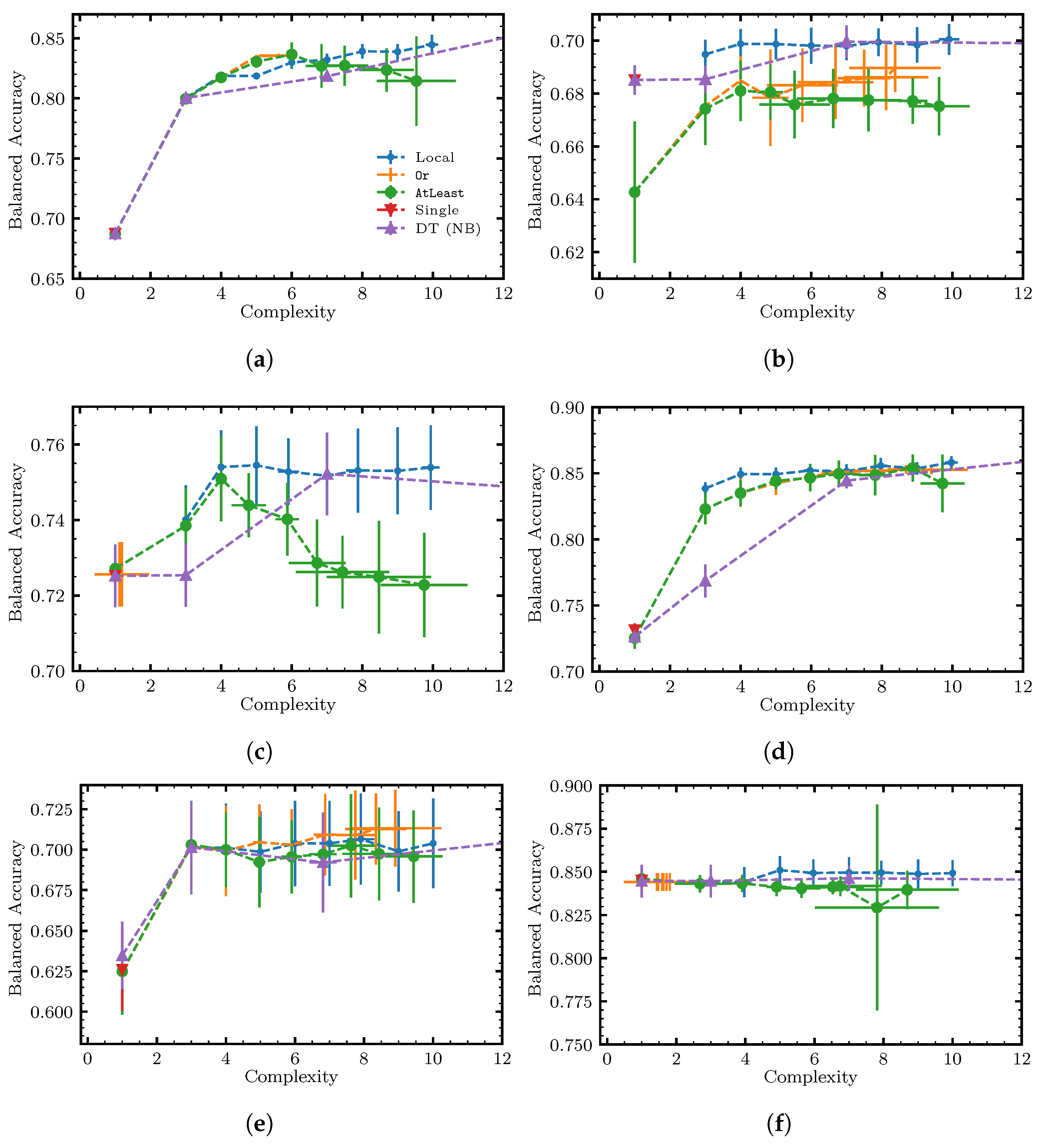
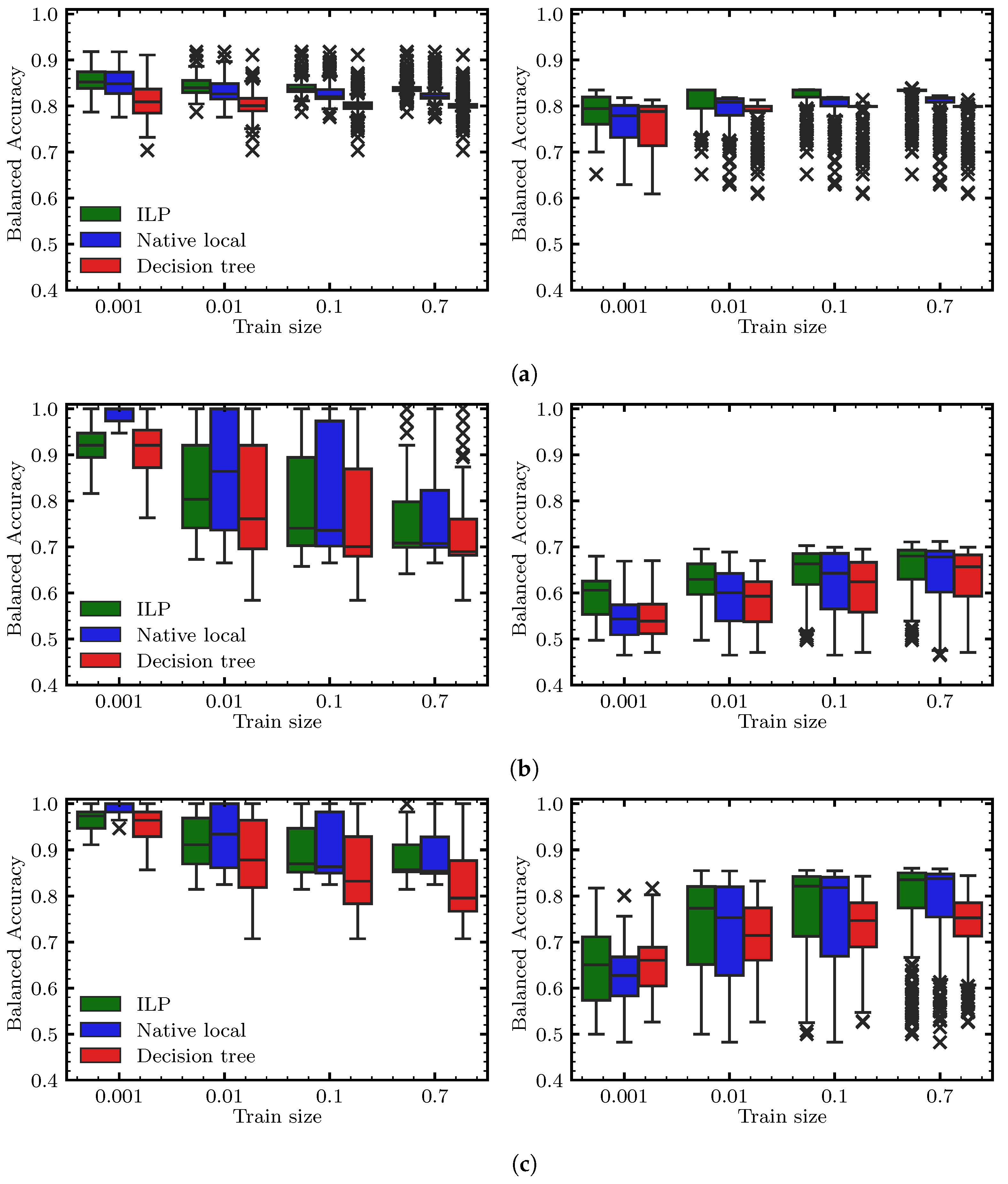
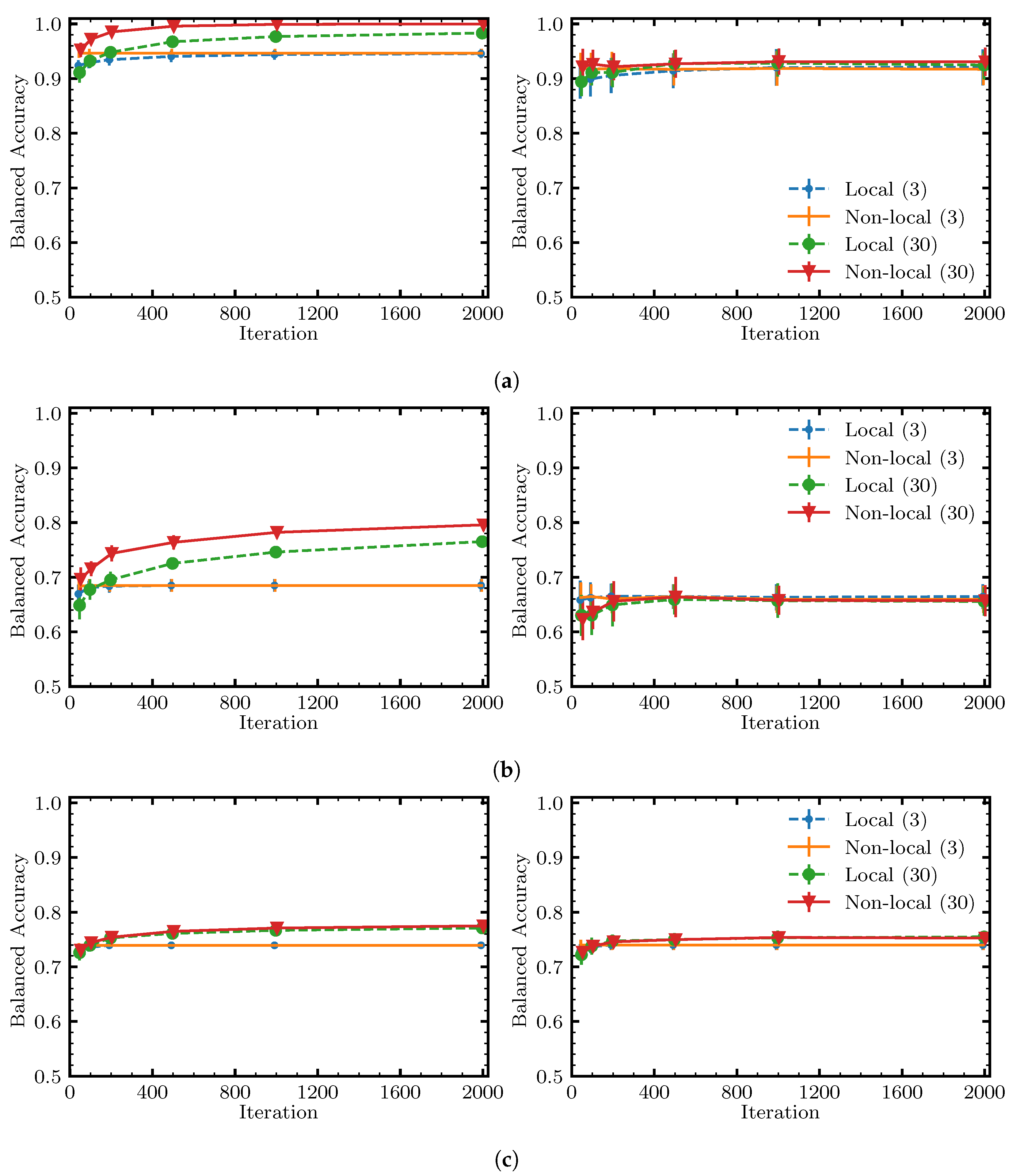
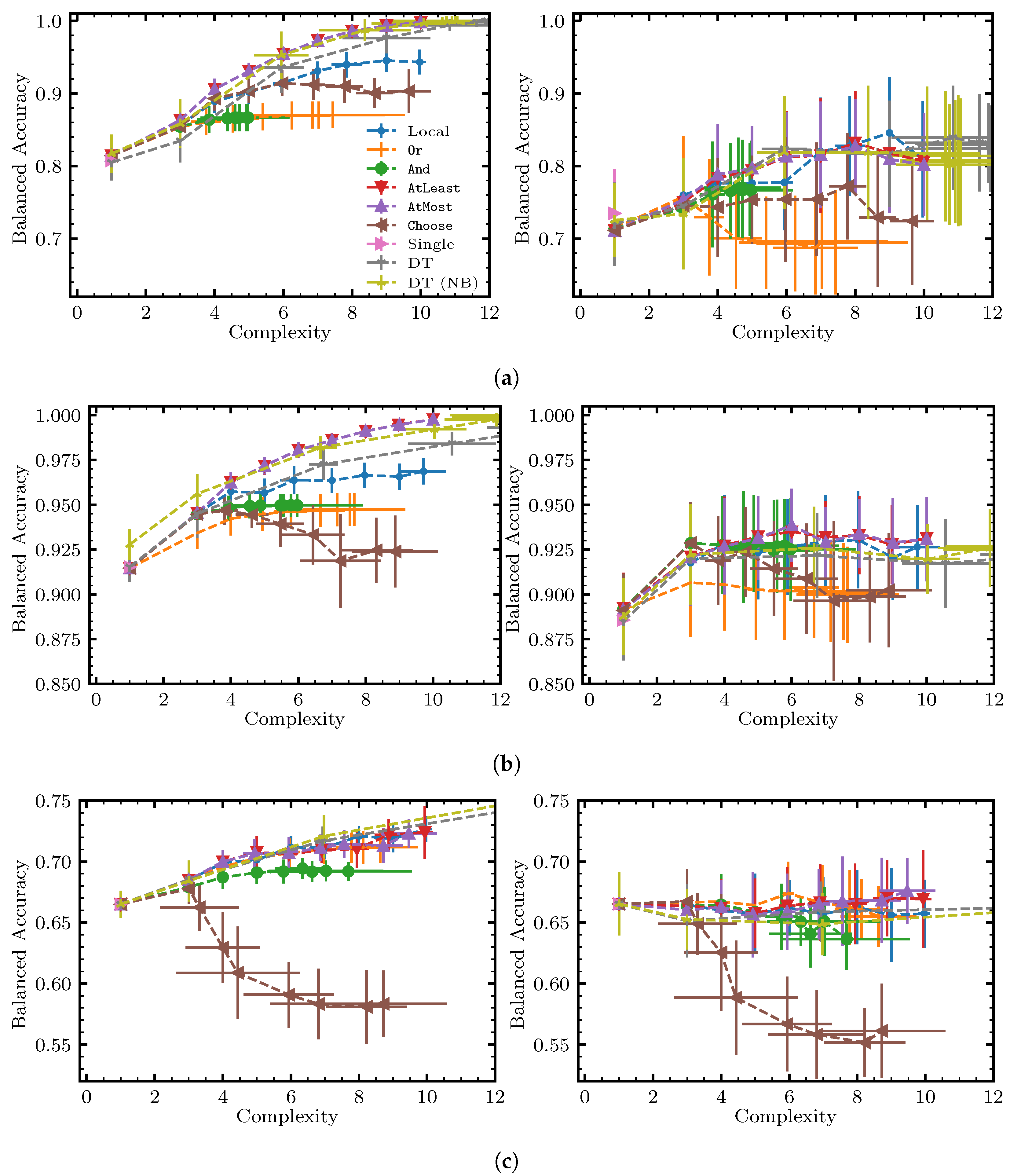
6. Benchmarking Methodology and Results
6.1. Research Questions
- RQ1.
- What is the performance of each solution approach with respect to the Pareto frontier, i.e., score vs. complexity?
- RQ2.
- Does sampling help scale to large datasets?
- RQ3.
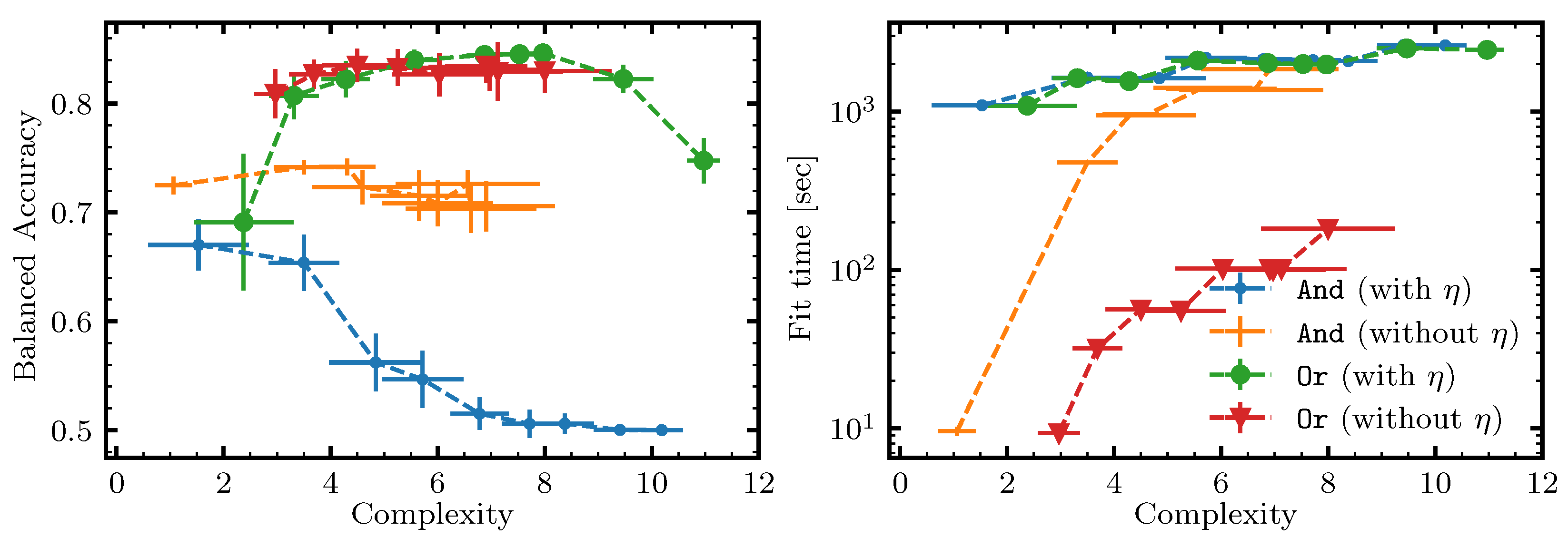
- Are non-local moves advantageous vs. using just local moves, and under what conditions?
6.2. Benchmarking Methodology
- Most frequent—A naive classifier that always outputs the label that is most frequent in the training data. This classifier always gives exactly 0.5 for balanced accuracy. We excluded this classifier from the figures to reduce clutter and because we considered it a lower baseline. This classifier was easily outperformed by all the other classifiers.
- Single feature—A classifier that consists of a simple rule, containing only a single feature. The rule is determined in training by exhaustively checking all possible rules consisting of a single feature or a single negated feature.
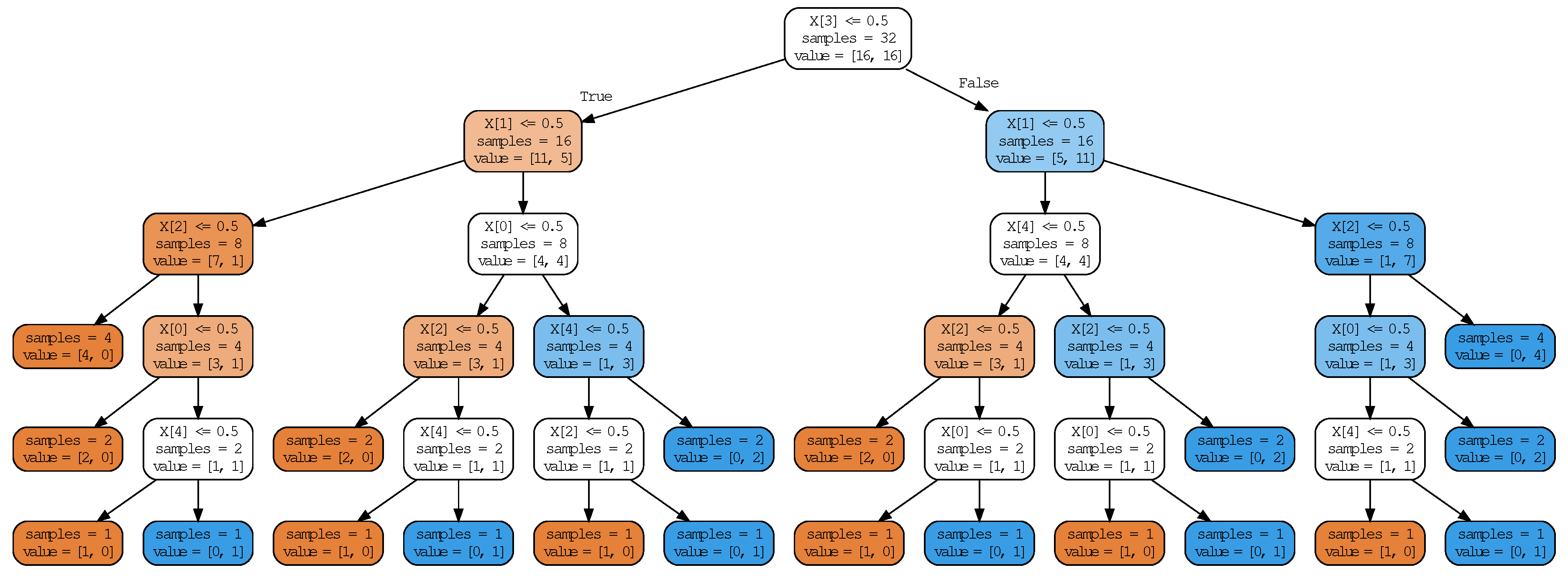
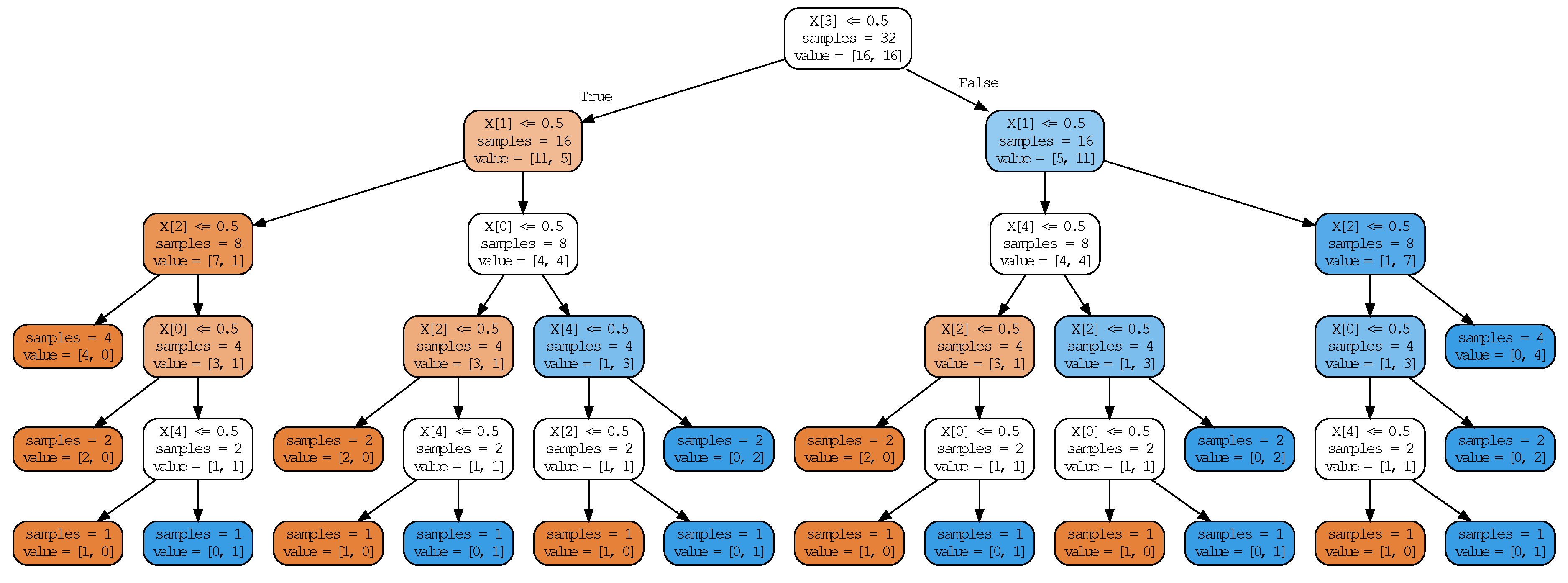
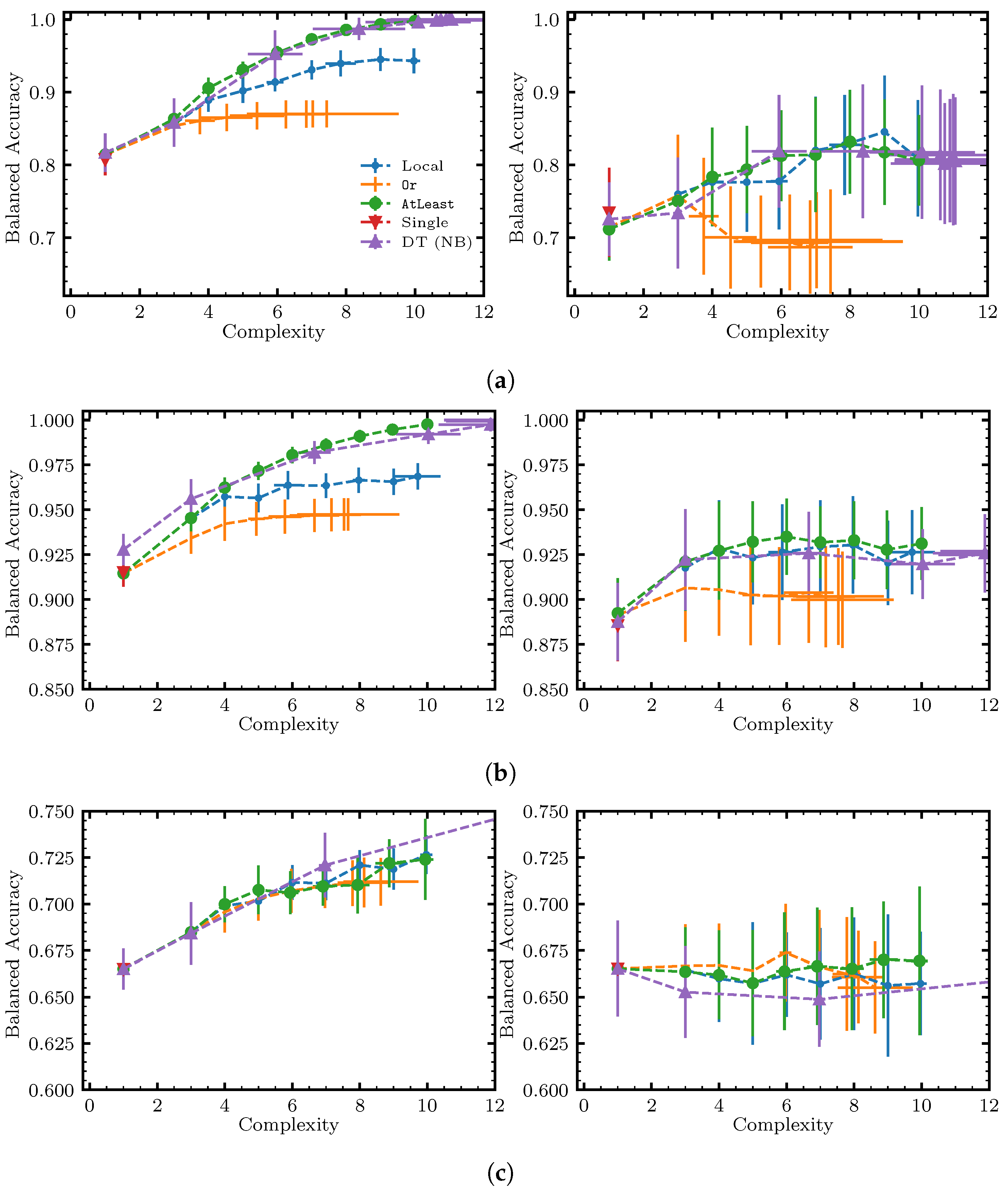
- Decision tree—A decision tree classifier, as implemented in scikit-learn [36], with class_weight = “balanced”. Note that decision trees are able to take non-binary inputs, so we also included the results obtained by training a decision tree on the raw data with no binarization. To control the complexity of the decision tree, we varied max_depth, which sets the maximum depth of the trained decision tree. The complexity is given by the number of split nodes (as described in Section 3.4).
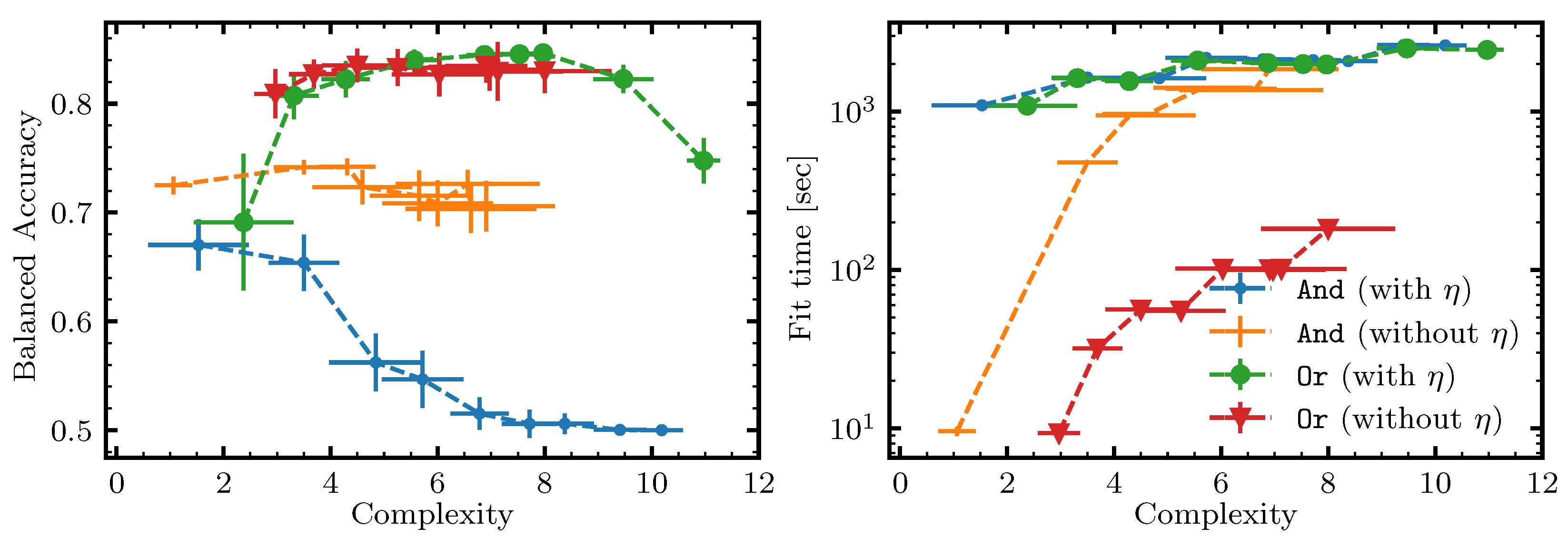
- ILP rule—A classifier that solves the ILP formulations, as described in Section 5.1, Section 5.2 and Section 5.3 for a depth-one rule with a given operator at the root, utilizing FICO Xpress (version 9.0.1) with a timeout of one hour. To limit the size of the problems, a maximum of 3000 samples was used for each cross-validation split.
- QUBO rule—A classifier that solves the QUBO formulations, as described in Section 5.4 for a depth-one rule with a given operator at the root, utilizing simulated annealing, as implemented in dwave-neal with num_reads and num_sweeps . To limit the size of the problems, a maximum of 3000 samples was used for each cross-validation split. The results were generally worse than those of the ILP classifier (guaranteed not to be better in terms of score), so to reduce clutter, we did not include them below (but some QUBO results can be seen in Figure 11). A likely explanation for the underwhelming results is explained in Section 5.6—this is a single bit-flip optimizer, but going from a feasible solution to a feasible solution in our QUBO formulations requires flipping more than one variable at a time.
- SA native local rule—The simulated annealing native local rule classifier, as described in Section 4.5, with , and . The temperatures follow a geometric schedule from 0.2 to .
- SA native non-local rule—The simulated annealing native local rule classifier with additional ILP-powered non-local moves, as described in Section 4.6. This classifier uses the same parameter values as the native local rule classifier and, in addition, the burn-in period consists of the first third of the steps, , , and the timeout for the ILP solver was set to one second.
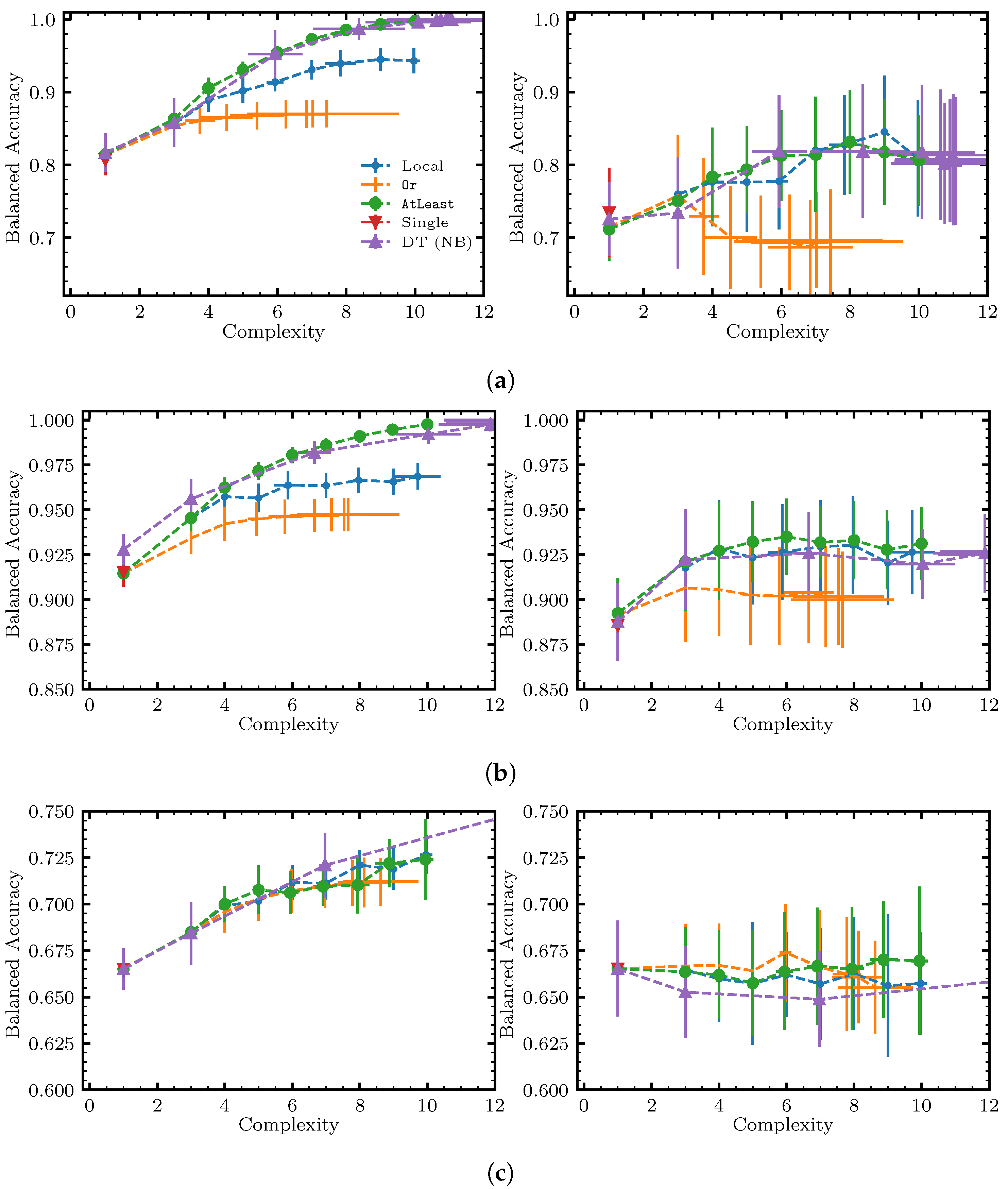
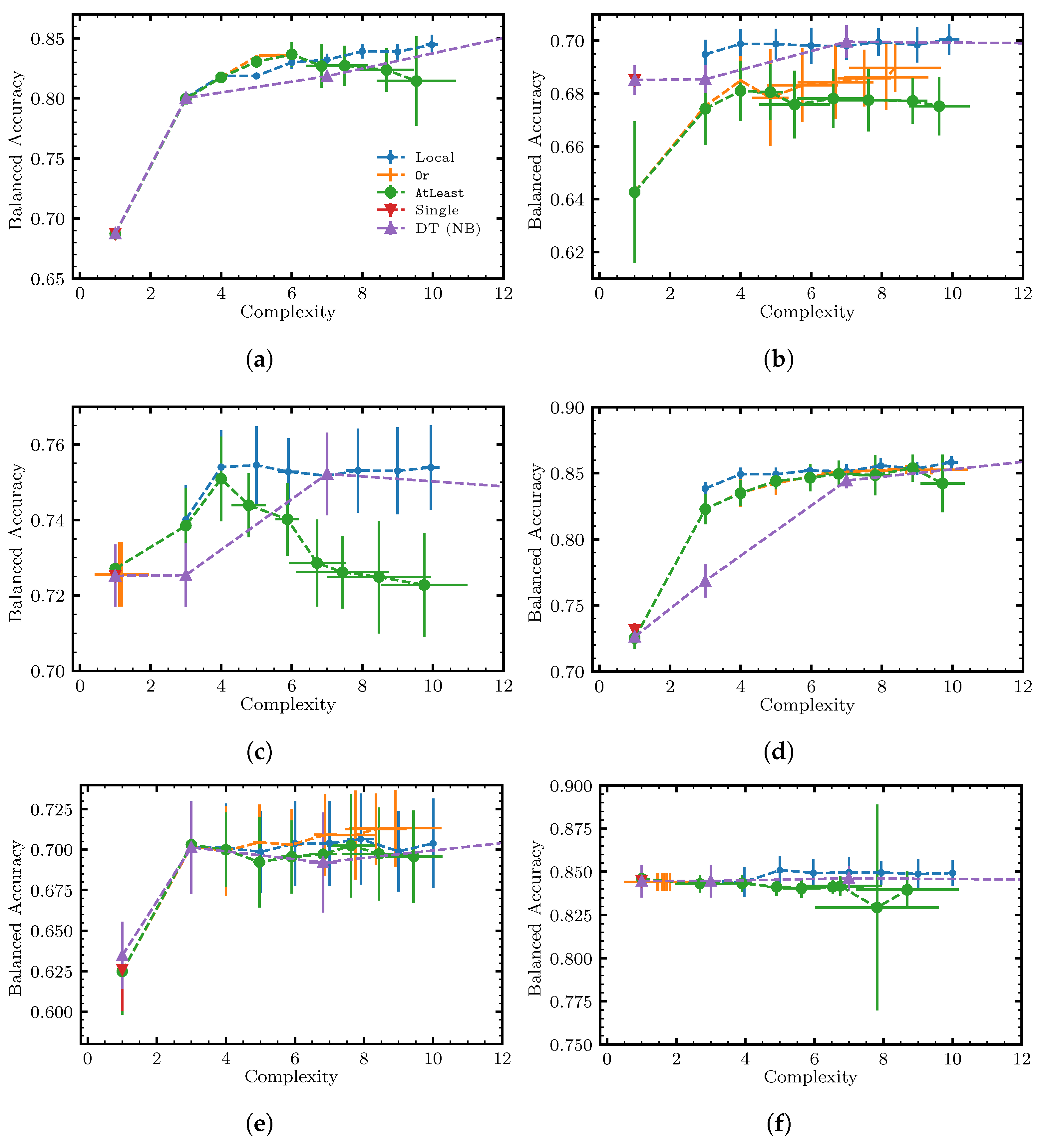
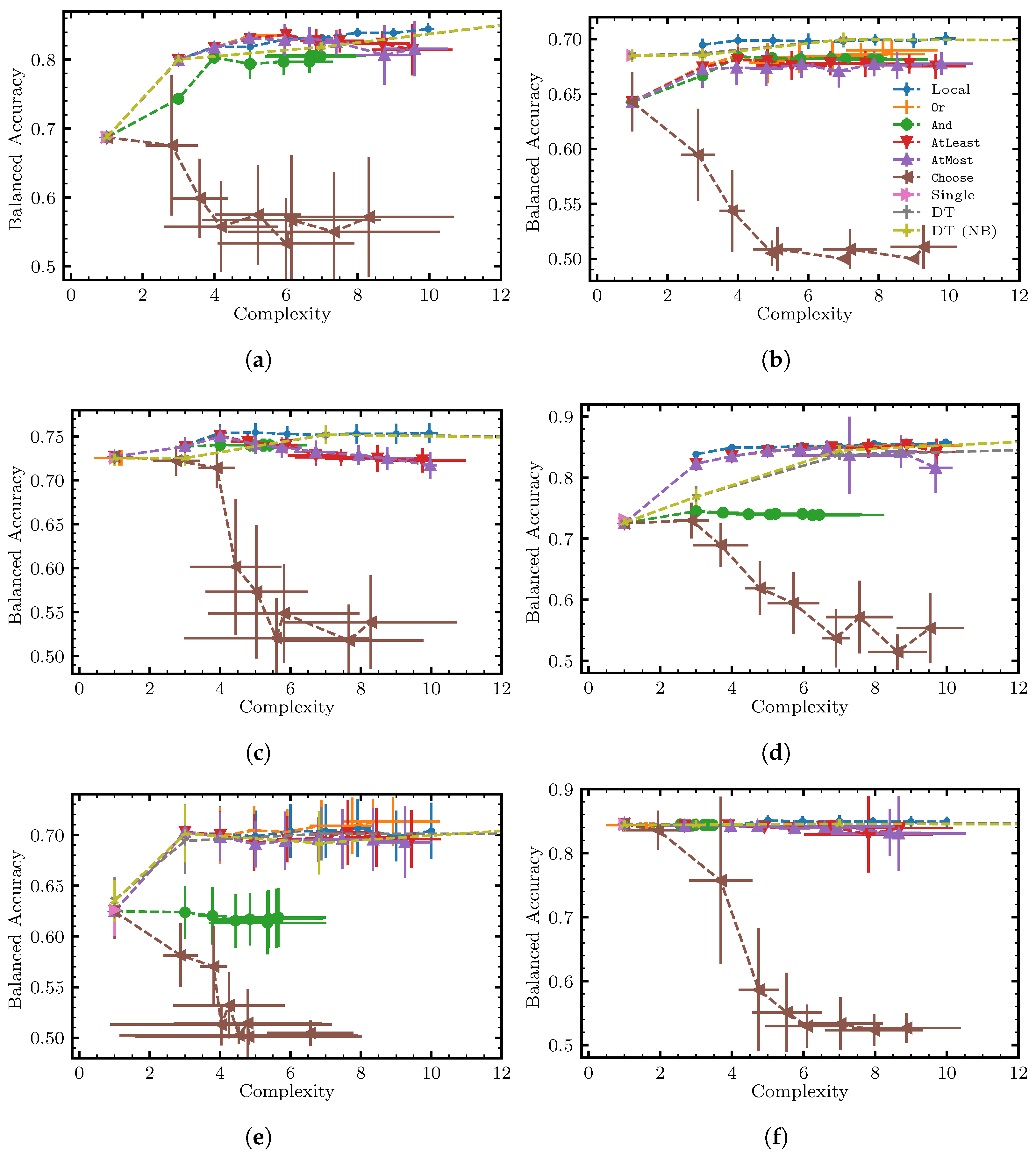
6.3. Results and Discussion
7. Conclusions and Outlook
- Datasets—The classifiers proposed here could be applied to other datasets, for example, in finance, healthcare, and life sciences.
- Operators—The definition of expressive Boolean formulas is (by design) flexible, as well as the operation of the corresponding classifiers. In particular, it is possible to remove some of the operators used in this study or introduce new operators such as AllEqual or Xor depending on the particular problem at hand.
- Use cases—The idea of representing data using a series of operators could be applied to other use cases, such as circuit synthesis [64].
- Binarization—The dependence on the binarization scheme could be studied. Early experiments we ran with another binarization scheme (based on equal-count bins) showed worse results. This raises the possibility that another binarization scheme may improve the presented results.
- Implementation—Our implementation for the native local solver was written in Python (see http://github.com/fidelity/boolxai for the open-sourced version of the native local solver, which will be available soon) and was not heavily optimized. We expect that our implementation of the native local solver could be significantly sped up, for example, by implementing it in a lower-level language or by judicious use of memoization.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Additional Results
References
- Burkart, N.; Huber, M.F. A survey on the explainability of supervised machine learning. J. Artif. Intell. Res. 2021, 70, 245–317. [Google Scholar] [CrossRef]
- Slack, D.; Hilgard, S.; Jia, E.; Singh, S.; Lakkaraju, H. Fooling LIME and SHAP: Adversarial attacks on post hoc explanation methods. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–8 February 2020; pp. 180–186. [Google Scholar]
- Lakkaraju, H.; Arsov, N.; Bastani, O. Robust and stable black box explanations. arXiv 2020, arXiv:2011.06169. [Google Scholar]
- Letham, B.; Rudin, C.; McCormick, T.H.; Madigan, D. Interpretable classifiers using rules and Bayesian analysis: Building a better stroke prediction model. Ann. Appl. Stat. 2015, 9, 1350–1371. [Google Scholar] [CrossRef]
- Wang, F.; Rudin, C. Falling rule lists. arXiv 2015, arXiv:1411.5899. [Google Scholar]
- Lakkaraju, H.; Bach, S.H.; Leskovec, J. Interpretable decision sets: A joint framework for description and prediction. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1675–1684. [Google Scholar]
- Ustun, B.; Rudin, C. Supersparse linear integer models for optimized medical scoring systems. Mach. Learn. 2016, 102, 349–391. [Google Scholar] [CrossRef]
- Angelino, E.; Larus-Stone, N.; Alabi, D.; Seltzer, M.; Rudin, C. Learning certifiably optimal rule lists. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 35–44. [Google Scholar]
- Zahedinejad, E.; Zaribafiyan, A. Combinatorial optimization on gate model quantum computers: A survey. arXiv 2017, arXiv:1708.05294. [Google Scholar]
- Sanders, Y.R.; Berry, D.W.; Costa, P.C.S.; Tessler, L.W.; Wiebe, N.; Gidney, C.; Neven, H.; Babbush, R. Compilation of fault-tolerant quantum heuristics for combinatorial optimization. PRX Quantum 2020, 1, 020312. [Google Scholar] [CrossRef]
- Reuther, A.; Michaleas, P.; Jones, M.; Gadepally, V.; Samsi, S.; Kepner, J. Survey and benchmarking of machine learning accelerators. In Proceedings of the 2019 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 24–26 September 2019; pp. 1–9. [Google Scholar]
- Bavikadi, S.; Dhavlle, A.; Ganguly, A.; Haridass, A.; Hendy, H.; Merkel, C.; Reddi, V.J.; Sutradhar, P.R.; Joseph, A.; Dinakarrao, S.M.P. A survey on machine learning accelerators and evolutionary hardware platforms. IEEE Design Test 2022, 39, 91–116. [Google Scholar] [CrossRef]
- Aramon, M.; Rosenberg, G.; Valiante, E.; Miyazawa, T.; Tamura, H.; Katzgraber, H.G. Physics-inspired optimization for quadratic unconstrained problems using a digital annealer. Front. Phys. 2019, 7, 48. [Google Scholar] [CrossRef]
- Mohseni, N.; McMahon, P.L.; Byrnes, T. Ising machines as hardware solvers of combinatorial optimization problems. Nat. Rev. Phys. 2020, 4, 363–379. [Google Scholar] [CrossRef]
- Valiante, E.; Hernandez, M.; Barzegar, A.; Katzgraber, H.G. Computational overhead of locality reduction in binary optimization problems. Comput. Phys. Commun. 2021, 269, 108102. [Google Scholar] [CrossRef]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res. 2022, 23, 1–39. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should I trust you? Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Lakkaraju, H.; Kamar, E.; Caruana, R.; Leskovec, J. Faithful and customizable explanations of black box models. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 131–138. [Google Scholar]
- Craven, M.; Shavlik, J. Extracting tree-structured representations of trained networks. Adv. Neural Inf. Process. Syst. 1995, 8, 24–30. [Google Scholar]
- Bastani, O.; Kim, C.; Bastani, H. Interpreting blackbox models via model extraction. arXiv 2017, arXiv:1705.08504. [Google Scholar]
- Malioutov, D.; Meel, K.S. MLIC: A MaxSAT-based framework for learning interpretable classification rules. In Proceedings of the International Conference on Principles and Practice of Constraint Programming, Lille, France, 27–31 August 2018; pp. 312–327. [Google Scholar]
- Ghosh, B.; Meel, K.S. IMLI: An incremental framework for MaxSAT-based learning of interpretable classification rules. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 203–210. [Google Scholar]
- Su, G.; Wei, D.; Varshney, K.R.; Malioutov, D.M. Interpretable two-level Boolean rule learning for classification. arXiv 2015, arXiv:1511.07361. [Google Scholar]
- Wang, T.; Rudin, C. Learning optimized Or’s of And’s. arXiv 2015, arXiv:1511.02210. [Google Scholar]
- Lawless, C.; Dash, S.; Gunluk, O.; Wei, D. Interpretable and fair boolean rule sets via column generation. arXiv 2021, arXiv:2111.08466. [Google Scholar]
- Malioutov, D.M.; Varshney, K.R.; Emad, A.; Dash, S. Learning interpretable classification rules with Boolean compressed sensing. In Transparent Data Mining for Big and Small Data; Springer: Berlin/Heidelberg, Germany, 2017; pp. 95–121. [Google Scholar]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Batcher, K.E. Sorting networks and their applications. In Proceedings of the Spring Joint Computer Conference, Atlantic City, NJ, USA, 30 April–2 May 1968; pp. 307–314. [Google Scholar]
- Asín, R.; Nieuwenhuis, R.; Oliveras, A.; Rodríguez-Carbonell, E. Cardinality networks and their applications. In Proceedings of the International Conference on Theory and Applications of Satisfiability Testing, Swansea, UK, 30 June–3 July 2009; pp. 167–180. [Google Scholar]
- Bailleux, O.; Boufkhad, Y. Efficient CNF encoding of Boolean cardinality constraints. In Proceedings of the International Conference on Principles and Practice of Constraint Programming, Kinsale, Ireland, 29 September–3 October 2003; pp. 108–122. [Google Scholar]
- Ogawa, T.; Liu, Y.; Ryuzo Hasegawa, R.; Koshimura, M.; Fujita, H. Modulo based CNF encoding of cardinality constraints and its application to MaxSAT solvers. In Proceedings of the 2013 IEEE 25th International Conference on Tools with Artificial Intelligence, Herndon, VA, USA, 4–6 November 2013; pp. 9–17. [Google Scholar]
- Morgado, A.; Ignatiev, A.; Marques-Silva, J. MSCG: Robust core-guided MaxSAT solving. J. Satisf. Boolean Model. Comput. 2014, 9, 129–134. [Google Scholar] [CrossRef]
- Sinz, C. Towards an optimal CNF encoding of Boolean cardinality constraints. In International Conference on Principles and Practice of Constraint Programming; Springer: Berlin/Heidelberg, Germany, 2005; pp. 827–831. [Google Scholar]
- Ignatiev, A.; Morgado, A.; Marques-Silva, J. PySAT: A Python toolkit for prototyping with SAT oracles. In SAT; Springer: Berlin/Heidelberg, Germany, 2018; pp. 428–437. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2021, 12, 2825–2830. [Google Scholar]
- Hoos, H.H.; Stützle, T. Stochastic Local Search: Foundations and Applications; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Pisinger, D.; Ropke, S. Large neighborhood search. In Handbook of Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2019; pp. 99–127. [Google Scholar]
- Kirkpatrick, S.; Gelatt, C.D., Jr.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef]
- Wolberg, W.H.; Street, W.N.; Mangasarian, O.L. Breast Cancer Wisconsin (Diagnostic) Data Set. UCI Machine Learning Repository. 1992. Available online: https://archive.ics.uci.edu/ml/datasets/breast+cancer (accessed on 1 November 2022).
- Durr, D.; Hoyer, P. A quantum algorithm for finding the minimum. arXiv 1996, arXiv:quant-ph/9607014. [Google Scholar]
- Farhi, E.; Goldstone, J.; Gutmann, S. A quantum approximate optimization algorithm. arXiv 2014, arXiv:1411.4028. [Google Scholar]
- Khosravi, F.; Scherer, A.; Ronagh, P. Mixed-integer programming using a Bosonic quantum computer. arXiv 2021, arXiv:2112.13917. [Google Scholar]
- Montanaro, A. Quantum speedup of branch-and-bound algorithms. Phys. Rev. Res. 2020, 2, 013056. [Google Scholar] [CrossRef]
- Bisschop, J. AIMMS modeling guide-integer programming tricks. In Pinedo, Michael. Scheduling: Theory, Algorithms, and Systems; AIMMS BV: Haarlem, The Netherlands, 2016. [Google Scholar]
- Hauke, P.; Katzgraber, H.G.; Lechner, W.; Nishimori, H.; Oliver, W.D. Perspectives of quantum annealing: Methods and implementations. Rep. Prog. Phys. 2020, 83, 054401. [Google Scholar] [CrossRef] [PubMed]
- Temme, K.; Osborne, T.J.; Vollbrecht, K.G.; Poulin, D.; Verstraete, F. Quantum Metropolis sampling. Nature 2011, 471, 87–90. [Google Scholar] [CrossRef]
- Baritompa, W.P.; Bulger, D.W.; Wood, G.R. Grover’s quantum algorithm applied to global optimization. SIAM J. Optim. 2005, 15, 1170–1184. [Google Scholar] [CrossRef]
- Tilly, J.; Chen, H.; Cao, S.; Picozzi, D.; Setia, K.; Li, Y.; Grant, E.; Wossnig, L.; Rungger, I.; Booth, G.H.; et al. The variational quantum eigensolver: A review of methods and best practices. Phys. Rep. 2022, 986, 1–128. [Google Scholar] [CrossRef]
- Glover, F.; Kochenberger, G.; Hennig, R.; Du, Y. Quantum bridge analytics I: A tutorial on formulating and using QUBO models. Ann. Oper. Res. 2022, 314, 141–183. [Google Scholar] [CrossRef]
- Yarkoni, S.; Raponi, E.; Bäck, T.; Schmitt, S. Quantum annealing for industry applications: Introduction and review. arXiv 2022, arXiv:2112.07491. [Google Scholar] [CrossRef]
- Error Sources for Problem Representation. 2023. Available online: https://docs.dwavesys.com/docs/latest/c_qpu_ice.html (accessed on 15 March 2023).
- Moro, S.; Cortez, P.; Rita, P. A data-driven approach to predict the success of bank telemarketing. Decis. Support Syst. 2014, 62, 22–31. [Google Scholar] [CrossRef]
- Farhi, E.; Goldstone, J.; Gutmann, S. Quantum adiabatic evolution algorithms versus simulated annealing. arXiv 2002, arXiv:quant-ph/0201031. [Google Scholar]
- Kaggle. Airline Customer Satisfaction. Kaggle. 2023. Available online: https://www.kaggle.com/datasets/sjleshrac/airlines-customer-satisfaction (accessed on 1 November 2022).
- Yeh, I.C.; Lien, C.-H. The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients. Expert Syst. Appl. 2009, 36, 2473–2480. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 1 November 2022).
- Kaggle. Telco Customer Churn. Kaggle. 2023. Available online: https://www.kaggle.com/datasets/blastchar/telco-customer-churn (accessed on 1 November 2022).
- Kaggle. Home Equity, Kaggle. 2023. Available online: https://www.kaggle.com/datasets/ajay1735/hmeq-data (accessed on 1 November 2022).
- Sakar, C.O.; Polat, S.O.; Katircioglu, M.; Kastro, Y. Real-time prediction of online shoppers’ purchasing intention using multilayer perceptron and LSTM recurrent neural networks. Neural Comput. Appl. 2019, 31, 6893–6908. [Google Scholar] [CrossRef]
- Little, M.; Mcsharry, P.; Roberts, S.; Costello, D.; Moroz, I. Exploiting nonlinear recurrence and fractal scaling properties for voice disorder detection. Biomed. Eng. Online 2007, 26, 23. [Google Scholar]
- Fayyad, U. Multi-interval discretization of continuous-valued attributes for classification learning. In Proceedings of the Thirteenth International Joint Conference on Artificial Intelligence (II), Chambery, France, 28 August–3 September 1993; Volume 2, pp. 1022–1027. [Google Scholar]
- Van der Ploeg, T.; Austin, P.C.; Steyerberg, E.W. Modern modelling techniques are data hungry: A simulation study for predicting dichotomous endpoints. BMC Med. Res. Methodol. 2014, 14, 1–13. [Google Scholar] [CrossRef]
- De Micheli, G. Synthesis and Optimization of Digital Circuits; McGraw-Hill Higher Education: Irvine, CA, USA, 1994. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Rules | Accuracy | Rule |
|---|---|---|---|
| f | 300 | 0.647 | mean fractal dimension > 0.0552 |
| ∼f | 300 | 0.914 | worst perimeter ≤ 108.9364 |
| Or | 179,400 | 0.931 | Or(worst concave points ≤ 0.1091, worst area ≤ 719.6364) |
| ∼Or | 179,400 | 0.944 | ∼Or(worst concave points > 0.1563, worst area > 988.6818) |
| And | 179,400 | 0.944 | And(worst concave points ≤ 0.1563, worst area ≤ 88.6818) |
| ∼And | 179,400 | 0.931 | ∼And(worst concave points > 0.1091, worst area > 719.6364) |
| Operator | with | without | ILP |
|---|---|---|---|
| Or | 2879 | 1027 | 1169 |
| And | 2879 | 1317 | 1169 |
| AtLeast | 3097 | 1959 | 1170 |
| AtMost | 3097 | 1959 | 1170 |
| Choose | 3811 | 2673 | 1527 |
| Name | Rows | Features | Binarized | Majority | Ref. |
|---|---|---|---|---|---|
| Airline Customer Satisfaction | 129,487 | 22 | 119 | 0.55 | [55] |
| Breast Cancer | 569 | 30 | 300 | 0.63 | [40] |
| Credit Card Default | 30,000 | 23 | 185 | 0.78 | [56] |
| Credit Risk | 1000 | 20 | 92 | 0.70 | [57] |
| Customer Churn | 7043 | 19 | 67 | 0.73 | [58] |
| Direct Marketing | 41,188 | 20 | 124 | 0.89 | [53] |
| Home Equity Default | 3364 | 12 | 93 | 0.80 | [59] |
| Online Shoppers’ Intentions | 12,330 | 17 | 104 | 0.85 | [60] |
| Parkinson’s | 195 | 22 | 217 | 0.75 | [61] |
| Dataset | Rule |
|---|---|
| Airline Customer Satisfaction | And(Inflight entertainment ≠ 5, Inflight entertainment ≠ 4, Seat comfort ≠ 0) |
| Breast Cancer | AtMost1(worst concave points ≤ 0.1533, worst radius ≤ 16.43, mean texture ≤ 15.3036) |
| Credit Card Default | Or(PAY_2 > 0, PAY_0 > 0, PAY_4 > 0) |
| Credit Risk | Choose1(checking_status = no checking, checking_status < 200, property_magnitude = real estate) |
| Customer Churn | AtMost1(tenure > 5, Contract ≠ Month-to-month, InternetService ≠ Fiber optic) |
| Direct Marketing | Or(duration > 393, nr.employed ≤ 5076.2, month = mar) |
| Home Equity Default | Or(DEBTINC > 41.6283, DELINQ ≠ 0.0, CLNO ≤ 11) |
| Online Shoppers’ Intentions | AtMost1(PageValues ≤ 5.5514, PageValues ≤ 0, BounceRates > 0.025) |
| Parkinson’s | AtMost1(spread1 > −6.3025, spread2 > 0.1995, Jitter:DDP > 0.0059) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rosenberg, G.; Brubaker, J.K.; Schuetz, M.J.A.; Salton, G.; Zhu, Z.; Zhu, E.Y.; Kadıoğlu, S.; Borujeni, S.E.; Katzgraber, H.G. Explainable Artificial Intelligence Using Expressive Boolean Formulas. Mach. Learn. Knowl. Extr. 2023, 5, 1760-1795. https://doi.org/10.3390/make5040086
Rosenberg G, Brubaker JK, Schuetz MJA, Salton G, Zhu Z, Zhu EY, Kadıoğlu S, Borujeni SE, Katzgraber HG. Explainable Artificial Intelligence Using Expressive Boolean Formulas. Machine Learning and Knowledge Extraction. 2023; 5(4):1760-1795. https://doi.org/10.3390/make5040086
Chicago/Turabian StyleRosenberg, Gili, John Kyle Brubaker, Martin J. A. Schuetz, Grant Salton, Zhihuai Zhu, Elton Yechao Zhu, Serdar Kadıoğlu, Sima E. Borujeni, and Helmut G. Katzgraber. 2023. "Explainable Artificial Intelligence Using Expressive Boolean Formulas" Machine Learning and Knowledge Extraction 5, no. 4: 1760-1795. https://doi.org/10.3390/make5040086
APA StyleRosenberg, G., Brubaker, J. K., Schuetz, M. J. A., Salton, G., Zhu, Z., Zhu, E. Y., Kadıoğlu, S., Borujeni, S. E., & Katzgraber, H. G. (2023). Explainable Artificial Intelligence Using Expressive Boolean Formulas. Machine Learning and Knowledge Extraction, 5(4), 1760-1795. https://doi.org/10.3390/make5040086