1. Introduction
In vision-based off-road terrain segmentation, imbalanced datasets present a significant obstacle for the adequate training of models which completely encompass all terrain classes. In modern driving datasets, the distributions of class labels are highly imbalanced resulting in a subset of classes appearing considerably more often leading to a “class imbalance” problem. In some cases such as the Rellis-3D outdoor dataset, four specific classes account for roughly 94% of total labeled pixels [
1]. Other off-road and urban driving datasets feature similar distributions [
2,
3,
4]. The presence of imbalanced class distributions lead to reduced model effectiveness, particularly for the very infrequent minority classes.
As models are predominantly trained through incremental corrective adjustments based on measured performance, sparse exposure to minority classes may bias training to favor majority class detection. In extreme cases, sparse exposure may lead to models ignoring the presence of minority classes entirely. To ensure the robustness of segmentation systems and to allow for a comprehensive solution to be developed, the training process and model must be resilient to imbalanced data distributions.
When considering the class imbalance problem, it presents itself in two main manners: (1) in the imbalanced distribution of occurrence frequency for a class pixel within a specific image, and (2) in the imbalanced occurrence of a class within each image in the dataset. Manner (1) occurs when the total amount of pixels pertaining to the majority classes greatly outnumber the minority classes. This imbalanced pixel distribution is readily seen when examining pixel label distributions of major driving datasets [
1,
2,
3,
4]. The second manner involves the frequency presence of each class within the set of dataset images. Since the more frequent classes are generally present in most if not all images, the model is more often exposed to them resulting in increased net influence. To remedy these issues, numerous approaches have been suggested in the contemporary literature. These approaches can be divided into two main types: data-level, and algorithmic-level methods [
5].
As class imbalance is a direct byproduct of infrequent class data occurrence within the dataset, a logical approach is to equalize the distribution of data prior to its use in model training [
5]. Data-level methods such as data augmentation provide a logical manner of increasing the overall presence of minority classes in training sets. Applying transformations to images containing the minority classes to generate synthetic data points results in some glaring issues, however. Since the new data generated forms new versions of past images, the resulting data will remain imbalanced overall or no longer accurately represent the desired training environment.
Rather than altering the dataset, algorithmic-level methods specifically target class imbalance and related effects through alterations to the standard training algorithm(s). A particularly popular subset of these being the modification of the loss/objective function used during training. To ensure that the model is not over-trained on majority class data, specialized loss functions counterbalance the influence of majority classes by increasing the impact of minority classes during training. The resulting advantage to this approach thereby being the reduction in both training time and the overall increase in achieved model performance. In the most extreme cases, this may allow models to detect priorly undetected classes as they become increasingly sensitive to them. These tailored loss-function approaches are found to be rather effective in increasing model performance within imbalanced environments [
5,
6]. As loss functions are extremely varied, we have set out to detail and apply them to our specific use-case environment.
The application of semantic segmentation to terrain segmentation has become increasingly widespread and developed greatly in recent years. Surveys such as [
7,
8,
9] provide detailed overviews of current models and approaches for semantic segmentation on off-road environments. These surveys, however, mainly focus on the design aspects such as model architecture and datasets, but do not consider class imbalance as well as possible approaches which remedy this issue.
Research surveys assessing and comparing loss function performance in imbalanced datasets has been published, but mainly focus on the medical imaging field [
6,
10]. The task of medical image segmentation suffers from the same issues of class imbalance as off-road terrain segmentation. Generally, medical images contain large areas entirely representing a single class (such as the background class). In Jadon et al. (2020), a study was conducted comparing the results of training with nine different loss functions on the segmentation of the NBFS Skull Stripping Dataset [
11]. The survey by Ma et al. (2021), then expanded upon this work, presenting 20 different loss functions and comparing their performance when employed on four different medical image segmentation datasets [
6]. These surveys both highlighted the potential impact the loss function can have on the resulting model performance. With some loss functions resulting in considerably greater performance when compared to others. As the problem faced in off-road terrain segmentation is extremely similar, these surveys have formed the basis for the selection of loss functions which will be evaluated within this publication.
To our knowledge, no prior work concerning the performance comparison of loss functions in off-road environments has yet to be published. Therefore, in this paper, we provide the following contributions:
We present a study of current loss functions tailored to solving class imbalance issues.
With the aforementioned loss functions, we train, evaluate, and compare their performance when applied on the Rellis-3D off-road dataset.
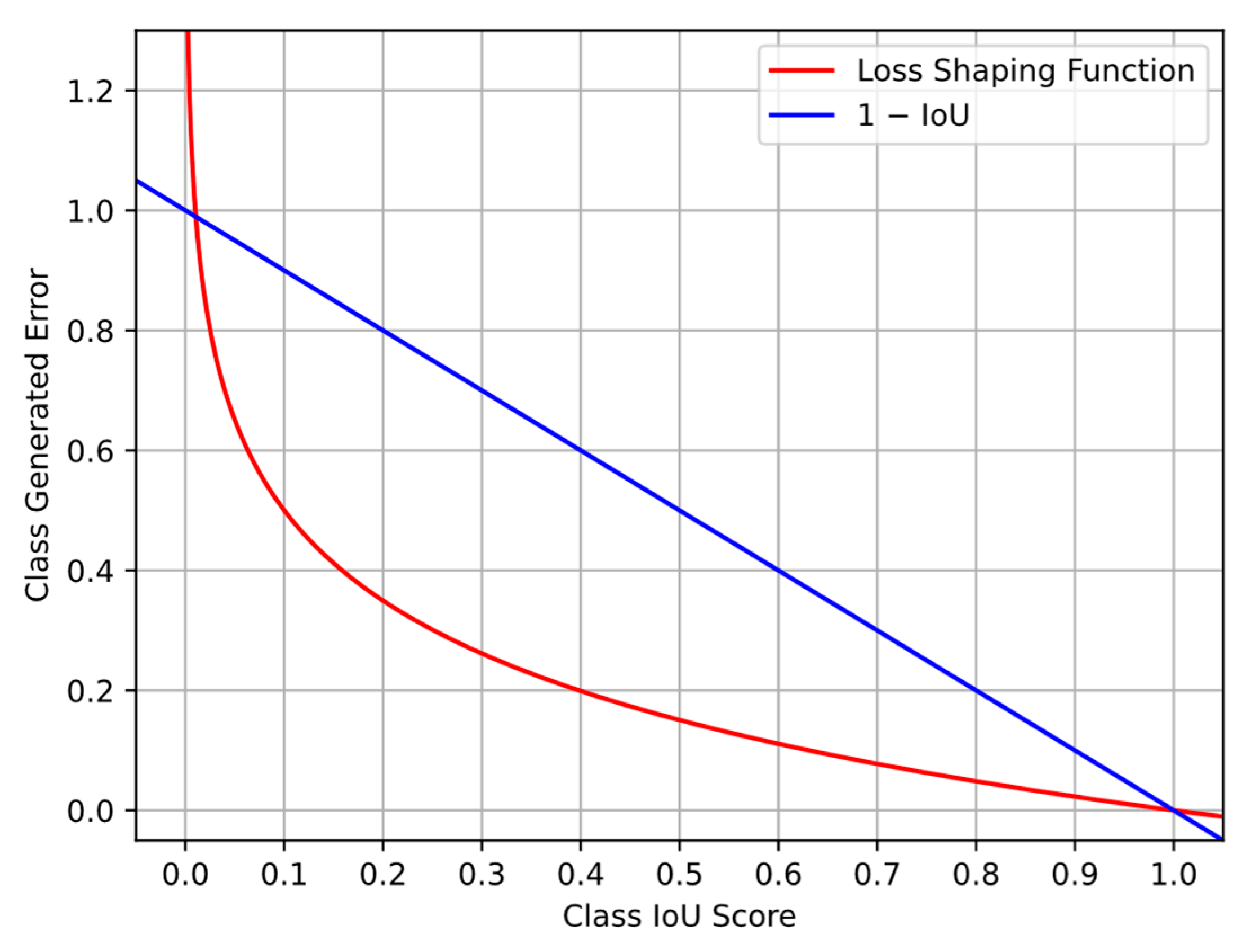
We present a novel loss function FCIoU which aims to further reduce the impact of class imbalance.
2. Loss Functions
The use of loss functions to counterbalance against class imbalance is widespread within the semantic segmentation literature [
12,
13,
14,
15,
16,
17,
18]. As the objective function dictates the direction that the model will be optimized, the loss function can be tailored to better target minority classes. Implementations of each loss function vary greatly but, in general, tend to be variations of currently existing and proven semantic segmentation loss functions such as the dice loss [
19], cross-entropy (CE) loss, or intersection over union (IoU) loss [
20] functions. The counterbalancing of pre-existing loss functions generally occur either by (1) indirectly targeting class imbalance through increasing the impact of individual poorly performing pixels [
12,
13,
17,
18], or (2) by applying a general weight to each class with the aim of increasing the overall loss generated by minority classes [
15,
16]. In this section, a detailed description of each loss function contained within this study is provided.
2.1. Cross-Entropy (CE) Loss
The cross-entropy (CE) loss function is a distribution-based loss function which has seen widespread utilization and has grown to become the de-facto standard for semantic segmentation tasks. CE loss measures the dissimilarity between the prediction and ground-truth probability distribution as described in Equation (1):
where
c represents a specific class within the entire set of classes
C,
represents a specific pixel instance within the set of all pixels
,
represents the ground-truth annotation label values (either 0 or 1), and
represents the probabilistic prediction output for the model defined as:
therefore, represents the conditional probability that the specific pixel in image I is part of the associated class . The probability value is obtained from the model output by applying the softmax function across every class. As can be inferred, the loss function only returns a non-zero value for the specific active class of the pixel where . Therefore, only the prediction score for the ground-truth class label value contributes to the loss measured.
The CE loss function, however, does have a particularly large downside when being employed with an imbalanced dataset. This downside is due to the underlying assumption made that the target distribution is balanced and evenly distributed. This leads to the loss function evaluating each pixel prediction evenly compared with others. As the majority classes appear in a considerably larger quantity of pixels, those classes generate a much greater portion of the total loss calculated for the system. As model training is tied to the scores generated, the CE loss function will indicate increased performance mainly when the majority class predictions are effective.
To prevent this, variations of the CE loss function have been developed to counterbalance the loss function to favour the low-performing minority classification methods. The simplest of these approaches, known as the weighted CE (WCE) loss function is configured to assign an array of static weights (
) for each class as defined by:
Examples of the use of this function can be seen in [
15]. This approach, in general, is not efficient, both in training optimization and training hyper-parameter tuning. Since the weights are manually configured, determining the best weights to employ can be a time-intensive laborious process which may require several iterations to determine. Additionally, initializing with the wrong weights will result in inefficient or ineffective training. In Jun et al., a 2021 survey comparing loss functions, the weighted cross entropy method scored the lowest performance consistently when compared to other methods [
6].
For the purposes of this study, only the base CE loss function will be employed as a baseline evaluation of the model’s performance. As the de facto standard loss function, the CE loss will serve as the point of comparison for the other loss functions which are tailored to handling class-imbalance.
2.2. Focal Loss
To avoid the issues inherent with assigning static weights, other methods such as the focal loss [
12] employ dynamic weighting for each pixel instance based on the pixel’s prediction certainty (
and is represented by:
The weighted term is therefore configured to be inversely proportional with the prediction value. A lower prediction score
will result in considerably larger loss than the higher prediction values. This will provide a general increase in the prediction accuracy for all samples and will indirectly aid in strengthening performance towards minority classes. An additional focusing parameter
is present to increase the overall impact of low predictions. For the purposes of the evaluation of the focal loss, the focusing parameter value of
will be used as it was determined to be the most effective in associated research [
6,
12].
2.3. Dice Loss
The dice loss operates by minimizing the dice coefficient metric [
21]. Since the dice coefficient is already employed to provide a measure of system performance [
10], this implementation presents an extension for the overall process. The dice loss measures the completement (1 −
score) of the dice score as follows:
The main advantage of the dice loss function and similar region-based loss functions, when compared to distribution-based loss functions, is how they are inherently indifferent to the number of pixels present in the image. This is due to how the function calculates a ratio () representing how closely tied the prediction region is with the ground-truth region. Therefore, the quantity of samples is irrelevant when calculating the value as only a relative metric is being obtained.
2.4. Tversky Loss
The Tversky loss [
18] is a variant of the dice loss that disproportionately penalizes false negative predictions which tend to occur more frequently in imbalanced cases and is defined by:
With the
and
being hyper-parameters which control the level at which false positives and false negatives are factored into the loss, respectively. For the purposes of the study, the values of
and
are used as was recommended in the original literature [
18].
2.5. IoU (Jaccard) Loss
The intersection over union (IoU) loss function employs a similar method to dice loss by converting a well-known performance metric, the IoU/Jaccard score, into a loss function. Since the IoU score has become commonplace in measuring the performance of semantic segmentation systems [
22,
23,
24], its conversion into a loss function enables direct optimization of performance metrics in a manner similar to dice loss:
2.6. Power Jaccard
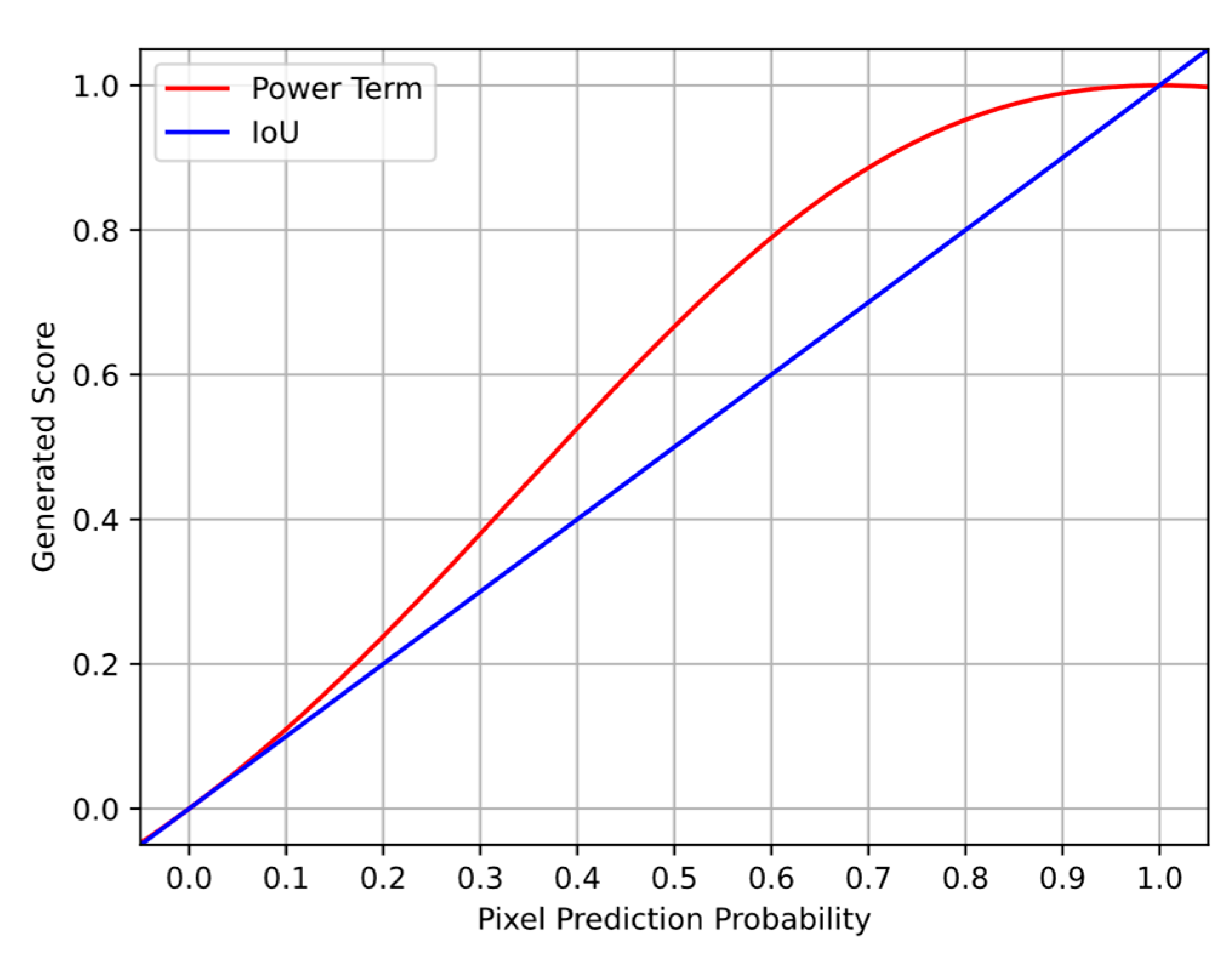
In a manner similar to focal loss, the power Jaccard loss function uses dynamic weighting to improve the segmentation ability of the IoU loss function [
17] as shown in Equation (8).
The power Jaccard function modifies the IoU score calculation formula through the new power term applied to the prediction and ground-truth values in the denominator. The addition of the power term results in the reduction of influence high certainty predictions have on the overall loss thereby increasing the impact of the minority classes. As was found in the associated literature paper, the value of resulted in optimal performance and is used within this survey.
2.7. Compound Loss Functions
Compound loss functions employ combinations of several loss functions to benefit from the individual advantages of each component loss functions. Component loss functions can thereby target different aspects of model training concurrently. This approach has come across a large quantity of success. In the loss function comparison survey by Jun et al. (2021), the combination loss functions consistently obtained the highest performance when compared to their counterparts [
6]. Out of all the compound loss functions presented in that study, the DiceTopK and DiceFocal loss functions obtained the best results and are included within this study.
2.8. DiceFocal Loss
The DiceFocal loss is the combination of the dice loss function and the focal loss function. The resulting loss from this function is calculated as follows:
2.9. DiceTopk Loss
Another variant of a dice-based combination loss is the DiceTopk loss which combines the Topk loss function with dice loss. The TopK loss function itself is a variant of the cross-entropy loss function where only a subset, typically examples where the model struggles the most, is considered when calculating the loss. The resulting loss function forces the optimizer to increasingly focus on hard samples. TopK loss selects its top “k” amount loss by either: (1) retaining the pixels with probability values below a set threshold value, and (2) retaining the top
percent of worst loss generating samples [
6]. For the purposes of this study, the Topk approach where
of the worst performing samples is utilized due to its comparatively higher performance than other iterations [
6]. The Topk (k = 10%) loss function utilized during the study is described in Equation (10):
where
represents the set of
worst pixels. The DiceTopK compound loss function is then calculated by:
5. Results and Comparison
This section contains the results obtained through the comparative study. Since the dirt and void class are sparsely presented, they will not be used for the performance analysis as was carried out in the original Rellis-3D publication [
1]. For the evaluation process, the test set provided by the Rellis-3D team was employed. This provided a targeted sample set which covered all classes within the dataset. The scores obtained for each metric were obtained for each image sample and averaged to represent a generalized view of the results.
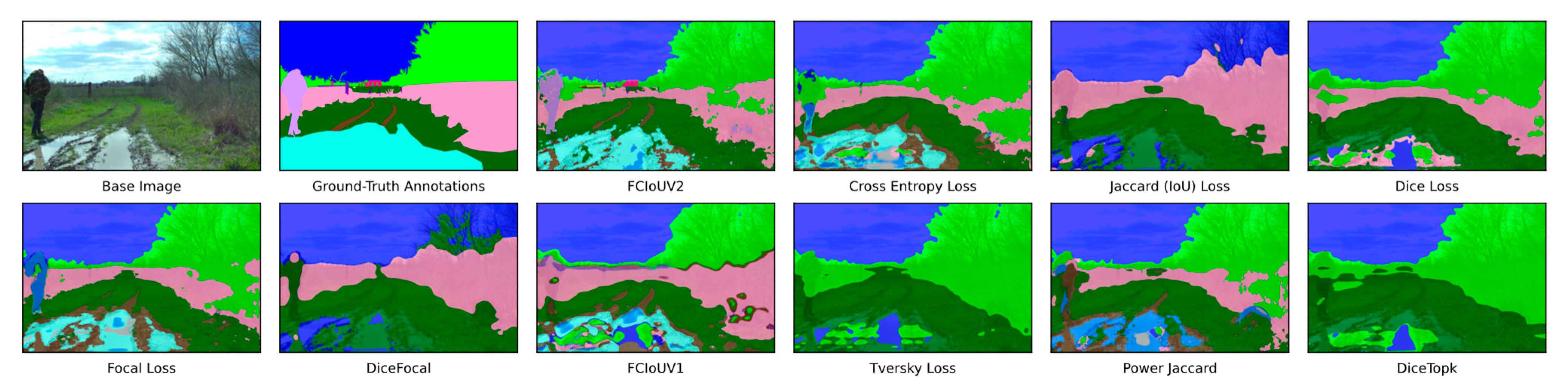
A visual representation of the single same image prediction obtained by models trained using each loss function is shown in
Figure 4. The base image and its accompanying ground-truth annotation image are additionally provided for reference.
As shown in
Figure 4, each loss function performed with varying levels of success. In general, the majority classes predictions are effective with corresponding areas of influence being well defined. Most loss functions, however, struggled greatly with the detection of the minority building and person classes which are represented in red and purple, respectively. Of the 10 loss functions, only the FCIoUV2 loss function resulted in the detection of both these minority classes demonstrating its effectiveness.
Indicated in
Table 2, the overall mIoU loss obtained by the various loss functions remained consistently low and are in stark contrast to the high performance (>0.75) values obtained for the dice score. This difference demonstrates the disparity in performance due to the imbalance class distribution. The large dice score values are the result of the general measurement of the overlap between prediction and ground-truth segmentations for each image. As the model performs generally well at predicting the majority classes, the resulting dice score remains high as most of the image (~75–90%), the majority classes, is rightfully being detected. The resulting ~10–25% of the area is, however, typically attributable to the minority image classes. As the model struggles to classify these minority classes, the mIoU metric remains much smaller. Since each class is being equally weighed when calculating the mIoU, the resulting score is considerably lower than the dice metric.
As indicated in
Table 2, our FCIoUv2 performs best in both the mIoU and dice score metric. These are then closely followed by the focal loss and CE loss functions. The results indicate a noticeable improvement in performance when targeted loss functions are employed. The performance values obtained for the majority and minority classes are represented in
Table 3 and
Table 4, respectively.
The loss function prediction performance for majority classes remains generally stable with each loss functions resulting in a similar set range of values. In extreme cases, however, some of the majority classes were not detected resulting in a zero measured performance. Out of the four majority classes, the sky and grass classes performed considerably better followed by the tree and bush classes. Interestingly, the two best performing classes (sky and grass) are accordingly the most numerous classes in the dataset as shown in
Figure 3. This indicates a distinct correlation between class-based performance and class-label occurrence frequency even for majority classes.
The minority class performance, as shown in
Table 4, did not exhibit a similar stability instead featuring a considerable portion of class performance with a near zero score. These results directly represent the potential impact of imbalanced datasets on model performance. The most negatively affected classes being the most infrequent building, log, and object classes thereby indicating a definitive link between model performance and class frequency. Out of all the of loss functions presented, only the FCIoUV1 and FCIoUV2 function obtained an above zero, albeit quite small, score for all classes thereby demonstrating the effectiveness of a targeted class-based IoU loss function approach. Of the two, the FCIoUV2 loss function greatly outperformed the FCIoUV1 loss function for almost all classes.
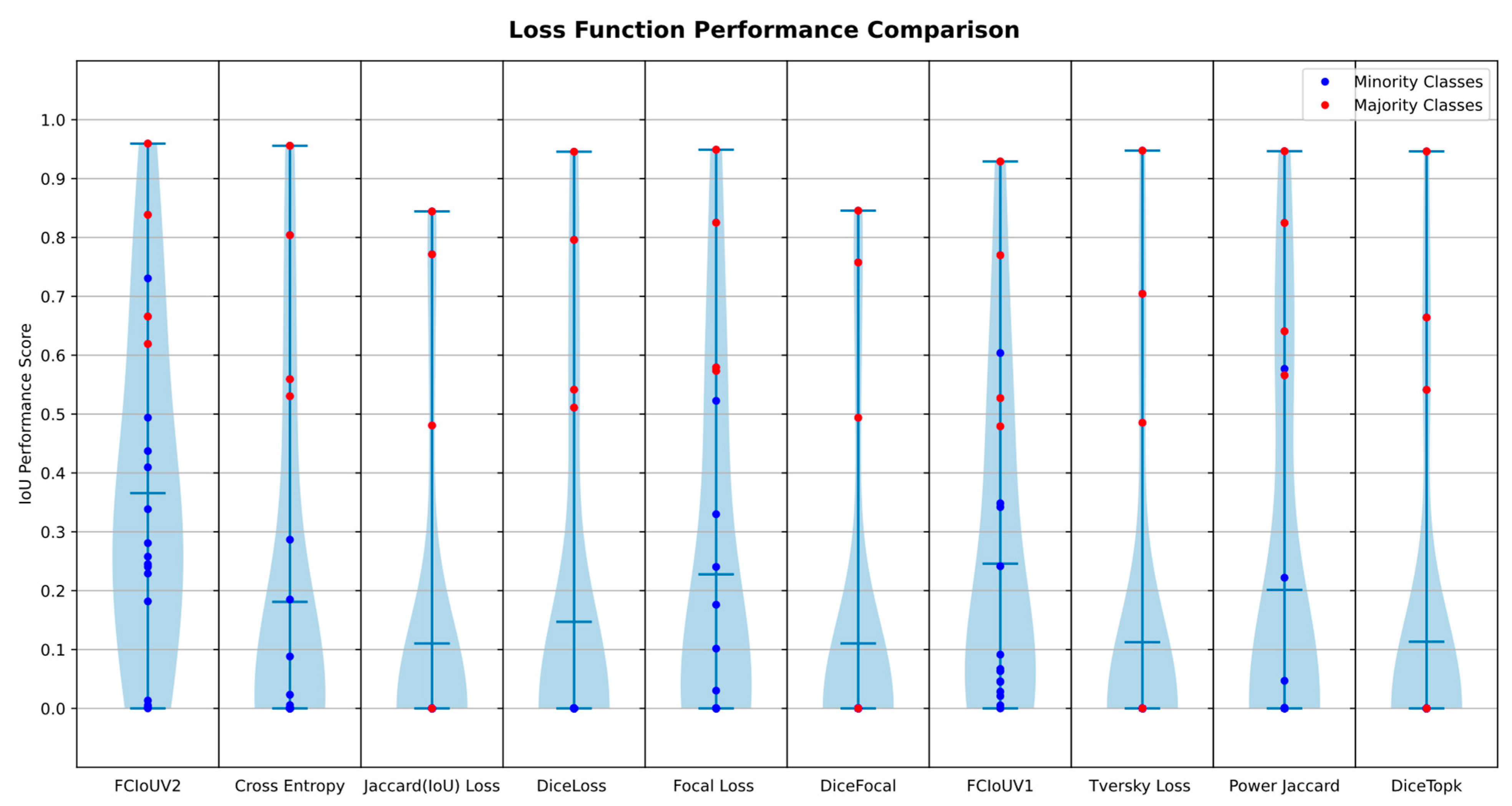
A visualization of the class-based performance results tabulated in
Table 3 and
Table 4 is presented within the violin plots shown in
Figure 5. The differences between the achieved classification performances for each loss function alongside the stark disparity in performance between majority and minority classes is evident within the plots.
Figure 5 is divided into separate columns per each loss function. Within each column, the resulting IoU scores for the Rellis-3D terrain classes (excluding the dirt class) are represented with circles, with majority and minority classes indicated in red and blue, respectively. The mean IoU (mIoU) score, being the average IoU score obtained for each class for the given loss function is indicated by the blue horizontal bar in each column. Furthermore, the distribution of IoU scores is further represented through the blue outlining regions surrounding the center vertical line. These distributions are obtained through kernel density estimation (KDE) and represent the relative empirical distribution of class results near the specified IoU performance score.
As was expected, the majority classes are shown to perform considerably better than their minority class counterparts. The minority classes, on the other end, performed quite poorly thereby shifting the performance distributions downwards and centering them near zero. Only a few of the loss functions did not directly exhibit this behaviour, with the focal loss, FCIoUV1, power Jaccard, and FCIoUV2 loss function exhibiting a raised distribution due to greater minority class scores. The FCIoUV2 featured the best performance distribution, with the center point of the distribution being raised to near ~0.3 IoU.
The FCIoUV2 loss function was found to perform best overall and featured the greatest performance for both majority and minority classes. The distribution represented in
Figure 5 demonstrate that the FCIoUV2 loss function met its intended goal of focusing the model’s attention on minority class detection while preserving majority class detection performance. Therefore, the FCIoUV2 was found to be an effective method of mitigating the impact of class imbalance on model performance.
6. Conclusions
In this work, we highlighted the importance of proper loss function selection towards negating the adverse effects of class imbalance. We surveyed 10 different loss functions and evaluated their performance when applied on a common segmentation model (U-Net) in an off-road environment. Additionally, we presented a novel loss function, the FCIoU loss function, which directly targeted and optimize model performance to counterbalance the impact of class imbalance.
Of the selection of loss functions, the FCIoUv2 was found to have performed the best, followed by the focal loss function and the FCIoUv1 loss function. This improvement in performance highlighted the importance of considering class imbalance when selecting loss functions. The targeted approach towards the optimization for class-based IoU loss and the counterbalancing to account for class-imbalance was found to greatly improve overall segmentation. Additionally, the difference in performance between v1 and v2 of the loss function demonstrates the importance of considering the loss at the pixel level rather than solely at the class-based level. This scope refinement greatly increased the homogeneity of the prediction class distribution, thereby allowing the smaller minority classes to be more readily detected.
In future works, we recommend further research into other possible loss-shaping functions. As this research did not go in depth into the wide variations of loss-shaping functions, other options could result in even greater performance increase. Additionally, a more in-depth comparative study concerning a wide array of different models and loss functions would allow for a more comprehensive examination of the impact of loss functions on system performance. We additionally recommend that the FCIoUv2 loss function be implemented in the training state-of-the-art off-road semantic segmentation systems. The benefits of implementing the FCIoUv2 will improve the performance of current semantic segmentation approaches.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}