
A Multi-Input Machine Learning Approach to Classifying Sex Trafficking from Online Escort Advertisements


Abstract
1. Introduction
2. Materials and Methods
2.1. Data, Software, and Hardware
2.2. Training, Validation, & Test Sets
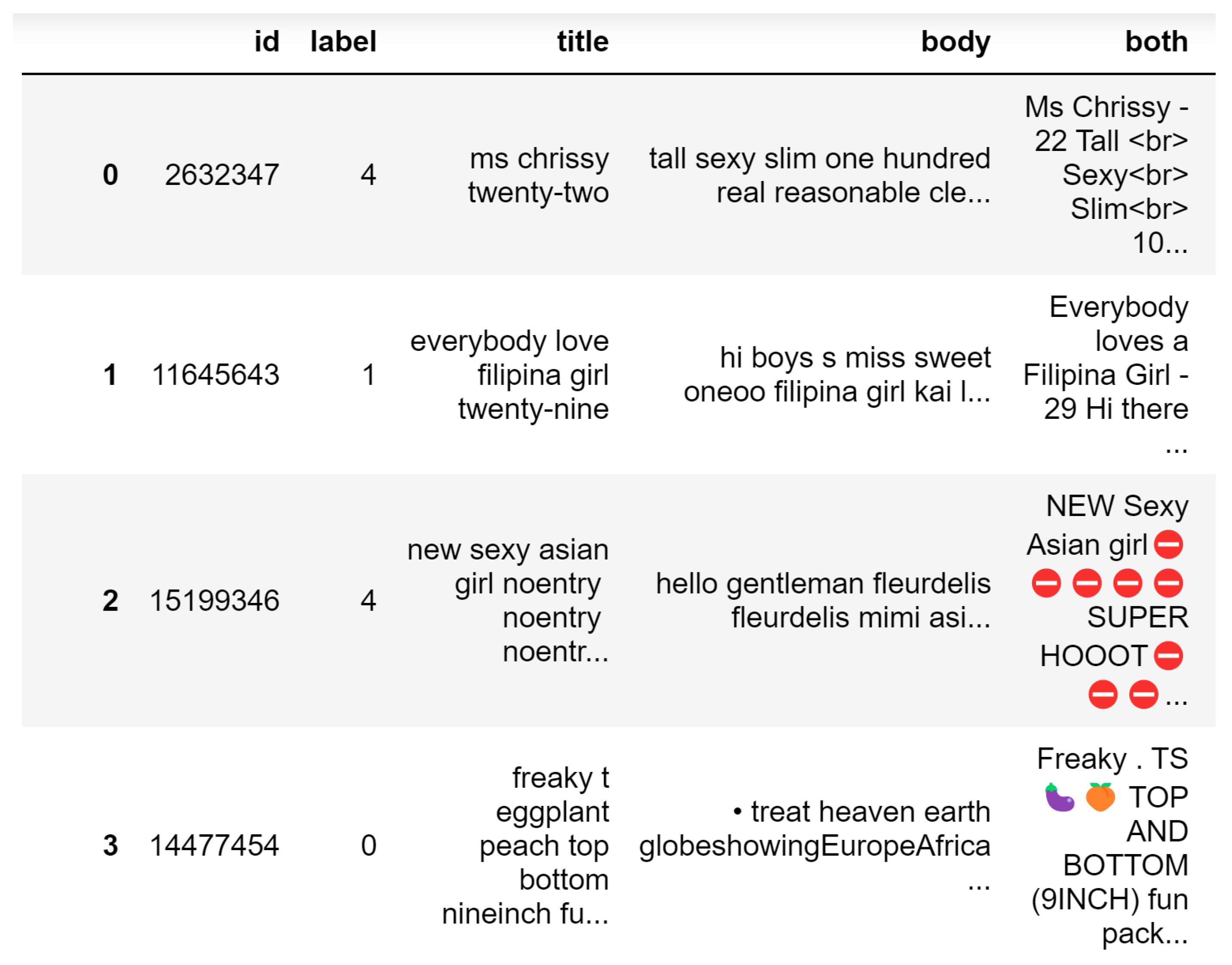
2.3. Image Creation
2.4. Text Preprocessing
2.5. Feature Creation
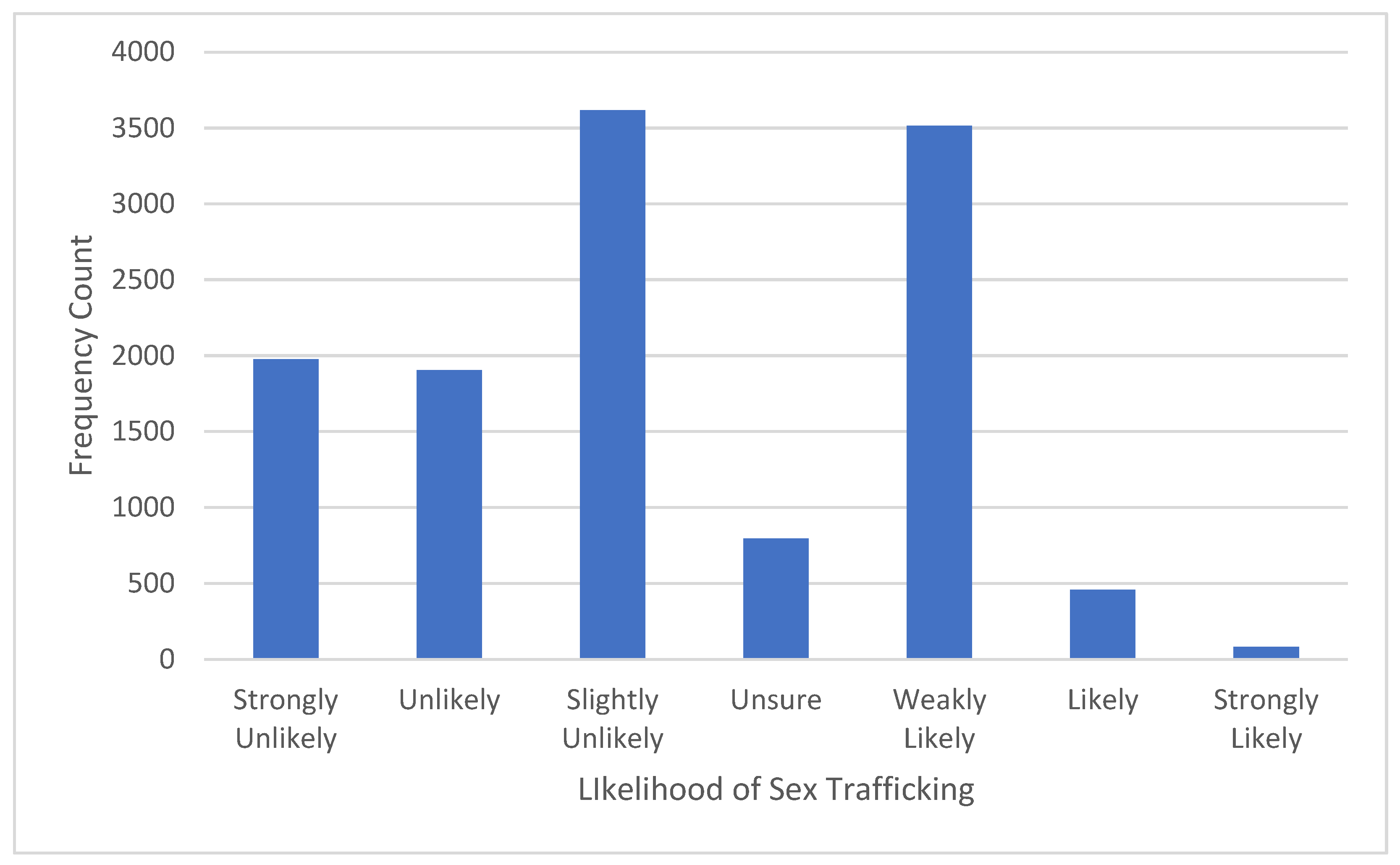
2.6. Label Definition & Processing
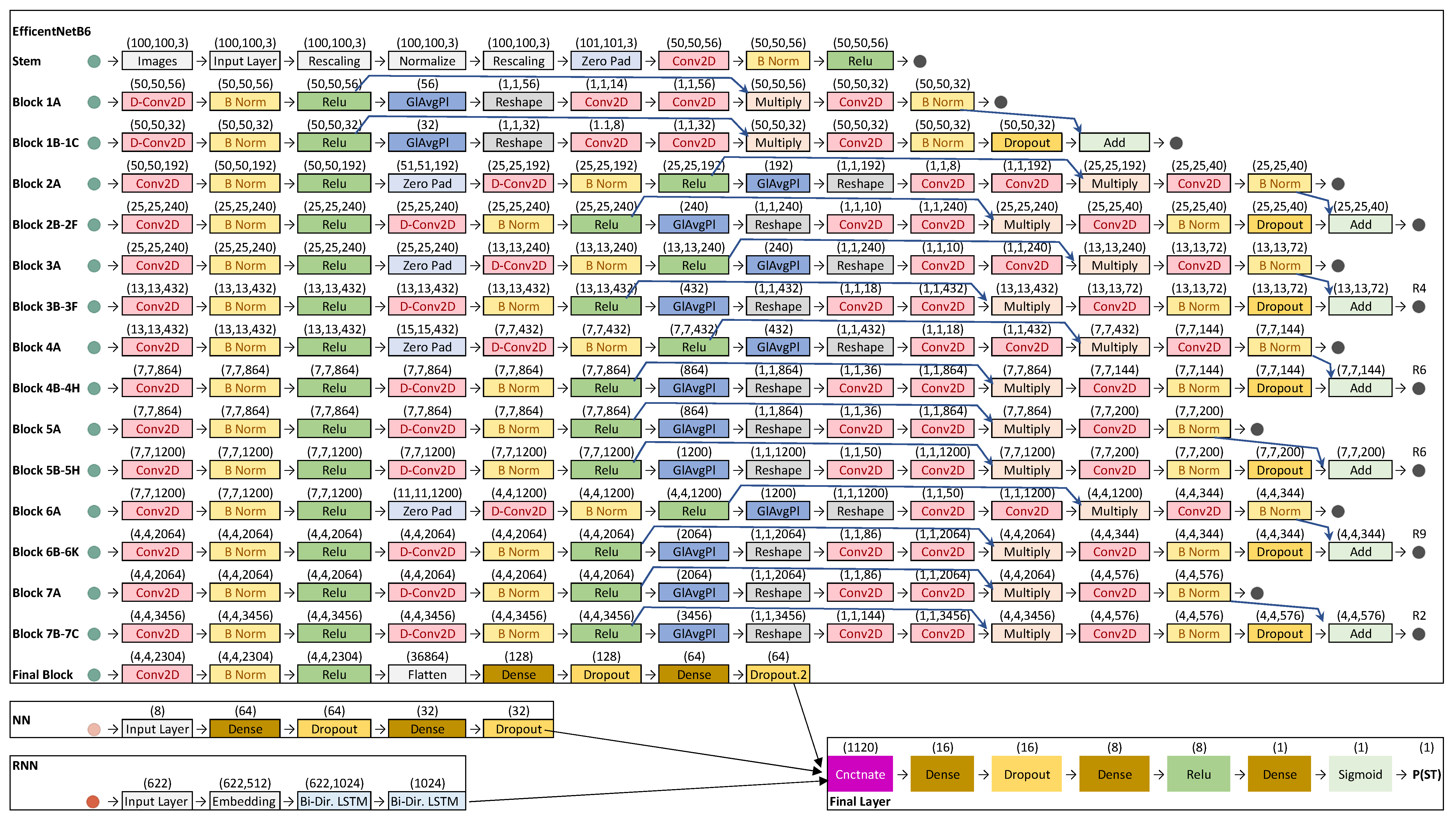
2.7. Models
2.8. Hyperparameter Tuning and Loss Metric
3. Results
3.1. Descriptive Statistics: Dependent Variable (Label)
3.2. Descriptive Statistics: Features
3.3. Model Comparison
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- UN Office of Drugs and Crime. Global Report on Trafficking in Persons 2020; UNODC: Vienna, Austria, 2021. [Google Scholar]
- NA Trafficking in Persons Report July 2022. U.S. Department of State (2022) 2022 Trafficking in persons report. U.S. Department of State, Office to Monitor and Combat Trafficking in Persons. Available online: https://www.state.gov/wp-content/uploads/2022/10/20221020-2022-TIP-Report.pdf (accessed on 22 February 2023).
- Tillyer, M.S.; Smith, M.R.; Tillyer, R. Findings from the US National Human Trafficking Hotline. J. Hum. Traffick. 2021, 1–10. [Google Scholar] [CrossRef]
- Dank, M.L.; Khan, B.; Downey, P.M.; Kotonias, C.; Mayer, D.; Owens, C.; Pacifici, L.; Yu, L. Estimating the Size and Structure of the Underground Commercial Sex Economy in Eight Major US Cities; The Urban Institute: Washington, DC, USA, 2014; Available online: https://www.urban.org/sites/default/files/publication/22376/413047-estimating-the-size-and-structure-of-the-underground-commercial-sex-economy-in-eight-major-us-cities_0_1.pdf (accessed on 22 February 2023).
- L’Hoiry, X.; Moretti, A.; Antonopoulos, G.A. Identifying Sex Trafficking in Adult Services Websites: An Exploratory Study with a British Police Force. Trends Organ. Crime 2021, 1–22. [Google Scholar] [CrossRef]
- Martin, C.; Curtis, B.; Fraser, C.; Sharp, B. The Use of a GIS-Based Malaria Information System for Malaria Research and Control in South Africa. Health Place 2002, 8, 227–236. [Google Scholar] [CrossRef] [PubMed]
- Martin, L.; Melander, C.; Karnik, H.; Nakamura, C. Mapping the Demand: Sex Buyers in the State of Minnesota; Jones Urban Research and Outreach: Minneapolis, MN, USA, 2017; Available online: https://conservancy.umn.edu/handle/11299/226520. (accessed on 22 February 2023).
- Keskin, B.B.; Bott, G.J.; Freeman, N.K. Cracking Sex Trafficking: Data Analysis, Pattern Recognition, and Path Prediction. Prod. Oper. Manag. 2021, 30, 1110–1135. [Google Scholar]
- Whitney, J.; Jennex, M.; Elkins, A.; Frost, E. Don’t Want to Get Caught? Don’t Say It: The Use of Emojis in Online Human Sex Trafficking Ads. In Proceedings of the International Conference on System Sciences, Hawaii, HI, USA, 3–6 January 2018; pp. 4273–4283. [Google Scholar] [CrossRef]
- Nodeland, B.; Belshaw, S. Establishing a Criminal Justice Cyber Lab to Develop and Enhance Professional and Educational Opportunities. Secur. Priv. 2020, 3, e123. [Google Scholar] [CrossRef]
- Tong, E.; Zadeh, A.; Jones, C.; Morency, L.-P. Combating Human Trafficking with Deep Multimodal Models. arXiv 2017, arXiv:170502735. [Google Scholar]
- Alvari, H.; Shakarian, P.; Snyder, J.K. Semi-Supervised Learning for Detecting Human Trafficking. Secur. Inform. 2017, 6, 1. [Google Scholar] [CrossRef]
- Wang, L.; Laber, E.; Saanchi, Y.; Caltagirone, S. Sex Trafficking Detection with Ordinal Regression Neural Networks. arXiv 2019, arXiv:190805434. [Google Scholar]
- Esfahani, S.S.; Cafarella, M.J.; Pouyan, M.B.; DeAngelo, G.; Eneva, E.; Fano, A.E. Context-Specific Language Modeling for Human Trafficking Detection from Online Advertisements. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1180–1184. [Google Scholar]
- Zhu, J.; Li, L.; Jones, C. Identification and Detection of Human Trafficking Using Language Models. In Proceedings of the 2019 European Intelligence and Security Informatics Conference (EISIC), Oulu, Finland, 26–27 November 2019; pp. 24–31. [Google Scholar]
- Granizo, S.L.; Caraguay, Á.L.V.; López, L.I.B.; Hernández-Álvarez, M. Detection of Possible Illicit Messages Using Natural Language Processing and Computer Vision on Twitter and Linked Websites. IEEE Access 2020, 8, 44534–44546. [Google Scholar] [CrossRef]
- Wiriyakun, C.; Kurutach, W. Feature Selection for Human Trafficking Detection Models. In Proceedings of the 2021 IEEE/ACIS 20th International Fall Conference on Computer and Information Science (ICIS Fall), Xi’an, China, 13–15 October 2021; pp. 131–135. [Google Scholar]
- Wiriyakun, C.; Kurutach, W. Extracting Co-Occurrences of Emojis and Words as Important Features for Human Trafficking Detection Models. J. Intell. Inform. SMART Technol. 2022, 7, 12.1–12.5. [Google Scholar]
- Van Rossum, G. The Python Library Reference, Release 3.8.2. Python Softw. Found. 2020, 32. Available online: https://www.python.org/downloads/release/python-382/ (accessed on 24 February 2020).
- Developers, T. TensorFlow. Available online: https://zenodo.org/record/6574269#.ZFscCXZByUk (accessed on 23 May 2022).
- Honnibal, M.; Montani, I. SpaCy 2: Natural Language Understanding with Bloom Embeddings, Convolutional Neural Networks and Incremental Parsing. Appear 2017, 7, 411–420. [Google Scholar]
- Bradski, G. The OpenCV Library. Dr. Dobbs J. Softw. Tools Prof. Program. 2000, 25, 120–123. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009; ISBN 0-596-55571-7. [Google Scholar]
- Nawi, N.M.; Atomi, W.H.; Rehman, M.Z. The Effect of Data Pre-Processing on Optimized Training of Artificial Neural Networks. Procedia Technol. 2013, 11, 32–39. [Google Scholar] [CrossRef]
- Alpaydin, E. Design and analysis of machine learning experiments. In Introduction to Machine Learning, 4th ed.; MIT Press: Cambridge, MA, USA, 2010; pp. 475–515. [Google Scholar]
- Graves, A. Long Short-Term Memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Nowak, J.; Taspinar, A.; Scherer, R. LSTM Recurrent Neural Networks for Short Text and Sentiment Classification; Springer: Berlin/Heidelberg, Germany, 2017; pp. 553–562. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the Machine Learning Research, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Apostolopoulos, I.D.; Apostolopoulos, D.I.; Spyridonidis, T.I.; Papathanasiou, N.D.; Panayiotakis, G.S. Multi-Input Deep Learning Approach for Cardiovascular Disease Diagnosis Using Myocardial Perfusion Imaging and Clinical Data. Phys. Med. 2021, 84, 168–177. [Google Scholar] [CrossRef] [PubMed]
- Dua, N.; Singh, S.N.; Semwal, V.B. Multi-Input CNN-GRU Based Human Activity Recognition Using Wearable Sensors. Computing 2021, 103, 1461–1478. [Google Scholar] [CrossRef]
- Defazio, A.; Jelassi, S. Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization. J. Mach. Learn. Res. 2022, 23, 1–34. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Data | Analysis | Findings |
|---|---|---|---|
| Tong et al. (2017) [11] | Trafficking-10k dataset (12,350 escort ads from Backpage rated by subject experts on 7-point scale) | Human trafficking deep network (HTDN), a deep multimodal model applied to both text and images | HTDN achieved 0.80 accuracy, 0.71 precision, and an F1 score of 0.67, and outperformed several baselines with different inputs. |
| Alvari et al. (2017) [12] | 20,000+ scraped Backpage escort ads; final unfiltered sample was 3543 (of these, 200 were rated as likely associated with ST by expert) | Semi-supervised Laplacian support vector machine (SVM) of unfiltered online escort ads (ads were filtered out if none of 12 ST indicators were present) | Extended S3VM—R model yielded better precision (0.91 vs. 0.86 for positive cases, 0.92 vs. 0.89 for negative cases), recall (0.91 vs. 0.88 for positive cases, 0.93 vs. 0.90 for negative cases), and F1 scores (0.91 vs. 0.87 for positive cases, 0.92 vs. 0.88 for negative cases) than the original Laplacian SVM. |
| Wang et al. (2019) [13] | Trafficking-10k dataset | Ordinal regression neural network | Accuracy of 0.82, as compared to HTDN’s 0.80. No recall or F1 scores reported. |
| Esfahani et al. (2019) [14] | 10,000 online escort ads from Backpage and Eroticmugshots, with 4385 ads flagged as positive by cross-referencing with list of ST-related phone numbers | Deep learning latent Dirichlet allocation (LDA) model with average word vector (AWV) and bidirectional encoder representation from transformers (BERT) | The LDA+AWD+BERT model outperformed simpler variations of the model (e.g., recall was 0.69 vs. 0.28–0.42) at 85% precision. |
| Zhu et al. (2019) [15] | Trafficking-10k dataset | Language selection model | Precision was 0.66 and recall 0.73. |
| Granizo et al. (2020) [16] | Twitter posts with hashtags related to minors and potential illicit (sexual) activity (n = 4096) | SVM vs. convolutional neural networks (CNN) | Detection of age in posts advertising sex yielded accuracy of 80.6% (SVM) vs. 97.3% (CNN) for faces, and 82.1% (SVM) vs. 51.4% (CNN) for upper body images. |
| Wiriyakun and Kurutach (2021, 2022) [17] | Trafficking-10k dataset with outcome in binary form (collapsed original 7 labels) | Feature selection approach | Reported 0.77 accuracy in best-performing model and F1 scores of 63.3% for random forest model, 64.8% logistic regression, and 61.3% linear SVM. |
| Model # | Model Type | Abbreviation |
|---|---|---|
| 1 | Neural Network (NN) | NN |
| 2 | EfficientNetB6 (ENET) | ENET |
| 3 | Recurrent Neural Network (RNN) | RNN |
| 4 | Multi-Input: ENET and NN | ENET + NN |
| 5 | Multi-Input: ENET and RNN | ENET + RNN |
| 6 | Multi-Input: NN and RNN | NN + RNN |
| 7 | Multi-Input: NN, ENET, and RNN | ENET + RNN + NN |
| Variable | Mean | Median | SD | Skew | Range | Min | Max |
|---|---|---|---|---|---|---|---|
| # Title Emojis | 20.3 | 18.0 | 13.3 | 1.5 | 162.0 | 1.0 | 163.0 |
| # Body Emojis | 113.7 | 96.0 | 155.8 | 8.6 | 2373.0 | 1.0 | 2374.0 |
| # “Sex” in Title | 0.2 | 0.0 | 0.4 | 2.2 | 4.0 | 0.0 | 4.0 |
| # “Sex” in Body | 0.7 | 0.0 | 3.0 | 10.9 | 71.0 | 0.0 | 71.0 |
| % Title Emojis | 0.3 | 0.3 | 0.1 | 1.2 | 0.9 | <0.1 | 0.9 |
| % Body Emojis | 0.2 | 0.23 | 0.1 | 2.7 | 0.9 | <0.1 | 1.0 |
| % “Sex” in Title | <0.1 | 0.0 | <0.1 | 3.6 | 0.1 | 0.0 | 0.1 |
| % “Sex” in Body | <0.1 | 0.0 | <0.1 | 4.8 | <0.1 | 0.0 | <0.1 |
| Model | Abbreviation | Epochs | Minutes per Epoch | Total Minutes | Accuracy | Recall | Specificity | Precision | F1 Score |
|---|---|---|---|---|---|---|---|---|---|
| 1 | NN | 20 | 0.067 | 1.333 | 0.73 | 0.35 | 0.91 | 0.67 | 0.46 |
| 2 | ENET | 10 | 2.933 | 29.333 | 0.74 | 0.42 | 0.89 | 0.66 | 0.51 |
| 3 | RNN | 2 | 3.000 | 6.000 | 0.81 | 0.57 | 0.93 | 0.80 | 0.67 |
| 4 | ENET + NN | 10 | 2.700 | 27.000 | 0.73 | 0.44 | 0.88 | 0.63 | 0.52 |
| 5 | ENET + RNN | 2 | 10.000 | 20.000 | 0.82 | 0.63 | 0.91 | 0.78 | 0.70 |
| 6 | NN + RNN | 4 | 3.250 | 13.000 | 0.82 | 0.65 | 0.90 | 0.76 | 0.70 |
| 7 | ENET + RNN + NN | 3 | 10.983 | 32.950 | 0.82 | 0.62 | 0.91 | 0.77 | 0.69 |
| Base | Tong et al. (2017) [11] | NR | NR | NR | 0.80 | 0.62 | NR | 0.71 | 0.67 |
| Predicted | ||||
|---|---|---|---|---|
| Not ST | ST | Total | ||
| Actual | Not ST | 1509 | 149 | 1658 |
| ST | 298 | 514 | 812 | |
| Total | 1807 | 663 | 2470 | |
| Precision | 78% | Specificity | 91% | |
| Recall | 63% | Accuracy | 82% | |
| Model | Hinge | Classification Probability | N | True Positives | False Positives | Precision |
|---|---|---|---|---|---|---|
| NN | 10 | 0.770 | 11 | 9 | 2 | 0.8182 |
| NN | 50 | 0.700 | 102 | 84 | 18 | 0.8235 |
| RNN | 10 | 0.960 | 10 | 9 | 1 | 0.9000 |
| RNN | 50 | 0.900 | 99 | 94 | 5 | 0.9495 |
| ENET | 10 | 0.990 | 11 | 8 | 3 | 0.7273 |
| ENET | 50 | 0.950 | 98 | 82 | 16 | 0.8367 |
| NN + RNN | 10 | 0.976 | 23 | 22 | 1 | 0.9565 |
| NN + RNN | 50 | 0.950 | 275 | 255 | 20 | 0.9273 |
| NN + ENET | 10 | 0.998 | 13 | 11 | 2 | 0.8462 |
| NN + ENET | 50 | 0.950 | 99 | 79 | 20 | 0.7980 |
| ENET + RNN | 10 | 0.845 | 14 | 14 | 0 | 1.0000 |
| ENET + RNN | 50 | 0.800 | 54 | 50 | 4 | 0.9259 |
| NN + RNN +ENET | 10 | 0.960 | 11 | 9 | 2 | 0.8182 |
| NN + RNN + ENET | 50 | 0.900 | 202 | 193 | 9 | 0.9554 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Summers, L.; Shallenberger, A.N.; Cruz, J.; Fulton, L.V. A Multi-Input Machine Learning Approach to Classifying Sex Trafficking from Online Escort Advertisements. Mach. Learn. Knowl. Extr. 2023, 5, 460-472. https://doi.org/10.3390/make5020028
Summers L, Shallenberger AN, Cruz J, Fulton LV. A Multi-Input Machine Learning Approach to Classifying Sex Trafficking from Online Escort Advertisements. Machine Learning and Knowledge Extraction. 2023; 5(2):460-472. https://doi.org/10.3390/make5020028
Chicago/Turabian StyleSummers, Lucia, Alyssa N. Shallenberger, John Cruz, and Lawrence V. Fulton. 2023. "A Multi-Input Machine Learning Approach to Classifying Sex Trafficking from Online Escort Advertisements" Machine Learning and Knowledge Extraction 5, no. 2: 460-472. https://doi.org/10.3390/make5020028
APA StyleSummers, L., Shallenberger, A. N., Cruz, J., & Fulton, L. V. (2023). A Multi-Input Machine Learning Approach to Classifying Sex Trafficking from Online Escort Advertisements. Machine Learning and Knowledge Extraction, 5(2), 460-472. https://doi.org/10.3390/make5020028