
Detection of Temporal Shifts in Semantics Using Local Graph Clustering

Abstract
1. Introduction
1.1. Literature Review
1.2. Contributions
- An unsupervised algorithm based on local graph clustering to automatically characterize and detect shifts in term semantics:
- (a)
- Clusters are incrementally built out, starting with the target term as the center of locality and adding to the cluster contextual words that meet the user-defined thresholds for informativeness and the word embedding dimension;
- (b)
- It has constant time complexity, where the constant is the user-defined description length for the target term, and hence is scalable in the size of the corpus;
- (c)
- The resulting “soft clusters” allow clusters of different terms to overlap to varying degrees.
- A novel empirical analysis of the semantics of the term “Chinavirus”:
- (a)
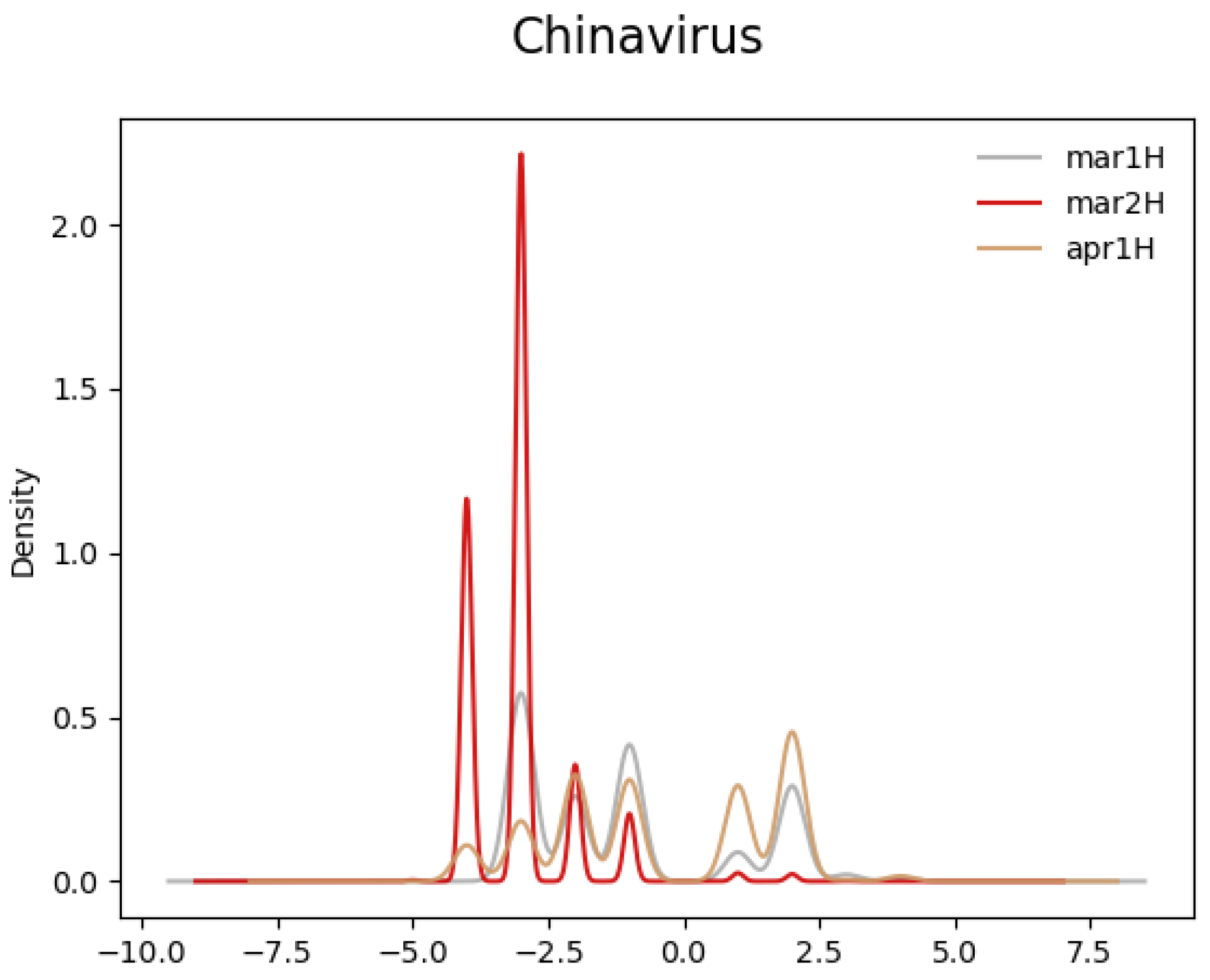
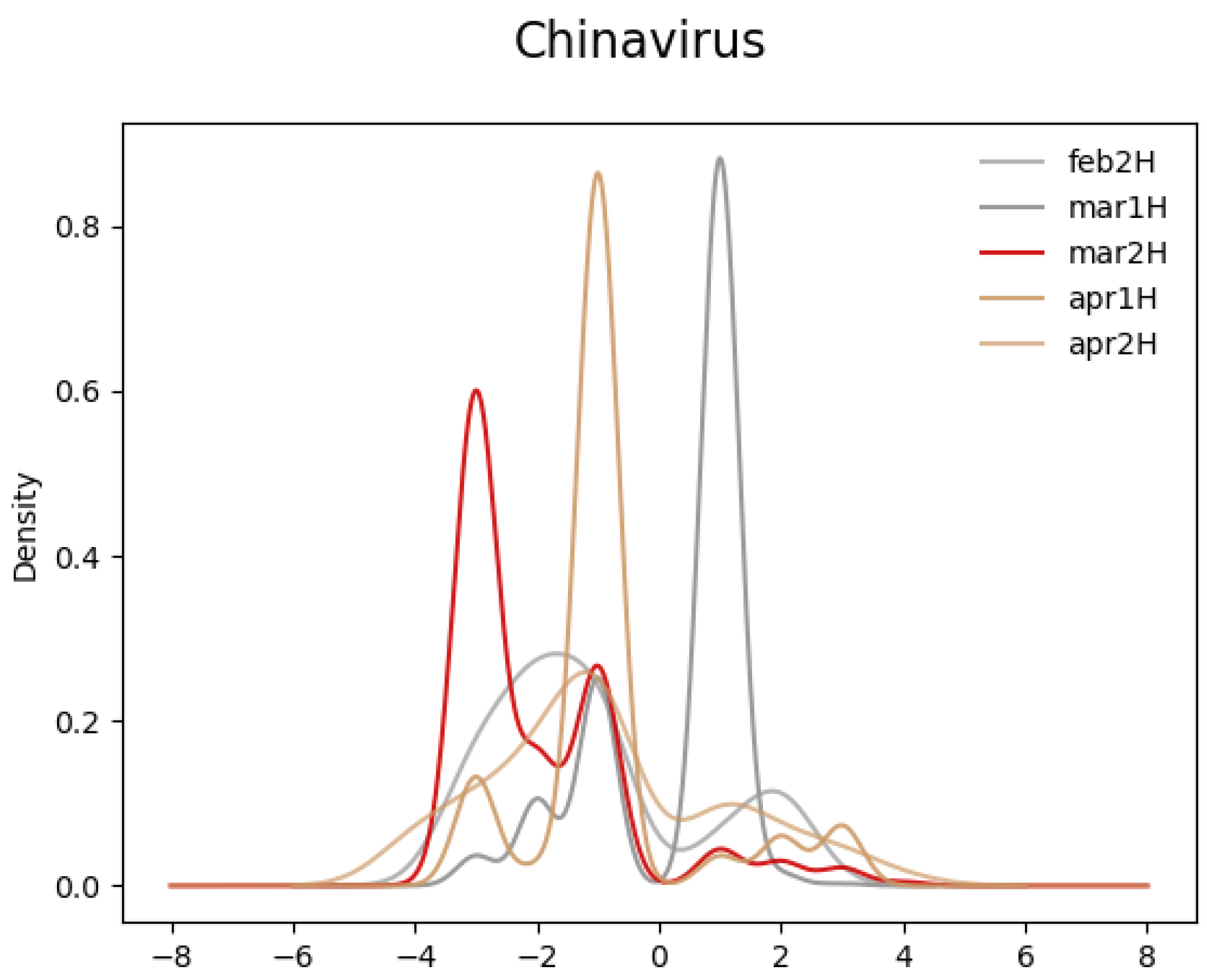
- Along the time dimension, the term took on significantly, albeit temporarily, more negative sentiment soon after its use by the White House in March 2020;
- (b)
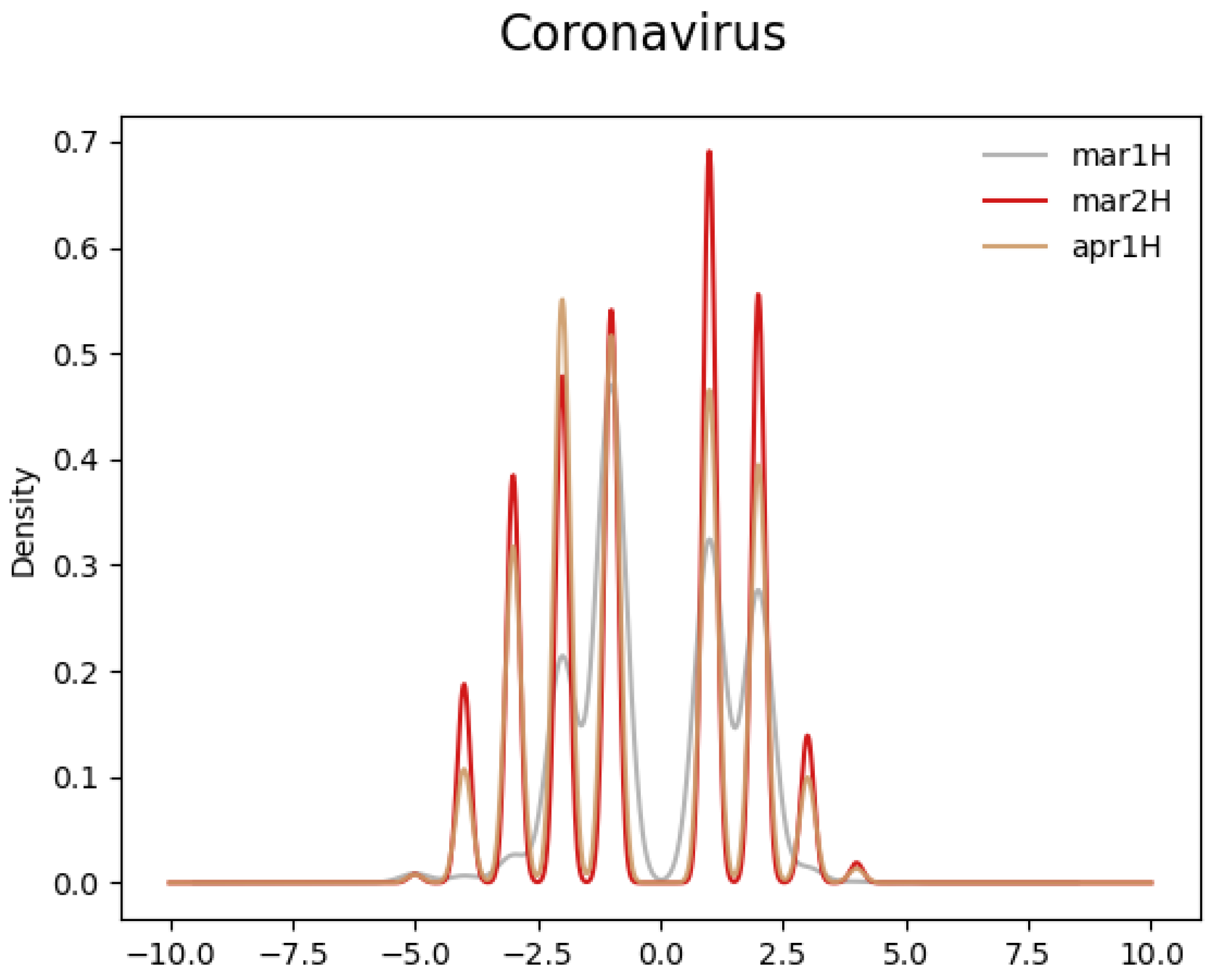
- Compared to the control term “Coronavirus”, the semantics of “Chinavirus” diverged significantly in March 2020.
2. Materials and Methods
2.1. Notation and Terminology
2.2. Local Graph Clustering Algorithm in [52]
2.3. Adapting the Local Graph Clustering Algorithm for Semantic Analysis
| Algorithm 1 GenerateSamples [52] |
Input: Target term , nonzero integers , target conductance . Output: A set from the volume-biased ESP with the stopping time depending on input parameters . Internal State: A set from the volume-biased ESP with ; the current location of the random walk; and for the current set .
|
| Algorithm 2 EvoPar() [52] |
Input: Target term , target volume k, target conductance , a constant . Output: A set of vertices.
|
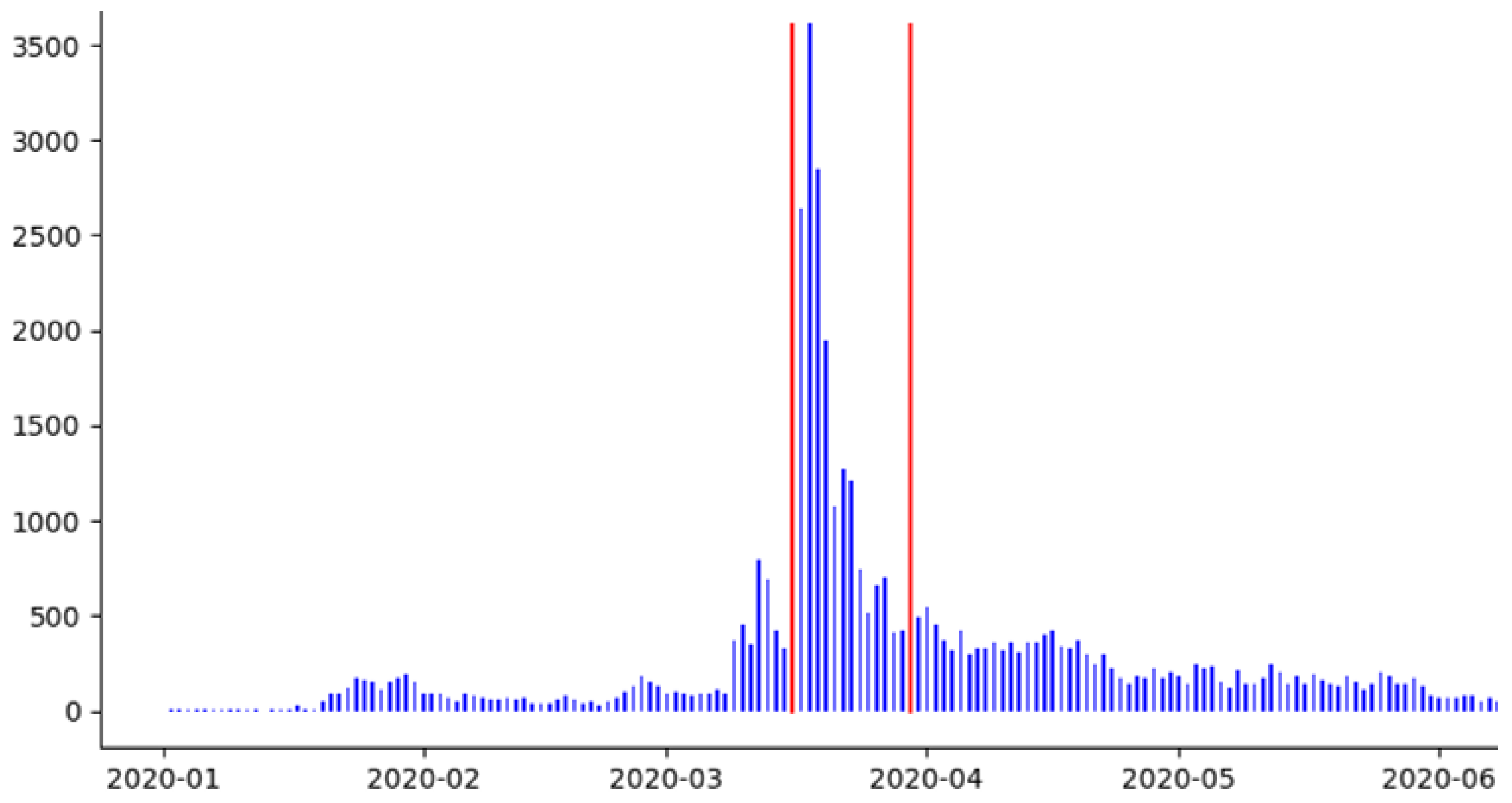
3. Datasets
4. Results
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liebeskind, C.; Dagan, I.; Schler, J. Statistical thesaurus construction for a morphologically rich language. In Proceedings of the Sixth International Workshop on Semantic Evaluation, Montréal, QC, Canada, 7–8 June 2012; pp. 59–64. [Google Scholar]
- Zaragoza, M.Q.; Torres, L.S.; Basdevant, J. Translating Knowledge Representations with Monolingual Word Embeddings: The Case of a Thesaurus on Corporate Non-Financial Reporting. In Proceedings of the 6th International Workshop on Computational Terminology, Marseille, France, 11–16 May 2020. [Google Scholar]
- Loukachevitch, N.; Parkhomenko, E. Thesaurus Verification Based on Distributional Similarities. In Proceedings of the 10th Global Wordnet Conference, Wroclaw, Poland, 23–27 July 2019; pp. 16–23. [Google Scholar]
- Levy, O.; Goldberg, Y.; Dagan, I. Improving distributional similarity with lessons learned from word embeddings. Trans. Assoc. Comput. Linguist. 2015, 3, 211–225. [Google Scholar] [CrossRef]
- Baroni, M.; Dinu, G.; Kruszewski, G. Don’t count, predict! a systematic comparison of context-counting vs. context-predicting semantic vectors. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 238–247. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Eckart, C.; Young, G. The approximation of one matrix by another of lower rank. Psychometrika 1936, 1, 211–218. [Google Scholar] [CrossRef]
- Schütze, H. Automatic word sense discrimination. Comput. Linguist. 1998, 24, 97–123. [Google Scholar]
- Horn, R.A.; Johnson, C.R. Matrix Analysis; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. JASIST 1990, 41, 391–407. [Google Scholar] [CrossRef]
- McDonald, S. Environmental Determinants of Lexical Processing Effort. Doctoral Dissertation, University of Edinburgh, Edinburgh, UK, 2000. [Google Scholar]
- Lemaire, B.; Denhière, G. Incremental construction of an associative network from a corpus. In Proceedings of the Annual Meeting of the Cognitive Science Society, Chicago, IL, USA, 4–7 August 2004; Volume 26. [Google Scholar]
- Bordenave, C.; Lelarge, M.; Massoulié, L. Non-backtracking spectrum of random graphs: Community detection and non-regular ramanujan graphs. In Proceedings of the 2015 IEEE 56th Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 2 February 2015; pp. 1347–1357. [Google Scholar]
- Saade, A.; Krzakala, F.; Zdeborová, L. Spectral clustering of graphs with the bethe hessian. arXiv 2014, arXiv:1406.1880. [Google Scholar]
- Dall’Amico, L.; Couillet, R.; Tremblay, N. Revisiting the bethe-hessian: Improved community detection in sparse heterogeneous graphs. arXiv 2019, arXiv:1901.09715. [Google Scholar]
- Le, C.M.; Levina, E. Estimating the number of communities in networks by spectral methods. arXiv 2015, arXiv:1507.00827. [Google Scholar]
- Coste, S.; Zhu, Y. Eigenvalues of the non-backtracking operator detached from the bulk. Random Matrices Theory Appl. 2021, 10, 215002. [Google Scholar] [CrossRef]
- Dall’Amico, L.; Couillet, R.; Tremblay, N. Community detection in sparse time-evolving graphs with a dynamical bethe-hessian. arXiv 2020, arXiv:2006.04510. [Google Scholar]
- Dumais, S.T. Latent semantic analysis. Annu. Rev. Inf. Sci. Technol. 2004, 38, 188–230. [Google Scholar] [CrossRef]
- Lund, K.; Burgess, C. Hyperspace analogue to language (hal): A general model semantic representation. In Brain and Cognition; Academic Press Inc Jnl-Comp Subscriptions: San Diego, CA, USA, 1996; Volume 30, pp. 92101–94495. [Google Scholar]
- Rohde, D.; Gonnerman, L.M.; Plaut, D.C. An improved model of semantic similarity based on lexical co-occurrence. Commun. ACM 2006, 8, 116. [Google Scholar]
- Bullinaria, J.A.; Levy, J.P. Extracting semantic representations from word co-occurrence statistics: A computational study. Behav. Res. Methods 2007, 39, 510–526. [Google Scholar] [CrossRef] [PubMed]
- Collobert, R. Word embeddings through hellinger pca. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, Gothenburg, Sweden, 26–30 April 2014. [Google Scholar]
- Hamerly, G.; Charles, E. Learning the k in k-means. Adv. Neural Inf. Process. Syst. 2003, 16, 281–288. [Google Scholar]
- Har-Peled, S.; Soham, M. On coresets for k-means and k-median clustering. In Proceedings of the Thirty-Sixth Annual ACM Symposium on Theory of Computing, Chicago, IL, USA, 13–15 June 2004. [Google Scholar]
- Biemann, C. Chinese whispers-an efficient graph clustering algorithm and its application to natural language processing problems. In Proceedings of the TextGraphs: The First Workshop on Graph Based Methods for Natural Language Processing, New York, NY, USA, 9 June 2006. [Google Scholar]
- Cai, Y.; Zhang, Z.; Cai, Z.; Liu, X.; Jiang, X. Hypergraph-structured autoencoder for unsupervised and semisupervised classification of hyperspectral image. IEEE Geosci. Remote Sens. Lett. 2021, 19, 5503505. [Google Scholar] [CrossRef]
- Lei, J.; Li, X.; Peng, B.; Fang, L.; Ling, N.; Huang, Q. Deep spatial–spectral subspace clustering for hyperspectral image. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2686–2697. [Google Scholar] [CrossRef]
- Sun, J.; Wang, W.; Wei, X.; Fang, L.; Tang, X.; Xu, Y.; Yu, H.; Yao, W. Deep clustering with intraclass distance constraint for hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4135–4149. [Google Scholar] [CrossRef]
- PBickel, J.; Sarkar, P. Hypothesis testing for automated community detection in networks. J. R. Stat. Soc. Ser. B Stat. Methodol. 2016, 78, 253–273. [Google Scholar] [CrossRef]
- Chen, K.; Lei, J. Network cross-validation for determining the number of communities in network data. J. Am. Stat. Assoc. 2018, 113, 241–251. [Google Scholar] [CrossRef]
- Li, T.; Levina, E.; Zhu, J. Network cross-validation by edge sampling. Biometrika 2020, 107, 257–276. [Google Scholar] [CrossRef]
- Yan, B.; Sarkar, P.; Cheng, X. Provable estimation of the number of blocks in block models. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Playa Blanca, Lanzarote, Canary Islands, 9–11 April 2018; pp. 1185–1194. [Google Scholar]
- Hu, J.; Qin, H.; Yan, T.; Zhao, Y. Corrected bayesian information criterion for stochastic block models. J. Am. Stat. Assoc. 2020, 115, 1771–1783. [Google Scholar] [CrossRef]
- Ma, S.; Su, L.; Zhang, Y. Determining the number of communities in degree-corrected stochastic block models. Mach Learn Res. 2021, 22, 1–63. [Google Scholar]
- Axel-Cyrille, N.N. SIGNUM: A graph algorithm for terminology extraction. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Haifa, Israel, 17–23 February 2008; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Ngomo, N.; Axel-Cyrille;Schumacher, F. Borderflow: A local graph clustering algorithm for natural language processing. In International Conference on Intelligent Text Processing and Computational Linguistics; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Li, K.; Qin, Y.; Ling, Q.; Wang, Y.; Lin, Z.; An, W. Self-supervised deep subspace clustering for hyperspectral images with adaptive selfexpressive coefficient matrix initialization. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 3215–3227. [Google Scholar] [CrossRef]
- Eismann, M.T.; Stocker, A.D.; Nasrabadi, N.M. Automated hyperspectral cueing for civilian search and rescue. Proc. IEEE 2009, 97, 1031–1055. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. Proc. KDD 1996, 96, 226–231. [Google Scholar]
- Zhang, H.; Kang, J.; Xu, X.; Zhang, L. Accessing the temporal and spectral features in crop type mapping using multi-temporal sentinel-2 imagery: A case study of Yi’an County, Heilongjiang province, China. Comput. Electron. Agric. 2020, 176, 105618. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer: Berlin, Germany, 2013. [Google Scholar]
- Elhamifar, E.; René, V. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.; Zhang, H.; Pižurica, A. Subspace clustering for hyperspectral images via dictionary learning with adaptive regularization. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5524017. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 171–184. [Google Scholar] [CrossRef]
- Reny, T.; Barreto, M. Xenophobia in the time of pandemic: Othering, anti-Asian attitudes, and COVID-19. Politics Groups Identities 2020, 10, 209–232. [Google Scholar] [CrossRef]
- Tsai, J.Y.; Phua, J.; Pan, S.; Yang, C. Intergroup contact, COVID-19 news consumption, and the moderating role of digital media trust on prejudice toward Asians in the United States: Cross-sectional study. J. Med. Internet Res. 2020, 22, e22767. [Google Scholar] [CrossRef] [PubMed]
- Hswen, Y.; Xu, X.; Hing, A.; Hawkins, J.B.; Brownstein, J.S.; Gee, G.C. Association of ’# Covid19’ Versus ’# Chinesevirus’ with Anti-Asian Sentiments on Twitter: March 9–23, 2020. Am. J. Public Health 2021, 111, 956–964. [Google Scholar] [PubMed]
- Mossel, E.; Neeman, J.; Sly, A. A proof of the block model threshold conjecture. Combinatorica 2018, 38, 665–708. [Google Scholar] [CrossRef]
- Andersen, R.; Gharan, S.; Peres, Y.; Trevisan, L. Almost optimal local graph clustering using evolving sets. J. ACM 2016, 63, 1–31. [Google Scholar] [CrossRef]
- “Donald Trump’s ‘Chinese Virus’: The Politics of Naming”, The Conversation. Available online: https://theconversation.com/donald-trumps-chinese-virus-the-politics-of-naming-136796 (accessed on 21 October 2021).
- Nielsen, F. A new ANEW: Evaluation of a word list for sentiment analysis in microblogs. In Proceedings of the ESWC 2011 Workshop on ’Making Sense of Microposts’: Big Things Come in Small Packages, Heraklion, Crete, 30 May 2011; pp. 93–98. [Google Scholar]
- Firth, J. A synopsis of linguistic theory, 1930–1955. In Studies in Linguistic Analysis; Blackwell: Oxford, UK, 1957. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| “Chinavirus” | “Coronavirus” | ||
|---|---|---|---|
| Chinavirus | Chinacovid | Coronavirus | Coronaviruses |
| Chinaviruses | Chinesecovid | Covidvirus | Covidviruses |
| Chineseviruses | Chinesevirus | Caronavirus | Caronaviruses |
| Chinacorona | Wuhanviruses | Virus-corona | Virus-covid |
| Wuhancovid | Wuhancorona | Coronaflu | Coronoviruses |
| CCPVirus | CCPCoronavirus | Coronacovid | Covidcorona |
| Wuhanchinavirus | Coronaoutbreak | Coronovirus | |
| Wuhanchinaviruses | |||
| Chinawuhanvirus | |||
| Chinesecoronavirus | |||
| Chinesecoronaviruses | |||
| ChineseCommunistPartyvirus | |||
| ChineseCommunistPartyviruses | |||
| Period a | Words b | Vocabulary b | Tweets b | AuthorIDs b |
|---|---|---|---|---|
| Jan2H | 123,874 | 10,985 | 10,462 | 8881 |
| Feb1H | 129,545 | 12,286 | 10,748 | 7190 |
| Feb2H | 363,394 | 20,113 | 17,639 | 10,927 |
| Mar1H | 2,261,059 | 52,724 | 176,386 | 93,339 |
| Mar2H | 2,745,589 | 65,138 | 215,908 | 99,069 |
| Apr1H | 1,322,025 | 45,444 | 99,874 | 47,457 |
| Apr2H | 866,074 | 37,137 | 65,139 | 31,404 |
| May1H | 593,134 | 30,621 | 43,706 | 21,972 |
| May2H | 432,832 | 25,620 | 32,425 | 17,494 |
| restaurant | livestock | divulge | hotpot | wheel | floor |
| remainder | initiative | Chinese | gaslit | storm | fight |
| designation | sacrifice | married | undone | funny | front |
| inevitable | historical | forward | global | sadly | army |
| sabotaging | possible | quicker | insult | guess | sight |
| investment | together | strategy | faster | slump | drug |
| supervisor | ingenious | suspend | spiral | unite | alive |
| overreach | quarantine | cronies | apologizes | exile | scare |
| morality | panicked | kissing | moronovirus | abject | stud |
| mourner | sacrifice | laughts | accusation | goofy | dog |
| antiviral | baselessly | urine | compassion | poked | hoax |
| pollution | espionage | fucked | overwhelmed | clout | loser |
| assassin | dripping | evils | prohibition | risking | alien |
| exposure | inability | outrage | unbecoming | stroke | secrets |
| derailed | enflames | destroy | denounce | namaste | nutjob |
| tearful | dumbkirk | debunk | discharges | cooking | chased |
| butthead | robbing | selfish | dangerous | diarrhea | cheat |
| debunk | despair | huawei | heartattack | ill | protest |
| scream | gorillas | thrive | concussion | mystery | alarmed |
| repellant | distance | chaotic | marauding | follies | bedbug |
| migraine | prosecute | purifier | exterminate | illicit | racism |
| explodes | pangolin | lizard | reelection | fuck | kloots |
| cancellation | robitussin | interfere | greenlit | bravely | nuk |
| disruptions | humiliates | overcome | prophecy | disobey | ease |
| animalistic | equanimity | pharmacy | hosepipe | unmask | sigh |
| moisturized | heatstroke | decouple | cheapgas | service | fiery |
| envelopment | propagate | guillotine | confront | dirty | gosh |
| untouchable | retraction | crackhead | helpless | pumped | goofy |
| overeacting | perpective | concerned | funeral | punitive | piss |
| perpetuates | inadequate | scramble | ecstatic | midget | cost |
| breathmints | planetizen | deadlier | colonial | faceass | fuel |
| precipitate | unfriended | populism | educate |
| hospitable | collapsed | crackpot | pumped | stranger | nuk |
| celebration | blockhead | feckless | pissing | breach | ease |
| overshadow | possessive | regarded | sodexo | nutcase | bane |
| excellence | expensive | rampage | stabbed | reckless | dirty |
| deprivation | disappear | bungling | unstable | ghetto | revive |
| panoramic | apologize | evacuate | cringed | fucking | goof |
| fucknugettes | strangled | punitive | squeak | cleanly | ruined |
| martyrdom | virulence | prevent | flagging | midget | dirt |
| determined | reputable | kickback | badass | faceass | sigh |
| contender | downside | delusional | babble |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, N.; Chatterjee, S.; Di, Y.; Bhattacharyya, S. Detection of Temporal Shifts in Semantics Using Local Graph Clustering. Mach. Learn. Knowl. Extr. 2023, 5, 128-143. https://doi.org/10.3390/make5010008
Hwang N, Chatterjee S, Di Y, Bhattacharyya S. Detection of Temporal Shifts in Semantics Using Local Graph Clustering. Machine Learning and Knowledge Extraction. 2023; 5(1):128-143. https://doi.org/10.3390/make5010008
Chicago/Turabian StyleHwang, Neil, Shirshendu Chatterjee, Yanming Di, and Sharmodeep Bhattacharyya. 2023. "Detection of Temporal Shifts in Semantics Using Local Graph Clustering" Machine Learning and Knowledge Extraction 5, no. 1: 128-143. https://doi.org/10.3390/make5010008
APA StyleHwang, N., Chatterjee, S., Di, Y., & Bhattacharyya, S. (2023). Detection of Temporal Shifts in Semantics Using Local Graph Clustering. Machine Learning and Knowledge Extraction, 5(1), 128-143. https://doi.org/10.3390/make5010008