
Tree-Structured Model with Unbiased Variable Selection and Interaction Detection for Ranking Data

Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Variable Selection
| Algorithm 1 Main effect detection. |
|
| Algorithm 2 Interaction effect detection. |
|
2.3. Point Selection and Stopping Rule
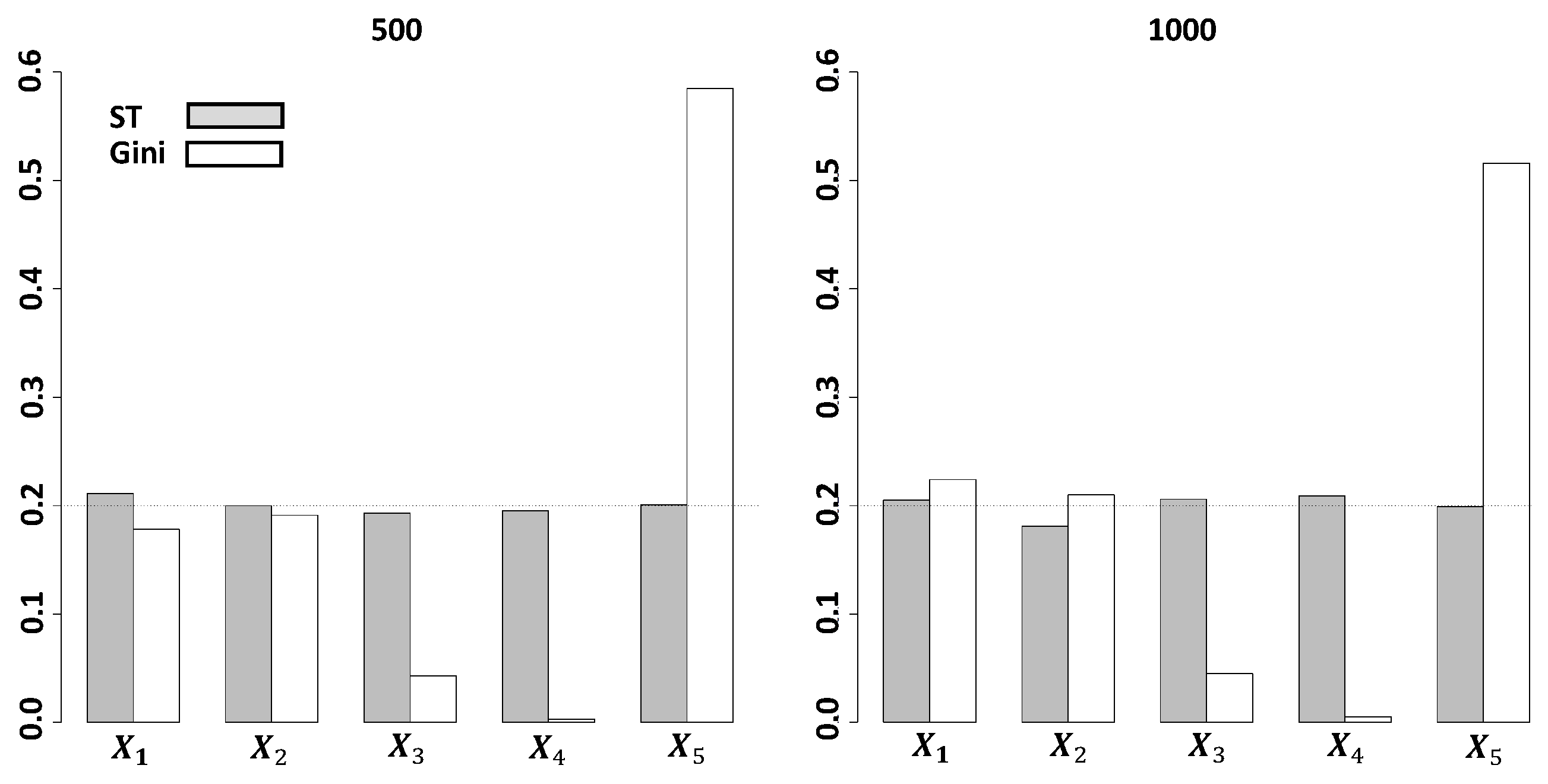
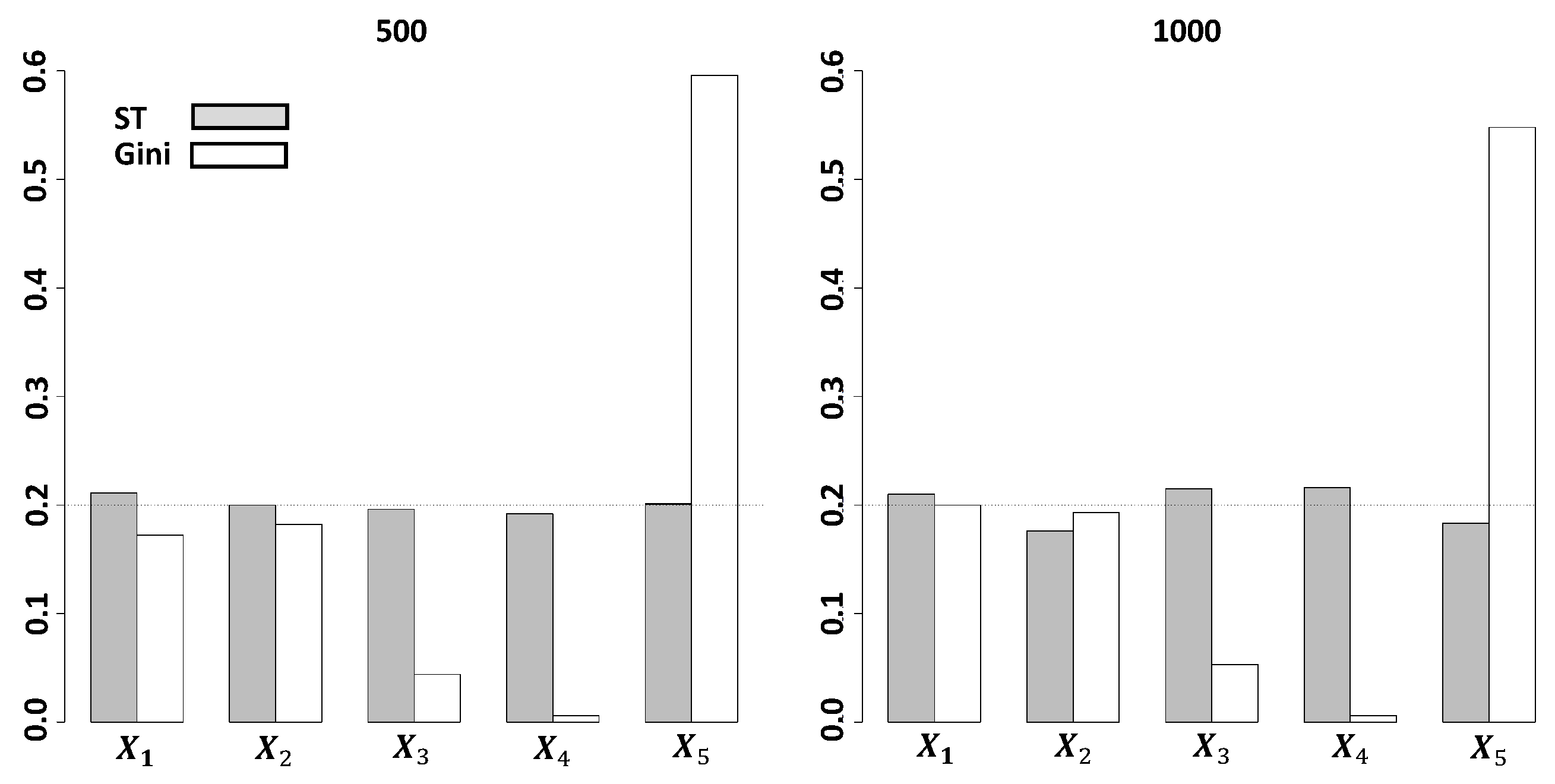
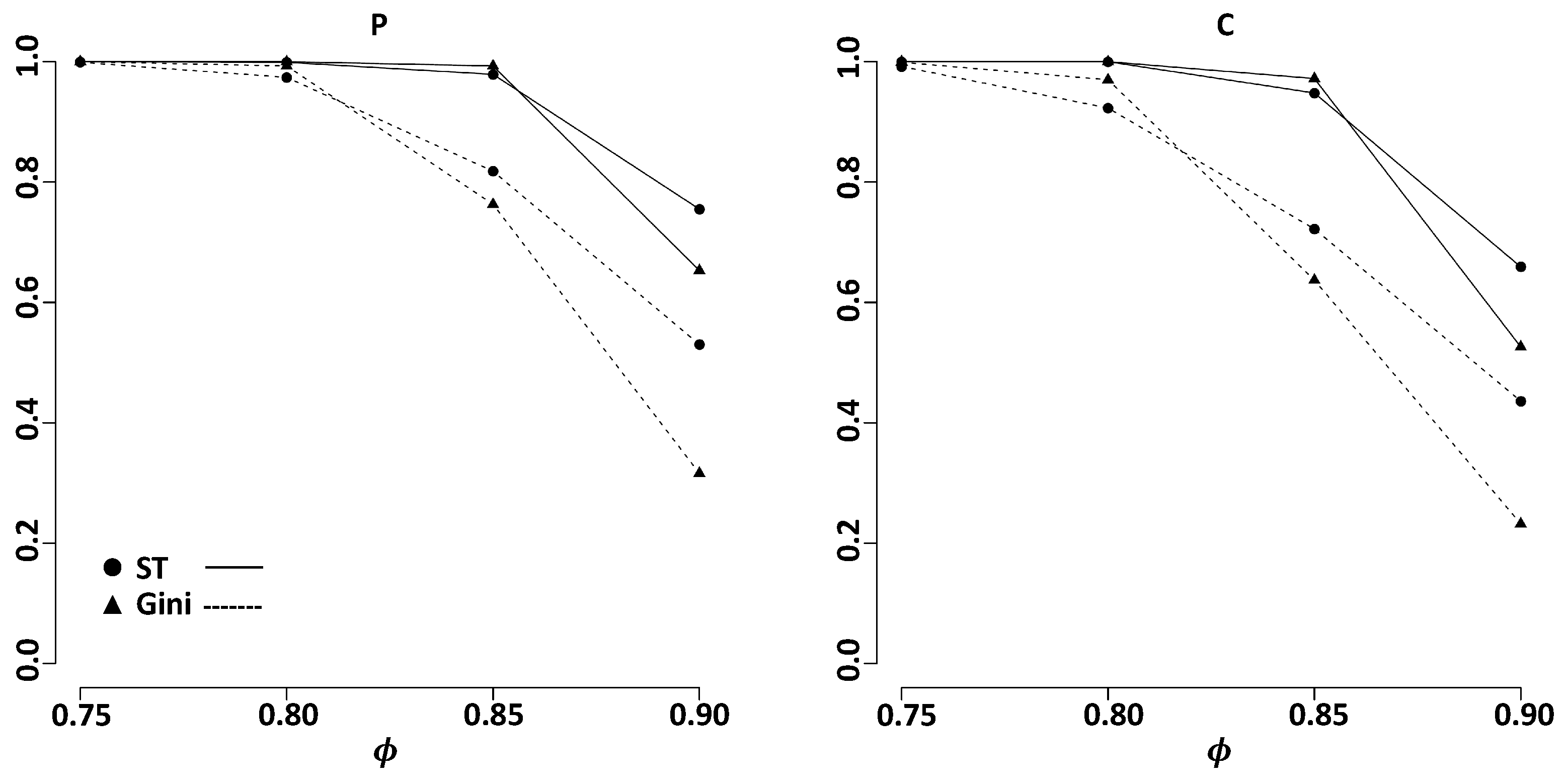
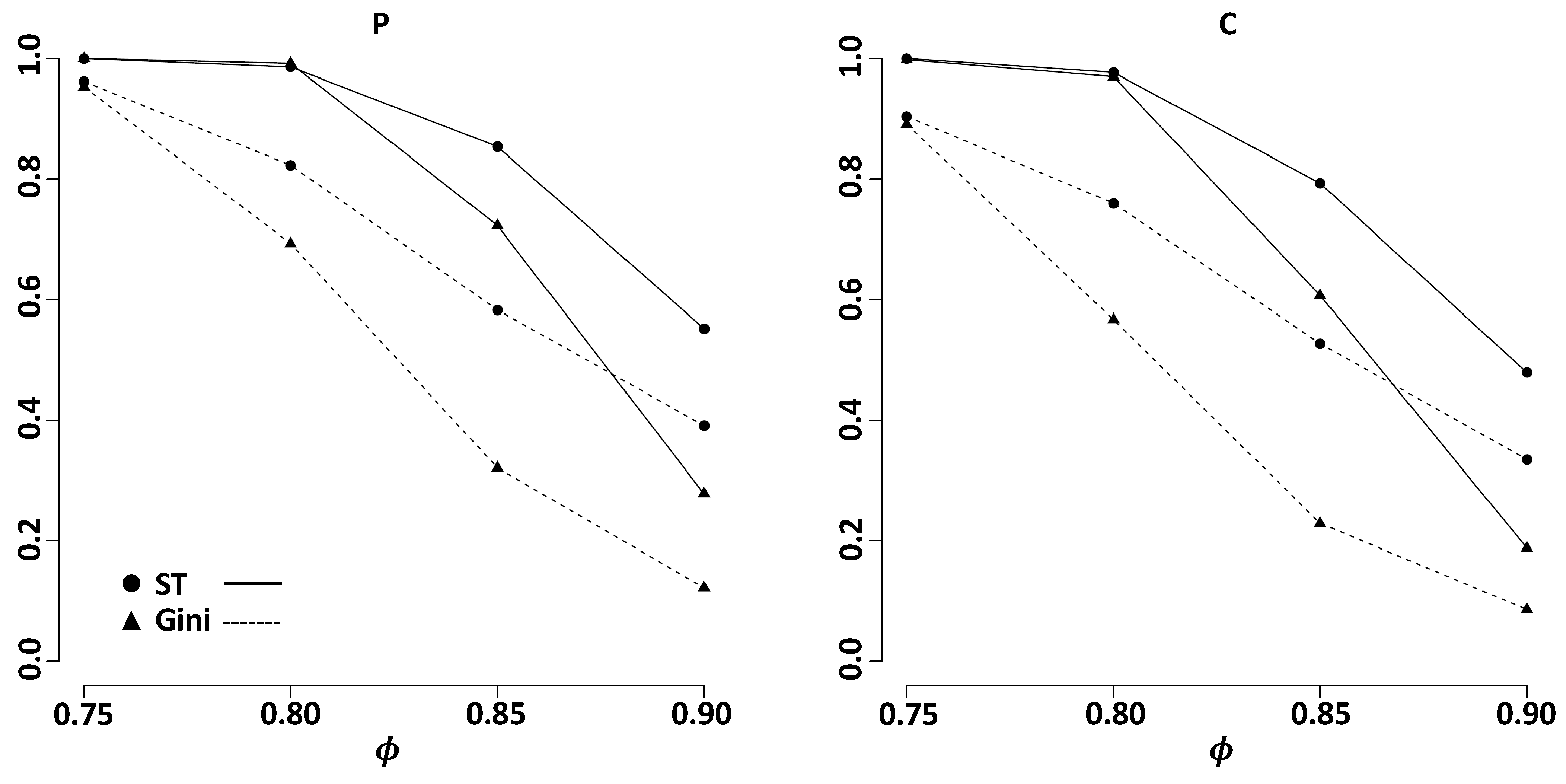
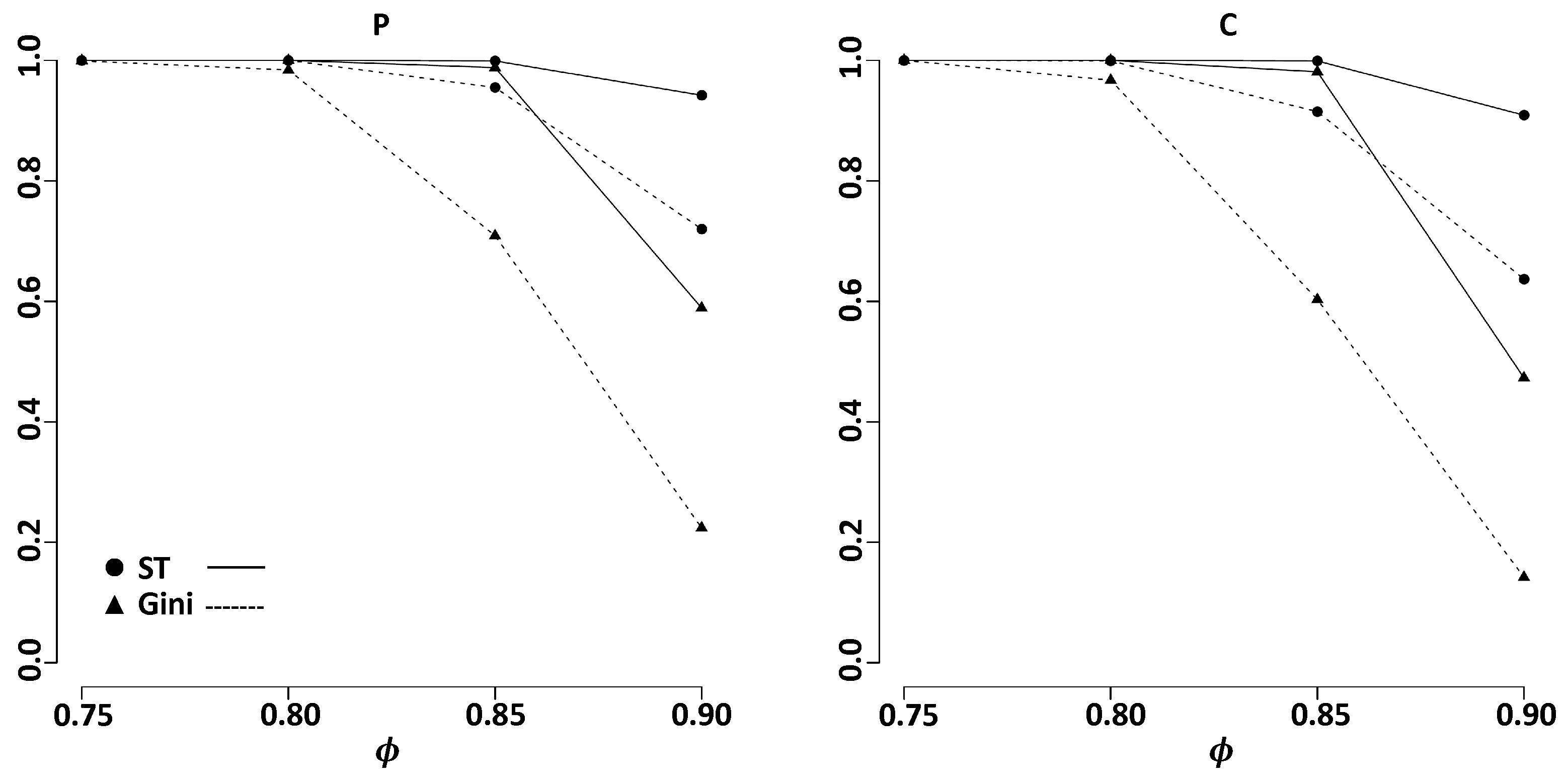
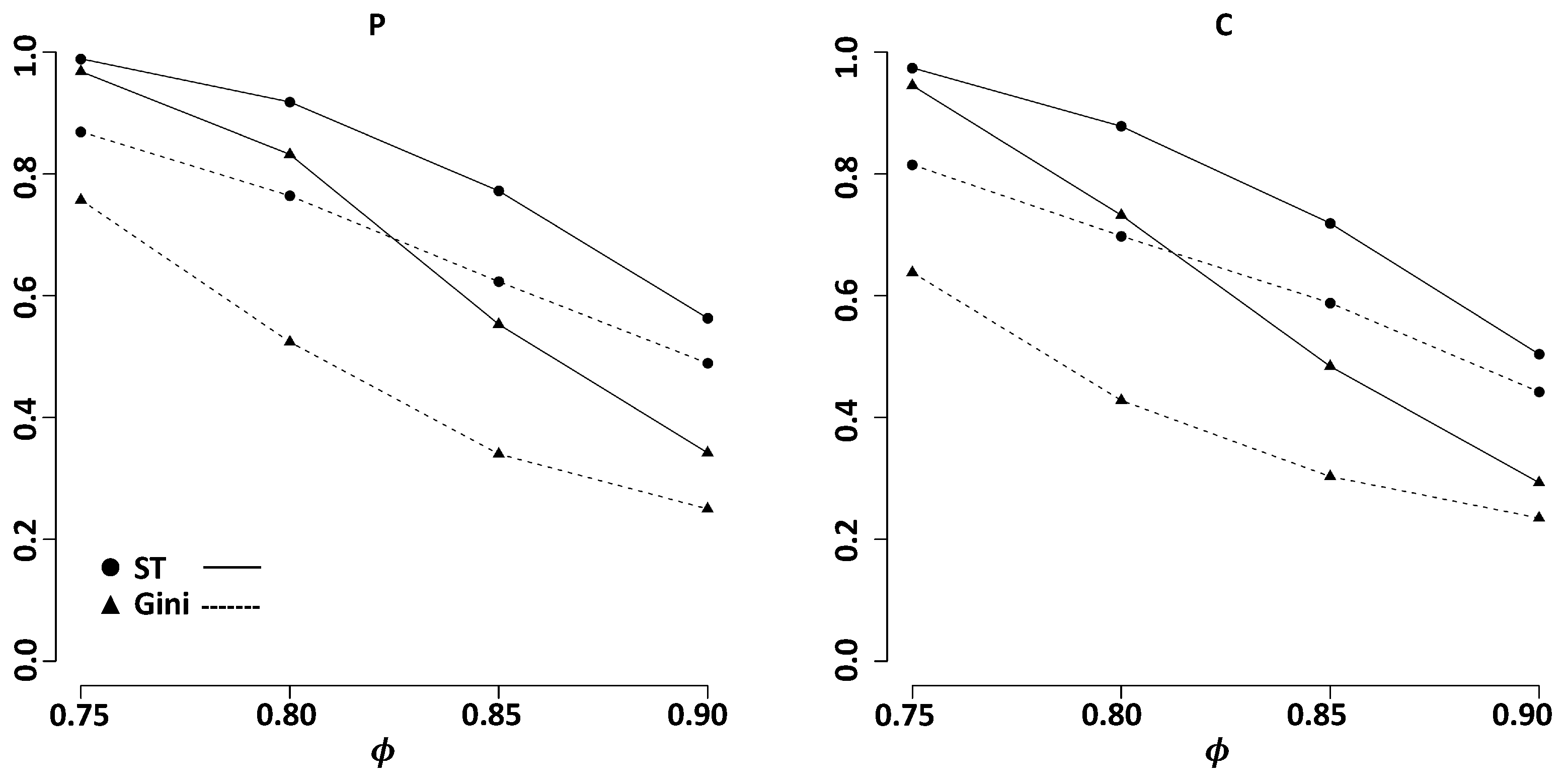
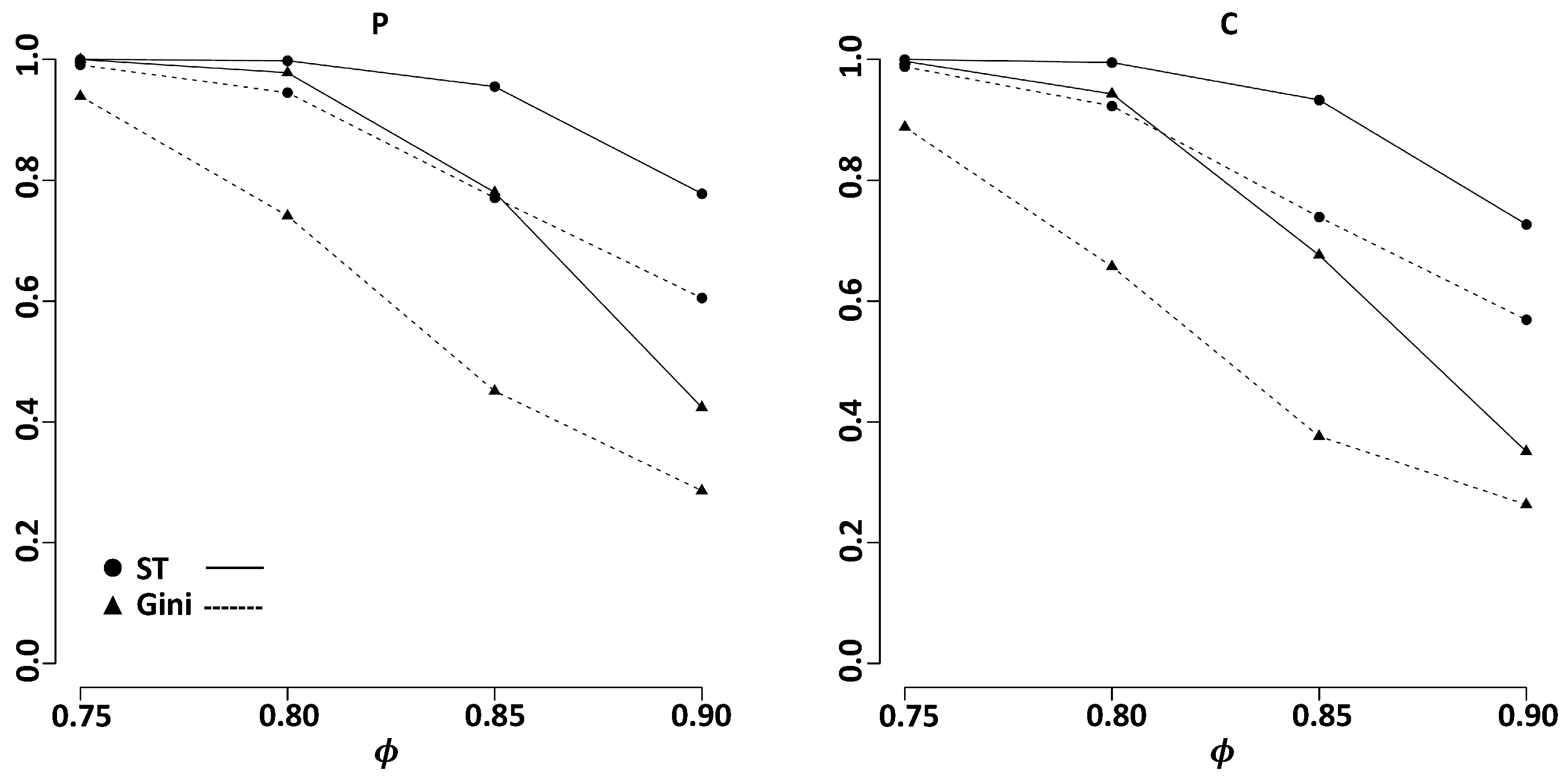
3. Simulation Studies on Variable Selection
3.1. Independent Case
3.2. Dependent Models
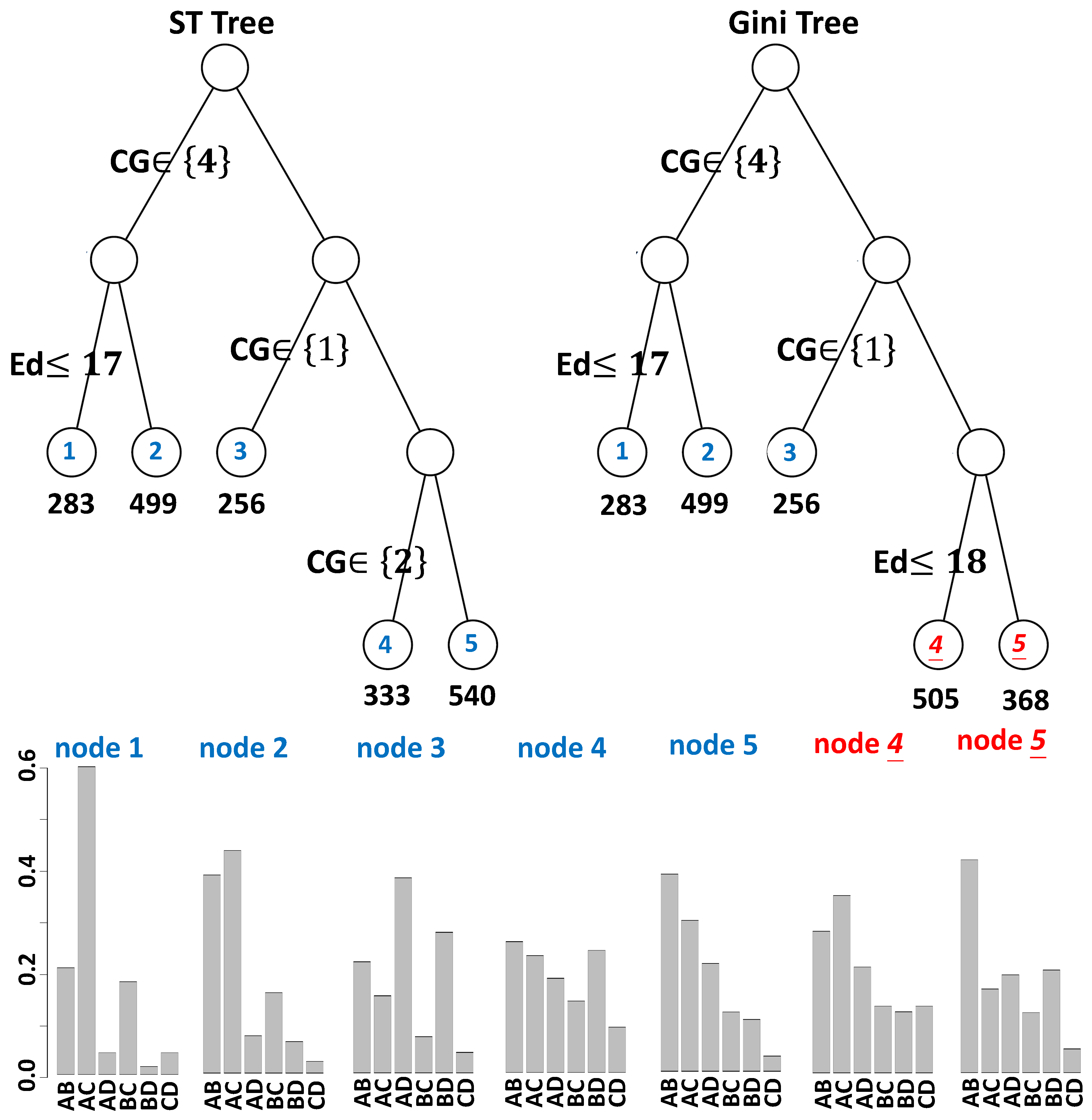
4. Data Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees, 1st ed.; Chapman & Hall: New York, NY, USA, 1984. [Google Scholar]
- Buri, M.; Tanadini, L.G.; Hothorn, T.; Curt, A. Unbiased Recursive Partitioning Enables Robust and Reliable Outcome Prediction in Acute Spinal Cord Injury. J. Neurotrauma 2022, 39, 266–276. [Google Scholar] [CrossRef] [PubMed]
- Loh, W.Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Acuña-Soto, C.; Liern, V.; Pérez-Gladish, B. Normalization in TOPSIS-based approaches with data of different nature: Application to the ranking of mathematical videos. Ann. Oper. Res. 2021, 296, 541–569. [Google Scholar] [CrossRef]
- Handayani, D.O.D.; Lubis, M.; Lubis, A.R. Prediction analysis of the happiness ranking of countries based on macro level factors. Int. J. Artif. Intell. 2022, 11, 666–678. [Google Scholar] [CrossRef]
- Hackert, M.Q.N.; Brouwer, W.B.F.; Hoefman, R.J.; van Exel, J. Views of older people in the Netherlands on wellbeing: A Q-methodology study. Soc. Sci. Med. 2019, 240, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Patil, G.R.; Sharma, G. Urban Quality of Life: An assessment and ranking for Indian cities. Transp. Policy 2022, 124, 183–191. [Google Scholar] [CrossRef]
- Harakawa, R. Ranking of importance measures of tweet communities: Application to keyword extraction from COVID-19 tweets in Japan. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1029–1040. [Google Scholar] [CrossRef] [PubMed]
- Adlakha, K.; Sharma, S. Brand positioning using Multidimensional Scaling technique: An application to herbal healthcare brands in Indian market. J. Bus. Perspect. 2020, 24, 345–355. [Google Scholar] [CrossRef]
- Finch, H. An introduction to the analysis of ranked response data. Pract. Assess. Res. Eval. 2022, 27, 7. [Google Scholar]
- Marden, J.I. Analyzing and Modeling Rank Data, 1st ed.; Chapman & Hall: New York, NY, USA, 1996. [Google Scholar]
- Lee, P.H.; Philip, L.H. Distance-based tree models for ranking data. Comput. Stat. Data Anal. 2010, 54, 1672–1682. [Google Scholar] [CrossRef]
- Yu, P.L.H.; Gu, J.; Xu, H. Analysis of ranking data. Wiley Interdiscip. Rev. Comput. Stat. 2019, 11, e1483. [Google Scholar] [CrossRef]
- Plaia, A.; Sciandra, M. Weighted distance-based trees for ranking data. Adv. Data Anal. Classif. 2019, 13, 427–444. [Google Scholar] [CrossRef]
- Yu, P.L.H.; Wan, W.M.; Lee, P.H. Decision Tree Modeling for Ranking Data; Fürnkranz, J., Hüllermeier, E., Eds.; Preference Learning; Springer: Berlin/Heidelberg, Germany, 2010; pp. 83–106. [Google Scholar]
- Cheng, W.; Hühn, J.; Hüllermeier, E. Decision tree and instance-based learning for label ranking. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 161–168. [Google Scholar]
- Kung, Y.H.; Lin, C.T.; Shih, Y.S. Split variable selection for tree modeling on rank data. Comput. Stat. Data Anal. 2012, 56, 2830–2836. [Google Scholar] [CrossRef]
- Simonoff, J.S. Analyzing Categorical Data; Springer: New York, NY, USA, 2003. [Google Scholar]
- Vermunt, J. Multilevel latent class models. Sociol. Methodol. 2003, 33, 213–239. [Google Scholar] [CrossRef]
- Strobl, C.; Wickelmaier, F.; Zeileis, A. Accounting for individual differences in Bradley-Terry models by means of recursive partitioning. J. Educ. Behav. Stat. 2011, 36, 135–153. [Google Scholar] [CrossRef]
- Loh, W.Y.; Shih, Y.S. Split selection methods for classification trees. Stat. Sin. 1997, 7, 815–840. [Google Scholar]
- Loh, W.Y. Regression trees with unbiased variable selection and interaction detection. Stat. Sin. 2002, 12, 361–386. [Google Scholar]
- Diaconis, P. Group Representations in Probability and Statistics. Lect. Notes-Monogr. Ser. 1988, 11, i-192. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Country |
|---|---|
| 1 | Italy (113), the Netherlands (48), Denmark (95) |
| 2 | France (106), Spain (35), Belgium (115), Croatia (24), Greece (53) |
| 3 | West Germany (52), East Germany (48), Iceland (62), Czechia (144), |
| Romania (60), Bulgaria (64), Malta (29), Luxembourg (32), Slovenia (49) | |
| 4 | Estonia (70), Latvia (66), Lithuania (50), Poland (109), Slovakia (103), |
| Hungary (77), Russia (170), Ukraine (66), Belarus (71) |
| Model | Condition |
|---|---|
| I | |
| II | |
| II | |
| IV | |
| V |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shih, Y.-S.; Kung, Y.-H. Tree-Structured Model with Unbiased Variable Selection and Interaction Detection for Ranking Data. Mach. Learn. Knowl. Extr. 2023, 5, 448-459. https://doi.org/10.3390/make5020027
Shih Y-S, Kung Y-H. Tree-Structured Model with Unbiased Variable Selection and Interaction Detection for Ranking Data. Machine Learning and Knowledge Extraction. 2023; 5(2):448-459. https://doi.org/10.3390/make5020027
Chicago/Turabian StyleShih, Yu-Shan, and Yi-Hung Kung. 2023. "Tree-Structured Model with Unbiased Variable Selection and Interaction Detection for Ranking Data" Machine Learning and Knowledge Extraction 5, no. 2: 448-459. https://doi.org/10.3390/make5020027
APA StyleShih, Y.-S., & Kung, Y.-H. (2023). Tree-Structured Model with Unbiased Variable Selection and Interaction Detection for Ranking Data. Machine Learning and Knowledge Extraction, 5(2), 448-459. https://doi.org/10.3390/make5020027