

E2H Distance-Weighted Minimum Reference Set for Numerical and Categorical Mixture Data and a Bayesian Swap Feature Selection Algorithm

Abstract
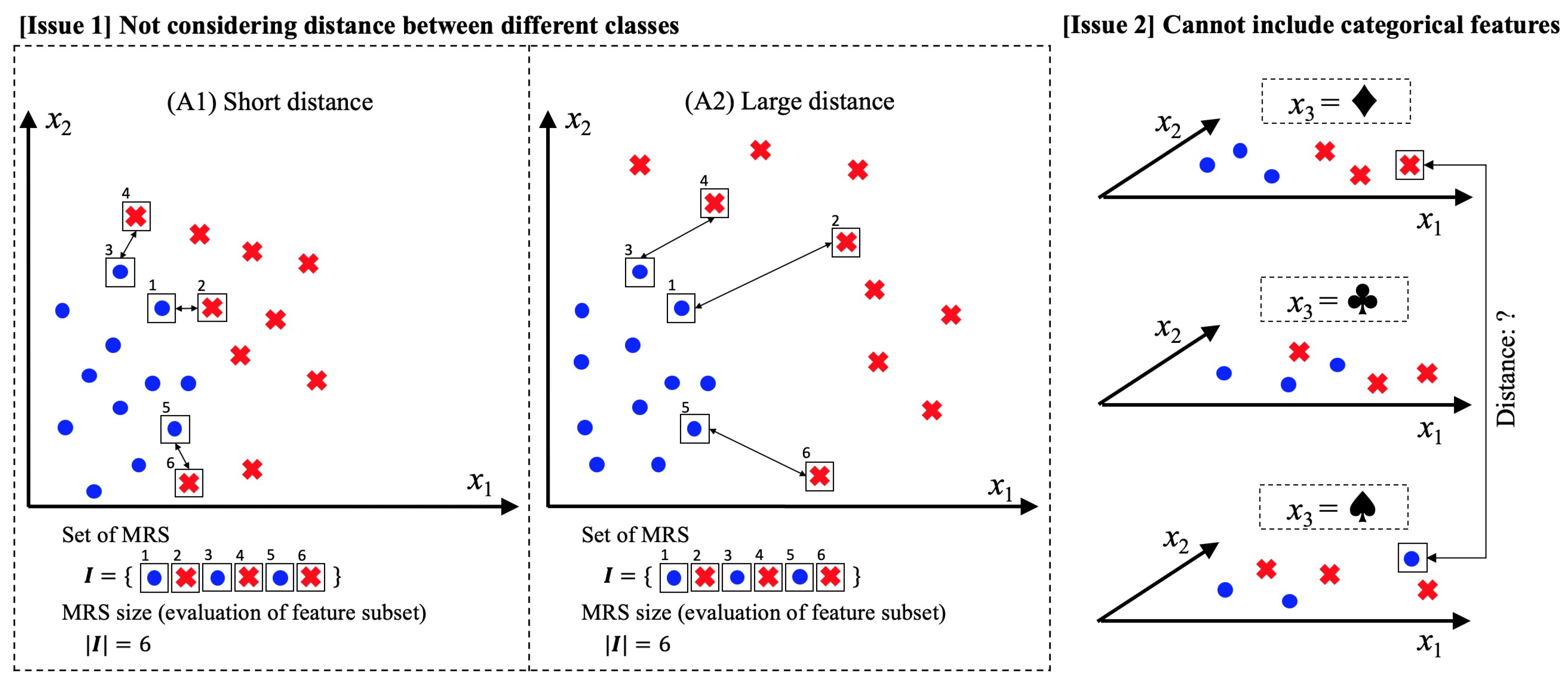
1. Introduction
2. Proposed Method
2.1. Mathematical Representation of Feature Subset Selection
2.2. E2H Distance-Weighted MRS Algorithm
| Algorithm 1 E2H MRS feature evaluation algorithm |
|
2.3. Distance Function
2.4. Evaluation Function of a Feature Subset
2.5. Bayesian Swap Feature Selection Algorithm
| Algorithm 2 Bayesian swap feature subset selection algorithm (BS-FS) |
|
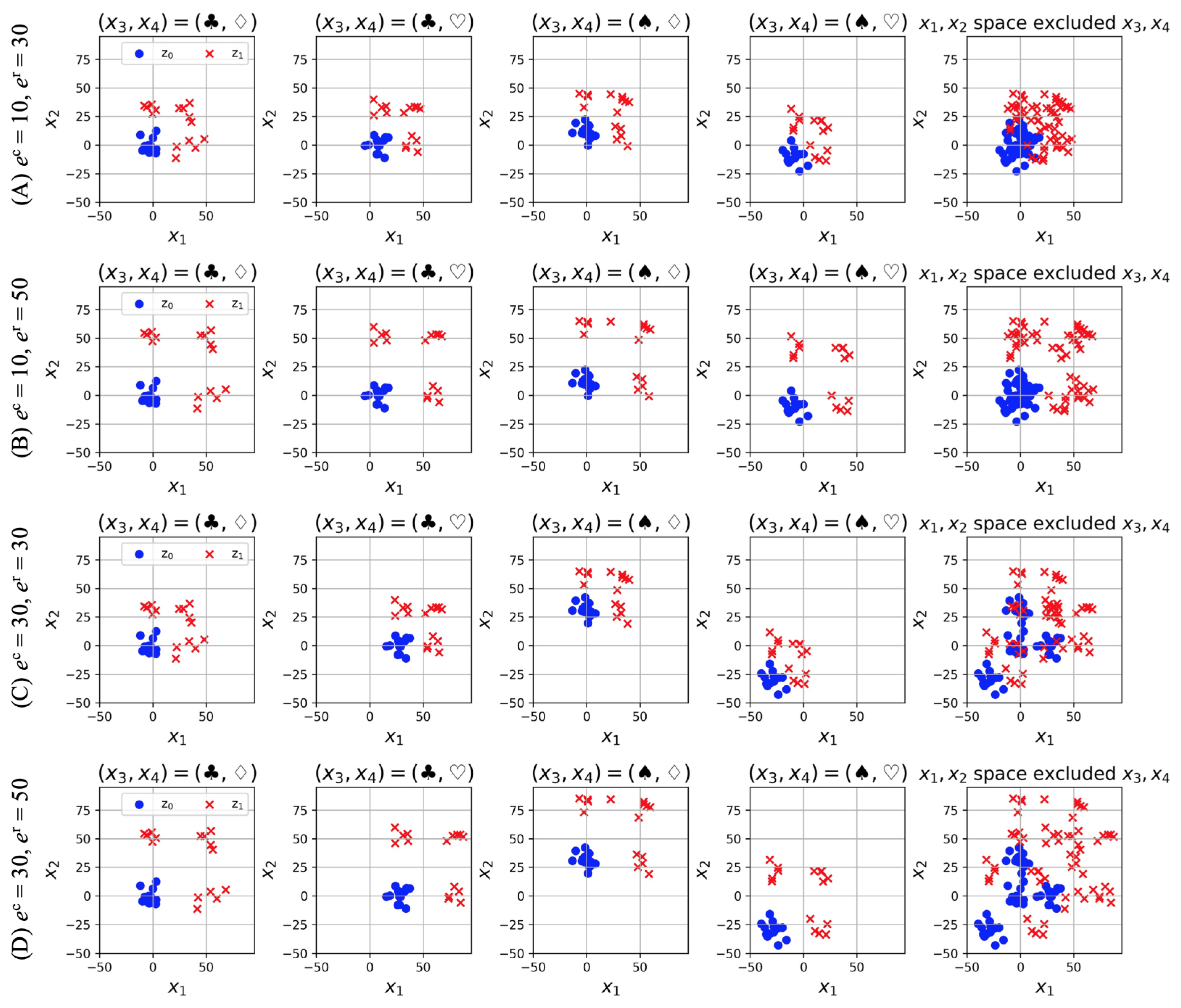
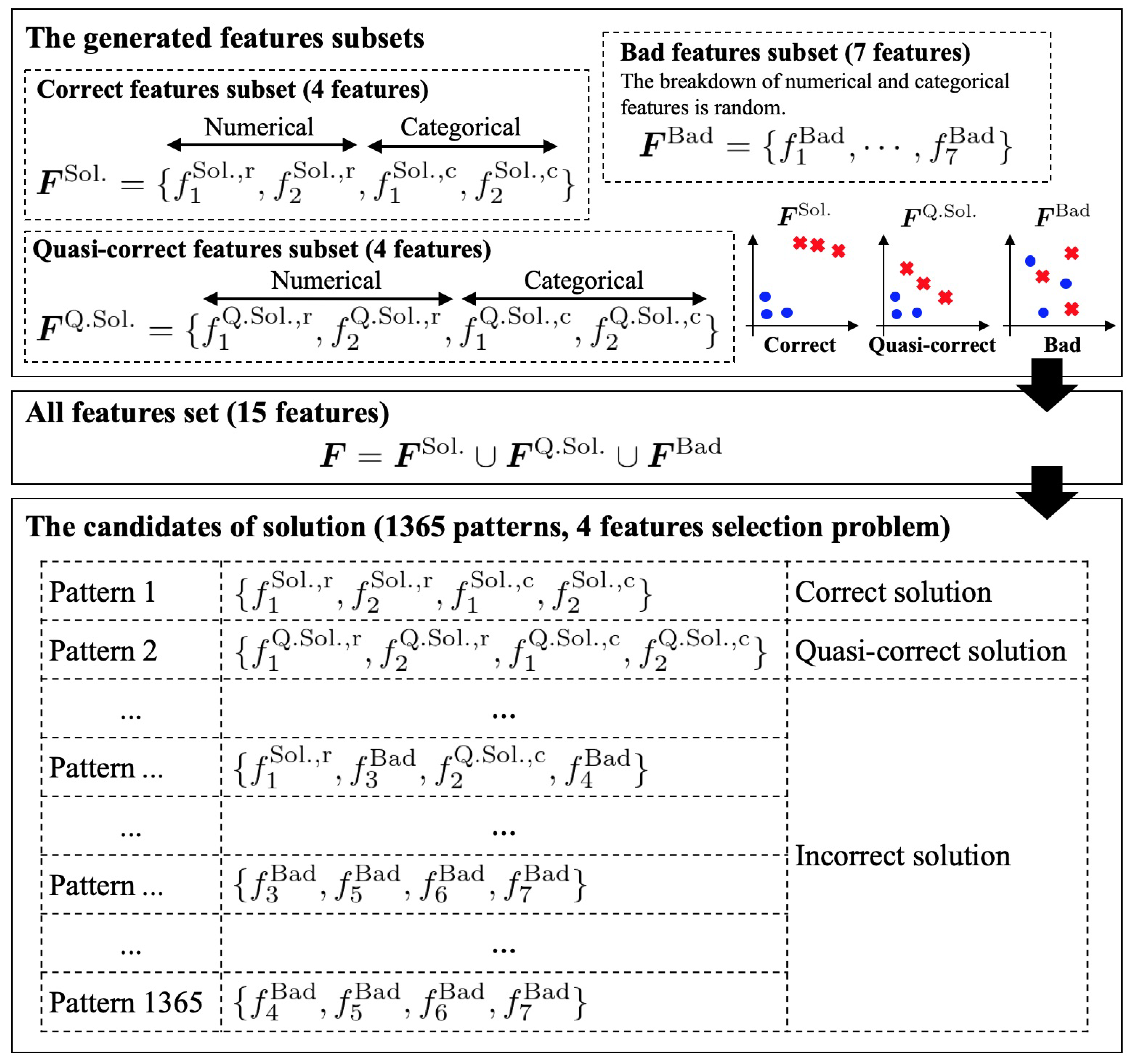
3. Artificial Dataset for the Verification of the Proposed Methods
4. Experiment 1: Relationship between the Distance between Different Classes and the E2H MRS Evaluation
4.1. Objective and Outline
4.2. Result and Discussion
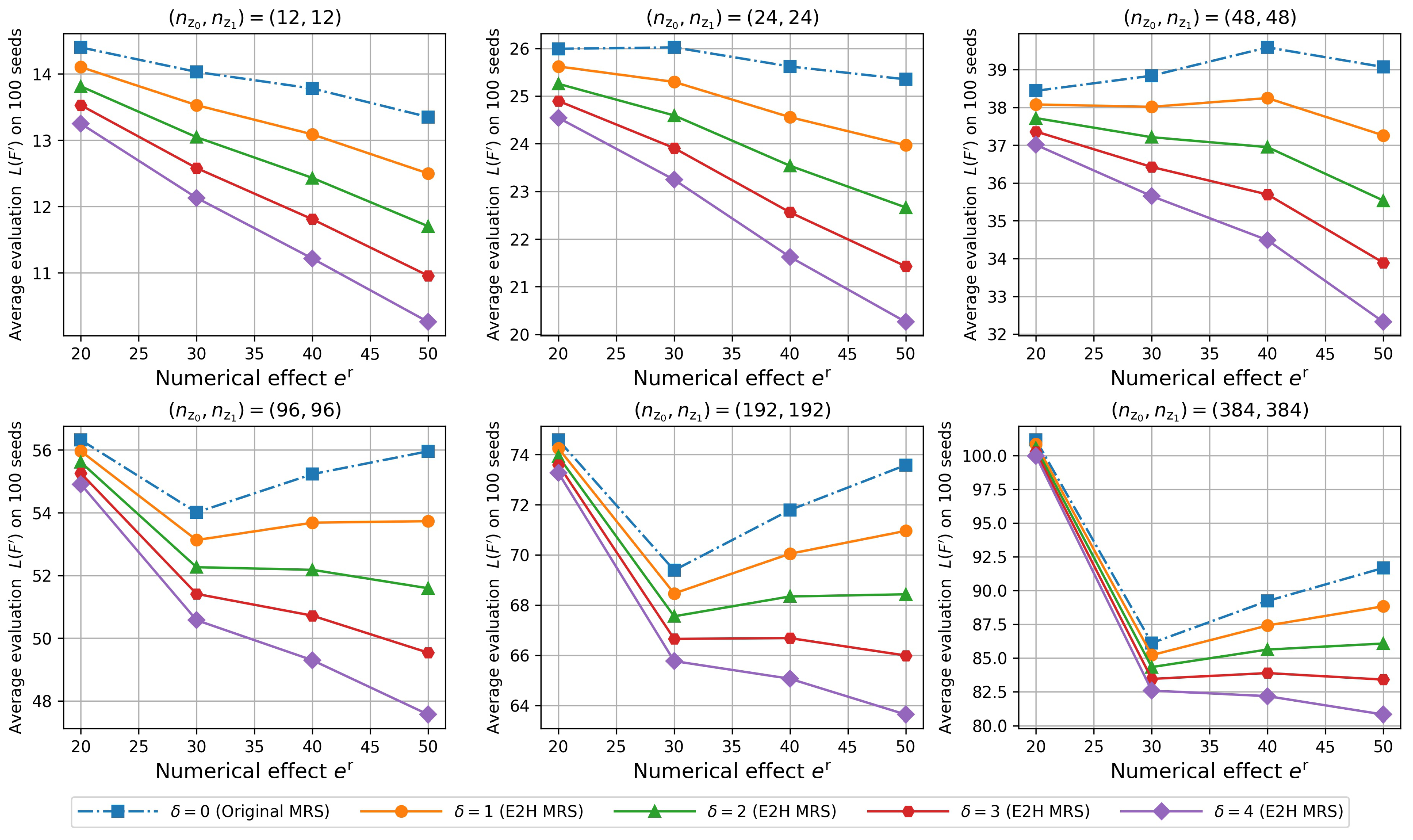
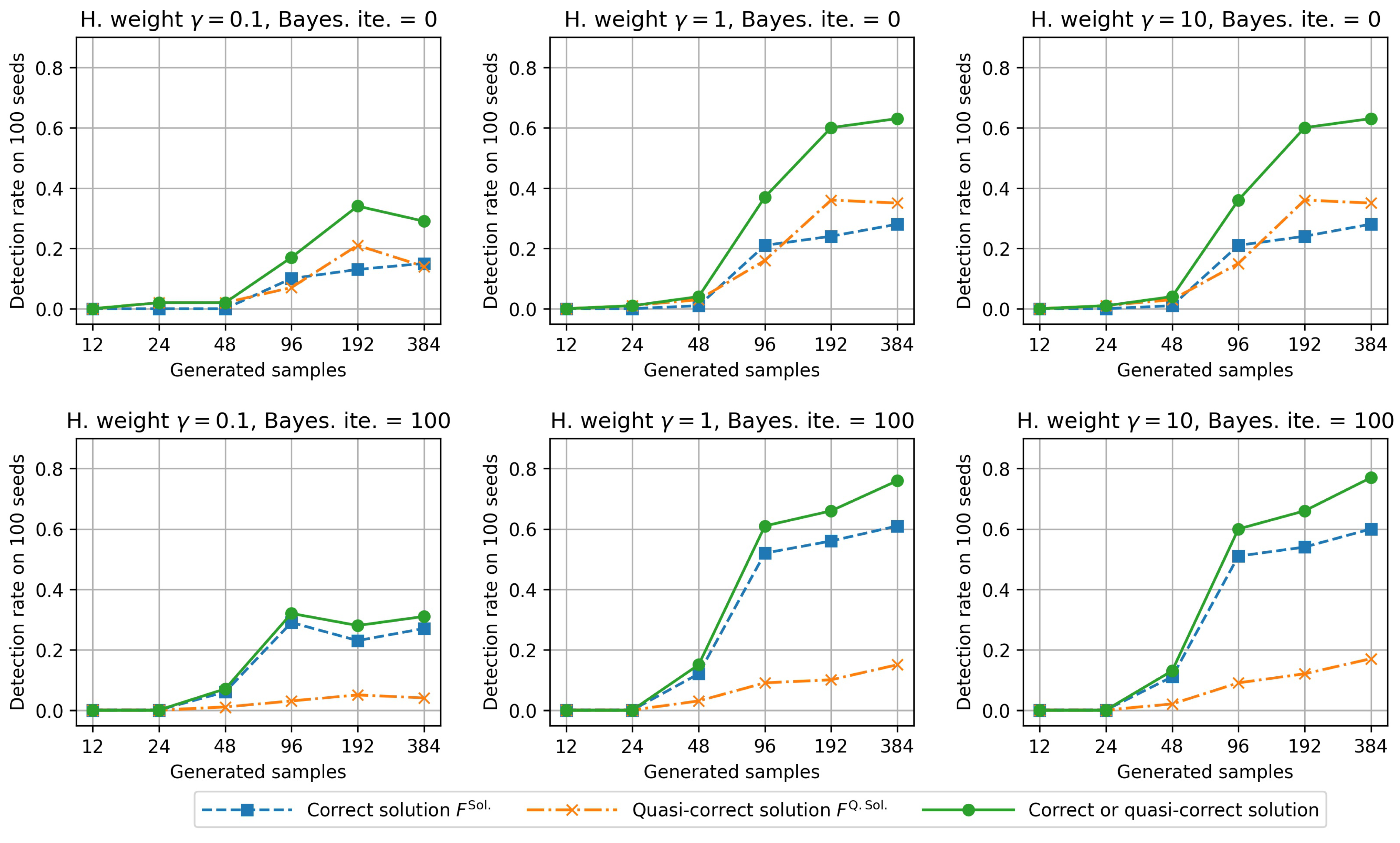
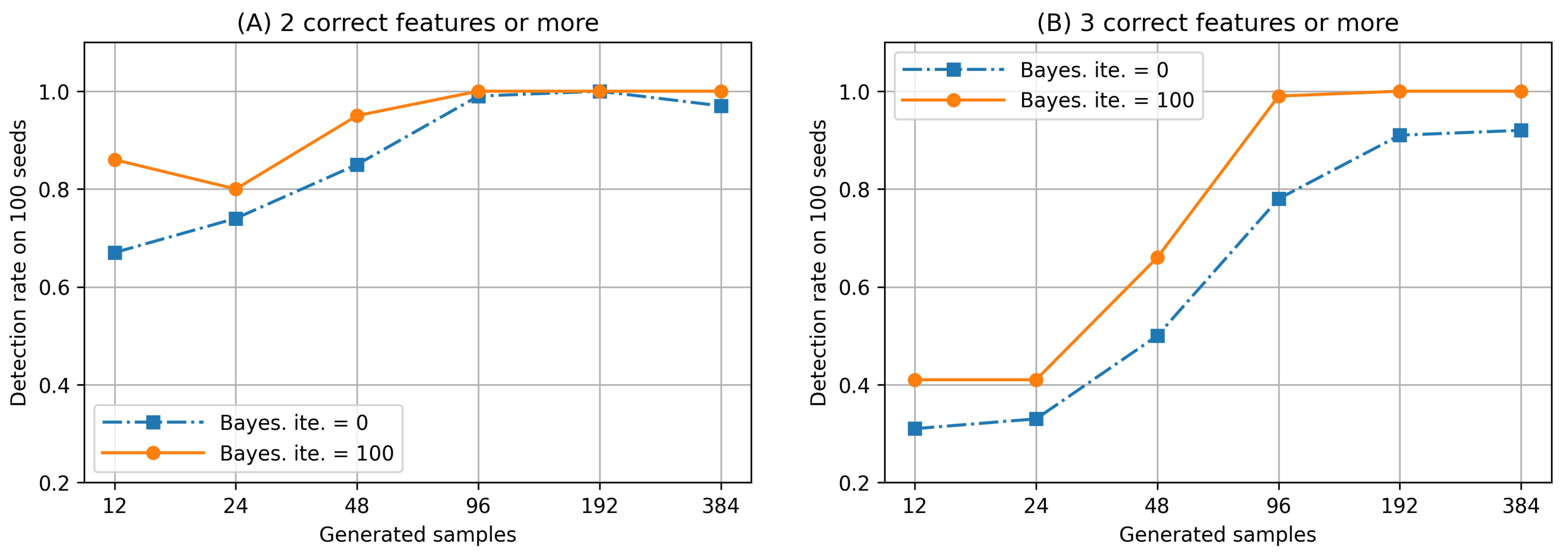
5. Experiment 2: Effectiveness of BS-FS in Finding Desirable Feature Subsets
5.1. Objective and Outline
5.2. Result and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Variables and Their Meanings Table
Appendix A.1. Variables for Representing Problem Description
| Variables | Meanings |
| The all features set collected by the users who want to find desirable features subset. | |
| The all numerical features set in . | |
| The all categorical features set in | |
| The size of , i.e., . | |
| The size of , i.e., . | |
| n | The size of , i.e., . |
| The i-th element of , i.e., one of numerical features. | |
| The i-th element of , i.e., one of categorical features. | |
| One of the features subset of . | |
| m | The size of . |
| The evaluation function for the features subset . | |
| The optimal features subset leading to the minimum value of . | |
| z | Either class or . |
| The features vector of class . | |
| The part of feature vector that consists numerical values. | |
| The part of feature vector that consists categorical values. | |
| The dimension number of . | |
| The dimension number of . |
Appendix A.2. Variables for Representing the Proposed Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Type 1 | Meanings |
|---|---|---|
| Calculation | The mixture distance between two features vectors and . | |
| Calculation | The squared Euclidean distance between two numerical features and . | |
| Calculation | The Hamming distance between two categorical features and . | |
| Calculation | The function for checking whether and are the same or not. If their are the same, it outputs 0, if not, it outputs 1. The function is used for the Hamming distance . Note that and are i-th elements of categorical features vectors and , respectively. | |
| Manually | The weight of the Hamming distance . When users have a hypothesis in which categorical features are important for classification, they set a large value. When users set , the effect of categorical features on distance disappears. The range is . | |
| Calculation | It is the minimum reference set (MRS) leading to the correct classification (no error) of all samples by using features subset . MRS was proposed in the original study [18]. | |
| Calculation | The average distance between different classes of set . Appears in Algorithm 1. | |
| Calculation | The evaluation function of features subset considered both of MRS size and distance . The lower the value, the better is the feature space for classification. This is equivalent to . | |
| Manually | The effect of the distance between different classes on the evaluation function. This parameter is manually set by the users. When they emphasize the distance between different classes compared with MRS size, they set a large value. The range is . | |
| b | Manually | Iterations of the Bayesian optimization. Appears in Algorithm 2. This parameter is manually set by the users. When they want to improve accuracy of the obtained solution, they set a large value. The computational cost is highly dependent on this value. |
| Calculation | The solution of features subset for classification obtained by Algorithm 2. The solution’s evaluation is expected to be close to the optimal solution’s evaluation . |
References
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Gopika, N.; Kowshalaya, M. Correlation Based Feature Selection Algorithm for Machine Learning. In Proceedings of the 3rd International Conference on Communication and Electronics Systems, Coimbatore, Tamil Nadu, India, 15–16 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 692–695. [Google Scholar]
- Yao, R.; Li, J.; Hui, M.; Bai, L.; Wu, Q. Feature Selection Based on Random Forest for Partial Discharges Characteristic Set. IEEE Access 2020, 8, 159151–159161. [Google Scholar] [CrossRef]
- Yun, C.; Yang, J. Experimental comparison of feature subset selection methods. In Proceedings of the Seventh IEEE International Conference on Data Mining Workshops (ICDMW 2007), Omaha, NE, USA, 28–31 October 2007; pp. 367–372. [Google Scholar]
- Lin, W.C. Experimental Study of Information Measure and Inter-Intra Class Distance Ratios on Feature Selection and Orderings. IEEE Trans. Syst. Man Cybern. 1973, 3, 172–181. [Google Scholar] [CrossRef]
- Huang, C.L.; Wang, C.J. A GA-based feature selection and parameters optimizationfor support vector machines. Expert Syst. Appl. 2006, 31, 231–240. [Google Scholar] [CrossRef]
- Stefano, C.D.; Fontanella, F.; Marrocco, C.; Freca, A.S.D. A GA-based feature selection approach with an application to handwritten character recognition. Pattern Recognit. Lett. 2014, 35, 130–141. [Google Scholar] [CrossRef]
- Dahiya, S.; Handa, S.S.; Singh, N.P. A feature selection enabled hybrid-bagging algorithm for credit risk evaluation. Expert Syst. 2017, 34, e12217. [Google Scholar] [CrossRef]
- Li, G.Z.; Meng, H.H.; Lu, W.C.; Yang, J.Y.; Yang, M.Q. Asymmetric bagging and feature selection for activities prediction of drug molecules. BMC Bioinform. 2008, 9, S7. [Google Scholar] [CrossRef]
- Loh, W.Y. Fifty Years of Classification and Regression Trees. Int. Stat. Rev. 2014, 82, 329–348. [Google Scholar] [CrossRef]
- Loh, W.Y. Classification and regression trees. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Roth, V. The generalized LASSO. IEEE Trans. Neural Networks 2004, 15, 16–28. [Google Scholar] [CrossRef]
- Osborne, M.R.; Presnell, B.; Turlach, B.A. On the LASSO and its Dual. J. Comput. Graph. Stat. 2000, 9, 319–337. [Google Scholar] [CrossRef]
- Bach, F.R. Bolasso: Model Consistent Lasso Estimation through the Bootstrap. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008. [Google Scholar] [CrossRef]
- Palma-Mendoza, R.J.; Rodriguez, D.; de Marcos, L. Distributed ReliefF-based feature selection in Spark. Knowl. Inf. Syst. 2018, 57, 1–20. [Google Scholar] [CrossRef]
- Huang, Y.; McCullagh, P.J.; Black, N.D. An optimization of ReliefF for classification in large datasets. Data Knowl. Eng. 2009, 68, 1348–1356. [Google Scholar] [CrossRef]
- Too, J.; Abdullah, A.R. Binary atom search optimisation approaches for feature selection. Connect. Sci. 2020, 32, 406–430. [Google Scholar] [CrossRef]
- Chen, X.W.; Jeong, J.C. Minimum reference set based feature selection for small sample classifications. ACM Int. Conf. Proc. Ser. 2007, 227, 153–160. [Google Scholar] [CrossRef]
- Mori, M.; Omae, Y.; Akiduki, T.; Takahashi, H. Consideration of Human Motion’s Individual Differences-Based Feature Space Evaluation Function for Anomaly Detection. Int. J. Innov. Comput. Inf. Control. 2019, 15, 783–791. [Google Scholar] [CrossRef]
- Zhao, Y.; He, L.; Xie, Q.; Li, G.; Liu, B.; Wang, J.; Zhang, X.; Zhang, X.; Luo, L.; Li, K.; et al. A Novel Classification Method for Syndrome Differentiation of Patients with AIDS. Evid.-Based Complement. Altern. Med. 2015, 2015, 936290. [Google Scholar] [CrossRef]
- Mori, M.; Flores, R.G.; Suzuki, Y.; Nukazawa, K.; Hiraoka, T.; Nonaka, H. Prediction of Microcystis Occurrences and Analysis Using Machine Learning in High-Dimension, Low-Sample-Size and Imbalanced Water Quality Data. Harmful Algae 2022, 117, 102273. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, Y.; Zhu, Z.; Pan, J.S. MRS-MIL: Minimum reference set based multiple instance learning for automatic image annotation. In Proceedings of the International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 2160–2163. [Google Scholar]
- Cerda, P.; Varoquaux, G. Encoding High-Cardinality String Categorical Variables. IEEE Trans. Knowl. Data Eng. 2022, 34, 1164–1176. [Google Scholar] [CrossRef]
- Beliakov, G.; Li, G. Improving the speed and stability of the k-nearest neighbors method. Pattern Recognit. Lett. 2012, 33, 1296–1301. [Google Scholar] [CrossRef]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Ram, P.; Sinha, K. Revisiting kd-tree for nearest neighbor search. In Proceedings of the ACM International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1378–1388. [Google Scholar]
- Ekinci, E.; Omurca, S.I.; Acun, N. A comparative study on machine learning techniques using Titanic dataset. In Proceedings of the 7th International Conference on Advanced Technologies, Hammamet, Tunisia, 26–28 December 2018; pp. 411–416. [Google Scholar]
- Kakde, Y.; Agrawal, S. Predicting survival on Titanic by applying exploratory data analytics and machine learning techniques. Int. J. Comput. Appl. 2018, 179, 32–38. [Google Scholar] [CrossRef]
- Huang, Z. Extensions to the k-Means Algorithm for Clustering Large Data Sets with Categorical Values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Wen, T.; Zhang, Z. Effective and extensible feature extraction method using genetic algorithm-based frequency-domain feature search for epileptic EEG multiclassification. Medicine 2017, 96. [Google Scholar] [CrossRef] [PubMed]
- Song, J.; Zhu, A.; Tu, Y.; Wang, Y.; Arif, M.A.; Shen, H.; Shen, Z.; Zhang, X.; Cao, G. Human Body Mixed Motion Pattern Recognition Method Based on Multi-Source Feature Parameter Fusion. Sensors 2020, 20, 537. [Google Scholar] [CrossRef]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. Adv. Neural Inf. Process. Syst. 2011, 42. [Google Scholar]
- Optuna: A Hyperparameter Optimization Framework. Available online: https://optuna.readthedocs.io/en/stable/ (accessed on 1 November 2022).







| Feature Space | Setting Parameters 1 | MRS Size | Damping Coefficient | Score 2 |
|---|---|---|---|---|
| (A) | (0, 0) | 48 | 1.000 | 48.00 |
| (B) | (0, 0) | 56 | 1.000 | 56.00 |
| (C) | (0, 0) | 63 | 1.000 | 63.00 |
| (D) | (0, 0) | 67 | 1.000 | 67.00 |
| (A) | (1, 1) | 35 | 0.983 | 34.41 |
| (B) | (1, 1) | 26 | 0.960 | 24.95 |
| (C) | (1, 1) | 35 | 0.993 | 34.77 |
| (D) | (1, 1) | 27 | 0.981 | 26.48 |
| (A) | (1, 5) | 35 | 0.844 | 29.54 |
| (B) | (1, 5) | 26 | 0.661 | 17.20 |
| (C) | (1, 5) | 35 | 0.935 | 32.73 |
| (D) | (1, 5) | 27 | 0.822 | 22.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Omae, Y.; Mori, M. E2H Distance-Weighted Minimum Reference Set for Numerical and Categorical Mixture Data and a Bayesian Swap Feature Selection Algorithm. Mach. Learn. Knowl. Extr. 2023, 5, 109-127. https://doi.org/10.3390/make5010007
Omae Y, Mori M. E2H Distance-Weighted Minimum Reference Set for Numerical and Categorical Mixture Data and a Bayesian Swap Feature Selection Algorithm. Machine Learning and Knowledge Extraction. 2023; 5(1):109-127. https://doi.org/10.3390/make5010007
Chicago/Turabian StyleOmae, Yuto, and Masaya Mori. 2023. "E2H Distance-Weighted Minimum Reference Set for Numerical and Categorical Mixture Data and a Bayesian Swap Feature Selection Algorithm" Machine Learning and Knowledge Extraction 5, no. 1: 109-127. https://doi.org/10.3390/make5010007
APA StyleOmae, Y., & Mori, M. (2023). E2H Distance-Weighted Minimum Reference Set for Numerical and Categorical Mixture Data and a Bayesian Swap Feature Selection Algorithm. Machine Learning and Knowledge Extraction, 5(1), 109-127. https://doi.org/10.3390/make5010007