
XAIR: A Systematic Metareview of Explainable AI (XAI) Aligned to the Software Development Process


Abstract
:1. Introduction
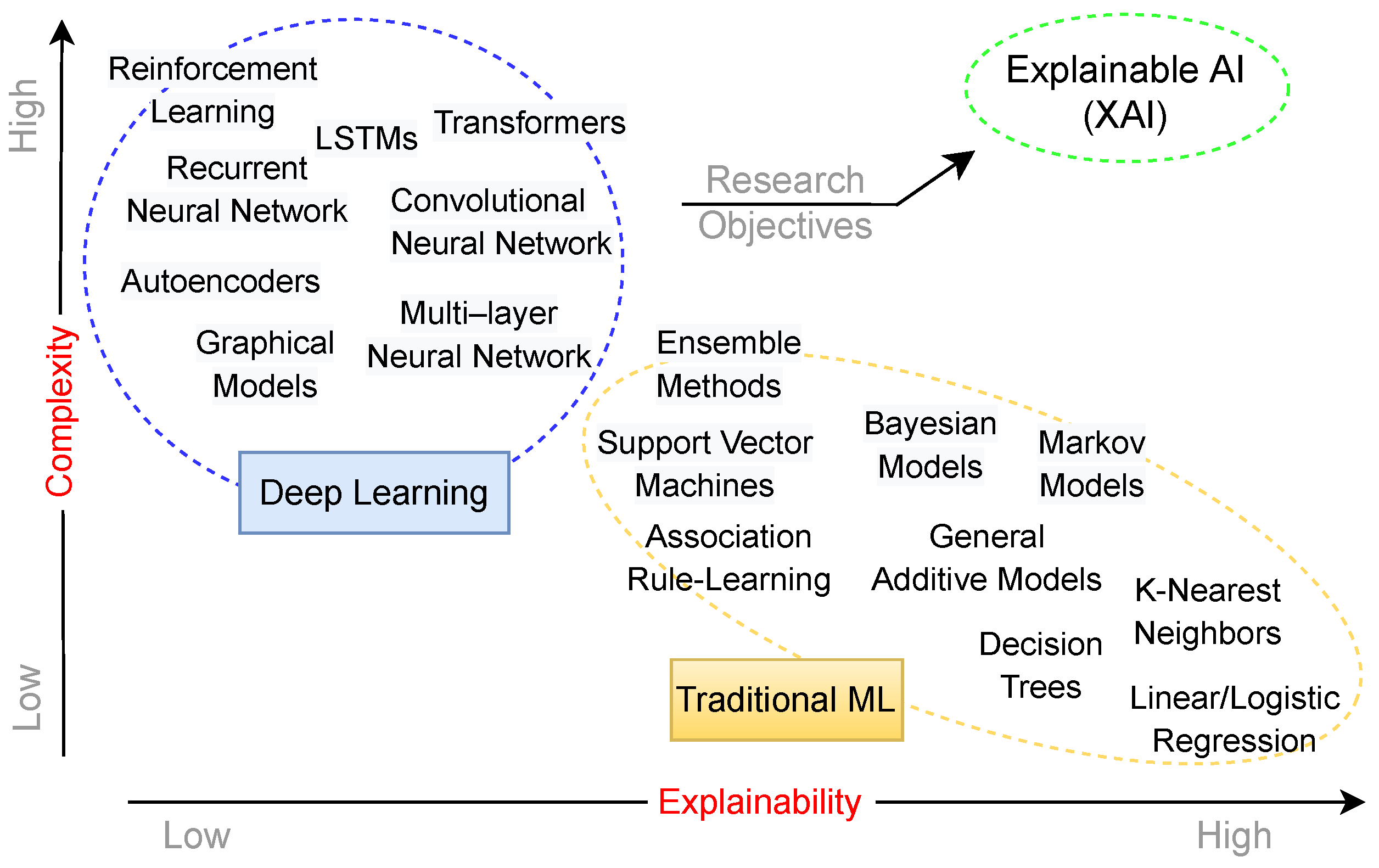
2. Background
2.1. Important Concepts
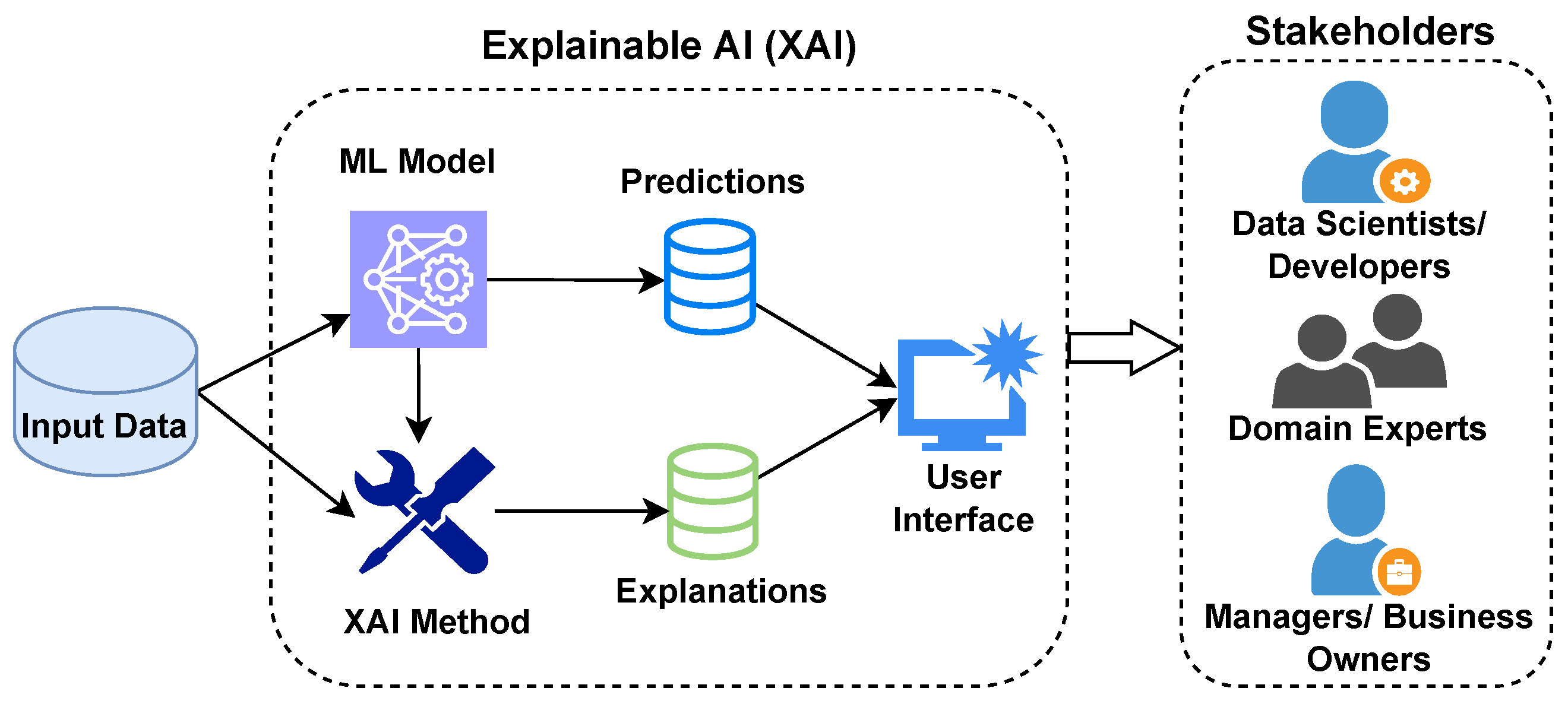
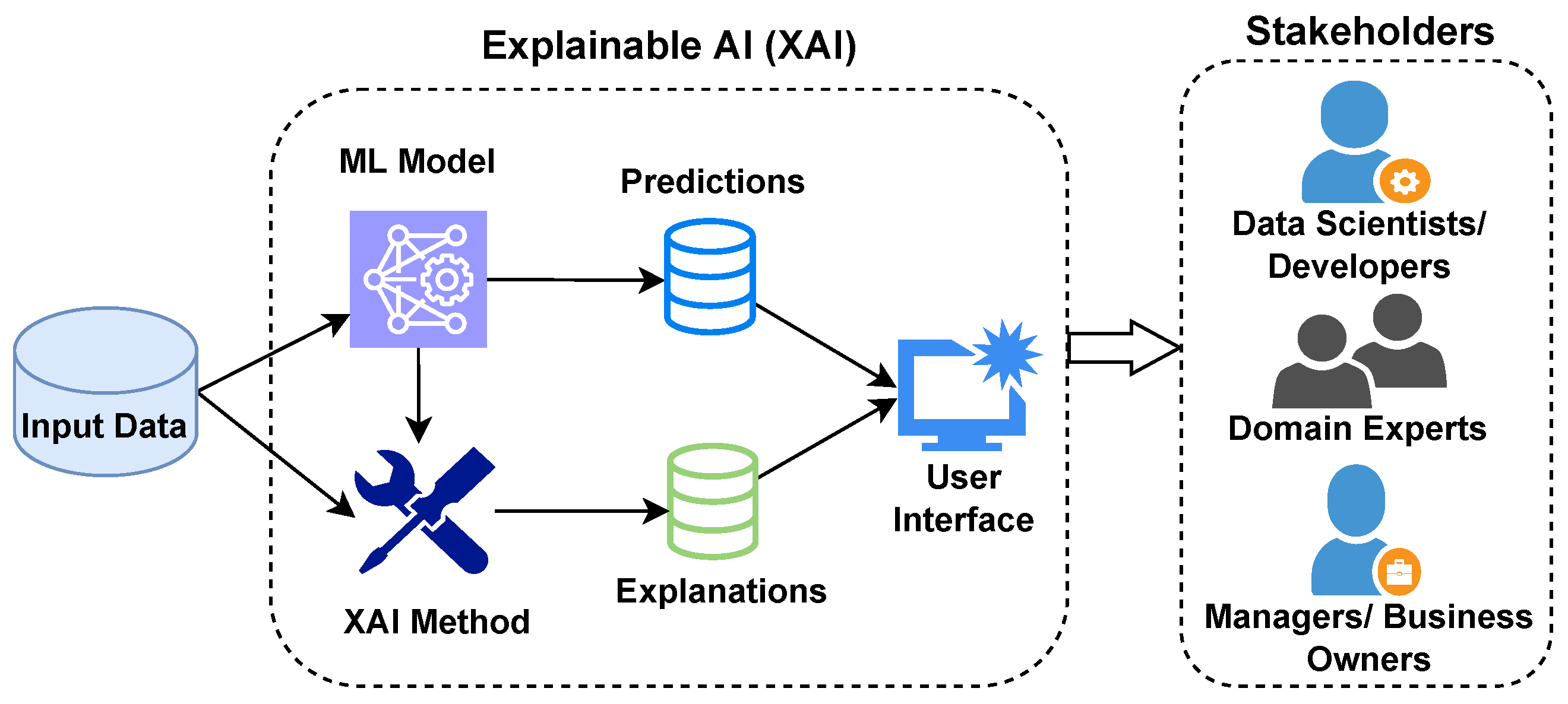
2.2. XAI Components
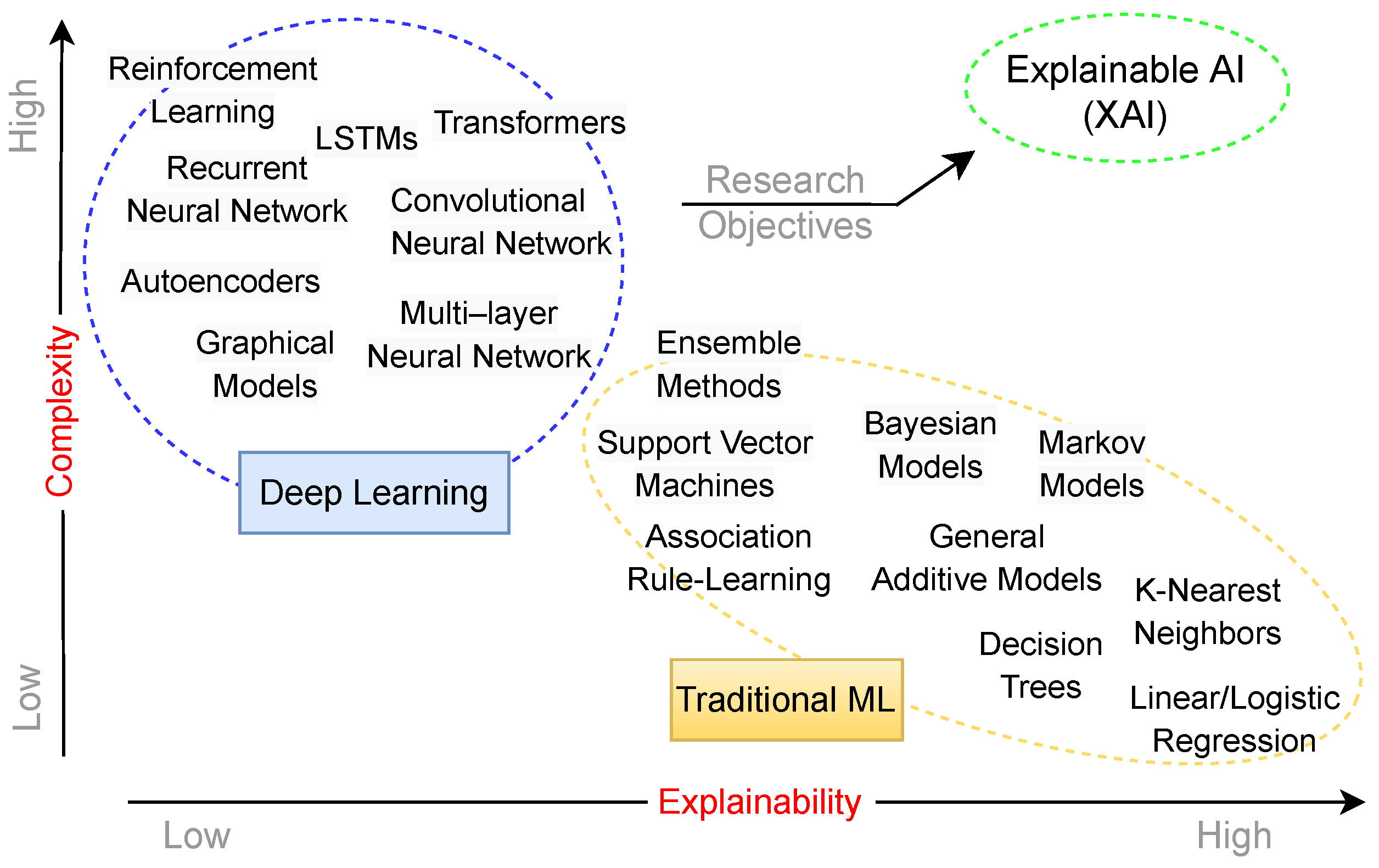
2.3. Black- and White-Box Models
2.4. Global and Local Interpretability
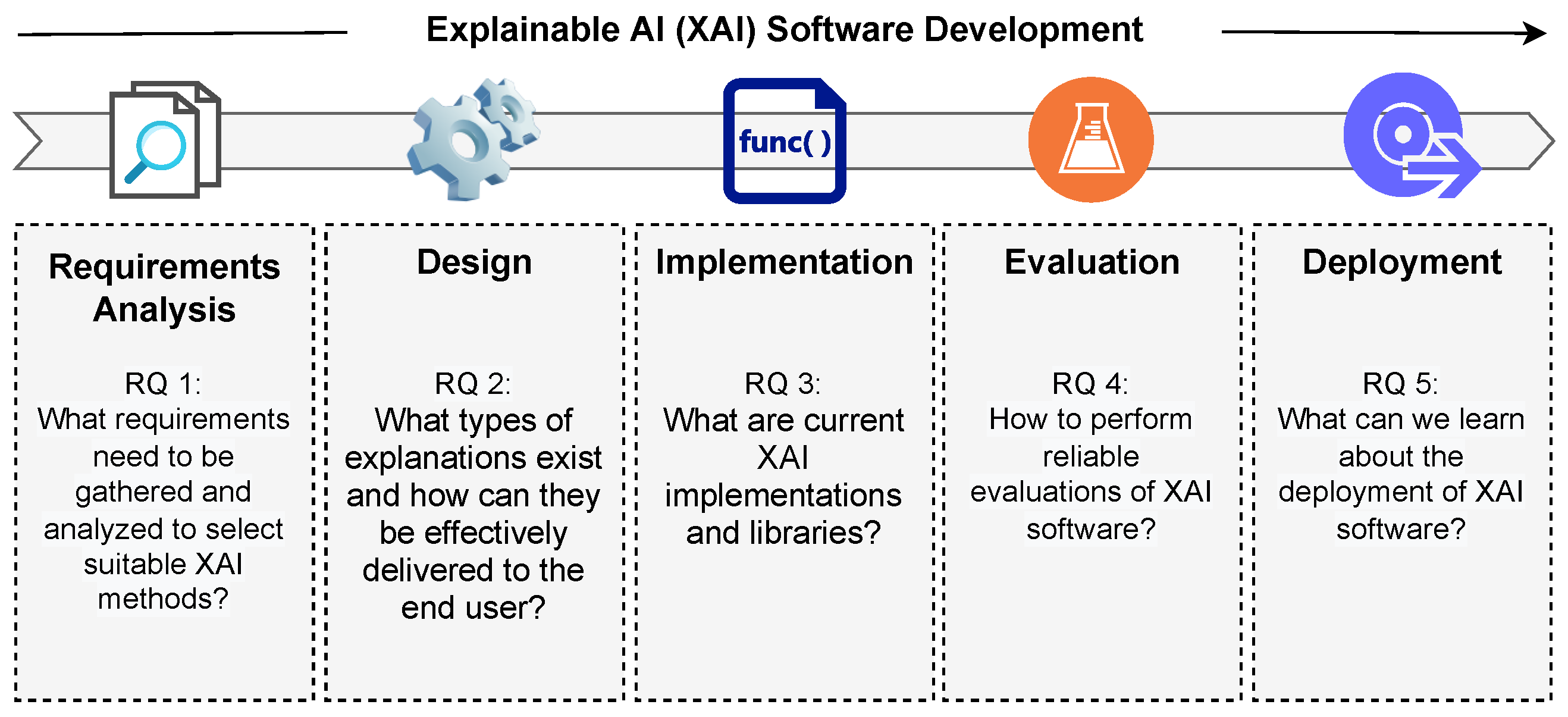
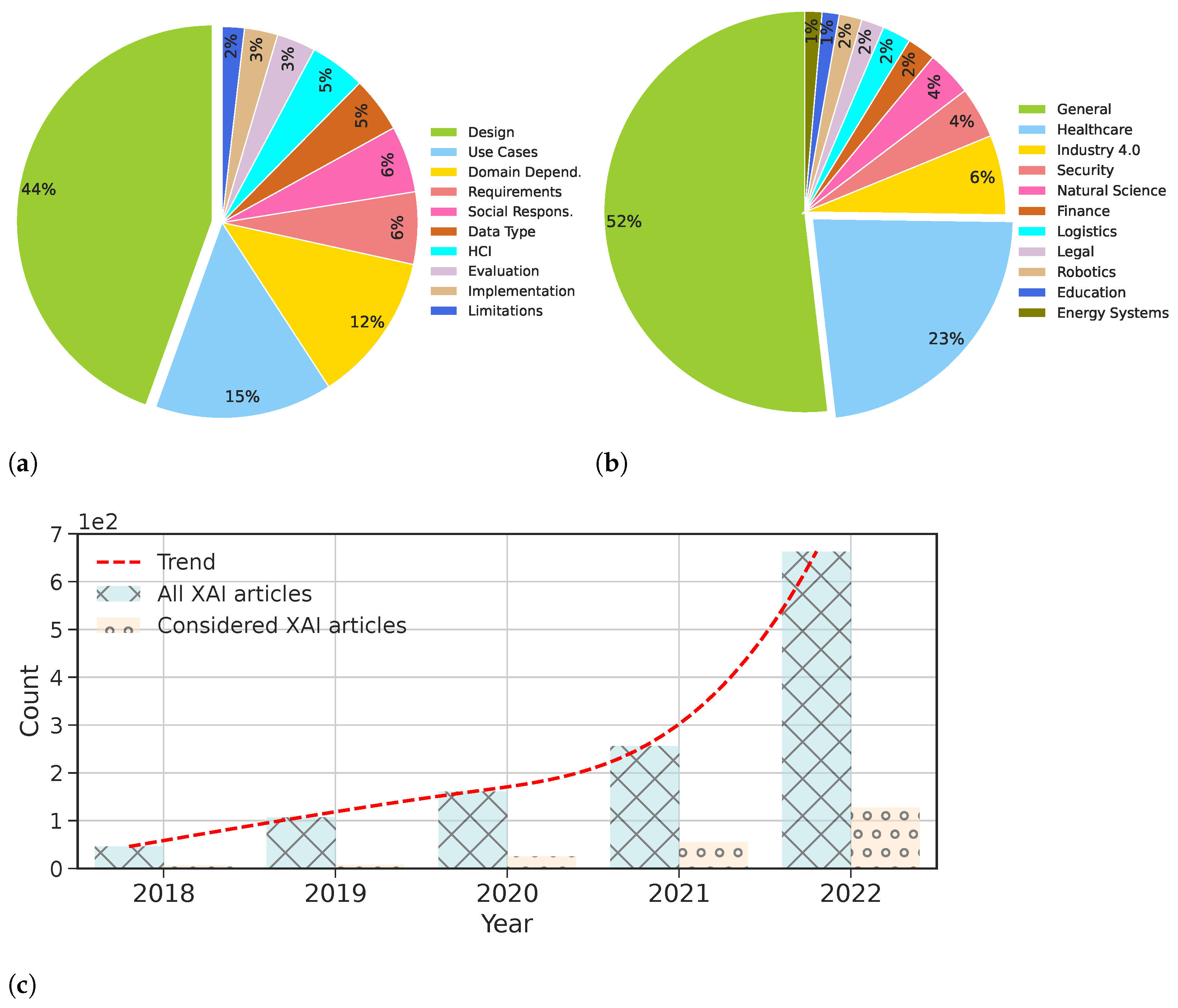
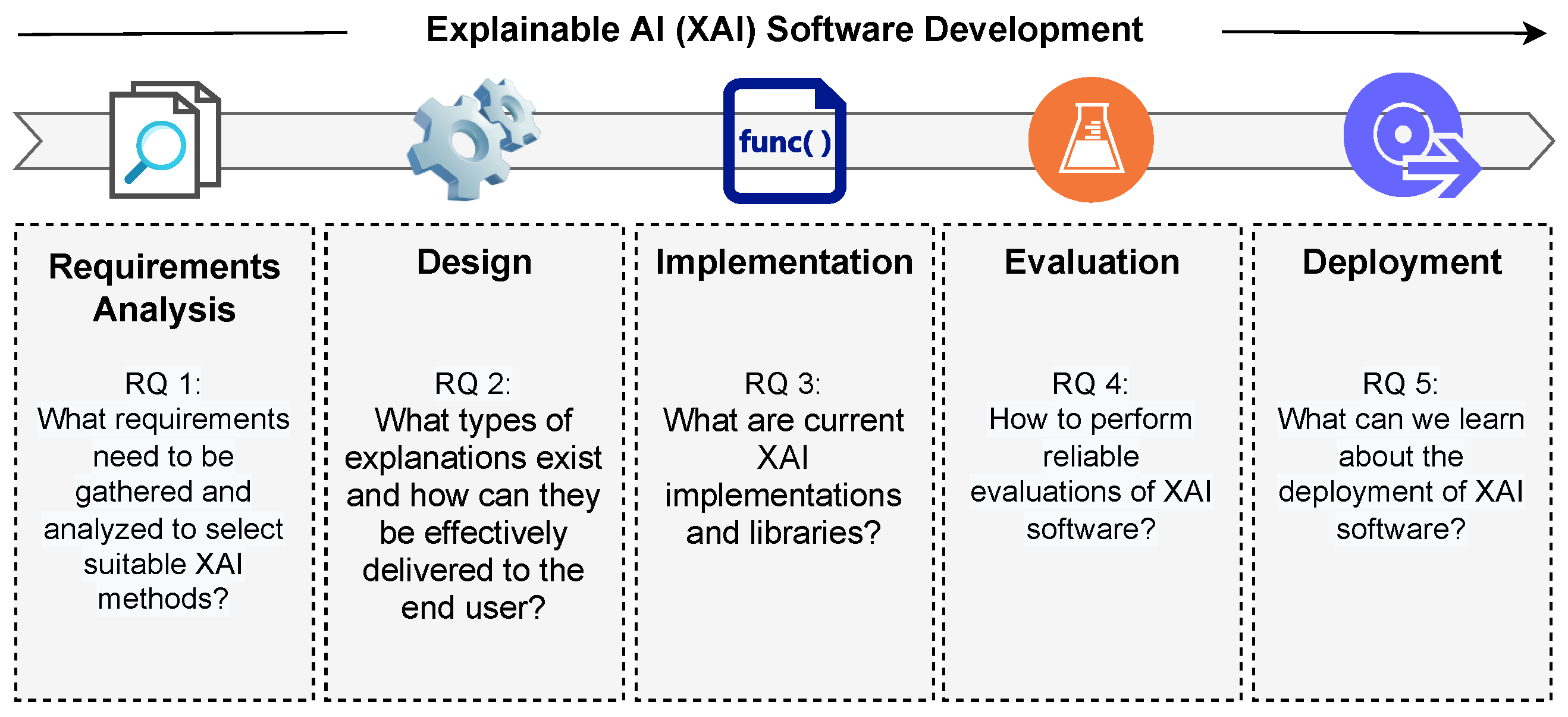
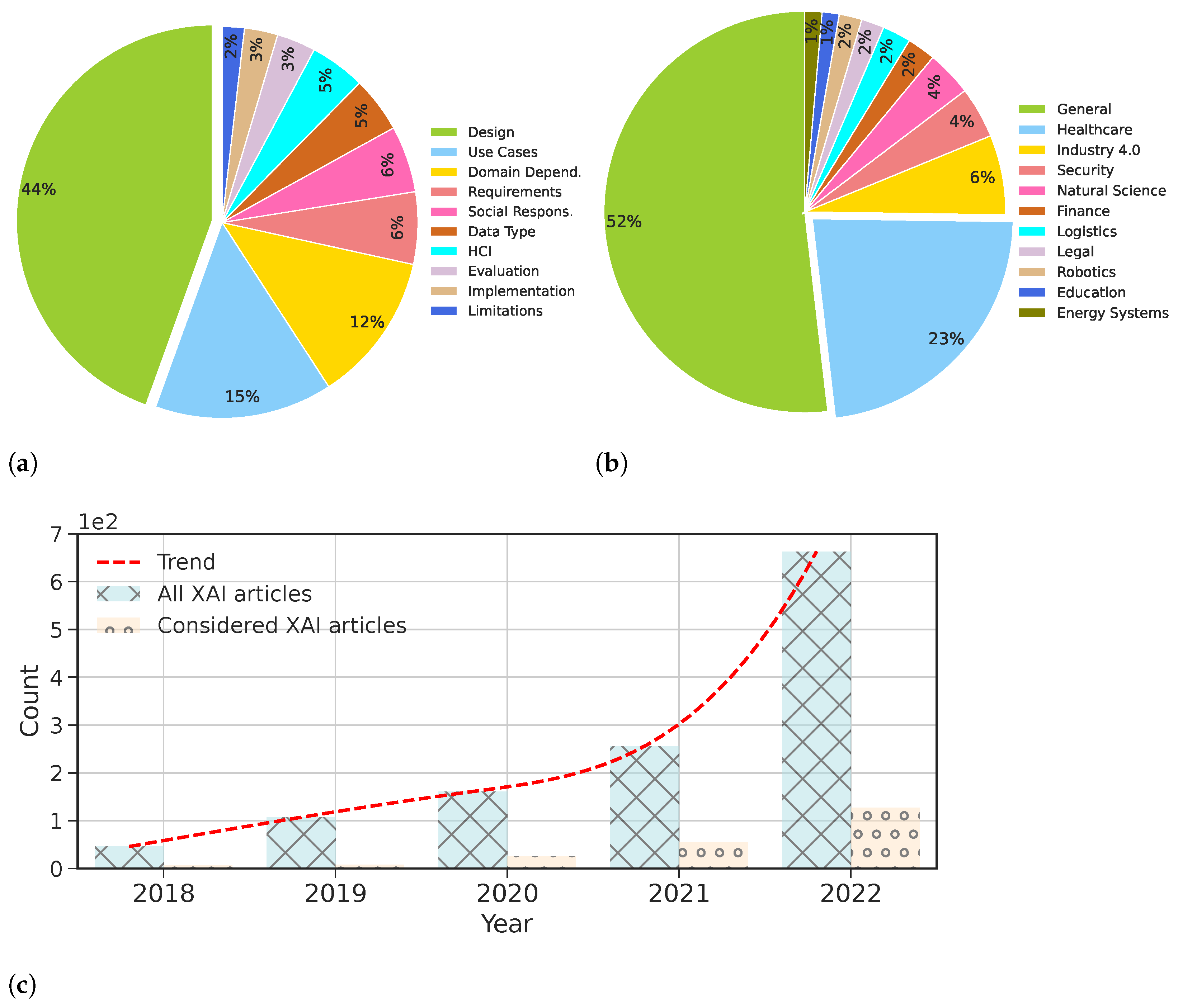
3. Research Methodology
4. Requirement Analysis
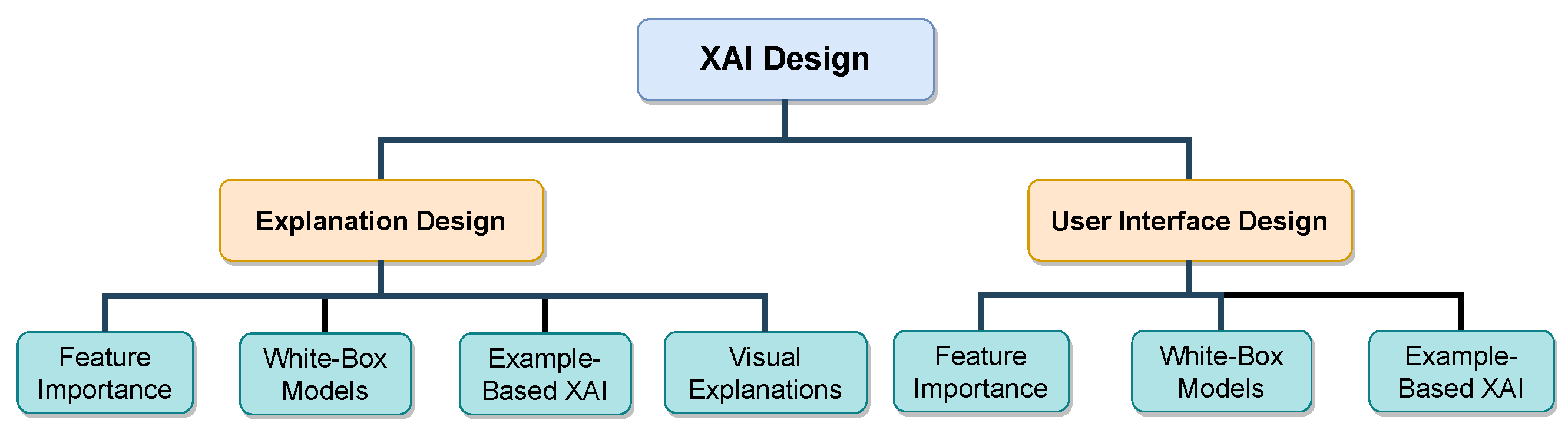
5. Design Phase
5.1. Explanation Design
5.1.1. Feature Importance
5.1.2. White-Box Models
5.1.3. Example-Based XAI
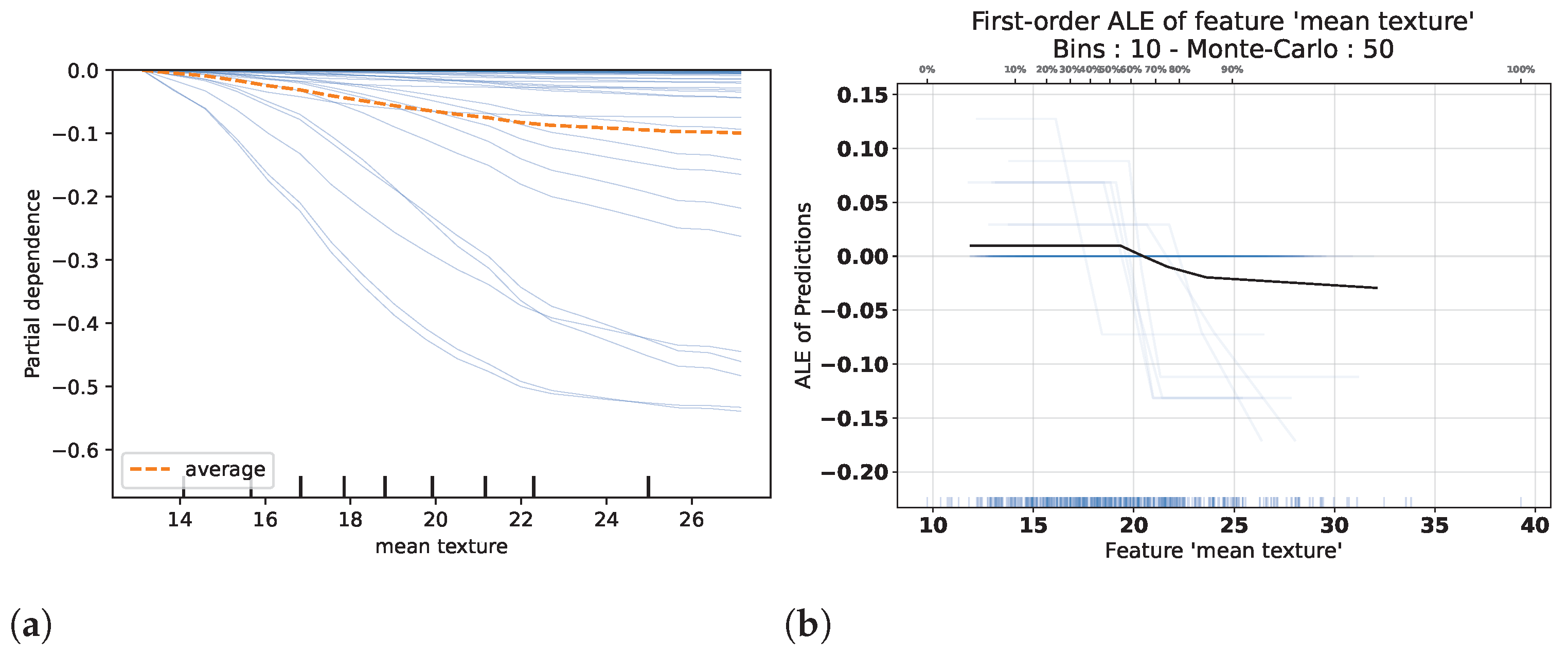
5.1.4. Visual XAI
5.2. Explainable User Interface Design
6. Implementation Phase
7. Evaluation Phase
7.1. Computational Evaluation
7.2. Human-Based Evaluation
8. Deployment Phase
9. Discussion and Research Opportunities
9.1. XAI Method Selection
9.2. Future Directions
10. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Smith, S.; Patwary, M.; Norick, B.; LeGresley, P.; Rajbhandari, S.; Casper, J.; Liu, Z.; Prabhumoye, S.; Zerveas, G.; Korthikanti, V.; et al. Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model. arXiv 2022, arXiv:2201.11990. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 12 June 2015. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. arXiv 2010, arXiv:2010.11929. [Google Scholar]
- Muhammad, K.; Ullah, A.; Lloret, J.; Del Ser, J.; de Albuquerque, V.H.C. Deep Learning for Safe Autonomous Driving: Current Challenges and Future Directions. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4316–4336. [Google Scholar] [CrossRef]
- Fountas, S.; Espejo-Garcia, B.; Kasimati, A.; Mylonas, N.; Darra, N. The Future of Digital Agriculture: Technologies and Opportunities. IT Prof. 2020, 22, 24–28. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Regulation (EU) 2016/679 of the European Parliament and of the Council; Council of the European Union: Luxembourg, 2016.
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Cabitza, F.; Campagner, A.; Ciucci, D. New frontiers in explainable AI: Understanding the GI to interpret the GO. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Dublin, Ireland, 25–28 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 27–47. [Google Scholar]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Angelov, P.P.; Soares, E.A.; Jiang, R.; Arnold, N.I.; Atkinson, P.M. Explainable artificial intelligence: An analytical review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2021, 11, e1424. [Google Scholar] [CrossRef]
- Belle, V.; Papantonis, I. Principles and practice of explainable machine learning. Front. Big Data 2021, 4, 39. [Google Scholar] [CrossRef]
- Langer, M.; Oster, D.; Speith, T.; Hermanns, H.; Kästner, L.; Schmidt, E.; Sesing, A.; Baum, K. What do we want from Explainable Artificial Intelligence (XAI)?–A stakeholder perspective on XAI and a conceptual model guiding interdisciplinary XAI research. Artif. Intell. 2021, 296, 103473. [Google Scholar] [CrossRef]
- McDermid, J.A.; Jia, Y.; Porter, Z.; Habli, I. Artificial intelligence explainability: The technical and ethical dimensions. Philos. Trans. R. Soc. A 2021, 379, 20200363. [Google Scholar] [CrossRef]
- Minh, D.; Wang, H.X.; Li, Y.F.; Nguyen, T.N. Explainable artificial intelligence: A comprehensive review. Artif. Intell. Rev. 2021, 55, 3503–3568. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Classification of explainable artificial intelligence methods through their output formats. Mach. Learn. Knowl. Extr. 2021, 3, 615–661. [Google Scholar] [CrossRef]
- Speith, T. A review of taxonomies of explainable artificial intelligence (XAI) methods. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 2239–2250. [Google Scholar]
- Saeed, W.; Omlin, C. Explainable AI (XAI): A Systematic Meta-Survey of Current Challenges and Future Opportunities. arXiv 2021, arXiv:2111.06420. [Google Scholar] [CrossRef]
- Chazette, L.; Klünder, J.; Balci, M.; Schneider, K. How Can We Develop Explainable Systems? Insights from a Literature Review and an Interview Study. In Proceedings of the International Conference on Software and System Processes and International Conference on Global Software Engineering, Pittsburgh, PA, USA, 20–22 May 2022; pp. 1–12. [Google Scholar]
- Mueller, S.T.; Hoffman, R.R.; Clancey, W.; Emrey, A.; Klein, G. Explanation in Human-AI Systems: A Literature Meta-Review, Synopsis of Key Ideas and Publications, and Bibliography for Explainable AI. arXiv 2019, arXiv:1902.01876. [Google Scholar]
- Li, X.; Xiong, H.; Li, X.; Wu, X.; Zhang, X.; Liu, J.; Bian, J.; Dou, D. Interpretable deep learning: Interpretation, interpretability, trustworthiness, and beyond. arXiv 2022, arXiv:2103.10689. [Google Scholar] [CrossRef]
- Dwivedi, R.; Dave, D.; Naik, H.; Singhal, S.; Rana, O.; Patel, P.; Qian, B.; Wen, Z.; Shah, T.; Morgan, G.; et al. Explainable AI (XAI): Core ideas, techniques, and solutions. Acm Comput. Surv. 2022. [Google Scholar] [CrossRef]
- Wulf, A.J.; Seizov, O. Artificial Intelligence and Transparency: A Blueprint for Improving the Regulation of AI Applications in the EU. Eur. Bus. Law Rev. 2020, 31, 4. [Google Scholar] [CrossRef]
- Merhi, M.I. An Assessment of the Barriers Impacting Responsible Artificial Intelligence. Inf. Syst. Front. 2022, 1–14. [Google Scholar] [CrossRef]
- Srinivasan, R.; Chander, A. Explanation perspectives from the cognitive sciences—A survey. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 4812–4818. [Google Scholar]
- Islam, M.R.; Ahmed, M.U.; Barua, S.; Begum, S. A systematic review of explainable artificial intelligence in terms of different application domains and tasks. Appl. Sci. 2022, 12, 1353. [Google Scholar] [CrossRef]
- Degas, A.; Islam, M.R.; Hurter, C.; Barua, S.; Rahman, H.; Poudel, M.; Ruscio, D.; Ahmed, M.U.; Begum, S.; Rahman, M.A.; et al. A survey on artificial intelligence (AI) and explainable AI in air traffic management: Current trends and development with future research trajectory. Appl. Sci. 2022, 12, 1295. [Google Scholar] [CrossRef]
- Ersöz, B.; Sağıroğlu, Ş.; Bülbül, H.İ. A Short Review on Explainable Artificial Intelligence in Renewable Energy and Resources. In Proceedings of the 2022 11th International Conference on Renewable Energy Research and Application (ICRERA), Istanbul, Turkey, 18–21 September 2022; IEEE: New York, NY, USA, 2022; pp. 247–252. [Google Scholar]
- Başağaoğlu, H.; Chakraborty, D.; Lago, C.D.; Gutierrez, L.; Şahinli, M.A.; Giacomoni, M.; Furl, C.; Mirchi, A.; Moriasi, D.; Şengör, S.S. A Review on Interpretable and Explainable Artificial Intelligence in Hydroclimatic Applications. Water 2022, 14, 1230. [Google Scholar] [CrossRef]
- Katarya, R.; Sharma, P.; Soni, N.; Rath, P. A Review of Interpretable Deep Learning for Neurological Disease Classification. In Proceedings of the 2022 8th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 25–26 March 2022; IEEE: New York, NY, USA, 2022; Volume 1, pp. 900–906. [Google Scholar]
- Fuhrman, J.D.; Gorre, N.; Hu, Q.; Li, H.; El Naqa, I.; Giger, M.L. A review of explainable and interpretable AI with applications in COVID-19 imaging. Med Phys. 2022, 49, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Anagnostou, M.; Karvounidou, O.; Katritzidaki, C.; Kechagia, C.; Melidou, K.; Mpeza, E.; Konstantinidis, I.; Kapantai, E.; Berberidis, C.; Magnisalis, I.; et al. Characteristics and challenges in the industries towards responsible AI: A systematic literature review. Ethics Inf. Technol. 2022, 24, 1–18. [Google Scholar] [CrossRef]
- Royce, W.W. Managing the development of large software systems: Concepts and techniques. In Proceedings of the 9th International Conference on Software Engineering, Monterey, CA, USA, 30 March–2 April 1987; pp. 328–338. [Google Scholar]
- Van Lent, M.; Fisher, W.; Mancuso, M. An explainable artificial intelligence system for small-unit tactical behavior. In Proceedings of the National Conference on Artificial Intelligence, Orlando, FL, USA, 18–22 July 1999; AAAI Press: Menlo Park, CA, USA; MIT Press: Cambridge, MA, USA, 2004; pp. 900–907. [Google Scholar]
- Goodman, B.; Flaxman, S. European Union regulations on algorithmic decision-making and a “right to explanation”. AI Mag. 2017, 38, 50–57. [Google Scholar] [CrossRef] [Green Version]
- Barocas, S.; Friedler, S.; Hardt, M.; Kroll, J.; Venka-Tasubramanian, S.; Wallach, H. In Proceedings of the FAT-ML Workshop Series on Fairness, Accountability, and Transparency in Machine Learning, Stockholm, Sweden, 13–15 July 2018; p. 7.
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef] [PubMed]
- Mohseni, S.; Zarei, N.; Ragan, E.D. A Multidisciplinary Survey and Framework for Design and Evaluation of Explainable AI Systems. arXiv 2018, arXiv:1811.11839. [Google Scholar] [CrossRef]
- Samek, W.; Montavon, G.; Lapuschkin, S.; Anders, C.J.; Muller, K.R. Explaining Deep Neural Networks and Beyond: A Review of Methods and Applications. Proc. IEEE 2021, 109, 247–278. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Notions of explainability and evaluation approaches for explainable artificial intelligence. Inf. Fusion 2021, 76, 89–106. [Google Scholar] [CrossRef]
- Okoli, C. A Guide to Conducting a Standalone Systematic Literature Review. Commun. Assoc. Inf. Syst. 2015, 37, 43. [Google Scholar] [CrossRef] [Green Version]
- Roscher, R.; Bohn, B.; Duarte, M.F.; Garcke, J. Explainable machine learning for scientific insights and discoveries. IEEE Access 2020, 8, 42200–42216. [Google Scholar] [CrossRef]
- Chazette, L.; Brunotte, W.; Speith, T. Exploring explainability: A definition, a model, and a knowledge catalogue. In Proceedings of the 2021 IEEE 29th International Requirements Engineering Conference (RE), Notre Dame, IN, USA, 20–24 September 2021; pp. 197–208. [Google Scholar]
- Vassiliades, A.; Bassiliades, N.; Patkos, T. Argumentation and explainable artificial intelligence: A survey. Knowl. Eng. Rev. 2021, 36, e5. [Google Scholar] [CrossRef]
- Israelsen, B.W.; Ahmed, N.R. “Dave...I Can Assure You...That It’s Going to Be All Right...” A Definition, Case for, and Survey of Algorithmic Assurances in Human-Autonomy Trust Relationships. ACM Comput. Surv. 2019, 51, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Qiu, H.; Mellia, M.; Li, Y.; Li, H.; Xu, K. Interpreting AI for Networking: Where We Are and Where We Are Going. IEEE Commun. Mag. 2022, 60, 25–31. [Google Scholar] [CrossRef]
- Omeiza, D.; Webb, H.; Jirotka, M.; Kunze, L. Explanations in autonomous driving: A survey. arXiv 2021, arXiv:2103.05154. [Google Scholar] [CrossRef]
- Sheh, R. Explainable Artificial Intelligence Requirements for Safe, Intelligent Robots. In Proceedings of the 2021 IEEE International Conference on Intelligence and Safety for Robotics (ISR), Tokoname, Japan, 4–6 March 2021; pp. 382–387. [Google Scholar]
- Adams, J.; Hagras, H. A type-2 fuzzy logic approach to explainable AI for regulatory compliance, fair customer outcomes and market stability in the global financial sector. In Proceedings of the 2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Gerlings, J.; Shollo, A.; Constantiou, I. Reviewing the Need for Explainable Artificial Intelligence (xAI). In Proceedings of the 54th Hawaii International Conference on System Sciences, Maui, HI, USA, 5 January 2021; p. 1284. [Google Scholar]
- Sokol, K.; Flach, P. Explainability fact sheets. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; Hildebrandt, M., Ed.; Association for Computing Machinery: New York, NY, USA; ACM Digital Library: New York, NY, USA, 2020; pp. 56–67. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Qin, Y.; Li, Q. Trusted Artificial Intelligence: Technique Requirements and Best Practices. In Proceedings of the 2021 International Conference on Cyberworlds (CW), Caen, France, 28–30 September 2021; pp. 303–306. [Google Scholar]
- Cheng, L.; Varshney, K.R.; Liu, H. Socially Responsible AI Algorithms: Issues, Purposes, and Challenges. J. Artif. Intell. Res. 2021, 71, 1137–1181. [Google Scholar] [CrossRef]
- Trocin, C.; Mikalef, P.; Papamitsiou, Z.; Conboy, K. Responsible AI for Digital Health: A Synthesis and a Research Agenda. Inf. Syst. Front. 2021, 1–19. [Google Scholar] [CrossRef]
- Ntoutsi, E.; Fafalios, P.; Gadiraju, U.; Iosifidis, V.; Nejdl, W.; Vidal, M.E.; Ruggieri, S.; Turini, F.; Papadopoulos, S.; Krasanakis, E.; et al. Bias in data–driven artificial intelligence systems—An introductory survey. WIREs Data Min. Knowl. Discov. 2020, 10, e1356. [Google Scholar] [CrossRef] [Green Version]
- Yepmo, V.; Smits, G.; Pivert, O. Anomaly explanation: A review. Data Knowl. Eng. 2022, 137, 101946. [Google Scholar] [CrossRef]
- Sahakyan, M.; Aung, Z.; Rahwan, T. Explainable Artificial Intelligence for Tabular Data: A Survey. IEEE Access 2021, 9, 135392–135422. [Google Scholar] [CrossRef]
- Zucco, C.; Liang, H.; Di Fatta, G.; Cannataro, M. Explainable Sentiment Analysis with Applications in Medicine. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine, Madrid, Spain, 3–6 December 2018; Zheng, H., Ed.; IEEE: Piscataway, NJ, USA, 2018; pp. 1740–1747. [Google Scholar] [CrossRef]
- Nazar, M.; Alam, M.M.; Yafi, E.; Mazliham, M.S. A Systematic Review of Human-Computer Interaction and Explainable Artificial Intelligence in Healthcare with Artificial Intelligence Techniques. IEEE Access 2021, 9, 153316–153348. [Google Scholar] [CrossRef]
- Chromik, M.; Butz, A. Human-XAI Interaction: A Review and Design Principles for Explanation User Interfaces. In Human-Computer Interaction—INTERACT 2021; Ardito, C., Lanzilotti, R., Malizia, A., Petrie, H., Piccinno, A., Desolda, G., Inkpen, K., Eds.; Information Systems and Applications, incl. Internet/Web, and HCI; Springer: Cham, Switzerland, 2021; pp. 619–640. [Google Scholar]
- Dazeley, R.; Vamplew, P.; Foale, C.; Young, C.; Aryal, S.; Cruz, F. Levels of explainable artificial intelligence for human-aligned conversational explanations. Artif. Intell. 2021, 299, 103525. [Google Scholar] [CrossRef]
- Naiseh, M.; Jiang, N.; Ma, J.; Ali, R. Explainable Recommendations in Intelligent Systems: Delivery Methods, Modalities and Risks. In Research Challenges in Information Science; Dalpiaz, F., Zdravkovic, J., Loucopoulos, P., Eds.; Lecture Notes in Business Information Processing; Springer: Cham, Switzerland, 2020; Volume 385, pp. 212–228. [Google Scholar] [CrossRef]
- Wickramasinghe, C.S.; Marino, D.L.; Grandio, J.; Manic, M. Trustworthy AI Development Guidelines for Human System Interaction. In Proceedings of the 2020 13th International Conference on Human System Interaction (HSI), Tokyo, Japan, 6–8 June 2020; Muramatsu, S., Ed.; IEEE: Piscataway, NJ, USA, 2020; pp. 130–136. [Google Scholar] [CrossRef]
- Dybowski, R. Interpretable machine learning as a tool for scientific discovery in chemistry. New J. Chem. 2020, 44, 20914–20920. [Google Scholar] [CrossRef]
- Turvill, D.; Barnby, L.; Yuan, B.; Zahir, A. A Survey of Interpretability of Machine Learning in Accelerator-based High Energy Physics. In Proceedings of the 2020 IEEE/ACM International Conference on Big Data Computing, Applications and Technologies (BDCAT), Leicester, UK, 7–10 December 2020; pp. 77–86. [Google Scholar]
- Górski, Ł.; Ramakrishna, S. Explainable artificial intelligence, lawyer’s perspective. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Law, Sao Paulo, Brazil, 21–25 June 2021; Maranhão, J., Wyner, A.Z., Eds.; ACM: New York, NY, USA, 2021; pp. 60–68. [Google Scholar] [CrossRef]
- Atkinson, K.; Bench-Capon, T.; Bollegala, D. Explanation in AI and law: Past, present and future. Artif. Intell. 2020, 289, 103387. [Google Scholar] [CrossRef]
- Anjomshoae, S.; Omeiza, D.; Jiang, L. Context-based image explanations for deep neural networks. Image Vis. Comput. 2021, 116, 104310. [Google Scholar] [CrossRef]
- Puiutta, E.; Veith, E. Explainable reinforcement learning: A survey. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Dublin, Ireland, 25–28 August 2020; pp. 77–95. [Google Scholar]
- Guo, W. Explainable artificial intelligence for 6G: Improving trust between human and machine. IEEE Commun. Mag. 2020, 58, 39–45. [Google Scholar] [CrossRef]
- Alamri, R.; Alharbi, B. Explainable student performance prediction models: A systematic review. IEEE Access 2021, 9, 33132–33143. [Google Scholar] [CrossRef]
- Fiok, K.; Farahani, F.V.; Karwowski, W.; Ahram, T. Explainable artificial intelligence for education and training. J. Def. Model. Simulation Appl. Methodol. Technol. 2021, 19, 154851292110286. [Google Scholar] [CrossRef]
- Webster, J.; Watson, R.T. Analyzing the Past to Prepare for the Future: Writing a Literature Review. MIS Q. 2002, 26, xiii–xxiii. [Google Scholar]
- Balsamo, S.; Di Marco, A.; Inverardi, P.; Simeoni, M. Model-based performance prediction in software development: A survey. IEEE Trans. Softw. Eng. 2004, 30, 295–310. [Google Scholar] [CrossRef]
- Abrahamsson, P.; Salo, O.; Ronkainen, J.; Warsta, J. Agile Software Development Methods: Review and Analysis. arXiv 2017, arXiv:1709.08439. [Google Scholar] [CrossRef]
- Liao, Q.V.; Pribić, M.; Han, J.; Miller, S.; Sow, D. Question-Driven Design Process for Explainable AI User Experiences. arXiv 2021, arXiv:2104.03483. [Google Scholar]
- Köhl, M.A.; Baum, K.; Langer, M.; Oster, D.; Speith, T.; Bohlender, D. Explainability as a non-functional requirement. In Proceedings of the 2019 IEEE 27th International Requirements Engineering Conference (RE), Jeju, Republic of Korea, 23–27 September 2019; pp. 363–368. [Google Scholar]
- Hall, M.; Harborne, D.; Tomsett, R.; Galetic, V.; Quintana-Amate, S.; Nottle, A.; Preece, A. A systematic method to understand requirements for explainable AI (XAI) systems. In Proceedings of the IJCAI Workshop on eXplainable Artificial Intelligence (XAI 2019), Macau, China, 11 August 2019; Volume 11. [Google Scholar]
- e-Habiba, U.; Bogner, J.; Wagner, S. Can Requirements Engineering Support Explainable Artificial Intelligence? Towards a User-Centric Approach for Explainability Requirements. arXiv 2022, arXiv:2206.01507. [Google Scholar]
- Liao, Q.V.; Gruen, D.; Miller, S. Questioning the AI: Informing Design Practices for Explainable AI User Experiences. In CHI’20; Bernhaupt, R., Mueller, F.F., Verweij, D., Andres, J., McGrenere, J., Cockburn, A., Avellino, I., Goguey, A., Bjørn, P., Zhao, S., et al., Eds.; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–15. [Google Scholar] [CrossRef]
- Sheh, R.; Monteath, I. Defining Explainable AI for Requirements Analysis. KI-Künstliche Intell. 2018, 32, 261–266. [Google Scholar] [CrossRef]
- Hoffman, R.R.; Mueller, S.T.; Klein, G.; Litman, J. Metrics for explainable AI: Challenges and prospects. arXiv 2018, arXiv:1812.04608. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. arXiv 2013, arXiv:1311.2901. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; Krishnapuram, B., Ed.; ACM Digital Library; ACM: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, b.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Pedreschi, D.; Turini, F.; Giannotti, F. Local Rule-Based Explanations of Black Box Decision Systems. arXiv 2018, arXiv:1805.10820. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. Proc. AAAI Conf. Artif. Intell. 2018, 32, 1527–1535. [Google Scholar] [CrossRef]
- Fisher, A.; Rudin, C.; Dominici, F. All Models are Wrong, but Many are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously. J. Mach. Learn. Res. 2019, 20, 1–81. [Google Scholar]
- Casalicchio, G.; Molnar, C.; Bischl, B. Visualizing the Feature Importance for Black Box Models. In Machine Learning and Knowledge Discovery in Databases; Berlingerio, M., Bonchi, F., Gärtner, T., Hurley, N., Ifrim, G., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; pp. 655–670. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. arXiv 2017, arXiv:1703.01365. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [Green Version]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features through Propagating Activation Differences. arXiv 2017, arXiv:1704.02685. [Google Scholar]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). arXiv 2018, arXiv:1711.11279. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing higher-layer features of a deep network. Univ. Montr. 2009, 1341, 1. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 2921–2929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. arXiv 2016, arXiv:1610.02391. [Google Scholar] [CrossRef]
- Abnar, S.; Zuidema, W. Quantifying Attention Flow in Transformers. arXiv 2020, arXiv:2005.00928. [Google Scholar]
- Chefer, H.; Gur, S.; Wolf, L. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 782–791. [Google Scholar]
- Zilke, J.R.; Loza Mencía, E.; Janssen, F. DeepRED—Rule Extraction from Deep Neural Networks. In Discovery Science; Calders, T., Ceci, M., Malerba, D., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; pp. 457–473. [Google Scholar]
- Craven, M.; Shavlik, J. Extracting Tree-Structured Representations of Trained Networks. Adv. Neural Inf. Process. Syst. 1995, 8, 24–30. [Google Scholar]
- Liu, X.; Wang, X.; Matwin, S. Improving the Interpretability of Deep Neural Networks with Knowledge Distillation. In Proceedings of the 18th IEEE International Conference on Data Mining Workshops, Orleans, LA, USA, 18–21 November 2018; Tong, H., Ed.; IEEE: Piscataway, NJ, USA, 2018; pp. 905–912. [Google Scholar] [CrossRef] [Green Version]
- Seo, S.; Huang, J.; Yang, H.; Liu, Y. Interpretable Convolutional Neural Networks with Dual Local and Global Attention for Review Rating Prediction. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 28 August 2017; Cremonesi, P., Ed.; ACM Digital Library. ACM: New York, NY, USA, 2017; pp. 297–305. [Google Scholar] [CrossRef]
- Choi, E.; Bahadori, M.T.; Sun, J.; Kulas, J.; Schuetz, A.; Stewart, W. RETAIN: An Interpretable Predictive Model for Healthcare using Reverse Time Attention Mechanism. arXiv 2016, arXiv:1608.05745. [Google Scholar]
- Bien, J.; Tibshirani, R. Prototype selection for interpretable classification. Ann. Appl. Stat. 2011, 5, 2403–2424. [Google Scholar] [CrossRef] [Green Version]
- Kim, B.; Khanna, R.; Koyejo, O.O. Examples are not enough, learn to criticize! Criticism for Interpretability. Adv. Neural Inf. Process. Syst. 2016, 29, 2280–2288. [Google Scholar]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual Explanations Without Opening the Black Box: Automated Decisions and the GDPR. Ssrn Electron. J. 2017, 31, 2018. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Goldstein, A.; Kapelner, A.; Bleich, J.; Pitkin, E. Peeking Inside the Black Box: Visualizing Statistical Learning with Plots of Individual Conditional Expectation. J. Comput. Graph. Stat. 2015, 24, 44–65. [Google Scholar] [CrossRef] [Green Version]
- Apley, D.W.; Zhu, J. Visualizing the effects of predictor variables in black box supervised learning models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Shapley, L.S. A Value for n-Person Games. In Contributions to the Theory of Games; Kuhn, H.W., Tucker, A.W., Eds.; Annals of Mathematics Studies; Princeton Univ. Press: Princeton, NJ, USA, 1953; pp. 307–318. [Google Scholar] [CrossRef]
- Rakitianskaia, A.; Engelbrecht, A. Measuring saturation in neural networks. In Proceedings of the 2015 IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 7–10 December 2015; pp. 1423–1430. [Google Scholar]
- Ghorbani, A.; Wexler, J.; Zou, J.Y.; Kim, B. Towards Automatic Concept-based Explanations. Adv. Neural Inf. Process. Syst. 2019, 32, 9273–9282. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceedings of the 2011 International Conference on Computer Vision (ICCV 2011), Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2018–2025. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2018, arXiv:1409.0473. [Google Scholar]
- Vashishth, S.; Upadhyay, S.; Tomar, G.S.; Faruqui, M. Attention Interpretability Across NLP Tasks. arXiv 2019, arXiv:1909.11218. [Google Scholar]
- Pruthi, D.; Gupta, M.; Dhingra, B.; Neubig, G.; Lipton, Z.C. Learning to Deceive with Attention-Based Explanations. arXiv 2019, arXiv:1909.07913. [Google Scholar]
- Jain, S.; Wallace, B.C. Attention is not Explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 3543–3556. [Google Scholar] [CrossRef]
- Zhang, Q.; Wu, Y.N.; Zhu, S.C. Interpretable convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8827–8836. [Google Scholar]
- Guillaume, S. Designing fuzzy inference systems from data: An interpretability-oriented review. IEEE Trans. Fuzzy Syst. 2001, 9, 426–443. [Google Scholar] [CrossRef] [Green Version]
- Hüllermeier, E. Does machine learning need fuzzy logic? Fuzzy Sets Syst. 2015, 281, 292–299. [Google Scholar] [CrossRef]
- Mencar, C.; Alonso, J.M. Paving the Way to Explainable Artificial Intelligence with Fuzzy Modeling. In Fuzzy Logic and Applications; Fullér, R., Giove, S., Masulli, F., Eds.; Springer: Cham, Switzerland, 2019; pp. 215–227. [Google Scholar]
- Bouchon-Meunier, B.; Laurent, A.; Lesot, M.J. XAI: A Natural Application Domain for Fuzzy Set Theory. In Women in Computational Intelligence: Key Advances and Perspectives on Emerging Topics; Smith, A.E., Ed.; Springer: Cham, Switzerland, 2022; pp. 23–49. [Google Scholar] [CrossRef]
- Trivino, G.; Sugeno, M. Towards linguistic descriptions of phenomena. Int. J. Approx. Reason. 2013, 54, 22–34. [Google Scholar] [CrossRef]
- Rizzo, L.; Longo, L. An empirical evaluation of the inferential capacity of defeasible argumentation, non-monotonic fuzzy reasoning and expert systems. Expert Syst. Appl. 2020, 147, 113220. [Google Scholar] [CrossRef]
- Rizzo, L.; Longo, L. A qualitative investigation of the degree of explainability of defeasible argumentation and non-monotonic fuzzy reasoning. In Proceedings of the 26th AIAI Irish Conference on Artificial Intelligence and Cognitive Science, Dublin, Ireland, 6–7 December 2018; pp. 138–149. [Google Scholar]
- Rizzo, L.; Longo, L. Inferential Models of Mental Workload with Defeasible Argumentation and Non-monotonic Fuzzy Reasoning: A Comparative Study. In Proceedings of the 2nd Workshop on Advances in Argumentation in Artificial Intelligence, Trento, Italy, 20–23 November 2018; pp. 11–26. [Google Scholar]
- Ming, Y.; Xu, P.; Cheng, F.; Qu, H.; Ren, L. ProtoSteer: Steering Deep Sequence Model with Prototypes. IEEE Trans. Vis. Comput. Graph. 2020, 26, 238–248. [Google Scholar] [CrossRef]
- Gurumoorthy, K.S.; Dhurandhar, A.; Cecchi, G.; Aggarwal, C. Efficient Data Representation by Selecting Prototypes with Importance Weights. In Proceedings of the 19th IEEE International Conference on Data Mining, Beijing, China, 8–11 November 2019; Wang, J., Shim, K., Wu, X., Eds.; IEEE: Piscataway, NJ, USA, 2019; pp. 260–269. [Google Scholar] [CrossRef] [Green Version]
- Li, O.; Liu, H.; Chen, C.; Rudin, C. Deep Learning for Case-Based Reasoning Through Prototypes: A Neural Network That Explains Its Predictions. Proc. AAAI Conf. Artif. Intell. 2018, 32, 3530–3537. [Google Scholar] [CrossRef]
- van Looveren, A.; Klaise, J. Interpretable Counterfactual Explanations Guided by Prototypes. In Machine Learning and Knowledge Discovery in Databases. Research Track; Oliver, N., Pérez-Cruz, F., Kramer, S., Read, J., Lozano, J.A., Eds.; Lecture Notes in Artificial Intelligence; Springer: Cham, Switzerland, 2021; pp. 650–665. [Google Scholar]
- Kuhl, U.; Artelt, A.; Hammer, B. Keep Your Friends Close and Your Counterfactuals Closer: Improved Learning From Closest Rather Than Plausible Counterfactual Explanations in an Abstract Setting. arXiv 2022, arXiv:2205.05515. [Google Scholar]
- Madsen, A.; Reddy, S.; Chandar, S. Post-hoc Interpretability for Neural NLP: A Survey. arXiv 2021, arXiv:2108.04840. [Google Scholar] [CrossRef]
- Gunning, D.; Aha, D. DARPA’s Explainable Artificial Intelligence (XAI) Program. AI Mag. 2019, 40, 44–58. [Google Scholar] [CrossRef]
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.; Wattenberg, M. SmoothGrad: Removing noise by adding noise. arXiv 2017, arXiv:1706.03825. [Google Scholar]
- Vig, J. A Multiscale Visualization of Attention in the Transformer Model; Association for Computational Linguistics: Florence, Italy, 2019. [Google Scholar]
- Wang, N.; Wang, H.; Jia, Y.; Yin, Y. Explainable Recommendation via Multi-Task Learning in Opinionated Text Data. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; Collins-Thompson, K., Ed.; ACM Conferences. ACM: New York, NY, USA, 2018; pp. 165–174. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Rohrbach, A.; Darrell, T.; Canny, J.; Akata, Z. Textual Explanations for Self-Driving Vehicles. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 4–14 September 2018. [Google Scholar]
- Li, X.H.; Cao, C.C.; Shi, Y.; Bai, W.; Gao, H.; Qiu, L.; Wang, C.; Gao, Y.; Zhang, S.; Xue, X.; et al. A survey of data-driven and knowledge-aware explainable ai. IEEE Trans. Knowl. Data Eng. 2020, 34, 29–49. [Google Scholar] [CrossRef]
- Parr, T.; Grover, P. How to Visualize Decision Trees. 2020. Available online: https://explained.ai/decision-tree-viz/, (accessed on 1 December 2022).
- Ming, Y.; Qu, H.; Bertini, E. RuleMatrix: Visualizing and Understanding Classifiers with Rules. J. Mag. 2018, 25, 342–352. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Zhou, S.; He, Y. Growing decision trees on support-less association rules. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 265–269. [Google Scholar]
- Keane, M.T.; Smyth, B. Good Counterfactuals and Where to Find Them: A Case-Based Technique for Generating Counterfactuals for Explainable AI (XAI). In Case-Based Reasoning Research and Development; Watson, I., Weber, R., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; pp. 163–178. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Arya, V.; Bellamy, R.K.E.; Chen, P.-Y.; Dhurandhar, A.; Hind, M.; Hoffman, S.C.; Houde, S.; Liao, Q.V.; Luss, R.; Mojsilović, A.; et al. One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques. arXiv 2019, arXiv:1909.03012. [Google Scholar]
- Klaise, J.; van Looveren, A.; Vacanti, G.; Coca, A. Alibi: Algorithms for Monitoring and Explaining Machine Learning Models. 2019. Available online: https://github.com/SeldonIO/alibi (accessed on 1 December 2022).
- Kokhlikyan, N.; Miglani, V.; Martin, M.; Wang, E.; Alsallakh, B.; Reynolds, J.; Melnikov, A.; Kliushkina, N.; Araya, C.; Yan, S.; et al. Captum: A unified and generic model interpretability library for PyTorch. arXiv 2020, arXiv:2009.07896. [Google Scholar]
- Biecek, P. DALEX: Explainers for Complex Predictive Models in R. J. Mach. Learn. Res. 2018, 19, 1–5. [Google Scholar]
- Mothilal, R.K.; Sharma, A.; Tan, C. Explaining Machine Learning Classifiers through Diverse Counterfactual Explanations. In Proceedings of 2020 Conference on Fairness, Accountability, and Transparency; 2020; pp. 607–617. Available online: https://github.com/interpretml/DiCE (accessed on 1 December 2022).
- Nori, H.; Jenkins, S.; Koch, P.; Caruana, R. InterpretML: A Unified Framework for Machine Learning Interpretability. arXiv 2019, arXiv:1909.09223. [Google Scholar]
- PAIR, G. PAIR Saliency: Framework-Agnostic Implementation for State-of-the-Art Saliency Methods. 2022. Available online: https://github.com/PAIR-code/saliency (accessed on 1 December 2022).
- Oracle. Skater: Unified Framework for Model Interpretation. 2022. Available online: https://github.com/oracle/Skater (accessed on 1 December 2022).
- Hedström, A.; Weber, L.; Bareeva, D.; Motzkus, F.; Samek, W.; Lapuschkin, S.; Höhne, M.M.C. Quantus: An explainable AI toolkit for responsible evaluation of neural network explanations. arXiv 2022, arXiv:2202.06861. [Google Scholar]
- Dijk, O. Explainerdashboard: Quickly Deploy a Dashboard Web App for Interpretability of Machine Learning Model. 2022. Available online: https://github.com/oegedijk/explainerdashboard (accessed on 1 December 2022).
- Alammar, J. Ecco: An Open Source Library for the Explainability of Transformer Language Models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations. Association for Computational Linguistics, Online, 1–6 August 2021. [Google Scholar]
- Hu, B.; Tunison, P.; Vasu, B.; Menon, N.; Collins, R.; Hoogs, A. XAITK: The explainable AI toolkit. Appl. AI Lett. 2021, 2, e40. [Google Scholar] [CrossRef]
- ISO/IEC TR 24028:2020; Overview of Trustworthiness in Artificial Intelligence. International Organization for Standardization: Vernier, Switzerland, 2020.
- Lopes, P.; Silva, E.; Braga, C.; Oliveira, T.; Rosado, L. XAI Systems Evaluation: A Review of Human and Computer-Centred Methods. Appl. Sci. 2022, 12, 9423. [Google Scholar] [CrossRef]
- Wanner, J.; Herm, L.V.; Heinrich, K.; Janiesch, C. A social evaluation of the perceived goodness of explainability in machine learning. J. Bus. Anal. 2021, 5, 29–50. [Google Scholar] [CrossRef]
- Robnik-Šikonja, M.; Bohanec, M. Perturbation-Based Explanations of Prediction Models. In Human and Machine Learning; Springer: Cham, Switzerland, 2018; pp. 159–175. [Google Scholar] [CrossRef]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080. [Google Scholar] [CrossRef] [Green Version]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the 2018 IEEE 5th International Conference on data science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 80–89. [Google Scholar]
- Löfström, H.; Hammar, K.; Johansson, U. A Meta Survey of Quality Evaluation Criteria in Explanation Methods. In Proceedings of the International Conference on Advanced Information Systems Engineering, Leuven, Belgium, 28 June–2 July 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 55–63. [Google Scholar]
- Pavlidis, M.; Mouratidis, H.; Islam, S.; Kearney, P. Dealing with trust and control: A meta-model for trustworthy information systems development. In Proceedings of the 2012 Sixth International Conference on Research Challenges in Information Science (RCIS), Valencia, Spain, 16–18 May 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–9. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Yeh, C.K.; Hsieh, C.Y.; Suggala, A.; Inouye, D.I.; Ravikumar, P.K. On the (in) fidelity and sensitivity of explanations. Adv. Neural Inf. Process. Syst. 2019, 32, 10967–10978. [Google Scholar]
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Bhatt, U.; Xiang, A.; Sharma, S.; Weller, A.; Taly, A.; Jia, Y.; Ghosh, J.; Puri, R.; Moura, J.M.F.; Eckersley, P. Explainable machine learning in deployment. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; Hildebrandt, M., Ed.; ACM Digital Library. Association for Computing Machinery: New York, NY, USA, 2020; pp. 648–657. [Google Scholar] [CrossRef]
- Nguyen, A.p.; Martínez, M.R. On quantitative aspects of model interpretability, 2020. arXiv 2020, arXiv:2007.07584. [Google Scholar]
- Rong, Y.; Leemann, T.; Borisov, V.; Kasneci, G.; Kasneci, E. A Consistent and Efficient Evaluation Strategy for Attribution Methods, 2022. arXiv 2022, arXiv:2202.00449. [Google Scholar]
- Silva, W.; Fernandes, K.; Cardoso, M.J.; Cardoso, J.S. Towards complementary explanations using deep neural networks. In Understanding and Interpreting Machine Learning in Medical Image Computing Applications; Springer: Berlin/Heidelberg, Germany, 2018; pp. 133–140. [Google Scholar]
- Chalasani, P.; Chen, J.; Chowdhury, A.R.; Jha, S.; Wu, X. Concise Explanations of Neural Networks using Adversarial Training, 2018. arXiv 2018, arXiv:1810.06583. [Google Scholar]
- Li, L.; Zhang, Y.; Chen, L. Generate Neural Template Explanations for Recommendation. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; d’Aquin, M., Dietze, S., Eds.; ACM Digital Library. Association for Computing Machinery: New York, NY, USA, 2020; pp. 755–764. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Keane, M.T.; Kenny, E.M.; Delaney, E.; Smyth, B. If Only We Had Better Counterfactual Explanations: Five Key Deficits to Rectify in the Evaluation of Counterfactual XAI Techniques. arXiv 2021, arXiv:2103.01035. [Google Scholar] [CrossRef]
- Adebayo, J.; Gilmer, J.; Muelly, M.; Goodfellow, I.; Hardt, M.; Kim, B. Sanity Checks for Saliency Maps. arXiv 2018, arXiv:1810.03292. [Google Scholar]
- Nyre-Yu, M.; Morris, E.; Moss, B.C.; Smutz, C.; Smith, M. Explainable AI in Cybersecurity Operations: Lessons Learned from xAI Tool Deployment. In Proceedings of the Usable Security and Privacy (USEC) Symposium, San Diego, CA, USA, 28 April 2022. [Google Scholar]
- Mitchell, M.; Wu, S.; Zaldivar, A.; Barnes, P.; Vasserman, L.; Hutchinson, B.; Spitzer, E.; Raji, I.D.; Gebru, T. Model cards for model reporting. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 2–31 January 2019; pp. 220–229. [Google Scholar]
- Pushkarna, M.; Zaldivar, A.; Kjartansson, O. Data Cards: Purposeful and Transparent Dataset Documentation for Responsible AI. arXiv 2022, arXiv:2204.01075. [Google Scholar]
- Bender, E.M.; Friedman, B. Data Statements for Natural Language Processing: Toward Mitigating System Bias and Enabling Better Science. Trans. Assoc. Comput. Linguist. 2018, 6, 587–604. [Google Scholar] [CrossRef] [Green Version]
- Gebru, T.; Morgenstern, J.; Vecchione, B.; Vaughan, J.W.; Wallach, H.; Iii, H.D.; Crawford, K. Datasheets for datasets. Commun. ACM 2021, 64, 86–92. [Google Scholar] [CrossRef]
- Holland, S.; Hosny, A.; Newman, S.; Joseph, J.; Chmielinski, K. The dataset nutrition label. Data Prot. Privacy 2020, 12, 1. [Google Scholar]
- Alsallakh, B.; Cheema, A.; Procope, C.; Adkins, D.; McReynolds, E.; Wang, E.; Pehl, G.; Green, N.; Zvyagina, P. System-Level Transparency of Machine Learning; Technical Report; Meta AI: New York, NY, USA, 2022. [Google Scholar]
- Arnold, M.; Bellamy, R.K.; Hind, M.; Houde, S.; Mehta, S.; Mojsilović, A.; Nair, R.; Ramamurthy, K.N.; Olteanu, A.; Piorkowski, D.; et al. FactSheets: Increasing trust in AI services through supplier’s declarations of conformity. IBM J. Res. Dev. 2019, 63, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Karunagaran, S. Making It Easier to Compare the Tools for Explainable AI. 2022. Available online: https://partnershiponai.org/making-it-easier-to-compare-the-tools-for-explainable-ai/ (accessed on 1 December 2022).
- Belaid, M.K.; Hüllermeier, E.; Rabus, M.; Krestel, R. Do We Need Another Explainable AI Method? Toward Unifying Post-hoc XAI Evaluation Methods into an Interactive and Multi-dimensional Benchmark. arXiv 2022, arXiv:2207.14160. [Google Scholar]
- Meskauskas, Z.; Kazanavicius, E. About the New Methodology and XAI-Based Software Toolkit for Risk Assessment. Sustainability 2022, 14, 5496. [Google Scholar] [CrossRef]
- Marín Díaz, G.; Galán, J.J.; Carrasco, R.A. XAI for Churn Prediction in B2B Models: A Use Case in an Enterprise Software Company. Mathematics 2022, 10, 3896. [Google Scholar] [CrossRef]
- Maltbie, N.; Niu, N.; van Doren, M.; Johnson, R. XAI Tools in the Public Sector: A Case Study on Predicting Combined Sewer Overflows. In Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, 23–28 August 2021; Association for Computing Machinery: New York, NY, USA, 2021. ESEC/FSE 2021. pp. 1032–1044. [Google Scholar] [CrossRef]
- Hevner, A.R.; March, S.T.; Park, J.; Ram, S. Design science in information systems research. MIS Q. 2004, 28, 75–105. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Explanation Type | Black-Box Model | Method | Scope | Functionality | Source |
|---|---|---|---|---|---|
| Feature Importance | Any | LIME | Local | Surrogate Model | [88] |
| LORE | Local | Surrogate Model | [90] | ||
| Anchors | Local | Surrogate Model | [91] | ||
| Occlusion | Local | Input Perturbation | [86] | ||
| Permutation Feature Importance | Global | Input Perturbation | [92] | ||
| Shapley Feature Importance | Global | Game-Theory | [93] | ||
| SHAP | Both | Game-Theory | [87] | ||
| Neural Network | Guided Backpropagation | Local | Backpropagation | [94] | |
| Integrated Gradients | Local | Backpropagation | [95] | ||
| Layerwise Relevance Propagation | Local | Backpropagation | [96] | ||
| DeepLift | Local | Backpropagation | [97] | ||
| Testing with Concept Activation Vectors | Global | Human Concepts | [98] | ||
| Activation Maximization | Global | Forwardpropagation | [99] | ||
| CNN | Deconvolution | Local | Backpropagation | [86] | |
| Class Activation Map | Local | Backpropagation | [100] | ||
| Grad-CAM | Local | Backpropagation | [101] | ||
| Transformer | Attention Flow/Attention Rollout | Local | Network Graph | [102] | |
| Transformer Relevance Propagation | Local | Backpropagation | [103] | ||
| White-Box Model | Any | Rule Extraction | Global | Simplification | [104] |
| Tree Extraction | Global | Simplification | [105] | ||
| Model Distillation | Global | Simplification | [106] | ||
| CNN | Attention Network | Global | Model Adaption | [107] | |
| RNN | Attention Network | Global | Model Adaption | [108] | |
| Example-Based | Any | Prototypes | Global | Example (Train Data) | [109] |
| Critisisms | Global | Example (Train Data) | [110] | ||
| Counterfactuals | Global | Fictional data point | [111] | ||
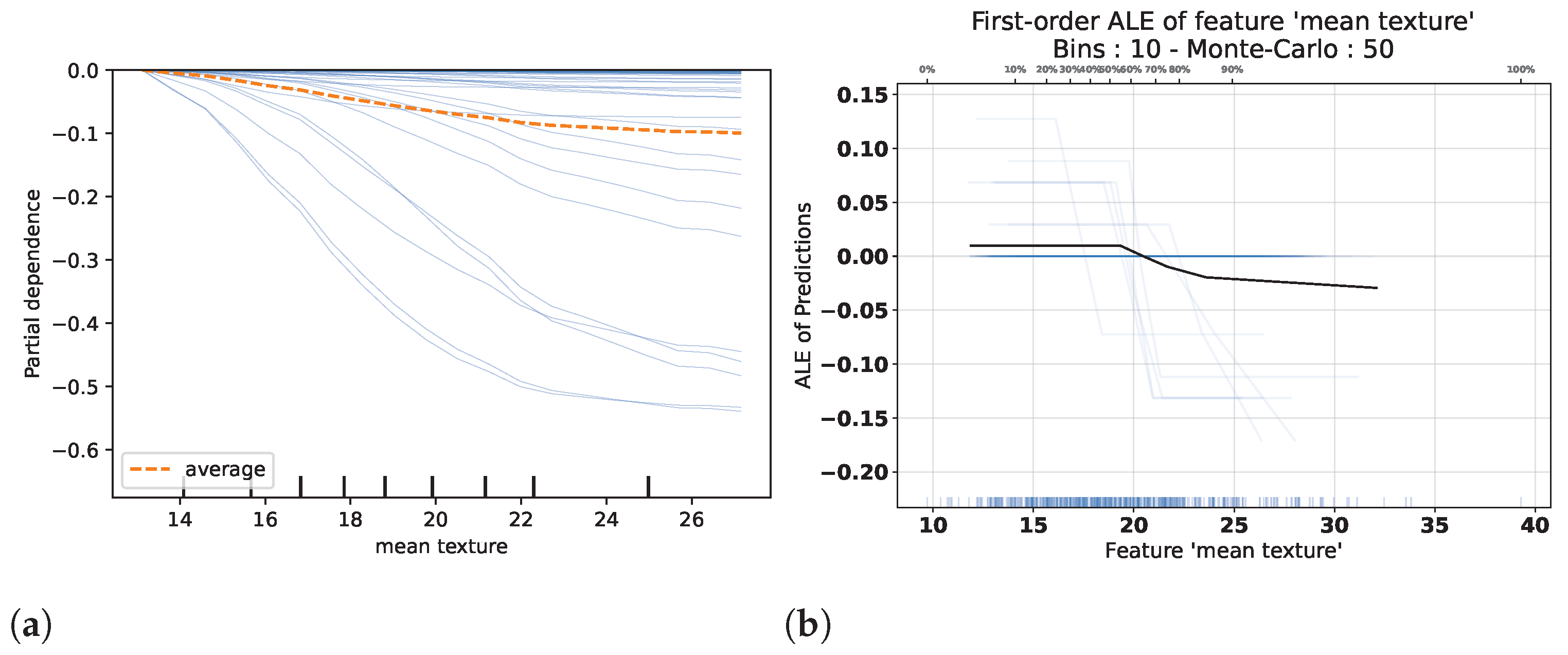
| Visual Explanations | Any | Partial Dependence Plot | Global | Marginalization | [112] |
| Individual Conditional Expectation | Global | Marginalization | [113] | ||
| Accumulated Local Effects | Global | Accumulation | [114] |
| Name | Focus | Feature Importance | White-Box Models | Example-Based XAI | Visual XAI | Framework |
|---|---|---|---|---|---|---|
| AIX 360 [151] | General | LIME, SHAP | Decision Rules, Model Distillation | Prototypes, Contrastive Explanations | — | — |
| Alibi [152] | General | Anchors, Integrated Gradients, SHAP, | — | Contrastive Explanations, Counterfactuals | ALE | TensorFlow |
| Captum [153] | Neural Networks | DeepLift, Deconvolution, Integrated Gradients, SHAP, Guided Backpropagation, GradCam, Occlusion, PFI | — | — | — | PyTorch |
| DALEX [154] | General | LIME, SHAP, PFI | — | — | ALE, PDP | — |
| DiCE [155] | Counterfactuals | — | — | Counterfactuals | — | — |
| InterpretML [156] | General | LIME, SHAP, Morris Sensitivity Analysis | Explainable Boosting, Decision Tree, Decision Rules, Regression | — | PDP | — |
| PAIR Saliency [157] | Saliency Maps | Integrated Gradients, GradCam, Occlusion, Guided Backpropagation, Ranked Area Integrals, SmoothGrad | — | — | — | PyTorch, TensorFlow |
| Skater [158] | General | Layerwise Relevance Propagation, LIME, Integrated Gradients, Occlusion, PFI | Bayesian Rule List, Decision Tree | — | PDP | TensorFlow |
| Quantus [159] | Quantitative Evaluation | — | — | — | — | TensorFlow, PyTorch |
| ExplainerDashboard [160] | General | SHAP, PFI | Decision Tree | — | PDP | Scikit-learn |
| Ecco [161] | NLP | Integrated Gradients, Saliency, DeepLift, Guided Backprop | — | — | — | PyTorch |
| XAITK [162] | General | Saliency Maps | Decision Tree | Explanation by Example | — | — |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Clement, T.; Kemmerzell, N.; Abdelaal, M.; Amberg, M. XAIR: A Systematic Metareview of Explainable AI (XAI) Aligned to the Software Development Process. Mach. Learn. Knowl. Extr. 2023, 5, 78-108. https://doi.org/10.3390/make5010006
Clement T, Kemmerzell N, Abdelaal M, Amberg M. XAIR: A Systematic Metareview of Explainable AI (XAI) Aligned to the Software Development Process. Machine Learning and Knowledge Extraction. 2023; 5(1):78-108. https://doi.org/10.3390/make5010006
Chicago/Turabian StyleClement, Tobias, Nils Kemmerzell, Mohamed Abdelaal, and Michael Amberg. 2023. "XAIR: A Systematic Metareview of Explainable AI (XAI) Aligned to the Software Development Process" Machine Learning and Knowledge Extraction 5, no. 1: 78-108. https://doi.org/10.3390/make5010006
APA StyleClement, T., Kemmerzell, N., Abdelaal, M., & Amberg, M. (2023). XAIR: A Systematic Metareview of Explainable AI (XAI) Aligned to the Software Development Process. Machine Learning and Knowledge Extraction, 5(1), 78-108. https://doi.org/10.3390/make5010006