
Explainable Machine Learning Reveals Capabilities, Redundancy, and Limitations of a Geospatial Air Quality Benchmark Dataset


Abstract
:1. Introduction
2. Related Work
2.1. Data-Driven Air Pollution Modeling
2.2. Explainable Machine Learning in Earth Science
2.3. Scientific Insights through Explainable AI
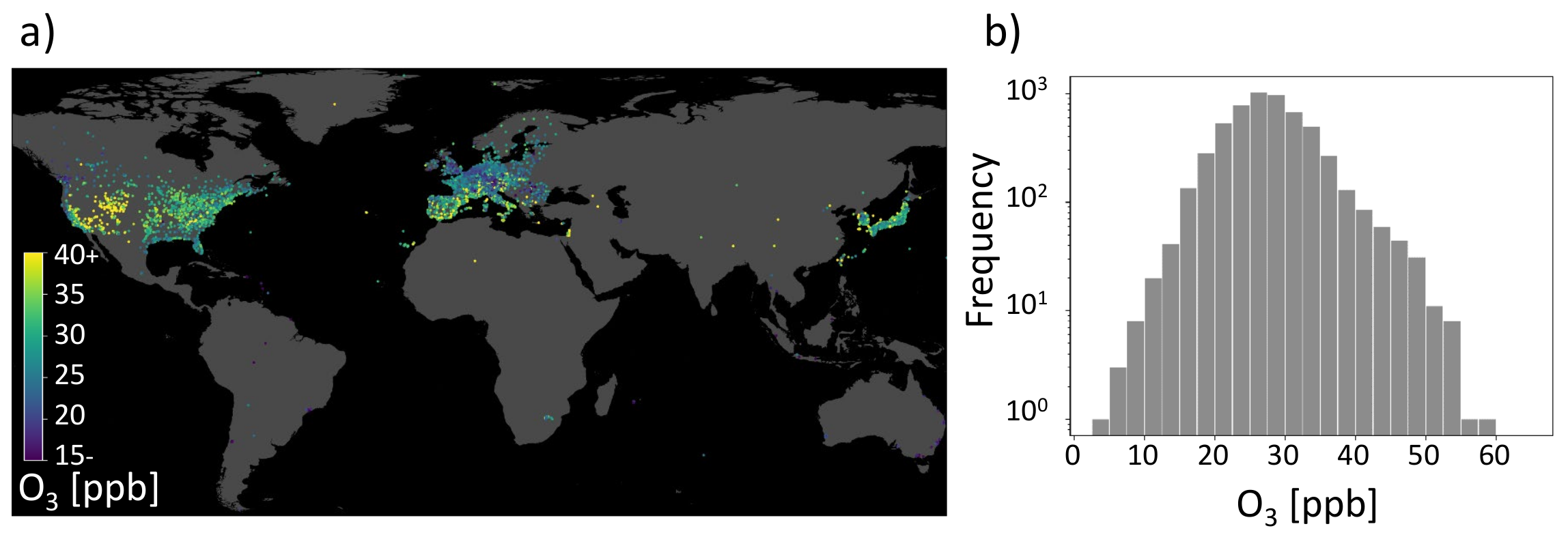
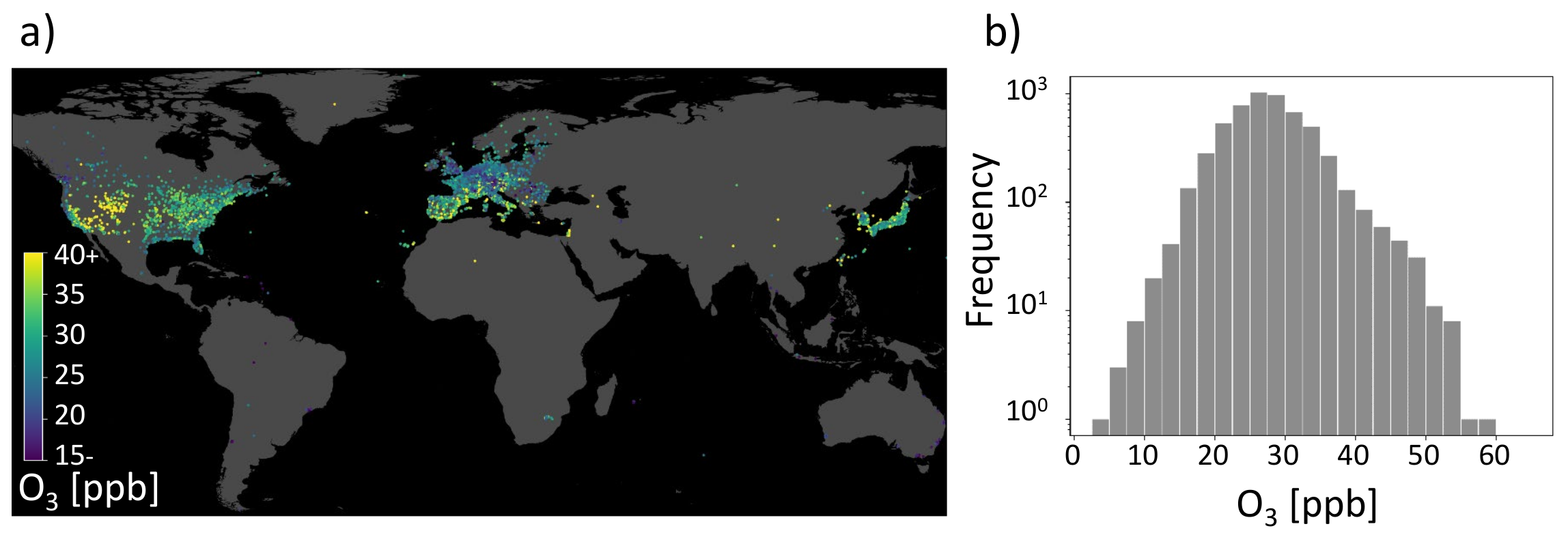
3. AQ-Bench Dataset
4. Methods
4.1. SHAP
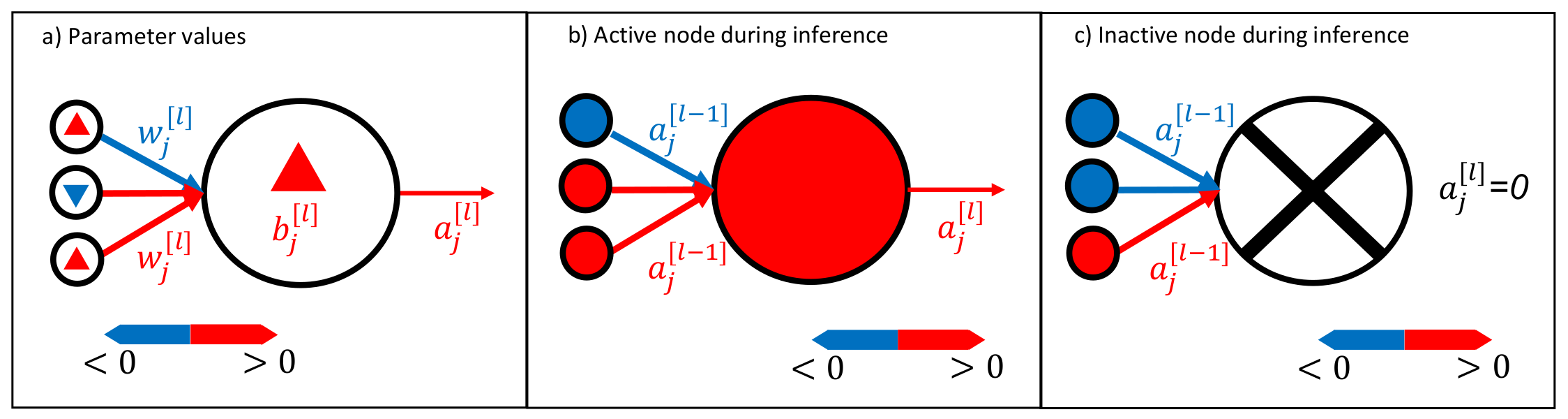
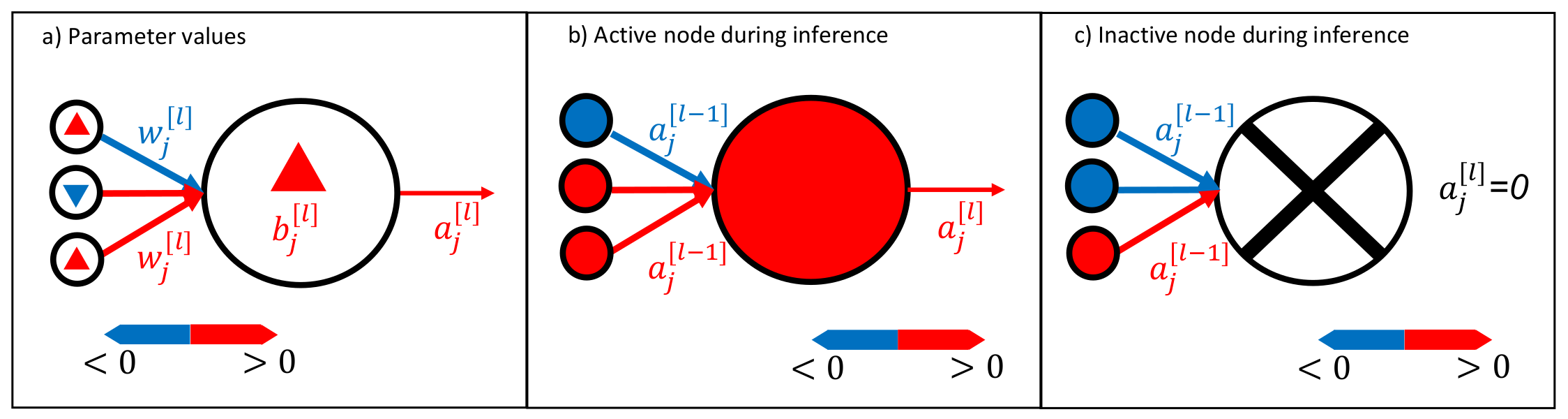
4.2. Neural Network Activation
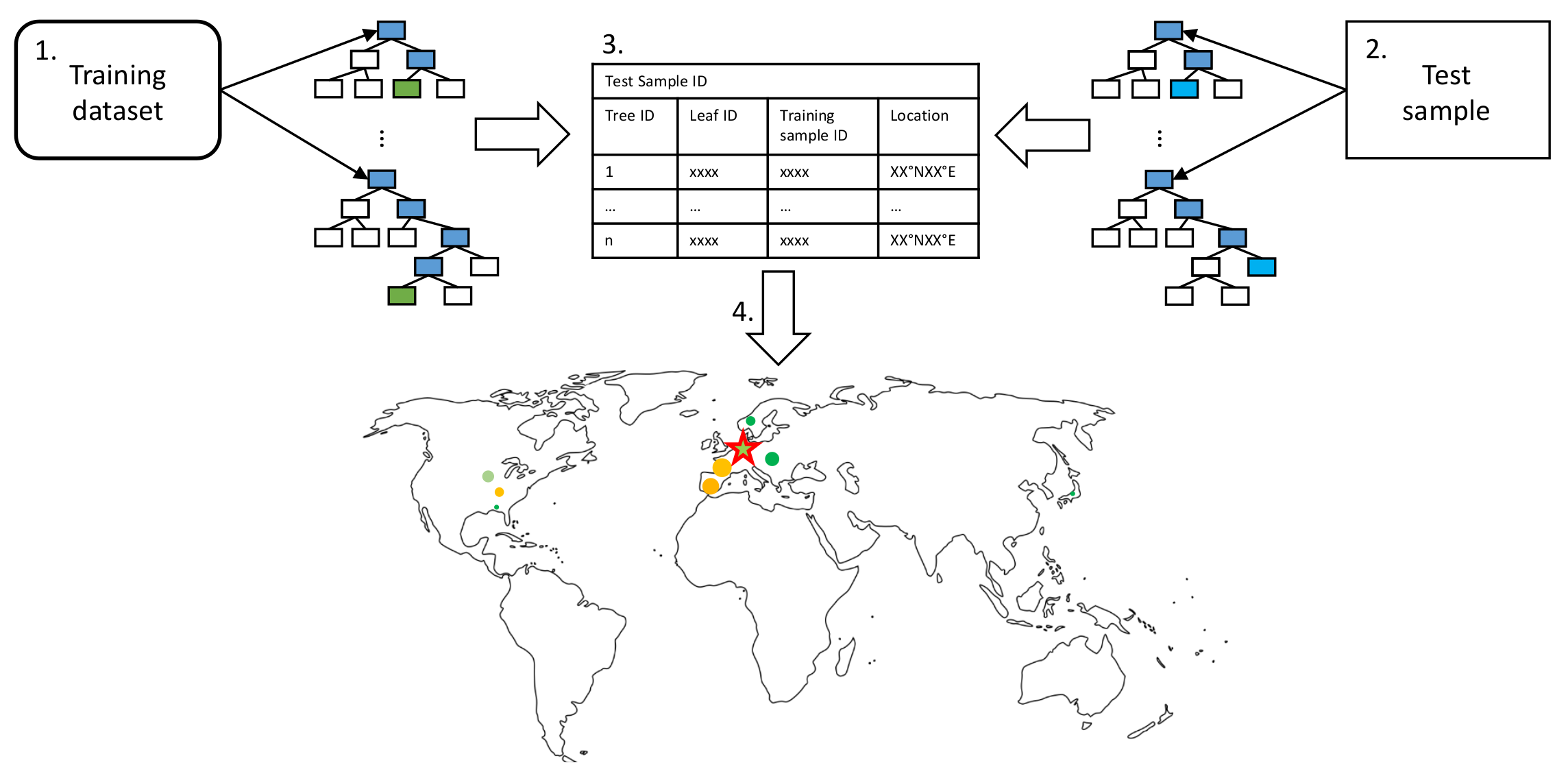
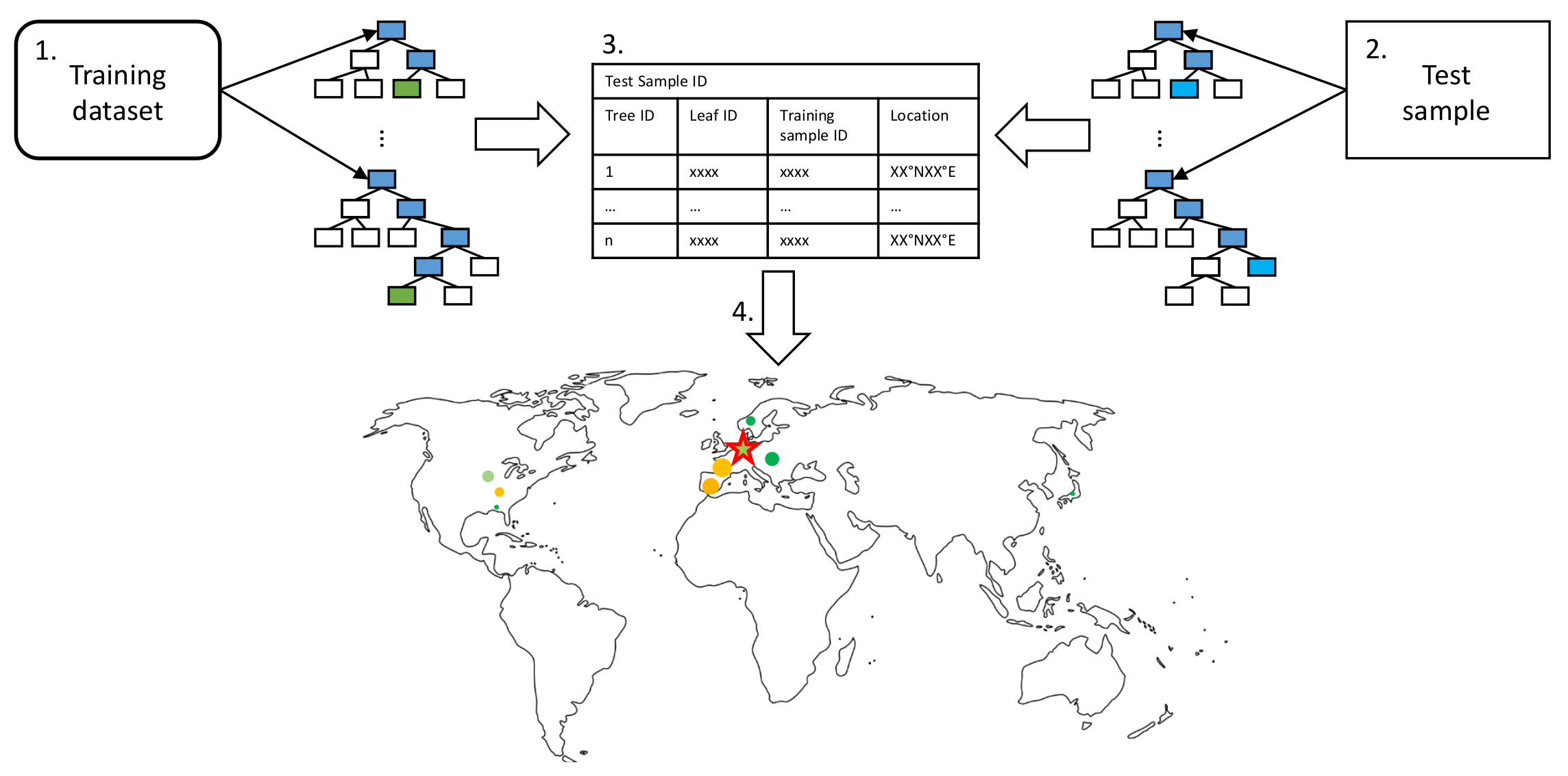
4.3. Random Forest Activation
- Propagate all training samples through the trained random forest. Keep track of the tree IDs, leaf node IDs, and corresponding training sample IDs.
- Propagate a single test sample through the random forest. Track the corresponding responsible tree IDs and leaf node IDs for the prediction.
- To identify training samples that are most relevant for a given prediction, keep track of the relative frequency of the training samples contributing to the leaf node predictions responsible for a given test sample prediction.
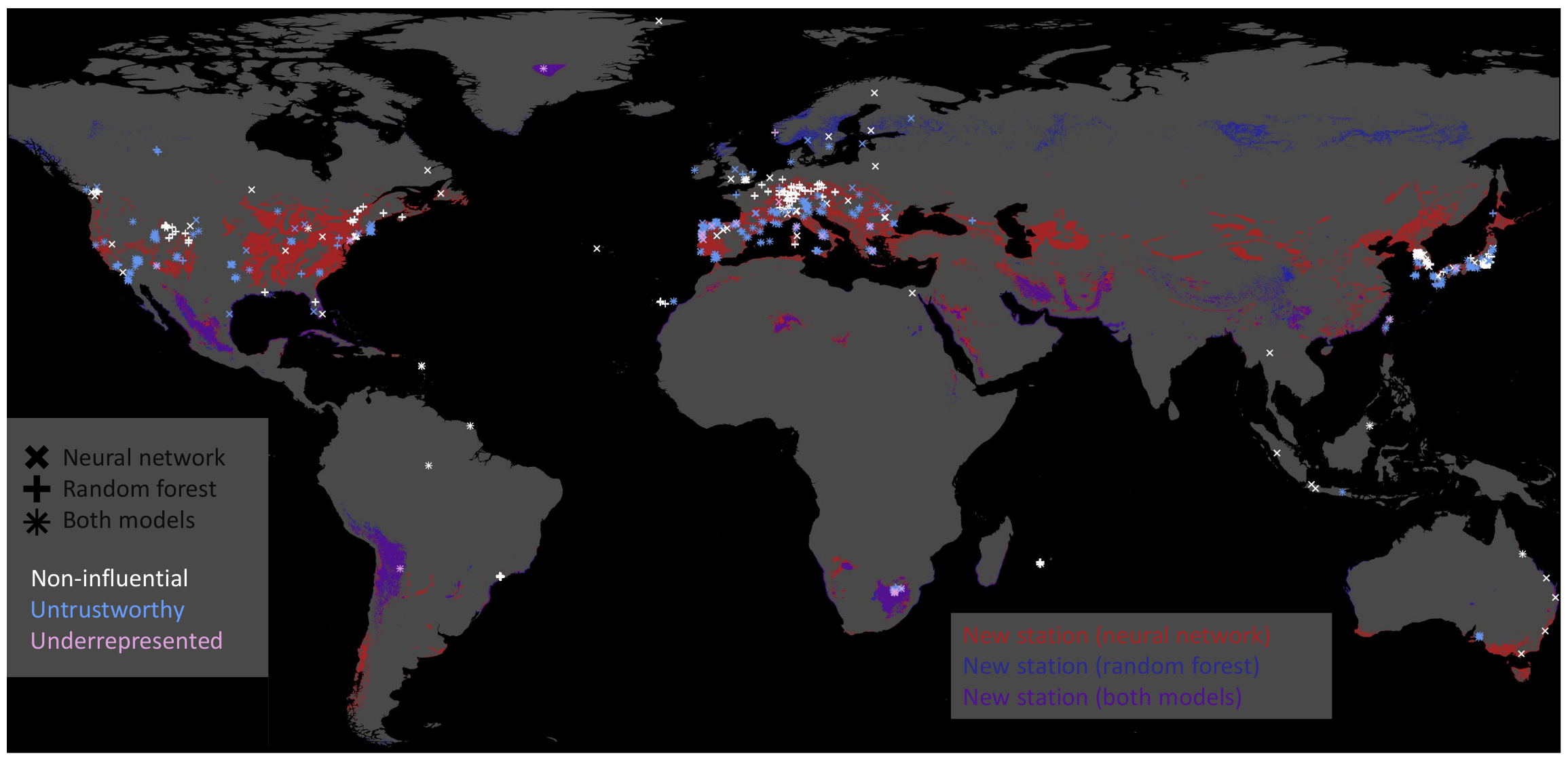
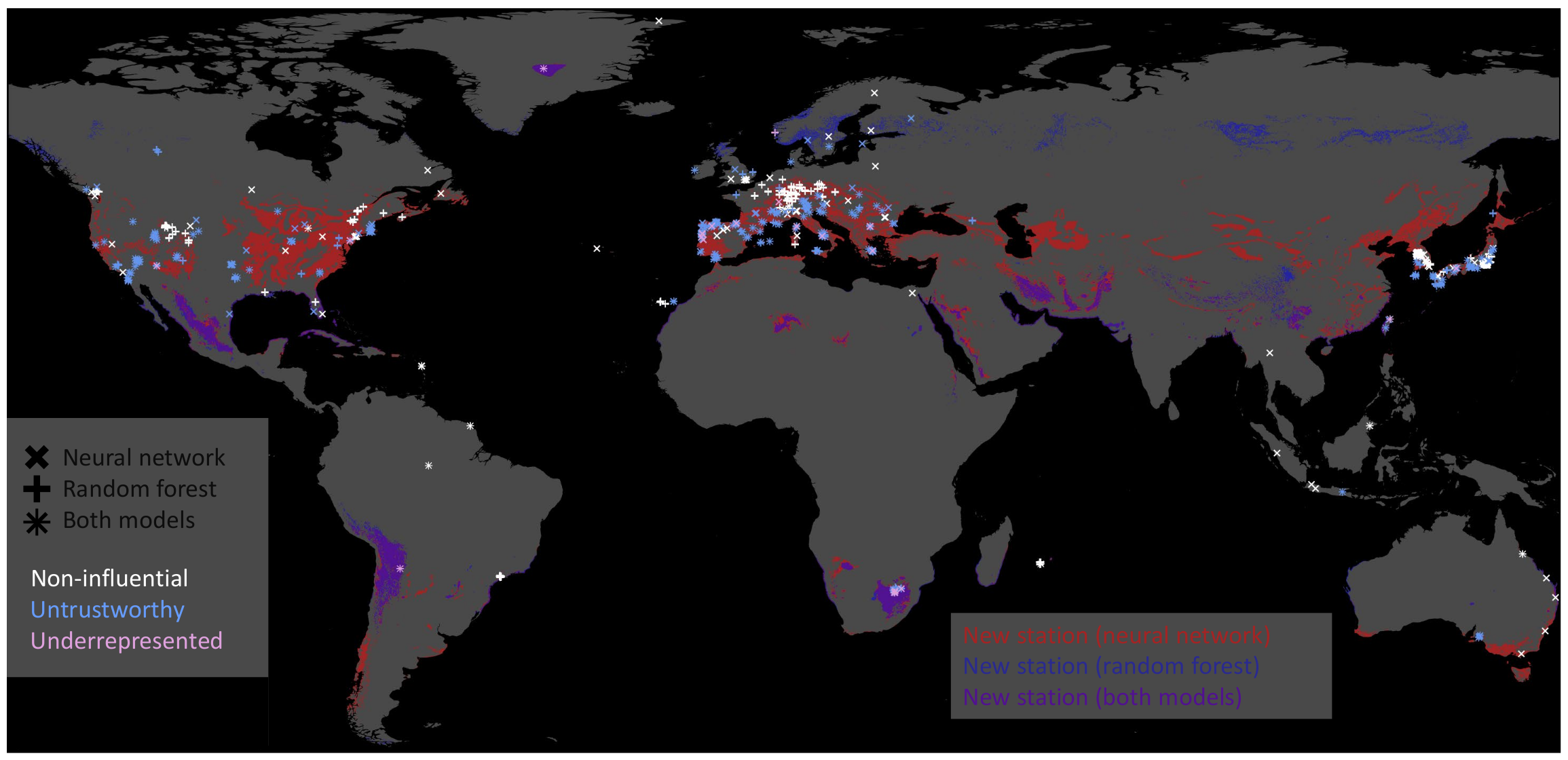
- Since each training sample has geographical information; influential training samples can be visualized on a map. The marker size indicates the frequency of a specific training sample contributing to the leaf nodes responsible for a particular prediction.
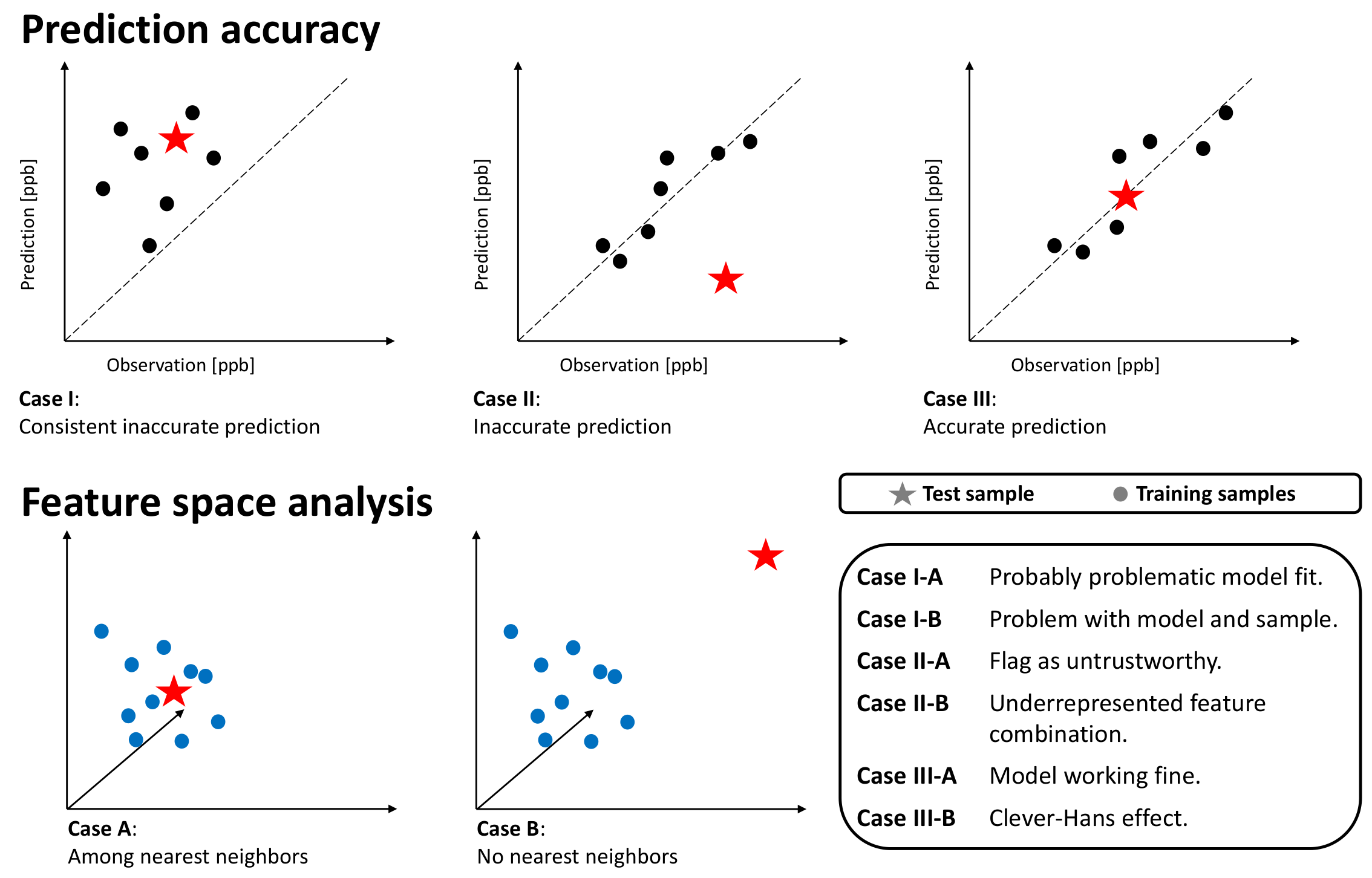
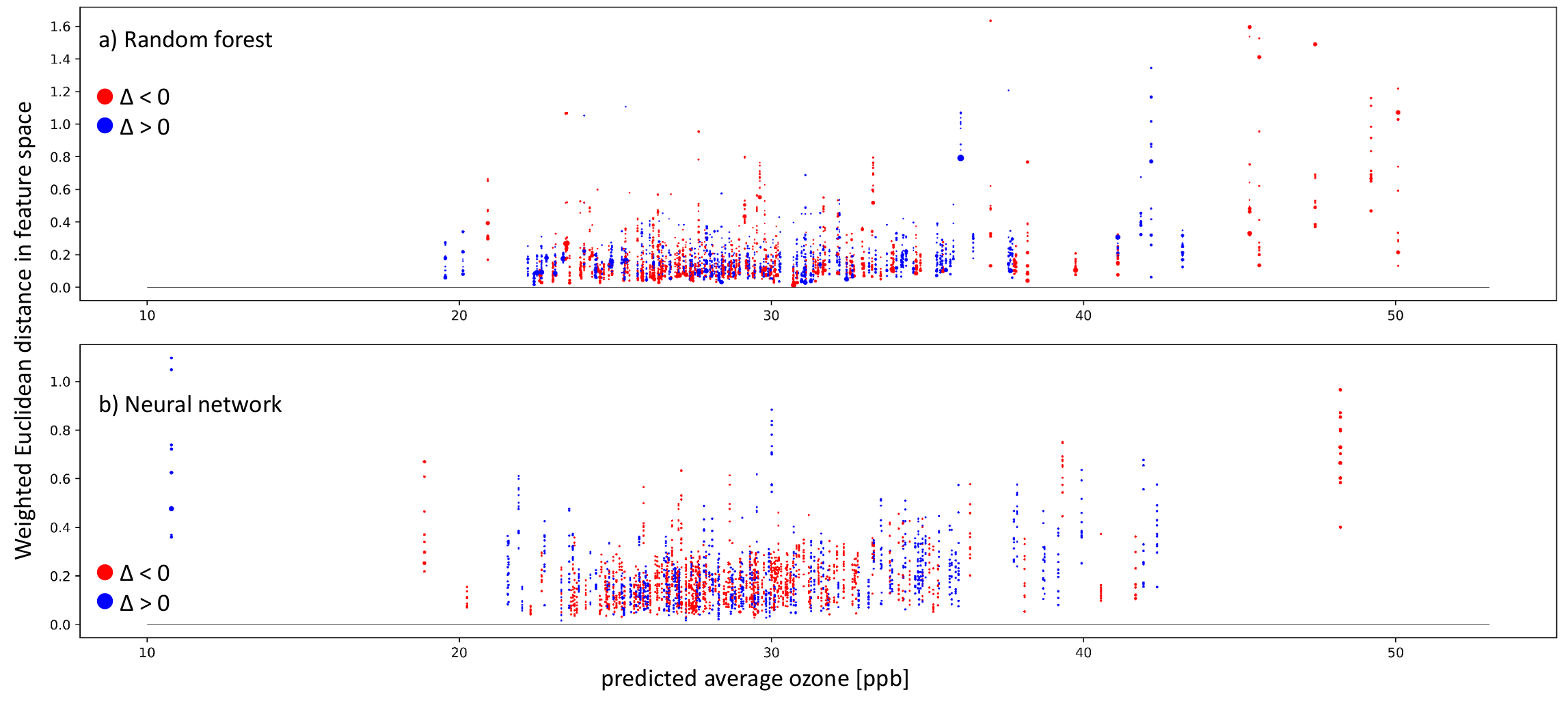
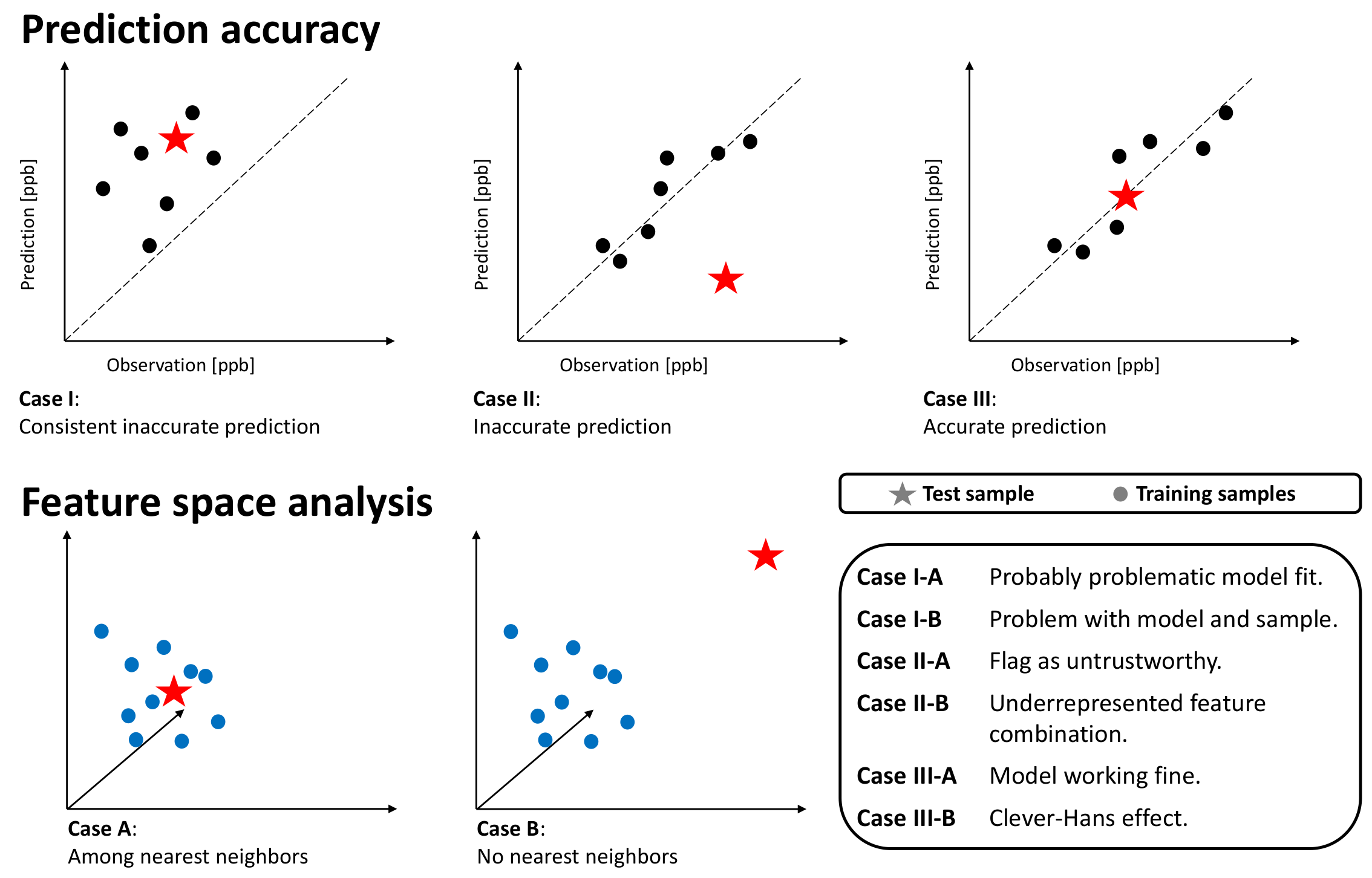
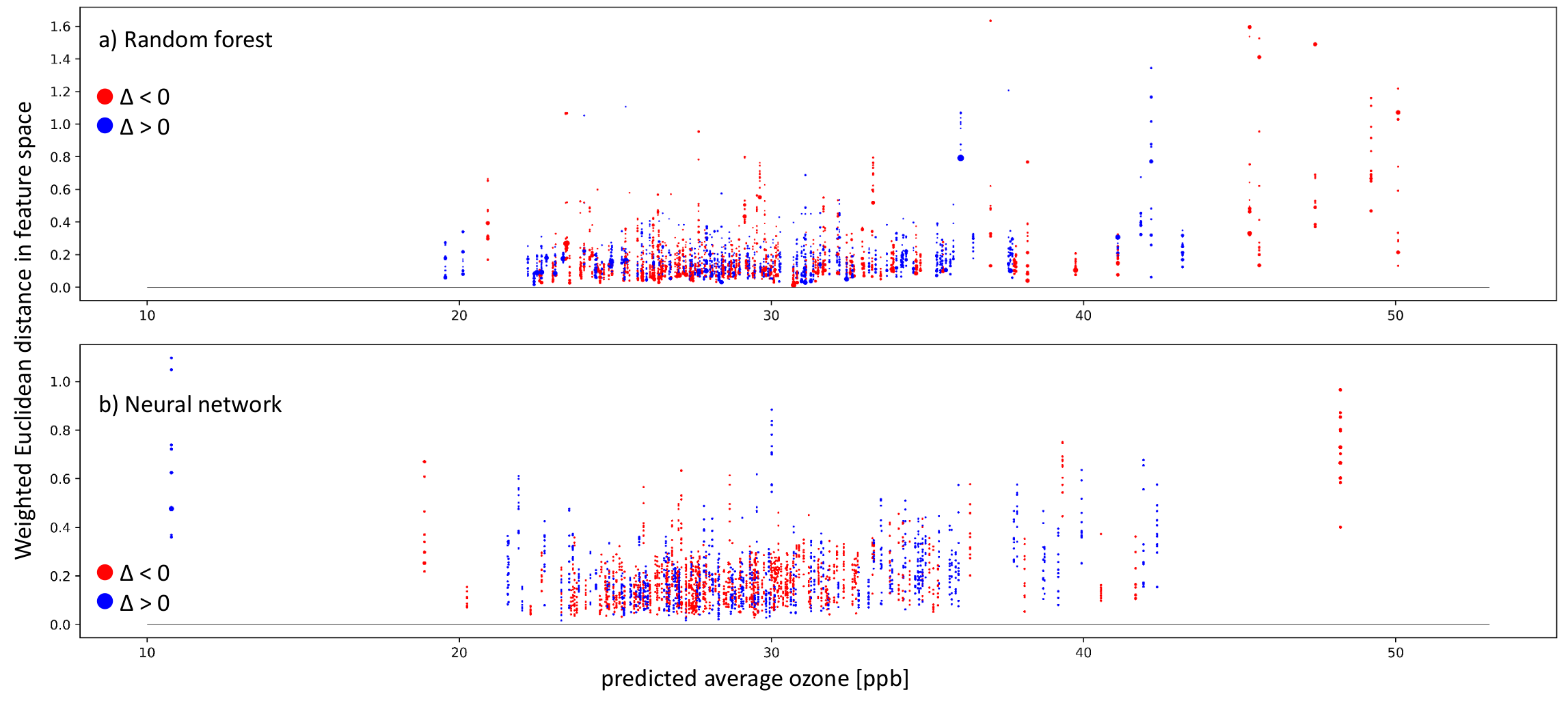
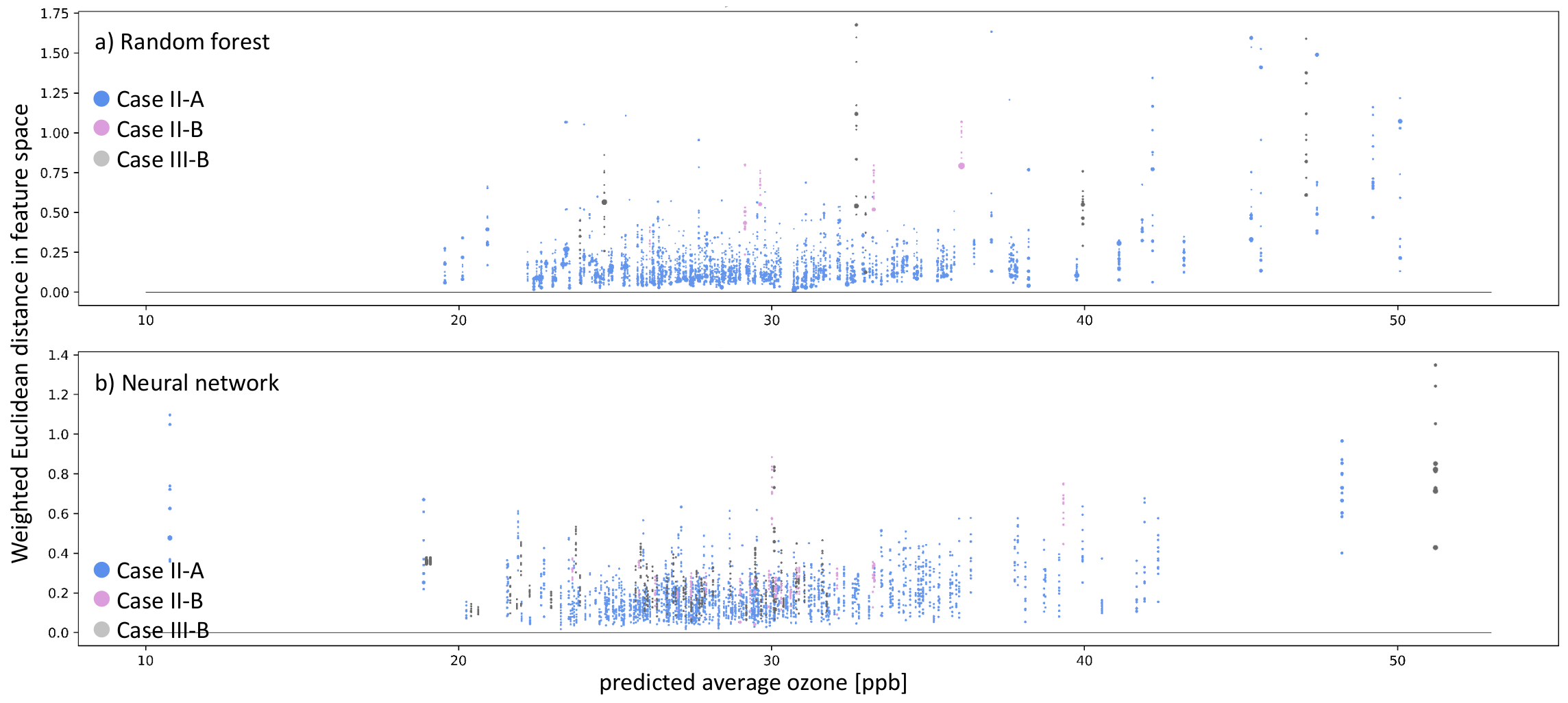
4.4. Explaining Inaccurate Predictions with k-Nearest Neighbors
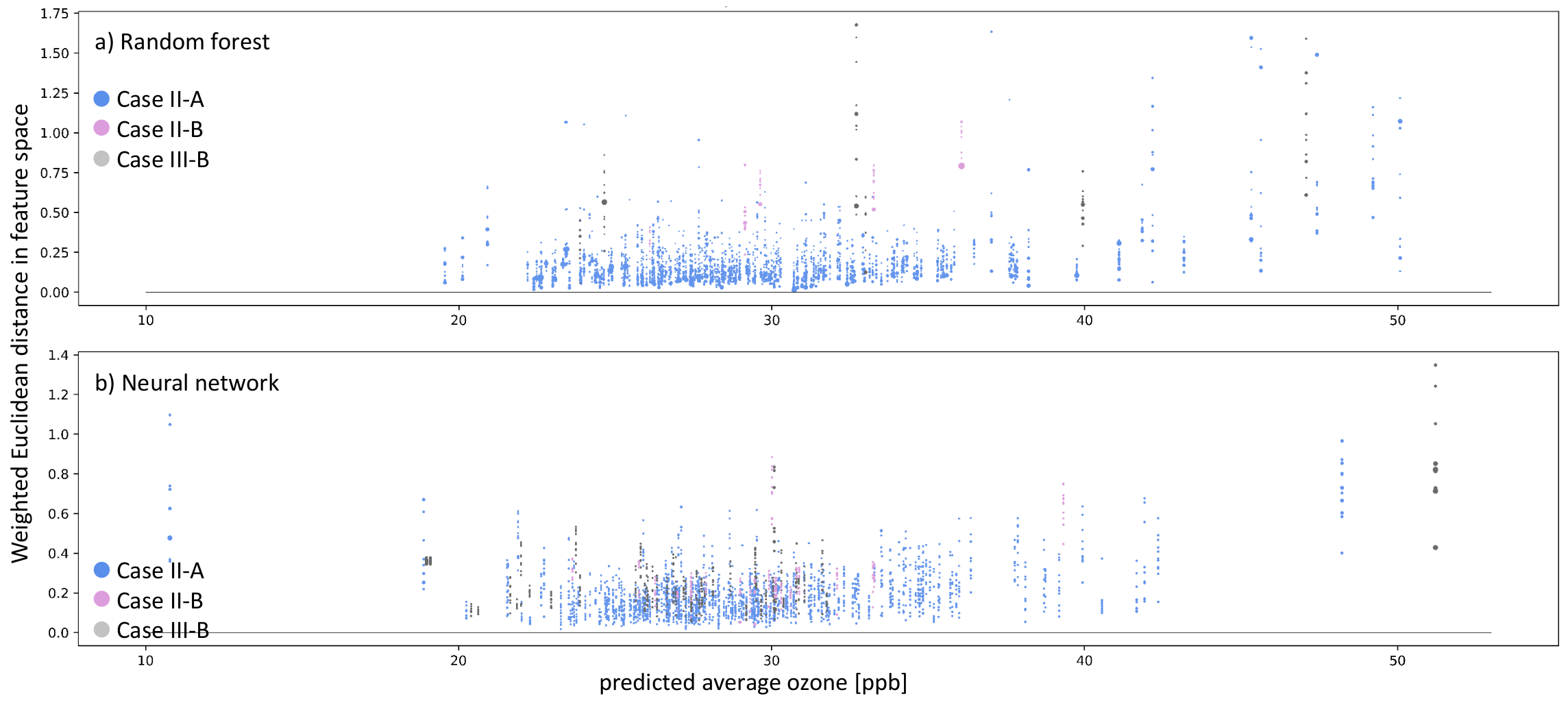
- Case-I-A: A sample of k-nearest neighbors leads to consistent, inaccurate predictions. The k-nearest neighbors and the test station are located next to each other in the feature space. The inaccurate prediction of the test sample is not unexpected. In this case, the model might not be fitted well.
- Case-I-B: A sample of k-nearest neighbors leads to consistent, inaccurate predictions. The k-nearest neighbors and the test station are not located next to each other in the feature space. The inaccurate prediction of the test sample is not unexpected. In this case, the model might not be fitted well, and the test sample is not well represented– too many problems.
- Case-II-A: The model accurately predicts a sample of k-nearest neighbors, while it inaccurately predicts the test sample. The k-nearest neighbors and the test station are located next to each other in the feature space. Therefore, the inaccurate prediction of the test sample is unexpected. This could point to either an erroneous test sample or a model limitation. In any case, this prediction is untrustworthy.
- Case-II-B: A sample of k-nearest neighbors leads to accurate prediction, while the test sample is inaccurately predicted. The k-nearest neighbors and the test station are not located next to each other in the feature space. Thus, the inaccurate prediction of the test sample is not unexpected. This points to an underrepresented test sample.
- Case-III-A: A sample of k-nearest neighbors leads to scattered accurate predictions. The test sample is accurately predicted. In the feature space, the accurately predicted test sample has nearest neighbors. The models are predicting a correct value. This is the usual case for a healthy prediction.
- Case-III-B: A sample of k-nearest neighbors leads to scattered predictions; both accurate and inaccurate predictions are possible. The test sample is accurately predicted but due to the wrong reasons. The accurately predicted test sample has no nearest neighbors in the feature space. The models are predicting a correct value but due to the wrong reason. We can flag this case as the Clever-Hans effect [35].
5. Experimental Setup
5.1. Model Training
5.2. Evaluation Metrics
5.3. SHAP Values
5.4. Visualization of Individual Predictions
5.5. Identify k-Nearest Neighbors and Classify Predictions
5.6. Train on a Reduced Dataset
6. Results
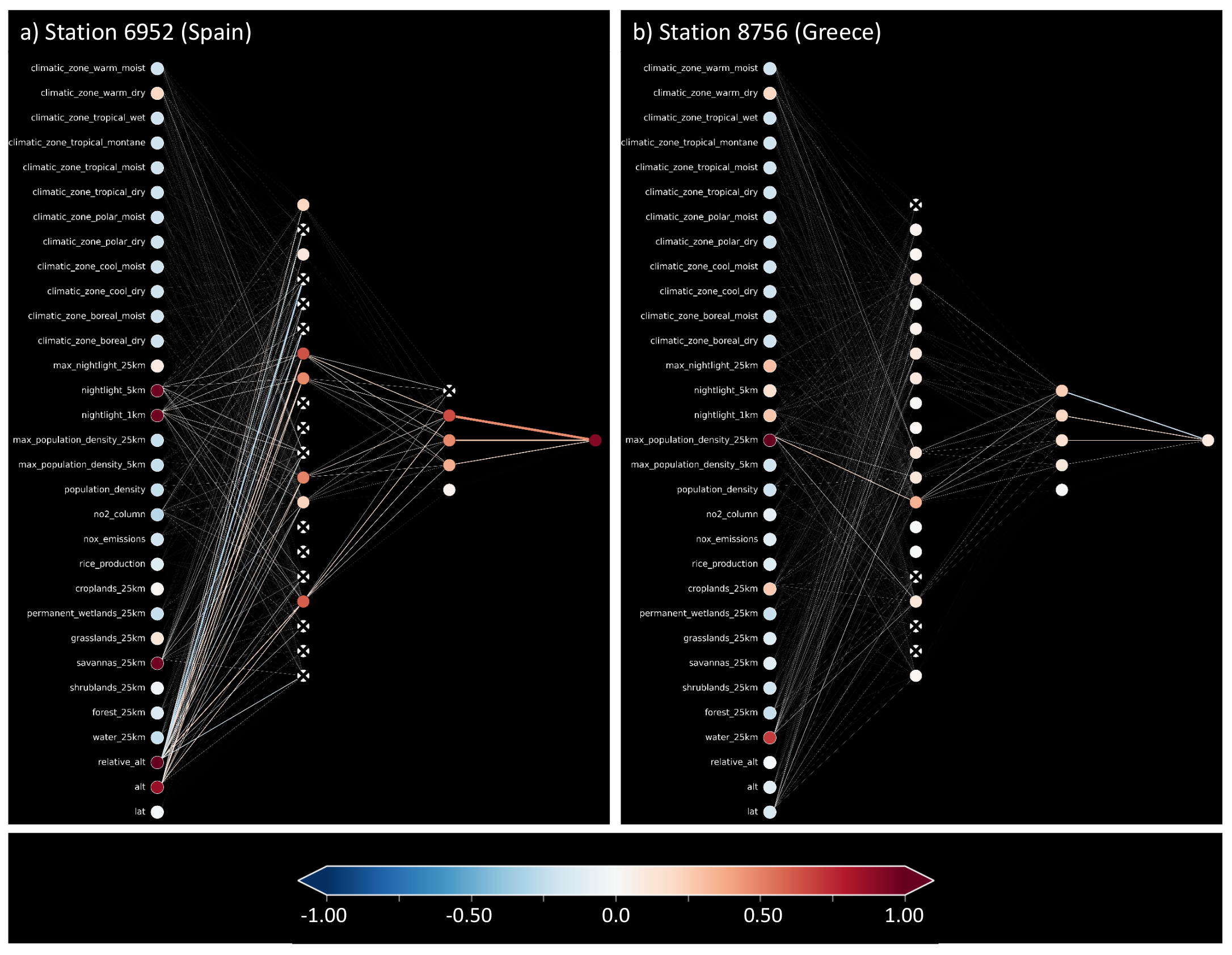
6.1. SHAP Global Importance
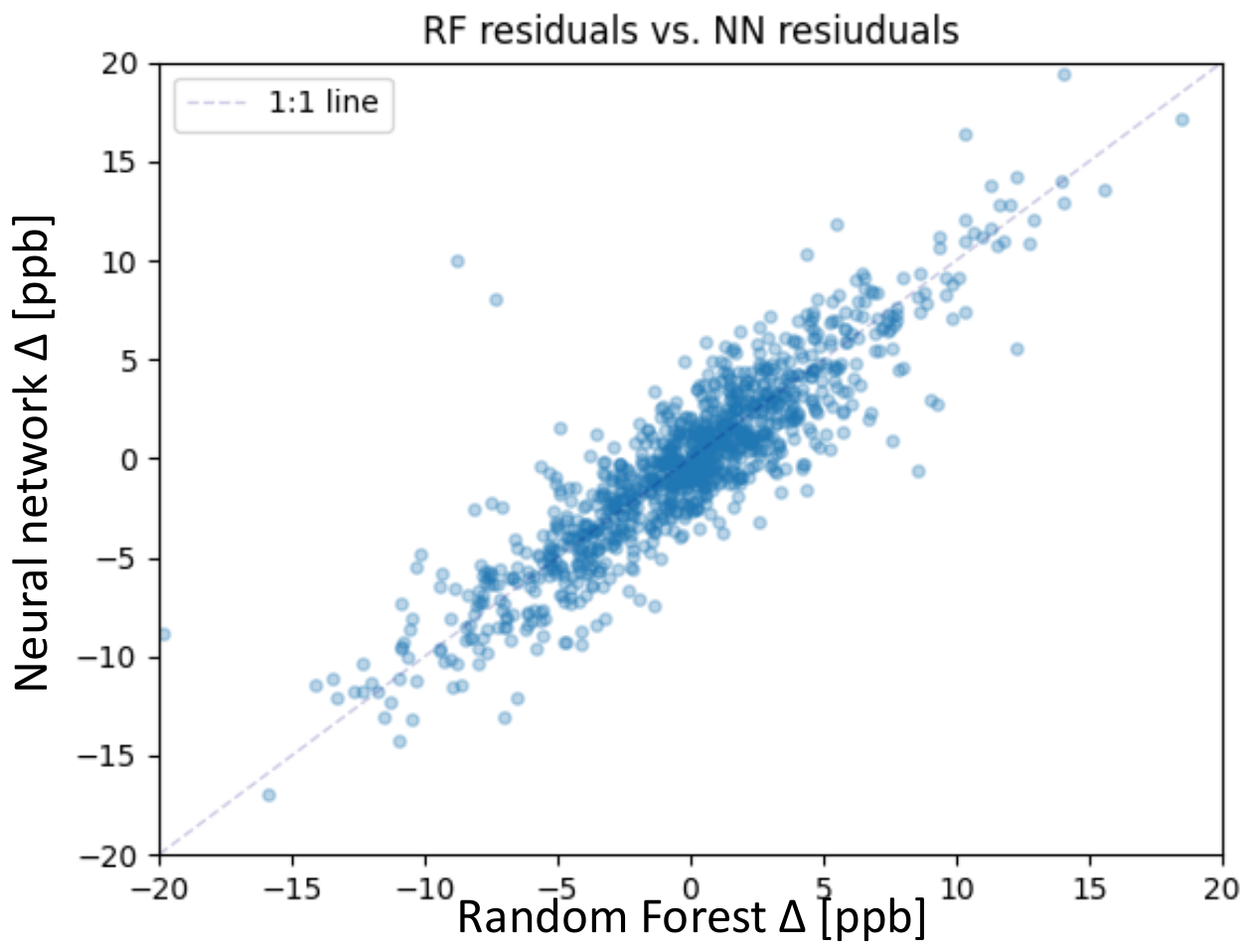
6.2. Comparison of Neural Network and Random Forest Performance and Residuals
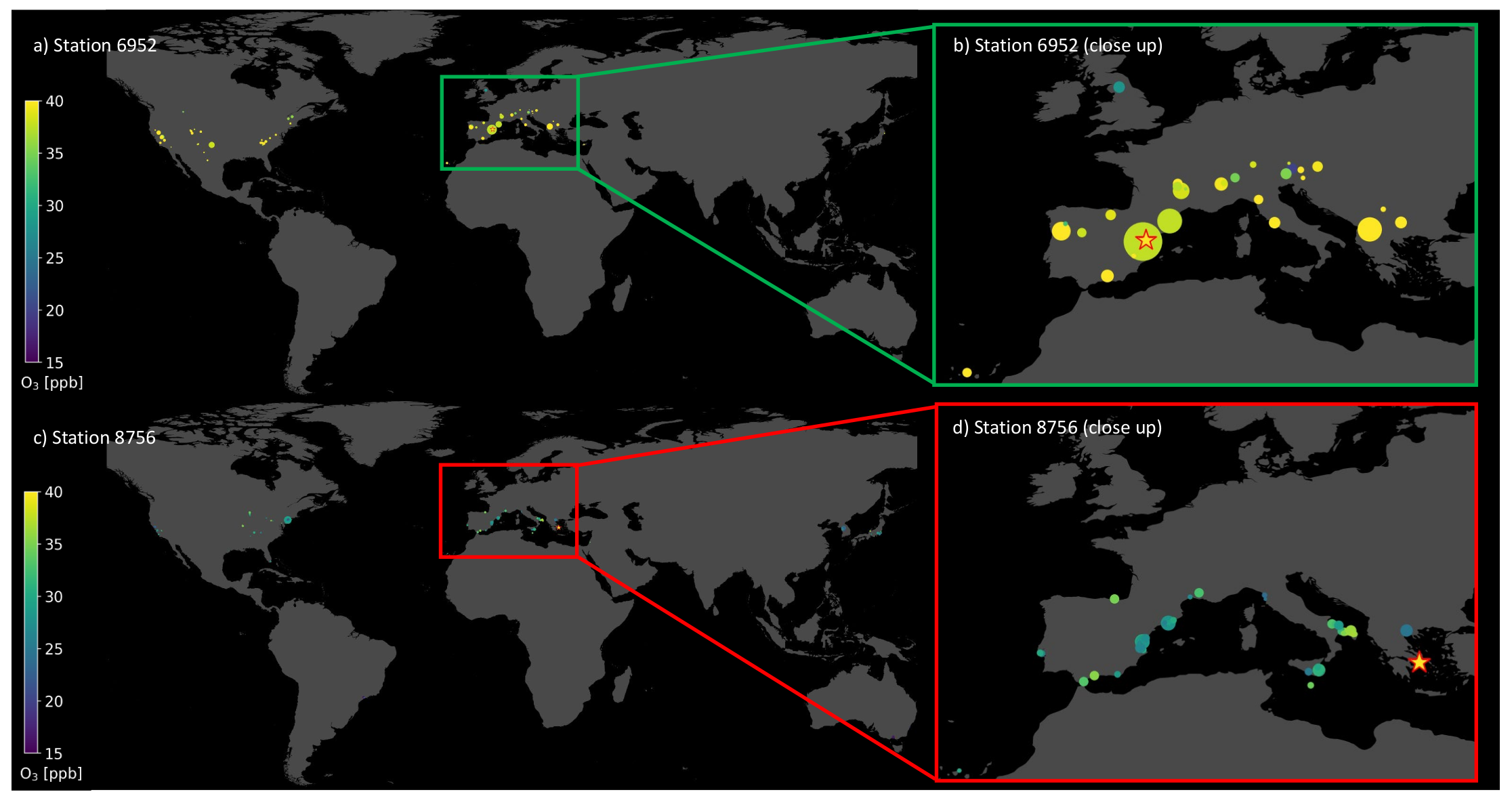
6.3. Visualization of Individual Predictions
6.4. Explaining Inaccurate Predictions
6.5. Training without Irrelevant Training Samples
7. Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. SHAP Importance with Feature Variable Names

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Importance RF [%] | Importance NN [%] |
|---|---|---|
| lat | 23.96 | 20.5 |
| relative_alt | 16.21 | 11.93 |
| alt | 10.44 | 8.16 |
| nightlight_5km | 9.73 | 4.35 |
| forest_25km | 5.37 | 13.54 |
| population_density | 4.41 | 1.8 |
| nightlight_1km | 4.12 | 8.77 |
| water_25km | 4.11 | 7.5 |
| max_population_density_25km | 3.54 | 0.32 |
| no2_column | 3.51 | 6.31 |
| max_population_density_5km | 3.04 | 1.21 |
| savannas_25km | 2.68 | 0.84 |
| croplands_25km | 1.73 | 1.74 |
| grasslands_25km | 1.68 | 0.77 |
| nox_emissions | 1.62 | 0.84 |
| climatic_zone_warm_dry | 1.18 | 5.27 |
| shrublands_25km | 0.65 | 1.67 |
| max_nightlight_25km | 0.35 | 0.39 |
| climatic_zone_warm_moist | 0.33 | 2.49 |
| climatic_zone_cool_moist | 0.32 | 0.14 |
| rice_production | 0.3 | 0.58 |
| permanent_wetlands_25km | 0.27 | 0.15 |
| climatic_zone_cool_dry | 0.25 | 0.13 |
| climatic_zone_tropical_dry | 0.14 | 0.13 |
| climatic_zone_tropical_wet | 0.03 | 0.11 |
| climatic_zone_tropical_moist | 0.02 | 0.09 |
| climatic_zone_boreal_moist | 0.0 | 0.11 |
| climatic_zone_polar_moist | 0.0 | 0.07 |
| climatic_zone_boreal_dry | 0.0 | 0.1 |
| climatic_zone_polar_dry | 0.0 | 0.0 |
| climatic_zone_tropical_montane | 0.0 | 0.0 |
Appendix B. Hyperparameters
| Random Forest | |
|---|---|
| Number of trees | 100 |
| Criterion | RMSE |
| Depth | Unlimited |
| Bootstrapping | Training samples |
| Neural Network | |
| Learning rate | |
| L2 lambda | |
| Batch size | No mini batches |
| Number of epochs | 15,000 |
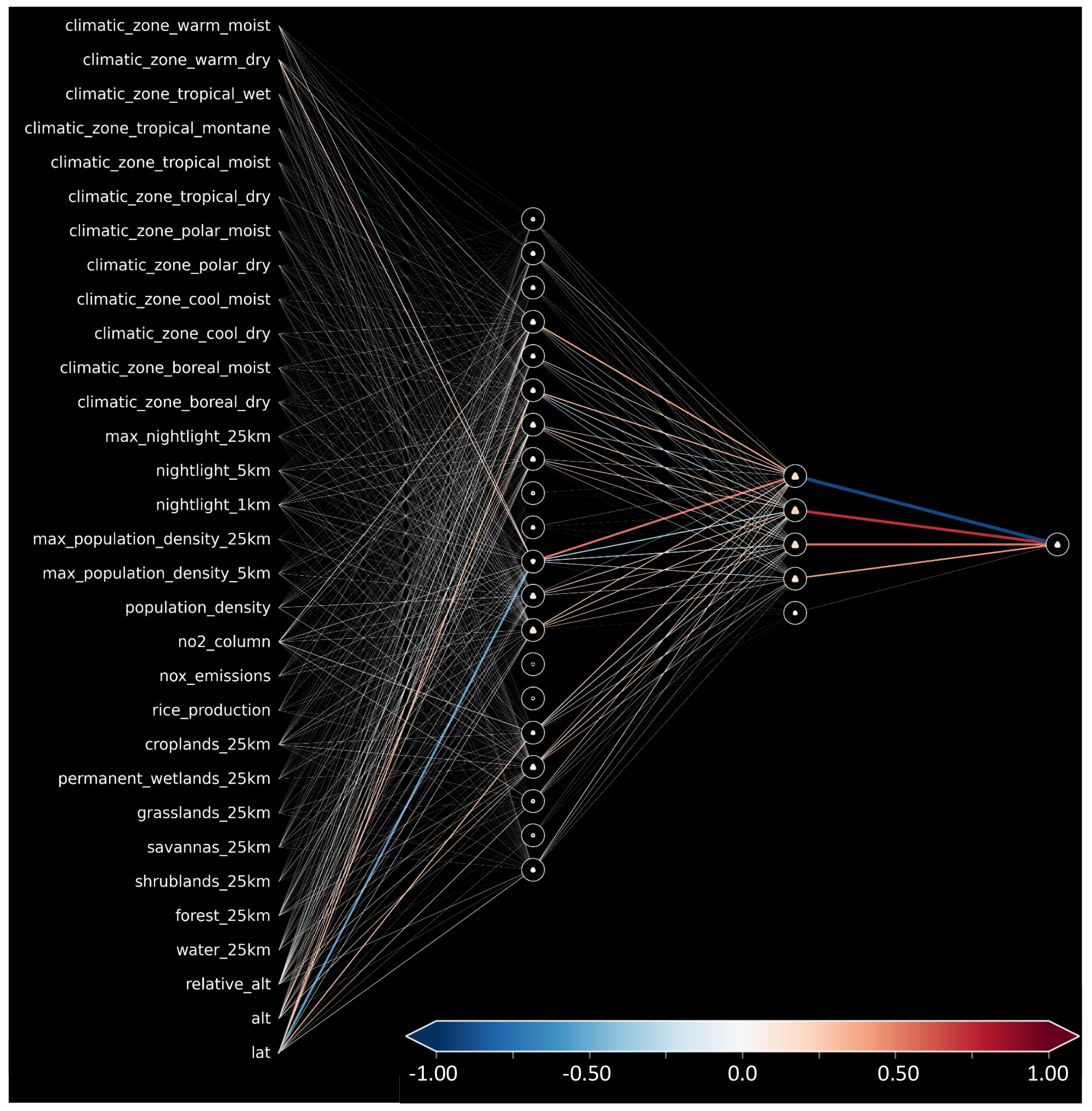
Appendix C. Trained Neural Network Visualization

References
- 4.2 Million Deaths Every Year Occur as a Result of Exposure to Ambient (Outdoor) Air Pollution. Available online: https://www.who.int/health-topics/air-pollution#tab=tab_1 (accessed on 12 December 2021).
- Schultz, M.G.; Akimoto, H.; Bottenheim, J.; Buchmann, B.; Galbally, I.E.; Gilge, S.; Helmig, D.; Koide, H.; Lewis, A.C.; Novelli, P.C.; et al. The Global Atmosphere Watch reactive gases measurement network. Elem. Sci. Anth. 2015, 3. [Google Scholar] [CrossRef] [Green Version]
- Schultz, M.G.; Schröder, S.; Lyapina, O.; Cooper, O.; Galbally, I.; Petropavlovskikh, I.; Von Schneidemesser, E.; Tanimoto, H.; Elshorbany, Y.; Naja, M.; et al. Tropospheric Ozone Assessment Report: Database and Metrics Data of Global Surface Ozone Observations. Elem. Sci. Anth. 2017, 5, 58. [Google Scholar] [CrossRef] [Green Version]
- Gaudel, A.; Cooper, O.R.; Ancellet, G.; Barret, B.; Boynard, A.; Burrows, J.P.; Clerbaux, C.; Coheur, P.F.; Cuesta, J.; Cuevas, E.; et al. Tropospheric Ozone Assessment Report: Present-day distribution and trends of tropospheric ozone relevant to climate and global atmospheric chemistry model evaluation. Elem. Sci. Anth. 2018, 6, 39. [Google Scholar] [CrossRef]
- Rao, S.T.; Galmarini, S.; Puckett, K. Air Quality Model Evaluation International Initiative (AQMEII) advancing the state of the science in regional photochemical modeling and its applications. Bull. Am. Meteorol. Soc. 2011, 92, 23–30. [Google Scholar] [CrossRef] [Green Version]
- Schultz, M.G.; Stadtler, S.; Schröder, S.; Taraborrelli, D.; Franco, B.; Krefting, J.; Henrot, A.; Ferrachat, S.; Lohmann, U.; Neubauer, D.; et al. The chemistry–climate model ECHAM6.3-HAM2.3-MOZ1.0. Geosci. Model Dev. 2018, 11, 1695–1723. [Google Scholar] [CrossRef] [Green Version]
- Wagner, A.; Bennouna, Y.; Blechschmidt, A.M.; Brasseur, G.; Chabrillat, S.; Christophe, Y.; Errera, Q.; Eskes, H.; Flemming, J.; Hansen, K.; et al. Comprehensive evaluation of the Copernicus Atmosphere Monitoring Service (CAMS) reanalysis against independent observations: Reactive gases. Elem. Sci. Anth. 2021, 9, 00171. [Google Scholar] [CrossRef]
- Cabaneros, S.M.; Calautit, J.K.; Hughes, B.R. A review of artificial neural network models for ambient air pollution prediction. Environ. Model. Softw. 2019, 119, 285–304. [Google Scholar] [CrossRef]
- Kleinert, F.; Leufen, L.H.; Schultz, M.G. IntelliO3-ts v1.0: A neural network approach to predict near-surface ozone concentrations in Germany. Geosci. Model Dev. 2021, 14, 1–25. [Google Scholar] [CrossRef]
- Stirnberg, R.; Cermak, J.; Kotthaus, S.; Haeffelin, M.; Andersen, H.; Fuchs, J.; Kim, M.; Petit, J.E.; Favez, O. Meteorology-driven variability of air pollution (PM1) revealed with explainable machine learning. Atmos. Chem. Phys. Discuss. 2020, 2020, 1–35. [Google Scholar] [CrossRef]
- Betancourt, C.; Stomberg, T.; Roscher, R.; Schultz, M.G.; Stadtler, S. AQ-Bench: A benchmark dataset for machine learning on global air quality metrics. Earth Syst. Sci. Data 2021, 13, 3013–3033. [Google Scholar] [CrossRef]
- Gu, J.; Yang, B.; Brauer, M.; Zhang, K.M. Enhancing the Evaluation and Interpretability of Data-Driven Air Quality Models. Atmos. Environ. 2021, 246, 118125. [Google Scholar] [CrossRef]
- Betancourt, C.; Stomberg, T.T.; Edrich, A.-K.; Patnala, A.; Schultz, M.G.; Roscher, R.; Kowalski, J.; Stadtler, S. Global, high-resolution mapping of tropospheric ozone—Explainable machine learning and impact of uncertainties. Geosci. Model Dev. Discuss. 2022. (in preparation). [Google Scholar]
- Tuia, D.; Roscher, R.; Wegner, J.D.; Jacobs, N.; Zhu, X.; Camps-Valls, G. Toward a Collective Agenda on AI for Earth Science Data Analysis. IEEE Geosci. Remote Sens. Mag. 2021, 9, 88–104. [Google Scholar] [CrossRef]
- Brokamp, C.; Jandarov, R.; Rao, M.; LeMasters, G.; Ryan, P. Exposure assessment models for elemental components of particulate matter in an urban environment: A comparison of regression and random forest approaches. Atmos. Environ. 2017, 151, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Mallet, M.D. Meteorological normalisation of PM10 using machine learning reveals distinct increases of nearby source emissions in the Australian mining town of Moranbah. Atmos. Pollut. Res. 2021, 12, 23–35. [Google Scholar] [CrossRef]
- AlThuwaynee, O.F.; Kim, S.W.; Najemaden, M.A.; Aydda, A.; Balogun, A.L.; Fayyadh, M.M.; Park, H.J. Demystifying uncertainty in PM10 susceptibility mapping using variable drop-off in extreme-gradient boosting (XGB) and random forest (RF) algorithms. Environ. Sci. Pollut. Res. 2021, 28, 1–23. [Google Scholar] [CrossRef]
- Tian, Y.; Yao, X.A.; Mu, L.; Fan, Q.; Liu, Y. Integrating meteorological factors for better understanding of the urban form-air quality relationship. Landsc. Ecol. 2020, 35, 2357–2373. [Google Scholar] [CrossRef]
- Lu, H.; Xie, M.; Liu, X.; Liu, B.; Jiang, M.; Gao, Y.; Zhao, X. Adjusting prediction of ozone concentration based on CMAQ model and machine learning methods in Sichuan-Chongqing region, China. Atmos. Pollut. Res. 2021, 12, 101066. [Google Scholar] [CrossRef]
- Alimissis, A.; Philippopoulos, K.; Tzanis, C.; Deligiorgi, D. Spatial estimation of urban air pollution with the use of artificial neural network models. Atmos. Environ. 2018, 191, 205–213. [Google Scholar] [CrossRef]
- Wen, C.; Liu, S.; Yao, X.; Peng, L.; Li, X.; Hu, Y.; Chi, T. A novel spatiotemporal convolutional long short-term neural network for air pollution prediction. Sci. Total Environ. 2019, 654, 1091–1099. [Google Scholar] [CrossRef]
- Sayeed, A.; Choi, Y.; Eslami, E.; Jung, J.; Lops, Y.; Salman, A.K.; Lee, J.B.; Park, H.J.; Choi, M.H. A novel CMAQ-CNN hybrid model to forecast hourly surface-ozone concentrations 14 days in advance. Sci. Rep. 2021, 11, 10891. [Google Scholar] [CrossRef] [PubMed]
- McGovern, A.; Lagerquist, R.; Gagne, D. Using machine learning and model interpretation and visualization techniques to gain physical insights in atmospheric science. In Proceedings of the ICLR AI for Earth Sciences Workshop, Online, 29 April 2020. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. In Workshop at International Conference on Learning Representations; Citeseer: Princeton, NJ, USA, 2014. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing higher-layer features of a deep network. Univ. Montr. 2009, 1341, 1. [Google Scholar]
- Yan, X.; Zang, Z.; Luo, N.; Jiang, Y.; Li, Z. New interpretable deep learning model to monitor real-time PM2. 5 concentrations from satellite data. Environ. Int. 2020, 144, 106060. [Google Scholar] [CrossRef]
- Bennett, A.; Nijssen, B. Explainable AI Uncovers How Neural Networks Learn to Regionalize in Simulations of Turbulent Heat Fluxes at FluxNet Sites; Earth and Space Science Open Archive ESSOAr: Washington, DC, USA, 2021. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [Green Version]
- Roscher, R.; Bohn, B.; Duarte, M.F.; Garcke, J. Explainable machine learning for scientific insights and discoveries. IEEE Access 2020, 8, 42200–42216. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems 30 (NeurIPS 2017 Proceedings); Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; NeurIPS: Long Beach, CA, USA, 2017; pp. 4765–4774. [Google Scholar]
- Toms, B.A.; Barnes, E.A.; Hurrell, J.W. Assessing Decadal Predictability in an Earth-System Model Using Explainable Neural Networks. Geophys. Res. Lett. 2021, e2021GL093842. [Google Scholar] [CrossRef]
- Schramowski, P.; Stammer, W.; Teso, S.; Brugger, A.; Herbert, F.; Shao, X.; Luigs, H.G.; Mahlein, A.K.; Kersting, K. Making deep neural networks right for the right scientific reasons by interacting with their explanations. Nat. Mach. Intell. 2020, 2, 476–486. [Google Scholar] [CrossRef]
- Lapuschkin, S.; Wäldchen, S.; Binder, A.; Montavon, G.; Samek, W.; Müller, K.R. Unmasking Clever Hans predictors and assessing what machines really learn. Nat. Commun. 2019, 10, 1096. [Google Scholar] [CrossRef] [Green Version]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning, 1st ed.; MIT Press Cambridge: Cambridge, UK, 2016. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Probst, P.; Wright, M.N.; Boulesteix, A.L. Hyperparameters and tuning strategies for random forest. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1301. [Google Scholar] [CrossRef] [Green Version]
- Bilgin, Z.; Gunestas, M. Explaining Inaccurate Predictions of Models through k-Nearest Neighbors. In Proceedings of the International Conference on Agents and Artificial Intelligence, Online, 4–6 February 2021; pp. 228–236. [Google Scholar]
- Meyer, H.; Pebesma, E. Predicting into unknown space? Estimating the area of applicability of spatial prediction models. Methods Ecol. Evol. 2021, 12, 1620–1633. [Google Scholar] [CrossRef]
- Sofen, E.; Bowdalo, D.; Evans, M. How to most effectively expand the global surface ozone observing network. Atmos. Chem. Phys. 2016, 16, 1445–1457. [Google Scholar] [CrossRef] [Green Version]
- Petermann, E.; Meyer, H.; Nussbaum, M.; Bossew, P. Mapping the geogenic radon potential for Germany by machine learning. Sci. Total Environ. 2021, 754, 142291. [Google Scholar] [CrossRef]


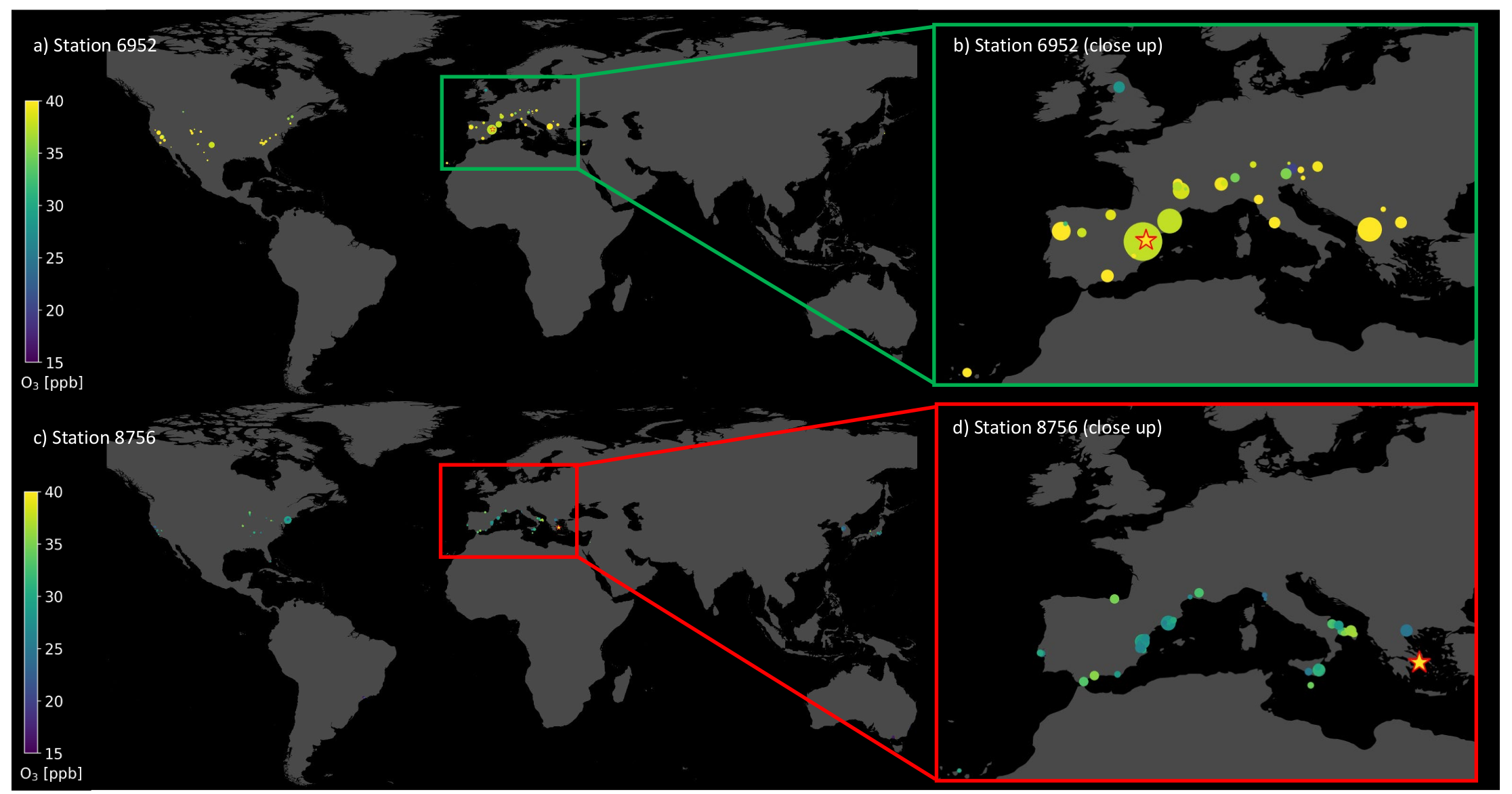
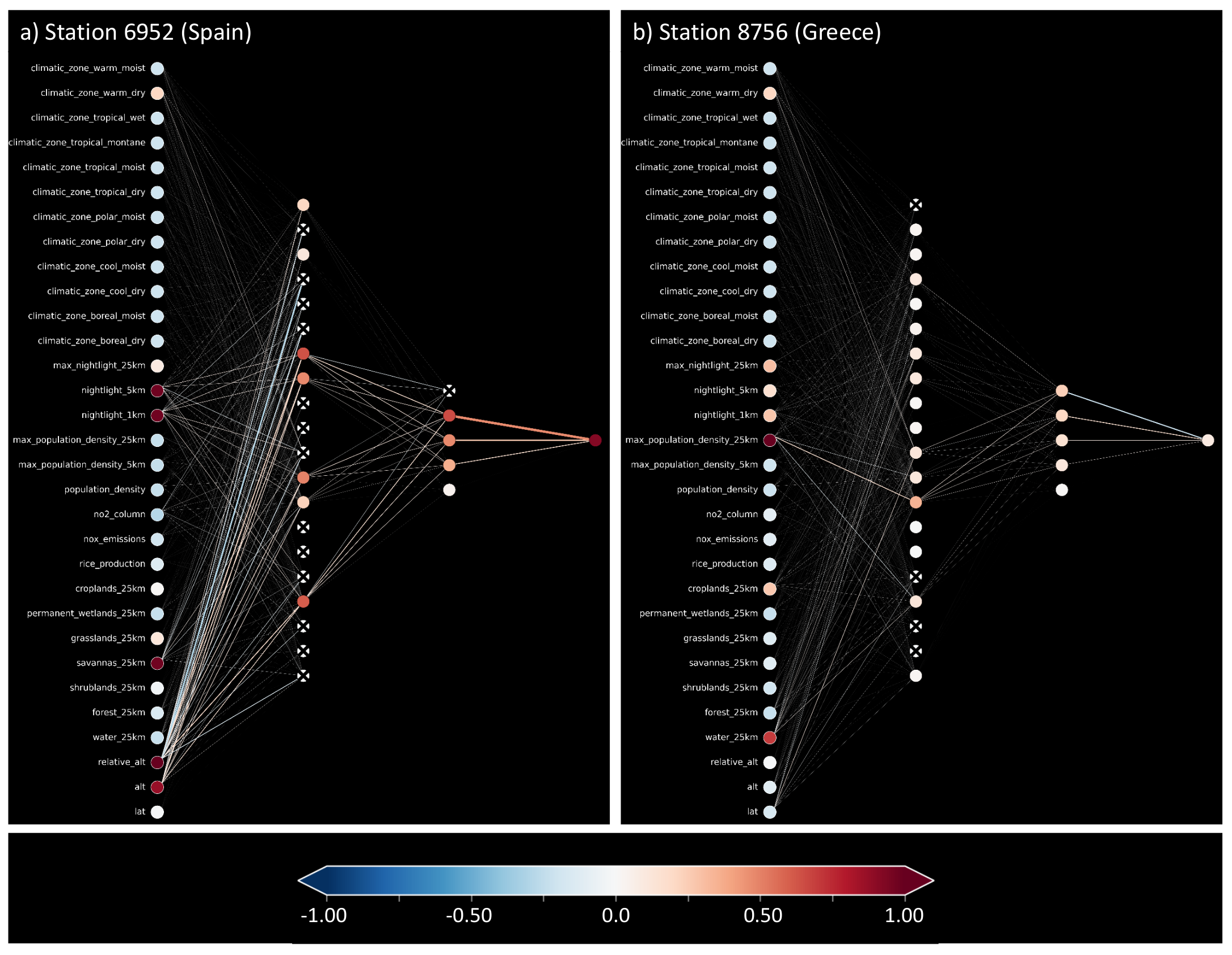
| Station ID | Observation y | ||||
|---|---|---|---|---|---|
| 6952 | 42.44 | 42.00 | 0.43 | 41.99 | 0.44 |
| 8756 | 40.17 | 29.32 | 10.86 | 27.45 | 12.72 |
| Feature Description | Importance RF [%] | Importance NN [%] |
|---|---|---|
| Absolute latitude | 23.96 | 20.5 |
| Relative altitude | 16.21 | 11.93 |
| Altitude | 10.44 | 8.16 |
| Nightlight in 5 km area | 9.73 | 4.35 |
| Forest in 25 km area | 5.37 | 13.54 |
| Population density | 4.41 | 1.8 |
| Nightlight in 1 km area | 4.12 | 8.77 |
| Water in 25 km area | 4.11 | 7.5 |
| Maximum population density in 25 km area | 3.54 | 0.32 |
| NO emissions | 3.51 | 6.31 |
| Maximum population density in 5 km area | 3.04 | 1.21 |
| Savannas in 25 km area | 2.68 | 0.84 |
| Croplands in 25 km area | 1.73 | 1.74 |
| Grasslands in 25 km area | 1.68 | 0.77 |
| NO emissions | 1.62 | 0.84 |
| Warm, dry climate | 1.18 | 5.27 |
| Shrublands in 25 km area | 0.65 | 1.67 |
| Maximum nightlight in 25 km area | 0.35 | 0.39 |
| Warm, moist climate | 0.33 | 2.49 |
| Cool, moist climate | 0.32 | 0.14 |
| Rice production | 0.3 | 0.58 |
| Permanent wetlands in 25 km area | 0.27 | 0.15 |
| Cool, dry climate | 0.25 | 0.13 |
| Tropical, dry climate | 0.14 | 0.13 |
| Tropical, wet climate | 0.03 | 0.11 |
| Tropical, moist climate | 0.02 | 0.09 |
| Boreal, moist climate | 0.0 | 0.11 |
| Polar, moist climate | 0.0 | 0.07 |
| Boreal, dry climate | 0.0 | 0.1 |
| Polar, dry climate | 0.0 | 0.0 |
| Tropical, montane climate | 0.0 | 0.0 |
| Random Forest | [%] | RMSE [ppb] |
|---|---|---|
| Training | 95.75 | 1.33 |
| Validation | 56.99 | 4.08 |
| Test | 53.03 | 4.46 |
| Neural Network | ||
| Training | 64.21 | 3.52 |
| Validation | 58.34 | 3.87 |
| Test | 49.46 | 4.59 |
| Random Forest | [%] | RMSE [ppb] |
|---|---|---|
| Reference | 53.03 | 4.46 |
| Test | 52.32 | 4.49 |
| Neural Network | ||
| Reference | 49.46 | 4.59 |
| Test | 47.45 | 4.72 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stadtler, S.; Betancourt, C.; Roscher, R. Explainable Machine Learning Reveals Capabilities, Redundancy, and Limitations of a Geospatial Air Quality Benchmark Dataset. Mach. Learn. Knowl. Extr. 2022, 4, 150-171. https://doi.org/10.3390/make4010008
Stadtler S, Betancourt C, Roscher R. Explainable Machine Learning Reveals Capabilities, Redundancy, and Limitations of a Geospatial Air Quality Benchmark Dataset. Machine Learning and Knowledge Extraction. 2022; 4(1):150-171. https://doi.org/10.3390/make4010008
Chicago/Turabian StyleStadtler, Scarlet, Clara Betancourt, and Ribana Roscher. 2022. "Explainable Machine Learning Reveals Capabilities, Redundancy, and Limitations of a Geospatial Air Quality Benchmark Dataset" Machine Learning and Knowledge Extraction 4, no. 1: 150-171. https://doi.org/10.3390/make4010008
APA StyleStadtler, S., Betancourt, C., & Roscher, R. (2022). Explainable Machine Learning Reveals Capabilities, Redundancy, and Limitations of a Geospatial Air Quality Benchmark Dataset. Machine Learning and Knowledge Extraction, 4(1), 150-171. https://doi.org/10.3390/make4010008