1. Introduction
Sports broadcasting and streaming are becoming increasingly popular, and the interest for viewing videos from sports events grows daily. For example,
billion viewers tuned in to watch the 2018 FIFA World Cup [
1], and as of 2020, soccer had a global market share of about
of the 250 billion USD spectator sports industry [
2]. The amount of content worldwide, such as footage, event highlights, goal and player statistics, scores, and rankings, is enormous, not to mention rapidly growing, and there is a huge interest from numerous actors to consume this available content. In this respect, it is important to provide game summaries, as has been done for decades, and more recently, to dedicate streams for particular categories of events, such as goals, cards, saves, and penalties. However, generating such summaries and event highlights requires the tedious and expensive task of manually detecting and clipping events. The process of generating summaries, event highlights, and tags is often performed redundantly by different actors for different purposes.
A typical tagging center in live operation for both broadcast and streaming services is shown in
Figure 1, where a first-level operator can follow one or more games concurrently, and by the push of a button at the time of an event, publish the event to users. Note that not all tagging centers neccessarily use the same kind of pipeline (two levels of operation introduced to reduce the publishing latency, by annotating first and refining the event later); however, the same type of costly operations are still required, regardless of the complexity of the labeling procedure, i.e., splitting the task into two levels, or undertaking it as a single combined procedure. The published event is then often automatically clipped using static “−A” frames and “+B” frames from the annotated event position. Depending on the available resources, a second-level manual and more fine-granular annotation operation can be performed. This is a relatively time-consuming operation, but it is of significant importance to improve the user experience of viewers.
In this context, automating the entire pipeline is considered to be the “holy grail” in sports video production, since it would allow for the faster generation of game highlights at a much lower cost and with lower latency. Here, recent developments in artificial intelligence (AI) technology have shown great potential, but state-of-the-art results [
3,
4,
5,
6,
7] are far from good enough for practical scenarios that have demanding real-time requirements, where the detection of certain events such as goals and cards must have
accuracy. Even though the detection operation has by far received the most attention, it is probably the easiest initial operation in the overall tagging pipeline, which potentially includes various other operations after event detection.
In this paper, we focus on improving the second level of operations—namely, the more time-consuming and expensive, fine-grained annotation stage, where manually detected events are enhanced and refined. Automating this process has the potential to both save resources and improve quality, as this last production step is often not performed due to time limitations and costs. We aim to develop an AI-based solution to identify appropriate time intervals to highlight clips on a video’s timeline by defining the optimal start and stop point for each event. Thus, instead of a human operator manually searching frame-by-frame back and forth, we use AI technology to find scene changes, game turnovers, logo transitions, cheering, and replays to detect an event’s time interval automatically. In particular, after experimenting with a variety of Machine Learning (ML) models, we present a system that can find logo transitions using models based on ResNet [
8] and VGG [
9] and undertake scene boundary detection using a TransNet V2 [
10] model pre-trained on the ClipShots [
11] and IACC.3 [
12] datasets. Cheering by players and fans can optionally be removed by detecting scenes between the event and replays. These sub-systems are then combined into an automated clipping system. Our experimental results show that both scene changes and logo transitions are detected with high accuracy, and a subjective assessment from 61 participants clearly indicates that an automated system can provide event highlights of high quality.
This work is a continuation of [
13], where an initial event detection framework based on logo transition and scene boundary detection was proposed. We extend this work by making the following contributions:
We elaborate further on the logo detection component, providing more details on the technical implementation, and additionally present a complexity analysis in terms of execution time;
We elaborate further on the scene boundary detection component, providing more details on the technical implementation, and additionally present an analysis of misclassified transitions (false positives and false negatives);
We add a new component to our pipeline, whereby cheering and celebration scenes can optionally be trimmed;
We provide a more detailed description of the datasets and performance metrics we have used;
We run a subjective evaluation (user study) involving 61 participants in order to evaluate the quality of our overall pipeline and present the results in the form of an A/B study across various participant classes;
We add a discussion of the potential pitfalls of our pipeline and the generalizability of our approach.
In summary, we have developed an algorithmic video clipping system for soccer, which is able to perform in real-time, automating the most labor-intensive part of the highlight generation process and potentially reducing production costs. Such a system is applicable to various other sports broadcasts such as skiing, handball, or ice hockey, and presents a viable potential to affect future sports productions.
The rest of this paper is organized as follows. In
Section 2, we provide a brief overview of related work in the fields of action detection and event clipping. We elaborate on our proposed framework in
Section 3, followed by our implementation and experiments in
Section 4. We present the results from our subjective evaluation campaign in
Section 5. We raise a number of discussion points in
Section 6 and conclude the paper in
Section 7.
2. Related Work
Recent research has successfully used ML to solve video-related problems and to present viewers with video segments of desired events in an efficient manner. Here, we present selected works in the area of event detection and event clipping.
Event detection, also called action detection or action spotting, has lately received a great deal of attention. For example, multiple variants of two-stream convolutional neural networks (CNNs) have been applied to the problem [
14,
15] and extended to include 3D convolution and pooling [
16,
17]. Wang et al. [
18,
19] proposed temporal segment networks (TSN), and C3D [
20] explored 3D convolution learning spatio-temporal features. Tran et al. [
21] used (2+1)D convolutions to allow the network to learn spatial and temporal features separately. Further approaches aim at finding temporal points in the timeline [
3,
7,
22,
23,
24,
25,
26], but even though many of these works present interesting approaches and promising results, such technologies are not yet ready to be used in real-life deployments. The reason is that most of the proposed models are computationally expensive and relatively inaccurate. In deployments where action/event annotation results are used in an official context (e.g., live sports broadcasts), these must be
accurate—i.e., no false alarms or missed events are allowed—so manual operations are still needed. In this paper, our goal is to automate the manual process of event tagging for soccer videos, while maintaining accuracy and efficiency.
In the area of
event clipping, the amount of existing work is limited. Koumaras et al. [
27] presented a shot detection algorithm, and Zawbaa et al. [
28] implemented a more tailored algorithm to handle cuts that transitioned gradually over several frames. Zawbaa et al. [
29] classified soccer video scenes as long, medium, close-up, and audience/out of field, and several papers presented good results regarding scene classification [
29,
30,
31]. Video clips can also contain replays after an event, and replay detection can help to filter out irrelevant replays. Ren et al. [
32] introduced the class labels play, focus, replay, and breaks. Detecting replays in soccer games using a logo-based approach was shown to be effective using a support vector machine (SVM) algorithm, but not as effective using an artificial neural network (ANN) [
28,
29]. Furthermore, it was shown that audio may be an important modality for finding good clipping points. Raventos et al. [
33] used audio features to give an importance score to video highlights, and Tjondronegoro et al. [
34] used audio for a summarization method, detecting whistle sounds based on the frequency and pitch of the audio. Finally, some work focused on learning spatio-temporal features using various ML approaches [
15,
17,
21], and Chen et al. [
35] used an entropy-based motion approach to address the problem of video segmentation in sports events.
These works indicate a potential for the AI-supported production of sports videos. For example, extracting temporal information can be very useful for generating highlight clips. However, the presented results are still limited, and most importantly, the actual event clipping operation is not addressed. Computing should be possible to undertake with very low latency, as the production of highlight clips needs to be done in real-time, for the majority of use cases.
4. Experiments and Results
In the following, we explain how we combined the individual components mentioned in
Section 3 into a full-fledged automated event clipping system. We experimented with various approaches for each component of our pipeline, and we finally present two models that automatically find the appropriate time interval for goal event extraction.
4.1. Datasets
To develop our automated clipping system, we used two different soccer datasets. We used the open SoccerNet v2 [
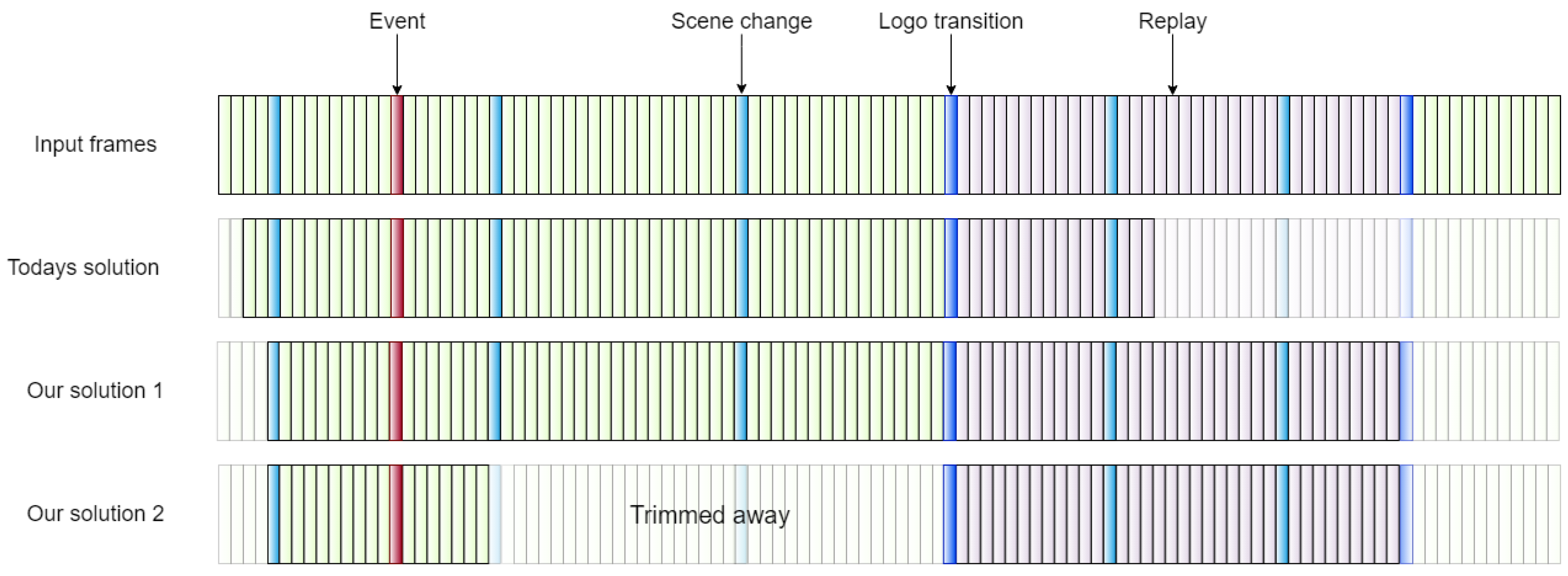
39] dataset and an in-house collected dataset of goals from the Norwegian “Eliteserien”. SoccerNet contains a large number of manually annotated, complete games with more than 100,000 different annotations across various event classes, with 1643 goals in particular, and around 150,000 scene change timestamps. Our “Eliteserien” dataset is smaller, with 300 clips of goals. These clips start 25 s before the annotated goal and end 50 s after. Furthermore, for scene boundary detection, we extracted 100 frames around each of the scene change timestamps of SoccerNet. We analyzed several sequences to get a better idea about how a goal event is built up and concluded that these events are typically structured as shown in the first row in
Figure 2.
4.2. Implementation Details
Our tested models were implemented using Python version 3.7.10 (gcc version 7.3.0) with Numpy 1.19.2, Keras 2.4.3, Sklearn 0.24.1, and Tensorflow 2.4.1, and the experiments were run on a DGX-2 server. Both datasets were split into train, validation, and test sets. For Eliteserien, we split each of the 50 clips into
train,
validation, and
test sets. The SoccerNet dataset is split according to the game that the frames are extracted from, and we used the split recommended by the SoccerNet team. This resulted in 29 games for training, 6 for validation, and 5 for testing. To avoid large weight values and to prevent the exploding gradient problem, we normalized our pixel values to be centered around zero—i.e., between
and 1—similar to the pre-processing function of ResNet50 V2 in Keras [
40]. Furthermore, when training our models, we augmented each image in the training set with a random degree of shear between 0 and
. Shear distorts the image along an axis to rectify the perception angles and can represent looking at an object from different angles. The images also were subjected to a random value between 0–20% of zoom for each axis independently. The lost pixels were filled with the nearest pixel’s value. There was also a
chance of horizontal flip. These augmentations happened on the fly with the use of Keras ImageDataGenerator [
41].
4.3. Metrics
To evaluate the performance of different ML models, we have used precision, recall, and F1-score. Given that the true positive (TP) is the number of samples correctly identified as positive, true negative (TN) is the number of samples correctly identified as negative, false positive (FP) is the number of samples wrongly identified as positive, and false negative (FN) is the number of samples wrongly identified as negative, these metrics are defined as follows:
- Recall
is a measure of sensitivity and is defined as the ratio of samples that are correctly identified as positive over all positive samples:
- Precision
is also called Positive Predictive Value (PPV) and is defined as the ratio of samples that are correctly identified as positive over all samples that are identified as positive (i.e., the fraction of retrieved samples that are actually relevant):
- F1 score
is defined as the harmonic mean of the precision and recall:
In addition to the above metrics, system performance metrics such as complexity, processing speed, and resource consumption are of interest. In our work, we have used the achieved frame rate (FPS) as a metric representing the ability of the system for performing in real-time.
4.4. Logo Detection Performance
As mentioned in
Section 3, we used VGG16 [
9], ResNet [
8], a simple CNN, and a lightweight VGG for the task of logo detection. To train the CNN models, we initialized the weights using the Glorot uniform initialization [
42] with the Adam optimizer [
43] to improve the weights. We used binary cross-entropy as the loss function. Because ResNet50 V2 comes with pre-trained weights on ImageNet [
44], we used these, and all data were pre-processed as described above. In general, we used a learning rate of
and a batch size of 32. We ran training with early stopping using a patience of 10 epochs, meaning that we stopped if the loss of the validation set did not improve for 10 epochs. We also reduced the learning rate by a factor of 10, with a patience of 7 epochs on plateau, meaning that there was no improvement for validation loss. This was to fine-tune the model in the last epochs. We ran training for a maximum of 40 epochs. For both Eliteserien and Premier League data, we used several input resolutions and switched between RGB (3 channels) and grayscale (1 channel) images as a trade-off between computation time and accuracy. To train the SVM models, we started by extracting features either using the VGG16 network or the simple CNN. Then, we used a grid search for hyper-parameter tuning (across different regularization parameter and learning rate values), which returned the best estimator. We defined a max iteration of 100 epochs.
Table 1 shows the top 10 models for the Eliteserien dataset, as tested on 50 different clips. It can be observed from these results that there is a good performance on the test set, with the VGG-inspired model using a grayscale
input reaching
recall and precision. The SVM-based model with different inputs shows similar scores, albeit slightly worse. We noticed that some models had a significant decrease in performance, especially on the recall, between the training and testing. This may be due to overfitting, which is discussed in
Section 6. The models correctly identify more than 15 frames, meaning they will still perform well as part of the logo detection component. As the test set is quite small and includes some team logos that are not present in the training set, even one misclassified logo frame can have a significant impact on the recall. While investigating the performance of the models on the full clips from Eliteserien, we deduced that all models perform well enough to find all logos we tested on without any false positives.
Table 2 shows the top 10 models for the larger Premier League dataset (extracted from SoccerNet), using the best configurations tuned on the validation set. The results for the CNNs are overall good, where the models are capable of finding most logos with few false negatives. If we consider the two-level tagging scenario mentioned earlier, where the first level marks the event on the timeline and publishes the event with a static clipping at the start (−A frames from the event frame) and stop (+B frames) times (see
Figure 1a), our module will have significantly fewer background frames, and the false negatives are a much smaller problem. We find that, even with more complex logos, our strategy works well.
Finally, to determine whether logos can be detected in real-time, we present the computational efficiency of various models and inputs in
Table 3. Regardless of the tested configurations, we observe that the processed frame rate is far beyond a 30 or 50 FPS real-time threshold. Even though the execution cost for the different CNN models is relatively high, we do not need to compromise in order to get acceptable performance in practice.
For use in our final system, we select the best-performing models on both datasets. The best model for Eliteserien is VGG-inspired with an input resolution of ( F1-score), and the best model for SoccerNet is ResNet with an input resolution of ( F1-score).
4.5. Scene Boundary Detection Performance
As mentioned in
Section 3, we used the TransNet V2 [
10] model for the task of scene boundary detection, which comes with a pre-trained model. We first compared the pre-trained model with the model trained on our soccer clips exclusively.
The SoccerNet scene boundary detection (SBD) dataset is a set of clips made from all shot boundary transitions in SoccerNet [
39], classified into abrupt, smooth, and logo transitions. TransNet V2 takes 100 frames as input in
resolution, and we therefore extracted 100 frames from each shot boundary. To make it more robust towards the variable placement of the boundary frame, we randomly selected a frame between frames 30 and 60, which were considered the shot boundary. We also made sure that close shot boundaries were also annotated for each of our clips. The dataset contains over 150,000 shot boundaries, with 43,000 logo transitions, 85,000 abrupt transitions, 28,000 smooth transitions, and 153 labeled “other”. The dataset uses the same train, validation, and test split as provided by [
3] in order to evaluate full-length matches as well. For the presented results, we used a tolerance of a predicted value of
frames, meaning the prediction must be within a distance of 24 frames of the actual scene change to be considered a true positive (correct prediction).
We start by testing on the SoccerNet SBD dataset to identify the performance on extracted scene changes. The results are presented in
Table 4. There are only small differences, but we can observe that the pre-trained model performs better than the model trained from scratch on all classes except for the abrupt class. On the abrupt class with the trained model, we observe a higher recall than that of the pre-trained model. We experience the same when we combine abrupt and gradual transitions in one metric. In the context of the function the component has in our system, we prioritize precision over recall, as the recall is high for both. The consequences of a false positive are more severe than those of a false negative, as it may result in a clip in the middle of a scene sequence. A false negative will lead to the system making a default cut, but false positives will potentially fool the system into including/excluding scenes that it is not supposed to.
To determine how accurately the model can predict scene changes on the entire videos, not only the single boundary clips, we repeated the experiment on the full SoccerNet test set, containing 100 full-length games. The results are shown in
Table 5. The recall performance is in line with the previous test, but we observe lower scores in general.
When analyzing the results per game, we observed an almost perfect score of above for some, while models predicted hundreds of false positives for others. This may be due to various match properties, such as team jersey and advertising board colors, lighting conditions, production style, etc., which caused a model to detect false positives. It is also possible that the quality of some of the annotations was poor, as false positives were clustered in the same matches. However, to investigate further, we manually reviewed some of the false positives and false negatives predicted by the pre-trained model.
We started with the matches from the test set from Premier League season 2016–2017. More carefully checking a large number of “false predictions”, we observed that several of them were wrongly classified as false; i.e., the annotators seem to have missed or omitted several scene changes in the annotation process. To identify more details, we analyzed 10 random soccer periods from 10 different games. After thoroughly considering 1378 false positives, we surprisingly learned that only 2 of them were actual errors. Almost all cases of the false negatives we observed were abrupt or smooth transitions. Moreover, looking at the false positives in
Figure 4, it is possible to observe the change of the background, which may easily be misclassified as an abrupt or fade transition. For false negatives (scene boundaries that the model misses to identify), we observed that these were mostly logos and smooth transitions. As illustrated in
Figure 5, these are very challenging cases.
Overall, we conclude that our scene boundary detection component has a good performance, and due to the slightly higher values for the pre-trained model, we use this model in our final pipeline. It should be noted here that in order to remain consistent and comparable with existing studies using the same well-established and benchmarked dataset, we chose to use our results based on the SoccerNet dataset as it is (without modification, e.g., with respect to potentially mislabeled samples) in our final pipeline.
4.6. Optional Trimming Performance
Our system can optionally remove cheering and celebration scenes to further reduce the length of a highlight clip. This is done by identifying scene changes between the main goal event and the replays, which often start with a logo transition. The first goal scene is almost always from a single camera, meaning that all camera/scene changes before the logo transition are most likely spectators cheering and players celebrating.
After the goal, we include X seconds of celebration. Empirically derived, we search for a scene change between 5–10 s after the goal, but if not found, we clip after 8 s by default. In order for the replay clips not to come in abruptly, we also include a part of the last scene before the replay begins; i.e., up to the last Y seconds of the last scene before the replay is included, with a maximum of 5 s. Our assumption is that a replay always comes with a logo transition before or after. If two logo transitions are detected, we assume that the replay begins after the first.
4.7. Final Pipeline
In our final pipeline, we combine the three components described above. In
Section 4.4, we have shown that the logo transition detection component performs well on both logo frame datasets. The best model for Eliteserien is VGG-inspired with an input resolution of
(100% F1-score), and the best model for SoccerNet is ResNet with an input resolution of
(
% F1-score). We use these models in our final pipeline. In
Section 4.5, we achieved good results from training TransNet V2 [
10] on SoccerNet; however, it did not outperform the pre-trained model trained on ClipShots [
11] and IACC.3 [
12]. We therefore use the pre-trained model in our final pipeline. In
Section 4.6, we described our initial tests to find suitable thresholds for trimming the video clip further by removing frames between the goal event and the replay. This component was designed by examining the production patterns in real soccer broadcasts. Clipping at scene changes can improve the quality by avoiding the scenario where a clip starts a few frames before a scene change. This utilizes the broadcast production as well, as a scene changes often happen when something exciting happens.
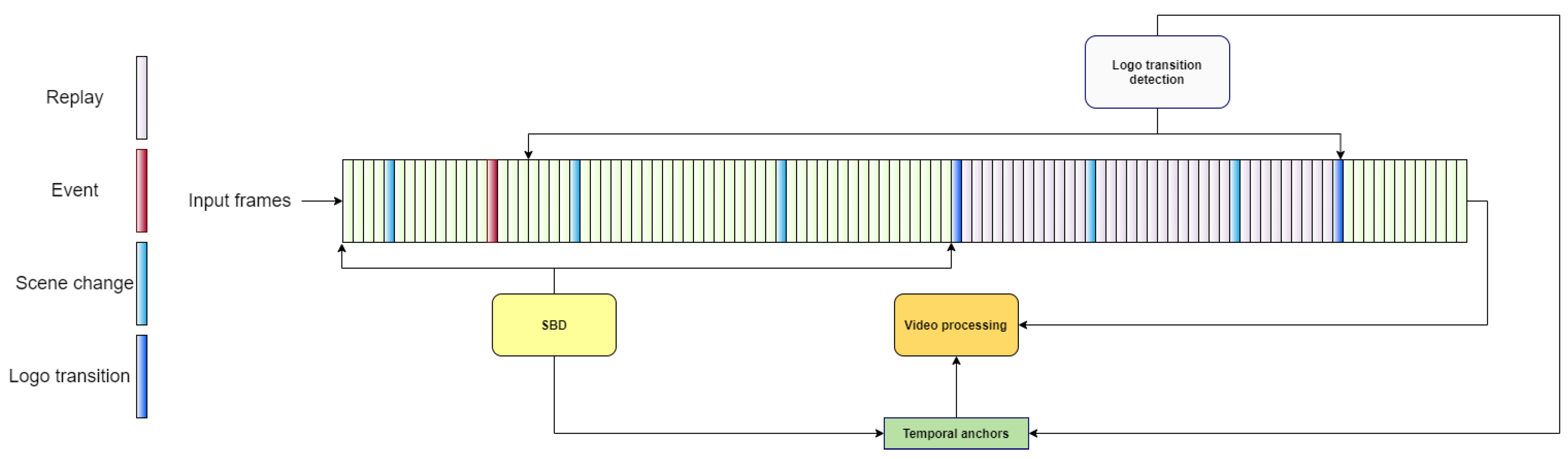
Our clipping system is depicted in
Figure 6. The input to the system is a frame sequence containing an annotated event from the first-level tagging operation, with enough video available on both sides of the event’s point in time. The system first identifies logo and scene boundary transitions, which are marked with timestamps. These timestamps are then used by a video processing module, which converts the input frame sequence into a final highlight clip based on the clipping protocol described in Algorithm 1.
As shown in
Figure 6, the SBD component is run from the start of the frame sequence and identifies a set of temporal anchor points (timestamps) that are potential clipping points. The logo transition detection component is run between the event itself and the end of the frame sequence and returns temporal anchor points that are potential clipping points for the end of the highlight clip. Together with the temporal anchor point of the annotated event itself (manually tagged by the first-level operator), these anchor points are inputs to the clipping procedure described in Algorithm 1 as
scene change transitions, logo transitions, event, and the actual clipping is undertaken by the module shown as “video processing” in
Figure 6.
The clipping protocol works as follows (Algorithm 1): it determines the start point based on the scene that starts 12 to 5 s (
startInterval) before the goal event. It chooses the scene furthest from the event. If there is no scene change, a default value of 10 s (
defaultStart) is used. The end point is chosen to be in the middle of the last logo transition, or if no logo transition is found, as the last scene between 8 s (
defaultCut) and 25 s (
defaultEnd) after the event. The
defaultEnd value is used if no scene change or logo transition is found. If the option to trim celebration scenes is enabled, the first 5–10 s (
cutInterval) after the event are searched for a scene change to identify the start of the cut. If no scene change is found, then the
defaultCut value is used as the start of the cut. All frames between this point and the first logo transition are cut.
| Algorithm 1: Clipping protocol for goal events. |
![Make 03 00049 i001]() |
5. Subjective Evaluation
The quality of a highlight clip is strongly subjective. Therefore, we also evaluated the performance of our pipeline in terms of end-user perception, in comparison to the static clipping method used by the industry today. We ran a subjective evaluation campaign via an online survey, where the participants were asked to visually compare and score different clipping methods. In particular, our goal was to benchmark the static clipping method with our pipeline (automatically generated highlight clips, with and without cheering scenes).
In total, 64 people participated in a user study, giving their consent for the collection of their metadata and answers. Participant metadata consisted of information about the participants such as age, gender, whether they have an interest in sports/soccer, their viewing habits, and whether they have video editing experience. In order to limit the length of our user study to 10–12 min, we randomly selected five events representing different goal situations as listed in
Table 6. We ran the following algorithms in various combinations on these five events:
Original: The default static clipping of −A and +B seconds around the identified point in time where the event happened;
Our model—full: Automatic clipping using logo transition and scene boundary detection;
Our model—short: Automatic clipping using logo transition and scene boundary detection, where we also shortened the clip by removing cheering and celebration scenes.
In each question corresponding to one event, a brief description of the event was provided, and the participants were asked to rate two alternative clips on a scale between 1 (very poor) to 10 (broadcast ready) and optionally give comments. Overall, all participants assessed the same 10 clips, in the same pairwise fashion, to provide trustful results and direct comparisons. After removing 3 outliers (participants who responded with a maximum rating to all clips), we ended up with 61 participants, male and female, in an age range between 19 and 59 years old.
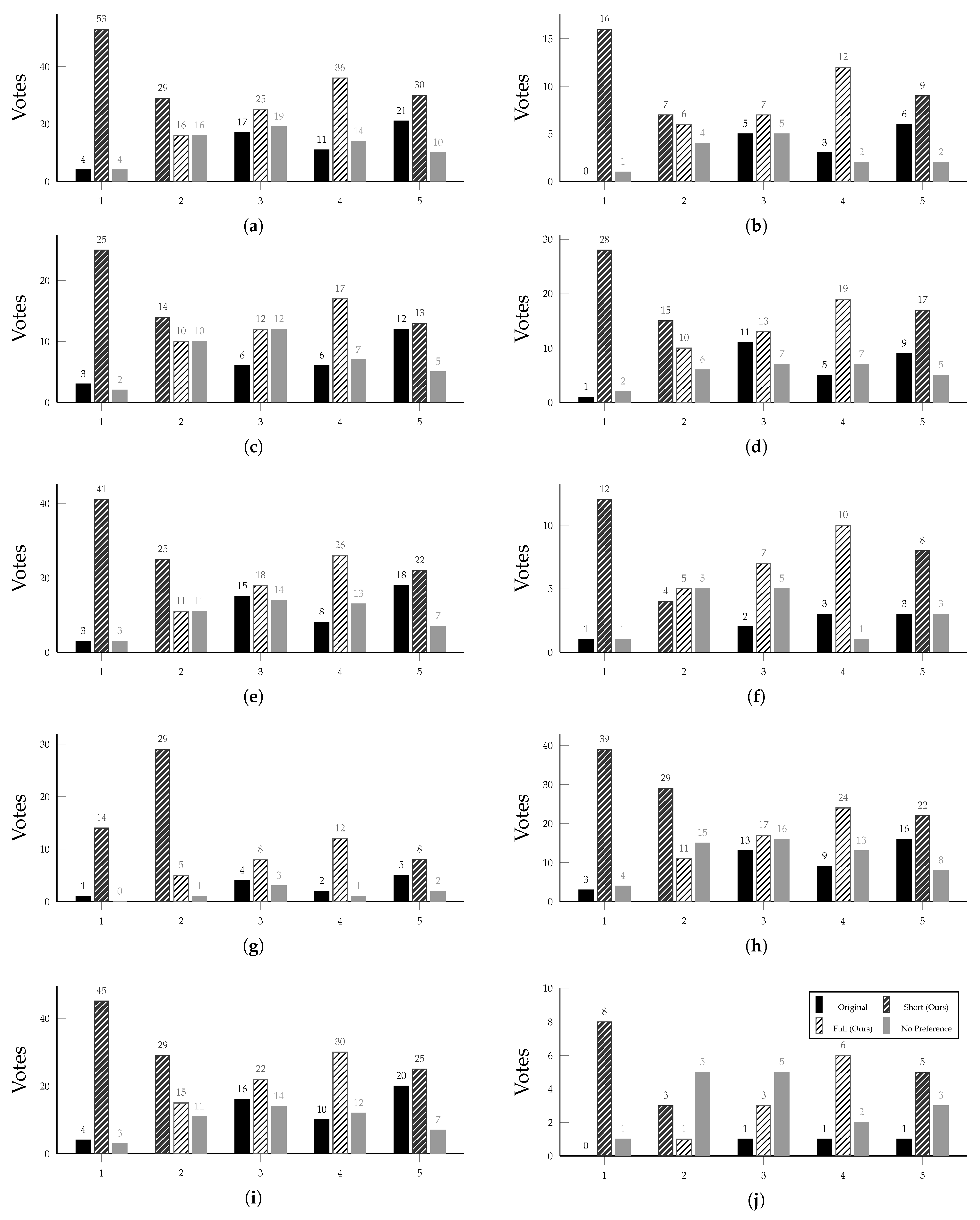
Figure 7 presents the results from our study, in the form of an A/B test. The overall scores over all participants are shown in
Figure 7a. As we can observe, our models received better scores over all comparisons, and the additional clipping that removed cheering scenes produced the most preferred highlight clips. Our “short” model received an average score of
, our “full” model an average of
, and the original model an average of
. Details about the scores for each participant class can be found in
Table 7. Among the participant class (b), those with video editing experience, two participants were professional editors. Both confirmed that our models result in a significant improvement over the original; i.e., giving our models
and
higher average scores on the Likert scale, respectively. However, the results also show that there is still some room for improvement. Considering the additional features often employed by traditional broadcast productions, such as scene fading, custom transitions, new audio tracks targeted for specific clips, etc., to improve viewer experience, it can be said that automated pipelines have some room to improve.
6. Discussion
Our proposed pipeline generates highlight clips that are accurate in terms of capturing logo transition and scene change boundaries, as well as being better perceived by viewers compared to traditional clipping methods. However, there was an open issue that we would like to address in this section.
Taking into account the results from
Section 4.4 for Eliteserien and comparing the performance of various models on the validation and test sets, we identified a possible overfitting problem.
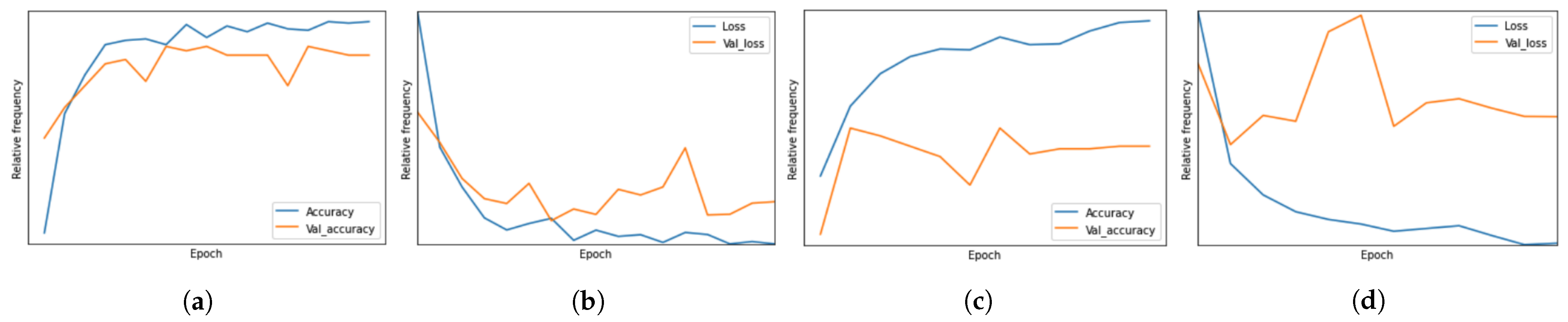
Figure 8 presents the learning curves for Simple CNN and ResNet, where ResNet training ran for 12 epochs, and the simple CNN ran for 14 epochs. For the ResNet model (
Figure 8c,d), the validation loss stops improving already after two epochs, while the training loss keeps improving. This suggests overfitting. The simple CNN model has a steadier decrease of loss before it stops improving afterseven epochs. This can be the result of a small dataset and low complexity.
Focusing in detail on the logos that are missed, we observed that most are within the first five frames of a team logo transition, and we noticed that these team logos are not present in the training set. To tackle this problem, we generated a synthetic dataset to train the models to recognize all team logos. We created a logo collection by extracting images from both Eliteserien and Premier League using the FFmpeg tool and then the surrounding frames to obtain the logo transition. Each lasted for 20 frames in total, 10 of which were fade-in, 5 fully covered the logo, and 5 were fade-outs. For a number of selected models, we checked the validation results from training on the dataset supplemented with synthetic logo frames. The results of this experiment demonstrated that training with the original training set together with our synthetic logo images led to an increase of recall and helped the models to recognize team logos that were not encountered during training. However, we also observed a decrease in precision for all models, as more backgrounds were now misclassified. Although overfitting can be a significant problem for some tasks, there is a limit to how much harm it can do for the task of logo detection, due to most frames in the transition being very similar. We observed that the models only misclassify the earliest frames while still hitting all the rest. Since all the frames later in the transition were correctly classified, we did not consider the trade-off to be worth the change in this case and decided not to go forward with these models. It should also be noted that the results of our study are hard to generalize across different broadcaster domains and production environments (e.g., different leagues). As can be seen from
Table 1 and
Table 2, even within the same content domain (soccer video), different models can be optimal for different datasets (Eliteserien and Premier League). Model configurations and training depend heavily on the target soccer league, as different leagues even have different logo transitions, and there are different production protocols on how scenes and replays are presented. Therefore, one cannot necessarily rely on the current version of our pipeline in plug-and-play form, and our selected models may need to be re-trained with relevant datasets from the corresponding soccer league.
7. Conclusions
An AI-based production pipeline can be of great value for broadcasters and streaming services that provide sports videos. In this context, we have experimented with automating the process of event clipping from soccer videos, using logo transition and scene boundary detection, and optional trimming. We found that different ML models work best for different datasets (soccer leagues from different countries). For logo detection, a VGG-inspired CNN using a grayscale input resolution of
was best for the Norwegian Eliteserien dataset, achieving a
F1-score, but for the more complex English Premier League logo dataset, a ResNet using an RGB input of resolution
was the best fit, achieving an
F1-score. Regarding scene boundary detection, we trained and evaluated TransNet-V2 [
10] on the SoccerNet shot boundary dataset but found the performance of the pre-trained version to be better, yielding an F1-score of
. We combined these models in an end-to-end event clipping pipeline. Running a subjective user study, we saw that our pipeline could consistently produce more compelling highlight clips compared to the traditional method based on static clipping, which is currently used in Eliteserien.
Based on objective metrics as well as a subjective evaluation, we showed that an automated pipeline is able to provide highlight clips of a reliable standard. We also identified that what is considered a compelling highlight clip is subjective, and there might be differences in the production strategy preferred by different viewers. Nevertheless, our work gives a strong foundation and motivation for future studies using ML to generate automatic highlight clips from soccer videos. AI-based automated systems can potentially save a great deal of manual resources and reduce costs for existing tagging centers, as well as facilitating the deployment of such centers for lower level leagues which do not have sufficient resources in the first place.
There are a number of aspects of our work that we plan to improve as future work. These include the handling of different types and even sub-types of events (e.g., different events in the same category such as corner goals, penalty goals, and counter-attack goals, as well as altogether different events such as cards and substitutions), the investigation of multiple modalities for event detection and clipping (e.g., using stadium and commentary audio alongside video), the exploration of different scene transitions (e.g., fade-in and fade-out at the cuts), and a large-scale benchmark study to compare against professionally clipped events in order to solidify the effectiveness of our system.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}