
Analysis of Explainers of Black Box Deep Neural Networks for Computer Vision: A Survey


Abstract
:1. Introduction
1.1. Motivation: Ethical Questions


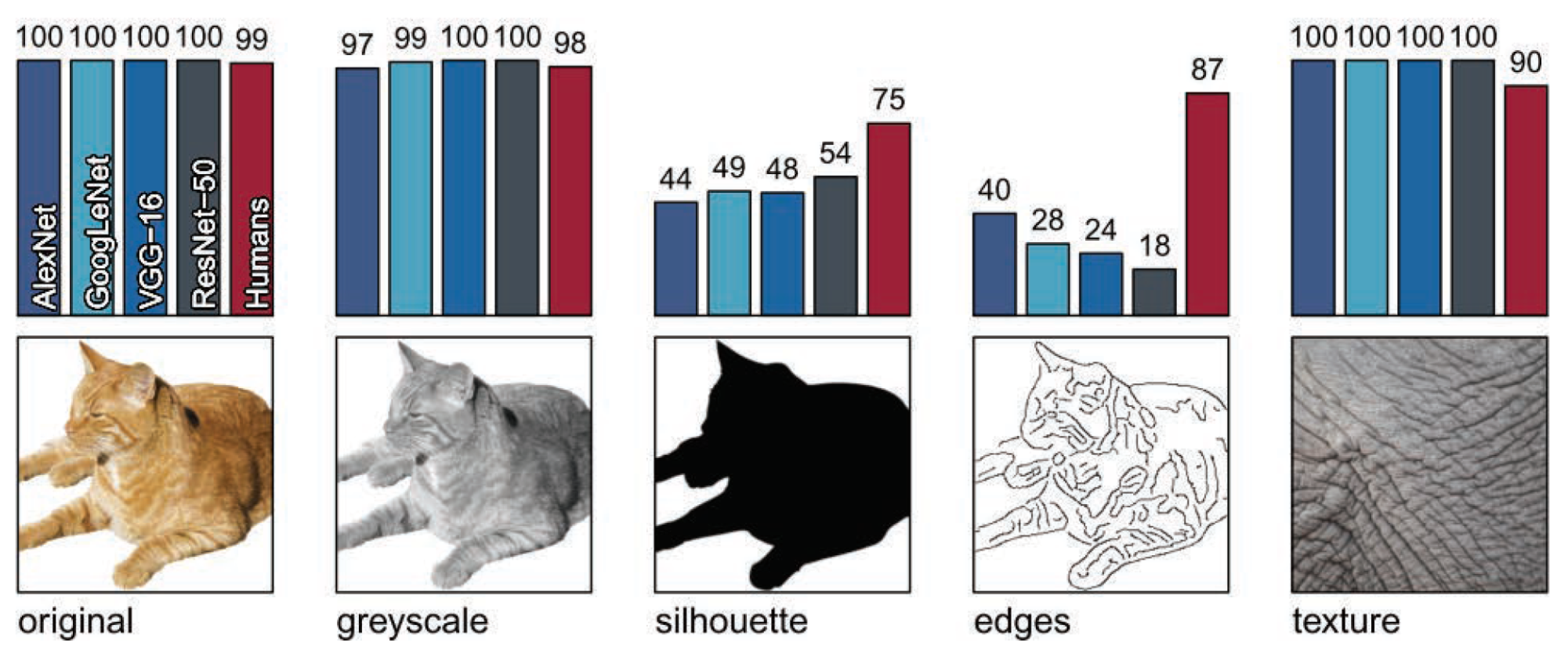
1.2. Contribution
2. Overview of Explaining Systems for DNNs
2.1. Early Machine Learning Explaining Systems
2.2. Methods and Properties of DNN Explainers
- Ante hoc or intrinsically interpretable models [50]. Ante hoc systems give explanations starting from the input of the model and going through the model parameter by parameter, for instance enabling one to gauge which decisions are made step by step until the predictions;
- Post hoc techniques entail baking explainability into a model from its outcome, such as marking what part of the input data is responsible to the final decision, for example in LIMEs. These methods can be applied more easily to different models, but say less about the whole model in general.
- Local; the model can be explained only for each single prediction;
- Global; the whole system can be explained and the logic can be followed from the input to every possible outcome.
- Model specific, tied to a particular type of black box or data;
- Model agnostic, indifferently usable.
- Another method is the decomposition, isolation, transfer, or limitation of portions of networks, e.g., layers to obtain further insights into which way single parts of the architecture influence the results [53], or Deep Taylor Decomposition (DTD) [54]. Automatic Rule Extraction and Decision Trees are anchored in this area, as well;
- Gradients or variants of (Guided) BackPropagation (GBP) can emphasize important unit changes and thereby draw attention to sensitive features or input data areas [55,56,57]. The magnitudes of gradients show the importance of input to output scores. With these techniques, it is also able to produce artificial prototype class member images that maximize a neuron activation or class confidence value [58,59].
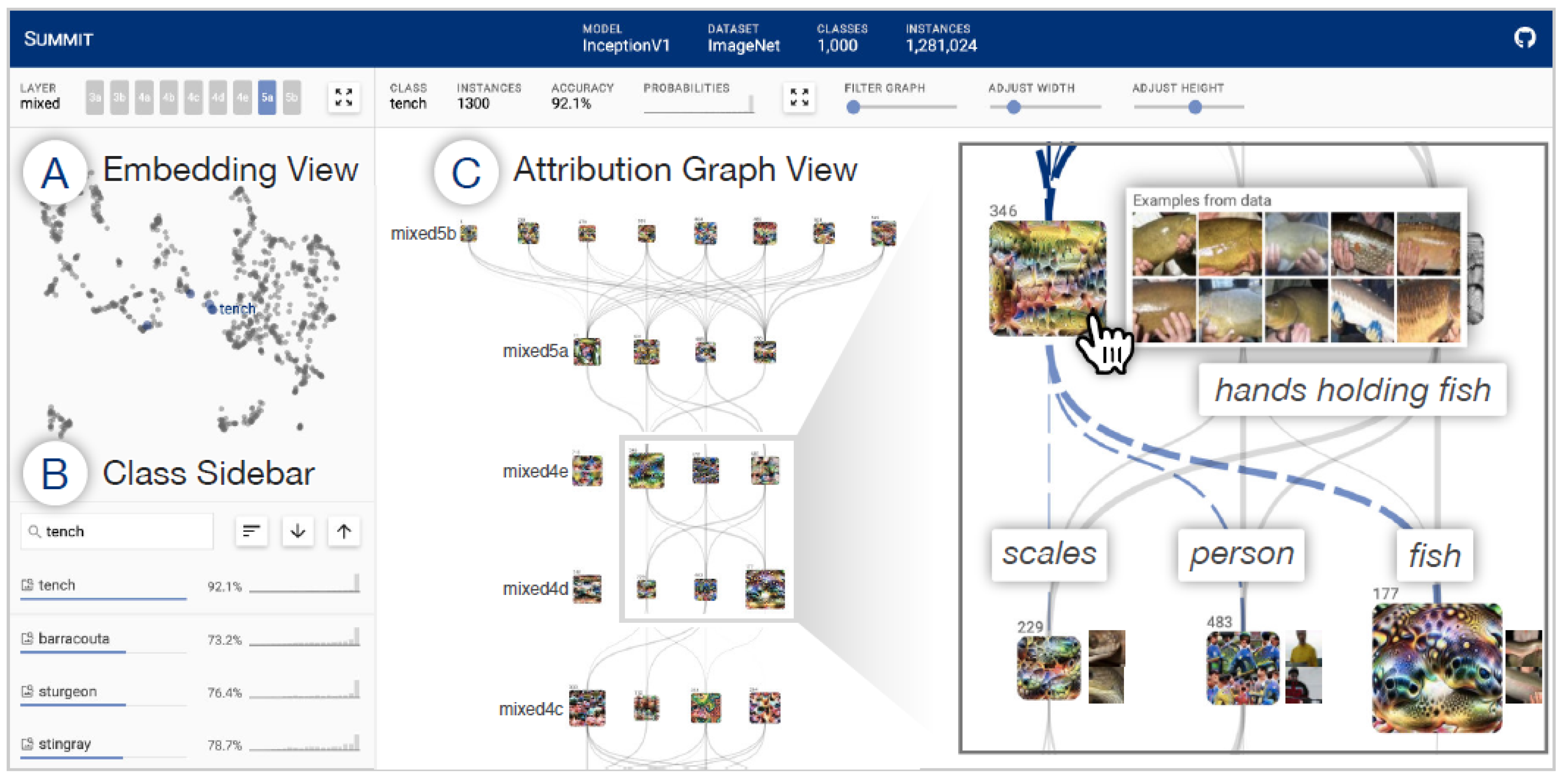
- Visualizations: To visualize an explanation, there are many options [60]. There are explainers that create visualizations that give an explanation by “digesting” the mechanisms of a model down to images, which themselves have to be interpreted. A further tool is to look at the activations produced on each layer of a trained CNN as it processes an image or video. Another one enables visualizing features at each layer of a DNN via regularized optimization in the image space [61]. Visualizations of particular neurons or neuron layers show responsible features that lead to a maximum activation or the highest possible probability of a prediction [62] and can be split into generative models or saliency maps. Salience maps of important features are calculated, and they show superpixels that have influenced the prediction most, for example [7] (Figure 6). To create a map of important pixels, one can repeatedly feed an architecture with several portions of inputs and compare the respective output, or one can visualize them directly by going rearwards through the inverted network from an output of interest;
- Grouped in this category as well is exploiting neural networks with activation atlases through feature inversion. This method can reveal how the network typically represents some concepts [63];
- Considering image or text portions that maximize the activation of interesting neurons or whole layers can lead to the interpretation of the responsible area of individual parts of the architecture.
- An explainer or explanator [48] is a synonym for an explaining system or explaining process that gives answers to questions in understandable terms, which could, computationally, be considered a program execution trace. For instance, if the question is how a machine is working, the explainer makes the internal structure of a machine more transparent to humans. A further question could be why a prediction was made instead of another, so the explainer should point to where the decision boundaries between classes are and why particular labels are predicted for different data points [66];
- Interpretability is a substantial first step to reach the comprehension of a complex conceptat some level of detail, but is insufficient alone [64];
- Explainability includes interpretability, but this does not always apply the other way round. It provides relevant responses to questions and subdivides their meaning into terms understandable by a human [64,67]. Explainability does not refer to a human model, but it technically highlights decision-relevant parts of machine representations [68];
- Comprehensibility or understandable explanation: An understandable explanation must be created by a machine in a given time (e.g., one hour or one day) and can be comprehended by a user, who need not to be an expert, but has an educational background. The user keeps asking a finite number of questions of the machine until he/she can no longer ask why or how because he/she has a satisfactory answer; we say he/she has comprehended.
- Completeness: A complete explanation records all possible attributes from the input to the output of a model. A DNN with its millions of parameters is too complex; hence, a complete explanation would not be understandable. This makes it necessary to focus on the most important reasons and not all of them;
- Compactness: A compact explanation has a finite number of aspects. Because the parameters and operations of a DNN are finite, one can obtain a complete explanation of a DNN after a finite number of steps. That is why compactness follows from completeness if the considered connections are finite. A DNN can be explained, for instance, completely and compactly or compactly and understandably;
- Causality: This is the relationship between cause and effect; it is not a synonym for causability;
- Causability: Causability is about measuring and ensuring the quality of an explanation and refers to a human model [68].
2.3. Selected DNN Explainers Presented
2.4. Analysis of Understanding and Explaining Methods
2.5. Open Problems in Understanding DNNs and Future Work
3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Das, A.; Rad, P. Opportunities and challenges in explainable artificial intelligence (xai): A survey. arXiv 2020, arXiv:2006.11371. [Google Scholar]
- Chen, Y.; Ouyang, L.; Bao, F.S.; Li, Q.; Han, L.; Zhu, B.; Ge, Y.; Robinson, P.; Xu, M.; Liu, J.; et al. An interpretable machine learning framework for accurate severe vs. non-severe COVID-19 clinical type classification. Lancet 2020. [Google Scholar] [CrossRef]
- Fan, X.; Liu, S.; Chen, J.; Henderson, T.C. An investigation of COVID-19 spreading factors with explainable ai techniques. arXiv 2020, arXiv:2005.06612. [Google Scholar]
- Karim, M.; Döhmen, T.; Rebholz-Schuhmann, D.; Decker, S.; Cochez, M.; Beyan, O. Deepcovidexplainer: Explainable COVID-19 predictions based on chest X-ray images. arXiv 2020, arXiv:2004.04582. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should i trust you? Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Moosavi-Dezfooli, S.M. DeepFool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Bose, A.J.; Aarabi, P. Adversarial attacks on face detectors using neural net based constrained optimization. In Proceedings of the IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018. [Google Scholar]
- Jia, R.; Liang, P. Adversarial examples for evaluating reading comprehension systems. arXiv 2017, arXiv:1707.07328. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust physical-world attacks on deep learning visual classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ranjan, A.; Janai, J.; Geiger, A.; Black, M.J. Attacking Optical Flow. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016. [Google Scholar]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. A General Framework for Adversarial Examples with Objectives. ACM Trans. Priv. Secur. (TOPS) 2019, 22, 1–30. [Google Scholar] [CrossRef]
- Goodman, F. European union regulations on algorithmic decision-making and a right to explanation. In Proceedings of the ICML Workshop on Human Interpretability in ML, New York, NY, USA, 23 June 2016. [Google Scholar]
- Muller, H.; Mayrhofer, M.T.; Van Veen, E.B.; Holzinger, A. The Ten Commandments of ethical medical AI. Computer 2021, 54, 119–123. [Google Scholar] [CrossRef]
- Holmes, J.; Meyerhoff, M. The Handbook of Language and Gender; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Bolukbasi, T.; Chang, K.W.; Zou, J.Y.; Saligrama, V.; Kalai, A.T. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Adv. Neural Inf. Process. Syst. 2016, 29, 4349–4357. [Google Scholar]
- Hirschberg, J.; Manning, C.D. Advances in natural language processing. Science 2015, 349, 261–266. [Google Scholar] [CrossRef]
- Greenwald, A.G.; McGhee, D.E.; Schwartz, J.L. Measuring individual differences in implicit cognition: The implicit association test. J. Personal. Soc. Psychol. 1998, 74, 1464–1480. [Google Scholar] [CrossRef]
- Chakraborty, T.; Badie, G.; Rudder, B. Reducing Gender Bias in Word Embeddings. Computer Science Department, Stanford University. 2016. Available online: http://cs229.stanford.edu/proj2016/report/ (accessed on 15 March 2018).
- Font, J.E.; Costa-Jussa, M.R. Equalizing gender biases in neural machine translation with word embeddings techniques. arXiv 2019, arXiv:1901.03116. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-trained CNNs are biased towards texture; Increasing shape bias improves accuracy and robustness. arXiv 2018, arXiv:1811.12231. [Google Scholar]
- Hastie, T.; Tibshirani, R. Generalized additive model (GAM). Stat. Sci. 1986, 1, 297–318. [Google Scholar]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees. Monterey; Wadsworth International Group: Monterey, CA, USA, 1984. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics New York; Springer: New York, NY, USA, 2001. [Google Scholar]
- Salzberg, S.L. C4. 5: Programs for Machine Learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc., 1993; Kluwer Academic: Boston, MA, USA, 1994. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Goldstein, A.; Kapelner, A.; Bleich, J.; Pitkin, E. Peeking inside the black box: Visualizing statistical learning with plots of individual conditional expectation. J. Comput. Graph. Stat. 2015, 24, 44–65. [Google Scholar] [CrossRef]
- Van Lent, M.; Fisher, W.; Mancuso, M. An explainable artificial intelligence system for small-unit tactical behavior. In Proceedings of the National Conference on Artificial Intelligence, San Jose, CA, USA, 25–29 July 2004. [Google Scholar]
- Shortliffe, E.H. Mycin: A knowledge-based computer program applied to infectious diseases. In Proceedings of the Annual Symposium on Computer Application in Medical Care, San Francisco, CA, USA, 5 October 1997; American Medical Informatics Association: Bethesda, MD, USA, 1977. [Google Scholar]
- Baehrens, D.; Schroeter, T.; Harmeling, S.; Kawanabe, M.; Hansen, K.; MÞller, K.R. How to explain individual classification decisions. J. Mach. Learn. Res. 2010, 11, 1803–1831. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Kononenko, I. Inductive and Bayesian learning in medical diagnosis. Appl. Artif. Intell. Int. J. 1993, 7, 317–337. [Google Scholar] [CrossRef]
- Becker, B.; Kohavi, R.; Sommerfield, D. Visualizing the simple Bayesian classifier. In Information Visualization in Data Mining and Knowledge Discovery; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 237–249. Available online: https://dl.acm.org/doi/10.5555/383784.383809 (accessed on 7 October 2021).
- Možina, M.; Demšar, J.; Kattan, M.; Zupan, B. Nomograms for visualization of naive Bayesian classifier. In European Conference on Principles of Data Mining and Knowledge Discovery, Proceedings of the 8th European Conference on Principles and Practice of Knowledge Discovery in Databases, Pisa, Italy, 20–24 September 2004; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Poulet, F. Svm and graphical algorithms: A cooperative approach. In Proceedings of the Fourth IEEE International Conference on Data Mining (ICDM’04), Brighton, UK, 1–4 November 2004. [Google Scholar]
- Hamel, L. Visualization of support vector machines with unsupervised learning. In Proceedings of the IEEE Symposium on Computational Intelligence and Bioinformatics and Computational Biology, Toronto, ON, Canada, 28–29 September 2006. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Ciresan, D.; Giusti, A.; Gambardella, L.M.; Schmidhuber, J. Deep neural networks segment neuronal membranes in electron microscopy images. Adv. Neural Inf. Process. Syst. 2012, 25, 2843–2851. [Google Scholar]
- Ciresan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Le, Q.V.; Zou, W.Y.; Yeung, S.Y.; Ng, A.Y. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2019, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Goebel, R.; Chander, A.; Holzinger, K.; Lecue, F.; Akata, Z.; Stumpf, S.; Kieseberg, P.; Holzinger, A. Explainable AI: The new 42? In International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Proceedings of the Second IFIP TC 5, TC 8/WG 8.4, 8.9, TC 12/WG 12.9 International Cross-Domain Conference, CD-MAKE 2018, Hamburg, Germany, 27–30 August 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Lipton, Z.C. The mythos of model interpretability. arXiv 2016, arXiv:1606.03490. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layerwise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [Green Version]
- Montavon, G.; Lapuschkin, S.; Binder, A.; Samek, W.; Müller, K.R. Explaining nonlinear classification decisions with deep taylor decomposition. Pattern Recognit. 2017, 65, 211–222. [Google Scholar] [CrossRef]
- Springenberg, J.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. In Proceedings of the ICLR (Workshop Track), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In European Conference on Computer Vision (ECCV), Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Zhang, J.; Bargal, S.A.; Lin, Z.; Brandt, J.; Shen, X.; Sclaroff, S. Top-down neural attention by excitation backprop. Int. J. Comput. Vis. 2018, 126, 1084–1102. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, A.; Dosovitskiy, A.; Yosinski, J.; Brox, T.; Clune, J. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. Adv. Neural Inf. Process. Syst. 2016, 29, 3387–3395. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Samek, W.; Binder, A.; Montavon, G.; Lapuschkin, S.; Müller, K.R. Evaluating the visualization of what a deep neural network has learned. IEEE Trans. Neural Networks Learn. Syst. 2016, 28, 2660–2673. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Nguyen, A.; Fuchs, T.; Lipson, H. Understanding neural networks through deep visualization. arXiv 2015, arXiv:1506.06579. [Google Scholar]
- Dosovitskiy, A.; Brox, T. Inverting visual representations with convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Carter, S.; Armstrong, Z.; Schubert, L.; Johnson, I.; Olah, C. Activation Atlas. Distill 2019, 4, e15. [Google Scholar] [CrossRef]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018. [Google Scholar]
- Remler, D.K.; Van Ryzin, G.G. Research Methods in Practice: Strategies for Description and Causation; Sage Publications: Thousand Oaks, CA, USA, 2014. [Google Scholar]
- Ridgeway, G.; Madigan, D.; Richardson, T.; O’Kane, J. Interpretable Boosted Naïve Bayes Classification; AAAI: Palo Alto, CA, USA, 1998. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Holzinger, A.; Malle, B.; Saranti, A.; Pfeifer, B. Towards multi-modal causability with Graph Neural Networks enabling information fusion for explainable AI. Inf. Fusion 2021, 71, 28–37. [Google Scholar] [CrossRef]
- Martens, D.; Vanthienen, J.; Verbeke, W.; Baesens, B. Performance of classification models from a user perspective. Decis. Support Syst. 2011, 51, 782–793. [Google Scholar] [CrossRef]
- Freitas, A.A. Comprehensible classification models: A position paper. ACM SIGKDD Explor. Newsl. 2014, 15, 1–10. [Google Scholar] [CrossRef]
- Letham, B.; Rudin, C.; McCormick, T.H.; Madigan, D. Interpretable classifiers using rules and bayesian analysis: Building a better stroke prediction model. Ann. Appl. Stat. 2015, 9, 1350–1371. [Google Scholar] [CrossRef]
- Ustun, B.; Rudin, C. Methods and models for interpretable linear classification. arXiv 2014, arXiv:1405.4047. [Google Scholar]
- Letham, B.; Rudin, C.; McCormick, T.H.; Madigan, D. An interpretable stroke prediction model using rules and Bayesian analysis. In Proceedings of the Workshops at the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013. [Google Scholar]
- Zilke, J.R.; Mencía, E.L.; Janssen, F. DeepRED—Rule extraction from deep neural networks. In International Conference on Discovery Science, Proceedings of the 19th International Conference, DS 2016, Bari, Italy, 19–21 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Fu, L. Rule generation from neural networks. IEEE Trans. Syst. Man Cybern. 1994, 24, 1114–1124. [Google Scholar]
- Craven, M.; Shavlik, J.W. Extracting tree-structured representations of trained networks. Adv. Neural Inf. Process. Syst. 1996, 8, 24–30. [Google Scholar]
- Bottou, L.; Peters, J.; Quiñonero-Candela, J.; Charles, D.X.; Chickering, D.M.; Portugaly, E.; Ray, D.; Simard, P.; Snelson, E. Counterfactual reasoning and learning systems: The example of computational advertising. J. Mach. Learn. Res. 2013, 14. [Google Scholar]
- Hainmueller, J.; Hazlett, C. Kernel regularized least squares: Reducing misspecification bias with a flexible and interpretable machine learning approach. Politi. Anal. 2014, 22, 143–168. [Google Scholar] [CrossRef]
- Nie, W.; Zhang, Y.; Patel, A. A theoretical explanation for perplexing behaviors of backpropagation-based visualizations. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 3809–3818. [Google Scholar]
- Kindermans, P.J.; Schütt, K.T.; Alber, M.; Müller, K.R.; Erhan, D.; Kim, B.; Dähne, S. Learning how to explain neural networks: Patternnet and patternattribution. arXiv 2017, arXiv:1705.05598. [Google Scholar]
- Haufe, S.; Meinecke, F.; Görgen, K.; Dähne, S.; Haynes, J.D.; Blankertz, B.; Bießmann, F. On the interpretation of weight vectors of linear models in multivariate neuroimaging. Neuroimage 2014, 87, 96–110. [Google Scholar] [CrossRef] [Green Version]
- Lakkaraju, H.; Bach, S.H.; Leskovec, J. Interpretable decision sets: A joint framework for description and prediction. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Choi, E.; Bahadori, M.T.; Sun, J.; Kulas, J.; Schuetz, A.; Stewart, W. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chattopadhyay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V. Grad-CAM++: Generalized Gradient-based Visual Explanations for Deep Convolutional Networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Anonymous. On Evaluating Explainability Algorithms. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Babiker, H.K.B.; Goebel, R. An introduction to deep visual explanation. arXiv 2017, arXiv:1711.09482. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Babiker, H.K.B.; Goebel, R. Using KL-divergence to focus deep visual explanation. arXiv 2017, arXiv:1711.06431. [Google Scholar]
- Zintgraf, L.M.; Cohen, T.S.; Adel, T.; Welling, M. Visualizing deep neural network decisions: Prediction difference analysis. arXiv 2017, arXiv:1702.04595. [Google Scholar]
- Robnik-Šikonja, M.; Kononenko, I. Explaining classifications for individual instances. IEEE Trans. Knowl. Data Eng. 2008, 20, 589–600. [Google Scholar] [CrossRef] [Green Version]
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.; Wattenberg, M. Smoothgrad: Removing noise by adding noise. arXiv 2017, arXiv:1706.03825. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70. [Google Scholar]
- Huk Park, D.; Anne Hendricks, L.; Akata, Z.; Rohrbach, A.; Schiele, B.; Darrell, T.; Rohrbach, M. Multimodal explanations: Justifying decisions and pointing to the evidence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hohman, F.; Park, H.; Robinson, C.; Chau, D.H. Summit: Scaling Deep Learning Interpretability by Visualizing Activation and Attribution Summarizations. arXiv 2019, arXiv:1904.02323. [Google Scholar]
- Buhrmester, V.; Münch, D.; Bulatov, D.; Arens, M. Evaluating the Impact of Color Information in Deep Neural Networks. In Iberian Conference on Pattern Recognition and Image Analysis, Proceedings of the 9th Iberian Conference, IbPRIA 2019, Madrid, Spain, 1–4 July 2019; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Sturm, I.; Lapuschkin, S.; Samek, W.; Müller, K.R. Interpretable deep neural networks for single-trial EEG classification. J. Neurosci. Methods 2016, 274, 141–145. [Google Scholar] [CrossRef] [Green Version]
- Bojarski, M.; Choromanska, A.; Choromanski, K.; Firner, B.; Jackel, L.; Muller, U.; Zieba, K. Visualbackprop: Visualizing cnns for autonomous driving. arXiv 2016, arXiv:1611.05418. [Google Scholar]
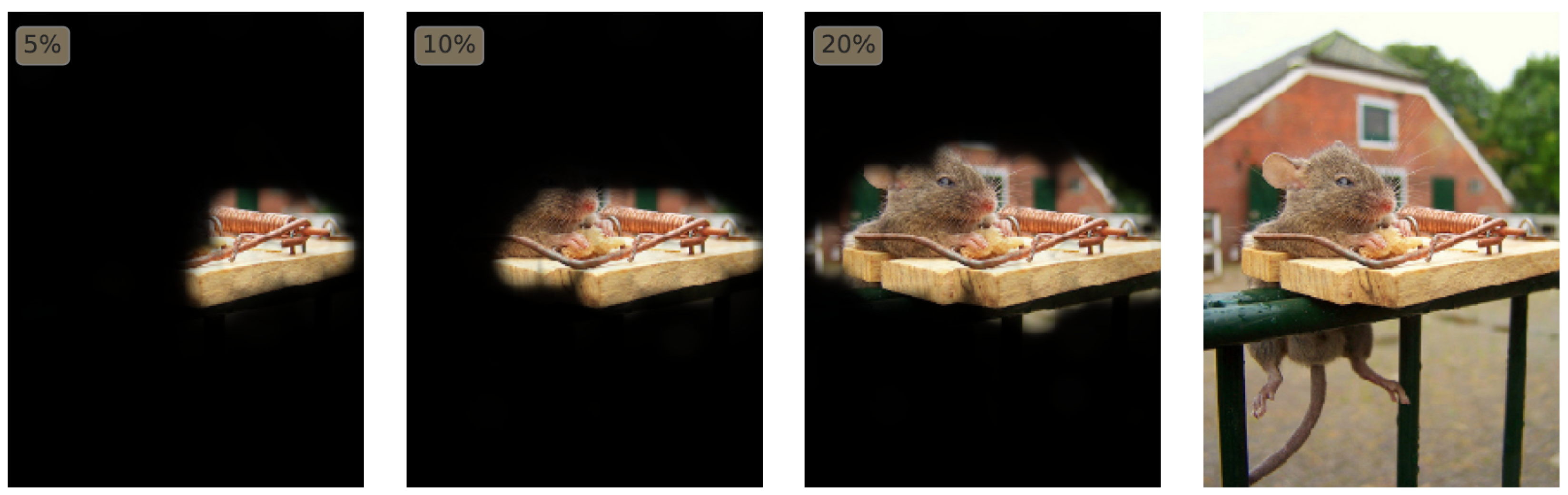
- Fong, R.C.; Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lei, T.; Barzilay, R.; Jaakkola, T. Rationalizing neural predictions. arXiv 2016, arXiv:1606.04155. [Google Scholar]
- Radford, A.; Jozefowicz, R.; Sutskever, I. Learning to generate reviews and discovering sentiment. arXiv 2017, arXiv:1704.01444. [Google Scholar]
- Thiagarajan, J.J.; Kailkhura, B.; Sattigeri, P.; Ramamurthy, K.N. TreeView: Peeking into deep neural networks via feature-space partitioning. arXiv 2016, arXiv:1611.07429. [Google Scholar]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Turner, R. A model explanation system. In Proceedings of the IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Italy, 13–16 September 2016. [Google Scholar]
- Krishnan, S.; Wu, E. Palm: Machine learning explanations for iterative debugging. In Proceedings of the 2nd Workshop on Human-In-the-Loop Data Analytics, Chicago, IL, USA, 14–19 May 2017. [Google Scholar]
- Narayanan, M.; Chen, E.; He, J.; Kim, B.; Gershman, S.; Doshi-Velez, F. How do humans understand explanations from machine learning systems? An evaluation of the human-interpretability of explanation. arXiv 2018, arXiv:1802.00682. [Google Scholar]
- El Bekri, N.; Kling, J.; Huber, M.F. A Study on Trust in Black Box Models and Post hoc Explanations. In Proceedings of the 14th International Conference on Soft Computing Models in Industrial and Environmental Applications (SOCO 2019), Seville, Spain, 13–15 May 2019. [Google Scholar]
- Fong, R.; Patrick, M.; Vedaldi, A. Understanding Deep Networks via Extremal Perturbations and Smooth Masks. arXiv 2019, arXiv:1910.08485v1. [Google Scholar]
- Torchray. 2019. Available online: github.com/facebookresearch/TorchRay (accessed on 7 October 2021).
- Fan, F.L.; Xiong, J.; Li, M.; Wang, G. On interpretability of artificial neural networks: A survey. IEEE Trans. Radiat. Plasma Med. Sci. 2021, 5, 741–760. [Google Scholar] [CrossRef]
- Fan, F.L.; Xiong, J.; Li, M.; Wang, G. IndependentEvaluation GitHub Code. 2021. Available online: https://github.com/FengleiFan/IndependentEvaluation (accessed on 7 October 2021).
- Burkart, N.; Huber, M.F. A Survey on the Explainability of Supervised Machine Learning. J. Artif. Intell. Res. 2021, 70, 245–317. [Google Scholar] [CrossRef]
- Agarwal, N.; Das, S. Interpretable Machine Learning Tools: A Survey. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; pp. 1528–1534. [Google Scholar]
- Hooker, S.; Erhan, D.; Kindermans, P.J.; Kim, B. Evaluating feature importance estimates. arXiv 2018, arXiv:1806.10758. [Google Scholar]
- Yeh, C.K.; Hsieh, C.Y.; Suggala, A.S.; Inouye, D.; Ravikumar, P. How Sensitive are Sensitivity-Based Explanations? arXiv 2019, arXiv:1901.09392. [Google Scholar]
- Alexandrov, N. Explainable AI decisions for human-autonomy interactions. In Proceedings of the 17th AIAA Aviation Technology, Integration, and Operations Conference, Denver, CO, USA, 5–9 June 2017. [Google Scholar]

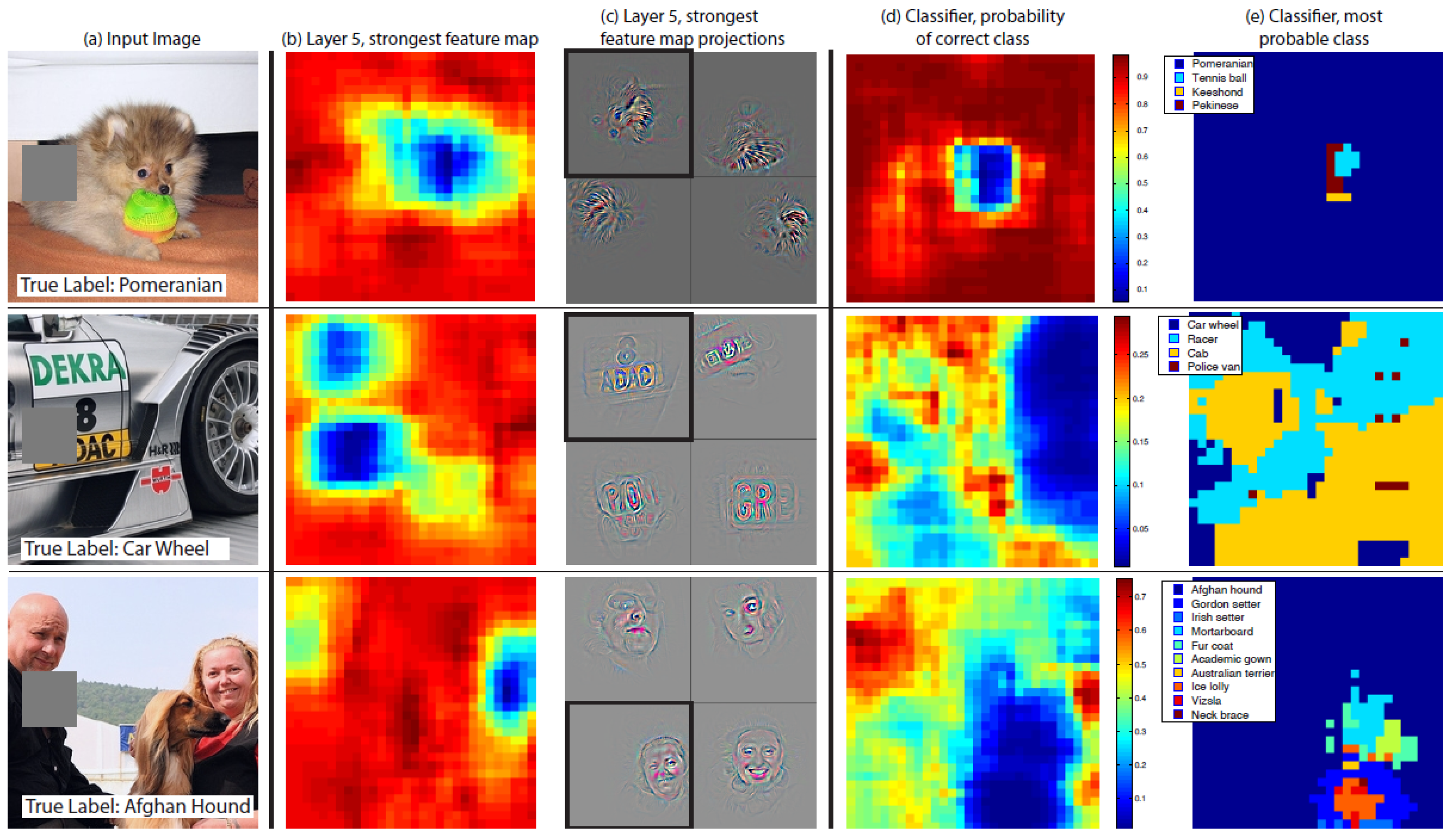

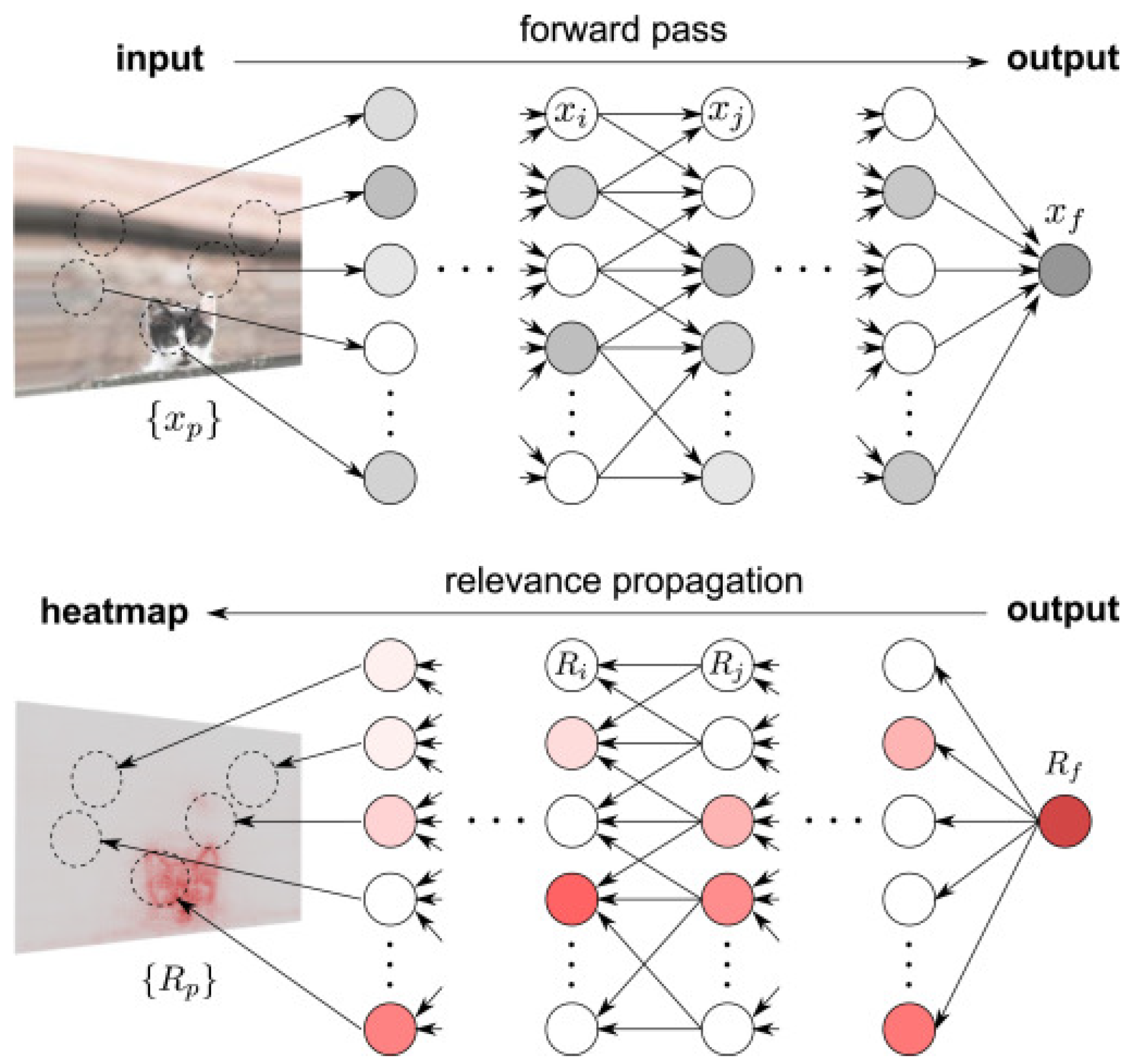




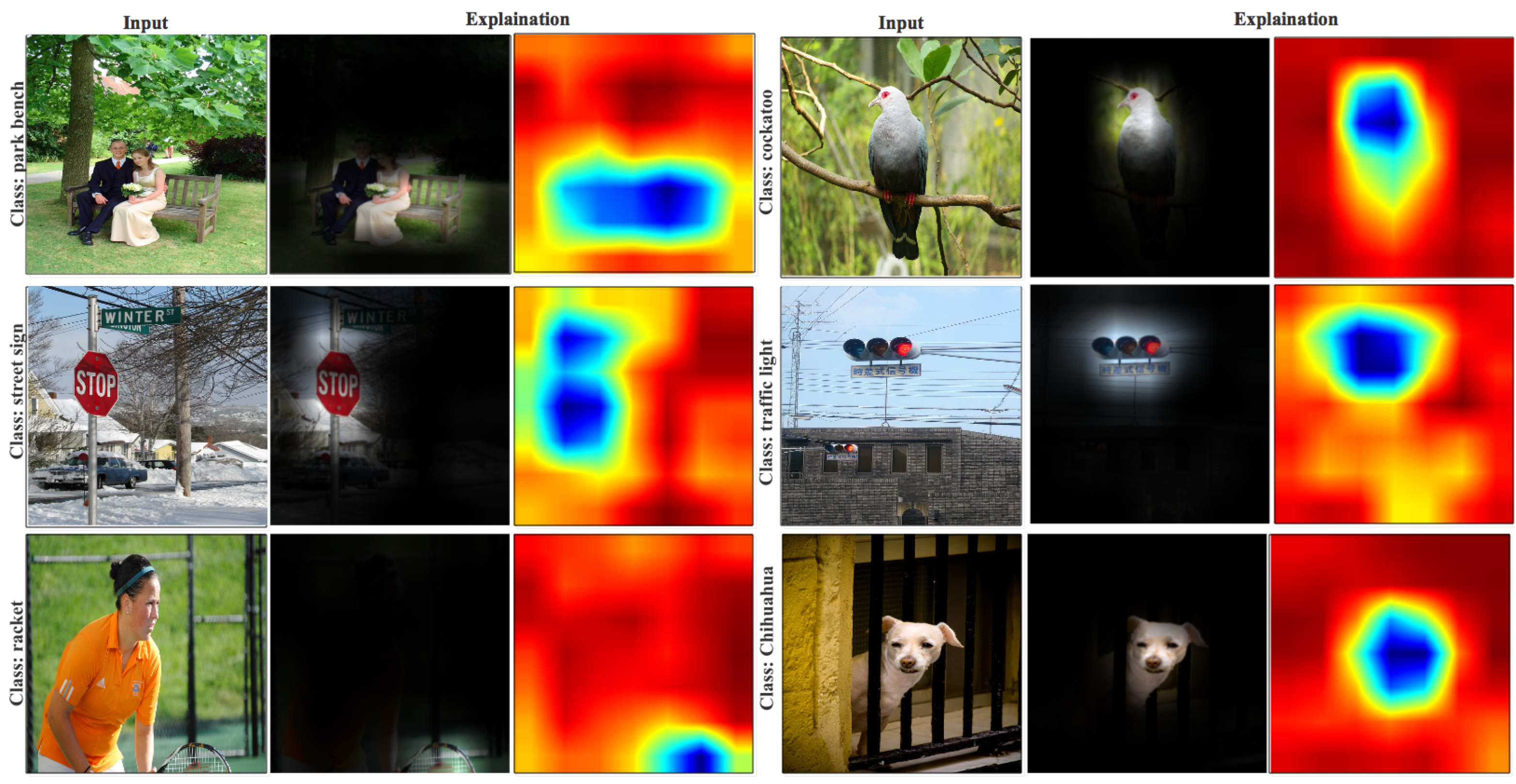



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Authors | Data | Method | Properties |
|---|---|---|---|---|
| Deep Inside | [59] | image | saliency mask | local, post hoc |
| DeconvNet | [51] | image | gradients | global, post hoc |
| All-CNN | [55] | image | gradients | global, post hoc |
| Deep Visualization | [61] | image | neurons activation | global, ante hoc |
| Deep Learning | [88] | image | visualization | local, post hoc |
| Show, attend, tell | [100] | image | saliency mask | local, ante hoc |
| LRP | [53] | image | decomposition | local, ante hoc |
| CAM | [85] | image | saliency mask | local, post hoc |
| Deep Generator | [58] | image | gradients, prototype | local, ante hoc |
| Interpretable DNNs | [101] | image | saliency map | local, ante hoc |
| VBP | [102] | image | saliency maps | local, post hoc |
| DTD | [54] | image | decomposition | local, post hoc |
| Meaningful | [103] | image | saliency mask | local, post hoc, agn. |
| PDA | [93] | image | feature importance | local, ante hoc |
| DVE | [92] | image | visualization | local, post hoc |
| Grad-CAM | [86] | image | saliency mask | local, post hoc |
| Grad-CAM++ | [87] | image | saliency mask | local, post hoc |
| Smooth-Grad | [95] | image | sensitivity analysis | local, ante hoc |
| ME | [97] | image | visualization | local, post hoc |
| Summit | [98] | image | visualization | local, ante hoc |
| Activation atlases | [63] | image | visualization | local, ante hoc |
| SP-LIME | [7] | text | feature importance | local, post hoc |
| Rationalizing | [104] | text | saliency mask | local, ante hoc |
| Generate reviews | [105] | text | neurons activation | global, ante hoc |
| BRL | [71] | tabular | Decision Tree | global, ante hoc |
| TreeView | [106] | tabular | Decision Tree | global, ante hoc |
| IP | [107] | tabular | neurons’ activation | global, ante hoc |
| KT | [75] | any | rule extraction | global, ante hoc |
| Decision Tree | [27] | any | Decision Tree | global, ante hoc, agn. |
| CIE | [77] | any | feature importance | local, post hoc |
| DeepRED | [74] | any | rule extraction | global, ante hoc |
| LIME | [7] | any | feature importance | local, post hoc, agn. |
| NES | [108] | any | rule extraction | local, ante hoc |
| BETA | [82] | any | Decision Tree | global, ante hoc |
| PALM | [109] | any | Decision Tree | global, ante hoc |
| DeepLift | [84] | any | feature importance | local, ante hoc |
| IG | [96] | any | sensitivity analysis | global, ante hoc |
| RETAIN | [83] | EHR | reverse time atten. | global, ante hoc |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buhrmester, V.; Münch, D.; Arens, M. Analysis of Explainers of Black Box Deep Neural Networks for Computer Vision: A Survey. Mach. Learn. Knowl. Extr. 2021, 3, 966-989. https://doi.org/10.3390/make3040048
Buhrmester V, Münch D, Arens M. Analysis of Explainers of Black Box Deep Neural Networks for Computer Vision: A Survey. Machine Learning and Knowledge Extraction. 2021; 3(4):966-989. https://doi.org/10.3390/make3040048
Chicago/Turabian StyleBuhrmester, Vanessa, David Münch, and Michael Arens. 2021. "Analysis of Explainers of Black Box Deep Neural Networks for Computer Vision: A Survey" Machine Learning and Knowledge Extraction 3, no. 4: 966-989. https://doi.org/10.3390/make3040048
APA StyleBuhrmester, V., Münch, D., & Arens, M. (2021). Analysis of Explainers of Black Box Deep Neural Networks for Computer Vision: A Survey. Machine Learning and Knowledge Extraction, 3(4), 966-989. https://doi.org/10.3390/make3040048