
Transfer Learning in Smart Environments †



Abstract
1. Introduction
- Versatile IoT configurations: Human contribution cannot cope with the ever-increasing number of IoT devices. By introducing new devices or applying changes to the smart environment, the configurations and rules need to be revisited and checked. As such, we need a configuration management approach that supports flexibility, dynamicity, and incremental change in smart environments.
- IoT service transfer: While users can manage, train, and configure the services in their private environment, it is not easy to transfer such configurations to semi-private spaces, such as hotel rooms, cars, hospital rooms, open city spaces, and offices. For instance, suppose an individual has defined some rules to maintain his/her thermal comfort at home based on services such as a motion detector, an air conditioning system, and the body temperature measured by a wearable device. To achieve the same thermal comfort in a semi-private environment such as hotel rooms or offices, the rules need to be adjusted based on the semantics and standards of the target spaces.
- Transfer learning: The smart space services, embodied in machine learning models, are commonly associated with time-consuming and costly processes, such as large-scale data collection, data labeling, network training, and fine-tuning models. Sharing and reuse of these elaborated models in a different space would facilitate the adoption of services for the inhabitants and accelerate the uptake of machine learning in smart building applications. The model adoption process, which is referred to as transfer learning, is commonly undertaken by a human who is capable of understanding the implicit semantics of spaces, devices, and the relevant information resources and services. Therefore, self-explaining and machine-understandable models are the key requirements to accelerate the transfer learning between smart spaces.
2. Related Work
3. Characteristics of Knowledge Sharing in Built Environments
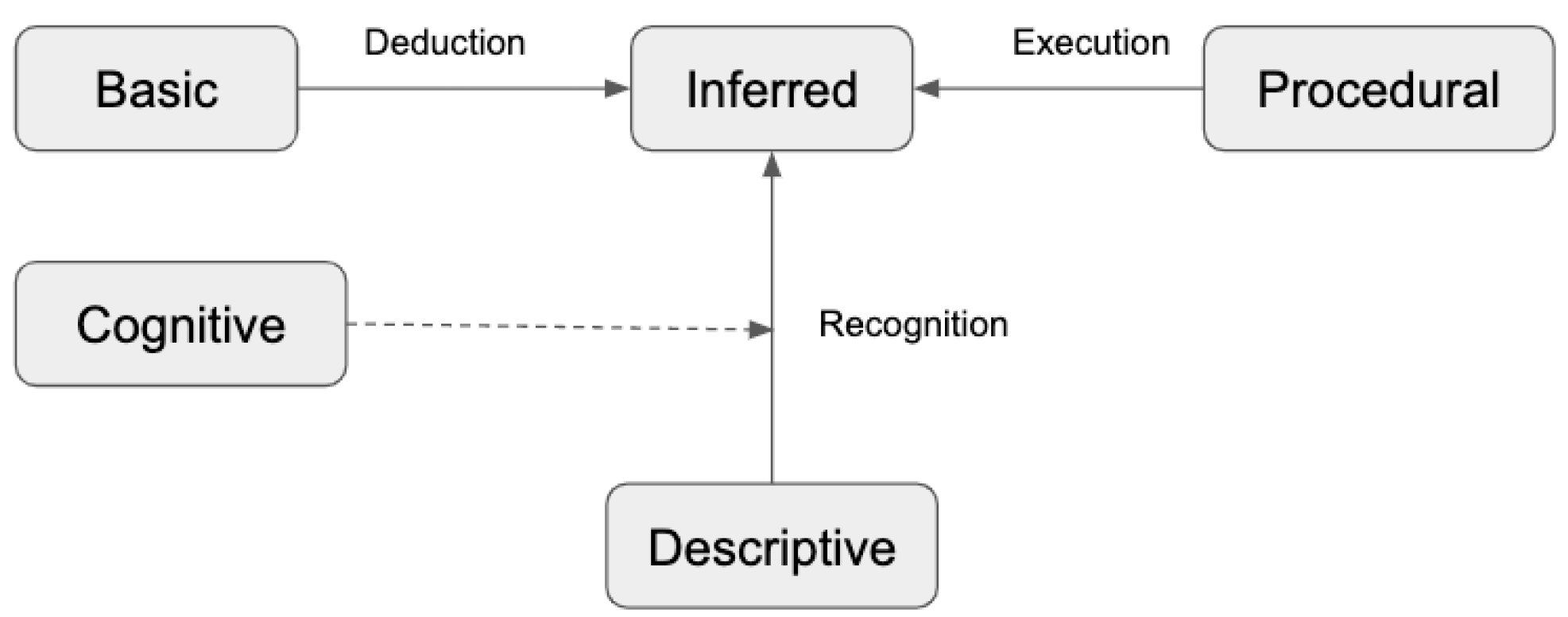
3.1. Knowledge Types in Built Environments
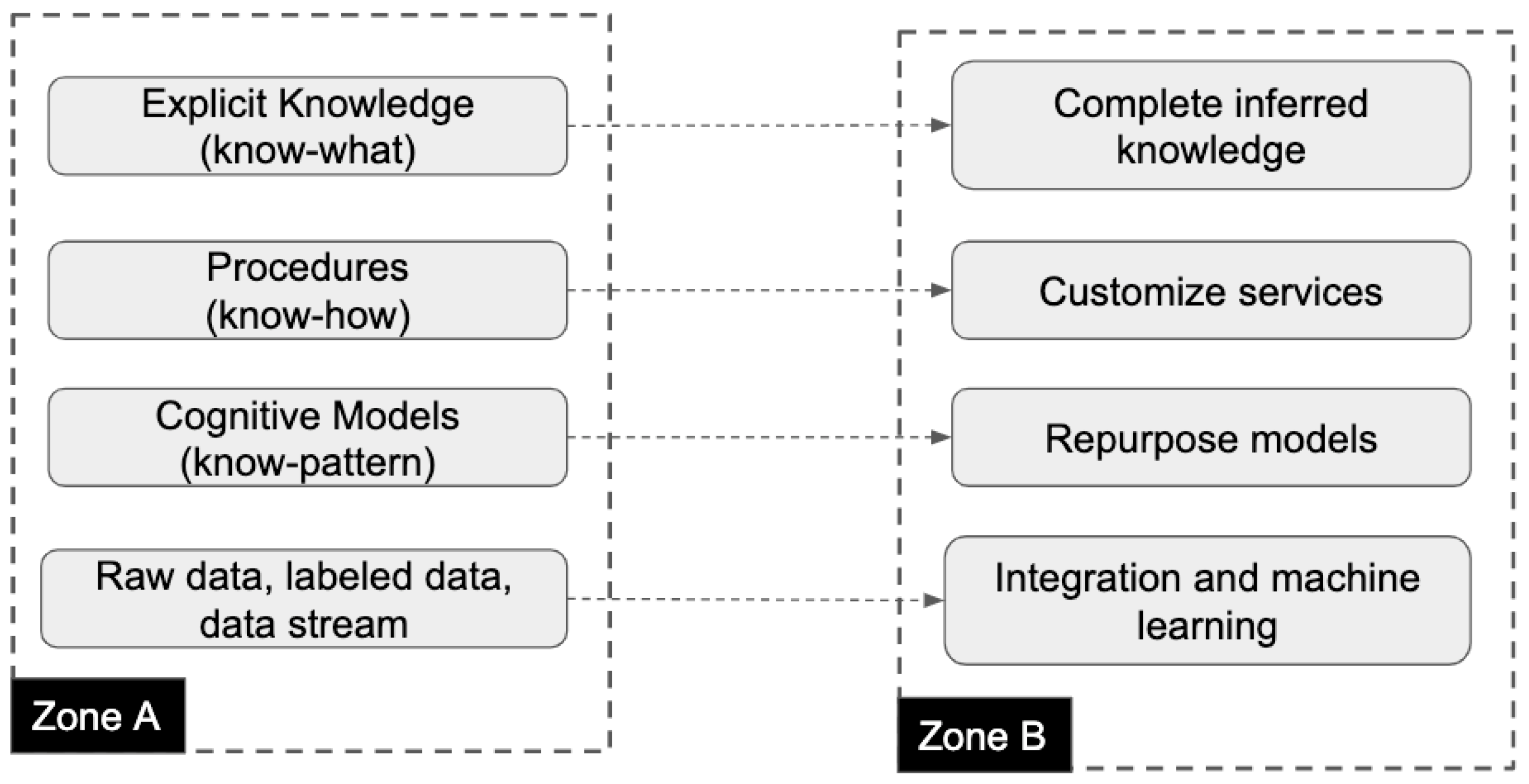
3.2. Maturity Levels of Knowledge Sharing and Reuse
- Data level (one star): A one-star space is capable of making its static data available to other spaces and at the same time use the available static data of other spaces. Examples of such data in a smart environment include basic space information, space relationships to other building entities, static datasets, and available IoT devices. At this maturity level, information can be captured in static files, building management systems, or more elegantly via a knowledge graph that binds various domains together and makes the data machine-interpretable.
- Stream level (two stars): When space is capable of offering or processing real-time data streams using stream processing techniques, space is considered to be a two-star space. In this context, spaces may share their data streams (e.g., via publishing or broadcasting nodes) or use the available data streams (e.g., via subscription or API calls) to access and process the stream data. Similar to data level, the dynamic level resources can be offered and consumed by means of plain data objects, or by following the principles of Linked Data and using linked stream data. For example, space may offer the data of its temperature sensor as linked stream data that can be consumed by other spaces and systems for various use cases.
- Service level (three stars): A space that is capable of offering services to other spaces or use the offered services of other spaces is a three-star space. At this level, services are considered to be black-box components that can be accessed based on their advertised description. In other words, spaces offer their services as is, and let other spaces call those exposed services to achieve their goals. For example, space can offer its ML model as a service and let other spaces use it based on the advertised service signature. Similar to the data and stream levels, services level can also benefit from a semantic framework in order to present their signature in a machine-interpretable way.
- Inference level (four stars): A space that is capable of inferring new knowledge or customizing the available services is a four-star space. At this level, space can interpret the semantics of available resources such as sensors, actuators, and data streams to create a solution or adopt and customize an existing solution based on its settings and requirements. Space can achieve this by means of an inference engine, expert system, or other available services. As an example, consider an IoT application that depends on a number of sensors, actuators, and data streams. In order to transfer such a service chain to a new space, we would need to adopt the blueprint of that IoT application and customize it based on the available sensors and actuators in the target space.
- Learning level (five stars): A five-star space is capable of undertaking a task by monitoring its resources or learning from other spaces. For instance, consider the occupancy prediction use case. A five-star space is able to find ML models from other spaces with similar goals, create a pipeline to acquire the necessary input features from its sensor data, and predict the number of people in the space. Additionally, in an advanced scenario, space may undertake a transfer learning process that re-purposes existing ML models to achieve better predictions for the target space.
4. Learning in Smart Spaces
4.1. Knowledge Communication Methods
- The first and simplest method of communication between spaces is running queries on the explicit knowledge. Since the explicit knowledge can be articulated and codified, the spaces with a common understanding of domain concepts can formulate relevant queries based on common shared concepts (ontologies) and interpret the returning results to complete their inferred knowledge. For instance, two spaces that belong to the same thermal zone of a building can share information about the corresponding Air Handling Unit (AHU) and its power meter.
- Procedures can be shared as a whole (e.g., black-box service on a cloud) or get adopted and customized for use in the context of the target space. As an example, consider a procedure that requires interaction with specific types of sensors/actuators or the need to communicate with external services to accomplish a task. To adopt such procedures, we might need to replace the sensors and adjust their communications based on the resources available at the target space. For instance, in a temperature control scenario that includes a simple sense-actuate cycle, we need to adjust the procedure based on the available IoT services in the target space.
- Some domain knowledge can be captured by elaborated models. These models can transform parts of human tacit knowledge into explicit knowledge that can be used by machines. Machine learning models are examples of such a knowledge acquisition method that facilitates the sharing of cognitive-based approaches. Such models can be repurposed and retrained in the target zone to satisfy the contextual requirements. For instance, a speech recognition model can be adapted and repurposed to cope with the noise in the target space.
- A common type of communication between spaces is sharing data in different formats, frequencies, and structures. Such data could be in the form of raw data that are shared for data integration purposes or labeled data (e.g., images with labeled objects) for machine learning purposes.
4.2. Cognitive Knowledge Reuse
5. Case Study: Occupancy Prediction
5.1. Dataset
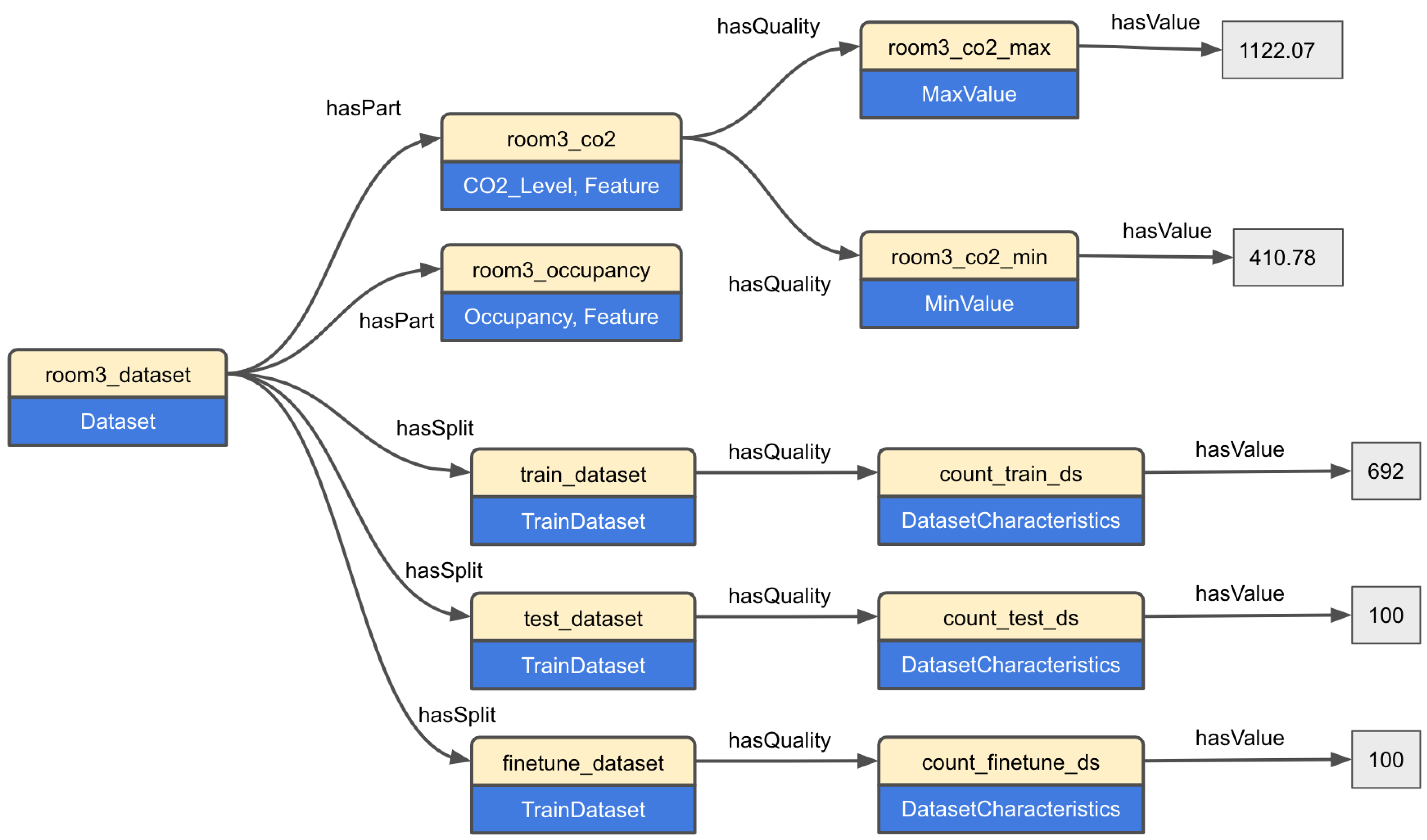
5.2. Knowledge Graph
- Several spaces may have similar properties and use (e.g., library or classroom). As such, the models of space that depend on those properties can be shared and reused by other similar spaces. The space similarity, depending on the use case, can be characterized by features such as the room’s function, size, or capacity. In the case of our occupancy prediction model, rooms of the same size and capacity are expected to behave similarly.
- The training dataset also plays an important role in the accuracy of model predictions. If the machine learning model is created based on a small or low variance feature, its behavior in a new space will be unpredictable. Since all such statistical metadata are included in the proposed knowledge graph, the space agent can compare the range of its input features to those of the training dataset of the adopted model and make sure the model is adequately good for transfer learning purposes.
- The machine learning models are also characterized by their performance indicators. For instance, the loss indicator, which is widely used in machine learning processes, can be used for comparison and ranking of the available models for a given task.
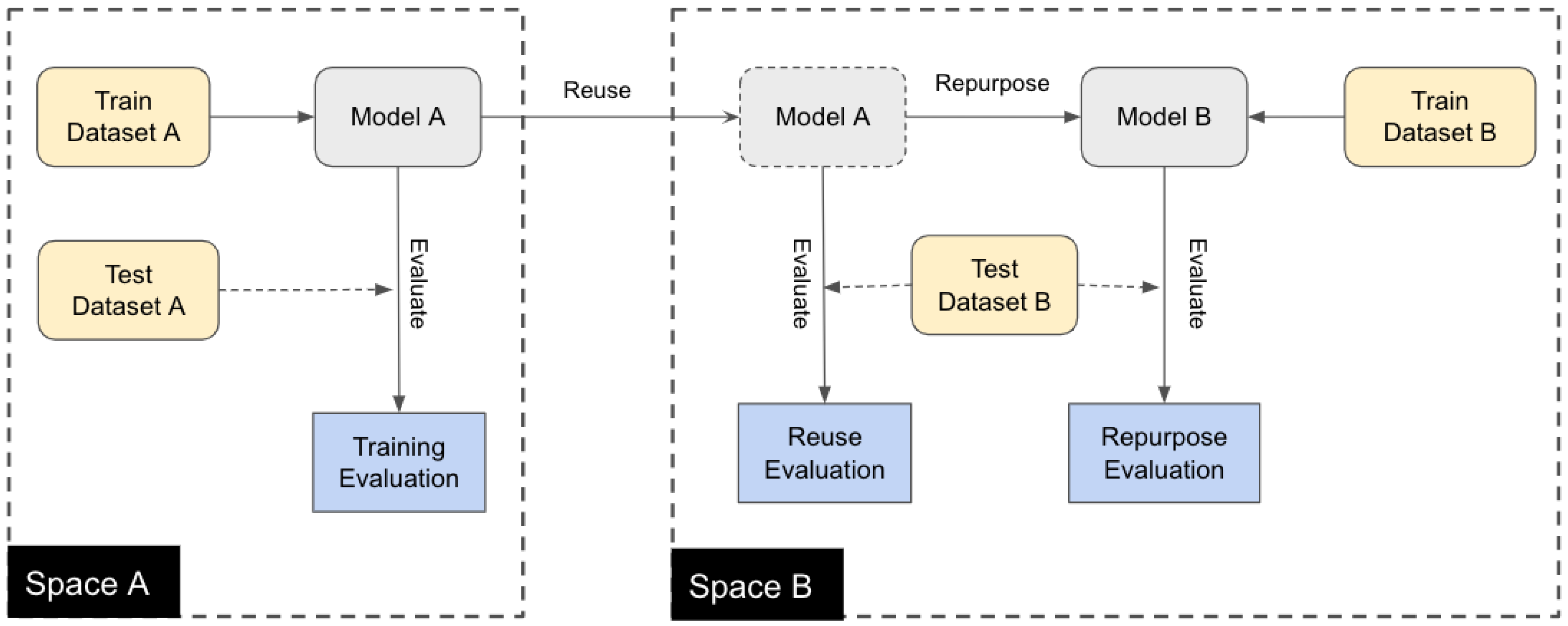
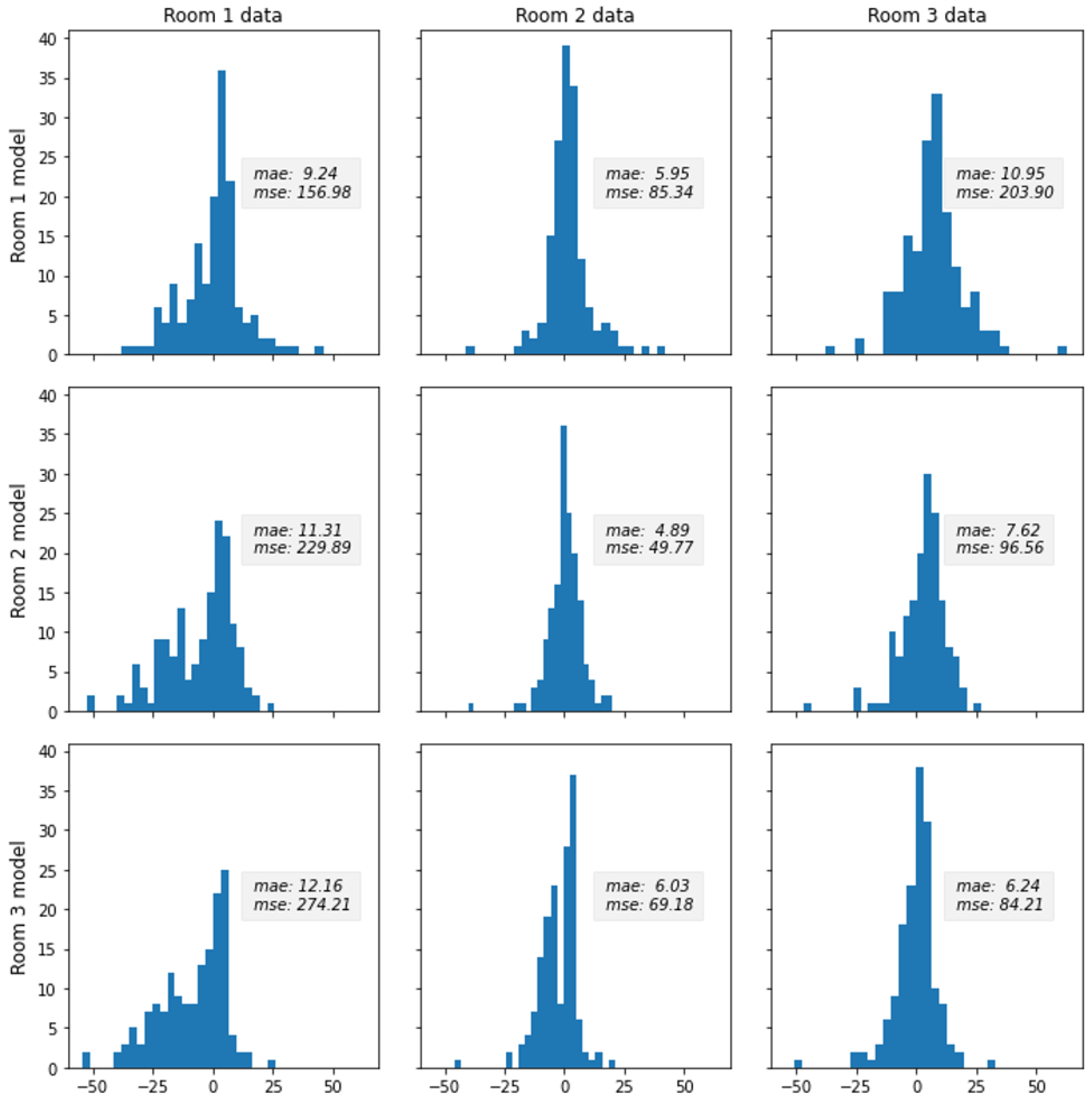
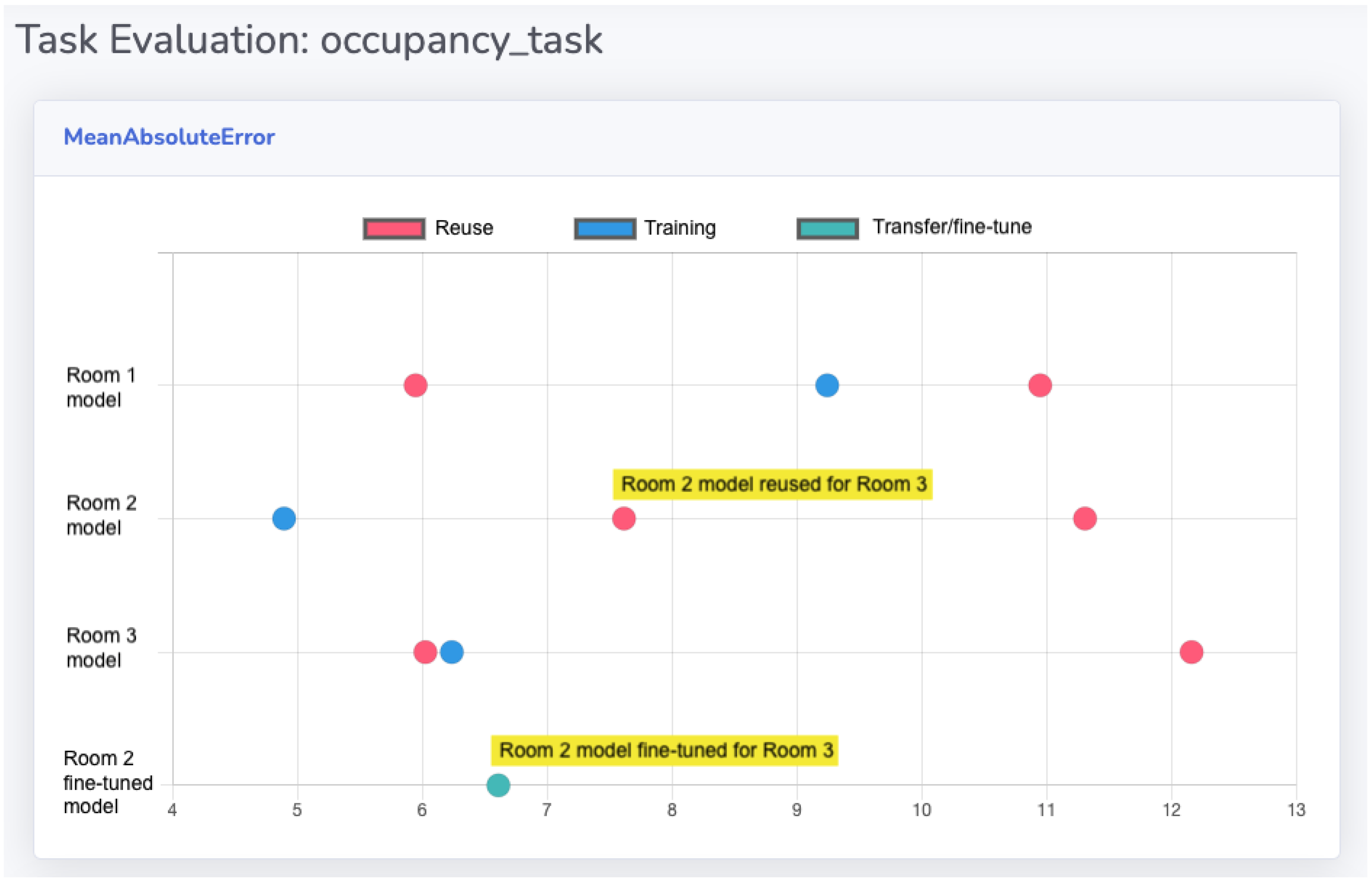
5.3. Transfer Learning
- Training evaluation: In this case, both training and testing datasets are from the same space and originate from the same raw dataset or sensors. As discussed earlier, this model usually offers the best performance.
- Reuse evaluation: In this case, the model is adopted as-is and tested based on a test dataset from target space. Provided that the source and target spaces have similar characteristics, this method yields acceptable results at a low cost (no training costs and a small test dataset for evaluation).
- Transfer learning and/or fine-tuning evaluation: In this case, the original model is retrained based on a small training dataset from the target space and usually provides better results compared to the as-is reuse of original models.
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singh, D.; Merdivan, E.; Psychoula, I.; Kropf, J.; Hanke, S.; Geist, M.; Holzinger, A. Human activity recognition using recurrent neural networks. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Hamburg, Germany, 27–30 August 2017. [Google Scholar]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; de Melo, G.; Gutierrez, C.; Gayo, J.E.L.; Kirrane, S.; Neumaier, S.; Polleres, A.; et al. Knowledge Graphs. arXiv 2020, arXiv:cs.AI/2003.02320. [Google Scholar]
- Bonatti, P.A.; Decker, S.; Polleres, A.; Presutti, V. Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web (Dagstuhl Seminar 18371). Available online: https://drops.dagstuhl.de/opus/volltexte/2019/10328/pdf/dagrep_v008_i009_p029_18371.pdf (accessed on 19 March 2021).
- Holzinger, A. From machine learning to explainable AI. In Proceedings of the 2018 World Symposium on Digital Intelligence for Systems and Machines (DISA), Košice, Slovakia, 23–25 August 2018; pp. 55–66. [Google Scholar]
- Dosilovic, F.; Brcic, M.; Hlupic, N. Explainable Artificial Intelligence: A Survey. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 0210–0215. [Google Scholar]
- Geng, Y.; Chen, J.; Jiménez-Ruiz, E.; Chen, H. Human-centric transfer learning explanation via knowledge graph. arXiv 2019, arXiv:1901.08547. [Google Scholar]
- Omran, P.G.; Wang, Z.; Wang, K. Knowledge graph rule mining via transfer learning. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2019; pp. 489–500. [Google Scholar]
- Ishii, H.; Ullmer, B. Tangible bits: Towards seamless interfaces between people, bits and atoms. In Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 1 March 1997. [Google Scholar]
- Wikipedia. BuildingSMART, Industry Foundation Classes (IFC). Available online: https://en.wikipedia.org/wiki/BuildingSMART (accessed on 14 April 2020).
- Törmä, S. Semantic linking of building information models. In Proceedings of the 2013 IEEE Seventh International Conference on Semantic Computing, Irvine, CA, USA, 16–18 September 2013; pp. 412–419. [Google Scholar]
- Anjomshoaa, A.; Shayeganfar, F.; Mahdavi, A.; Tjoa, A. Toward constructive evidence of linked open data in AEC domain. In Proceedings of the 10th European Conference on Product and Process Modelling (ECPPM2014), Vienna, Austria, 17–19 September 2014; pp. 535–542. [Google Scholar]
- Curry, E.; O’Donnell, J.; Corry, E.; Hasan, S.; Keane, M.; O’Riain, S. Linking building data in the cloud: Integrating cross-domain building data using linked data. Adv. Eng. Inform. 2013, 27, 206–219. [Google Scholar] [CrossRef]
- Anjomshoaa, A. Blending Building Information with Smart City Data. In S4SC@ ISWC; Citeseer: State College, PA, USA, 2014; pp. 1–2. [Google Scholar]
- Balaji, B.; Bhattacharya, A.; Fierro, G.; Gao, J.; Gluck, J.; Hong, D.; Johansen, A.; Koh, J.; Ploennigs, J.; Agarwal, Y.; et al. Brick: Towards a unified metadata schema for buildings. In Proceedings of the 3rd ACM International Conference on Systems for Energy-Efficient Built Environments, Palo Alto, CA, USA, 16–17 November 2016. [Google Scholar]
- Xing, T.; Sandha, S.S.; Balaji, B.; Chakraborty, S.; Srivastava, M. Enabling edge devices that learn from each other: Cross modal training for activity recognition. In Proceedings of the 1st International Workshop on Edge Systems, Analytics and Networking, Munich, Germany, 10 June 2018. [Google Scholar]
- Deng, L.; Li, D.; Yao, X.; Cox, D.; Wang, H. Mobile network intrusion detection for IoT system based on transfer learning algorithm. Clust. Comput. 2019, 22, 9889–9904. [Google Scholar] [CrossRef]
- Publio, G.C.; Esteves, D.; Ławrynowicz, A.; Panov, P.; Soldatova, L.; Soru, T.; Vanschoren, J.; Zafar, H. ML-Schema: Exposing the Semantics of Machine Learning with Schemas and Ontologies. arXiv 2018, arXiv:cs.LG/1807.05351. [Google Scholar]
- Mour, V.; Dey, S.; Jain, S.; Lodhe, R. Feature Store for Enhanced Explainability in Support Ticket Classification. In CCF International Conference on Natural Language Processing and Chinese Computing; Springer: Berlin/Heidelberg, Germany, 2020; pp. 467–478. [Google Scholar]
- Hermann, J.; Del Balso, M. Meet Michelangelo: Uber’s Machine Learning Platform. 2017. Available online: https://eng.uber.com/michelangelo (accessed on 19 March 2021).
- Zaharia, M.; Chen, A.; Davidson, A.; Ghodsi, A.; Hong, S.A.; Konwinski, A.; Murching, S.; Nykodym, T.; Ogilvie, P.; Parkhe, M.; et al. Accelerating the Machine Learning Lifecycle with MLflow. IEEE Data Eng. Bull. 2018, 41, 39–45. [Google Scholar]
- Baylor, D.; Breck, E.; Cheng, H.T.; Fiedel, N.; Foo, C.Y.; Haque, Z.; Haykal, S.; Ispir, M.; Jain, V.; Koc, L.; et al. Tfx: A tensorflow-based production-scale machine learning platform. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Ismail, M.; Gebremeskel, E.; Kakantousis, T.; Berthou, G.; Dowling, J. Hopsworks: Improving user experience and development on hadoop with scalable, strongly consistent metadata. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017. [Google Scholar]
- Hélie, S.; Sun, R. Incubation, insight, and creative problem solving: A unified theory and a connectionist model. Psychol. Rev. 2010, 117, 994. [Google Scholar] [CrossRef] [PubMed]
- Handzic, M. Knowledge management: A research framework. In Proceedings of the European Conference on Knowledge Management, Bled, Slovenia, 8–9 November 2001. [Google Scholar]
- Alavi, M.; Leidner, D.E. Knowledge management and knowledge management systems: Conceptual foundations and research issues. MIS Q. 2001, 107–136. [Google Scholar] [CrossRef]
- Sangogboye, F.C.; Arendt, K.; Singh, A.; Veje, C.T.; Kjærgaard, M.B.; Jørgensen, B.N. Performance comparison of occupancy count estimation and prediction with common versus dedicated sensors for building model predictive control. In Building Simulation; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10, pp. 829–843. [Google Scholar]
- Wang, W.; Chen, J.; Hong, T. Occupancy prediction through machine learning and data fusion of environmental sensing and Wi-Fi sensing in buildings. Autom. Constr. 2018, 94, 233–243. [Google Scholar] [CrossRef]
- Arief-Ang, I.B.; Hamilton, M.; Salim, F.D. A scalable room occupancy prediction with transferable time series decomposition of CO2 sensor data. ACM Trans. Sens. Netw. (TOSN) 2018, 14, 1–28. [Google Scholar] [CrossRef]
- Kleinbaum, D.G.; Dietz, K.; Gail, M.; Klein, M.; Klein, M. Logistic Regression; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Schwee, J.H.; Johansen, A.; Jørgensen, B.N.; Kjærgaard, M.B.; Mattera, C.G.; Sangogboye, F.C.; Veje, C. Room level occupant counts and environmental quality from heterogeneous sensing modalities in a smart building. Sci. Data 2019, 6, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Curry, E. Real-Time Linked Dataspaces: Enabling Data Ecosystems for Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Shared Knowledge | Description |
|---|---|---|
| ★ | Data Level | Space is capable of making its static data available to other spaces and using the available static data of other spaces |
| ★★ | Stream Level | Space is capable of offering or processing real-time data streams using stream processing techniques |
| ★★★ | Services Level | Space is capable of offering services as a black-box component to other spaces or using the offered services of other spaces |
| ★★★★ | Inference Level | Space is capable of inferring new knowledge or customizing the available services based on available rules |
| ★★★★★ | Learning Level | Space is capable of undertaking a task by monitoring its resources or learning from other spaces |
| Room ID | Room Type | Size (m2) | Seating Capacity | Volume (m3) |
|---|---|---|---|---|
| Room 1 | lecture | 139 | 84 | 461.48 |
| Room 2 | study zone | 125 | 32 | 418.75 |
| Room 3 | study zone | 125 | 32 | 418.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anjomshoaa, A.; Curry, E. Transfer Learning in Smart Environments. Mach. Learn. Knowl. Extr. 2021, 3, 318-332. https://doi.org/10.3390/make3020016
Anjomshoaa A, Curry E. Transfer Learning in Smart Environments. Machine Learning and Knowledge Extraction. 2021; 3(2):318-332. https://doi.org/10.3390/make3020016
Chicago/Turabian StyleAnjomshoaa, Amin, and Edward Curry. 2021. "Transfer Learning in Smart Environments" Machine Learning and Knowledge Extraction 3, no. 2: 318-332. https://doi.org/10.3390/make3020016
APA StyleAnjomshoaa, A., & Curry, E. (2021). Transfer Learning in Smart Environments. Machine Learning and Knowledge Extraction, 3(2), 318-332. https://doi.org/10.3390/make3020016